Month: May 2025

MMS • Sergio De Simone

LMEval aims to help AI researchers and developers compare the performance of different large language models. Designed to be accurate, multimodal, and easy to use, LMEval has already been used to evaluate major models in terms of safety and security.
One of the reasons behind LMEval is the fast pace at which new models are being introduced. This makes it essential to evaluate them quickly and reliably to assess their suitability for specific applications, says Google researchers. Among its key features are compatibility with a wide range of LLM providers, incremental benchmark execution for improved efficiency, support for multimodal evaluation—including text, images, and code—and encrypted result storage for enhanced security.
For cross-provider support, it is critical that evaluation benchmarks can be defined once and reused across multiple models, despite differences in their APIs. To this end, LMEval uses LiteLLM, a framework that allows developers to use the OpenAI API format to call a variety of LLM providers, including Bedrock, Hugging Face, Vertex AI, Together AI, Azure, OpenAI, Groq, and others. LiteLLM translates inputs to match each provider’s specific requirements for completion, embedding, and image generation endpoints, and produces a uniform output format.
To improve execution efficiency when new models are released, LMEval runs only the evaluations that are strictly necessary, whether for new models, prompts, or questions. This is made possible by an intelligent evaluation engine that follows an incremental evaluation model.
Written in Python and available on GitHub, LMEval requires you to follow a series of steps to run an evaluation. First, you define your benchmark by specifying the tasks to execute, e.g., detect eye colors in a picture, along with the prompt, the image, and the expected results. Then, you list the models to evaluate and run the benchmark:
benchmark = Benchmark(name='Cat Visual Questions',
description='Ask questions about cats picture')
...
scorer = get_scorer(ScorerType.contain_text_insensitive)
task = Task(name='Eyes color', type=TaskType.text_generation, scorer=scorer)
category.add_task(task)
# add questions
source = QuestionSource(name='cookbook')
# cat 1 question - create question then add media image
question = Question(id=0, question='what is the colors of eye?',
answer='blue', source=source)
question.add_media('./data/media/cat_blue.jpg')
task.add_question(question)
...
# evaluate benchmark on two models
models = [GeminiModel(), GeminiModel(model_version='gemini-1.5-pro')]
prompt = SingleWordAnswerPrompt()
evaluator = Evaluator(benchmark)
eval_plan = evaluator.plan(models, prompt) # plan evaluation
completed_benchmark = evaluator.execute() # run evaluation
Optionally, you can save the evaluation results to a SQLite database and export the data to pandas for further analysis and visualization. LMEval uses encryption to store benchmark data and evaluation results to protect against crawling or indexing.
LMEval also includes LMEvalboard, a visual dashboard that lets you view overall performance, analyze individual models, or compare multiple models.
As mentioned, LMEval has been used to create the Phare LLM Benchmark, designed to evaluate LLM safety and security, including resistance to hallucination, factual accuracy, bias, and potential harm.
LMEval is not the only cross-provider LLM evaluation framework currently available. Others include Harbor Bench and EleutherAI’s LM Evaluation Harness. Harbor Bench, limited to text prompts, has the interesting feature of using an LLM to judge result quality. In contrast, EleutherAI’s LM Evaluation Harness includes over 60 benchmarks and allows users to define new ones using YAML.
OpenSearch 3.0 Now Generally Available, with a Focus on Vector Database Performance and Scalability
MMS • Renato Losio

The OpenSearch Software Foundation has announced the general availability of OpenSearch 3.0, the first major release in three years and the first since the project joined the Linux Foundation. This version introduces native support for the Model Context Protocol (MCP), along with pull-based data ingestion and gRPC support, aimed at improving scalability and integration.
OpenSearch was launched in 2021 by AWS as a fork of Elasticsearch 7.10, following Elastic’s license change. With performance as a key focus of this release, OpenSearch 3.0 delivers up to 9.5x faster vector search compared to version 1.3, thanks to support for GPU acceleration and more efficient indexing.
OpenSearch 3.0 upgrades to Apache Lucene 10 and introduces enhancements to data ingestion, transport, and management. James McIntyre, senior product marketing manager at AWS, Saurabh Singh, engineering leader at AWS, and Jiaxiang (Peter) Zhu, senior system development engineer at AWS, explain:
The latest version of Apache Lucene offers significant improvements in performance, efficiency, and vector search functionality. These types of improvements pave the way for larger vector and search deployments, enabling AI workloads to scale factorially over time.
Lucene 10 introduces improvements in both I/O and search parallelism, and requires JVM version 21 or later—resulting in some breaking changes and prompting a major version update. Elasticsearch, which reverted to an open source model under the AGPL license last year, recently released version 9.0.0-rc1, which also supports the latest version of Lucene.
The latest OpenSearch release also adds support for gRPC and pull-based ingestion, and introduces reader-writer separation. This allows indexing and search workloads to be configured independently, ensuring consistent, high-performance operation for each. McIntyre, Singh, and Zhu add:
Benefiting from underlying HTTP/2 infrastructure, gRPC supports multiplexing and bidirectional data streams, enabling clients to send and receive requests concurrently over the same TCP connection. Performance gains can be especially pronounced for users working with large and complex queries, where the overhead of deserializing requests can compound when using JSON.
OpenSearch now also supports index type detection and integrates the dynamic data management framework Apache Calcite, enabling iterative query building and exploration. This is achieved by incorporating the query builder into OpenSearch SQL and PPL. In a popular thread on Hacker News, Joe Johnston writes:
Elastic still has the edge on features. Especially Kibana has a lot more features than Amazon’s fork (…) A lot of my consulting clients seem to prefer Opensearch lately. That’s mainly because of the less complicated licensing and the AWS support.
Comparing OpenSearch and Elasticsearch, user Macha adds:
One thing that Opensearch misses that would have been very nice to have on a recent project is enrich processors.
OpenSearch is open source under the Apache 2.0 license. More details about the latest release are available in the release notes on GitHub.
MMS • RSS
Shares of MongoDB Inc (MDB, Financial) fell 3.29% in mid-day trading on May 30. The stock reached an intraday low of $182.69, before recovering slightly to $183.14, down from its previous close of $189.37. This places MDB 50.50% below its 52-week high of $370.00 and 30.09% above its 52-week low of $140.78. Trading volume was 922,832 shares, 39.2% of the average daily volume of 2,352,027.
Wall Street Analysts Forecast
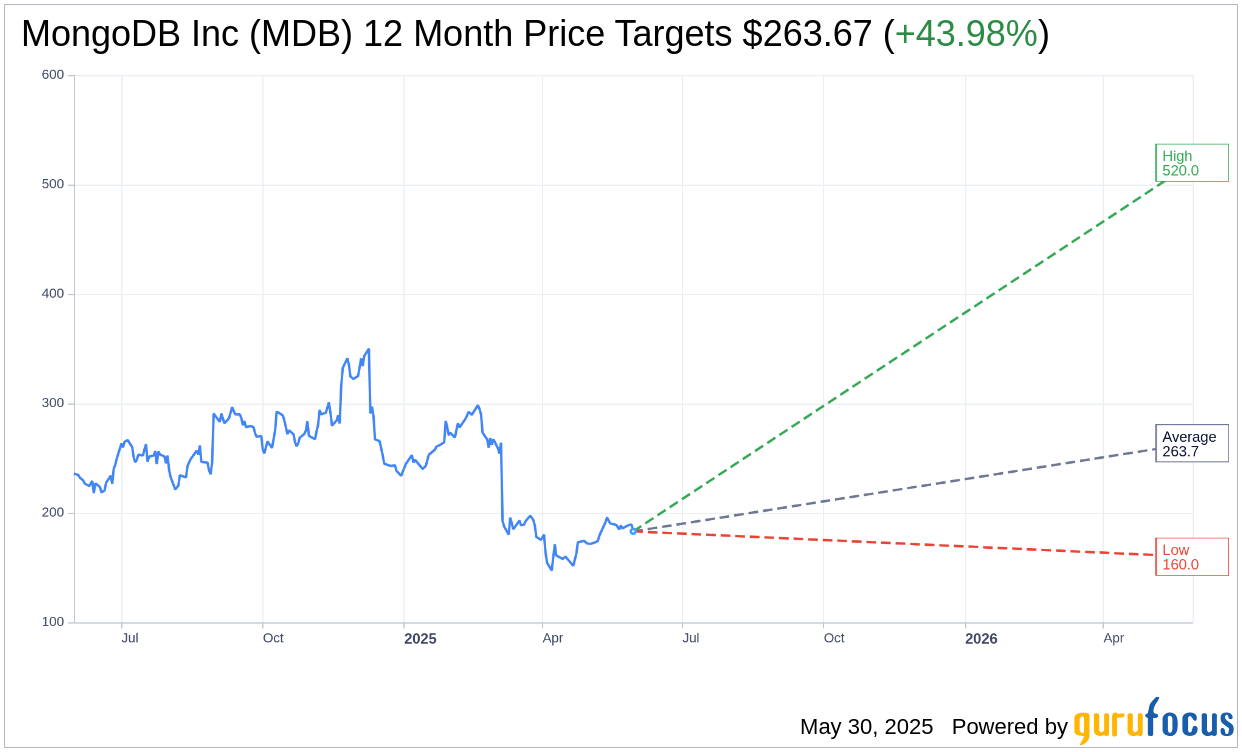
Based on the one-year price targets offered by 34 analysts, the average target price for MongoDB Inc (MDB, Financial) is $263.67 with a high estimate of $520.00 and a low estimate of $160.00. The average target implies an upside of 43.98% from the current price of $183.14. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 37 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 2.0, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $438.59, suggesting a upside of 139.49% from the current price of $183.135. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
This article, generated by GuruFocus, is designed to provide general insights and is not tailored financial advice. Our commentary is rooted in historical data and analyst projections, utilizing an impartial methodology, and is not intended to serve as specific investment guidance. It does not formulate a recommendation to purchase or divest any stock and does not consider individual investment objectives or financial circumstances. Our objective is to deliver long-term, fundamental data-driven analysis. Be aware that our analysis might not incorporate the most recent, price-sensitive company announcements or qualitative information. GuruFocus holds no position in the stocks mentioned herein.
MMS • RSS
Lansforsakringar Fondforvaltning AB publ bought a new position in MongoDB, Inc. (NASDAQ:MDB – Free Report) in the 4th quarter, according to its most recent disclosure with the Securities & Exchange Commission. The firm bought 24,778 shares of the company’s stock, valued at approximately $5,769,000.
Several other hedge funds and other institutional investors have also recently bought and sold shares of MDB. Centaurus Financial Inc. raised its stake in MongoDB by 19.0% during the fourth quarter. Centaurus Financial Inc. now owns 2,499 shares of the company’s stock worth $582,000 after acquiring an additional 399 shares in the last quarter. Universal Beteiligungs und Servicegesellschaft mbH acquired a new position in MongoDB during the fourth quarter worth $13,270,000. Azzad Asset Management Inc. ADV raised its stake in MongoDB by 17.7% during the fourth quarter. Azzad Asset Management Inc. ADV now owns 7,519 shares of the company’s stock worth $1,750,000 after acquiring an additional 1,132 shares in the last quarter. Infinitum Asset Management LLC acquired a new position in MongoDB during the fourth quarter worth $8,148,000. Finally, Polar Asset Management Partners Inc. acquired a new position in MongoDB during the fourth quarter worth $14,458,000. 89.29% of the stock is owned by institutional investors.
Analysts Set New Price Targets
MDB has been the subject of several recent analyst reports. Oppenheimer dropped their price objective on MongoDB from $400.00 to $330.00 and set an “outperform” rating for the company in a research note on Thursday, March 6th. Barclays dropped their price objective on MongoDB from $280.00 to $252.00 and set an “overweight” rating for the company in a research note on Friday, May 16th. Daiwa America upgraded MongoDB to a “strong-buy” rating in a research note on Tuesday, April 1st. Needham & Company LLC dropped their price objective on MongoDB from $415.00 to $270.00 and set a “buy” rating for the company in a research note on Thursday, March 6th. Finally, Robert W. Baird lowered their target price on MongoDB from $390.00 to $300.00 and set an “outperform” rating for the company in a research note on Thursday, March 6th. Nine analysts have rated the stock with a hold rating, twenty-three have issued a buy rating and one has issued a strong buy rating to the company. According to data from MarketBeat.com, the company currently has an average rating of “Moderate Buy” and an average target price of $286.88.
Check Out Our Latest Research Report on MongoDB
MongoDB Stock Performance
MDB traded down $2.24 during midday trading on Friday, reaching $187.12. 2,627,437 shares of the company were exchanged, compared to its average volume of 1,927,996. MongoDB, Inc. has a one year low of $140.78 and a one year high of $370.00. The stock has a market capitalization of $15.19 billion, a P/E ratio of -68.29 and a beta of 1.49. The stock’s 50-day simple moving average is $174.36 and its 200 day simple moving average is $233.50.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The company had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same quarter last year, the business posted $0.86 EPS. On average, research analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Insiders Place Their Bets
In other MongoDB news, CAO Thomas Bull sold 301 shares of the business’s stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total value of $52,148.25. Following the sale, the chief accounting officer now owns 14,598 shares in the company, valued at approximately $2,529,103.50. The trade was a 2.02% decrease in their position. The transaction was disclosed in a legal filing with the SEC, which is accessible through this link. Also, Director Dwight A. Merriman sold 3,000 shares of the business’s stock in a transaction that occurred on Monday, March 3rd. The shares were sold at an average price of $270.63, for a total value of $811,890.00. Following the completion of the sale, the director now owns 1,109,006 shares in the company, valued at $300,130,293.78. The trade was a 0.27% decrease in their position. The disclosure for this sale can be found here. In the last three months, insiders have sold 25,203 shares of company stock worth $4,660,459. Company insiders own 3.60% of the company’s stock.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Discover the top 7 AI stocks to invest in right now. This exclusive report highlights the companies leading the AI revolution and shaping the future of technology in 2025.
MMS • Robert Krzaczynski

Google has released MedGemma, a pair of open-source generative AI models designed to support medical text and image understanding in healthcare applications. Based on the Gemma 3 architecture, the models are available in two configurations: MedGemma 4B, a multimodal model capable of processing both images and text, and MedGemma 27B, a larger model focused solely on medical text.
According to Google, the models are designed to assist in tasks such as radiology report generation, clinical summarization, patient triage, and general medical question answering. MedGemma 4B, in particular, has been pre-trained using a wide range of de-identified medical images, including chest X-rays, dermatology photos, histopathology slides, and ophthalmologic images. Both models are available under open licenses for research and development use, and come in pre-trained and instruction-tuned variants.
Despite these capabilities, Google emphasizes that MedGemma is not intended for direct clinical use without further validation and adaptation. The models are intended to serve as a foundation for developers, who can adapt and fine-tune them for specific medical use cases.
Some early testers have shared observations on the models’ strengths and limitations. Vikas Gaur, a clinician and AI practitioner, tested the MedGemma 4B-it model using a chest X-ray from a patient with confirmed tuberculosis. He reported that the model generated a normal interpretation, missing clinically evident signs of the disease:
Despite clear TB findings in the actual case, MedGemma reported: ‘Normal chest X-ray. Heart size is within normal limits. Lungs well-expanded and clear.
Gaur suggested that additional training on high-quality annotated data might help align model outputs with clinical expectations.
Furthermore, Mohammad Zakaria Rajabi, a biomedical engineer, noted interest in expanding the capabilities of the larger 27B model to include image processing:
We are eagerly looking forward to seeing MedGemma 27B support image analysis as well.
Technical documentation indicates that the models were evaluated on over 22 datasets spanning multiple medical tasks and imaging modalities. Public datasets used in training include MIMIC-CXR, Slake-VQA, PAD-UFES-20, and others. Several proprietary and internal datasets were also used under license or participant consent.
The models can be adapted through techniques like prompt engineering, fine-tuning, and integration with agentic systems using other tools from the Gemini ecosystem. However, performance can vary depending on prompt structure, and the models have not been evaluated for multi-turn conversations or multi-image inputs.
MedGemma provides an accessible foundation for research and development in medical AI, but its practical effectiveness will depend on how well it is validated, fine-tuned, and integrated into specific clinical or operational contexts.
MMS • Daniel Dominguez

At Build 2025, Microsoft announced updates aimed at extending the use of AI agents across Windows, GitHub, Azure, and Microsoft 365. The releases align with the company’s vision for an Agentic Web, where AI agents function more independently across platforms and services.
GitHub Copilot Adds Autonomous Coding Agent
Microsoft announced an upgrade to GitHub Copilot that transforms it from a code suggestion tool into an autonomous agent. The new Copilot agent can be assigned GitHub issues, generate pull requests, and revise code based on user feedback. It works asynchronously by creating isolated development environments, using reasoning to analyze code and propose changes. Security features include respect for branch protections and requirements for human approval before triggering automated workflows. The agent is available for GitHub Copilot Enterprise and Pro+ subscribers.
Windows 11 Integrates Model Context Protocol
Microsoft is integrating the Model Context Protocol (MCP), developed by Anthropic, directly into Windows 11. This allows AI agents to interact with native applications, system services, and external tools. Additionally, Microsoft launched Windows AI Foundry, a framework for running AI models locally on Windows devices. It supports both open-source and proprietary models across CPUs, GPUs, and NPUs, and is intended for use on Copilot+ PCs. These tools are designed to facilitate local AI processing for improved speed and privacy.
Copilot Tuning Offers Low-Code Customization
Microsoft 365 now includes a feature called Copilot Tuning, which allows organizations to tailor AI agents to their internal data and processes using a low-code interface. Built into Copilot Studio, the feature lets users fine-tune models without requiring technical expertise. It supports custom agents built on organizational knowledge, language, and workflows. Copilot Tuning will include prebuilt templates for tasks such as expert Q&A, document generation, and summarization.
Azure AI Foundry Expands Agent Tools
Azure AI Foundry introduced updates aimed at simplifying the development and management of AI agents. The platform now supports models like Grok 3 from xAI, Flux Pro 1.1 from Black Forest Labs, and over 10,000 open-source models via Hugging Face. Developers can fine-tune these models using techniques such as LoRA, QLoRA, and DPO. Foundry Agent Service is now generally available, offering ready-to-use components for secure AI agent creation. Additional tools include a model leaderboard and a router that selects the most appropriate model per task.
Microsoft Discovery Targets Scientific Research
Microsoft unveiled a new platform called Microsoft Discovery, aimed at supporting scientific research using AI agents. The platform is designed to automate steps throughout the research lifecycle, from hypothesis generation to data analysis. Discovery uses modular components and integrates with domain-specific data sources and plugins. It relies on a graph-based knowledge engine to map and analyze relationships across scientific data sets, enabling collaboration between researchers and AI agents on routine and analytical tasks.
Discussions about Microsoft Build 2025 reflect a mix of excitement, skepticism, and frustration, largely centered on the event’s AI-heavy focus, technical demos, and disruptions.
In X, developers expressed excitement about GitHub Copilot’s new agent features, saying
They were thrilled about how it streamlines debugging and coding tasks.
A user on r/AIAssisted was enthusiastic about the agentic web’s potential, particularly praising the revamped GitHub Copilot as an asynchronous coding agent, saying:
It could transform how developers handle tasks like bug fixes, and appreciated Microsoft’s open-sourcing of Copilot Chat in VS Code for collaborative development.
On r/dotnet, a user expressed disappointment, calling Build 2025 noting that even prominent presenters struggled with AI features, and felt Microsoft was overly focused on AI at the expense of other .NET advancements
The era of failed AI demos
Meanwhile Christiaan Brinkhoff, Product and Community Leader for Windows Cloud & AI shared:
This is just the beginning… The future of #AI is being built right now across the cloud, on the edge and on Windows. From working with Windows 11 on the client to #Windows365 in the cloud, we’re building to support a broad range of scenarios, from AI development to core IT workflows, all with a security-first mindset.
In summary, Microsoft’s updates reflect a broader push to embed AI agents across its platforms while supporting open standards and local execution. The company aims to make AI development more accessible and modular, with a focus on practical integration over hype.
MMS • Emerson Murphy-Hill

Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today I’m sitting down with Emerson Murphy-Hill. Emerson, welcome. Thanks for taking the time to talk to us.
Emerson Murphy-Hill: Of course. Happy to be here.
Shane Hastie: My normal starting point with these conversations is who’s Emerson?
Introductions [01:05]
Emerson Murphy-Hill: I’m a research scientist at Microsoft at the moment. I’ve been here eight months, maybe not quite a year. Mostly my career has been working on developer tools and developer productivity and right now focused on AI tools. And in particular, actually at the moment I’m part of the Excel organization at Microsoft. And you might know Excel as the world’s most popular functional programming language sort of on the end user side. But also I’ve got lots of experience on the professional developer side. So before this I was working with Teams working on Visual Studio and VS Code and GitHub.
And then before that I was at Google working on their internal developer tools. They have a big mono repo, so they’ve got some somewhat specialized developer tools there. And in particular on their engineering productivity research team. And before that I was a professor at North Carolina State University researching developer tools. So yes, that’s my background.
Shane Hastie: So let’s tackle the big one first, or one of the big ones first. What is developer productivity?
The Challenge of Measuring Developer Productivity [02:13]
Emerson Murphy-Hill: Yes, so this is a tough question, right? Because I think executives want to measure it. And even as individuals, I think we care about being productive. Me, all the time when I feel like I have a productive workday, I feel really good about myself and I can point to these things that I did or I can just feel like I was in the zone, I was in flow. But of course executives want to know about it too. And especially in the AI world that we live in, lots of people want to know about, if I invest in these AI tools, is that going to pay off in terms of developer productivity? So clearly an important topic.
There’s been lots of different ways to measure it, lots of different frameworks and none of them are just that single number that you want, to say, “This thing is more productive than that thing”. But I think one thing it comes down to is… I would characterize it as two different things. One is about product and one is about process. So in terms of product, what are you outputting? That could be lines of code, that could be features, that could be fixing bugs, and you can measure that in a variety of ways. So you can look at number of lines written per day or you can look at number of pull requests written or you could map that to features.
Again, not the greatest thing in the world. And when I think about what makes me productive, it’s often not the number of pull requests that I’m writing. I think what’s most important to me there when it comes to productivity is just self-reflection. And so at Google for instance, we would do large scale surveys. Actually, Microsoft does this too, where we ask developers about how they’re feeling about their own productivity? And in some way you asking people to self-rate how productive they were. On one hand you look at that and you’re like, “Well, why should we trust people to be able to self-rate?” And how does that allow you to compare across people and across products?
And definitely all those are valid concerns too. But I like to think of humans as entities that are taking in all sorts of signals, ones that are easily observable and ones that are much harder to observe, synthesizing them all together and they can take that all together and their gut feeling about how productive they are, I think all in all, is pretty reliable. And so that’s typically how I think about it, those two aspects.
And some of the work that I’ve done in the past includes looking at the factors that drive developer productivity. There’s, for instance, open offices versus closed offices. I’m in a closed office right now, but there’s open offices just behind me, right? And the industry generally has been shifting to open offices over closed offices to many people’s consternation. But there’s a question of how much open offices changes people’s productivity as opposed to closed. And it’s not obvious, necessarily. Open offices are nice because you chat with your colleagues, sometimes you hear conversations that are relevant to you. That’s just one factor that may influence productivity.
There’s other things like what programming language are you using? How competent is the team of people around you? Are you getting yourself into a lot of technical debt? And so, one of the pieces of research we’ve done is to try to weigh those different factors. So we ran a study at three different companies at Google, ABB, and I’ll send you the link later. I’m forgetting the name of the third company that we did it with.
It’ll probably occur to me in a minute, but a smaller company than those two. And we just asked them a variety of questions about these things that prior research suggests drive productivity and how that actually relates to their self-related productivity, how those two correlate together? And as it might not surprise you, the people factor rose to the top. Things like having psychological safety on your team, turns out it’s a big, strong correlate with productivity.
Other studies we’ve done have revealed some surprises. So for instance, meetings, I think is something that people think a lot about when they think about productivity, right? Meetings slow me down. I certainly have a lot of meetings these days and I feel like if I had less, I’d be more productive. And so there’s questions about, on the other hand, meetings help you get unblocked too, right? They provide you information you wouldn’t have gotten otherwise.
The Impact of Team Dynamics and Psychological Safety [06:35]
And so I think, when you ask people to complain, ask people about what’s slowing them down, a lot of times they’ll say, “I have too many meetings”. But one study we ran at Google, we actually looked at the amount of meetings people had on their calendars and we looked at a few different ways to measure productivity and we looked at how they correlated. And in fact, we had this very clever statistical approach called diff and dip, where you look at changes over time and you look at how the changes correlate, right?
So what you might expect that is if my meeting load increases, my productivity would decrease, at least according to the traditional belief about meetings. And as if my meeting load decreased, my productivity should increase. Well, it turns out that wasn’t true. It turns out there wasn’t a relationship between changes in meeting load and changes in productivity, which contradicts this belief that many people, and myself sometimes, have about the relationship between those two things.
And so this sort of research about productivity has been a big part of my work over the years. And one of the things that I love about working in big tech is we’ve got lots of engineers doing lots of amazing work. And at scale you can study these folks and understand things about productivity. And, like I said, I think we’re all individually, also as engineers, are interested in improving our own productivity and what makes us productive. And so not just interesting, it’s also personally relevant to us all, I think.
Shane Hastie: Where does remote or not factor into that?
Difficulties in Comparing Remote and In-office Productivity [08:14]
Emerson Murphy-Hill: This is a good question. I think that a lot of the research that I did on this was either pre-pandemic or during the pandemic. And I think we did do some research on it during the pandemic. We had this shock where everybody was working in person. In fact, Google at the time was a very in-person company and everybody had to go home, right? It was tough for me personally, right? Because I’m actually, I’m in the office today, I’m a big in-office person even when I don’t have to be.
And I think, I couldn’t tell you what the results were, whether people were more or less productive. But I can tell you what we concluded by looking at this, which was, the change wasn’t just that people were working from home. The change was people’s lives were upended and people were really worried about getting a disease. I mean it wasn’t even the standard work from home, right? At the time, it was working from home, plus our kids are there. We don’t have quite as an efficient setup as we normally would. So it was a very abnormal time.
And then post-pandemic… I haven’t done any research on it since, but we can think about post-pandemic, okay, we’re settling down, we’ve got more of a routine. My kids are back in school, so that’s a plus. I’ve got a pretty good setup. And now if you were to compare people who are in office versus people who are out of office, it’s tougher because now we have a self-selection issue. I would say that people who are working from home more often have gravitated to that, often because they feel that they’re more productive from home. And people like me who are in the office tend to be there because we feel that we’re more productive.
And so differences you might see might be sort of differences in preferences and difference in these types of people. Maybe for lack of a better term, introverts versus extroverts, although that probably doesn’t divide that cleanly along those lines. But differences between the two populations who have self-selected, I think make it quite difficult to compare the groups at the moment. But maybe there’s an opportunity to look at these companies that are forcing people back to the office because then you take out that element of choice.
Although I will say I’m curious about your experience, but what I’ve seen is that at lots of companies, people who have more sway at the company, people in leadership roles can often decide for themselves about whether they’re going to be at home or not, independent of mandate. And also even if you mandate working from office at a high level, often individuals will make their own choices and will cover for each other. And so even if you were to study a back-to-office mandate, I’ll bet actually at many companies, there’s still a large amount of variation from team to team and from company to company.
Shane Hastie: Well certainly what little I’ve seen and discussions in the organizations that are doing the mandates, those folks who would self-select to not be there are often choosing to not be there. And so you end up… I think my take at this point is that we are going to see the organizations for whom people who want to be in the office self-select, and those who are more fluid, self-select to that space.
Emerson Murphy-Hill: Yes, it’s an interesting dynamic, the self-selection too. And I feel we’re also at a weird point in the industry where workers, and engineers included, have less power than they used to have even four or five years ago, right? So the job market for engineers has definitely tightened up. And so five years ago while we might’ve been able to strongly enforce our preferences and if we didn’t want to work in the office and someone was making us, we could easily get a job somewhere else. And that’s definitely become more challenging now. So it’s some combination of what your preferences are of working in office versus working from home, and your ability to move, for which there doesn’t seem to be a lot of options.
Shane Hastie: One of the points that’s been made about remote work, there’s two elements to it that I think you, I know, dig into areas that you’re particularly focused on. The one is being able to work remote actually allows us to be more inclusive and working remote potentially impacts our career growth in that we’re not in the face of our managers. So let’s tackle the equity one there at the beginning to start with. So equity in engineering I know is an area that you are passionate about and interested in. What’s happening there?
Systemic Bias and Inequality in Many Dimensions [13:13]
Emerson Murphy-Hill: Yes, for sure. And I’d love to say I got into this area because it was a deep conviction that I had, but I’ll say I probably just stumbled into it. I’ll give you an example. When I was a professor, I was teaching a graduate level software engineering class and we were talking about diagrams and we were talking about UML diagrams at the time. And a blind student in my class, he raises his hand and he says, “Okay, what am I supposed to do?” And I was like, “Oh no, I actually don’t know what you’re supposed to do. That’s a really good question”.
It was foolish of me for walking into that lecture and not having an answer for what folks who can’t see the squares and the lines on the display, what they’re supposed to do. But it was a moment of reflection for me to think about, “Well, what are these folks supposed to do?” So that student and I ended up going on and writing a research paper about this. He went out and he found a bunch of blind professional engineers, blind and low vision engineers working in industry, and talked to them about what their experience was? How did they work with their colleagues? When they went to the whiteboard, what did the blind colleagues do? What sort of development environments they were using? How were they coding? Were some languages easier than others? And so that was an educational experience for me.
And then also when I was a professor, I was just sitting around as professors do, with some colleagues. And I had been a fan of some of the social science research about equity. In particular, I always thought that these studies where they send out resumes to a bunch of companies and they systematically change the name at the top of the resume, so they change a man’s name to a woman’s name or vice versa, or they change what sounds like a white name to what sounds like a Black name at the top. And then they look at these resumes you send out to a bunch of different jobs. How many people come back and how many interviews are these people offered? They’re fake. They’re not real people, so they don’t actually interview. But you look at how many callbacks, essentially, you get from that.
And sure enough, both in tech and outside for certain types of jobs, women often will get fewer callbacks than ostensibly a man will. I always thought this was really interesting and very good evidence, right? I’m interested in research, I’m interested in data, and I thought it was just really convincing evidence that there’s bias in hiring, for instance. And the hiring is not really my research focus, but what I am interested in is the developer tools.
And so anyway, this other professor and I were sitting around and we were talking about this idea and how it might relate to us. And it just occurred to us that a pull request is something like an interview, where you’re making a judgment about the code or a judgment about the person or a judgment about the resume. And we said, “Well, this thing where you put different people’s names at the top, could you do that with pull requests and would it make any difference?” And we didn’t end up going in an experimental direction. We said, “Well, there’s already a million pull requests out there on GitHub with different people’s names at the top. And does it make a difference if the pull request was authored by a man or authored by a woman?”
And so we did a research project about this and we looked at millions of pull requests and we had this technique where we could connect it with gender data from social media and we could infer people’s genders based on that. And that story was a little bit complicated because it turns out there’s not just a raw difference between genders and acceptance of their pull requests. It turns out it depends on whether you signal your gender through your profile picture. So if you’re a woman and you use a profile picture, your pull request is less likely to be accepted. But if you don’t use a picture, you just use the standard avatar, so you can’t really tell who the person’s gender is, women actually do better than men.
And I thought that’s really interesting. This is congruent with what you would expect from that social science literature, which suggests that there’s some discrimination happening. And certainly congruent with individual people’s experience who I’ve talked to who they get their pull requests rejected. And sometimes women will do that and they’ll say, “It seems like I got more pushback here than I might have if I were a man”, or, “Why was that rejected but this other one was accepted?”
And on an individual level it’s really hard to tell what’s going on, right? Same with job applications. Are you being discriminated against or not? And so the GitHub study was my second foray and I just thought it was a really interesting… Engineering, it’s just a very interesting process to study these social dynamics. And I think what’s especially interesting about engineering is the type of work that we do is, at least at a high level, it’s very well regimented. We do code reviews of each other’s code. A lot of it’s public. Even if it’s private at a large company for instance, it’s typically on some platform, there’s a process, there’s approval, there’s comments, there’s merging. And that sort of structure allows you to look at these social factors in a more structured way than you might be able to otherwise.
And then we did the study on GitHub and I actually joined Google to do something very similar. They were also interested in equity issues in engineering. And so we repeated that study that we did on GitHub inside of Google, and it turned out it was quite a similar thing, as you might expect. They don’t exactly get their pull requests accepted or rejected, but they can have more or less pushback, more or less feedback that has to be addressed. Turns out women tend to get more feedback than men do on their pull requests and it takes longer to get them accepted. It turns out it’s the same for engineers of color.
And I think what the biggest surprise for me was… Maybe not a surprise, but it was about age. And it turns out the older you are, the more pushback you get too. And it’s not about level, how highly leveled you are, because the higher level you are, the less pushback you get, which arguably that could just be about confidence. You’ve been promoted, so you’re probably pretty good at your job. And also the longer you’ve been at a company, the less pushback you get too. Again, I think for similar reasons.
Although that issue of leveling or of tenure, it’s interesting for me to think about, well, is it because these folks who have been there longer are more competent? Or is it just because someone at a higher level, we just defer to them more often? We assume they’re more competent, so we just give them a pass. And in fact, some of the very, very senior engineers that I talk to, a lot of them will say, “I actually can’t get a very fair code review often, because people just assume that I know exactly what I’m doing”.
So in any case, after you control for that, it turns out the older you are, the more pushback you get. And in fact, it was the strongest effect in that study, which is that if you are compared to a new college grad, if you’re 60 year old plus, you’re about three times higher likelihood of having a high pushback code review. Very strong effect there.
I’ll give you maybe one other example of a study within Google where equity in the engineering system comes up. It turns out that not only do folks from historically marginalized groups tend to get more pushback than folks from majority groups, it turns out that those folks also are asked to do fewer code reviews. So women are actually asked to do fewer code reviews than men.
Well, we think part of that, these sort of large scale studies, it’s a little hard to pin it on why exactly. But I think the theory that’s typically used here is role congruity theory, which is are you stereotypically the person who fits into that role? And stereotypically men are engineers. And so when you want someone to review your code, who do you typically think of? Well, you’ll think about people on your team, but you might be a little bit more likely to choose a man. Because if you want to think of a good engineer, you’re just a little bit more likely to think of a man than a woman. That’s the hypothesis anyway.
But it turns out there are also some systemic reasons why this happens too, why people are more likely to select men than women. So one of those reasons is that, at least in the code base we were looking at, it turns out that men were more likely to be owners of the code base that they work with. So different parts of the code base, you can specify different owners, and for many different teams, that means they just choose an owner. So a lot of times people will choose the tech lead, they’ll choose someone senior on the team, but it’s an individual process where you make choices.
And what we know about those choices is that people’s biases inevitably creep in. Any sort of decisions you’re making like that, it’s hard to keep biases out. So what we found is that men were just more likely to be owners. And if you’re an owner, you’re a more, let’s say, useful code reviewer, right? Because any pull request typically either the author or the reviewer has to be an owner. So owners tend to be more useful reviewers. So the way we think about how ownership is assigned, this is a structural way that biases sort of creep in and have downstream consequences.
One engineer gave me an example where she was a tech lead for a team. She was working with four or five other engineers, I think they were all men. And it turns out the rest of the team, they were reviewing each other’s code and they wouldn’t send her a code review very often. It didn’t really bother her very much. In some sense doing more code review is just more work so she could focus on her own thing so it wasn’t such a big deal.
But when the performance review time came around, what happened was is her boss gave her feedback. She said, “You should probably really do more code reviews. It would help you sort of integrate with the team, show more technical leadership”. And she was like, “Ugh, they’re not even sending me the code reviews”. So not doing code reviews ends up sometimes having some negative downstream consequences. So anyway, some research insights into equity in the engineering process.
Shane Hastie: How do we overcome these, what are almost systemic structures?
Anonymous Code Reviews to Avoid Bias [23:49]
Emerson Murphy-Hill: Yes, it’s a great question. So this one about when I’m reviewing someone’s code, am I going to give them more or less feedback depending on their gender? Or am I going to give people more or less feedback for their race or ethnicity? I think that we all consider ourselves good people. I’m not doing it intentionally. I think what we can look at, is we can just look at parallel fields where this happens and what do they typically do about it?
And I think with the code review example, they call it the blind auditions was a good example, where they audition musicians to be in an orchestra and they do it behind a curtain. So you can hear the person doing the audition but you don’t know anything about what they look like. And when they did this originally for this orchestra, they tended to get more women than when they were actually watching the person themselves. So hiding people’s demographics when it’s appropriate to do so.
And in fact, this is something that we did at Google to help with the code review process. And so what we did is we implemented an anonymous code review. So as a reviewer, what you would do is if someone sends you a code review, you wouldn’t see the person’s name at the top of the code review. What you’d see is you’d see actually something like in Google Docs where you see anonymous animal. It would show anonymous aardvark or something, and you would just try to review the code.
And we did a study about this where we ran it with a few hundred engineers. We had them do it for a couple of weeks, and we looked at some of the engineering outcomes to see whether it was really harmful to an engineering process, whether it slowed people down. You imagine it might, right? Because if you know who it is, you can make some certain assumptions. Whether that’s a good idea or not is another question, what they know and what they don’t know.
And so what we found is actually it didn’t significantly slow down the engineering process. People reviewed the code with approximate thoroughness. It took them about the same amount of time to do it. There was a little evidence that actually they were a little bit more thorough. There’s a way that we could link these changes to rollbacks. When there was a pull request that went bad, sometimes they had to roll it back. It turned out for the anonymous code reviews, they were a little less likely to be rolled back than the ones where people could see people’s identities. Now, we don’t know whether we solved the equity issue. We just didn’t have enough people to know, necessarily. But we showed that it’s pretty feasible to not show the authors’ names at the top of the code review.
One of the things we did learn though, is that occasionally people do really need to know who wrote the code. So for certain types of security changes, you want to make sure that people aren’t giving themselves access to something that they shouldn’t have. But it turned out these types of changes where you really need to know who the author is, they’re pretty rare. And we found out, I think less than 5% of the cases that people need to do that. And in fact, what we implemented in the anonymous code review tool is there was just a button you could press, just two clicks, and it would show you who the person is.
And so the idea there, is lots of these systems where the default way of doing the process is a way that’s anonymous, but if you really need to break the glass, go ahead. But it turned out it doesn’t happen very often. So it’s not a huge deal. As far as I know, today at Google, they still have anonymous code review as option as a way that you can review each other’s code and it’s still being practiced in certain parts of the code base where it’s a good place to do that, where you don’t necessarily even know who the author or who the reviewer is.
Shane Hastie: It’s almost impossible to have a conversation today without talking about AI and equity and bias in AI. What do we need to do with that in terms of developer tools?
AI Tools and Equity in Engineering [27:47]
Emerson Murphy-Hill: Yes, I think there’s some interesting opportunities and challenges here. My engineering, on a day-to-day basis, I feel like I’m really enjoying, sorry to prop Microsoft’s own product here, but I’m really enjoying working in VS Code with agent mode. I can specify what I want at a high level and the agents go and do it. And it doesn’t always get me what I want but, back to productivity, I do feel more productive while I’m doing it. I like being able to ask dumb questions essentially to different Copilots and say, “It feels like it’s too late to ask, but I don’t know what this acronym means”.
And so I think there are some equity, again, opportunities and challenges here. So one of the opportunities I would say, is a study that we did at Google, we asked people about reaching out and asking questions to others. And we asked it to folks at different groups. And folks from historically marginalized groups said that they were somewhat less likely to want to ask for help in a semi-public forum. So Google has an internal system that’s something like Stack Overflow. People can ask questions. It’s highly encouraged.
And with some people from marginalized groups, women for example, told us is, “It doesn’t feel like people are always treated respectfully on those. And I don’t want to subject myself to that. And also I don’t want to… If that does happen to me, and it may not, but if that does happen to me, I don’t want it to be there permanently for my manager to see or for some other person at the company to see. I don’t want it to be such a permanent fixture”.
And questions and the answers are supposed to be permanent so that other people can learn. But this dynamic means that folks from marginalized groups, if they’re less comfortable asking questions like this, then they’re not as productive as they could be. I know for myself, a lot of times I don’t ask questions as soon as I should, and I’m really nervous about it and I’m nervous about looking dumb. And so you really need to have an engineering environment where it’s easy to ask questions. And if the engineering systems are getting in the way or making it harder for me to ask questions, that’s just going to slow down engineering.
And so what this has to do with folks from historically marginalized groups, if people are less likely to ask these questions, then that’s going to be a problem. And in terms of AI, what I love about Copilot is that my questions are not visible to other people. No one else can see it. It’s just me. I feel very comfortable. And so I think an opportunity here is, I think it will allow people who wouldn’t normally be super comfortable asking questions in a public setting or even in a private setting with just a few colleagues can get those questions answered.
And I think there’s a secondary opportunity, which is when asking those questions to a Copilot first before you ask a colleague often feels like a good step, just like Googling something is a good step. It shows you put in some work. It also demonstrates that it’s not a dumb question. If you can’t find it via Googling and you can’t find it via a large language model, it gives you some confidence that asking a person is not going to be embarrassing. So I think that as the models get better and better, I think this is a great opportunity for equity to increase in our engineering environment.
Just to give you an example of something that I worry about with AI, is how people who are using AI are treated. So I’ll give you an example. Just this week I’m talking to my manager and talking about this change that I’m making, and I’m saying, “I don’t know, this change seems to work not a hundred percent. Claude 3.7 helped me write it”.
Now, if you were my manager and you heard me say that, what do you think about that? Does that make me a competent engineer because I’m relying on the best possible AI tools that are out there? Or does that make me lazy? Because I’m not certain, does that make me a bad engineer because I wasn’t able to verify it? And maybe you’re thinking I’m not competent enough to write my own code, I have to get AI to do it for me.
Those are two possible views, and your actual view might be somewhere in between. But my worry is that the way you think about my use of AI depends on my demographics and depends on what you think about me as a competent engineer. So what I worry about is if I were a woman and I said that you would think, “Oh, she doesn’t know what she’s doing. This is a crutch for her”. Whereas if I’m a man, I think you’re a little bit more likely to say, “Oh, he’s just doing best practices here”.
So I think those sorts of inequities, it’s not really the AI that’s causing it, but because there’s uncertainty around AI, I worry about these social phenomenons that we’ve seen in code review and we see in meetings. I’m worried that they’re exacerbated and AI is just going to prod further inequities like that.
Shane Hastie: I will confess, the first time I used AI tools to do real work, I felt like I was cheating.
Emerson Murphy-Hill: Yes, it’s magic, right? Many, many times. And it feels like it’s not real work, but you’re going to save. When you can get a job done faster, it’s hard to argue with that, right?
Shane Hastie: For sure. Emerson, some really interesting points, really good conversation here. If people want to continue the conversation with you, where do they find you?
Emerson Murphy-Hill: Yes, find me on LinkedIn for sure. I haven’t updated my public webpage in a while, but if you find any of my papers, my email address is at the top of it. But yes, feel free to reach out, happy to talk. You can certainly find the research papers that we’ve talked about. Maybe we can link to them in the show notes, but you can also find them on Google Scholar, for instance.
Shane Hastie: Wonderful. Well, thank you so much for taking the time to talk to us today.
Emerson Murphy-Hill: Of course. Thanks, Shane.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw unusually large options trading activity on Wednesday. Traders bought 23,831 put options on the stock. This is an increase of 2,157% compared to the average daily volume of 1,056 put options.
MongoDB Price Performance
Shares of NASDAQ:MDB opened at $188.45 on Thursday. The company’s fifty day moving average price is $174.52 and its 200-day moving average price is $234.21. The firm has a market capitalization of $15.30 billion, a price-to-earnings ratio of -68.78 and a beta of 1.49. MongoDB has a one year low of $140.78 and a one year high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). The company had revenue of $548.40 million during the quarter, compared to the consensus estimate of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same period in the previous year, the company earned $0.86 EPS. As a group, equities research analysts expect that MongoDB will post -1.78 EPS for the current year.
Wall Street Analyst Weigh In
A number of research analysts have recently weighed in on the stock. KeyCorp downgraded shares of MongoDB from a “strong-buy” rating to a “hold” rating in a research report on Wednesday, March 5th. Barclays reduced their target price on shares of MongoDB from $280.00 to $252.00 and set an “overweight” rating for the company in a research report on Friday, May 16th. UBS Group set a $350.00 target price on shares of MongoDB in a research report on Tuesday, March 4th. Oppenheimer reduced their target price on shares of MongoDB from $400.00 to $330.00 and set an “outperform” rating for the company in a research report on Thursday, March 6th. Finally, Citigroup reduced their target price on shares of MongoDB from $430.00 to $330.00 and set a “buy” rating for the company in a research report on Tuesday, April 1st. Nine analysts have rated the stock with a hold rating, twenty-three have given a buy rating and one has given a strong buy rating to the company. Based on data from MarketBeat, MongoDB presently has a consensus rating of “Moderate Buy” and an average price target of $286.88.
Check Out Our Latest Stock Report on MDB
Insider Transactions at MongoDB
In other MongoDB news, CFO Srdjan Tanjga sold 525 shares of the company’s stock in a transaction dated Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $90,961.50. Following the completion of the sale, the chief financial officer now directly owns 6,406 shares of the company’s stock, valued at approximately $1,109,903.56. This represents a 7.57% decrease in their position. The sale was disclosed in a document filed with the SEC, which is accessible through the SEC website. Also, Director Dwight A. Merriman sold 3,000 shares of the company’s stock in a transaction dated Monday, March 3rd. The stock was sold at an average price of $270.63, for a total transaction of $811,890.00. Following the completion of the sale, the director now directly owns 1,109,006 shares of the company’s stock, valued at $300,130,293.78. The trade was a 0.27% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold a total of 25,203 shares of company stock valued at $4,660,459 over the last three months. Corporate insiders own 3.60% of the company’s stock.
Hedge Funds Weigh In On MongoDB
Institutional investors have recently made changes to their positions in the stock. Strategic Investment Solutions Inc. IL bought a new position in shares of MongoDB in the 4th quarter worth $29,000. Cloud Capital Management LLC bought a new position in shares of MongoDB during the 1st quarter valued at $25,000. NCP Inc. bought a new position in shares of MongoDB during the 4th quarter valued at $35,000. Hollencrest Capital Management bought a new position in shares of MongoDB during the 1st quarter valued at $26,000. Finally, Cullen Frost Bankers Inc. grew its holdings in shares of MongoDB by 315.8% during the 1st quarter. Cullen Frost Bankers Inc. now owns 158 shares of the company’s stock valued at $28,000 after purchasing an additional 120 shares during the last quarter. Institutional investors own 89.29% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

MarketBeat just released its list of 10 cheap stocks that have been overlooked by the market and may be seriously undervalued. Enter your email address and below to see which companies made the list.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw unusually large options trading activity on Wednesday. Investors acquired 36,130 call options on the stock. This is an increase of 2,077% compared to the average daily volume of 1,660 call options.
Insiders Place Their Bets
In other news, CEO Dev Ittycheria sold 18,512 shares of the firm’s stock in a transaction dated Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $3,207,389.12. Following the transaction, the chief executive officer now directly owns 268,948 shares in the company, valued at approximately $46,597,930.48. This trade represents a 6.44% decrease in their position. The transaction was disclosed in a filing with the SEC, which can be accessed through the SEC website. Also, CAO Thomas Bull sold 301 shares of the firm’s stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the transaction, the chief accounting officer now owns 14,598 shares in the company, valued at approximately $2,529,103.50. The trade was a 2.02% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold a total of 25,203 shares of company stock valued at $4,660,459 in the last ninety days. Corporate insiders own 3.60% of the company’s stock.
Institutional Inflows and Outflows
Several institutional investors have recently made changes to their positions in the company. Vanguard Group Inc. increased its position in shares of MongoDB by 6.6% in the first quarter. Vanguard Group Inc. now owns 7,809,768 shares of the company’s stock worth $1,369,833,000 after acquiring an additional 481,023 shares in the last quarter. Franklin Resources Inc. increased its position in shares of MongoDB by 9.7% in the fourth quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock worth $478,398,000 after acquiring an additional 181,962 shares in the last quarter. UBS AM A Distinct Business Unit of UBS Asset Management Americas LLC increased its position in shares of MongoDB by 11.3% in the first quarter. UBS AM A Distinct Business Unit of UBS Asset Management Americas LLC now owns 1,271,444 shares of the company’s stock worth $223,011,000 after acquiring an additional 129,451 shares in the last quarter. Geode Capital Management LLC increased its position in shares of MongoDB by 1.8% in the fourth quarter. Geode Capital Management LLC now owns 1,252,142 shares of the company’s stock worth $290,987,000 after acquiring an additional 22,106 shares in the last quarter. Finally, Amundi increased its position in shares of MongoDB by 53.0% in the first quarter. Amundi now owns 1,061,457 shares of the company’s stock worth $173,378,000 after acquiring an additional 367,717 shares in the last quarter. 89.29% of the stock is owned by hedge funds and other institutional investors.
MongoDB Price Performance
Shares of MDB opened at $188.45 on Thursday. The firm’s 50 day moving average is $174.52 and its 200-day moving average is $234.21. The stock has a market capitalization of $15.30 billion, a P/E ratio of -68.78 and a beta of 1.49. MongoDB has a 12-month low of $140.78 and a 12-month high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). The business had revenue of $548.40 million during the quarter, compared to analyst estimates of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same period in the prior year, the firm earned $0.86 EPS. As a group, equities research analysts forecast that MongoDB will post -1.78 EPS for the current fiscal year.
Wall Street Analysts Forecast Growth
A number of research firms have recently issued reports on MDB. Citigroup reduced their price target on shares of MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a research report on Tuesday, April 1st. Robert W. Baird reduced their price target on shares of MongoDB from $390.00 to $300.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. Wedbush reduced their price target on shares of MongoDB from $360.00 to $300.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. Monness Crespi & Hardt upgraded shares of MongoDB from a “sell” rating to a “neutral” rating in a research report on Monday, March 3rd. Finally, Morgan Stanley reduced their price target on shares of MongoDB from $315.00 to $235.00 and set an “overweight” rating on the stock in a research report on Wednesday, April 16th. Nine investment analysts have rated the stock with a hold rating, twenty-three have issued a buy rating and one has assigned a strong buy rating to the stock. According to MarketBeat, the stock currently has a consensus rating of “Moderate Buy” and an average price target of $286.88.
Check Out Our Latest Stock Analysis on MDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Unlock the timeless value of gold with our exclusive 2025 Gold Forecasting Report. Explore why gold remains the ultimate investment for safeguarding wealth against inflation, economic shifts, and global uncertainties. Whether you’re planning for future generations or seeking a reliable asset in turbulent times, this report is your essential guide to making informed decisions.
MMS • Karsten Silz

Broadcom recently launched Spring Boot 3.5 and various Spring projects, and is working on Spring Framework 7.0 and Spring Boot 4.0 for a November 2025 debut.
Null safety in Java has recently been a special area of interest. JEP Draft 8303099, Null-Restricted and Nullable Types (Preview), is a work-in-progress and not yet a candidate for inclusion in an upcoming JDK release at this time. However, the JSpecify initiative, consisting of member organizations such as: Google (lead), Spring, JetBrains, among others, provides standard annotations for Java static analysis.
InfoQ spoke with Broadcom’s Sébastien Deleuze, Spring Framework Core Committer, and Michael Minella, Director of the Open-Source Support Spring team. They answered questions on handling the Java AOT cache, finding libraries with JSpecify support, and the recent changes to the Spring support policy.
InfoQ: Users often deploy Spring Boot applications as container images stored in a registry. However, to start applications faster with Project Leyden’s JEP 483, users must also store and distribute at least one Ahead-Of-Time (AOT) cache file for each container image. What are some best practices for that?
Sébastien Deleuze: Spring Boot is flexible here. It provides an extract command to unpack an executable JAR, which can be used with a Class Data Sharing (CDS) or AOT cache.
AOT cache will soon support an “express warmup” with JEP 515, Ahead-of-Time Method Profiling, proposed for Java 25, and JEP Draft Ahead-of-Time Code Compilation. The profiling data should come from an instance with realistic workload, potentially from production. The AOT cache will then not necessarily ship within the container image, and the integration will likely happen at the platform level. For example, we are integrating the AOT cache with Spring AOT in Tanzu Platform and Tanzu Spring to optimize Spring applications automatically.
As for shipping the cache within the container image, Spring Boot uses open-source Buildpacks to create container images. They can automatically do the training run with CDS and ship the resulting cache file within the container image. The AOT cache could ship the same way. It is worth noticing that unlike OpenJDK Project CRaC, CDS and AOT cache do not dump the raw Java process memory, avoiding the risk of leaking secrets or passwords. A best practice is to use a dedicated top-level container layer for the AOT cache, benefitting from caching the application layer and below.
InfoQ: The JSpecify initiative defines the semantics of null safety in Java and standardizes code annotations like @Nullable or @NonNull. Starting with Spring Boot 4.0, all Spring portfolio projects will eventually use JSpecify. But how does a Spring developer know which non-Spring libraries use JSpecify?
Deleuze: There is not yet a canonical place for libraries using JSpecify. But it’s an interesting idea we will share with the working group. Outside of Spring, we have seen Google, Gradle, and GraphQL adding JSpecify annotations to their libraries.
There are three key points regarding JSpecify adoption:
First, JSpecify defines three kinds of nullness: nullable (@Nullable annotation), non-null (@NonNull annotation), and unspecified (Java default). The Java default behavior applies to libraries that do not specify the nullness of their APIs. This works well when mixing null-safe and null-unsafe code, especially when null-safe APIs use null-unsafe libraries.
Second, the granularity can be more specific than a whole library. The @NullMarked annotation is typically used at the package level to declare non-null type usage by default. Nullable type usage is then marked explicitly with @Nullable. A library can progressively add null safety this way, even at the class or method level.
Finally, JSpecify has an ongoing effort to define the nullness of the JDK itself more comprehensively, as only a subset of its APIs has nullness specified.
InfoQ: The last release of a Spring Boot generation is an LTS release. Spring Boot 2.7 from May 2022 got 18 months of free updates (“OSS support”) and more than 4.5 years of paid updates (through enterprise support). Spring Boot 3.5 will only get 13 months of free updates but more than 7 years of paid ones. Why?
Michael Minella: We make minor version upgrades as simple as possible. But because a major version upgrade makes a larger ask, we have always given it more time. For instance, Spring Boot 2.7 launched in May 2022 with 18 months of OSS support and another 15 months of enterprise support. In contrast, Spring Framework 5.3, the main dependency of Spring Boot 2.7, had 50 months of OSS support and another 24 months of enterprise support. Our policy was inconsistent across the portfolio, and we wanted to do better.
So, we updated our support policy in February 2025 with two major changes. First, all support timelines now align with Spring Boot. Historically, support timelines across the portfolio depended upon the release date – different projects had different support dates. In the future, users only need to know Spring Boot’s support dates: OSS support is 13 months past the Spring Boot release it aligns with, and enterprise support is 12 months past that (both rounded to the end of the month). This standardizes support durations across the portfolio and leaves only two support timeline dates: June 30 and December 31. We are currently updating the website to make it clearer.
Second, we created a unified LTS policy instead of each project doing its own: The last minor version of a major generation, like 3.5, gets five years of additional enterprise support (on top of the 13 months of OSS support and one year regular enterprise support). This provides users with over seven years of total support timeline, the longest we have ever offered.
Over the years, our community has made it clear they need more time for a major upgrade. By providing significantly more support overall and simplifying things, we meet the community’s needs in the most sustainable way possible. Based on the feedback so far, the community agrees.
Developers can learn more about null-restricted and nullable types in this InfoQ news story and JSpecify 1.0.0 in this InfoQ news story. This InfoQ news story describes JEP 483, Ahead-of-Time Class Loading & Linking, the first deliverable of Project Leyden.