Month: May 2025

MMS • Daniel Dominguez
Mistral AI announced the release of Devstral, a new open-source large language model developed in collaboration with All Hands AI. Devstral is aimed at improving the automation of software engineering workflows, particularly in complex coding environments that require reasoning across multiple files and components. Unlike models optimized for isolated tasks such as code completion or function generation, Devstral is designed to tackle real-world programming problems by leveraging code agent frameworks and operating across entire repositories.
Devstral is part of a new class of agentic language models, which are designed not just to generate code, but to take contextual actions based on specific tasks. This agentic structure allows the model to perform iterative modifications across multiple files, conduct explorations of the codebase, and propose bug fixes or new features with minimal human intervention. These capabilities are aligned with the demands of modern software engineering, where understanding project structure and dependencies is as important as writing syntactically correct code.
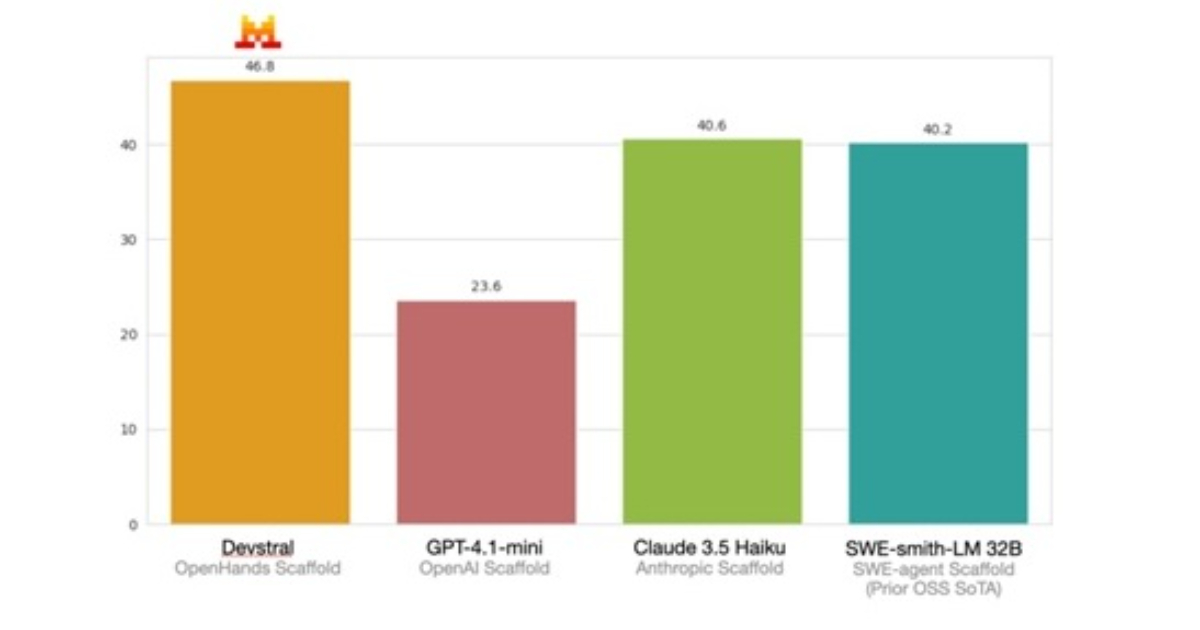
According to Mistral’s internal evaluations, Devstral achieves a performance score of 46.8% on SWE-Bench Verified, a benchmark composed of 500 manually screened GitHub issues. This score places it ahead of previously published open-source models, surpassing them by over six percentage points. The benchmark tests not only whether models can generate valid code but whether that code actually resolves a documented issue in a real project. When compared on the same OpenHands framework, Devstral outperforms significantly larger models such as Deepseek-V3-0324, which has 671 billion parameters, and Qwen3 232B-A22B, highlighting the model’s efficiency.
Devstral was fine-tuned from the Mistral Small 3.1 base model. Before training, the vision encoder was removed, resulting in a fully text-based model optimized for code understanding and generation. It supports a long context window of up to 128,000 tokens, allowing it to ingest large codebases or extended conversations in a single pass. With a parameter size of 24 billion, Devstral is also relatively lightweight and accessible for developers and researchers. The model can run locally on a consumer-grade GPU such as the NVIDIA RTX 4090, or on Apple Silicon devices with 32GB of RAM. This lowers the barrier to entry for teams or individuals working in constrained environments or handling sensitive codebases.
Mistral has made Devstral available under the permissive Apache 2.0 license, which allows both commercial and non-commercial use, as well as modifications and redistribution. The model can be downloaded through various platforms including Hugging Face, LM Studio, Ollama, and Kaggle. It is also accessible via Mistral’s own API under the identifier devstral-small-2505.
Community feedback reflects a mix of excitement and critical evaluation. Product Builder, Nayak Satya commented:
Another promising enhancement from Mistral. This company is silently building some great additions for AI space. Europe is not far behind in AI when Mistral stands tall. Meantime can it be added inside VS studio or any modern IDE’S folks?
On Reddit’s r/LocalLLaMA, users praised Devstral’s performance, user Coding9 posted:
It works in Cline with a simple task. I can’t believe it. Was never able to get another local one to work. I will try some more tasks that are more difficult soon!
Although Devstral is released as a research preview, its deployment marks a step forward in the practical application of LLMs to real-world software engineering. Mistral has indicated that a larger version of the model is already in development, with more advanced capabilities expected in upcoming releases. The company is inviting feedback from the developer community to further refine the model and its integration into software tooling ecosystems.
MMS • RSS
GF Fund Management CO. LTD. purchased a new position in MongoDB, Inc. (NASDAQ:MDB – Free Report) in the 4th quarter, according to its most recent Form 13F filing with the Securities and Exchange Commission. The fund purchased 14,000 shares of the company’s stock, valued at approximately $3,259,000.
Other large investors have also recently made changes to their positions in the company. B.O.S.S. Retirement Advisors LLC bought a new position in MongoDB in the fourth quarter worth about $606,000. Union Bancaire Privee UBP SA purchased a new position in shares of MongoDB in the 4th quarter worth approximately $3,515,000. HighTower Advisors LLC raised its stake in shares of MongoDB by 2.0% during the 4th quarter. HighTower Advisors LLC now owns 18,773 shares of the company’s stock worth $4,371,000 after acquiring an additional 372 shares in the last quarter. Nisa Investment Advisors LLC lifted its position in MongoDB by 428.0% during the fourth quarter. Nisa Investment Advisors LLC now owns 5,755 shares of the company’s stock valued at $1,340,000 after acquiring an additional 4,665 shares during the last quarter. Finally, Jones Financial Companies Lllp lifted its position in MongoDB by 68.0% during the fourth quarter. Jones Financial Companies Lllp now owns 1,020 shares of the company’s stock valued at $237,000 after acquiring an additional 413 shares during the last quarter. 89.29% of the stock is owned by institutional investors.
MongoDB Price Performance
MDB opened at $185.85 on Friday. The firm has a fifty day moving average price of $174.70 and a 200 day moving average price of $235.98. MongoDB, Inc. has a 1 year low of $140.78 and a 1 year high of $370.00. The stock has a market cap of $15.09 billion, a P/E ratio of -67.83 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The firm had revenue of $548.40 million during the quarter, compared to analysts’ expectations of $519.65 million. During the same period in the previous year, the firm posted $0.86 EPS. Equities analysts expect that MongoDB, Inc. will post -1.78 EPS for the current year.
Insider Buying and Selling
In other MongoDB news, insider Cedric Pech sold 1,690 shares of the stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $292,809.40. Following the transaction, the insider now directly owns 57,634 shares of the company’s stock, valued at $9,985,666.84. This trade represents a 2.85% decrease in their ownership of the stock. The transaction was disclosed in a document filed with the SEC, which is accessible through this hyperlink. Also, CEO Dev Ittycheria sold 18,512 shares of the business’s stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $3,207,389.12. Following the sale, the chief executive officer now directly owns 268,948 shares of the company’s stock, valued at $46,597,930.48. This represents a 6.44% decrease in their position. The disclosure for this sale can be found here. In the last 90 days, insiders sold 33,538 shares of company stock valued at $6,889,905. 3.60% of the stock is owned by company insiders.
Wall Street Analyst Weigh In
A number of equities analysts have recently issued reports on MDB shares. The Goldman Sachs Group reduced their price target on MongoDB from $390.00 to $335.00 and set a “buy” rating on the stock in a research report on Thursday, March 6th. Canaccord Genuity Group reduced their target price on MongoDB from $385.00 to $320.00 and set a “buy” rating on the stock in a research report on Thursday, March 6th. Loop Capital downgraded MongoDB from a “buy” rating to a “hold” rating and lowered their price target for the stock from $350.00 to $190.00 in a report on Tuesday, May 20th. Cantor Fitzgerald initiated coverage on shares of MongoDB in a report on Wednesday, March 5th. They set an “overweight” rating and a $344.00 price objective on the stock. Finally, Truist Financial decreased their price objective on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating for the company in a research report on Monday, March 31st. Nine analysts have rated the stock with a hold rating, twenty-three have given a buy rating and one has issued a strong buy rating to the stock. According to data from MarketBeat.com, the stock has an average rating of “Moderate Buy” and an average target price of $288.91.
Check Out Our Latest Analysis on MDB
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Just getting into the stock market? These 10 simple stocks can help beginning investors build long-term wealth without knowing options, technicals, or other advanced strategies.
MMS • Jordan Miller

Transcript
Miller: It was a cold, dark night in New York City. Rich Hickey pondered in his study, frustrated with complexity, mutated state, never-ending inherited boilerplate. He suspected there could be a better way, without sacrificing power, performance, or changing of state. He admired functional programming philosophies, but was interested to see if they could be applied more practically. Because Lisps were uncommon academically, they were born in the dungeon of MIT. Schemeing on recursion and list processing, but humans are chaotic, and our data, it reflects that. Sequential data, linked lists, good to teach theoretically, but for production, not a reality. Associative structures, hashmaps, like an array, are more authentic. Rich thought, maybe this was the way.
Speaking of humans living chaotically, this time back in 2007 in Washington, D.C., I was a young, creative rebel, frustrated with authority. The only class for me was the one I skipped, or the CSS for my MySpace pics. I didn’t believe that STEM was for me. I thought math was difficult, and the answers eluded me. When it came time to choose a path academically, I chose the school of hard knocks into grateful dead university. Years of meetups and talks and blogs and YouTubes and slides, Clojure had proved itself, scaled up in size. The community swelled, excited with hope. Simple made easy was finally in scope.
Meanwhile, back in central PA, a dreadheaded vagabond was not doing ok. It turns out my plan of selling grilled cheese on lot wasn’t actually as compelling or lucrative or legal as I thought. Jobs weren’t careers, and the hours sure sucked. My brain was so bored, but then in walked some luck. “You’re looking for something lucrative and fun? Have you tried programming?” My experience level was none. “This fire new book just dropped. It’s for people like you. It’s called, ‘Clojure for the Brave and True.'” I started to listen. What’s a todo? What do you mean just join the Slack, read some books, eval, apply, and get cool? Fast forward 2019.
November days in PA were getting colder and shorter. I found fun hacking away, putting data in order. I was poking around in the Clojurian Slack, when it was Alex Miller who answered me back. “No more opportunity grant stipends for the conj, I’m afraid, but I’m happy to gift you a ticket. No need to pay. I hope you enjoy our humble programming group. Please remember to apply for a grant for my conference, StrangeLoop”. I had no idea the effects this would have. Maybe Alex did. He is Clojure’s cool dad. I met folks. I took notes, for loop, friends forever. I learned things. I earned wings talking about compile errors. I got a job. I flew away, finally free from my cage.
Background
My name is Jordan, also known as lambduhhh. In addition to the zillion projects I have going on, lately I’ve just been writing music. When I sat down to write the hook intro for this, it came out like that. I just decided to run with it. I think it went well, somewhere between The Night Before Christmas and Dr. Seuss, I think.
Understanding Curiosity
How many of you feel confident that you know the core philosophies of Clojure? Anybody confident enough to explain to a junior dev, to a child, of the two? Let’s explore how curiosity can turn that hesitation into confidence. Whether you’re new to Clojure or you’re an experienced Clojurian, this talk is about how curiosity drives growth, both for individuals and entire ecosystems. It’s about how asking the right questions and seeking feedback and embracing uncertainty can transform overconfidence into wisdom, and complexity into simplicity. This is something we do in Clojure land, we love to be pedantic and define words. It’s just our thing. Let’s start with understanding curiosity.
The Latin root of curiosity is curiosus, meaning careful, diligent, or eager to know. It suggests intentional attention and care, and a focused effort to understand. I actually really love this definition. I love Brené Brown. She’s just awesome. She expands on this in her book, “Atlas of the Heart”. She defines curiosity as recognizing a gap in our knowledge about something that interests us and then becoming emotionally and cognitively invested in closing that gap through exploration and learning. It starts with interest, and it can go from mild curiosity to passionate investigation rabbit holes. It’s about vulnerability and courage and the willingness to engage with uncertainty and risk and go somewhere you don’t know. Together, these definitions show us that curiosity isn’t just passive wonder. It’s an active commitment to seeking understanding and growth. Curiosity is what bridges the gap between what we know, what we don’t know, and what we don’t realize that we don’t know. I’m going to explore that journey with you.
Outline
First, we’re going to talk about Rich Hickey and the evolution of the Clojure ecosystem. Then I’m going to talk about my personal story of learning, failure, growth, all the good stuff. Then I’m going to do a showcase of the mature Clojure ecosystem. That’s going to be the actionable part. That’s really going to drive home how maturity can drive curiosity, and vice versa.
Rich Hickey and the Evolution of the Clojure Ecosystem
Rich Hickey was working as a software developer, navigating the same issues many of you have faced. Immutable state causing frustrating, hard-to-reproduce bugs. Concurrency becoming essential, but it was still difficult and error-prone. Nobody knew how to reason about it. Then, endless boilerplate code in languages like Java with inheritance hierarchies. OO really promised this reusability, but in reality, you didn’t get to reuse anything. You had to redefine everything. It was adding complexity instead of reducing it. Developers were immediately drawn to the potential, like immutability, concurrency, Lisp for the JVM. Some of you all were all here. The early adopters were passionate. For a while, it felt like Clojure could solve everything. As the excitement grew, so did the tension. Developers had very strong opinions about what they wanted Clojure to become.
In 2009, Rich responded with a now famous essay, “Open Source is Not About You”. In it, he reminded everybody of the purpose of open source. It’s about the software, it’s not about individual expectations. It’s about a way to share ideas and solutions, but it’s not a guarantee that every request will be implemented. This essay was pretty polarizing. It did set the tone for how Clojure would evolve. Like, not through satisfying every demand or trying to become popular, but staying focused on the core philosophy of simplicity and practicality. Rich’s response shows us another kind of curiosity.
A curiosity to ask, what makes open source sustainable in the long run? His essay helped clarify that Clojure wasn’t chasing clout or trying to gain popularity. It was about solving real problems and being used in a very real way. This moment really marked a critical turning point. It helped align the community around Clojure’s core philosophy and its principles: simplicity, immutability, power, focus. It reflected something that we see that’s bigger, a pattern we see with pretty much almost every piece of new technology, the rise of the hype. The cycle starts with this Peak of Inflated Expectations, where the hype runs high, everyone thinks the new technology is going to solve all these problems.
Then, reality sets in, the Trove of Disillusionment, where challenges emerge, things get more real, and excitement fades. A lot of technologies don’t move on past this stage. If you have a technology with staying power, like you have curiosity, perseverance, it can lead to refinement, where tools, libraries, communities come together and start supporting and getting closer to the promise that technology made in the beginning. At the end goes the Plateau of Productivity, where the technology becomes a trusted tool in the domain. Clojure’s journey aligns almost perfectly with this curve.
As the initial excitement faded, developers started to question Clojure. Is it too niche? Lisp, isn’t that academic? What is with the parentheses? Can it scale? Many developers found functional programming unfamiliar, and the Lisp syntax, like the prefix notation, was just too much. Clojure’s growth slowed. That’s when we entered the Trove of Disillusionment. Some of these critiques showed up on Hacker News. I think some of those threads were called like, is Clojure dead? They said things like, Clojure isn’t the most beginner-friendly language, which is true. However, Rich remained steadfast. In 2011, he delivered his influential talk, Simple Made Easy, where he emphasized the distinction between simplicity and ease, and the importance of managing complexity through immutable data structures and pure functions, keeping it functional.
This talk was huge in reshaping perceptions and encouraging developers to see Clojure not as a complex tool, but as a means to achieve simplicity. This really laid the groundwork for the Slope of Enlightenment. During this period, Rich also teamed up with the core team and Stu Halloway to develop Datomic, an immutable, time-aware database that’s the ideological extension of Clojure. Clojure is open source. If Clojure had a product baby and it was a database, that’s Datomic. It was released in 2012. It’s all the same thing: simplicity, immutability, power, focus, and thinking about data as a first-class citizen.
Today, Clojure is a mature, trusted language powering mission-critical systems across industries like finance, healthcare, and e-commerce. In 2020, Nubank acquired Cognitect, which is the consultancy and the core team behind Clojure and Datomic. That solidified its place in enterprise development. It’s not just an academic experiment. This is solving real-world problems at scale. The ecosystem has grown to include beginner-friendly tools like Babashka for scripting. We just talked about Datomic, which is a little bit more advanced. Clojure’s journey through the Gartner Hype Cycle reflects how curiosity and persistence can transform hype into sustained innovation.
Personal Story of Learning, Failure, and Growth
What’s the point of this talk? Just as curiosity shaped Clojure’s journey, it shaped mine too. When I started programming, I wasn’t thinking about immutability, simplicity, or best practices. I knew nothing. I was thinking about survival. I was thinking about finding something that could bring stability to my life, and growth. Just like Clojure, my path also wasn’t a straight line. It was messy. It’s been humbling. It’s been full of lessons that I didn’t even realize that I needed at the time. How many of you have ever thought, I got this, be cake, only to discover later that maybe you didn’t got this? Glad we’re in the same, got to humble it down. When I first started programming, I wasn’t even sure I was programming. Like I said, I was just making my MySpace pics look pretty. I didn’t think that STEM was for me. I thought programming was something that genius people did, and math seemed really out of reach.
Part of that probably had to do with the fact that I didn’t have the discipline to do the homework. My only exposure was passively in class. Looking back, hindsight is 20-20 on that one. Because of all that, I went into another direction. For years, I didn’t touch code. I didn’t own a computer. I just thought I wasn’t smart enough to belong in tech. Fast-forward to my mid-20s, when I realized that I needed a career that was stable and challenging. I was working as a bartender, and it was one of my customers at the bar could come in with his laptop. At first, I hesitated because, wasn’t I already too far behind? Haven’t all you all been doing this since forever? Don’t you have the programmer gene? People believed in me, and that was really important in my journey. As I’ve learned since then, curiosity is one of my top values, just personal development. I dove right in.
So unconsciously incompetent, I specifically remember a joke I told online on Facebook. I was excited to be learning programming, and somebody had been doing something in JavaScript, and I commented something that very clearly showed that I did not know the difference between Java and JavaScript. I was like, yes, I’m down with the Java 2, but, yes, no. What I did is I learned how to learn better. Turns out, it was active learning. As it turns out, MIT puts out all the good stuff basically for free. I started with something called Scheme school, and SICP, the purple book right there, “Structure and Interpretation of Computer Programs”, is a classic title from MIT. There are these lectures that go along with it that are really good, especially to watch now. What’s cool is that was a time in programming where women did programming. About half the class was women, so it was cool to see that. That also goes in ups and downs.
As I said, most importantly, I had lots of people that believed that I could be a programmer too. I was handed a book, written by somebody that believed that Clojure is for everyone. I coded along with content produced by people that I’m now really proud to call friends. I started to produce more like edutainment content as I got farther along in my career because teaching is a good way to learn. That’s when I realized how much I didn’t know. This phase was humbling and exciting. Aided by my REPL, I was exploring and building and taking too long to do everything. Every day was a new flow. Every new concept was like climbing a mountain. I just kept going, just curious little cat over here. It was really impactful to find a community where I felt like I belonged. I felt the Clojure community really just embraced me. I felt like I belonged. It’s really cool.
This was not on accident. This is ripped from a paper called, “The History of Clojure”. Just as much as Rich had intentionally designed Clojure for the professional programmer, he had also intentionally established and required a tone of supportiveness, positivity, and respect that had been seized upon, maintained, and enforced by the community itself as one of the core values, and points of pride. The Clojure community is friendly, and we’re helpful and we tolerate nothing less. We’re aggressive about it. Eventually, I got my first job as a programmer. Winter 2019, I interviewed all day on a Thursday, accepted an offer on Friday. Then packed all my things into a minivan, drove five hours, and on Tuesday, I signed a lease in Charlottesville, Virginia. I was like, “I made it. I’m a real person now. I’m a real programmer”. That confidence went on for a little bit. I started experimenting using advanced techniques before I fully understood the basics. I realized that I still don’t really understand the basics. I was a bug hunter in the ClojureScript code base.
Despite painting a picture of an overly eager, newly minted programmer, my performance reviews were good and I was really complimented on my ability to leverage communication as a means to solve the real problem. Although I was told that I needed to be more pragmatic, I was not sure what that meant because I did not yet have the experience that causes you to be more pragmatic. I ended up getting fired from my first job as a result of that hubris. Ask me my feelings about Clojure transducers sometimes. Then I got another ClojureScript job. It was a startup that failed.
Then, I was yearning for learning and I pursued opportunities to level up. I started working at Vouch with the maintainer of the ClojureScript compiler because I was doing ClojureScript. That’s with David. Over the course of three years, I rode on this dichotomy. On one hand, my edutainment content was getting super popular and I seemed to be on this rainbow rocket to Clojure fame. Thinking I had it all figured out, then only to have reality check me really hard when I kept getting fired. These failures were devastating and they taught me something really important though. Overconfidence can only take you so far. If you’re not curious, if you’re not actually actively asking questions and seeking feedback and looking for improvement, you’re not growing.
This was in Charlottesville. I was so excited, overconfident. Everything’s fine. Then this was, I don’t want to say rock bottom, but this last tech job apocalypse, it got me. It was my first time of really getting got by the loss of jobs. After losing my second job, I knew that something had to change, and I couldn’t rely on overconfidence anymore. I needed a new approach. Around this time, Rich did his talk, Design in Practice. This is at the Clojure Conj in 2023. He mentioned this book, “The Socratic Method: A Practitioner’s Handbook”. That book has been a turning point for me, and started just thinking about my own thinking. It breaks down the Socratic dialogues to the different techniques that are used. Those dialogues are meant to show a way of thinking, a way of questioning yourself. I got really into asking better questions and finding inconsistencies and being a hypocrite, and leaning into my cognitive dissonance and exploring it, and just shamelessly seeking feedback. I love being wrong, it’s so great.
Fun fact, a lot of this thinking is actually done in Google Sheets. Building on Rich’s talk from last year, Alex actually did a talk at the Conj, and that was titled, Design in Practice in Practice. I recommend both those talks. It’s a really good way to structure your thinking. I’ve run every tool possible. I’ve done Miro. I’ve done Lucid. I’ve done all of the things. Google Sheets though? The cycle of curiosity, experimenting, failing, learning, repeating, also known as screwing around, finding out, recording it.
Four months ago, I joined the Datomic Developer Success Team at Nubank. I work on the Clojure ecosystem and developing it as part of Nubank. I still don’t have all the answers. I love not knowing answers, remember? I’ve learned that curiosity is the key to growth. By staying curious, I’ve not only improved as a developer, but I’ve also connected with a community that values real learning and real thinking. Like my story, just like Clojure, isn’t about being perfect, it’s about growing and learning and solving real problems. That’s my journey. It wasn’t a straight line and it wasn’t without failure. Every step of the way, curiosity kept me moving forward. Progress isn’t linear.
The Journey in Context
Now let’s zoom out and put the story in context, my story. Who’s heard of the Dunning-Kruger effect? Psychologist David Dunning and Justin Kruger identified a cognitive bias where people with low competence in a skill overestimate their ability. There’s often a burst of overconfidence. It’s been named, the Peak of Mount Stupid. As we gain more experience, reality sets in and confidence drops, this is known as the Valley of Despair. I think that the Socratic word for it is aporia. If we keep going, curiosity and perseverance can help us climb up the Slope of Enlightenment until we reach a place of more balanced, humble competence. Looking back, my journey as a programmer mirrors this exactly.
At first, I didn’t know how much I didn’t know. I didn’t know so much, I just signed up to be a programmer overnight. I’m like, “That looks cool. Ok, sure”. Maybe in that case, it worked in my favor. In the next couple years of software development aided by my REPL, I bikeshed up Mount Ignorance. After losing my second job, I arrived at the Peak of Mount Stupid. Losing my second job in three years, while I was under contract to buy my house, was my Valley of Despair, a humbling but necessary step towards growth. Considering my personal values more deeply and embracing curiosity, it’s helping me climb out of this, but it’s a daily battle.
Here’s where it gets interesting. My journey isn’t just personal. It mirrors the journey of Clojure itself as seen through the Gartner Hype Cycle. The Peak of Inflated Expectations maps to the Peak of Mount Stupid, where excitement and overconfidence reign. The Trough of Disillusionment matches the Valley of Despair, where reality sets in and challenges become clear. The Slope of Enlightenment is named the same in both frameworks, a period of growth and refinement driven by curiosity. Clojure’s story and my story follow the same arc because they’re both about the process of learning and growth.
Actually, both of these frameworks have been criticized for being just recording the normal process of life and putting too much stock in the data. What’s the takeaway here? If both the Dunning-Kruger effect and the Gartner Hype Cycle are inevitable, how do we move forward? Anybody have any guess? Is it curiosity, the word I’ve said 20 times? Maybe. The answer is curiosity. Curiosity keeps us asking questions and seeking feedback and staying open to growth. It’s what helped me climb out of the Valley of Despair and it’s what helped Clojure move from hype to maturity. Curiosity bridges that gap between that overconfidence and true wisdom and skill. It’s the antidote to both individual and community versions of the same struggle.
Clojure’s Mature Ecosystem
So far, we’ve explored two journeys. One, Clojure’s evolution through the Gartner Hype Cycle and my personal growth story through the Dunning-Kruger effect. We’ve seen how curiosity played a critical role in both, transforming hype and overconfidence into sustained growth and basic competence. What’s this look like in practice? How has curiosity shaped the tools and libraries that make Clojure not just language, but a vibrant, mature ecosystem? In this final section, I want to highlight some of the more exciting developments that maybe you’ve missed out on because our community is insular. We don’t really hang out on all of the places that normally you would find developers, for example, Stack Overflow. We have our own Clojurian Slack. We used to congregate on Twitter, but now that’s dead, so that’s cool. Whether you’re new to Clojure or you’re an experienced Clojurian, I want to show you these tools in a way that matches up with your experience.
I talked about this a little bit, but this is called the four stages of competence model. If you really oversimplified it, it’s novice, intermediate, and expert. I actually crowdsourced a lot of these answers. We’re going to start at novice, and for each level, I’m going to do the passive introduction. I’m going to think of these as like books, talks, things that you can passively take in. Then, the second part I’m going to share tools, libraries, frameworks, that bleeding edge stuff we were just talking about. If you’re a complete novice, and you don’t know where to start with Clojure, I do recommend, “Clojure for the Brave and True”. Although, skip the first couple chapters, because they talk about Leiningen, which is an outdated build tool that we’ve replaced with tools.deps. It tries to get you started on Emacs. Do not. Another book, “Programming Clojure”, is a pragmatic programmer’s book by Alex.
The fourth edition is going to come out, because there have been sneak peek, there have been some updates to Java that actually used to be like a code golf thing, like the opening section was like, this is it in Java. Then it was like, this is it in Clojure, and like a tiny little, but Java improved, actually, inspired by Clojure. Java improved, because Brian Goetz hangs out with the Clojure crew. They’re redoing, the fourth edition should be out. There are so many significant Rich Hickey talks. You just got to start, but Simple Made Easy is really notable. Also, Hammock Driven Development, you have to see just so you can get all the hammock jokes. It’s like a cultural touchpoint. Really, that’s just about stopping and thinking, not coding, thinking.
The other thing you can check out is my podcast, it’s called, Lost in Lambduhhs, and that is independently produced, so your expectations need to go down here, way down. Actually, I initially started it as an excuse to teach myself production skills, and people like it, so I do continue to do it. It’s just inconsistent, so I’ll just give you that. A lot of the tools that we’re talking about, I’ve interviewed a lot of those authors. The whole point of Lost in Lambduhhs is to meet the person behind the GitHub, because I figure if we humanize the people that make our tools, we can be more empathetic to them. We get into some really awesome conversations. I don’t know why Buddhism has been a theme of this season, but completely unrelated, every single person is like, Buddhism has come up. That’s cool.
Here we have the tools, because we like active, active learning. If you go to clojure.camp. At this point, we’re a learning community, I think would be the best way to describe it. With one of my co-founders a couple weeks ago at the Conj, we actually did a whole talk about Clojure Camp that does the story from beginning to end, and what we’ve learned. One of the rabbit holes that I have jumped down is pedagogy and learning and teaching. We’ve really been using Clojure Camp as a learning experience experiment, trying to figure out how to teach new skills at scale. It’s not cohort-based, it’s just a Discord with some buddies that meet sometimes and talk about some code, do some mob programming. A few years ago, we got the Clojure CLI and deps.edn, that has been a game changer. You can just go and go, clj, and just get a REPL. Look at that, so easy, “Hey friends, hello world”, we love that. We have finally got good IDE support.
Saying that, I do Emacs, because when I learned Clojure, that was the path, that’s what you did. You learned Emacs. You had paredit, you could balance your parentheses and everything was fine, but it was hard. We don’t have that be hard anymore. Calva for VS Code is amazing. It even has a Clojure tutorial built in it. It’s just a plugin. If you want to put it on expert mode, you can even go on VS Code, there’s even plugins for Emacs key bindings. You can still use your paredit, which is useful. Then use the tool that you’re actually familiar with. There’s also Cursive for IntelliJ. I use that. I love JetBrains.
One of our open-source contributors, actually the one that urged me to start my podcast in the beginning, is Michiel Borkent, also known as borkdude. This man is legendary in our culture. He has made clj-kondo, which is linting support, and Babashka, which is native, fast-starting Clojure interpreter for scripting. In the Clojure survey, we added a question about, what are you using? Is it Babashka? It was like up to 90% of Clojure developers are using Babashka, which is nuts.
Now we’re going to go over to intermediate level. Intermediate level, at this stage, you’ve started experimenting, and you’ve realized, this Clojure stuff is cool, but you know there’s more to learn. You can actually build some real useful applications, and you can explore some advanced capabilities. You don’t have to think about how to balance every single thing. Hopefully, at this point, you’ve started to actually use the REPL. If you’ve started to do that, good on you, because a lot of people never get that far, and so they never reap the benefit of a fast feedback loop, which is really disappointing. Actually, I think this just got put into print. Clojure Brain Teasers is 25 puzzles to help identify flaws in your existing mental model, and then correct it. I have been working on this book for the last two years with Alex Miller.
At first, my imposter syndrome was so high. I get an email from one of my heroes, you want to co-author a book? Yes, I would. It took a very long time. One of the things that he valued was my curiosity and my ability to ask questions. We realized how beneficial it is to have somebody that is closer to the level of competence the actual audience of the book would be reading, because Alex is so unconsciously competent, he’s so fluent that he can’t even understand what’s so hard about concurrency.
These are more intermediate resources. Other intermediate resources. We have, “Clojure Applied”. That is also a pragmatic programmer book. That is authored by Alex and Stu. “Grokking Simplicity”, was released a few years ago. That is Eric Normand, who has been hugely influential helping me in my learning journey. Purelyfunctional.tv is his website. He does weekly newsletters. “Grokking Simplicity” really emphasizes functional programming principles and why they matter. It goes into like deep dive into, but it’s still approachable at the same time. It’s hard to do that, and he did it very well. Debugging with a Scientific Method, by Stu. That’s another really great talk about how to use the REPL.
Lastly, the Cognicast podcast, which is now, I think, called The Hammock by Nubank. What’s cool, little fun fact trivia, is in 2021, I was interviewed. I was doing enough memes. I was making enough waves. They were like, who is this girl? They interviewed me. The person that interviewed me is Robert Randolph, who is now my manager. That was like just a very slow roll. I think they just kept an eye waiting for my competence or wisdom or something to get better. I’m really grateful for the team that I work on now and my manager, because I’ve never experienced having a good manager before. I get to now. It’s just so amazing.
Here are more tools. Portal is a data visualization inspector that goes into your REPL and helps you with the workflow. I actually have a podcast episode where I talk to the author and creator of that, Chris, djblue. Add-lib helps you dynamically add libraries to your REPL during development. Also, to the ClojureScript ecosystem, we got shadow-cljs. It’s the build tool that we needed because it simplifies working with ClojureScript and npm. As I explained earlier, actually, the majority of my professional experience has been with ClojureScript. Watching specifically how shadow helped that ecosystem and make it more accessible to people, that was really cool to be there for that. We have a whole data science sect because Clojure is so good for data science. The only problem is that all the data science libraries are in Python. Bummer? Not really. We have libpython-clj, which helps bridge that. You can use all your favorite Python libraries for your data science, but then actually think about the reasoning in Clojure. That’s cool.
The Scicloj group, as it’s called, they are in the Clojure in Slack, but they actually hang out mostly on Zulip because they mirror the Slack to the Zulip, and then it keeps the history forever, because data science people. Makes sense, they want the data. There are really cool things. It’s almost like an ecosystem inside an ecosystem, the Scicloj data science story. When I did that poll asking, they mentioned Tablecloth, saying it simplifies data manipulation and visualization for analysts and scientists. I’m not a data scientist. I wish I could elaborate on this more.
If you are, you should go into the Slack and start being curious. FlowStorm debugger, I have tried that. That’s cool. It’s a debugging tool that you can use with your REPL for this interactive, fast-tracking program flow. You have to experience it. I feel like I can’t really communicate how awesome the REPL workflow is. It’s like, normally you have to send over your entire program. With a REPL, it’s literally line by line. You have such a tight feedback loop with the data that you’re working on that you can ask it direct questions. It’s awesome because it helps you grow through the exploration. I have a hypothesis that that is why I’ve been able to accelerate as quickly as I have in programming is because of the aid of this feedback loop, of helping me, because there are three things to become an expert, and it’s not 10,000 hours. It all boils down to deliberate practice, which is giving feedback to others, asking for feedback for yourself, and then giving feedback to yourself. The REPL helps you achieve that.
Expert. At this stage, you’ve mastered the fundamentals, and you’re pushing boundaries with what’s possible with Clojure. This is where the curiosity leads into innovation, the innovation story. Here are the tools that represent the cutting edge. 2012, that’s not cutting edge. As I mentioned, I work on the Datomic team. It’s free software, but not free software like that. It’s free to use, not open source. It’s really awesome. It’s used by companies like Netflix.
As we talked about earlier, Nubank went so all in on Datomic, they literally just acquired the consultancy that made it in the language. They feel pretty strongly about it. Because as it turns out, it’s crazy that we mutate state in databases, like when you actually think about it. If you’re asking a question to something, and then you’re changing it, we don’t do that. It’s really good for applications like FinTech and health. When you really don’t want to lose your data, you can’t lose your data, that’s what Datomic is for. XTDB, they are another Clojure-based database that has the time-aware features that I was just talking about.
I think they call it bitemporal capabilities. That just means that you can say, at any point in time, what was the state of this like? That’s because we don’t change the data. There’s also Electric, I think the company is Hyperfiddle, but Electric and Missionary. There’s actually a lot of tools done by Electric. They’re reactive programming frameworks. I am a fan of Dustin Getz, the person behind Hyperfiddle. We went through beginning, intermediate, and expert, and now we have the very tip-top of the chain, Google Sheets, the one true tool for thinking.
Conclusion
Originally, Rich Hickey said, when he embarked on Clojure, he was not, nor did he aspire to be a designer. From now on, he was responsible for Clojure. The success of Clojure changed his life and career in ways that he never thought possible. Clojure Camp gave me the opportunity to be a learning experience designer. That’s one thing I do have in common with Rich, is that Clojure has changed my life in ways that I am so grateful for and I never thought possible. That’s why I’m so passionate about sharing it with everybody.
See more presentations with transcripts
MMS • RSS
Two Sigma Advisers LP purchased a new position in MongoDB, Inc. (NASDAQ:MDB – Free Report) during the fourth quarter, according to its most recent disclosure with the Securities & Exchange Commission. The institutional investor purchased 28,000 shares of the company’s stock, valued at approximately $6,519,000.
Other hedge funds have also modified their holdings of the company. Strategic Investment Solutions Inc. IL acquired a new position in shares of MongoDB in the fourth quarter worth $29,000. NCP Inc. acquired a new position in shares of MongoDB in the fourth quarter worth $35,000. Coppell Advisory Solutions LLC increased its stake in shares of MongoDB by 364.0% in the fourth quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after acquiring an additional 182 shares during the last quarter. Smartleaf Asset Management LLC increased its stake in shares of MongoDB by 56.8% in the fourth quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock worth $87,000 after acquiring an additional 134 shares during the last quarter. Finally, Manchester Capital Management LLC increased its stake in shares of MongoDB by 57.4% in the fourth quarter. Manchester Capital Management LLC now owns 384 shares of the company’s stock worth $89,000 after acquiring an additional 140 shares during the last quarter. 89.29% of the stock is owned by institutional investors and hedge funds.
MongoDB Trading Down 1.4%
Shares of NASDAQ:MDB traded down $2.73 during trading on Monday, hitting $185.85. 1,248,300 shares of the company were exchanged, compared to its average volume of 1,933,814. The stock has a market cap of $15.09 billion, a price-to-earnings ratio of -67.83 and a beta of 1.49. MongoDB, Inc. has a fifty-two week low of $140.78 and a fifty-two week high of $370.00. The firm has a fifty day moving average price of $174.61 and a two-hundred day moving average price of $234.84.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing the consensus estimate of $0.64 by ($0.45). The company had revenue of $548.40 million for the quarter, compared to analyst estimates of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same period last year, the firm earned $0.86 EPS. As a group, research analysts predict that MongoDB, Inc. will post -1.78 EPS for the current year.
Wall Street Analysts Forecast Growth
MDB has been the topic of a number of research reports. Barclays dropped their price target on shares of MongoDB from $280.00 to $252.00 and set an “overweight” rating on the stock in a research note on Friday, May 16th. Wells Fargo & Company downgraded shares of MongoDB from an “overweight” rating to an “equal weight” rating and lowered their target price for the stock from $365.00 to $225.00 in a research report on Thursday, March 6th. Robert W. Baird lowered their target price on shares of MongoDB from $390.00 to $300.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. KeyCorp downgraded shares of MongoDB from a “strong-buy” rating to a “hold” rating in a research report on Wednesday, March 5th. Finally, Macquarie lowered their target price on shares of MongoDB from $300.00 to $215.00 and set a “neutral” rating on the stock in a research report on Friday, March 7th. Nine investment analysts have rated the stock with a hold rating, twenty-three have issued a buy rating and one has issued a strong buy rating to the company’s stock. According to MarketBeat, MongoDB currently has a consensus rating of “Moderate Buy” and an average target price of $288.91.
Get Our Latest Stock Report on MDB
Insider Buying and Selling at MongoDB
In related news, CEO Dev Ittycheria sold 18,512 shares of the stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $3,207,389.12. Following the sale, the chief executive officer now owns 268,948 shares in the company, valued at approximately $46,597,930.48. This trade represents a 6.44% decrease in their position. The transaction was disclosed in a legal filing with the SEC, which is accessible through this link. Also, CAO Thomas Bull sold 301 shares of the firm’s stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.25, for a total transaction of $52,148.25. Following the transaction, the chief accounting officer now directly owns 14,598 shares of the company’s stock, valued at $2,529,103.50. The trade was a 2.02% decrease in their position. The disclosure for this sale can be found here. Insiders have sold a total of 33,538 shares of company stock valued at $6,889,905 in the last three months. 3.60% of the stock is currently owned by company insiders.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Looking for the next FAANG stock before everyone has heard about it? Enter your email address to see which stocks MarketBeat analysts think might become the next trillion dollar tech company.
Java News Roundup: Java Turns 30, Hibernate ORM 7.0, Embabel, jaz, Open Liberty, Eclipse DataGrid
MMS • Michael Redlich

This week’s Java roundup for May 19th, 2025 features news highlighting: Java’s 30th birthday; the release of Hibernate ORM 7.0 and Hibernate Validator 9.0; the May 2025 edition of Open Liberty; the first beta release of JobRunr 8.0; and the introduction of Embabel, jaz, and Eclipse DataGrid.
Happy 30th Birthday, Java!
On May 23rd, 1995 at the Sun World conference in San Francisco, California, Sun Microsystems formally introduced the Java programming language. Oracle marked this milestone with their 30th Birthday Event, hosted by Java Developer Advocates, Ana-Maria Mihalceanu, Billy Korando and Nicolai Parlog along with Sharat Chander, Senior Director, Product Management & Developer Engagement at Oracle. This special six-hour event featured many guests on a variety of topics. InfoQ will follow up with a more detailed news story.
OpenJDK
With Rampdown Phase One scheduled for June 5, 2025, the following JEPs have been elevated from Proposed to Target to Targeted for JDK 25:
Similarly, the following JEPs have been elevated from Candidate to Proposed to Target for JDK 25:
The reviews for the JEPs that have been Proposed to Target are expected to conclude by Tuesday, May 27, 2025.
Version 7.5.2 of the Regression Test Harness for the JDK, jtreg, has been released and ready for integration in the JDK. The most significant changes include: support for using the ${test.main.class} template to use the current class name for test actions; the ability to configure the default timeout value in jtreg tests via a properties file; and support for .jasm and .jcod files in patched Java modules. Further details on this release may be found in the release notes.
JDK 25
Build 24 of the JDK 25 early-access builds was made available this past week featuring updates from Build 23 that include fixes for various issues. More details on this release may be found in the release notes.
For JDK 25, developers are encouraged to report bugs via the Java Bug Database.
Jakarta EE
In his weekly Hashtag Jakarta EE blog, Ivar Grimstad, Jakarta EE Developer Advocate at the Eclipse Foundation, provided an update on Jakarta EE 11 and Jakarta EE 12, writing:
The Jakarta EE 11 TCK is very close to being finalized, so it looks like we are on the path of getting the Jakarta EE 11 Platform release out the door in the middle of June.
The work with Jakarta EE 12 is on track according to the Jakarta EE 12 Release Plan. Plan reviews have been completed, and discussions right now are around which specifications to add (if any) to the Platform, and which to possibly deprecate.
The road to Jakarta EE 11 included five milestone releases, the release of the Core Profile in December 2024, the release of Web Profile in April 2025, and a first release candidate of the Platform before its anticipated GA release in June 2025.
Spring Framework
It was a busy week over at Spring as the various teams have delivered GA releases of Spring Boot, Spring Security, Spring Authorization Server, Spring Session, Spring Integration, Spring for GraphQL, Spring AI and Spring Web Services. Further details may be found in this InfoQ news story.
The Spring Data team has introduced their plan to lower the barrier to entry related to the different approaches with technologies (GraalVM, CRaC, CDS, etc.) that reduce application startup times. With the upcoming release of Spring Data 2025.1 (AKA version 4.0), repositories will be migrating to Ahead-of-Time compilation. This means they will be shifting all the “repository preparations that are done at application startup to build time.” This may be accomplished by setting the spring.aot.repositories.enabled property to true.
Microsoft Azure
Microsoft has introduced their new Azure Command Launcher for Java, named jaz, to address “suboptimal resource utilization in cloud-based deployments, where memory and CPU tend to be dedicated for application workloads (use of containers and VMs) but still require intelligent management to maximize efficiency and cost-effectiveness.” This means that instead of writing:
$ JAVA_OPTS="-XX:... several JVM tuning flags"
$ java $JAVA_OPTS -jar myapp.jar"
Developers can now write:
$ jaz -jar myapp.jar
jaz is currently in private preview and requests for access may be made here.
Open Liberty
IBM has released version 25.0.0.5 of Open Liberty featuring bug fixes and the ability for the MicroProfile Telemetry 2.0 (mpTelemetry-2.0) feature to collect and send Open Liberty HTTP access logs, such as export traces, metrics, and logs, to OpenTelemetry.
Quarkus
The Quarkus team has announced that Quarkus MCP Server 1.2.0 now supports streamable HTTP, along with the stdio and SSE transports, that make it possible to connect mobile applications and cloud services to MCP servers. While this is considered a full implementation, the Quarkus team plans future releases to include resumability and redelivery.
Hibernate
The release of Hibernate ORM 7.0.0.Final delivers new features such as: a new QuerySpecification interface that provides a common set of methods for all query specifications that allow for iterative, programmatic building of a query; and a migration from Hibernate Commons Annotations (HCANN) to the new Hibernate Models project for low-level processing of an application domain model. There is also support for the Jakarta Persistence 3.2 specification, the latest version targeted for Jakarta EE 11. More details on this release may be found in the release notes and the migration guide.
The release of Hibernate Validator 9.0.0.Final provides bug fixes, dependency upgrades and notable changes such as: new constraints, @KorRRN and @BitcoinAddress, annotations that check for a valid Korean resident registration number and a well-formed BTC (Bitcoin) Mainnet address, respectively; and a new BOM that provides dependency management for all of the published artifacts. This release is the compatible implementation of the Jakarta Validation 3.1 specification.
Details on both of these releases may be found in this blog post by Gavin King, Senior Distinguished Engineer at IBM and creator of Hibernate.
Embabel Agent Framework
Rod Johnson, former CEO at Atomist and father of the Spring Framework, has introduced the Embabel Agent Framework for the JVM written in Kotlin. As described by Johnson:
It introduces some ideas that I think are novel: a planning step using a non-LLM AI algorithm; and a rich domain model that can expose behavior as LLM tools as well as in Java or Kotlin code.
Embabel was built on Spring and offers a full MCP integration with Spring AI. InfoQ will follow up with a more detailed news story.
JobRunr
The first beta release of JobRunr 8.0.0 features: ahead-of-time scheduled recurring jobs where JobRunr schedules a recurring job as soon as the previous run is finished; and support for Kotlin serialization with a new KotlinxSerializationJsonMapper class, an implementation of the JsonMapper interface, for an improved experience when writing JobRunr applications in Kotlin. Further details on this release may be found in the release notes.
Eclipse DataStore
The Eclipse Foundation and Microstream have introduced a new open-source project, Eclipse DataGrid, designed to be a pure Java in-memory data processing layer for distributed EclipseStore applications. As a result, Microstream will open-source their in-memory data platform and transfer the codebase to Eclipse DataGrid. Features include: a distributed Java object graph model; seamless integration with the Java Streams API; and integration with Apache Lucene and Kubernetes.
MMS • RSS
USS Investment Management Ltd trimmed its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 15.2% in the 4th quarter, according to its most recent filing with the Securities and Exchange Commission (SEC). The firm owned 13,409 shares of the company’s stock after selling 2,412 shares during the quarter. USS Investment Management Ltd’s holdings in MongoDB were worth $3,121,000 as of its most recent SEC filing.
Other hedge funds and other institutional investors have also added to or reduced their stakes in the company. Strategic Investment Solutions Inc. IL bought a new position in MongoDB in the 4th quarter worth approximately $29,000. NCP Inc. bought a new position in MongoDB in the 4th quarter worth approximately $35,000. Coppell Advisory Solutions LLC boosted its stake in MongoDB by 364.0% in the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after purchasing an additional 182 shares during the period. Smartleaf Asset Management LLC raised its holdings in shares of MongoDB by 56.8% during the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock worth $87,000 after acquiring an additional 134 shares in the last quarter. Finally, Manchester Capital Management LLC raised its holdings in shares of MongoDB by 57.4% during the 4th quarter. Manchester Capital Management LLC now owns 384 shares of the company’s stock worth $89,000 after acquiring an additional 140 shares in the last quarter. 89.29% of the stock is currently owned by institutional investors.
Insider Transactions at MongoDB
In other news, CEO Dev Ittycheria sold 18,512 shares of the stock in a transaction on Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $3,207,389.12. Following the transaction, the chief executive officer now owns 268,948 shares of the company’s stock, valued at approximately $46,597,930.48. This represents a 6.44% decrease in their position. The transaction was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through this link. Also, CAO Thomas Bull sold 301 shares of the stock in a transaction on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total value of $52,148.25. Following the transaction, the chief accounting officer now directly owns 14,598 shares in the company, valued at $2,529,103.50. The trade was a 2.02% decrease in their position. The disclosure for this sale can be found here. In the last 90 days, insiders have sold 33,538 shares of company stock valued at $6,889,905. 3.60% of the stock is currently owned by corporate insiders.
MongoDB Stock Down 1.4%
Shares of MongoDB stock opened at $185.85 on Friday. The stock’s fifty day moving average is $174.75 and its two-hundred day moving average is $236.90. The company has a market capitalization of $15.09 billion, a PE ratio of -67.83 and a beta of 1.49. MongoDB, Inc. has a 52 week low of $140.78 and a 52 week high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing the consensus estimate of $0.64 by ($0.45). The business had revenue of $548.40 million during the quarter, compared to the consensus estimate of $519.65 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. During the same period last year, the company earned $0.86 EPS. As a group, research analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Analyst Ratings Changes
Several analysts have recently issued reports on MDB shares. Stifel Nicolaus decreased their price objective on MongoDB from $340.00 to $275.00 and set a “buy” rating on the stock in a report on Friday, April 11th. The Goldman Sachs Group decreased their price objective on MongoDB from $390.00 to $335.00 and set a “buy” rating on the stock in a report on Thursday, March 6th. Barclays decreased their price objective on MongoDB from $280.00 to $252.00 and set an “overweight” rating on the stock in a report on Friday, May 16th. Truist Financial decreased their price objective on MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a report on Monday, March 31st. Finally, Oppenheimer decreased their price objective on MongoDB from $400.00 to $330.00 and set an “outperform” rating on the stock in a report on Thursday, March 6th. Nine equities research analysts have rated the stock with a hold rating, twenty-three have assigned a buy rating and one has issued a strong buy rating to the company’s stock. Based on data from MarketBeat, MongoDB presently has a consensus rating of “Moderate Buy” and an average target price of $288.91.
Check Out Our Latest Stock Analysis on MongoDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Nuclear energy stocks are roaring. It’s the hottest energy sector of the year. Cameco Corp, Paladin Energy, and BWX Technologies were all up more than 40% in 2024. The biggest market moves could still be ahead of us, and there are seven nuclear energy stocks that could rise much higher in the next several months. To unlock these tickers, enter your email address below.
MMS • Craig Risi
Cloudflare has unveiled thirteen new Model Context Protocol (MCP) servers, enhancing the integration of AI agents with its platform. These servers allow AI clients to interact with Cloudflare’s services through natural language, streamlining tasks such as debugging, data analysis, and security monitoring.
An MCP server is a specialized type of server introduced by Cloudflare as part of their infrastructure to support AI agents in executing, debugging, and managing tasks securely and efficiently.
The concept of MCP servers is built around the idea of giving AI agents (like those used in autonomous workflows or natural language interfaces) safe, controlled access to the tools and data they need to operate effectively. These servers don’t just run arbitrary workloads—they are tightly scoped, auditable environments that expose specific capabilities to AI models.
The new MCP servers from Cloudflare introduce several key features designed to enhance the capabilities of AI agents interfacing with cloud infrastructure. The thirteen new servers and what they do are described below, as detailed in Cloudflare’s blog post.
The Workers Observability Server provides valuable insights into application logs and errors. This feature is crucial for rapid debugging and optimizing performance, enabling AI agents and developers to diagnose issues more efficiently.
With the Radar Server, AI agents gain access to global internet traffic data. This allows for sophisticated analysis of network trends and detection of anomalies, supporting a wide range of use cases from cybersecurity to performance monitoring.
The Logpush Server plays a critical role in summarizing log data, making it easier to identify and troubleshoot issues in log delivery mechanisms. It helps ensure logs are reaching their intended destinations and maintains visibility over logging workflows.
The AI Gateway Server enables inspection of AI Gateway logs. This means agents can review prompt histories and model responses, allowing for better debugging, tuning, and understanding of AI behavior within applications.
The AutoRAG Server is particularly useful for enabling AI agents to search and retrieve information from documents. This boosts response accuracy by grounding AI outputs in reliable and relevant data sources.
The DNS Server allows AI agents to query and manage DNS records. By providing access to DNS configurations, agents can assist in tasks such as domain management, troubleshooting DNS issues, and ensuring proper routing of internet traffic.
The KV (Key-Value) server enables AI agents to interact with Cloudflare’s key-value storage system. This functionality is essential for managing configuration data, feature flags, and other dynamic settings that applications rely on for real-time operations.
Through the Pages server, AI agents can access and manage Cloudflare Pages deployments. This includes capabilities like monitoring deployment statuses, reviewing build logs, and initiating new deployments, thereby streamlining the continuous integration and deployment processes.
The Queues Server provides AI agents with the ability to interact with message queues. This is particularly useful for managing asynchronous tasks, processing background jobs, and ensuring reliable communication between different parts of an application.
AI agents can utilize the R2 Server to access Cloudflare’s object storage solution. This allows for operations such as uploading, retrieving, and managing large datasets or media files, which is crucial for applications that handle significant amounts of unstructured data.
The Turnstile Server enables AI agents to configure and monitor Cloudflare’s CAPTCHA alternative. By managing Turnstile settings, agents can help protect applications from automated abuse while ensuring a seamless user experience.
Finally, the Audit Logs Server facilitates querying of audit logs. This is essential for maintaining compliance and conducting thorough security audits, providing traceability of actions across systems that the AI interacts with.
These servers are accessible to any MCP client supporting remote connections, including platforms like Claude.ai. This development signifies a step towards more seamless integration between AI agents and cloud services, promoting efficiency and automation in various operational tasks.
MMS • Julia Furst Morgado

Transcript
Olimpiu Pop: Hello, everybody. I’m Olimpiu Pop, an InfoQ editor. Today, we have Julia, who spoke about bringing light into chaos at KubeCon. We were curious to hear more about it. So, Julia, please introduce yourself.
Julia Morgado: Yes, sure. Thank you for having me, it’s a pleasure. As you said, my name is Julia, and I currently work as a global technologist on the product strategy team at Veeam. And my background is non-traditional; I worked in law. I’m originally from Brazil, worked in law, then business, and then I found technology, and I transitioned into tech. Nowadays, I work a lot on helping explain tech and break down complex concepts, talk more about the business side of tech, and focus a lot on Cloud Native technologies and data protection strategies.
So, I work with customers and partners to design solutions for resiliency, disaster recovery, and Cloud Native infrastructures. I’m also a CNCF ambassador, an AWS container hero, and an ambassador for other programs. I organise events in New York City, so the KCD, Kubernetes Community Day, the AWS Community Day and a monthly meetup that is part of the CNCF. So I’m very involved with the Cloud Native community. And fun fact, I speak four languages, so I speak English, obviously, Portuguese, French and Spanish.
Olimpiu Pop: That’s impressive. Well, today we’ll keep it to English, even though I’ll be happy to exercise the four words I know in Spanish and Portuguese, but let’s keep it to English.
Okay. So what was surprising this year at KubeCon was that this was my fourth European KubeCon, and for me, what was unexpected was that it was the first time the discussions were more high-level. So we heard in the keynotes, people talking about how the platform and infrastructure teams can influence the user experience. And I think that would be the optic that I will try to use today in our discussion. You mentioned chaos, and obviously if your infrastructure goes down, that would be chaos among other stuff, and everybody will just run left and right. Let’s start by describing again what was the scenario because you mentioned edge and you mentioned shopping experience, if I remember correctly. Because edge is so broad, let’s narrow it down and understand the devices on the edge to better understand how that is framed.
How mini Kubernetes clusters on the edge can help avoid chaos [03:14]
Julia Morgado: Yes, so the talk I gave was called, Chaos to Control: Kubernetes Resiliency at the edge. And it was recorded, probably the recording will be available soon. However, the scenario we shared at KubeCon was from a global retail customer with over 500 edge locations. Each store is running Kubernetes locally, essentially mini clusters at the edge. And you can think of edge computing as having mini data centres in each store instead of sending everything to a prominent central location. And each store was processing right there, restocking alerts of when inventory was running low, personalised promotions based on customers’ data, all the operations, so point of sales, everything.
But with edge come many challenges, it’s not like running on the cloud on-prem. There are constraints like resource constraints. Devices running in Kubernetes at the edge, are usually lightweight, so they have less CPU, RAM and storage. There are network issues because you’re not always connected so that the source can lose connectivity any time. So everything has to work even without the internet. There are a lot of security risks, which is what we focused on at the talk, because the more edge devices you have, the more doors you leave open for attackers, and that was the case.
So the retail customer was hit by a ransomware attack. It started with phishing email, which usually is what we see. Someone clicks on an email, and then it gets access to the whole system and encrypts the system, and many things happen. And we went over a little bit, everything spread through the clusters, and when that happens, usually traditional backup solutions and traditional things that we like to say, keep your system resilient, they don’t work for edge locations. Because usually, like I mentioned, you rely on a centralised infrastructure, and with edge locations, you don’t have that centralized failover like with traditional data centres. Also, you are in a disconnected environment, so you can’t have that fast and local restore. So it’s very complicated and you need a backup solution specialized for that. So we went over backup solutions, yeah-
Olimpiu Pop: Let me stop you a bit to consolidate what you had. You’re very enthusiastic about this. So that means that everything that you have as a system looks like a spider web. Each of the shops is its own, let’s put it like that, box that has everything that theoretically needs to run. And at points, it probably connects to the centre to get more data or to get updates.
Can you share how the information kept flowing? At points, I might imagine that you need to get information from the main repository or something like that. Can you share a bit about how that works?
Julia Morgado: Yes, so it’s connected to the cloud and a local data center, but the connectivity is intermittent. It only connects to get the updates, but it’s not always connected. That’s one of the issues with edge locations.
Olimpiu Pop: Okay, well, that’s mainly the definition of it, but this is a more different aspects. And you touch on very interesting aspects, because more than the traditional thing where you’ll have to worry only about the connectivity and getting the information upright and so on, so forth. You are dealing also with, probably personnel that has less digital literacy. Because I would expect that people that are working in a supermarket are not exactly digitally literate, so that’s probably why the door is open to other stuff.
Okay. So, for me, it’s impressive to have the whole system restarted in about 10 minutes. How far along was the system affected? Was it isolated to one shop, or were a couple of shops affected?
Julia Morgado: No, a couple, so several. I don’t know the exact number to be precise, but several shops were affected and it was spreading fast, but then we were able to contain it. And because it’s a huge process and the talk at KubeCon was focused on the recovery part, the backup and recovery and how to build a more resilient environment. However, disaster response is another aspect of what happened. When a ransomware hits, what do you have to do? Do you have an incident response plan? So several shops were impacted, but I don’t know the exact number.
Olimpiu Pop: That’s not that important. How did you handle it? I mean, how do you prepare for such a thing? Because I’m sure that these things were prepared in advance, the system was thought to be recoverable in a decent way. So, how should I start doing that if I’m at this point?
Julia Morgado: So actually, we were brought in after the incident happened. They were using other things before. And what we did was build a more resilient environment for them and with that we used some open source tools, part of the CNCF, and some non-open source tools as well. But we focused on backup and recovery solutions, also, S3 compatible object storage for that. And if I can mention names. So they started using Kasten by Veeam, which is the data management platform designed specifically for Kubernetes and edge locations as well, for backup and restore and disaster recovery tasks. And Canister, which is a project from the CNCF, is an open-source framework that allows you to define custom data management tasks through blueprints. So you just write YAML files that know how to handle the application, like if you need to flush a database before a backup, or if you need to run custom logic during a restore. And they work with several databases, several applications, and that helps with that resiliency.
How to prepare for service disruption [10:12]
Olimpiu Pop: Okay. YAML is quite a known language among the Cloud Native Foundation and its users. So what should I have? How should I think about it from an overview? Should I think about frequency? Should I think about particular tables that they want to target, or how would that work?
Julia Morgado: Yes, you should think about what are the most important applications that you have to backup. Ideally, you should backup everything, but also, you need to think about are they stateful, are they stateless? You need to back up stateful applications. This is a common controversy in the Cloud Native space. We are seeing stateful applications on Kubernetes and they need to be backed up. And frequency is something important, but you also have incremental backups, that’s something that you can do. So instead of backing up everything every time, which can be slow and resource heavy, you only backup what’s changed since the last snapshot. So this speeds up the backup window, reduces the storage needs, and it’s perfect for bandwidth-constrained edge locations. So this is something that they implemented as well with Kasten by Veeam.
Olimpiu Pop: Okay. So let’s assume that we have a solution that does that for us, it’s the time shuttle that moves us left and depending on what we need. How it’ll happen? I mean, as you mentioned, it’s recording only snapshots. If I need, I don’t know, I’m losing the whole database, that means that I will have to apply multiple snapshots. I suppose that one is done automatically anyway.
Julia Morgado: No. So first you do a full image backup, so it’s not just snapshots. You have the entire application level backup, and then with the incremental backup, you do only snapshots. But you have a whole backup of your infrastructure, your application, and then you can recover from that. So you have these two types, and the incremental one is only the changes, so you don’t have to do a whole image level backup every week, let’s say. You can just do the snapshots, if something changes, you have it there. But when you need to do a restore, you still have the full image level backup that you can restore from. So you have several options, yes.
Olimpiu Pop: Okay. So that means that we need to take the things separately. We have stateful systems, and then based on those, we’re just ensuring that we have the data. The stateless systems, while they’re doing computation and probably they’re relying on stateful data, so they’re just pulling data out of that and that’s mainly it. What else? What else should we bear in mind?
Julia Morgado: So, like I mentioned, the storage. Where are you going to send that data to? So usually people, we would see in the past, file system, et cetera, but now we’re seeing a lot of object storage, so you send that to the cloud. And it’s great because it’s scalable, so it grows with your data automatically. It’s off-site, so you can keep them safe in case one of the locations is hit. Usually you store it in the cloud, so all these big providers have their own object storage that is very powerful. You can make it immutable, so for a ransomware attacks, or even accidental deletions, those happen a lot. Like you said, people are not very digital literate, what’s the expression that you mentioned?
Olimpiu Pop: Yes, something like that.
Julia Morgado: Yes. There are a lot of accidental deletions, but if you make that data immutable, no one, not even the admin, can change it, encrypt it in case of a malicious actor, or delete it. And it’s very cost-effective because you pay as you go.
Use zero-trust and immutable data to reduce disruption’s blast radius [14:25]
Olimpiu Pop: Let me see if I can translate these things for myself. So what you’re saying is there are two different things. One of them, whenever we are building the system, we should use, as much as possible, immutable data, because that allows us to be safe and not alter something that’s already existing. And then to put another degree of isolation, like probably zero trust, where you’re just making sure that always you have to check it and then that will limit the blast radius.
Julia Morgado: Yes. And part of the zero trust, I would say also, only people that need access, or you should limit the amount of permissions that people have to perform a backup, to be able to manage the infrastructure. Because the more permissions people have, the more accidents can happen. And this is part also of zero trust, etc. You can do that with RBAC, and it’s a very famous principle in the Cloud Native space.
Olimpiu Pop: Because we discussed that, I was happily surprised by the Cloud Native Foundation’s keynotes and the level of the talks. Everybody’s talking about the user experience. How was it felt on the user side? I mean, in 10 minutes, they can have a coffee or two if you are really nervous, but theoretically, things should have happened quite fast.
Julia Morgado: Yes. You mean the recovery?
Olimpiu Pop: Yes, the recovery. So now, obviously, during the backup phase, users are not affected, they don’t know that’s happening. It’s behind the scenes, it’s happening. But obviously the point when you have a problem with the system, you’ll just have probably wrong data if the system is not fully affected. Or if, as you mentioned, the system was encrypted, most probably the guys had more problems, they couldn’t work, they couldn’t use it. So if I would be a cashier or whatever, something operator for the warehouse, what would be my experience during, or the ideal experience of recovering from a failure?
Julia Morgado: So like you said, ideally, the user, not the backup admins or the technical people, the users that are just dealing at each location, they don’t really see any disruption. That’s the perfect recovery scenario. And it means your edge location, your environment, is pretty resilient and has a good backup and recovery plan. But for that, you need some things. So I didn’t even touch on that, but everything is automated. So not only is the recovery fast, but it’s all automated.
So something happened, it already triggers the restore and all the policies are enforced. Also, everything should be tested. So if there is a disaster scenario and you tested it before, you’re going to see, you can recover in less than 10 minutes and then the user won’t even have to deal with any downtime. That’s the goal. Because even five minutes of your system not working, like you said, cashiers at supermarkets, if the system is not working, it means hundreds of money lost into sales et cetera. So if you have everything automated, tested prior to anything happening, your user won’t face any downtime. They will have a smooth experience.
Olimpiu Pop: Okay. So that means that, more than just preparing the system, we need to prepare the users. So probably doing something like drills, different type of scenarios where you’re just trying to cover as much as possible. Okay, that’s a good idea.
Julia Morgado: But when you say users, users is mostly, I mean, technical people, the infrastructure engineers, everyone that’s handling those systems. The user, like we said, the cashier, there isn’t much that they can do when something like that happens. They can go and open a ticket or something, but it’s not in their hands to recover the system. And that’s a big problem at edge locations, because they don’t have, usually, IT personnel in each store. So it usually takes even more time. But if you have something that’s automated and tested and has, for example, GitOps integrated, then it’s going to be much faster. And the cashier or other users, they won’t even experience anything, they won’t feel any disruption.
Olimpiu Pop : So that means that each store individually, or each edge location individually, had its backup mechanism locally.
Julia Morgado: Yes. So each cluster can handle its own backup and restore without needing a central control plane.
Olimpiu Pop: Okay. And that means that these backups are stored in a isolated location or they are in an air-gapped environment, given that you mentioned that-
Julia Morgado: Object storage, yes.
Olimpiu Pop: Good. And do you have any kind of off-site storage?
Julia Morgado: Yes. So at Veeam, we talk a lot about the 3-2-1-1-0 backup rule. I don’t know if you’ve heard of it. But usually you need three different copies of the data in two different type of medias. One of them should be off-site, in another location, just in case something happens with your production copy. And one of these copies should be offline, air-gapped or immutable, which is what I meant. No one can tamper it, encrypt it, delete it. And then the 0 at the end, is for zero errors. So you should be always testing it and make sure that there are no errors after the backup recoverability verification. So it’s an easy rule to remember, 3-2-1-1-0. And if you have that, you are probably in a great place, you have a very resilient system.
Exercise for outages [20:41]
Olimpiu Pop: Okay. That’s good to know. And how often should you have drills? Is it related to the size of the data? What will be another choreography rule?
Julia Morgado: Yes, so it depends on the RTO and RPO. If it’s some type of data that is extremely critical, you should have drills often. Everyone, all personnel should be able to know, oh, in case of anything happens, who’s going to be the point of contact, who will deal with restore operations? You should have all of that documented, because when things happen, people get, how can I explain? Like it’s chaos, like the title of the talk and no one knows what to do. There is also a lot of blaming, “Oh, they should have done that. They didn’t do that”. So when you have everything documented, it’s easier to say, “Yes, let’s do one, two, and three. Person A is going to do one, person B is supposed to do two”. If someone is not on call or they are traveling on vacation, you know who to contact if needed. So everything, this is all part of the incident response plan as well, and it should be tested regularly.
Olimpiu Pop: Okay, that makes sense. So that’s very enlightening, thank you for that. But during KubeCon, there were a lot of things that were spoken. Any takeaways that you would like to implement moving forward for other potential scenarios?
Julia Morgado: Yes. So, still talking a little about resiliency, that it’s the topic of the podcast and also my talk. It’s mostly, resiliency is not optional anymore. So everyone’s talking about GitOps, we’re talking about GitOps, observability, AI, ML, but at the end of the day, if your cluster crashes and your data isn’t safe, then none of that matters. And there are a lot of threats like ransomware and especially at edge locations, which is so fragile, resiliency must be built in.
And so also security and backup are being seen as part of the same ecosystem now and not separate concerns. Security, I’m sure you saw that at KubeCon, is always a big thing. So this time and at the last one, North America, I saw that as well, it’s always a core focus. And now they’re integrating backup into that, which I think is very important, data is the livelihood of any business. But like you mentioned, I saw that they emphasized the importance of integrating security in each layer of the Cloud Native stack, with particular attention to zero trust principles. And also, they talked a lot about supply chain, which I think is also a very important topic, so security in the supply chain. I also saw, not that related to resiliency anymore, observability was also a big thing at KubeCon. So ensuring and having a strong emphasis on observability to meet compliance requirements, such as, there are some outlined at the EU Cyber Resiliency Act, they mentioned that at one of the keynotes, if I’m not mistaken.
Olimpiu Pop: Yes. It was Friday.
Julia Morgado: Yes, exactly. So there was a lot going on at KubeCon. I’m still digesting everything.
Olimpiu Pop: So to conclude, what you’re saying is that, now, things are happening in real time, more or less, so observability is the mechanism through which, if we implement it, we’ll always know what happens and know exactly where we are. And then more than everything else, that is important, so high availability data is even more than that, because it means that you have servers available, but if you don’t have the proper data, your system is not working as expected. And last but not least, even though the things change lately, the Cyber Resilience Act will just ask you to be more aware of what you’re doing on the supply chain side. So those things have to be boiled down into the business continuity plan of your company as well.
Okay. That was a interesting deep dive.
Julia Morgado: Yes, thank you for having me. It was a pleasure.
Olimpiu Pop: Same here.
Julia Morgado: I love talking about Cloud Native things, KubeCon experiences. I always encourage and recommend everyone to attend at least one KubeCon if they can. I know not everyone is able to, but for those that don’t know, CNCF also provides scholarships for KubeCons. I think you have to apply with at least two months in advance, but you should check out their website. So there are scholarships, usually also if you’ve been laid off, you can get a free ticket to attend a KubeCon. So there are a lot of opportunities.
And just for those that are more interested in Cloud Native technologies in general, I would say just start, get involved. Go on the CNCF Slack channel, there are several channels for each of the open source projects or there are like first-time contributors and you can just say, “Hey, I’m new here, but I want to get more involved”. There are so many ways people can learn and get involved in that community, and I think it’s a very welcoming community. I don’t know about you, but I always love going to KubeCons and meeting people and learning more about technology.
Olimpiu Pop: Yes, it’s, as mentioned and discussed with several people, I just went there without any plans and I always met somebody, old friend or new friend, and that was quite nice. So yes, the Kubernetes is more than just a technology, is a community and everything else that’s in its ecosystem.
Okay. Obrigado, Julia.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
![]() Lazard Asset Management LLC cut its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 100.0% during the 4th quarter, according to its most recent disclosure with the Securities and Exchange Commission. The firm owned 384 shares of the company’s stock after selling 42,557,620 shares during the quarter. Lazard Asset Management LLC’s holdings in MongoDB were worth $88,000 as of its most recent SEC filing.
Lazard Asset Management LLC cut its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 100.0% during the 4th quarter, according to its most recent disclosure with the Securities and Exchange Commission. The firm owned 384 shares of the company’s stock after selling 42,557,620 shares during the quarter. Lazard Asset Management LLC’s holdings in MongoDB were worth $88,000 as of its most recent SEC filing.
Several other institutional investors have also made changes to their positions in MDB. Union Bancaire Privee UBP SA bought a new position in MongoDB in the 4th quarter valued at about $3,515,000. HighTower Advisors LLC lifted its position in shares of MongoDB by 2.0% during the 4th quarter. HighTower Advisors LLC now owns 18,773 shares of the company’s stock worth $4,371,000 after buying an additional 372 shares during the last quarter. Nisa Investment Advisors LLC boosted its stake in MongoDB by 428.0% in the fourth quarter. Nisa Investment Advisors LLC now owns 5,755 shares of the company’s stock valued at $1,340,000 after buying an additional 4,665 shares in the last quarter. Jones Financial Companies Lllp grew its position in MongoDB by 68.0% in the fourth quarter. Jones Financial Companies Lllp now owns 1,020 shares of the company’s stock valued at $237,000 after acquiring an additional 413 shares during the last quarter. Finally, Smartleaf Asset Management LLC raised its stake in MongoDB by 56.8% during the fourth quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock worth $87,000 after acquiring an additional 134 shares in the last quarter. 89.29% of the stock is currently owned by institutional investors.
MongoDB Price Performance
Shares of MDB opened at $185.85 on Monday. The stock has a 50-day moving average of $174.70 and a 200-day moving average of $235.57. The company has a market cap of $15.09 billion, a PE ratio of -67.83 and a beta of 1.49. MongoDB, Inc. has a one year low of $140.78 and a one year high of $370.00.
<!—->
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The business had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same quarter last year, the firm posted $0.86 EPS. Analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Insider Buying and Selling at MongoDB
In related news, CEO Dev Ittycheria sold 8,335 shares of the stock in a transaction dated Wednesday, February 26th. The shares were sold at an average price of $267.48, for a total transaction of $2,229,445.80. Following the completion of the transaction, the chief executive officer now owns 217,294 shares in the company, valued at approximately $58,121,799.12. This represents a 3.69% decrease in their ownership of the stock. The transaction was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through this link. Also, CAO Thomas Bull sold 301 shares of the firm’s stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total transaction of $52,148.25. Following the sale, the chief accounting officer now owns 14,598 shares of the company’s stock, valued at $2,529,103.50. This trade represents a 2.02% decrease in their position. The disclosure for this sale can be found here. In the last three months, insiders have sold 33,538 shares of company stock worth $6,889,905. Corporate insiders own 3.60% of the company’s stock.
Analyst Ratings Changes
Several equities research analysts recently issued reports on the stock. Daiwa Capital Markets started coverage on shares of MongoDB in a report on Tuesday, April 1st. They set an “outperform” rating and a $202.00 price target on the stock. Needham & Company LLC lowered their price target on shares of MongoDB from $415.00 to $270.00 and set a “buy” rating for the company in a report on Thursday, March 6th. Mizuho dropped their price target on MongoDB from $250.00 to $190.00 and set a “neutral” rating for the company in a research note on Tuesday, April 15th. Barclays reduced their price objective on MongoDB from $280.00 to $252.00 and set an “overweight” rating on the stock in a research report on Friday, May 16th. Finally, Redburn Atlantic upgraded MongoDB from a “sell” rating to a “neutral” rating and set a $170.00 target price for the company in a research report on Thursday, April 17th. Nine analysts have rated the stock with a hold rating, twenty-three have given a buy rating and one has given a strong buy rating to the stock. Based on data from MarketBeat, the company currently has a consensus rating of “Moderate Buy” and an average price target of $288.91.
Read Our Latest Analysis on MDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Warm Springs Advisors Inc. Makes New $1.69 Million Investment in MongoDB, Inc. (NASDAQ:MDB)
MMS • RSS
Warm Springs Advisors Inc. purchased a new stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) during the 4th quarter, according to its most recent 13F filing with the Securities and Exchange Commission. The fund purchased 7,263 shares of the company’s stock, valued at approximately $1,691,000. MongoDB makes up approximately 1.6% of Warm Springs Advisors Inc.’s portfolio, making the stock its 20th largest position.
A number of other hedge funds have also modified their holdings of MDB. Strategic Investment Solutions Inc. IL acquired a new stake in MongoDB during the fourth quarter valued at $29,000. NCP Inc. acquired a new stake in shares of MongoDB during the 4th quarter valued at about $35,000. Coppell Advisory Solutions LLC lifted its holdings in shares of MongoDB by 364.0% during the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock valued at $54,000 after buying an additional 182 shares during the last quarter. Smartleaf Asset Management LLC grew its stake in shares of MongoDB by 56.8% in the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock valued at $87,000 after buying an additional 134 shares in the last quarter. Finally, Manchester Capital Management LLC increased its holdings in MongoDB by 57.4% in the fourth quarter. Manchester Capital Management LLC now owns 384 shares of the company’s stock worth $89,000 after buying an additional 140 shares during the last quarter. 89.29% of the stock is owned by institutional investors and hedge funds.
MongoDB Stock Down 1.4%
MDB stock opened at $185.85 on Friday. MongoDB, Inc. has a twelve month low of $140.78 and a twelve month high of $370.00. The company has a market cap of $15.09 billion, a PE ratio of -67.83 and a beta of 1.49. The business’s 50-day simple moving average is $174.75 and its 200 day simple moving average is $236.90.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). The firm had revenue of $548.40 million during the quarter, compared to the consensus estimate of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same quarter in the prior year, the business posted $0.86 EPS. On average, equities research analysts anticipate that MongoDB, Inc. will post -1.78 EPS for the current year.
Insiders Place Their Bets
In other MongoDB news, CAO Thomas Bull sold 301 shares of the firm’s stock in a transaction dated Wednesday, April 2nd. The shares were sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the transaction, the chief accounting officer now owns 14,598 shares in the company, valued at $2,529,103.50. This trade represents a 2.02% decrease in their ownership of the stock. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available at this link. Also, insider Cedric Pech sold 1,690 shares of the company’s stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $292,809.40. Following the completion of the sale, the insider now owns 57,634 shares in the company, valued at approximately $9,985,666.84. This represents a 2.85% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold 33,538 shares of company stock worth $6,889,905 over the last 90 days. Corporate insiders own 3.60% of the company’s stock.
Analyst Upgrades and Downgrades
MDB has been the subject of several recent research reports. The Goldman Sachs Group decreased their target price on shares of MongoDB from $390.00 to $335.00 and set a “buy” rating for the company in a research report on Thursday, March 6th. Truist Financial lowered their target price on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a research report on Monday, March 31st. Loop Capital cut MongoDB from a “buy” rating to a “hold” rating and reduced their price target for the stock from $350.00 to $190.00 in a research report on Tuesday. Canaccord Genuity Group decreased their price target on MongoDB from $385.00 to $320.00 and set a “buy” rating for the company in a research note on Thursday, March 6th. Finally, Wedbush cut their price objective on MongoDB from $360.00 to $300.00 and set an “outperform” rating on the stock in a research note on Thursday, March 6th. Nine investment analysts have rated the stock with a hold rating, twenty-three have issued a buy rating and one has given a strong buy rating to the company. Based on data from MarketBeat, MongoDB has an average rating of “Moderate Buy” and an average target price of $288.91.
View Our Latest Stock Report on MongoDB
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

With the proliferation of data centers and electric vehicles, the electric grid will only get more strained. Download this report to learn how energy stocks can play a role in your portfolio as the global demand for energy continues to grow.