Month: May 2025

MMS • Renato Losio

Last month, Synadia threatened to pull NATS from the Cloud Native Computing Foundation (CNCF), moving from the Apache 2.0 license to a non-open source license. While the dispute lasted only a few days, with both Synadia and CNCF agreeing that the project remains in the open source ecosystem, the dispute left many concerned about the long-term availability and support of open source projects.
NATS is an open source messaging system that enables secure, high-performance, and scalable communication between distributed systems and services. After developing and maintaining the project under the Apache 2.0 license for many years, and donating it to the CNCF in 2018, Synadia announced last month its plan to withdraw the NATS server from the foundation and adopt the Business Source License (BUSL), a non-open source license. Derek Collison, creator of NATS.io and CEO of Synadia, wrote:
For the NATS ecosystem to flourish, Synadia must also thrive. This clarity has guided our decision-making and planning (…) Synadia’s customers, partners, and the broader NATS ecosystem derive tremendous value from the features and capabilities of the NATS server. Synadia and its predecessor company funded approximately 97% of the NATS server contributions.
While a discussion about the future of the project was taking place in the CNCF TOC repository, the foundation explained why the open source commitments and principles were under threat and disputed the ownership of the NATS trademark, sparking concerns about the future of the popular project. Foundation-backed open source software has traditionally offered greater stability than corporate-owned projects, making NATS’ potential departure from CNCF a significant exception.
After a few days of discussions and updates, Synadia and the CNCF announced on May 1st that they had reached an agreement: Synadia would transfer the NATS trademark registrations to the Linux Foundation, without forking the project, while the CNCF would retain control over the project’s infrastructure and assets. If Synadia chooses to fork the project for a proprietary offering in the future, it will have to do so under a new name.
In the article “OSS: Two Steps Forward, One Step Back,” Stephen O’Grady, principal analyst and cofounder at RedMonk, writes:
The flareup starkly revealed traditional fault lines in the wider open source community around the role of foundations. For many, this situation provided an opportunity not to protest the alleged about face but rather to attack foundations generally and the CNCF specifically for their shortcomings, both perceived and real (…) Vendors that choose to donate projects to foundations do so understanding, or at least should, that donation is a one way door.
Discussing “NATS goes Nuts – Quite Unique Open Source controversy,” Peter Zaitsev, founder of Percona and open source advocate, adds:
There’s a lesson here for the CNCF too. If it wants people to trust the projects it hosts, it needs to make sure situations like this don’t happen. That means locking down all the key assets -like trademarks and licensing rights- before fully accepting a project.
Discussing the future of Synadia and the NATS project after the agreement was reached, Collison explained how Synadia is now considering a commercial distribution that would embed the OSS NATS Server targeted for specific use cases, with the company still providing commercial support for the open source solution. O’Grady concludes:
The NATS storm was a black eye for open source broadly. Between the simmering antagonism towards foundations at scale, the direct attacks on the CNCF specifically and the revelations about NATS’ performance and Synadia’s alleged behaviors, it was not a great week for open source.
Seven years after joining the CNCF, NATS has yet to achieve “graduated” status and continues to operate under the “incubating” designation, one of the factors that contributed to the dispute.
Azure AI Foundry Agent Service GA Introduces Multi-Agent Orchestration and Open Interoperability
MMS • Steef-Jan Wiggers
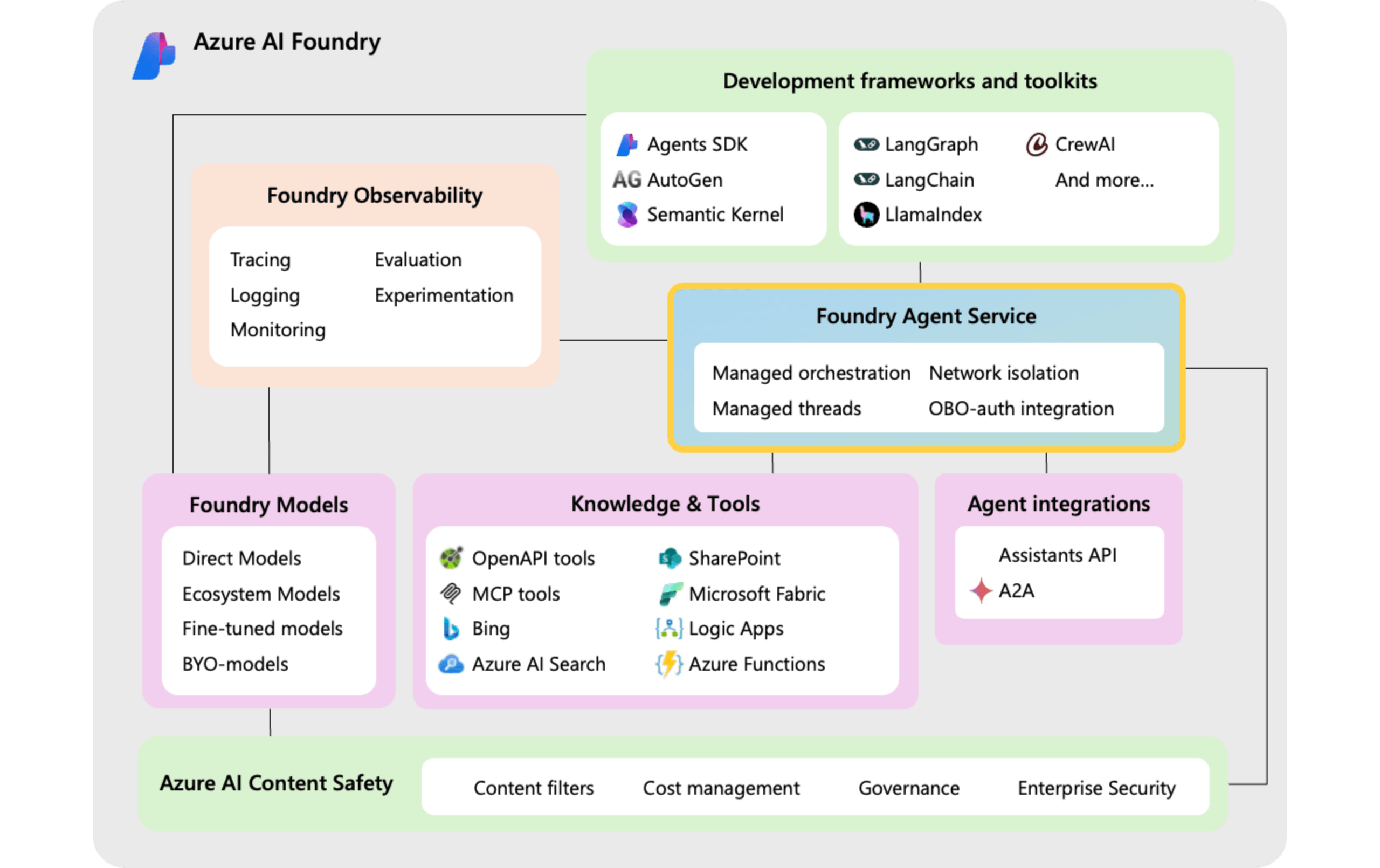
Microsoft recently announced the general availability (GA) of the Azure AI Foundry Agent Service at its annual Build conference, a flexible, use-case-agnostic platform for building, deploying, and managing AI agents, designed as microservices (benefiting from modularity and scalability), for a wide range of applications.
The company first introduced the service at Ignite as Azure AI Agent Service, which sits within Azure AI Foundry, allowing developers to create and run an agent using either OpenAI SDKs or Azure AI Foundry SDKs with just a few lines of code. It was later available in public preview in the Azure AI Foundry SDK and the Azure AI Foundry portal. Moreover, with the GA release, the company states that it is introducing several powerful new features and integrations that make it even easier for developers to build and scale their agent solutions.
(Source: Microsoft Learn documentation)
One of the key enhancements in the GA release is the robust support for Multi-Agent Orchestration that coordinates specialized agents to perform structured, long-running tasks. The orchestration capability is built around two core components: first, Connected Agents (preview) enable point-to-point interactions, allowing agents to call upon other specialized agents as tools for task delegation, modular processing, and context-specific workflows where each contributes independently to the solution; and second, Multi-Agent Workflows (preview) offer a structured, stateful orchestration layer that coordinates multiple agents through complex, multi-step processes by handling context management, error recovery, and long-running durability, making them ideal for scenarios requiring agents to maintain context across multiple steps, like customer onboarding or supply chain automation.
The Foundry Agent Service integrates directly with the converged runtime for Semantic Kernel and AutoGen to support advanced multi-agent orchestration.
Recognizing that AI agents thrive within interconnected ecosystems, the GA release of Azure AI Foundry Agent Service strongly emphasizes open and interoperable tools. Developers can now leverage the extensive library of over 1,400 Azure Logic Apps workflows as tools for their agents, enabling seamless automation of complex business processes and even triggering agents directly from Logic Apps.
Furthermore, the platform significantly expands its knowledge integration capabilities by adding SharePoint as a first-party tool alongside Microsoft Fabric and Bing Search, providing agents with richer, context-aware insights. The ecosystem is further enriched through access to a growing catalog of partner tools from various domains and a library of reusable agent code samples from Microsoft and the community, accelerating development and expanding agent capabilities.
A key aspect of this open approach is the introduction of the Agent2Agent (A2A) API head, which enables interoperability with other agent platforms – allowing open-source orchestrators with A2A connectors to utilize Foundry Agent Service agents without requiring custom integrations, facilitating multi-turn conversations between diverse agents. Moreover, the commitment to open protocols extends to multi-cloud scenarios, allowing developers to connect Foundry agents with agents from platforms like SAP Joule and Google Vertex AI. Furthermore, Azure AI Foundry Agent Service integrates with popular agent orchestration frameworks like Crew AI, LangGraph, and LlamaIndex.
In addition, the GA release of Azure AI Foundry Agent Service incorporates robust features for evaluation, monitoring (AgentOps), governance, and safety. Built-in evaluation tools allow developers to assess agent performance across key metrics like accuracy and efficiency. At the same time, integrated tracing provides detailed insights into agent processing workflows for optimization.
Daniel Christian, a Microsoft MVP and certified trainer, emphasized this open approach on X:
Models, Models, everywhere, but they are all available to connect with the Azure AI Foundry Agent Service.
In addition, Jiadong Chen, a Cloud architect and Microsoft MVP, tweeted:
AI agents are quietly transforming industries. With Azure AI Foundry and Azure AI Agent Service, businesses deploy LLM-powered multi-agent systems to handle everything from real-time analytics to customer interactions. Picture a retail chain using AI agents to predict inventory shortages or a hospital automating patient triage — all while Azure’s scalable infrastructure keeps data secure. The result? Productivity spikes, costs plummet, and innovation accelerates.
Lastly, Microsoft envisions the Azure AI Foundry Agent Service as a dynamic foundation for intelligent agent ecosystems, with ongoing efforts focused on unifying the Semantic Kernel and AutoGen SDKs, integrating containerized agents for streamlined orchestration, and broadening support for an even wider array of external agents.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) has been given a consensus rating of “Moderate Buy” by the thirty-three brokerages that are presently covering the company, MarketBeat.com reports. Nine research analysts have rated the stock with a hold rating, twenty-three have assigned a buy rating and one has assigned a strong buy rating to the company. The average 1 year price objective among brokers that have updated their coverage on the stock in the last year is $288.91.
A number of equities research analysts have weighed in on MDB shares. Monness Crespi & Hardt upgraded shares of MongoDB from a “sell” rating to a “neutral” rating in a research note on Monday, March 3rd. Rosenblatt Securities reaffirmed a “buy” rating and set a $350.00 price objective on shares of MongoDB in a report on Tuesday, March 4th. Scotiabank reaffirmed a “sector perform” rating and set a $160.00 price objective (down from $240.00) on shares of MongoDB in a report on Friday, April 25th. Wedbush decreased their price objective on MongoDB from $360.00 to $300.00 and set an “outperform” rating on the stock in a report on Thursday, March 6th. Finally, Robert W. Baird decreased their price objective on MongoDB from $390.00 to $300.00 and set an “outperform” rating on the stock in a report on Thursday, March 6th.
Get Our Latest Analysis on MongoDB
MongoDB Trading Down 1.4%
Shares of MDB stock opened at $185.85 on Friday. MongoDB has a 1 year low of $140.78 and a 1 year high of $370.00. The firm has a market capitalization of $15.09 billion, a P/E ratio of -67.83 and a beta of 1.49. The firm’s fifty day simple moving average is $174.70 and its 200 day simple moving average is $235.98.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The firm had revenue of $548.40 million for the quarter, compared to analyst estimates of $519.65 million. During the same period last year, the business earned $0.86 earnings per share. Equities research analysts anticipate that MongoDB will post -1.78 EPS for the current fiscal year.
Insider Activity
In related news, Director Dwight A. Merriman sold 3,000 shares of the stock in a transaction that occurred on Monday, March 3rd. The shares were sold at an average price of $270.63, for a total value of $811,890.00. Following the sale, the director now directly owns 1,109,006 shares in the company, valued at $300,130,293.78. This trade represents a 0.27% decrease in their position. The sale was disclosed in a legal filing with the SEC, which is available at this link. Also, CEO Dev Ittycheria sold 18,512 shares of the stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $3,207,389.12. Following the completion of the sale, the chief executive officer now owns 268,948 shares in the company, valued at $46,597,930.48. This represents a 6.44% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold a total of 33,538 shares of company stock valued at $6,889,905 in the last 90 days. 3.60% of the stock is owned by company insiders.
Institutional Trading of MongoDB
Hedge funds have recently modified their holdings of the company. B.O.S.S. Retirement Advisors LLC acquired a new stake in MongoDB during the 4th quarter worth $606,000. Union Bancaire Privee UBP SA acquired a new stake in MongoDB during the 4th quarter worth $3,515,000. HighTower Advisors LLC raised its stake in MongoDB by 2.0% during the 4th quarter. HighTower Advisors LLC now owns 18,773 shares of the company’s stock worth $4,371,000 after buying an additional 372 shares during the period. Nisa Investment Advisors LLC raised its stake in MongoDB by 428.0% during the 4th quarter. Nisa Investment Advisors LLC now owns 5,755 shares of the company’s stock worth $1,340,000 after buying an additional 4,665 shares during the period. Finally, Jones Financial Companies Lllp raised its stake in MongoDB by 68.0% during the 4th quarter. Jones Financial Companies Lllp now owns 1,020 shares of the company’s stock worth $237,000 after buying an additional 413 shares during the period. 89.29% of the stock is currently owned by institutional investors and hedge funds.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Explore Elon Musk’s boldest ventures yet—from AI and autonomy to space colonization—and find out how investors can ride the next wave of innovation.
Spring News Roundup: GA Releases of Spring Boot, Security, Auth Server, Integration, AI
MMS • Michael Redlich

There was a flurry of activity in the Spring ecosystem during the week of May 19th, 2025, highlighting GA releases of Spring Boot, Spring Security, Spring Authorization Server, Spring Session, Spring Integration, Spring for GraphQL, Spring AI and Spring Web Services.
Spring Boot
The release of Spring Boot 3.5.0 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: new annotations, @ServletRegistration and @FilterRegistration, to register instances of the Jakarta Servlet Servlet and Filter interfaces, respectively; and the ability to customize structured logging stack traces. More details on this release may be found in the release notes and this InfoQ news story.
Spring Security
The release of Spring Security 6.5.0 ships with bug fixes, dependency upgrades and new features such as: an implementation of the OAuth 2.0 Demonstrating Proof-of-Possession (DPoP) specification; and support for Micrometer context propagation to propagate authorization between an instance of the ThreadLocalAccessor interface and reactive operations. Further details on this release may be found in the release notes and what’s new page.
Similarly, the release of Spring Security 6.4.6 features a resolution to CVE-2025-41232, a vulnerability where Spring Security Aspects, under certain conditions, may not correctly locate method security annotations on private methods potentially leading to an authorization bypass. More details on this release may be found in the release notes.
Spring Authorization Server
The release of Spring Authorization Server 1.5.0 delivers bug fixes, dependency upgrades and new features such as: an implementation of the OAuth 2.0 Pushed Authorization Requests (PAR) specification and the aforementioned OAuth 2.0 Demonstrating Proof of Possession (DPoP) specification; and a replacement of the deprecated Spring Boot @MockBean annotation with the preferred Spring Framework @MockitoBean annotation where applicable. Further details on this release may be found in the release notes.
Spring for GraphQL
The release of Spring for GraphQL 1.4.0 ships with dependency upgrades and a new feature that adds a name field, of type String and annotated with @Nullable, to the DataLoader class for improved registration of data loaders. More details on this release may be found in the release notes.
Spring Session
The release of Spring Session 3.5.0 features many dependency upgrades and a resolution to a race condition and ClassCastException during integration testing using an instance of the SessionEventRegistry class due to the class assuming there is only one single event type for each session ID. Further details on this release may be found in the release notes.
Spring Integration
The release of Spring Integration 6.5.0 delivers bug fixes, dependency upgrades and new features such as: a new AbstractRecentFileListFilter class, an implementation of the FileListFilter interface, that accepts only recent files based on a provided age; and implementations of the Spring Framework MessageChannel interface now throw a MessageDispatchingException when an application context has not yet started or stopped at runtime. More details on this release may be found in the release notes and what’s new page.
Spring AI
The release of Spring AI 1.0.0 features: a ChatClient interface that supports 20 AI models with multi-modal inputs and an output with a structured response; an Advisors API that serves as an interceptor chain for developers to modify incoming prompts by injecting retrieval data and conversation memory; and full support for the Model Context Protocol. Further details on this release may be found in the release notes and this InfoQ news story. Developers can also learn how to create their first Spring AI 1.0 application in this user guide.
Spring Web Services
The release of Spring Web Services 4.1.0 delivers bug fixes, dependency upgrades and new features such as: support for configuring arbitrary options for Apache Web Services Security for Java (WSS4J) via the Wss4jSecurityInterceptor class; and the ability to create custom implementations of the MethodArgumentResolver and MethodReturnValueHandler interfaces. More details on this release may be found in the release notes.
MMS • Mark Silvester

Cisco’s innovation arm, Outshift, has unveiled JARVIS. An AI-powered assistant designed to streamline platform-engineering workflows. JARVIS offers a conversational interface that simplifies complex tasks, reducing both execution time and cognitive overhead.
Cisco has developed JARVIS as a member of the platform-engineering team. JARVIS can integrate with over 40 tools and, among other tasks, can seamlessly provision infrastructure, onboard new applications to CI and retrieve important documents with all instructions originating from natural language. The team at Cisco communicate with JARVIS using tools they already use every day, such as Jira, Webex and Backstage. The team can assign Jira tickets to JARVIS, and it executes the work.
The results have been significant. In a LangChain blog post, they reported that “Tasks that previously took a week, such as setting up CI/CD pipelines, can now be completed in under an hour.” According to a NetworkWorld blog post, “Engineers spend up to 70% of their time on repetitive tasks rather than innovation. JARVIS automates these workflows, turning day-long processes into minute-long ones.”
JARVIS is powered by a hybrid AI architecture that combines multiple techniques. Built using LangGraph, the main engine behind JARVIS is large language models (LLMs) that provide the natural-language processing capability to best interpret developer requests. However, the responses generated by the LLMs are not immediately trusted. JARVIS implements three additional safeguards to ensure accuracy and reliability. First, it uses rule-based validation through symbolic logic to confirm that outputs adhere to predefined standards, such as naming conventions. Second, it enforces clearly defined, repeatable workflows to ensure tasks are executed consistently, without allowing the AI to improvise. Finally, it introduces agent supervision, where one agent reviews and verifies the work of another, adding an additional layer of quality control.
To answer knowledge questions, JARVIS leverages retrieval-augmented generation (RAG) by allowing its AI agents to supplement their in-memory knowledge by looking up information from external sources of structured data like wikis and codebases.
At present, JARVIS is only used internally at Cisco. However, the company has announced plans to open-source key components such as its integration with Backstage and standalone agents. The project is also contributing to the Internet of Agents initiative of intelligent software agents that can communicate and collaborate across shared protocols.
Bill Gates, co-founder of Microsoft, sees AI agents like JARVIS as a part of the future. In a 2024 blog post, he noted, “Agents are not only going to change how everyone interacts with computers. They’re also going to upend the software industry, bringing about the biggest revolution in computing since we went from typing commands to tapping on icons.”
MMS • Sergio De Simone

The new release of LiteRT, formerly known as TensorFlow Lite, introduces a new API to simplify on-device ML inference, enhanced GPU acceleration, support for Qualcomm NPU (Neural Processing Unit) accelerators, and advanced inference features.
One of the goals of the latest LiteRT release is to make it easier for developers to harness GPU and NPU acceleration, which previously required working with specific APIs or vendor-specific SDKs:
By accelerating your AI models on mobile GPUs and NPUs, you can speed up your models by up to 25x compared to CPU while also reducing power consumption by up to 5x.
For GPUs, LiteRT introduces MLDrift, a new GPU acceleration implementation that offers several improvements over TFLite’s GPU delegate. These include more efficient tensor-based data organization, context- and resource-aware smart computation, and optimized data transfer and conversion.
This results in significantly faster performance than CPUs, than previous versions of our TFLite GPU delegate, and even other GPU enabled frameworks particularly for CNN and Transformer models.
LiteRT also targets neural processing units (NPUs), which are AI-specific accelerators designed to speed up inference. According to Google’s internal benchmarks, NPUs can deliver up to 25× faster performance than CPUs while using just one-fifth of the power. However, there is no standard way to integrate these accelerators, often requiring custom SDKs and vendor-specific dependencies.
Thus, to provide a uniform way to develop and deploy models on NPUs, Google has partenered with Qualcomm and MediaTek to add support for their NPUs in LiteRT, enabling acceleration for vision, audio, and NLP models. This includes automatic SDK downloads alongside LiteRT, as well as opt-in model and runtime distribution via Google Play.
Moreover, to make handling GPU and NPU acceleration even easier, Google has streamlined LiteRT’s API to let developers specify the target backend to use when creating a compiled model. This is done with the CompiledModel::Create method, which supports CPU, XNNPack, GPU, NNAPI (for NPUs), and EdgeTPU backends, significantly simplifying the process compared to previous versions, which required different methods for each backend.
The LiteRT API also introduces features aimed at optimizing inference performance, especially in memory- or processor-constrained environments. These include buffer interoperability via the new TensorBuffer API, which eliminates data copies between GPU memory and CPU memory; and support for asynchronous, concurrent execution of different parts of a model across CPU, GPU, and NPUs, which, according to Google, can reduce latency by up to 2x.
LiteRT can be downloaded from GitHub and includes several sample apps demonstrating how to use it.
MMS • Renato Losio

Redis 8 has recently hit general availability, switching to the AGPLv3 license. A year after leaving its open source roots to challenge cloud service providers and following the birth of Valkey, Redis has rehired its creator and moved back to an open source license.
Initially released under the more permissive BSD license, Redis switched to the more restrictive and not open source SSPLv1 license in March 2024, sparking concerns in the community and triggering the successful Valkey fork. Just over a year later, the project’s direction has changed again, and Redis 8.0 is once more open source software, this time under the terms of the OSI-approved AGPLv3 license.
According to Redis’ announcement, the new major release delivers several performance improvements, including up to 87% faster commands, up to 2× higher throughput in operations per second, and up to 18% faster replication. It also introduces the beta of Vector Sets, which is discussed separately on InfoQ. Salvatore Sanfilippo (aka ‘antirez’), the creator of Redis, explains:
Five months ago, I rejoined Redis and quickly started to talk with my colleagues about a possible switch to the AGPL license, only to discover that there was already an ongoing discussion, a very old one, too. (…) Writing open source software is too rooted in me: I rarely wrote anything else in my career. I’m too old to start now.
A year ago, the more restrictive license triggered different forks of Redis, including the very successful and CNCF-backed Valkey that gained immediate support from many providers, including AWS and Google Cloud. AWS has launched ElastiCache for Valkey and MemoryDB for Valkey at significant discounts compared to their ElastiCache for Redis version offering.
While noting that Valkey is currently outperforming Redis 8.0 in real-world benchmarks, Khawaja Shams, CEO and co-founder of Momento, welcomes Sanfilippo’s return to Redis and writes:
I am genuinely excited about his return because it is already impactful. He’s following through on his promise of contributing new features and performance optimizations to Redis. More profoundly, Redis 8.0 has been open-sourced again.
While many predict that developers using Valkey will not switch back to Redis, they also acknowledge that Valkey will face tougher competition. Peter Zaitsev, founder of Percona and open source advocate, highlights one of the advantages of Redis:
While a lot has been said about Redis going back to opensource with AGPLv3 License, I think it has been lost it is not same Redis which has been available under BSD license couple of years ago – number of extensions, such as RedisJSON which has not been Open Source since 2018 are now included with Redis under same AGPLv3 license. This looks like an important part of the response against Valkey, which does not have all the same features, as only the “core” Redis BSD code was forked
The article “Redis is now available under the AGPLv3 open source license” confirms that, aside from the new data type (vector sets), the open source project now integrates various Redis Stack technologies, including JSON, Time Series, probabilistic data types, and the Redis Query Engine into core Redis 8 under AGPL.
The new major release and licensing change have sparked popular threads on Reddit, with many practitioners suggesting it’s too late and calling it a sign of a previous bad decision. Some developers believe the project’s greatest asset remains its creator, while Philippe Ombredanne, lead maintainer of AboutCode, takes a more pessimistic view of the future:
Users see through these shenanigans. For Redis, the damage to their user base is likely already done, irreparable and the shattered trust never to be regained.
Redis is not the first project to switch back from SSPLv1 to AGPL following a successful fork and a loss of community support and trust. A year ago, Shay Banon, founder and CEO of Elastic, announced a similar change for Elasticsearch and Kibana, as reported on InfoQ.
Microsoft Announced Edit, New Open-Source Command-Line Text Editor for Windows at Build 2025
MMS • Bruno Couriol

At its Build 2025 conference, Microsoft announced Edit, a new open-source command-line text editor, to be distributed in the future as part of Windows 11. Edit aims to provide a lightweight native, modern command-line editing experience similar to Nano and Vim.
Microsoft explained developing Edit because 64-bit Windows lacked a default command-line text editor, a gap since the 32-bit MS-DOS Edit. Microsoft opted for a modeless design to be more user-friendly than modal editors like Vim (see Stackoverflow’s Helping One Million Developers Exit Vim) and built its own tool after finding existing modeless options either unsuitable for bundling or lacking Windows support.
Microsoft positions Edit as a simple editor for simple needs. Features include mouse support, the ability to open multiple files and switch between them, find and replace capabilities (including regex), and word wrap. The user interface features a modern interface and input controls similar to Visual Studio Code. There is however no right-click menu in the app.
Written in Rust, the editor stands small, at less than 250KB in size.
Discussions among developers on platforms like Reddit and Hacker News show varied reactions. Many commenters debated the necessity of a new CLI editor on Windows, questioning its use case given existing options. Some feel it’s redundant for those already using WSL with Nano or Vim or other tools like Git Bash, while others see it as potentially useful for quick, basic edits in a native Windows context without needing third-party installs or WSL.
Edit’s main contributor chimed in with a detailed rationale behind the in-house development:
We decided against nano, kilo, micro, yori, and others for various reasons. What we wanted was a small binary so we can ship it with all variants of Windows without extra justifications for the added binary size. It also needed to have decent Unicode support. It should’ve also been one built around VT output as opposed to Console APIs to allow for seamless integration with SSH. Lastly, first-class support for Windows was obviously also quite important. I think out of the listed editors, micro was probably the one we wanted to use the most, but… it’s just too large.
Microsoft has released Edit’s source code under the MIT license. Edit is not currently available in the stable channel of Windows 11. However, users can download Microsoft Edit from the project’s GitHub page.
MMS • Tom Akehurst

Key Takeaways
- Mocking gRPC services allows you to validate gRPC integration code during your tests while avoiding common pitfalls such as unreliable sandboxes, version mismatches, and complex test data setup requirements.
- The WireMock gRPC extension supports familiar HTTP stubbing patterns to be used with gRPC-based integration points.
- WireMock’s Spring Boot integration enables dynamic port allocation and automatic configuration injection, eliminating the need for fixed ports and enabling parallel test execution while making test infrastructure more maintainable and scalable.
- API mocking can accelerate and simplify many testing activities, but complex systems contain failure modes that can only realistically be discovered during integration testing, meaning this is still an essential practice.
- While basic unidirectional streaming methods can be mocked, more work is still needed for WireMock to support advanced testing patterns.
When your code depends on numerous external services, end-to-end testing is often prohibitively slow and complex due to issues such as unavailable sandboxes, unstable environments, and difficulty setting up necessary test data. Additionally, running many hundreds or thousands of automated tests against sandbox API implementations can result in very long build/pipeline run times.
Mock-based testing offers a practical alternative that balances comprehensive testing with execution speed. Plenty of tools exist that support mocking of REST APIs, but gRPC is much less widely supported despite its growing popularity, and much less has been written about this problem. In this article, we’ll show you how you can use familiar JVM tools – Spring Boot, gRPC, and WireMock together. We’ll also discuss some of the tradeoffs and potential gotchas to consider when testing against mocked gRPC APIs.
Mocks, integration testing and tradeoffs
API mocking involves a tradeoff – a faster, more deterministic and cheaper-to-create API implementation at the expense of some realism. This works because many types of tests (and thus risks managed) do not rely on nuances of API behaviour we’ve chosen not to model in a mock, so we get the benefits without losing out on any vital feedback.
However, some types of defects will only surface as the result of complex interactions between system components that aren’t captured in mock behaviour, so some integration testing is still necessary in a well-rounded test strategy.
The good news is that this can be a small fraction of the overall test suite, provided that tests are created with an explicit judgement about whether they’re expected to reveal the type of complex integration issue mentioned above.
The tools we’ll be using
First, let’s define the terms we’ll be using – feel free to skip down to the next section if you’re already familiar!
gRPC is a modern network protocol built on HTTP/2 and leveraging Protocol Buffers (Protobuf) for serialization. It is often used in microservice architectures where network efficiency and low latency are important.
Spring Boot is a framework within the Spring ecosystem that simplifies Java application development through convention-over-configuration principles and intelligent defaults. It enables developers to focus on business logic while maintaining the flexibility to customize when needed.
WireMock is an open source API simulation tool that enables developers to create reliable, deterministic test environments by providing configurable mock implementations of external service dependencies.
Why mock gRPC in Spring Boot?
While building an app or service that calls out to gRPC services, you need there to be something handling those calls during development. There are a few options here:
- Call out to a real service implementation sandbox.
- Mock the interface that defines the client using an object mocking tool like Mockito.
- Mock the gRPC service locally and configure your app to connect to this during dev and test.
The first option can often be impractical for a number of reasons:
- The sandbox is slow or unreliable.
- It’s running the wrong version of the service.
- Setting up the correct test data is difficult.
- The service isn’t even built yet.
The second option avoids the above issues but significantly reduces the effectiveness of your tests due to the fact that not all of the gRPC-related code gets executed. gRPC is a complex protocol with a number of failure modes, and ideally, we want to discover these in our automated tests rather than in staging, or even worse, production.
So this leaves mocking the gRPC service over the wire, which brings the advantages of executing the gRPC integration code during your tests while avoiding the pitfalls of relying on an external sandbox. This is what we’ll explore in the remainder of this article.
Where it gets tricky
Setting up mock services for testing often introduces configuration complexity that can undermine the benefits of the mocking approach itself. A particular pain point arises from the practice of using fixed port numbers for mock servers in order to be able to configure the local environment to address them. Having fixed ports prevents parallelization of the tests, making it difficult to scale out test runners as the test suite grows. Fixed ports can also cause errors in some shared tenancy CI/CD environments.
WireMock’s Spring Boot integration addresses these challenges through dynamic port allocation and configuration injection. By automatically assigning available ports at runtime and seamlessly injecting these values into the application context, it eliminates the need for manual port management while enabling parallel test execution. This functionality, combined with a declarative annotation-based configuration system, significantly reduces setup complexity and makes the testing infrastructure more maintainable.
The second problem is that while API mocking tools have traditionally served REST and SOAP protocols well, gRPC support has remained notably scarce. To close this gap, we’ll use the newly released WireMock gRPC extension. The extension is designed to bring the same powerful mocking capabilities to gRPC-based architectures while preserving the familiar stubbing patterns that developers use for traditional HTTP testing.
Putting it all together
The following is a step-by-step guide to building a Spring Boot app that calls a simple gRPC “echo” service and returns the message contained in the request. If you want to check out and run some working code right away, all the examples in this article are taken from this demo project.
We’ll use Gradle as our build tool, but this can quite easily be adapted to Maven if necessary.
Step 1: Create an empty Spring Boot app
Let’s start with a standard Spring Boot application structure. We’ll use Spring Initializr to scaffold our project with the essential dependencies:
plugins {
id 'org.springframework.boot' version '3.2.0'
id 'io.spring.dependency.management' version '1.1.4'
id 'java'
}
group = 'org.wiremock.demo'
version = '0.0.1-SNAPSHOT'
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
Step 2: Add gRPC dependencies and build tasks
Since gRPC requires service interfaces to be fully defined in order to work, we have to do a few things at build time:
● Generate Java stubs, which will be used when setting up stubs in WireMock.
● Generate a descriptor (.dsc) file, which will be used by WireMock when serving mocked responses.
Add the gRPC starter module
implementation
'org.springframework.grpc:spring-grpc-spring-boot-starter:0.2.0'
Add the Google Protobuf libraries and Gradle plugin
plugins {
id "com.google.protobuf" version "0.9.4"
}
In the dependencies section:
protobuf 'com.google.protobuf:protobuf-java:3.18.1'
protobuf 'io.grpc:protoc-gen-grpc-java:1.42.1'
Ensure we’re generating both the descriptor and Java sources:
protobuf {
protoc {
artifact = "com.google.protobuf:protoc:3.24.3"
}
plugins {
grpc {
artifact = "io.grpc:protoc-gen-grpc-java:$versions.grpc"
}
}
generateProtoTasks {
all()*.plugins {
grpc {
outputSubDir = 'java'
}
}
all().each { task ->
task.generateDescriptorSet = true
task.descriptorSetOptions.includeImports = true
task.descriptorSetOptions.path = "$projectDir/src/test/resources/grpc/services.dsc"
}
}
}
Add a src/main/proto folder and add a protobuf service description file in there:
package org.wiremock.grpc;
message EchoRequest {
string message = 1;
}
message EchoResponse {
string message = 1;
}
service EchoService {
rpc echo(EchoRequest) returns (EchoResponse);
}
After adding this, we can generate the Java sources and descriptor:
./gradlew generateProto generateTestProto
You should now see a file called services.dsc under src/test/resources/grpc and some generated sources under build/generated/source/proto/main/java/org/wiremock/grpc.
Step 3: Configure application components for gRPC integration
Now that we have Java stubs generated, we can write some code that depends on them.
We’ll start by creating a REST controller that takes a GET to /test-echo and calls out to the echo gRPC service:
@RestController
public class MessageController {
@Autowired
EchoServiceGrpc.EchoServiceBlockingStub echo;
@GetMapping("/test-echo")
public String getEchoedMessage(@RequestParam String message) {
final EchoResponse response = echo.echo(EchoServiceOuterClass.EchoRequest.newBuilder().setMessage(message).build());
return response.getMessage();
}
}
Then we’ll configure a Spring Boot application that initialises the gRPC service bean (that we need so it can be injected into the REST controller):
@SpringBootApplication
public class SpringbootGrpcApplication {
@Bean
EchoServiceGrpc.EchoServiceBlockingStub echo(GrpcChannelFactory channels) {
return EchoServiceGrpc.newBlockingStub(channels.createChannel("local").build());
}
public static void main(String[] args) {
SpringApplication.run(SpringbootGrpcApplication.class, args);
}
}
Step 4: Set up an integration test class
Now we can start to build some tests that will rely on gRPC mocking.
First, we need to configure a few things in the test class.
@SpringBootTest(
webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT,
classes = SpringbootGrpcApplication.class
)
@EnableWireMock({
@ConfigureWireMock(
name = "greeting-service",
portProperties = "greeting-service.port",
extensionFactories = { Jetty12GrpcExtensionFactory.class }
)
})
class SpringbootGrpcApplicationTests {
@InjectWireMock("greeting-service")
WireMockServer echoWireMockInstance;
WireMockGrpcService mockEchoService;
@LocalServerPort
int serverPort;
RestClient client;
@BeforeEach
void init() {
mockEchoService = new WireMockGrpcService(
new WireMock(echoWireMockInstance),
EchoServiceGrpc.SERVICE_NAME
);
client = RestClient.create();
}
}
There’s quite a bit happening here:
- The
@SpringBootTestannotation starts our Spring application, and we’ve configured it to use a random port (which we need if we’re going to ultimately parallelize our test suite). @EnableWireMockadds the WireMock integration to the test, with a single instance defined by the@ConfigureWireMocknested annotation.- The instance is configured to use
Jetty12GrpcExtensionFactory, which is the gRPC WireMock extension. - @InjectWireMock injects the WireMockServer instance into the test.
- The
WireMockGrpcService, which is instantiated in theinit()method, is the gRPC stubbing DSL. It wraps the WireMock instance, taking the name of the gRPC service to be mocked. - We’ll use the
RestClientto make test requests to the Spring app, using the port number indicated by@LocalServerPort.
Now we’re ready to write a test. We’ll configure the gRPC echo service to return a simple, canned response and then make a request to the app’s REST interface and check that the value is passed through as we’d expect:
@Test
void returns_message_from_grpc_service() {
mockEchoService.stubFor(
method("echo")
.willReturn(message(
EchoResponse.newBuilder()
.setMessage("Hi Tom")
)));
String url = "http://localhost:" + serverPort + "/test-echo?message=blah";
String result = client.get()
.uri(url)
.retrieve()
.body(String.class);
assertThat(result, is("Hi Tom"));
}
The interesting part here is the first statement in the test method. This is essentially saying “when the echo gRPC method is called, return an EchoResponse with a message value of ‘Hi Tom’”.
Note how we’re taking advantage of the Java model code generated by the protoc tool (via the Gradle build). WireMock’s gRPC DSL takes a generated model and associated builder objects, which gives you a type-safe way of expressing response bodies and expected request bodies.
The benefit of this is that we a) get IDE auto-completion when we’re building body objects in our stubbing code, and b) if the model changes (due to a change in the .proto files), it will immediately get flagged by the compiler.
Step 5: Add dynamic responses
There are some cases where working with generated model classes can be overly constraining, so WireMock also supports working with request and response bodies as JSON.
For instance, suppose we want to echo the message sent in the request to the response rather than just returning a canned value. We can do this by templating a JSON string as the response body, where the structure of the JSON matches the response body type defined in the protobuf file:
@Test
void returns_dynamic_message_from_grpc_service() {
mockEchoService.stubFor(
method("echo").willReturn(
jsonTemplate(
"{"message":"{{jsonPath request.body '$.message'}}"}"
)));
String url = "http://localhost:" + serverPort + "/test-echo?" +
"message=my-messsage";
String result = client.get()
.uri(url)
.retrieve()
.body(String.class);
assertThat(result, is("my-messsage"));
}
We can also use all of WireMock’s built-in matchers against the JSON representation of the request:
mockEchoService.stubFor(
method("echo").withRequestMessage(
matchingJsonPath("$.message", equalTo("match-this"))
)
.willReturn(
message(EchoResponse.newBuilder().setMessage("matched!"))
));
Current limitations
At present, WireMock’s gRPC extension has quite limited support for unidirectional streaming, allowing only a single request event to trigger a stub match, and only a single event to be returned in a streamed response. Bidirectional streaming methods are currently not supported at all.
In both cases, these are due to limitations in WireMock’s underlying model for requests and responses, and the intention is to address this in the upcoming 4.x release of the core library.
Of course, this is all open source, so any contributions to this effort would be very welcome!
Additionally, only a limited range of standard Protobuf features have been tested with the extension, and occasionally, incompatibilities are discovered, for which issues and PRs are also gratefully received.
And we’re done!
If you’ve made it this far, you hopefully now have a good idea of how gRPC mocking can be used to support your Spring Boot integration tests.
Note that while this is the approach we recommend, there is always a tradeoff involved: mocking cannot capture all real-world failure modes. We would recommend using tools such as contract testing or ongoing validation against the real API to increase the reliability of your tests.
There’s more that we haven’t shown here, including errors, faults, verifications and hot reload. The gRPC extension’s documentation and tests are great places to look if you want to learn more.
For more information about the WireMock Spring Boot integration, see this page.
MMS • RSS
The Ampere Porting Advisor is a fork of the Porting Advisor for Graviton, an open source project from AWS, which, in turn, is a fork of the Arm High Performance Computing group’s Porting advisor.
Originally, it was coded as a Python module that analyzed known incompatibilities for C and Fortran code. This tutorial walks you through building and using the tool and how to act on issues identified by the tool.
The Ampere Porting Advisor is a command line tool that analyzes source code for known code patterns and dependency libraries. It then generates a report with any incompatibilities with Ampere’s processors. This tool provides suggestions of minimal required and/or recommended versions to run on Ampere processors for both language runtime and dependency libraries.
It can be run on non-Arm64 based machines (like Intel and AMD) and Ampere processors are not required. This tool does not work on binaries, only source code. It does not make any code modifications, it doesn’t make API level recommendations, nor does it send data back to Ampere.
Please Note: Even though we do our best to find known incompatibilities, we still recommend to perform the appropriate tests to your application on a system based on Ampere processors before going to production.
This tool scans all files in a source tree, regardless of whether they are included by the build system or not. As such, it may erroneously report issues in files that appear in the source tree but are excluded by the build system. Currently, the tool supports the following languages/dependencies:
Python 3+
- Python version
- PIP version
- Dependency versions in requirements.txt file
Java 8+
- Java version
- Dependency versions in pom.xml file
- JAR scanning for native method calls (requires JAVA to be installed)
Go 1.11+
- Go version
- Dependency versions on go.mod file
C, C++, Fortran
- Inline assembly with no corresponding aarch64 inline assembly.
- Assembly source files with no corresponding aarch64 assembly source files.
- Missing aarch64 architecture detection in autoconf config.guess scripts.
- Linking against libraries that are not available on the aarch64 architecture.
- Use of architecture specific intrinsic.
- Preprocessor errors that trigger when compiling on aarch64.
- Use of old Visual C++ runtime (Windows specific).
- The following types of issues are detected, but not reported by default:
- Compiler specific code guarded by compiler specific pre-defined macros.
- The following types of cross-compile specific issues are detected, but not reported by default.
- Architecture detection that depends on the host rather than the target.
- Use of build artifacts in the build process.
For more information on how to modify issues reported, use the tool’s built-in help: ./porting-advisor-linux-x86_64 -–help
If you run into any issues, see our CONTRIBUTING file in the project’s GitHub repository.
Running the Ampere Porting Advisor as a Container
By using this option, you don’t need to worry about Python or Java versions, or any other dependency that the tool needs. This is the quickest way to get started.
Pr-requisites
- Docker or containerd + nerdctl + buildkit
Run Container Image
After building the image, we can run the tool as a container. We use -v to mount a volume from our host machine to the container.
We can run it directly to console:
docker run --rm -v my/repo/path:/repo porting-advisor /repoOr generate a report:
docker run --rm -v my/repo/path:/repo -v my/output:/output porting-advisor /repo --output /output/report.htmlWindows example:
docker run --rm -v /c/Users/myuser/repo:/repo -v /c/Users/myuser/output:/output porting-advisor /repo --output /output/report.htmlRunning the Ampere Porting Advisor as a Python Script
Pr-requisites
- Python 3.10 or above (with PIP3 and venv module installed).
- (Optionally) Open JDK 17 (or above) and Maven 3.5 (or above) if you want to scan JAR files for native methods.
- Unzip and jq is required to run test cases.
Enable Python Environment
Linux/Mac:
python3 -m venv .venv source .venv/bin/activatePowershell:
python -m venv .venv ..venvScriptsActivate.ps1Install requirements
- pip3 install -r requirements.txt
Run tool (console output)
- python3 src/porting-advisor.py ~/my/path/to/my/repo
Run tool (HTML report)
- python3 src/porting-advisor.py ~/my/path/to/my/repo –output report.html
Running the Ampere Porting Advisor as a Binary
Generating the Binary
Pre-requisites
- Python 3.10 or above (with PIP3 and venv module installed).
- (Optionally) Open JDK 17 (or above) and Maven 3.5 (or above) if you want the binary to be able to scan JAR files for native methods.
The build.sh script will generate a self-contained binary (for Linux/MacOS). It will be output to a folder called dist.
By default, it will generate a binary named like porting-advisor-linux-x86_64. You can customize generated filename by setting environment variable FILE_NAME.
./build.shFor Windows, the Build.ps1 will generate a folder with an EXE and all the files it requires to run.
.Build.ps1Running the Binary
Pre-requisites
Once you have the binary generated, it will only require Java 11 Runtime (or above) if you want to scan JAR files for native methods. Otherwise, the file is self-contained and doesn’t need Python to run.
Default behavior, console output:
$ ./porting-advisor-linux-x86_64 ~/my/path/to/my/repoGenerating HTML report:
$ ./porting-advisor-linux-x86_64 ~/my/path/to/my/repo --output report.htmlGenerating a report of just dependencies (this creates an Excel file with just the dependencies we found on the repo, no suggestions provided):
$ ./porting-advisor-linux-x86_64 ~/my/path/to/my/repo --output dependencies.xlsx --output-format dependenciesUnderstanding an Ampere Porting Advisor Report
Here is an example of the output report generated with a sample project:
./dist/porting-advisor-linux-x86_64 ./sample-projects/
| Elapsed Time: 0:00:03
Porting Advisor for Ampere Processor v1.0.0
Report date: 2023-05-10 11:31:52
13 files scanned.
detected go code. min version 1.16 is required. version 1.18 or above is recommended. we detected that you have version 1.19. see https://github.com/AmpereComputing/ampere-porting-advisor/blob/main/doc/golang.md for more details.
detected python code. if you need pip, version 19.3 or above is recommended. we detected that you have version 22.3.1
detected python code. min version 3.7.5 is required. we detected that you have version 3.10.9. see https://github.com/AmpereComputing/ampere-porting-advisor/blob/main/doc/python.md for more details.
./sample-projects/java-samples/pom.xml: dependency library: leveldbjni-all is not supported on Ampere processor.
./sample-projects/java-samples/pom.xml: using dependency library snappy-java version 1.1.3. upgrade to at least version 1.1.4
./sample-projects/java-samples/pom.xml: using dependency library zstd-jni version 1.1.0. upgrade to at least version 1.2.0
./sample-projects/python-samples/incompatible/requirements.txt:3: using dependency library OpenBLAS version 0.3.16. upgrade to at least version 0.3.17
detected go code. min version 1.16 is required. version 1.18 or above is recommended. we detected that you have version 1.19. see https://github.com/AmpereComputing/ampere-porting-advisor/blob/main/doc/golang.md for more details.
./sample-projects/java-samples/pom.xml: using dependency library hadoop-lzo. this library requires a manual build more info at: https://github.com/AmpereComputing/ampere-porting-advisor/blob/main/doc/java.md#building-jar-libraries-manually
./sample-projects/python-samples/incompatible/requirements.txt:5: dependency library NumPy is present. min version 1.19.0 is required.
detected java code. min version 8 is required. version 17 or above is recommended. see https://github.com/AmpereComputing/ampere-porting-advisor/blob/main/doc/java.md for more details.
Use --output FILENAME.html to generate an HTML report. - In the report, we see several language runtimes (Python, pip, golang, Java) and their versions detected. All these messages communicate the minimum version and recommended version for these languages. Some of these lines detect that prerequisite versions have been found and are purely informative.
- We also see some messages from the dependencies detected in the Project Object Model (POM) or a Java project. These are dependencies that will be downloaded and used as part of a Maven build process, and we see three types of actionable messages:
Dependency requires more recent version
./sample-projects/java-samples/pom.xml: using dependency library snappy-java version 1.1.3. upgrade to at least version 1.1.4
- Messages of this type indicate that we should use a more recent version of the dependency, which will require rebuilding and validation of the project before continuing .
Dependency requires a manual build
./sample-projects/java-samples/pom.xml: using dependency library hadoop-lzo. this library requires a manual build more info at: https://github.com/AmpereComputing/ampere-porting-advisor/blob/main/doc/java.md#building-jar-libraries-manually
- In this case, a dependency does support the architecture, but for some reason (perhaps to test hardware features available and build an optimized version of the project for the target platform) the project must be manually rebuilt rather than relying on a pre-existing binary artifact
Dependency is not available on this architecture
./sample-projects/java-samples/pom.xml: dependency library: leveldbjni-all is not supported on Ampere processor.
- In this case, the project is specified as a dependency but is not available for the Ampere platform. An engineer may have to examine what is involved in making the code from the dependency compile correctly on the target platform. This process can be simple but may also take considerable time and effort. Alternatively, you can adapt your project to use an alternative package providing similar functionality which does support the Ampere architecture and modify your project’s code appropriately to use this alternative.
A Transition Example for C/C++
MEGAHIT is an NGS assembler tool available as a binary for x86_64. A customer wanted to run MEGAHIT on Arm64 as part of an architecture transition. But the compilation failed on Arm64 in the first file:

The developer wanted to know what needed to be changed to make MEGAHIT compile correctly on Arm64.
In this case, Ampere Porting Advisor (APA) can play a key role. After scanning the source repository of the MEGAHIT project with APA, we get a list of issues that need to be checked before rebuilding MEGAHIT on Arm64:
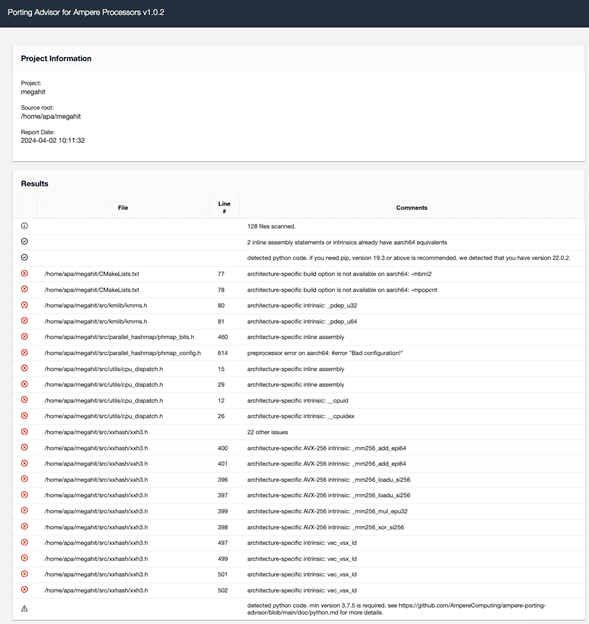
Let’s investigate each error type in the list and correct them for Arm64 if necessary.
Architecture-specific build options

These errors will be triggered once APA detected build options not valid on Arm64.
The original CMakeList.txt is using x86_64 compile flags by default without checking CPU Architectures. To fix this, we can test a CMAKE_SYSTEM_PROCESSOR condition to make sure the flags reported by APA will be only applied to x86_64 architectures.
Architecture specific instructions

The architecture specific instructions error will be triggered once APA detected non-Arm64 C-style functions being used in the code. Intrinsic instructions are compiled by the compiler directly into platform-specific assembly code, and typically each platform will have their own set of intrinsics and assembly code instructions optimized for that platform.
In this case, we can make the use of pre-processor conditionals to only compile the _pdep_u32/64 and __cpuid/ex instructions when #if defined(x86_64) is true for the HasPopcnt() and HasBmi2() functions. For vec_vsx_ld, it is already wrapped in a pre-processor conditional, and will only be compiled on Power PC architecture, so we can leave it as is.
Architecture specific inline assembly

The architecture specific instructions error will be triggered once APA detected assembly code being used in the code. We need to check whether the snippet of assembly code is for Arm64 or not.
The MEGAHIT project only uses the bswap assembly code in phmap_bits.h when it is being compiled on the x86_64 architecture. When being compiled on other architectures, it compiles a fall-back implementation from glibc. So no changes are required in phmap_bits.h.
In cpu_dispatch.h,two inline functions HasPopcnt() and HasBmi2() unconditionally include the x86_64 assembly instruction cpuid to test for CPU features on x86_64. We can add a precompiler conditional flag #if defined(x86_64) to make sure this code is not called on Arm64, and we will always return false.
Architecture specific SIMD intrinsic
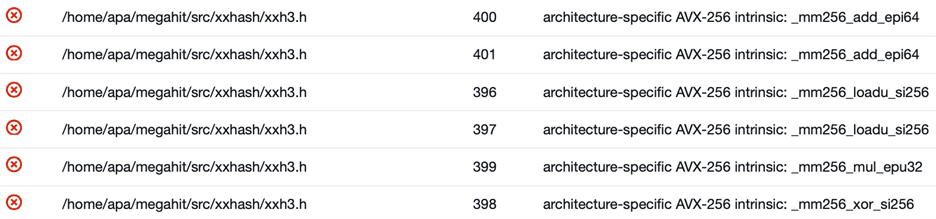
The architecture specific instructions error will be triggered once APA detected x86_64 SIMD instructions like AVX256 or AVX512 being used in the code. These SIMD instructions are wrapped by precompiler conditional flags and will usually not cause any functionality issue on Arm64.
If there were no SIMD implementation of the algorithm for Arm64, there could be a performance gap compared to x86_64. In this case, there is a NEON SIMD implementation for Arm64 in xxh3.h and this implementation will be cherry picked by the compiler based on the CPU architecture. No further actions need to be taken.
Preprocessor error on AArch64
The preprocessor error will be triggered by APA to indicate that the Arm64 architecture may not be included in a pre-compile stage. In this case, we can see that the pre-compile conditional is for x86_64 only and does not concern the Arm64 architecture.
Rebuild and test
Once all these adjustments have been made, we could rebuild the project:
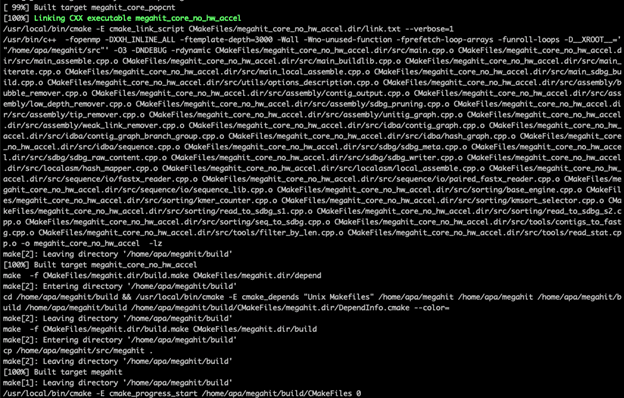
The project compiled successfully. We then checked whether it passed the project’s test suite:
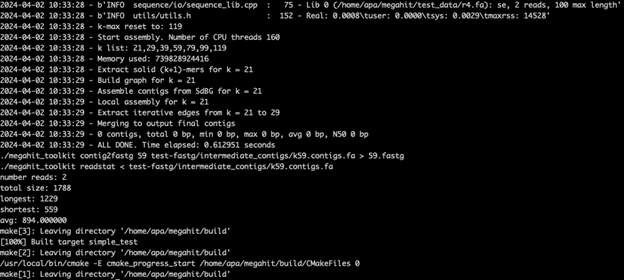
After we have manually checked and fixed all the potential pitfalls reported by APA, MEGAHIT is now able to build and run on Ampere processors.