Month: May 2025

MMS • RSS
Tairen Capital Ltd purchased a new position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) during the fourth quarter, according to the company in its most recent disclosure with the Securities & Exchange Commission. The firm purchased 49,900 shares of the company’s stock, valued at approximately $11,617,000. MongoDB accounts for about 1.7% of Tairen Capital Ltd’s investment portfolio, making the stock its 18th largest position. Tairen Capital Ltd owned approximately 0.07% of MongoDB at the end of the most recent reporting period.
Other large investors also recently bought and sold shares of the company. Strategic Investment Solutions Inc. IL purchased a new position in MongoDB during the fourth quarter worth approximately $29,000. NCP Inc. purchased a new position in shares of MongoDB in the 4th quarter valued at $35,000. Coppell Advisory Solutions LLC raised its stake in shares of MongoDB by 364.0% in the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock valued at $54,000 after acquiring an additional 182 shares during the period. Smartleaf Asset Management LLC raised its stake in shares of MongoDB by 56.8% in the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock valued at $87,000 after acquiring an additional 134 shares during the period. Finally, Manchester Capital Management LLC raised its stake in shares of MongoDB by 57.4% in the 4th quarter. Manchester Capital Management LLC now owns 384 shares of the company’s stock valued at $89,000 after acquiring an additional 140 shares during the period. Hedge funds and other institutional investors own 89.29% of the company’s stock.
Insider Activity at MongoDB
In related news, CEO Dev Ittycheria sold 8,335 shares of MongoDB stock in a transaction dated Wednesday, February 26th. The shares were sold at an average price of $267.48, for a total value of $2,229,445.80. Following the sale, the chief executive officer now directly owns 217,294 shares in the company, valued at $58,121,799.12. This trade represents a 3.69% decrease in their position. The sale was disclosed in a document filed with the SEC, which is available through this hyperlink. Also, CAO Thomas Bull sold 301 shares of MongoDB stock in a transaction dated Wednesday, April 2nd. The shares were sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the sale, the chief accounting officer now owns 14,598 shares in the company, valued at approximately $2,529,103.50. This represents a 2.02% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold a total of 34,423 shares of company stock worth $7,148,369 in the last ninety days. 3.60% of the stock is owned by insiders.
Wall Street Analysts Forecast Growth
A number of equities analysts have recently commented on MDB shares. Redburn Atlantic raised shares of MongoDB from a “sell” rating to a “neutral” rating and set a $170.00 target price on the stock in a research note on Thursday, April 17th. Scotiabank reissued a “sector perform” rating and issued a $160.00 target price (down previously from $240.00) on shares of MongoDB in a research note on Friday, April 25th. The Goldman Sachs Group cut their target price on shares of MongoDB from $390.00 to $335.00 and set a “buy” rating on the stock in a research note on Thursday, March 6th. Rosenblatt Securities reaffirmed a “buy” rating and set a $350.00 price target on shares of MongoDB in a research note on Tuesday, March 4th. Finally, KeyCorp downgraded shares of MongoDB from a “strong-buy” rating to a “hold” rating in a research note on Wednesday, March 5th. Eight investment analysts have rated the stock with a hold rating, twenty-four have assigned a buy rating and one has assigned a strong buy rating to the stock. According to MarketBeat.com, the stock has a consensus rating of “Moderate Buy” and a consensus price target of $293.91.
Get Our Latest Research Report on MDB
MongoDB Stock Performance
NASDAQ MDB opened at $191.29 on Friday. MongoDB, Inc. has a one year low of $140.78 and a one year high of $379.06. The company has a 50-day simple moving average of $174.91 and a 200-day simple moving average of $238.95. The firm has a market capitalization of $15.53 billion, a PE ratio of -69.81 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The business had revenue of $548.40 million during the quarter, compared to analyst estimates of $519.65 million. During the same period last year, the firm posted $0.86 earnings per share. Equities analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current year.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s guide to investing in 5G and which 5G stocks show the most promise.
Spring AI 1.0 Released, Streamlines AI Application Development with Broad Model Support
MMS • A N M Bazlur Rahman

The Spring team has announced the general availability of Spring AI 1.0, a framework designed to simplify the development of AI-driven applications within the Java and Spring ecosystem. This release, the result of over two years of development and eight milestone iterations, delivers a stable API. It integrates with a wide range of AI models for chat, image generation, and transcription. Key features include portable service abstractions, support for Retrieval Augmented Generation (RAG) via vector databases, and tools for function calling. Spring AI 1.0 enables developers to build scalable, production-ready AI applications by aligning with established Spring patterns and the broader Spring ecosystem.
Spring AI provides out-of-the-box support for numerous AI models and providers. The framework integrates with major generative AI providers, including OpenAI, Anthropic, Microsoft Azure OpenAI, Amazon Bedrock, and Google Vertex AI, through a unified API layer. It supports various model types across modalities, including chat completion, embedding, image generation, audio transcription, text-to-speech synthesis, and content moderation. This enables developers to integrate capabilities such as GPT-based chatbots, image creation, or speech recognition into Spring applications.
The framework offers portable service abstractions, decoupling application code from specific AI providers. Its API facilitates switching between model providers (e.g., from OpenAI to Anthropic) with minimal code changes, while retaining access to model-specific features. Spring AI supports structured outputs by mapping AI model responses to Plain Old Java Objects (POJOs) for type-safe processing. For Retrieval Augmented Generation (RAG), Spring AI integrates with various vector databases, including Cassandra, PostgreSQL/PGVector, MongoDB Atlas, Milvus, Pinecone, and Redis, through a consistent Vector Store API, enabling applications to ground LLM responses in enterprise data. The framework also includes support for tools and function calling APIs, allowing AI models to invoke functions or external tools in a standardized manner to address use cases like “Q&A over your documentation” or “chat with your data.”
Spring AI 1.0 includes support for the Model Context Protocol (MCP), an emerging open standard for structured, language-agnostic interaction between AI models (particularly LLMs) and external tools or resources. The Spring team has contributed its MCP implementation to ModelContextProtocol.io, where it serves as an official Java SDK for MCP services. This reflects Spring AI’s focus on open standards and interoperability.
To facilitate MCP integration, Spring AI provides dedicated client and server Spring Boot starters, enabling models to interact with tools like this example weather service:
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.stereotype.Component;
@Component
public class WeatherTool {
@Tool(name = "getWeather", description = "Returns weather for a given city")
public String getWeather(String city) {
return "The weather in " + city + " is 21°C and sunny.";
}
}
These starters are categorized as follows:
- Client Starters:
spring-ai-starter-mcp-client(providing core STDIO and HTTP-based SSE support) andspring-ai-starter-mcp-client-webflux(offering WebFlux-based SSE transport for reactive applications). - Server Starters:
spring-ai-starter-mcp-server(for core STDIO transport support),spring-ai-starter-mcp-server-webmvc(for Spring MVC-based SSE transport in servlet applications), andspring-ai-starter-mcp-server-webflux(for WebFlux-based SSE transport in reactive applications).
Developers can begin new Spring AI 1.0 projects using Spring Initializr, which preconfigures necessary dependencies. Including the desired Spring AI starter on the classpath allows Spring Boot to auto-configure the required clients or services.
An example of a simple chat controller is as follows:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
private final ChatClient chatClient;
public ChatController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/ask")
public String ask(@RequestParam String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
}
At a minimum, the following key-value in application.properties is necessary to run the above example.
spring.ai.openai.api-key=YOUR_API_KEY
spring.ai.openai.chat.model=gpt-4
Spring AI introduces higher-level APIs for common AI application patterns. A fluent ChatClient API offers a type-safe builder for chat model interactions. Additionally, an Advisors API encapsulates recurring generative AI patterns such as retrieval augmentation, conversational memory, and question-answering workflows. For instance, a RAG flow can be implemented by combining ChatClient with QuestionAnswerAdvisor:
ChatResponse response = ChatClient.builder(chatModel)
.build()
.prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(userText)
.call()
.chatResponse();
In this example, QuestionAnswerAdvisor performs a similarity search in the VectorStore, appends relevant context to the user prompt, and forwards the enriched input to the model. An optional SearchRequest with an SQL-like filter can constrain document searches.
The release incorporates Micrometer for observability, allowing developers to monitor AI-driven applications. These integrations facilitate embedding AI capabilities into Spring-based projects for various applications, including real-time chat, image processing, and transcription services.
For more information, developers can explore the Spring AI project page or begin building with Spring AI at start.spring.io. This release provides Java developers with a solution for integrating AI capabilities, offering features for scalability and alignment with idiomatic Spring development.
MMS • RSS
Loop Capital has revised its rating on MongoDB (MDB, Financial), moving it from a Buy to a Hold, and adjusted the price target downwards to $190 from $350. Recent evaluations suggest that the Atlas platform by MongoDB is seeing underwhelming market adoption. This trend of deceleration in platform use is likely to persist, potentially hindering the growth of artificial intelligence workloads on Atlas, as per the firm’s analysis.
Loop Capital foresees continued slowing in the consumption growth of Atlas until MongoDB demonstrates advancements in reaching its current market goals, particularly in boosting its presence among large enterprise customers. The firm also notes that the cloud database platform market, which MongoDB targets, remains fragmented and has not consolidated around leading vendors.
Wall Street Analysts Forecast
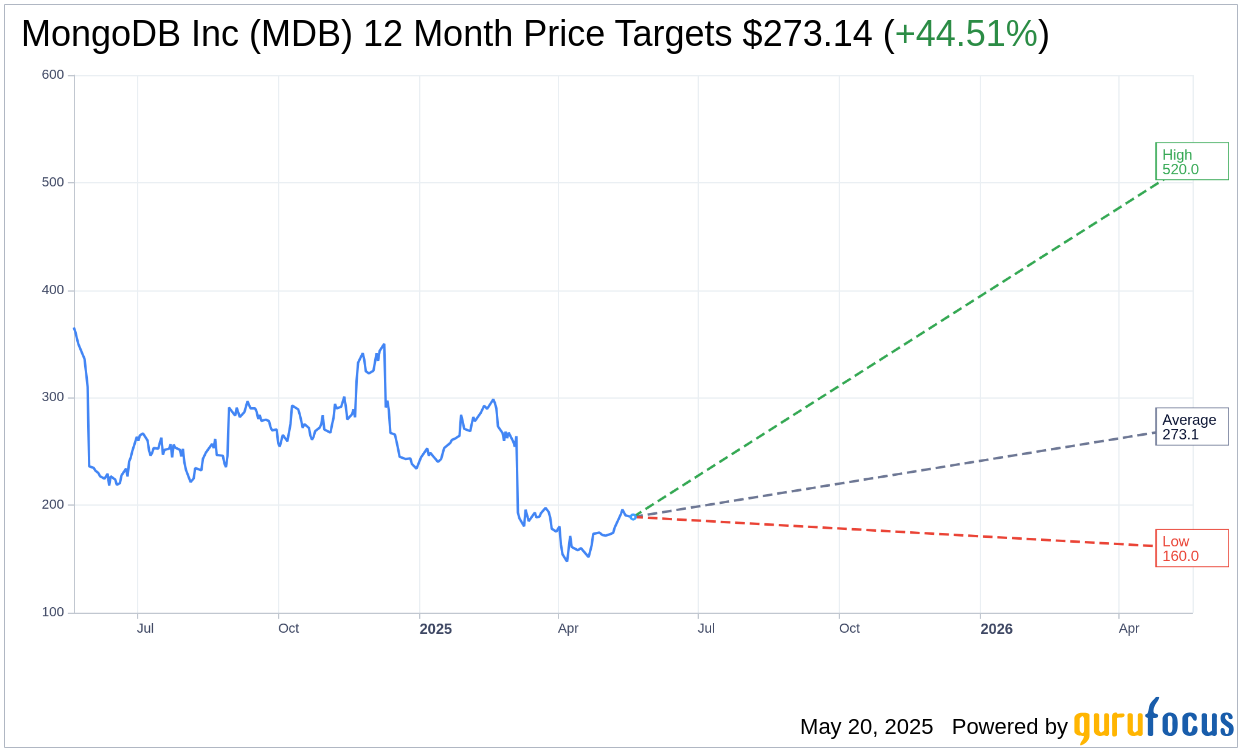
Based on the one-year price targets offered by 34 analysts, the average target price for MongoDB Inc (MDB, Financial) is $273.14 with a high estimate of $520.00 and a low estimate of $160.00. The average target implies an
upside of 44.51%
from the current price of $189.01. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 37 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 2.0, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $438.57, suggesting a
upside
of 132.04% from the current price of $189.01. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MDB Key Business Developments
Release Date: March 05, 2025
- Total Revenue: $548.4 million, a 20% year-over-year increase.
- Atlas Revenue: Grew 24% year-over-year, representing 71% of total revenue.
- Non-GAAP Operating Income: $112.5 million, with a 21% operating margin.
- Net Income: $108.4 million or $1.28 per share.
- Customer Count: Over 54,500 customers, with over 7,500 direct sales customers.
- Gross Margin: 75%, down from 77% in the previous year.
- Free Cash Flow: $22.9 million for the quarter.
- Cash and Cash Equivalents: $2.3 billion, with a debt-free balance sheet.
- Fiscal Year 2026 Revenue Guidance: $2.24 billion to $2.28 billion.
- Fiscal Year 2026 Non-GAAP Operating Income Guidance: $210 million to $230 million.
- Fiscal Year 2026 Non-GAAP Net Income Per Share Guidance: $2.44 to $2.62.
For the complete transcript of the earnings call, please refer to the full earnings call transcript.
Positive Points
- MongoDB Inc (MDB, Financial) reported a 20% year-over-year revenue increase, surpassing the high end of their guidance.
- Atlas revenue grew 24% year over year, now representing 71% of total revenue.
- The company achieved a non-GAAP operating income of $112.5 million, resulting in a 21% non-GAAP operating margin.
- MongoDB Inc (MDB) ended the quarter with over 54,500 customers, indicating strong customer growth.
- The company is optimistic about the long-term opportunity in AI, particularly with the acquisition of Voyage AI to enhance AI application trustworthiness.
Negative Points
- Non-Atlas business is expected to be a headwind in fiscal ’26 due to fewer multi-year deals and a shift of workloads to Atlas.
- Operating margin guidance for fiscal ’26 is lower at 10%, down from 15% in fiscal ’25, due to reduced multi-year license revenue and increased R&D investments.
- The company anticipates a high-single-digit decline in non-Atlas subscription revenue for the year.
- MongoDB Inc (MDB) expects only modest incremental revenue growth from AI in fiscal ’26 as enterprises are still developing AI skills.
- The company faces challenges in modernizing legacy applications, which is a complex and resource-intensive process.
MMS • RSS
Loop Capital has revised its rating for MongoDB (MDB, Financial), moving it from a Buy to a Hold. Alongside this change, Loop Capital has established a price target of $190 for the stock. This adjustment reflects the analysts’ current assessment of the company’s valuation and market conditions.
Wall Street Analysts Forecast
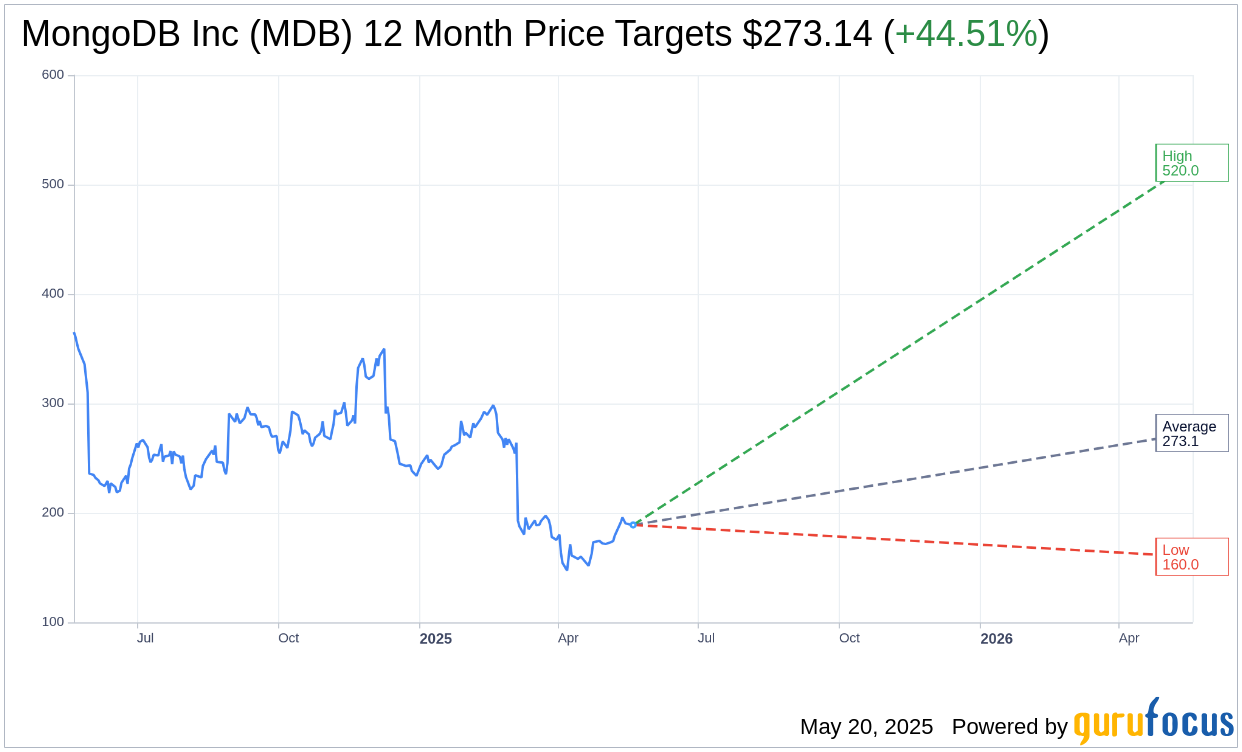
Based on the one-year price targets offered by 34 analysts, the average target price for MongoDB Inc (MDB, Financial) is $273.14 with a high estimate of $520.00 and a low estimate of $160.00. The average target implies an
upside of 44.51%
from the current price of $189.01. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 37 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 2.0, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $438.57, suggesting a
upside
of 132.04% from the current price of $189.01. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MDB Key Business Developments
Release Date: March 05, 2025
- Total Revenue: $548.4 million, a 20% year-over-year increase.
- Atlas Revenue: Grew 24% year-over-year, representing 71% of total revenue.
- Non-GAAP Operating Income: $112.5 million, with a 21% operating margin.
- Net Income: $108.4 million or $1.28 per share.
- Customer Count: Over 54,500 customers, with over 7,500 direct sales customers.
- Gross Margin: 75%, down from 77% in the previous year.
- Free Cash Flow: $22.9 million for the quarter.
- Cash and Cash Equivalents: $2.3 billion, with a debt-free balance sheet.
- Fiscal Year 2026 Revenue Guidance: $2.24 billion to $2.28 billion.
- Fiscal Year 2026 Non-GAAP Operating Income Guidance: $210 million to $230 million.
- Fiscal Year 2026 Non-GAAP Net Income Per Share Guidance: $2.44 to $2.62.
For the complete transcript of the earnings call, please refer to the full earnings call transcript.
Positive Points
- MongoDB Inc (MDB, Financial) reported a 20% year-over-year revenue increase, surpassing the high end of their guidance.
- Atlas revenue grew 24% year over year, now representing 71% of total revenue.
- The company achieved a non-GAAP operating income of $112.5 million, resulting in a 21% non-GAAP operating margin.
- MongoDB Inc (MDB) ended the quarter with over 54,500 customers, indicating strong customer growth.
- The company is optimistic about the long-term opportunity in AI, particularly with the acquisition of Voyage AI to enhance AI application trustworthiness.
Negative Points
- Non-Atlas business is expected to be a headwind in fiscal ’26 due to fewer multi-year deals and a shift of workloads to Atlas.
- Operating margin guidance for fiscal ’26 is lower at 10%, down from 15% in fiscal ’25, due to reduced multi-year license revenue and increased R&D investments.
- The company anticipates a high-single-digit decline in non-Atlas subscription revenue for the year.
- MongoDB Inc (MDB) expects only modest incremental revenue growth from AI in fiscal ’26 as enterprises are still developing AI skills.
- The company faces challenges in modernizing legacy applications, which is a complex and resource-intensive process.
Article: RxJS Best Practices in Angular 16: Avoiding Subscription Pitfalls and Optimizing Streams
MMS • Shrinivass Arunachalam Balasubramanian

Key Takeaways
- Use AsyncPipe to handle observable subscriptions in templates. It manages unsubscriptions without the need for manual cleanup, thus preventing memory leaks.
- Favor flattening and combining streams over nesting streams. RxJS operators like switchMap, mergeMap, exhaustMap, or even debounceTime declaratively describe the desired dataflow and automatically manage subscription/unsubscription of their dependencies.
- Combine takeUntil with DestroyRef for clear subscription cleanup.
- Use catchError and retry to gracefully manage failure and recovery from failure
- Use Angular signals for updates triggered by the UI. For event streams, stick with RxJS observables. This combination helps you leverage both tools to their full potential.
Introduction
Angular 16 marks the introduction of the modern reactive Angular version, It introduces foundational tools like DestroyRef and signals. These new introductions have redefined how developers handle reactivity, lifecycle management and state updates, setting the stage for Angular 17/18 and beyond.
This article explores RxJS best practices focusing on the modern ecosystem and extending seamlessly to Angular 17/18, ensuring your code remains efficient and future proof.
The Evolution of RxJS Management in Angular
Before Angular 16, developers mostly relied on manual lifecycle management such as ngOnDestroy and lacked native tools for lightweight reactivity. Angular 16’s DestroyRef and signals address this need for tools by abstracting cleanup logic and enabling granular state reactivity. Version 16 laid the groundwork for a modern reactivity paradigm, which has been further refined by Angular 17/18 without altering core principles.
DestroyRef is a game-changing tool that streamlines observable cleanup by abstracting lifecycle management. The introduction of this class marks the beginning of a modern reactive ecosystem, where developers can focus more on logic and less on boilerplate. Angular 17/18 further refines these patterns, such as improving signal-observable interoperability and enhancing performance optimizations. The best practices outlined here are developed for Angular 16, but they apply equally to Angular 17/18.
Similarly, while RxJS operators such as switchMap and mergeMap have long helped flatten nested streams, their proper use was often obscured by over-reliance on multiple, ad-hoc subscriptions. The goal now is to combine these techniques with Angular’s new capabilities, such as signals, to create reactive code that is both concise and maintainable.
Angular 16’s signals marks a turning point in state management, enabling lightweight reactivity without subscriptions. When combined with RxJS, they form a holistic reactive toolkit for modern angular application.
Best Practices
AsyncPipe
In the modern Angular ecosystem (starting with Angular 16), the AsyncPipe is the cornerstone of reactive UI binding. It automatically unsubscribes when components are destroyed, a feature critical for avoiding memory leaks. This pattern remains a best practice in Angular 17/18, ensuring your templates stay clean and reactive. Subscriptions and unsubscriptions can now be handled by the AsyncPipe without your intervention. This results in a much cleaner template and less boilerplate code.
For example, consider a component that displays a list of items:
- {{ item.name }}
When you use AsyncPipe to bind the observable to the template, Angular checks for updates. The component also cleans up when it destroys itself. This approach is beautiful due to its simplicity; you write less code and avoid memory leaks.
Flatten Observable Streams with RxJS Operators
For Angular developers, handling nested subscriptions is a common source of frustration. You may have encountered a situation in which a series of observables have to occur sequentially. RxJS operators like switchMap, mergeMap, and concatMap offer a sophisticated alternative to nesting subscriptions within subscriptions, the latter of which leads to a complex issue in your code very quickly.
Imagine a search bar that retrieves potential plans as the user inputs. If you don’t have the right operators, you can wind up recording every keystroke. Instead, debounce input using a combination of operators, and when the user modifies their query, switch to a new search stream.
// plan-search.component.ts
import { Component, OnInit } from '@angular/core';
import { Subject, Observable } from 'RxJS';
import { debounceTime, distinctUntilChanged, switchMap } from 'RxJS/operators';
import { PlanService } from './plan.service';
@Component({
selector: 'app-plan-search',
template: `
- {{ plan }}
`
})
export class PlanSearchComponent implements OnInit {
private searchTerms = new Subject();
plans$!: Observable;
constructor(private planService: PlanService) {}
search(term: string): void {
this.searchTerms.next(term);
}
ngOnInit() {
this.plans$ = this.searchTerms.pipe(
debounceTime(300),
distinctUntilChanged(),
switchMap(term => this.planService.searchPlans(term))
);
}
}
Using operators this way flattens multiple streams into a single, manageable pipeline and avoids the need to manually subscribe and unsubscribe for every action. This pattern makes your code not only cleaner but also more responsive to user interactions.
Unsubscription and Error Handling
Letting observables run endlessly, which results in memory leaks, is one of the traditional anti-patterns in Angular. Having a good unsubscribe plan is essential. Although unsubscription is frequently handled by the AsyncPipe in templates, there are still situations in which TypeScript code requires explicit unsubscription. In certain situations, it might be quite beneficial to use operators like takeUntil or Angular’s onDestroy lifecycle hook.
For example, when subscribing to a data stream in a component:
import { Component, OnDestroy } from '@angular/core';
import { Subject } from 'rxjs';
import { takeUntil } from 'rxjs/operators';
import { DataService } from './data.service';
@Component({
selector: 'app-data-viewer',
template: ``
})
export class DataViewerComponent implements OnDestroy {
private destroy$ = new Subject();
constructor(private dataService: DataService) {
this.dataService.getData().pipe(
takeUntil(this.destroy$)
).subscribe(data => {
// handle data
});
}
ngOnDestroy() {
this.destroy$.next();
this.destroy$.complete();
}
}
Using operators like catchError and retry in conjunction with unsubscription strategies helps make sure that your application handles unforeseen errors with grace. By combining problem discovery with quick fixes, this integrated method produces code that is strong and maintainable.
Combining Streams
Often, you’ll need to merge the outputs of several observables. You can display data from various sources using operators such as combineLatest, forkJoin, or zip. They help you merge streams with simplicity. This method keeps a reactive and declarative style. It also updates without manual intervention when one or more source streams change.
Imagine combining a user’s profile with settings data:
import { combineLatest } from 'rxjs';
combineLatest([this.userService.getProfile(), this.settingsService.getSettings()]).subscribe(
([profile, settings]) => {
// process combined profile and settings
}
);
This strategy not only minimizes complexity by avoiding nested subscriptions, but also shifts your mindset toward a more reactive, declarative style of programming.
Integrate Angular 16 Signals for Efficient State Management
While RxJS continues to play a pivotal role in handling asynchronous operations, Angular 16’s new signals offer another layer of reactivity that simplifies state management. Signals are particularly useful when the global state needs to trigger automatic updates in the UI without the overhead of observable subscriptions. For example, a service can expose a signal for the currently selected plan:
// analysis.service.ts
import { Injectable, signal } from '@angular/core';
@Injectable({ providedIn: 'root' })
export class AnalysisService {
currentPlan = signal('Plan A');
updateCurrentPlan(newPlan: string) {
this.currentPlan.set(newPlan);
}
}
By combining signals with RxJS streams in your components, you can enjoy the best of both worlds: a clean, declarative state management model alongside powerful operators to handle complex asynchronous events.
Signals vs.s Observables
Angular 16 contains RxJS Observables and Signals, which allow for reactive programming, but they serve different needs. Signals simplify UI state management, while Observables handle asynchronous operations. Signals are a core part of Angular 16’s modern reactivity model, designed for scenarios where UI state needs immediate updates (such as toggling a modal or theme)
Signals are lightweight variables that automatically update the UI when their value changes. For example, tracking a modal’s open/close functionality (isModalOpen = signals.set(false)) or a user’s theme preference like dark and white mode. No subscriptions are needed; the changes trigger updates instantly.
Observables excel at managing sync operations like API calls. They use operators like debounceTime and switchMap to process data over time. For example, consider this example for a search result with retries:
this.service.search(query).pipe(retry(3), catchError(error => of([])))
Use Signals for local state (simple, reactive state) and Observables for async logic. Here is an example for a search bar where a signal track input, converted to an observable for debouncing an API calls:
query = signal('');
results$ = toObservable(this.query).pipe(
debounceTime(300),
switchMap(q => this.service.search(q))
);
Adopt a Holistic Approach to Reactive Programming
The key to writing maintainable and efficient Angular applications is to integrate these best practices into a cohesive, holistic workflow. Rather than viewing these techniques as isolated tips, consider how they work together to solve real-world problems. For instance, using the AsyncPipe minimizes manual subscription management, which, when combined with RxJS operators to flatten streams, results in code that is not only efficient but also easier to understand and test.
In real-world scenarios, such as a live search feature or a dashboard that displays multiple data sources, these practices collectively reduce code complexity and improve performance. Integrating Angular 16 signals further simplifies state management, ensuring that the user interface remains responsive even as application complexity grows.
Conclusion
As Angular evolves, so do the best practices we use to manage state, handle user input, and compose complex reactive streams. Leveraging the AsyncPipe simplifies template binding; flattening nested subscriptions with operators like switchMap makes your code more readable; and smart unsubscription strategies prevent memory leaks – all while error handling and strong typing add additional layers of resilience.
By adopting these strategies, you ensure your application thrives in Angular’s modern ecosystem (16+), leveraging RxJS for asynchronous logic and Angular’s native tools for state and lifecycle management. These practices we went over are forward-compatible with Angular 17/18, ensuring your code remains efficient and maintainable as the framework evolves.
For more advanced asynchronous processing, RxJS remains indispensable. But when it comes to local or global state management, Angular signals offer a fresh, concise approach that reduces boilerplate and automatically updates the UI. Merging these practices ensures that your Angular 16 applications remain efficient, maintainable, and, importantly, easy to comprehend, even as they grow in complexity.
Java News Roundup: LangChain4j 1.0, Vert.x 5.0, Spring Data 2025.0.0, Payara Platform, Hibernate
MMS • Michael Redlich

This week’s Java roundup for May 12th, 2025 features news highlighting: the GA releases of LangChain4j 1.0, Eclipse Vert.x 5.0 and Spring Data 2025.0.0; the May 2025 edition of the Payara Platform; second release candidates for Hibernate ORM 7.0 and Hibernate Reactive 3.0; and the first beta release of Hibernate Search 8.0.
OpenJDK
It was a busy week in the OpenJDK ecosystem during the week of May 12th, 2025 highlighting: two JEPs elevated from Proposed to Target to Targeted and four JEPs elevated from Candidate to Proposed to Target for JDK 25; and one JEP elevated from its JEP Draft to Candidate status. Two of these will be finalized after their respective rounds of preview. Further details may be found in this InfoQ news story.
JDK 25
Build 23 of the JDK 25 early-access builds was made available this past week featuring updates from Build 22 that include fixes for various issues. More details on this release may be found in the release notes.
For JDK 25, developers are encouraged to report bugs via the Java Bug Database.
Jakarta EE
In his weekly Hashtag Jakarta EE blog, Ivar Grimstad, Jakarta EE Developer Advocate at the Eclipse Foundation, provided an update on Jakarta EE 11 and Jakarta EE 12, writing:
The release of the Jakarta EE 11 Platform specification is right around the corner. The issues with the service outage that affected our Jenkins CI instances are now resolved, and the work is progressing. The release date is expected to be in June.
All the plans for Jakarta EE 12 have been completed and approved (with the exception of Jakarta Activation, which will have its plan review started on Monday [May 19, 2025]).
Two new specifications, Jakarta Portlet 4.0 and Jakarta Portlet Bridge 7.0, have been migrated over from JSR 362 and JSR 378, respectively. They join the new Jakarta Query 1.0 specification.
The road to Jakarta EE 11 included four milestone releases, the release of the Core Profile in December 2024, the release of Web Profile in April 2025, and a fifth milestone and first release candidate of the Platform before its anticipated GA release in June 2025.
Spring Framework
The fifth milestone release of Spring Framework 7.0.0 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: support for the Jackson 3.0 release train that deprecate support for the Jackson 2.0 release train; and updates to the new new API versioning feature that allows for validating supported API versions against only explicitly configured ones. There was also a deprecation of the PropertyPlaceholderConfigurer and PreferencesPlaceholderConfigurer classes for removal. Further details on this release may be found in the release notes.
The release of Spring Framework 6.2.7 and 6.1.20 address CVE-2025-22233, a follow up to CVE-2024-38820, a vulnerability in which the toLowerCase() method, defined in the Java String class, had some Locale class-dependent exceptions that could potentially result in fields not being protected as expected. This was a result of the resolution for CVE-2022-22968 that made patterns of the disallowedFields field, defined in DataBinder class, case insensitive. In this latest CVE, cases where it is possible to bypass the checks for the disallowedFields field still exist.
The release of Spring Data 2025.0.0 ships with new features such as: support for the Vector interface and vector search in the MongoDB and Apache Cassandra databases; and support for the creation of indices using storage-attached indexing from Cassandra 5.0. The upcoming GA release of Spring Boot 3.5.0 will upgrade to Spring Data 2025.0.0. More details on this release may be found in the release notes.
The third milestone release of Spring Data 2025.1.0 ships with: support for JSpecify on sub-projects, such as Spring Data Commons, Spring Data JPA, Spring Data MongoDB, Spring Data LDAP, Spring Data Cassandra, Spring Data KeyValue, Spring Data Elasticsearch; and the ability to optimize Spring Data repositories at build time using the Spring AOT framework. Further details on this release may be found in the release notes.
The first release candidate of Spring AI 1.0.0 features “the final set of breaking changes, bug fixes, and new functionality before the stable release.” Key breaking changes include: renaming of fields, such as CHAT_MEMORY_RETRIEVE_SIZE_KEY to TOP_K, in the VectorStoreChatMemoryAdvisor class; and a standardization in the naming convention of the chat memory repository that now includes repository as a suffix throughout the codebase. The team is planning the GA release for Tuesday, May 20, 2025. More details on this release may be found in the upgrade notes and InfoQ will follow up with a more detailed news story of the GA release.
Payara
Payara has released their May 2025 edition of the Payara Platform that includes Community Edition 6.2025.5, Enterprise Edition 6.26.0 and Enterprise Edition 5.75.0. All three releases deliver: dependency upgrades; a new features that adds the capability to move the master password file to a user defined location; and a resolution to a NullPointerException upon attempting to retrieve the X.509 client certificate sent on an HTTP request using the jakarta.servlet.request.X509Certificate request attribute. Further details on these releases may be found in the release notes for Community Edition 6.2025.5 and Enterprise Edition 6.26.0 and Enterprise Edition 5.75.0.
Eclipse Vert.x
After eight release candidates, Eclipse Vert.x 5.0 has been released with new features such as: support for the Java Platform Module System (JPMS); a new VerticleBase class that replaces the deprecated AbstractVerticle class due to the removal of the callback asynchronous model in favor of the future model; and support for binary data in the OpenAI modules. More details on this release may be found in the release notes and list of deprecations and breaking changes.
LangChain4j
The formal release (along with the fifth beta release) of LangChain4j 1.0.0 delivers modules released under the release candidate, namely: langchain4j-core; langchain4j; langchain4j-http-client; langchain4j-http-client-jdk and langchain4j-open-ai with the the remaining modules still under the fifth beta release. Breaking changes include: a rename of the ChatLanguageModel and StreamingChatLanguageModel interfaces to ChatModel and StreamingChatModel, respectively; and the OpenAiStreamingChatModel, OpenAiStreamingLanguageModel and OpenAiModerationModel classes now map exceptions to align with the other OpenAI*Model classes. Further details on this release may be found in the release notes
Hibernate
The second release candidate of Hibernate ORM 7.0.0 delivers new features such as: a new QuerySpecification interface that provides a common set of methods for all query specifications that allow for iterative, programmatic building of a query; and a migration from Hibernate Commons Annotations (HCANN) to the new Hibernate Models project for low-level processing of an application domain model. There is also support for the Jakarta Persistence 3.2 specification, the latest version targeted for Jakarta EE 11. The team anticipates this as the only release candidate before the GA release. More details on this release may be found in the release notes and the migration guide.
The second release candidate of Hibernate Reactive 3.0.0 (along with version 2.4.8) provides notable changes such as: the removal of JReleaser configuration from the codebase as it will be now located inside the release scripts; and the addition of Java @Override annotations to places where it was missing. These versions upgrade to Hibernate ORM 7.0.0.CR2 and 6.6.15.Final, respectively. Further details on these releases may be found in the release notes for version 3.0.0.CR2 and version 2.4.8.
The first beta release of Hibernate Search 8.0.0 ships with: dependency upgrades; compatibility with the latest versions of Elasticsearch 9.0 and OpenSearch 3.0; and the first implementation of the type-safe field references and the Hibernate Search static metamodel generator. More details on this release may be found in the release notes.
MMS • Bruno Couriol

Mark Russinovich, Chief Technology Officer for Microsoft Azure, delved in a recent talk at Rust Nation UK into the factors driving Rust adoption, providing concrete examples of Rust usage in Microsoft products, and detailing ongoing efforts to accelerate the migration from C/C++ to Rust at Microsoft by leveraging generative AI.
The original motivation for recommending Rust originated from a detailed review of security vulnerabilities. Russinovick says:
[The] journey actually begins with us looking at the problems we’ve had with C and C++ [… Looking at a] summary of Microsoft security response centers triaging of the vulnerabilities over the previous 10 years across all Microsoft products, 70% of the vulnerabilities were due to unsafe use of memory specifically in C++ and we just see this trend continuing as the threat actors are going after these kinds of problems. It also is causing problems just in terms of incidents as well.
Other major IT companies and security organizations have expressed similar conclusions. Google’s security research team, Project Zero, reported that out of the 58 in-the-wild 0-days for the year, 39, or 67% were memory corruption vulnerabilities. Memory corruption vulnerabilities have been the standard for attacking software for the last few decades and it’s still how attackers are having success. Mozilla also estimated a few years back that 74% of security bugs identified in Firefox’s style component could have been avoided by writing this component in Rust. In fact, Rust’s language creator, Graydon Hoare, contended at the Mozilla Annual Summit in 2010 in one of the earliest presentations about Rust that C++ was unsafe is almost every way, and featured no ownership policies, no concurrency control at all, and could not even keep const values constant.
Microsoft’s “Secure Future Initiative”, which Russinovich links to breaches performed by two nation-state actors, commits to expanding the use of memory-safe languages. Microsoft recently donated $1 million to the Rust Foundation to support a variety of critical Rust language and project priorities.
Russinovich further detailed examples of Rust in Microsoft products. In Windows, Rust is used in security-critical software. That includes firmware development (Project Mu), kernel components, a cryptography library (e.g. rustls symcrypt support), and ancillary components (e.g., DirectWrite Core).
In Office, Rust is being used in some performance-critical areas. The Rust implementation of a semantic search algorithm in Office, delivered to customers on CosmosDB and PostgreSQL, proved to be more performant and memory efficient than the C++ version, providing a significant win for large-scale vector searches.
Following a directive mandating that no more systems code be written in C++ in Azure, Rust is used in several Azure-related software. Caliptra is an industry collaboration for secure cloud server firmware. Key firmware components are written entirely in Rust and are open-sourced. Azure Integrated HSM is a new in-house security chip deployed in all new servers starting in 2025. The firmware and guest libraries are written in Rust to ensure the highest security standards for cryptographic keys. Russinovich also mentioned Azure Boost agents, Hyper-V (Microsoft’s hypervisor), OpenVMM (a modular, cross-platform Virtual Machine Monitor recently open-sourced), and Hyperlight as partly or entirely written in Rust.
Developer feedback at Microsoft has generally been positive but also included negatives. On the positive side, developers liked that if Rust code compiles, it generally works as expected, leading to faster iteration. Reduced friction in development leads to more motivation to write tests. Developers become more conscious of memory management pitfalls. The Rust ecosystem and Cargo are appreciated for dependency management. Performance increases are often observed (though not always the primary goal). Data-race-related concurrency bugs are reduced. Memory-safety-related vulnerabilities are significantly reduced.
On the negative side, developers mentioned that C++ interop remains difficult. The initial learning curve for Rust is further perceived as steep. Dynamic linking is a challenge. Reliance on some non-stabilized Rust features is a concern. Integrating Cargo with larger enterprise build systems requires effort. Foreign Function Interface (FFI) is tough to do safely, even in Rust. Tooling is still behind when compared with other languages.
Russinovich further describes Microsoft’s efforts to accelerate the migration of C/C++ legacy code to Rust. One area is verified crypto libraries, using formal verification techniques for C and then transpiling to safe Rust (see Compiling C to Safe Rust, Formalized). Microsoft is also exploring using large language models for automated code translation.
Russinovich concluded by reiterating Microsoft’s strong commitment to Rust across the company and emphasizing Rust’s increasing maturity and adoption:
You know people will come and say, hey wait, there’s this new language that’s even better than Rust. It’s more easy to use than Rust and I say well when is it going to be ready? Because we’re over 10 years into Rust and you know we’re finally ready because it takes a long time for a language to mature, for the tooling to mature, and we’re not even finally, you know, completely done with maturing the Rust toolchain. Anybody that wants to come along at this point and disrupt something that’s already as good as Rust has a very high hill to climb. So I don’t see anything replacing Rust anytime soon […] We’re 100% behind Rust.
Readers are strongly encouraged to view the full talk on YouTube. It contains abundant valuable examples, technical explanations, and demos.
Rust Nation UK is a multi-track conference dedicated to the Rust language and community. The conference features workshops, talks, and tutorials curated for developers of all levels. The conference is held annually at The Brewery.
MMS • Robert Krzaczynski

OpenAI has launched Codex, a research preview of a cloud-based software engineering agent designed to automate common development tasks such as writing code, debugging, testing, and generating pull requests. Integrated into ChatGPT for Pro, Team, and Enterprise users, Codex runs each assignment in a secure sandbox environment preloaded with the user’s codebase and configured to reflect their development setup.
Codex is powered by codex-1, a version of OpenAI’s o3 model optimized for programming tasks. It was trained using reinforcement learning on real-world examples and is capable of generating code aligned with human conventions. The model iteratively runs code and tests until a correct solution is reached. Once a task is completed, Codex commits its changes within the sandbox and provides test outputs and terminal logs for transparency.
The Codex sidebar in ChatGPT enables users to assign tasks or ask questions about their codebase through a text prompt. The model can edit files, run commands, and execute tests, with typical completion times ranging from one to thirty minutes. Codex supports AGENTS.md files—repository-level instructions that help guide the agent through project-specific practices and testing procedures.
Codex CLI, a command-line companion interface, is open source and uses API credits. However, as clarified by Fouad Matin, a member of technical staff at OpenAI, Codex access within ChatGPT is included with Pro, Team, and Enterprise subscriptions:
Codex is included in ChatGPT (Pro, Team, Enterprise) pricing with generous access for the next two weeks.
The system, however, does not yet support full application testing with live user interfaces. As one Reddit user pointed out:
Most software engineering is web development these days. How does it handle that, where you have separate layers for certain things, environment variables, and UI interfaces? Does it actually run the app so the user can test it, or do they need to push the change and then pull down a copy to test locally? That would be very annoying. Ideally, in the future, the agents can just test it themselves, but I guess they are not good enough yet.
Codex runs in an isolated container without internet access or UI execution capabilities. While it can handle test suites, linters, and type checkers, final verification and integration remain in the hands of human developers.
OpenAI has also introduced Codex mini, a lighter model designed for faster interactions and lower latency, now the default engine in Codex CLI and available via API as codex-mini-latest. It is priced at $1.50 per million input tokens and $6 per million output tokens, with a 75% prompt caching discount.
The release reflects OpenAI’s broader strategy to eventually support both real-time AI coding assistants and asynchronous agent workflows. While Codex currently connects with GitHub and is accessible from ChatGPT, OpenAI envisions deeper integrations in the future, including support for assigning tasks from Codex CLI, ChatGPT Desktop, and tools such as issue trackers or CI systems.
MMS • Daniel Dominguez

Windsurf has introduced its first set of SWE-1 models, aimed at supporting the full range of software engineering tasks, not limited to code generation. The lineup consists of three models SWE-1, SWE-1-lite, and SWE-1-mini, each designed for specific scenarios.
SWE-1 is focused on tool-call reasoning and is reported to perform similarly to Claude 3.5 Sonnet, while being more cost-efficient to operate. SWE-1-lite, which replaces the earlier Cascade Base model, offers improved quality and is accessible without restrictions to all users. SWE-1-mini is a compact, high-speed model that enables passive prediction features in the Windsurf Tab environment.
The SWE models are designed to address limitations in existing coding models by introducing flow awareness, a framework that enables models to reason over long-running, multi-surface engineering tasks with incomplete or evolving states. The models are trained on user interactions from Windsurf’s own editor and incorporate contextual awareness from terminals, browsers, and user feedback loops.
Windsurf evaluated the performance of SWE-1 through both offline benchmarks and blind production experiments. The benchmarks included tasks such as continuing partially completed development sessions and completing engineering goals end-to-end. In both cases, SWE-1 showed performance close to current frontier foundation models, and superior to open-weight and mid-sized alternatives.
Production experiments used anonymized model testing to compare SWE-1’s contributions in real-world use cases. Metrics such as daily lines of code accepted by users and edit contribution rates showed that SWE-1 is actively used and retained by developers. SWE-1-lite and SWE-1-mini were developed using similar methodologies, with lite aimed at mid-tier performance and mini tuned for latency-sensitive tasks.
All models are built around the concept of a shared timeline, which allows users and the AI to operate together in a collaborative flow. Windsurf plans to expand this approach and refine the SWE model family by leveraging data generated through its integrated development environment.
Initial community reactions to the SWE-1 model family highlight interest in its broader approach to software engineering tasks beyond coding. Developers have noted the usefulness of SWE-1’s tool-call reasoning and its ability to handle incomplete workflows across different development environments.
Web and app developer Jordan Weinstein shared:
Super impressive so far. Though when testing supabase MCP with SWE1 it errors in Cascade. Lite does not.
And Technical Leader Leonardo Gonzalez commented:
Most AI coding assistants miss 80% of what developers actually do. SWE-1 changes the game.
The release coincides with OpenAI’s acquisition of Windsurf, a move intended to strengthen its presence in the growing market for AI-powered software engineering tools, where competitors such as Anthropic’s Claude and Microsoft’s GitHub Copilot have established a strong foothold. OpenAI is expected to integrate Windsurf’s engineering-focused AI capabilities into its own ecosystem, including platforms like ChatGPT and Codex, further expanding its presence in software development tools.
Podcast: How developer platforms, Wasm and sovereign cloud can help build a more effective organization
MMS • Max Korbacher

Transcript
Olimpiu Pop: Hello everybody. I’m Olimpiu Pop an InfoQ editor, and I had the pleasure of intersecting with Max at KubeCon the other day, and we said that we’ll stay for a chat to understand better what happens in the platform space because he’s so focused on multiple things. Max Koerbaecher, please introduce yourself.
Max Koerbaecher: Sure, thank you very much, Olimpiu. My name is Max Koerbaecher I’m the founder of Liquid Reply and what I’ve done the last years, it’s actually a lot of different stuff. Right now, primarily working around platform, platform engineering, how to build internal development platforms, but also going into sovereign cloud and how with open source and other technologies you can provide data sovereignty for your end users. But around that, I founded some years ago the technical advisory group for environmental sustainability in the Cloud Native Computing Foundation, today just the emeritus advisor. So, I stepped down to give the more energetic people space and keep pushing on the topic, as it requires a lot of energy.
I’m also part of the Linux Foundation Europe Advisory Board. Take a look at different initiatives and see how the organization can support the European open-source ecosystem better and give it some room to develop its landscape. And yes, I have a little bit of background in the Kubernetes release team. I was involved for three years in two different roles on the organizational side, and I’m hosting now the fourth year in a row the Cloud Native Summit Munich, which was formerly known as KCD Munich and organized also organised some meetups around all the Kubernetes and cloud native platform engineering and so on and so forth. Long, long story.
Olimpiu Pop: I’m remembering now all the encounters that we had in the last four years since I’m attending Kubernetes or KubeCon, mainly in Europe. And then I remember that we met also in DevOps, and it seems that we are always riding with the wave before that. As you mentioned, green technology was a subject, and I remember a lot of the graphs that you had that remained in my mind. Last year, I don’t recall the presentation, to be honest, but I know that your company had something to do with spin and wasn’t as connected there. So I’ll leave that for later. But mainly, you always seem to be focused on community-urgent issues and cloud-native, so that’s pretty much the topic you’re looking into. And this year somehow, you try to push all those things in one basket because you spoke about how a platform can bring a company together. Please tell me more about that. You also wrote a book about it, right?
Do you need a platform? [03:13]
Max Koerbaecher: Exactly. So I wrote last year, together with Andreas Grabner from Dynatrace and Hilliary Lipsig from Red Hat, a book about it called Platform Engineering for Architects. And it’s trying to do what you explain. Platform engineering is not always about the technology. The technology itself is solvable, it’s manageable, and if you cannot fix it, then give it one or two additional months since someone else will do so. So I think we are in an inspiring time, seeing the change in the technologies used and the approaches taken, but what is always missing is the missing clue between all of that. And I’m not talking about CI/CD pipelines and bash scripts and whatnot. Here, really, it’s the people and sometimes even the processes, the communication, and how we come to the point of building a platform.
And in our book, we question pretty often, do we need the platform? Do we need to go to the cloud? How to build it the right way? If so, are you sure, sure about it, that it is doing the right thing for you? And we help throughout the book to find the relevant decision points so that in the end, you know process-wise, precisely what you are doing and come to the fact that you integrate the different technologies. But our key conclusion is that you need to find a purpose for the platform. If you know what the purpose of the platform, is then you’re good to go. If you cannot define it, if you just say, “I was at the last KubeCon and it was filled with many cool, fantastic talks about platform engineering and how they change the world”. Yes, it might be like that; this is true for many organisations. However, just because this approach has worked for other organisations, it doesn’t mean it will work for you too. And yes, this is what we aim to bring together and provide more experience around.
Olimpiu Pop: That’s very interesting, because it’s usually a discussion of that kind. I mean, now we’re discussing platforms. Before that, we spoke about frameworks, different cloud providers, and so on and so forth. And it’s always the discussion. Well, it’s a very shallow discussion compared to what you mentioned, buy versus build and the other stuff. So, what you said is that we need a platform with a purpose. When do you feel that, first of all, a platform is needed? What’s the most common goal for having a platform?
Max Koerbaecher: That’s a difficult question because there is no generic answer to it. Many companies find this point for themselves for different reasons. There are a few public resources around it, like how Expedia measures the success of a platform, how GitHub measures the success of a platform or how Toyota measures the success of a platform. And all three do it differently. So one is looking into the development speed and how many contributions happen. So, most likely how they end up building a platform or thought it’s a good idea to create a platform is maybe because they had a problem in the delivery speed of their software, while the others are looking into numbers, right? Just running on an IDP saves us 5 million euros per year. So maybe it was a cost problem in the past, or perhaps the software development cycle cost too much money. And so, you’re looking for ways to improve it or increase its performance.
Therefore, again, it’s not a generic answer available for it. But let’s see, the most interesting part to really find this point is to go through a lot of questions and identify, like, okay, do I have problems in my software development process, or do I believe I have too many bottlenecks in my organization while producing digital products? I may have different hosting requirements, and I cannot force the whole organization to understand five different hosting providers, so I need to find a way to do that, and so on and so forth. We have one customer at the moment who’s focusing a lot on a very, very complex regulation. They have to fulfill a lot of compliance rules, and there’s two ways to do it. Still, the only way I believe there will be a long-term success is to build a platform around it because it’s easier to provide through one single endpoint all the compliance rules and ensure that in the development of the software and the delivery of the software and the operations of the software, this is always already there.
The other way around this, you have to enforce for every application that this customer is going to migrate to the cloud, and there will be thousands of applications somewhere that the compliance rules fit. Now, some people will say, “Hey, it’s the same if I push it to the cloud or if I push it to, let’s say, Kubernetes as a platform”. Absolutely. But from our experience in the past, it’s easier and faster to build a compliance framework around Kubernetes than to build a compliance framework around a cloud provider or to be precise, within a cloud provider. And that’s so because a cloud provider has tons of limitations and tons of things that do not work the way you would like to have them, and at some point, you very often need to fall back to the good old engineering path and build it by yourself.
Olimpiu Pop: Thank you for that. Let me confirm that I understand it correctly. So, what you’re saying is that most of the technology we face doesn’t have a one-size-fits-all solution, and it’s essential to examine what we have in our courtyard and ensure that we’re solving the problem. Even if the problem is viewed from a business or technological perspective, you should establish a metric in place and ensure that building the platform will enable us to address it effectively. Okay, that sounds good.
Signs that the Kubernetes ecosystem is getting more mature [08:55]
I was just counting the editions of KubeCon that I’ve attended, and this was the fourth one. And I know that I was thinking that technology should have another purpose, as you said, some goal, some primary goal. And in the end, each business we work with, regardless of what they’re building, should have the ultimate goal of helping our customers make their work better through our software. And this year, it was the first time I heard about this at KubeCon during a keynote. The guys from eBay were saying that they are thinking at the SRE level, specifically about the cyber reliability and engineering aspects of user experience. And it was as if I heard the angels sing, and I listened to the fireworks going off, and I said, “Finally, we are getting there”. And would that be a sign of the platform’s coming of age? People are finally realising how they should use it.
Max Koerbaecher: Well, it’s a sign that Kubernetes is becoming mature. And then platforms on top of that are just representing this majority now, and how rigid it can be. Earlier this year, I was discussing with someone about how boring Kubernetes have become. So, there isn’t much to talk about, but that’s not entirely true, because there are tons of changes happening continuously. But where in the past you were always like, it was every release, you were sitting in the evening and waiting that the release notes going on and you’re looking into and like, “Oh, my God, do I need to kill all my Kubernetes cluster I’ve deployed in the last months or can I just seamlessly upgrade?” That time is over.
The community, as well as the end users and the people who deliver additional services around it, such as myself, are trying to find a way to explain that now, Kubernetes is no longer the problem. It’s a little overhead, but it’s not a significant problem or headache. If you spend weeks fixing your Kubernetes, you’re doing something wrong. You should focus on delivering something that helps your organization create value. And this slowly comes together one-to-one into a platform.
Now, “platform” is also not a good term, I must say, right? We’ve been discussing different kinds of platforms for 20 years, but a sound, old cloud-native platform, with some container at its core, is where, at least in our community, we feel well and feel good. And to slowly turn away from staring at this tech and look more at the people who are using it, I think that’s just the step we’ve been waiting for a very long time, showing that the technology is rich enough so that we can now focus more on the user. Because open source has always had this perception of, ‘ Hey, it always looks a little bit ugly. ‘ It’s always more complicated to use and so on. However, I think that has changed now, and it now provides enough space, at least in the cloud-native community, to say, “Hey, make it open source, make it sexy and usable, and give it a purpose or allow it to deliver a purpose”.
When to use Kubernetes [12:01]
Olimpiu Pop: That sounds nice. I’m smiling because at the point when I was earlier in my career, I was following the shiniest thing, like pretty much everybody. And then you’re looking for the boring technology, and I don’t know why, but Yoda is speaking in my head like, “Learn you will, you Padawan”. And now I feel that, as you said, the industry or the cloud-native space is becoming more mature, and a lot of other things are building on top of that. However, there is always, at least in my circles, the question of whether to use Kubernetes or not, and that’s a sign of the maturity of the engineers. When will it be feasible for someone to consider Kubernetes? What would be the scale that you have to look into just to say, “We’re going the Kubernetes way?” Regardless of whether it’s through a cloud provider or you’re just implementing it yourself?
Max Koerbaecher: Complicated, to come to the point that Kubernetes makes sense, it’s more like an evolution, right? If you are a large enterprise company, you will likely find numerous use cases to adopt Kubernetes and make it work effectively. Often, you have the other issue that you then have 10 initiatives at the same time, and practically, you’re wasting nine times more money than you want to save. If you are a medium-sized company and the biggest challenge for you is hosting your ERP system, website, and 10 internal tools, Kubernetes may not be the right solution. If you’re a startup and don’t have money, don’t start with Kubernetes. It’s not that Kubernetes itself is drastically more expensive, but you need to spend a decent amount of engineering time, and you need to hire at least one or two people who are in some way good with that tool to make your infrastructure work.
You can focus on going serverless, for example. When you want to create a prototype and are looking to bring up an MVP quickly, it’s fine to go serverless. Still, you can also, at the same point in time, pull out the companies that built everything on serverless in the past and are now migrating back to containers, trying to get into Kubernetes because it has reached such a scale that they have lost control of their system. Because serverless is also not the easiest thing to observe regarding what’s going on. There are, however, numerous cases where it doesn’t make sense to opt for Kubernetes. Earlier in the Kubernetes book club, we also discussed the same question, where we agreed that we should not bring that.
And my co-author brought up an example: if you use embedded systems, you should also avoid using Kubernetes. And it’s like, yes, well, for me, embedded systems are very far from using Kubernetes. Still, Iot itself and the whole edge deployment topic are a very significant aspect of the cloud-native ecosystem. There’s our user group around it, and there’s our telco group around it, which also works with Edge, so it’s reasonable to consider it. Where does it make sense, and where doesn’t it make sense?
So, for me, there are other questions where you can use it. You may want to either build a platform to host thousands or hundreds of random applications that are not very special. In that case, I show you quote unquotes a platform can be a good approach to unify all the different core services which you need: security compliance, make the life for operations easier, unify how you deploy software, how you keep it up and running, blah, blah, blah. All cool, good way. The other way, and this for me, the ideal use case. If I have one large digital product that is built of many different services, many different components, and they all need to in some way wipe together, they need to grow and get smaller, they need to be fault resistant, they need to allow a seamless global upgrade from versions distributed around the world, whatever. Then Kubernetes places its competencies to the best.
Olimpiu Pop: Okay, fair enough. To summarise, if you have minimal applications, consider an alternative solution. There are better ways to do it than this. But if you need to normalize your deployments and you have massive operations, it’ll help you. And this reminds me of the talk I attended last year from Mercedes-Benz. They were discussing having thousands, I don’t remember exactly, in the lower thousands, so 2,000 to 4,000 developers. They had a team of six platform engineers who were able to build the platform and deliver all of those features because they had a very proper and disciplined way of doing things. So that was eye-opening for me. However, I’ll return with a challenging yet interesting perspective.
Can WebAssembly and Kubernetes work together? [16:49]
You mentioned IoT, and it’s growing. I have a piece of that pie on my plate as well. And as you said, telco is, well, a longer edge because it’s big, they have other resources, and it has more different types of scenarios. However, I am involved in the smaller-scale Iot, where devices are deployed throughout various locations, and similar applications are utilised. However, I’m still considering a platform that can handle heterogeneous ecosystems, as they often involve multiple embedded software components and various versions. There is also an intersection point that is occurring more frequently now, and that’s the combination of WebAssembly and Kubernetes. You were on the SpinKube, if I remember correctly, as a connector.
Max Koerbaecher: Yes, partially. So initially, my team developed something called the Spin Operator. The idea was to make it super simple to get started with WebAssembly on Kubernetes. And in the end, the guys did such a fantastic job that it was even too boring to create a demo, as it was essentially just two CLI calls, and you were simply running on your Kubernetes cluster. The thing is, it wasn’t production-ready; it was lean, simple, and easy, but as often is the case, it was an experimental thing. My team collaborated with Fermyon, Microsoft, and SUSE to take it to the next level, making it production-ready and incorporating their reliability to ensure it’s robust enough for even production use cases. And in the end, I do not want to say we developed Spin or SpinKube; that would be incorrect, but my team contributed to a small, minor portion of making that happen.
Olimpiu Pop: Nice. Well, it’s a good company to be in. SUSE, Microsoft and Fermyon have a cloud focused on WebAssembly. So what’s your thought? Will WebAssembly make your footprint smaller? How much difference would it make?
Max Koerbaecher: First of all, I believe it would make our lives easier in some way because it removes all the things that can go wrong and the dirty tasks that you may not want to do as a developer or sys admin, right? So it’s for me, not about the size of the container. It’s also interesting, but it’s more about the security factor that you have their compiled binary format, which you can modify. Practically, it cannot do much if you do not grant it explicit rights. That’s one of the most significant parts that I love about it. In terms of size, performance, or sustainability, we also examined this aspect. WebAssembly doesn’t need to be more resource-efficient or more sustainable because, on the one hand, the execution time of the software remains relatively constant.
There’s no speed or improvement just because you run a WebAssembly. The only difference is that a WebAssembly container can start in 110 to 150 milliseconds. So in the blink of an eye, you can start a container. But does it allow us, that a container doesn’t need to run continuously, where a regular Docker container is also swift. Let’s say it takes a second, sometimes less, sometimes more, but it’s significantly larger in the amount of data that needs to be stored. For a container, yes, you can create a Docker container or a standard container, which can be tiny, a couple of megabytes, or 100 megabytes, depending on your needs. That would be best practice. The reality for almost everything, as seen in large and medium-sized companies, is even more alarming: the container has several hundred megabytes or gigabytes. It sometimes takes dozens of seconds to start up, or even minutes to prepare.
And so that’s where, on the other hand, WebAssembly boils it down to like, “There’s your code, execute it”. There’s no bullshit going around. There are no unusual scripts triggered in our other container, and we have preheated something. No, you are forced to make your software start and run. That’s it. And through that, yes, the container of WebAssembly is comparatively small. Some say you can go down to kilobytes. If you megabyte one, two, three, four, five megabytes, it is a good medium. Sometimes it can also become bigger. That’s not the thing. But it becomes very, very small in this regard. The technology itself is impressive. I like it because it eliminates all the headaches of maintaining, patching, and hardening the operating system in a container, leaving you to simply “Here’s your software”. You can use it everywhere. You can run it alongside every other container, but the platforms, cloud providers, and your local platforms do not support the speed of starting a WebAssembly container.
It’s great that I can start and stop a WebAssembly container in milliseconds, but it doesn’t help me if a node on AWS takes 7, 8, 9, or 10 minutes to start up, right? So this is the problem in the end. And so, either cloud providers need to start providing services again in the serverless space that can catch up with WebAssembly. And that will happen sooner or later. Or, from my perspective, where my sustainability expert comes in again, especially for a little while, slowly, platforms in an enterprise context, I see it as a possibility to fill in the blanks.
So, the Kubernetes platform is only sustainable or sound in its resource consumption if it utilises almost 100 per cent of the resources; only then is the resource consumption efficient, right? And so you can fill it up; you can have your static workload, with the heavy applications running at the bottom, and then the more flexible applications running on top. And then to fill up the planks, you can include, for example, a WebAssembly container, because you can kill it very quickly and move it somewhere else without even realising it.
How many platform engineers are needed to build your developer portal/platform? [22:49]
Olimpiu Pop: Okay, that’s a nice thought. To summarise those points, you mentioned that WebAssembly can be very fast if used appropriately. Still, companies that simply bloat their WebAssembly binaries or whatever they are called should look for an alternative. And to make things sustainable, I need to mention that sustainability is both financially and environmentally, because they’re interconnected, and it’ll mean that we have to utilise the entire resource that we have. And WebAssembly can be built on top of it because if it starts very, very fast, it allows it just to spin left and right regardless of whether people are seeing it or not. Interesting. However, this is an interesting space, and we can discuss it at length, but ultimately, this is only the runtime, right? It’s the basic stuff, and then we have the application built on top of it. And you mentioned that currently you’re looking more into internal developer portals, and that’s, again, another buzzword because I remember that last year backstage had the most developers allocated for building it.
What’s your experience with developer portals?
Max Koerbaecher: We need to draw a clear line in my wording. It’s always an internal development platform, not a portal, because there are not that many portals. Either you go backstage if you want to go open source; Red Hat has a wrapper around it. All other solutions are commercial. And we need to be aware that, as cool as backstage is, it is a burdensome child. Many organisations are starting with it, failing with it, and I get very, very mad about it.
We were a few weeks ago on a platform engineering executive roundtable. Almost everyone reported they have around three to five people working on their developer portal, and they don’t see any kind of benefit coming out of it. The problem with this standpoint is that it becomes locked into platform engineering and building platforms in the second row. And that’s a massive problem for me. That’s why I always like to take it down; first, we talk about an internal development platform because it’s bigger than just UI. The platform itself can provide you with tons of features and capabilities, and it can be adjusted to whatever you need. And then you are back to the example which you mentioned from Mercedes-Benz tech innovation, where they, with a reasonably small team, can serve a vast number of developers.
And they’re not alone by themselves. Customers we are working with have similar or larger scales, and we can see this practically in this ratio. We always say like five to five. So 5,000 developers require five platform engineers, right? When I look at the organization which we support, we usually come up to the scale of these teams in this regard. And if you need more people, then you have done something wrong with your platform – something like that. For sure, it’s also always complicated, but that’s a little prominent example for me.
But yes, developer portals themselves are a huge buzzword. I think sometimes it’s cooked too hot than what can really, really deliver. For my KubeCon demo from a talk which I gave from KubeCon, the demo, I also spin up an own IDP with the Kanoa project. Everything runs very smoothly. Argo runs smoothly, Argo Workflows comes up like a chime. External DNS, no problem. AWS EKS on an auto mode also, no problem, everything cool. Backstage killed me for weeks. I spent dozens of hours making that little… Sorry, I’m getting angry here. Fill in some bad words that come to mind first to get it up and running. And then when it was up and running, you want to fix something, you want to integrate something else, compile it, push it, proc again, it’s like, man, it can’t be.
So I can understand the pain around it. And that’s why I always like to say an IDP is not backstage. An IDP is a platform that your developers use and love, so you have it. One of our biggest customers runs everything in GitHub, that’s an IDP. They do not have a portal, and the developer portal is developed and maintained by a different team. Although they do not want to imply that no one cares, they are focused on their tasks. But the platform itself runs without it. So it’s not needed for making your organization successful in this space.
Olimpiu Pop: I zoned out a bit when you mentioned that developers have to be happy, and that’s one of the newest metrics that people are discussing. So we had DORA and then we had space, and then out of a sudden we thought about DevEx, and in the end that’s important. If the people are happy with what they’re having and, as you said, they avoid the frustration that comes from building something that allows them to be very creative and then deliver the value that they want. Ultimately, for me, the platform – the tool we use – regardless of the label we assign, should serve as a connecting bridge between the operational space and the development space. And that allows us to build bridges in the organization and break down the silos. Because, in the end, that’s what we’ve tried for so long to do, and now my feeling is that we’re closer than ever to achieving that.
Okay. We touched on a wide range of topics, and you’re at the forefront of everything. First of all, should I have asked you something else? What would be the topic I should have been keen to ask you?
Max Koerbaecher: I’m glad you didn’t touch AI.
Olimpiu Pop: Well, everybody touches AI. So we can leave it there for now.
Max Koerbaecher: With those few words. It was touched, too. It’s very complicated to think about what’s next because so many things are happening at the same time right now. What we will see, and that’s what the organizations currently struggle with, is still to adopt the cloud. We are far ahead in the platform engineering community. We treat cloud just like an API that is tame. Yes, I need to know some limits and so forth, but usually we don’t invest so much energy in it and just fix the problem, then focus back on what delivers value to the users. But that’s still one of the most significant problems which we see with our enterprises that they’re working on. Besides that, I think we can do way more better in the space of providing application platforms. So when we talk about an IDP, we usually talk just about infrastructure and CI/CD and security and compliance and whatsoever.If you look in all kinds of reference architecture, they always look into resources and cloud provider and all the infrastructure part. Almost nothing looks the application level.
For this one, I really loved in the past Heroku and I think they are currently back on track. Somehow after the acquisition of Salesforce, they vanished for a few years and now they’re back and shiny and put out their nose and like, “Hey, here we are. We are still a cool platform. Come to me”. And I think you see similar platforms like Versal for example, which focus a hundred percent only on one problem. Give me your application, I put it somewhere and make you happy. And I think in that space we really still miss good solutions that are putting the right perspective into it, but also because it’s complex to make people in that space really happy in the end because they either want to touch the infrastructure or they don’t want to touch the infrastructure or the application becomes so complicated that they need 500 different configurations around it and so on and so forth.
So I can understand that there’s no simple solution to it. On the other hand, we have the same for all the Kubernetes and infrastructure space. We have thousands of config possibilities and millions of compositions that are possible and so on. So I think there will come up something in some time, but at the moment we don’t see anything.
Olimpiu Pop: Okay, so let me see if I understand it correctly. I don’t know if you saw it, but I had a large light bulb on top of my head when you said about internal developer platforms and application space. Because the thing that I just thought about is how cool would that be to have the qualities view on the infrastructure guys, the infrastructure team working together with the enablement team and delivering interesting building blocks that everybody can use in a uniform manner. And then we are just making things fast, secure, compliant because whether we like it or not, compliance is a very important topic. Is that around your thoughts as well?
Max Koerbaecher: Yes, in some way. I mean that’s the promise which we carry around since years and decades of doing cloud, right? But the reality is it really isn’t. We are getting more and more far away from it. We always add layers on the bottom. I don’t know, maybe we hope to fill up the whole thing until we reach the top. Maybe that’s the idea behind it, but we don’t think about what we can add from the top to it. That’s why I like other projects in this space and also WebAssembly because it forces me to reduce some part of the infrastructure. I said even just to take out the operating system of a container, that’s already a big change. It sounds stupid, but how many organizations spend thousands of thousands of euros and build hours and people on building so-called golden images in secure images and then the next developer comes around the corner wants to use, I don’t know, Rust, and suddenly nothing works again, right?
And so I think there’s, for example, wasmCloud, a very cool approach, also an open-source project, also part of the CNCF that can run practically everywhere. If you like Kubernetes, throw it on Kubernetes. If you like VMs, throw it on VMs. If you want to have it somewhere else, it can run somewhere else. There’s no real limit around it. But they have taken out every other complexity and just take your application and make it deployable, make it robust. If some connection drops somewhere, the tool will try to find other connection paths. If it doesn’t happen, it waits until it gets back connection and so on. It almost feels like a serverless platform, but it isn’t a serverless platform and it almost feels like a distributed ledger technology. But it isn’t a DLT, it’s not a blockchain, right? It sits somewhere in the middle. And I think there we can see in the next year, I guess, more development, more interest to try this out.
Would a sovereign cloud make your life easier? [33:17]
Olimpiu Pop: Okay. One of the elephants in the room passed by and that’s AI. We left it passed by us, but there is another one and I wouldn’t have mentioned it if you didn’t have touched on that and that’s over in cloud. Unfortunately the way things are looking, that’s something that probably people will start asking, if they didn’t already, “So what are we doing? Are we cutting the transatlantic cables and building new clouds or are they still already existing?”
Max Koerbaecher: Well, I think we shouldn’t do the China move, and, as we learn, trading relationships are very important. But I think what people slowly come to the point is that it doesn’t make sense to just ride on one horse in the end or just follow one horse. And that we need to find our own strengths back in some way. And that always sounds a little bit political, but it’s really not about they versus us or whoever, it’s more about we have lost in the last years a lot of our capabilities and we run behind the technological innovation. This is for multiple reasons. It’s from the investment structures which are way better in the US and people just give you a couple of million dollars. On the other hand, they have a problem with money. So it’s not good to give us the full hand of money if you do not have enough money in your other hand, right?
Nevertheless, I don’t think we should cut the cables, but we need to be aware of that. That’s the very fascinating, interesting part in the sovereign cloud itself. You have a legal aspect which you cannot fulfill with any solution existing except it is provided by 100% European entity owned organization that has zero connections to the US or China or Russia. Also, all of them want to sneak peek into what you’re doing there. That doesn’t matter so much. And the other part is you need to ensure that you have your data all the time encrypted. And I think this is right now the time not only of sovereign cloud and sovereignty about your data, but also confidential computing. I think that in many discussions, which I see is the second or third thing which comes up is it’s not enough to just legally do the things but we also need to protect it from end to end. And I think that’s the both things which we see at the moment coming up.
Beside that, cloud providers are developing. I’m super glad that we can work with Stack-It together in the German market or Scaleway more international and have tons of other options out there. We also can discuss about what is a cloud provider because we have a lot of providers, infrastructure as a service provider for example, that have almost cloud-like services, but not always someone would take them as a cloud provider.
But I really like to see that there’s a push. I really like to see that people challenge the new infrastructures which are getting built, try to understand how they’re working, how they’re different, maybe getting frustrated about it. That’s also my experience on some part. But I also always say the cloud as we know is broken because it’s just like a digital version of how you have done IT the last 60 years before. So maybe it’s time to really rethink how we are doing it. This will not happen for the large enterprises. They’re stuck in their structures, but everyone else can maybe find a way to do it a little bit better and not spend countless hours networking and firewalling and whatsoever and just find ways to really focus on providing, again, more cool features and spend time in being innovative and create new stuff.
Olimpiu Pop: So for me, how it translated from my personal experience and what we discussed is that the sovereign movement is more about aligning with our values, our European values, and ensuring that the data is safe, it’s computed safe, and it’s stored safe inside the European Union, in each entity of the European Union where you need to have the data, and that’s mainly it. Keep your data close and ensure that it’s used by the people that actually have the right of using it properly. Okay, well I think this is a nice sum up of what we discussed up to now looking to a bright future. [inaudible 00:37:26] Max, thank you for your time and hope to see you soon.
Max Koerbaecher: Thank you for having me. I wish you a nice evening.
Olimpiu Pop: Thank you.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.