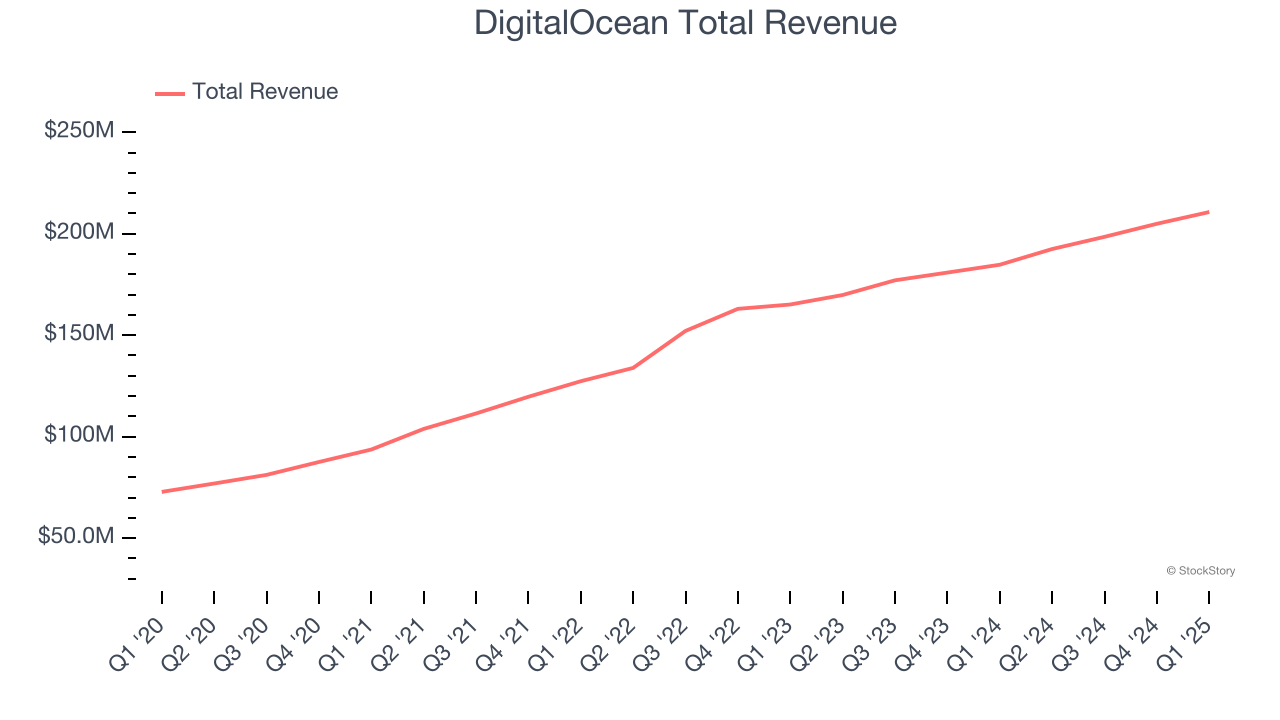
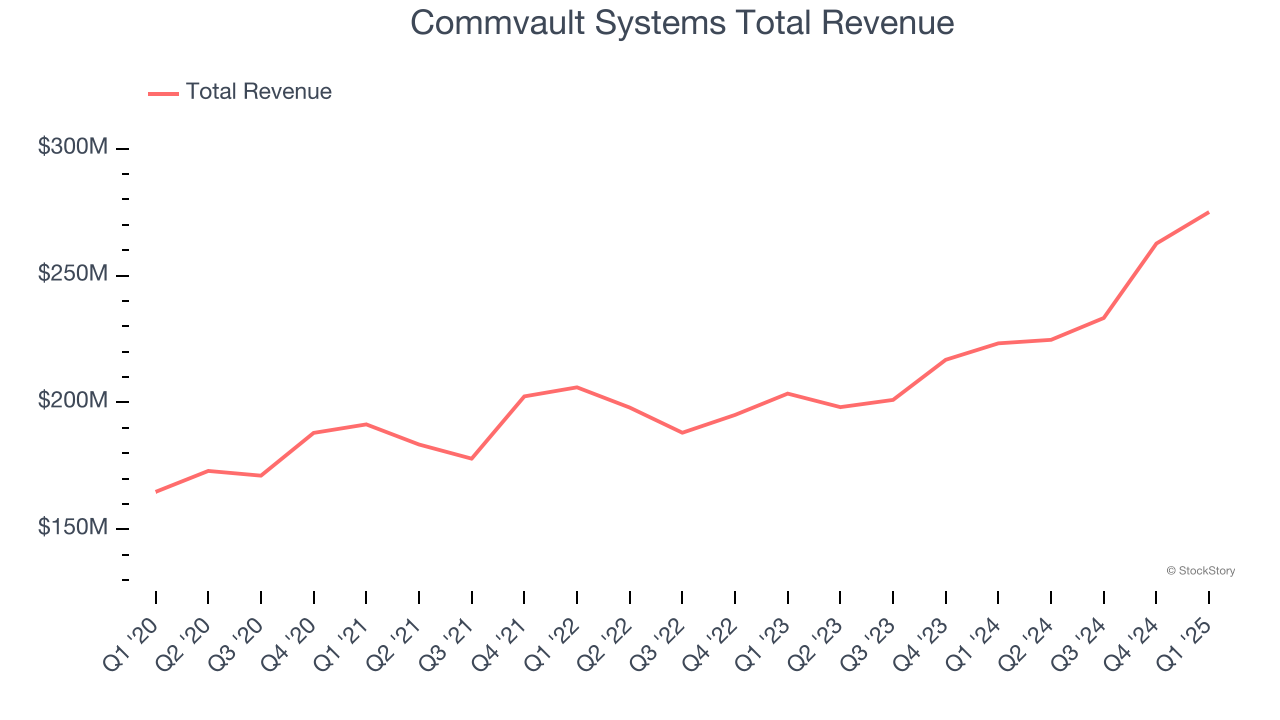
Transcript
Shane Hastie: Good day folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today I have the privilege of sitting down with Holly Cummins. Holly, welcome. Thanks for taking the time to talk to us today.
Holly Cummins: Oh, my pleasure.
Shane Hastie: InfoQ readers, QCon attendees will be familiar with you, but there’s probably four people in the audience who aren’t. Who’s Holly, tell us who you are and what got you where you are today.
Introductions [01:08]
Holly Cummins: So I’m Holly Cummins. I work for Red Hat and before that I was a long time IBMer. I think one of the joys of a career in technology is that I’ve done all sorts of things. So I’m currently part of the Quarkus team. I’m an engineer on the Quarkus team, but before that I worked as a consultant. So I was sort of helping organizations take advantage of the cloud, which was an incredible experience in terms of working with all sorts of different organizations and seeing some organizations that just were so incredibly effective. And then other organizations that maybe needed a little bit of help and needed a nudge in the right direction. And then I’ve been a performance engineer and I’ve worked on WebSphere and yes, all sorts.
Shane Hastie: Most recently at QCon London, you gave a couple of talks that I’d like to dig into. Let’s deal with the first one, productivity is messing around and having fun. Really?
The productivity paradox [02:08]
Holly Cummins: Yes. I mean that was a talk I did with Trisha G, and of course, we chose the title to be a bit provocative. It’s not intuitively obvious that that’s the case, but there is actually a lot of evidence that the way we think about productivity isn’t actually making us more productive. It’s making us less productive. And some of the things that we feel too guilty to do are actually the things that make us more effective. Because what we’re doing in technology, it’s not the same as working on a factory where we have an assembly line and we can just measure ourselves by how many things are coming off the end of the assembly line. We’re problem solving. And that’s fundamentally a creative activity. And one of the challenges we have because it’s a creative activity, because its knowledge work is it’s quite difficult to measure how effective we are.
We can’t just look and say how many widgets are rolling off the assembly line? And if we do it really wrong, we’ll try to and we’ll say, “Well, how many lines of code are running off the assembly line?” And that of course leads to some pretty terrible anti-patterns that I think probably all of us have seen where if you incentivize lines of code, you get lines of code. But lines of code are not an asset. Code is a liability. What you want is the minimum amount of code to solve the problem and the sorts of activities that allow us to solve the problem are not necessarily sitting down and typing as quickly as we can. There are things like thinking about how to solve the problem and where do we think best. We tend to not think best at a desk in front of a computer. We tend to think best doing things that are pretty apparently unproductive.
So a lot of us, for example, will solve problems in the shower. There’s something about being away in that environment where you can’t really do anything. You can’t bring your keyboard into the shower. And so then that just breathes a section of your mind to solve problems.
A lot of people find as well, things like loading the dishwasher or knitting or walking, that’s when you’re actually most productive. And it’s kind of good because I think there’s sort of a double win here because actually all of those things are sort of nice in their own right as well. So we’re in this really fortunate position where the things that make us more productive are actually the things that we kind of would want to do anyway. But the problem happens because they don’t look like productive activities. They look like we’re slacking off, they look like we’re just sort of loafing around. And so then it’s about how do we gather the narrative to give ourselves permission to do these things.
Shane Hastie: Yes, I don’t know whether my boss would be particularly happy with a timesheet entry that said showering, but you’re right, it is in this freer space, freer mental space. So we know this, but our organizations don’t seem to be getting this message. How do we communicate that?
The science behind creative downtime [05:15]
Holly Cummins: With all communication? Really it’s about figuring out the language of the person that you’re speaking to and communicating it to them in their terms. And in general, the business will want to see things in financial terms. So it’s quite useful to be able to actually quantify some of the benefits of this. But it’s also quite useful to be able to present the concrete evidence for it because there is quite a lot of evidence for it. So we can pull, for example, from psychological research because psychological research has actually been able to measure physiologically what’s going on when we have a shower, when we knit, there’s a part of the brain called the default mode network. So there’s a sub-discipline of psychology or what they do is they put people into an MRI machine and then they get them to do some task and they see which areas of the brain become more active.
And what they can see is that if they get people to do nothing at all, there’s one area of the brain or a network in the brain that becomes more active and it’s the doing nothing that enables activity in this area. And it’s called the default mode network. And so what’s the default in the mode network responsible for? It’s responsible for things like creativity, it’s responsible for things like problem solving.
Interestingly as well, it’s also responsible for something called mental time travel, which sounds amazing because it makes it sound like we’re going back and we’re being in medieval England, it’s nothing so exciting. It’s just when you replay what happened yesterday, that’s the default mode network. So we can sort of see at a physiological level what’s going on. We can also model it mathematically, which is kind of interesting. So again, if we need to communicate to someone who doesn’t want the sort of fluffy wuffy, “I feel nice when I do nothing”, who wants the, “Okay, what’s going on?”
Because if we look at queuing theory, that’s modeling how systems do work. And of course our organization is a system. We are a system. And what queuing theory tells us is that if you have a slightly random arrival rate of work, you need to have some period when the people doing the work are actually doing nothing at all.
Otherwise, what ends up happening is because there’s an asymmetry and if work is arriving faster than you can do it will just keep building up and up and up. And then the wait times in the system become well, infinite. You need to have some points in the system where the system appears to be doing nothing in order to keep the latency okay. And it’s exactly the same for us. So we need to have some periods in our day when we’re not doing anything or else any incoming task has potentially infinite latency, which isn’t what our management want.
Shane Hastie: But this is almost antithetical to what we’re seeing and hearing in the industry today. The push for more, do more with less, all of that.
“Do more with less” is counterproductive [08:22]
Holly Cummins: Yes, absolutely. And I think that’s why it’s really important to talk about this because the push to do more and more, more, it’s just wrong and it’s just counterproductive. I saw a social media post recently from someone and they were in the VC space and what they were doing was they had a group for their founders and I think it was WHOOP, maybe it wasn’t a tool that I’ve used, but they were tracking how much sleep their founders were getting. And they wanted their founders to be getting five hours of sleep a night because that shows that they really dedicated.
But again, this is something that there’s enormous amounts of evidence that if you go to work tired, that is equivalent to going to work drunk, you’re not achieving more, you are achieving less, you’re making more errors. And so if you said to people, “Would you like your employees to go to work drunk?” Everybody would be like, “No, that doesn’t seem like a good idea. I think I’d like to be a high quality organization”. But when you said, do you want your employees to go to work exhausted, people are like, “Oh yes, that shows were really..”. And it shows that productivity will be lower and the quality of life will be lower. So why would you want to have that double lose when you could be having the double win instead?
Shane Hastie: Which brings us to what is efficiency.
The efficiency trap [09:41]
Holly Cummins: Yes, and I think mean efficiency is interesting because we have sort of an intuitive definition of efficiency. When we talk about efficiency, what we tend to think of is, “Oh yes, efficiency means doing more”. But actually in a technical sense, efficiency is doing less. And if you want to be specific, efficiency is doing less in achieving the same results, which is obviously an important qualifier. But we tend to think of efficiency as ramming as much in as possible. And that’s not actually going to give us a good outcome. And again, we can see this for people and it’s sort of hard to accept for people because it seems a bit kind of fluffy.
But we see the exact same trade-offs and decisions being made in other fields where it’s more mechanical so it’s easier to accept. So for example, one lesson is that efficiency is always limited. So with an internal combustion engine, there is a top limit on its efficiency of about 36%. No matter how well engineered it is, it is never going to be more than that level of efficiency, which is irritating because you ideally would want more efficiency. Ideally we’d have like 120 efficiency. But then the other thing that’s really interesting is so we have this cap of 30%, but if you look at the efficiency of typical cars on the road, they’re not operating at that 36% level. They’re operating around more like 20%.
And is that because the engineers who designed those cars were sort of lazy and couldn’t be bothered? No, it was a deliberate decision to detune the engines because if the engines operate at that higher efficiency, they wear out faster. So you have this sort of short-term efficiency of how much fuel is going in and how much speed do I get out? And then you have this longer term efficiency of, “Does my engine actually last or do I have to replace my engine more often?” And the analogy with people is pretty obvious as well. If people work too much, it may seem like this short-term gain, but then you get burnout and that doesn’t help anybody.
Shane Hastie: There are times though when you do want the racing car and you’re prepared to throw the engine away.
When to push hard and the importance of recovery periods [11:50]
Holly Cummins: Yes, I think that’s right. And similarly, there’s times in the workplace where for all the sort of nice hand waving of, “Wouldn’t it be nice if we only worked at a sustainable pace? It only works seven and a half hours a day”. There’s times when you have a deadline, there’s times when you are racing against the competition when you need to get to market. So I think keeping that flexibility is important, but just making the conscious trade-off and saying this is going to be a period of high intensity, and then after that period of high intensity, I’m going to have a period of recovery. And again, actually that period of recovery can be very fruitful. So when I used to work in WebSphere, this was 15 years ago, the release cycles were quite different.
So you do a release every two years and it’s such a special occasion and if you miss that release train, you are not getting another chance for two years. So everybody is desperately trying to get into that release. And then of course then you sort of end up with this cycle where, I mean we’ve learned not to do that, right? Because everything gets shoved into the release. The quality is about the quality that you would expect if everything gets shoved in, so then you have to wait for the .1 or the .2 before you actually adopt it. And you think, “Um”. But leaving all that aside, what would happen is we would race to do this release working evenings and getting pizzas brought in and that kind of thing.
And then we would meet the deadline and then it would be like, “Okay”. And then what our management would say is, “Okay, we’re going to have a sprint where we are not going to be project managing this. You just do what you want to do”. Some of our best features came from those time off sprints because people could deal with the technical debt that had been bothering them or there was something that they just knew that would be really good, but they hadn’t managed to persuade project management to put it into the project plan. So they would just implement the feature and then it would go out and people would be like, “Ah, this is amazing”. So even that sort of apparent gift of time to work on what people wanted to work on ended up having quite big productivity benefits.
Shane Hastie: Shifting tac a tiny bit, before we started, I made the slightly tongue in cheek comments about we take the best engineer and we promote them and leave them to be the worst manager. How do we avoid that in our organizations?
Management vs. technical career tracks [14:13]
Holly Cummins: I think often that happens because in an organization, if the management track has higher advancement opportunities than the engineering track, people will be pragmatic and they will move across to that track. And so I think what we need to do is just make sure that we provide an opportunity for engineers who are really good engineers and really bad managers to stay in the engineering track, but be rewarded proportionally to the value that they’re bringing to the organization, which can be really quite significant.
Shane Hastie: And what about those that we want to go into that management track? What’s the advice for the engineer who is interested in going into management?
Holly Cummins: I mean, I have to answer this with caution because I have never been a manager and I have always been lucky enough to be in organization where there was a non-management track that went to quite senior levels. And so I’ve quite happily stayed on that track and never ventured across because I had a suspicion I wouldn’t be very good at it. But I think part of it then again, it’s about the opportunities for professional development, isn’t it? And so we see you have that with all of these things, you need to have that time to invest and then you get a higher reward.
And so that goes back to the efficiency conversation of maybe actually the way to get the highest value isn’t just in the short-term ring every bit of time out of people. We see it in the code base that maybe the way to get the biggest numbers of features isn’t to race through every feature and never put any time into technical debt. And it’s the same for people. Maybe the way to get the best person isn’t to sort of never give them any time for professional development, never give them any time for going off reading, learning. Because if we do that, we win in the short-term, but lose in the long term.
Shane Hastie: And advice for the person who wants to follow your path and stay in that technical… what should they, the more entry-level person who’s listening to this and looks at you and said, “I want to be like that”. What should they be focusing?
Staying technical: the curiosity factor [16:39]
Holly Cummins: I mean, I think so much of it is about the curiosity and keeping that curiosity always alive. I saw a quote recently and it said that creativity is when you do things from a place of curiosity rather than a place of fear. And I think this is such a creative industry, even if we don’t call it creative and it changes every single week. There’s new technologies, there’s new skills. And so we have to have that mindset where we’re embracing that newness and interested in what’s coming along. And also I think always looking to make things better as well.
I think sometimes, especially if we get a bit burned out or we get a bit ground down, you kind of look around and everything’s a bit terrible and there’s all this friction, you kind of go, “I can’t be bothered to change it”. And you have to have that interest in saying, “What’s not helping me? What’s not helping my colleagues? How can I fix it? Let’s make this happen”. And so sort of combining the curiosity and then let’s always be trying to make things better. Let’s be looking for the things that are bad. Let’s be continuously improving.
Shane Hastie: What are the trends that you’re seeing in our industry today that we should be thinking about and jumping onto?
The shift from author to editor role with AI tools and managing industry “fashion” [17:58]
Holly Cummins: I have mixed feelings. Having just said we should be curious and we should be embracing the new. I sometimes have mixed feelings about trends. A colleague of mine said yesterday that ours is a fashion industry and that’s completely true. So we do see some of these things come along where you have to pay attention to it in order to be in with the cool kids, but is it actually adding value? I’m not sure. But I think certainly one of the trends that we’re seeing at the moment is this move for all of us as engineers to be working higher up the stack and to be at the level where we’re managing code and managing code generation rather than writing it ourselves. And I think that’s an interesting transition that we need to figure out, “Well, what does my role look like now if I used to be a coder and now I’m a coder of coders, how does that feel? How do I manage that?”
Shane Hastie: I’ve described it and heard it described as the shift from author to editor.
Holly Cummins: Yes, I like that. And Annie Vella wrote this amazing blog where she was talking about exactly that. And in terms of our identity as software engineers, we came into it to do one thing and now we’re doing something else. And are we okay with that? Did I sign up to be an editor? Yes, it’s a period of change, I think for sure.
Shane Hastie: What are the underlying truths that aren’t changing?
Timeless truths in software engineering [19:37]
Holly Cummins: Oh, I like this. I think so much of it is not changing and we can get caught up in looking at these sizzles of change on the top and then miss all of the stuff that hasn’t changed. In our talk, Trisha and I referred a lot to Fred Brooks because if you read The Mythical Man-Month, so much stuff in there is exactly the same. And even stuff, maybe this has changed a little bit just in the last year, now that we’ve with that shift from author to editor, but even stuff like Fred Brooks wrote that you could expect to write 10 lines of code a day. And you look at that and you think, “That’s ridiculous. I can write 10 lines of code in five minutes. How?”
And then you sort of step back and you look at your output over the whole year, and then you look at how much of it is tests, infrastructure stuff, and then you look at how much of your time is going into meetings and conversations and design discussions. And then you divide that by 365 and you’re like, “Oh, actually that’s about 10 lines of code today”. So that side of it that there’s always overheads, there’s always, always overheads. How do we manage those overheads? Which overheads are the good overheads that we need? Because otherwise we just produce chaos. And which overheads are the overheads that actually we should be pushing back on and saying, “Why am I having to do this reporting? Why am I having to go to these meetings?”
And for both people and machines, that coordination just remains a huge challenge. So at the machine level, at the code level, it’s about the concurrency and how do we get the minimum amount of interlock that allows our code to function while still giving us good throughput and the number of cores is going up. That is a trend that we’re definitely seeing. So concurrency becomes more important. And then at the human level, it’s the exact same. How many meetings do I need to go to in order to ensure that my colleagues and I are pulling in the same direction without losing all of my time to meetings? So you can apply Amdahl’s law to code or you can apply Amdahl’s law to teams.
Shane Hastie: One of the things that we often hear is that the cognitive load on the engineer today is more than it used to be, and it’s getting more constantly. How do we manage that?
Managing cognitive load [21:58]
Holly Cummins: Yes, that one’s really hard. And I have such mixed feelings about it because when you look at a lot of the things that we’re being asked to do now, like shift left. On the one hand, shift left is an absolutely brilliant way of reducing these feedback cycles, improving the efficiency, getting away from that model where we sort of do the bad thing and then we throw it over the wall to the other team who says, you did the bad thing. And then we go back and we redesign it. But on the other hand, shift left for us is bringing it exactly as you say, all this cognitive load.
And there’s all these new skills that we need to know because now I need to be a deployment engineer because I need to understand where stuff is going. And if I want to have mechanical sympathy and write highly tuned code, then I need to have some hardware understanding as well. And I need to be a UX engineer and I need to have the front end skills and I need to do the security. Shift left should definitely apply to security. And then there’s so much. So I think really the only way that you can get rid of cognitive load is to, as more stuff comes in, you have to be getting rid of stuff.
And we’re seeing this a little bit, I think, because it used to be that as a software engineer you were working in such a low level, you were working in assembly, and now we can work in something that’s much more, even a modern high level language is so much more human-readable. So that piece of cognitive load has gone away. And a lot of our tools, we are sort of going up the stack. So in Java for example, we don’t need to be working with a low level concurrency constructs anymore. We can use structured concurrency or something like that. And so hopefully the ideal is for every piece of cognitive load that goes away, another comes in, but that they stay a bit in balance whether we’ve achieved it or not, I don’t know.
Shane Hastie: What are your hopes and dreams for our profession?
The joy of software engineering [23:56]
Holly Cummins: I think ours is such a fantastic profession. I feel so lucky to be a software engineer. So one thing that I do hope is that our industry carries on. There’s been a bit of concern now of will AI make us all disappear? And I don’t think that’s going to happen.
I think Jevons paradox means that our appetite for software is just going to continue growing. But I hope that at the moment, certainly in the right organization, this is such a joyful profession to be in. And we have such a nice combination of the problem solving and the creativity and the creation as well, which is sort of the same as creativity, but sort of not. And so I do hope that that will continue. And one thing I have really loved is the democratization of our profession. So we are seeing more and more people from different walks of life joining it. I really hope that continues because I think that’s so healthy for our industry.
Shane Hastie: Thanks very much. I’ve certainly enjoyed the conversation. If people want to continue the conversation, where can they find you?
Holly Cummins: So I’ve got a website at hollycummins.com, and there I sort of share talks. I blog, but not as often as I would like to, of course, I’ve got the backlog. But yes, I think that’s probably the best place. Or you can find me on Bluesky as well.
Shane Hastie: Wonderful. Thanks so much for taking the time to talk to us today.
Holly Cummins: Oh, thanks very much.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.