Month: July 2025

MMS • Matt Foster

Meta has begun rewriting its mobile messaging infrastructure in Rust, gradually replacing a legacy C codebase that engineers say had become increasingly difficult to maintain and frustrating to work with. In episode 76 of The Metatech Podcast, members of Meta’s Messaging Infrastructure team outlined their motivations for the transition, citing memory safety, developer happiness and long-term maintainability as the main drivers.
The library at the center of the effort, ships in every Facebook, Messenger, Instagram, Instagram Lite, VR-headset and wearable build, touching billions of users each day.
Developers describe the old C runtime in terms of functions that stretched hundreds of lines and manual memory bookkeeping: variables were allocated at the top of a file and freed a thousand lines later, and even small refactors felt perilous.
Spaghetti begets spaghetti
…Meta software engineer Elaine quipped, capturing a broken-windows effect in which messy code encouraged more mess. Memory-management mistakes occasionally slipped into production and escalated into hard-to-debug on-call incidents.
Rust’s compile-time ownership checks remove entire classes of those errors, but the team emphasizes day-to-day happiness as much as safety. Cleaner semantics, deterministic formatting with rustfmt, and real-time feedback from Rust-Analyzer allow easier iteration and faster feedback. Performance still matters, yet the driving metric has shifted to developer velocity and confidence.
The learning curve for Rust can often be seen as daunting. Most of the engineers tackling the rewrite arrived with little or no Rust background—Elaine jokes she only knew “the crab logo” and later dreamt about the move keyword. To support this transition, the team leaned on One-on-one walkthroughs and patient code reviews to speed up the onboarding.
Meta’s open-code culture also helped: posting questions to specific Rust working-groups brought expert answers, turning a steep learning curve into a shared adventure rather than a solitary hurdle.
Tooling improvements have carried over to operations. Today an engineer can set a breakpoint in a mixed C/Rust stack and watch the debugger hop seamlessly into Rust frames, with fully symbolicated mobile crash logs—support that didn’t exist just months ago.
As happier workflows, faster feedback, and safer refactors take hold, Engineers described feeling more confident making changes, with engineer Buping remarking that Rust’s compile-time checks made it easier to identify and remedy broken code.
The Rust working group has attracted engineers across the organization who are motivated to productionize Rust on mobile. While the long-term roadmap isn’t spelled out, early signs of internal interest suggest a growing appetite for adoption.
Meta’s team felt it was too early to quantify time savings from the migration, but they can take encouragement from others further along the path. Cloudflare reports faster, more reliable development and code that’s easier for engineers to reason about. Google reached a similar conclusion in its shift from C++, noting that contributors required less effort to write, review, and build code in Rust. Together, these examples highlight how developer experience, not just raw performance, is becoming a decisive factor in language and tooling migrations.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw unusually large options trading on Wednesday. Stock investors acquired 36,130 call options on the stock. This is an increase of 2,077% compared to the average volume of 1,660 call options.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw unusually large options trading on Wednesday. Stock investors acquired 36,130 call options on the stock. This is an increase of 2,077% compared to the average volume of 1,660 call options.
MongoDB Trading Up 3.9%
MongoDB stock opened at $217.12 on Thursday. The firm has a 50-day moving average of $197.71 and a 200-day moving average of $214.60. The firm has a market cap of $17.74 billion, a P/E ratio of -190.46 and a beta of 1.41. MongoDB has a 1-year low of $140.78 and a 1-year high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its earnings results on Wednesday, June 4th. The company reported $1.00 EPS for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The firm had revenue of $549.01 million for the quarter, compared to analysts’ expectations of $527.49 million. During the same quarter in the previous year, the business posted $0.51 EPS. The company’s quarterly revenue was up 21.8% on a year-over-year basis. Research analysts forecast that MongoDB will post -1.78 earnings per share for the current fiscal year.
Insiders Place Their Bets
<!—->
In related news, Director Hope F. Cochran sold 1,174 shares of the company’s stock in a transaction dated Tuesday, June 17th. The shares were sold at an average price of $201.08, for a total transaction of $236,067.92. Following the transaction, the director directly owned 21,096 shares in the company, valued at approximately $4,241,983.68. This represents a 5.27% decrease in their position. The sale was disclosed in a document filed with the SEC, which is accessible through this hyperlink. Also, Director Dwight A. Merriman sold 820 shares of the company’s stock in a transaction dated Wednesday, June 25th. The shares were sold at an average price of $210.84, for a total transaction of $172,888.80. Following the transaction, the director owned 1,106,186 shares in the company, valued at $233,228,256.24. The trade was a 0.07% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold 32,746 shares of company stock valued at $7,500,196 over the last ninety days. 3.10% of the stock is owned by insiders.
Hedge Funds Weigh In On MongoDB
Several institutional investors and hedge funds have recently bought and sold shares of MDB. HighTower Advisors LLC boosted its holdings in MongoDB by 2.0% during the 4th quarter. HighTower Advisors LLC now owns 18,773 shares of the company’s stock valued at $4,371,000 after acquiring an additional 372 shares during the period. Jones Financial Companies Lllp raised its stake in shares of MongoDB by 68.0% during the fourth quarter. Jones Financial Companies Lllp now owns 1,020 shares of the company’s stock valued at $237,000 after acquiring an additional 413 shares in the last quarter. 111 Capital purchased a new position in MongoDB during the 4th quarter valued at about $390,000. Park Avenue Securities LLC increased its position in MongoDB by 52.6% during the 1st quarter. Park Avenue Securities LLC now owns 2,630 shares of the company’s stock valued at $461,000 after purchasing an additional 907 shares during the period. Finally, Cambridge Investment Research Advisors Inc. increased its position in MongoDB by 4.0% during the 1st quarter. Cambridge Investment Research Advisors Inc. now owns 7,748 shares of the company’s stock valued at $1,359,000 after purchasing an additional 298 shares during the period. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
Analysts Set New Price Targets
MDB has been the topic of several research reports. William Blair reissued an “outperform” rating on shares of MongoDB in a report on Thursday, June 26th. Wedbush restated an “outperform” rating and issued a $300.00 price target on shares of MongoDB in a report on Thursday, June 5th. Citigroup lowered their price target on shares of MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a report on Tuesday, April 1st. Macquarie reiterated a “neutral” rating and issued a $230.00 price target (up from $215.00) on shares of MongoDB in a research note on Friday, June 6th. Finally, Mizuho lowered their price target on MongoDB from $250.00 to $190.00 and set a “neutral” rating for the company in a report on Tuesday, April 15th. Eight equities research analysts have rated the stock with a hold rating, twenty-six have assigned a buy rating and one has issued a strong buy rating to the company’s stock. Based on data from MarketBeat, the stock currently has an average rating of “Moderate Buy” and a consensus target price of $282.39.
Read Our Latest Stock Report on MDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
The global shift toward artificial intelligence (AI) and modern data architectures is reshaping the tech landscape, creating both challenges and opportunities for companies at the forefront of innovation. Among them, MongoDB (NASDAQ: MDB) stands out as a critical player in the $300 billion cloud database market, leveraging its cloud-native platform and strategic AI integrations to capitalize on secular trends. But is this a compelling investment? Let’s dissect MongoDB’s positioning through the lens of secular tailwinds, execution quality, and valuation to determine its appeal.
The Confluence of AI and Data Modernization

The rise of AI demands scalable, flexible data infrastructure. Traditional relational databases, with their rigid schemas and on-premise constraints, are increasingly replaced by cloud-native, NoSQL alternatives like MongoDB’s Atlas. This shift is driven by two unstoppable forces:
1. The AI Revolution: Enterprises are investing in AI-driven applications, which require real-time data processing, unstructured data handling, and seamless integration with tools like vector databases.
2. Legacy System Modernization: Companies are overhauling outdated IT architectures to support agile, cloud-based workflows.
MongoDB’s Atlas platform, now contributing 71% of revenue and growing at 27% annually, is a direct beneficiary of these trends. Its unified architecture—combining operational databases with vector search and AI tools—eliminates the need for siloed systems, reducing costs and complexity. Recent milestones, such as the MongoDB 8.0 release (with 25% faster performance) and the Voyage AI acquisition (enhancing Gen AI accuracy), further cement its leadership.
Execution: Growth, Partnerships, and Innovation
MongoDB’s execution in 2025 has been nothing short of impressive. Key metrics include:
– Revenue Growth: 22% year-over-year in Q3, driven by subscription revenue (97% of total sales).
– Customer Base: Over 50,700 customers, including 2,189 with over $100K ARR—a 2.3% quarterly increase in high-value clients.
– Partnerships: Strategic alliances with hyperscalers (AWS, Azure) and AI innovators (Anthropic, Cohere) expand its ecosystem.
The MongoDB AI Applications Program (MAAP), now generally available, is a game-changer. By providing an end-to-end stack for AI development—spanning data ingestion, model training, and deployment—MongoDB reduces the friction for enterprises building AI tools. Meanwhile, its Atlas Vector Search (ranked #1 in Retool’s 2024 AI report) addresses the growing demand for semantic search in applications like recommendation engines and customer service bots.
Valuation: High Multiples, But Justified by Momentum?
MongoDB trades at a forward PS ratio of 7.31, elevated relative to its peers (e.g., Snowflake’s 6.2 or Datadog’s 12.5). This premium reflects its growth trajectory and strategic bets on AI. However, the company’s financials are mixed:
– Operating Losses: GAAP net loss of $86M for LTM 2025, though non-GAAP net income grew to $98M.
– Cash Reserves: A robust $2.45B provides a safety net for R&D and acquisitions.
Analysts, however, are bullish. The consensus “Strong Buy” rating and a $289.26 average price target (34% above current levels) suggest confidence in MongoDB’s ability to scale margins and monetize its AI investments. The stock’s free cash flow of $166M (up 12% YoY) further supports its growth narrative.
Risks and Considerations
- Valuation Risk: High multiples could compress if growth slows or competition intensifies (e.g., AWS’s DynamoDB or Google’s Bigtable).
- Profitability Lag: GAAP losses persist, though non-GAAP metrics show progress.
- Market Volatility: The stock’s beta of 1.41 means it’s prone to swings in tech sentiment.
The Investment Case: A Long-Term Play with Catalysts
MongoDB is a play on the twin megatrends of cloud adoption and AI-driven modernization. Its execution—evident in product innovation, customer retention, and ecosystem partnerships—positions it to capture market share from legacy databases. While valuation is rich, the $2.38B net cash position and strong free cash flow mitigate near-term risks.
For investors, the key catalysts ahead include:
1. Q4 Earnings (August 28, 2025): A beat on revenue or margin expansion could reaccelerate the stock.
2. AI Integration Milestones: Adoption of MAAP and Voyage AI’s capabilities by enterprise clients.
3. Market Share Gains: Penetration in regulated sectors (finance, healthcare) where its Queryable Encryption and security features are critical.
Final Take: Buy the Dip, Hold for the Long Game
MongoDB is not for the faint-hearted. Its valuation requires confidence in sustained growth and margin improvement. However, the company’s leadership in AI-native data infrastructure and its execution to date make it a strategic holding for investors focused on the next phase of the tech revolution.
Recommendation: Consider accumulating shares on dips below $200, with a long-term horizon. The $289 price target implies significant upside, but monitor catalysts like earnings and customer wins. For conservative investors, pairing a small position with options or a staggered entry could manage volatility.
In the AI era, data infrastructure is the new operating system—MongoDB is building its seat at the table.
MMS • RSS
<!–>
Wolfe Research analyst Joshua Tilton initiates coverage on $MongoDB (MDB.US)$ with a buy rating, and sets the target price at $280.
According to TipRanks data, the analyst has a success rate of 56.2% and a total average return of 8.1% over the past year.
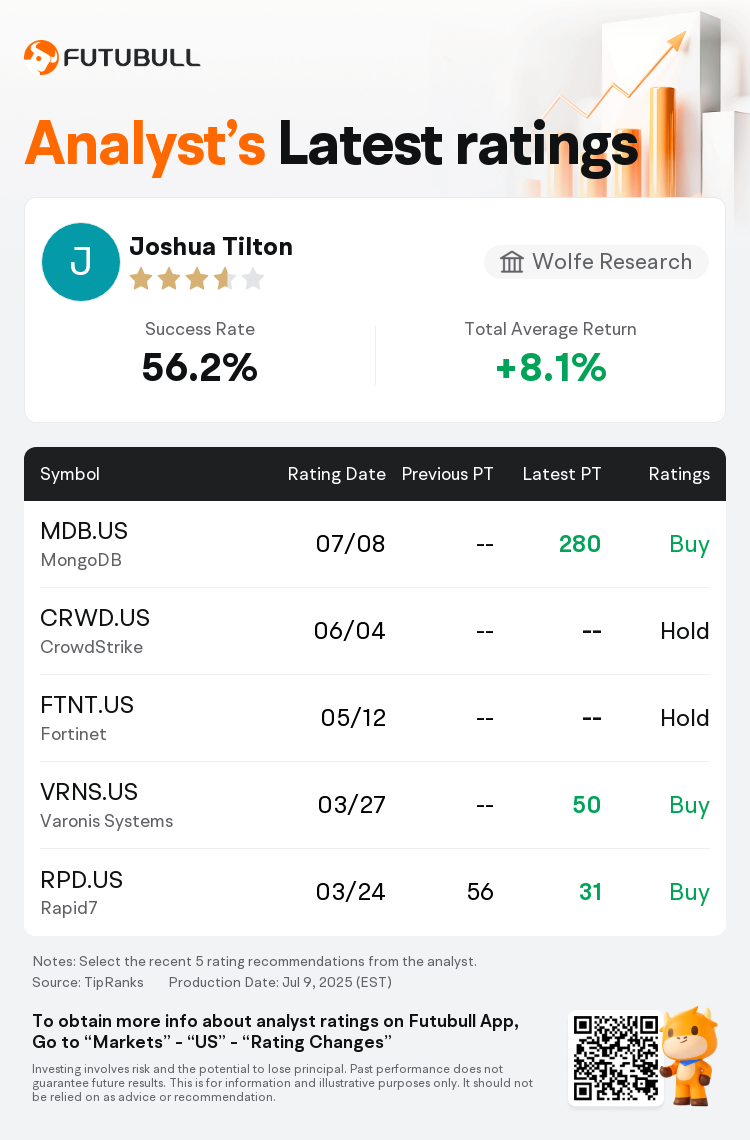
 Note:
Note:
TipRanks, an independent third party, provides analysis data from financial analysts and calculates the Average Returns and Success Rates of the analysts’ recommendations. The information presented is not an investment recommendation and is intended for informational purposes only.
Success rate is the number of the analyst’s successful ratings, divided by his/her total number of ratings over the past year. A successful rating is one based on if TipRanks’ virtual portfolio earned a positive return from the stock. Total average return is the average rate of return that the TipRanks’ virtual portfolio has earned over the past year. These portfolios are established based on the analyst’s preliminary rating and are adjusted according to the changes in the rating.
TipRanks provides a ranking of each analyst up to 5 stars, which is representative of all recommendations from the analyst. An analyst’s past performance is evaluated on a scale of 1 to 5 stars, with more stars indicating better performance. The star level is determined by his/her total success rate and average return.
–>
MMS • RSS
- MongoDB (MDB, Financial) receives a favorable ‘Outperform’ rating from Wolfe Research, aiming for a $280 target.
- Analysts predict a 31.70% upside with average price target estimates reaching $279.65.
- GF Value suggests a significant potential upside of 78.69% over the next year.
Shares of MongoDB (MDB) surged by approximately 2% as Wolfe Research commenced coverage with an ‘Outperform’ rating, setting a price target of $280. This optimistic outlook stems from enhanced execution and favorable market conditions, leading analysts to anticipate a positive shift in investor sentiment toward infrastructure investments.
Wall Street Analysts Forecast
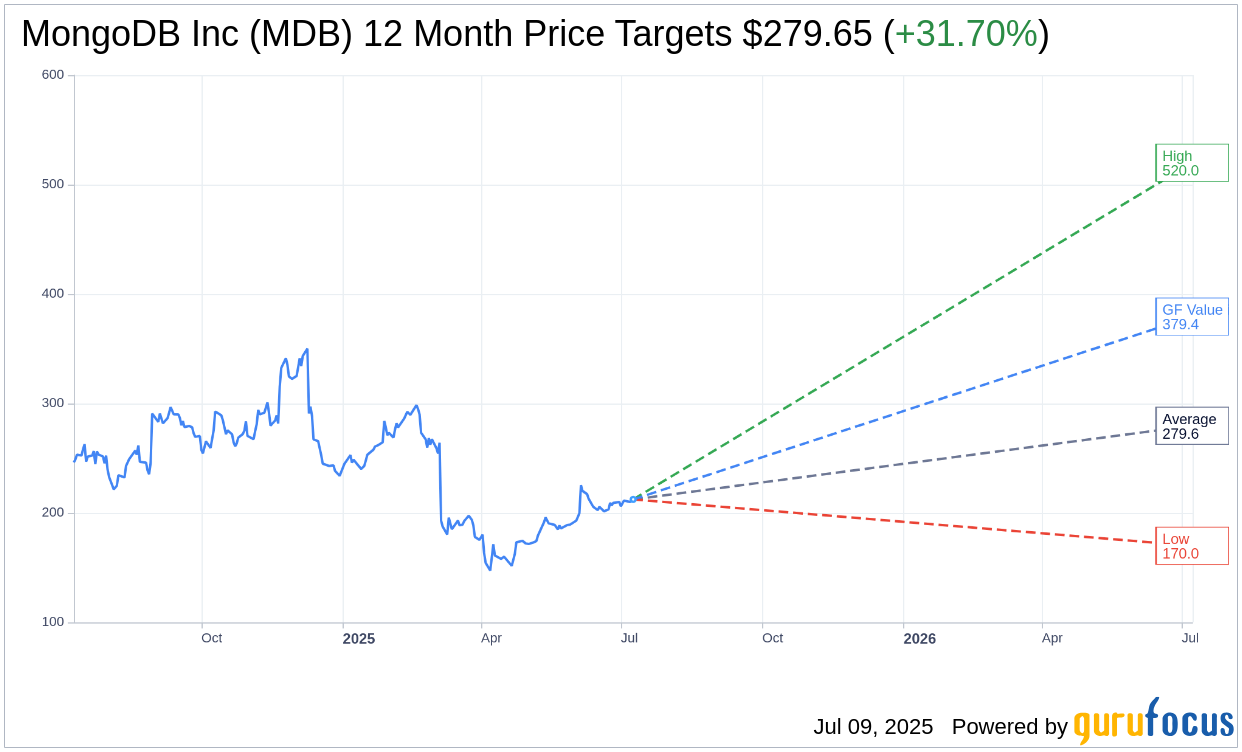
According to forecasts by 35 analysts, MongoDB Inc (MDB, Financial) is projected to reach an average price target of $279.65 within a year, spanning from a low end of $170.00 to a high of $520.00. This average target suggests a potential upside of 31.70% from the current stock price of $212.34. For more detailed estimates, visit the MongoDB Inc (MDB) Forecast page.
The consensus from 37 brokerage firms rates MongoDB Inc (MDB, Financial) at an average of 1.9, which corresponds to an “Outperform” status. This rating system ranges from 1 to 5, where 1 indicates a Strong Buy and 5 a Sell.
Based on GuruFocus projections, the estimated GF Value for MongoDB Inc (MDB, Financial) in the next year stands at $379.42, pointing to an impressive potential upside of 78.69% from the current trading price of $212.34. The GF Value represents GuruFocus’ calculated fair value, derived from historical trading multiples, past business growth, and future business performance estimates. Visit the MongoDB Inc (MDB) Summary page for more in-depth data.
MMS • Govind Kamtamneni Hien Luu Karthik Ramgopa Srini Penchikala

Transcript
Srini Penchikala: Welcome to today’s InfoQ Live roundtable webinar, titled, “AI Agents and LLMs: Scaling the Next Wave of Automation”. In this webinar, we will discuss the latest advancements in Large Language Models, or LLMs, and the recent trend of AI agents and agentic AI architectures. I am Srini Penchikala. I serve as the lead editor of the AI, ML, and Data Engineering Community at infoq.com.
For you today, we have an excellent panel with subject matter experts and practitioners, from different specializations and organizations in the AI and ML space. Our panelists are Hien Luu from Zoox, Karthik Ramgopal from LinkedIn, and Govind Kamtamneni from Microsoft.
Would you like to introduce yourself and tell our audience what you’ve been working on?
Hien Luu: My name is Hien Luu. I currently work at Zoox. We are in the autonomy space. I lead the ML platform team there. I’ve been working on the ML infrastructure area for many years now. One of my hobbies is teaching. I’ve been teaching at an extension school in the areas of generative AI. It’s been really fun. Right now is a very exciting time. Everybody knows we’re in the midst of an AI revolution, so much innovation and advancement is going on at the moment. It’s really fun.
Govind Kamtamneni: I’m part of our Global Black Belt team, basically an extension of engineering here. I’m a technical director here. I work with close to 200 customers since we launched this Azure OpenAI service. It’s obviously been, as Hien noted, a revolution. Every experience and application is being evolved to be AI native. Essentially, I personalize or automate parts of your workflows or your experiences. There’s a lot that we’ll discuss here, things that are working for customers, but also not working.
Karthik Ramgopal: My name is Karthik Ramgopal. I’m a distinguished engineer at LinkedIn. I’m the tech lead of our product engineering team, which is responsible for all of our member and enterprise facing products. I’m also the overall tech lead for all of our generative AI initiatives, platform, and product, as well as increasingly internal productivity use cases as well. Everyone said a huge revolution is going on right now. In my opinion, after the industrial revolution, this is going to be the biggest transformation we are going to see of society in general. As with anything else, there is a lot of advancement, but also a lot of hype and noise. What I’m hoping we will see through the panel today is how to cut through some of that and focus on real-world insights, and examples of what you can actually do and what you will be able to do in the future, potentially with these technologies.
Srini Penchikala: As I always say, definitely, we want to highlight the AI innovations that our audience should be hyped about and not the hype of the AI innovations.
What’s an AI Agent?
There are so many different definitions and claims about agentic AI solutions. To set a common base of understanding for this discussion and for this forum, can you define what’s an AI agent and how AI agent-based applications are different from traditional AI applications that have some type of a job scheduler, a workflow, and a decision-making capability built in. How is this different from those other apps?
Hien Luu: It’s good to establish some kind of a baseline. Initially, when I learned about AI agents probably about a year ago from Andrew Ng, he introduced that, I got really confused. Like, what does it mean? The term, it’s hard to digest in terms of what it encompasses and stuff like that. For me, after reading a lot of blogs, learning, whatever, the thing that really helped me understand is really step back and really understand the term, what is agentic or the agentic part of AI really means in terms of its own definition. I looked it up and according to the dictionary, it says like, the ability to act independently and achieve outcomes through self-directed actions. I think when I read that and I map that to, there’s a lot of discussion about what AI agent systems are, it’s starting to make a lot of sense. Hopefully that makes it a little bit easier for other folks that are a little bit confused about what AI agents are. With that, right now we map it to what AI agents are.
Essentially, these are applications or systems, they’re designed to solve certain complex tasks or to have certain specific goals. They’re all typically centered around like o1 LLMs. LLMs now are extremely smart, so that you can use to help with reasonings, plannings, and now that tool use are a part of our tool sets now in terms of building LLM applications. These application systems where they use these tools, they can plan, they can reason, they can interact with environments, and they maintain and control how these systems accomplish tasks, essentially. That’s where the agentic part comes in, of using these smart LLMs now that can reason and plan. That’s my way of interpreting what this means.
I think the three concepts that I learned that’s helped with understanding is the autonomy aspect of it. This is one aspect that’s different than your classical AI, ML systems, where they’re designed to solve specific tasks and stuff like that. The autonomy to figure out what are the process, the steps to solve the problems. The second one is the adaptability, that they now can reason and plan, they can adapt the steps based on the tools that they use in the active environment. I think the last one is the goal orientation. It’s another part of these AI agent systems. I’ll end with this one statement, or a definition that I saw, which I really like in simple terms is, an AI system using LLMs in a loop. You might have heard that before. I want to comment on one more thing, though. Andrew Ng just said something like, instead of arguing over what the definition is like, we can acknowledge that there are actually the different degrees of being agentic into our systems.
Agentic AI vs. AI Agents: What’s the Difference?
Srini Penchikala: AI agents versus agentic AI, these two terminologies, how do you define those?
Karthik Ramgopal: Agentic AI refers to the entire system. If you look at the system, it comprises of AI agents, but it also comprises of orchestrators to orchestrate across these AI agents. It comprises of tools which you call in order to interact with the real world to do something. Again, systems for coordinating with these tools like MCP, which we’ll get into a bit later in this discussion. You also have registries of various kinds to announce things, to access things. That end-to-end system is what is called as an agentic AI system. An agent is just one small component of this system.
Govind Kamtamneni: I think that’s well put. In fact, Berkeley has been coining this term Compound AI system for products that we’re going to ship eventually, because there will be aspects of a workflow that requires agency. For example, let’s say you have an email automation system. I’m actually working with this customer who’s doing this at scale. Let’s say you send a tracking number. It automatically replies back what he’s doing there. There’s part of that where, of course, it has to access tools, but then when it drafts that email and sends it to the end user, it’ll obviously factor in the tool’s response. This is where the LLM’s stochasticity comes into play. It can personalize the response. Maybe the reader or the person that sent the request based on their maybe reading comprehension, it could adjust the response to be more terse, short or lengthy. I think you can have workflows that are more predefined.
Obviously, we have those, business process automation, for the last 20 years we’ve been doing that. You can introduce agency steps within the workflow. It’s a spectrum. There are some SWE agents, we’ll probably get to this later, software engineering agents that can be more goal oriented, that can have a lot more agency to how they create that orchestration and create code paths autonomously. It is definitely a spectrum. The gist of it is, use the LLM in the control flow, depending on if you use the LLM to drive more of the control flow, then it becomes a lot more agentic, which means it also introduces a lot more uncertainty, let’s put it that way. You can put it on rails, and you can have more control over the code path and the control flow, that makes it more of a workflow with some agency.
Karthik Ramgopal: I think one key difference with the earlier systems is what Govind was alluding to, which is the emerging ability of these systems to autonomously learn and generate tools often to solve the problem. It’s called metacognition, which is learning how to learn. This is still an emergent ability. We are seeing in some of these cases, these agents are able to author snippets of code or are able to orchestrate across tools, for example, to unblock themselves to solve a particular task. Again, it sometimes goes off the rails. Sometimes these agents get stuck. These are still very nascent capabilities. That is a key difference from the systems of yore, where the level of agency, the level of cognition, and hence the level of autonomy enabled is significantly higher.
Agentic AI Use Cases: Overkill or Fit-for-Purpose?
Srini Penchikala: Agentic AI architectures are new and still evolving. Like you mentioned, they will have to go through some growing pains before they become more valuable than the biases and hallucinations, which we’ll talk more later in the discussion. Just staying at the use case level, what are some use cases or applications that you are seeing where AI agents are a really good fit? Also, the other side of that question is, what are the use cases where AI agents and agentic AI solutions are either overkill or are not recommended for the applications?
Karthik Ramgopal: I think any sort of knowledge work automation is where AI agents are excelling right now. I think it’s only going to be a matter of time before somebody hooks up an AI model to a set of actuators to interact with the real world and they can do physical tasks as well. At least I haven’t heard of anything happening at scale so far like that. Right now, it’s mostly limited to these forms of knowledge work. Anything which involves a computer, anything which involves software, anything which involves calling an API, and anything which involves orchestrating a bunch of different things to make it happen. That is what it’s pretty good at. What are some of the impediments there? The first impediment is that it goes off the rail and quality suffers.
The second is that the evaluation of whether it is doing the job correctly or not is hard. The third is, even with all the cost reductions, these models are still incredibly expensive and GPU capacity is fairly constrained at scale on account of a variety of factors. There are some organic limitations in terms of cost, in terms of compute availability, and in some cases in terms of latency, which are also inhibiting crazy adoption. Where are they not good? Obviously, if you have any workflow where you want to have a lot of tight control and you do not want agency, effectively you’re following algorithmic business logic, AI agents are overkill. They’re going to be expensive, and they’re also unnecessary.
One thing which you can still do is you can always use AI in order to help you generate that logic or generate that code beforehand before you deploy it. It’s like moving it further left in the chain. You do it at build time instead of doing it at runtime, and you still have a human verify it before you go and deploy it.
How Reliable/Accurate Should AI Agents Be?
Srini Penchikala: How reliable does an agentic AI system need to be in order to be useful? For example, 90% accuracy sounds pretty good, but picking up the pieces after 10% wrong results sounds like a lot of work. Again, where are we right now, and where are we going with this?
Govind Kamtamneni: Obviously, the classical answer is it depends. Depends on your use case and your risk appetite. I have some digital native customers who are pushing the frontier. Think of, for example, one of the, not GenAI, but traditional ML systems, since Hien is here. Tesla, for example, pushes the frontier, and issue software updates for all kinds of FSD things. I was actually experiencing FSD and it’s getting better, but there are those 10% cases where it does go off the rails. As a brand, Tesla is fine taking that risk on. I think it depends on the experience you want to provide to the end user. Obviously, we’re all here to serve their needs at the end of the day. If you think your end user wants the latest and greatest, if you can caveat that experience. Even when ChatGPT launched, I think even now on the bottom, it says, responses might be inaccurate or something like that. Just keep in mind that it will have implications to your brand, like the trust. You don’t want to tolerate too much risk or push that risk onto the end user.
Hien Luu: I think like most new technology, there’s a certain amount of learnings and there’s a certain amount of risks. Technology will get better. I think it’s basically a journey for all of us to be on and learn. You want to be smart about how to apply in certain use cases that are the consequence of a wrong decision that is not too bad. We can learn from that experience and then build on top of that and apply to more complex use cases in the future. That’s the current state of where we are. There are definitely a lot of use cases where AI or agentic AI can be really tremendous, like we saw with deep research. That use case is tremendous in terms of the ability to save time to do research.
Karthik Ramgopal: I think it’s really hard if you talk about these quality percentages as a whole, because most of the use cases where AI is applied today, the product is fairly complex. If it weren’t, why would you use AI. You’d just code it up. It’s important to talk about components of the system and your level of risk tolerance in each of these components. There’s also this concept of building confidence models and invoking human in the loop.
At least with the capabilities of AI systems right now, doing full autonomy is mostly like a pipe dream, except for very few use cases. Human in the loop and a lot of AI system architectures need to be designed for this, because you cannot put SLAs on humans. You can put SLAs on systems where you actively invoke the human to ask for clarification or to ask for approval or to ask for input before you undertake a sensitive action. That is, again, a pattern which you can fundamentally integrate. It’s also important to note that you have to be very careful with the definition of quality and correctness if you’re doing tasks in a loop or if you’re doing tasks in a chain. Because what happens is that if you have 90% accuracy everywhere, the error rates build up. First, it’ll be 90%, then it’ll be 81%, so on and so forth. Progressively, it could result in a much worse error rate than what you anticipated at the beginning.
Srini Penchikala: Also, on the other hand, so we can use these solutions to iteratively train and learn. Like you said, they can learn about learning. You can use that to your advantage.
Karthik Ramgopal: It’s very important to mirror the real world in the way you design these applications. I can give you a classic example, coding agents. How do coding agents correct themselves? Just like humans do. You feed them the compiler error and then they look at it and then they know, here is where I messed up. Without that integration with the tool which provides them access to the compiler error, they are equally in the dark, just like you would be if you aren’t seeing error log show up in your CI/CD system.
Govind Kamtamneni: I hundred percent agree. We do see a lot of systems like Cognition’s Devin, for example, does a good job. Even some of the coding agents when they’re misaligned, it does ask for the human to provide clarification. Sometimes they also reward hack. As a human, you have to validate the response that it generated. For example, some of these software engineering agents, they will accomplish your acceptance criteria, but then they might have hardcoded parts of it. We see that as well. Obviously, humans are very much in the loop. We just have to work with them at a much more higher-level abstraction. The end result is output for a human goes up. Human is very much in the loop.
The Architectures of Agentic AI (Technical Details)
Srini Penchikala: Let’s talk about the technical details of these architectures. What do the agentic AI application architectures comprise of? What are the key components? Then, how do they interact with each other? In other words, what additional tools and infrastructure do we need to develop and deploy these applications?
Govind Kamtamneni: I actually have a huge blog post about this with decision tree and all that. You can probably search my name and search for how to build AI agents fast. Essentially, it is almost as similar as building earlier microservices that are cloud native that we built. You need an orchestration layer or component, then obviously the model is doing the reasoning. You need to have round trips with the model. The most important thing with all AI agents and with the round trips with the model is the context.
Ultimately, you’re going to be spending most of your time on organizing that information layer and the information retrieval aspect. Providing the right context is literally everything. That layer is also very important. The ways you organize information can be more semantic. There’s a lot of vector databases. Pretty much every database now supports vector index capabilities. That just allows you to improve the quality of your retrieval. Then you can, of course, stitch them together, as Karthik was saying, but be careful when you have too many multi-agents that are interacting with each other, the error rate can compound. More importantly, the quality attributes of the system. At the end of the day if you want reliable, highly available systems, you got to make sure that there’s a gateway in front of your system that handles authentication and authorization for agents as well.
Entitlements are very important for agents. You’ll see a lot of the identity providers, including from Microsoft, we have Entra ID, move in this space where we’re going to facilitate agents to have their own identities, because we do envision a world where a lot of flows with agents accessing data or tools is on behalf of user flows. We do envision a world where agents are going to be more event-driven. They’re going to act independently and they’ll then ask the human or someone for permissions. In that case, entitlements is very important. That’s more coming soon, but for now, just making sure that you have proper fine-grained authorization for the resources that the agents are going to access, or the orchestration layer is going to access.
Then, even between the orchestration and the model layer, usually we recommend some L7 gateway that can handle failovers or things of that nature, because these models ultimately, they’re doing a lot of matrix multiplications and they very much introduce latency to the experience. They are not super reliable. There’s a lot of capacity problems. You want to handle that scenario at scale. Then, yes, just packaging up, like you would package any microservice and deploying it to any container-based solution, that’s all the same. I think the one most important thing here is evals. Evaluations are key.
Obviously, the models are saturating a lot of benchmarks that showcase reasoning. Yes, they’re highly good polymaths that can reason well, but the evals that you care about, at the end of the day whatever experience you’re stitching, like create a benchmark for that, create evaluations that are idiosyncratic for your use case. Then there’s a lot of libraries, we have one from Azure AI, but there’s libraries out there on evals, there’s RAGAs. Use those eval libraries and also do continuous monitoring, and make sure you collect user feedback. That data is also very rich potentially if you ever want to fine-tune and things like that. Make sure to store that data. There’s a lot there. It’s like the existing ways of doing cloud native twelve-factor apps still apply, but then there’s all these nuances with GenAI stuff.
Hien Luu: That’s very true, what you said there. A lot of people tend to focus on those, ok, what are the new ways of building systems, these AI systems. Similar to how we thought about building classical AI, ML system where you saw that famous picture where AI, the model is just a small piece of the overall bigger system. An AI system is similar in a way, a lot of pieces that we learned over the last 20, 30 years of building microservices, all that’s still applicable. The AI part is still just a small part of the overall system. There are some new parts, like Govind mentioned, that’s very specific to the nature of these stochastic systems with evaluations and all that stuff like that.
Karthik Ramgopal: The rules never change. Good systems design is still good systems design. Account for the increased level of non-determinism in these systems, and that results in a variety of ways. First is observability. A lot of these stochastic systems we have for observability don’t work here. You do not have predefined paths. By definition, there is a lot of agency, and there is a lot of possibilities and various paths which can be taken. You need to invest in an observability solution which will give you intelligible data from what’s happening in production in the system. That’s the first.
The second is from a hardware resource capacity planning perspective as well, that this non-determinism gets in. Have you provisioned enough resources or do you have enough safeguards built into your system to be able to throttle workloads to be able to asynchronously execute them when capacity is available, prioritize them appropriately. Again, these problems happen at a certain amount of scale. That’s important. I think the third thing is, a lot of these systems, in addition to being slow, also fail because you have so many moving components, you have so much non-determinism, so you may not get the right output every time. How robust is your error handling, graceful degradation, escalation to human in the loop, all these things? These are not just systems design, like they have to reflect every way, from your UI to your AI. Because some of these also manifest themselves in the UI as to how do you respond to users. That end-to-end picture is super important.
Srini Penchikala: I’m glad you all mentioned these additional topics that we need to be cognizant about in terms of AI context, authentication, authorization, API gateway routing, circuit breaker, observability, Karthik, you mentioned that. I was envisioning we would be talking about these more like next year, like a phase two of AI agents. I’m glad that we’re all talking about them now, because these should not be afterthoughts. They should be built into the systems right from the beginning.
Leveraging AI Agents in the SDLC (Software Development Life Cycle)
Most of our audience are senior technical leaders in their organizations. They would like to know how they can benefit from AI agents in their day-to-day work tasks, which is basically software development and so on. How can we leverage AI agents in different parts of the SDLC process? What is the new role of a software developer with more and more development tasks being managed by AI programs? How can we be still relevant and not necessarily fear about AI agents, but embrace them and use them to better ourselves?
Karthik Ramgopal: I think what you said at the last is very important. You should not fear it. You should embrace it, and see how you can use it best. I can talk a bit about how I use AI in my day-to-day development. The first is I don’t vibe code. There is so much hype about vibe coding. I still don’t believe in the hype. It may be good for prototyping small things, but building anything serious, which is what I think software developers end up doing in professional environments, not so great yet. Maybe it will get there. What I do use though, is I use a bunch of these AI native IDEs. LinkedIn is part of the Microsoft family, so we use GitHub Copilot quite a bit. GitHub Copilot is getting better off late with agent mode and all these things, especially in VS Code.
Again, I use GitHub Copilot quite a bit to understand the code base, ask it questions, which I’d have to research manually normally, as well as ask it to make changes. It still makes mistakes, although it’s getting better. The onus is still on me to have an understanding of, first, how do I use the tool? How do I prompt it the best? How do I ask the follow-up questions in the right way? What model do I choose? Because you have the reasoning models, you have the regular generative models, which are non-reasoning for certain kinds of tasks. Certain models are good. Again, you get to know some of these things as you start interacting with these tools more and more. The second is, how do I review the output it produces? One of the challenges I’m facing already is that AI is a great productivity accelerator, but it can produce reams and volumes of code way faster than a human can. I need to keep up with the ability to review it because it can still make mistakes.
More importantly, the mistakes it makes are often very subtle in nature. It’s not very obvious. You have to have an extra eye for detail. If anything, your conceptual knowledge, as well as your general ability to understand large pieces of information and synthesize results from it, needs to get better in order for all of you to keep up, all of us to keep up, in this new world. That is one area, coding assistants and things like that. You can also use it for unit test generation of various kinds. You don’t need to write pesky tests yourself, although they are still very important for quality. Then there are also aspects of using AI further right, where you can use it in order to understand anomalies in your traffic patterns, incident root causing, deployment failures, debugging issues there. That is one entire category of things. You can also move further left, where even during the design process, you can use AI quite a bit.
For example, we have integrated Glean at LinkedIn. I end up using Glean quite a bit because it’s connected to our entire corpus of documents, Office 365, Google Docs, our internal wikis, which contain a ton of information. If I’m doing some research, for example, to write a design doc, I will start with a Glean chat prompt, which essentially saves a bunch of grunt work for me from going, finding that information, putting references appropriately, and crafting the design. Again, that initial outline, which is produced, I will refine it later with my HI, human intelligence, in order to get it into the final shape.
Srini Penchikala: What other parts of the SDLC are you guys seeing that AI agents are being used?
Hien Luu: I think testing is an area that these models can help quite a bit. Most software engineers probably don’t like that much writing tests. I think that’s an area that we can leverage these tools to help with that. Not just writing tests, but also asking insightful questions about edge cases or other things that Karthik brought up. I would love to use that. Stepping back now, I don’t code as much anymore, but if I were an engineer and that’s 100% of my daily tasks, I would probably give more thought about like, what kinds of questions, because these LLMs are there to answer our questions.
If we can come up with smart, intelligent questions that are relevant to help our software engineering tasks, I think I would spend a lot more time thinking about what kind of question I should ask them such that I can improve whatever task I’m doing, whether it’s improving the robustness of the microservice, or handling throttling, or whatever that is. I think that’s a different mindset, and a mindset that software engineers need to start building more of like how to think about what kind of thoughtful questions that would be useful for their tasks.
Govind Kamtamneni: Yes, hundred percent. I just want to add that the answers are all there. It’s about the questions that we ask and how we ask that matters. What I’m doing a lot is I’m actually reading a lot. GitHub Copilot obviously has this developer inner loop experience, but there’s also the outer loop experience called Padawan. It’s similar to Cognition’s Devin, and there are others out there that do that. What I’m using is to have it generate, it’s kind of like a deep research of your code base, when you go to a new code base and have it generate Mermaid diagrams and stuff, and really have a systems thinking approach. I’m using my Kindle a lot more now because I’m reading and understanding what Hien and Karthik are saying, so that I can ask the better question and pass the context that is needed to solve the very focused problem or a use case that needs to be implemented. We’re also going to launch SRE agent, and there’s a bunch of these agentic experiences that will augment you.
At the same time, the onus is on the human to ultimately, again, I think it all goes back to ask the right question because the answers are all there. These models, like o3 high reasoning, if you think about just the benchmark, like you are interacting with a polymath that is one of the smartest coder out there. They’re saturating all kinds of coding benchmarks, and it’s only going to get better. Ultimately, it’s up to you to know that user need that you’re solving and mapping it throughout the SDLC process and leveraging these models throughout the process.
Karthik Ramgopal: I want to give a very crude example. When IDEs came about, we saw a transformation in the development process with respect to how people were coding inside the text editors. You had the ability to do structured find and replace. You had the ability to open files side by side. You had syntax highlighting. Developer productivity went up so much. You had debugging within the IDE. This is similar. It’s just an additional tool, which gives you even more power over your code. Don’t look only at code. Code is an important critical aspect of the SDLC, but there are a lot of other aspects also. There are AI tools which help you automate end-to-end, as Govind and Hien pointed out.
Govind Kamtamneni: I was going to add one quote by Sam Altman. I think it’s really catchy. It’s like, “Don’t be a collector of facts, be a connector of dots”.
Srini Penchikala: The facts can be relative. No, I agree with you also. I’m definitely more interested in the shift left side of the SDLC process. Automatically writing tests for the code is important, but how much of that code is really relevant to your requirements, really relevant to your design? Again, we can use AI agents to solve problems the right way, and also, we can use them to solve the right problems. I think it goes both ways. Govind, I’m looking forward to all those different products you mentioned about. Padawan sounds like a Star Trek connection there, for the outer loop experience.
Accuracy, Hallucination, and Bias with AI Agents
One thing we’ve been concerned about AI programs in general is the accuracy of their output, because they have their own concerns. The accuracy of the output and the hallucinations. Now we bring in the AI agents into the mix and automate as many tasks as possible, try to let the agents do what humans have been doing. How do you see this whole accuracy and the hallucination and biases space transforming with the agents? How worse will it get?
Hien Luu: In a short answer, it’s facts of life, so we have to deal with that. This uncertainty comes to us since day one of building an AI system already. There are all these undeterministics, they give you probabilities of an answer of a prediction, whether it’s spam or not spam. There’s a measure that we’ve been taking, but it’s more exaggerated with the hallucination, the natural language aspect of it’s still more challenging than a numeric value. Definitely, it’s a challenge. A lot of enterprises are concerned if they want to apply this into their real-world use cases, where the consequences are not just content generation, but it could impact their user or whatever that’s causing damages. Definitely a big concern for enterprises. I think there’s studies after study why enterprises are way behind in terms of adopting these technologies.
In general, I think these LLMs are getting smarter. These AI frontier labs, they spend a lot of effort in improving or reducing hallucination, but nevertheless, there’s still that. The question is, what can we do as we build these agentic systems? At first, you understand, for your particular use case or use cases, the hallucinations, what the cause of those might be. If you’re building a very domain specific agentic system and using the models and maybe those models were not trained with your domain specific area, that may be an indication that you might have to do something with that in terms of the knowledge cutoff or the limit of it. Understanding what the underlying causes might be for your use cases is the first thing to do.
In terms of what actions, or methods, or strategy that you can employ, I think there’s sets of good practices that are out there now. Start with grounding. I think it’s a very common technique now with grounding in terms of the context. Go back to what Govind said, it’s all about the context. Grounding the relevant information and stuff like that. That’s why RAG has become very powerful because of the ability to ground with relevant content in the prompting context. This is something that a lot of people don’t spend a whole lot of effort in.
At the end of the day, it’s like we’re interacting with LLMs through prompting, and what we say in the prompt matters. Well-crafted prompt engineering is still extremely valuable and relevant to help with these kinds of challenges. Be specific with all the other stuff that good prompt engineering practices. Other things you can do outside of that is the guardrails we talked about earlier that people mentioned. Human in loop too, that’s another aspect that you can build into your system at a proper time to involve the human when the responses seem suspicious and doesn’t pass the smell check thing.
Then, evaluation, evaluation, evaluation. It’s all out there now. Are actually people doing it or not? That’s a different question. Building evaluation requires a lot of upfront investments. I think you want to do that iteratively and incrementally as well. It’s not something that you probably can come up with a whole set then you’re done. It’s something that needs to be dealt with in an incremental manner. At the end of the day, there’s techniques to help with reducing, but eliminating, I think we’re not there yet, as far as my understanding goes. I’d love to hear experiences from Govind and Karthik of actually working with their customers and building AI agentic systems at LinkedIn.
Karthik Ramgopal: I can share some of the other techniques which we use. The first is this technique called critique loops, where effectively you have another observer critique the response, using the outcomes, and see if it meets the smell test of those outcomes. Again, this is a technique you use in evals as well.
At runtime, though, you cannot use this very heavily. You cannot put a powerful model. You cannot have a very complex critique logic, because, again, it’s going to consume compute cycles and latency. There’s always this tradeoff between quality and latency and compute costs. In your offline evals, you can actually put a more powerful model, in order for you to actually evaluate the responses of your system and understand where it failed. I think there was a question about, how do I do evaluation? Should I do random sampling? Random sampling is a good starter, but it first starts with the definition of accuracy. Do you have an objective definition of what being accurate means? Which is actually quite hard in these non-deterministic systems to get a comprehensive definition of that.
Once you have that, then you can decide how to pick and choose, because, ideally, you do not want to do random. You want to get a representative variation of responses and ensure that you did well across them. Again, that requires some analysis of your data itself. Something which a lot of folks do is they capture traces. Of course, they anonymize these traces to ensure that personal information is not emitted in whatever way possible. After that, they feed these traces offline to their more powerful model, which then runs the eval and tries to figure out what to do. The other interesting technique, which can be used is that sometimes you really do not need AI, as I said before, because you do not want reasoning.
In those cases, don’t use AI or use a less powerful model. For example, for a bunch of classification tasks, you could use a much simpler AI model. You don’t need an LLM. Of course, it’s easier to do with an LLM, but is it the most efficient? Is it the most reliable? Probably not. It’s going to be cheapest model. In some cases, you can just fall back to business logic. Last but not the least, and I say this very carefully, sometimes, when all else fails, you can also apply various kinds of fine-tuning techniques in order for you to create fine-tuned models. I say when all else fails because people prematurely jump to it without trying all they can do with prompt engineering, and RAG, and the right systems architecture, because it’s expensive, since the foundation models keep advancing.
As long as you have a fine-tuned model, you have to maintain it. You have to ensure that when the task specification changes, you haven’t had loss in generalization, which results in worse performance. Pick your poison carefully, but that is also a technique which is useful in some cases.
Govind Kamtamneni: Prompt rewrite is another one that is pretty much baked in now, for example, in our search service. Things like that can help a lot.
Srini Penchikala: Yes, definitely. I agree with you all. Like you all mentioned, with AI, there’s a lot more options available. As a developer, as an end user, I would like to have more options that I can pick from rather than fewer options. With more options comes more evaluation and more discipline. That’s what it is.
Model Context Protocol, (MCP) and the Evolution of AI Solutions
Regarding the next topic, we can jump into probably the biggest recent development in this space, the Model Context Protocol, MCP. I know I’ve been seeing several publications, articles on a daily basis on this. They claim it’s an open protocol that standardizes how applications provide context to LLMs. They also say that it will help you build agents and complex workflows on top of LLMs. That’s the definition on their website. Can you share your experience on how you see this MCP, where it fits, overall, in the evolution of AI solutions? How can it help? What can we use it for? Where do you see this going? I think it’s a good standard that we have now, but like any standard, it will probably have to evolve.
Govind Kamtamneni: Actually, let’s think about a world without any standards or protocols, like how things are developed actually right now. If you have an agentic system, let’s pick user onboarding just for the sake of it. Let’s say you’re building a Compound AI system that does user onboarding and hopefully has some agency in some of the workflow tasks there. Let’s say a new employee joins, the developer that is developing this orchestration layer has to understand SuccessFactors, or ServiceNow APIs, and deterministically code according to those API specs. Also, the day two aspect of that, handle the day two aspect.
If ServiceNow changes their interface, this developer has to change this orchestration layer. If you think about employee onboarding, maybe you first have to create a new employee record in SuccessFactors, or something like that. Then you have to maybe issue a laptop or something like that. That could be a ticket in ServiceNow with all the details. Then maybe even notify the manager or get manager’s approval and things like that. That could be a Team’s message or something like that. You need to know all these API specs and maintain them and all that stuff. I think going forward, it’s becoming clear that we’re not just developing systems for humans, but actually for AI agents to consume. If all these systems instead had some standard that they could all conform with a standard protocol and hopefully a standard transport layer. That’s what MCP is basically proposing. Anthropic started it. It’s fair to say that everyone is embracing it. Let’s see how it goes because the governance layer is still shaky.
For now, at least everyone is building essentially a simple facade proxy on their existing SuccessFactors, or ServiceNow, or GitHub, this MCP server. The host of MCP, let’s pick VS Code, for example, or GitHub Copilot, or this onboarding agentic system that could then work with these MCP servers and they have to follow the standard. The client developer now doesn’t have to know SuccessFactors’ idiosyncratic APIs, and implement them and maintain them. It’s the same MCP standard for all these other systems. Ultimately for these models, again, they’re very great at reasoning, but for them to be economically useful, they have to work with a lot of systems in the real world, for example, this onboarding workflow, to be successful. It has to integrate with all these systems. I think going forward it’s great that we have some standard, finally, at least for now.
Then, of course, there’s also Agent-to-Agent standard that is emerging. There’s the new standard I was just reading that is a superset of Agent-to-Agent, I think it’s called NANDA. We’ll see which one wins out. It’s good that the industry is rallying. This is nothing new. We had in the past, obviously we’re communicating over HTTP. That was a standard established by the Internet Foundation or something. There’s CNCF. Kubernetes is pretty much the standard orchestration layer now. I think standards bodies are good. It was just a matter of time, especially a platform shift this big as, I think it’s bigger than the internet. Obviously, this is a standard for agents to talk with resources and tools.
Primarily, there’s also prompts and other things there. There’s also hopefully a standard that’ll emerge where agents can talk to other agents, have a registry. That’s what A2A is trying to do. Then, hopefully, this other swarm of agents, a new standard by MIT, that’s also out there. There’s a lot there, but it’s where we are right now. I do think it’s an evolving space.
Karthik Ramgopal: I think MCP is still an evolving standard. It’s a great way in order to connect externally. It still has some gaps primarily around security, authentication, authorization, which are pretty critical, which is why we haven’t deployed it internally yet. I’m sure it’s just a matter of time before the community solves these problems. I think the important thing to note here is that MCP is primarily a protocol for calling tools. It isn’t a protocol for Agent-to-Agent communication, because Agent-to-Agent isn’t a synchronous RPC, or even a streaming RPC. It’s way more complicated. You have asynchronous handoffs, you have human in the loops, you have multi-interaction patterns, which is why the protocols like A2A and agency and the other emerging ones, I think will be better fits. Right now, amidst the hype, everyone is trying to force fit MCP everywhere. Be thoughtful about where you use it and where you don’t.
Hien Luu: It makes a lot of sense. I think everybody agrees that it has its own place for tool use. If that becomes a standard, then it opens up a whole slew of, make it easy to integrate and use tool use. An example that came to mind, something in the past, like we have something called REST, a protocol for dealing with HTTP, but this is specifically for LLMs. Let’s see where it’s going. There’s a lot of explosion of MCP servers out there that I see. Let’s see where it goes. I think it makes a lot of sense.
The Future of AI Agents – Looking into the Crystal Ball
Srini Penchikala: To conclude this webinar, I would like to put you all on the spot. What’s a prediction that you think will happen in the next 12 months? If we were to have a similar discussion 12 months from now, what do you think we should be excited about?
Karthik Ramgopal: I am feeling like an oracle today, so I will predict one thing. I think that the transformer architecture and LxMs in general will start getting increasingly applied to traditional relevance surfaces like search and recommendation systems, because right now the cost curve as well as the technological advancement is at a point where it is starting to become feasible. I think we will see an improvement in quality of these surfaces as well, apart from the agentic applications. That’s my prediction.
Govind Kamtamneni: I have this AGI thing up there. I take Satya’s approach there, which is, if it can be economically useful, and I think his number is $100 billion of economic value, then it’s AGI. Because we see a lot of benchmarks, they’re absolutely saturating. At the end of the day, can it improve human well-being? That is GDP. If we can start, whether it’s MCP or whatever, start actually giving actuators to these reasoners. Hopefully, again, the ultimate goal is output per human going up. We’re starting to see that. Cursor was the first product – and I’ll say that even as a competitor – to hit $100 million ARR. The fastest ever to $100 million recurring revenue. Hopefully, we’ll see it in other domains, not just software engineering. Then, human well-being is actually improving with everything we’re doing. Hopefully, that’ll happen in the next two years.
Hien Luu: This is probably less of a prediction, but it’s something I would love to see, especially in the enterprise, how AI agents are being applied in enterprise scenarios. We’d love to see more practical use cases being out there and see how that really works out in the enterprise. I think the part that’s exciting is about Agent-to-Agent, multi-agent systems. There’s a lot of discussion about that. It seems pretty fascinating. You get these agents talking to each other and they do their own things. I would love to see how that manifests into real-world useful use cases as well. Hopefully we’ll see those in the next 12 months.
Srini Penchikala: I’m kind of the same way. I think these agents will help us have less thrashing of lives at work and in personal lives, so we can focus on more important things, whatever they mean, to enjoy our lives and also help the community.
Govind Kamtamneni: I just wanted to add, shared prosperity. Wherever it happens, people should not be afraid. There should be a positive outcome for everyone.
Srini Penchikala: To quote the Spock.
See more presentations with transcripts
MMS • RSS
LBP AM SA decreased its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 54.6% during the 1st quarter, according to the company in its most recent disclosure with the Securities & Exchange Commission. The firm owned 111,806 shares of the company’s stock after selling 134,285 shares during the quarter. LBP AM SA owned approximately 0.14% of MongoDB worth $19,611,000 as of its most recent SEC filing.
Several other institutional investors also recently bought and sold shares of MDB. Cloud Capital Management LLC purchased a new position in MongoDB during the first quarter worth about $25,000. Strategic Investment Solutions Inc. IL purchased a new position in shares of MongoDB in the fourth quarter valued at approximately $29,000. Coppell Advisory Solutions LLC boosted its stake in shares of MongoDB by 364.0% in the fourth quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock valued at $54,000 after purchasing an additional 182 shares during the period. Aster Capital Management DIFC Ltd purchased a new position in shares of MongoDB in the fourth quarter valued at approximately $97,000. Finally, Fifth Third Bancorp boosted its stake in shares of MongoDB by 15.9% in the first quarter. Fifth Third Bancorp now owns 569 shares of the company’s stock valued at $100,000 after purchasing an additional 78 shares during the period. 89.29% of the stock is currently owned by institutional investors and hedge funds.
MongoDB Trading Up 3.9%
Shares of NASDAQ MDB traded up $8.22 on Wednesday, reaching $217.12. 3,143,044 shares of the company traded hands, compared to its average volume of 1,969,598. MongoDB, Inc. has a fifty-two week low of $140.78 and a fifty-two week high of $370.00. The company has a 50 day moving average of $197.71 and a 200 day moving average of $214.60. The stock has a market capitalization of $17.74 billion, a PE ratio of -190.46 and a beta of 1.41.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 EPS for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The company had revenue of $549.01 million during the quarter, compared to the consensus estimate of $527.49 million. During the same quarter in the prior year, the company posted $0.51 EPS. The company’s quarterly revenue was up 21.8% compared to the same quarter last year. As a group, research analysts expect that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Insider Buying and Selling
In other MongoDB news, CEO Dev Ittycheria sold 3,747 shares of the stock in a transaction that occurred on Wednesday, July 2nd. The shares were sold at an average price of $206.05, for a total value of $772,069.35. Following the completion of the sale, the chief executive officer owned 253,227 shares of the company’s stock, valued at $52,177,423.35. This trade represents a 1.46% decrease in their ownership of the stock. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is available through the SEC website. Also, Director Hope F. Cochran sold 1,174 shares of the stock in a transaction that occurred on Tuesday, June 17th. The shares were sold at an average price of $201.08, for a total transaction of $236,067.92. Following the completion of the sale, the director directly owned 21,096 shares of the company’s stock, valued at $4,241,983.68. This trade represents a 5.27% decrease in their position. The disclosure for this sale can be found here. In the last quarter, insiders sold 32,746 shares of company stock valued at $7,500,196. 3.10% of the stock is currently owned by corporate insiders.
Wall Street Analysts Forecast Growth
MDB has been the topic of several analyst reports. Needham & Company LLC reaffirmed a “buy” rating and issued a $270.00 target price on shares of MongoDB in a report on Thursday, June 5th. Redburn Atlantic raised shares of MongoDB from a “sell” rating to a “neutral” rating and set a $170.00 price objective on the stock in a report on Thursday, April 17th. Truist Financial cut their price objective on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a report on Monday, March 31st. Wolfe Research assumed coverage on shares of MongoDB in a report on Wednesday. They set an “outperform” rating and a $280.00 price objective on the stock. Finally, William Blair reaffirmed an “outperform” rating on shares of MongoDB in a report on Thursday, June 26th. Eight analysts have rated the stock with a hold rating, twenty-six have issued a buy rating and one has issued a strong buy rating to the company. According to data from MarketBeat.com, MongoDB presently has a consensus rating of “Moderate Buy” and an average target price of $282.39.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Wondering what the next stocks will be that hit it big, with solid fundamentals? Enter your email address to see which stocks MarketBeat analysts could become the next blockbuster growth stocks.
MMS • RSS
Investing.com — Wolfe Research initiated coverage of MongoDB (NASDAQ:MDB) with an Outperform rating and a $280 price target in a note Wednesday.
The firm highlighted a conservative setup, market tailwinds, and a compelling valuation as reasons to be bullish on the stock.
“While it’s not easy defending decelerating growth with decaying margins,” analysts wrote, “we see a conservative numbers setup… with improving execution… and market tailwinds that at current valuations mark an opportunity too difficult to ignore!”
Despite a 10% year-to-date decline in MongoDB shares, Wolfe sees the company well-positioned for upside.
“MDB sits at the intersection of two powerful secular shifts: Enterprise Data Modernization and the early innings of AI deployment.”
Wolfe highlighted stabilizing top-line growth and improving margins, noting that their upside model implies high teens margins and roughly $400 million in incremental revenue next year.
Wolfe also underscored the size and structure of MongoDB’s market. “This is STILL a $120B+ market growing double digits with some of the best terminal margins in all of software… and Mongo is a TOP 5 vendor (#1 in Document Stores),” they wrote.
Furthermore, the analysts believe that investor sentiment is shifting from applications to infrastructure, where “unit economics makes it a bit easier to bet lower in the stack.”
Year-to-date, infrastructure stocks are up 14% compared to a 2% decline for broader application names.
“In a market of Data > Apps… MDB stands as one of the few companies that fits the mold as a top 20 growth company (@ $2B scale),” added Wolfe Research.
The firm concluded, “Better numbers, Better narrative and Better margins [are] setting the stage for a Better stock.”
Related articles
Wolfe says MongoDB opportunity ’too difficult to ignore’
TD Cowen lowers PVH rating to Hold on structural risks, shares down
Apple stock falls after White House trade advisor says company thinks it’s too big
MMS • RSS

MMS • RSS
Analysts at Wolfe Research started coverage on shares of MongoDB (NASDAQ:MDB – Get Free Report) in a report released on Wednesday, MarketBeat reports. The firm set an “outperform” rating and a $280.00 price target on the stock. Wolfe Research’s price target indicates a potential upside of 28.96% from the company’s current price.
Several other research firms have also recently issued reports on MDB. Citigroup lowered their price objective on shares of MongoDB from $430.00 to $330.00 and set a “buy” rating for the company in a research report on Tuesday, April 1st. Needham & Company LLC restated a “buy” rating and set a $270.00 price objective on shares of MongoDB in a report on Thursday, June 5th. Truist Financial lowered their target price on MongoDB from $300.00 to $275.00 and set a “buy” rating for the company in a report on Monday, March 31st. Guggenheim raised their price target on MongoDB from $235.00 to $260.00 and gave the company a “buy” rating in a research note on Thursday, June 5th. Finally, Barclays upped their price objective on shares of MongoDB from $252.00 to $270.00 and gave the stock an “overweight” rating in a research note on Thursday, June 5th. Eight investment analysts have rated the stock with a hold rating, twenty-six have issued a buy rating and one has issued a strong buy rating to the company’s stock. According to data from MarketBeat, the company has an average rating of “Moderate Buy” and a consensus price target of $282.39.
Read Our Latest Stock Report on MDB
MongoDB Price Performance
Shares of NASDAQ:MDB traded up $8.22 during trading on Wednesday, hitting $217.12. The company had a trading volume of 3,143,044 shares, compared to its average volume of 1,969,596. The company has a fifty day simple moving average of $196.81 and a two-hundred day simple moving average of $214.59. The stock has a market cap of $17.74 billion, a price-to-earnings ratio of -190.46 and a beta of 1.41. MongoDB has a one year low of $140.78 and a one year high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The company had revenue of $549.01 million for the quarter, compared to analyst estimates of $527.49 million. During the same period in the prior year, the company posted $0.51 EPS. The firm’s revenue for the quarter was up 21.8% on a year-over-year basis. On average, equities research analysts anticipate that MongoDB will post -1.78 earnings per share for the current year.
Insider Activity at MongoDB
In other MongoDB news, CEO Dev Ittycheria sold 25,005 shares of MongoDB stock in a transaction on Thursday, June 5th. The stock was sold at an average price of $234.00, for a total value of $5,851,170.00. Following the sale, the chief executive officer owned 256,974 shares in the company, valued at $60,131,916. The trade was a 8.87% decrease in their ownership of the stock. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available through the SEC website. Also, Director Hope F. Cochran sold 1,174 shares of the business’s stock in a transaction that occurred on Tuesday, June 17th. The shares were sold at an average price of $201.08, for a total transaction of $236,067.92. Following the completion of the sale, the director directly owned 21,096 shares in the company, valued at $4,241,983.68. This trade represents a 5.27% decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last three months, insiders have sold 32,746 shares of company stock worth $7,500,196. Insiders own 3.10% of the company’s stock.
Institutional Trading of MongoDB
A number of institutional investors and hedge funds have recently bought and sold shares of MDB. Cloud Capital Management LLC purchased a new stake in shares of MongoDB during the first quarter worth approximately $25,000. Hollencrest Capital Management purchased a new stake in shares of MongoDB in the 1st quarter valued at approximately $26,000. Cullen Frost Bankers Inc. raised its holdings in shares of MongoDB by 315.8% in the 1st quarter. Cullen Frost Bankers Inc. now owns 158 shares of the company’s stock valued at $28,000 after purchasing an additional 120 shares in the last quarter. Strategic Investment Solutions Inc. IL purchased a new stake in shares of MongoDB during the 4th quarter worth $29,000. Finally, Coppell Advisory Solutions LLC grew its stake in shares of MongoDB by 364.0% during the fourth quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after purchasing an additional 182 shares in the last quarter. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Explore Elon Musk’s boldest ventures yet—from AI and autonomy to space colonization—and find out how investors can ride the next wave of innovation.