Category: Uncategorized

MMS • RSS

Upskilling platform Multiverse has appointed Donn D’Arcy as chief revenue officer to support its continued global expansion.
Donn joins from MongoDB, where he led EMEA operations and helped scale revenue to $700 million.
He brings over a decade of experience in high-growth tech companies, including senior roles at BMC Software.
Donn said: “Enterprise AI adoption won’t happen without fixing the skills gap.
“Multiverse is the critical partner for any company serious about making AI a reality, and its focus on developing people as the most crucial component of the tech stack is what really drew me to the organisation.
“The talent density, and the pathway to hyper growth, means the next chapter here is tremendously exciting.”
Donn’s appointment follows a series of recent hires at Multiverse and supports its mission to accelerate AI adoption through workforce upskilling.
The company now works with more than a quarter of the FTSE 100, alongside NHS trusts and local councils.
Multiverse has doubled its revenue over two years and recently pledged to deliver 15,000 new AI apprenticeships by 2027.
Euan Blair, founder and chief executive of Multiverse, added: “Truly seizing the AI opportunity requires companies to build a bridge between tech and talent – both within Multiverse and for our customers.
“Bringing on a world-class leader like Donn, with his incredible track record at MongoDB, is a critical step in our goal to equip every business with the workforce of tomorrow.”
Looking to promote your product/service to SME businesses in your region?
Find out how Bdaily can help →
Couchbase enters definitive agreement to be acquired by Haveli for $1.5B – SiliconANGLE
MMS • RSS
NoSQL cloud database platform company Couchbase Inc. has entered a definitive agreement to be acquired by Haveli Investments LP in an all-cash transaction valued at approximately $1.5 billion.
Under the terms of the deal, Couchbase shareholders will receive $24.50 per share in cash, a premium of 67% compared to the company’s closing stock price on March 27 and up 29% compared to Couchbase’s share price on June 18, the last full day of trading before the acquisition announcement.
The proposal does have a go-shop period, a period where Couchbase can solicit other offers; however, that period ends at 11:59 p.m. on Monday, June 23.
Founded in 2011, Couchbase is a distributed NoSQL database company that offers a modern data platform for high-performance, cloud-native applications. The company’s architecture combines JSON document storage with in-memory key-value access to allow enterprises to build scalable and responsive systems across different industries.
Couchbase’s platform offers support for multimodel workloads, including full-text search, real-time analytics, eventing and time-series data, which are all accessible through a SQL-like language called SQL++. The platform is also designed for horizontal scalability, high availability and global data replication, allowing for operations across hybrid and multi-cloud environments.
The company offers both self-managed and fully managed deployments through Couchbase Server and Couchbase Capella, its Database-as-a-Service. It also extends functionality to the edge with Couchbase Mobile, a mobile service that offers offline-first access and synchronization for mobile and IoT applications.
Couchbase is also keen on artificial intelligence, with coding assistance for developers, plus AI services for building applications that include retrieval-augmented generation-powered agents, real-time analytics and cloud-to-edge vector search.
The company has a strong lineup of customers, including Cisco Systems Inc., Comcast Corp., Equifax Inc., General Electric Co., PepsiCo Inc., United Airways Holdings Inc., Walmart Inc. and Verizon Communications Inc.
The acquisition will see Couchbase return to private ownership, after the company went public on the Nasdaq in July 2021. According to Reuters, Haveli Investments already held a 9.6% stake in Couchbase before making its takeover offer.
“The data layer in enterprise IT stacks is continuing to increase in importance as a critical enabler of next-gen AI applications,” said Sumit Pande, senior managing director at Haveli Investments, in an announcement statement. “Couchbase’s innovative data platform is well positioned to meet the performance and scalability demands of the largest global enterprises. We are eager to collaborate with the talented team at Couchbase to further expand its market leadership.”
If another would-be acquirer doesn’t emerge before Tuesday, the deal is still subject to customary closing conditions, including approval by Couchbase’s stockholders and the receipt of required regulatory approvals.
Matt McDonough, senior vice president of product and partners at Couchbase, spoke with theCUBE, SiliconANGLE Media’s livestreaming studio, in March, where he discussed how platforms must not only process vast volumes of real-time data, but also support emerging AI models and applications without compromising performance.
Image: Couchbase
Support our open free content by sharing and engaging with our content and community.
Join theCUBE Alumni Trust Network
Where Technology Leaders Connect, Share Intelligence & Create Opportunities
11.4k+
CUBE Alumni Network
C-level and Technical
Domain Experts
15M+
theCUBE
Viewers
Connect with 11,413+ industry leaders from our network of tech and business leaders forming a unique trusted network effect.
SiliconANGLE Media is a recognized leader in digital media innovation serving innovative audiences and brands, bringing together cutting-edge technology, influential content, strategic insights and real-time audience engagement. As the parent company of SiliconANGLE, theCUBE Network, theCUBE Research, CUBE365, theCUBE AI and theCUBE SuperStudios — such as those established in Silicon Valley and the New York Stock Exchange (NYSE) — SiliconANGLE Media operates at the intersection of media, technology, and AI. .
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a powerful ecosystem of industry-leading digital media brands, with a reach of 15+ million elite tech professionals. The company’s new, proprietary theCUBE AI Video cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.
MMS • Sergio De Simone

Anthropic has recently introduced support for connecting to remote MCP servers in Claude Code, allowing developers to integrate external tools and resources without manual local server setup.
The new capability makes it easier for developers to pull context from their existing tools, including security services, project management systems, and knowledge bases. For example, a developer can use the Sentry MCP server to get a list of errors and issues in their project, check whether fixes are available, and apply them using Claude, all within a unified workflow.
Additional integration examples include pulling data from APIs, accessing remote documentation, working with cloud services, collaborating on shared team resources, and more.
Before Claude Code natively supported remote MCP server, developers had to set up a local MCP server to integrate it with their existing toolchain.
Remote MCP servers offer a lower maintenance alternative to local servers: just add the vendor’s URL to Claude Code—no manual setup required. Vendors handle updates, scaling, and availability, so you can focus on building instead of managing server infrastructure.
For authentication, Claude Code supports OAuth 2.0 over HTTP or SSE, allowing developers to authenticate directly through the terminal without needing to provide an API key. For example, here’s how you can connect Claude Code to GitHub MCP:
$ claude mcp add --transport sse github-server https://api.github.com/mcp
>/mcp
The /mcp command, executed within Claude Code, opens an interactive menu that provides the option to authenticate using OAuth. This launches your browser to connect automatically to the OAuth provider. After successful authentication through the browser, Claude Code store the received access token locally.
Several Reddit users commented on Anthropic’s announcement, downplaying its significance and noting that, while convenient, this feature is far from being a game changer.
Others, however, emphasized the importance of Claude Code gaining support for streamable HTTP as an alternative to stdio for connecting to MCP servers.
According to Robert Matsukoa, former head of product engineering at Tripadvisor and currently CTO at Fractional, this is not just a convenient upgrade, but one that “alters the economics of AI tool integration”:
Remote servers eliminate infrastructure costs previously required for local MCP deployments. Teams no longer need to provision servers, manage updates, or handle scaling for MCP services.
However, Matsukoa notes that using MCP servers tipically increases costs by 25-30% due to the larger contexts pulled from external sources and that remote MCPs, by making this task easier, can actually compound those costs. So, careful consideration is required as to where it makes sense:
MCP’s advantages emerge in scenarios requiring deep contextual integration: multi-repository debugging sessions, legacy system analysis requiring historical context, or workflows combining multiple data sources simultaneously. The protocol excels when Claude needs to maintain state across tool interactions or correlate information from disparate systems.
Conversely, for workflows based on CLIs and standard APIs, he sees no need to go the MCP route.
Anthropic published a list of MCP servers developed in collaboration with their respective creators, but a more extensive collection is available on GitHub.
MMS • RSS
Cherry Creek Investment Advisors Inc. raised its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 529.0% in the first quarter, according to its most recent disclosure with the Securities and Exchange Commission. The institutional investor owned 8,058 shares of the company’s stock after buying an additional 6,777 shares during the quarter. Cherry Creek Investment Advisors Inc.’s holdings in MongoDB were worth $1,413,000 at the end of the most recent quarter.
Other hedge funds also recently bought and sold shares of the company. HighTower Advisors LLC lifted its stake in MongoDB by 2.0% during the fourth quarter. HighTower Advisors LLC now owns 18,773 shares of the company’s stock valued at $4,371,000 after buying an additional 372 shares in the last quarter. Jones Financial Companies Lllp increased its holdings in shares of MongoDB by 68.0% in the 4th quarter. Jones Financial Companies Lllp now owns 1,020 shares of the company’s stock valued at $237,000 after purchasing an additional 413 shares during the period. Smartleaf Asset Management LLC increased its holdings in shares of MongoDB by 56.8% in the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock valued at $87,000 after purchasing an additional 134 shares during the period. 111 Capital acquired a new position in shares of MongoDB in the 4th quarter valued at about $390,000. Finally, Park Avenue Securities LLC increased its holdings in shares of MongoDB by 52.6% in the 1st quarter. Park Avenue Securities LLC now owns 2,630 shares of the company’s stock valued at $461,000 after purchasing an additional 907 shares during the period. 89.29% of the stock is owned by hedge funds and other institutional investors.
Insiders Place Their Bets
In other news, Director Hope F. Cochran sold 1,175 shares of the firm’s stock in a transaction on Tuesday, April 1st. The stock was sold at an average price of $174.69, for a total value of $205,260.75. Following the completion of the sale, the director now directly owns 19,333 shares in the company, valued at approximately $3,377,281.77. This trade represents a 5.73% decrease in their ownership of the stock. The sale was disclosed in a filing with the SEC, which is available through this link. Also, insider Cedric Pech sold 1,690 shares of the firm’s stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $292,809.40. Following the completion of the sale, the insider now owns 57,634 shares of the company’s stock, valued at approximately $9,985,666.84. This trade represents a 2.85% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold 50,382 shares of company stock worth $10,403,807 over the last three months. 3.10% of the stock is currently owned by corporate insiders.
Analyst Ratings Changes
A number of equities analysts have recently weighed in on the company. Royal Bank Of Canada reiterated an “outperform” rating and issued a $320.00 target price on shares of MongoDB in a report on Thursday, June 5th. Guggenheim upped their target price on MongoDB from $235.00 to $260.00 and gave the company a “buy” rating in a report on Thursday, June 5th. DA Davidson reiterated a “buy” rating and issued a $275.00 target price on shares of MongoDB in a report on Thursday, June 5th. Macquarie reiterated a “neutral” rating and issued a $230.00 target price (up previously from $215.00) on shares of MongoDB in a report on Friday, June 6th. Finally, Piper Sandler increased their price objective on MongoDB from $200.00 to $275.00 and gave the stock an “overweight” rating in a report on Thursday, June 5th. Eight investment analysts have rated the stock with a hold rating, twenty-four have given a buy rating and one has assigned a strong buy rating to the company’s stock. According to MarketBeat.com, the stock presently has a consensus rating of “Moderate Buy” and an average target price of $282.47.
Get Our Latest Stock Analysis on MongoDB
MongoDB Stock Down 1.3%
MongoDB stock traded down $2.65 during mid-day trading on Friday, hitting $201.50. 3,609,482 shares of the company were exchanged, compared to its average volume of 1,963,536. The business has a fifty day moving average of $185.96 and a 200 day moving average of $221.16. MongoDB, Inc. has a 1-year low of $140.78 and a 1-year high of $370.00. The company has a market capitalization of $16.46 billion, a PE ratio of -176.75 and a beta of 1.39.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, topping the consensus estimate of $0.65 by $0.35. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The firm had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. During the same period in the prior year, the company posted $0.51 earnings per share. The business’s revenue for the quarter was up 21.8% compared to the same quarter last year. Research analysts expect that MongoDB, Inc. will post -1.78 earnings per share for the current year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Today, we are inviting you to take a free peek at our proprietary, exclusive, and up-to-the-minute list of 20 stocks that Wall Street’s top analysts hate.
Many of these appear to have good fundamentals and might seem like okay investments, but something is wrong. Analysts smell something seriously rotten about these companies. These are true “Strong Sell” stocks.
MMS • Robert Krzaczynski

Chris McCord has released Phoenix.new, a browser-native agent platform that gives large language models full-stack control over Elixir development environments. Designed to work entirely in the cloud, Phoenix.new spins up real Phoenix apps inside ephemeral VMs—complete with root shell access, a full browser, GitHub integration, and live deployment URLs—allowing LLM agents to build, test, and iterate in real time.
Phoenix.new allows users to spin up Elixir projects directly in their browser. The agents can install packages, modify code, launch servers, and even run integration tests, all without touching the local machine. Each environment is powered by Fly.io’s infrastructure and behaves like a full development system, complete with a root shell and live preview URLs.
What distinguishes Phoenix.new is its alignment with the Phoenix framework’s real-time and collaborative features. When an agent adds a front-end component, it goes beyond verifying compilation—it launches a browser session, loads the application, and interacts with it programmatically. Updates are reflected live across open preview tabs, enabling continuous feedback during development.
Phoenix.new agents can also explore live databases via CLI tools, propose schema-aware Ecto models, and generate full-stack apps that use WebSockets, LiveView, and Presence. Developers can guide the agents or let them work asynchronously—triaging GitHub issues, generating pull requests, and iterating independently on running codebases.
In a live demo at ElixirConfEU, Phoenix.new generated a functional Tetris game using Phoenix LiveView from a single prompt. While there are few public examples combining LiveView with game logic, the agent was able to draw on general knowledge of web frameworks and interactive applications to complete the task.
While Phoenix.new operates inside Fly.io’s virtual machines, questions have been raised about vendor lock-in. Responding to one such concern on Hacker News, McCord clarified:
Everything starts as a stock phx.new app which uses SQLite by default. Nothing is specific to Fly. You should be able to copy the git clone URL, paste,
cd && mix deps.get && mix phx.serverlocally and the app will just work.
McCord envisions a future where agent collaboration happens not only during coding sessions but continuously, even while developers are offline. With growing support for multiple languages and frameworks beyond Elixir, Phoenix.new is poised to become a powerful entry point for cloud-native, AI-assisted development.
The platform is available now at phoenix.new, with continued updates planned throughout 2025.
TC39 Advances Nine JavaScript Proposals, Including Array.fromAsync, Error.isError, and using
MMS • Bruno Couriol

The Ecma Technical Committee 39 (TC39), the body responsible for the evolution of JavaScript (ECMAScript), recently advanced nine proposals through its stage process, with three new language features becoming part of the standard: Array.fromAsync, Error.isError, and explicit resource management with using.
Array.fromAsync is a utility for creating arrays from asynchronous iterables. This simplifies collecting data from sources like asynchronous generators or streams, eliminating the need for manual for await...of loops.
The feature explainer provides the following real-world example from the httptransfer module:
async function toArray(items) {
const result = [];
for await (const item of items) {
result.push(item);
}
return result;
}
it('empty-pipeline', async () => {
const pipeline = new Pipeline();
const result = await toArray(
pipeline.execute(
[ 1, 2, 3, 4, 5 ]));
assert.deepStrictEqual(
result,
[ 1, 2, 3, 4, 5 ],
);
});
With the new syntax, this becomes:
it('empty-pipeline', async () => {
const pipeline = new Pipeline();
const result = await Array.fromAsync(
pipeline.execute(
[ 1, 2, 3, 4, 5 ]));
assert.deepStrictEqual(
result,
[ 1, 2, 3, 4, 5 ],
);
});
The Error.isError() method also advances to Stage 4, providing a reliable way to check if a value is an error instance. The alternative instanceof Error was considered unreliable because it will provide a false negative with a cross-realm (e.g., from an iframe, or node’s vm modules) Error instance.
Another proposal reaching Stage 4 is Explicit Resource Management, introducing a using declaration for managing resources like files or network connections that need explicit cleanup. This proposal is motivated in particular by inconsistent patterns for resource management: iterator.return() for ECMAScript Iterators, reader.releaseLock() for WHATWG Stream Readers, handle.close() for NodeJS FileHandles, and more.
There are also several footguns that the proposal alleviates. For instance, when managing multiple resources:
const a = ...;
const b = ...;
try {
...
}
finally {
a.close();
b.close();
}
Import Attributes (formerly Import Assertions) advances to Stage 3. This feature allows developers to add metadata to import declarations to provide information about the expected type of the module, such as JSON or CSS.
Other proposals moving forward at various stages include Promise.try, aimed at simplifying error handling in promise chains, RegExp.escape for safely escaping strings within regular expressions, and more. Developers may review the full list in a blog article online.
TC39 is the committee that evolves JavaScript. Its members include, among others, all major browser vendors. Each proposal for an ECMAScript feature goes through the following maturity stages:
- Stage 0: Strawman
- Stage 1: Proposal
- Stage 2: Draft
- Stage 3: Candidate
- Stage 4: Finished
A feature will be included in the standard once its proposal has reached stage 4 and thus can be used safely. Browser support may however lag behind adoption of the features in the standard.
MMS • RSS
Sowell Financial Services LLC purchased a new stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) in the 1st quarter, according to its most recent Form 13F filing with the Securities and Exchange Commission (SEC). The institutional investor purchased 1,502 shares of the company’s stock, valued at approximately $263,000.
Other large investors have also recently bought and sold shares of the company. Strategic Investment Solutions Inc. IL acquired a new position in MongoDB during the fourth quarter valued at approximately $29,000. NCP Inc. acquired a new stake in shares of MongoDB in the fourth quarter valued at approximately $35,000. Coppell Advisory Solutions LLC lifted its position in shares of MongoDB by 364.0% in the fourth quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock valued at $54,000 after buying an additional 182 shares during the last quarter. Smartleaf Asset Management LLC lifted its position in shares of MongoDB by 56.8% in the fourth quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock valued at $87,000 after buying an additional 134 shares during the last quarter. Finally, J.Safra Asset Management Corp lifted its position in shares of MongoDB by 72.0% in the fourth quarter. J.Safra Asset Management Corp now owns 387 shares of the company’s stock valued at $91,000 after buying an additional 162 shares during the last quarter. 89.29% of the stock is owned by institutional investors and hedge funds.
Analysts Set New Price Targets
A number of analysts have recently issued reports on the company. Piper Sandler raised their price objective on MongoDB from $200.00 to $275.00 and gave the company an “overweight” rating in a research report on Thursday, June 5th. Oppenheimer cut their price objective on MongoDB from $400.00 to $330.00 and set an “outperform” rating for the company in a research report on Thursday, March 6th. Stifel Nicolaus cut their price objective on MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a research report on Friday, April 11th. Daiwa Capital Markets assumed coverage on MongoDB in a research report on Tuesday, April 1st. They issued an “outperform” rating and a $202.00 price objective for the company. Finally, KeyCorp cut MongoDB from a “strong-buy” rating to a “hold” rating in a research report on Wednesday, March 5th. Eight research analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has issued a strong buy rating to the company. According to MarketBeat.com, MongoDB has a consensus rating of “Moderate Buy” and a consensus target price of $282.47.
View Our Latest Research Report on MongoDB
Insider Buying and Selling at MongoDB
In related news, Director Hope F. Cochran sold 1,174 shares of the company’s stock in a transaction that occurred on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the transaction, the director now directly owns 21,096 shares of the company’s stock, valued at approximately $4,241,983.68. This represents a 5.27% decrease in their position. The transaction was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through the SEC website. Also, CAO Thomas Bull sold 301 shares of the company’s stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total value of $52,148.25. Following the transaction, the chief accounting officer now directly owns 14,598 shares in the company, valued at approximately $2,529,103.50. This trade represents a 2.02% decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last quarter, insiders have sold 50,382 shares of company stock worth $10,403,807. Insiders own 3.10% of the company’s stock.
MongoDB Price Performance
MDB stock traded down $2.65 during midday trading on Friday, reaching $201.50. 3,609,482 shares of the stock were exchanged, compared to its average volume of 1,963,536. The stock has a market capitalization of $16.46 billion, a PE ratio of -176.75 and a beta of 1.39. MongoDB, Inc. has a 52 week low of $140.78 and a 52 week high of $370.00. The company has a fifty day moving average price of $185.96 and a 200 day moving average price of $221.16.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The business had revenue of $549.01 million for the quarter, compared to analyst estimates of $527.49 million. During the same quarter in the previous year, the company posted $0.51 EPS. MongoDB’s quarterly revenue was up 21.8% compared to the same quarter last year. As a group, analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Discover the 10 Best High-Yield Dividend Stocks for 2025 and secure reliable income in uncertain markets. Download the report now to identify top dividend payers and avoid common yield traps.
Couchbase jumps 28% after agreeing to be acquired for $24.50 per share – Yahoo Finance
MMS • RSS

Shares of Couchbase (BASE) have jumped $5.40, or 28.5%, to $24.33 after the company announced a definitive agreement to be acquired by Haveli Investments for $24.50 per share in an all-cash transaction valued at approximately $1.5B. Some other names in the cloud-based database platforms, NoSQL database, data storage, an infrastructure software space include MongoDB (MDB), DigitalOcean (DOCN), Elastic (ESTC) and Datadog (DDOG).
Published first on TheFly – the ultimate source for real-time, market-moving breaking financial news. >;elm:context_link;itc:0;sec:content-canvas” class=”link “>Try Now>>
Read More on BASE:
MMS • RSS

Cohesity is getting closer to MongoDB by providing more advanced performance and control capabilities for backup and recovery of MongoDB databases.
Cyber resilience supplier Cohesity says it’s among the first data protection software providers to deliver MongoDB workload protection through the MongoDB Third Party Backup Ops Manager API with its DataProtect offering. Rubrik also supports this API.
Document database supplier MongoDB produces one of the top five NoSQL databases and has a massive user community. It is a publicly owned business that earned revenues of $2 billion in fiscal 2025 and competes against traditional relational database heavyweights like Oracle and IBM. MongoDB sells both an on-premises version of its database and a cloud version, called Atlas, which is sold through the AWS, Azure, and GCP clouds.

Vasu Murthy, Cohesity SVP and chief product officer, stated: “With ransomware attacks now commonplace, cyber resilience is a strategic priority for all organizations. This is particularly true of large enterprises, which have a very low tolerance for risk. Downtime for any reason can mean millions of dollars and massive reputational damage. As trusted providers for many of the world’s largest companies, Cohesity and MongoDB are working together to strengthen our customers’ ability to bounce back fast.”
Cohesity said its DataProtect-MongoDB integration, now generally available, features:
- Parallel data streams to enable billions of objects to be processed instantaneously.
- Cohesity’s backups get customers’ MongoDB databases back online 4x faster than traditional methods.
- A scale-out architecture providing petabyte-sized support on a single platform. Customers can reduce their data footprint with global, variable-length deduplication and compression.
- Immutable write once, read many (WORM) storage, data encryption in flight and at rest, continuous data protection, secure SSL authentication, and a multi-layer defense posture based on Zero Trust security principles.
- Business continuity and redundancy with protection of replica sets and sharded clusters with flexible secondary, primary, or fixed preferred backup nodes – enabling continuous availability and failover readiness. Customers can achieve stricter SLAs (both RPOs and RTOs) and eliminate data loss in high-velocity environments.
- Support for sharded and Replica Set deployments.
- Application-consistent backups across complex MongoDB deployments through tightly integrated snapshot orchestration.
- Disaster recovery with restoration of MongoDB clusters in-place or to new environments following failures or ransomware events.
- Safe evaluation of performance enhancements or upgrades on alternate hardware with no production downtime.
- Seamless refreshment of development environments using out-of-place recovery from clean, consistent MongoDB backups.
A Cohesity blog says the integrated DataProtect-MongoDB offering “is designed for enterprises with large-scale, mission-critical MongoDB environments – think global banks, financial services firms, and Fortune 500 companies.”
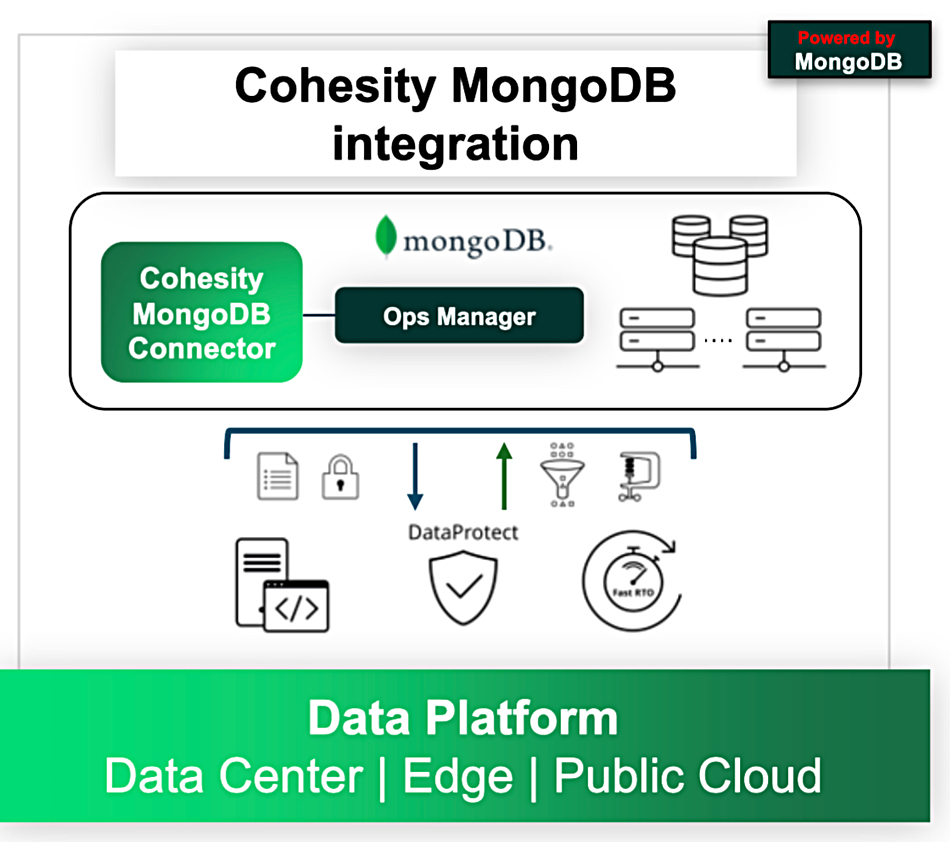
It “auto-discovers MongoDB Ops Manager (OM) objects, enabling a frictionless and intuitive user experience. It also fully supports OM instances running in High Availability (HA) mode and with SSL encryption – ensuring secure, resilient protection for even the most demanding environments.”

MongoDB’s SVP of Product Management, Benjamin Cefalo, said: “As the leading document database for modern applications, MongoDB empowers organizations to build, scale, and innovate faster. Our collaboration with Cohesity reinforces that mission by helping customers protect their data with robust, enterprise-grade resilience – without compromising the agility and performance developers expect from our platform.”
MMS • Robert Krzaczynski
AlphaWrite is a new framework designed to enhance creative writing with structure and measurable improvements. Developed by Toby Simonds, it employs an evolutionary process to iteratively boost storytelling quality during inference.
Creative generation has long been a challenge for large language models (LLMs), not due to a lack of fluency, but because of the difficulty in evaluating subjective qualities such as character development, emotional impact, and narrative cohesion. AlphaWrite addresses this by borrowing ideas from evolutionary algorithms and systems like AlphaEvolve, applying them to story generation.
The system operates in iterative cycles. It first generates a broad population of diverse stories, varying in author style and theme. Then, an LLM-based judge conducts pairwise comparisons using a detailed narrative quality rubric and Elo rating system. Top-performing stories are selected to spawn variants with guided improvements in structure, dialogue, or prose, among other dimensions. This process is repeated across generations, aiming to refine stories over time.
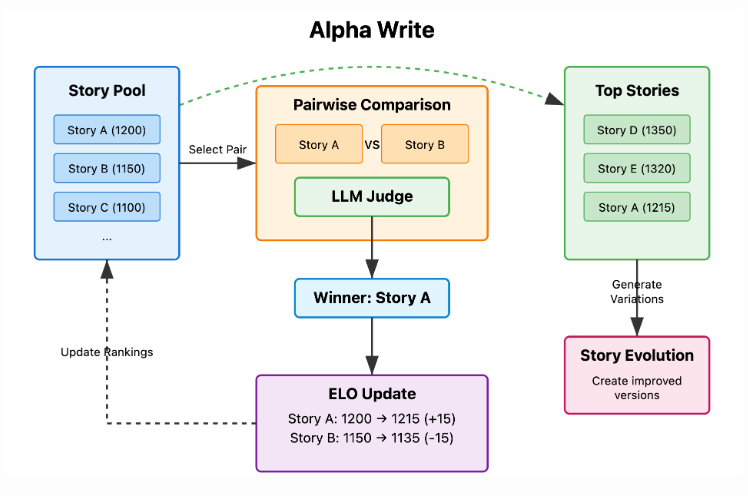
Source: tobysimonds.com
As Toby Simonds, a creator of AlphaWrite, shared on X:
The magic is in the evolutionary pressure. Stories don’t just get generated once – they compete, mutate, and improve across generations. Top performers become ‘parents’ for the next generation, while weak stories get replaced by promising variants.
Early experiments using Llama 3.1 8B suggest notable gains. Stories produced by AlphaWrite were preferred 72% of the time over initial single-shot generations and 62% over stories created through sequential prompting, both statistically significant. The system also supports recursive improvement: refined outputs are distilled into the base model, which can then undergo another round of evolution.
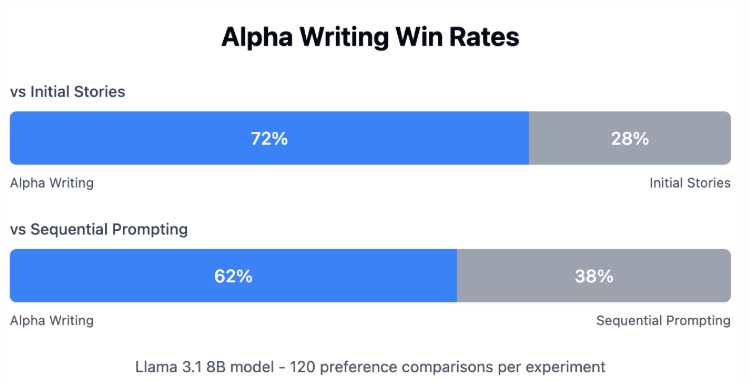
Source: tobysimonds.com
While the results are promising, not everyone welcomes the development. One user on Hacker News commented:
If there is something that I would like AI to never touch, it’s that. Please stop making the world worse.
In response, another user added:
Not everyone shares your same worldview… You don’t have to participate; ignore AI-generated or AI-assisted content… But you also don’t have to devalue and dismiss the interests of others.
These differing reactions reflect broader cultural tensions around AI’s role in creative domains—whether it enhances or erodes human expression. The AlphaWrite team acknowledges that evaluating story quality remains subjective and warns of risks like prompt bias and creative convergence.
Nonetheless, AlphaWrite’s potential reaches beyond fiction. The authors note that the system helped draft parts of their paper and could be adapted to technical writing, marketing, and academic content. With suitable rubrics, the method could be applied to optimize specific writing tasks or even to improve foundation models themselves.
The code is available in the AlphaWrite GitHub repository for developers and researchers to explore.