Category: Uncategorized

MMS • RSS
Exchange Traded Concepts LLC raised its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 92.3% during the 1st quarter, according to its most recent disclosure with the Securities & Exchange Commission. The firm owned 15,571 shares of the company’s stock after buying an additional 7,472 shares during the period. Exchange Traded Concepts LLC’s holdings in MongoDB were worth $2,731,000 at the end of the most recent quarter.
A number of other hedge funds also recently made changes to their positions in MDB. Vanguard Group Inc. raised its stake in MongoDB by 0.3% in the 4th quarter. Vanguard Group Inc. now owns 7,328,745 shares of the company’s stock valued at $1,706,205,000 after acquiring an additional 23,942 shares during the period. Franklin Resources Inc. boosted its holdings in shares of MongoDB by 9.7% during the 4th quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock worth $478,398,000 after buying an additional 181,962 shares during the period. Geode Capital Management LLC grew its stake in MongoDB by 1.8% in the 4th quarter. Geode Capital Management LLC now owns 1,252,142 shares of the company’s stock valued at $290,987,000 after buying an additional 22,106 shares during the last quarter. First Trust Advisors LP raised its holdings in MongoDB by 12.6% in the 4th quarter. First Trust Advisors LP now owns 854,906 shares of the company’s stock valued at $199,031,000 after acquiring an additional 95,893 shares during the period. Finally, Norges Bank acquired a new stake in MongoDB during the fourth quarter worth approximately $189,584,000. 89.29% of the stock is owned by institutional investors and hedge funds.
Insider Transactions at MongoDB
In other MongoDB news, insider Cedric Pech sold 1,690 shares of the firm’s stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $292,809.40. Following the completion of the sale, the insider now directly owns 57,634 shares in the company, valued at approximately $9,985,666.84. This trade represents a 2.85% decrease in their ownership of the stock. The transaction was disclosed in a document filed with the SEC, which can be accessed through this hyperlink. Also, CAO Thomas Bull sold 301 shares of MongoDB stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the sale, the chief accounting officer now directly owns 14,598 shares of the company’s stock, valued at approximately $2,529,103.50. This trade represents a 2.02% decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last ninety days, insiders sold 49,208 shares of company stock valued at $10,167,739. Corporate insiders own 3.10% of the company’s stock.
Analyst Upgrades and Downgrades
Several research firms have recently commented on MDB. Wedbush reaffirmed an “outperform” rating and issued a $300.00 target price on shares of MongoDB in a research report on Thursday, June 5th. UBS Group increased their price objective on MongoDB from $213.00 to $240.00 and gave the stock a “neutral” rating in a research report on Thursday, June 5th. Piper Sandler boosted their target price on shares of MongoDB from $200.00 to $275.00 and gave the company an “overweight” rating in a research report on Thursday, June 5th. Cantor Fitzgerald upped their price target on shares of MongoDB from $252.00 to $271.00 and gave the company an “overweight” rating in a research note on Thursday, June 5th. Finally, Canaccord Genuity Group dropped their price objective on shares of MongoDB from $385.00 to $320.00 and set a “buy” rating for the company in a research note on Thursday, March 6th. Eight analysts have rated the stock with a hold rating, twenty-four have assigned a buy rating and one has issued a strong buy rating to the company’s stock. According to data from MarketBeat, the company has a consensus rating of “Moderate Buy” and an average price target of $282.47.
Check Out Our Latest Research Report on MDB
MongoDB Price Performance
Shares of MongoDB stock traded up $3.10 during midday trading on Tuesday, reaching $205.60. The company had a trading volume of 1,852,561 shares, compared to its average volume of 1,955,294. The stock has a fifty day moving average price of $182.98 and a 200 day moving average price of $223.93. MongoDB, Inc. has a fifty-two week low of $140.78 and a fifty-two week high of $370.00. The firm has a market cap of $16.69 billion, a PE ratio of -75.04 and a beta of 1.39.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The firm had revenue of $549.01 million for the quarter, compared to the consensus estimate of $527.49 million. During the same quarter in the previous year, the company earned $0.51 EPS. The company’s revenue for the quarter was up 21.8% on a year-over-year basis. As a group, sell-side analysts forecast that MongoDB, Inc. will post -1.78 EPS for the current year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

MarketBeat’s analysts have just released their top five short plays for June 2025. Learn which stocks have the most short interest and how to trade them. Enter your email address to see which companies made the list.
MMS • RSS
MongoDB has open-sourced a tool called Kingfisher that it uses internally to “rapidly scan and verify secrets across Git repositories, directories, and more”, publishing it under an Apache 2.0 licence this week. (GitHub here.)
Unlike Wiz’s recent Llama-3.2-1B-based secret scanner, this one proudly uses some turbo-charged regex rather than generative AI to work.
Staff security engineer Mick Grove said he created Kingfisher at MongoDB after growing dissatisfied with the “array of tools, from static code analyzers to secrets managers” that he was using to detect and manage exposed secrets before they turned into security risks for the company.
One frustration was the range of false positives such tools generate.
Kingfisher, he said, actively validates the secrets it detects – claiming it is significantly faster than rival OSS tools like TruffleHog or Gitleaks. Users can run it for service‑specific validation checks (AWS, Azure, GCP, etc.) to confirm if a detected string is a live credential, the Kingfisher repo says; i.e. it can be used for testing database connectivity and calling cloud service APIs to confirm whether the secret is active and poses a risk.
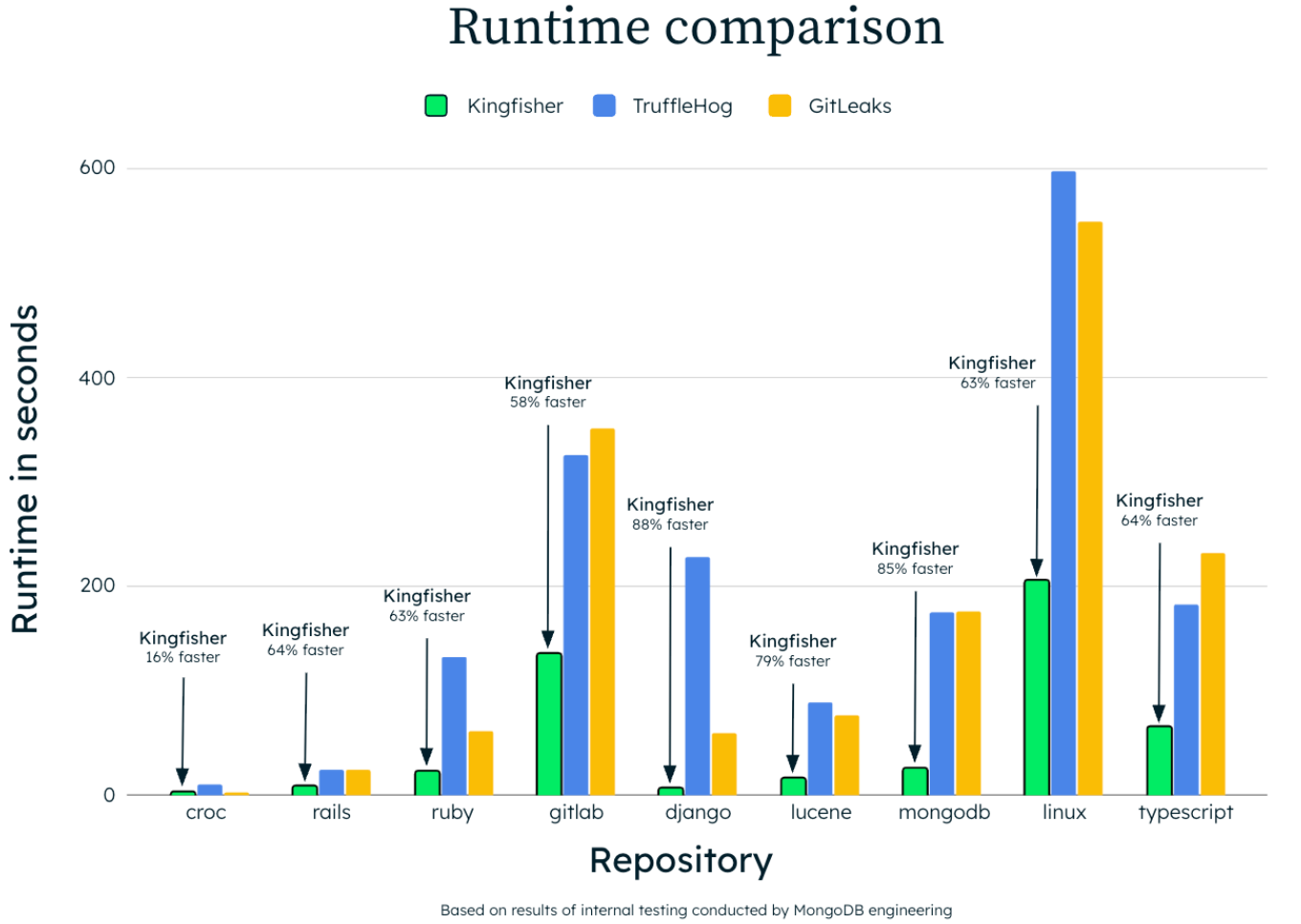
It can parse source code across 20+ programming languages.
(The project was “initially inspired by and built on top of a forked version of” the Apache 2.0 licensed Nosey Parker tool developed by Praetorian for offensive security engagements. “Kingfisher re-engineers and extends its foundation with modern, high-performance technologies” said Grove.)
Kingfisher “combs through code repositories, Git commit histories, and file systems. Kingfisher performs this to rapidly uncover hard-coded credentials, API keys, and other sensitive data. It can be used seamlessly across GitHub and GitLab repositories, both remote and local, as well as files and directories on disk,” Grove wrote of the Rust-based toolkit.
It “combines Intel’s hardware‑accelerated Hyperscan regex engine with language‑aware parsing via Tree‑Sitter, and ships with 700+ built‑in rules to detect, validate, and triage secrets before they ever reach production.”
MMS • RSS
The mix of Java, AWS, and MongoDB is helping the fuel industry run more efficiently and serve customers better.

Sasikanth Mamidi
The fuel sector might not seem like the most obvious place to look for innovation, but technology is quietly reshaping how things work there, too. From managing fuel pumps to tracking tank levels and offering loyalty rewards, digital tools like Java, AWS, and MongoDB are playing a more increasingly significant role.
A seasoned professional, Sasikanth Mamidi, whose work spans across cloud platforms and large-scale applications, has been central to these changes. As a Senior Software Engineer Lead who has been in the industry over 15 years, he helped build a Spring Boot application that runs on AWS Lambda and uses Kinesis streams to move data quickly and securely. The system uses MongoDB Atlas to store real-time data and has greatly assisted in reducing operating costs by 15%, while keeping fuel dispensers running 95% of the time.
He shared how serverless computing, where systems automatically scale without needing physical servers, has been a key part of this shift. One platform built with AWS Lambda and Amazon API Gateway cut infrastructure costs by 20%. It means better performance for less money-something every business aims for. But the impact of these initiatives isn’t just about reducing costs. Real-time event handling is a major requirement in this space. “With is kinds of feature implementation with this tech stack, we saved millions of dollars from Fuel thefts, almost 20% cost reductions in the maintenance of ATGs,” he added. “We also achieved to deliver accurate reconciliation reports, also we can send fuel sales report in terms of volumes and dollars on demand for all the stores.”
Another big improvement through the development of a mobile application that was built to let customers authorize pumps, fuel their vehicles, and get receipts-completely contact-free. “This was implemented at the Covid which helps the customers to reduce the contact to the pumps and also gave very exciting experience too,” he noted. The app also ties into a loyalty system where users earn points and get discounts based on how much fuel they buy. The company also replaced expensive third-party tracking devices with a cloud-based system. Before, they had to rent equipment just to read fuel tank data. Now, data is pulled directly from each location and stored in MongoDB, making it easy to generate reports, track inventory, and even detect unusual activity. This change alone led to a 15% cost saving, while also making maintenance easier and more efficient.
Additionally, the loyalty system has turned out to be more than a bonus feature-it’s a way to better understand customers. The backend can analyze fuel usage, suggest personalized offers, and send real-time promotions that encourage people to head inside stores after fueling up. The goal is not just to sell fuel but to increase overall business.
Mamidi also highlighted how none of this was easy. Before these systems were in place, most operations relied on manual monitoring or external vendors. It was costly and often inaccurate. Now, with cloud technology, the same tasks can be done faster, more reliably, and at a lower cost.
Looking ahead, there are even more possibilities. The next step can be adding AI to make fuel pumps smarter-turning them into kiosks where people can place orders, see personalized ads, or even pay for in-store items. With better cloud infrastructure, updates can roll out automatically, helping keep everything running smoothly across locations.
In short, the mix of Java, AWS, and MongoDB is helping the fuel industry run more efficiently and serve customers better. It’s a reminder that even industries that seem unchanged for decades are being reshaped by smart use of technology.
“Exciting news! Mid-day is now on WhatsApp Channels  Subscribe today by clicking the link and stay updated with the latest news!” Click here!
Subscribe today by clicking the link and stay updated with the latest news!” Click here!
Subscribe today by clicking the link and stay updated with the latest news!” Click here!

MMS • Daniel Curtis

Biome, the all-in-one JavaScript toolchain, has released v2.0 Beta. Biome 2.0 Beta introduces a number of new features in this beta which bring it closer to ESLint and Prettier, such as plugins, to write custom lint rules, domains to group your lint rules by technology and improved sorting capabilities.
Biome has support for JavaScript, TypeScript, JSX, TSX JSON and GraphQL and claims to be 35x faster when compared to Prettier.
While ESLint and Prettier have long been the default choices for JavaScript and TypeScript projects, developers have had to maintain multiple configurations, plugins, and parsers to keep these tools working together. Biome’s goal is to consolidate all of that under one high-performance tool written in Rust. Although the goal is clear, Biome has still been missing features compared to ESLint and Prettier, as noted here on Reddit:
“I’ve replaced ESLint + Prettier in favor of Biome, however it does feel incomplete. YAML, GraphQL, import sorting and plugins are missing.”
Biome v2.0 aims to address these missing features. Plugins will allow users to match custom code snippets and report diagnostics on them, they are a first step in extending the linting rules for Biome users, and the team have indicated in their release blog that they have “plenty of ideas for making them more powerful”.
The plugins should be written using GritQL, which is an open-source query language created by GritIO for searching and modifying source code. Plugins can be added into a project by adding a reference to all the .grit plugin files within a project’s configuration. It is noted in the documentation that not all GritQL features are supported yet in Biome, and there is a GitHub issue that tracks the status of feature support.
Domains are a way to organise all the linting rules by technology, framework or domain, and there are currently four domains: next, react, solid and test. It is possible to control rules for the full domain in the biome config. Biome will also automatically inspect a package.json file and determine which domains should be enabled by default.
Improved Import Organizer is causing some excitement from early adopters. The improvements include the organizer now bundling together imports onto a single line when they come from the same module or file. Custom ordering configuration has also been added which provides the functionality for custom import ordering using the new import organizer. An example, or common use case of this is being able to group type imports at either the start or end of the import chunk.
Biome has a guide dedicated to developers looking to migrate from ESList and Prettier over to Biome. It includes two separate commands for automatically migrating both ESLint and Prettier. There is a note in the migration guide for Prettier that Biome does attempt to match as closely as possible, but there may be differences due to Biome’s different defaults.
Originally forked from Rome, Biome was born and built by the open-source community. Since then, the project has grown with contributions from former Rome maintainers and new community members alike. The Biome GitHub repository is now actively maintained, and the project has continued to grow.
The full documentation for Biome v2.0 Beta is available on biomejs.dev, including rule references and setup instructions for various environments.
MMS • RSS
The fuel sector might not seem like the most obvious place to look for innovation, but technology is quietly reshaping how things work there, too. From managing fuel pumps to tracking tank levels and offering loyalty rewards, digital tools like Java, AWS, and MongoDB are playing a more increasingly significant role.
A seasoned professional, Sasikanth Mamidi, whose work spans across cloud platforms and large-scale applications, has been central to these changes. As a Senior Software Engineer Lead who has been in the industry over 15 years, he helped build a Spring Boot application that runs on AWS Lambda and uses Kinesis streams to move data quickly and securely. The system uses MongoDB Atlas to store real-time data and has greatly assisted in reducing operating costs by 15%, while keeping fuel dispensers running 95% of the time.
He shared how serverless computing, where systems automatically scale without needing physical servers, has been a key part of this shift. One platform built with AWS Lambda and Amazon API Gateway cut infrastructure costs by 20%. It means better performance for less money-something every business aims for. But the impact of these initiatives isn’t just about reducing costs. Real-time event handling is a major requirement in this space. “With is kinds of feature implementation with this tech stack, we saved millions of dollars from Fuel thefts, almost 20% cost reductions in the maintenance of ATGs,” he added. “We also achieved to deliver accurate reconciliation reports, also we can send fuel sales report in terms of volumes and dollars on demand for all the stores.”
Another big improvement through the development of a mobile application that was built to let customers authorize pumps, fuel their vehicles, and get receipts-completely contact-free. “This was implemented at the Covid which helps the customers to reduce the contact to the pumps and also gave very exciting experience too,” he noted. The app also ties into a loyalty system where users earn points and get discounts based on how much fuel they buy. The company also replaced expensive third-party tracking devices with a cloud-based system. Before, they had to rent equipment just to read fuel tank data. Now, data is pulled directly from each location and stored in MongoDB, making it easy to generate reports, track inventory, and even detect unusual activity. This change alone led to a 15% cost saving, while also making maintenance easier and more efficient.
Additionally, the loyalty system has turned out to be more than a bonus feature-it’s a way to better understand customers. The backend can analyze fuel usage, suggest personalized offers, and send real-time promotions that encourage people to head inside stores after fueling up. The goal is not just to sell fuel but to increase overall business.
Mamidi also highlighted how none of this was easy. Before these systems were in place, most operations relied on manual monitoring or external vendors. It was costly and often inaccurate. Now, with cloud technology, the same tasks can be done faster, more reliably, and at a lower cost.
Looking ahead, there are even more possibilities. The next step can be adding AI to make fuel pumps smarter-turning them into kiosks where people can place orders, see personalized ads, or even pay for in-store items. With better cloud infrastructure, updates can roll out automatically, helping keep everything running smoothly across locations.
In short, the mix of Java, AWS, and MongoDB is helping the fuel industry run more efficiently and serve customers better. It’s a reminder that even industries that seem unchanged for decades are being reshaped by smart use of technology.
MMS • RSS

Cybersecurity researchers have discovered a massive database online, exposing 2.7 million patients and 8.8 million records, all of which were found to be fully accessible to the public without any password protection or other security.
According to a report from Cybernews, the database is an exposed MongoDB containing appointment records and other details on dental patients. As of writing, the owner of the database remains unconfirmed. However, clues point to it originating from Gargle, a marketing group that works with systems specializing in oral health, in an effort to bring in more clients and expand their patient base.
Gargle’s work often relies on managing patient care databases and other infrastructure, Cybernews said. In this case, it seems that may also mean patient records, assuming this lot was exposed by the marketing company.
Information online includes names, birth dates, addresses, contact information, and patient demographic information, such as gender. It also includes appointment records, including some procedure information and chart IDs from various institutions.
Cybernews said the data could be easily discovered with any scanning tool and any actor with basic cybersecurity knowledge could gain access to the full trove.
Gargle is based in Utah. The full-service marketing group often builds websites for dental practices that allow patients to log in and schedule appointments, get updates from their attending clinicians and more. As for how the database ended up publicly available online, Cybernews said it’s most likely an oversight.
“MongoDB databases power thousands of modern web applications, from e-commerce platforms to healthcare portals,” the researchers wrote. “In this case, the leak likely stemmed from a common and often overlooked vulnerability where databases are left exposed without proper authentication due to human error.”
Cybernews called this type of breach a “recurring blind spot that continues to haunt companies of all sizes and across various industries.”
MMS • RSS

An enterprise IT and cloud services provider, Tier 5 Technologies, has partnered with MongoDB, a database for modern applications, to harness Africa’s digital economy potential projected to reach $100 billion.
The partnership, also aimed at fostering the expansion of Tier 5 Technologies services into the West African market, specifically in Nigeria, was launched at a recent “Legacy Modernisation Day” event in Lagos.
Speaking at the event, Anders Irlander Fabry, the Regional Director for Middle East and Africa at MongoDB, described the partnership as a pivotal step in deepening their presence in Nigeria.
SPONSOR AD
“Tier 5 Technologies brings a proven track record, a strong local network, and a clear commitment to MongoDB as their preferred data platform.
“They’ve already demonstrated their dedication by hiring MongoDB-focused sales specialists, connecting us with top C-level executives, and closing our first enterprise deals in Nigeria in record time. We’re excited about the impact we can make together in this strategic market,” he added.
The Director of Sales, Tier 5 Technologies, Afolabi Bolaji, stressed the importance of the partnership, describing it as a broader shift in how global technology leaders perceive Africa.
“This isn’t just a reseller deal; we have made significant investments in MongoDB because we believe it will underpin the next generation of African innovation. Many of our customers from nimble fintechs to established banks already rely on it. Now, they’ll have access to enterprise-grade features, local support, and global expertise.
“With surging demand for solutions in fintech, logistics, AI, and edtech across the continent, this partnership holds the potential for transformative impact and signals a long-term commitment to Africa’s technological future, helping to define how Africa builds its digital economy from the ground up,” he said.
MMS • Bruno Couriol

The latest version of Svelte includes a new functionality dubbed attachments that enhances a web application’s DOM with interactive and reactive features. Svelte Attachments replace Svelte Actions.
Just like with Svelte Actions, developers use attachments to provide code to run when a component or DOM element is mounted or unmounted. Typically, the provided code would provision a listener for an event of interest, and remove that listener when the attachment target is unmounted. Attachments can also be used in conjunction with third-party libraries that require a target DOM element. Attachment that depends on reactive values will rerun when those values change.
Follows an example using the ScrambleTextPlugin from the GSAP animation library:
<script>
import { gsap } from 'gsap'
import { ScrambleTextPlugin } from 'gsap/ScrambleTextPlugin'
gsap.registerPlugin(ScrambleTextPlugin)
function scramble(text, options) {
return (element) => {
gsap.to(element, {
duration: 2,
scrambleText: text,
...options
})
}
}
let text = $state('Svelte')
</script>
<input type="text" bind:value={text} />
<div {@attach scramble(text)}></div>
When the DOM is mounted for the first time, the text Svelte will be scrambled. Additionally, any further change to the text value will also cause the text to be scrambled. Developers can experiment with the example in the Svelte playground.
Thus Svelte Attachments extend Svelte Actions which did not provide similar reactivity to its parameters. Additionally, Svelte Attachment can be set up on Svelte components, while Svelte Actions can only be declared on DOM elements. The release provides a mechanism to create attachments from actions, thus allowing developers to reuse existing libraries of actions.
Attachments can be used to encapsulate behavior separately from markup (as done in other UI frameworks, e.g. hooks in React). Examples of behaviors that were already implemented as actions and can now benefit from attachment affordances include clipboard copying, clickboard pasting into an element, capturing a click outside an element, masking user input, animating an element, pointer drag-to-scroll behavior, provisioning of shortcut keys, make an element swipeable, download on click, and many more.
Developers are invited to read the full documentation article online for an exhaustive view of the feature, together with detailed examples and explanations. Developers may also review the corresponding pull request for details about the motivation behind the feature and comments from developers.
MMS • RSS

MMS • Craig Risi

In April 2025, GitHub announced an update to its Command Line Interface (CLI), introducing enhanced support for triangular workflows – a common pattern among open-source contributors who work with forked repositories.
Triangular workflows involve three key components: the original repository (upstream), a personal fork (origin), and the local development environment. Developers typically clone their fork, set the upstream remote to the original repository, and configure their Git settings to pull updates from upstream while pushing changes to their fork. This setup allows contributors to stay synchronized with the main project while working independently.
Prior to this update, the GitHub CLI’s gh pr commands did not fully align with Git’s handling of such configurations, resulting in challenges with managing pull requests within triangular workflows. The latest enhancement ensures that the CLI respects Git’s push and pull configurations, allowing for seamless creation and management of pull requests from a fork to the upstream repository.
This improvement has been well-received by the developer community. On LinkedIn, GitHub highlighted the update, stating:
“Streamline your fork-based contributions with the latest GitHub CLI update! There’s now more support for triangular workflows, which means managing pull requests between your fork and the original repo is now significantly smoother and more efficient.”
A user, N8Group, responded with:
“It’s great to see the GitHub CLI finally supporting triangular workflows! This solves a long-standing pain point for teams with forks and complex branch strategies.”
For developers engaged in open-source projects or those who frequently work with forked repositories, this enhancement to the GitHub CLI simplifies the workflow, reducing friction and aligning command-line operations more closely with Git’s native behavior.
Triangular workflows – where developers fork a repository, make changes locally, and submit pull requests back to the original repository – are common in open-source and collaborative development. Outside of this new GitHub approach, Continuous Integration/Continuous Deployment (CI/CD) platforms have varying levels of support for these workflows, each with its own set of features and limitations.
GitLab facilitates triangular workflows by allowing users to fork repositories and create merge requests that return changes to the upstream project. CI/CD pipelines can be configured to run for these merge requests, providing a seamless integration experience. Additionally, GitLab offers features like fork synchronization and pull mirroring to keep forks up-to-date with the upstream repository.
Bitbucket also supports pipelines for pull requests from forks, but there are some caveats. By default, pipelines do not run automatically for pull requests from forks to prevent unauthorized access to secrets and other sensitive data. Repository administrators must explicitly enable this feature and carefully manage permissions to strike a balance between security and contributor convenience.
Interested readers can learn more at the GitHub blog and download the CLI via their favourite package manager or the cli.github.com website.