Category: Uncategorized

MMS • Ben Linders

Leadership observability means observing yourself as you lead. Alex Schladebeck shared at OOP conference how narrating thoughts, using mind maps, asking questions, and identifying patterns helped her as a leader to explain decisions, check bias, support others, and understand her actions and challenges.
Employees and other leaders around you want to understand what leads to your decisions, Schladebeck said. Leadership observability is treating oneself as the system that is under observation, she explained:
It’s being able to ask questions and get meaningful answers because “my brain” is capable of telling me why I acted / reacted / communicated / decided the way I did.
Heuristics give us our “gut feeling”. And that’s useful, but it’s better if we’re able to take a step back and get explicit about how we got to that gut feeling, Schladebeck mentioned. If we categorise and label things and explain what experiences lead us to our gut feeling, then we have the option of checking our bias and assumptions, and can help others to develop the thinking structures to make their own decisions, she explained:
I had a colleague who had to decide which of their team to put forward for a customer project. I was able to share my context of assessing the person on their technical skills and their ability to represent the company.
Schladebeck recommends that leaders narrate their thoughts to reflect on, and describe their own work to the ones they are leading. They can do this by asking themselves questions like, “Why do I think that?”, “What assumptions am I basing this on?”, “What context factors am I taking into account?” Look for patterns, categories, and specific activities, she advised, and then you can try to explain these things to others around you.
To visualize her thinking as a leader, Schladebeck uses mind maps. She groups things and experiences together, and makes different branches for different topics:
I categorise the mindmap branches with categories of what I’m doing, such as “making decisions”, “dealing with conflict”, “managing time and tasks&rquot;. Then I collect activities within them like “collecting options”, “pros and cons”, “personal preference”. And then I add examples as they happen.
Schladebeck also describes general continuums of thought, such as “planning versus exploring” and “directing versus letting others lead”. Using these things, she tries to make her inner workings clearer for others.
Observing her self-confidence as a leader, Schladebeck found out how she increases it:
I try to remind myself that I’ve managed all my hard days and tasks so far. I call my coach or my friends if I need extra support. And a look at the world stage reminds me that there are people in much higher jobs with much lower qualifications than me!
She also observed how she deals with conflicts, which is something that she is still working on to further improve it:
At the moment my focus is to listen carefully and ask for the facts / concrete examples on both sides. Based on those, we can start conversations.
Schladebeck mentioned that by observing how she leads, she has learned which activities are hard for her (like “keeping quiet and letting others decide!” and “interacting to understand when I disagree”) – and, more importantly, why they are hard. Once she can identify why she doesn’t manage a specific thing very well, she can choose to work specifically on those aspects. It helps her to be aware of “what I’m doing” on a daily basis:
Being able to link your current activity back to a higher goal is very important in leadership work!
InfoQ interviewed Alex Schladebeck about what she learned from observing how she leads.
InfoQ: How do you balance making decisions versus having other people decide?
Alex Schladebeck: I’m still working on this! I’m currently trying to leave a gap, some seconds, before I jump into the conversation with my input. This leaves room for others, and for my brain to catch up to the situation and think about whether my input is needed right now.
InfoQ: What if a decision may disappoint people, how would you handle it?
Schladebeck: It’s not often that absolutely no one is disappointed! This is why being clear and explicit about how and why you make decisions is important. What is the context? What are the risks or opportunities?
And – of course we’re going to disappoint people, and it’s ok that they are disappointed. I don’t try to convince them otherwise. Accepting the feeling doesn’t mean that you’ll change the decision. It does mean you understand the human who is affected.
InfoQ: Has there been an observation that surprised you?
Schladebeck: When my then-boss would cancel a meeting at short notice, I would wonder why he did that. It didn’t feel respectful. And then I was the proud owner of the manager-level calendar when my role changed… I realised that short-term management of your calendar is necessary. Sometimes you have three meetings planned in parallel! And only really on the day do you find out which ones are really happening.
On the other hand, if you try to clear your calendar weeks in advance to make sure you only have one meeting at a time, the effort is often wasted. By the time the week in question rolls around you have three again!
I’ve also become a short-term calendar manager. What I try to do though is be very clear about how and why that happens. And if I have people who really don’t like it, then I make sure their meetings don’t get moved at short notice. That, however, does mean that they might get moved more.
MMS • Mark Silvester

GitHub recently introduced a prototype AI coding agent designed to fix bugs and propose code changes through pull requests autonomously.
Unlike GitHub Copilot, which assists developers in real time, the new agent operates independently, scanning codebases, identifying issues, and submitting suggested fixes as pull requests. This represents a shift from developer assistance to a more autonomous code-maintenance model.
According to GitHub, the agent builds on the capabilities of Copilot and leverages CodeQL for semantic code analysis, which enables understanding the meaning and structure of code beyond simple text matching. It is also integrated with a software library of common vulnerability and bug patterns. Once it detects a relevant issue, the agent formulates a potential fix and opens a pull request, complete with code changes and a descriptive message outlining the rationale. Developers can then review, modify, or merge the pull request as needed.
The announcement coincides with the rise of autonomous AI agents in software development. Tools like SWE-agent from Princeton have demonstrated early results in multi-step bug fixing and test-driven development. These tools are part of a broader trend towards software that can not only assist but also act, handling iterative development tasks with minimal human oversight. GitHub CEO Thomas Dohmke described this shift by stating, “Instead of you just asking a question and it gives you an answer, you give it a problem and then it iterates on that problem together with the code that it has access to”.
The GitHub team emphasised that this prototype is still in early development and is being tested internally. It is not yet available for public use, and GitHub has not announced a timeline for broader rollout. However, the company said that the technology represents a long-term investment in reducing the manual burden of software maintenance and improving code health at scale.
Developers have shown interest in GitHub’s coding agent as a way to automate routine bug fixing. In a Reddit thread, early users described successful test runs and called the tool a potential “game changer.” However, some raised concerns about trust, testing coverage, and change management. A GitHub Community discussion also highlighted worries around the implications of AI-generated pull requests, particularly in complex codebases.
The move aligns with GitHub’s broader AI strategy, which includes integrating large language models into workflows beyond code generation, such as documentation, issue triaging, and now, autonomous pull request creation. As part of this strategy, GitHub continues to explore how AI can take on repetitive engineering tasks, freeing developers to focus on higher-level design and problem-solving.
MMS • RSS
PRESS RELEASE
Published June 12, 2025
Codefacture is a software development company founded in Türkiye that is accelerating its growth to meet increasing global demand for custom-built CRM, ERP, custom software, and enterprise automation solutions.

Ankara, Türkiye – In response to surging demand for intelligent, adaptable enterprise software, Codefacture, a fast-growing innovator in CRM, ERP, and custom software development, has announced a major operational expansion. This strategic initiative is designed to support larger-scale development, broaden client services, and extend the company’s reach across Türkiye, Europe, and North America.
Founded in 2024, Codefacture is a software development company that has quickly established itself as a trusted partner for businesses seeking flexible, scalable, and fully customized digital solutions. From manufacturers needing smarter resource planning to service providers optimizing their customer engagement workflows, Codefacture’s platforms are designed to fit the specific way each business operates – not the other way around.
With this expansion, the company is positioning itself to serve an even broader array of industries and geographies while maintaining the high level of customization and personal attention it’s known for.
A Custom-First Approach to Business Software
Unlike many enterprise software providers who offer rigid, off-the-shelf systems, Codefacture’s approach is grounded in adaptability. Every platform it delivers is built around the unique processes, data structures, and operational goals of the client. This has made the company particularly valuable to mid-size and enterprise businesses that are outgrowing legacy tools or facing challenges adapting generic platforms to complex, industry-specific needs.
All of Codefacture’s platforms and custom software solutions are built using a modern, scalable technology stack designed for performance, flexibility, and rapid development. The team leverages powerful frameworks and libraries such as Node.js, Laravel, React, Vue.js, Next.js, and Tailwind CSS to deliver intuitive and responsive user experiences. On the backend, Codefacture works with a range of SQL databases as well as NoSQL solutions, ensuring data structures are optimized for each client’s specific needs. The use of TypeScript and Python further enhances code quality, scalability, and integration capabilities across complex systems.
CRM and ERP Solutions Built for Real-World Complexity
Modern businesses demand more than just functionality – they need systems that map perfectly to their workflows. Codefacture designs and delivers custom-built CRM and ERP solutions that go beyond conventional software limitations. From streamlining sales pipelines to automating inventory and financial processes, each platform is configured to match the exact operational structure of the client.
Whether replacing outdated legacy tools or introducing ERP to a fast-growing enterprise for the first time, Codefacture’s systems are engineered for performance, transparency, and adaptability.
Custom Software Development for Specialized Business Needs
Codefacture delivers fully custom software solutions designed to meet the unique operational challenges of each business. From internal tools to external platforms, every product is built from the ground up to reflect the client’s exact workflows, goals, and data environment. By avoiding one-size-fits-all templates, Codefacture ensures that each solution is intuitive, scalable, and aligned with long-term strategy. This approach enables organizations to streamline operations, improve performance, and respond faster to change through software that’s specifically designed – not adapted.
Strategic Growth for Sustainable Impact
The newly announced expansion involves key investments in three core areas:
- Team Growth: Codefacture is significantly increasing its workforce, hiring software engineers, UI/UX designers, project managers, and customer success specialists. This will allow the company to support larger client portfolios and reduce turnaround times for product development and support.
- Technology Infrastructure: The company is upgrading its development stack and infrastructure to support larger, more complex deployments. New integrations and APIs are being developed to enhance cross-platform functionality, and a new DevOps pipeline is being rolled out to accelerate delivery cycles.
- Client Experience: Codefacture is enhancing its onboarding and support processes with expanded documentation, dedicated account management, and a new analytics dashboard that gives clients real-time insights into their system performance and business metrics.

Expanding Into New Markets
As Codefacture expands, it is actively seeking opportunities in new markets. With strong demand from Europe and North America, the company is exploring partnerships with resellers, consultants, and implementation partners to bring its platforms to a wider range of organizations.
Early interest has been particularly strong from sectors such as:
- Manufacturing – Where demand for modular, transparent ERP systems is critical for cost control and agility.
- Healthcare – Where custom CRM solutions are being used for patient outreach, scheduling, and compliance.
- Education – Where schools and universities need systems to manage admissions, communications, and internal workflows.
- Logistics – Where real-time visibility and data-driven decision-making are becoming industry standards.
Codefacture’s expansion strategy includes not only growth in client acquisition but also knowledge-sharing: the company plans to launch webinars, industry whitepapers, and case studies over the next year to help businesses better understand how tailored software can reshape their operations.
A Vision-Driven Company in a Fast-Changing World
Digital transformation is no longer optional – it’s an operational necessity. Yet for many businesses, transformation is delayed by the complexity of their processes and the lack of software flexible enough to fit them. Codefacture exists to solve this exact problem.
Driving Digital Transformation with Adaptability at the Core
The global business landscape is evolving faster than ever. Off-the-shelf tools often create more friction than they solve. Codefacture exists to eliminate that gap – by delivering tailored platforms that enable companies to streamline operations, improve visibility, and scale without compromise.
About Codefacture
Codefacture was founded in 2024 in Ankara, Türkiye, with a mission to revolutionize how businesses adopt and scale enterprise software. By focusing on deeply customized CRM, ERP, business automation platforms and custom software, the company empowers its clients to unlock greater efficiency, transparency, and scalability.
Whether automating inventory control, managing large sales teams, or coordinating procurement, Codefacture’s tools are designed to adapt, evolve, and grow with every business they touch.
Vehement Media
MMS • Daniel Dominguez
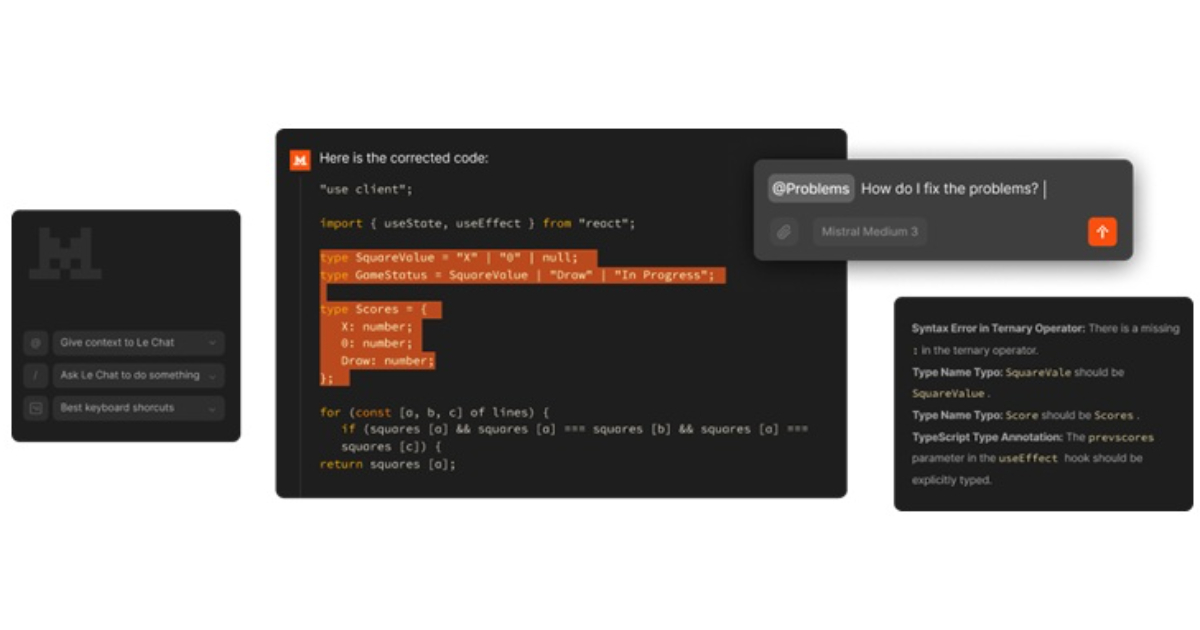
Mistral has introduced Mistral Code, a new AI-powered development tool aimed at improving the efficiency and accuracy of coding workflows. Mistral Code utilizes advanced AI models to offer developers intelligent code completion, real-time suggestions, and the capability to interact with the codebase using natural language. By understanding the structure and relationships within a project, Mistral Code delivers context-aware support for a range of tasks, helping developers write and optimize code more effectively.
Mistral Code can assist with real-time code completion, offering suggestions for code as developers type, which helps reduce errors and speed up the development process. It also identifies syntax and logical errors, providing suggestions for correcting them, which minimizes the time spent on debugging.
In addition to its code completion and debugging capabilities, Mistral Code also generates code documentation automatically. This includes inline comments and API documentation, improving the maintainability of the code and making it easier for teams to collaborate. The tool can even generate unit and system tests to ensure the code produced is fully functional, reducing the burden on developers to manually create tests.
Mistral Code is also designed to assist with code migration. It can generate code snippets in target languages, allowing teams to adapt their existing codebases to new frameworks or languages with ease. Furthermore, the platform analyzes code performance, identifying bottlenecks and offering suggestions for optimizing speed and efficiency.
The AI models behind Mistral Code, such as Codestral and Devstral, are built to be fully customizable and tunable, allowing developers to adjust the models to fit the specific needs of their codebase. This flexibility enables the platform to integrate into different development environments, whether for individual developers or larger teams. The platform supports enterprise-grade features, including team management, detailed analytics, and deployment flexibility.
Community feedback on Mistral’s code is largely positive, with developers praising its efficient, clean code generation across languages. AI and Data specialist Shubham Sharma commented:
Mistral Code revolutionizes enterprise AI development—delivering frontier-grade coding models directly into secure, compliant workflows. No more POC purgatory.
And Fahim in Tech user shared:
If your team needs an AI assistant that understands your code, respects your security, and actually helps ship features not just autocomplete lines Mistral Code might be your new favourite tool.
Mistral Code is integrated directly into JetBrains and VS Code, which simplifies the workflow by allowing developers to stay within their existing development environment. While tools like Windsurf, Cursor, and Copilot offer code completion and assistance, Mistral Code allows natural language interactions with the codebase and offers customizable AI models.
AWS Unveils Independent European Governance and Operations for European Sovereign Cloud
MMS • Steef-Jan Wiggers
AWS has announced key components of its independent European governance for the AWS European Sovereign Cloud, including a new EU-controlled parent company and a dedicated Security Operations Center. With this strategic move, AWS aims to launch its first region in Brandenburg, Germany, by the end of 2025, specifically to meet the stringent digital sovereignty requirements of European governments and enterprises.
The AWS European Sovereign Cloud is designed to combine operational autonomy with the expansive service portfolio of the AWS Cloud. AWS emphasizes its long-standing “sovereign-by-design” approach, where customers control data location and movement. These stringent requirements are primarily driven by industry concerns over data access and extraterritorial laws, such as the U.S. CLOUD Act. This new cloud builds on that commitment, offering the same performance, innovation, security, and scale AWS customers expect.
A new European organization and operating model will be established for the AWS European Sovereign Cloud, comprising a new parent company and three subsidiaries incorporated in Germany, all of which will be led by EU citizens residing in the EU and subject to local laws. Kathrin Renz, currently vice president of AWS Industries, will serve as the company’s first managing director, legally bound to act in the best interest of the AWS European Sovereign Cloud.
Furthermore, the model ensures that customer content and metadata remain within the EU, with operations managed exclusively by personnel residing in the EU. Its dedicated infrastructure will be entirely located within the EU, physically and logically separate from other AWS regions, with no critical dependencies on non-EU infrastructure. It will also feature independent services, such as its own Amazon Route 53 (utilizing European Top-Level Domains) and a dedicated “root” European Certificate Authority for SSL/TLS certificates, alongside Euro currency billing.
An independent advisory board, comprising at least four EU citizens (including one independent member not affiliated with Amazon), will be established. This board will provide expertise and accountability on sovereignty-related aspects and act in the best interest of the AWS European Sovereign Cloud. The design also enables continuous operation even in the event of a connectivity interruption with the rest of the world.
The AWS European Sovereign Cloud will feature a dedicated European Security Operations Center (SOC) mirroring global security practices. This SOC will be led by an EU citizen residing in the EU, who will be responsible for advising the managing director and supporting customers and regulators on security matters.
AWS has also closely collaborated with European regulators, including the German Federal Office for Information Security (BSI), signing a co-operation agreement to further governance and technical standards for operational separation and data flow management. To provide verifiable trust and adherence to sovereignty controls, AWS is introducing the Sovereign Requirements Framework (SRF). The AWS European Sovereign Cloud will maintain key certifications, including ISO/IEC 27001:2013, SOC 1/2/3 reports, and BSI C5 attestation, with independent third-party audits based on the SRF, available via AWS Artifact.

(Source: About Amazon News)
The AWS European Sovereign Cloud initiative comes amidst a significant and ongoing push in Europe for greater technological sovereignty. David Linthicum, a prominent industry analyst, commented on this broader trend in a tweet on X:
The growing push in Europe to reduce reliance on US-based cloud providers is a bold and important move toward technological sovereignty. By promoting homegrown solutions, the EU is striving for greater control over sensitive data and reduced dependency on external powers. However, this shift raises an important question: Could Europe be sacrificing access to the advanced capabilities offered by leading US cloud providers in the process? US cloud giants have set the standard for cutting-edge innovation in areas such as artificial intelligence, machine learning, and scalable global infrastructure.
Linthicum further noted that while Europe’s push to develop its own cloud ecosystem (citing initiatives like Gaia-X) is a step in the right direction, it faces “steep challenges in terms of infrastructure investment, scalability, and competing with over a decade of expertise and innovation.” He concluded that:
Striking the right balance will be critical. Europe must ensure its sovereignty efforts don’t unintentionally limit access to crucial capabilities that drive innovation and competitive advantage in a globally connected economy.
This initiative from AWS comes as other major cloud providers are also making significant commitments to address European concerns about digital sovereignty. For instance, Microsoft recently announced five digital commitments to strengthen its support for Europe’s technological landscape, including a 40% expansion of its European datacenter capacity, a pledge to uphold digital resilience (including a “European cloud for Europe” overseen by a European board), and the completion of its EU Data Boundary project.
The first AWS European Sovereign Cloud Region is set to launch in the State of Brandenburg, Germany, by the end of 2025, backed by a €7.8 billion investment – a commitment that ensures customers can meet their evolving digital sovereignty needs without compromising on the full power of AWS.
It will offer a comprehensive suite of services, including artificial intelligence (Amazon Bedrock, Amazon Q, Amazon SageMaker), compute, containers, database, networking, and security. These services, built on AWS’s sovereign-by-design foundation, will simplify how customers achieve digital sovereignty while gaining the security, control, compliance, and resilience they need. Customers will also benefit from a wide range of AWS Partner Solutions. Once launched, the AWS European Sovereign Cloud will be open to all customers and partners, reinforcing AWS’s long-term commitment to Europe’s digital future.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw some unusual options trading activity on Wednesday. Investors bought 36,130 call options on the stock. This represents an increase of approximately 2,077% compared to the average volume of 1,660 call options.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw some unusual options trading activity on Wednesday. Investors bought 36,130 call options on the stock. This represents an increase of approximately 2,077% compared to the average volume of 1,660 call options.
Insider Buying and Selling at MongoDB
In related news, insider Cedric Pech sold 1,690 shares of the firm’s stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $292,809.40. Following the transaction, the insider now owns 57,634 shares in the company, valued at $9,985,666.84. This trade represents a 2.85% decrease in their ownership of the stock. The transaction was disclosed in a legal filing with the Securities & Exchange Commission, which is available through the SEC website. Also, Director Hope F. Cochran sold 1,175 shares of the firm’s stock in a transaction that occurred on Tuesday, April 1st. The shares were sold at an average price of $174.69, for a total transaction of $205,260.75. Following the transaction, the director now owns 19,333 shares in the company, valued at $3,377,281.77. This represents a 5.73% decrease in their position. The disclosure for this sale can be found here. Over the last 90 days, insiders have sold 49,208 shares of company stock worth $10,167,739. 3.10% of the stock is owned by company insiders.
Institutional Investors Weigh In On MongoDB
A number of institutional investors have recently modified their holdings of the stock. OneDigital Investment Advisors LLC boosted its stake in shares of MongoDB by 3.9% during the 4th quarter. OneDigital Investment Advisors LLC now owns 1,044 shares of the company’s stock valued at $243,000 after buying an additional 39 shares during the period. Avestar Capital LLC raised its holdings in shares of MongoDB by 2.0% during the 4th quarter. Avestar Capital LLC now owns 2,165 shares of the company’s stock valued at $504,000 after purchasing an additional 42 shares in the last quarter. Aigen Investment Management LP raised its holdings in shares of MongoDB by 1.4% during the 4th quarter. Aigen Investment Management LP now owns 3,921 shares of the company’s stock valued at $913,000 after purchasing an additional 55 shares in the last quarter. Handelsbanken Fonder AB raised its holdings in shares of MongoDB by 0.4% during the 1st quarter. Handelsbanken Fonder AB now owns 14,816 shares of the company’s stock valued at $2,599,000 after purchasing an additional 65 shares in the last quarter. Finally, O Shaughnessy Asset Management LLC raised its holdings in shares of MongoDB by 4.8% during the 4th quarter. O Shaughnessy Asset Management LLC now owns 1,647 shares of the company’s stock valued at $383,000 after purchasing an additional 75 shares in the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
MongoDB Stock Down 1.1%
<!—->
Shares of NASDAQ:MDB opened at $210.60 on Thursday. The firm has a fifty day moving average of $179.38 and a two-hundred day moving average of $227.94. The firm has a market capitalization of $17.10 billion, a P/E ratio of -76.86 and a beta of 1.39. MongoDB has a 12-month low of $140.78 and a 12-month high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. The company had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The company’s revenue for the quarter was up 21.8% on a year-over-year basis. During the same quarter last year, the business posted $0.51 EPS. Equities research analysts expect that MongoDB will post -1.78 earnings per share for the current fiscal year.
Wall Street Analysts Forecast Growth
A number of research analysts recently commented on MDB shares. JMP Securities reiterated a “market outperform” rating and set a $345.00 price objective on shares of MongoDB in a research note on Thursday, June 5th. Macquarie reiterated a “neutral” rating and set a $230.00 price objective (up previously from $215.00) on shares of MongoDB in a research note on Friday, June 6th. Wedbush reiterated an “outperform” rating and set a $300.00 price objective on shares of MongoDB in a research note on Thursday, June 5th. Morgan Stanley reduced their target price on shares of MongoDB from $315.00 to $235.00 and set an “overweight” rating for the company in a report on Wednesday, April 16th. Finally, KeyCorp cut shares of MongoDB from a “strong-buy” rating to a “hold” rating in a report on Wednesday, March 5th. Eight equities research analysts have rated the stock with a hold rating, twenty-four have given a buy rating and one has given a strong buy rating to the stock. Based on data from MarketBeat.com, the stock has a consensus rating of “Moderate Buy” and a consensus target price of $282.47.
View Our Latest Stock Report on MDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the recipient of some unusual options trading on Wednesday. Investors purchased 23,831 put options on the stock. This is an increase of 2,157% compared to the average daily volume of 1,056 put options.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the recipient of some unusual options trading on Wednesday. Investors purchased 23,831 put options on the stock. This is an increase of 2,157% compared to the average daily volume of 1,056 put options.
Insider Activity
In other news, insider Cedric Pech sold 1,690 shares of MongoDB stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $292,809.40. Following the completion of the sale, the insider now owns 57,634 shares in the company, valued at approximately $9,985,666.84. This trade represents a 2.85% decrease in their position. The sale was disclosed in a legal filing with the SEC, which can be accessed through this link. Also, Director Hope F. Cochran sold 1,175 shares of MongoDB stock in a transaction dated Tuesday, April 1st. The shares were sold at an average price of $174.69, for a total value of $205,260.75. Following the sale, the director now owns 19,333 shares of the company’s stock, valued at approximately $3,377,281.77. This trade represents a 5.73% decrease in their position. The disclosure for this sale can be found here. Insiders sold a total of 49,208 shares of company stock valued at $10,167,739 in the last ninety days. 3.10% of the stock is currently owned by insiders.
Institutional Inflows and Outflows
A number of institutional investors and hedge funds have recently made changes to their positions in the stock. Cloud Capital Management LLC purchased a new position in MongoDB during the 1st quarter worth $25,000. Hollencrest Capital Management purchased a new stake in MongoDB during the 1st quarter valued at about $26,000. Cullen Frost Bankers Inc. grew its stake in MongoDB by 315.8% during the 1st quarter. Cullen Frost Bankers Inc. now owns 158 shares of the company’s stock valued at $28,000 after purchasing an additional 120 shares during the last quarter. Strategic Investment Solutions Inc. IL purchased a new stake in MongoDB during the 4th quarter valued at about $29,000. Finally, NCP Inc. acquired a new position in shares of MongoDB in the 4th quarter valued at about $35,000. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
MongoDB Stock Down 1.1%
<!—->
Shares of NASDAQ MDB opened at $210.60 on Thursday. The business has a fifty day simple moving average of $179.38 and a two-hundred day simple moving average of $227.94. The firm has a market cap of $17.10 billion, a PE ratio of -76.86 and a beta of 1.39. MongoDB has a twelve month low of $140.78 and a twelve month high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The business had revenue of $549.01 million for the quarter, compared to the consensus estimate of $527.49 million. During the same period last year, the business posted $0.51 EPS. The business’s revenue was up 21.8% compared to the same quarter last year. On average, research analysts expect that MongoDB will post -1.78 earnings per share for the current year.
Wall Street Analyst Weigh In
A number of equities analysts have commented on the company. Citigroup decreased their price target on MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a research note on Tuesday, April 1st. Monness Crespi & Hardt upgraded MongoDB from a “neutral” rating to a “buy” rating and set a $295.00 price target on the stock in a research report on Thursday, June 5th. Canaccord Genuity Group dropped their price target on MongoDB from $385.00 to $320.00 and set a “buy” rating on the stock in a research report on Thursday, March 6th. Cantor Fitzgerald boosted their target price on MongoDB from $252.00 to $271.00 and gave the stock an “overweight” rating in a report on Thursday, June 5th. Finally, Needham & Company LLC reissued a “buy” rating and issued a $270.00 target price on shares of MongoDB in a report on Thursday, June 5th. Eight analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has given a strong buy rating to the stock. Based on data from MarketBeat, the company presently has an average rating of “Moderate Buy” and an average target price of $282.47.
View Our Latest Report on MongoDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the target of some unusual options trading activity on Wednesday. Traders bought 36,130 call options on the stock. This represents an increase of 2,077% compared to the typical daily volume of 1,660 call options.
MongoDB Price Performance
MDB stock traded up $0.06 during trading hours on Thursday, reaching $210.66. The stock had a trading volume of 2,180,893 shares, compared to its average volume of 1,956,303. The stock has a 50-day simple moving average of $179.38 and a 200 day simple moving average of $227.94. The stock has a market capitalization of $17.10 billion, a PE ratio of -76.88 and a beta of 1.39. MongoDB has a fifty-two week low of $140.78 and a fifty-two week high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, topping the consensus estimate of $0.65 by $0.35. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The firm had revenue of $549.01 million during the quarter, compared to the consensus estimate of $527.49 million. During the same period last year, the business posted $0.51 earnings per share. The business’s revenue for the quarter was up 21.8% compared to the same quarter last year. On average, sell-side analysts forecast that MongoDB will post -1.78 EPS for the current fiscal year.
Analyst Upgrades and Downgrades
A number of analysts have weighed in on the stock. Royal Bank of Canada reissued an “outperform” rating and issued a $320.00 price target on shares of MongoDB in a report on Thursday, June 5th. Guggenheim boosted their target price on MongoDB from $235.00 to $260.00 and gave the stock a “buy” rating in a report on Thursday, June 5th. The Goldman Sachs Group dropped their target price on shares of MongoDB from $390.00 to $335.00 and set a “buy” rating for the company in a research note on Thursday, March 6th. Truist Financial dropped their price objective on MongoDB from $300.00 to $275.00 and set a “buy” rating for the company in a report on Monday, March 31st. Finally, Cantor Fitzgerald lifted their price objective on MongoDB from $252.00 to $271.00 and gave the stock an “overweight” rating in a research note on Thursday, June 5th. Eight research analysts have rated the stock with a hold rating, twenty-four have assigned a buy rating and one has assigned a strong buy rating to the company. According to data from MarketBeat.com, the stock presently has a consensus rating of “Moderate Buy” and a consensus price target of $282.47.
Read Our Latest Analysis on MongoDB
Insider Activity
In related news, Director Hope F. Cochran sold 1,175 shares of MongoDB stock in a transaction on Tuesday, April 1st. The shares were sold at an average price of $174.69, for a total value of $205,260.75. Following the transaction, the director now owns 19,333 shares in the company, valued at $3,377,281.77. This trade represents a 5.73% decrease in their position. The sale was disclosed in a legal filing with the SEC, which is available through this link. Also, CEO Dev Ittycheria sold 25,005 shares of the stock in a transaction that occurred on Thursday, June 5th. The shares were sold at an average price of $234.00, for a total value of $5,851,170.00. Following the sale, the chief executive officer now owns 256,974 shares of the company’s stock, valued at approximately $60,131,916. The trade was a 8.87% decrease in their position. The disclosure for this sale can be found here. Insiders have sold a total of 49,208 shares of company stock worth $10,167,739 in the last ninety days. Corporate insiders own 3.10% of the company’s stock.
Institutional Inflows and Outflows
Several hedge funds have recently made changes to their positions in MDB. Strategic Investment Solutions Inc. IL acquired a new position in MongoDB during the fourth quarter valued at approximately $29,000. Cloud Capital Management LLC bought a new stake in shares of MongoDB in the 1st quarter valued at about $25,000. NCP Inc. acquired a new stake in MongoDB during the 4th quarter valued at approximately $35,000. Hollencrest Capital Management bought a new position in MongoDB during the first quarter worth $26,000. Finally, Cullen Frost Bankers Inc. lifted its stake in shares of MongoDB by 315.8% in the 1st quarter. Cullen Frost Bankers Inc. now owns 158 shares of the company’s stock valued at $28,000 after purchasing an additional 120 shares during the period. 89.29% of the stock is owned by institutional investors.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s guide to investing in 5G and which 5G stocks show the most promise.
MMS • Robert Krzaczynski
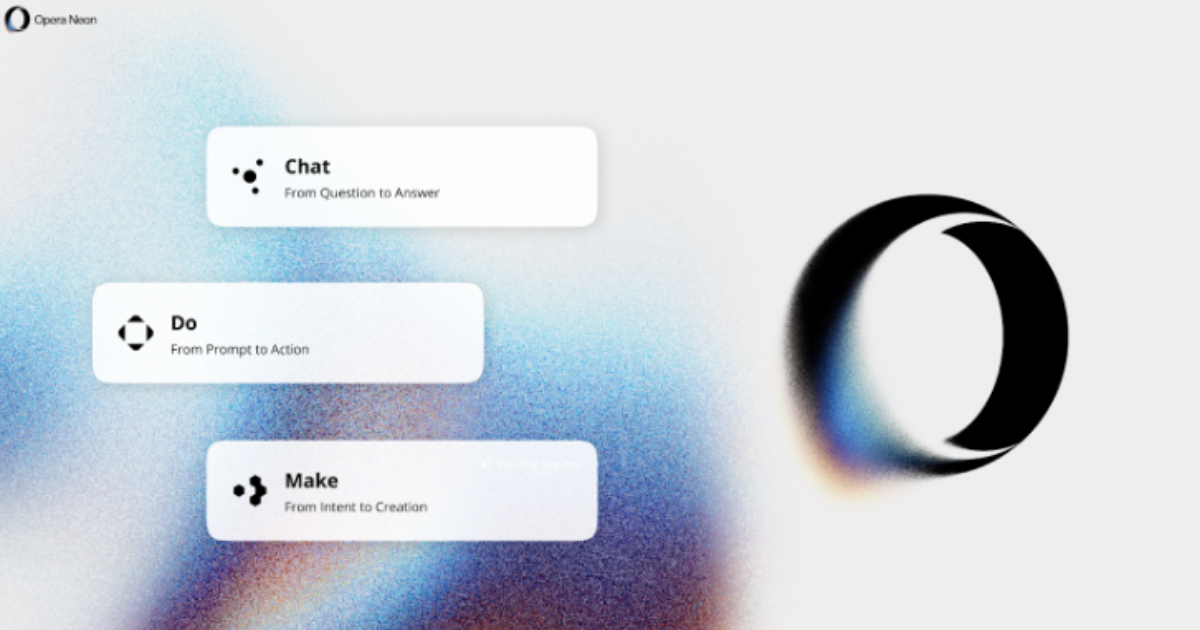
Opera has introduced Opera Neon, a new browser that goes beyond traditional web navigation by integrating AI agents capable of interpreting user intent, performing tasks, and supporting creative workflows. The launch reflects a move toward what Opera describes as “agentic browsing,” where the browser takes an active role in helping users accomplish goals, such as automating tasks or generating content, rather than simply displaying websites.
Neon is the result of several years of development and includes three core AI-driven functions: Chat, Do, and Make. The Chat function embeds a conversational AI assistant directly into the browser, enabling users to ask questions, look up information, or receive contextual summaries related to the page they’re viewing, without switching tabs or apps.
The Do agent, previously previewed under the name Browser Operator, is built to automate routine web tasks. It can fill out forms, search for travel bookings, or carry out online purchases by interpreting webpage structures and content. Importantly, Opera says these actions happen locally within the browser, reducing reliance on external servers and maintaining user privacy.
The third feature, Make, introduces generative capabilities. Users can ask Neon to create websites, reports, code snippets, or visual assets. These tasks are processed in a cloud-based virtual machine that runs independently, allowing projects to continue even if the user disconnects. This setup enables more complex, asynchronous workflows that traditional browsers are not equipped to handle.
The use of both local and cloud-based processing—local for basic tasks and cloud for more complex ones—has raised practical questions among users. A user on X asked:
Does the browser divide the AI agent into two operating modes? Can it be run locally or in a virtual machine?
Opera’s technical breakdown suggests that yes, the system uses both on-device and cloud-based agents depending on the task type and resource demands.
Henrik Lexow, a senior AI product director at Opera, framed the release as an invitation for experimentation:
We see it as a collaborative platform to shape the next chapter of agentic browsing together with our community.
The early response from the community is positive. Jitendra Gupta, a technical lead and AI enthusiast, wrote on LinkedIn:
Imagine your browser actually working for you instead of just waiting for commands. This feels like the start of a whole new era—Web 4.0—where our browser helps us think, create, and stay productive.
Opera Neon is offered as a premium subscription product, with early access now available via a waitlist at operaneon.com.
MMS • Artenisa Chatziou

QCon AI New York (December 16-17, 2025), from the team behind InfoQ and QCon, has announced its Program Committee to shape talks focused on practical AI implementation for senior software engineering teams. The committee comprises senior practitioners with extensive experience in scaling AI in enterprise environments.
The 2025 Program Committee includes:
- Adi Polak – director of advocacy and developer experience engineering at Confluent, and author on scaling machine learning. Adi brings expertise in data-intensive AI applications and the infrastructure challenges of production ML systems.
- Randy Shoup – SVP of engineering at Thrive Market, with previous leadership roles at eBay, Google, and Stitch Fix. Shoup’s background in building scalable, resilient systems will inform content on enterprise-grade AI architecture.
- Jake Mannix – technical fellow for AI & relevance at Walmart Global Tech, with experience at LinkedIn and Twitter. Mannix contributes expertise in applying AI at scale within large enterprise contexts.
- Wes Reisz – QCon AI New York 2025 chair, technical principal at Equal Experts, and 16-time QCon chair.
QCon AI will focus on practical strategies for software engineers and teams looking to implement and scale artificial intelligence within enterprise environments.
Many teams are challenged by transitioning AI from promising proof-of-concepts (PoCs) to robust, value-driving production systems. QCon AI is specifically designed to help senior software engineers, architects, and team leaders navigate these issues and scale artificial intelligence within enterprise environments.
The conference program will feature practitioner-led strategies and case studies from companies successfully scaling AI, with sessions covering:
- Strategic AI integration using proven architectural patterns
- Building production-grade enterprise AI systems for scale and resilience
- Connecting Dev, MLOps, Platform, and Data practices to accelerate team velocity
- Navigating compliance, security, cost, and technical debt constraints in AI projects
- Using AI for design, validation, and strategic decision-making
- Showing clear business impact and return on investment from AI initiatives
“QCon AI is specifically designed to help software engineers navigate these issues in AI adoption and integration, focusing on the applied use of AI in delivering software to production.”
Reisz explained.
“The goal is to help teams not only embrace these changes but ship better software.”
Early bird registration is available. Book your seat now.