Category: Uncategorized
GitLab 17.11 Enhances DevSecOps with Custom Compliance Frameworks and Expanded Controls

MMS • Craig Risi

On April 17, 2025, GitLab released version 17.11, introducing significant advancements in compliance management and DevSecOps integration. A standout feature of this release is the introduction of Custom Compliance Frameworks, designed to embed regulatory compliance directly into the software development lifecycle.
These frameworks allow organizations to define, implement, and enforce compliance standards within their GitLab environment. With over 50 out-of-the-box controls, teams can tailor frameworks to meet specific regulatory requirements such as HIPAA, GDPR, and SOC 2. These controls cover areas like separation of duties, security scanning, authentication protocols, and application configurations.
To create a custom compliance framework, as detailed in GitLab’s own post, users identify applicable regulations and map them to specific controls. Within GitLab’s Compliance Center, they can define new frameworks, add requirements, and select relevant controls. Once established, these frameworks can be applied to projects, ensuring consistent compliance across the organization.
Integrating compliance directly into the development workflow offers several key advantages. By automating compliance checks, teams can significantly reduce the manual effort typically required for tracking and documentation. This streamlining not only saves time but also ensures greater accuracy and consistency. Real-time monitoring of compliance status accelerates audit readiness, allowing organizations to respond quickly and efficiently to regulatory requirements. Furthermore, embedding compliance controls into every stage of development enhances the overall security posture, ensuring that security and regulatory standards are continuously enforced throughout the software delivery lifecycle.
With the release of Custom Compliance Frameworks, Ian Khor, a product manager at GitLab, highlighted the significance of this milestone, stating:
Big milestone moment – Custom Compliance Frameworks is now officially released in GitLab 17.11! This feature has been a long time coming, and I’m incredibly proud of the team that brought it to life.
Khor emphasized the collaborative effort across product, engineering, UX, and security teams to ensure that organizations can define, manage, and monitor compliance requirements effectively within GitLab.
Joel Krooswyk, CTO at GitLab, also expressed enthusiasm about the new features in GitLab 17.11, particularly the compliance frameworks.
Psst – hey – did you hear? GitLab 17.11 dropped today, and there are 3 huge things I’m excited to share. 1. Compliance frameworks. 50 of them, ready to pull into your projects.
In addition to compliance enhancements, GitLab 17.11 introduces over 60 improvements, including more AI features on GitLab Duo Self-Hosted, custom epic, issue, and task fields, CI/CD pipeline inputs, and a new service accounts UI. These updates aim to streamline development workflows and enhance overall productivity.
MMS • RSS
MongoDB, Inc. ![]() MDB popped following its Q1 FY26 earnings release, with shares surging more than 12% post-earnings. The beat-and-raise quarter came alongside stronger profitability and a bold $1 billion share buyback announcement, reigniting investor optimism in a stock that had recently struggled with macro and execution concerns.
MDB popped following its Q1 FY26 earnings release, with shares surging more than 12% post-earnings. The beat-and-raise quarter came alongside stronger profitability and a bold $1 billion share buyback announcement, reigniting investor optimism in a stock that had recently struggled with macro and execution concerns.
This article will cover MongoDB’s business model, its competitive advantages, total addressable market (TAM), and the latest Q1 results to assess whether the recent performance supports or challenges my investment thesis.
What is MongoDB?
MongoDB is a leading provider of NoSQL database technology, offering a flexible, JSON-like document model instead of rigid relational tables. Its core products include MongoDB Atlas, a fully managed cloud database service, and MongoDB Enterprise Advanced, a self-managed on-premise solution for enterprises.
The company’s mission is to simplify and accelerate application development. By using MongoDB, developers can store and query diverse data types with ease, which speeds up project timelines and adapts to changing requirements better than traditional SQL databases. MongoDB’s platform has grown into a full-fledged developer data platform that includes capabilities like full-text search, analytics, mobile data sync, and now vector search for AI applications. As of the latest quarter, over 57,100 customers utilise MongoDB’s technology, reflecting its widespread adoption across various industries. In essence, MongoDB provides the plumbing behind modern applications, from web and mobile apps to IoT and AI systems, and its products aim to be the default database infrastructure for new software projects.
Competitive Advantage and TAM
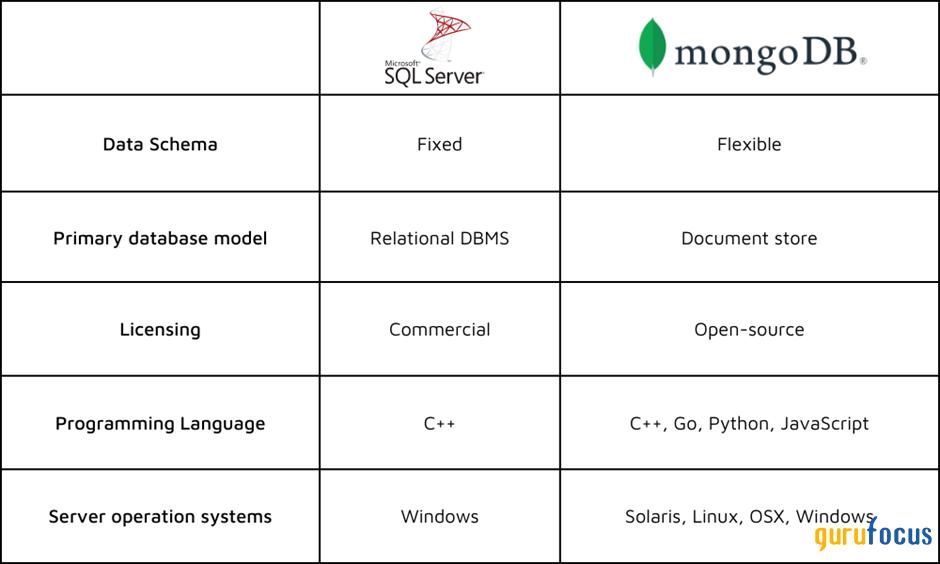
Source: Ardentisys
MongoDB’s approach gives developers far more flexibility than traditional SQL databases. While traditional SQL databases follow a rigid model, where data is stored in structured tables with fixed schemas, MongoDB’s NoSQL model stores data in flexible, JSON-like documents. This difference defines how quickly teams can iterate, adapt, and scale.
In a SQL environment, changing the schema often requires complex migrations. MongoDB, on the other hand, allows for dynamic fields, nested arrays, and schema evolution with minimal disruption
Scalability is another key distinction. Relational databases typically scale vertically, requiring more powerful hardware to handle growing workloads. MongoDB was designed to scale horizontally, distributing data across multiple nodes to support large-scale, real-time applications in cloud environments.
These architectural differences make MongoDB more aligned with modern development needs, particularly in cases where speed, agility, and scalability are critical. As a result, NoSQL databases like MongoDB have become the preferred choice for a growing number of use cases, from web and mobile apps to AI and IoT platforms.
With this distinction being said, MongoDB’s competitive advantage stems from its modern architecture and developer-centric approach in a massive market. The database management system market is estimated to be over $85 billion in size, yet much of it still relies on decades-old relational database technology. However, the global NoSQL market size of approximately $10 billion in 2024 is still small but growing rapidly, expected to grow at a CAGR of 29.50% between 2025 and 2034.
MongoDB’s document model natively handles both structured and unstructured data and maps more naturally to how developers think in code. This flexibility allows companies to represent the messiness of real-world data and evolve their schemas without costly migrations. Applications built on MongoDB can iterate faster and scale more easily because the database does not require rigid schemas or complex join operations. According to management, this fundamental architectural advantage translates to faster time-to-market, greater agility, and the ability to scale without re-architecting, which is why customers increasingly entrust MongoDB with mission-critical workloads.
Another pillar of MongoDB’s moat is its developer mindshare and ecosystem. The company has invested heavily in making its platform accessible, from an open-source foundation to a free-tier Atlas offering and a wide array of developer tools and integrations. This approach creates a self-reinforcing dynamic: the more developers adopt MongoDB, the richer its ecosystem becomes, through community-driven documentation, integrations, and support, which in turn attracts even more developers. Over time, these network effects deepen the platform’s defensibility.
The lack of attracting developers was something that can define a platform’s fate. A great example is Windows Phone which failed to convince developers to build for it. As Ben Thompson said, The number one reason Windows Phone failed is because it was a distant third in a winner-take-all market; this meant it had no users, which meant it had no developers, which meant it had no apps, which meant it had no users. This was the same chicken-and-egg problem that every potential smartphone competitor has faced since, and a key reason why there are still only two viable platforms.
Each new generation of startups and IT projects choosing MongoDB adds to a virtuous cycle: those applications grow, require bigger paid deployments, and demonstrate MongoDB’s reliability at scale, attracting even more adoption. This bottom-up adoption complements MongoDB’s direct sales focus on enterprises, enabling it to grab market share in a large, under-penetrated market. Management frequently notes that MongoDB still has a relatively small fraction of the overall database market, leaving ample room for growth as organizations modernize their data infrastructure.
Crucially, MongoDB’s advantage is being reinforced as industry trends shift towards the company’s strengths. The rise of cloud-native computing, microservices, and AI-driven applications all favor flexible, distributed data stores. MongoDB’s platform was built for cloud, distributed, real-time, and AI-era applications, whereas many competitors are now scrambling to bolt on similar capabilities. In fact, some legacy database vendors have started retrofitting features like JSON document support or vector search onto their products as afterthoughts, which MongoDB’s CEO characterizes as a passive admission that MongoDB’s approach is superior.
New Technology
In keeping with its focus on staying at the forefront of modern application development, MongoDB has aggressively embraced the AI wave. A key development was the acquisition of Voyage AI, an AI startup specializing in embedding generation and re-ranking models for search. Announced in early 2025, the Voyage AI deal (approximately a $200+ million purchase) was aimed at redefining the database for the AI era by baking advanced AI capabilities directly into MongoDB’s platform. By integrating Voyage’s state-of-the-art embedding and re-ranking technology, MongoDB enables its customers to feed more precise and relevant context into AI models, significantly improving the accuracy and trustworthiness of AI-driven applications. In practical terms, this means a company using MongoDB can now do things like generate vectors (embeddings) from its application data, perform semantic searches, and retrieve context for an AI model’s queries, all within MongoDB itself. Developers no longer need a separate specialized vector database or search system.
MongoDB is already showing progress from this integration. The company released Voyage 3.5, an updated set of AI models, which reportedly outperform other leading embedding models while reducing storage requirements by over 80%. This is a significant improvement in efficiency and accuracy, making AI features more cost-effective at scale for MongoDB users. It also helps solve the AI hallucination problem by grounding LLMs in a trusted database, thereby increasing output accuracy.
Beyond Voyage, MongoDB launched broader AI initiatives such as the MongoDB AI Innovators Program (in partnership with major cloud providers and AI firms) to help customers design and deploy AI-powered applications. Early pilot programs using MongoDB’s AI features have yielded promising results, dramatically cutting the time and cost needed to modernize legacy applications with AI assistance.
Financial Results (Q1 FY2026)
MongoDB’s Q1 FY2026 delivered strong results above expectations, regaining the company’s momentum. Revenue for Q1 came in at $549.0 million, a 22% increase year-over-year (YoY), and comfortably ahead of Wall Street’s $528 million consensus estimate. Atlas revenue grew 26% YoY and made up 72% of total revenue in Q1, reflecting strong usage trends. While other segments like Enterprise Advanced and services also posted growth, Atlas remains the primary driver of MongoDB’s momentum. The company added approximately 2,600 net new customers in the quarter, bringing the total customer count to over 57,100. This was the highest quarterly addition in six years, suggesting MongoDB’s strategy to focus on higher-value clients and strong self-service adoption is paying off. In the words of CEO Dev Ittycheria, we got off to a strong start in fiscal 2026 as MongoDB executed well against its large opportunity.
MongoDB has shown significant improvements in profitability and efficiency, although it’s still unprofitable on a GAAP basis. The company recorded a non-GAAP operating income of $87.4 million in Q1, which represents a 16% increase. This is a jump from the 7% non-GAAP operating margin a year ago. Operating expenses grew more slowly than planned, particularly due to more measured hiring, which contributed to the margin outperformance. Non-GAAP net income was $86.3 million, or $1.00 per diluted share, doubling Non-GAAP EPS from the prior year period.
On a GAAP basis, MongoDB reported a net loss of $37.6 million ($0.46 per share) for the quarter, which is still an improvement from the $80.6 million loss ($1.10 per share) a year earlier. The GAAP loss was much narrower than expected with analysts forecasting a loss of around $0.85 per share. Gross margins remain healthy but are shrinking. Q1 gross margin was 71.2%, 72 basis points lower than last year’s 72.8% due to the revenue mix.
Despite MongoDB’s strong top-line performance, stock-based compensation (SBC) remains elevated, consuming 24% of total revenue in Q1. For a company growing revenue in the high single digits and still unprofitable on a GAAP basis, this level of dilution is concerning.
MongoDB’s cash flow generation and balance sheet also underscore its improving efficiency. Operating cash flow in Q1 rose to approximately $110 million, up from $64 million a year ago, while free cash flow nearly doubled to $106 million. The improvement was driven by higher operating profits and solid collections, leading MongoDB to end the quarter with $2.5 billion in cash and short-term investments and no debt. In fact, boosted by the quarter’s results, MongoDB’s Board of Directors authorized an additional $800 million buyback authorization, on top of $200 million authorized last quarter, bringing the total program to $1.0 billion. This is a strong vote of confidence by management in the company’s future. It’s also a shareholder-friendly move to offset dilution from stock-based compensation and the Voyage deal. Due to a blackout period linked to the CFO transition, no shares were repurchased in Q1, but the company indicated buybacks would begin shortly. To put it in perspective, this share buyback is roughly 5% of MongoDB’s market capitalization.
Guidance
Looking ahead, MongoDB management struck an optimistic tone and raised their outlook for the full fiscal year. Citing a strong start to the year, the company increased its FY2026 revenue guidance by $10 million to a range of $2.25$2.29 billion. This implies roughly 13% YoY growth at the midpoint, and it incorporates some conservatism for potential macro headwinds in the second half (including an expected $50 million headwind from lower multi-year license revenue in FY26). Management also boosted its profitability outlook, raising the full-year non-GAAP operating income guidance by 200 basis points in margin. The updated guidance calls for FY26 non-GAAP operating income of $267 to $287 million and non-GAAP EPS of $2.94 to $3.12. Previously, the company had expected $210$230 million in non-GAAP operating income (EPS $2.44$2.62) for the year, so this upward revision is substantial. MongoDB appointed Mike Berry as its new Chief Financial Officer in late May. Berry, a seasoned executive with over 30 years of experience and prior CFO roles at NetApp, McAfee, and FireEye, replaces Michael Gordon, who stepped down earlier this year after nearly a decade with the company. Berry’s track record in scaling enterprise software businesses and driving operational discipline aligns well with MongoDB’s current phase of improving margins and shareholder returns.
Valuation
MongoDB’s stock price has rallied on the back of its strong Q1 report, reflecting renewed investor enthusiasm. Even after this jump, it’s still undervalued in some multiples compared to its peers.
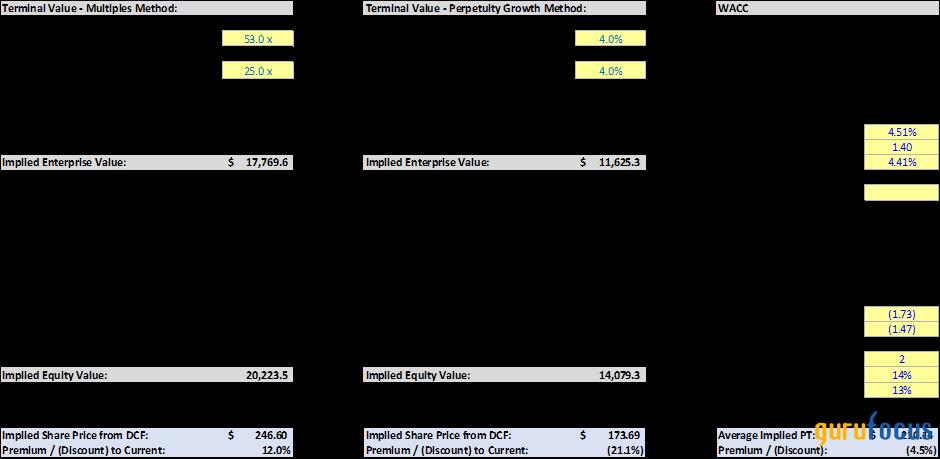
Source: Author
Valuation multiples paint a mixed picture. MongoDB trades at the lowest price-to-sales and price-to-gross-profit ratios among its software peers, which could reflect its strong gross margins. However, it may also signal growing investor skepticism about the company’s long-term growth trajectory and ability to convert usage into durable profitability.
Meanwhile, MongoDB’s price-to-earnings-growth ratio is the highest in the group, primarily because its revenue growth is expected to decelerate into the low double digits. In contrast, peers like Snowflake ![]() SNOW and Datadog
SNOW and Datadog ![]() DDOG continue to command premium valuations, backed by faster top-line expansion and stronger free cash flow margins.
DDOG continue to command premium valuations, backed by faster top-line expansion and stronger free cash flow margins.
Another way to assess the opportunity is through a discounted cash flow analysis that blends multiple-based and perpetuity growth assumptions. I estimate a fair value of around $210 per share, suggesting the stock is fairly valued after the post-earnings rally.
Source: Author
Finally, in the first quarter of the calendar year, MongoDB has seen the same number of guru sellers as buyers. Baillie Gifford (Trades, Portfolio), Jefferies Group (Trades, Portfolio), and Paul Tudor Jones (Trades, Portfolio) have reduced their positions in the stock, with some trimming up to 98%. On the other hand, Lee Ainslie (Trades, Portfolio) has created a new position, while Steven Cohen (Trades, Portfolio) and PRIMECAP Management (Trades, Portfolio) add to their position significantly.
Risks
MongoDB’s long-term opportunity remains compelling, but several risks warrant attention. The most immediate is the sensitivity of Atlas revenue to macroeconomic conditions. Because Atlas follows a usage-based pricing model, any slowdown in customer consumption, whether from tighter IT budgets or reduced application traffic, can quickly translate into revenue deceleration. In fact, management acknowledged some softness in April before usage rebounded in May, prompting them to maintain a cautious full-year outlook.
A second area of concern lies in the company’s non-Atlas license revenue, which is expected to decline at a high single-digit rate this year. This includes a roughly $50 million headwind from multiyear license renewals that took place in the prior year. As customers continue shifting to cloud-based solutions, these traditional license revenues may remain volatile and difficult to predict, creating a drag on MongoDB’s overall subscription growth in the short term.
Lastly, competition from major cloud providers and open-source alternatives remains persistent. AWS DocumentDB, Google Firestore, and Postgres-based document stores represent credible threats. These platforms are often bundled with broader cloud services or offered at lower price points, creating pricing pressure. MongoDB’s advantage lies in its developer-friendly architecture and integrated tooling, but maintaining that lead will require ongoing innovation and execution.
Final Take
MongoDB delivered a strong quarter, regaining some favour with Wall Street following two disappointing earnings periods. The company added its highest number of net new customers in six years, demonstrating continued developer interest and adoption. However, management is forecasting a revenue slowdown, with low double-digit growth expected. SBC also remains elevated, a concern given MongoDB’s ongoing GAAP unprofitability. I want to see continued progress on profitability, margin expansion, and more disciplined equity compensation practices, particularly as the company matures. This quarter was a solid step in the right direction, but I need to see more. I’ll hold my position for another quarter or two before deciding whether MongoDB can sustainably deliver on its potential.
AWS Introduces Open Source Model Context Protocol Servers for ECS, EKS, and Serverless
MMS • Steef-Jan Wiggers

AWS has released a set of open-source Model Context Protocol (MCP) servers on GitHub for Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), and AWS Serverless. These are specialized servers that enhance the capabilities of AI development assistants, such as Amazon Q Developer, by providing them with real-time, contextual information specific to these AWS services.
While Large Language Models (LLMs) within AI assistants typically rely on general public documentation, these MCP servers offer current context and service-specific guidance. Hence, developers can receive more accurate assistance and proactively prevent common deployment errors when building and deploying applications on AWS.
Hariharan Eswaran concluded in a Medium blog post:
The launch of MCP servers is about empowering developers with tools that keep up with the complexity of modern cloud-native apps. Whether you’re deploying containers, managing Kubernetes, or going serverless, MCP servers let your AI assistant manage infrastructure like a team member — not just a chatbot.
Furthermore, according to the company, leveraging these open-source solutions allows developers to accelerate their application development process by utilizing up-to-date knowledge of AWS capabilities and configurations directly within their integrated development environment (IDE) or command-line interface (CLI). Moreover, the key features and benefits include:
- Amazon ECS MCP Server: Simplifies containerized application deployment to Amazon ECS by configuring necessary AWS resources like load balancers, networking, auto-scaling, and task definitions using natural language. It also aids in cluster operations and real-time troubleshooting.
- Amazon EKS MCP Server: Provides AI assistants with up-to-date, contextual information about specific EKS environments, including the latest features, knowledge base, and cluster state. This enables more tailored guidance throughout the Kubernetes application lifecycle.
- AWS Serverless MCP Server: Enhances the serverless development experience by offering comprehensive knowledge of serverless patterns, best practices, and AWS services. Integration with the AWS Serverless Application Model Command Line Interface (AWS SAM CLI) streamlines function lifecycles and infrastructure deployment. It also provides contextual guidance for Infrastructure as Code decisions and best practices for AWS Lambda.
The announcement details practical examples of using the MCP servers with Amazon Q CLI to build and deploy applications for media analysis (serverless and containerized on ECS) and a web application on EKS, all through natural language commands. The examples showcase the AI assistant’s ability to identify necessary tools, generate configurations, troubleshoot errors, and even review code based on the contextual information provided by the MCP servers.
The announcement has already garnered positive attention from the developer community. Maniganda, commenting on a LinkedIn post, expressed enthusiasm:
The ability for AI to interact with AWS compute services in real-time will undoubtedly streamline operations and enhance efficiency. I’m looking forward to seeing how the open-source framework evolves and the impact it will have on Kubernetes management.
Users can get started by visiting the AWS Labs GitHub repository for installation guides and configurations. The repository also includes MCP servers for transforming existing AWS Lambda functions into AI-accessible tools and for accessing Amazon Bedrock Knowledge Bases. Deep-dive blogs are available for those wanting to learn more about the individual MCP servers for AWS Serverless, Amazon ECS, and Amazon EKS.
MMS • Sergii Gorbachov
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today I’m sitting down with Sergii Gorbachov. Sergii, welcome. Thank you for taking the time to talk to us today.
Sergii Gorbachov: Thank you. Thank you for inviting me.
Introductions [01:02]
Shane Hastie: We met because you recently gave a really interesting talk at QCon San Francisco. Do you want to just give us the high-level picture of that talk?
Sergii Gorbachov: Sounds good. The project that I presented was around code migration. It was a migration project that took about 10 months.
We moved from Enzyme to React Testing Library. Those are the libraries that help you create tests to test React.
The interesting piece there was that I combined a traditional approach using AST or Abstract Syntax Tree and LM. Together with the traditional and new approaches, I was able to save a lot of engineering hours and finish this project a lot faster than initially was planned.
Shane Hastie: Real-world, hands-on implementation of the large language models in production code bases. Before we go any further, who is Sergii?
Sergii Gorbachov: Sure, yes, I can talk more about myself. My name is Sergii Gorbachov, and I am a staff engineer at Slack.
I’m part of the Developer Experience Organization, and I’m a member of the front-end test frameworks team, so I deal with anything front-end testing related.
Shane Hastie: What got you interested even, in using the LLM models?
What Got You Into Using AI/LLMs? [02:30]
Sergii Gorbachov: Well, first of all, of course hype. You go on LinkedIn, or you go to any talks or conferences, you see that AI is very prominent. I think, everyone should probably learn about new technologies, so that was the initial push for me.
Also, before Slack, I worked at a fintech company, it was called Finn AI, where I built a testing framework for their chatbot.
I was already acquainted with some of the conversational systems that use artificial intelligence, not large language models, but regular more typical models.
Then of course, the reality of working as a front-end or software developer engineering test, working with front-end technologies, that’s changed quite often.
I think JavaScript is notorious for all of these changes, and the libraries change so drastically, that there are so many breaking changes that you need to, in our case, rewrite 20,000 tests
Doing it manually would take too long. It would be about, we calculated 10 to 15,000 engineering hours, if we went with the manual conversion and using developer time with that.
At that time, Anthropic came out with one of their LLM, large language models, and one of the use cases that people were talking about is code-generation and conversion, so that’s why we decided to try it.
Of course, at that time they were not very popular. There were not too many use cases that were successful, so we had to just try it out.
To be honest, we were desperate, because that much amount of work, and we had to do it and had to help ourselves.
Shane Hastie: What were the big learnings?
Key Learnings from AI Implementation [04:18]
Sergii Gorbachov: I’d say, one of the biggest learnings is that AI by itself was not a very successful tool.
I saw that it was an over-hyped technology, and if we used AI by itself to convert code A to code B, in our case from one framework to another framework, in the same language, so the scope was large but not very wildly large.
It was still not performing well, and we had to control the flow. We had to collect all the context ourselves, and we also had to use the conventional traditional approaches, together with AI.
I think, that’s the main biggest learning, is that our traditional common things that we have been using for decades are still relevant, and AI does not displace them completely, it only complements them, it’s just another tool.
It’s useful, but it cannot completely replace what we’ve been doing before.
Shane Hastie: What does it change? Particularly in how people interact and how our roles as developers change?
How Developer Roles Are Changing [05:29]
Sergii Gorbachov: Sure. In this specific example for Enzyme to RTL conversion, I’d say, the biggest part of AI was the generation part and large language models. Those are generative models, and that’s where we saw that there were no other tools available in the industry.
Usually that role is done by actual developers, where you, for example, convert something, you use those tools manually, and then you have to write the code.
That piece is now more automated, and in our case, for our project, was done by the LM models. The developers role shifted more to reviewing, fixing, verifying, so it was more a validation part that was done by the developers.
Shane Hastie: One of the consistent things that I’m hearing in the industry, and in almost any role adopting generative AI, is that shift from author to editor.
That is a mindset shift. If you’re used to being the author, what does it take to become the editor, to be that reviewer rather than the creator?
Sergii Gorbachov: Well, that’s more of a extreme use case. Maybe it exists in real life, but I would say, realistically it’s, you are a co-author.
Yes, you’re a co-author with the AI system, and you still have to write code, you definitely spend a lot more time reviewing the code and guiding the system, rather than writing everything yourself.
In that respect, I don’t think that I personally, in my development experience, I don’t miss that part, writing some of the scaffolding or code that is very straightforward, that I can just maybe copy and paste from other sources.
Now, I can just ask the LM to do that easy bit for me, and go produce the code and write code myself, that is more complex, where more thinking is necessary.
Yes, definitely the role of a developer, at least in my experience, has shifted to more of a co-author and a person who drives this process.
To a certain extent, it’s still also very empowering, because I’m in control of everything, but I’m not the person who does all the work.
Shane Hastie: We’ve been abstracting you further and further away from the underlying bare metal, so to speak. Is this just another abstraction layer, or is there something different?
AI as the Next Abstraction Layer [08:15]
Sergii Gorbachov: I think it’s definitely another abstraction layer on top of our regular work, or another layer, how we can interact with various coding languages or systems, but it could be the final one.
What is going above just natural language? Because that’s how we interact with the models. You use natural language to build tools, so the next step is just implanting it in our brains, and then controlling them with our minds, which I don’t think will happen.
The difference I think, with previous technologies that would change how developers work, is that this is the final level and we are able to use tools that we use in everyday life, like language or natural language, I guess.
This is the key that is so easy and sometimes it’s, I guess, it may be democratizing the process of writing software, because you don’t really need to know some of those hardcore algorithms, or maybe sometimes learn how a specific program and language works.
Rather, you need to understand the concepts, the systems, as something more abstract, and I guess intellectually challenging.
I see how many people changed in terms of how they write code, let’s say, managers, who typically do not write code, but they possess all of this very interesting information.
For example, what qualities of a systems are important, so they can codify that knowledge and then an AI system will just code it for them.
Of course, there are some limitations of what an AI system can do, but the key here is that it enables some people, especially those who possess some of the knowledge, but they don’t know the programming language.
Shane Hastie: Thinking of developer education, what would you say to a junior developer today? What should they learn?
Advice for Junior Developers [10:16]
Sergii Gorbachov: My background is in social sciences and humanities, so maybe this whole shift fits me very well, because I can operate at a higher level where you think about, you take a system, you break it down, and when for example, in humanities, you always look at the very non-deterministic systems, let’s say languages or things that are more related to humans, and it’s very hard to pinpoint what’s going to happen next, or how the system behaves.
I would suggest focusing more on system analysis or understanding, I guess, some of the … Or taking maybe more humanities classes, that help you analyzing very complex things that we deal with every day, like talking to other people or relationships, psychological courses.
Then, that would give the ability or this apparatus to handle something so non-deterministic, like dealing with an LM, and being able to create the right prompts that would generate good code.
Shane Hastie: If we think of the typical CI pipeline series of steps, how does that change? What do we hand over to the tools, and what do we still control?
Impact on CI/CD and Development Workflows [11:47]
Sergii Gorbachov: I think, we’re still controlling the final product, and we still I think, have the ownership of the code that we produce, regardless of what tools we use, AI or no AI tools.
We still have to be responsible. We cannot just generate a lot of code, and today generation is the easiest part. The most difficult part is that you have generated so much code that you don’t know what it does, you don’t know how to validate it.
Long-term, it could be problematic, because there is a lot of duplication, some of the abstractions are not created. Long-term, I think we should still think about code quality, and control what we generate and what code is produced.
As for the whole experience, human experience, does it change? With CI systems in particular, they have served very well for us to automate certain tasks.
Let’s say you create a PR, you write your code and all of those tests linters run there, and one of those, let’s say, linters on steroids, could be an AI system that would just check our code.
It would probably not change too much of our work today, but it will be able to provide us extra feedback that we should act on. That’s I think, the reality right now.
Long-term, for example, another initiative that I’ve been working on, is test generation, and test generation is a part that no other tools can do.
Let’s say, a developer or you or me, create a piece of code and then you do not cover it with tests.
In that case, you can hook up an AI system that would generate the tests, suggest it for you, and maybe create a background job that you would be able to come back later, in one day or two days, and fix those tests or add them.
Especially for features that are not production facing, let’s say, it’s a prototype. It changes how we might be doing our job, especially for testing, where it could switch how we view, for example, some of the tasks, if they can be outsourced to an AI system, and usually AI system take longer than 10 to 20 minutes to produce some artifact.
Then, we would just change our way of working. Rather than doing everything right away in an alternative fashion, we would just create the bare bones and then ask all of those systems to do something for us in the cloud, in CI systems, and come back the next day or in two days and continue on them, or just validate and verify that what has been produced is of good quality or not.
Shane Hastie: One of the things that we found in the engineering culture trends discussion recently, was pull requests seem to be getting bigger, more code. That’s antithetical to the advice that’s been the core for the last, well, certainly since DevOps was a thing. How is that impacting us?
Challenges with Larger Pull Requests [15:19]
Sergii Gorbachov: I guess, one of the metrics that I sometimes look at is PR throughput, and definitely, if for example, your PR has a lot more code, then it would take a longer time for other people to review it, or a developer to add a code for that feature to be working.
It’s definitely, probably making, AI systems make it more possible for you to generate and create more code.
I’m not sure exactly what the future with this is, but the idea that everyone had, for example, the AI systems will increase the PR throughput and merging a lot more code.
I mean, creating maybe more PR’s is not the reality, because there is just too much code and we just maybe are using their own metrics here, and there is a mismatch between what has been before, versus the speed that AI allows us to produce that code with.
There is more code, but I think that maybe the final metrics should be slightly different, rather than what has been before, or what has been popular in DevOps such as PR size or PR throughput.
Shane Hastie: Again, a fairly significant shift. What are some of the important metrics that you look at?
Important Metrics and Tool Selection [16:51]
Sergii Gorbachov: I work at a more local level, and I come from a testing background, and I deal with front-end test frameworks.
Some of the important metrics for me specifically, is how long developers wait for our tests to run, so they can go to the next step, or before they get feedback.
Things like test suite runtime, test file or test case runtime, and those are our primary metrics for developers to be happy with … Creating the PR and getting some feedback.
I think that’s the main one for us. Wouldn’t look for … There’s probably a lot more other metrics, that people at my company are looking at, but for our team, for our level, that’s the main one.
Shane Hastie: There’s an abundance of tools, how do we choose?
Sergii Gorbachov: I think, that at this time, especially in my work, I can see ourselves more a reactive team, and when we see a problem, we sometimes cannot foresee it, but when we see a problem, we should probably use whatever tools are available for us at that time, rather than spending time and investing too much into building our own things to predict whatever is going to come next.
For example, for my previous work, for all these tools for test generation or Enzyme to RTL conversion, of course, we looked at all of the available tools, but there was nothing, because some of those tools are not created with an AI component in mind.
I think right now, a lot of my work, or people in the DevOps role, they spend a lot more time on building the infrastructure for all of these AI tools to consume that information.
Let’s say, in end-to-end testing, which is at the highest level of the testing pyramid, you sometimes get an area or a failed test, and it’s very difficult to understand what’s the root cause of this, because your product, your application might be so distributed and there is no clear associations between some of those errors.
Let’s say, you have three services and one service fails, but in your test you only see that an element, for example, did not show up.
It’s a great use case for an AI system, that can intelligently identify the root cause. Without the ability to get all of the deformation from all of those services while the test is running, it would be impossible.
Those systems, those pipelines, they at this point do not exist. I see that, at my company, that sometimes we’re used to more traditional, typical use of, let’s say, logs, where you have very strict permission rules, so that you cannot get access to some of the information from your development environment, where tests are running.
Those are the things that I think, it makes sense to invest and build, in order to beef up these AI systems. The more context you provide for them, the better they are.
I think therefore, some of the tools that we’ve been building, that’s how our work has changed. We are building these infrastructure and context collection tools, rather than using AI for all of that.
Following, I think, an AI endpoint or using an AI tool is probably the easiest, but collecting all of that other stuff is usually 80% of the success in the project.
Shane Hastie: What other advice, what else would tell your peers about your experience using the generative AI tools, in anger, in the real world?
Advice for Others on Using AI Code [20:58]
Sergii Gorbachov: I would say, one of the things that I saw among my peers and in other companies, or on LinkedIn, is that people are trying to build these very massive systems that can solve any problem.
I think, the best result that we got from our tools, was when the scope is so minimal, the smaller the better. Try to analyze the problem that you are trying to solve and break it down as much as you can, and then, try to solve and automate that one little piece.
In that case, it’s very easy to understand if it works or it doesn’t work. For example, if you can quantify the output, let’s say, in our case we usually count things like saving engineering hours. How long would it take me to do that one little thing? Let’s say, we’ve save 30 seconds, but we run our tests 30,000 times a month.
There you go, that’s some metrics that you can go and tell to your managers or present to the company, so that you can get more time and more resources to build the system, and show that there is an actual impact.
Go very, very, small, and then try to show impact. I think, those are two things. I guess, the third one is just, try it out. If it doesn’t work, then it’s all right, and if it’s a small project, then you wouldn’t waste too much time, and always there’s the learning part in it.
Shane Hastie: Sergii, lots of good advice and interesting points here. If people want to continue the conversation, where do they find you?
Sergii Gorbachov: They can find me on LinkedIn. My name is Sergii Gorbachov.
Shane Hastie: We’ll include that link in the show notes.
Sergii Gorbachov: Perfect, yes.
Shane Hastie: Thanks so much for taking the time to talk to us today.
Sergii Gorbachov: Thank you.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Soledad Alborno
Transcript
Alborno: My name is Soledad Alborno. I’m a product manager at Google. I’m here to talk about what to pack for your GenAI adventure. We’re going to talk about what skills can you reuse when building products, GenAI products, and what are the new skills and new tools that we have to learn to build successful products. I’m an information system engineer. I was an engineer for 10 years and then moved to product. I’m an advocate for equality and diversity. I’ve been building GenAI products for the last two years.
In fact, my first product in 2023 was Summarize. Summarize was the first GenAI product or feature for Google Assistant. We had a vision on building something that helped the user get the gist of long-form text. Have you ever received a link from a friend or someone that you know, saying, you have to read this, and you open it and it’s so long and you don’t have time? That’s the moment when you pull up Google Assistant and now Gemini, and you ask, give me a summary of this. It’s going to create a quick summary of the information you have in your screen. In this case, this is how it looks like. You tap the Summarize button and it generates a summary that you can see, in three bullet points. We will talk about, when I started this product and what I learned at the end.
My GenAI Creation Journey
When I started building Summarize, I thought I was like a very seasoned product manager, 10 years of experience. I can do any kind of products. Let’s start. That was good. I had a lot of tools in my backpack. On the way, I learned that I had to interact with this big monster, the non-deterministic monster that is LLM and GenAI, I call it here Moby-Dick. In my journey of building this product, I learned to treat and build datasets. I learned to create ratings and evals. I will share with you some tips on how do we build those evals and datasets so it makes a successful product. I had to learn to deal with hallucinations, very long latencies and how do we make this thing faster. Because you ask for a summary, you don’t want to wait 10 seconds to get the result. Trust and safety, so a lot of things related to GenAI are related to trust and safety, and we had to work with that.
Traditional Product Management Tools are Still Useful
I’m going to start with a few questions. Have you ever used any kind of LLM? Have you used prompt engineering to build a product? Just prompt engineering: you set up some roles for the model, you made it work. Are you right now building a GenAI product in your role? Have you ever fine-tuned a model? Do you design evals or analyze rating results for a product? Do you believe your current tools and skills are useful to create GenAI products? Whatever you know is very useful to create AI products.
My role is to be a product manager. In order to be a product manager, I need to know my users. I’m the voice of the user in my products. I need to know technology because I build technical solutions for my users. I need to know business because whatever product I build needs to be good for my business and be aligned to the strategy. That’s my role.
In my role, the tools and skills that I get as anyone that works in any startup or how to lead any project know, the first one is business and market fit. I need to know, who are my competitors, what’s happening in this market, how to align to the business goal, how do we make money with this product? It’s still very relevant in the GenAI world. No changes there. I need to know, who are my target users? Are these professional users? Are these people students, they are doctors? What is the age I’m targeting? Very important as well for generative AI products. You need to know your users because they will interact with the product. I need to know, what are the users’ pain points? What are the problems? What are the things that will help me understand how to build a solution for them and prove that my solution helped them to solve a real problem and bring real value to them? I need to know, then work with my teams and everyone to build a solution for those problems. To build a solution, I’m going to write the requirements.
These are still very relevant terms for any product, software product. There are little differences there that we will talk about. The last two things are metrics. We need to know how to measure this product to be successful. Go-to market, how are we going to push this product in the market, our marketing strategies, and so on? Everything relevant, all your skills, everything that you have in your backpack so far, everything is useful for GenAI. The difference is in the solution and requirements. There are very small differences there. This is where we need to help our engineering teams to pick the right GenAI stack. They will start asking, what type of model. Do I need a small model, a big model, a model on device? Does it need to be multimodal or text only? What is this model and how do we pick it?
Activity – Selecting the Right GenAI Stack
Next, I’m going to work on a little exercise that will help us to understand, what is the difference between a small model and a big model, and why do we care? The first thing I want to tell you is we care because small models are cheaper to run than bigger models. That’s the first thing why we care. Let’s see what is the quality of them. Who loves traveling here? Any traveler? Who can help me with this question? Lee, your task is super simple. Using only those words, adventure, new, lost, food, luggage, and beach, you have to answer three questions, only those words. Why do you love traveling?
Lee: Got leaner luggage. Food, and beach, and adventure, and new.
Alborno: Describe a problem you had when traveling.
Lee: Luggage, lost, food, adventure.
Alborno: What’s your dream vacation?
Lee: Adventure.
Alborno: As you can see, it’s a little hard to answer these very easy questions with restricted vocabulary. This represents a model with few parameters. It’s fast to run. It’s only a few choices, but it’s cheaper. The response is not that good. It doesn’t feel like human. What happens when we add a little more words to the same exercise? It’s the same questions. Now we have extra words: adventure, new, lost, food, luggage, beach, in, paradise, the, we, our, airport, discover, relax, and sun. Why do you love traveling?
Lee: Adventure, discover, relax, currently paradise.
Alborno: Describe a problem you had when traveling.
Lee: Lost, new, the sun sometimes.
Alborno: What is your dream vacation?
Lee: Not in the airport. Beach, adventure, paradise, sun.
Alborno: We are getting a little better, getting a little longer responses. Still some hallucination in the middle. Hallucination means that the model is inventing stuff that is not in the intent of the response because it doesn’t have more information than what we have here in the vocabulary. The last one is, using all the words in the British dictionary and at least three words, we are introducing some prompt here, why do you love traveling?
Lee: I like the travel to be good. I like the adventure of going to new places and discovering the history and the culture of the people.
Alborno: Describe a problem you had when traveling.
Lee: The airport’s usually a free work zone. I lost money, being lost.
Alborno: What is your dream vacation?
Lee: Going somewhere new, that the people are friendly and inviting.
Alborno: You can see when the model has more information, more parameters, then it’s easier for the answers to be better quality and to represent human in a better way. You can borrow this exercise to present this to anyone, any customer that doesn’t know about how this works. It works very well. I did it a couple of times.
Requirements to Select the Right GenAI Stack
Let’s go back to the requirements. How do we make sure that we help the engineering team to define the right model or the right stat to use in my product? There are many things we need to define. Four of the things that are very important are the input and the output, but not in the general way. We need to think about, what are the modalities? Is my system text only, text, images, voices, video, attachment, document? What is the input of my process and my product? What is the output? Is it text? Is it images? Are we generating images? Are we updating images? What is the output that we need from the model? Accuracy versus creativity. Is this a product to help people create new things? Is it a GenAI product for canvas or to create images for a social network, for TikTok, for Instagram? What is it? If it’s creative, then it’s ok. It’s very easy. LLMs are very creative.
If we need more accuracy, like a GenAI product to help doctors to diagnose illnesses, then we need accuracy. That’s a different topic. It’s a different model, different techniques. We will use RAG, or fine-tune it in a different way. The last one is, how much domain specific knowledge? Is this just a chatbot that talks about whatever the user will ask or is it a customer support agent for a specific business? In which case, you need to upload all the domain specific knowledge from that business. For instance, if it is doing recommendations to buy a product, you need to upload all the information for the product.
For Summarize, I have the following requirements. User input was text. We started thinking, we are going to use the text and the images from the article. Then, the responses were not improving. The model was slower, so we decided to use text to start, and the responses were good enough for our product. In the output, we said, what is the output? Here it was a little complicated because we all know what a summary is. We all have different definitions of a summary. I had to use user experience research to understand, what is a summary for my users? Is it like two paragraphs, one paragraph, two sentences, three bullet points? Is it 50 words or 300 words?
All of these matter when we decide what is this product going to do. We had to go a little into talking with a lot of people and understanding, at the end of the day, what we decided is three bullet points was something that everyone would agree is a good summary. We went with that definition for my output. We wanted no hallucinations. Not in the typical term of, do not add flowers in an article that is talking about the stock. It was no hallucination in the sense, do not add any information that is not in the original article, because LLMs were trained with all of this massive amount of information. They tend to fill in the gaps and the summaries will have information from other places. We needed to make sure the summary accurately represented the article. For that, we had to create metrics and numbers.
Actually, metrics, automated metrics. It’s a number that represents how good the summary represents the original article. We did that to improve our quality of the summaries, too. Last, we didn’t have any domain specific knowledge. We just had the input from the article we were trying to summarize.
The Data-Driven Development Lifecycle
Once we have all the requirements, we say, how do we start developing this thing? The first thing was, create a good dataset. We started. When I work with my product teams, we work with a small, medium, and large dataset. The small dataset is 100 inputs that we can get from different previous studies, from logs of our previous system, or whatever. Sometimes the team makes the inputs. We create 100 prompts and we test. That’s a small dataset. It’s nice because in a small dataset, you can have different prompts, different results from different models for the same prompt. You can compare it with your eyes. You can feel what is better and feel where is the missing point for each of them. We have a medium dataset that usually I use that with the raters and in the evals. That’s about 300 examples.
A large dataset, it’s like 3,000 examples or more, depending on the context, on the product. That big dataset is more for training and validation and fine-tuning. First, we create our datasets. Second, when I had the 100 examples dataset, we went to prompt engineering and just take the foundational model, do some prompting, just generate a summary for this, and get the results. Maybe do another one with generate a summary in three bullet points. Generate a summary that is shorter than 250 words. We try different prompts, so we can evaluate this thing.
Then, in some of the cycles, we also have model customization. Here is when we use RAG or fine-tuning to improve the model, and the evaluation, which is actually using an evaluation criteria. We send these examples to raters, people that will say, this is good or not, or more or less. Then, we can have patterns. We use these patterns to add more data to the dataset, and go again. This is a cycle. We keep going until we feel that the quality is good and the result of the evaluation is good.
What is next is, how do we make sure the evaluation is good? What is a good summary for me, may be a bad summary for Alfredo or for someone else. We have what we call evaluation criteria. For that, we will try it out. What you see on top is the abstract of this talk. It’s in the QCon page. It’s basically describing what I’m going to talk about in this talk. I asked LLMs to generate three summaries, 1, 2, and 3. The first summary was creating a paragraph format. It actually talked about the presentation. We have the essential tools and skills to develop GenAI products. It talked about covering core product manager principles, and considerations for building LLMs and so on. The second one is very not formal. It’s like GenAI stuff, AI products, or whatever. Yes, it’s a summary, but it’s in a very different tone.
The third one is just three bullet points, very short. It doesn’t have a lot of details. Who here thinks that the first one is the best summary for this text? Who here thinks that the second one is the best summary? Who thinks the third one is the best summary here? As you can see, we have different perceptions. This is subjective. We need to create an evaluation criteria. This is an example, not the one that we created.
In this evaluation criteria, we have four different things. We have format quality. Is the response clear? Is it like human language? Does it have the right amount of words or the right format? Completeness, which is, does the summary have all the key points from the original text? Conciseness, which is, does it have only the necessary content without being repetitive or too detailed? Accuracy, which is, does the summary have information only from the original text? What we do with this, once we set up the evaluation criteria, we send this evaluation criteria with a sample of about 300 prompts or text to raters, and ask them, can you evaluate this? Usually, they are tools like this, where they can see two summaries or three summaries next to each other.
They have to rate, from 1 to 5, format quality, which of them has the best format? You can see number 3 is a little more structured, has more points than number 2. Which of them is more complete? Number 1 has more details than number 3. Which of them is more accurate? You can see, for instance, number 3 maybe is not that accurate because it says LLM considerations. I don’t know if that was part of the original text. Conciseness, number 3 was more concise. What happens here is, usually we use raters. Two or three raters will rate each of the data points. We can create average. This is a 300 dataset. That will give me actually an indication. Because for some summaries, some text is going to be tricky, but for others, no. In general, we will have a sense of how good is the summary based on this evaluation criteria.
Risk Assessment for GenAI
The last point is our risk assessment. Once we have all our summaries and the full product, we need to think about three topics, trust and safety, legal, and privacy. This will also be part of the dataset generation later. For instance, can we summarize articles that talk about which mushrooms can we use to make a meal to eat? If true, how do we check that the summary generated is actually safe and it will not do any damage to any of our users? We have seen examples of this, where AI told users to eat poisonous mushrooms. We don’t want that happening. We really need to think about our output. Is it safe, always safe? What are the risk patterns? Like in traditional software, we were always thinking about, what are the attack vectors? What are the risk patterns we have in this product? How do we add data to the dataset so we can prove that the model is reacting well? We have legal concerns.
One of the things I always care about when we talk about legal is, where is the data coming from, the data that we are using in our datasets? Do we have access to that data? Is it generated or not? Also, legal comes into play when we have things like, for instance, disclaimers. What are we going to tell our users about the use of LLMs? How do we tell them that we may have hallucinations? Privacy, which is, what do we do with the personal information we feed this machine? In some cases, there is no personal information, which is great. When we have personal information, how do we create datasets to prove that the personal information is not put at risk?
Conclusion
All of our tools that we learned with product creation are useful for GenAI products. There are a few new skills and things that come into play, but these things will keep changing. New tools will be added. New processes will be created. In GenAI, the only constant is change.
Questions and Answers
Participant 1: You talked about evaluation criteria. Could they have been generated by AI as well?
Alborno: Yes. The evaluation criteria is not only the definition of what are the areas that we want to evaluate, but we need to provide description of that evaluation criteria to our raters, and what does it mean to have one star versus five stars versus three stars? Usually, all of that goes into a description, because when you have a team of 20 raters, we need them to use the same criteria to evaluate.
Participant 2: You mentioned the definition of a summary is different for different people. You gathered some data to look at experience research. Google has those resources, but not every other company does. Are there any product intuition that you can share with us that if you don’t have those resources, how can we approach these problems?
Alborno: You start with product intuition, yes, very important. Then, I think team food and dogfood are very important, and to have the instrumentation to measure that, in team food and dogfood, to measure the success. I think that’s important. Sometimes, when we develop product, and this is not GenAI product, products in general, we leave the metrics to the end. We didn’t have time to implement these metrics, and we release anyway. Sometimes we do that. Then, we risk gathering this information that is so important. Start there with good metrics. Then, try it in team food and dogfood, like small groups of users. Then, test different things until you have something that works better. Then, you go to production.
Participant 3: You mentioned at the beginning that for the same prompt you’re going to get different results. How do you then manage to make your development lifecycle reproducible? Do you have any tips for that?
Alborno: In my experience, building GenAI products in the last two years, the best way I’ve seen to control the diversity of results was with fine-tuning and providing examples to the machine of what do I want it to generate. In the beginning in Summarize, and this was in the beginning of GenAI, it was very different to what it is just a few months later. In the beginning, we would say, generate a summary under 150 words, and the thing would generate a 400-word summary. We were like, “No way, we cannot ship something like that”. We had to use a lot of examples before, so the machine understood what it is, a 150-word summary, to do it. If you use Gemini 1.5 now, for instance, it knows what is 150 words. It’s better to follow instructions. You may not need that fine-tuning.
Participant 3: For the evaluation study, did you use human raters, or did you also use GenAI?
Alborno: We used both, because we have resources. Then, you can hire a company to do the ratings. We used that, because it’s important to have human input. We also generated automatic rating systems. It’s our first version of those systems, now it’s very more complex than that. The first version of those systems. What I’m doing with my friends as well, is like, ask an LLM in a second instance to rate the previous result. You feed the rules and the evaluation criteria, and it’s going to generate good ratings, too.
Participant 4: I’m curious how you protect against, or think about bias in your evaluation criteria. Because even as I was thinking about summarizing, women, on average, use a lot more words than men, and people may. They probably have different ideas of what they want a summary to be. I’m just curious how you approach that in general, and with the evaluation criteria being specific, how do you define what complete is?
Alborno: What we used in that sense, because this summary was a summary of the original text, the original text may have bias, and the summary will have bias. That’s just by design, because what we tested is that the summary reflects what is in the original article. If you are reading an article that you don’t agree with the content, and you know it has flaws, and you generate a summary, you should be able to realize those flaws in the summary. In this case, for a summary, it’s not a problem, because it’s going to be based on the original text. You don’t want to insert any bias, but that you measure by comparing those two things. In other products, you may have bias, and that’s a different thing.
Participant 5: This is a good description of product development, how you launch in the first place. How do you then think of product management? The core tech stack continued to evolve. There’s knowledge cutoff. There’s new capability. When do you go back and revisit?
Alborno: LLMs keep evolving. Every version is better than the previous one. I think what is important in my lifecycle is that the dataset, the evaluation criteria, and the process that we use to make sure that the results are good, do not change. You can change the machine, and you can fine-tune it, make it smaller, or bigger, or whatever. Then, you still have the framework to test and produce the same quality, or actually check if the new model has a better quality or not. It’s very important to have this time in, what are my requirements, what is my evaluation criteria, and what is my dataset that I will use?
Participant 6: How do you deal with different languages potentially having different constraints on that? For example, we were discussing Spanish. You usually need more words to express the same thing. Three hundred words in Spanish, you may be able to convey less content than 300 words in English.
Alborno: First, you want your dataset to be diverse and representative to your user base. If your user base is multiple languages, then you have multiple languages in your dataset and your criteria. Second, we set the number based on the time it would take to read those words. Because assistant is a system that you use, it’s voice-based too, you can ask, give me a summary, and listen to a summary. We measure that the summary should be able to be read in less than two minutes or something like that. You create a metric that’s not based on the language, but based on the amount of attention you need to process the output.
Participant 7: I was reading through your data lifecycle diagram and it kind of presents the system. It’s been a long rating physical system and probably has momentum to it. What happens if one of the components fails? For example, you’ve got a key criteria or, for example, you have raters and it turns out your rating company that you use is not trustworthy [inaudible 00:35:24]. How do you stabilize the system if there’s a sudden crash?
Alborno: Between the evaluation phase and the dataset augmentation phase, you need to do some analysis. If you see that everything is good, you still have your small dataset that you can visualize and check one by one. If there are big errors, you will find them because there are so many raters and so many data in the dataset that you need to be able to highlight those errors. Sometimes what we do is we remove some of these outliers from the dataset, or pay special attention to them and increase the dataset using more examples like those. It’s all about the evaluation of the result of the evaluation phase.
See more presentations with transcripts
MMS • Ben Linders

Becoming a principal engineer requires more than technical skill, it’s about influence, communication, and strategy. Success means enabling teams by shaping culture, Sophie Weston said. In her talk at QCon London, she suggested developing deep skills in multiple domains, with general, collaborative skills. Skills from life outside work, like sports, volunteering, or gaming, can add valuable perspective and build leadership potential.
Principal engineer is often the highest level of the individual contributor path. Getting there needs more than just having deep technical expertise, as Weston explained:
It’s about influence, communication, and strategy. It’s about understanding that your career isn’t just about climbing; it’s about navigating, adapting, and growing in ways that matter to you.
Principal engineers focus less on what teams build and more on how they build, Weston said. It’s helping teams do great work, creating an environment where people thrive. By reducing friction, they help teams and the wider organisation move faster, avoid unnecessary obstacles, and stay on track.
According to Weston, engineering leadership consists of:
- Setting technical direction. This is about guiding teams and helping them to make smart architectural and technical choices.
- Driving good engineering practices. Helping teams build software efficiently and deliver real value – both to the business and its customers.
- Shaping culture. Mentoring, coaching, and making the organisation a place where engineers thrive.
Weston mentioned that as a principal engineer, she’s passionate about creating a good engineering culture that is good both for the organisation to deliver value effectively and efficiently and for the people working in it:
We want to have impressive DORA metrics, but not at the expense of burning people out.
Engineers need to broaden their skill set if they want to advance towards engineering leadership. Technical knowledge, no matter how deep, no matter how impressive, is not going to be enough, Weston said. She suggested developing deep skills in multiple domains, with general, collaborative skills as well:
Being Pi-shaped is valuable, but leadership demands more breadth. You need to become a “broken comb”—someone with expertise in multiple areas and the ability to connect insights across domains.
As a “broken comb”, you don’t just have expertise in multiple areas; you have varying depths of knowledge to bridge gaps, connect ideas, and solve problems creatively, Weston said.
Weston argued that people should bring their whole selves to work. She mentioned things that people do outside of their job, where they can learn and practice useful leadership skills:
If you’re part of a sports team, you will be building skills in team working and resilience. If you do volunteering, say in a youth group for example, you’ll develop skills in coaching and problem-solving. Maybe gaming is your thing, in which case you are likely to have strong skills in strategic thinking and adaptability.
Getting involved in the tech community and helping to organise events is a fantastic way to learn and practice new skills, Weston mentioned.
Don’t undervalue skills that you learn in other parts of your life and how they can help you in your career journey. We often talk about the importance of psychological safety and the need for people to be able to bring their whole selves to work and be themselves at work, this applies in a wider career context too, Weston said.
The skills you learn outside of work are equally valuable as the ones you learn through actually doing your job, Weston said. Sometimes they are more valuable because they represent more teeth on your “broken comb”. It’s not just the skills themselves that are valuable, but the additional perspective you have from having acquired them in a different setting, Weston concluded.
MMS • Daniel Curtis

Vitest, the modern Vite-native test runner, has introduced Vitest Browser Mode, offering developers an alternative to traditional DOM simulation libraries like JSDOM. The addition of browser mode to Vitest allows tests to run in an actual browser context, offering more realistic and reliable testing behavior for UI applications built with React, Vue, or Svelte.
Vitest Browser Mode is currently experimental.
Vitest Browser Mode was introduced to help improve testing with more accurate and reliable test results, it does this by running tests in a real browser context using Playwright or WebDriverIO. This mode allows for realistic browser rendering and interaction.
Historically, JSDOM has been the default simulated environment for running front-end tests in Node.js. It simulates a browser DOM inside Node, making it a convenient and fast option for unit testing. However, due to the fact that JSDOM isn’t a real browser, its implementation can sometimes fall short for advanced use cases, such as layout calculations, CSS behavior, or APIs not yet supported in JSDOM. Vitest aims to replace JSDOM environments with an easy migration path.
React Testing Library, a lightweight library for testing React components, is built on top of the DOM Testing Library, which provides utilities to interact with the DOM. It has long relied on JSDOM for simulating DOM interaction. With the introduction of Vitest Browser Mode, it is possible to migrate away from React Testing Library as a number of the APIs have been natively rewritten in the same familiar pattern of React Testing Library. Kent C. Dodds, the author of React Testing Library, says he has never been so happy to see people uninstalling React Testing Library in favor of the native implementation.
Vitest also provides support for other frameworks, such as Vue and Svelte. There is also a community package available for Lit. It supports multiple different browser environments depending on which platform you use, if you opt for WebDriverIO, it supports testing in four different browsers, Firefox, Chrome, Edge and Safari. Playwright supports Firefox, Webkit and Chromium.
There are some drawbacks to using Vitest Browser Mode, as outlined in their documentation, such as it being in experimental mode and therefore still early in its development. It can also have longer initialization times compared to other testing patterns.
Vite is an open-source, platform-agnostic build tool named after the French word for ‘quick’. It was written by Evan You, the creator of VueJS. Vitest is a next generation Vite-native framework that reuses Vite’s config and plugins; it supports ESM, TypeScript and JSX out of the box.
Full documentation for Browser Mode is available on the Vitest website including setup guides and examples.
MMS • Robert Krzaczynski

Perplexity has released Labs, a new feature for Pro subscribers designed to support more complex tasks beyond question answering. The update marks a shift from search-based interactions toward structured, multi-step workflows powered by generative AI.
Perplexity Labs enables users to perform a wide range of tasks, including generating reports, analyzing data, writing and executing code, and building lightweight web applications, all within a single interface. Users can access Labs via a new mode selector available on web and mobile platforms, with desktop support coming soon.
While Perplexity Search focuses on concise answers and Research (formerly Deep Research) offers more in-depth synthesis, Labs is designed for users who need finished outputs. These can include formatted spreadsheets, visualizations, interactive dashboards, and basic web tools.
Each Lab includes an Assets tab, where users can view or download all generated materials, including charts, images, CSVs, and code files. Some Labs also support an App tab that can render basic web applications directly within the project environment.
According to Aravind Srinivas, CEO and co-founder of Perplexity:
Introducing Perplexity Labs: a new mode of doing your searches on Perplexity for much more complex tasks like building trading strategies, dashboards, headless browsing tasks for real estate research, building mini-web apps, storyboards, and a directory of generated assets.
In practical terms, Labs automates and combines tasks that would otherwise require multiple software tools and considerable manual input. This is particularly relevant for tasks involving structured research, data processing, or prototyping.
Initial feedback has highlighted the speed and contextual accuracy of the platform. Sundararajan Anandan shared:
I recently tried Perplexity Labs, and it is a game-changer. Tasks that once took hours of manual research and formatting were distilled into crisp, actionable insights in under 10 minutes. While it is still early and the platform will need time to mature, the initial experience is genuinely impressive.
However, some early users have pointed out areas for improvement. In particular, follow-up interactions and code revisions after the initial generation are currently limited. As one Reddit user commented:
The biggest problem with Labs is that it doesn’t handle follow-ups very well. It basically requires you to be a one-shotting ninja.
The company has also announced that it is standardizing terminology, renaming “Deep Research” to simply “Research” to clarify the distinctions between the three modes: Search, Research, and Labs.
Perplexity Labs is now live and available to all Pro users. Additional examples and use cases are available via the platform’s Projects Gallery, designed to help users get started with practical tasks.
MMS • Craig Risi

In a recent blog post, Pinterest Engineering detailed its approach to addressing network throttling challenges encountered while operating on Amazon EC2 instances. As a platform serving over 550 million monthly active users, ensuring consistent performance is paramount, especially for critical services like their machine learning feature store, KVStore.
Pinterest observed increased latency and occasional service disruptions in KVStore, particularly during periods of high traffic. These issues often led to application timeouts and cascading failures, adversely affecting user engagement on features like the Homefeed. The root cause was traced to network performance limitations inherent in certain EC2 instance types, which offer “up to” a specified bandwidth. For example, an instance labeled with “up to 12.5 Gbps” might have a baseline bandwidth significantly lower, relying on burst capabilities that are not guaranteed. When network usage exceeded these baselines, packet delays and losses ensued, impacting application performance.
In 2024, Pinterest initiated a migration to AWS’s Nitro-based instance families, such as transitioning from i3 to i4i instances, aiming for improved performance. However, this shift introduced new challenges. During bulk data uploads from Amazon S3 to their wide-column databases, they observed significant performance degradation, particularly in read latencies, resulting in application timeouts. These findings prompted a temporary halt to the migration of over 20,000 instances.
With improved visibility into their network performance, Pinterest implemented several key strategies to mitigate EC2 network throttling. One of the primary approaches was selecting EC2 instances with higher baseline network bandwidth to better support their workloads, moving away from instances that only promised burstable performance. They also introduced traffic shaping techniques to regulate data flow and ensure network usage stayed within optimal thresholds.
In addition, Pinterest distributed workloads more evenly across multiple instances, reducing the risk of overloading any single resource. These combined efforts significantly enhanced the reliability and stability of their systems, effectively minimizing latency spikes and preventing the kind of service disruptions that had previously impacted user experience.
Pinterest’s experience underscores the importance of understanding the nuances of cloud infrastructure, particularly the implications of network bandwidth limitations on EC2 instances. By proactively monitoring and adjusting their infrastructure, they successfully navigated the challenges of network throttling, ensuring a smoother experience for their vast user base.
MMS • Steef-Jan Wiggers

Virt8ra, a significant European initiative positioning itself as a major alternative to US-based cloud vendors, has announced a substantial expansion of its federated infrastructure. The platform, which initially included Arsys, BIT, Gdańsk University of Technology, Infobip, IONOS, Kontron, MONDRAGON Corporation, and Oktawave, coordinated by OpenNebula Systems, has now been joined by six new cloud service providers: ADI Data Center Euskadi, Clever Cloud, CloudFerro, OVHcloud, Scaleway, and Stackscale.
Quentin Adam, CEO of Clever Cloud, commented:
By championing open source and empowering local providers across the EU, Virt8ra is not only helping to reduce our continent’s reliance on hyperscalers and Big Tech vendors, but also laying foundations for a truly autonomous and innovative digital future.
Launched in January 2025 by a consortium of eight European tech organizations coordinated by OpenNebula Systems, Virt8ra aims to establish a sovereign and interoperable cloud ecosystem across the European Union. Leveraging the open-source OpenNebula cloud technology, the initiative prioritizes data localization, flexibility, and vendor independence. The initial phase offered compute and storage resources across six EU member states: Croatia, Germany, the Netherlands, Poland, Slovenia, and Spain.
A commenter on Reddit pointed out the broader challenge, stating:
Infrastructure AND the associated software, if I may add! One of the strengths of Azure and AWS, justifying their services, which are 10 times as expensive as those of OVH or Scaleway, is the huge software suite that comes with it. With LLMs and the associated productivity gains, I guess Europe could catch up quite quickly. However, we need to create strong incentives for European companies to switch to European cloud providers.
Just three months later, this expansion significantly broadens Virt8ra’s reach and capacity. Dr. Ignacio M. Llorente, CEO of OpenNebula Systems and Chair of the Cloud-Edge Working Group at the European Alliance for Industrial Data, Edge, and Cloud, emphasized Virt8ra’s importance as “a key step toward building a sovereign and interoperable cloud ecosystem in Europe.”
Furthermore, Virt8ra is designed to facilitate the easy deployment of distributed applications spanning the cloud-edge continuum, with a strong emphasis on AI and machine learning. The infrastructure is currently being validated through enterprise use cases that demonstrate innovations in AI-enabled orchestration, mechanisms for Data Act-compliant cloud migration and data egress, and the future potential for multi-tenant “AI-as-a-Service” offerings for both inference and training.
In addition, the collaborative effort is taking place within the framework of the Important Project of Common European Interest on Next Generation Cloud Infrastructure and Services (IPCEI-CIS). The IPCEI-CIS, approved by the European Commission in December 2023 and supported by 12 EU Member States, represents the European Union’s largest open-source project to date, backed by over €3 billion in public and private funding. Dr. Alberto P. Martí, chair of the IPCEI-CIS Industry Facilitation Group, commented:
I’m proud to see the EU industry finally taking the lead in developing strategic open-source technologies and delivering tangible solutions for creating sovereign digital infrastructure across Europe.
The ultimate objective of Virt8ra is to integrate and validate a European sovereign virtualization stack built around OpenNebula, delivering an open-source, vendor-neutral solution for managing the entire cloud-edge continuum. An objective that might empower EU businesses and public organizations, strengthen their digital sovereignty, and reduce their reliance on non-European hyperscalers and Big Tech vendors.