Category: Uncategorized

MMS • Vlad Khononov
Transcript
Thomas Betts: Hello and welcome to another episode of the InfoQ Podcast. Today I’m joined by Vlad Khononov. Vlad is a software engineer with extensive industry experience working for companies large and small in roles ranging from webmaster to chief architect. His core areas of expertise include software architecture, distributed systems, and domain-driven design. He’s a consultant, trainer, speaker, and the author of Learning Domain-Driven Design. But today we’re going to be talking about the ideas in Vlad’s latest book, Balancing Coupling in Software Design. Vlad, welcome to the InfoQ Podcast.
Vlad Khononov: Hey Thomas. Thank you so much for having me.
Balance coupling is the goal, not no coupling [01:07]
Thomas Betts: So the title of your book, Balancing Coupling, and I think a lot of architects and engineers are familiar with the idea of wanting low coupling, we want to have our systems loosely coupled. But as your book points out, that’s really an oversimplification that we don’t want to have no coupling, we need to have a balanced coupling. So can you explain why that’s an oversimplified idea to say, we just want loose coupling everywhere?
Vlad Khononov: Yes. So by the way, a loose coupling is okay. What I’m really afraid of is people saying, let’s decouple things. Let’s have completely independent components in our system, which is problematic because if you ask yourself, what is a system? What makes a system? Then the answer is a system is a set of components working together to achieve some overarching goal. Now, in order to achieve that goal, it’s not enough to have those components, they have to work together. Those interactions is what makes the value of that whole system greater than the sum of its components, sum of its parts. And those interactions is what we usually call coupling. If you look that word up in a dictionary, coupled means connected.
So to make the system work, we need coupling. Now, of course, too much of a good thing is going to be bad. We need water, any living organism that we know of on this planet needs water to survive. However, if you’re going to drink too much water, well guess what’s going to happen? Nothing good is going to happen. Same with coupling. We cannot eliminate it because just as in the case of water, you’re not going to survive, a system is not going to survive. So we need to find that “just right” amount of coupling that will make the system alive. It will allow it to achieve that overarching goal.
Thomas Betts: I like the idea of if we add too much water, maybe that’s how we get to the big ball of mud, that everything is completely connected. And we can’t see where there should be good separations between those couples, you can’t see the modules that should be there that make the system understandable. And I know that’s part of it is, we want to get to small enough modules that we can understand and work with and evolve over time without having to handle the entire big ball of mud, if you will.
If the outcome can only be discovered by action and observation, it indicates a complex system [03:35]
Thomas Betts: So that coupling itself, that’s not the problem. The problem really is the complexity. And I think people sometimes correlate the two that if I have a highly coupled system that everything’s talking to each other that’s causing the complexity. Can you distinguish where coupling and complexity are not always the same thing, one isn’t always the bad?
Vlad Khononov: Yes. That’s a great point. And the thing is, when we are designing the system, we need to find that “just right” amount of coupling to make it work. And if you go overboard, as you said, we’ll end up with that monster that we usually call “big ball of mud”. And that pretty much describes what we are afraid of, complexity. I guess anyone with a few years of experience in software engineering has that experience of working on a big ball of mud project that maybe it works, but nobody has the courage to modify it because you don’t know what’s going to happen following that change. Whether it’s going to break now or it’s going to break a week later after it was deployed to production. And what is going to break? And that relationship between an action and its outcome is my preferred way of describing complexity.
If you’re working on a system and you want to do something, and you know exactly what’s going to happen, that’s not complexity. If you can ask someone, and some other external expert knows what’s going to happen, that’s not complexity either. However, if the only way to find out the outcome of the thing you want to do is to do it and then observe what happens, then you’re dealing with a system that is complex, and that means that the design of that system makes those interactions much harder than we as people can fathom. We have our cognitive limits, our cognitive abilities, if you look at studies, they’re not looking good by the way. And it means that the design of that system exceeds our cognitive abilities, it’s hard for us to understand what’s going on there. Of course, it has something to do with coupling. However, it’s not because of coupling, but because of misdesigned coupling.
Thomas Betts: Yes. And then I think your book talks about the idea of sharing too much knowledge, that coupling is where knowledge is being transferred. And so the idea of cognitive load being exceeded, the knowledge that I have to have in order to troubleshoot this bug is, I have to understand everything. Well, I can’t understand everything and remember it all, so I’m just going to try and recreate it. And in order for me to try and recreate it, I have to have the full integration stack, right? I have to have everything running, be able to debug all the way through. And the flip side of that is somebody wants to be able to have that experience because they’re used to having the big monolith, the big ball of mud. They’re like, “I don’t understand it, so I’m going to just see what happens”.
Once they’re working in microservices, then they get to, “Well, I can’t actually step through the code once I send the request to the other call, how do I know what happens?” How do you help get people into that mindset of you’re making it better, but it’s a different shift of the paradigm that you can’t just run everything, but the benefit is you don’t have to know about it once it goes past that boundary.
Three dimensions of coupling [07:23]
Vlad Khononov: Yes. And that’s the thing about coupling, we are way too used to oversimplify it. As, Hey, coupling is bad. Let’s eliminate all the coupling, that’s how we get modular software systems. However, if you look what happens when you connect any two components, when you couple any two components in a system. What happens beneath the surface? Then you’ll see that coupling is not that simple, it’s not uni-dimension. Actually, it manifests itself in three dimensions. As you mentioned, first of all, we have that knowledge sharing. You have two components working together. How are they going to work together? How are they going to communicate with each other? How are they going to understand each other? They need to exchange to share that knowledge.
Then we have the dimension of distance. If you have two objects in the same file, then the distance between the source code of the two objects is short. However, if those two objects belong to different microservices, then you have different code bases, different projects, different repositories, maybe even different teams. Suddenly the distance grows much bigger. Why is that important? Well, the longer the distance that is traveled by the knowledge, the sooner it’ll cause that cognitive overload. And we’ll say, “Hey, that’s complexity. We need to decouple things”. So distance is a very important factor when designing coupling.
And the third dimension is a dimension of time, of volatility because oh, why do we care? We want to be able to change the system. We wanted to change its components, their behavior. Maybe we will modify existing functionalities, maybe we’ll add new ones. For that, we want to make sure that the coupling is just right. However, if that is not going to happen, maybe because the component is a part of a legacy system, or maybe the business is not interested in investing any effort in that specific area, then the effect of coupling is going to be much lower. So we better prioritize our efforts on other parts with higher volatilities.
Distance and knowledge sharing are intertwined [09:49]
Thomas Betts: So I want to talk about that distance part first. I think that’s a new way of thinking of the problem because I think we can relate to, I’m going to separate this into microservices and that’ll solve my problem. And if you go back to the combination of how much knowledge is being shared, and how far away it is. Well, if I have all the code in my monolith, then the distance between the code is pretty low, right? I can change all the code all at once, but that also leads to a lot of complexity because I might not be able to easily see what code I need to change because there’s too much of it.
Now, if I take it into the microservices approach, I can say, I only need to change this. There’s only so much code to look at, I can understand it. But if I say, if I make a change here, I also need to make a change in this upstream or downstream service, that they have to know that I’m making a change. Then you’re saying that, that’s where the knowledge comes in, the knowledge being shared is tightly coupled. Is that a good explanation of what you’re trying to say?
Vlad Khononov: Yes, yes. That’s where complexity gets complex. Essentially, we have two types of complexities when working on any system. First, let’s say that you’re working on one of its components, and it is a small big ball of mud, let’s call it a small ball of mud. Then we could say that the local complexity of that component is high. We don’t understand how it works, and if you want to change something, we don’t know what’s going to happen. Now, there is another type of complexity and that’s global complexity, and this one is about the interactions on a higher level of abstraction. Say we have our component and other components of that system, and they’re integrated in a way that makes it hard to predict how changing one of the components is going to be, whether it’s going to require simultaneous changes in other components. So that’s global complexity.
The difference between the two as you mentioned is distance. And way back when the microservices hype just started, people wanted to decouple things by increasing the distance because previously we had all the knowledge concentrated in a monolith, let’s call it the old-school monolith. Everything in one physical boundary. Now, back then decoupling involved extracting functionalities into microservices, so we increased the distance. However, way too many projects focused just on that, on increasing the distance. They were not focused enough on, “Hey, what is that knowledge that is going to travel that increased distance?” And that’s how many companies ended up transforming their old-school monoliths into new shiny distributed monoliths. So they kind of traded local complexity into global complexity.
Coupling is only a problem if a component is volatile [13:04]
Thomas Betts: And that only becomes a problem when that third element, that third dimension of volatility rears its head. Because as long as those two things don’t change, the fact that they share knowledge over a long distance shouldn’t matter. But if one of those has to make a change and it has to affect the other one, now you’ve got the distributed ball of mud problem, that everything in two different services has to change. You actually made the problem worse by going to microservices. So that’s where all three factors have to be considered, correct?
Vlad Khononov: Yes, exactly. And that’s funny because all those companies that tried doing that, of course, they didn’t decompose their whole systems on the very first day of that microservice endeavor. No, they start with a small proof of concept, and that proof concept is successful. So they said, “Hey, let’s go on. Let’s proceed and apply the same decomposition logic everywhere else”. Now, the difference is that POC is usually down on something that is not business critical, its volatility is low. So you are kind of safe introducing complexity there. So the mistake was taking those less business critical components, extracting them, and thinking that they will achieve the same result with other components of the system. And of course, there once you step into that distributed big ball of mud area, well, suddenly microservices became evil and people started praising monoliths.
Thomas Betts: Right. We didn’t understand what we were doing, we didn’t understand why we were trying to accomplish it. We thought the problem was “everything’s too close, we’ll solve it by just moving it apart”. But if you don’t factor in, how is the knowledge changing? How is the volatility affected? Because yes, that first one might work, it doesn’t matter if they’re close together in one monolith or separate. If there’s no volatility, if things aren’t changing, it doesn’t matter where it lives.
But once you get to, this is something that we’re going to be making changes to really quickly. Because that was the other thing that people said, if we go to microservices, we can make changes really quickly, and then they maybe make even more changes faster, but they run into all these issues that separate teams in separate modules and separate microservices are trying to change things all at once, and then they lead back to, we have to still have all this communication, or we have this major integration step that just you weren’t ready for it because you did the thing wrong. When you make them move to microservices, you have to consider all three factors. What is changing? And if I know it’s going to change, what do I do differently then? Because obviously we still want to break those things up, but how do I say this is going to be a volatile module, it’s going to have core business, it’s going to be evolving. What’s the solution then? Because I want to be able to change it.
Distance affects where code lives as well as the lifecycle to maintain related components [16:22]
Vlad Khononov: Yes. That dimension of space distance is very tricky, and what makes it even trickier is that it has, let’s call it sub dimensions. So first we have that physical distance between source codes. The greater that distance gets, the harder it is going to be to modify the two components simultaneously. So that’s one thing. We have another force that works in the opposing direction, and that’s lifecycle coupling. The closer things are, the more related their life cycles. So they will be developed, tested, deployed together. If you have components implemented in the same physical boundary, for example.
As you go toward the other end, then you are reducing those lifecycle dependencies. And then we have social technical factors, those two components are implemented by the same team, or do we have to coordinate the change with multiple teams? And suddenly the distance can grow even larger, and the lifecycle coupling will be reduced even further. So distance is super important, but as you mentioned, what makes it all, let’s call it painful, is that knowledge that is going to travel that distance.
Thomas Betts: Right. So if I know that this thing is going to be changing, in some ways those changes affect the knowledge that is being shared, right? If I’m adding new features and functionality, that means there’s more knowledge in this module. And if I have to communicate those changes, that’s the challenge. So is the trade-off of, I’m going to have more volatility in this module, I have to reduce the knowledge that’s being shared, reduce that integration strength of how tightly those two things are coupled. Is that a matter of defining good API batteries, for example?
Vlad Khononov: Yes. So we have to manage that knowledge that we are sharing across the boundaries, we have to make it explicit. Now, the thing about knowledge is, as you said, the more knowledge we’re sharing, the more cascading changes will follow because the more knowledge we share, the harder chances that the piece of that shared knowledge will change, and then we’ll have to communicate that change to the other component, to the coupled component.
Four levels for measuring coupling [19:10]
Vlad Khononov: Now, how do we evaluate knowledge? What units should be used to measure knowledge? That’s a tricky question. It’s tricky, and I’m not sure we have an answer for that. However, what we do have is a methodology from the ’70s called structure design. And in it there was a model for measuring or for evaluating interdependencies between components of a system called module coupling. That model had six levels, they were focused around the needs of systems that were written in those days. But essentially these levels describe different types of knowledge that can be exchanged across boundaries of components.
In my model, in the balanced coupling model, I adapted module coupling and changed its name to integration strength. I had to change its name because the levels of the model are completely different because again, they have to be accessible to people working on modern systems. I reduced the levels to four basic types of knowledge to make it easier to remember them. And if you need finer-grained details, then you can use a different model from a different era called connascence to measure the degrees of those types of knowledge.
Intrusive coupling [20:47]
Vlad Khononov: So the basic four types of knowledge are from highest to lowest. First of all is intrusive coupling. Say you have a component with a public interface that should be used for integration, however, you say, “Okay, that’s fine. I have a better way. I will go to your database directly, pick whatever I need, maybe modify it”. In other words, intrusive coupling is all about using private interfaces for integration.
Once you introduce that dependency on private interfaces, you basically have a dependency on implementation details. So any change can potentially break the integration. So with intrusive coupling, you have to assume that all knowledge is shared.
Thomas Betts: Right. That’s the classic, if you have a microservice, you own your own database. And no one else is allowed to go there, they have to go through this boundary. And I like that you’re calling back to, these are papers written 50 years ago. And no one was talking about microservices there, no one was talking about having several databases, but it’s still the same idea; if I can structure this so that in order for this to go through, it has to go through this module. That’s why C++ evolved to have object-oriented design to say, “I have this class and it has behavior, and here’s public and private data”. And that’s what you’re talking about, if you can just get all the way through, there’s no point in having that public versus private interface.
Vlad Khononov: Yes. Yes. It’s funny, if you look at one of the books from that period, one that I particularly like is called Composite/Structure Design by Glenford Myers. And if you ignore the publishing date, it sounds like he is talking about the problems we’re facing today. It’s crazy. It’s crazy.
Thomas Betts: What’s the next level after that intrusive coupling?
Functional coupling [22:45]
Vlad Khononov: Yes. So after intrusive coupling, we have functional coupling. And here we’re sharing the knowledge of functional requirements. We’re shifting from how the component is implemented, to what that component implements, what is that business functionality? Again, that’s quite a high amount of knowledge that is shared by this type because if you share that kind of knowledge, then probably any change in the business requirements is going to affect both of the coupled components, so they will change together.
Model coupling [23:22]
Vlad Khononov: Next, we have model coupling, which means we have two components that are using the same model of the business domain. Now, DDD people will get it right away. But the idea is when we are developing a software system, we cannot encode all the knowledge about its business domain, it’s not possible. If you are building a medical system, you’re not going to become a doctor, right? Instead, what we are doing is we’re building a model of that business domain that focuses only on the areas that are relevant for that actual system. Now, once you have two components based on the same model, then if you have an insight into that business domain and you want to improve your model, then guess what? Both of them will have to change simultaneously. So that’s model coupling.
Contract coupling [24:17]
And the lowest level is contract coupling. Here we have an integration contract, you can think about it as a model of a model that encapsulates all other types of knowledge. It doesn’t let any knowledge of the implementation model outside of the boundary, that means you can evolve it without affecting the integration contract. You’re not letting any knowledge of functional requirements across the boundaries, and of course, you want to protect your implementation details.
Examples of the four types of coupling [24:51]
Thomas Betts: Right. So just to echo that back. If you’re talking about, you said DDD people will get this right away. If I have a new invoice coming in that I want to pay, maybe I have an expense management system where somebody says, “Here’s a new thing to pay, I’m going to submit it to the expense management system”, and it has to go through an approval process to say, yes, it’s approved. Then all the way at the end we have our accounts payable person who’s going to log in and say, “Oh, I need to go pay this invoice, I have to pay the vendor”, right? There’s an invoice that flows all the way through the system, but if you say, “I need to know how is it going to get paid at the end, all the accounting details upfront”, it’s tightly coupled.
If you think about it from who’s doing the work, you might have the invoice request that starts in expense management, and then the paid invoice. And those ideas of, I have one model, but the words sound the same, but ubiquitous language says in this domain, that’s what this means. And I work on accounting systems, so the invoice, whether you’re in accounts payable or accounts receivable, we both have invoices, but they’re exactly the opposite. Am I going to pay someone or is someone going to pay me? And so ubiquitous language helps us reduce the cognitive load because I know in this space, I’m only talking about this part of the workflow because it’s satisfying this person, this role, they’re doing their job.
And so that’s going to the levels of coupling you’re talking about. The contract coupling says, I’m going to hand off from here, to the next, to the next, and I don’t have to know what’s going to happen a week from now with this because once it exceeds my boundary, I’m done with it. And the intrusive coupling is, they’re all editing the same database record and everybody knows about all the details. And somewhere above that is, I have to know that there’s this next workflow of pay the invoice versus submit the invoice, and everybody knows about those things. Is that a good example of how to see those different layers in there?
Vlad Khononov: Yes, absolutely. Absolutely. There are so many creative ways to introduce intrusive coupling. There are such interesting death-defying stunts we can pull. For example, maybe you’re introducing, not a dependency, but you rely on some undocumented behavior, that’s intrusive coupling. Maybe you’re working in, let’s say an object-oriented code base and a component that you are interacting with returns you an array or a list of objects, and then you can go ahead and modify it. And because it’s reference type, it’s going to affect the internals of that component. So that’s another creative example of intrusive coupling. By the way, a reader of the book sent it to me. And I was like, “Oh, why haven’t I thought about it when I was writing the book? It’s such a great example”.
Modularity is the opposite of complexity [28:01]
Thomas Betts: Yes. Well, I think what you’re describing is, that’s the difference between the local and the global complexity, right? We think about these as microservices, I’m going to separate big modules out. But the same problems occur within our code base because even if you’re working in a monolith, you can structure… This is where the book talked about modular monoliths. You can set up your code, so even if it’s stored in one repository, you can make it easier to understand. And that gets to, this class doesn’t have to know about the 900 other classes that are in the project, I only know about the 10 that are close to me.
Vlad Khononov: Yes. Exactly. And by the way, it brings us back to the topic of complexity, or rather the opposite of complexity. So if complexity is, if we’re going to define it as the relationship between an action and its outcome, then modularity is the opposite. It’s a very strong relationship between an action and its outcome. So if we want to design a modular system, we want to be able to know what we have to change, that’s one thing. And the second thing is, once we make the change, what’s going to happen? That I would say is the idea of modularity.
Modular monoliths can reduce complexity [29:19]
Vlad Khononov: Now, how can we do it? How can we achieve what you described? Let’s say that you have a monolith that can be a big ball of mud, but it also can be a modular monolith. If the thing is, the core ideas are the same. You can increase the distance, you don’t have to step across its physical boundary. You can introduce distance in the form of modules within that monolith. You can put related things together because let’s say you have one boundary with lots of unrelated things. And how can we define unrelated things? Things that are not sharing knowledge between them.
So if they’re located close to each other, then it will increase the cognitive load to find what we have to change there, right? So we can reduce the cognitive load by grouping related things, those components that have to share a knowledge in logical groups, logical modules. And that’s how we can achieve modular monoliths, which is by the way, in my opinion, the first step towards decomposing a system into microservices because it’s way easier to fix a mistake once you are in the same physical boundary.
Thomas Betts: Right. You’re keeping the distance a little bit closer, you’re separating it logically into separate namespaces, different directory structures, but you’re not making a network call, right?
Vlad Khononov: Exactly.
Thomas Betts: That’s definitely increasing the distance. You’re not necessarily handing over to another team. You might be, but maybe it is still the same team just saying, “Hey, I want to be able to think about this problem right now, and I don’t want to have to think about these other problems”, and so let me just split the code. But that causes you as an architect designing this to say, “What makes sense? What do I move around? Where am I having the problem understanding it because there’s too much going on, there’s too much local complexity? And let’s look for that and figure out how do I increase the distance a little bit so that the knowledge that’s being shared stays within the things that are close”. And you start looking for, have I introduced distance while not reducing the knowledge, right? That’s what you’re trying to do, is have the knowledge transfer go down that integration strength when you’re adding distance, right?
If shared knowledge is appropriately high, then balance it with distance [31:45]
Vlad Khononov: Yes. Yes, absolutely. We always want to reduce integration strength; we want to always minimize the knowledge. But if you’re familiar with the business domain, you kind of know that, hey, here, I need to use the same model of the business domain, here we have closely related business functionalities. So it doesn’t matter if you want to reduce it to the minimum, you can’t. You have to remain on that level of, let’s say for example, functional coupling. Once you observe that level of knowledge being shared, then you have to take it into consideration, and balance it with another dimension, which is distance. Don’t spread those things apart because otherwise that’s going to be cognitive load, and as a result, complexity.
Thomas Betts: Right. And again, this is where the volatility comes into place. So if I’m focused on, let’s go from our big ball of mud to having a more organized modular monolith. Then I can look at, oh, where are we seeing lots of changes? Where’s the business evolving a lot and where is it not? And so I can now focus on, if we’re going to pull one service out, because let’s say we actually have scaling needs, we need to make sure that this part of the system can grow up to 10 times the size, but the rest of it, we don’t need to scale up as big. Those types of things you can look at, well, what’s volatile? And then if you pull it out of that monolith, you say, “I’m adding the distance, have I reduced the knowledge to a safer coupling level?” I haven’t kept that high integration strength, that you still know about my private methods and how to call my database even though I pulled you out because you haven’t actually done anything to solve the volatility problem, right?
Evaluating volatility requires understanding the business domain [33:35]
Vlad Khononov: And volatility, initially it sounds like something simple, the simplest dimension of the three. Oh my god, it’s not. It’s tricky because to truly predict the rate of changes in a component, it’s not enough to look at maybe your experience, or at the source code because there are things we can differentiate between, essential volatility and accidental volatility or accidental in-volatility. Accidental volatility can be because of, or design of the system, things are changing just because that’s the way the system is designed. And accidental in-volatility can happen. Let’s say that you have an area of the system that the business wants to optimize, but it is designed in such a way that people are afraid to touch it. And the business is afraid to touch it, to modify it as well as a result. So to truly, truly evaluate volatility, you have to understand the business domain. You have to analyze the business strategy, what differentiates that system from its competitors. Again, DDD people are thinking about core subdomains right now.
Thomas Betts: Yes.
Vlad Khononov: And once you identify those areas based on their strategic value to the company, then you can really start thinking about the volatility levels desired by the business.
Thomas Betts: You mentioned things happen internal and external, so the business might have, we want to pursue this new business venture, or this was an MVP, and the MVP has taken off, we want to make sure it’s a product we can sell to more people, but we need to make changes to it. So there are business drivers that can change the code, but there’s also internal things. Like I just need to make sure my code is on the latest version of whatever so that it’s not sitting there getting obsolete, and hasn’t gotten security patches or whatever. So some of those, the system’s just going to evolve over time because you need to keep, even the legacy code, you need to keep up to date to some standards. And then there’s the, no, we want to make big changes because the business is asking us to, right? So the architect has to factor in all of those things, as well as I think you mentioned the socio-technical aspects, right? Who is going to do the work? All of this comes into play, it’s not always just one simple solution. You can’t just go to loose coupling, right?
Balancing the three dimensions of coupling [36:13]
Vlad Khononov: Yes. It’s complicated. I’m not going to say that it’s complex, but it’s complicated. But the good news is that once you truly understand the dynamics of system design, it doesn’t really matter what level of abstraction you’re working on. The underlying rules are going to be the same, whether it’s methods within an object or microservices in a distributed system, the underlying ideas are the same. If you have a large amount of knowledge being shared, balance it by minimizing the distance. If you’re not sharing much knowledge, you can increase the distance. So it’s one of the two, either knowledge is high and the distance is low, or vice distance is high but knowledge is low. Or, or things are not going to change, which is volatility is low, which can balance those two altogether.
Thomas Betts: Right. So if you just looked at strength and distance, how much knowledge is being shared over too long? That looks bad. But if it’s never going to change, you don’t care. If it does change, then it’s not balanced. On the flip side, if it’s going to change a lot, then you need to think about the relationship between the integration strength and the distance. So if there’s not much knowledge being shared over a long distance, that’s okay, or if there’s a lot of knowledge shared over a small distance, that’s okay. So you can have one but not both, if things are changing. But if things aren’t changing, you don’t care.
Vlad Khononov: Yes. And of course, things are not changing today, maybe something is going to change on the business side tomorrow. And as an architect you have to be aware of that change and its implications on the design. The classical example here is, I am integrating a legacy system, nobody is going to change it, and I can just go ahead and grab whatever I need from its database, that’s fine. Another classic example is, again, DDD influence, some functionality that is not business critical, but you have to implement it, which is usually in DDD lexicon is called a supporting subdomain. Usually they’re going to be much less water than core subdomains. However, business strategy might change, and suddenly that core subdomain will evolve into a core one. Suddenly there is that big strategy change that should be reflected in the design of the system. So it’s three dimensions working together, and whether it will end up with modularity or complexity depends on how you’re balancing those forces.
Thomas Betts: Right. And I think you got to the last point I wanted to get to is, we can design this for today based on what we know, but six months, six years from now, those things might shift not because of things we can predict right now. And if you try and design for that future state, you’re always going to make some mistakes, but you want to set yourself up for success. So do the small things first. Like if it is reorganize your code so it’s a little easier to understand, that seems like a benefit, but don’t jump to, I have to have all microservices.
And I liked how you talked about how this can be applied at the system level, or the component level, or the code level. I think you described this as the fractal approach of, no matter how much you keep looking at it, the same problem exists at all these different layers of the system. So that coupling and balance is something you have to look at, at different parts of your system either inside a microservice at the entire system level, and what are you trying to solve for at different times, right?
Vlad Khononov: Yes. And that’s by the way, why I’m saying that if you pick up a book from the ’70s, like that book I mentioned, Composite/Structured Design, it looks way too familiar. The problems that they’re facing, the problems they’re describing, the solutions they’re applying are also going to be quite familiar once you step over those terms that are used there because those terms are based on languages like FORTRAN and COBOL. Yes, you need some time, some cognitive effort to understand what they mean. But yes, the underlying ideas are the same, it’s just a different level of abstraction that was popular back then. Not popular, that’s all they had back then.
Wrapping up [40:57]
Thomas Betts: So if you’ll want to follow up with you or want to learn more about your balanced coupling model, any recommendations of where they can go next?
Vlad Khononov: Yes. So on social media aspect, I am the most active on LinkedIn at the moment. I have accounts on other social networks like Bluesky, Twitter, et cetera. Right now LinkedIn is my preferred network. At the moment I’m working on a website called Coupling.dev, so if you’re listening to this, I hope that it is already live and you can go there and learn some stuff about coupling.
Thomas Betts: Well, Vlad Khononov, I want to thank you again for being on the InfoQ Podcast.
Vlad Khononov: Thank you so much, Thomas. It’s an honor and a pleasure being here.
Thomas Betts: And listeners, we hope you’ll join us again soon for a future episode.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Announcing QCon AI: Focusing on Practical, Scalable AI Implementation for Engineering Teams
MMS • Artenisa Chatziou

QCon conferences have been a trusted forum for senior software practitioners to share real-world knowledge and navigate technology shifts for nearly two decades. Today, as artificial intelligence adoption transitions from experimental phases to running within critical enterprise systems, InfoQ and QCon are introducing QCon AI, a new conference dedicated to the practical challenges of building, deploying, and scaling AI reliably. The inaugural event will take place in New York City on December 16-17, 2025.
This conference is designed specifically for senior software developers, architects, and engineering leaders – the practitioners tasked with making AI work securely, reliably, and effectively within complex enterprise environments. Recognizing that the landscape is filled with hype, QCon AI focuses squarely on what’s working now. The program, curated by senior engineers actively running AI systems at scale, prioritizes actionable patterns and blueprints over theoretical possibilities.
QCon AI builds directly on the QCon legacy of facilitating peer-to-peer learning without hidden product pitches. As QCon AI 2025 Conference Chair, Wes Reisz, Technical Principal @ Equal Experts, ex-VMWare, ex-ThoughtWorks,16-time QCon Chair, and InfoQ Podcast Co-host emphasizes.
“Forget the AI hype. QCon AI is focused on helping you build and scale AI reliably. The teams speaking at QCon AI share how they are delivering and scaling AI – warts and all”.
Attendees can expect deep dives into the practicalities of integrating AI into the software development lifecycle, architecting resilient and observable production AI systems, managing MLOps, optimizing costs, ensuring responsible governance, and proving business value. We believe it’s crucial to share hard-won lessons – including failures – from those who have navigated these challenges.
A key theme for QCon AI is the collaborative nature of successful AI implementation. Scaling AI isn’t a solo task; it requires alignment across multiple departments, including development, MLOps, platform, infrastructure, and data teams. QCon AI is structured to benefit teams attending together. Shared learning experiences can accelerate the adoption of effective patterns, foster better cross-functional understanding, reduce integration risks, and help align team members, from Staff+ engineers and architects to ML engineers and engineering leaders, on strategy and execution.
By bringing together experienced practitioners to share what truly works in enterprise AI, QCon AI aims to equip engineering teams with the confidence and knowledge needed to move from prototype to production successfully.
More information about QCon AI, including program details as they become available, can be found on the conference website.
MMS • RSS
LPL Financial LLC lowered its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 7.0% in the fourth quarter, according to the company in its most recent disclosure with the SEC. The firm owned 36,670 shares of the company’s stock after selling 2,771 shares during the period. LPL Financial LLC’s holdings in MongoDB were worth $8,537,000 at the end of the most recent quarter.
A number of other institutional investors and hedge funds have also made changes to their positions in the business. Hilltop National Bank grew its stake in shares of MongoDB by 47.2% in the fourth quarter. Hilltop National Bank now owns 131 shares of the company’s stock valued at $30,000 after buying an additional 42 shares in the last quarter. NCP Inc. acquired a new position in MongoDB during the fourth quarter worth approximately $35,000. Continuum Advisory LLC increased its stake in MongoDB by 621.1% in the third quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock valued at $40,000 after purchasing an additional 118 shares during the period. Versant Capital Management Inc boosted its stake in shares of MongoDB by 1,100.0% during the fourth quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock worth $42,000 after buying an additional 165 shares during the period. Finally, Wilmington Savings Fund Society FSB acquired a new position in MongoDB in the 3rd quarter valued at about $44,000. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
Wall Street Analysts Forecast Growth
MDB has been the subject of several research analyst reports. Citigroup cut their price objective on MongoDB from $430.00 to $330.00 and set a “buy” rating for the company in a research report on Tuesday, April 1st. Macquarie decreased their price target on shares of MongoDB from $300.00 to $215.00 and set a “neutral” rating on the stock in a report on Friday, March 7th. Rosenblatt Securities restated a “buy” rating and issued a $350.00 price target on shares of MongoDB in a report on Tuesday, March 4th. Royal Bank of Canada dropped their price objective on MongoDB from $400.00 to $320.00 and set an “outperform” rating on the stock in a report on Thursday, March 6th. Finally, Morgan Stanley dropped their target price on shares of MongoDB from $350.00 to $315.00 and set an “overweight” rating on the stock in a report on Thursday, March 6th. Seven analysts have rated the stock with a hold rating, twenty-four have given a buy rating and one has issued a strong buy rating to the stock. According to MarketBeat.com, the company currently has an average rating of “Moderate Buy” and a consensus target price of $312.84.
Check Out Our Latest Research Report on MongoDB
MongoDB Stock Performance
MongoDB stock traded down $7.01 during midday trading on Monday, reaching $147.38. 5,169,359 shares of the company’s stock were exchanged, compared to its average volume of 1,771,877. The firm has a market cap of $11.97 billion, a price-to-earnings ratio of -53.79 and a beta of 1.49. MongoDB, Inc. has a 52 week low of $140.96 and a 52 week high of $387.19. The stock’s 50-day simple moving average is $236.68 and its 200 day simple moving average is $261.78.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing the consensus estimate of $0.64 by ($0.45). The firm had revenue of $548.40 million for the quarter, compared to analyst estimates of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same period in the previous year, the business posted $0.86 earnings per share. Research analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Insiders Place Their Bets
In related news, CAO Thomas Bull sold 301 shares of the firm’s stock in a transaction on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the transaction, the chief accounting officer now directly owns 14,598 shares of the company’s stock, valued at $2,529,103.50. This trade represents a 2.02 % decrease in their position. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available at this hyperlink. Also, CFO Srdjan Tanjga sold 525 shares of the stock in a transaction on Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $90,961.50. Following the sale, the chief financial officer now owns 6,406 shares of the company’s stock, valued at approximately $1,109,903.56. This trade represents a 7.57 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold 58,060 shares of company stock worth $13,461,875 over the last ninety days. Corporate insiders own 3.60% of the company’s stock.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Almost everyone loves strong dividend-paying stocks, but high yields can signal danger. Discover 20 high-yield dividend stocks paying an unsustainably large percentage of their earnings. Enter your email to get this report and avoid a high-yield dividend trap.
Java News Roundup: Jakarta EE 11 Web Profile, GlassFish, TornadoVM, Micronaut, JHipster, Applet API
MMS • Michael Redlich

This week’s Java roundup for March 31st, 2025 features news highlighting: the formal release of the Jakarta EE 11 Web Profile; the eleventh milestone release of GlassFish 8.0.0; point releases TornadoVM 1.1.0, Micronaut 4.8.0 and JHipster 8.10.0; and a new JEP candidate to remove the Applet API.
OpenJDK
JEP 504, Remove the Applet API, was elevated from its JEP Draft 8345525 to Candidate status. This JEP proposes to remove the Applet API, deprecated in JDK 17, due it’s continued obsolescence since applets are no longer supported in web browsers.
JDK 25
Build 17 of the JDK 25 early-access builds was made available this past week featuring updates from Build 16 that include fixes for various issues. More details on this release may be found in the release notes.
For JDK 25, developers are encouraged to report bugs via the Java Bug Database.
GlassFish
The eleventh milestone release of GlassFish 8.0.0 delivers bug fixes, dependency upgrades and improved specification compatibility for various new features of Jakarta EE 11. This relese passes the final Jakarta EE 11 Web Profile TCK. Further details on this release may be found in the release notes.
Jakarta EE 11
In his weekly Hashtag Jakarta EE blog, Ivar Grimstad, Jakarta EE Developer Advocate at the Eclipse Foundation, provided an update on Jakarta EE 11, writing:
Jakarta EE 11 Web Profile is released! It’s a little later than planned, but we’re finally there, and Jakarta EE 11 Web Profile joins Jakarta EE 11 Core Profile among the released specifications. It has been a tremendous effort to refactor the TCK.
Eclipse GlassFish was used as the ratifying compatible implementation of Jakarta EE 11 Web Profile. I would expect other implementations, such as Open Liberty, WildFly, Payara, and more to follow suit over the next weeks and months. Check out the expanding list of compatible products of Jakarta EE 11.
The road to Jakarta EE 11 included four milestone releases, the release of the Core Profile in December 2024, the release of Web Profile in April 2025, and a fifth milestone and first release candidate of the Platform before its anticipated release in 2Q 2025.
TornadoVM
The release of TornadoVM 1.1.0 provides bug fixes and improvements such as: support for mixed precision FP16 to FP32 computations for matrix operations; and a new method, mapOnDeviceMemoryRegion(), defined in the TornadoExecutionPlan class that introduces a new Mapping On Device Memory Regions feature that offers device buffer mapping for different buffers. More details on this release may be found in the release notes.
Micronaut
The Micronaut Foundation has released version 4.8.0 of the Micronaut Framework featuring Micronaut Core 4.8.9 that include: improvements to the Micronaut SourceGen module that now powers bytecode generation of internal metadata and expressions; and the ability to activate dependency injection tracing so that developers can better understand what Micronaut is doing at startup and when a particular bean is created. There were also updates to many of Micronuat’s modules. Further details on this release may be found in the release notes.
Quarkus
Quarkus 3.21.1, the first maintenance release, ships with bug fixes, dependency upgrades and improvements such as: allow execution model annotations (@Blocking, @NonBlocking, etc.) on methods annotated with SmallRye GraphQL @Resolver due to the resolver throwing an error; and a resolution to a Java UnsupportedOperationException when using the TlsConfigUtils class to configure TLS options in a Quarkus project using the Application-Layer Protocol Negotiation (ALPN) extension. More details on this release may be found in the release notes.
JHipster
The release of JHipster 8.10.0 provides notable changes such as: a workaround to a ClassCastException using Spring Boot and Hazelcast upon logging in to a JHipster application; numerous dependency upgrades, most notably Spring 3.4.4; and many internal improvements to the code base. Further details on this release may be found in the release notes.
The release of JHipster Lite 1.31.0 ships with a dependency upgrades to Vite 6.2.4 that resolves two CVEs affecting previous versions of Vite 6.2.4 and 6.2.3, namely: CVE-2025-31125, a vulnerability, resolved in version 6.2.4, in which Vite exposes content of non-allowed files using URL expressions ?inline&import or ?raw?import, to the development server; and CVE-2025-30208, a vulnerability, resolved in version 6.2.3, where the restrictions imposed by the Vite /@fs/ filesystem variable can be bypassed by adding expressions, ?raw?? or ?import&raw??, to the URL and returns file content if it exists. More details on this release may be found in the release notes.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) insider Cedric Pech sold 1,690 shares of MongoDB stock in a transaction dated Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $292,809.40. Following the transaction, the insider now directly owns 57,634 shares of the company’s stock, valued at approximately $9,985,666.84. This trade represents a 2.85 % decrease in their ownership of the stock. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available through this hyperlink.
MongoDB Stock Down 4.5 %
NASDAQ:MDB traded down $7.01 during trading hours on Monday, hitting $147.38. 5,169,359 shares of the stock traded hands, compared to its average volume of 1,771,869. The stock has a 50 day moving average price of $236.68 and a 200 day moving average price of $261.78. The company has a market cap of $11.97 billion, a price-to-earnings ratio of -53.79 and a beta of 1.49. MongoDB, Inc. has a 1 year low of $140.96 and a 1 year high of $387.19.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing the consensus estimate of $0.64 by ($0.45). The firm had revenue of $548.40 million during the quarter, compared to the consensus estimate of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same period in the prior year, the company posted $0.86 EPS. Equities analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Institutional Trading of MongoDB
Institutional investors and hedge funds have recently added to or reduced their stakes in the business. Vanguard Group Inc. grew its holdings in MongoDB by 0.3% during the 4th quarter. Vanguard Group Inc. now owns 7,328,745 shares of the company’s stock valued at $1,706,205,000 after buying an additional 23,942 shares in the last quarter. Franklin Resources Inc. boosted its position in shares of MongoDB by 9.7% during the fourth quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock worth $478,398,000 after acquiring an additional 181,962 shares during the last quarter. Geode Capital Management LLC grew its stake in MongoDB by 1.8% during the fourth quarter. Geode Capital Management LLC now owns 1,252,142 shares of the company’s stock valued at $290,987,000 after acquiring an additional 22,106 shares in the last quarter. First Trust Advisors LP increased its holdings in MongoDB by 12.6% in the 4th quarter. First Trust Advisors LP now owns 854,906 shares of the company’s stock valued at $199,031,000 after acquiring an additional 95,893 shares during the last quarter. Finally, Norges Bank purchased a new stake in MongoDB in the 4th quarter worth $189,584,000. Institutional investors own 89.29% of the company’s stock.
Wall Street Analyst Weigh In
A number of research analysts have issued reports on MDB shares. KeyCorp cut MongoDB from a “strong-buy” rating to a “hold” rating in a research note on Wednesday, March 5th. Mizuho lifted their price target on MongoDB from $275.00 to $320.00 and gave the stock a “neutral” rating in a research report on Tuesday, December 10th. Loop Capital cut their price objective on shares of MongoDB from $400.00 to $350.00 and set a “buy” rating on the stock in a research report on Monday, March 3rd. Stifel Nicolaus decreased their target price on shares of MongoDB from $425.00 to $340.00 and set a “buy” rating for the company in a report on Thursday, March 6th. Finally, Tigress Financial raised their price target on shares of MongoDB from $400.00 to $430.00 and gave the company a “buy” rating in a research report on Wednesday, December 18th. Seven equities research analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has issued a strong buy rating to the stock. Based on data from MarketBeat.com, MongoDB presently has an average rating of “Moderate Buy” and an average price target of $312.84.
Check Out Our Latest Analysis on MongoDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

MarketBeat’s analysts have just released their top five short plays for April 2025. Learn which stocks have the most short interest and how to trade them. Enter your email address to see which companies made the list.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CAO Thomas Bull sold 301 shares of the firm’s stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the transaction, the chief accounting officer now owns 14,598 shares in the company, valued at $2,529,103.50. This represents a 2.02 % decrease in their position. The sale was disclosed in a legal filing with the SEC, which is accessible through this hyperlink.
MongoDB Stock Down 4.5 %
MongoDB stock traded down $7.01 during trading hours on Monday, hitting $147.38. The stock had a trading volume of 5,169,359 shares, compared to its average volume of 1,771,869. The stock’s 50-day moving average price is $236.68 and its 200-day moving average price is $261.78. MongoDB, Inc. has a 12-month low of $140.96 and a 12-month high of $387.19. The stock has a market capitalization of $11.97 billion, a P/E ratio of -53.79 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). The firm had revenue of $548.40 million during the quarter, compared to analysts’ expectations of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same quarter in the previous year, the firm earned $0.86 earnings per share. On average, research analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Institutional Investors Weigh In On MongoDB
Institutional investors have recently modified their holdings of the business. Strategic Investment Solutions Inc. IL purchased a new position in MongoDB in the 4th quarter worth about $29,000. Hilltop National Bank grew its stake in shares of MongoDB by 47.2% in the fourth quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after acquiring an additional 42 shares during the period. NCP Inc. purchased a new position in shares of MongoDB during the fourth quarter valued at approximately $35,000. Continuum Advisory LLC lifted its position in MongoDB by 621.1% during the third quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock valued at $40,000 after purchasing an additional 118 shares during the period. Finally, Versant Capital Management Inc boosted its holdings in MongoDB by 1,100.0% in the fourth quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock worth $42,000 after purchasing an additional 165 shares during the last quarter. 89.29% of the stock is owned by hedge funds and other institutional investors.
Analyst Ratings Changes
MDB has been the topic of a number of recent analyst reports. Macquarie cut their price target on shares of MongoDB from $300.00 to $215.00 and set a “neutral” rating on the stock in a report on Friday, March 7th. Loop Capital cut their target price on MongoDB from $400.00 to $350.00 and set a “buy” rating on the stock in a research note on Monday, March 3rd. China Renaissance initiated coverage on MongoDB in a report on Tuesday, January 21st. They set a “buy” rating and a $351.00 price target on the stock. Royal Bank of Canada cut their price objective on MongoDB from $400.00 to $320.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. Finally, Rosenblatt Securities reissued a “buy” rating and set a $350.00 target price on shares of MongoDB in a research note on Tuesday, March 4th. Seven research analysts have rated the stock with a hold rating, twenty-four have given a buy rating and one has issued a strong buy rating to the company. According to data from MarketBeat.com, MongoDB presently has an average rating of “Moderate Buy” and a consensus target price of $312.84.
Get Our Latest Analysis on MongoDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s list of seven stocks and why their long-term outlooks are very promising.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CFO Srdjan Tanjga sold 525 shares of the company’s stock in a transaction dated Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $90,961.50. Following the completion of the sale, the chief financial officer now owns 6,406 shares of the company’s stock, valued at $1,109,903.56. This represents a 7.57 % decrease in their position. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this hyperlink.
MongoDB Stock Down 4.5 %
Shares of NASDAQ MDB traded down $7.01 during mid-day trading on Monday, reaching $147.38. 5,169,359 shares of the company were exchanged, compared to its average volume of 1,771,869. The stock has a market capitalization of $11.97 billion, a P/E ratio of -53.79 and a beta of 1.49. The company’s 50-day simple moving average is $236.68 and its 200-day simple moving average is $261.78. MongoDB, Inc. has a twelve month low of $140.96 and a twelve month high of $387.19.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). The firm had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same quarter in the prior year, the firm earned $0.86 EPS. As a group, equities research analysts expect that MongoDB, Inc. will post -1.78 EPS for the current year.
Institutional Inflows and Outflows
Large investors have recently added to or reduced their stakes in the company. OneDigital Investment Advisors LLC boosted its position in shares of MongoDB by 3.9% in the fourth quarter. OneDigital Investment Advisors LLC now owns 1,044 shares of the company’s stock valued at $243,000 after acquiring an additional 39 shares during the period. Hilltop National Bank raised its stake in MongoDB by 47.2% in the 4th quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after purchasing an additional 42 shares in the last quarter. Avestar Capital LLC boosted its holdings in MongoDB by 2.0% in the 4th quarter. Avestar Capital LLC now owns 2,165 shares of the company’s stock valued at $504,000 after purchasing an additional 42 shares during the period. Aigen Investment Management LP grew its position in shares of MongoDB by 1.4% during the 4th quarter. Aigen Investment Management LP now owns 3,921 shares of the company’s stock worth $913,000 after purchasing an additional 55 shares in the last quarter. Finally, Perigon Wealth Management LLC increased its holdings in shares of MongoDB by 2.7% during the fourth quarter. Perigon Wealth Management LLC now owns 2,528 shares of the company’s stock worth $627,000 after purchasing an additional 66 shares during the period. Institutional investors own 89.29% of the company’s stock.
Analysts Set New Price Targets
Several research analysts recently weighed in on the stock. Tigress Financial lifted their price objective on shares of MongoDB from $400.00 to $430.00 and gave the stock a “buy” rating in a research note on Wednesday, December 18th. Stifel Nicolaus decreased their price target on shares of MongoDB from $425.00 to $340.00 and set a “buy” rating for the company in a report on Thursday, March 6th. Daiwa America upgraded shares of MongoDB to a “strong-buy” rating in a research report on Tuesday, April 1st. DA Davidson lifted their target price on MongoDB from $340.00 to $405.00 and gave the stock a “buy” rating in a report on Tuesday, December 10th. Finally, Needham & Company LLC lowered their price target on MongoDB from $415.00 to $270.00 and set a “buy” rating for the company in a report on Thursday, March 6th. Seven analysts have rated the stock with a hold rating, twenty-four have given a buy rating and one has given a strong buy rating to the company. Based on data from MarketBeat, the stock currently has an average rating of “Moderate Buy” and an average price target of $312.84.
Read Our Latest Stock Analysis on MDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Looking to profit from the electric vehicle mega-trend? Enter your email address and we’ll send you our list of which EV stocks show the most long-term potential.
MMS • Sergio De Simone

Conducted between December 2024 and January 2025, the State of React Native 2024 Survey collected insights from around 3,500 React Native developers to capture the current state of key tools and technologies in the React Native ecosystem and help developers make better decisions, explains Software Mansion software engineer Bartłomiej Bukowski, who curated the survey.
The State of React native 2024 Survey covers over 15 distinct areas, including used APIs, libraries, state management, navigation, debugging, build and publish, and others.
In terms of demographics, around 30% of respondents have been working as developers for over 10 years, and 96% identified as male, across more than 20 countries.
Over 80% of respondents worked in teams of up to five developers, mostly targeting the iOS and Android platforms across a wide range of industry sectors, including finance, education, entertainment, communication, productivity, and many more. Nearly 50% of respondents reported that their top-performing React Native app has fewer than 1,000 users, while 37% of developers have apps with over 10,000 users. 50% of the respondents have released five apps or more.
According to Amazon developer advocate Anisha Malde, these responses highlight the diversity of the React Native ecosystem and its versatility, as reflected in the range of app scale and industry sectors.
Among the most used platform APIs, respondents listed the Camera API, Notifications, Permissions, Deep Linking, and others. Quite interestingly, three of them also rank among the top five pain points, namely Notifications, Deep Linking, and Permissions.`
React dev & OSS maintainer Vojtech Novak offered an explanation, noting that push notifications “are not trivial to set up, have an extremely large surface area, notable cross-platform differences, and quirks such as behavior dependent on the application”. This also applies to background processing, although it is not one of the most commonly used APIs.
State management is a major topic in the React ecosystem, with tools like Redux, Redux Toolkit, and others taking the spotlight. Redux received the most negative feedback, with around 18% of respondents expressing dissatisfaction. In contrast, React’s built-in state management was positively regarded by 31% of respondents, while Zustand followed closely with 21% of positive remarks.
According to Galaxies.dev founder Simon Grimm:
Zustand continues its rise as the go-to modern state management library, offering a refreshingly simple developer experience. Besides the React built-ins, no other libraries leaves developers with such a positive experience after using it. Which also shows that using the Context API is still extremely popular, and actually an acceptable solution for the needs of most small apps.
As a final note, the survey highlights a growing trend toward the adoption of automated solutions, such as Expo’s EAS Build, which 71% of respondents reported using. While manual methods like Xcode and Android Studio are becoming less prevalent, they remain widely used by 59.7% and 54.5% of respondents, respectively.
There is much more to the React Native 2024 Survey than what can be covered here, so be sure to check out the official report for all the details.
MMS • Steef-Jan Wiggers
AWS has announced the availability of parallel test execution in AWS CodeBuild, a fully-managed continuous integration service. According to the company, this new feature significantly reduces build times by allowing test suites to run concurrently across multiple build compute environments.
The announcement highlights the growing challenge of lengthy test execution times in continuous integration (CI) pipelines as projects become increasingly complex. These long cycles can delay feature delivery, hinder developer productivity, and increase costs.
Thomas Fernandez wrote in a Semaphore blog post on parallel testing:
Parallel testing lets us do more while waiting less. It’s an essential tool to keep sharp and ready so we can always establish a fast feedback loop.
With parallel test execution in CodeBuild, developers can now configure their build process to split test suites and run them in parallel across multiple independent build nodes. CodeBuild provides environment variables to identify the current node and the total number of nodes, enabling intelligent test distribution. The feature supports a sharding approach with two main strategies:
- Equal distribution: Sorts test files alphabetically and distributes them evenly across parallel environments.
- Stability: Uses a consistent hashing algorithm to maintain file-to-shard assignments even when test files are added or removed.
To enable parallel testing, developers configure the batch fanout section in their buildspec.xml file, specifying the desired level of parallelism. The pre-installed codebuild-tests-run utility is used in the build step to manage test execution and sharding based on the chosen strategy. A sample of a buildspec.yml that shows parallel test execution with Cucumber on a Linux platform looks like:
version: 0.2
batch:
fast-fail: false
build-fanout:
parallelism: 5
ignore-failure: false
phases:
install:
commands:
- echo 'Installing Ruby dependencies'
- gem install bundler
- bundle install
pre_build:
commands:
- echo 'prebuild'
build:
commands:
- echo 'Running Cucumber Tests'
- cucumber --init
- |
codebuild-tests-run
--test-command "cucumber"
--files-search "codebuild-glob-search '**/*.feature'"
post_build:
commands:
- echo "Test execution completed"
CodeBuild also offers automatic merging of test reports from the parallel executions into a single, consolidated test summary. This simplifies result analysis by providing aggregated pass/fail statuses, test durations, and failure details in the CodeBuild console, via the AWS CLI, or through integration with other reporting tools.
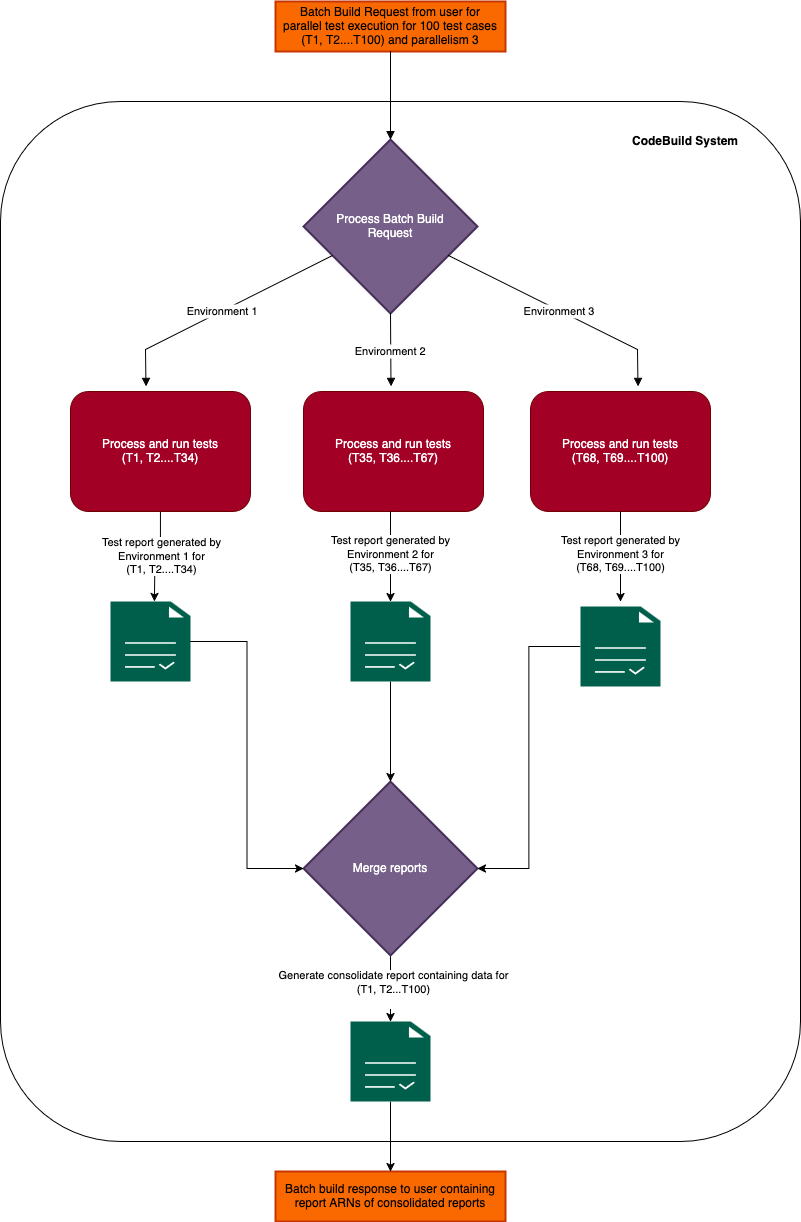
(Source: AWS Documentation)
A demonstration highlighted in an AWS blog post on the feature showed a reduction in total test time from 35 minutes to 6 minutes (including environment provisioning) for a Python project with 1,800 tests when running on ten parallel compute environments.
Sébastien Stormacq, a principal developer advocate at AWS, wrote:
The 1,800 tests of the demo project take one second each to complete. When I run this test suite sequentially, it took 35 minutes to complete. When I run the test suite in parallel on ten compute environments, it took 6 minutes to complete, including the time to provision the environments. The parallel run took 17.9 percent of the time of the sequential run.
This new capability is compatible with all testing frameworks, and the AWS documentation provides examples for popular languages and frameworks like Django, Elixir, Go, Java (Maven), Javascript (Jest), Kotlin, PHPUnit, Pytest, Ruby (Cucumber), and Ruby (RSpec). For frameworks with specific requirements for test file lists, CodeBuild provides the CODEBUILD_CURRENT_SHARD_FILES environment variable, which contains a newline-separated list of test files for the current shard.
Parallel test execution in AWS CodeBuild is available today in all AWS regions where CodeBuild is offered, across all three compute modes: on-demand, reserved capacity, and AWS Lambda compute, with no additional cost beyond the standard CodeBuild pricing for the resources used.
MMS • Amitai Stern

Transcript
Stern: We’re going to talk about topologies for cost-saving autoscaling. Just to get you prepared, it’s not going to be like I’m showing you, this is how you’re going to autoscale your environment, but rather ways to think about autoscaling, and what are the pitfalls and the architecture of OpenSearch that limit autoscaling in reality. I’m going to start talking about storing objects, actual objects, ice-core samples. Ice-core samples are these cylinders drilled from ice sheets or glaciers, and they provide us a record of Earth’s climate and environment.
The interesting thing, I believe, and relevant to us in these ice-core samples is that when they arrive at the storage facility, they are parsed. If you think about it, this is probably the most columnar data of any columnar data that we have. It’s a literal column. It’s sorted by timestamp. You have the new ice at the top and the old ice at the bottom. The way the scientific community has decided to parse this data is in the middle of the slide. It’s very clear to them that this is how they want it parsed. This person managing the storage facility is going to parse the data that way, all of it. Because the scientific community has a very narrow span of inquiry regarding this type of data, it is easy to store it. It is easy to make it very compact. You can see the storage facility is boring. It’s shelves. Everything is condensed. A visitor arriving at the facility has an easy time looking for things. It’s very well-sorted and structured.
If we take a hypothetical example of lots of visitors coming, and the person here who is managing the storage facility wants to scale out, he wants to be able to accommodate many more visitors at a time. What he’ll do is he’ll take all those ice-core samples, and cut them in half. That’s just time divided by two. That’s easy. Add a room. Put all these halves in another room. You can spread out the load. The read load will be spread out. It really makes things easy. It’s practically easy to think about how you’d scale out such a facility. Let’s talk about a different object storage facility, like a museum, where we don’t really know what kind of samples are coming in. If you have a new sample coming in, it could be a statue, it could be an archaeological artifact, it could be a postmodern sculpture of the Kraken or dinosaur bones. How do we index these things in a way that they’re easy to search? It’s very hard.
One of the things that’s interesting is that a visitor at a museum has such a wide span of inquiry. Like, what are they going to ask you? Or a person managing the museum, how does he index things so that they’re easily queryable? What if someone wants the top-k objects in the museum? He’ll need these too, but they’re from completely different fields. When your objects are unstructured, it’s very hard to store them in a way that is scalable. If we wanted to scale our museum for this hypothetical situation where many visitors are coming, it’s hard to do. Would we have to take half of this dinosaur skeleton and put it in another room? Would we take samples from each exhibit and make a smaller museum on the side? How do you do this? In some real-world cases, there’s a lot of visitors who want to see a specific art piece and it’s hard. How do you scale the Mona Lisa? You cannot. It’s just there and everybody is going to wait in line and complain about it later.
Similarly, to OpenSearch, you can scale it. That’s adding nodes. It’s a mechanical thing. You’re just going to add some machines. Spreading the load when your data is unstructured is difficult. It’s not a straightforward answer. This is why in this particular type of system and in Elasticsearch as well, you don’t have autoscaling native to the software.
Background
I’m Amitai Stern. I’m a member of the Technical Steering Committee of the OpenSearch Software Foundation, leading the OpenSearch software. I’m a tech lead at Logz.io. I manage the telemetry storage team, where we manage petabytes of logs and traces and many terabytes of monitoring and metric data for customers. Our metrics are on Thanos clusters, and everything else that I mentioned, logs and traces, are all going to be stored on OpenSearch clusters.
What Is OpenSearch?
What is OpenSearch? OpenSearch is a fork of Elasticsearch. It’s very similar. It’s been a fork for the last three years. The divergence is not too great. If you’re familiar with Elasticsearch, this is very much relevant as well. OpenSearch is used to bring order to unstructured data at scale. It’s the last line over here. It is a fork of Elasticsearch. Elasticsearch used to be open source. It provided an open-source version, and then later they stopped doing that. OpenSearch is a fork that was primarily driven by AWS, and today it’s completely donated to the Linux Foundation. It’s totally out of their hands at this point.
OpenSearch Cluster Architecture
OpenSearch clusters are monolithic applications. You could have it on one node. From here on in the talk, this rounded rectangle will represent a node. A node in OpenSearch can have many roles. You can have just one and it’ll act as its own little cluster, but you could also have many and they’ll interact together. That’s what monolithic applications are. Usually in the wild, we’ll see clusters divided into three different groups of these roles. The first one would be a cluster manager. The cluster manager nodes are managing the state where indexes are, creating and deleting indexes. There’s coordinating nodes, and they’re in charge of the HTTP requests. They’re like the load balancer for the cluster. Then there’s the data nodes. This is the part that we’re going to want to scale. Normally this is where the data is. The data is stored within a construct called an index. This index contains both the data and the inverted index that makes search fast and efficient.
These indices are split up, divided between the data nodes in a construct called a shard. Shards go from 0 to N. A shard is in fact a Lucene index, just to make things a little bit confusing. You already used the term index, so you don’t need to remember that. They’re like little Lucene databases. On the data nodes are three types of pressure if you’re managing one. You’re managing your cluster. You have the read pressure, all the requests coming in to pull data out as efficiently as possible and quickly as possible, and this write pressure of all these documents coming in. There’s the third pressure when you’re managing a cluster, which is the financial one. Since if your read and writes are fairly low, you’ll get a question from your management or from the CFO like, what’s going on? These things cost a lot of money: all this disk space, all the memory, and CPU cores. It’s three types of pressure.
Why Autoscale?
Let’s move on to why would you even autoscale? Financially, cluster costs a lot of money. We want to reduce the amount of nodes that we have. What if we just had enough to handle the scale? This blue line will be the load. The red line is the load that we can accommodate for with the current configuration. Leave it vague that way. Over-provisioned is blue, and under-provisioned is the red over there. If we said the max load is going to be x, and we’re just going to say, we just provision for there. We’ll have that many nodes. The problem would be that we’re wasting money. This is good in some cases if you have the money to spend. Normally, we’re going to try and reduce that. You opt for manual scaling. Manual scaling is the worst of both worlds. You wait too long to scale up because something’s happening to the system. It’s bad performance. You scale up.
Then you’re afraid to scale down at this point because a second ago, people were complaining, so you’re going to wait too long to scale down. It’s really the worst. Autoscaling is following that curve automatically. That’s what we want. This is the holy grail, some line that follows the load. When we’re scaling OpenSearch, we’re scaling hardware. We have to think about these three elements that we’re scaling. We’re going to scale disk. We’re going to scale memory. We’re going to scale CPU core. These are the three things we want to scale. The load splits off into these three. Read load doesn’t really affect the disk. You can have a lot of read load or less read load. It doesn’t mean you’re going to add disk. We’re going to focus more on the write load and its effects on the cluster, because it affects all three of these components. If there’s a lot of writes, we might need to add more disk, or we might need more CPU cores because the type of writing is a little more complex, or we need more memory.
Vertical and Horizontal Scaling
I have exactly one slide devoted to vertical scaling because when I was going over the talk with other folks, they said, what about vertical scaling? Amazon, behind the scenes when they’re running your serverless platform, they’re going to vertically scale it first. If you have your own data center, it could be easy to do that relatively. Amazon do this because they have the capability to vertically scale easily. If you’re using a cloud, it’s harder. When you scale up, usually you go from one set of machines to the next scale of machines. It means you have to stop that machine and move data. That’s not something that’s easily done normally. Vertically scaling, for most intent and purposes in most companies, is really just the disk. That is easy. You can increase the number of EBS instances. You can increase the disk over there. Horizontal scaling is the thing you need to know how to do.
If you’re managing and maintaining clusters, you have to know how to do this. OpenSearch, you just have to add a node, and it gets discovered by the cluster, and it’s there. Practically, it’s easy. There’s a need to do this because of the load, the changing load. There’s an expectation, however, that when you add a node, the load will just distribute. This is the case in a lot of different projects. Here, similar to the example with the museum, it’s not the case. You have to learn how the load is spread out. You have to actually change that as well. How you’re maintaining the data, you have to change that as you are adding nodes.
If the load is disproportionately hitting one of the nodes, we call that a hotspot. Any of you familiar with what hotspots are? You get a lot of load on one of those nodes, and then writes start to lag. Hotspots are a thing we want to avoid. Which moves us into another place of, how do we actually distribute this data so it’s going to all these nodes in the same fashion and we’re not getting these hotspots? When we index data into OpenSearch, each document gets its own ID. That ID is going to be hashed, and then we’re going to do a Mod of N. N being the number of shards. In this example, the Mod is something that ends with 45, and Mod 4, because we have 4 shards. That would be equal to 1, so it’s going to go to shard number 1. If you have thousands of documents coming in, each with their own unique ID, then they’re going to go to these different shards, and it more or less balances out. It works in reality.
If we wanted to have the capability to just add a shard, make the index just slightly bigger, why can’t we do that? The reason is this hash Mod N. If we were to potentially add another shard, our document is now stored in shard number 1, and we want it to scale up, so we extended the index just a bit.
The next time we want to search for that ID, we’re going to do hash Mod to see where it is. N just changed, it’s 5 and not 4. We’re looking for the document in a different shard, and it is now gone. That’s why we have a fixed number of shards in our indices. We actually can’t change that. When you’re scaling OpenSearch, you have to know this. You can’t just add shards to the index. You have to do something we call a rollover. You take the index that you’re writing to, and you add a new index with the same aliases. You’re going to start writing to the new index atomically. This new index would have more shards. That’s the only way to really increase throughput.
Another thing that’s frustrating when you’re trying to horizontally scale a cluster is that there’s shared resources. Each of our data nodes is getting hit with all these requests to pull data out and at the same time to put data in. If you have a really heavy query with a leading wildcard, RegEx, something like that, hitting one or two of your nodes, the write throughput is going to be impacted. You’re going to start lagging in your writes. Why is this important to note? Because autoscaling, often we look at the CPU and we say, CPU high at nodes. That could be because of one of these two pressures. It could be the write pressure or the read. If it’s the read, it could be momentary, and you just wasted money by adding a lot of nodes.
On the one hand, we shouldn’t look at the CPU, and we might want to look at the write load and the read load. On the other hand, write load and read load could be fine, but you have so many shards packed in each one of your nodes because you’ve been doing all these rollover tasks that you get out of memory. I’m just trying to give you the feeling of why it’s actually very hard to do this thing where you’re saying, this metric says scale up.
Horizontally Scaling OpenSearch
The good news is, it’s sometimes really simple. It does come at a cost, similarly to eating cake. It is still simple. If the load is imbalanced on one of those three different types, disk, memory, or CPU, we could add extra nodes, and it will balance out, especially if it’s disk. Similarly, if the load is low on all three, it can’t be just one, on all three of those, so low memory, low CPU, low disk, we can remove nodes. That’s when it is simple, when you can clearly see the picture is over-provisioned or under-provisioned. I want to devote the rest of the talk to when it’s actually complicated because the easy is really easy. Let’s assume that we’re looking at one of those spikes, the load goes up and down. Let’s say we want to say that when we see a lot of writes coming in, we want to roll over. When they go down, we want to roll over again because we don’t want to waste money. The red is going to say that the writes are too high. We’re going to roll over.
Then we add this extra node, and so everything is ok. Then the writes start to go down, we’re wasting money at this point. There’s 20% load on each of these nodes. If we remove a node, we get a hotspot because now we just created a situation where 40% is hitting one node, a disproportionate amount of pressure on one. That’s bad. What do we do? Do another rollover task, and now it’s 25% to each node. We could do this again and again on each of these. If it’s like a day-night load, you’d have way too many shards already in your cluster, and you’d start hitting out of memory. Getting rid of those extra shards is practically hard. You have to find a way to either do it slowly by changing to size-based retention, or you can do merging of indexes, which you can do, but it’s very slow. It takes a lot of CPU.
Cluster Topologies for Scaling
There is a rather simple way to overcome this problem, and that is to overshard. Rather than have shards spread out one per node, I could have three shards per node. Then, when I want to scale, I’ll add nodes and let those shards spread out. The shards are going to take up as much compute power as it can from those new nodes, so like hulking out. That’s the concept. However, finding the sweet spot between oversharding and undersharding becomes hard. It’s difficult to calculate. In many cases, you’d want to roll over again into an even bigger index. I’m going to suggest a few topologies for scaling in a way that allows us to really maintain this sweet spot between way too many, way too few shards. The first kind is what I’d call a burst index.
As I mentioned earlier, each index has a write alias. That’s where you’re going to atomically be writing. You can change this alias, and it’ll switch over to whatever index you point to. It’s an important concept to be familiar with if you’re managing a cluster. What we’re suggesting is to have these burst indices prepared in case you want to scale out. They can be maintained for weeks, and they will be that place where you direct traffic when you need to have a lot of it directed there. That’s what we would do. We just change the write alias to the write data stream. That would look something like this. There’s an arbitrary tag, a label we can give nodes called box_type. You could tell an index to allocate its shards on a specific box_type or a few different box_types. The concept is you have burst type, the box_type: burst, and you have box_type: low.
As long as you have low throughput in your writes, and again, that is probably the best indicator of I need more nodes, is the write throughput. If we have a low throughput on the writes, we don’t need our extra nodes. The low write throughput index is allocated to indexes that have the low box_type. If throughout the day the throughput is not so low and we anticipate that we’re going to have a spike, and this, again, it’s so tailored to your use case that I can’t tell you exactly what that is. If you see, in many cases, it is that the write throughput is growing on a trend, then what you do is you add these extra nodes. You don’t need to add nodes that are as expensive as the other ones. Why? Because you don’t intend to have that amount of disk space used on them. They’re temporary. You could have a real small and efficient disk there on these new box_types. You create the new ones. The allocation of our burst index says it can be on either low or burst or both. All you have to do is tell that index that you’re allowed to have total shards per node, 1.
Then it automatically will spread out to all of these nodes. At this point, you’re prepared for the higher throughput, and you switch the write alias to be the high throughput index. This is the burst index type. As it goes down, you can move the shards back by doing something called exclude of the nodes. You just exclude these nodes, and shards just fly off of it to other nodes. Then you remove them. This is the first form of autoscaling. It works when you don’t have many tenants on your cluster. If you have one big index, and it may grow or shrink, this makes sense.
However, in some cases, we have many tenants, and they’re doing many different things all at the same time. Some throughputs spike, when others will go down. You don’t want to be in a situation where you’re having your cluster tailored just for the highest throughput tenant. Because then, again, you are wasting resources.
Which brings me to the second and last topology that I want to discuss here, which is called the burst cluster. It is very similar to the previous one, but the difference is big. We’re not just changing the index that we’re going to within the cluster, we’re changing the direction to a completely different cluster. We wouldn’t be using the write alias, we would be diverting traffic. It would look something like this. If each of these circles is a cluster, and each of them have that many nodes, why would we have a 10, and a 5, and a 60? The reason is we’d want to avoid hotspots. You should fine-tune your clusters initially for your average load. The average load for a low throughput might be 5 nodes, so you want only 5 shards. For a higher throughput, you want a 10-node cluster, so you have 10 shards each. If you’re suffering from hotspots, all you have to do to fix that is spread the shards perfectly on the cluster. That means zero hotspots.
In this situation, we’ve tailored our system so that on these green clusters, the smaller circles, they’re fine-tuned for the exact amount of writes that we’re getting. Then one of our tenants spikes while the others don’t. We move only that tenant to send all their data, we divert it to the 60-node cluster, capable of handling very high throughputs, but not capable of handling a lot of disk space. It’s not as expensive as six times these 10-node clusters. It is still more expensive. Data is being diverted to a totally different environment. We use something called cross-cluster search in order to search on both. From the perspective of the person running the search, nothing has changed at any point. It’s completely transparent for them.
In terms of the throughput, nothing has changed. They’re sending much more data, but they don’t get any lag, whoever is sending it. All the other tenants don’t feel it. There are many more tenants on this 10-node cluster, and they’re just living their best life over there. You could also have a few tenants sending to this 60-node cluster. You just have to manage how much disk you’re expecting to fill at that time of the burst. A way to make this a little more economical is to have one of your highest throughput tenants always on the 60-node cluster. You still maintain a reason to have them up when there’s no high throughput tenants on these other clusters. This is a way to think of autoscaling in a way that is a bit outside of the box and not just adding nodes to a single cluster. It is very useful, if you are running a feature that is not very used in OpenSearch, but is up and coming, called searchable snapshots.
If you’re running searchable snapshots, all your data is going to be on S3, and you’re only going to have metadata on your cluster. The more nodes you have that are searching S3, the better. They can be small nodes with very small disk, and they could be searching many terabytes on S3. If you have one node with a lot of disk trying to do that, the throughput is going to be too low and your search is going to be too slow. If you want to utilize these kinds of features where your data is remote, you have to have many nodes. That’s another reason to have such a cluster just up and running all the time. You could use it to search audit data that spans back many years. Of course, we don’t want to keep it there forever.
A way to do that is just snapshot it to S3. Snapshots in OpenSearch are a really powerful tool. They’re not the same as they are in other databases. It takes the index as it is. It doesn’t do any additional compression, but it stores it in a very special way, so it’s easy to extract it and restore a cluster in case of a disaster. We would move the data to S3 and then restore it back into these original clusters that we had previously been running our tenants on. Then we could do a merge task. Down the line, when the load is low, we could merge that data into smaller indexes if we like. Another thing that happens usually in these kinds of situations is that you have retention. Once the retention is gone, just delete the data, which is great. Especially if you’re in Europe, you have to delete it right on time. This is the burst cluster topology.
Summary
There are three different resources that we want to be scaling. You have to be mindful when you’re maintaining your cluster which one is the one that causes the pressure. If you have very long retention, then disk space. You have to start considering things like searchable snapshots or maintaining maybe a cross-cluster search where you have just data sitting on a separate cluster that’s just accumulating in very large disks, whereas your write load is on a smaller cluster. That’s one possibility. If it’s memory or CPU, then you would definitely have to add stronger machines. We have to think about these things ahead of time. Some of them are a one-way door.
If you’re using AWS and you add to your disk space, in some cases, you may find it difficult to reduce the disk space again. This is a common problem. When I say that, the main reason it is is because when you want to reduce a node, you have to shift the data to the other nodes. In certain cases, especially after you’ve added a lot of disk, that can take a lot of time. Some of them are a one-way door. Many of them require a restart of a node, which is potential downtime. We talked about these two topologies, I’ll remind you, the burst index and the burst cluster, which are very important to think about as completely different options. I like to highlight that that first option that I gave, the hulking out, like the oversharding proposition, is also viable for many use cases.
If you have a really easy trend that you can follow, your data is just going up and down, and it’s the same at noon. People are sending 2x. Midnight, it goes down to half of that. It keeps going up and down. By all means, have a cluster that has 10 nodes with 20 shards on it. When you hit that afternoon peak, just scale out and let it spread out. Then when it gets to the evening, then scale down again. If that’s your use case, you shouldn’t be implementing things that are this complex. You should definitely use the concept of oversharding, which is well-known.
Upcoming Key Features
I’d like to talk about some upcoming key features, which is different than when I started writing this presentation. These things changed. The OpenSearch Software Foundation, which supports OpenSearch, one of the things that’s really neat is that from it being very AWS-centric, it has become much more widespread. There’s a lot of people from Uber and Slack, Intel, Airbnb, developers starting to take an interest and developing things within the ecosystem. They’re changing it in ways that will benefit their business.
If that business is as big as Uber, then the changes are profound. One of the changes that really affects autoscaling is read/write separation. That’s going to come in the next few versions. I think it’s nearly beta, but a lot of the code is already there. I think this was in August when I took this screenshot, and it was a 5 out of 11 tasks. They’re pretty much there by now. This will allow you to have nodes that are tailored for write and nodes that are tailored for read. Then you’re scaling the write, and you’re scaling the read separately, which makes life so much more simple.
The other one, which is really cool, is streaming ingestion. One of the things that really makes it difficult to ingest a lot of data all at once is that today, in both Elasticsearch and OpenSearch, we’re pushing it in. The index is trying to do that, trying to push the data and ingest it. The node might be overloaded, in which case the shard will just say, I’m sorry, CPU up to here, and you get what is called a write queue. Once that write queue starts to build, someone’s going to be woken up, normally. If you’re running observability data, that’s a wake-up call. In pull-based, what you get is the shard is hardcoded to listen and retrieve documents from a particular partition in for example, Kafka. It would be pluggable, so it’s not only Kafka.
Since it’s very common, let’s use Kafka as an example. Each shard will read from a particular partition. A topic would represent a tenant. You could have a shard reading from different partitions from different topics, but per topic, it would be one, so shard 0 from partition 0. What this gives us is the capability for the shard to read as fast as it can, which means that you don’t get the situation of a write queue, because it’s reading just as fast as it possibly can, based on the machine, wherever you put it. If you want to scale, in this case, it’s easy. You look at the lag in Kafka. You don’t look at these metrics in terms of the cluster. The metrics here are much easier. Is there a lag in Kafka? Yes. I need to scale. Much easier. Let’s look at CPU. Let’s look at memory. Let’s see if the shards are balanced. It’s much harder to do. In this case, it will make life much easier.
Questions and Answers
Participant 1: I had a question about streaming ingestion. Beyond just looking at a metric, at the lag in Kafka, does that expose a way to know precisely up to which point in the stream this got in the document? We use OpenSearch in a bunch of places where we need to know exactly what’s available in the index so that we can propagate things to other systems.
Stern: It is an RFC, a request for comments.
Participant 1: There’s not a feature yet.
Stern: Right now, it’s in the phase of what we call a feature branch, where it’s being implemented in a way that it’s totally breakable. We’re not going to put that in production. If you have any comments like that, please do comment in the GitHub. That would be welcome. It’s in the exact phase where we need those comments.
Participant 2: This is time-series data. Do you also roll your indexes by time, like quarterly or monthly, or how do you combine this approach with burst indexes with a situation where you have indexes along the time axis.
Stern: If it’s retention-based? One of the things you can do is you have the burst index. You don’t want it to be there for too long. The burst index, you want it to live longer than the retention?
Participant 2: It’s not just the burst indexes, your normal indexes are separated by time.
Stern: In some cases, if your indexes are time-based and you’re rolling over every day, then you’re going to have a problem of too many shards if you don’t fill them up enough. You’ll have, basically, shards that have 2 megabytes inside them. It just inflates too much. If you have 365 days or two years of data, that becomes too many shards. I do recommend moving to size-based, like a hybrid solution of size-based, as long as it’s less than x amount of days, so that you’re not exactly on the date but better. Having said that, the idea is that you have your write alias pointed at the head. Then after a certain amount of time, you do a rollover task. The burst index, you don’t roll over, necessarily. That one, what you do instead of rolling over, you merge, or you do a re-index of that data into the other one. You can do that. It just takes a lot of time to do. You can do that in the background. There’s nitty-gritty here, but we didn’t go into that.
Participant 3: I think you mentioned separation of reading and writing. It’s already supported in OpenSearch Serverless in AWS. Am I missing something? The one that you are talking about, is it going to come for the regular OpenSearch, and it’s not yet implemented?
Stern: I don’t work at AWS. I’m representing open source. Both of these are going to be completely in open source.
Participant 3: That’s what I’m saying. It seems like it’s already there in version, maybe 2.13, 2.14, something like that. You mentioned it is a version that is coming, but I have practically observed that it’s already there, in Amazon serverless.
Stern: Amazon serverless is a fork of OpenSearch. It took a nice amount of engineers more than a year to separate these two things, these concepts of OpenSearch is a multi-application and having to read/write. A lot of these improvements, they’re working upstream. They like to add these special capabilities, like read/write separation. Then they contribute a lot of the stuff back into the open source. In some cases, you’ll have features already available in the Amazon OpenSearch offering, then later, it’ll get introduced into the OpenSearch open source.
Participant 3: The strategies that you explained just now, and they are coming, especially the second one, one with the Kafka thing, is there a plan?
Stern: Again, this is very early stage, the pull-based indexing. That one is at a stage where we presented the API that we imagine would be useful for this. We developed the concept of it’ll be pluggable, like which streaming service you’d use. It’s at a request for comments stage. I presented it because I am happy to present these things and ask for comments. If you have anything that’s relevant, just go on GitHub and say, we’re using it for this, and one-to-one doesn’t make sense to us. If that’s the case, then yes.
Participant 3: It can take about six months to a year?
Stern: That particular one, we’re trying to get in under a year. I don’t think it’s possible in six months. That’s a stretch.
Participant 4: I think this question pertains to both the burst index and the burst cluster solution. I think I understand how this helps for writing new documents. If you have an update or a delete operation, where you’re searching across your old index, or your normal index, and then either the burst index or the burst cluster, and that update or that delete is reflected in the burst cluster, how does that get rectified between those two?
Stern: One of the things you have to do if you’re maintaining these types of indexes, like a burst index, is you would want to have a prefix that signifies that tenant, so that any action you do, like a deletion, you’d say, delete based on these aliases. You have the capability of specifying either the prefix with a star in the end, like a wildcard. You could also give indexes, and it’s very common to do this, especially if it’s time-series data, to give a read alias per day. You have an index, and it contains different dates with the tenant ID connected to them. When you perform a search, that tenant ID plus November 18th, then that index is then made available for search. You can do the same thing when you’re doing operations like get for a delete. You can say, these aliases, I want to delete them, or I want to delete documents from them. It can go either to the burst cluster, or it could go to the indexes that have completely different names, as long as the alias points to the correct one.
The cluster means you have to really manage it. You have to have some place where you’re saying, this tenant has data here and there, and the date that I changed the tenant to be over there, and the date that I changed them back. It’s very important to keep track of those things. I wouldn’t do it within OpenSearch. A common mistake when you’re managing OpenSearch, is to say, I have OpenSearch, so I’m going to just store lots of information in it, not just the data that I built the cluster for. It should be a cluster for a thing and not for other things. Audit data should be separated from your observability data. You don’t want to put them in the same place.
Participant 5: A question regarding the burst clusters, as well as the burst nodes that you have. With clusters, how do you redirect the read load directly? Is the assumption that we do cross-cluster search? With OpenSearch dashboards in particular, when you have all your alerts and all that, and with observability data, you’re acquiring a particular set of indexes, so when you move the data around clusters, how do you manage the search?
Stern: For alerting, it is very difficult to do this if you’re managing alerting using just the index. If you use a prefix, it could work. If you’re doing cross-cluster search, the way that that feature works is that, in the cluster settings, you provide the clusters that it can also search on. Then when you run a search, if you’re doing it through Amazon service, it should be seamless. If you’re running it on your own, you do have to specify, instead of just search this index, it doesn’t know that it has to go to the other cluster. You have to say, within this cluster, and that cluster, and the other cluster, search for this index. You have to add these extra indexes to your search.
Participant 5: There is a colon mechanism where you put in. Basically, what you’re expecting here is, in addition to write, with read, we have to keep that in mind before spinning up a burst cluster.
Stern: You have to keep track where your data is when you’re moving it.
Participant 5: The second part of the question with burst nodes is, I’m assuming you’re amortizing the cost of rebalancing. Because whenever the node goes up and down, so your cluster capacity, or the CPU, because shards are moving around, and that requires CPU, network storage, these transport actions are happening. You’re assuming, as part of your capacity planning, you have to amortize that cost as well.
Stern: Yes. Moving a shard while it’s being written to, and it has already 100 gigs on it, moving that shard is a task that is just going to take time. You need high throughput now. It’s amortized, but it’s very common to do a rollover task with more shards when your throughput is big. It’s the same. You’d anyway be doing this. You’d anyway be rolling over to an index that has more shards and more capability of writing on more nodes. It’s sort of amortized.
Participant 5: With the rollover, you’re not moving the data, though. It’s new shards getting created.
Stern: Yes. We don’t want to move data when we’re doing the spread-out. That really slows things down.
See more presentations with transcripts