Month: December 2022

MMS • Daniel Dominguez
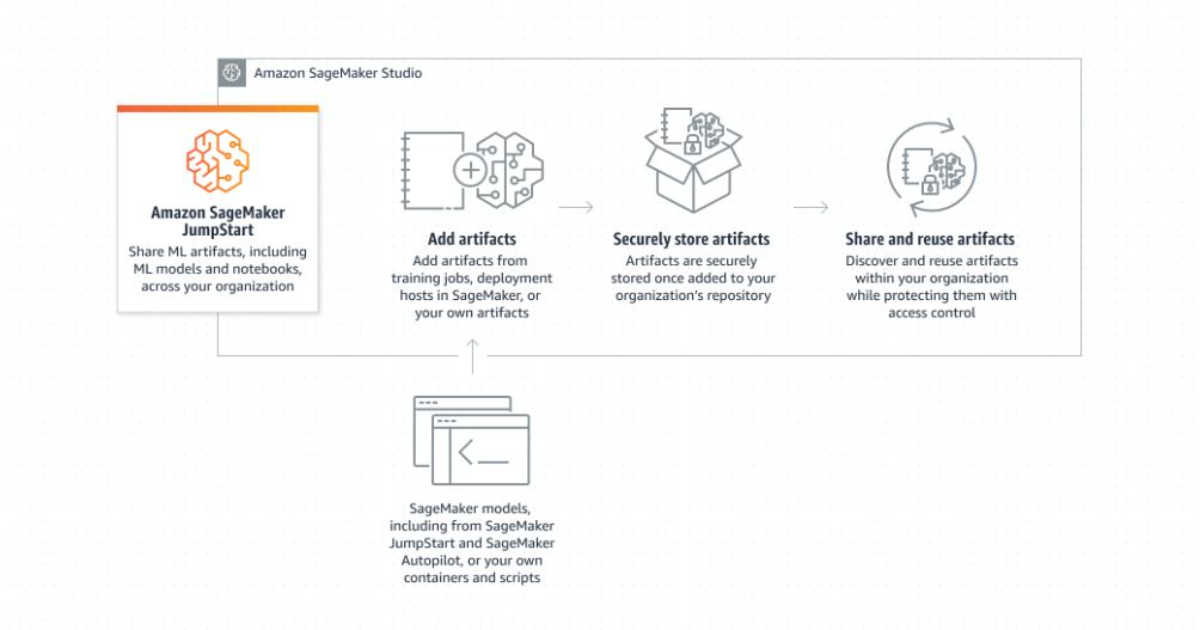
AWS announced that it is now easier to share machine learning artifacts like models and notebooks with other users using SageMaker JumpStart. Amazon SageMaker JumpStart is a machine learning hub that helps users accelerate their journey into the world of machine learning. It provides access to built-in algorithms and pre-trained models from popular model hubs, as well as pre-trained foundation models for tasks such as article summarization and image generation.
SageMaker JumpStart offers end-to-end solutions to solve common use cases in machine learning. One of the key features is the ability to share machine learning artifacts, such as models and notebooks, with other users within the same AWS account. This makes it easy for data scientists and other team members to collaborate and increase productivity, as well as for operations teams to put models into production.
A variety of built-in algorithms from model hubs like TensorFlow Hub, PyTorch Hub, HuggingFace, and MxNet GluonCV are available with SageMaker JumpStart. These algorithms address a range of machine learning applications, such as sentiment analysis and picture, text, and tabular data classification, and may be accessible using the SageMaker Python SDK.
To share machine learning artifacts using SageMaker JumpStart, users can simply go to the Models tab in SageMaker Studio and select the “Shared models” and “Shared by my organization” options. This allows users to discover and search for machine learning artifacts that have been shared within their AWS account by other users. Additionally, users can add and share their own models and notebooks that have been developed using SageMaker or other tools.
SageMaker JumpStart also provides access to large-scale machine learning models with billions of parameters, which can be used for tasks like article summarization and generating text, images, or videos. These pre-trained foundation models can help reduce training and infrastructure costs, as well as allowing for customization for a specific use case.
By sharing machine learning models and notebooks, users can centralize model artifacts, make them more discoverable, and increase the reuse of models within an organization. Sharing models and notebooks can help to streamline collaboration and improve the efficiency of machine learning workflows.