Month: April 2023

MMS • Almir Vuk
Article originally posted on InfoQ. Visit InfoQ

Earlier this month, Uno Platform released Preview 5 of its plugin for Figma, offering enhanced features for designers and developers. The latest version of the plugin allows the creation of custom colors, eliminating color limitations, and enables the import of Design Systems Packages (DSP) for sharing design system information across various tools and designs. Additionally, new controls such as Pips Pager and TabBar with vertical orientation, as well as the ItemsRepeater feature, offer even greater flexibility to create highly dynamic and interactive designs.
Uno Platform has introduced new features that provide users with enhanced flexibility in managing the themes and colors of their apps. These features empower users to customize their app’s visual appearance and tailor it to their unique preferences and brand identity, resulting in personalized and visually appealing user experiences.
The significant new feature is the Design System Package (DSP) importing, which allows users to create and save custom material color palettes that can be easily imported into the Uno Figma plugin to quickly change the app’s theme. This feature streamlines the process of applying consistent colors across different designs and layouts, providing greater control and flexibility in implementing colors in app designs.
In addition, Uno Platform has added a custom color feature that eliminates restrictions on the number of colors used in a design, enabling designers and developers to create colors that suit their specific requirements. This feature offers designers greater creative freedom to create unique and customized color schemes that enhance the overall design aesthetic.
This Preview 5 introduces three new controls, including the highly anticipated vertical-oriented TabBar. TabBar control provides developers and designers with the ability to toggle between horizontal and vertical navigation bars, making it especially valuable for designing tablet-format applications. With this feature, designers can offer improved usability by utilizing a vertical navigation bar that complements the larger screen size.
PipsPager is another new control in Preview 5. This dynamic and versatile element offers advanced functionality for creating interactive designs, allowing developers and designers to create paginated interfaces with rich features such as smooth transitions, animations, and gestures. With its customizable design, PipsPager is ideal for applications that require complex navigation and data manipulation.
Furthermore, Preview 5 introduces the ItemsRepeater control, a data-driven panel that offers a unique approach to displaying collections of items. The original release blog post delivers the following statement:
ItemsRepeater is not a complete control, but rather a flexible panel that provides a template-driven layout for displaying collections of data. It offers greater customization options, allowing designers to have full control over the visual appearance and behaviour of the repeated items, making it highly suitable for designing interfaces with complex data presentation requirements.
Preview 5 also brings two notable updates to its image preview and display features. The placeholder image has been refined to aid designers in creating more accurate visual representations of their designs, and the need to alter images to a random preview image generated by the plugin has been eliminated. Images will now appear in the plugin precisely as they are displayed in the Figma file.
The Uno Platform for Figma plugin is rapidly developing into a robust tool that facilitates the app development process for developers and designers. Its latest features empower users to take greater control of their design and development workflow, enabling them to quickly move from the design phase to development without encountering common obstacles. And lastly, in addition to the original release blog post, users can find the detailed YouTube video tutorial published by the Uno Platform team, the video provides step-by-step instructions on how to download and launch the plugin.
MMS • Matt Campbell
Article originally posted on InfoQ. Visit InfoQ

Amazon moved CodeCatalyst into full general availability with a number of new features. CodeCatalyst provides templates to streamline creating the project’s infrastructure, CI/CD pipelines, development environments, and issue management system. New features with the GA release include better support for GitHub repos, integration with Amazon CodeWhisperer, and support for AWS Graviton processors.
Released at re:Invent in 2022, CodeCatalyst is built on four foundational elements: blueprints, CI/CD automation, remote development environments, and issue management. Blueprints set up the application code repository, including a sample app, define the infrastructure, and run pre-defined CI/CD workflows.
With the GA release, there are now blueprints for static websites built with Hugo or Jekyll and intelligent document processing workflows. These join the already released blueprints that support building single-page applications, .NET serverless applications, and AWS Glue ETLs.
When a project is created from a blueprint, a full CI/CD pipeline is also provided. This pipeline can be modified with actions from the provided library. As well, any GitHub action can be used directly within a project either within an existing pipeline or to build a net-new pipeline. Editing the pipeline can be done either via a graphical drag-and-drop editor or by editing the YAML directly.
CodeCatalyst provides developer environments that are hosted within AWS. These environments are defined using the devfile standard providing a repeatable and consistent workspace. The devfile standard is an open standard for defining containerized developer environments. These environments can integrate with a number of IDEs such as AWS Cloud9, VS Code, and JetBrains IDEs.
Finally, CodeCatalyst projects provide built-in issue management tied to the code repository. This facilitates assigning code reviews and pull requests. Adding new teammates to a project does not require an AWS account per user. Instead, users can be added to an existing project via their email address.
Additional new features include support for creating new projects from existing GitHub repositories. Note that empty or archived repos can’t be used and the GitHub repositories extension isn’t compatible with GitHub Enterprise Server repos. The CodeCatalyst Dev Environments now also supports GitHub repositories. This supports cloning an existing branch of the linked GitHub repo into the Dev Environment.
CodeCatalyst Dev Environments also now support Amazon CodeWhisperer. Amazon CodeWhisperer is an AI-supported coding assistant that generates code suggestions within the IDE. At the time of release, only AWS Cloud9 and VisualStudio Code are supported. Amazon CodeWhisperer is similar to GitHub’s Copilot, which recently released a new AI model.
This release also adds support for running workflow actions on either on-demand or pre-provisioned AWS Graviton processors. According to Brad Bock, Senior Product Marketing Manager at AWS, and Brian Beach, Principal Tech Lead at AWS, “AWS Graviton Processors are designed by AWS to deliver the best price performance for your cloud workloads running in Amazon Elastic Compute Cloud (Amazon EC2)“.
As noted by Bock and Beach, CodeCatalyst is about reducing the cognitive load on developers:
Teams deliver better, more impactful outcomes to customers when they have more freedom to focus on their highest-value work and have to concern themselves less with activities that feel like roadblocks.
Cognitive load has been receiving more attention as developers have increased responsibilities to manage and maintain to deliver working software to production. Paula Kennedy, COO at Syntasso, echos this sentiment:
With the evolution of “DevOps” and the mantra “you build it, you run it”, we’ve seen a huge increase in cognitive load on the developers tasked with delivering customer-facing products and services.
Amazon CodeCatalyst can be used on the AWS Free Tier. More details about the release can be found on the AWS blog as well as within the documentation.
Meet the Undisputed King of Real-Time in Serverless Databases – Analytics India Magazine
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
|
Listen to this story |
If real-time use cases on serverless databases had a face it would be of Redis. “Obviously, we at Redis are convinced that SDBaaS Redis is ideal for real-time applications,” said Yiftach Shoolman, co-founder and CTO of Redis, in a blog post, sharing how the popular key-value database system was ahead in the game.
| SDBaaS is a cloud-based database service that allows developers to focus on building applications while operation works of running the applications are taken care of by the cloud provider. |
“The serverless database-as-a-service (SDBaaS) market opportunity is huge, and it is another reason why Redis Enterprise Cloud makes sense for any real-time use cases,” said Shoolman.
According to Shoolman, Redis Enterprise Cloud is easy to manage, flexible, scalable, and extremely cheap. The company believes that the cost of operation is much more meaningful than the cost of storing data, and each operation in Redis is cost-effective. “It ensures real-time experience for your end users, as any database operation can be executed in less than 1 msec,” he added.
In a previous interview with AIM, Schoolman spoke about the challenges with real-time applications. He said that from the time a request is put, nobody wants to wait for more than 0.1s i.e. 100ms, and that every delay in a database is reflected 100 times more to the end user. If a database is slow, the delay is even more aggravated for the end user.
“There’s always a misconception that Redis is expensive because it runs on memory but in the real time world, it is cheaper,” he said.
Redis vs DynamoDB
On the other hand, DynamoDB is a NoSQL database service provided by Amazon. To maintain a swift performance, DynamoDB spreads the data and traffic over a number of servers so as to handle the storage and throughput. The database can create tables capable of storing and retrieving any volume of information at any level of traffic.
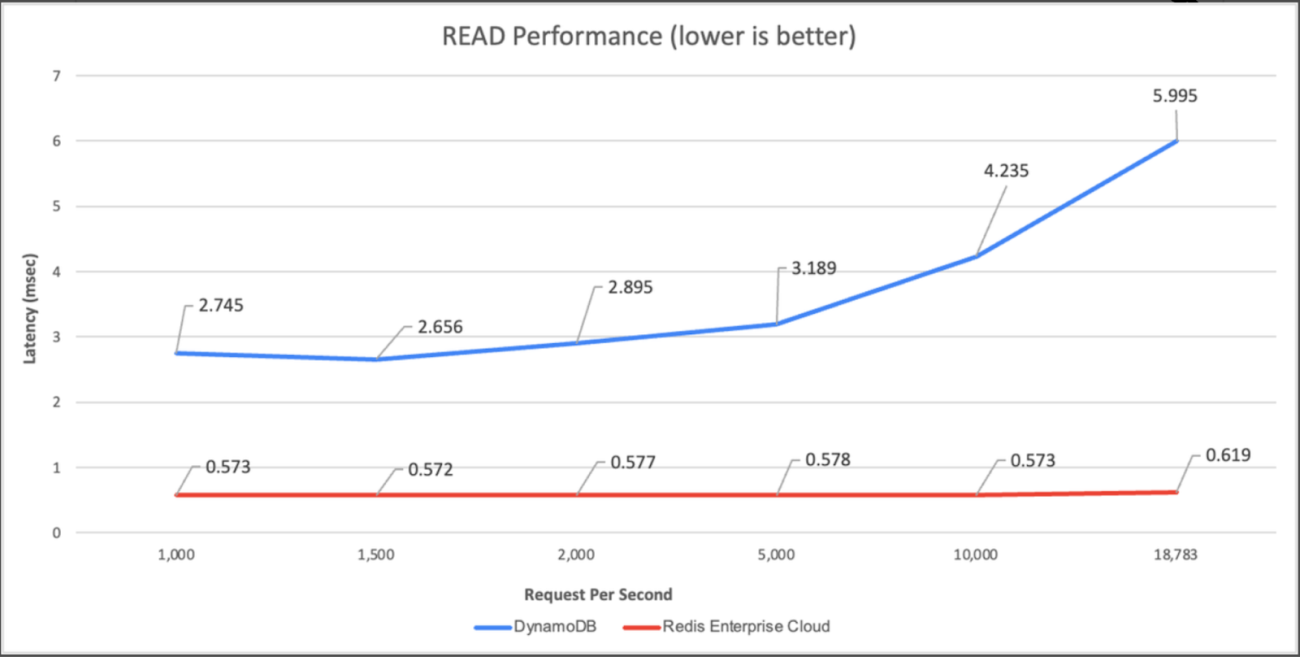
In comparison between the two, Redis comes out on top. At 1,000 requests per second, Redis Enterprise Cloud is 6.44 times faster and 15% cheaper than DynamoDB, and at 18,000 requests per second, the cost is at 2% of DynamoDB and 11 times faster.
On comparing Redis and DynamoDB on read (process of retrieving data from the database) and update (process of modifying existing data in the database) performance, by running common workloads with a 50GB fixed dataset, Redis maintained an end-to-end latency of 0.5-0.6 msec while Dynamodb performed no faster than 2.7ms (for read) and 4.4ms (for update).
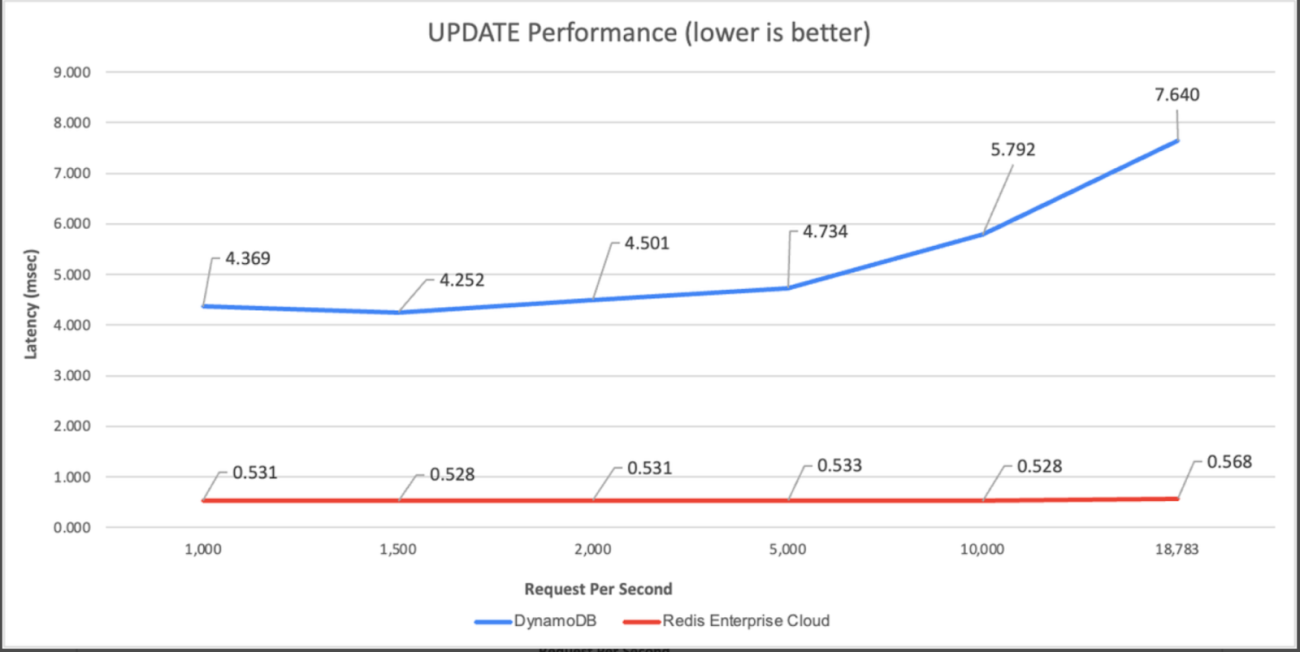
Source: Redis blog
Redis Enterprise Cloud was built on a serverless architecture from the start, and allows developers to be billed for what they set. Redis enables a single core to manage a large number of operations when compared to other databases that use dozens or hundreds of cores. This results in making the database highly cost-effective. Redis relies on DRAM (Dynamic Random Access Memory) which is faster and more expensive than SSD (Solid State Drive), but the cost for the service is based on the number of operations and not how much data is stored.
Redis vs the World
In addition to DynamoDB, there are a few other SDBaaS platforms that have versatile uses, and probably comes close to Redis’ performance.
MongoDB
A serverless NoSQL database, data in MongoDB is stored in the form of a document. This makes it simpler for developers by providing a flexible schema. When it comes to performance, Redis is faster as it has an in-memory database. This means it is more suited for building intricate data structures, whereas MongoDB is ideal for medium-sized enterprises. However, Redis uses more RAM than MongoDB with large datasets.
CockroachDB
CockroachDB is a distributed, scalable, and generally available open-source relational database management system which is designed to support transactions across multiple nodes in a cluster. CockroachDB can handle large volumes of data and can be used for a wide range of applications. Simply put, the database is designed for scalability and fault tolerance whereas Redis prioritizes high performance and low latency.
With time, choosing an appropriate cloud database has become an increasingly complicated task. In order to enhance efficiency and cost-effectiveness, developers need to sort through a diverse range of instance types, determine the most suitable number of cores, and evaluate several pricing alternatives. Considering how each database is different from the other, it boils down to their functionalities and intended use. Going by the comparison benchmarks and Redis’ in-memory database that pushes for speedy performance, its superiority in the segment is clear.
MMS • Nsikan Essien
Article originally posted on InfoQ. Visit InfoQ
Momento now offers Momento Topics, a serverless event messaging system that supports publish-subscribe communication patterns. This service is designed to provide a messaging pipeline for event-driven architectures and subsequent feature releases will allow direct AWS Lambda invocations and change data capture events triggered from Momento Cache.
Momento aims to enable developers to quickly write reliable and powerful applications. Their first product, Momento Cache, launched in 2022, is a serverless cache for database and application use cases that has been described by serverless advocate Alex DeBrie as “a cache for the 21st century—for the serverless, cloud-enabled era.” Momento Topics is the second service from the Momento team and is designed to immediately deliver published messages to all current subscribers of a topic, after which they are discarded. Momento recommends this service for scenarios where low latency message delivery is prioritized over occasional message loss. As messages are not stored indefinitely on Momento Topics, usage is billed against volumes of data moved via the service.
The key benefits of Momento Topics include a simplified pricing model with a 50GB free tier, configuration-free management of topics, and millisecond tail latencies at high scale. To use Momento Topics, applications need to install the Momento SDK, which has varying levels of support across eight programming languages and frameworks, including Node.js, .NET, and Java. As Momento Topics is backed by Momento Cache, applications will need to connect to an existing cache instance via the SDK prior to publishing or subscribing. Below is a code snippet showing how to set up the client to publish in Node.js:
import {
TopicClient,
TopicPublish,
Configurations,
CredentialProvider,
} from '@gomomento/sdk';
const momento = new TopicClient({
configuration: Configurations.Laptop.v1(),
credentialProvider: CredentialProvider.fromEnvironmentVariable({
environmentVariableName: 'MOMENTO_AUTH_TOKEN',
}),
});
const publishResponse = await momento.publish(cacheName, topicName, value);
if (publishResponse instanceof TopicPublish.Success) {
console.log('Value published successfully!');
} else {
console.log(`Error publishing value: ${publishResponse.toString()}`);
}
To subscribe, the code is similar, with the addition that the client needs to register a callback that can be triggered when new items arrive:
const response = await momento.subscribe(cacheName, topicName, {
onItem: handleItem,
onError: handleError,
});
function handleItem(item: TopicItem) {
console.log('Item received from topic subscription; %s', item);
}
function handleError(error: TopicSubscribe.Error) {
console.log(`Error received from topic subscription; ${error.toString()}`);
}
The Momento team has also announced plans to enhance the subscription functionality of Momento Topics with two features. The first, Executors, would allow Lambda functions to be directly invoked as subscribers to topics, while the second, Triggers, would allow subscriptions to be triggered based on changes to data stored within Momento Cache.
Momento Topics is comparable to services like AWS Eventbridge, Azure Event Grid, and GCP Eventarc, as it focuses on decoupled application integration via events. While it offers a similar serverless and low configuration overhead to other services, it differs in regard to its dead-lettering/event delivery capabilities. Where the other services do not guarantee event delivery order and utilize dead-lettering, Momento Topics provides messages with sequence numbers and aims to enable initialization of subscriptions from a checkpointed sequence number. Another key difference with Momento Topics is the amount of publishers and subscribers it supports natively. While AWS Eventbridge, Azure Event Grid, and GCP Eventarc have integrations with their wider ecosystems, Momento Topics has only announced future integrations with AWS Lambda and Momento Cache.
Further information on how to get started with Momento Topics can be found on its documentation page.
MMS • Jim Barton
Article originally posted on InfoQ. Visit InfoQ

Transcript
Barton: We’re going to talk about sidecars, eBPF, and the future of service mesh technology. My name is Jim Barton. I am a field engineer with solo.io here in North America. Solo is a company that’s very passionate about application networking, especially in a cloud native context. We supported a number of the largest and most influential open source projects in that space, things like Istio and Envoy proxy, as well as other projects like GraphQL and Cilium.
Parsimony (The Law of Simplicity)
I wanted to set the stage for this presentation, I want to take you back to something that happened just a few months before my graduation from engineering school a long time ago. This story goes back to a competition that was held with my IEEE student chapter, actually multiple IEEE student chapters from around our region that got together and had a contest. It was a robot car racing contest. You had a car that was to trace a line very much like what you see here in the picture. The idea was to go as fast as possible, and to beat out all the other schools. This was a high energy competition that had a lot of entrants from a lot of different engineering schools, a lot of really interesting designs. Most of them were fairly complex, some of them were a little funny. At any rate, to boil it all down, there were two designs that worked their way through the single elimination competition. One of them was this huge behemoth of a design. It had this giant central core, and these rotating legs that came off that central core, each with their own wheels. The superstructure would rotate, and would propel this vehicle down the black path there. It came from a very large, very well-respected engineering school, had a big following with a big operations team. It was a pretty impressive thing to watch.
As the competition went on, this entrant went all the way to the finals. Then there was an underdog that went through to the finals as well. It was pretty much the polar opposite of our giant behemoth. It was a little tiny entrant from a small engineering school, they sent a single delegate to this convention. He built this thing, it looked like it used the chassis of a child slot car, and had a little tiny, sweeping photodetector at the head of the car with a little battery and a little motor to drive things. It just swished its way down the track and was beating all of these much bigger, much better funded competitors. We got to the end of the competition, and there were two finalists left standing, the big behemoth with the giant rotating legs and the D cell batteries hooked into the superstructure against the little tiny one designer slot car.
I learned a lot of things my senior year of college, but that particular day taught me a lesson that I have never forgotten. That is the lesson of parsimony. Parsimony, simply being the law of simplicity. When you have a design goal in engineering, and there are multiple paths to get there, all other things being equal, the simplest path, the fewest moving parts are generally the best. As we transition into discussing the future of service mesh, the way that I see the trends in the marketplace right now, it’s all about simplicity, recognizing that we need to move toward more simple designs of our service mesh technology. There have been some really exciting developments in that space, just within the past month or two. We’re going to talk to you about that as we go forward.
Before Service Mesh
To set up that discussion, let’s go back to the “beginning.” Let’s assume you’re living in prehistoric times, let’s say 2017, and you have services that need to communicate with each other. Before there was service mesh technology, you might have two services, service A and service B. Let’s say you are a financial institution or a government entity, or in some other industry like telco that’s heavily regulated. Maybe you have a requirement like, all communication between all services need to be encrypted and use mTLS technology. Let’s say that requirement was presented to you in these prehistoric times, how might you fulfill that? You’d go out, you’d Google TLS libraries for whatever language service I’m using. Maybe you’d integrate that, and you’d test it out with the service or services it needed to communicate with. You’d deploy it and everything would be fine.
That approach is fine as far as it goes. The problem is, there aren’t many of us sitting in on this session, who live in such a small-scale environment. We often live in environments that look something more like this. I spent a number of years at Amazon, and we actually had a chart that was on a lot of walls in a lot of places that we call the Death Star. The Death Star showed, at some snapshot in time, all of the various microservice interactions that were happening within the Amazon application network. The simple approach where each application dealt with its own security infrastructure, metrics production, advanced routing capabilities, that sort of thing. It really didn’t scale very well into an environment like this. It caused us to ask a number of questions about if we want to build microservice networks at scale, how can we best answer questions like this? How do we secure communication between services in a repeatable, reliable fashion? How do we manage things like timeouts and communication failures? How do we control and route our traffic? How can we publish consistent metrics? How can we observe interactions among all of these various services?
Service Mesh Separates Concerns
We began to realize collectively as a community that a lot of these concerns that we talk about here are actually cross-cutting. They apply to all of these services. Wouldn’t it be good rather than building this undifferentiated heavy lifting logic into each and every application, what if we could externalize that in some way and handle these cross-cutting concerns in some piece of infrastructure? The first architecture that came out of just about every service mesh platform in that era was through something called sidecar injection. You see that depicted here where there would be a sidecar injected that lived next to the application code in question, and would actually manage these kinds of connect, secure, observe concerns on behalf of the application. There you can see some of the very common capabilities that evolved or that were design goals for this first round of service mesh technology. The key pillars here being connect, secure, observe what’s going on inside your complex application network.
How Istio Works Today – Data Plane, Sidecar Proxies
Whether we’re talking about the Istio service mesh, or a variety of other service meshes that are out there, a lot of them operated along this same basic architectural line. That is, there are two components, there’s a data plane component and a control plane component. The data plane component is actually responsible for the processing of the request. What would happen is, at some point, an Envoy proxy would be injected into each one of those services as a sidecar, and the sidecar handling all of these cross-cutting, connect, secure, observe concerns. When an application needed to talk to another application, say service A needs to talk to service B, then those kinds of issues, metrics, publication, and failover, and timeout, could all be handled by these Envoy proxies that would intercept all of the requests going in and out of various service components. Let’s say you have a security mandate. You have a security mandate, and by simply injecting these sidecars into your applications and applying some very simple policies, then you could guarantee that your network of microservices was using proper security practices to manage traffic inside the mesh. That’s the data plane.
How Istio Works Today – Control Plane
The data plane also depends on a control plane. The control plane is the brains of the operation. There is some outside stimulus that comes in, maybe it’s a kubectl command, or it’s an Argo controller that’s applying configuration, something like that, that’s actually specifying what kinds of policies we want to apply within our service mesh network. The control plane then is responsible for taking those policy specifications, translating those into configuration for the various Envoy proxies deployed in all of the services around our network, and making sure that those Envoy configurations are distributed properly, out to the various services so that those policies can be enforced in the best and proper place. That’s been the general state of the service mesh technology for a while now.
Istio Sidecar Model Challenges
Let’s be clear, there are a lot of people who have been and who are very successful using this architectural approach, because it does solve a lot of problems. There are a lot of cross-cutting concerns that are able to be absorbed into the mesh components so that that work no longer has to be done in the application code itself, which is a very good thing. There are operational challenges that have arisen as we gained experience over the intervening, say, four years since Istio went 1.0 GA release in 2018. Over the intervening years, we’ve learned a lot. This is a great quote from a very senior engineer at T-Mobile named Joe Searcy, and what he said, the biggest enemy of service mesh adoption has always been complexity of the resource and operational overhead to manage the service mesh for a large enterprise, makes adoption cumbersome, even as projects like Istio have worked to decrease complexity. We’re talking here about this particular approach. While it does remove a lot of cross-cutting concerns from the underlying application, it can be fairly complex to administer, especially at scale.
Let’s talk about briefly just a couple of those issues. Then we’ll talk about some of the innovations that are going on right now to address that, from an operational complexity standpoint. This shows you a typical Istio deployment, obviously simplified quite a bit. You can see we have three nodes that are deployed presumably in our Kubernetes cluster. There are a number of apps that are deployed, some of them with multiple instances. Because we’re using Istio, we have an Envoy proxy sidecar that’s injected into each one of those application pods. There are issues that can happen, let’s say, because these components, the application workload and the proxy, live in the same pod, there can be issues when you’re trying to take down a service, maybe to apply an update to the underlying workload software, maybe to apply an update to Envoy itself, or to the Istio data plane. There can be issues like, for example, let’s say the application comes up first, app 1, and the sidecar, there’s a race condition there. The sidecar hasn’t quite made it yet. The application starts to try to do its thing to fulfill its mission. It sends out requests, but there’s no sidecar to intercept that request and apply whatever policies are relevant. As a result, it may spew a number of failures as it’s in this race condition, startup phase. That’s not a good thing.
There’s converse sorts of problems that can happen when services are trying to shut down, and so forth. This race condition, that’s an artifact of the fact that we’ve injected this proxy into the pod. It’s something that we’d like to avoid if possible. Although our goal is for applications to not be aware of the mesh, in fact, sometimes it does need to happen. For example, here’s a case where we have a pod that spins up a job, and so this is a job that’s going to run for some period of time. It completes its mission, and then it shuts down. We have operational issues like when that job shuts down, you can have conditions where perhaps because the sidecar is still running, that pod is not cleaned up properly. Those resources are not cleaned up in a proper timely fashion, in order to use those resources as efficiently as possible. That’s something we’d like to address as well.
There’s also a very popular topic of latency. What happens here with our sidecars is those are injected into the application workload. Those sidecars have, obviously certain latency that’s associated with them. These are fully configured Envoy proxies that live as sidecars in Istio. They have a full layer 7 TCP stack that has to be traversed, every time traffic goes in or out. You can see, you get some latencies that build up going from the application to its sidecar into another sidecar. Then to the serving application, that can be a few milliseconds of processing time. That’s something we’d like to improve as well.
Then, finally, from a cost standpoint, all of these Envoy sidecars that we are provisioning, they cost money, they cost memory, and CPU, and actual money. One of the things that we see in our business as we talk to people is that often, because you don’t want these sidecars to be under-provisioned, because that creates issues. What happens is often people tend to overprovision the sidecars, give them more capacity than they need. That actually results in an unnecessary spending of money, which is something we would like to avoid as well. Those are some of the challenges.
Introducing Istio Ambient Mesh
Again, this model has worked very well for a number of years, but there are some challenges and we’d like to be able to address that. The folks at Google and Solo have been talking about this problem for roughly a year, maybe a little longer now, and have just contributed in the September timeframe to the Istio project, a new sidecarless data plane option that allows service meshes to operate completely, if that’s what you want, without sidecars. That has a number of really important implications that we’ll be talking about. Things like cost reduction, and simplifying operations, and improving performance. We will talk about all of those.
Including Applications in Ambient
One of the things from an operational standpoint that you see is it’s much easier to get started with Istio Ambient Mesh due to the simplified onboarding process. When you were working in a sidecar mode, obviously, every workload in a namespace that you wanted to include into the mesh, you have to go inject sidecars into each one of those. It’s a decently heavyweight process. Whereas with ambient mode, it’s simply a matter of labeling your namespace as being, I want this namespace to be something that participates in the mesh using ambient mode. What happens is the appropriate infrastructure will get spun up to make that a reality, but without any change to the underlying workload itself. You’ll see that in the demonstration in just a few minutes. Similarly, if you want to take things out of the mesh, it’s a very simple process, where you’re just simply taking away that infrastructure, the Istio CNI will change some routing rules. Basically, the underlying workload itself remains completely untouched. Pretty good stuff.
Ambient Architecture
How this works, is there are two layers to the Istio ambient mode, two new layers that you can use. These modes can interoperate with each other as well. If you have existing workloads that operate in a sidecar fashion, and you want to spin up, let’s say, new services that operate in ambient mode, those two can interact with each other. There are no issues there at all. Going forward, we anticipate a lot of the new adoption in Istio once ambient is really, fully production ready. We see a lot of new adoption going in this direction. Ambient mode is available in Istio 1.15 on an experimental, basically on a beta basis. It’s not considered ready for production use yet, but we are moving up the experience curve very quickly and expect it to be a predominant deployment model going forward. When we add ambient mode to a namespace, what we actually get are potentially two different sets of components. There is a secure transport layer that operates on a per node basis, it handles just level 4 issues. Its primary purpose is to manage securing traffic between workloads. We’ll show you a picture of that in just a moment.
Then, in cases where you also need layer 7 policies, things that require HTTP headers, maybe retries and fault injection, and advanced load balancing, those sorts of things that require layer 7 HTTP access, those policies will be delegated off to a separate set of layer 7 proxies that we’re calling waypoint proxies. Two layers here, one is ztunnel that handles primarily level 4 security mTLS kinds of concerns. Then a second waypoint proxy layer that operates at layer 7 and handles the higher-level set of concerns typically associated with HTTP. In terms of the control plane architecture, as you can see there at the bottom, that’s unchanged. Same APIs as before. The control plane is the same old istiod control plane that you may have used if you’ve used Istio in the past. It will program the ztunnels and the waypoint proxies exactly the way it’s always programmed sidecars, and will continue to program sidecars in the future. Those are the two layers of the ambient architecture.
What you see with a request, so let’s say we just care about establishing mTLS through our network, and that’s a common adoption pattern that we see for Istio. People often don’t want to bite off on the full connect, secure, observe, all the features of Istio initially. A lot of times they come to us with a mandate, like for example, federal agencies, public sector clients come to us with a mandate, say from the Biden administration that we have to use mTLS security among all the applications in our mesh. We do that here with this ztunnel component. What’s going to happen is, if app A wants to talk to app B, the request goes to the ztunnel. The ztunnel then directs that to the ztunnel, where the target application is, manage this communication, the request and the response back and forth between the two, and life is good.
It’s very possible then to do this incremental adoption of Istio using ambient mesh, where if all you care about is mTLS, you can get by with just these very simple per node deployments that are not injected as sidecars into your applications. If layer 7 policies are needed, and they often are, then we’re going to introduce the notion of a waypoint proxy where you can provision these proxies as you want. They don’t have to be on any particular node. You can provision using standard Istio service deployments. They’re going to handle all of the layer 7 kinds of policies that need to be applied to a particular request. You don’t have to worry about the details of how these proxies get programmed, istiod control plane is going to take care of that for you. You simply specify via the API, what you want done, and the control plane is going to make sure that the proper components are programmed as they need to be. Those are the two layers.
Why Istio Ambient Mesh?
From a benefit standpoint, we see right off, reduced cost. That one’s a pretty obvious one. Instead of having, in this case, we got 12 workloads across 3 nodes, each with their own layer 7 proxy, we can now eliminate those proxies in favor of an approach that uses, again, if we’re doing just security, we can do a proxy per node as opposed to a sidecar proxy per pod, so really reduces the set of infrastructure that is required there. In doing that, we see some pretty dramatic cost reductions. You can actually go visit this blog, if you’d like to explore this in more detail, bit.ly/ambient-cost, will take you there. Just to give you the conclusions of this, comparing the sidecar approach to the ambient approach, especially for cases where you’re doing incremental adoption of just the security features of Istio, you can see pretty dramatic, in some cases, like 75% reduction of the amount of CPU and memory required to accomplish the same objective. Going back to our original theme of simplicity, we’re trying to make this new model as simple as possible.
Another thing, and this is perhaps the most significant benefit of the ambient architecture, from what people are telling us is the potential for simplifying applications. We’ve talked about some of the issues around upgrades, and around adding new applications or taking things out of the mesh, this becomes a much easier process now. If we’re doing a rolling upgrade, say there’s an Envoy CVE at layer 7, and we need to roll that out throughout our service mesh network, we don’t have to go take down every single workload that’s in the mesh, in order to make that happen, we can simply do an update at the proxy layer. Immediately those changes will be visible to the entire mesh without the actual applications being impacted. That is a huge benefit here. We can see this graphically here where this is our initial pre-ambient setup. If we just need the security components, we could go to something like this where we have, rather than one sidecar per proxy, we have one per node where workloads are deployed. Those are not injected as sidecars. They are their own standalone ztunnel deployments. Then if we need more sophisticated layer 7 processing, we can add that as well as a separate set of deployments. We can scale those up independently of one another based on how much traffic we anticipate to be going to the service account in question.
From a performance standpoint, just a very simple analysis here that I think nevertheless illustrates what’s going on. We have these ztunnel proxies that are configured with Envoy and layer 4. Because they’re just dealing with the bottom level of the TCP stack, they’re much more efficient than if you have to go through the full layer 7 stack. We anticipate the proxy overhead of these layer 4 proxies, about a half millisecond back of the envelope on average. Layer 7, so the waypoint proxy is typically 2 milliseconds of latency added. You can see no mesh is obviously the baseline case, there’s no proxy overhead there. In the traditional model with L4 plus L7, and you’re guaranteed to have to traverse two of these proxies on each request-response, that’s about 4 milliseconds of added latency. Whereas if you’re just doing layer 4, again, secure communication, that can be as low as 1 millisecond of overhead, or with the full layer 7 policies taken into account, even there, there’s typically a significant reduction, say from 4 to 3 milliseconds. We think this is something especially applied at scale where people are going to see pretty dramatic differences in performance cost and operational overhead.
Ambient Mesh Demo
We’re going to switch over at this point and show you a demo of ambient mesh in action. We’re going to start by installing Istio. If you come here and look at our cluster, we don’t have Istio system installed. We have a handful of applications, some very simple sample applications that we’ll use to demonstrate this capability. The sleep service here, if we exec into this, we can curl helloworld, and get a response from one of the services. In this case, I see it load balancing between v1 and v2. I can even curl a specific version if I want. I can curl the other version as well. What we want to do is we want to install Istio. We want to implement service mesh capabilities without having to deploy a sidecar. Let’s come over here, and we will run Istio install. We’ll run it using istioctl. We will set the profile to ambient mode. Let’s take a moment. We’ll install some familiar components like the istiod control plane. It installs ingress gateways as well. Then we’ll come to some of the new components like the ztunnel that we’ve been talking about. If I come back here, and we look to the bottom pane, we see that Istio system has been installed as a namespace. If I click into that namespace, we see some components that run as a CNI plugin on the node. We see the istiod control plane, and we see the ztunnel agents that are deployed in a daemon set, one per node.
The next thing we’re going to do is we’re going to add our applications in the default namespace to this ambient mesh. What we’re going to do is label the default namespace with ambient mode, or data point mode, which is equivalent to ambient. Now we’ll automatically add the workloads that are in the default namespace, these services are going to go into the ambient mesh. If you notice, there are no sidecars. In fact, these applications have been running for a while, so we didn’t have to restart them or inject anything into them. We didn’t have to change their descriptors or anything. If we come in to the sleep application, which we see is running on the ambient worker node, and we exec into that, and we come back down here to this pane, we find that the ztunnel that’s running on the ambient worker node, and let’s say we watch its logs. Let’s do that full screen. If we now do our curl to helloworld, then what we should see is traffic that’s now going through the ztunnel. If you look a little bit closer at the logs, we can see things like while it’s trying to do some mutual TLS, or it’s invoking SPIFFE and establishing mutual TLS. Let’s take a closer look when we make those calls through the ztunnel. What does that actually look like? We’re going to do a kubectl debug in the Istio system namespace around the ztunnel, and we will use netshoot to help us understand what’s going on here. Let’s take a look at this.
Let’s come back here, and let’s make a couple of curls actually just to capture some traffic between sleep and helloworld. We’ll stop now, we probably have enough traffic. Let’s come back a little further up here. We should see that when the traffic is going through, like here we see traffic getting to the ztunnel. Then when it gets there, we have TLS encryption. The traffic going over the ztunnels, we get mutual TLS between the sleep and the helloworld service. As a reminder, we didn’t inject any sidecars into these workloads. We didn’t have to restart those workloads. All we’ve done in ambient mode is we’ve been able to include those workloads and the communication between them as part of the service mesh. A big part of the service mesh is also enabling layer 7 capabilities. That’s where the waypoint proxy or the layer 7 capabilities of the ambient mesh comes into the picture. Instead of the traffic passing between these tunnels, we can actually pass them and hand them off to a layer 7 Envoy proxy, which then implements certain capabilities like retries, fault injection, header-based manipulations, and so forth.
In this demo, we’re going to deploy a waypoint proxy, and we’re going to inject a layer 7 policy fault injection. In this case, we’ll observe how we can implement layer 7 capabilities in the service mesh in ambient mode without sidecars. To do this, let’s get out of termshark. Now we’re going to apply a waypoint proxy. Let’s take a look at that, the layer 7 proxy for the helloworld services. One thing you’ll notice is we don’t try to share layer 7 components between different identities, we want to keep those separate and try and avoid noisy neighbor problems. We can create this waypoint proxy by applying this. Then we should see a new proxy come up, that would enable us to write layer 7 policies about traffic going into the helloworld service.
Now, if I come back, we can take a look at a virtual service, which is a familiar API in Istio that specifies traffic rules, when a client tries to talk to helloworld, and in this case, we’ll do some layer 7 matching, and then we’ll do some fault injection. A hundred percent of the time, we will delay the calls by 5 seconds. Let’s apply this virtual service, and then we’ll go back to our client. Now when we curl the helloworld service, we should see a delay of 1, 2, 3, 4, 5 seconds. We should see that potentially load balance across both v1 and v2. As you can see, we get layer 7 capabilities, we get layer 4 capabilities and mutual TLS. We can write policies about this communication between these services, and we have not touched the applications. We can include them and even exclude them dynamically. If we’re done with this service, and we don’t want it anymore, then all we have to do is just uninstall it. Then we’ll remove the system namespace and come back to our applications. You see that they’re not touched. Go into one of the applications, we make a curl. Then without ambient in place, the services continue to work, just as we expected.
Summarizing Istio Ambient Mesh
To summarize what we’ve seen so far with Istio Ambient Mesh, both from a presentation and a demonstration standpoint, three core benefits remain. We want to reduce cost. We want to perhaps, most importantly, simplify operations. We want to make the service mesh truly transparent to applications. Decouple the proxy from the applications and just make it part of the core infrastructure, and so simplifying doing things like application updates. We want to improve performance as well by taking advantage of this new proxy configuration that allows us to just bite off on the functionality that we need for our particular use cases.
Responses to Istio Ambient
What are the responses that we’ve seen to ambient mesh so far? I think the general responses have been very positive. Occasionally, there’s been a wait and see. Yes, this is interesting, but let’s see an introduction before we get too excited. This is one that I think is really interesting. This is from Matt Klein. Matt Klein is at Lyft, and was the founder of Envoy proxy built back in the mid-2010s. He says, “This is the right path forward. Sidecars have been an unfortunate implementation detail in the past. Now we’re going to see mesh features that get absorbed into the underlying infrastructure, excited to see how this evolves.” Going back to our quote from the beginning of this talk from Joe Searcy at T-Mobile. He says the opportunities that ambient Mesh provides are extremely exciting, better transparency for applications, fewer moving parts, simpler invocation, huge potential in savings of compute resources and engineering hours. Those are all really good things.
There’s at least one episode of unintentional humor. This is from the CEO of a company that leads the Linkerd community which has doubled down on its sidecar-based architecture. He actually put out a joke tweet in response to all of the chatter around ambient mesh, and said, “By the way, Linkerd, we’re actually going to switch to having a sidecarless option as well,” put some things in there to try to provide hints that he was joking. You can see a day or two later, he realized people weren’t getting the joke, so he had to come back and say, “Yes, this is a joke. We really like sidecars with Linkerd.” That was some fun that came out of this whole announcement process.
What’s Next in Service Mesh?
What’s next beyond this in service mesh? There are two capabilities. I want to talk about both of them on the data plane. That’s where we see a lot of the innovation happening these days, is in the data plane itself. One of the things we want to be able to do is to improve the performance of these new components. What we did for the experimental implementation that’s out there now is with the ztunnels. Those are implemented as Envoy proxies that are just configured to operate at level 4. There are some additional opportunities for increasing performance of that even more. What we see is being able to perhaps replace the Envoy proxy there with an even lighter-weight ztunnel implementation, even using technologies like eBPF. eBPF allows us to do things like packet filtering in the kernel of the operating system, and so it’s extremely efficient. It’s not something that’ll be a revolution in terms of what’s going on here. The architecture is going to remain the same, but just providing a more efficient implementation based on eBPF to actually make those ztunnels run even faster than they do today.
One other thing I want to talk about here is a different level of innovation. We’ve talked a lot about the architecture of the data path. I also want to talk about, there’s a lot of innovation happening with service mesh at the edge of the mesh as well. One really good example of that, that I’m excited about is GraphQL innovation. Just very quickly, with GraphQL, today, what we typically see in enterprises who deploy it is you have an architecture that looks roughly like what’s on the right here. You have an API gateway, something that’s like you’ve been using before that serves up your REST interfaces in your maybe gRPC, whatever APIs you have out there. Then you end up having to build this separate server component that knows just about GraphQL, how to assemble GraphQL responses from underlying services and that sort of thing. We’re not sure that’s the best approach. What if you could have GraphQL APIs that don’t require dedicated servers? What if you could reuse existing API gateways to serve GraphQL? It’s like they already serve OpenAPI, gRPC, other kinds of interfaces, why can’t they serve GraphQL as well? Why do we need to stand up a separate server component or set of server components in order to enable GraphQL? That doesn’t make a lot of sense. What if you could do that in a way that would allow things like declarative configuration, as well as leveraging your existing API contracts?
Solo has done a lot of work in this space, specifically in a service mesh context. Basically, the takeaway from the story is, what if you could actually absorb the GraphQL server capability into a filter in your Envoy proxy at the edge of your network? Basically, inspect existing applications and their interface contracts, derive GraphQL schema from that, be able to stitch those together to create a super graph that spans multiple services, and deploy those in an API gateway. We think that’s a powerful innovation growing in popularity API standard in GraphQL.
Resources
If you would like to learn more about any of the things we’ve talked about, especially ambient mesh, I definitely recommend this resource. There’s a Bitly link that will take you there, bit.ly/ambient-book. This a completely free book from O’Reilly, written by a couple of people at Solo, and basically goes through in a fair amount of detail, Istio Ambient Mesh, and will help you understand exactly what the objectives and implementations are there. There’s also a hands-on workshop, if you’re like me, and you like to get your hands on the keyboard to understand this stuff better. Encourage you to follow that Bitly link there, bit.ly/ambient-workshop. It will take you through a hands-on exercise for getting started with ambient mesh.
Did Parsimony Win the Day?
Back to our original story. What happened? We got to the finals. We had the big behemoth design with the committee and so forth, and the little tiny car with the single designer. Who won the day? The behemoth designers, they got in there at the starting line, two people carry it up to the starting gate, they twist up all the potentiometers to make it run as fast as possible. They spun it up a little too much, and the thing actually goes careening off the track. The little car just shuffles its way around the track, and it wins the day, much to the delight of all the college students who were there watching the finals of this competition. In my view, there was a happy ending, David beat Goliath. Parsimony and simplicity won the day. That’s what we think is going to happen in the service mesh community as well is that simplicity and ambient mesh are going to be ruling the day very soon.
Questions and Answers
Betts: You mentioned that the three pillars were secure, connect, and observe. The ambient mesh really seemed to focus on reducing the complexity and it helps for those connections. Then security doesn’t have to be configured as many places. Does it help with the observability as well?
Barton: Yes, absolutely. I’m not sure that ambient per se really addresses so much the observability concerns. There’s a ton of metrics that already get published out of Istio and Envoy proxy. If you’ve ever done anything with Envoy proxy, whether in a service mesh context or not, you’ll know that there’s just a raft of metrics that gets published there. I don’t think ambient really is going to enhance the observability per se, but it does just allow that to be delivered in a more cost-efficient fashion.
Betts: Do you see any service mesh deployments that aren’t using Kubernetes?
Barton: Obviously, no one, at the scale that I expect the people on this session are managing, you’re not dealing with Greenfields. Definitely, Istio has a lot of best practices established around non-service mesh deployments. We blog about it quite a bit at Solo, because these are the kinds of real-world issues that we encounter. I would not recommend trying to deploy Istio without any Kubernetes context at all. In other words, if Kubernetes is not part of the strategic direction of your organization, then I wouldn’t recommend going there. Definitely, if you’re in a mode, like a lot of the organizations we deal with where this is our objective is to move toward Kubernetes, and cloud native, and Istio service mesh deployments, then definitely can accommodate services that are deployed in VMs, or EC2s, or wherever.
Betts: If you’re doing the migration from a monolith architecture, and breaking it up into microservices, this is pricing that you’re thinking about, should it be one of the very first things you do, or should you figure out and learn Kubernetes first, and then layer on the Istio?
Barton: Anytime you’re contemplating a major organizational change, and this is independent of Kubernetes, or service mesh, start small, ideally. Start with something where you can wrap your mind around it and understand it, and that’s non-critical, and that you can manage the situation. Then, over time, layer in additional complexity and outside elements and that sort of thing. Just as a general rule, I think that’s a good idea.
Betts: eBPF, the Extended Berkeley Packet Filters, like even saying the acronym seems hard to me. It seems like one of those really low-level things that somebody’s really excited about, but me as an application developer, an architect, I don’t want to have to learn that. Is that something that you see eventually becoming something that’s sold as a package. Like, just get this add-in and it adds eBPF. It’s the thing that you had before, but now it’s lower level so it’s faster.
Barton: I think you hit it exactly right. It’s like I drive a car, I know very little about the internals, how an internal combustion engine operates. It’s something that just exists below the level of abstraction I care about. For the majority of people who are consumers of service mesh technology, I’d say the same would be true of eBPF. It provides a critical service. It’s going to make things run faster. It’s going to be below the level that most people are consciously dealing with. There are exceptions. In fact, if you go to academy.solo.io, you’ll see courses on eBPF, so you can learn more about it. There are people who clearly need to be able to understand it. Generally speaking, we think that will be commoditized, just baked into the service mesh layers. I know that Istio is clearly moving in that direction. I think some of the other alternatives that are out there, I know Kuma is moving in that direction, and probably some others as well.
Betts: Istio seems to be synchronous in terms of communication, does that come with scaling concerns? For async, can consumers control the rate of request consumption? Is that possible out of the box? Does he even have it in the right context, it’s about messaging and queuing solution?
Barton: You can definitely use Istio with asynchronous sorts of models. There’s no question about that. I view those two independently. I’ve done a lot of work building enterprise systems over the years and frequently will move into an asynchronous mode for applications that require extreme degrees of scalability and where the use case fits that. Definitely, Istio can be used in context of both synchronous and asynchronous services. The whole idea with Istio and with any service mesh, is to be as transparent as possible to the underlying applications. In the ideal world, it’s like an official at a sporting event. Ideally, I want to be there to enjoy the sporting event. I don’t want to watch guys in striped shirts blow whistles. That’s not my goal.
Betts: It should get out of the way, and like you said, a good abstraction. You don’t have to know about the details of how it’s doing it, but it shouldn’t also raise up to the level of your application has to know about all the Istio plumbing that’s there to be properly implemented.
You started to tease at the end, there’s future of GraphQL changes. Where’s that in the pipeline? Is that in the works, is it a year out?
Barton: No, definitely not a year out. I can speak with some authority to what Solo is doing in that space. Solo has a couple of products in this space. One is a standalone application gateway, it integrates with Istio, but does not require Istio. In that environment, there’s a full GraphQL solution that’s already there that basically allows you to absorb GraphQL server capabilities up into the Envoy proxy. There’s essentially a beta version of that that’s available in Solo’s commercial service mesh product that’s based on Istio as well that’ll be full implementation within a couple of months. Yes, it’s really exciting stuff. We see massive migrations of people toward GraphQL as an API standard, and we think a lot of the architectural decisions that are coming along with that are a little unfortunate. They don’t make a lot of sense to me. Why would we want a separate [inaudible 00:54:03] kind type of API server instance to serve up this API, when we already have something that serves up like REST, and OpenAPI, and gRPC, and so forth. Why can’t we bring those all together?
See more presentations with transcripts
MMS • Charity Majors
Article originally posted on InfoQ. Visit InfoQ

Transcript
Majors: My name is Charity Majors. I’m the co-founder and CTO of honeycomb.io, co-author of “Database Reliability Engineering,” and the newly available “Observability Engineering” book, which I wrote with Liz Fong-Jones and George Miranda.
Traditional Paths to Management
We’re going to be talking about the engineer manager pendulum. It started with a blog post that I wrote way back in 2017. For those of us who have been around for a while, there are traditionally two paths to management. One is the tech lead, the “best engineer” on the team, who then gets tapped to be a manager, and low-key resents it, but does it, and the career manager who becomes a manager at some point in their career, and takes that path and just sticks with it. They stop writing code. They stop doing technical work. Over time, this leads to decreased employability, and it leads to a lot of anxiety on the part of the manager who knows that they’re a little bit trapped in that role. It can seem a little threatening when you’re working with more technical managers.
Assumptions About Management
There are a lot of assumptions that we tend to have about management just by default. That it’s a one-way trip. That management is a promotion. That you make more money. That this is the best way to have and wield influence. That once you start managing, you want to climb the ladder. That this is really the only chance you get for career progression. That the best engineers make the best managers. This is all crap. These are all flawed, if not problematic. It results in a lot of managers who don’t really want to be managing or who become managers for the wrong reasons. I believe that your team deserves a manager who actually wants to be managing people, who actually wants to develop that skill set, not just someone who is resentfully filling in because they’re the only person or because they got tapped.
What The Team and Manager Deserve
The team deserves a manager who isn’t bitter about having to go to meetings instead of writing code. The team deserves a manager who has actual interest in sociotechnical processes, systems, and nurturing people in their careers. Lastly, and I think most controversially, I think the engineering teams deserve a manager whose technical skills are fresh enough and strong enough that the manager can independently evaluate their work, guide their development, and resolve technical conflicts. There are lots of teams where it doesn’t work this way. There are lots of teams where you’ve got a manager and a tech lead. The manager just relies on the tech lead to tell them if something is good or bad, or to develop the people. I’m not saying this can and doesn’t work. It does and it can. I feel like it’s a much weaker position to be in for the manager. I feel like it’s a compromise that whenever you’re having to outsource a major slice of your judgment to someone else and you can’t independently evaluate that, it’s not great.
You as a manager/tech lead/senior contributor in tech, you also deserve some things. No matter whether you’re an IC or a manager, you deserve to have career advancement. You deserve a role that is not a trap. You deserve something that you find interesting and compelling. You deserve to have the ability to keep your technical skills up to date and relevant, even if you’re a manager or a director, even if you’re a VP. I think that you deserve to preserve optionality. Especially if you aren’t sure what you want to do, you have a 30 or 40-year long career. Who actually knows what they’re going to want to do when they’re 50 years old? I think that you deserve to have the information that you need in order to preserve as many options as possible for the future. Relatedly, you deserve to have a long and interesting career where you can make choices that help you become more employable, not less.
I think that instead of just identifying as a manager or an engineer, as you progress in your career, I think it’s better to just think of yourself as a technologist, or as a technical leader, someone who needs those skill sets in order to really reach your fullest potential. It’s certainly true that there’s an immense depth and breadth of experience that accrues to people who go back and forth. In fact, the greatest technical leaders that I’ve ever worked with have all done both roles and had both skill sets. This used to be a pretty radical idea. In 2017, when I wrote this post, there was a lot of, whoa. Now, it’s not that radical. It’s pretty much common wisdom. This is great. It doesn’t mean that the journey is done. I’ve put some links there. I also wrote some follow-up posts about climbing the ladder, about management isn’t a promotion, why is that great.
I’m going to run through the material from the blog post. I’m going to spend more time on stuff about like, how to do this, if you’re an engineer or a manager. How to go back and forth. Why you should go back and forth. When not to go back and forth? Most importantly, as someone who has influence in an organization, how do you institutionalize this? How do you make this a career path inside your company so that it’s not just like the burnouts and the outliers and the people who are comfortable forging a new path, or who have nothing left to lose? Rather, how this is something that we include as an opportunity and an option when we’re coaching people in their career development. How do we make this bond?
The Best Line Managers, Staff-Plus Engineers, and Tech Leads
The best line managers, I think are never more than a few years away from doing hands-on work themselves. There’s no substitute for the credibility that you develop, by demonstrating that you have hands-on ability, and more importantly, that you have good judgment. You should never really become a manager until you’ve done what you want to do with senior engineering. Till you’ve accomplished what you want to accomplish. Until you feel solid and secure in your technical skills as an engineer because those skills are only going to decay when you become a manager. Keeping those skills relatively fresh gives you unimpeachable credibility, helps you empathize with your team. It gives you a good gut feeling for where their actual pain is. It keeps you maximally employable, preserves your options. You can’t really debug sociotechnical systems, or tune them, or improve processes, or resolve conflicts unless you have those skill sets.
Conversely, I think that the best staff engineers, staff-plus engineers, and tech leads tend to be people who have spent time as a manager, doing full time people management. There’s no substitute for management when it comes to really connecting business problems to technical outcomes. Understanding what motivates people. Most of what you do as a senior contributor, whether you’re an engineer or a manager, you don’t accomplish it through authoritarianism, or from telling people what to do. You do it by influencing people. You do it by painting a picture of the future that they want to join, and they want to contribute to, and they want to own. Even basic things like running a good meeting. This is a skill set that you develop as a manager that can really supercharge your career. You don’t have to choose one or the other, fortunately. You can do either. You can do both. You shouldn’t just pick a lane and stay there. However, you do have to choose one at a time. This is because there are certain characteristics of both roles that are opposing and not reconcilable. Lots of people are good at both of these things, but they’re good at it serially. They’re not good at it simultaneously. Nobody can do both of these things at once and do a good job of them because both people and code require the same thing, sustained, focused attention. Being a good engineer involves blocking out interruptions so you can focus and learn and solve problems. Being a good manager involves being interrupted all the time. You can’t really reconcile these in a single role. You can only grow in one of these areas at a time.
If you aren’t already an extremely experienced engineer, don’t go and become a manager. I know lots of people who have gotten tapped for management after two or three years as an engineer. It’s almost never the right choice. This tends to happen, especially to women, because women have people skills. It also can come from this very well-meaning place of wanting to promote women and wanting to put women into leadership and to management. It’s not a fast track to success. It isn’t. It derails your career as an engineer. It makes it much harder to go back from management to engineering. I don’t recommend people to turn to management until they have seven, eight years as an engineer. This is an apprenticeship industry. It really takes almost a decade to go from having the basics of a degree, some algorithms and data structures, to really having a craft that you’ve mastered. That you can then step away from, and be able to come back to it. There’s a myth around the best engineers make the best managers, though, and that’s just not true. You do not have to be the best engineer in order to be a good manager. There is no positive correlation that I have ever detected between the best engineers and the best managers. You do need to experience confidence and good judgment, and you need to have enough experience that your skills won’t atrophy. I think of it a lot like speaking a language. You learn a language best through immersion. If you step away, if you leave the country, or you stop speaking it every day, you get rusty. You stop thinking in that language. Just like when you stop writing code every day, your ability to write that code goes down more quickly than you expect.
If you do decide to try management, I think that you should commit to it to your experiment. Management is not a promotion, it’s a change of career. When you switch from writing code to managing, all of your instincts about whether or not you’re doing a good job or not, you can no longer trust them. It takes a solid two years, I think, just to learn enough about the job to be able to start to trust your gut, and to be able to start to follow your own instincts. I think that when you try and manage the first time, so more than 2 years, but less than 5. After a couple 2, 3 years, your skills do begin to significantly decay, especially the first time. Swinging back is a skill in and of itself. I think that after the first time, the requirements loosen a bit. After the second time, even more so. After a while, you will get good at going back and forth between the roles. Obviously, the more that you can keep your skills sharp while you’re managing, the more you can keep your hands warm, the more that you can continue to do some technical work even outside the critical path, the better. You will become unhireable more quickly than you will become unable to do the other skill set. People tend to be pretty conservative when hiring for a role that you’re not currently performing. Your best opportunity to go back and forth usually happens internally in the job where people already know you and trust you. It’s a lot harder to be an engineer and get hired as a manager. It’s not unthinkable, happens all the time. It’s harder, and there’s a higher bar, if you’re a manager and want to get hired as an engineer or vice versa.
Management Skills
Like I just said, technical skills are a lot like speaking a language. Speak it every day to keep sharp. Interesting management is not like that. Once you have your management skills, they don’t tend to decay in the same way. They tend to stick with you. That said, technical skills are portable. Yes, you need to learn about the local systems. You get better and more efficient and effective at a code base once you know it. Management skills, people skills are a lot more portable. You can take them from place to place with you and you don’t really have to start at the same low level and work your way up. You tend to bring them with you. You don’t need as much intimate knowledge of context. When you become a manager, you’re going to hear a lot of people tell you, stop writing code, stop doing technical work. I understand why people give this advice. It’s coming from a very good place. It’s coming from a well-intentioned place. Because most team managers, when they become a manager, they err on the side of falling back to their comfort zone whenever things get tough. We all do this. It feels good to spend time in your area of competency and it feels hard to spend time outside of it. If you feel very comfortable as a tech lead, and as an engineer, when you get exhausted and overloaded as a manager, your tendency is going to want to be to go back and just write some code to clear your head. That’s where people give you the advice to stop doing technical work. It’s bad advice. It makes your skills decay a lot more quickly. It loosens your overtime. The ties of empathy that you have with your team grow weaker. It’ll be harder to get back in the flow if you do want to be an engineer. I think that the right advice to give here is a subtler version of this. Stop writing code in the critical path. Don’t do anything that people are going to be waiting on you for, or depending on you for in order to get their jobs done. Keep looking for little ways to contribute. Pick up little tasks, Jira tickets, whatever.
My favorite piece of advice for managers is, don’t put yourself in the on-call rotation. Because then, that’s the critical path. You’re going to be blocking people. I remember doing this myself. I was like, I want to keep hands-on, I’m going to stay in the rotation, help my team out. As I got busier as a manager, what ended up happening was, it ended up placing an unfair burden on my team. This was at Facebook. If I was in like some performance review meeting or something important, and I got paged, I’d have to ask someone on my team to cover for me. Even when other people weren’t on-call, they ended up having to do work just to cover for me. My favorite piece of advice here is not to put yourself in the on-call rotation. Do make yourself the first escalation point of first resort. Not last resort, first resort. If your on-call has had a tough night, that they got paged a few times, put yourself in for the next night. Make sure that everyone knows if you’re on the weekend, and you want to take your kids to see the movies. Put me in, I’ll cover it for two or three hours, no problem. If you want to take a long car drive, anything you need to do, I’m your person of first resort. This has a bunch of benefits. It helps you stay sharp. It keeps your finger on the pulse of like, what is it really like to be an engineer here? How painful is it? Is my time being abused? Is my sleep being abused. It’s just such a relief for your team to have someone like that because you’re burst capacity. They don’t have to do complicated tradeoffs or make sure that they’re giving as much time, each person they’re asking to take over for them. It makes things a lot less complicated. It means the on-calls becomes easier for everyone. They’re very grateful. It earns you a lot of credibility and a lot of love.
You Can’t Be an Engineering Line Manager Forever
If you become an engineering manager, I talked in the beginning about how there are two primary pathways. One is to be the top dog engineer who becomes manager. The other is people become a manager, and then just stay a manager forever. I don’t think that that’s a good choice. I don’t think that you can really just be an engineering line manager forever. I think it’s a very fragile place to sit long term. You can’t be an engineering manager forever. I just don’t think you can be a very good one. You get worse at it. As your tech skills deteriorate, you’ll find yourself in the position of having to interview for new engineering manager jobs, and not knowing the tech stack. You’re slowly going to become one of those managers that’s just a people manager and doesn’t have enough domain experience to resolve conflicts, or to evaluate people’s work. If two people on the team are each claiming that the other one is at fault, how do you figure out who’s telling the truth, or if it’s broadly shared? You need to stay sharp enough. This means periodically going back to the world to refresh your skills. You should not ever plan on being a tech lead/manager, especially not long term.
This blog post that I linked to by Will Larson, is the best one I’ve ever read on why this is so bad for your team. His take on it is much more about that the tech lead manager is a common thing that people do to ease engineers into management. You’re a tech lead manager with two or three direct reports instead of six or eight direct reports. You don’t actually get enough management time to become better at your management skills. That’s his argument. I think it’s a good one. My argument is that from the perspective of your team, you’re taking up all the oxygen. If you’re the tech lead/manager, as a manager, it’s your job to be developing your people and building them into the position of tech lead. It’s not your job to sit there. The longer you sit there as tech lead/manager, the worse of a tech lead you’re going to become, and the more you’re starving your own team of those growth opportunities. While it’s sometimes unavoidable, or natural in the short term, it’s not a stable place to sit and it’s not a good place to sit.
Management Is Not Equal to Leadership
Every engineering manager who’s managing for a couple years, reaches this fork in the road, and you have two choices. Either you can climb the ladder, and try to be promoted to senior manager, director, VP, or you need to swing back and go back to the well and refresh your technical skills. That’s a fork in the road. The reasons for the decision is because, first of all, management, we talk a lot about technical leadership and technical management. Those are not the same thing. Leadership does not equal management. There are lots of ways to have leadership in a technical organization, that do not involve management. I think of management as being organizational leadership, and engineering as being actual technical leadership. Obviously, there are areas of overlap. You can’t be a great technical leader without having some organizational work. You can’t be a great organizational leader, without having some pretty sophisticated technical leadership. What’s important here is for this to be a conscious choice for you not just to slip into it, because managers in particular, you’re getting promoted. This feels good. It feeds your ego. You have this sense of career progression. It always feels great for someone to be like, I see more in you, would you like to be a director? Yes. Managers in particular have this tendency to look up 10 years later or so, and realize that they weren’t making the decisions because it made them happy. That, in fact, their decisions have made them less employable, and less satisfied. When you’ve been a manager for 10 years, it’s really hard to go back and be an engineer. You’re locked into that decision, in a lot of ways.
Everyone starts out thinking that they want to climb the ladder, just like almost every engineer starts out assuming that they want to be manager someday. I feel like almost the only way to demonstrate to many people that they don’t actually want to be a manager is for them to do the job. There’s nothing like doing the job to demystify how much power and control you actually have and how many constraints you actually have. Everybody’s mom is going to say, congratulations, when you become a manager, because everyone perceives this as being a big promotion and a big step up. It’s validation for your skills and how awesome you are. It’s very rare for people to say congratulations, you’ve gone from a manager to being an engineer, which is why I think we have to consciously lean in that direction, so that people make the decision that actually makes them the most fulfilled and satisfied instead of just the one that garners you praise and accolades.
This is one reason why I think it matters so much to keep reinforcing the fact that management is not a promotion, it’s a change of career. Because if management is not a promotion, then engineering is not a demotion. You really want people doing this job, because it makes them feel the most engaged and fulfilled, not the job that gives them the most money and prestige, because over time, this is when they do their best work. This is what keeps you from being burned out. This is what keeps you actually checked in and enjoying your work. This is a cultural change, and it’s super important. We really need to lower the barrier to entry to management, demystify the role. Right now, it’s like, how do you become a manager? It’s a mystery. You sit around maybe hoping to get tapped. You’re envious of whoever gets tapped. I think that it’s so much healthier if we as organizational leaders ask everyone in your organization, every engineer, do you want to be a manager someday?
Career Paths are Luck and Opportunism
It’s an unsettling truth that a lot of your career path is ultimately going to come down to luck and opportunism. Nobody is good at picking good startups that are going to take off and explode, or we would all be working at them, or a VC wouldn’t be such a rolling of the dice. A lot of the opportunities that you have in your career are going to come down to whether or not you are fortunate. This is why I think it’s so important, especially early, for the first decade or two of your career to make decisions not based on, “I want to go there, I want to do that.” It’s really hard to get to a specific place, but rather to be prepared, to maintain your optionality, maximize your options. Make sure that you’re prepared for interesting and exciting opportunities that come your way, because you can’t force them. You can’t force an individual opportunity to happen. Opportunities tend to be everywhere, if you can avoid being super attached to a particular outcome. You can equip yourself with skills. This is a fast moving, chaotic, exciting industry, with new things popping up constantly: new frameworks, new databases, new companies, new rules, new job descriptions.
One pro tip is, the more you want to make a name for yourself, the more you should jump on something that’s early in the hype cycle, when it starts to seem to have legs, late in the early adopter cycle before the early majority, because then everybody’s hungry for what you have to say. Learn a little bit, talk about it, write about it. It’s easy to improve your profile, easy to recruit. This is why it’s so important to act to preserve your optionality. That looks like the following list. Keeping your tech skills sharp. Making friends. Developing a professional network, not just the people you work with. That’s really important. It is a small industry, and over the course of your career, if you change jobs every few years, you’re going to amass a long list of friends and acquaintances, and people that you can trust. Sometimes, especially earlier in your career you do need to intentionally work to form those relationships outside of where you work.
Writing and speaking about your work. This is especially important for marginalized folks. It’s a real jujitsu move, because there may be a tendency for people to discount your technical work or your expertise. It’s also true that just being Googleable for your name, plus that technology, overwhelmingly acts to counter that bias. Because people are biased to think that people who are famous for something, or even well known for something, or even show up in Google for something must know what they’re talking about. If you’re a minority in tech, it’s really easy to get attention, which means that if you write and speak about something, it’s a great pro move to turn your weaknesses into strengths. Change your role, if not your job, every two or three years. In my experience, two and a half years into a role, you’re going to know what you’re doing. When you start to get that feeling of, I know what I’m doing. That’s danger zone. You want to train yourself to fear that feeling, not to feel like, yes. This is an industry where you don’t want to get comfortable. It’s still good advice, I think, to become a T-shaped engineer, which means going deep in one area of technology, and broad otherwise. The reason this is awesome is because, if you’re just a dilettante, if you just learn a little bit about everything, it’s a different skill, different way of thinking than if you go deep on something. If you just go deep on one thing, that’s very niche. If you’ve gone deep on something, then going deep on another thing is easier, and going deep on another thing gets even easier. Like developing the skill set to go deep, and then developing your broad literacy is just really powerful. Like I was saying, developing a public profile is easier than you think it is, and pretty powerful.
Downsides of Climbing the Ladder
I mentioned that almost everyone starts out by default thinking that they want to climb the ladder. Obviously, the upsides are money and power. There are downsides too. For every rung that you climb, there are an order of magnitude fewer job openings, and they become very specific and very customized, it becomes a lot harder to find a place you fit. A VP or a CTO, it’s not uncommon for it to take a year for them to find someplace, because you become a specialist, whether you want to or not. Right now, for us, we’re trying to hire a VP or CMO of marketing, and there are probably 20 people in the world who fit the cross-section of skills that we need. People become much more risk averse, when they’re hiring extremely senior roles, because you can and should make or break whether a company is successful or not. The higher you climb the ladder on the management side, the harder it becomes to go back to engineering. This is something when I mentioned that managers have a tendency to wake up 10 years later and be like, I’m miserable. This is because the work that actually brings most of just meaning and joy has to do with seeing the impact on people, creating things, fixing things, watching our work have an impact on people’s lives. The cycle time is a lot shorter when you’re a developer or an engineer, or whatever. The cycle time becomes so long, and your impact becomes so diffused, and it’s hard to know if or when you can really take credit for anything. This is the thing that for most people who are senior leaders, it dawns on you slowly over time, and all of a sudden, you realize that you haven’t been happy in a very long time. That dopamine hit that you get from fixing a problem or building something or shipping something, it’s powerful. Don’t underestimate the impact that it has in bringing you joy every day.
Your job tenure lengthens. As an engineer, it’s no big deal to leave your job every 18 months to 3 years, 5 years is considered a very long time at a company. It’s not the same as a leader because when you’re a director or not, it takes a year or two for you to even start to have the impact and make the relationships that you need and everything. You can’t really job hop as easily. You can’t really have the impact you need to unless you invest in. This is part of why it takes longer to find a job, but you even want to hold those jobs for longer. Your choices are a lot riskier. You can only really have one job at a time for the most part. I think as an engineer, we tend to underestimate or devalue just how valuable it is, and what a relief it is that you can pretty much walk out the door and into another job whenever you feel like it. As a senior engineering manager end up, more of your ability to succeed is actually out of your hands. Your reputation will be defined largely by your company’s success, whether it succeeds or fails, or does a middling job. There are lots of people who are doing just incredible work out there who will never get the credit that they deserve, because they are not working someplace that has a really shiny pedigree. There are lots of people who work at really shiny companies who are doing craptastic work, but they’re getting too much credit because the company is succeeding. They’re surrounded by strong contributors. It’s really hard to tell if a manager is doing a good job or not, honestly.
Institutionalizing the Pendulum
As I started out saying, the landscape looks very different today than it did in 2017. Nowadays, lots of people go back and forth between engineering and management. This is great. I think that we’re still in the very early days of creating institutional support for the pendulum. It remains something that is driven by individuals who are burned out or who are not afraid to blaze their own path or whatever. We’re not going to succeed until this is seen as a normal pattern. How do we do this? You need institutional support, which means you need the higher-ups to understand why it matters. Execs tend to see it as a wasted investment, whenever a director or VP goes back to being an IC. They’re like, we invested all this time and energy and money into building this senior leader, and now they’re just going to go back and write code. This is really short-sighted. This argument doesn’t naturally care to many leaders, because it is uniquely this way in engineering, and maybe product and design. It’s not the same in most other parts of the company. For technical organizations, this is the best way to grow great engineering leadership, because you are so uniquely powerful when you have both skill sets.
It’s great for the organization if a VP decides to go back to being an IC, instead of leaving the company. It’s great. They build credibility with other senior engineers. They have so much empathy and knowledge of the business side of things and how that decomposes into important technical work. They have this ability to explain things to engineers, so that they don’t become disaffected and demoralized and detached from the reasons that we’re doing the job that we’re doing. This is how you retain top talent. Otherwise, a lot of people will get restless and leave every few years. You can carve such a compelling path for people by making it possible for people to scratch both itches. There are lots of people out there who will join a different company when they want to be an engineer, or when they wouldn’t go back to management because they don’t have that institutional support to go back and forth. It does absolutely get trickier to go back and forth when you’re higher up. It’s pretty easy as a line manager, or a senior engineer to just go back and forth. It gets trickier when you’re a director or a VP. It’s hard to generalize about those cases because they tend to be very sui generis. It’s always worth it. If somebody has reached that level, it is worth it to you to retain them. This is also how you preserve institutional memory in both leadership on the management side and leadership on the engineering side. Somebody who’s been building your company with you for years, they’re just as valuable, whether or not they’re leading people or technology.
Finally, I feel like institutionalizing this pendulum is one of the fundamental ways that we emphasize and reify the fact that management is not synonymous with leadership. Technical leadership is just as important, it is not a loss. There are so many companies out there that are running so wastefully when it comes to hiring engineers, building teams. Companies are just not good at the sociotechnical systems of building and running and owning great software. Having people with dual fluency, it’s such a superpower. I’m often urging people to try and get their leadership to read that Jez Humble and Nicole Forsgren book, “Accelerate,” because that’s another thing that it’s not intuitive, and it’s not natural. It’s not immediately apparent to anyone why speed is safety for software. We’re humans. When we get discombobulated or afraid, we slow down. We freeze up. We want to go slower so that it’s safe. That book does this great job of dispelling the myth, that slowing down will make for better software, because it won’t. Speeding up makes for better software. It’s not intuitive, but it’s so true, that that kind of hybrid leadership adds up to incredible strength as an organization. The pendulum contributes both to more excellent management and better technical execution.
The concrete things you can do, is align your levels and your comp plans. Ask everyone about their career goals. Don’t just make it this magical, that fairy will come and tap you on the shoulder if you’re getting a chance to be a manager. Ask everyone. It doesn’t mean that you make everyone a manager. If someone expresses that they’d like to be manager someday, and if you’re like, “You’d be a terrible manager.” This is a learning opportunity. You can decompose management into all of its constituent skills, and work on them. Some people may surprise you. They may get really good at these things when they didn’t start out that way. Other people may surprise you. They may start out thinking they want to be a manager, but then they try running meetings, they try hiring and recruiting, they try mentorship, then they’ve realized gradually that they don’t actually enjoy the things that are relevant to management. Most importantly, practice transparency, because I feel like the number one reason that most people go into management is because they’re sick of being left out. They’re tired of not being in the room when it happens. They’re tired of not having a say. They’re tired of not knowing what’s happening. They just want to know what is going on. I’ve heard so many people at healthy organizations, I was one of these people, I became a manager because I was tired of being left out. I thought that I wanted to run things, but, actually, all I wanted was I wanted to be in the room. I wanted to have a say in the work that I did. Most of your top performers will feel the same way. If you don’t want everyone to become a manager, because it’s the only way that they can have a say in things, then you should start by practicing actual transparency.
Conclusion
Please don’t build a system where people have to be a manager if they want to be in the loop. Hierarchies are inevitable, because they’re efficient and effective. The command-and-control management is toxic. You can have hierarchy without authoritarianism. Management is overhead, let’s not forget this. Management is a support function, it’s not a boss. It can be helpful to just practice visualizing your hierarchy upside down like a tree. Your management is a support system, not dominance. Ultimately, we’re all here because of the work that ICs are doing, building things, shipping code, fixing things, making users happy. That’s the reason we exist. We don’t exist to glorify management. If you’re not happy as a manager, please don’t do it. You’re not fooling anyone, and it hurts everyone around you. You might feel like you’re making a grand sacrifice to better the company, but I promise you, you’re not. Be honest with yourself. If you don’t enjoy it, find a way to get out of it. Don’t be one of the reasons that people burn out of tech.
Finally, you can build a very long, healthy, flourishing career just by leaning into your curiosity, your love of learning, your remembering to be afraid of feeling too comfortable. Surround yourself with amazing people. Go where amazing people are, and be one of the amazing people that people want to follow. Don’t stay at a toxic job just because there are great people there. Don’t reward terrible managers with your presence. There are places that run healthy companies, where they’re honest and transparent with you. I think that embracing the engineer manager pendulum is a really good sign of a lot of healthy cultural traits. It’s something to look for. In the end, only you get to say what success actually looks like for you.
See more presentations with transcripts
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

HuggingChat is a new AI-powered chatbot available for testing on Hugging Face. HuggingChat is able to carry through many tasks that have made ChatGPT attract lot of interest recently, including drafting articles, solve coding problems, or answer questions.
HuggingChat has 30 billion parameters and is at the moment the best open source chat model according to Hugging Face. The AI startup, however, plans to expose all chat models available on the Hub in the long-term.
The goal of this app is to showcase that it is now (April 2023) possible to build an open source alternative to ChatGPT.
As Hugging Face clarifies, HuggingChat is currently based on the latest LLaMa model developed by the project OpenAssistant.
OpenAssistant has the rather ambitious goal of going beyond ChatGPT:
We are not going to stop at replicating ChatGPT. We want to build the assistant of the future, able to not only write email and cover letters, but do meaningful work, use APIs, dynamically research information, and much more, with the ability to be personalized and extended by anyone.
An additional goal they have in mind is making this AI-based assistant to be small and efficient so that it can be run on consumer hardware.
OpenAssistant itself is managed under LAION, a non-profit organization that provides open datasets, tools, and models to foster machine learning research, including the LAION-5B dataset on which Stable Diffusion is based.
Currently, HuggingChat enforces a strict privacy model, whereby messages are only stored to display them to the user and are not even shared for research or training purposes. Additionally, users are not authenticated nor identified using cookies. This will likely change in future, though, to let users share their conversations with researchers.
As mentioned, HuggingChat is the first AI-powered chat project that is open-source. The code for the UI can be found on GitHub while the inference backend runs text-generation-inference on Hugging Face’s Inference API infrastructure.
This means that the app can be deployed to a Hugging Face Space and customize it in a number of ways, including swapping models, modify the UI, change the policy about storing user messages, and so on.
MMS • Jesse McGinnis
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Hey, folks, QCon London is just around the corner. We’ll be back in person in London from March 27 to 29. Join senior software leaders at early adopter companies as they share how they’ve implemented emerging trends and best practices. You’ll learn from their experiences, practical techniques, and pitfalls to avoid so you get assurance you’re adopting the right patterns and practices. Learn more at qconlondon.com. We hope to see you there today.
Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today, I’m sitting down with Jesse McGinnis from Shopify. Jesse, welcome. Thanks for taking the time to talk to us today.
Jesse McGinnis: Thanks, Shane. Thanks for having me. Excited to be here.
Shane Hastie: Now, we met when you gave a talk at QCon San Francisco last year on building high trust and high performing teams at Shopify in a remote world. Before we get into that, who’s Jesse?
Jesse McGinnis: Great question. I don’t know. Who is Jesse? I mean, there’s so much to that question, but the usual answer, I work at Shopify. I’m a senior lead. I’ve been here for approaching six and a half years, which is wild to think about. I love helping teams and people figure out how they can be the best versions of themselves. It’s been a joy chasing that the last couple of years. Before that, much more focused on building products, getting into code much more, waxing those sets of skills. I’ll go back there at some point in the next some number of years and continue that pendulum, but right now it really is about helping people figure out how to do the best version of the work. And, yeah, I’m in very balmy southern Ontario right now where we have about a foot of snow outside and a wind chill of minus 30. It’s great.
Shane Hastie: And I’m sitting in a summery Otaki in bottom of the North Island New Zealand.
Jesse McGinnisL Sounds horrible.
Shane Hastie: Isn’t technology wonderful that we can be together and I don’t have to be in a foot of snow? So what does trust look like in a remote world?
Being deliberate about enabling trust in a remote environment [02:01]
Jesse McGinnis: I do think in many ways it’s not any different than what it is like in person. Can you have candid conversations? Are people willing to show up? Can people bring their authentic selves without having to be guarded or heavily guarded? Will they challenge their peers, their leaders? I think it’s a lot of that. And then, in remote, you just have to put a lot more work into creating space to let that build and develop. That might come naturally when you sit beside someone or get to have lunch with them every day or bump into them in the hallway, because none of those opportunities exist automatically when you’re remote.
Shane Hastie: What does that deliberate look like?
Jesse McGinnis: Part of it is being willing to set aside space for creating that initial social connection, creating that really, to some extent, almost surface level trust, the small talk, the opportunity to play a casual game together. And it can feel really weird to say, “Here is our regimented 45 minutes to have fun together”, but you just have to get past that because if you don’t set it up, I mean, you might get really lucky and have a team that’s very outgoing and hungry for it and will do it of their own volition, but my experience has been that there’s not a ton of those humans. Because they’ll also feel the same trepidation that you might be facing in creating fun time except for they’re not in a position of authority and it’s like, “Well, am I allowed to go book a thing on everyone’s calendars?”
Enabling time for people to get to know each other on a deeper level [03:20]
So it’s creating space to let people be human together, to socialize, have that on some recurring cadence and rotate through different kinds of lightweight activities to help break the ice and still create opportunity to do surface communication conversation and have that first initial introduction. You can go deeper than that, and I think you should, but I’ll also say, I think even having time for “fun” is more than what a lot of people do because they feel like it’s work. “We’re here to do a job. I’m not supposed to set up time to socialize with my coworkers or my team.” And so even if you just stop at creating space for fun, you’ve already done better than a lot of people that I’ve seen. Where I think magic happens though is when you go deeper and you create very intentionally set up spaces where humans can reveal a little bit more about who they are behind the curtain, show their full selves. And this is something that I think even in office a lot of teams didn’t do.
Again, it might have happened naturally if you had board games in the office or drinks around and people could hang out together or you went out together for a social activity or you’d been working with someone for a really long time and had just naturally built up that really deep trust. But a lot of teams in office or in person didn’t set up dedicated space to expedite deep trust building. And in remote I think it’s even more important because you have so many less natural opportunities. And so if you’ve established a little bit of that surface trust building, help break the ice, help us know who we all are and can feel comfortable having a conversation with each other, then you can start layering in deeper conversations. And there’s a lot of different prompts you can use. The New York Times Questions To Fall In Love is my favourite default one because it has a nice progression of what’s your favourite superpower, up to things like, what’s the relationship with your mother? And everything in between.
Those kinds of questions allow you, to some extent, expose more about who you are to your peers. In many cases, when I’ve run it, I’ve seen people not realize things that they have in common with each other that they can then take away for their own one-on-one. And, again, digital environments, people should have one-on-ones that aren’t manager report related. You can have a coffee chat with a friend. You should. But now that you’ve had this space where you expose more of who you are, have these conversations open up, that gives fodder for one-on-ones. That helps teams feel heard. I think it makes it easier for people to feel comfortable being honest about how they’re doing or how their day is going. Once you’ve talked about the relationship with your parents or your beliefs about death or some of the scariest moments of your life with people, a lot of other stuff is easy as well.
That’s the raw stuff about you as a human after you’ve been willing to open up, had the space to open up, had moments to have these kinds of conversations multiple times. A lot of other conversations are in many regards trivial, emotionally at the very least. So then it’s really just about the work at hand. I think intentionality and purpose built spaces can be magic for a lot of different things, and trust is one of those.
Shane Hastie: What does a great team look like?
Great teams form on the foundation of trust where working together is fun [06:31]
Jesse McGinnis: I think it depends on the type of work you’re doing, but I do think as a default, any team that I would want to be a part of is one that people have fun. I really do think work isn’t always rainbow and sunshine and joyful, but I think it should have lots of moments of fun and engagement and interest. And so you need to know the people that you’re working with. Hopefully, you have a level of trust with them where you can be honest and authentic and unguarded about how you’re feeling, what you care about, what you’re passionate about. You can bring your full self and you don’t have to put a whole bunch of energy into being really careful with what you say or how you present yourself or how you challenge or how you shy away. You have fun and fun not just in, again, the surace level.
I think you should have some of those fun game things, but working together itself is fun, and I do deeply believe, when you have capable people that know the fundamental skills or are interested in learning how to get good at those skills and have the opportunity to do so, if you have people that you have fun with, with the work that you’re doing and you trust, that team will get very good, very fast. And maybe fold in some reflection and introspection moments so that the team can identify where it’s not as good as it needs to be or where the rough spots are or where there’s opportunity to improve and you’ve created this environment, this pot that’s just going to bubble over into a fantastic team.
Shane Hastie: And how, from a team leader perspective, do we set up these teams to be successful?
Things team leaders can do to set teams up to be successful [08:02]
Jesse McGinnis: There’s a lot of different things that you pull into. I’m trying to figure out which one is my favorite pull in here, but what I’ll go with is, how do you set this up? There’s a few core ingredients that have to be established to get to one of these kinds of high performing teams. I think everyone needs to know what their purpose is. You need to know where you’re going. You need to know why you’re going there. You need to care about whatever that is, or care about something. Maybe you’re consulting and you don’t actually care about the consulting project that you’re attached to, but you care about some interesting piece of technology you’re exploring or the particular client or the team you’re working with. You need to identify something that as a team you can be excited and passionate and energized by and know that it is important or valuable or meaningful in some way.
Know where you’re going. Know why that matters. That gives you direction. That gives you a sense of purpose. That anchors a lot of other pieces. You should set up and create intentional spaces for the team to build trust. Again, create those avenues. Be the strong facilitator if you don’t have one already baked into the team to create service level conversation and then well facilitated safe spaces to have deep, honest, authentic conversation and build that real trust.
Process matters
And then, depending on how you work, the type of work you do, the scale of the work, you’re going to have different kinds of processes and rituals around it, but don’t ignore process. Process is often I think tagged as a dirty word in our industry, but everything is process, everything. If you don’t do something, there’s still a process that exists whether you want it to or not. It just might be something very chaotic and very not well suited to the work that is actually happening.
And so take some time to think about, given the kind of work we’re doing, given our team size, given the context of the work that we’re doing and the space that we exist within, what systems or processes or nudges can I or should I set up to help this team be successful? That can be something like the full textbook answer of Scrum, which works for very specific kinds of projects. It can be something like Kanban. It can be something completely free form with a check-in every couple weeks because you’re doing deeply emergent and explorative work that’s very independent. You have to be willing to pick and set that up intentionally. And I think, regardless of what process you have, you should have some system for retrospective and reflection. I really do think being self-aware and looking back at how things are going and having that avenue for the team to self-identify how it can get better is really critical to building a sustainable, high performing team.
And that invites the team in to fix and improve itself. It’s not your job as a lead to make a high performing team. That’s the team’s job. Your job is to make sure that they have the tools they need, the space they need, the opportunity they need to get there.
Shane Hastie: This is not a skillset that technologists are renowned for having. How do organizations help our technical leaders, the people who want to move into that space, build these skills? You mentioned for your own journey from coding and development into this leader position now, the team leading, what do you need to learn to do this?
Leadership is a skillset that can be learned [11:12]
Jesse McGinnis: I believe organizations can accelerate it for you. You have to want it, first and foremost. So that is actually maybe even the first step. Make sure this is a thing that you want to go spend time learning and getting good at, because if it’s not a thing you’re excited about, it’s all going to be a slog and you might get good at it, but you’re not going to enjoy it, which means you’re not going to be energized by it, which means you’re not going to want to practice all of the things that feed into becoming really excellent. And so make sure it is a thing you want to explore. Where organizations can help, I think mentorship programs, peer groups, and then I would say accelerators. So when I think about Shopify, the way we approach this, there is a pretty strong expectation that the people who are already in this craft of people leadership are mentoring and growing the people that are aspiring to be people leaders, is an expectation that exists.
We have a dev manager accelerator though that focuses on what I would say are your management fundamentals, self-reflection, how to run successful one-on-ones, how to give good feedback, and all of them have explicit space for practice with a facilitator present. And that maybe that’s really what the actual answer here is, is that all of this is just stuff you have to practice. There isn’t a cheat code. I mean, there’s books you can read that speak to different strategies to take or different ways to show up as a facilitator, but, like many of the things that we have in this industry, practice actually will get you there really fast. That’s not going to be great the first few times. If you have someone nearby who can give you feedback on how that went, you’ll get there faster.
And if you don’t have that someone and you’re in a position where you have to do these things, I’ve done this in the past and I have seen other leaders do this where we shy away from admitting what we’re not good at yet, the sense that we need to show up perfect or well established or we know all of the answers. And people see through that. And especially when you’re new to something, just being upfront like, “Hey, I’m going to try something this week that I’ve never done before with a really hard, detailed, deep conversation. And I’ve read a blog post that talked about a way to run this and I don’t know how it’s going to go, but this is what I’m trying to do.” Being honest and authentic about your aims, about what you’re worried about opens the door, first of all, just by being upfront like, “Hey, I’m going to do this thing that I’m really unsure about, but I’m really excited about what it might do for us,” you’ve already been honest and authentic. You’ve already opened the door for other people to be honest and authentic.
You’ve invited the room to give you feedback, or you should invite the room to give you feedback afterwards, which means you can learn, and then you’ve gotten some practice in. And then the second time you do it, you can still be honest with where you’re at. Hopefully, you will have got feedback that you can refine and iterate on, and then ask again. And you’re creating your own space to learn and grow with your team. None of that was specific or tactical. I think tactically, when you are facilitating or when you’re showing up as a people leader or when you’re working with other humans, what’s really important to always remember is that you are dealing with other humans. We are all complicated. We are all nuanced. Communication is hard and things won’t come across the way that you want and you won’t hear them the same way that they intended. And so give yourself grace, give yourself space, give yourself an opportunity to learn and fumble and hit a whole bunch of walls, and just be ready to learn from it and carry on.
Shane Hastie: Standing back a bit, looking outside of where you are now, what’s happening in our industry at the moment?
Reflecting on the macroeconomic climate in early 2023 [14:31]
Jesse McGinnis: It’s chaotic with the macroeconomic environment and companies I think getting wary about longer term prospects around revenues and all of that. As they should, they’re doing very heavy introspection. To me, I see some trends emerging of people getting very critical about do we have people working on the most important things versus stuff that maybe isn’t as critical or core to our business. I have seen some trends around, our people hate the word, but utilized the most efficient for humans. We’re not machines or resources that we throw at things, so it’s a gross language, but are people positioned and set up to do their best work, as maybe a nicer way to frame that? And so what I’m seeing happening is companies are, I’m going to ignore the layoff piece because that gets into a whole other complex macro piece, but companies are redirecting humans to their most critical pieces of their business and I think looking for ways to clear overhead or distraction.
Making space in calendars by removing meetings [15:32]
And so I think a pretty common trope at this point is every year around the new year, there’s a lot of energy around, “Call out all of the meetings. Get rid of all of the distractions. Let everyone just work.” And I actually do agree. When you’re doing large scale communications, you need to be bold so all meetings are bad. Cut them all. Delete them for three weeks and then figure it out afterwards. That’s how you turn a giant ship. But, obviously, there’s nuance in here and it’s really hard to communicate that nuance. The media, at least in its headlines, is never going to have a nuanced headline. It might exist in the article. And so this trend towards dramatically scaling back meetings, I think to me the takeaway shouldn’t be, “All meetings are bad.” It’s, “Make sure that meetings and moments together serve you.” That they’re useful, that they do what you want them to do, and they’re not a thing that you have become a slave to.
It’s the same with all process. When we go into our rounds of, “All process is bad. Agile has become a horrible thing. We need to get back to just the work,” it’s when we become a slave to the thing versus the thing being a tool that serves us is where you start to see it go bad. And so, with the current meeting trend, yeah, Shopify cut all those meetings at the beginning of the year. I cut all of my meetings personally every quarter. I just delete my calendar and then reschedule stuff back in because that’s just how I make sure that all of the stuff serves me and I’m not just falling into a trap. So I thought it was useful. I found it good. I have not told my teams to not add back meetings that were critical to them or important to their work or help them socialize or help them connect deeper or planning meetings that help them coordinate so that they could spend the rest of the week being focused on good work instead of having to have 30 one-on-ones to coordinate.
I think what it ultimately comes down to is intentionality and awareness. In this meeting, what do I want it to do? What does it need to accomplish? Is it doing that? If it isn’t, can I fix it or should it go away, or is there an alternative way to approach this? And maybe one last call out, at least thinking about my own experience at Shopify, I do think we had relied on meetings in the early days of our transition to being a remote company to work in similar ways that we did when we were an office-based company. And a transition that we are still going through and figuring out is, what does it mean to really be a remote first company that’s globally distributed? What are the different patterns that we should adopt for how we communicate, get on the same page, jam on ideas? I still think even in that world synchronous time together is super valuable for certain things, but what things were we doing synchronously that maybe we would be better served by doing in a different async way?
Shane Hastie: Tell us about the book, Embrace Uncertainty.
Jesse’s book – Embrace Uncertainty [18:09]
Jesse McGinnis: Yes. I would say a field Guide to Scrum that me and a few coworkers wrote seven or eight years ago really centered on trying to get to the good parts. If you’ve never done this before or if you’ve read lots of books and it’s been a while, you need a refresher, can you read this on a plane ride and get some good practical tactics to help a team work better? It has a little bit of a centric focus on in-person work because it was written in the times when I was personally completely against the idea of remote work. But if you fuzz your eyes around the parts that anchor on that, it still actually applies pretty well digitally. I would say it still is the defaults that all of my teams run with on how to use I would say Scrum Light in a way that can be very productive without too much overhead and keep the team in charge of how that all runs.
There’s a foreword that we added to the book a couple of years after we published it. The real thing for all things process related is, again, that intentionality and awareness of, what are you trying to achieve? You can carbon copy if you have no idea what to do, but you can’t stay in that carbon copy. So I like the defaults that, that book proposes because they’ve worked really well for me. But all of those defaults change with every single team that I lead or have been attached to because each team is different and needs slightly different things to be successful. It’s a starting place, not an end state.
Shane Hastie: Jesse, thanks very much for your time today. Some really interesting conversation. If people want to continue the conversation, where do they find you?
Jesse McGinnis: I have all of my various social links and messaging platforms are on my personal website at J-C-M-C-G-I-N-N-I-S.com, but Twitter, LinkedIn, and increasingly Mastadon are the places that I reside on the internet.
Shane Hastie: Wonderful. Thank you so much.
Jesse McGinnis: Thanks, Shane.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • David Rant
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- With metrics teams must remember Goodhart’s law: “When a measure becomes a target, it ceases to be a good measure.”
- Low-performing teams take a hit on stability when they try to increase their deployment frequency simply by working harder.
- Driving improvements in the metric may lead to taking shortcuts with testing causing buggy code or producing brittle software quickly.
- A high change failure rate may reduce the effectiveness of the other metrics in terms of measuring progress toward continuous delivery of value to your customers.
Since 2014, Google’s DevOps Research and Assessment (DORA) team has been at the forefront of DevOps research. This group combines behavioural science, seven years of research, and data from over 32,000 professionals to describe the most effective and efficient ways to deliver software. They have identified technology practices and capabilities proven to drive organisational outcomes and published four key metrics that teams can use to measure their progress. These metrics are:
- Deployment Frequency
- Lead Time for Changes
- Mean Time to Recover
- Change Failure Rate
In today’s world of digital transformation, companies need to pivot and iterate quickly to meet changing customer requirements while delivering a reliable service to their customers. The DORA reports identify a range of important factors which companies must address if they want to achieve this agility, including cultural (autonomy, empowerment, feedback, learning), product (lean engineering, fire drills, lightweight approvals), technical (continuous delivery, cloud infrastructure, version control) and monitoring (observability, WIP limits) factors.
While an extensive list of “capabilities” is great, for software teams to continually improve their processes to meet customer demands they need a tangible, objective yardstick to measure their progress. The DORA metrics are now the de facto measure of DevOps success for most and there’s a consensus that they represent a great way to assess performance for most software teams, thanks to books like Accelerate: The Science of Lean Software and DevOps (Forsgren et al, 2018) and Software Architecture Metrics (Ciceri et al, 2022).
But when handling metrics, teams must always be careful to remember Goodhart’s law: “When a measure becomes a target, it ceases to be a good measure.” The danger is that metrics become an end in themselves rather than a means to an end.
Let’s explore what this might look like in terms of the DORA metrics — and how you can avoid pulling the wool over your own eyes.
Deployment Frequency
For the primary application or service you work on, how often does your organisation deploy code to production or release it to end users?
At the heart of DevOps is an ambition that teams never put off a release simply because they want to avoid the process. By addressing any pain points, deployments cease to be a big deal, and your team can release more often. As a result, value is delivered sooner, more incrementally, allowing for continuous feedback from end users, who then shape the direction of travel for ongoing development work.
For teams who are currently only able to release at the end of a biweekly sprint or even less often, the deployment frequency metric hopefully tracks your progress toward deployments once a week, multiple times a week, daily, and then multiple times a day for elite performers. That progression is good, but it also matters how the improvements are achieved.
What does this metric really measure? Firstly, whether the deployment process is continuously improving, with obstacles being identified and removed. Secondly, whether your team is successfully breaking up projects into changes that can be delivered incrementally.
As you celebrate the latest increase in deployment frequency, ask yourself: are our users seeing the benefit of more frequent deployments? Studies have shown that low-performing teams take a big hit on stability when they try to increase their deployment frequency simply by working harder (Forsgren, Humble, and Kim, 2018). Have we only managed to shift the dial on this metric by cracking the whip to increase our tempo?
Lead Time for Changes
For the primary application or service you work on, what is your lead time for changes (that is, how long does it take to go from code committed to code successfully running in production)?
While there are a few ways of measuring lead times (which may be equivalent to or distinct from “cycle times,” depending on who you ask), the DORA definition is how long it takes from a feature being started, to a feature being in the hands of users.
By reducing lead times, your development team will improve business agility. End users don’t wait long to see the requested features being delivered. The wider business can be more responsive to challenges and opportunities. All this helps improve engagement and interplay between your development team, the business, and end users.
Of course, reduced lead times go hand in hand with deployment frequency. More frequent releases make it possible to accelerate project delivery. Importantly, they ensure completed work doesn’t sit around waiting to be released.
How can this metric drive the wrong behaviour? If your engineering team works towards the metric rather than the actual value the metric is supposed to measure, they may end up taking shortcuts when it comes to testing and releasing buggy code, or code themselves into a corner with fast but brittle approaches to writing software.
These behaviours produce a short-term appearance of progress, but a long-term hit to productivity. Reductions in lead times should come from a better approach to product management and improved deployment frequency, not a more lax approach to release quality where existing checks are skipped and process improvements are avoided.
Mean Time to Recover
For the primary application or service you work on, how long does it generally take to restore service when a service incident or a defect that impacts users occurs (for example, unplanned outage, service impairment)?
Part of the beauty of DevOps is that it doesn’t pit velocity and resilience against each other but makes them mutually beneficial. For example, frequent small releases with incremental improvements can more easily be rolled back if there’s an error. Or, if a bug is easy to identify and fix, your team can roll forward and remediate it quickly.
Yet again, we can see that the DORA metrics are complementary; success in one area typically correlates with success across others. However, driving success with this metric can be an anti-pattern – it can unhelpfully conceal other problems. For example, if your strategy to recover a service is always to roll back, then you’ll be taking value from your latest release away from your users, even those that don’t encounter your new-found issue. While your mean time to recover will be low, your lead time figure may now be skewed and not account for this rollback strategy, giving you a false sense of agility. Perhaps looking at what it would take to always be able to roll forward is the next step on your journey to refine your software delivery process.
It’s possible to see improvements in your mean time to recovery (MTTR) that are wholly driven by increased deployment frequency and reduced lead times. Alternatively, maybe your mean time to recovery is low because of a lack of monitoring to detect those issues in the first place. Would improving your monitoring initially cause this figure to increase, but for the benefit of your fault-finding and resolution processes? Measuring the mean time to recovery can be a great proxy for how well your team monitors for issues and then prioritises solving them.
With continuous monitoring and increasingly relevant alerting, you should be able to discover problems sooner. In addition, there’s the question of culture and process: does your team keep up-to-date runbooks? Do they rehearse fire drills? Intentional practice and sufficient documentation are key to avoiding a false sense of security when the time to recover is improving due to other DevOps improvements.
Change Failure Rate
For the primary application or service you work on, what percentage of changes to production or releases to users result in degraded service (for example, lead to service impairment or service outage) and subsequently require remediation (for example, require a hotfix, rollback, fix forward, patch)?
Change failure rate measures the percentage of releases that cause a failure, bug, or error: this metric tracks release quality and highlights where testing processes are falling short. A sophisticated release process should afford plenty of opportunities for various tests, reducing the likelihood of releasing a bug or breaking change.
Change failure rate acts as a good control on the other DORA metrics, which tend to push teams to accelerate delivery with no guarantee of concern for release quality. If your data for the other three metrics show a positive trend, but the change failure rate is soaring, you have the balance wrong. With a high change failure rate, those other metrics probably aren’t giving you an accurate assessment of progress in terms of your real goal: continuous delivery of value to your customers.
As with the mean time to recover, change failure rate can—indeed should—be positively impacted by deployment frequency. If you make the same number of errors but deploy the project across a greater number of deployments, the percentage of deployments with errors will be reduced. That’s good, but it can give a misleading sense of improvement from a partial picture: the number of errors hasn’t actually reduced. Perhaps some teams might even be tempted to reduce their change failure rate by these means artificially!
Change failure rate should assess whether your team is continuously improving regarding testing. For example, are you managing to ‘shift left’ and find errors earlier in the release cycle? Are your testing environments close replicas of production to effectively weed out edge cases? It’s always important to ask why your change failure rate is reducing and consider what further improvements can be made.
The Big Picture Benefits of DevOps
Rightfully, DORA metrics are recognized as one of the DevOps industry standards for measuring maturity. However, if we think back to Goodhart’s Law and start to treat them as targets rather than metrics, you may end up with a misleading sense of project headway, an imbalance between goals and culture, and releases that fall short of your team’s true potential.
It’s difficult to talk about DORA metrics without having the notion of targets in your head; that bias can slowly creep in and before long you’re unknowingly talking about them in terms of absolute targets. To proactively avoid this slippery slope, focus on the trends in your metrics – when tweaking your team’s process or practices, relative changes in your metrics over time give you much more useful feedback than a fixed point-in-time target ever will; let them be a measure of your progress.
If you find yourself in a team where targets are holding you hostage from changing your process, driving unhelpful behaviours, or so unrealistic that they’re demoralising your team, ask yourself what context is missing that makes them unhelpful. Go back and question what problem you’re trying to solve – and are your targets driving behaviours that just treat symptoms, rather than identifying an underlying cause? Have you fallen foul of setting targets too soon? Remember to measure first, and try not to guess.
When used properly, the DORA metrics are a brilliant way to demonstrate your team’s progress, and they provide evidence you can use to explain the business value of DevOps. Together, these metrics point to the big-picture benefits of DevOps: continuous improvements in the velocity, agility, and resilience of a development and release process that brings together developers, business stakeholders, and end users. By observing and tracking trends with DORA metrics, you will have made a good decision that facilitates your teams and drives more value back to your customers.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Google recently announced an API abuse detection dashboard powered by machine learning algorithms.
Machine learning-powered abuse-detection dashboards are available in Advanced API Security, a feature of Apigee API management that enables customers to quickly detect API security misconfigurations, bad bots, and malicious activities. In addition, the models behind the dashboard are trained to detect business logic attacks by Google’s internal teams to help protect their public-facing APIs.
Shelly Hershkovitz, a product manager at Google Cloud, explains in a blog post:
Business logic attacks are harder to detect using static security policies, which allows attackers to manipulate legitimate functionality to achieve a malicious goal without triggering any static security alerts.
The dashboard helps filter through alerts designed to detect less complex attacks, which often result in many non-critical alerts, or manage a multitude of bot attacks simultaneously, enabling security teams to address significant issues more efficiently.
Furthermore, the dashboard can surface critical events with “human-friendly” titles that attempt to capture the essential elements of the attack, such as the source of the attack, the APIs affected, and the duration of the attack allowing security teams to deal with the event faster. In addition, the dashboard also provides a way to drill down into the attack and ways to cross-reference with other similar attacks, along with recommendations on actions to remediate the event as quickly as possible.
Security teams can access abuse detection through the Apigee UI, the Security Incidents API, or the Security Stats API.
Google strengthened its API Management (ApiGee) service in response to the increase in cyberattacks and associated losses. According to IBM’s 2022 Cost of a Data Breach Report mentioned in the blog post by Hershkovitz, the average cost of a data breach is $4.35 million.
Furthermore, Sarah Klein, a regulatory, privacy, and cybersecurity professional, wrote in a LinkedIn blog post:
While many companies limit identifying “data breaches” to incidents defined by various laws or regulatory pronouncements they are obligated to comply with, it is inadequate for a maturing data industry. In addition, as companies rely more on APIs to provide services or products to their customers or use them internally to automate data processes, security experts must proactively change the narrative and treat API abuse as a data breach.
Therefore, besides Google, other companies enhance security with a feature like API Abuse detection in their products. Cloudflare, for instance, has API Abuse detection capability, which can monitor an API for calls that are out of sequence, a likely indication that it’s being abused. Or Microsoft through Defender for APIs, which offers complete lifecycle protection, detection, and response coverage for APIs.