Month: May 2023

MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

Researchers from Caltech, Stanford, the University of Texas, and NVIDIA have collaboratively developed and released Voyager, an LLM power agent that utilizes GPT-4 to engage in Minecraft gameplay. Voyager demonstrates remarkable capabilities by learning, retaining knowledge, and showcasing exceptional expertise in Minecraft.
Voyager operates autonomously, continuously exploring the virtual world, acquiring diverse skills, and making groundbreaking discoveries without any human intervention. Voyager’s innovation lies in its automatic curriculum that optimizes exploration, an ever-expanding skill library for storing and retrieving complex behaviors, and an iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program enhancement.
Voyager consists of three key components: an automatic curriculum for open-ended exploration, a skill library for increasingly complex behaviors, and an iterative prompting mechanism that uses code as action space.
Utilizing blackbox queries to interact with GPT-4, Voyager circumvents the need for model parameter fine-tuning. The skills developed by Voyager are both temporally extended and interpretable, resulting in rapid compound growth of the agent’s capabilities and mitigating catastrophic forgetting.
According to Jim Fan, one of the researchers of the project, GPT-4 experiment in Minecraft is a good place to start when creating effective AI agents. Autonomous agents with broad capabilities are the next step in artificial intelligence. They are motivated by curiosity and survival to explore, plan, and learn new abilities in open environments.
Compared with baselines, Voyager unlocks the wooden level 15.3x faster in terms of the prompting iterations, the stone level 8.5x faster, the iron level 6.4x faster, and Voyager is the only one to unlock the diamond level of the tech tree.
An unparalleled attribute of Voyager is its ability to utilize the learned skill library in a fresh Minecraft world to solve novel tasks from scratch, a feat that other approaches struggle to achieve when generalizing.
Lifelong learning agents are AI models designed to acquire knowledge and skills continuously throughout their operational lifespan. They possess the ability to adapt, learn, and improve as they encounter new information and experiences. Lifelong learning agents excel in retaining and transferring knowledge, allowing them to handle diverse tasks and domains effectively. Their capacity for continuous learning makes them valuable in various fields, including gaming, robotics, healthcare, and education.
With Voyager, Minecraft enters a new era of innovation, laying the foundation for future advancements in embodied lifelong learning agents.
MMS • Edin Kapic
Article originally posted on InfoQ. Visit InfoQ

Version 4.54.0 of Microsoft Authentication Library (MSAL) for .NET brings official support for using managed identities when authenticating services that run in Azure. Furthermore, it features better error information for UWP applications and several bug fixes.
The most important feature added in this version is the general availability of support for managed identities in Azure. Managed identities are Azure Active Directory identities that are automatically provisioned by Azure and can be used from workloads running in Azure without explicit authentication with application secrets and keys.
Using managed identities instead of standalone application identities can significantly lower the developer time needed to authenticate services in Azure when accessing other resources. As Jimmy Bogard, creator of MediatR and AutoMapper libraries, mentions in his tweet from July last year, using managed identities in the same MSAL library fixes the problem of using two libraries for the same task.
In the following code sample, developers can specify that the application uses a system-assigned managed identity that Azure creates automatically for each resource and then retrieve the authentication token by calling the AcquireTokenForManagedIdentity method.
IManagedIdentityApplication mi = ManagedIdentityApplicationBuilder.Create(ManagedIdentityId.SystemAssigned)
.Build();
AuthenticationResult result = await mi.AcquireTokenForManagedIdentity(resource)
.ExecuteAsync()
.ConfigureAwait(false);
Users can also create user-assigned managed identities as resources in Azure and assign them to the services that should use them, allowing multiple resources to have the same managed identity.
The support for managed identities in MSAL was added in December 2022 for version 4.49.0. It was an experimental feature without support for using it in production environments. Half a year later, version 4.54.0 is generally available and can be used in production workloads.
Another added feature in this version is the automatic refresh of the authentication tokens for confidential clients that use an app token provider extension called WithAppTokenProvider. From the documentation comments, it seems that this enhancement was required for wrapping the Azure SDK usage of the library to allow for managed identity authentication.
The MsalException class has a new property called AdditionalExceptionData, which holds any extra error information coming from the underlying providers. Currently, the property is only filled for exceptions from the Windows 10/11 Web account manager (WAM) broker mechanism. The WAM broker is only used in Universal Windows Platform (UWP) applications. Windows applications that use MAUI don’t use the WAM broker, as the integration happens on the NET 6 runtime level.
For telemetry purposes, there is a new enum value for long-running requests that use OBO (on-behalf-of) authentication flows. It helps with the correct assessment of authentication failures.
Among the bug fixes in this release, two are related to iOS-specific errors. When using ahead-of-time compilation (AOT), JSON deserialisation with overflow properties would break. This behaviour was added in version 4.52.0, and now it’s fixed. The other iOS bug that is fixed is the incorrect referencing of the Microsoft.iOS library due to using several package repositories internally for MAUI applications.
Finally, a small bug in the interactive token retrieval (using the AcquireTokenInteractive method) was fixed. It failed if the user chose another account from the Microsoft login dialogue account chooser if the code calls the WithAccount method to preselect the user in the UI. Now the code checks for the returned user account and succeeds even if another account is selected in the UI.
Two weeks after the release of version 4.54.0, the team released an updated build with a few bug fixes and a minor feature that exposes the cache details in the telemetry logged automatically by MSAL. This build has version number 4.54.1.
The MSAL GitHub project has 170 open issues and 2048 closed issues at the moment. The updated MSAL library is distributed as a NuGet package called Microsoft.Identity.Client.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
At the annual Build conference, Microsoft announced Azure Deployment Environments‘ general availability (GA). This service allows development teams to create segregated instances within Azure for deploying and managing applications in different stages, such as development, testing, and production, to ensure controlled and consistent deployment processes.
Last year at Ignite conference, the company released the public preview of Azure Deployment Environments after a private preview earlier. The GA release includes new features gathered from the feedback of customers using the private preview onwards. These features are:
In addition, Microsoft is working on an integration between Azure Deployment Environments and the Azure Developer CLI (azd), which has been available since last year.
Sagar Chandra Reddy Lankala, a senior program manager at Microsoft, explains the benefits of Azure Deployment Environments in an Azure Developer Community blog post:
By enabling self-service deployment for developers, Azure Deployment Environments also benefits platform engineers and other admins, eliminating redundant work while giving them centralized control to keep environments secure and cost-effective. Rather than repeatedly provisioning environments for different developers, platform engineers provide developers with a catalog of standardized, pre-approved templates, promoting collaboration and knowledge sharing.
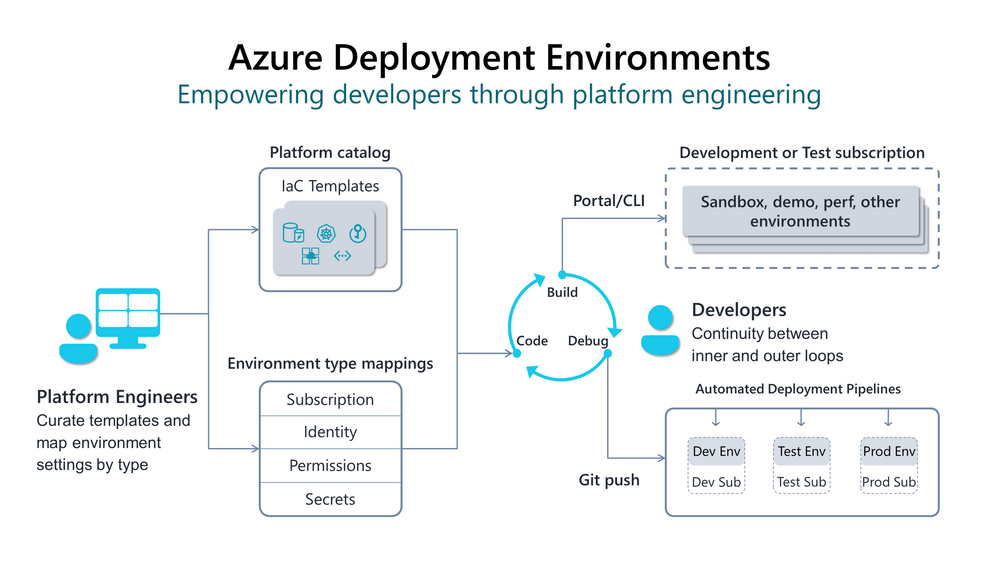
With the service, users also can establish predetermined rules regarding which roles have the authorization to deploy specific types of environments (such as development, testing, staging, or production), and they can ensure these environments are deployed in the appropriate subscription or management group, incorporating all relevant policies and cost controls.
For developers, the service provides means to spin up an environment to explore Azure or have a sandbox environment for testing purposes. Through the Azure Portal, they can create and access the environments.

Azure Deployment Environments is an addition to the existing services, such as CodeSpaces and Microsoft Dev Box the company made available earlier to enhance developer productivity and coding environments. CodeSpaces allows developers to get a VM with VSCode quickly, and similarly, with Microsoft Dev Box, they can get an entire preconfigured developer workstation in the cloud.
Scott Hanselman, a partner PM at Microsoft – Developer Division Community Manager, concluded in a video on Azure Development Environments:
It’s really going to help enterprises take it to the next level. This is the promise of the cloud, its scale and elasticity for your engineering systems.
More details of Azure Deployment Environments are available on the documentation landing page. Pricing-wise, the service is free, and customers will only be charged for other Azure resources like compute storage and networking created in environments.
MMS • Craig Risi
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Shifting left is popular in domains such as security, but it is also essential for achieving better test automation for CI/CD pipelines
- By shifting left, you can design for testability upfront and get testing experts involved earlier in your unit tests leading to a better result
- Not all your tests should be automated for your CI/CD pipelines; instead focus on the tests that return the best value while minimizing your CI/CD runtimes
- Other tests can then be run on a scheduled basis to avoid cluttering and slowing the main pipeline
- Become familiar with the principles of good test design for writing more efficient and effective tests
The rise of CI/CD has had a massive impact on the software testing world. With developers requiring pipelines to provide quick feedback on whether their software update has been successful or not, it has forced many testing teams to revisit their existing test automation approaches and find ways of being able to speed up their delivery without compromising on quality. These two factors often contradict each other in the testing world as time is often the biggest enemy in a tester’s quest to be as thorough as possible in achieving their desired testing coverage.
So, how do teams deal with this significant change to ensure they are able to deliver high-quality automated tests while delivering on the expectation that the CI pipeline returns feedback quickly? Well, there are many different ways of looking at this, but what is important to understand is that the solutions are less technical and more cultural ones – with the approach to testing needing to shift rather than big technical enhancements to the testing frameworks.
Shifting Left
Perhaps the most obvious thing to do is to shift left. The idea of “shifting left” (where testing is moved earlier in the development cycle – primarily at a design and unit testing level) is already a common one in the industry that is pushed by many organizations and is becoming increasingly commonplace. Having a strong focus on unit tests is a good way of testing code quickly and providing fast feedback. After all, unit tests execute in a fraction of the time (as they can execute during compilation and don’t require any further integration with the rest of the system) and can provide good testing coverage when done right.
I’ve seen many testers shy away from the notion of unit testing because it’s writing tests for a very small component of the code and there is a danger that key things will be missed. This is often just a fear due to the lack of visibility in the process or a lack of understanding of unit tests rather than a failure of unit tests themselves. Having a strong base of unit tests works as they can execute quickly as the code builds in the CI pipeline. It makes sense to have as many as possible and to cover every type of scenario as possible.
The biggest problem is that many teams don’t always know how to get it right. Firstly, unit testing shouldn’t be treated as some check box activity but rather approached with the proper analysis and commitment to test design that testers would ordinarily apply. And this means that rather than just leaving unit testing in the hands of the developers, you should get testers involved in the process. Even if a tester is not strong in coding, they can still assist in identifying what parameters to look for in testing and the right places to assert to deliver the right results for the integrated functionality to be tested later.
Excluding your testing experts from being involved in the unit testing approach means it’s possible unit tests could miss some key validation areas. This is often why you might hear many testers give unit tests a bad wrap. It’s not because unit testing is ineffectual, but rather simply that they often didn’t cover the right scenarios.
A second benefit of involving testers early is adding visibility to the unit testing effort. The amount of time (and therefore money) potentially wasted by teams duplicating testing efforts because testers end up simply testing something that was already covered by automated testing is probably quite high. That’s not to say independent validation shouldn’t occur, but it shouldn’t be excessive if scenarios have already been covered. Instead, the tester can focus on being able to provide better exploratory testing as well as focus their own automation efforts on integration testing those edge cases that they might never have otherwise covered.
It’s all about design and preparation
To do this effectively though requires a fair amount of deliberate effort and design. It’s not just about making an effort to focus more on the unit tests and perhaps getting a person with strong test analysis skills in to ensure test scenarios are suitably developed. It also requires user stories and requirements to be more specific to allow for appropriate testing. Often user stories can end up high-level and only focus on the detail from a user level and not a technical level. How individual functions should behave and interact with their corresponding dependencies needs to be clear to allow for good unit testing to take place.
Much of the criticism that befalls unit testing from the testing community is the poor integration it offers. Just because a feature works in isolation doesn’t mean it will work in conjunction with its dependencies. This is often why testers find so many defects early in their testing effort. This doesn’t need to be the case, as more detailed specifications can lead to more accurate mocking allowing for the unit tests to behave realistically and provide better results. There will always be “mocked” functionality that is not accurately known or designed, but with enough early thought, this amount of rework is greatly reduced.
Design is not just about unit tests though. One of the biggest barriers to test automation executing directly in the pipeline is that the team that deals with the larger integrated system only starts a lot of their testing and automation effort once the code has been deployed into a bigger environment. This wastes critical time in the development process, as certain issues will only be discovered later and there should be enough detail to allow testers to at least start writing the majority of their automated tests while the developers are coding on their side.
This doesn’t mean that manual verification, exploratory testing, and actually using the software shouldn’t take place. Those are critical parts of any testing process and are important steps to ensuring software behaves as desired. These approaches are also effective at finding faults with the proposed design. However, automating the integration tests allows the process to be streamlined. These tests can then be included in the initial pipelines thereby improving the overall quality of the delivered product by providing quicker feedback to the development team of failures without the testing team even needing to get involved.
So what actually needs to be tested then?
I’ve spoken a lot about specific approaches to design and shiting left to achieve the best testing results. But you still can’t go ahead and automate everything you test, because it’s simply not feasible and adds too much to the execution time of the CI/CD pipelines. So knowing which scenarios need to be appropriately unit or integration tested for automation purposes is crucial while trying to alleviate unnecessary duplication of the testing effort.
Before I dive into these different tests, it’s worth noting that while the aim is to remove duplication, there is likely to always be a certain level of duplication that will be required across tests to achieve the right level of coverage. You want to try and reduce it as much as possible, but erring on the side of duplication is safer if you can’t figure out a better way to achieve the test coverage you need.
Areas to be unit tested
When it comes to building your pipeline, your unit tests and scans should typically fall into the CI portion of your pipeline, as they can all be evaluated as the code is being built.
Entry and exit points: All code receives input and then provides an output. Essentially, what you are looking to unit test is everything that a piece of code can receive, and then you must ensure it sends out the correct output. By catching everything that flows through each piece of code in the system, you greatly reduce the number of failures that are likely to occur when they are integrated as a whole.
Isolated functionality: While most code will operate on an integrated level, there are many functions that will handle all computation internally. These can be unit-tested exclusively and teams should aim to hit 100% unit test coverage on these pieces of code. I have mostly come across isolated functions when working in microservice architectures where authentication or calculator functions have no dependencies. This means that they can be unit tested with no need for additional integration.
Boundary value validations: Code behaves the same when it receives valid or invalid arguments, regardless of whether it is entered from a UI, some integrated API, or directly through the code. There is no need for testers to go through exhaustive scenarios when much of this can be covered in unit tests.
Clear data permutations: When the data inputs and outputs are clear, it makes that code or component an ideal candidate for a unit test. If you’re dealing with complex data permutations, then it is best to tackle these at an integration level. The reason for this is that complex data is often difficult to mock, slow to process, and will slow down your coding pipeline.
Security and performance: While the majority of load, performance, and security testing happens at an integration level, these can also be tested at a unit level. Each piece of code should be able to handle an invalid authentication, redirection, or SQL/code injection and transmit code efficiently. Unit tests can be created to validate against these. After all, a system’s security and performance are only as effective as its weakest part, so ensuring there are no weak parts is a good place to start.
Areas for integration automation
These are tests that will typically run post-deployment of your code into a bigger environment – though it doesn’t have to be a permanent environment and something utilizing containers works equally well. I’ve seen many teams still try and test everything in this phase though and this can lead to a very long portion of your pipeline execution. Something which is not great if you’re looking to deploy into production on a regular basis each day.
So, the importance is to only test those areas where your unit tests are going to cover satisfactorily, while also focusing on functionality and performance in your overall test design. Some design principles that I give later in this article will help with this.
Positive integration scenarios: We still need to automate integration points to ensure they work correctly. However, the trick is to not focus too much on exhaustive error validation, as these are often triggered by specific outputs that can be unit tested. Rather focus on ensuring successful integration takes place.
Test backend over frontend: Where possible, focus your automation effort on backend components than frontend components. While the user might be using the front end more often, it is typically not where a lot of the functional complexity lies, and backend testing is a lot faster and therefore better for your test automation execution.
Security: One of the common mistakes is that teams rely on security scans for the majority of their security testing and then don’t automate some other critical penetration tests that are performed on the software. And while some penetration tests can’t be executed in a pipeline effectively, many can and these should be automated and run regularly given their importance, especially when dealing with any functionality that covers access, payment, or data privacy. These are areas that can’t be compromised and should be covered.
Are there automated tests that shouldn’t be included in the CI/CD pipelines?
When it comes to automation, it’s not just about understanding what to automate, but also what not to automate, or even if there are tests that are automated, they shouldn’t always land in your CI/CD pipelines. And while the goal is to always shift left as much as possible and avoid these areas, for some architectures it’s not always possible and there may be some additional level of validation required to satisfy the needed test coverage.
This doesn’t mean that tests shouldn’t be automated or placed in pipelines, rather just that they should be separated from your CI/CD processes and rather executed on a daily basis as part of a scheduled execution and not part of your code delivery.
End-to-end tests with high data requirements: Anything that requires complex data scenarios to test should be reserved for execution in a proper test environment outside of a pipeline. While these tests can be automated, they are often too complex or specific for regular execution in a pipeline, plus will take a long time to execute and validate, making them not ideal for pipelines.
Visual regression: Outside of functional testing it is important to often perform visual regression against any site UI to ensure it looks consistent across a variety of devices, browsers, and resolutions. This is an important aspect of testing that often gets overlooked. However, as it doesn’t deal with actual functional behavior, it is often best to execute this outside of your core CI/CD pipelines, though still a requirement before major releases or UI updates.
Mutation testing: Mutation testing is a fantastic way of being able to check the coverage of your unit testing efforts and see what may have been missed by adjusting different decisions in your code and see what it misses. However, the process is quite lengthy and is best done as part of a review process rather than forming part of your pipelines.
Load and stress testing: While it is important to test the performance of different parts of code, you don’t want to put a system under any form of load or stress in a pipeline. To best do this testing, you need a dedicated environment and specific conditions that will stress the limits of your application under test. Not the sort of thing you want to do as part of your pipelines.
Designing effective tests
So, it’s clear that we need a shift-left approach that relies heavily on unit tests with high coverage, but then also a good range of tests covering all areas to get the quality that is likely needed. It still seems like a lot though and there is always the risk that the pipelines can still take a considerable time to execute, especially at a CD level where the more time-intensive integration tests will be executed post-code deployment.
There is also a manner of how you design your tests though that will help make this effective. Automating tests that are unnecessary is a big waste of time, but so are inefficiently written tests. The biggest problem here is that often testers don’t have a full understanding of the efficiency of their test automation, focusing on execution rather than looking for the most processor and memory-effective way of doing it.
The secret to making all tests work is simplicity. Automated tests shouldn’t be complicated. Perform an action, and get a response. And so it is important to stick to that when designing your tests. The following below attributes are important things to follow in designing your tests to keep them both simple and performant.
1. Naming your tests
You might not think naming tests are important, but it matters when it comes to the maintainability of the tests. While test names might not have anything to do with the test functionality or speed of execution, it does help others know what the test does. So when failures occur in a test or something needs to be fixed, it makes the maintenance process a lot quicker and that is important when waging through the many thousands of tests your pipeline is likely to have.
Tests are useful for more than just making sure that your code works, they also provide documentation. Just by looking at the suite of unit tests, you should be able to infer the behavior of your code. Additionally, when tests fail, you can see exactly which scenarios did not meet your expectations.
The name of your test should consist of three parts:
- The name of the method being tested
- The scenario under which it’s being tested
- The behavior expected when the scenario is invoked
By using these naming conventions, you ensure that it’s easy to identify what any test or code is supposed to do while also speeding up your ability to debug your code.
2. Arranging your tests
Readability is one of the most important aspects of writing a test. While it may be possible to combine some steps and reduce the size of your test, the primary goal is to make the test as readable as possible. A common pattern to writing simple, functional tests is “Arrange, Act, Assert”. As the name implies, it consists of three main actions:
- Arrange your objects, by creating and setting them up in a way that readies your code for the intended test
- Act on an object
- Assert that something is as expected
By clearly separating each of these actions within the test, you highlight:
- The dependencies required to call your code/test
- How your code is being called, and
- What you are trying to assert.
This makes tests easy to write, understand and maintain while also improving their overall performance as they perform simple operations each time.
3. Write minimally passing tests
Too often the people writing automated tests are trying to utilize complex coding techniques that can cater to multiple different behaviors, but in the testing world, all it does is introduce complexity. Tests that include more information than is required to pass the test have a higher chance of introducing errors and can make the intent of the test less clear. For example, setting extra properties on models or using non-zero values when they are not required, only detracts from what you are trying to prove. When writing tests, you want to focus on the behavior. To do this, the input that you use should be as simple as possible.
4. Avoid logic in tests
When you introduce logic into your test suite, the chance of introducing a bug through human error or false results increases dramatically. The last place that you want to find a bug is within your test suite because you should have a high level of confidence that your tests work. Otherwise, you will not trust them and they do not provide any value.
When writing your tests, avoid manual string concatenation and logical conditions such as if, while, for, or switch, because this will help you avoid unnecessary logic. Similarly, any form of calculation should be avoided – your test should rely on an easily identifiable input and clear output – otherwise, it can easily become flaky based on certain criteria – plus it adds to maintenance as when the code logic changes, the test logic will also need to change.
Another important thing here is to remember that pipeline tests should execute quickly and logic tends to cost more processing time. Yes, it might seem insignificant at first, but with several hundreds of tests, this can add up.
5. Use mocks and stubs wherever possible
A lot of testers might frown on this, as the thought of using lots of mocks and stubs can be seen as avoiding the true integrated behavior of an application. This is true for end-to-end testing which you still want to automate, but not ideal for pipeline execution. Not only does it slow down pipeline execution, but creates flakiness in your test results as external functions are not operational or out of sync with your changes.
The best way to ensure that your test results are more reliable, along with allowing you to take greater control of your testing effort and improve coverage is to build mocking into your test framework and rely on stubs to intercept complex data patterns that an external function to do it for you.
6. Prefer helper methods to Setup and Teardown
In unit testing frameworks, a Setup function is called before each and every unit test within your test suite. Each test will generally have different requirements in order to get the test up and running. Unfortunately, Setup forces you to use the exact same requirements for each test. While some may see this as a useful tool, it generally ends up leading to bloated and hard-to-read tests. If you require a similar object or state for your tests, rather use an existing helper method than leveraging Setup and Teardown attributes.
This will help by introducing:
- Less confusion when reading the tests, since all of the code is visible from within each test.
- Less chance of setting up too much or too little for the given test.
- Less chance of sharing state between tests which would otherwise create unwanted dependencies between them.
7. Avoid multiple asserts
When introducing multiple assertions into a test case, it is not guaranteed that all of them will be executed. This is because the test will likely fail at the end of an earlier assertion, leaving the rest of the tests unexecuted. Once an assertion fails in a unit test, the proceeding tests are automatically considered to be failing, even if they are not. The result of this is then that the location of the failure is unclear, which also wastes debugging time.
When writing your tests, try to only include one assert per test. This helps to ensure that it is easy to pinpoint exactly what failed and why. Teams can easily make the mistake of trying to write as few tests as possible that achieve high coverage, but in the end, all it does is make future maintenance a nightmare.
This ties into removing test duplication as well. You don’t want to repeat tests through the pipeline execution and making what they test more visible helps the team to ensure this objective can be achieved.
8. Treat your tests like production code
While test code may not be executed in a production setting, it should be treated just the same as any other piece of code. And that means it should be updated and maintained on a regular basis. Don’t write tests and assume that everything is done. You will need to put in the work to keep your tests functional and healthy, while also keeping all libraries and dependencies up to date too. You don’t want technical debt in your code- don’t have it in your tests either.
9. Make test automation a habit
Okay, so this last one is less of an actual design principle and more of a tip on good test writing. Like with all things coding-related, knowing the theory is not enough and it requires practice to get good and build a habit, so these testing practices will take time to get right and feel natural. The skill of writing a proper test though is incredibly undervalued and one that will add a lot of value to the quality of the code so the effort and extra effort required are certainly worth it.
Conclusion – it’s all about good test design
As you can see, test automation across your full stack can still work within your pipeline and provide you with a high level of regression coverage while not breaking or slowing down your pipeline unnecessarily. What it does require though is a good test design to work effectively and so the unit and automated tests will need to be well-written to be of most value.
A good DevOps testing strategy requires a solid base of unit tests to provide most of the coverage with mocking to help drive the rest of the automation effort up, leaving only the need for a few end-to-end automated tests to ensure everything works in order and allow your team to take confidence that the pipeline tests will successfully deliver on their quality needs.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

New Jersey, United States – The Global NoSQL Software Market is comprehensively and accurately detailed in the report, taking into consideration various factors such as competition, regional growth, segmentation, and market size by value and volume. This is an excellent research study specially compiled to provide the latest insights into critical aspects of the Global NoSQL Software market. The report includes different market forecasts related to market size, production, revenue, consumption, CAGR, gross margin, price, and other key factors. It is prepared with the use of industry-best primary and secondary research methodologies and tools. It includes several research studies such as manufacturing cost analysis, absolute dollar opportunity, pricing analysis, company profiling, production and consumption analysis, and market dynamics.
The competitive landscape is a critical aspect every key player needs to be familiar with. The report throws light on the competitive scenario of the Global NoSQL Software market to know the competition at both the domestic and global levels. Market experts have also offered the outline of every leading player of the Global NoSQL Software market, considering the key aspects such as areas of operation, production, and product portfolio. Additionally, companies in the report are studied based on key factors such as company size, market share, market growth, revenue, production volume, and profits.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @ https://www.verifiedmarketresearch.com/download-sample/?rid=153255
Key Players Mentioned in the Global NoSQL Software Market Research Report:
Amazon, Couchbase, MongoDB Inc., Microsoft, Marklogic, OrientDB, ArangoDB, Redis, CouchDB, DataStax.
Global NoSQL Software Market Segmentation:
NoSQL Software Market, By Type
• Document Databases
• Key-vale Databases
• Wide-column Store
• Graph Databases
• Others
NoSQL Market, By Application
• Social Networking
• Web Applications
• E-Commerce
• Data Analytics
• Data Storage
• Others
The report comes out as an accurate and highly detailed resource for gaining significant insights into the growth of different product and application segments of the Global NoSQL Software market. Each segment covered in the report is exhaustively researched about on the basis of market share, growth potential, drivers, and other crucial factors. The segmental analysis provided in the report will help market players to know when and where to invest in the Global NoSQL Software market. Moreover, it will help them to identify key growth pockets of the Global NoSQL Software market.
The geographical analysis of the Global NoSQL Software market provided in the report is just the right tool that competitors can use to discover untapped sales and business expansion opportunities in different regions and countries. Each regional and country-wise Global NoSQL Software market considered for research and analysis has been thoroughly studied based on market share, future growth potential, CAGR, market size, and other important parameters. Every regional market has a different trend or not all regional markets are impacted by the same trend. Taking this into consideration, the analysts authoring the report have provided an exhaustive analysis of specific trends of each regional Global NoSQL Software market.
Inquire for a Discount on this Premium Report @ https://www.verifiedmarketresearch.com/ask-for-discount/?rid=153255
What to Expect in Our Report?
(1) A complete section of the Global NoSQL Software market report is dedicated for market dynamics, which include influence factors, market drivers, challenges, opportunities, and trends.
(2) Another broad section of the research study is reserved for regional analysis of the Global NoSQL Software market where important regions and countries are assessed for their growth potential, consumption, market share, and other vital factors indicating their market growth.
(3) Players can use the competitive analysis provided in the report to build new strategies or fine-tune their existing ones to rise above market challenges and increase their share of the Global NoSQL Software market.
(4) The report also discusses competitive situation and trends and sheds light on company expansions and merger and acquisition taking place in the Global NoSQL Software market. Moreover, it brings to light the market concentration rate and market shares of top three and five players.
(5) Readers are provided with findings and conclusion of the research study provided in the Global NoSQL Software Market report.
Key Questions Answered in the Report:
(1) What are the growth opportunities for the new entrants in the Global NoSQL Software industry?
(2) Who are the leading players functioning in the Global NoSQL Software marketplace?
(3) What are the key strategies participants are likely to adopt to increase their share in the Global NoSQL Software industry?
(4) What is the competitive situation in the Global NoSQL Software market?
(5) What are the emerging trends that may influence the Global NoSQL Software market growth?
(6) Which product type segment will exhibit high CAGR in future?
(7) Which application segment will grab a handsome share in the Global NoSQL Software industry?
(8) Which region is lucrative for the manufacturers?
For More Information or Query or Customization Before Buying, Visit @ https://www.verifiedmarketresearch.com/product/nosql-software-market/
About Us: Verified Market Research®
Verified Market Research® is a leading Global Research and Consulting firm that has been providing advanced analytical research solutions, custom consulting and in-depth data analysis for 10+ years to individuals and companies alike that are looking for accurate, reliable and up to date research data and technical consulting. We offer insights into strategic and growth analyses, Data necessary to achieve corporate goals and help make critical revenue decisions.
Our research studies help our clients make superior data-driven decisions, understand market forecast, capitalize on future opportunities and optimize efficiency by working as their partner to deliver accurate and valuable information. The industries we cover span over a large spectrum including Technology, Chemicals, Manufacturing, Energy, Food and Beverages, Automotive, Robotics, Packaging, Construction, Mining & Gas. Etc.
We, at Verified Market Research, assist in understanding holistic market indicating factors and most current and future market trends. Our analysts, with their high expertise in data gathering and governance, utilize industry techniques to collate and examine data at all stages. They are trained to combine modern data collection techniques, superior research methodology, subject expertise and years of collective experience to produce informative and accurate research.
Having serviced over 5000+ clients, we have provided reliable market research services to more than 100 Global Fortune 500 companies such as Amazon, Dell, IBM, Shell, Exxon Mobil, General Electric, Siemens, Microsoft, Sony and Hitachi. We have co-consulted with some of the world’s leading consulting firms like McKinsey & Company, Boston Consulting Group, Bain and Company for custom research and consulting projects for businesses worldwide.
Contact us:
Mr. Edwyne Fernandes
Verified Market Research®
US: +1 (650)-781-4080
UK: +44 (753)-715-0008
APAC: +61 (488)-85-9400
US Toll-Free: +1 (800)-782-1768
Email: sales@verifiedmarketresearch.com
Website:- https://www.verifiedmarketresearch.com/
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

When and how to migrate data from SQL to NoSQL are matters of much debate. It can certainly be a daunting task, but when your SQL systems hit architectural limits or your cloud provider expenses skyrocket, it’s probably time to consider a move.
Many IT organizations have followed the principles in this paper and have migrated successfully from RDBMS to the Scylla NoSQL database.
Read the whitepaper to learn:
- SQL versus NoSQL Overview
- Tradeoffs between Flexibility, Scale and Cost
- Architectural Differences Between SQL and NoSQL
- Considerations for successful SQL to NoSQL Migrations
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

OpenAI made its official ChatGPT app available on the US App Store, providing voice-based input, GPT-4 support for paying users, and faster response times. The company said they will soon start the roll out to additional countries and that an Android version is in the making.
According to OpenAI, the launch of their iOS app responds to the aim of making their technology more readily accessible to users. As a side-effect, OpenAI will likely get to establish some order in the App Store, which has been flooded by many ChatGPT clients in the last few months, with several of them allegedly having 7-figure revenues. Although this does not necessarily mean all of those apps are profitable, as Twitter user Andrey Zagoruyko remarks, it clearly hints at the huge interest that ChatGPT has met among the general public.
While several comments on Hacker News point out that the app does not seem much more than a Web view wrapper around OpenAI website, it still provides a couple of distinctive features that bring an improved user experience, including full chat history and chat synchronization across devices, as well as voice input. That leads to think that the app is in fact API-based, rather than a WebView wrapper.
Voice-based input leverages OpenAI Whisper, a 1.6 billion parameter AI model that can transcribe and translate speech audio from 97 different languages. Whisper is open source and available on GitHub, including both source code and pre-trained model files. While Whisper can be used through an API, it appears that OpenAI ChatGPT app is integrating it natively for improved responsiveness.
This is confirmed by a “tear-down” analysis carried through at Emerge Tools, provider of a number of analysis tool for mobile apps. The analysis showed that the app binary takes up 41MB, of which almost the half are debugging symbols, attesting the still “experimental” nature of the implementation. The app includes a number of dependencies, such as MixPanel for analytics, DataDog for logging, Sentry for performance monitoring, and others.
As to chat history, OpenAI has provided the ability of disabling it in its last update, with the main benefit of keeping chats private to devices. When chat history is enabled, indeed, OpenAI will use it to improve their models. If you disable chat history, though, your chats will only be stored for 30 days.
As mentioned, the app is currently available only to US-based iOS users, but it will reach other countries in the next weeks, says OpenAI, while the Android version is coming soon.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Becoming an empowered team means solving problems rather than shipping features. Empowering software engineers and involving them early in discovery work can result in better products. If we measure outcomes rather than output, we can also hold teams accountable. Martin Mazur spoke about unlocking engineering potential at NDC Oslo 2023.
Supporting software engineers to empower them means trusting them and getting out of their way, Mazur said. We have, for years, broken down software engineers’ innovation capacity by removing them from the discussion on what to build, he mentioned. Innovation happens when real customer problems meet new technology – nobody knows what tech can do except for the engineers. By involving engineers early in discovery work, we can create products that exceed our customers’ expectations, Mazur said.
In order to cope with empowered work, engineers need to be able to navigate uncertainty, plan their work, have meaningful conversations, and understand how value is created, Mazur said. These are skills that they can learn, but in the context that most engineers have been working, they’ve never had a reason to learn them, he mentioned.
Mazur mentioned that if we look at competence as both width and depth, at some point in your career you really don’t get a huge effect from going deeper. Instead, broadening skills and looking at things, such as business models, design principles and interpersonal skills can raise engineers to new levels, he suggested:
It’s easy to get started by, for example, attending an unusual talk at a conference or picking a book you wouldn’t normally read.
Keeping teams accountable for results can be tricky if you don’t have the right culture and organization, Mazur said. People must feel empowered and in control of their work to accept accountability. He mentioned that the best thing we can do is to measure our team’s success on the outcome, that is, the impact they’ve created for the user, product, or business, not the output they have generated:
If we measure outcomes, we can also hold teams accountable for that outcome. If we measure output, we only know that they’ve worked at a desired pace, not what value that work actually generated.
Mazur suggested that software developers should invest in other types of skills than purely technical skills. These investments have a greater payout for those individuals, their teams, products, and, ultimately, the world, he concluded.
InfoQ interviewed Martin Mazur about how to unlock engineering potential.
InfoQ: What makes solving users’ problems more important than delivering features?
Martin Mazur: It’s all about the value we create with our software. A feature is only valuable to the user, their organization, and ultimately the world if it solves something – i.e., features we build that are never used are a huge waste of human potential.
InfoQ: What do teams need to be able to solve problems?
Mazur: It’s not one single thing, there are several factors that need to be present in order for teams to be able to solve problems. Ultimately, most teams and organizations need a culture change. We need to reach a point where people deeply care about their software’s impact on the end user. This requires organizations that are led with context and not control; teams must be delegated problems, trusted to solve them, and held accountable for the results.
InfoQ: How can teams improve the way that they make decisions?
Mazur: The most important thing around becoming better at making decisions is distinguishing good decisions from good outcomes, and vice versa. A good decision is something that, given all the information at hand, is the correct course of action. That means if you had to redo the decision, you would have made the same call again and again. Good decisions can still lead to bad outcomes.
Once we understand that, we know we have to act on the information we have, not the information we wish we had. To summarize, a decision is like a bet – and just like a bet, it has odds; the correct decision is the one with the best odds.
Often engineers get stuck on all the information they don’t have and end up in analysis paralysis. What happens then is that there is usually no time to wait, and not making a decision is also a decision. We end up with the default option which could be either good or bad – the equivalent of a coin flip.
InfoQ: What’s your advice to teams? And to individual software developers?
Mazur: The best advice for both is always asking two questions about your work.
“What is it for?” and “Who is it for?” and not do a surface-level job answering those questions. Really dig deep and figure out what problem the product solves and for who – this will create a new perspective for your work.
Java News Roundup: Java Turns 28, Payara Platform, Micronaut 4.0-M5, Spring Updates, JHipster Lite
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for May 22nd, 2023 features news from OpenJDK, JDK 21, Spring Cloud 2022.0.3, Spring Shell 3.1.0, 3.0.4 and 2.1.10, Spring Security Kerberos 2.0-RC2, Payara Platform, Quarkus 3.0.4 and 2.13.8, WildFly 28.0.1, Micronaut 4.0-M5, Helidon 2.6.1, MicroStream 8.1.0, Apache Camel 3.20.5, JDKMon 17.0.61, JHipster Lite 0.33.0, Java’s 28th Birthday and Azul State of Java survey.
OpenJDK
JEP 451, Prepare to Disallow the Dynamic Loading of Agents, has been promoted from Candidate to Proposed to Target for JDK 21. Originally known as Disallow the Dynamic Loading of Agents by Default, and following the approach of JEP Draft 8305968, Integrity and Strong Encapsulation, this JEP has evolved from its original intent to disallow the dynamic loading of agents into a running JVM by default to issue warnings when agents are dynamically loaded into a running JVM. Goals of this JEP include: reassess the balance between serviceability and integrity; and ensure that a majority of tools, which do not need to dynamically load agents, are unaffected. The review is expected to conclude on May 31, 2023. InfoQ will follow up with a more detailed news story.
In response to numerous questions about the design philosophy of the exhaustiveness checking in pattern switch, Brian Goetz, Java language architect at Oracle, and Gavin Bierman, consulting member of technical staff at Oracle, have published a document detailing the connection between the properties of unconditionality, exhaustiveness and remainder.
JDK 21
Build 24 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 23 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 21, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
The release of Spring Cloud 2022.0.3, codenamed Kilburn, delivers compatibility with Spring Boot 3.1 and updates to Spring Cloud sub-projects such as: Spring Cloud OpenFeign 4.0.3, Spring Cloud Commons 4.0.3, Spring Cloud Kubernetes 3.0.3 and Spring Cloud Starter Build 2022.0.3. There are, however, breaking changes with the removal of sub-projects: Spring Cloud CLI, Spring Cloud for Cloud Foundry and Spring Cloud Sleuth. More details on this release may be found in the release notes.
Versions 3.1.0, 3.0.4 and 2.1.10 of Spring Shell have been released featuring notable fixes such as: an instance of the ConfirmationInput class does not show the option selected when typing; and having target method argument as a boolean argument fails if the @Option or @ShellOption annotations are not used. These versions build upon Spring Boot versions 3.1.0, 3.0.7 and 2.7.12, respectively. Further details on these releases may be found in the release notes for version 3.1.0, version 3.0.4 and version 2.1.10.
The second release candidate of Spring Security Kerberos 2.0.0 features a dependency upgrade to Spring Security 6.1.0. More details on this release may be found in the release notes.
Payara
Payara has released their May 2023 edition of the Payara Platform that includes Community Edition 6.2023.5, Enterprise Edition 6.2.0 and Enterprise Edition 5.51.0. All three versions feature resolutions to: address CVE-2023-1370, a vulnerability in which the unregulated recursive parsing of JSON nested arrays and objects in Json-smart, a JSON processor library, may lead to a stack overflow and crash the software; and the exception “JVM option${ } already exists in the configuration” upon creating JVM option using Web UI. There were also dependency upgrades to: Jackson 2.15.0, SnakeYAML 2.0, JSON Smart 2.4.10 and Docker Image for JDKs 8u372, 11.0.19, and 17.0.7. Further details on these versions may be found in the release notes for Community Edition 6.2023.5, Enterprise Edition 6.2.0 and Enterprise Edition 5.51.0.
Quarkus
Quarkus 3.0.4.Final, the third maintenance release (version 3.0.1 was the initial release), provides improvements in documentation and notable bug fixes such as: failed native image builds when the quarkus.package.output-directory property is set; a “No current injection point found” error when using a @ConfigMapping in conjunction with an onStartup() method; and fix location and content location headers in RestEasy Reactive. More details on this release may be found in the changelog.
Similarly, Quarkus 2.13.8 was also released with notable bug fixes, many of them backports, such as: a fix for the warning message quarkus.oidc.application-type=service; encrypt the OIDC session cookie value by default; filter out RESTEasy-related warning related to an Apache HTTP Client not being closed in the ProviderConfigInjectionWarningsTest class; and a recent Netty version update that introduced warnings while building a native image of MongoDB Client. Further details on this release may be found in the release notes.
WildFly
WildFly 28.0.1 has been released featuring dependency upgrades and notable bug fixes such as: the testContextPropagation() test defined in the ContextPropagationTestCase class will occasionally fail when using Long Running Actions; a deployable, yet non-functional QS app on OpenShift resulting from an update to Helm Charts in todo-backend, a quickstart for backend deployment on OpenShift; and the isExpired() method defined in the ExpirationMetaData interface does not conform to the logic in the LocalScheduler class.
Micronaut
On the road to version 4.0, the Micronaut Foundation has released Micronaut 4.0.0-M5 featuring numerous dependency upgrades and improvements such as: add @BootstrapContextCompatible, an annotation indicating that a bean can be loaded into the Bootstrap Context, to JSON message readers; the ability to disable SLF4J initialization when Micronaut environments are used in Micronaut OpenAPI; and use the bean definition type for unexpected duplicate beans in custom singleton-like scope based on the AbstractConcurrentCustomScope class. More details on this release may be found in the release notes.
Helidon
Oracle has released Helidon 2.6.1 with dependency upgrades and notable changes such as: update the isReleased() method defined in the ByteBufDataChunk class to use an instance of the AtomicBoolean class to prevent race conditions that may call the release callback more than once; add the @Target(ElementType.METHOD) annotation for the @MPTest annotation to specify a specific target; and fixes for the overloaded create() methods defined in the WritableMultiPart class. Further details on this release may be found in the release notes.
MicroStream
The release of MicroStream 8.1.0 delivers integration with Quarkus 3 and a fix for which the Stream API doesn’t unload as expected when using the Lazy Collections API.
The Micronaut team has also introduced the Quarkus Extension for MicroStream that allows accessing the functionality of MicroStream in Quarkus applications through the use of annotations.
Apache Camel
Apache Camel 3.20.5 has been released featuring bug fixes, dependency upgrades and improvements, primarily in the camel-jbang module, such as the ability to: load YAML files that only define Java beans; use a filename to generate the ID of a route when creating a Camel file in the XML DSL with camel-jbang; and run camel-jbang from an empty folder and then reload when new files are added. More details on this release may be found in the release notes.
JDKMon
Version 17.0.61 of JDKMon, a tool that monitors and updates installed JDKs, has been made available this past week. Created by Gerrit Grunwald, principal engineer at Azul, this new version: adds a property to the jdkmon.properties file to disable notifications; and provides fixes to issues related to detected CPU architectures and multiple builds of the same JDK version.
JHipster
The JHipster team has released version 0.33.0 of JHipster Lite with many dependency upgrades and notable changes such as: sharing module properties between landscape and patch screens; a fix on native hints for the integration of JGit; and the addition of the DestroyRef provider. Further details on this release may be found in the release notes.
Happy 28th Birthday, Java!
Java turned 28 years old this past week as the language was introduced at the SunWorld 1995 conference on May 23, 1995. The Java developer relations team at Oracle celebrated with a 28 Hours of Java event hosted by Ana Maria Mihalceanu, Nicolai Parlog and Sharat Chander. Topics included: live coding and exploration, presentations, conversations with Java luminaries, and fun games. This was the agenda:
- An exploration on JUnit Pioneer with Nicolai.
- Data-Oriented Programming in Java (21) presented by Nicolai.
- A conversation with Gavin Bierman on pattern matching facilitated by Nicolai.
- Exploring JEP 451, Prepare to Disallow the Dynamic Loading of Agents, and JEP Draft 8305968, Integrity and Strong Encapsulation, with Nicolai.
- A conversation with Ron Pressler discussing platform integrity (JEP Draft 8305968), JEP 445, Unnamed Classes and Instance Main Methods (Preview), and JEP 453, Structured Concurrency (Preview), facilitated by Nicolai.
- Growing Up with Java presented by Ana.
- Playing Byte Legend with Ana.
- Java State of the Union and Why Community Matters presented by Sharat.
- A roundtable discussion with Pratik Patel, Mohammed Aboullaite, Venkat Subramaniam, Andres Almiray, Ixchel Ruiz and Vincent Mayers facilitated by Sharat.
- A conversation with Brian Goetz, facilitated by Nicolai, discussing Project Valhalla with a focus on how to surface value and primitive types and nullability in the language.
- A conversation with Gunnar Morling facilitated by Nicolai.
- Java Next presented by Nicolai.
- Playing Slay the Spire (written in Java) and exploring modding with Nicolai.
- Project Amber: The SolutionFactory To Java’s Problems presented by Nicolai.
- From Idea to IDE presented by Nicolai.
- Ask Me Anything session with Nicolai.
- Closing remarks by Nicolai.
This special event was live-streamed on the Java YouTube channel.
Developer Surveys
Azul has launched their State of Java survey in which the areas of study include: OpenJDK distributions and Java versions developers are using; Java-based infrastructures and languages; and Java applications running in public clouds. The survey closes on June 15, 2023.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

After adding support for desktop apps and the Web, JetBrains multiplatform declarative UI toolkit now runs on iOS in alpha.
Based on Google Jetpack Compose, recently updated with improved performance and extensions, Compose Multiplatform runs natively on Android and, thanks to Kotlin Multiplatform on Windows, Linux, macOS, and the Web, too. The addition of iOS extends Compose Multiplatform to all major OSes.
The approach followed by Compose Multiplatform is to provide the same API across all supported platforms, replicating Jetpack Compose APIs:
The APIs in Compose Multiplatform are the same ones that have already been tried and tested in Jetpack Compose. That means developers who have experience writing modern Android user interfaces using Jetpack Compose can transfer those skills directly to write a shared user interface with Compose Multiplatform, targeting iOS and beyond.
This includes state management, layout composition, and animations. For a number of features that are strictly OS-dependent, like loading resources, Compose Multiplatform provides its own higher-level abstractions to maximize portability.
On iOS, Compose Multiplatform uses canvas-based rendering, using the Skiko graphics library. Also known as Skia for Kotlin, Skiko is based on Skia, Google’s graphics library used for Chrome, ChromeOS, and Flutter.
This approach means that Compose Multiplatform apps have the same look and feel across all supported platforms, similarly to Flutter apps. Unlike Flutter, though, Compose Multiplatform provides Material and Material 3 widgets out of the box, so Compose Multiplatform apps will just look like plain-vanilla Android apps. While Material is the only widget look-and-feel currently supported on iOS, JetBrains has not yet made a final decision about whether to provide a native widget look-and-feel.
An important aspect of creating cross-platform apps is interoperability with the underlying OS SDK. Compose Multiplatform for iOS provides a two-way interop layer on top of UIKit, with two main classes, UIKitView and ComposeUIViewController. UIKitView enables embedding platform-specific widgets like maps, web views, media players, and camera feeds within a Compose UI. ComposeUIViewController can be used instead to embed Compose screens in UIKit and SwiftUI applications. This can be helpful to gradually convert an existing app into a Compose app.
To start working with Compose Multiplatform for iOS, you will need a machine running recent version of macOS, Xcode, Android Studio, and the Kotlin Multiplatform Mobile plugin. All additional dependencies can be managed through CocoaPods.
The best place to start is one of the project templates provided by JetBrains. Those include a basic iOS/Android app, an image viewer, a chat app, and many more. A number of tutorials are also available to guide you through using the most common UI elements in a Compose Multiplatform app.