Month: January 2023

MMS • Anthony Alford

Researchers from DeepMind and the University of Toronto announced DreamerV3, a reinforcement-learning (RL) algorithm for training AI models for many different domains. Using a single set of hyperparameters, DreamerV3 outperforms other methods on several benchmarks and can train an AI to collect diamonds in Minecraft without human instruction.
The DreamerV3 algorithm includes three neural networks: a world model which predicts the result of actions, a critic which predicts the value of world model states, and an actor which chooses actions to reach valuable states. The networks are trained from replayed experiences on a single Nvidia V100 GPU. To evaluate the algorithm, the researchers used it on over 150 tasks in seven different domains, including simulated robot control and video game playing. DreamerV3 performed well on all domains and set new state-of-the-art performance on four of them. According to the DeepMind team:
World models carry the potential for substantial transfer between tasks. Therefore, we see training larger models to solve multiple tasks across overlapping domains as a promising direction for future investigations.
RL is a powerful technique that can train AI models to solve a wide variety of complex tasks, such as games or robot control. DeepMind has used RL to create models that can defeat the best human players at games such as Go or Starcraft. In 2022, InfoQ covered DayDreamer, an earlier version of the algorithm that can train physical robots to perform complex tasks within only a few hours. However, RL training often requires domain-expert assistance and expensive compute resource to fine-tune the models.
DeepMind’s goal with DreamerV3 was to produce an algorithm that works “out of the box” across many domains without modifying hyperparameters. One particular challenge is that the scale of inputs and rewards can vary a great deal across domains, making it tricky to choose a good loss function for optimization. Instead of normalizing these values, the DeepMind team introduced a symmetrical logarithm or symlog transform to “squash” the inputs to the model as well as its outputs.
To evaluate DreamerV3’s effectiveness across domains, the researchers evaluated it on seven benchmarks:
- Proprio Control Suite: low-dimensional control tasks
- Visual Control Suite: control tasks with high-dimensional images as inputs
- Atari 100k: 26 Atari games
- Atari 200M: 55 Atari games
- BSuite: RL behavior benchmark
- Crafter: survival video game
- DMLab: 3D environments
DreamerV3 achieved “strong” performance on all, and set new state-of-the-art performance on Proprio Control Suite, Visual Control Suite, BSuite, and Crafter. The team also used DreamerV3 with default hyperparameters to train a model that is the first one to “collect diamonds in Minecraft from scratch without using human data.” The researchers contrasted this with VPT, which was pre-trained from 70k hours of internet videos of human players.
Lead author Danijar Hafner answered several questions about the work on Twitter. In response to one user, he noted:
[T]he main point of the algorithm is that it works out of the box on new problems, without needing experts to fiddle with it. So it’s a big step towards optimizing real-world processes.
Although the source code for DreamerV3 has not been released, Hafner says it is “coming soon.” The code for the previous version, DreamerV2, is available on GitHub. Hafner notes that V3 includes “better replay buffers” and is implemented on JAX instead of TensorFlow.
MMS • Edin Kapic

The open-source UI framework for cross-platform C# and XAML applications, Uno, has been updated to version 4.7. It brings a simplified solution experience in Visual Studio, performance updates on different platforms and other minor updates.
Uno platform is an alternative UI platform for building multidevice applications in C# and XAML. It was launched in 2018, after years of internal use by a Canadian company nventive. It allows developers to write applications for Windows, iOS, Android, WebAssembly, macOS and Linux. It is released under Apache 2.0 open-source license on GitHub.
While the official cross-platform UI libraries from Microsoft, Xamarin and .NET MAUI, strive to use native controls on each supported platform, Uno uses a mixed approach. It leverages the underlying UI primitives to render the same chromeless UI everywhere while it uses the cross-platform 2D graphics library Skia to draw the same UI style on all platforms. Internally, it leverages WinUI 3 API on Windows and reproduces the same API surface to all supported platforms, as demonstrated by the pixel-perfect port of the Windows Calculator app. For .NET developers, this means they should start designing and implementing the WinUI application first and Uno would take care of rendering and running it on all the supported platforms.
Version 4.7 of Uno platform simplifies the solution development experience in Visual Studio. In the previous versions of Uno, the Visual Studio solution had one project per each supported platform (or head, in Uno jargon) plus a shared project (with the suffix ‘.Shared’) where the shared code and shared assets live. In Uno 4.7, this shared project is removed and replaced with a new cross-platform library. This means that NuGet packages, for example, can now be added to the shared library only and not on every targeted head project (device-specific project in Visual Studio). Similarly, the new project template now includes the Uno Fluent Symbols font for all devices.
The framework team also took care of user feedback on GitHub and improved the performance of several back-ends. Specifically, WebAssembly applications are now trimmed to remove unused XAML styles and controls. .NET 7 performance updates are used for loading and unloading of controls in WebAssembly target applications, resulting in an alleged 8% runtime improvement.
Linux targets now use .NET native ahead-of-time (AOT) compilation, with faster startup and improved performance, skipping the use of JIT (just-in-time) .NET feature. Android performance has been enhanced by moving portions of cross-platform code instructions entirely to the Java side of the solution.
Updating Uno solutions to 4.7 involves updating the underlying NuGet packages. New solutions will use the shared library approach for the Visual Studio solution, while the existing solutions will keep the shared project approach.
According to .NET developers’ discussions on social media, the main advantage of the Uno platform over MAUI or Xamarin is being the only cross-platform .NET framework to support writing WebAssembly and Linux applications in C# and XAML.
AWS Gives Developers More Control over Lambda Function Runtime with Runtime Management Controls
MMS • Steef-Jan Wiggers
AWS recently introduced runtime management controls which provide more visibility and control when Lambda applies runtime updates to functions.
With runtime management controls, developers now have three new capabilities they can leverage:
- Visibility into which patch version a runtime function uses and when runtime updates are applied
- Synchronize runtime updates with function deployments
- Rollback functions to an earlier runtime version
These capabilities are available by choosing one of the update modes for the lambda runtime using AWS CLI and Lambda AWS Management Console. In addition, developers can choose the Infrastructure as Code (IaC) route and use tools such as AWS CloudFormation and the AWS Serverless Application Model (AWS SAM).
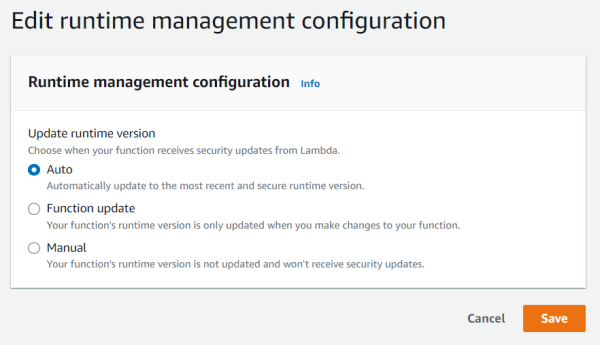
Jonathan Tuliani, a principal product manager at AWS, explains in an AWS blog post the runtime version update modes:
You can specify one of three runtime update modes: auto, function update, or manual. The runtime update mode controls when Lambda updates the function version to a new runtime version.
Source: https://aws.amazon.com/blogs/compute/introducing-aws-lambda-runtime-management-controls/
The auto mode is the default, where Lambda takes care of the update, where functions will receive runtime updates in two phases. First, Lambda will apply a new runtime version to newly created or updated functions and, after that, to any remaining functions.
In the second mode, function update, Lambda updates functions to the latest available runtime version whenever a developer changes their function code or configuration, similar to the first phase of auto mode, yet will leave any other function untouched.
And finally, the manual mode gives developers complete control over their function’s runtime version. It allows them to perform a rollback to a previous version. However, AWS strongly recommends using manual mode only for short-term remediation of code incompatibilities.
Eric Hammond, an AWS Hero, posted on the AWS Community social :
I’m going to stick with the default “Automatic” updates to the AWS Lambda runtime stack, because:
– I rarely update the code in my functions
– I don’t want to add more manual tasks to my life, and
– I’ve never experienced a problem with the automatic updates so far
where “so far” is over eight years of running services with AWS Lambda.
Furthermore, Ben Kehoe, an AWS Serverless Hero, tweeted:
The hardest part of serverless is giving up control. Everyone says it’s good to update your dependencies and runtime versions. It’s a *good* thing to be forced to do that.
And additionally, he tweeted:
You should know how to use this new Lambda runtime version control for emergencies, but consider it radioactive. Use a Step Function that will automatically turn it off after 1 or 2 sprints.
Lastly, more details on runtime management controls are available on the documentation page.
MMS • Alessio Alionco

Key Takeaways
- Current barriers to digital transformation include the lack of skilled developers and complex technical stacks
- Stack extensibility significantly increases a company’s agility and competitiveness
- Low-code BPA (Business Process Automation) can help address the challenges organisations face
- Low-code increases process resiliency and conserves developer resources
- There are some important factors to consider when exploring low-code options
No matter how fast technology evolves, for some businesses, they often feel one step behind. In department after department, from HR and purchasing to finance and marketing, situations exist where key software solutions don’t quite meet organizational needs. For workers, department managers and most assuredly IT, that’s a problem.
The insatiable appetite for business agility exerts enormous pressure on IT organizations to select, integrate and deploy appropriate and complete enterprise platforms. Oftentimes, however, there is a gap between what a tech stack can do, and what it should do.
Digital transformation, the initiative that has driven most IT activity for nearly a decade, has actually widened the gaps in departmental tech stacks. Digital transformation usually focuses on big-ticket implementations; it can leave behind the less visible, yet essential workflows and processes that stitch together major platforms. Adding to the situation in recent years has been the shortage of qualified developers, which makes well-connected solutions that much more difficult to achieve.
Consequently, business teams often labor with technologies that are not fully formed, fully explained, or appropriate for current work requirements. In frustration, they create their own workarounds using manual processes or ad hoc software.
Unsanctioned shadow IT solutions can produce arcane procedures, inconsistent workflows, and a lack of visibility – not to mention security and scalability issues.
When companies can’t keep up with the pace of change, they lose their status as market leaders. Speed to value declines, as rigid systems become too unwieldy and expensive to modify. Chaotic tech environments overtake what should be smooth and well-prescribed automation.
Extensibility Challenges
Stack extensibility – the ability to nimbly expand the capabilities of existing tech solutions – is an essential trait of well-designed IT ecosystems. Yet creating this important advantage isn’t easy.
Vertical solutions solve specific problems, but are rigid; on the other hand, horizontal solutions, while more flexible, are expensive to modify. Moreover, customizing legacy components can be challenging when developers are busy elsewhere in the enterprise.
Other alternatives do exist. Many organizations purchase additional modules within the application ecosystem, hoping they will be sufficient to solve their unique problems. Robotic Process Automation (RPA) is a choice that, while effective at addressing specific needs, requires business teams themselves to connect – and still leaves tech stacks open to complexity and a lack of control.
Controlling the Outcome
Low-code BPA (Business Process Automation), on the other hand, has advantages that puts it at the forefront of approaches to stack extensibility. Low-code increases process resiliency by empowering business teams with an easy-to-use, easy-to-understand and, most of all, IT-sanctioned set of tools. Using these building blocks, end users can close gaps with solutions that complement and coordinate existing components, rather than competing with or complicating them.
Many IT benefits accrue to the low-code method. It conserves developer resources and reduces backlogs by enabling business teams to do much of the work on their own. It standardizes processes, which makes it easier to enforce security mandates. Because scalability is built into the low-code framework, supplemental coding is minimal.
End-users appreciate having IT-approved capabilities that allow them to make changes quickly. Instead of waiting for a custom-built solution, they are able to adapt as business needs evolve. Workflows become more relevant, more convenient, and more productive.
Tried and Tested
Leading enterprises have experienced the advantages of low-code enabled stack extensibility. Samsonite, the global luggage maker, was struggling with several gaps in its purchasing workflows. Requests were executed through email and file sharing, and departmental staff had to sift through old messages simply to find the information required to initiate purchase quotes from suppliers.
Low-code BPA ended those problems. After analyzing the procurement process to standardize procedures and make sure they adhered to both internal policies and external legal, finance and tax requirements, Samsonite’s purchasing team began creating workflows that included necessary approvals at each stage. The stack extensibility solution streamlined the request/fulfillment process, enabling purchasers and requesters to receive automatic notifications and alerts.
Within the first five months, Samsonite was able to eliminate an estimated 2,370 hours of manual work and achieve an overall ROI of 177 percent.
“Our new system not only gives us the control we need to ensure everyone abides by our rules and policies, but it also creates an easily accessible trail for future audits,” noted Mauricio Rizzi, Samsonite’s Customer Service and Procurement Manager.
Another example is CNH, a leading industrial vehicle manufacturer based in London. CNH was dealing with a tech stack of 15 different systems implemented during its digital transformation process. A lack of integration between those systems was holding back the efficiency of the company’s People Ops department, forcing the staff to manually input, store and communicate information through email or on paper.
After adopting low-code BPA, the People Ops team was able to build and support a number of improved processes and experiences. The system gave them more ownership and flexibility than through their former, more traditional methods.
“Now I can teach any person within our People Ops organization how to use our low-code solution, and they can use it for almost any process,” said Diogo Ayres, CNH Services Designer. “It lets us provide a seamless and consistent experience for employees and candidates.”
How To Make No/Low-Code Work For You
Citizen development — when a non-technical user is able to create new applications without writing a line of code using no or low code solutions– is an impactful way to increase a team’s daily efficiency or streamline an existing business process. Citizen developers are an integral part of optimizing and scaling an organization’s operations. However, cultivating a symbiotic relationship between IT teams and citizen developers is key to ensuring success and prioritizing quality output.
IT needs to collaborate with citizen developers throughout the process to ensure maximum safety and efficiency. From the beginning, it’s important to confirm the team’s overall approach, select the right tools, establish roles, set goals, and discuss when citizen developers should ask for support from IT. Appointing a leader for the citizen developer program is a great way to help enforce these policies and hold the team accountable for meeting agreed-upon milestones.
To encourage collaboration and make citizen automation a daily practice, it’s important to work continuously to identify pain points and manual work within business processes that can be automated. IT should regularly communicate with teams across the business, finance and HR departments to find opportunities for automation, clearly mapping out what change would look like for those impacted. Gaining buy-in from other team leaders is critical, so citizen developers and IT need to become internal advocates for the benefits of automation.
Another non-negotiable ground rule is that citizen developers should only use IT-sanctioned tools platforms. This gives IT the necessary insight and ability to monitor the quality and security of new applications. IT can also set up “sandbox environments” to reduce risks and allow developers to create apps without interfering with other systems. Ultimately, IT is responsible for monitoring all citizen developer activities and application development.
To help no/low-code solutions integrate smoothly with their existing IT infrastructure, companies should:
- Look for software with features that support security and compliance efforts, such as SSO, MFA, and permission management.
- Compare software uptimes and availability, to minimize the risk of disruption.
- Make sure the software vendor offers appropriate support so that the IT team isn’t burdened with unnecessary maintenance. When it comes to conserving IT resources, no/low-code software that enables citizen developers and invites business users into the problem-solving process will also help cut down on the IT backlog.
- Last but not least, consider no/low-code solutions that can handle multiple use cases across a variety of departments. Scalability and stack extensibility are cost-containment strategies that deliver the most value when solutions are easily adaptable and which integrate with a wide range of apps and systems.
Investing in the right no/low code solution is the first step, but investing in internal training and skills development is even more important. Companies need to give citizen developers the proper education, support, and resources to learn. Growth doesn’t happen overnight; IT needs to approach citizen development with patience and teamwork. Creating a collaborative learning environment also helps mitigate the risks of citizen developers pursuing shadow IT solutions or making costly mistakes.
The point of citizen development is to empower non-technical employees, not eliminate IT. While citizen development may sound like a threat to IT departments, it’s actually the opposite. Citizen development is about helping IT professionals. While it may take some time in the beginning, this investment will pay off when citizen developers are able to build and connect quality automated workflows on their own.
Foreseeing the Future
Stack extensibility, especially when enabled by low-code BPA, significantly increases the agility and competitiveness of the typical enterprise. Critical applications remain relevant and utility goes up, without custom development or the need to dive into the organization’s central (and typically most expensive) tech investments.
Under this progressive approach, business users become partners with IT, working from the same playbook. Developer resources, always at a premium, are conserved and extended. Stakeholders are able to move quicker – and everyone’s lives are made a lot easier as a result.
There may never be a time when technology can fully anticipate the needs of business; however, flexible, secure and easy-to-use connective solutions can make dynamic environments a lot less troublesome – and allow enterprises to move forward with confidence. With stack extensibility, IT no longer has to predict the future. Instead, it can simply plan for it.
MMS • Robert Krzaczynski

The first preview release of ML.NET 3.0, available since December, contains the integration with Intel oneAPI Data Analytics Library that leverages SIMD extensions on 64-bit architectures, which are available on Intel and AMD processors.
ML.NET 3.0 allows importing more machine learning capabilities into existing .NET applications. This feature eliminates the need to code complex methods to generate predictive models.
Intel oneAPI Data Analytics Library helps accelerate data analysis of large datasets by providing highly optimised algorithmic building blocks for all stages of the data analysis such as preprocessing, modelling or decision-making. These blocks are independent of any communication layer. The library optimises data acquisition along with algorithmic calculations to increase scalability and throughput.
Jake Radzikowski and Luis Quintanilla mentioned in the last Machine Learning Community Standup that the ML.NET team worked closely with Intel to optimise Intel hardware, but it is also compatible with AMD CPUs. ML.NET 3.0 brings some new algorithms and improves the existing ones. The next step of the ML.NET 3.0 development will be integrating these algorithms with AutoML and Model Builder. More details about the upcoming features and improvements are accessible on the ML.NET roadmap.
oneAPI Data Analytics Library integrates with ML.NET, speeding up the training of the following trainers: L-BGFS, Ordinary Least Squares, FastTree and FastForest. L-BGFS is used for regression tasks, Ordinary Least Squares for classification and the last two for both regression and classification.
In order to start using oneAPI Data Analytics Library in ML.NET, it is necessary to install the latest Microsoft.ML 3.0 preview version and the Microsoft.ML.OneDal NuGet package. In addition, a key element is setting the MLNET_BACKEND environment variable to ONEDAL. There is also a known problem on Windows with the library loading. In order to fix this, it is necessary to add the ‘runtimes-x64native’ directory in the ‘bin’ directory of the application to the PATH environment variable.
A usage example is available on GitHub.
MMS • Matt Campbell

Docker has released version 0.11 of BuildKit, the Docker backend for building images. The release adds a number of new features including attestation creation, reproducible build improvements, and cloud cache backend support.
This release adds support for two types of attestations: software bill of materials (SBOMs) and SLSA provenance. An SBOM is a record of the components that were included within the image. While this new support is similar to docker sbom it allows image authors to embed the results into the image. Building an SBOM can be done using the --sbom flag:
$ docker buildx build --sbom=true -t / --push .
An SBOM can be inspected using the imagetools subcommand. The following command would list all the discovered dependencies within the moby/buildkit image:
$ docker buildx imagetools inspect moby/buildkit:latest --format '{{ range (index .SBOM "linux/amd64").SPDX.packages }}{{ println .name }}{{ end }}'
github.com/Azure/azure-sdk-for-go/sdk/azcore
github.com/Azure/azure-sdk-for-go/sdk/azidentity
github.com/Azure/azure-sdk-for-go/sdk/internal
github.com/Azure/azure-sdk-for-go/sdk/storage/azblob
...
The other form of supported attestation is an SLSA provenance. The Supply chain Levels for Software Artifacts (SLSA) is a security framework providing standards and controls related to supply chain security. Provenance is metadata about how the artifact was built including information on ownership, sources, dependencies, and the build process used.
The provenance built by Buildx and BuildKit includes metadata such as links to source code, build timestamps, and the inputs used during the build process. A Provenance attestation can be created by enabling the new --provenance flag:
$ docker buildx build --provenance=true -t / --push .
As with SBOMs, imagetools can be used to query the provenance:
$ docker buildx imagetools inspect moby/buildkit:latest --format '{{ json (index .Provenance "linux/amd64").SLSA.invocation.configSource }}'
{
"digest": {
"sha1": "830288a71f447b46ad44ad5f7bd45148ec450d44"
},
"entryPoint": "Dockerfile",
"uri": "https://github.com/moby/buildkit.git#refs/tags/v0.11.0"
}
Provenance generation also includes an optional mode parameter that can be set to include additional details. In max mode, all the above details are included along with the exact steps taken to produce the image, a full base64 encoded version of the Dockerfile, and source maps.
Previously, producing bit-for-bit accurate reproducible builds has been a challenge due to timestamp differences between runs. This release introduces a new SOURCE_DATE_EPOCH build argument, that if set, will cause BuildKit to set the timestamps in the image config and layers to the specified Unix timestamp.
BuildKit now has support for using both Amazon S3 and Azure Blob Storage as cache backends. This helps with performance when building in environments, such as CI pipelines, where runners may be ephemeral. The backends can be specified using the new --cache-to and --cache-from flags:
$ docker buildx build --push -t /
--cache-to type=s3,region=,bucket=,name=[,parameters...]
--cache-from type=s3,region=,bucket=,name= .
$ docker buildx build --push -t /
--cache-to type=azblob,name=[,parameters...]
--cache-from type=azblob,name=[,parameters...] .
More details about the release can be found on the Docker blog and within the changelog. Questions and issues can be brought to the #buildkit channel on the Docker Community Slack.
Optimized Reads and Optimized Writes Improve Amazon RDS Performances for MySQL Compatible Engines
MMS • Renato Losio

AWS recently introduced RDS Optimized Reads and RDS Optimized Writes, which are designed to enhance the performance of MySQL and MariaDB workloads running on RDS. These new functionalities can improve query performances and provide higher write throughput but are available on a limited subset of instances and have multiple prerequisites.
RDS Optimized Reads is a feature that provides faster query processing, moving MySQL temporary tables to local NVMe-based SSD storage. According to the cloud provider, queries involving sorts, hash aggregations, high-load joins, and Common Table Expressions (CTEs) can execute up to 50% faster. The new feature was announced during re:Invent for RDS for MySQL workloads running 8.0.28 and above and it is now available for RDS for MariaDB too.
Only a subset of memory-optimized and general-purpose instances support it and the amount of instance storage available on the instance varies by family and size, from a minimum of 75 GB to a maximum of 3.8 TB. The use of local storage can be monitored with three new CloudWatch metrics: FreeLocalStorage, ReadIOPSLocalStorage, and WriteIOPSLocalStorage.
RDS Optimized Writes is instead a feature that delivers an improvement in write transaction throughput at no extra charge, and with the same level of provisioned IOPS, helping write-heavy workloads that generate lots of concurrent transactions. Jeff Barr, vice president and chief evangelist at AWS, explains:
By default, MySQL uses an on-disk doublewrite buffer that serves as an intermediate stop between memory and the final on-disk storage. Each page of the buffer is 16 KiB but is written to the final on-disk storage in 4 KiB chunks. This extra step maintains data integrity, but also consumes additional I/O bandwidth. (…) Optimized Writes uses uniform 16 KiB database pages, file system blocks, and operating system pages, and writes them to storage atomically (all or nothing), resulting in a performance improvement of up to 2x.
Torn Write Prevention (TWP) ensures 16KiB write operations are not torn in the event of operating system crashes or power loss during write transactions. The feature benefits from the AWS Nitro System and is currently available only if the database was created with a DB engine version and DB instance class that support the feature. A database restored from a snapshot can enable the feature only if it was initially created from a server that supports it. According to AWS, RDS Optimized Writes helps workloads like digital payments, financial trading, and gaming applications.
While some users question the lack of PostgreSQL support, Corey Quinn, chief cloud economist at The Duckbill Group, writes in his newsletter:
Not for nothing, but it’s super hard to square this enhancement with the absolutely relentless “RDS? NO! Use Aurora!” messaging we’ve gotten from AWS top to bottom for the past few years.
RDS Optimized Reads is currently available on M5d, R5d, M6gd, and R6gd instances only. Initially announced for memory-optimized r5 Intel instances running MySQL 8.0.30 and above only, RDS Optimized Writes is now available for a subset of Graviton instances too.
The re:Invent session covering both new features is available on YouTube.
Mockito 5 Supports Mocking Constructors, Static Methods and Final Classes Out of the Box
MMS • Johan Janssen
Mockito, the mocking framework for Java unit tests, has released version 5.0.0, switching the default MockMaker interface to mockito-inline in order to better support future versions of the JDK and allows mocking of constructors, static methods and final classes out of the box. The baseline increased from Java 8 to Java 11, as supporting both versions became costly, and managing changes in the JDK, such as the SecurityManager, proved difficult.
Before this release, Mockito didn’t support mocking final classes out of the box, such as the following final class which contains one method:
public final class Answer {
public String retrieveAnswer() {
return "The answer is 2";
}
}
In the unit test a stub is used to replace the answer of the retrieveAnswer() method:
@Test
void testMockito() {
Answer mockedAnswer = mock();
String answer = "42 is the Answer to the Ultimate Question of Life,
the Universe, and Everything";
when(mockedAnswer.retrieveAnswer()).thenReturn(answer);
assertEquals(answer, mockedAnswer.retrieveAnswer());
}
Running the test displays the following exception:
org.mockito.exceptions.base.MockitoException:
Cannot mock/spy class com.app.Answer
Mockito cannot mock/spy because :
- final class
Mockito could mock final classes by supplying the mockito-inline dependency. However, starting with Mockito 5.0.0, the inline MockMaker is used by default and supports mocking of constructors, static methods and final classes. The subclass MockMaker is still available via the new mockito-subclass artifact, which is necessary on the Graal VM native image as the inline mocker doesn’t work.
The ArgumentMatcher interface allows the creation of a custom matcher which is used as method arguments for detailed matches. The ArgumentMatcher now supports varargs, with one argument, via the type() method. For example, in order to mock the following method with a varargs argument:
public class Answer {
public int count(String... arguments) {
return arguments.length;
}
}
It was always possible to match zero arguments or two or more arguments:
when(mockedAnswer.count()).thenReturn(2);
when(mockedAnswer.count(any(), any())).thenReturn(2);
The mock might also use one any() method as argument:
Answer mockedAnswer = mock();
when(mockedAnswer.count(any())).thenReturn(2);
However, before Mockito 5, the any() method would match any number of arguments, instead of one argument. The mock above would match with the following method invocations:
mockedAnswer.count()
mockedAnswer.count("one")
mockedAnswer.count("one", "two")
Mockito 5 allows to match exactly one varargs argument with:
when(mockedAnswer.count(any())).thenReturn(2);
Alternatively, Mockito 5 allows matching any number of arguments:
when(mockedAnswer.count(any(String[].class))).thenReturn(2);
Mockito 5 may be used after adding the following Maven dependency:
org.mockito
mockito-core
5.0.0
test
Alternatively, the following Gradle dependency may be used:
testImplementation 'org.mockito:mockito-core:5.0.0'
More information about Mockito 5.0.0 can be found in the detailed explanations inside the release notes on GitHub.
Java News Roundup: JDK 20 in Rampdown Phase 2, New JEP Drafts, JobRunr 6.0, GraalVM 22.3.1
MMS • Michael Redlich

This week’s Java roundup for January 23rd, 2023, features news from OpenJDK, JDK 20, JDK 21, GraalVM 22.3.1, TornadoVM 0.15, Spring Cloud Azure 5.0, Spring Shell 3.0.0 and 2.1.6, Spring Cloud 2022.0.1, Quarkus 2.16 and 3.0.Alpha3, Micronaut 3.8.3, JobRunr 6.0, MicroStream 8.0-EA2, Hibernate 6.2.CR2, Tomcat 10.1.5, Groovy 4.0.8 and 2.5.21, Camel Quarkus 2.16, JDKMon 17.0.45 and Foojay.io at FOSDEM.
OpenJDK
Angelos Bimpoudis, principal member of technical staff for the Java Language and Tools team at Oracle, has updated JEP Draft 8288476, Primitive types in patterns, instanceof, and switch. This draft, under the auspices of Project Amber, proposes to enhance pattern matching by allowing primitive types to appear anywhere in patterns.
Alex Buckley, specification lead for the Java language and the Java Virtual Machine at Oracle, has introduced JEP Draft 8300684, Preview Features: A Look Back, and A Look Ahead. This draft proposes to review the preview process that was introduced as JEP 12, Preview Features, for potential continuous improvement of the process.
Wei-Jun Wang, principal member of the technical staff at Oracle, has introduced JEP Draft 8301034, Key Encapsulation Mechanism API, a feature JEP that proposes to: satisfy implementations of standard Key Encapsulation Mechanism (KEM) algorithms; satisfy use cases of KEM by higher level security protocols; and allow service providers to plug-in Java or native implementations of KEM algorithms.
Archie Cobbs, founder and CEO at PatientEXP, has introduced JEP Draft 8300786, No longer require super() and this() to appear first in a constructor. This draft, also under the auspices of Project Amber, proposes to: allow statements that do not reference an instance being created to appear before the this() or super() calls in a constructor; and preserve existing safety and initialization guarantees for constructors.
JDK 20
As per the JDK 20 release schedule, Mark Reinhold, chief architect, Java Platform Group at Oracle, formally declared that JDK 20 has entered Rampdown Phase Two to signal continued stabilization for the GA release in March 2023. Critical bugs, such as regressions or serious functionality issues, may be addressed, but must be approved via the Fix-Request process.
The final set of six (6) features in JDK 20 will include:
Build 33 of the JDK 20 early-access builds was made available this past week, featuring updates from Build 32 that include fixes to various issues. More details on this build may be found in the release notes.
JDK 21
Build 7 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 6 that include fixes to various issues. More details on this build may be found in the release notes.
For JDK 20 and JDK 21, developers are encouraged to report bugs via the Java Bug Database.
GraalVM
Oracle has released the Community Edition of GraalVM 22.3.1 that aligns with the January 2023 edition of the Oracle Critical Patch Update Advisory. This release includes the updated versions of OpenJDK 19.0.2, 17.0.6 and 11.0.18, and Node.js 16.18.1. More details on this release may be found in the release notes.
TornadoVM
TornadoVM, an open-source software technology company, has released TornadoVM version 0.15 that ships with a new TornadoVM API with improvements such as: rename the TaskSchedule class to TaskGraph; and new classes, ImmutableTaskGraph and TornadoExecutionPlan, to optimize an execution plan for running a set of immutable task graphs. This release also includes an improved TornadoVM installer for Linux, an improved TornadoVM launch script with optional parameters and a new website for documentation.
Juan Fumero, research associate, Advanced Processor Technologies Research Group at The University of Manchester, introduced TornadoVM at QCon London in March 2020 and has since contributed this more recent InfoQ technical article.
Spring Framework
The release of Spring Cloud Azure 5.0 delivers: support for Spring Boot 3.0 and Spring Cloud 2022.0.0; improved security with passwordless connections; and redesigned Spring Cloud Azure documentation with improved scenarios. This version also includes upgrades to some of the deprecated APIs.
Versions 3.0.0 and 2.1.6 of Spring Shell have been released featuring compatibility with Spring Boot 3.0.2 and 2.7.8, respectively, along with backported bug fixes and improved handling of position arguments and collection types. More details on these releases may be found in the release notes for version 3.0.0 and version 2.1.6.
Spring Cloud 2022.0.1, codenamed Kilburn, has been released that ships with corresponding point releases of Spring Cloud sub-projects such as Spring Cloud Function, Spring Cloud Commons and Spring Cloud Gateway. This release is compatible with Spring Boot 3.0.2. More details on this release may be found in the release notes.
Quarkus
The release of Quarkus 2.16.0.Final delivers new features such as: support for time series operations and data preloading in the Redis extension; support for custom exception handling and xDS in the gRPC extension; improved configuration flexibility for the Cache extension; and several security-related improvements focused on improving the developer experience. More details on this release may be found in the changelog.
The third alpha release of Quarkus 3.0.0 features a third iteration of their Jakarta EE 10 stream that includes: the collective improvements of versions 2.15.0.Final, 2.15.1.Final, 2.15.2.Final, 2.15.3.Final and 2.16.0.Final; a migration to SmallRye Mutiny 2.0 and the Java Flow API; and a simplified handling of Kotlin by the Quarkus classloader designed to ease development on Kotlin-based Quarkus extensions. More details on this release may be found in the release notes.
Micronaut
The Micronaut Foundation has released Micronaut 3.8.3 featuring bug fixes and updates to modules: Micronaut OpenAPI and Micronaut Oracle Cloud. More details on this release may be found in the release notes.
JobRunr
After three milestone releases, version 6.0 of JobRunr, a utility to perform background processing in Java, has been released to the Java community. New functionality and improvements include: support for Spring Boot 3.0; Job Builders that provide a single API to configure all the aspects of a Job class via a builder pattern instead of using the @Job annotation; Job Labels such that jobs can be assigned labels that will be visible in the dashboard; allow for multiple instances of the JobScheduler class with different table prefixes inside one application; an update of all transitive dependencies; and improvements in performance and stability. More details on this release may be found in the release notes.
MicroStream
MicroStream has provided a version 8.0 preview of their Java-native object graph persistence layer. This second early-access release features: a move to JDK 11 with continued support for JDK 8; a read-only mode such that multiple processes can access the same storage; experimental implementations of ArrayList, HashMap and HashSet that are using a sharing mechanism; and improved integrations with Spring Boot and Quarkus.
Hibernate
The second release candidate of Hibernate ORM 6.2 implements a number of bug fixes based on Java community feedback from the first candidate release of Hibernate ORM 6.2. As a result, the SQL Abstract Syntax Tree, the ANTLR-based parser for their Hibernate Query Language, has been stabilized and the SQL MERGE command can now handle updates against optional tables.
Apache Software Foundation
Apache Tomcat 10.1.5 has been released with notable changes such as: correct a regression in the refactoring that replaced the use of the URL constructors; use the HTTP/2 error code, NO_ERROR, so that the client does not discard the response upon resetting an HTTP/2 stream; and change the default of the system property, GET_CLASSLOADER_USE_PRIVILEGED, to true unless the Expression Language library is running on Tomcat. More details on this release may be found in the changelog.
The release of Apache Groovy 4.0.8 delivers bug fixes and enhancements such as: improve the JaCoCo line code coverage of a Groovy assert statement; and introduce variants of the findAll() and findResults() methods to accept an optional collector argument. More details on this release may be found in the changelog.
Similarly, the release of Apache Groovy 2.5.21 ships with bug fixes and a dependency upgrade to ASM 9.4. More details on this release may be found in the changelog.
Maintaining alignment with Quarkus, version 2.16.0 of Camel Quarkus was released that aligns with Camel 3.20.1 and Quarkus 2.16.0.Final. It delivers support for four DSLs: JavaShell, Kotlin, Groovy and jOOR. More details on this release may be found in the release notes.
JDKMon
Version 17.0.45 of JDKMon, a tool that monitors and updates installed JDKs, has been made available this past week. Created by Gerrit Grunwald, principal engineer at Azul, this new version fixes an issue with download dialogs.
Foojay.io at FOSDEM 2023
The Friends of OpenJDK, Foojay.io, a community platform for the Java ecosystem, has announced that they will be hosting their own developer rooms at the upcoming FOSDEM 2023 conference scheduled for Saturday-Sunday, February 4-5, 2023.
FOSDEM, a two-day event organized by volunteers to promote the widespread use of free and open source software, will be providing a number of tracks and other developer rooms, AKA devrooms, hosted by other organizations and communities.
MMS • Matt Campbell

Google Cloud has released a public preview of Cloud SQL Proxy Operator. The operator simplifies the process of connecting an application running in Google Kubernetes Engine with a database deployed in Cloud SQL.
Cloud SQL Proxy Operator is an alternative to the existing connection methods. Currently, there are Cloud SQL connectors for Java, Python, and Go as well as the Cloud SQL Auth Proxy. The Cloud SQL Auth Proxy Operator, according to the project README, “gives you an easy way to add a proxy container to your [K]ubernetes workloads, configured correctly for production use.”
Luke Schlangen, Developer Advocate at Google, and Jonathan Hess, Software Engineer at Google, claim Cloud SQL Auth Proxy Operator provides a significant reduction in configuration code required. They indicate that configuration can be done “in 8 lines of YAML — saving you about 40 lines of YAML configuration (or thousands for large clusters)”.
Multiple Kubernetes applications can share the same proxy. Schlangen and Hess also indicate that GCP will maintain the operator including updating it to the latest recommendations. They share that, in the GA release, the proxy will have automatic deployments when the configuration changes.
The operator introduces a custom resource AuthProxyWorkload. This describes the Cloud SQL Auth Proxy configuration for the workload. The operator reads this resource and deploys a Cloud SQL Auth Proxy container to the workload pods. Prior to building the connection, the GKE cluster and Cloud SQL instances should be created, a service account for connecting should be set up, and Kubernetes secrets should be stored.
Configuring the operator can be done by first getting the Cloud SQL instance connection name:
gcloud sql instances describe quickstart-instance --format='value(connectionName)'
Then create a new YAML file containing the Cloud SQL Auth Proxy Operator configuration. In the example below, "" would be replaced by the connection name returned by the command above.
apiVersion: cloudsql.cloud.google.com/v1alpha1
kind: AuthProxyWorkload
metadata:
name: authproxyworkload-sample
spec:
workloadSelector:
kind: "Deployment"
name: "gke-cloud-sql-app"
instances:
- connectionString: ""
unixSocketPathEnvName: "DB_SOCKET_PATH"
socketType: "unix"
unixSocketPath: "/csql/pg"
Finally, the proxy configuration can be applied to Kubernetes:
kubectl apply -f authproxyworkload.yaml
AWS has a similar, but more general, connector service with AWS Controllers for Kubernetes (ACK). ACK provides an interface for using other AWS services directly from Kubernetes. ACK supports both Amazon Elastic Kubernetes Service (EKS) and Amazon Relational Database Service (RDS).
GCP indicates the project will follow semantic versioning with active releases getting all new features and security fixes for at least a year. Breaking changes will cause a major version bump. Deprecated versions will continue to receive security and critical bug fixes for one year.
Cloud SQL Proxy Operator is open-source and available under the Apache-2.0 license.