Month: January 2023
Critical Control Web Panel Vulnerability Still Under Exploit Months After Patch Available

MMS • Sergio De Simone

A 9.8 severity vulnerability in Control Web Panel, previously known as CentOS Web Panel, allows an attacker to remotely execute arbitrary shell commands through a very simple mechanism. Although readily patched, security organizations are reporting it is under active exploit.
The unauthenticated remote code execution vulnerability affecting Control Web Panel (CWP) was discovered by Numan Türle of Gais Cyber Security and patched in version 0.9.8.1147, released on October 25. The vulnerability remained undisclosed until the beginning of 2023 to ensure CWP users had enough time to patch their systems.
According to Türle, the vulnerability allows an attacker to run arbitrary Bash commands by sending a maliciously crafted payload to the login endpoint. For example, you could send a POST HTTP message including the string $(whoami) in a URL query parameter to have the Linux shell command whoami executed when the request payload is written to log.
The vulnerability appears to be the result of missing user input validation, which should always be applied to prevent command injection, coupled with the direct use of shell redirection to append a string to a file. At source code level, the vulnerability manifests itself with the use of double quotes in the appending command, which leads to the possibility of command substitution, as seen in the above example. The use of single quotes would have prevented the most trivial attack schemes, yet it would have not prevented all of them in the first place. It fact, it appears that offloading the execution of such a simple task as appending to file to the shell was hardly a justified choice in terms of security.
Türle publicly disclosed the vulnerability on January 3 2023, additionally posting a video showing how easy it is to exploit. It took only a couple of days for attacks attempting to exploit the vulnerability to be detected by GreyNoise, which additionally provided the figure of five distinct IP addresses that were originating them.
Control Web Panel is a Linux server administration software that specifically target enterprise Linux distros. While its popularity is not in the top tier, it is used by over 35k servers worldwide. All organizations using it should ensure they are running version 0.9.8.1147 or higher.
MMS • Tejas Shikhare

Subscribe on:
Transcript
Thomas Betts: GraphQL can be a great choice for client to server communication, but does require some investment to maximize its potential. Netflix operates a very large federated GraphQL platform. Like any distributed system, this has some benefits but also creates additional challenges. Today I’m joined by Tejas Shikhare, who will help explain some of the pros and cons you might want to consider if you try to follow their lead in scaling GraphQL adoption. Tejas is a senior software engineer at Netflix where he works on the API systems team. He has spent the last four years building Netflix’s federated GraphQL platform and helped to migrate Netflix’s consumer-facing APIs to GraphQL. Aside from GraphQL, he also enjoys working with distributed systems and has a passion for building developer tools and education. Tejas, welcome to the InfoQ podcast.
Tejas Shikhare: Thank you so much for having me, Thomas.
Quick overview of GraphQL [01:11]
Thomas Betts: t’s been a while since we’ve talked about GraphQL on the podcast. Our listeners are probably familiar with it, but let’s do a quick overview of what it is and what scenarios it’s useful for.
Tejas Shikhare: GraphQL has gained a lot of popularity over the last few years, and one of the most common scenarios that it’s useful for is building out… If your company has UIs and clients that are product-heavy and they aggregate data from many different sources, GraphQL allows you to not only act as an aggregation layer but also query language for your APIs so that the client can write a single query to fetch all the data that it needs to render. And we can build this into a GraphQL server and then connect to all these different sources of data and get together and return them back to the client. That’s the primary scenario with GraphQL, but at the end of the day it’s just a API protocol similar to REST, GRPC, etc., with the added layer of being a deep query language.
Thomas Betts: Yeah, I think there’s a couple of common scenarios. About a year ago we had the API Showdown on the podcast and we talked about REST versus GraphQL versus GRPC, and I remember over-fetching, and there’s a couple different scenarios, like this is a clear case where GraphQL makes it easier than calling a bunch of different APIs.
Tejas Shikhare: Exactly, and I think what GraphQL gives you is the ability to fetch exactly the data you want, and not more, not less, because you can ask for what data, so you can ask for every single field you want and that’s the only fields that server will give you back. And sometimes in REST, the way it works is you have an endpoint and it returns a set of data, and it might return more data than you need, and so you’re sending those bytes over the wire when the client doesn’t need them, so over-fetching is also another big problem that GraphQL solves.
Why Netflix adopted GraphQL [02:49]
Thomas Betts: What were some of the reasons Netflix decided to use it? I’m assuming you haven’t always had GraphQL, this was an adoption, something you chose to do after you’d had traditional REST APIs.
Tejas Shikhare: We have a pretty rich history on graph APIs in general. GraphQL came out I think in 2014, 2015, was open-sourced and then it started gaining popularity. But even before that, Netflix has already started thinking about something like GraphQL, so we open-sourced our own technology called Falcor, and it’s open source, you can find it on GitHub, but it’s very similar to GraphQL in spirit. And really where these technologies came from, it’s the problem space, and the problem space here lies around building rich UIs that collect data from many different sources and display them.
For us, it was the TV UI. When we started going into the TV streaming space and started building applications for the TV, that’s when we realized there is so much different data that we can show there that something like GraphQL would become really powerful, and that’s where Falcor came in. And we are still using Falcor in production, but GraphQL has gained so much popularity in the industry, it’s community-supported, there’s a lot of open source tooling, and that’s really when we decided, “Okay, why should we maintain something internally when we can use GraphQL, which is getting much more broader support, and then we can get in all the fixes and move with the community?” That’s the reason why we moved to GraphQL.
Benefits of GraphQL [04:10]
Thomas Betts: Gotcha. I like the idea that you had the problem and said, “We need a graph solution,” built your own and then you evolved away from it because there’s a better solution. It’s always hard for companies to admit that what they’re doing in-house isn’t always the best, and sometimes it is better to go get a different… Well, you made Falcor open source, but a different open source solution. Has that made it easier to hire more engineers onto your team working on building out GraphQL or get people who know how to use it?
Tejas Shikhare: The benefits are a lot, because firstly, GraphQL engineers, all over the place that you know you can hire. A lot of people have experience now today with GraphQL, so that’s great, but also the number of languages that support GraphQL. The framework itself has been implemented by the community in many different languages. We use GraphQL Java mostly, but then we also have a Node.js architecture internally that we could easily bring GraphQL onto, so that’s a big advantage, so your technology stack broadens as well, hiring is easier, and really I think you can work with the community to improve GraphQL in the ways that you want to. And that’s also another big win because we have members of our team who are actively involved in the GraphQL working group and advocating for features that we want in GraphQL in front of the open source community.
The history of GraphQL at Netflix [05:24]
Thomas Betts: You recently spoke at Qcon San Francisco and QCon Plus about GraphQL at Netflix. It was a follow-up to a presentation, I think about two years ago, of some of your coworkers. Is that when Netflix started using GraphQL, that was the advent of using federated GraphQL? What was happening then and what’s been happening the last two years?
Tejas Shikhare: Let me go into a little bit of a history. In Netflix, we have three main domains in engineering. Obviously the Netflix product is a big domain of engineering, but in the last few years we’ve also started investing heavily in our studio ecosystem, so think about people who are working on set, working on making the movies, they need applications too, that are backed by the servers. There’s so much complexity in that space. In fact, the data model is way more complex for the studio ecosystem than it is for the actual product, and that’s fairly new, so that started about 2018 timeframe, the investments there. And GraphQL was already thriving at that time, and that’s when we decided, “Okay, why don’t we start using GraphQL for our studio ecosystem?” And a lot of different teams were pretty excited about it, and that’s where GraphQL really got its grounding at Netflix and that’s where it shined.
And we realized very quickly, even within our studio ecosystem, we had 100s of applications, over 100 services, and that’s when we started thinking about we can’t have one GraphQL team maintain the API for all of these applications, so that’s where I think we started thinking about federated architecture, which allows you to break apart and distribute your GraphQL API to many different teams. That allowed us to scale, so really it picked up in our studio ecosystem, but then at the same time we paired up with the Netflix API team, which is responsible for the API for the product, which was still running in Falcor, as I mentioned, at the time. We started investigating how GraphQL could help in that area, and over time we started extending the federated architecture.
Two years ago when we first did the talk, we had mostly launched it for all of studio, but then over the last two years we started launching it for our Netflix product, so if you pull out iOS or Android phone that’s using GraphQL, and our goal is to have a lot more canvases on GraphQL over time. And additionally, we are also using it for our internal tools. You might be familiar with all these applications like Spinnaker, which allows us to do deployments, and we have a lot of internal UI applications that developers use, customer support applications. We are starting to move those to GraphQL as well. Really just all across the company.
Federated GraphQL [07:49]
Thomas Betts: The keyword you keep coming back to is federated, and you said that the federated model allowed more people to work on it. And what’s traditional GraphQL? Is it a monolith?
Tejas Shikhare: Traditionally, even when we first started, think of GraphQL as a BFF. It’s providing a backend for front end where you can aggregate data from many different sources, so if you have a microservice architecture, you can aggregate data from many different sources, put it all together and so the client can build a query against it. Traditionally what we do is we write the schema and for each field in the schema we write data fetchers, and the data fetchers actually fetch the data from the clients and then we solve the n plus one problem with data loaders so that we don’t have inefficient APIs.
That’s how traditionally GraphQL is implemented, but what you quickly observe is if you have a very big company, big organization, you have a lot of data, you have a lot of APIs, and the schema starts to grow pretty rapidly, and the consumers of the schema are also, you probably have more than a handful of applications that the consumers of the schema also start to grow. The central team becomes a bottleneck, so every time you want to add a new feature, the backend teams will add it first to the backend, then it adds it to the GraphQL server, and then the client team consumes from it. That becomes like the waterfall model for creating those APIs.
And what federation allows you to do, essentially, is it allows you to split up the implementation. You still have this unified API, the one schema, but the schema is split across many different teams, and each of those teams then implement the data fetchers for their particular part of the schema.
And then these data fetchers essentially do the same thing, really talk to the database or talk to another service in the backend and get the data, but now you split them up across many services, so you split up the operational burden of those data fetchers, you split up the implementation. And also then as soon as one backend team implements it, it’s directly available for the clients you use, so you don’t have to go through another layer to build it up. That’s where the federation gives you some of the advantages on top of doing the classic monolithic way.
Breaking up the API monolith [09:59]
Thomas Betts: It’s somewhat similar to a move from a monolith to microservices architecture then, that you’re saying. We’re going to have a lot of services because this one monolith is too hard for all of our developers to work in one place. We aren’t building new features fast enough, so we’re going to spread it out. Is that kind of a good analogy?
Tejas Shikhare: And that’s what inspired it, moving to federation, using that kind of a thing. We already did this with our monolith 10 years ago, and realized now we have a new monolith, which is the API monolith because that’s what we ended up building. And now federation allows us to split up the API monolith into smaller sub-graph services and that, but then you also run into the similar kind of challenges as you go from monolith to microservices. It’s not all roses, there are challenges involved, so there are also similar set of challenges when you move from the monolith GraphQL to a federated one.
Thomas Betts: Yeah, let’s dive into that. What’s the first thing? You say, “Okay, we’re going to take it from 1 team to 2 teams, and then 10 teams are going to be contributing to the one API,” because you said there’s still one graph, but now we’re going to have multiple people contribute to that. How does that work when it’s creating your first microservice? How do you create your first federated GraphQL instance?
Tejas Shikhare: In our case, our first federated GraphQL service was the monolith itself. In federated GraphQL… Our schema was exactly the same, so we exposed the monolith as the first sub-graph service in the federated ecosystem, so as far as the client is concerned, they can still make all of the same queries and do all that. Now we started to then reach out to a certain set of teams, so initially we bootstrapped this. Since we were maintaining the monolith initially, we went to the teams that would potentially own a sliver of the functionality of the monolith, went to their team and helped them build a sub-graph service. And basically the idea here is to not affect the clients at all, so clients can still make the same set of queries, and so we had this directive in GraphQL to make this kind of migration possible. It’s an override directive which allows us to specify to the…
In the federated architecture we have a gateway, so let me step back a little bit, and then the gateway talks to the sub-graph services and the gateway is responsible for doing the query planning and execution. And as part of the query planning, it checks each field that was requested in your query and see which service it comes from, and then it looks at this child field and then sees which service it comes from, and then based on that it builds a query plan.
Now what we can do is we have this one monolith, GraphQL. Let’s say we have three different domains within it, like movie, talent and production domain. This is our studio ecosystem. Now let’s say I want to pull out the talent domain and make it into its own sub-graph service, so I’ll identify the types that are specific to the talent and I’ll mark them with the key directive that tells them that this particular type can be federated.
Now, I can redefine that type, I can extend that type in the sub-graph service using the same key directive, so that’s something that they have to agree, and then I can slowly say, “Oh, these are the fields within, say the talent type.” And I can start saying that now for these fields, go to my sub-graph service, the new talent sub-graph service, and you can mark those at override. That tells the gateway, the router, that, oh, for this particular field, we know that this original service can provide it, but also this new service can provide it. And then the future query plan takes into account that, okay, we are going to send it to this new service. That’s how we started, so we did that for one service, the next service, and we slowly started pulling out until our monolith GraphQL became an empty shell and we got rid of it. It took about a whole year to do that because it had a lot of APIs in there, but that’s how we started.
Thomas Betts: Yeah, it sounds like a strangler fig pattern. You can build a new thing and then you start moving it over, so it’s again, following the patterns for how to move to microservices, the same thing for moving to federated.
Moving to GraphQL from Falcor or REST [13:51]
Thomas Betts: Let’s back all the way up though. I wanted to get into, you said that you were using Falcor for a while because you had the need for a graph, but then you had to switch to GraphQL. How is that different for we have a graph architecture for our APIs, versus somebody who doesn’t have that in place and they’re just getting started? You started in a different place than I think most people will be coming to GraphQL.
Tejas Shikhare: The example I described of migration earlier was all GraphQL in our studio ecosystem, because it was already GraphQL. In our consumer’s ecosystem we had Falcor APIs and then we had to migrate them to GraphQL, which is I think what you alluded to. And then also, what would someone who has no GraphQL or no Falcor would do? I hit the first one already, so I’m going to hit the second one, which is how did we do from Falcor to GraphQL, real quickly? As far as Falcor is concerned, it has similar concepts as GraphQL, but really moving from Falcor to GraphQL is a lift. It’s as good as moving from REST or GRPC to GraphQL because there’s not really that much in common in how it works, but conceptually it’s still similar, so it was a little bit easier, but not that easy.
The way we did the Falcor migration is we built a service on top of the Falcor service, a GraphQL monolithic service, a thin layer, and then we mapped the data fetchers for GraphQL data fetchers to call the Falcor routes, and that was additional engineering effort we had to put in, because that allowed us to convert. And then now that we had the GraphQL monolith service, then we applied the same pattern to move it to different services, which actually we haven’t completed yet, so now we are at a stage where we’ve just move to GraphQL and there’s only one service, but eventually our goal is to move it out to different services. Let’s say if you don’t have Falcor, it’s more conceptually different, you have REST APIs in your ecosystem, and you’re thinking about, “Oh, GraphQL is great for all of these things and I want to use it.”
In that case, I would follow a similar pattern where I’ll set up a new service, like a GraphQL service, and then start building the schema and implement the data fetcher so that it calls my existing REST endpoints. If you have a monolith, then maybe you can just build it within your monolithic service, so you have your REST API sitting alongside your GraphQL API, you can put it on a different port, and then have the GraphQL call into either your existing functions, your business logic. You still implement the data fetchers, but then they call into either your existing APIs or business logic. That’s the way I would start, and then once you have this GraphQL API that works and clients start using it, then obviously if you’re a big company, you want to start thinking about federation because you have a lot of services and you can grow and scale that GraphQL API, but really you want to see if that’s working well, maybe just keep going with that for a while. And we did that too for almost a year and a half before we even considered federation.
Thomas Betts: Yeah, I like how you talked about we had Falcor, we couldn’t just jump to GraphQL, we weren’t going to do a full replacement. Again, it was almost that strangler pattern. We’re going to put in an abstraction layer to help us with the transition rather than a big bang approach. You were able to make iterative things.
Why use GraphQL Federation? [16:44]
Thomas Betts: And then let’s go into what you were just saying about when do you get big enough that you say, “Hey, this is becoming hard to maintain.” What are the pros and cons of moving to federation and why would somebody say, “Hey, it’s worth the extra work that we have to do?” And what is the extra work when you get to federation? You don’t get all that for free.
Tejas Shikhare: First, let’s talk about the pros. Remember how I talked about earlier that the GraphQL service could become the central bottleneck? The first thing is you don’t have to implement the feature in the backend service, in the GraphQL service before the client can use it, so that is one of the big problems that federation solves, so you can just have the owning team implement the feature and it’s already available in the graph.
The second one, big pro is operational burden. You can split the operational burden instead of one central team being on call and the first line of support for all your APIs, you can kind of split that up and scale that a little bit better. We’ve seen that the more skill you have, you can see that part of the team, and I’ve known people who have worked on this team for a long time, that you can have some serious burnout on the engineering side. It’s just hard to be on call for frontline services all the time, and it’s stressful too. And you can hire more people to split up the on-call, but ultimately I think splitting up the support burden is very nice. That’s another win from moving to federation.
And then the third benefit, I think it’s a lot of companies, they’ll have these legacy applications that you don’t really develop actively, but you still have to maintain them, you have to expose those APIs, and what Federation allows you to do is you can convert those existing legacy applications into a sub-graph that you can contribute to the overall GraphQL API. It really allows you to modernize your legacy applications that you don’t really maintain, but then expose it to the graph and then the clients can start using the GraphQL API, so that’s a nice one. You can also do it in the monolith, but it’s always falls behind. It’s not like something a priority, but then the team owning it can modernize their own legacy application. I think it’s a nice little win from federation.
Yeah, we covered the wins, but obviously it comes with some of the challenges, and I think that was your primary question, and the challenges are many too, because previously one of the big things is now everyone has to implement their GraphQL APIs. Everyone has to learn GraphQL, because you’re federating the APIs, so each team is exposing a sub-graph service that’s a GraphQL API, and GraphQL, although it has some complexity over REST or GRPC. REST or GRPC it’s action handlers that you implement and then you call into your business logic. In GraphQL you get a query that can fetch multiple different kinds of data and then you learn how to use data fetchers, and then understand data loaders, so there is some complexity and learning curve there, which can be challenging if your entire company has to do it.
The second big challenge is I think the health of the API, like when we are designing an API, it’s easier to collaborate when you’re one team and building it by yourself, but it becomes very challenging when you have multiple teams, in our case 100s of them designing them in their own silo. And then does it combine together nicely to form a well-designed API that’s actually useful to the client? Because ultimately you’re building the API so that the client can consume from it, but if you just build something that’s not what the client needs, then you’re not really solving a problem, so that’s a big challenge with federation and really those are the two things that we’ve been focusing on improving, making GraphQL developer education better, but also making schema development easy.
Tooling to help with federation [20:04]
Thomas Betts: It sounds like you’ve had to have a lot of people working on being able to scale the effort of federation, like you said, learning and coming up with the training tools. Do you also have tools that you’re using to help monitor and learn what’s in the graph and study that? How many people are working on the tooling and the platform compared to how many developers are now using it?
Tejas Shikhare: We’ve been working on a lot of different tools to make implementing federation a little bit better. I’m going to put that into a few different buckets. We have observability, which is an important aspect of any server-side development, and that’s an important… We have a ton of tools that are federation-aware and GraphQL-aware that we’ve done. Then also the schema development and making the schema better, and then also feature development for the backend owners to make that easier. Roughly on the platform side, across these many buckets, my team focuses on GraphQL. We have about 6 or 7 people doing GraphQL-focused tooling, but then we work with say, the observability team, the Java platform team to make the Java platform easier, so maybe a total of 20 individuals from across all the different domains. And then I think on the developer side, we have over 1,000 at this point that are actually building and implementing sub-graphs, because we have the internal tools, the studio applications, the Netflix product API, the new games initiative, all of that we’ll build with GraphQL.
On the observability side, we focused on making distributed tracing easier with GraphQL, so essentially you can track how each request is planned and where it’s spending time. This is really good because it allows client developers to optimize their query by requesting fields that they feel like they need to render early versus render later, so they can see, but also allow backend developers to see where they might be introducing inefficiency in their system. That’s really powerful, and it is aware of these data fetchers that I was talking about earlier that it can track that in the distributed trace.
Then we also have metrics, GraphQL-aware metrics. Normally if you have a REST API or GRPC API, you’d create the success scenario and then you’d have all these different kinds of errors, like 400 and all those kind… And then you send it to your metric server.
But GraphQL is a little bit tricky because in GraphQL you can have partial failures and responses, so we had to make GraphQL-aware metrics that we do, and we map them onto the existing metrics that we have so that you can create these charts when there’s an outage to see, oh, what kind of error is happening? And you can track that up.
Really focusing on observability was important, and on top of that, for the schema development, one of the challenges I talked about is here. Observability just was stable stakes. It was something we had before and we needed to have almost the exact same experience with GraphQL and not anything harder.
But with schema design, it was one team doing it before and now we have multiple teams doing it, and firstly we needed a way to track schema health. We started tracking that, but then we realized people were doing too many things and it was impossible to do that, so we created the schema working group where people can come and ask for, showcase their schema, get a review done, and also discuss schema best practices.
And then once we had the schema best practices, we needed a way to enforce them. Enforce is a strong word, but really make people aware. We built this tool called Graph Doctor, which allows teams to get PR comments about what best practices they’re not following in their schema design, so that would come directly on their pull request, and also a lot of sample code to how to do the things right way and then point them to that so that they can go look at it and then just start doing it. Those are the two things that help with schema design.
Then the last part is when you move to microservice, you have to make the development of the service easier with feature branches and things like that, so we had to do a similar thing with GraphQL where we have this overall API, but your team is responsible for this small part of the API, but you don’t want to just push everything to production before… And you test in production, so you need a way to have your part of the graph merge with the rest of the graph in production and then give it to someone to test, so sort of like an isolated feature environment for people to use. That was another thing that we had to build, because previously the API team could just do it in the central monolith, but with this distributed ecosystem that was hard to do, and one of the big challenges. Those are the main key tools we focused on.
Schema-first development [24:25]
Thomas Betts: My question was a little vague and you covered everything I wanted you to say. Going back, you said you’ve got maybe 20 people, but that’s empowering 1,000 developers and that GraphQL, it’s how you’re doing work, but you basically have to treat it as a product that you manage internally and you’re constantly getting, I’m sure feature requests and hey, how can we improve this? How can we improve this part of the developer experience? Your last bit about the schema and the schema working group, I think that’s a whole nother conversation we could have. I believe in your QCon talk you’d said schema-first development was what you proposed. Can you describe what that is?
Tejas Shikhare: Another way to say it is API-first development, so starting with the API, so starting with the needs of the client, identifying the problem you’re trying to solve, working with the product manager, working with the client developers, and coming up with an API together that works for everyone. Because what we often tend to do, and I’ve been a backend engineer and guilty of this many times, is we implement something and we create an API for it, and then we said, “Oh, here’s the API, use it.” And that’s great if you’ve put a lot of thought into the API, you’ve thought of all the different use cases, but that’s not always the case, and what makes that easier is having a schema-first approach or an API-first approach where… Or design-first approach, another way to say it, is you really understand the needs, product needs, client needs, and then working backwards from there and figuring out with the API.
And once you do that, you might realize the stuff you have in the backend doesn’t fit quite nicely into that, and that’s when you’ve built a good API and you have to now start making the, or saying, “Oh, we maybe can provide this,” and then you start taking things out of the API so that it fits with your backend. But then you’ve really done the homework, and that ultimately leads to better APIs, more leverage for the company because these APIs then become reusable for other product features. Yeah, so that’s really what API-first design in my mind means.
Thomas Betts: One of my wonderings about GraphQL is that I could have all these APIs that were created and none of them met my needs as a consumer or the product manager, but I realize if I call three or four of them, I can get what I need, but now I have performance issues. Oh, in comes GraphQL, and it says, “Oh, I can just ask each of those for just the bit that I need and I’ve created this super API.” But you’re now talking about GraphQL as the primary way of doing things, and that that should influence the API development because people are writing those connecting layers and they’re always thinking about the final use of their service, not just, well, we need something that is the talent database here, I’ll just put all the data on one… Fetch one person by name or by id.
Tejas Shikhare: Yeah, exactly. I think that you nailed it there.
Thomas Betts: For non-GraphQL, when we just have REST APIs, one of the approaches is contract-driven development where you write the contract first, you write your open API spec or whatever it is, and then the consumer and the producer both agree to it, which is different than one side versus the other has to use it. There’s different ways you can test this to say, “Hey, I as a producer meet the spec and I as a consumer expect the backend to do that.” Is contract-driven development similar to the schema-first approach you’re doing or is that a different scenario?
Tejas Shikhare: Yes, exactly. I think it’s very similar. I think that’s yet another way to just say the same thing, because ultimately you’re building an API that works for the client and that the producer can provide, and schema is the contract in GraphQL, so oftentimes we refer to it as schema-first development, but really I think conceptually they’re very similar.
The evolution of APIs at Netflix [27:44]
Thomas Betts: You’ve been doing this project for a few years, we talked about some of the migration challenges, and I like that you focused on it as a project that you had to migrate and it’s still ongoing. Where are you at now in that evolution? When do you expect to be done, and what does done look like?
Tejas Shikhare: Where we are, I think we have a lot of people using GraphQL at Netflix for a lot of different things, and it’s almost a little bit chaotic where we are trying to tame the chaos a little bit, and we are in the phase where we are taming the chaos, because people are so excited they started using it and we saw some of those issues and we’re starting to tame the chaos. And really the next step is to migrate our core product APIs, because they experience a lot of scale challenges along with moving to a new kind of technology. It’s almost akin to changing parts of a plane mid-air because we have so high RPS on our product APIs, and really we need to maintain all of the engagement and all that stuff, so I suspect that will take us about a year to two to really move a lot of the core components onto GraphQL, while also making our GraphQL APIs healthier and better, instilling all these best practices, making the developer tools, and one day everything is in place and people are just developing APIs in this ecosystem.
And that’s when I think it’ll be in a complete space. We have the nice collaboration workflow that I talked about, schema-first development between the client and the server, and there’s all the platform tooling exists to enable that, and we have a lot of best practices built up that are enforced by the schema linting tool and things like that. I think we are probably around maybe a midway point in our journey, but probably still quite a bit of ways to go.
For more information [29:29]
Thomas Betts: Well, it sounds like you’re definitely pushing the boundaries with what GraphQL can do, what you’re using it. I’m sure there’ll be a lot of interesting things to look for in the future. Where can people go if they want to know more about you or what Netflix is doing with GraphQL?
Tejas Shikhare: I think for me, you can reach out to me on Twitter. My handle is tejas26. I love reading about GraphQL and engaging with the community there, so definitely reach out to me if you have questions about GraphQL and where we are going with it at Netflix. We have tons of stuff that we’ve published. We have a series of blog posts. We have open source, the DGS framework, which is Spring Boot, which is a way to do GraphQL in Spring Boot Java, which is what we are using internally. We have a couple of QCon talks, and even GraphQL Summit talks from coworkers, so if you just search Netflix federated GraphQL in Google, some of these resources will come up.
Thomas Betts: Tejas, thank you again for joining me today.
Tejas Shikhare: Thank you so much Thomas.
Thomas Betts: And thank you for listening and subscribing to the show, and I hope you’ll join us again soon for another episode of the InfoQ podcast.
Links
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Google Storage Transfer Service Now Supports Serverless Real-time Replication Capability
MMS • Steef-Jan Wiggers
Recently Google announced the preview support for event-driven transfer capability for its Storage Transfer Service (STS), which allows users to move data from AWS S3 to Cloud Storage and copy data between multiple Cloud Storage buckets.
STS is a service in the Google Cloud that allows users to quickly and securely transfer data between object and file storage across Google Cloud, Amazon, Azure, on-premises, and other storage solutions. In addition, the service now includes a preview capability to automatically transfer data that has been added or updated in the source location based on event notifications. This type of transfer is event-driven, as the service listens to event notifications to start a data transfer. Currently, these event-driven transfers are supported from AWS S3 or Cloud Storage to Cloud Storage.
In a Google Cloud blog post, authors Ajitesh Abhishek, Product Manager, and Anup Talwalkar, Software Engineer, both working at Google Cloud, explain:
For performing the event-driven transfer, STS relies on Pubsub and SQS. Customers must set up the event notification and grant STS access to this queue. Using a new field – “Event Stream” – in the Transfer Job, customers can specify the event stream name and control when STS starts and stop listening for events from this stream.
STS begins consuming the object change alerts from the source as soon as the Transfer Job is created. Any upload or change to an object now results in a change notification, which the service uses to transfer the object to the destination in real-time.

The new STS capability provides several benefits. Aman Puri, a consultant at Google Cloud, explains in a medium blog post the benefits:
Because event-driven transfers listen for changes to the source bucket, updates are copied to the destination in near-real time. As a result, the storage Transfer Service doesn’t need to execute a list operation against the source, saving time and money.
Use cases include:
• Event-driven analytics: Replicate data from AWS to Cloud Storage to perform analytics and processing.
• Cloud Storage replication: Enable automatic, asynchronous object replication between Cloud Storage buckets.
• DR/HA setup: Replicate objects from source to backup destination in order of minutes.
• Live migration: Event-driven transfer can power low-downtime migration, on the order of minutes of downtime, as a follow-up step to one-time batch migration.
Microsoft provides a similar capability in Azure with Event Grid Service, allowing event-driven data transfer from a storage container to various destinations. By leveraging a system topic on the storage and subscribing to blobCreated events through an Azure Function, data from the storage container can be copied to a destination like another storage container, AWS S3 Bucket, or Google Cloud bucket. Alternatively, an event could trigger a DataFactory pipeline.
Currently, the event-driven capability is available in various Google Cloud regions, and pricing details of STS are available on the pricing page.
MMS • Renato Losio

Since January 5th Amazon S3 encrypts all new objects by default with AES-256 to protect data at rest. S3 automatically applies server-side encryption using Amazon S3-managed keys for each new object, unless a different encryption option is specified.
The cloud provider claims that the change puts a security best practice into effect without impacts on performance: S3 buckets that do not use default encryption will now apply SSE-S3 as the default setting. Server-side encryption with customer-provided keys (SSE-C) and server-side encryption with AWS Key Management Service (SSE-KMS) are not affected by the change.
Since 2017 the S3 Default Encryption feature was already an optional setting available to enforce encryption for every object uploaded. Going forward, S3 will automatically apply SSE-S3 for all buckets without any customer-configured encryption setting. Sébastien Stormacq, principal developer advocate at AWS, explains why the change is significant:
While it was simple to enable, the opt-in nature of SSE-S3 meant that you had to be certain that it was always configured on new buckets and verify that it remained configured properly over time. For organizations that require all their objects to remain encrypted at rest with SSE-S3, this update helps meet their encryption compliance requirements without any additional tools or client configuration changes.
The encryption status for new object uploads and S3 Default Encryption configuration is available in CloudTrail logs providing an option to validate that all new data uploaded to S3 is encrypted. To explain the changes, AWS published a Default encryption FAQ, clarifying that S3 only encrypts new object uploads. To encrypt existing objects, the cloud provider suggests using S3 Batch Operations. While no changes are required to access objects, it is no longer possible to disable encryption for new uploads and client-side encrypted objects will now have an additional layer of encryption. Angelica Phaneuf, CISO of Army Software Factory, writes:
This is an amazing release by AWS and will progress the security posture of everyone using their cloud.
Segev Eliezer, penetration tester at LIFARS, comments:
Now they should configure IMDSv2 by default on EC2 instances and update GuardDuty’s IAM findings.
Security blogger Mellow Root thinks that disk encryption in AWS is close to useless and potentially harmful, claiming it is security theater:
I suggest spending your time on IAM permissions, backups, disaster recovery, appsec, or pretty much anything else before disk encryption.
Corey Quinn, chief cloud economist at The Duckbill Group, writes:
This is a clear win for customers. Personally, I find the idea of encrypting objects in S3 at rest to be something of a checkbox requirement and nothing more, but if that box gets checked by default for the rest of time I’m not going to complain any.
The S3 change applies to all AWS regions and there are no costs associated with using server-side encryption with SSE-S3.
MMS • Karsten Silz

Transcript
Silz: My name is Karsten Silz. I want to answer one question in my talk, which is, can we build mobile, web, and desktop frontends with Flutter and one codebase? The answer is yes, we can. I’ll show you. We shouldn’t, because I can only recommend Flutter on mobile. I’ll tell you why.
First, why and how can you build cross-platform frontends? How does Flutter work? I’ll tell you about my Flutter experiences, and then give you some advice on when to use which framework. Who made me the expert here? I did in a sense, because I built a Flutter app that’s in the app stores. I’m also a Java news editor at InfoQ. I help organize the QCon London and QCon Plus tracks on Java and frontend. I know what’s going on in the industry. I’ve also been a Java developer for 23 years. Even though I use Java, Angular, and Flutter, I’m not associated with these projects. I don’t try to sell you books, training courses. I’m not a developer advocate. I’d like to think that I give you options, but in the end, you decide.
Why Cross-Platform Frontends?
Why do we need cross-platform frontends? The reason is because our users are multi-platform. Thirty years ago when I started, I just needed to build a Windows application. These days, we need Mac and Linux, and of course, iOS and Android on mobile. We could try to build with the native SDKs, but that’s too expensive. What we want to do instead is have one framework and one language, and we call that cross-platform. We need cross-platform frontends because they’re cheaper, and they’re good enough. Good enough means good enough for enterprise and consumer apps. I’m not talking about games here. They’ve got separate frameworks. That’s why we need cross-platform frontends because they are cheaper.
How to Build Cross-Platform Frontends
Now that we know why, how can we build them? The answer should be web. That’s our default stack for cross-platform. Why? Because it’s the biggest software ecosystem we ever had, and it’s got the most developers. Granted, it’s a bit hard to learn. You’ve got HTML and CSS, and JavaScript and TypeScript, and Node.js, and npm, and Webpack and stuff. There are a couple of different frameworks out there, React, Angular, Vue are the most popular ones. How does it look like? We use HTML and CSS for the UI, and JavaScript and TypeScript. Case closed? No, unfortunately not because we’ve got issues on mobile. First of all, compared to native applications, we’ve got some missing functionality, mostly on iOS. We’ve got no push notifications, and background sync doesn’t work. We’re also somewhat restricted compared to native applications. We can’t store as much data and don’t have access to all hardware functionality. The apps are often slower and less comfortable in the browser, and they’re missing that premium feel of the native look and feel.
Let me give you an example of why I think native look and feel has advantages. It’s a German online banking app that I use. I had recently started to move from their web version on the left to a native app here on iOS. Why is the native app better here? First of all, on the web version, you need to tap the Hamburger Menu. It’s hard to reach and it’s not obvious, and it’s always two tabs, one for the menu, and then one for functionality. The NavMe on mobile is easy to reach, obvious, and it’s just one tap for the most used functionality. The web application also has these little twisties. I’m not sure my mom would recognize them. That she could actually tap on it. I’m sure she could tap on those big cards on the right-hand side. I think the native app just looks nicer. A native look and feel is important because it looks nicer, and it’s easier to use, because it works like all the other apps on your phone. The Google Apps team agrees with me, because on iOS, they are moving from Material-UI to native iOS UI elements. The responsible Google manager thinks that only with a native look and feel that apps can feel great on Apple platforms. If we do that, we actually have two cross-platform frameworks to juggle, we’ve got web and native, because we keep web for PC, and now we’ve got native for mobile.
I’ve been saying native, but that’s really three different things to me. Number one is it runs natively. It’s in the app stores, and it’s an app. Number two, it’s got a native look and feel. Number three, meaning access to native platform functionality. Given those criteria, what native cross-platform frameworks are out there? There’s a ton and you can find some more on my web page. I looked for open source Java like ones. I’m a Java guy, and I came up with these four: Flutter from Google, React Native from Meta/Facebook, and then Xamarin from Microsoft, which is currently being rewritten as .NET MAUI. It’s supposed to be out in Q2 2022. Then finally, we’ve got JavaFX, which used to be part of Java, but then got open sourced, and it’s now mostly maintained by a company called Gluon.
Which Framework Is Popular?
Which of these frameworks is popular? Why do I care about popularity? A couple of reasons. Number one, a popular technology is easier to use, easier to learn. There’s more tutorials, more training material out there, and more questions and answers on Stack Overflow. It’s also easier to convince your boss and your teammates. I think popularity can make a difference in two situations. If your options mostly score the same, then you could say, let’s go for the most popular one. Or if something is really unpopular, then you could opt to not use their technology. As it just happens, I measure technology popularity in four different ways. First of all, I look at employer popularity. I do that by looking at how often technologies are mentioned in job ads at Indeed. Indeed is the biggest job portal in the world, and I search across 62 countries. Why is that important? If you go ahead and propose new technology in your team, and your teammates rightfully worry, can I find a job? They go to a job portal, and see how many jobs are out there that look for that technology? On the other hand, your boss is worried, can I hire developers for this technology? He also goes and looks in a job portal, because if there aren’t any job ads out there, there may be something wrong with that technology.
Here are the mentions in job ads, going back to August, where React Native had 19,200 mentions, and it now has 25,800. You see these percentages underneath? What do they mean? I use Flutter, the runner-up, as the baseline at 100%. Flutter went from 8,400 to 10,400. We’ve got Xamarin as well going from 5,200 to 5,800. It increased a bit as well, roughly still at 60% of Flutter’s volume. Then JavaFX dropping to about 6% of Flutter’s volume with 600 mentions worldwide. I think the initial two numbers were inflated artificially by wrong measurements on my side. The takeaway here is that React Native added 6,600 adds, whereas Flutter only 2,000. Now I’m looking at developer popularity, how many courses are bought at Udemy, one of the biggest online training sites? Money being spent on courses is another good indicator. It goes back to March of last year. There, Flutter leads, going from 1 million to 3 million students, to 2.1 million. Here, React Native is the runner-up, going from 812,000 to 1.1 million. Xamarin here is a lot less compared to React Native, just about a quarter of its volume.
Then JavaFX on a search recently about plateauing at about 16% of React Native volume. We see Flutter increased by nearly 800k, React Native only by 320k. Another developer popularity measure is Google searches. Starting here, JavaFX peaking in December 2008, and Xamarin the third most popular one peaking in March 2017. React Native as the number two, peaking in July 2019, and Flutter peaking in March 2022. We can see that Flutter has about twice the search volume that React Native has. Last one for developer popularity is questions at Stack Overflow. We can see here JavaFX being number four. It peaked in the end of 2018. Xamarin peaked at the end of 2017. React Native peaked at the end of 2021. Flutter just peaked at the beginning of 2022. We can see that Flutter has about twice the number of questions than React Native. If anything, React Native should probably have more questions, because Flutter is a batteries included framework, and React Native gives you a lot more options and leaves you a lot more freedom. Naturally, you would expect more questions just out of general use, but still Flutter, twice as many questions as React Native. If you want to sum up popularity, employers love React Native, where React Native leads by 2.5x, and it’s pulling away from Flutter. Developers love Flutter, where Flutter leads by 2x, pulling away from React Native. If you’re interested in more technology popularity measurements, in my newsletter, I also measure JVM languages, framework, databases, and web frameworks.
The summary is that web is the biggest ecosystem we ever had with most developers. It’s a bit hard to learn, but we’ve got React, Angular, and Vue as the leading frameworks. For native, meaning running natively, native look and feel, and access to native functionality, we need that on mobile. Flutter is loved by developers, but employers prefer React Native. We also have .NET MAUI and JavaFX, which are less popular. That’s how we can build cross-platform frontends.
How Flutter Works
How does Flutter work? This is DASH, the mascot for Flutter and Dart. Flutter is a Google project, so of course the question on everybody’s mind is, will Google kill Flutter? That’s a hard earned reputation. We’ve got entire websites dedicated to how many projects and services Google killed, here this website counts 266. What’s the answer? Will Google kill Flutter? We don’t know. What’s bad is that Flutter has in-house competition, for instance, Angular. You may not think it but if you look at the Angular web page, for web, mobile web, native mobile, and native desktop. That clearly is very similar to Flutter. It’s confusing. Should I use Angular or should I use Flutter? Then we’ve got Jetpack Compose, which is Flutter for Android. On the plus side, there’s external commitment to Flutter. For instance, Toyota will use Flutter to build car entertainment systems. Canonical uses Flutter to rebuild Ubuntu Linux apps. We also saw that it’s popular with developers, and in second place of popularity with employers. That’s also a plus.
Flutter supports multiple platforms. How long have they been stable? Mobile went first, more than three years ago, then web in March of last year. Then PC, Windows, we saw that earlier this year. Linux and Mac are hopefully becoming stable, somewhere towards the end of this year. Flutter uses a programming language, Dart. It isn’t really used anywhere else, so it’s probably unknown to you if you haven’t done Flutter. That’s why I’d like to compare to Java, because Java is a lot more popular. Here’s some Java code with a class, some fields, and a method. What do we need to change to make it into top code? You saw there wasn’t really a whole lot, just a different way of initializing a list. That’s on purpose. Dart is built to be very similar to Java and C#. Although this is Dart, this is not how you would write Dart. This is what Concise Dart looks like, simpler variable declaration and simpler methods. For comparison, this is what Java looks like, so Java is more verbose. Dart was originally built for the browser and didn’t succeed there, but it did succeed with Flutter. You could say it’s a simplified Java for UI development, but it has features that Java doesn’t, like null safety, sound null safety, so less null pointer exceptions, and async/await borrowed from JavaScript to handle concurrency. Like many UI frameworks, it’s got one main thread, and you can also create your own threads, which are called isolates. In my app, I didn’t use that so far, and UI is still pretty fluid. Doing stuff on the main thread here works in Flutter.
Dart is really only used in Flutter. They both get released together, which means that Google has a chance to tune Dart for Flutter. Let me give you an example of syntactic sugar that Google put into Dart. Here, we’ve got some Dart code, Flutter code to be precise. We’ve got a column with three text fields. If you look closely, then you see we’ve got this, if isAdmin, and it does what you probably expect it does. Only if that isAdmin flag is true, you actually see the password fields, only admins see the password field. Of course, you could do that differently, you could define a variable and then have an if statement. This is more concise, because it’s not separate. It’s used in line here in the declaration. That means it’s more concise, less boilerplate code. Again, that’s an example of syntactic sugar that Google can put into Dart and Flutter.
Libraries are called plugins in Flutter. There’s this portal that you can go to and you see is about 23,000. Most of them are for mobile, not all are for web and desktop. Most of these plugins are open source. There is a good plugin survival ratio. I use many in my app, and over the last year and a half, none of them got abandoned. There’s even a team of developers that takes care of some important plugins if they actually do get abandoned. If something is wrong with a plugin, if you see a bug, or if you want to change it, then you also have the option of just forking it, and then putting the Git repo URL directly in your build file, so it makes it very easy to use a fork of a plugin. UI elements are called widgets. The most important feature here is that widgets are classes. You don’t have a graphical UI builder. There’s no CSS, no XML files. It’s just classes, everything is just attributes and classes and code. That’s really good for backend developers, because that’s the kind of code they’ve always written.
You’ve got to configure widgets. You configure the built-in widgets, mostly, but you can also create your own widgets. The important feature here is that Flutter doesn’t use the native UI element. Instead, it emulates them with a graphic engine called Skia. Skia is used in Chrome, Firefox, and Android. Again, no native SDK UI elements are used because Flutter paints pixels. For look and feel, you get widget sets, and there’s three different categories. The first one is the stuff that you can use everywhere. You’ve got container, row, column, text images. You will use these widgets no matter what platform you’re on. Then you’ve got two built-in widget sets, the Material Design which you can use everywhere, and that’s the native look and feel on Android, and you’ve got the iOS widget set. Then through third party, you get the look and feel on macOS, Windows, and Linux.
Sample Flutter App
I created a sample Flutter app, which has five native look and feel with one codebase. Here’s the sample Flutter app. Here, my sample application is running in an iOS emulator, it is an iOS UI. If I start typing something, then you can see the label disappearing. I got an iOS dialog, but because Flutter just paints pixel, I can switch this over here to look like Android. Now here, as you can see, I can type my name, the label remains and the dialog boxes look like Android. Now I’ve got the sample application running in a web browser, meaning that I’ve got Material-UI with a Hamburger Menu. I’ve got the Material-UI form here with the Material-UI dialogs. Let me do the same thing here. I want to switch over to a Windows look and feel, so now you see on the left-hand side a Windows look and feel and the form fields look different. You can see there’s a different dialog here too. Now I want to switch over to a macOS look and feel. You see it doesn’t work perfectly. There’s something here, a bug, I think it’s a Flutter bug. Now the form here looks different, more like iOS, and the dialog looks different too. That’s all possible because Flutter just paints pixels.
Let me recap what we just saw. We saw five native look and feel, and we could switch between that. We can switch between a look and feel because Flutter just paints pixels, it doesn’t use the native UI elements. You can see that if you dive into the web application, you see everything on the left, you’ve got buttons and a form field. On the right when you look, it’s really just a canvas, which you see down there. Flutter paints pixels. The sample app is on GitHub. How does that switch work? It works probably the way that you expect it to. I created my own widgets. Then each of these widgets has a switch statement, and depending on which platform I’m running, then I create either an iOS, an Android, or macOS, or Windows widget.
Architectural Choices
When you build a Flutter app, you have to make four architectural choices. The first one is, how do you handle global state in your application? The default way is something called provider. I use Redux, known from the web world in my app. Second is, what kind of widget set do you want to use? Do you use Material, do you use native, do you use custom, or do you mix them? I use native iOS and Android. Routing, there’s a simple router built in called navigator, which is fine for most cases. There’s a more complex one, which you probably don’t need. I use the simple one, the navigator. When it comes to responsive layout, that means to adapt to different screen sizes orientation, there’s nothing built into Flutter. You have to resort to a third party plugin. I use a plugin that takes the bootstrap grid, and applies it to Flutter.
Native integration means two different things. Number one is it means using Flutter in native apps, which works on iOS and Android. The WeChat app is an example here. WeChat is that Chinese app that does everything. A couple of screens were added to this app, and they were built with Flutter, whereas the rest of the application remained in native. That doesn’t currently work for web and desktop. At least for web, it’s under construction. What’s more common is the other way, to use native code in Flutter. You mostly do that through plugins. Stuff like camera, pictures, locations, you don’t have to write native code, because you use a Flutter plugin. Now on mobile, you can also show native screens, and the Google Maps plugin uses that to show you the native iOS and Android screens. You can also have a web view and show web pages in your Flutter app. Finally, you’ve got on mobile, at least a way to communicate with native code through channels, which is asynchronous publish and subscribe. Your Flutter code, your Dart code can call into iOS and Android code, and the other way around. Then there’s even a C API for some more hardcore cases.
Flutter apps run natively. How do they do that? They rely on the platform tool chains. That means if you want to build Android, you need to use Android Studio. If you want to build for iOS and macOS, you have to run Xcode on macOS. If you want to build for Windows, you have to run Visual Studio, the real Visual Studio for Windows, Community Edition does on Windows. The engine gets compiled down to JavaScript and C++ on the web, and C++ everywhere else. Your app gets converted, compiled into a native arm library on mobile, JavaScript on the web, C++ on Windows and Linux, and Objective-C on macOS. Code build and deploy is important to Flutter. Why? Because they’re striving for an excellent developer experience. I think they’re succeeding, and I believe that’s part of the reason why developers prefer Flutter over React Native.
If we look at the code, what IDEs can we use? Two are officially supported, IntelliJ/Android Studio and Visual Studio code. Flutter has developer tools, and has a couple of them. The first one is the inspector, which shows you the layout of your application. Then we’ve got the profiler for memory, CPU, and network helping you debug your application. A debugger is there as well. We even have a tool for the junk diagnosis, which means if your application doesn’t run as fluid, doesn’t hit 60 frames per second, you get some help there. The important part is that all of these are not just in an IDE, they also run when you launch your application from the terminal, because they’re built as a Flutter web application so they’re always available.
Project structure is a monorepo, so you get the code for all the platforms in one Git project. You’ve got one folder for Dart, and then one folder per platform. Some of these folders actually contain project for other IDEs. macOS and iOS are Xcode projects. Android is an Android Studio project. Then launching a native application happens through shell files, so you get an app delegate Swift file, or a main activity Kotlin file that kicks off the application.
Flutter has a fast build and deploy. That’s important especially on mobile, because there it’s slow. Deploying your iOS, Android app could easily take 30 seconds, a minute, or even more, just to see your application changes live and an emulator on the phone. Flutter, on the other hand, uses a virtual machine during development. That allows it to do something that’s called hot restart, where within 3 seconds, the entire application gets set back to its starting point. More important, hot reload, where within 1 second, your changes are live and running. That’s really something that keeps you very productive with Flutter, because you can see your changes live, instantly, you don’t have to wait 30 seconds or a minute, like with native development sometimes until your changes are active. I think that’s one of the main reasons why developers like Flutter so much, because within one second, your changes are live.
Flutter Platforms
Let’s take a look at the Flutter platforms. On mobile, I give it a thumbs up. Why? Because you get two apps for the price of one. You get native look and feel. You get access to native functionality. You’re even running faster with build and deploy the native applications. On the web, I give Flutter thumbs down. Why? Because the only UI elements we have is Material-UI versus hundreds or thousands of component libraries and skins on the web. You also don’t have access to the native libraries, which on the web would be all these JavaScript libraries. Because of that, on the web, you just have a tiny amount of libraries versus hundreds of thousands or millions of JavaScript libraries out there, just that subset of the Flutter libraries, those 23,000 libraries that work for web as well. On the desktop, I’m also giving Flutter the thumbs down. Why? First of all, why don’t you use a web application? Why do you want to build a desktop application? Users are used to web applications on the desktop, and web browsers have less restrictions there than on mobile. On the desktop, only Windows is stable, and only just barely for a couple of months. Whereas Mac and Linux are currently not stable, so you couldn’t really use it in production right now. You do have access to native platform functionality through C++. Unfortunately, the UI sets for Windows and macOS are incomplete. For instance, there is a dropdown missing on the macOS side. I’m not sure that all of these widget sets will be accurate and maintained going forward, because that’s a lot of work.
Let me sum up here. Dart is a simpler Java tuned for UI. Plugins are the libraries. We’ve got a decent amount, and they’re easy to work with. Widgets are the UI elements. You can configure the built-in ones or create your own, and they’re emulated. It doesn’t use the native UI elements. Widget set give you the look and feel. Material and iOS ship with Flutter. We’ve got more like macOS or Windows through third party. On mobile, you can embed Flutter into native apps or use native screens and code in Flutter. Flutter runs natively because it compiles to native code using the platform toolchain. Flutter has great DevTools and gives you a monorepo for all platforms, and has a fast build and deploy on mobile. In the platform check, Flutter only really shines on mobile, lesser on web and desktop. That’s how Flutter works.
My Flutter Experiences
On to my Flutter experiences. I am the co-founder of a startup. We are a B2B software as a service for Cat-Sitters. Our value proposition is that our apps remove friction and save time. I wrote all the code. Here is what it looks like under the hood. The backend is Java with Spring in a relational database. I use Firebase for authentication and file storage. The frontend is an Angular application for the manager, and a Flutter application for the Cat-Sitters. What’s the business case for Flutter? Why did I choose to use Flutter? Number one is I wanted to have unlimited storage and push notifications, so no restrictions here. I wanted the app to be as fast and easy to use as possible, and so I need a native UI for them. Then when I looked at my prototype, and looked at Dart, which is similar to Java and the fast code build and deploy cycle, then I realized I could be very productive with Flutter. That’s why I picked Flutter. Flutter on mobile gets a thumbs up for me. It works as designed, you get two apps for the price of one. It has some minor quibbles, like the similar, it doesn’t always stop the app so you kill it. That’s ok. If something goes wrong, then it’s usually Apple breaking stuff. For instance, I can’t paste from the clipboard into the Flutter app in the simulator for a couple of months now. Apple broke it, and I’m not sure when this will be fixed.
What’s good is that the Flutter team actually listens. A year or two ago, there was some concern on bugs piling up, so Flutter started fixing a lot more bugs. They also have quarterly dev surveys where you can give them feedback. Flutter paints pixels. It emulates, it doesn’t use native UI elements. It works well on iOS and Android, at least. It has some quibbles on iOS. For instance, the list tile doesn’t exist as a widget, so I cobbled together my own using some plugins. The one thing that’s a bit annoying is that when you deal with native UIs, Flutter doesn’t really give you help coordinating that. Because the Flutter team, when you ask them, say, you shouldn’t use native UI, you should customize Material-UI instead. It’s manageable.
Native Look and Feel: iOS vs. Android
Let me give you some examples of the native look and feel in my app, iOS versus Android. First, we’ve got the iOS on the left and Android on the right. If you know your way around these two platforms, then you can see on iOS, we have the button in the upper, whereas on Android, we have a floating action button. The iOS has a list indicator, whereas Android doesn’t have that. Here are some detailed screens from iOS. This one here is a recent addition, the animated segment control that took a couple of months until it showed up in Flutter because it needed to be added to the library. Then down here, I told you that there is no built-in list tile for iOS, so this is the custom control that I created based on some plugins and some customization on my own. Then finally, here, we see some buttons. They are the same on Android. This is a place where I use my own design, not using native buttons.
I also give a thumbs up to Firebase. What is Firebase? Firebase is Google’s backend as a service on mobile, web, and server. It’s got mostly free services like authentication and analytics, and some paid features like database or file storage. Especially on mobile, it’s helpful because it gives you one service instead of two. For instance, crash logging and test version distribution, both iOS and Android have their own version. Instead of using these two separate services, you just use the one Firebase service. It works good, and has good Flutter integration. You’ll find some more stuff on my talk page, for instance, how to use the power of mobile devices. How to keep UI cracked with one source of UI truth. How you could be consistent between your web app and your mobile app. How back to basics also applies to mobile apps. These are my Flutter experiences.
Summary
Let’s just sum up what we’ve heard so far. Why do we need cross-platform frontends? We need them because they are cheaper, and good enough. How can we build cross-platform frontends? The default answer is web because it’s the biggest software ecosystem ever with the most developers. React, Angular, Vue are popular frameworks. We need native, running native, native look and feel, and access to native functionality, especially on mobile. Developers like Flutter, employers prefer React Native. Then there’s .NET MAUI, and JavaFX a lot less popular. We also talked about how Flutter works. Dart is a simpler Java tuned for UI. Plugins are the libraries, easy to work with. Widgets are the UI elements, they’re emulated. The widget set give us the look and feel. Material and iOS ship with Flutter. We can get other through third party plugins. Native means access to all native functionality on mobile, which is a plus. Flutter runs natively because it compiles to native code with platform toolchains. It’s got great DevTools, a monorepo for all platforms, and got fast build and deploy on mobile. Flutter really only shines on mobile, lesser on web and desktop. My Flutter experiences, the business case was to overcome restriction, have a fast UI, and be productive. Flutter works, two apps for the price of one. Flutter paints pixels, also works. Firebase is also good because it offers free and paid services, which means one service instead of two separate ones on mobile. It also works.
Flutter vs. World
Let’s compare Flutter versus the world in two cases here. Number one, React Native versus Flutter, the arch enemy here. React Native uses JavaScript. Flutter uses Dart. React Native is a bit slower because it’s interpreted JavaScript at runtime. Flutter compiles to native and that’s why it’s faster. React Native uses the native UI elements, but Flutter paints pixel, emulates stuff. With React Native, we’ve got two separate projects, one for the web, and one for mobile. With Flutter, we get a monorepo for all supported platforms. Desktop support in React Native is unofficial for macOS and Windows, but with Flutter, it’s official: macOS, Windows, and Linux. I think Flutter fits Java very well. Why? Because it’s much more mature and popular than JavaFX. You’ve seen that here. Even though Dart is a different language, it’s similar to Java. It’s a simpler Java. You write UI as code with classes, and you can keep two of the three IDEs in Java for Flutter. The big question, when to use which native cross-platform framework? I go by developer experience. If you’re a web developer, then use React Native. If you’re a .NET developer, then use .NET MAUI. Everybody else I recommend to use Flutter.
Can we build mobile, web, and desktop frontends with Flutter and one codebase? The answer is yes, we can. We shouldn’t. Really only recommending mobile here, not web, desktop. Why? Because on mobile, we get two apps for the price of one. We can do everything that native apps can do with a faster build and deploy. On the web, we only have Material-UI as the UI elements, and we’ve got very few libraries compared to the JavaScript ecosystem. On the desktop, we probably shouldn’t be building a desktop app to begin with, and only Windows is stable there.
Resources
If you want to find the slides and the videos, additional information, the native UI sample app, want to get started with Flutter, links to tutorials and other information, or you want to get feedback, subscribe to my newsletter, then you head to this link, bpf.li/qcp.
Questions and Answers
Mezzalira: Have you ever played with Dart, server side?
Silz: I have not. I’m a Java guy. That’s just a much bigger ecosystem there. No comparison. I think there are some that do Dart on the server side, but there are also people that use Dart for other frameworks. I wouldn’t recommend it. There’s much better options on the backend.
Mezzalira: Knowing the power of Java and the Java community I can understand.
You talk about how Flutter is gaining traction at the developers’ level. What about organization level? Can you share your point of view on how the C-suite would think about Flutter, especially, obviously the technical department? If it has a nice penetration for developers.
Silz: I think there’s probably three things here. Why do people want to hire React Native developers a lot, but when you look at developers, they prefer Flutter? I think there’s three reasons here. Number one, is that if you’re using React on your project, and a lot of people do, then I think React Native as a mobile framework does make sense. That’s what I’m recommending. I think there’s some push from that perspective. The second thing is, I think people are just wary about Google stuff. I hear that often when I talk about Google or a Google project. They say, when are they going to abandon it? There’s a reason why these web pages are out there. I think people are a little bit wary. Then they look at Facebook, and they say, Facebook has React and React mobile, so they can’t kill it, because then they can’t build their apps anymore. The third reason is that Flutter explicitly says, we want to have a great dev experience. Smartly, they published their roadmap for the year and they said, nobody has to use Flutter, because there’s the built-in base options there. There’s other frameworks out there. We have to give developers a great experience so that they actually want to use Flutter. That’s why they put a lot of money into tools. I think that pays off. I think the tool side is probably stronger than what you get on React Native.
Mezzalira: How do you feel about Flutter supporting all the feature changes from the UI style on iOS and Android?
Silz: The background is, as I said, Flutter doesn’t use the native UI set. It uses emulation, so it has to paint everything itself. I think the answer there is threefold. Number one, I’m feeling really good about Material, because the Material stuff is Google’s own design language. They recently went through some changes. It used to be called Material Design. Now it’s Material You, and there are some changes. The Flutter team already said, we’re bringing these changes in there. I think, no worry about the Google Material Design language. It’s got the home turf advantage. On the iOS UI set, or widget set on iOS and iPadOS, ok. There hasn’t really been a big change there. The only thing is they made some changes, left some smaller changes, they came into the widget set as well. For instance, there was an animated segment control. In the past, you had that stay with one and then the animated one where the slider moves around. That took a couple of months, but it’s there. Now, if iOS ever makes a big UI redesign. I think probably, yes, as well. It may take a while. I think where I’m most worried about is the third party ones, the macOS and Windows ones. Those are hobbyists. They’re currently not complete. On macOS, there’s no dropdown in those widget sets. That’s where I’m most worried about. Will they ever be complete, and will they remain up to date? Because both of these UI elements, the macOS and Windows, they are somewhat in flux. That fluent, modern design of Windows still developing, and macOS still going through some changes there, too.
Mezzalira: Does Flutter repaint the entire UI for a small change? If yes, wouldn’t this be a costly operation?
Silz: The answer is no. Flutter has change detection. What Flutter does under the hood, it’s a declarative framework, the same way that React Native is, or SwiftUI, or Jetpack Compose, and .NET MAUI. What it means is that in your UI, you say my widgets. In my text field, I have this text, and this text, the state of that comes from a variable that I declare. If you then change this variable, and you enclose that in a set statement, then Flutter knows, ok, the state of the UI has changed, and now I need to repaint the UI. It knows because you only change that one variable that only the UI elements that use that one variable, they need to be repainted. I think there’s no worry there. I noted in other frameworks I sometimes hear like with React maybe that things can get out of hand, change detection and repainting, and stuff. Flutter has got that really well down. You don’t see your UI really becoming very stuttery. The only time that you see some stutter, typically is when you get to a new page, and you start loading data. Because as I said, everything happens, Flutter is single threaded. Unless you do something special, everything happens on the main thread, and so to keep the 60 frames per second you have to be a bit careful. I think in my app, for instance, occasionally, it stutters a bit if I open a list, and there’s 100 elements on there. If I were to pay more attention, put some work into it, that could be fixed as well.
Mezzalira: How much can we fine-tune the UI? How easy is changing behavior and styles?
Silz: It’s different from the web. In the web the solution would be to use a style sheet, and change that style sheet and reference it. There is no equivalent in these frameworks for that, because everything is code. My recommendation would be to create your own widgets. You create your own text field. You create your own button. I even have pages created, where I said, here’s a page, and it’s got an edit button, for instance. Then you’ve got one central component that you have to configure. If you want to change your theme or change your style, you would then go and change all your components. Of course, then you can get smart and say, I’ve got a class that tells me what colors to use, or what font size to use, and all your widgets use that. Recommendation is build your own widgets that just wrap the widgets that you want to use, and then you apply the styling configuration in your own widget. Then you’ve got one central point to change that, because as with all the other frameworks, there is no extra style sheet config file, property file where you can make these global changes. You have to do them in the code, so just the regular ways of making changes across all your classes apply.
Change detection is different from Angular. In Angular, you can just change your state, and angular figures out what changes. In Flutter, you have to make an explicit set state around your state changes to force that state change. That’s a difference that I find from Angular. Angular you just change your variable and Angular repaints it. In Flutter you do a set state, and then you put your state changes in that statement.
See more presentations with transcripts
MMS • Anna Shipman

Transcript
Shipman: This is the Financial Times website, ft.com. This screenshot is from sometime in 2015. The site at that time was powered by a monolith. In 2016, a new application was launched to power the ft.com website, and this is the new homepage. It is powered by a microservices architecture. Developers everywhere rejoiced. It’s faster. It’s responsive on mobile. It has a better user experience. It shipped hundreds of times a week. It didn’t take long for entropy to set in. Within a year and a half, things were not going so well. Over 80% of our 300-plus repos had no clear technical owner. Different teams were heading in different technical directions, and there were only five people left on the out-of-hours rota. Entropy is inevitable. It’s possible to fight entropy, and I’m going to tell you how.
Background
I’m Anna Shipman. I am the Technical Director for customer products at the Financial Times. My team is in charge of the ft.com website and our iOS and Android apps. I’ve been at the FT for about four years. Before I worked at the FT, I worked at the government digital service on the gov.uk website, which is also a microservices architecture. I’ve been a software engineer for nearly 20 years.
Outline
Fighting entropy takes place in three phases. Firstly, you have to start working towards order. Secondly, you have to actively remove haunted forests. Thirdly, you need to accept entropy and handle it. I’ll tell you how we did those things at the Financial Times and how you can too. Firstly, I’ll give you a little bit of background about the Financial Times. It’s a newspaper. It’s the pink one. We’re a news organization, we actually do a lot of other things as well. What I’m going to talk about is the ft.com website and our apps. You might think it’s just business news, but we do a lot of other things. It’s a subscription website, but some of the things we make free in the public interest. Something you might have seen is our Coronavirus tracker, this showed a lot of graphs of data about Coronavirus, and this is free to read.
The Falcon Monolith, and the Next Microservice
That is the screenshot of the old website powered by a monolith called Falcon. Falcon had to be deployed out of hours monthly. It’s very old school. There was just no way to move to continuous deployment. The other thing about it, which I think you can see when you look at the screenshot is that different parts of the site were owned by different parts of the business. There wasn’t really a coherent whole for a user. For two years, a small team worked on a prototype of what a new ft.com website could look like, called Next. Next has a microservices architecture. There’s a focus on speed, shipping, and measurement. In October 2016, Next was rolled out to everyone. Now it ships hundreds of times a week. It is much faster. It’s responsive on small devices, which the old site wasn’t. It’s got an A/B testing framework built-in so we can test our features before they go out to see if they’re going to be useful. It’s owned by one team, customer products. That’s my team. What that means is that product and design work together to form a coherent whole for the user. As a user, you get a coherent experience. That means that the tech is governed in one place.
The Financial Times Dev Team
I joined the Financial Times in April 2018, so about a year and a half after the launch. The FT is a great place to work, it has a great culture. This is a photo of our annual Rounders Tournament, which we managed to do last year. We are a diverse team with a lot of autonomy of what work we do. Everyone is smart, and really motivated by our purpose. Our purpose is speaking truth to power. Our motto is without fear and without favor. I think at this time, we can all understand the importance of a free press. All was not well with the tech. When I joined, I met all the engineers on my team, one to one, it’s about 60 engineers, and some common themes emerged. Firstly, the technical direction wasn’t clear. Teams weren’t aware of what other teams were working on. The tech was really diverging. For example, we have an API called Next API. One team told me that Next API was going to be deprecated, so they weren’t working on it anymore. Another team told me they were actively working on developing and improving Next API.
There were haunted forests. Haunted forests means areas of the code base that people are scared of touching. The phrase comes from a blog post by John Millikin. He says some of the ways that you can identify haunted forests are things like nobody at the company understands how the code should behave. It’s obvious to everyone in the team that the current implementation is not acceptable. Haunted forests, people are afraid to touch them, so they can’t improve them, and they negatively affect things around it, so they decrease productivity across the whole team, not just in that area. Another thing that came out was people said feature changes felt bitty. The changes we made didn’t feel like they were tied into a larger strategic goal. The clarity of direction that had come with the launch had dissipated. With a launch, it’s really easy to see where you’re going, to rally behind the mission. That clarity had really dissipated. It didn’t feel like we’re actually increasing value for our customers. One of my colleagues said something that really stuck in my mind, it doesn’t feel like we’re owning or guiding a system, just jamming bits in.
Over 80% of our 300-plus repos didn’t have an assigned technical owner. We had 332 repositories of which 272 were not assigned to a team. It didn’t mean they didn’t have a technical owner, it just meant we didn’t know who it was. That meant if something went wrong with it, we didn’t know who to approach, or if we wanted to improve it, again, we didn’t necessarily know who to ask. I learned tech is an operational risk that you just don’t know about yet. There were five people on the out-of-hours rota. The five people who were on the out-of-hours rota were all people who’d worked on the original Next. As they left, for example, moving to other projects within the FT or leaving the FT, they left the rota, and no new people joined. I’ll talk later on a bit about how we run our out-of-hours rota. The rota relies on there being a lot of people on it, so you get a good amount of time between incidents. Five people on the rota is not sustainable, people get burned out. Also, it’s not sustainable, long-term, because if nobody new is joining, eventually, those five people will leave the FT, and then we’ll have no one on the out-of-hours rota. Finally, the overall view of everyone was the system felt overly complex. When I joined, there was a small group of people called simplification squad, who were, alongside their work, they were meeting to try and work out ways that we could simplify our code base.
Entropy Is Inevitable
I recognized some of these themes from gov.uk. Gov.uk was also a microservices architecture. This is an architecture diagram. One way to solve these problems is to throw it in the bin and start again. Next cost £10 million, and it took 2 years to build. We don’t want to drive the tech so far into the ground that it is not retrievable, and we just have to throw it away and start again. Our vision is no next Next. What that means is a focus on sustainability, on making sure that we can continuously improve it. Swapping things out in flight as they become no longer the right tool for the job. In any case, there’s no point in throwing it away because we’d be here again in X years, because entropy is inevitable. Entropy means disorder. The second law of thermodynamics states, everything tends towards entropy. Basically, it’s a fundamental law of the universe that if you don’t stop it, things will gradually drift, the natural drift is from order to entropy. On the left side of this diagram, you’ve got a relatively neat little hand-drawn diagram. You’ve got order, but over time, it’ll drift towards what you see on the right-hand side, disorder. That means for software, over time, your system will become messy, it’ll become more complex, and eventually will become unmanageable.
You can fight entropy. The first thing you need to do is start working towards order, start working away from entropy. Stop just jamming bits in. You need to do this more consciously with microservices than with a monolith. Because microservices are smaller units which lend themselves more to smaller pieces of work. It’s easy to just jam bits in because you’re only working on the small bit, you’re not looking at the coherent whole. Conversely, it can make it harder to do larger, more impactful pieces of work. Because when you do, you have to make the change in multiple places. Sometimes that might mean across teams. Sometimes that might mean fundamentally changing what the microservices are. It might mean merging or getting rid of some microservices. It’s harder to do that when you come from a position of already having the investment in those microservices.
Clarify Your Tech Strategy
How do you do this? Firstly, you need to clarify and communicate what order looks like. What I’m talking about here is clarifying your tech strategy. Make your intentions clear. I said that our vision is no next Next. One strategy is, it’s diagnosis of the current situation. It’s the vision, where do you want to get to? It’s the concrete steps to get from here, where you are, to the vision where you want to get to. That’s your strategy. You need to communicate your strategy so that people know where to go when they’re trying to stop the drift towards entropy. You need to communicate your strategy. Everybody needs to know where you’re headed and what the strategy for getting there is. You need to communicate your strategy until you are sick of the sound of your own voice talking about it. Even then you need to carry on communicating. Because every time you talk about it, there’ll be someone who hasn’t heard it before. There’ll be somebody who wasn’t listening last time you talked about it, or they were there, but they’ve forgotten, or they’re new to the team. You just need to keep communicating your strategy so that everybody understands what they need to do in order to move away from entropy and towards order.
Start Working Towards Order
Once you’ve clarified your intention, so communicated them, you need to make it easy for people to move towards order. I’ll talk about some of the things we did on ft.com. One thing we did was we moved to durable teams. When I joined the FT, we had initiative based teams. For example, when we wanted to add podcasts to the site, we put a team together to add podcasts, and they worked together for about nine months. Then once podcasts were on the site and working well, they disbanded and went to work on other projects. There are a few problems with that model. One is around how teams work well together. You might have heard the model of forming, norming, storming, performing, which basically means you go through several phases before you start being a highly performing team. If you’re constantly building new teams, then you’re constantly doing that ramp-up. You’re constantly going through those phases, and you don’t get as long in the high performing stage, which is frustrating for the team and it’s not great for the product. Another problem is around technical ownership. Now we’ve resolved it. After that situation, if we’d wanted to make a change to podcasts, who would we go to? There wasn’t a team there. Or if something went wrong with podcasts, again, who would we ask?
What we did was we split up our estate into product domains. It’s not exactly like this now. This is the first draft. It’s very similar to what we have now. Each of these is a team, and they each have strategic oversight of that area, that product domain. They’re an empowered team, so each team is led by a product manager, delivery manager, and tech lead, and they set their direction and priorities because they work in this area. They’ve got the experience to identify what the most valuable work they could be doing is. The team is long-lived. That’s really important, because that means you can make big bets. You can do the impactful piece of work that may take a really long time to have a payoff, but it doesn’t matter, it’s a long-lived team so you’ll be there to see the payoff. They also own all the tech associated with that area. As part of this work, we’ve moved to full technical ownership. This means every system, repo, package, database, has a team assigned as a technical owner, and that team is responsible for supporting it if it goes wrong, and for working on the future strategic direction of it. That did mean that each of the durable teams ended up with some tech that they didn’t know about. Part of ownership is understanding how to be comfortable with how much work you need to do to make sure that you really know something. What things you’re comfortable with not knowing that well. What things are really important, and you need to make sure that you understand fully.
This is a work in progress. I showed you on this diagram, the platform’s team. The platform’s team have 72 repos. What technical ownership means in the context of 72 repos is still TBC, we’re still working on that. Also to note that durable teams improved a lot of things, they had great improvements, and the feature changes now feel like they’re really working towards a bigger thing. There are still problems. Still, some of the problems I mentioned with microservices are here too. You can still have siloed thinking. It can still be harder to do work that crosses domains. It’s definitely better than it was when there wasn’t that pattern about where things were.
Another way you can make it easy for people to move towards order is to have guardrails. What this is about is reducing the decisions that people need to make. Clarify how much complexity is acceptable for you on your project, on your work. On ft.com, we stick to Node.js and TypeScript. This is one example of guardrails. TypeScript is very similar to Node.js. It’s JavaScript but it’s strongly typed. Everything we write is in Node.js or TypeScript. That is one decision that you don’t have to make. That naturally reduces the complexity of things because everyone can understand all the code that’s written. On gov.uk, we didn’t do that. At the start when we were writing the site at the beginning, we talked a lot about how microservices allow you to use the right tool for the job. We include a programming language in that. People chose the tool that was the best tool for that particular microservice. What that meant was, we ended up after a couple years in the situation where most of our repos are written in Ruby, but we also had some that were written in Scala. Ruby and Scala are very different languages, very different mental models. You don’t get many engineers who are really good at Ruby and also really good at Scala. That made things like working across those services very difficult. It made hiring difficult when we were trying to do that. That’s something to watch out for. That’s the thing that increases entropy.
Now at GDS, they have the GDS way. GDS is the government digital service. What this does is it outlines the endorsed technologies. These are things that you could use that other people are using. It means that you get benefits, like it’s quicker to get started. You can use shared tech. These are guardrails rather than mandates. You can still do something different if your project needs it. It’s not you must use this. It’s like, it will be easier for you if you do because this is what others are using. I just want to pull out the thing I said about Scala. In the GDS way, they talk about not using Scala, for the reasons I mentioned. Scala is not one of the endorsed languages. If you’re interested in what they are, they are Node.js, Ruby, Python, Java, and Go.
Another way of thinking about this, very similar, is the golden path. This is a blog post by Charity Majors where she talks about the golden path, and she outlines how to create a golden path. What that’s about is defining what your endorsed technology is, and then making it really easy to follow that. I’m going to read a bit out of the blog post, which makes this point. You define what your default components are, and then tell all your engineers that going forward, the golden path will be fully supported by the org: upgrades, patches, security fixes, backups, monitoring, build pipeline, deploy tooling, artifact versioning, development environment, even tier-1 on-call support. Pave the path with gold, hence the name. Nobody has to use these components. If they don’t, they’re on their own, they’ll have to support it themselves. You’re not saying you have to use this technology, but we will make it easy for you if you do. That is one way to keep order within your system. Essentially, the first thing you have to do is start working towards order. The way you do that is clarify what order looks like, communicate it, and then make it easy to move towards order.
Actively Remove Haunted Forests
The second thing you need to do is actively remove haunted forests, because entropy is inevitable. Things will get gnarled up anyway. Even if you have everything I’ve said, even if you’ve got guardrails, even if you’ve got tech strategy that everybody understands, the fact is everything drifts towards entropy. It’s a natural law of the universe. Things will start to get messy anyway. This could look like things like the tech you used, it’s changed. It’s no longer fit for purpose, or it’s no longer available. Or you’ve added a lot of features, and the features are interacting with each other in ways that don’t quite work properly, or just things will happen, things get messy. Sometimes people talk about this as technical debt. It’s not actually the correct use of technical debt. What technical debt is, is where you make a decision, you make an active tradeoff, so you do something in a hacky way to get it done quickly, rather than the right way. What you’re doing is you’re borrowing against future supportability, future improvability and reliability. The reason it’s called technical debt is if you don’t pay that debt off, it starts accruing interest and everything starts getting harder. What you get through entropy isn’t, strictly speaking, technical debt, but the outcome is the same. You get the same problems. Things gradually get disordered, they get less logical, they get more complex, harder to reason about, they get harder to support.
You can go quite a long way by following the Boy Scout Motto of leave things better than you found them. Whenever you work on a part of your system, improve it, leave it better. Sometimes you will have to plan a larger piece of work. You’ll have to plan it and schedule it and make time for it. One of the things we did on ft.com was we replaced a package we had called n-ui. N-ui handled assets for us. It was basically on every page. It did things like building and loading client side code, configuring and loading templates. It did tracking. It did ads configuration. It did loads. It was a haunted forest. The current team didn’t feel confident at all making changes to it. It was really tightly coupled to decisions that had been made right at the beginning of the project. We put a small team together, and they spent some time splitting out all that functionality into a set of loosely coupled packages. It’s much simpler, it’s much easier to understand, and all of our engineers can now confidently make contributions to different parts of it. As a byproduct, this wasn’t like the stated aim of the project, but as a pleasant side effect. This has also increased the performance of the site.
You do have to schedule this work properly. This took a team of four people about nine months. That is a significant investment. It’s not something you can just do alongside feature delivery, it’s something you actually need to make time for. We’re about to kick off another piece of work, to a similar thing. This is a diagram of our APIs for displaying content. Over time it’s organically grown to look a bit like spaghetti. I went to the Next API. We have a situation now where we’ve got a new homepage, and the new homepage doesn’t use Next API. We’ve got a new app. The new app uses both Next API and the App API. We’re kicking off a project now to rationalize those content APIs.
My point here is, it’s not one and done. Tech changes, things change, entropy is inevitable. You will have to keep doing these types of pieces of work. Because of that, you need to learn how to sell the work. As it happens, coincidentally, recently, I read a really good article on InfoQ, which talks about how to sell this technical work to the business. The key points from the article are stories are really important. You structure your message, the piece of work you want to get done as a story with your business partner as the hero and you as the guide. Then you back it up with business orientated metrics and data. Things like productivity, turnaround time, performance, quality. Learning how to do these kinds of things is what helps you make sure you can set aside the time to fight entropy. Entropy is inevitable, so you have to make sure you schedule in larger simplification projects.
Accept Entropy and Handle It
Then the last thing you have to do once you’ve done those things, is you have to accept entropy. You have to accept that there will be disorder, and handle it. The fact is, you’ve accepted some level of complexity by using microservices. Whether you meant to or not, whether you know that or not, the fact of the matter is, you have taken that on. Because microservices trade complicated monoliths for complex interacting systems of simple services. The services themselves are simpler, the interactions are much more complex. To return to this gov.uk diagram, as an architecture diagram, this is not the most complicated diagram. Everything’s in its right place, the layers are separate. It’s clear where things live in the right place, things where things live. What is complex about this diagram is the interaction. You can see that there are different colors for different kinds of interaction. With microservices, there’s a possibility of cascading failures. Failure in one system causing failures in systems around them. The other thing about microservices is there’s a difficulty of spotting where an error is. The bug might be in one microservice, but we actually don’t see the impact several microservices away, and it can be quite hard to track that down.
A microservices architecture is already inherently more complex. If you your system is complex, the drift towards entropy will make things very messy. The main way you address this is you empower people to make the right decisions. The more people can understand what order looks like, and can make decisions about the work, the better. Devolve decision making as far as you can. Get to a position where people can make decisions about their work. For this, people need context, they need authority, and they need to know what to do. One really good way to get to this position is to involve people in building tech strategy. I don’t go off into a room on my own and think about the tech strategy. I work with a wide group of people to build our tech strategy. I work with senior engineers, tech leads, principal engineers, product, and delivery. The reason I think it’s really worth involving this wide group of people with tech strategy, is firstly, it’s really useful to share context with each other. We all have context each other don’t have. Specifically, like as leadership, I have context around the business and what other teams are working on, things like that. Then the teams actually know about the actual work. Input from people doing the work leads to better decisions. Also, if people have helped create a tech strategy, then they’ll feel more empowered to actually enact it.
The first way that I involved people with building the tech strategy is, when I first joined the FT, we had an away day with the people I mentioned, senior engineers, principal engineers, product delivery. We did this exercise, a card laying exercise. What you do here is you write down all the technical pieces of work we needed to do, and you lay them out on the floor. You start at one end of the room, and you put down what you think we need to do. January, and then February, and then March, and you lay them out in the room. Then as a group, you walk through them together. You start at January and you talk about the things that are on the floor. As you do that, you start to talk about things and how they depend on each other. You might say, we’ve got this thing in January, but actually it’s less important than this thing we’ve actually put in April. Let’s move that April thing earlier in the year. Or you might say, actually, this thing we’ve got in April really depends on this thing that we don’t have until May. We can’t do that because there’s dependencies, and we need to bring that May thing earlier. Doing this exercise is great. It was incredibly useful for me joining the FT, because at that stage, I didn’t know about the tech, so I got a lot of context. Everyone gets context that everyone else has in their heads. You also leave that room with a shared understanding of what the next steps are, and what order to do them in and what later steps are as well.
We did that right when I joined the FT. That exercise saw us through with the priorities and the next steps, and it saw us through for about two years. We’ve got to a situation where we need to do the exercise again, to see where we were. We’ve booked in another away day, we’ve booked in for the 24th of March 2020. On the 23rd of March 2020, the UK went into lockdown, so we cancelled that. We did not do it. We did not have that full away day, partly because I couldn’t work out a good way to do a card laying exercise remotely. Mainly because asking people to take part in a full day meeting remotely is a horrible thing to ask people to do. I didn’t want to do it. Over the next couple of years we worked on tech strategy together in various different ways. One thing we tried was, we had a Trello board. We did voting, and we discussed it. We did that a couple of times. There was one situation where we had to make some technical decisions. I just made those decisions with me and my technical leadership, my principal engineers. We made good decisions, decisions had to be made. I do not think that that is a very sustainable approach, because it is really important to involve the wider group in the tech strategy.
What we’ve done this time round, is we wrote a document with a proposal for what we thought the next priorities were for the tech strategy. We shared that document with a group of people, so senior engineers, principal engineers, product delivery, and gave them about a week to read it. Then we had six smaller meetings. Each principal engineer invited the tech lead and product manager of the teams that they oversee. That was a small group of about five to six people. Then we talked through the document. That was a smaller meeting. It was a shorter meeting, it was an hour. There are a few advantages to doing that. The point of the meeting, and the document, we shared the document for the comment and the meeting. This was for people to tell us what they thought of the suggested priorities. Had we missed something? Was there something that we had in the document that actually was more important than what we thought the priorities were? Where had we got it wrong? Did they think it was right? To get their input and to get further information that they had. We did that both via the document and then in these smaller meeting conversations. Because there’s a smaller meeting, it’s easier to contribute. It can be quite hard to contribute in a large meeting with 30 people. Another big advantage of doing it this way is that most of us don’t have our best ideas in the moment in the meeting. Quite often you think about something, you get a better idea when you’ve had a chance to reflect on it. This process allowed some reflection.
You had time to reflect from reading the document. Then there was a meeting and you could raise some thoughts there. Then also there was time after that where you could actually come back and comment on the document, or make some comments about the meeting. There’s disadvantages to doing it this way. It’s not perfect. One thing is it takes longer. With an away day, it’s one day and you’re done. You come out with your strategy. With this thing, you have a week between the meeting and the week for the document, it’s actually taken several weeks. The other bigger disadvantage is that you don’t hear what other groups think. I was the only one who got the full context there because I was in every meeting. Each smaller group only heard what those people in the group thought and they didn’t get the context from other teams. What we did about that was we made notes on every meeting in one shared document. Although they didn’t hear it, they could go and see what other teams had said. This has had quite a positive feedback. I think we will carry on doing this process, possibly with some refinement.
Documentation Is Key
The next thing I want to talk about in empowering people to move away from entropy and towards order is, it’s really important to have good documentation. I don’t need to tell you about the importance of documentation. What I will tell you is three kinds of documentation that we use. Firstly, I mentioned that there was a lack of awareness between engineering teams of work that was going on in other teams. What we found was that people with relevant experience in a different team could add useful experience to a plan, but they just didn’t know the work was happening. What we’ve done now is we’ve introduced these technical design documents. When tech leads are making architectural decisions, this is how they communicate them. They share them with other tech leads. They give two weeks for people to contribute, so that everyone in the group knows what change is happening, and also they can contribute if they have useful information. It also has the benefit of documenting the reason why architectural decisions are made as an architectural design record. This has addressed the problem that teams didn’t know what work was going on in other teams, especially architectural work that could impact them.
The second thing I want to talk about is this amazing application called Biz Ops. This is built by another group in the FT, our engineering enablement group. This is a brilliant application that has information about 1500 different services across the FT. It stores loads of information. I can go in here and I can see what teams are in customer products. I can drill down into a team and see what repos each of them own. I can drill down to the code. I send a link to GitHub. Or vice versa, Ops can see if the system is alerting. They can look in here, and they can see who owns that system, who’s the tech lead for that team. This is really incredibly useful.
The last form of documentation that I want to talk about is public blogging. I am a big fan of blogging as documentation. Because once it’s out there on the internet, it is really easy to share with anyone. It doesn’t get lost. It’s not somewhere where only some people have access. It’s out there. It’s good for sharing with people who are new to the team, sharing externally. It’s got a couple of big advantages. One is a blog post has to make sense. It really clarifies your thinking. There have been situations where I’ve been writing a blog post about a piece of work. As I’m writing the post, I’ve realized that there is something that we didn’t do that would have made sense to do, and so I’ve gone away, done that work so I can come back and finish writing the blog post. The other big advantage of blogging is it needs to be a good story. A good story means that you can communicate your ideas better. Writing the blog post as a story really helps with communicating it even through different mediums. One of the main audiences for our blog is the internal audience.
Increasing Out-of-Hours Rota Participation
The last thing I want to talk about here is how these things aren’t enough, and it’s not just enough to have involvement with tech strategy, it’s not just enough to have good documentation, you need to use a variety of different methods to solve problems. I’m going to talk to you about how we solved the problem that there were only five people on the out-of-hours rota. First, I’ll tell you a bit about how we do out-of-hours. We’ve got, outside of customer products, a different team, we’ve got a first-line Ops team, and they’re for the whole of the FT. They look after over 280 services. We have levels of service, and they look after services that are platinum or gold. They’re based in Manila, and they look after all of them. They can do various things. They can fail over from U.S. to EU or vice versa. They can scale up instances. They can turn things off and on again. There are various troubleshooting steps in the runbooks. They can take those steps. If they can’t solve the problem, then they call out each group’s out-of-hour support.
The out-of-hour support on customer products or across the FT is not in our contracts, it’s voluntary. It’s not something we have to do. It’s not voluntary, as in, you do get paid for doing it. You don’t have to do it. You don’t have to be on the out-of-hours rota. You don’t have to stay by your laptop making sure you don’t have a drink or anything like that. The way we do it is you’re on the rota all the time, but it’s best effort. Meaning, if you can’t take the call or you missed the call, that’s fine. Ops will just call the next person on the list. What they do is they call people in the order that they were not most recently called. They don’t call the same people all the time. They look to call someone who it’s been the longest since they were called out. If you do get called out, you can claim overtime, but you can take time off in lieu. We don’t get called out very often. Middle of the night call-outs, on average, they’re every two months. That’s how we do Ops out-of-ours.
When I joined, we were down to five people on the rota. Sometimes you need a variety of techniques. I’m going to tell you what techniques we used to improve that. The first thing I’ll talk about is our Documentation Day. We have runbooks. I’ll define what we mean by that, because people use it in different ways. Runbooks are documents on how to operate a service. At the FT, the runbooks have a lot of detail. They’ve got last release to production. They’ve got what failover it has, is it active-active? Is it a manual failover or an automatic failover? They’ve got architecture diagrams. They’ve got details about what monitoring is available. They’ve got some troubleshooting steps that can be taken by first-line support. They’ve got who to contact if there’s an issue. They weren’t up to date. These things definitely need to be up to date. Brilliant Jennifer Johnson, and some of her colleagues organized this Documentation Day, where everybody on customer products downed tools, and we spent the whole day making sure that the runbooks were up to date. This had the advantage of not just making sure that the runbooks were up to date, but also getting some understanding about different areas of the system.
Another thing we did, organized by another brilliant colleague, Sam Parkinson, was arranged incident workshops. What this was, was running through old incidents in a mock way. Actually, the picture I showed at the beginning here, this is people running through an incident workshop, which is why they look so cheerful. Basically, we took an old incident that had happened and ran through it, and role played through it. The main advantage of the incident workshops, the really great thing that came out of it was that more junior people saw more senior people not knowing what to do. Because when you’re more junior, you think that you need to know everything to be on the out-of-hours rota. You think, I’m going to get called in the middle of the night and I won’t know everything about it, and so I can’t join the out-of-hours rota, because you need to know everything to be on the out-of-hours rota. What they saw in the incident workshops was more senior people saying, “I have no idea what’s going on. I don’t know what this is. Here’s where I’d look.” These were really good. They really encouraged people to feel confident about joining the rota.
The last thing I want to talk about is we introduced a shadow rota. What that is, is you sign up for the rota as a shadow person. When there’s an incident, Ops will call the person who’s actually on the rota and they will also call a shadow rota person. You just get to watch and see what’s happening. Actually, we found that people on the shadow rota often make really valuable contributions to incidents, but they’re not on the hook for it. All these things together meant that we quadrupled the number of people on the rota. We went from 5 to 22, so more than quadrupled. We went from 5 to 22 people in the rota, and the team is about 60. That was really good. We’ve made our rota sustainable.
Summary
With your microservices architecture, you have accepted a level of complexity. The drift towards entropy will make it more messy, so you need to empower people to handle that. We fought entropy and won. We’ve now got a clear technical direction. We’ve got full technical ownership. We’ve quadrupled the out-of-hours rota. We lived happily ever after. Not quite. It’s an ongoing project, because entropy is inevitable. We have to carry on fighting these things. You can fight it. You start working towards order, actively remove haunted forests, and accept entropy and handle it.
Conclusion & Resources
There will always be complexity in microservices. There are things you can do to reduce and handle it. You have to address these things consciously, they won’t just happen. I’ve given you some tools you can use. I’ve got some useful links. The first one is my blog post about our tech strategy. The second is the article I mentioned on InfoQ about how to sell technical work to the business. The third one is our careers website.
Questions and Answers
Wells: The first question was about the built-in A/B testing capability. Is it considered to be owned by one of your platform teams or by a different durable team?
Shipman: We do have something that we built, an A/B testing framework, and that is owned by our platform team. On customer products, we have a platform team. We are looking to replace that because technology has moved on quite a lot since we built that, but it’s currently owned by the platforms team.
Wells: The second question is about the size of your platform team that are currently supporting 72 repositories.
Shipman: It varies. At the moment there are, I think four or five engineers. It’s quite a small team.
Wells: Is that big enough?
Shipman: We do have a couple of vacancies on that team that I would like to fill.
Wells: It’s always a challenge to have people working in a platform team, when you’ve also got feature development to be done, I think.
Shipman: They’ve come up with some really interesting ways to clarify which tech they’re supporting, and which tech they’ll help people with pull requests on, and which tech they’re not supporting at the moment.
It went really well. It was a good day. Definitely read Jen’s blog post about it.
Wells: The things that I really liked about it, is I think everyone gets quite excited but someone made trophies for everybody. There were these brilliant trophies. I was working in operations at this point, and the runbook, the quality of all of your runbooks just got so much better in one day. I’ve never seen developers be that excited about doing documentation for runbooks.
Shipman: There were branded pencils as well.
Wells: You said that the ability to tell a story is important, how can people get better at doing that?
Shipman: People suggested things like improvisation workshops are very good for getting into that kind of stuff. There’s a few people who talk a lot about how useful improvisation workshops are for helping you think about things.
Wells: Who are in charge of preparation of incident workshops? Do you have internal training team or some special squad?
Shipman: That was completely on the initiative of Sam Parkinson, who’s the one who wrote the blog post. He’s principal engineer on customer products. We do incident reports. After an incident, we have a blame-free postmortem when we write up what happened and our recommendations for next steps. It includes a timeline of what happened and when, and what steps were taken. He took some of those previous incidents and ran through them. We didn’t have a training team around that.
Wells: Although actually, the operations team at the FT also did do some things like that as well for other teams. People thought that idea was so great that they copied it.
Aside from explaining the context to encourage people to decide to do the right thing, were there any incentives that needed to be changed in order to encourage it?
Shipman: My sense of it was that people were really motivated by solving these problems. When I joined, there was this group of people called simplification squad. They were attacking this problem on a quite small scale, because they were doing something alongside their work. I think there was real interest in getting those problems addressed. The vibe I got was that people were really just enthusiastic about getting these problems solved.
Wells: I think if you’ve got something that’s a bit painful for people, anything that allows them to make themselves have less pain onwards, is great.
See more presentations with transcripts
MMS • Sergio De Simone

In a recent report, Israeli cybersecurity company Check Point warned that cybercriminals are already using ChatGPT to develop malicious programs on the Dark Web. According to Check Point, ChatGPT makes it possible for even unskilled threat actors to create functioning malware.
CPR’s analysis of several major underground hacking communities shows that there are already first instances of cybercriminals using OpenAI to develop malicious tools. As we suspected, some of the cases clearly showed that many cybercriminals using OpenAI have no development skills at all.
Check Point researchers found indeed at least three distinct such cases, ranging from exfiltrating scripts to ransomware-enabling encryption tools and including a marketplace to support fraudulent schemes.
In the first case, a seemingly skilled threat-actor leveraged ChatGPT capacity to translate from one language into another to recreate malware strains known from research publications. The key to get a functioning malicious script is to specify exactly what the program should do using pseudo-code, they noted. They shared a Python script able to search for a number of known file types, zip them, and send the zip over the Internet. In addition, they showed a Java program able to download PuTTY, a popular telnet/SSH client for Windows, and run it on the system.
Another threat-actor created a Python program to encrypt and decrypt files. While the script was just a collection of function, Check Point researchers noted it could be easily transformed into a tool for ransomware. In this case, the threat-actor stated it was their first attempt at writing a script.
In a third case, ChatGPT was used to create a marketplace to enable fraudulent activity, such as trading illegal or stolen goods, including accounts or credit cards and so on, using cryptocurrencies for transaction payments.
To illustrate how to use ChatGPT for these purposes, the cybercriminal published a piece of code that uses third-party API to get up-to-date cryptocurrency (Monero, Bitcoin and Etherium) prices as part of the Dark Web market payment system.
Check Point researchers admit that the ChatGPT-generated malware they identified on the Dark Web is still pretty basic, but, they say, it is only a matter of time until more sophisticated actors find their way to launch ChatGPT-enabled attacks. To make this point more cogent, they described in another article a number of techniques that can be used to create full phishing flows, including a plausible mail and an Excel file embeddin malicious VBA code. Additionally, they could create a port scanning script, a reverse shell, and a sandbox detection tool. In some cases, common English knowledge was enough to get a functioning program out of ChatGPT.
MMS • RSS
DataStax, the driving force behind the ongoing development of and commercialization of the open source NoSQL Apache Cassandra database, had been in business for nine years in 2019 when it made a hard shift to the cloud.
The company had already been working with organizations whose businesses already stretched into hybrid and multicloud environments, but its “cloud first” strategy was designed to make it easier for the company to grow and easier for customers to consume Cassandra. This cloud first approach is shared by many established and startup software companies alike.
Back then, DataStax had just unveiled Constellation, a cloud data platform for developers to build newer application and operations teams to manage them, with the first offering on the platform being DataStax Apache Cassandra as a Service. A year later, the company announced its Astra database cloud service and in 2021 released a new version of Astra for serverless deployments.
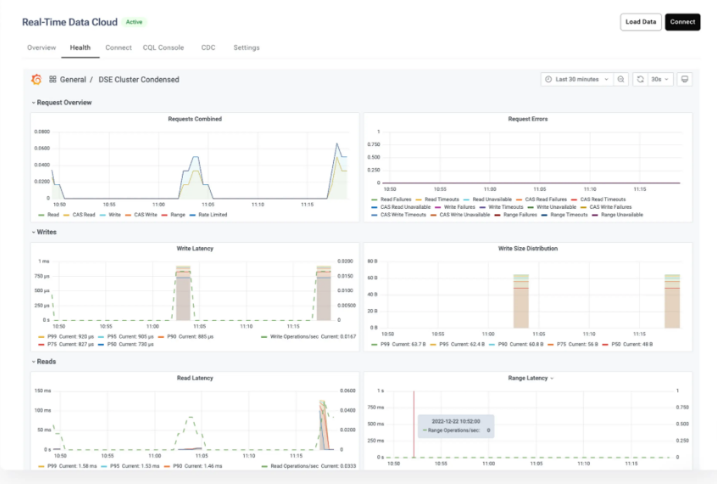
The transition to the cloud was important in making it easier for enterprises to use Cassandra, according to Ed Anuff, chief product officer at DataStax.
“Cassandra has always had the power and scale that make it a choice for when you’re dealing with huge amounts of data, but operationally was always kind of challenging,” Anuff tells The Next Platform. “Making it something that is available turnkey in the cloud – elastic, scalable, serverless – so you don’t have to worry about how much data you have, it just automatically scales, that was a pretty big deal. It sounds pretty simple and straightforward, but the implementation and execution of it was non-trivial.”
The embrace of serverless furthered that, he says. Cassandra and other NoSQL databases – think Amazon Web Services DynamoDB and Google Cloud Firestore – handle and store large datasets in real-time scenarios and are designed to scale to grow with those datasets. With serverless, “it means that you don’t think about nodes, you don’t think about anything other than how many reads do I do, how many rates do I do, and how much data am I storing, which is a much more obviously natural and convenient way to do it. Cassandra used to give you that infinite scale, but it was very challenging to operate,” Anuff says.
With that in place, the next challenge became how to help organizations that are using DataStax and Cassandra-based technologies to collect massive amounts of data to then leverage those data streams to train artificial intelligence (AI) and machine learning (ML) models. There is a long list of major organizations that use Cassandra – either alone or via DataStax products – from Apple and Bloomberg to Saab, Federal Express, Visa, Uber, and T-Mobile. Netflix uses Cassandra to capture every piece of data that’s generated when a customer clicks on anything, he says. DataStax saw an opportunity in making this event-based data usable in machine learning use cases.
“The first challenge for people in succeeding with ML is they have to have the data,” Anuff says. “The good news is all of our customers have that data or they wouldn’t be using Cassandra. But there are gaps in how to leverage it so that you can use it to train models and use it so that you can feed those models in real time with prediction. Again, the thing about Cassandra is it’s the database that’s used to power applications. It’s not that database that you use for an app. It’s not a data warehouse. It’s not something that you use for after-the-fact analytics. Let me generate a report. It’s what you use for powering your applications in real time. That meant that as we thought about unlocking this data and using ML to do it, we needed a way that could function in that real-time setting.”
That’s where Kaskada comes in. The startup offers a platform aimed at making it easier for enterprises to use data in AI and ML operations. It’s now owned by DataStax, which this week announced it was buying the Seattle company for an undisclosed amount. The deal comes seven months after DataStax announced a $115 million financing round. Conversations between the two companies began in September. Kaskada’s co-founders, chief executive officer Davor Bonaci and chief technology officer Ben Chambers, came from Google, where they helped develop Google Cloud’s Dataflow managed streaming analytics service. DataStax itself, as it was putting its cloud initiative in place, brought in people from Google and other hyperscalers, Anuff says, including himself.
Kaskada’s focus was on the challenge of taking real-time data streams and using them to train machine learning models and to feed the models with data in real time to more quickly delivering insights and predictions. Such capabilities were what DataStax was looking for, he says. Organizations were collecting such large datasets in anticipation of using them in machine learning models, but had to take a do-it-yourself approach, according to Anuff. DataStax wanted to give them the tools to make it happen.
“We had the strategy. It was always part of what we wanted to do with the company, to take it in this direction, and what we found was that you had this last-mile problem in being able to extract this data,” he says. “What the term for this specifically is called ‘feature engineering’ and what Kaskada is a feature engine. When you combine the feature engine with the cloud data store, you now have this intense system for taking this data, being able to use it within your models and feeding it and serving it back into the applications. That’s why we’re able to move very quickly because it’s a in many ways what we’re doing. We’re paving the footpaths that people have been doing on top of Cassandra for a while. … What we knew was that real-time ML was going to be the place that we play.”
Kaskada was able to address a key hurdle to using these streams of event data for machine learning operations. It’s important when training a machine learning model to ensure that the in structure and shape, and within its components, to be precisely the same each time, Anuff says. The data now tends to be “somewhat choppy” as people go in and out of the data, which makes it more difficult to feed it into services like TensorFlow or PyTorch. They may offer different capabilities, but they all want the data in structured formats, he says. Companies now typically have data scientists and engineers handle this with Jupyter notebooks and tools like Spark. The job can get done, but it difficult and time-consuming, taking weeks.
“What the Kaskada team’s insight was to go and say, ‘The majority of this work is stuff that we can express in a very concise form of query,’ so that’s what they did,” Anuff says. “They came up with a way that you could describe this data format that you want to extract from the event streams to feed it into the model and made it in such a way that a data engineer can go and do it in a very short amount of time. It turns what might have been a two-week process into a two-hour process. It’s a major-step function in productivity. We looked at that and we said, ‘This is exactly what our users who have this data, who are struggling to unlock it within ML, would benefit from.’ That’s the idea.”
DataStax is looking to more quickly now that Kaskada is in the fold. The company plans to open source the core Kaskada technology as soon as it can and will launch a new machine learning service based on the startup’s technology later this year. In a blog post, DataStax chairman and chief executive officer Chet Kapoor wrote that companies like Google, Netflix, and Uber are able to embed their machine learning models in their applications using real-time data, with the data being expose to the models via streaming services. Kaskada’s technology will help DataStax bring such capabilities to other companies, Kapoor wrote.
Article: InfoQ Software Trends Report: Major Trends in 2022 and What to Watch for in 2023
MMS • Daniel Bryant Wesley Reisz Thomas Betts Shane Hastie Srini P

Key Takeaways
- As a technical leader, the architect’s role is to communicate architecture decisions effectively with all stakeholders. We are seeing companies adopt Architecture decision records (ADRs) and make them standard practice.
- Recognizing the value of the senior individual contributor (IC) role, which is labeled as “Staff Plus.” Individuals in these roles have deep technical expertise but are also often “T-shaped” with a wide range of skills. These individuals can move between IC and management roles within their software development careers.
- DevOps and platform engineering practices can help reduce developer cognitive load and increase positive business outcomes.
- Treat application and data platforms as products; design, staff, and resource them appropriately.
- There are several innovations occurring in the AI/ML space in relation to modeling, transformation, and processing data.
- Everybody can contribute to implementing sustainable solutions within software development and IT.
- Invest in deliberate culture design. Instead of “back to the office” mandates with people commuting to their office to sit on video calls all day, leaders need to think about the benefits and costs for the organization, for the environment, and for the people.
2022 was another year of significant technological innovations and trends in the software industry and communities. The InfoQ podcast co-hosts met last month to discuss the major trends from 2022 and what to watch in 2023. InfoQ News Manager Daniel Bryant led and moderated the discussion. The panelists include Wesley Reisz, Shane Hastie, Thomas Betts, and Srini Penchikala.
This article is a summary of the 2022 software trends podcast. Check out the podcast episode and the full transcript of the discussion.
The main topics and themes discussed in the podcast were as follows:
- Architecture Decision Records (ADRs)
- Role of Staff Plus engineers
- Platform as a product
- AI-based assistants like ChatGPT
- Sustainability and Green IT
- Culture Design
The sections below summarize the key trends discussed by the group.
The Shift in Architect’s Role
One of the key personas at InfoQ is the architecture persona, the role of the architect, and how they can serve the teams around them and contribute to the success of software development projects and initiatives in their organizations. The architect’s role is shifting to be an active part of the development lifecycle, assisting the application teams with architecture decisions in a collaborative way rather than enforcing, and communicating decisions to the stakeholders at different levels of the organization.
The pandemic and hybrid work situations influenced the teams to communicate more asynchronously. The architect’s role in this context has become even more critical in terms of writing things down and ensuring the decisions are in the organization’s best interest for the long term. Diagrams of the architecture solutions are not sufficient anymore. They need to justify why a particular solution was designed that way in the first place.
Architecture decision records (ADRs) have been around for a while but are now being adopted by more companies. ADRs help in several ways, specifically in figuring out the architectural choices and writing them down. The teams can then discuss why they made a specific decision. You see the pros and the cons, and then it’s more of a collaborative process.
ADRs can be used to document and version the architecture decisions with details like “What is the decision you’re trying to make? What are the possible options you’re considering? What are the pros and cons of each option?” All of this information can be checked into a centralized Git repo. This way, the teams can establish the shared context of why they chose a specific technology or software over the alternate options.
Architecture decision-making should be collaborative, and ADRs can play a significant role in the process. Architects can use them first, establish the pattern, and figure out what works within their company. It’s also living documentation. Teams can change their mind and update the diagrams that are out of date. ADRs put it in a simple text format. They can update it, and then if they want to create a diagram, Mermaid diagrams are an excellent choice. Maintaining this type of living documentation, and the culture that supports it is also important.
People working as architects should avoid the “ivory tower architect” approach and work actively to embed the architecture outcomes and deliverables with the project in the same Git repo.
Increased Visibility of the “Staff Plus” Role
With the increasing adoption of the “Staff Plus” role in IT organizations, the role of each individual is changing positively. At a certain point in our careers, we as architects used to think, “What am I going to do now? I’ve gotten to this point where I am an architect. I’ve gotten to be a manager and into a director role.” Now, with Staff Plus, senior leaders at companies are starting to think, “What is the roadmap beyond that staff level?” The companies intentionally looking at Staff Plus is a significant development in this area.
Architecture is also getting the proper focus as a discipline and a software craftsmanship rather than just diagrams and artifacts. That’s where the architects are becoming more valuable to the enterprise because of what they can do and how they can contribute to the teams, rather than just creating some PowerPoint slide decks and throwing them over the wall. Most architects are becoming hands-on and involved throughout the software development life cycle. The architecture process is now iterative and incremental in delivering value to the customers.
Having the Staff Plus engineer position in the organization tends to be a T-shaped role where the individual can be broad across many disciplines but have deep expertise in a particular area. This role can help with thinking about the cross-cutting concerns, the big projects, and the big picture of how it solves multiple problems.
Charity Majors gave a talk at QCon San Francisco titled “The Engineer/Manager Pendulum” on consciously and deliberately bouncing in and out of that senior Staff Plus/Architect role and into management and then bouncing back. This way, people can build many deep competencies in different spaces and move back and forth. Managing your career like a product and deliberately making choices to help grow your career.
One of the trends we have seen since the beginning of the pandemic is the great resignation. 30% of people changed jobs, and 70%, according to some studies, are actively dissatisfied with their current position. This prompted a leadership level to create opportunities for people to move as their interests shifted without losing the people to other companies.
In some organizations, the senior IC or Staff Plus positions are being created more as evolved opportunities rather than appointed job postings. So, it’s not like the senior leadership is saying, “Okay, we will make you a senior Staff Plus engineer.” It’s the other way around. The team members can contribute not only technically but also organizationally. They’re able to manage their own people and the stakeholders and make the Staff Plus opportunities happen.
Platform Engineering and Reducing Developer Cognitive Load
When DevOps practices came out a few years ago, it was meant to be the best of both Dev and Ops worlds. It helped with many things, but in the process, we took cognitive load on our teams. It got really high, and burnout became an issue. Trying to keep a mental model of all the things a team has to deal with today, from Kubernetes to Istio to the sidecars to ingress—and then you’ve got to write code—is getting quite a bit of cognitive overload.
Platform engineering is another area that’s getting a lot of attention lately. The platform is a massive lever, and the idea with platform teams is how we can pull that lever and start to reduce the cognitive load. If you get it right, you can enable all the stream-aligned teams (Team Topologies) to deliver value.
To reduce the friction in development teams, the platform teams can help create internal developer platforms and offer self-service capabilities to onboard and host their apps. These platforms should support tasks like automatically provisioning infrastructure, seamlessly pushing app code in a CI/CD pipeline, and verifying the quality of the infrastructure components before giving the teams the go-ahead to start deploying their apps to the platform.
Internal developer portals like Spotify’s Backstage, a CNCF open source project, Netflix’s paved road, and other similar tools can help with goals of platform engineering.
We think next year we’ll see a lot more focus on internal development platforms.
Data Mesh and Data Platform as a Product
Data mesh is an important architecture model to help manage data from different sources, which are consumed by different clients and consumers, with a governance layer built-in.
Companies struggle with implementing a data mesh because they have to create a platform that allows them to take charge of the principles and tackle various individual data products. The goal is to have a standardized mesh where everyone can put the data in and get the data out they need, as opposed to having the bottlenecks.
We’re also seeing more focus on platforms as products. A new and interesting trend in this area is to have a product manager on a platform. It’s an interesting role because you have to be empathic and be able to engage with the developers, your customers, and the users. You have to be good at stakeholder management because the senior leadership team often asks questions like, “Why am I paying for this platform? What value is it adding?” The platform product manager needs to articulate that the platform engineering is an enabler and that we’re investing in solid foundations, either for platforms in terms of applications or platforms in terms of data.
IT is not just a cost center anymore; software is what’s enabling your business to be more productive. And platform engineering has a vital role in software development and maintenance.
Emerging Trends in AI, ML, and Data Engineering
Data, similar to architecture and security, is going through the “shift left” approach. Data is no longer just something you store somewhere. It is becoming a first-class citizen in terms of modeling, transformation, and processing. The end-to-end automated data pipelines are getting more attention because you cannot have the data in silos or duplication of data and the lower quality of the data—all those problems. +The database is one of the solutions for storing the data, but other trends like streaming first architectures where the data is coming in terms of data streams. How we process that kind of data is what’s driving the emerging architectures in the data engineering space.
There are also other trends, like streaming warehouses which focus on how we capture and analyze the data coming in terms of streams. Looking at all the major developments in this area, there are data-related trends, data management, and data engineering. Machine learning and artificial intelligence are the second area. The infrastructure to make all of this happen, data platforms and everything, is the third area currently going through a lot of innovation.
We need to think about data upfront as part of the entire system. How do we make sure we have observability, not just of the system, but of the data to make sure that the data is flowing through properly? Are we going to use AI models? Can we get our data in a way that we can feed it into a machine-learning model so we can get some of those benefits? All of these things have to be considered. So, that’s where architecture has to start thinking a little differently, not just here’s the product. Creating data separately as a focus on the data and architect for the data, it’s a different way of thinking.
Data, as they say, is the second most important asset of any company after the people. So yes, we definitely need to give it as much attention as possible. Data is going through a similar evolution that code and architecture have gone through in the past. There is a continuous CI/CD approach for data as well in terms of receiving the data, ingesting it, processing it, and versioning the data.
In terms of machine learning, probably there’s no other technology area that has gone through the same level of innovation as machine learning and AI did in 2022. GitHub’s Copilot project is one of the interesting innovations. It has been talked about as a tool to improve developers’ productivity. We’ve heard from some developers that Copilot has made them 100% more productive, so pretty much 2x productivity. The developers say they don’t write any basic functions anymore. They don’t need to remember how they’re written. Just ask Copilot and it generates all the code for them. They don’t even use websites like StackOverflow anymore. We also are seeing new technologies like ChatGPT that are getting a lot of attention in terms of how they can change not only developers’ lives but everybody else’s lives.
Legality, Ethics, and Sustainability Challenges with Computing
The software development community needs to be responsible not only in the legal area but also in ethical and sustainability domains. We need to focus on ethical aspects of ensuring that the products we build are good for the environment (green computing) and the broader community (social computing).
We should remember that inherent biases are built into any of the models. The data that these models are sampled and read off is what the models have built in. With new tools like ChatGPT, interacting with AI is no longer limited to AI/ML subject matter experts; pretty much anyone can use these AI assistant tools to generate new programs and scripts. This is why it’s more critical now than ever to be consciously and intentionally responsible for the products we deliver.
Everyone involved in the software industry in any capacity should start asking questions like “Can we make this a green solution?” “Where am I running this? Is it using green energy or is it running in one of the data centers that’s all coal-powered energy?”
Adrian Cockcroft recently spoke on DevSusOps topics about bringing sustainability concerns to development and operations. The idea is to manage sustainability as a non-functional requirement for developing and operating software systems. This includes measuring and reducing the carbon footprint, water stewardship, social responsibility in supply chains, and recycling to create a circular economy. You can use tools like the Cloud Carbon Footprint from Thoughtworks to estimate the carbon footprint of your apps hosted on the cloud providers.
What Will the Future of Work Look Like?
Another area that’s going to go through a major transformation in 2023 is the hybrid work model. Hybrid work environments, if done right, can be the best of both worlds: WFH (Work from Home) and RTO (Return to Office). But if it’s not managed properly, hybrid hell can become real. The reality of people commuting to the office, just because it’s a mandate, two or three days a week, is not coordinated well. People come into the office and spend most of the day on Zoom calls. We’ve got to start being deliberate about why we bring people together. There is a huge value in coming together in person.
Suppose the senior leadership teams are going to bring people together. In that case, they need to consider the cost for the organization, the environment, and the people and make sure that the benefit outweighs the cost. If we’re coming in, maybe it is one day a week, it should be the same day for everybody on the team and all the stakeholders we need to work with. This way, we can have collaborative conversations in person and leverage the humanity of it.
The in-person mandate cannot be “just come to the office Tuesday, Wednesday, and Thursday every week.” It has to be based on context and product lifecycle, not just driven by the calendar. If we are doing sprint planning, retrospectives, or brainstorming, that requires everybody, preferably in person so that they can collaborate for one or two days. Once the development phase starts, not everybody has to be in the office.
Companies should have a deliberate reason to bring people into offices. They should also let go of how we measure. It’s not about hours in front of a screen. It’s about outcomes.
If we think of the impact from a green and climate perspective, some organizations and governments are shifting to four-day work weeks. The studies are amazing. In every organization that has shifted to the four-day work week, productivity has stayed the same or gone up. People are more focused because now they’ve only got four days to get the work done.
Getting it right, bringing people together, and connecting as human beings allows you to be more comfortable and safer in your environment. It will enable you to be present better. The bond the in-person collaborations can cultivate is significant.
Looking Ahead to 2023
What do we as a group want to see in 2023? A deliberate culture design in organizations and some of the experiments; the four-day work week; more and more organizations bringing that on; outcome focused, humanistic workplaces.
We think we’re right at the inflection point with artificial intelligence becoming mainstream. An AI assistant can enhance the role of an architect. We can just ask the chatbot for helpful information, it can respond accordingly, help us think through, and give us the ability to be 10x better in delivering value to our stakeholders. We also think we’re going to see something come about in AI in the next 12 months that we didn’t expect to see, that it just becomes very mainstream, and we all start using it.
ChatGPT and other future AI solutions can do a better job helping people, but we don’t think they will replace humans anytime soon. We look forward to how data and AI/ML technologies can help with all aspects of our lives at the individual level, the community level, and the national and government level. How can AI help at all levels, not only in our offices, at work, and in our personal lives, but also in other areas like healthcare, governments, etc.?
The deeper we get into technical issues, the more we find out it’s about people, about organizations, and about communication. The technical stuff that comes along is not the hard part. We want to see the continuation of platform conversation next year, building stronger teams, being able to do more with less, and reducing cognitive load so that people can develop software and be happy and healthy doing it.
Other trends like low-code, no-code solutions are going to enable citizen developers. The way the world is communicating and collaborating is also changing, in most cases leveraging virtual reality (VR) based technologies.
References mentioned in the podcast:
MMS • Daniel Dominguez

Google AI released a research paper about Muse, a new Text-To-Image Generation via Masked Generative Transformers that can produce photos of a high quality comparable to those produced by rival models like the DALL-E 2 and Imagen at a rate that is far faster.
Muse is trained to predict randomly masked image tokens using the text embedding from a large language model that has already been trained. This job involves masked modeling in discrete token space. Muse uses a 900 million parameter model called a masked generative transformer to create visuals instead of pixel-space diffusion or autoregressive models.
Google claims that with a TPUv4 chip, a 256 by 256 image can be created in as little as 0.5 seconds as opposed to 9.1 seconds using Imagen, their diffusion model that they claim offers an “unprecedented degree of photorealism” and a “deep level of language understanding.” TPUs, or Tensor Processing Units, are custom chips developed by Google as dedicated AI accelerators.
According to the research, Google AI has trained a series of Muse models with varying sizes, ranging from 632 million to 3 billion parameters, finding that conditioning on a pre-trained large language model is crucial for generating photorealistic, high-quality images.
Muse also outperforms Parti, a state-of-the-art autoregressive model, since it uses parallel decoding and is more than 10 times faster at inference time than the Imagen-3B or Parti-3B models and three times faster than Stable Diffusion v1.4 based on tests using hardware that is equivalent.
Muse creates visuals that correspond to the various components of speech found in the input captions, such as nouns, verbs, and adjectives. Additionally, it shows knowledge of both visual style and multi-object features like compositionality and cardinality.
Generative image models have come a long way in recent years, thanks to novel training methods and improved deep learning architectures. These models have the ability to generate highly detailed and realistic images, and they’re becoming increasingly powerful tools for a wide range of industries and applications.