Month: February 2023

MMS • Sergio De Simone

GitHub Copilot adopted a new AI model which is both faster and more accurate than the previous one, says GitHub. Additionally, GitHub has started using AI to detect vulnerabilities in Copilot suggestion by blocking insecure coding patterns in real-time.
GitHub has brought three major technical improvements to Copilot, starting with adopting a new OpenAI Codex model which is able to synthesize better code, according to the company.
Besides the new AI model, Copilot is now able to better understand context using a technique called Fill-In-the-Middle (FIM):
Instead of only considering the prefix of the code, it also leverages known code suffixes and leaves a gap in the middle for GitHub Copilot to fill. This way, it now has more context about your intended code and how it should align with the rest of your program.
GitHub says that FIM is able to produce better results in a consistent way and with no added latency.
Finally, GitHub has improved the Copilot extension for Visual Studio Code to reduce the frequency of unwanted suggestions, which could prove disruptive for a developer’s flow. To that aim, Copilot is now taking into account some information about the user’s context, such as whether the last suggestion was accepted or not. This new approach made it possible to reduce unwanted suggestions by 4.5%, based on GitHub’s own metrics.
The cumulative effect of all these changes as well as of others released previously has been a net increase in the overall acceptance rate for Copilot code suggestions, which grew from 27% in June 2022 to 35% in December 2022.
As mentioned, another front where GitHub has started to apply AI is vulnerability prevention in code generated by Copilot. This is achieved by identifying insecure coding patterns, such as hardcoded credentials, SQL injection, and path injection. Once an insecure pattern is identified, it is blocked and a new suggestion is generated.
GitHub says it will further expand its LLMs ability to identify vulnerable code and distinguish it from secure code with the aim to change radically how developers avoid introducing vulnerabilities in their code.
The new AI model and vulnerabilty filtering system are available both in GitHub Copilot for Individuals and Copilot for Business.
MMS • Dan Benjamin

Subscribe on:
Transcript
Hi, everyone. Registration is now open for QCon London 2023, taking place from March 27th to the 29th. QCon International Software Development Conferences focus on the people that develop and work with future technologies. You’ll learn practical inspiration from over 60 software leaders deep in the trenches, creating software, scaling architectures, and fine-tuning their technical leadership to help you adopt the right patterns and practices. Learn more at QConLondon.com.
Srini Penchikala: Hi, everyone. My name is Srini Penchikala. I am the lead editor for the AI/ML and Data Engineering Community with the InfoQ website, and I’m also a podcast host. Thank you for tuning into this podcast today. In today’s podcast, I will be speaking with Dan Benjamin, the CEO of Dig Security. We will discuss three main topics that are very important in the current cloud computing environment: cloud data security, Data Security Posture Management, and Data Detection and Response. Let me first introduce our guest. Dan Benjamin is the co-founder and CEO of Dig Security. He leads a team of security professionals focused on discovering, classifying and protecting cloud data. Previously, Dan held cloud and security leadership roles at Microsoft and Google. Hi, Dan. Thank you for joining me in this podcast.
Dan Benjamin: Thank you so much for having me.
Introductions [01:16]
Srini Penchikala: Before we get started, can you introduce yourself and tell our listeners about your career in the cloud data security area and any other accomplishments you would like to highlight?
Dan Benjamin: Of course. So hi, everyone. Thank you so much for listening. Again, I’m Dan. I’m the co-founder and CEO of Dig Security. I’ve been in the cloud and security and engineering space for the past 20 years. I started in the Israeli Army in the 8200 Units. I was there for about four years. After the Army, I co-founded my first cybersecurity company in the IAM space, which helped organizations’ right-size permissions across the on-prem environment. That company got acquired by CA Technologies five years later. After that, I spent many years at Google Cloud and at Microsoft, both in Azure and in Office 365.
At Google Cloud, I mostly worked on building the startup program for Google Cloud that essentially helped startups from around the world, around 15,000 startups to build their entire infrastructure on top of Google Cloud. At Microsoft, I led the Microsoft CASB, which is cloud access security broker or SaaS security. And my last position was helping lead multi-cloud security strategy for the organization. So how does Microsoft transition from being a single-cloud security vendor or just doing agile security to helping organizations protect their AWS environment and GCP environment as well. I left Microsoft to co-fund Dig, and super-happy to be here.
Cloud Data Security [02:37]
Srini Penchikala: Let’s get started with the cloud data security topic. What is the current state of cloud data security?
Dan Benjamin: I think that currently, what we’re seeing is that most of the organizations today don’t really know how to answer three main questions. What data do we even own across our clouds, across AWS, across Azure, across GCP, especially if we’re running across multiple clouds? The second question is how is that data being used, by which machines, users, vendors, contractors? And lastly, how do we protect that data from being exfiltrated, misused or breached? And most of these organizations today don’t have a lot of opportunities or a lot of tools to help them answer these types of questions. And I always split the landscape to the different kind of options that they own. So if we go to the cloud native solutions, we can potentially use AWS Macie, or Azure Purview or Google Cloud DOP. But those solutions are not multi-cloud, they’re very manual, very, very, very, very expensive, and only support a very small subsets of the data stores that a typical organization owns.
Today, a typical enterprise holds at least 20 different types of data stores, whether it is on task solutions like RDS and Azure SQL and Google BigQuery. Whether it is IS data stores like VM running a database like a MySQL or MongoDB, or even environments like Snowflake and Atlas and Databricks. And with this kind of sprawl of technologies, sprawl of different types of data store types and thousands of data store instances, we need a solution that will help us discover and understand what data do we own, classify that information, and of course, help us protect that type of data. So we talked a little bit about the cloud native solutions, Macie, Purview, Google Cloud, DOP, that are not hitting the target for the other organizations. Then we can talk about the older vendors. We used to have data security solutions for the on-prem, but these solutions today don’t really work well for the public cloud.
Take Varonis today, I think one of the best data security companies in the market. Only do buckets in AWS, right? A typical enterprise today has 20 or 30 or 40 different types of additional data stores in the clouds that these types of solutions don’t support. And let’s take, for example, the privacy vendors. We used to have multiple privacy vendors that were born in the last five to 10 years. Those solutions were born for on-prem. They don’t really tackle the cloud native technologies. They’re not security vendors. They were born to help lawyers validate and make sure that we’re privacy-compliant.
So most of the organizations today don’t have proper solutions to essentially protect data in the cloud. And what we see today is that many times, when we come into an organization, they built many homegrown tools. They either build proxies themselves, they build scripts to essentially discover data across their databases or buckets. So the landscape today for data security in the cloud is super, super-fragmented, but I think we are seeing a shift both by the cloud native vendors and by multiple vendors that are coming up in the DSPM space and in the data security space that are trying to solve these types of topics that up until now, remained unsolved. We’re super-happy to talk about this topic today.
Challenges in securing data in cloud [05:55]
Srini Penchikala: You mentioned a couple of challenges with the cloud data security, but is there anything else you can highlight in terms of what are the constraints? I know storing the data in the cloud has become the main strategy for a lot of organizations. So what are the challenges in securing the data in the cloud?
Dan Benjamin: Other than the fact that we just have a lot of different types of technologies, without properly understanding and threat modeling and going deep dive into how these data stores actually work, most of these organizations don’t really know what to detect and how to properly manage these types of data stores. So for example, up until about a week ago, every time you stored a file in a bucket, it was automatically stored as a public file. Just now, AWS essentially changed that configuration setting, and today AWS makes sure that all files within buckets are specifically private and less named differently. Now, a typical organization that doesn’t have a lot of experience working in the cloud, they will not know how to essentially properly configure these types of data stores. That’s why Data Security Posture Management essentially comes to life. On the other side of it, you have different types of information that you keep.
So you have unstructured data like files, you have semi-structured data, like JSONs, and then you have structured data. So relational databases like RDS and Azure SQL and Google BigQuery. And with the sprawl of technologies, sprawl of different types of data storage types, these organizations mostly don’t know how to answer, “How’s the data moving inside the organization? Where do we have PII or PHI or PCI? Where do we have regulated data?” And all of these are mandated by the regulation. Take a healthcare company, they’re mandated by PHI to know all this information. Take a credit card company or a payments company. They’re mandated by PCI to understand and keep specific types of information secure. And when you come to these types of organizations today, they’re stranded. They just don’t have the right tool sets to essentially build these types of controls. And I think that’s where we’re seeing this explosion in this space of cloud data security that helps organizations tackle these types of problems.
Process lifecycle for securing data in cloud? [07:57]
Srini Penchikala: Can you discuss what a typical process lifecycle would look like in securing the data on cloud? It is not the same as securing the data on premise. So what does a typical process look like on the cloud?
Dan Benjamin: Whenever we talk with customers about securing data in the cloud, we always talk about three main steps. And the three main steps is first off, understanding what data do I have? And that’s a full discovery process. We need to understand where do we have data, whether it is on a managed solution like an RDS, a DynamoDB, a Redis and so on, or an unmanaged solution. So someone booted up the VM, installed MongoDB on it, or a database as a service. So initially, everything starts with full data asset discovery. We need to find the data stores that we own across our cloud environments. Then we need to understand what is the data security posture. And by data security posture, I’m essentially talking about multiple different topics. So first off, of course, how is data flowing inside the organization? Who has access to it?
Where do we have over-permissive access? Is the data sitting in the right locations around the globe? A lot of countries essentially have data sovereignty issues. So for example, European customer data today needs to sit in Europe, and Brazilian customer data needs to sit in Brazil. So we have a lot of data sovereignty issues. Then what is mandated by our compliance? Some compliance regulations today mandate us to have specific controls around our data, like data retention policies, data deletion policies, data encryption policies, logging, authorization. So we need to make sure that the posture of our data is correct. And once we both the data discovery in the data posture or in parallel, typically we see this in parallel, we also build the threat detection capabilities for the data stores themselves. What are the actions that we do allow and what are the actions that we want to be able to essentially detect?
I’ll give you a very simple scenario. Let’s say you have now a million customers, and that million customers datasets and a specific type of RDS. You would like to know if someone tries to now download the entire production database to their personal machine, right? That’s a very obvious request. Or you would like to know if someone does a select asterisks and download the entire production database to its personal notepad. These are very common scenarios that take a typical enterprise today, super-hard for them to essentially detect.
And why? Because they need to properly threat model each type of data store. They need to understand “How do we detect something like this in the logs? Do we have the right logs essentially enabled to properly detect those?” I always talk about these three main steps: discover the data, understand that we have the right posture of our data, and then understand that we’re able to detect the malicious events that we don’t want to happen with our data. And what do we do if we do see these types of events? Whether it is a mass download or a copy outside of our cloud, or a copy to an FTP or a copy to an external asset. All of these are events that we need to think about, talk about, test, and then of course, make sure that we have the right controls for those.
Data Security Posture Management [10:56]
Srini Penchikala: So let’s get into DSPM in more detail. How does the program help with discovering and classifying data assets?
Dan Benjamin: First off, when we talk about DSPM, this is a very new term. It was coined by Gartner, I think, around June or July of 2022, so very, very young. But it essentially talks about how do we essentially build data-centric security. So looking at the data and essentially building controls outwards, versus trying to essentially protect the perimeter, and hopefully, that will protect our data as well. So Data Security Posture Management is very similar or takes from its older brother of CSPM, Cloud Security Posture Management, that essentially talks about, how do we protect our infrastructure in the cloud from bad configuration and bad posture of our resources in the cloud.
Data Security Posture Management essentially talks about, how do we discover all of our data stores automatically across our clouds? How do we make sure that we understand what data do we own, classify it properly, have a deep understanding of what data should we have, and how that data is being interacted with? And of course make sure that we have the proper configurations for our data, wherever the data sits. Across dozens, if not hundreds of different types of data stores, and thousands and thousands of VMs, machines, path services, databases as a service, anything that might hold our information out there.
So that’s where this originates from. And I think we’re seeing an uptick in multiple companies that are coming into this space. We’re seeing an uptick in the need of customers to build and deploy DSPM projects. And I think it’s a blessing because most organizations today, when you come to them, they’ll say or admit at least in their rooms that in the last 18 months, they did encounter some sort of a data breach. They don’t feel that they have the right controls on top of their data. They don’t feel that they have the right controls to match their compliance regulations, and it’s just super-hard to essentially protect the data today. So DSPM is definitely a great step in the right direction, but it’s still a very young category. I think that most organizations today, when we at least started the company at the end of 2021, most organizations have struggled with data security projects in the past.
Take a data security project, on-prem, it used to take 12 to 18 months to implement for at least 30% of your data stores on-prem. And I think the cloud technologies that essentially allowed us to do this quicker, to essentially deploy projects like this quicker have increased the adoption. So today, we see one out of every five organizations are implementing data security projects. So we’re seeing a very big explosion in the space. And we’re happy to say that we’re one of the leaders of the specific space today in the market.
Srini Penchikala: If somebody is interested in learning more about the DSPM program, are there any other online resources outside of your website that you recommend?
Dan Benjamin: So first off, I think that the Gartner report is really good. It’s the hype cycle of data security. I think it’s really good. I think it’s very succinct, but it talks about why is the market moving into Data Security Posture Management, and what are the different types of catalysts. I think that we’re now seeing more and more resources, either by companies like us, so big security in our competitors, or by different types of other vendors. I even asked ChatGPT the other day, and I asked it, “Hey, ChatGPT, what is Data Security Posture Management?” And it actually gave a pretty good definition. So I think that’s super-cool to see, but I think there’s a lot of good resources. Dig in our blog, we have fantastic resources, and I think some of our competitors as well.
Definitely Google Data Security Posture Management. And I would either deep dive into the topic of “What is the difference between CSPM versus DSPM?” Which I think is an excellent question to ask. Or differences between on-prem data security and cloud data security, which I think is very interesting to also ask. So those are guided questions that I would definitely encourage people to do, and inquire. And if anyone wants to reach out and ask additional questions, I’m happy to answer. So my email is Dan@dig.security.
Srini Penchikala: You mentioned about ChatGPT, right? So I mean, it’s been found very interesting. I think we just need something called the JustDoItGPT, right? So not only it can tell us what the solution is, but it can do it. I’m just joking, but let’s go to the next main topic, Dan. It’s the data detection response, probably the most important part of the cloud data security. So maybe we can start with the definition. Can you define what is Data Detection and Response?
Dan Benjamin: Yeah, so Data Detection and Response essentially talks about how do we detect and respond to bad and malicious events that happen with our data wherever the data lives today. So I think it draws from endpoint detection and response and network detection and response. And now I saw an identity detection and response. It focuses on the 40% of the resources that we have in the cloud today that are looking to get protected, but we don’t have the right controls to essentially tackle there.
So Data Detection and Response essentially protects the data from bad usage. Bad usage can be either mistakes or it can be a malicious actor. And we see both of these in customer environments today. But drawing back to our previous discussion, if you think about cloud data security, we always think that a combination of Data Security Posture Management and Data Detection and Response is the way to go. And why? Because if we start with the posture management, what we were able to solve with deploying a Data Security Posture Management is how do we discover what data do we own and what is the posture or configuration or encryption status, or what kind of content do we own in the specific types of data stores?
But even if we deployed that type of solution, we’re still going to have hundreds, if not thousands of people, machines, vendors, contractors that have access to the data, and that access goes completely unmonitored. We don’t have any tools today to look at the activity that is done with the data itself. So with Data Detection and Response technologies, essentially, we look at each type of data activity. Admin events, data events, connections, resource events and so on. And we’re able to essentially detect if something bad happens with the data. I’ll give you an example. We onboarded one of the largest banks in the US. And what we were able to find is that for the past three years, every single day, there was a cron job that essentially ran at 3:00 PM. That cron job once a day was copying all their financial reports to an external AWS account that doesn’t belong to them.
Now, how can something like this even happen, right? Because no one really monitors how data’s being used after permissions are given. We don’t have the right tool sets. So a detection response solution, threat models, each type of data store understands what are the bad actions that can happen to it, draws context from the data sensitivity and the data posture and the auto discovery capabilities of the DSPM capabilities, and then essentially is able to flag, detect and respond to anything bad that might happen, whether it is a mass download, a mass upload, someone disabling encryption on an asset, making an asset public, someone copying data outside of a residency area, or a machine mounting a database backup and copying the information out or copying data to an FTP. Data detection response is the protection on the runtime level. How do we essentially protect from anything bad that might happen with data that is not associated to posture? At the bank, they had the proper encryption, they had the right size permissions, they had the right posture under controls over there, but the usage problem was where they essentially failed protecting the information itself.
So combining both usage and posture, I think, is the way to go. And this is not a new concept. If we go back to how we used to do data security on-prem, we used to have E-discovery solutions that used to find the data, and then we had DLP controls that essentially made sure that no sensitive data would exfiltrate through the actual endpoint or the specific machine or the specific email. In the cloud, we just don’t have one single entry point and exit points, and that’s why we need detection and response capabilities. So I see DDR as the evolution of DLP for clouds, which essentially allows us to understand and monitor how data should be used and respond to any malicious event that essentially happens. Hopefully that made sense.
Srini Penchikala: Yes. So the idea is to protect the data in all phases of data lifecycle, like data at rest, data in transit and data in use, right?
Dan Benjamin: Definitely.
Data Detection and Response [19:23]
Srini Penchikala: So DDR solutions use real time log analytics to monitor cloud environments that store data and detect data risks as soon as they occur. Can you discuss how a typical DDR solution works and what the application developers should be aware of?
Dan Benjamin: Of course. So a DDR solution, as you mentioned, taps into the existing logs that the organization owns, whether it is admin events that are stored in the cloud trail or in the stack driver solution for Google clouds. They tap into the data events, and they tap into the resource logging and connection logging for each type of data store. Now, of course, not all organizations have all the right logs enabled, and a DDR solution should flag what the organization is blind to. Which logs we should enable to be able to essentially detect something important. So a typical DDR solution will tap into the existing logs, either collect it themself or tap into the organization sink. Typically, if you have all logs being funneled to one specific system, let’s say a Splunk or a SIEM, then the DDR solution should also tap into that same sink, the same sink that you already funnel all the logs into.
But also, DDR solutions should enrich the content that these logs essentially bring. So either it is enrichment through understanding more information through threat intelligence sources, whether it is by CrowdStrike or Microsoft or any other solution that essentially can enrich and say that, “This IP is compromised” or “This specific actor might be compromised” and so on. It should also enrich more information because sometimes the logs are lacking by the clouds, right? So sometimes AWS will say, “Specific resources changed,” but AWS doesn’t mention what exactly has changed. So a DDR solution should go ahead and enrich the additional information in the additional context that they need to bring in from AWS or from Azure or from GCP. Now once we collected the logs, enriched the logs with either threat intelligence or additional API calls, then we need to clean up the actual data. De-duplicate, aggregate information, and be able to essentially do four main types of detections.
The first type of detection is, of course, single-event detections. “If event X happens, please wait.” Like an alert. Then you have multi-event detections. So if event X and Y happen, then alert and a specific something that essentially happens. Then you have sliding window alerts which say, “If a combination of events essentially happen in the last 30 minutes, then also bring up an alert.” And the last piece of it, of course, is an aggregation. “If you see more than X events or more than 1% of the events that essentially look something like this, then also raise an alert.” These are different types of an alerts that we already see and a typical DDR solution should be able to detect and respond to. The last piece of it is the response piece. Let’s say we saw an event, we saw a mass exfiltration event in a typical customer environment. What do we do now?
So some DDR solutions will either respond themselves. And that can be either suspending the user, removing the permissions, locking the identity out, requiring MFA, and so on. On the other side of it, some DDR solutions would also plug into a source solution, security orchestration solution like a Torq or a TINES or a Demisto and so on. And those solutions will be the ones that will essentially respond to the malicious event that happens. I see that most DDR solutions today can do both, either respond themselves or plug into your existing workflow that you already own. But detection without the response is not strong enough, but also having the proper, the right detections across your clouds, across your different types of data. So technologies are super-important as well.
Srini Penchikala: Can you mention what are some of the best practices for implementing cloud data security?
Dan Benjamin: when it comes to best practices for cloud data security, first off, I would say learn and understand your objectives. What are you trying to do? What are you trying to achieve? Some organizations just want to understand what data do they own and clean up, and I think that’s a valid approach. But many of the larger enterprises, they need to build the proper program. And for that program, you need to have a leader for that type of program. You need to have an owner that will acknowledge and handle these types of risks. You need to have the right tooling in place. So whether it is Dig Security or using some sort of a cloud native solution, or using one of your old vendors that will essentially want to expand into the data security space. And once you have the program, you have the right person in place, you have the right tools, start resolving the issues that you find across your clouds.
Focus on the big things first. Focus on the bigger locations of the explosive data, how I like to say it, but we actually have a blog post about it. So I definitely recommend to people to read our blog posts that talks about how to build an enterprise data security team. We talk about this process that a lot of organizations are going through today, and how to identify the right person to lead the team, what are the responsibilities of a data security team today, and how to properly protect the information in the cloud. So definitely recommend it.
Srini Penchikala: Yeah, definitely. I think the team is the most important part of the strategy. Right?
Dan Benjamin: Definitely.
Srini Penchikala: And also, are there any standards or guidelines or any consortiums that our listeners can follow on this topic?
Dan Benjamin: So not yet. I think that this year, we’re going to see more and more consolidation in the market. This is a very new category. I know that Gartner is now working on an innovation insight that will talk about how does a DSPM solution look like across 10 of the other vendors that they’ve already seen. And I also think that the privacy and data security regulations are going to mandate additional controls, and that’s going to be more aligned with the industry today. I think today it’s a little bit of a Wild Wild West, so you can read the GDPR requirements and you can read the FTC safeguards requirements that essentially mandate every single FTC-regulated company to follow some sort of controls. You can look at PCI requirements and CCPI requirements. So each one of them is a little bit different, but they’re very similar in nature and what they’re trying to achieve for the end user.
Srini Penchikala: Yeah, definitely. I think shift left security is the new strategy, right? Do you have any additional comments before we wrap up today’s discussion?
Dan Benjamin: I’ll be happy to talk with any organization exploring data security controls for their cloud infrastructure, exploring Data Security Posture Management, and exploring Data Detection Response. Please visit us at dig.security to learn more.
Srini Penchikala: Sounds good. Thank you, Dan, very much for joining this podcast. It’s been great to discuss one of the very important topics, the cloud data security. This is the perfect timing to talk about how to secure data in the cloud where moving data to the cloud is becoming more popular. To our listeners, thank you for listening to this podcast. If you would like to learn more about data engineering or AI and ML topics and the security as well, check out the AI/ML and Data Engineering Community page on InfoQ website. I encourage you to listen to the recent podcast we have posted, and also check out the articles and news items we have on these topics on the website. Thank you.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Steef-Jan Wiggers
Microsoft has announced that its Azure Application Gateway, a cloud-based solution that provides secure, scalable, and reliable access to web applications, now supports mutual Transport Layer Security (mTLS) and Online Certificate Status Protocol (OCSP).
The mTLS support ensures that both the server and client authenticate each other before establishing a secure connection. At the same time, OCSP checks the status of digital certificates in real time, reducing the risk of cyber attacks. Implementing mTLS and OCSP in Azure Application Gateway enhances security, improves compliance, and reduces the risk of cyber attacks.
The additional layer of security provided by mTLS ensures that the authenticity of both the client and server is validated, making it more secure than TLS – suitable where organizations follow a zero-trust approach.
Application Gateway supports certificates issued from both public and privately established certificate authorities. It also supports TLS termination at the gateway, which improves performance and reduces resource consumption on the backend servers.
With OCSP support in the application gateway, users can have it send a client certificate to the backend application server in case it needs client certificate information for audit purposes or may want to issue a token or cookie to a client certificate. To achieve that, users can set up a rewrite rule to send the client certificate as an HTTPS header.
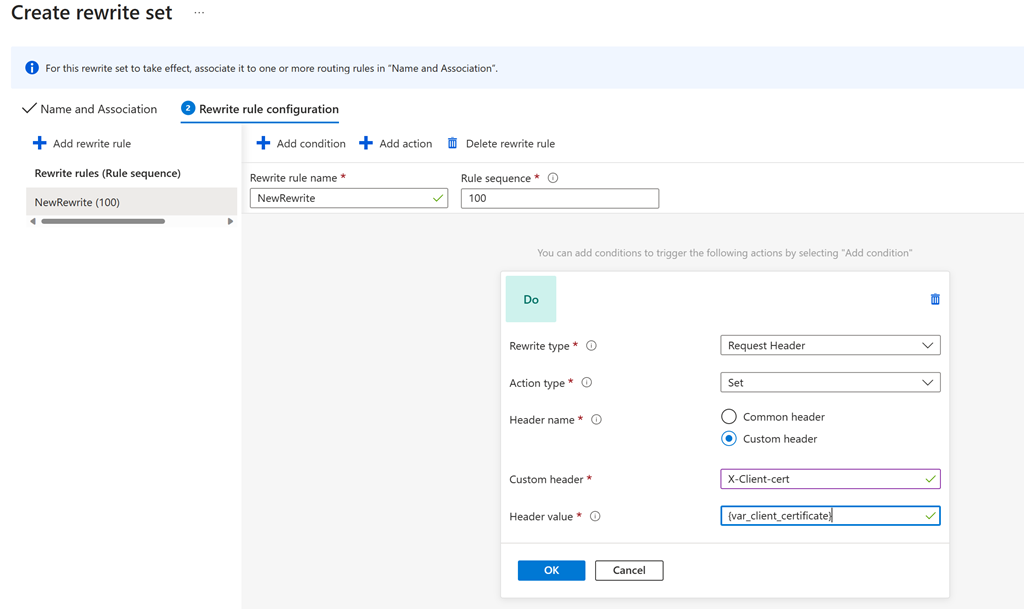
Furthermore, with OCSP support, users can verify the status of the client certificate in real time. This can prevent man-in-the-middle attacks by ensuring that the present certificate is still valid and has not been compromised.
Rajesh Nautiyal, a Senior Technical Program Manager, explains in an Azure blog post:
When a client initiates a connection to an Application Gateway configured with mutual TLS authentication, not only can the certificate chain and issuer’s distinguished name be validated, but the revocation status of the client certificate can be checked with OCSP (Online Certificate Status Protocol). During validation, the certificate presented by the client will be looked up via the defined OCSP responder defined in its Authority Information Access (AIA) extension. In the event the client certificate has been revoked, the application gateway will respond to the client with an HTTP 400 status code and reason. On the other hand, if the certificate is valid, the request will continue to be processed by the application gateway and forwarded to the defined backend pool.
To enable mTLS and OCSP on Application Gateway, customers must configure their backend servers with certificates signed by trusted authorities. In addition, they must also upload their root or intermediate CA certificates to Application Gateway.
Microsoft recommends mTLS specifically:
- For communication between Internet of Things (IoT) devices, each device presents its certificate to the other to authenticate.
- In a microservice architecture, making communication between APIs more secure and preventing malicious APIs from communicating with them.
- Preventing attacks like brute force or credential stuffing.
Users can configure mTLS after provisioning an Azure Application Gateway or on an existing one through the SSL setting tab in the portal. Alternatively, they can use PowerShell.
Lastly, more details on Azure Application Gateway are available in the documentation pages and FAQs.
MMS • Mehnaaz Abidi

Key Takeaways
- The top three areas in 2023 to rebuild culture in tech teams are team freedom, remote or hybrid working, and protecting diversity.
- Get your motivation back by focusing on building culture within your immediate team, and not across the company.
- Invest in yourself; don’t wait for your company to give you learning opportunities.
- The true culture of a company can be seen in how they off-board employees and treat their ex-employee network. An ex-employee is a stronger future employee.
- Don’t feel the pressure to be an advocate of your company, but rather be an advocate of your team.
At QCon San Francisco 2022 and QCon Plus December 2022, I talked about the software industry learning to adjust to a new global reality after the pandemic and its impact on flow metrics. My talk was called, “How to win as a tech team in a new reality that feels like a Mad Max movie?” I had shared some quick tips to help tech leaders build culture for hybrid and remote teams as the world tried to return to normalcy. I had emphasised post-covid needs to retain female tech employees, and why it was important to include culture building as a new metric within the flow framework.
Since that talk, a wave of layoffs hit the software industry and changed the definition of tech culture.
It was brutal to see the non-human approach taken by some companies while others truly surprised me by going the extra mile to support leaving employees. Many will juggle feeling lucky and relieved to have their jobs while being guilt-ridden for the suffering of former colleagues.
In 2020, Harvard Business Review compared this to survivor’s guilt where one would question,
“Why did I make it but they didn’t? How am I going to face friends who were laid off when struggling financially while I’m still employed? Will the employer do another round of layoffs and treat me the same as they did them?”
Trust in employers will be a hard-earned reward for many companies in the coming years.
Since then, I’ve taken extra steps to understand this situation across multiple tech companies, and the diverse choices made to support employees who survived, and those they had to say good-bye to.
In this article, I will focus on those of us who have stayed behind, and how to rebuild culture in our tech teams.
How to find your motivation again after experiencing your colleagues being let go?
Is it even possible when you’re experiencing very low trust in your employer?
The answer doesn’t lie in another company, but rather what you can do in your current workplace.
It’s easy to think that a new workplace will solve for some of the cultural misfits in your existing team. In Microsoft’s 2022 New Future of Work report, they mentioned the top culture-related reasons for finding a new job are disrespect, non-inclusive, unethical, cutthroat and abusive elements. In my experience, it’s been hard to judge such elements with star-studded employer branding and a few interviews where hiring managers feel the pressure to show the best side of the company. So our best chance as an employee to find culture-fit is to improve our existing “team” culture.
I’m emphasising “team” over company. I would take the parallel of helping people be well-fed in your neighbourhood to solving world hunger. Scale and scope is critical to the success of building good culture in tech teams. You can still sleep peacefully knowing your neighbourhood is healthy while there are larger problems to solve for the country.
So recognize your sphere of influence within the scope of your immediate team. If you’re an engineering manager or engineer, keep the focus on your squad including PMs and designers. If you’re in a functional team setup like Architecture, then keep the focus on the team around the manager and direct reports. If you’re a manager of managers, like a Sr director of engineering, then again keep the focus on your immediate direct reports while asking them to replicate the framework for their teams. Don’t overwhelm yourself trying to build culture simultaneously for multiple teams.
Now that you’ve reduced pressure on yourself and your team by reducing the scope, start to understand if you:
- Trust your team members
- Can have a good laugh with them
- Agree on common concerns within the team, and
- Can imagine working at least one calendar year with them?
If the answer to any of these questions is a yes, then you’ve found your safety net in this Mad Max movie. You have a team with whom you can work to improve psychological safety and rebuild the broken culture left behind from the layoffs. For many of us, work and life are interconnected, and we develop close friendships within these spaces. Losing a colleague, who was like a friend, may have triggered guilt, anger, denial, regret and much more. So start here. Give yourself and your team members enough room to talk about “how they’re feeling”.
If you were in a managerial position during the layoffs, it becomes important that you establish your sincerity before attempting this. For example, an engineering manager who had exited some tenured freelancers over an email for company cost saving, will see very little response from their team when attempting to run an engagement survey or trying to talk about team culture. With their email-exit approach, they’re no longer seen as a person under pressure by their team, but as a title. Subconsciously, the engineering manager has set the message that “I see my team as resources and not people. I didn’t care enough to even have a conversation before letting go of my team members.” So the team will avoid any attempts from the engineering manager to build a connection till they can prove their care for the team is genuine.
The Microsoft report also stated that employees who feel cared for at work are 3.2x more likely to be happy at work. This doesn’t have to be through the employer and many employees will find any such efforts to be fake after experiencing their approach in the layoffs. But what can be genuine is the care that you get from your immediate team members.
Focus your level of energy, commitment, persistence and creativity within your own team. You will see your motivation rise without needing to fake your commitment to the company. Don’t feel the pressure to be an advocate of your company, but be an advocate of your team.
What are the top three focus areas for rebuilding culture in affected tech teams?
Team culture is not a bunch of frameworks put together, but a comfortable space where your team can feel connected to each other, mourn, heal and celebrate.
Let’s start with the #1 ask from tech teams when it comes to work satisfaction – freedom
Since the Flintstones and before the layoffs, product x tech x business would often intersect with a disagreement. Many companies came up with pages of solid prioritisation frameworks and techniques. But prioritisation always came at the cost of some team feeling constrained. So we could never truly balance great prioritisation with well-rounded work satisfaction. I have seen amazing features driving very strong retention numbers, but the team behind it feeling those were not the right things to work on.
So how do we develop a greater sense of freedom within the team without getting burned out by priorities that we can’t influence (especially due to current difficult market conditions)?
Find time to do a round of trash talking about the priority in your team. Once you get the pressure/ stress out of your system, you will find that there is still immense freedom within such priorities. I worked with a team once who were put under immense pressure to completely redesign their entire product “asap”. We went through the five stages of grief – denial, anger, bargaining, depression and acceptance.
When we hit the acceptance stage, magic happened. The team found purpose in working together on this initiative and found their freedom to think differently about the product. But the negativity of the request coming top-down had taken away their ability to be creative earlier. In the current market conditions and reactive nature of companies, top-down priorities are only going to increase.
As a result, a team can start with acceptance and find their freedom to be creative earlier – or – like the other team, go through the five stages of grief to reach the same state later.
#2 ask is for remote or work from home to continue
While adhering to company policy on remote or hybrid work, each team can create flexibility for their individual team members on working from a non-office location. Have your own rituals to support each other through work-life balance, especially for primary caregivers.
Teams can always advise their HR to not put in fixed days to work from the office but give employees the option to choose the days based on the needs of their team. I’m seeing many HR teams already recognising this and supporting employees in deciding what’s best for their team. But if your HR team is still undecided, then hold your ground as a team. The only reason to push all employees to work fixed days from the office is ivory tower thinking that it will boost company culture.
Don’t let go of your hybrid work-from-home routine in an effort to increase your visibility/ worth due to fear of job loss. We cannot let anyone undo the progress made in having a stronger work-life balance, especially from fears triggered by the mass layoffs. Instead, increase your visibility by improving your online communication skills within your team and outside.
A few things that worked for me:
- Use every email as a chance to introduce yourself: In tech, we often write internal emails when we have to explain large concepts or align a large group on a decision. Use it as a chance to let the receivers know who you are and why they should listen to you.
- Be an empath by balancing detail with clarity: I had read in an article many years ago which said that “the only thing worse than listening to someone when you’ve no idea what they’re talking about is listening to them ramble on.” Always keep it simple and clarify upfront the expected outcome of your conversation. Ask them if they need to know more and don’t overwhelm them with too much technical information.
- Confident and regular sharing for recall value: engineers often struggle to increase their visibility outside of their team. I learnt to be confident by observing news channel journalists and how they hold intense conversations with facts and the right tone. They taught me the art of having meaningful conversations that project confidence under pressure, and how to leave a room with impact. My advice is to find influencers who can help improve how-you-show-up, and start creating visibility for yourself in existing company virtual formats like team demos, all hands, townhall, stakeholder updates, etc. If it’s too hard for you to talk to a live audience, then create visibility on a channel where you find comfort, for example, writing regular tech articles and getting your company excited about it.
#3 is to protect diversity in your team
It’s been tough for many tech leaders to hire a diverse workforce. It’s been years of work in the making to strengthen diverse communities and connect them to tech roles. The recent layoffs eliminated those efforts within minutes. So many of us now hold the responsibility to protect the remaining diversity in our teams.
My own focus is to better understand how to improve psychological safety for female team members. The pandemic was especially difficult for women in tech, and the industry saw a huge drop in their retention. Many factors, including being primary caretaker, factored in their decision to either pause their careers or move away from it. Returning from maternity leave had already become difficult and now with the added complexity of mass layoffs, they’re not even sure if they’re returning to the same team.
Female tech workers are needing more support than ever, and it’s especially important we focus on more customised retention measures to support them. I’ve heard a story where a female tech employee got an email of being laid off while she was in labour and read the full details minutes after she delivered her baby. She had worked for this Fortune Top 5 company for 9 years. We cannot allow this kind of precedent to be set up by any company, in any country. Period. As a female tech leader, I cannot accept such behaviour from any company.
I’m reacting to this reality by taking on more responsibility to ensure safeguarding the interests of women in tech. And I am happy to see many of my industry female peers take on similar responsibility towards our community.
I leave you with the thought that company culture is no longer a sum of individual team cultures. There won’t be a causal link between higher team eNPS and company eNPS. Employers who tried to make this layoff exercise simpler for themselves have unleashed a side effect of mistrust in the tech industry that will stay with us for a long time, and which will impact the way work is being done. For a sustainable future workplace, it will be crucial for these companies to give space to each team to lead the rebuilding of their culture.
Some employees will enthusiastically participate, but it will take time for others to rebuild healthy working relationships. It will be time-consuming, challenging, and prone to setbacks. However, it will be done at the team’s pace and on a more solid ground of trust. And in the end, you’ll not only help your team recover from this event, but will also create a healthier, more effective company.
MMS • Aditya Kulkarni

Slack has recently open-sourced its type checker, Hakana. Based on Psalm and written in Rust, Hakana’s main objective is to enforce good code quality. Additionally, Hakana can also perform security analysis.
Matt Brown, Senior Staff Engineer at Slack made the announcement in a blog post. Type safety refers to the extent to which language tools can assist in preventing type errors when executing code in a production environment. Following Slack’s migration from PHP to Hack, it became necessary to use a more rigorous type checker than the default PHP type checkers. To address this need, last year, Slack started developing Hakana internally.
Hakana, currently used in Slack, helps to prevent unused functions and private methods and also prevents unused assignments within closures. It can detect both impossible and redundant type-checks, warn the team about potential SQL injection attacks, and cross-site scripting vulnerabilities, and prevent misuse of internal Slack APIs.
Using the security analysis provided by Psalm as a foundation, Hakana analyzes how data moves between functions in a codebase, and verifies whether attacker-controlled data can appear in undesired places. Hakana’s security analysis uses interprocedural analysis, that enables detecting SQL injection by examining types at function boundaries.
The tech community on Reddit took a notice of this announcement. Brown interacted with the Reddit users through this post (Reddit user muglug in the comments), throwing some light on the decision to continue with Hack and answering some questions related to the pace of development.
As a side, Zend 2023 PHP Landscape Report highlighted that 46% of respondents deployed their PHP applications on AWS, dipping on-premised deployments by over 10% year-on-year. The survey also showed that during the survey period (October to December 2022), PHP 7.4 was the most used PHP version. PHP 7.4 reached end-of-life in November 2022.
From the performance aspect, Hakana runs five times faster than Psalm. Such performance is desirable at Slack, where the codebase size is about 5 million lines of code. Brown also mentioned that Hakana can be extended with plugins. As an example, Slack employs a customized plugin to inform Hakana that a method invocation on their internal Result object, $some_result->is_ok(), is similar to the more elaborate $some_result is ResultSuccess type check.
Brown acknowledged that while there are very few organizations using Hack language, open-sourcing Hakana may prove valuable to the broader programming language community. Since Hakana was built on the foundation of Psalm, making it open-source can be considered as a way of reciprocating the favor to the community.
MMS • Daniel Dominguez
Hugging Face, a top supplier of open-source machine learning tools, and AWS have joined together to increase the access to artificial intelligence (AI). Hugging Face’s cutting-edge transformers and natural language processing (NLP) models will be made available to AWS customers as a result of the cooperation, making it simpler for them to develop and deploy AI applications.
Hugging Face has become well-known in the AI community for its free, open-source transformers library, which is used by thousands of programmers all around the world to build cutting-edge AI models for a range of tasks, including sentiment analysis, language translation, and text summarization. By partnering with AWS, Hugging Face will be able to provide its tools and expertise to a broader audience.
Generative AI has the potential to transform entire industries, but its cost and the required expertise puts the technology out of reach for all but a select few companies, said Adam Selipsky, CEO of AWS. Hugging Face and AWS are making it easier for customers to access popular machine learning models to create their own generative AI applications with the highest performance and lowest costs. This partnership demonstrates how generative AI companies and AWS can work together to put this innovative technology into the hands of more customers.
AWS has increased the scope of its own generative AI offerings. For instance, it improved the AWS QuickSight Q business projections to comprehend common phrases like “show me a forecast.” The Microsoft-owned GitHub Copilot, which uses models built from OpenAI’s Codex, has competition in the form of AWS’s Amazon CodeWhisperer, an AI programming assistant that autocompletes software code by extrapolating from a user’s initial hints.
As part of the collaboration, Hugging Face’s models will be integrated with AWS services like Amazon SageMaker, a platform for creating, honing, and deploying machine learning models. This will make it simple for developers to create their own AI applications using pre-trained models from Hugging Face without needing to have considerable machine learning knowledge.
The future of AI is here, but it’s not evenly distributed, said Clement Delangue, CEO of Hugging Face. Accessibility and transparency are the keys to sharing progress and creating tools to use these new capabilities wisely and responsibly. Amazon SageMaker and AWS-designed chips will enable our team and the larger machine learning community to convert the latest research into openly reproducible models that anyone can build on.
Hugging Face offers a library of over 10,000 Hugging Face Transformers models that you can run on Amazon SageMaker. With just a few lines of code, you can import, train, and fine-tune pre-trained NLP Transformers models such as BERT, GPT-2, RoBERTa, XLM, DistilBert, and deploy them on Amazon SageMaker.
Hugging Face and AWS’s partnership is anticipated to have a big impact on the AI market since it will make it possible for more companies and developers to use cutting-edge AI tools to generate unique consumer solutions.
Podcast: Internships Enabling Effective Collaboration Between Universities and Companies
MMS • Lukas Hermann
Subscribe on:
Transcript
Shane Hastie: Hey folks, QCon London is just around the corner. We’ll be back in-person in London from March 27 to 29. Join senior software leaders at early adopter companies as they share how they’ve implemented emerging trends and best practices. You’ll learn from their experiences, practical techniques and pitfalls to avoid, so you get assurance you’re adopting the right patterns and practices. Learn more at qconlondon.com. We hope to see you there.
Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Tonight for me and this morning for our guest, I’m sitting down with Lukas Hermann. Lukas is the VP of technology at MANTA, and is based in Prague in the Czech Republic. Lukas, welcome. Thanks for taking the time to talk to us today.
Lukáš Hermann: Shane, thank you for having me here.
Shane Hastie: Probably a good starting point is who’s Lukas?
Introductions [01:03]
Lukáš Hermann: Okay, so as you mentioned, I’m VP of technology at MANTA. I’m based in Prague, Czech Republic, where we have our largest development center. I graduated in software engineering at Charles University in Prague and during my studies, I focused on compilers and component architecture.
I started to work for Czech company and thanks to my interest in compilers, I got to a project where one of our customers tried to figure out how their data flows through their data warehouse, to make their development more agile and also to resolve data incidents faster. And it quickly became clear, that without understanding what code used to move data in their environment does, could be real tedious manual work, or the results won’t be accurate.
And at the same time, we realized that this is exactly something where our colleagues from university that did the research on compilers could help. And this problem is also something unique for that particular customer, but it might be also interesting possibly to any larger company that works with data. So therefore, we use that opportunity to apply for funding provided by Czech government, that enables to connect companies solving real problems with universities doing complex research. We got that funding and therefore, there was a time to develop something useful and also to find our first customers abroad. And from that time, I was leading a small team of internal developers and student and I was also talking to our potential customers to find out what they need. And before the government funding successfully ended, we found out that what we built had a big potential and we decided to spin off to create an independent company and to find also private funding and customers ourselves. And six years later, after several rounds of investments, I lead an international 70 person engineering team, building the best data learning solution on the market. And just like at the beginning, I’m still in charge of the cooperation with universities.
Shane Hastie: The reason we got together is to talk about this collaboration, cooperation with universities. So, tell us a little bit about what has been described as the one-year interview.
Identifying collaboration opportunities between universities and private companies [03:16]
Lukáš Hermann: So, as I mentioned, yeah, we started as a research project closely working with universities. And from the nature of what we do there, there are many open topics to explore. So, what we do at each year, we create a list of research topics based on issues that we encountered, or ideas in our roadmap that are complex enough for final theses. It might be anything from new approaches, how to analyze code, through metadata processing, optimization, to effective data lineage, visualization layouts, whatever we need to solve. And we present these topics to students at university events or through our university colleagues that teach them. And from that, we get a list of candidates that are interested in one or more topics. Some are interested in bachelor thesis, some in master thesis disease, and even in some team software projects.
So then, when we evaluate all the candidates in our interview process to assist their knowledge and potential and motivation, and we select some of them for our internship program. And from that point, basically we help the students to find their official thesis supervisor at the university. And we also assign one of our developers, usually a leader of the team that invented the topic. And we ensure that basically, these guys are … meet regularly during the whole project. So, the results are aligned with expectations both from the university and also from our side.
At the beginning, we give students lot of time to learn about our product and about the topic because these topics are quite, quite complex. So they get literature and documentation that is related to their topic. And when it’s clear what the problem they are going to solve and what are the possible approaches, we led the topic to be officially assigned at the university. And from that point, they have usually six to nine months to work on further analyze this design, implementation, testing documentation. It’s like all the work is done by them, but us helping them.
And for the whole time, they’re part of one of our development teams. So, they have the same rituals, like standups, code reviews, so they can learn how the whole development process works. And once they’re close to the end, we make sure that they have enough time to work on the text of their thesis and pass all the exams at the university, evaluate with them how the cooperation went and what are their possible extensions of their work if they stay as regular employees? It’s so good that it brings us the tight connection with universities, always getting fresh ideas from the current research. We can also reach out to students even before they start thinking about having a job. Students can work on the thesis that will have some impact and won’t end just in their libraries. They don’t have to look for another job that is not connected with their interests because these internships are paid, so they can learn how the real software development look like. And if they don’t want to continue with us, then they already have better position on the job market thanks to their experience.
Shane Hastie: One of the things that I’ve heard that has been commented on internship programs, is often the interns bring the very academic perspective, which is useful, but they don’t bring the discipline and rigor and quality that a commercial product needs. How do you bridge that gap?
Research is done while being part of the development team [06:43]
Lukáš Hermann: Yeah, that’s a very good question. So, from the very beginning, all the students really participate in all the processes within the development team. So, all the code that they produce needs to go through code reviews by more senior developers. And so, they ensure that the code that they produce is a good quality. And that’s not only about the code, but also about their design, about the way how they prepare tests. So, everything is always under the review, so we ensure that the quality meets our standards.
Again, sometimes those topics are more like research topics or prototypes. So basically, what the code is produced will not be used then in production because it’s basically just trying to find a solution to some algorithm or to some problem and then it’s rewritten for the production usage. But if the code is good quality, we can even use it in production.
Shane Hastie: You mentioned that you allocate them a mentor or somebody senior in the organization, that’s obviously taking time out of these people’s days. How do you ensure that they do provide the level of support that somebody learning needs?
Mentors support the learning and help instil good habits [07:50]
Lukáš Hermann: So, all the mentors has the same nature of providing this mentorship to the students. So, they have the same goal that they understand that there are lot of research topics that their team don’t have time for. So, they know that the students will help them to focus on one of the topics that they can solve as a team, and the investments in them will pay off. So, they know, “Okay, so if I invest this amount of hours in the student, he has the whole focus on that topic for the whole year. So, at the end would be something useful for my team so that they are ready to invest that time.”
Shane Hastie: Tell us a story. Tell us the story of one of your interns, how’ve they worked out, what’s happened?
The story of one intern [08:32]
Lukáš Hermann: Yeah, so one example of a student, his name is Andre. He started at MANTA on his bachelor thesis on one of our scanners that analyzes data flows in one of the reporting tools that we support. And when he was working on that scanner, he realized that there was one part of the technology that used complex language to describe data movement, that we really didn’t count at the beginning because it was some kind of reporting tool. And we thought, Okay, it would be easy for bachelor thesis. But he was not afraid.
He learned how it could be analyzed and he succeeded. And after he finished it, the bachelor thesis, I liked it, I liked the topic, he spent some time improving the scanner, making it part of our product. And the next academic year he was about to search for a topic for a team software project that was needed at the software engineering program that he studied.
At that point, we were looking for a new team that would help us to analyze actually Python, which was gaining popularity among data scientists. And with our help, he was able to find like four other students that were interested in having the software project and he became a leader of the team, even very young leader. And after one year, they were able to develop a good working prototype, to successfully defend that project at the university. And then he continued working on this scanner and now he’s working on one of the topics actually for his master thesis. And he’s still involved in testing of this scanner, also with our customers.
Shane Hastie: So, he’s stayed effectively … is he still an intern or working towards his masters, or is he a full-time employee?
Lukáš Hermann: Yeah, so he’s still working for his masters, but he’s already like full-time because again, his master thesis connected to what we do. So basically, he could be like full-time and working on his master thesis.
Shane Hastie: What’s the overhead, what’s the cost to the organization of doing this?
There is little actual cost to the organization [10:24]
Lukáš Hermann: Since basically what we do really requires the research, we would need to do something like that even if we don’t use students. We would need to start working with some researchers. And we also do that, we work with some researchers at the universities that help us to solve those topics that are hard to find a solution for them. So, we already do that, so we don’t see it as a inefficiency. We think that there are many things that we will develop and it won’t work. We would need to try it, try it again. So, we see it as a foundation of what we do. The problems that we solve are not easy, nobody’s solved that before. So, we count with this nature. And obviously there are only some teams that are working on research projects, there are different teams working on something, let’s say more standard in the development process, and they don’t have these inefficiencies.
Shane Hastie: If an organization wasn’t in the bleeding edge of research, would it be worth their while, do you think?
Finding the right match of research and work for your organization [11:18]
Lukáš Hermann: I believe that what they need to do first, is really to try to identify the topics that might be interesting for researchers and students. So, if they have such topics, and it might be really anything, like from optimization of some algorithm that they use to make a better performance or scalability, or maybe they’re thinking about some new product feature, maybe connected to machine learning, AI or whatever, and that they’re not sure if they want to really invest in that, they just want to explore if there are possibilities, how to solve this problem. If they identify such topics, they can contact the universities that perform research in those topics that are close to what they need, and they should try to establish the partnership with them.
So, it’s always ideal to start with the researchers that might be interested in those topics. And once you find those and then find it interesting, then you need to find ways how to present these topics to students. And ideally, it starts with those researchers who are most also the teachers of those students. So, they have the best contact with them and they can convince that this topic is interesting, something worked, investing their time. And also, you can present these topics at that job first. But definitely, going through teachers have better effect.
And then if you really think that maybe that product branch might be something where you want to invest for longer time, you can even try to level up that cooperation with the university and either create some research program together with them, funded solely by your company. Or maybe you can even look for some incentives or initiatives from government or other parties, that want to support this, the cooperation between industry and universities.
Shane Hastie: Stereotypically, academics want to be above the commercial realities. How do you inspire them to take an interest in the commercial world?
Encouraging researchers to focus on commercial challenges [13:12]
Lukáš Hermann: Yeah, it’s true that our researchers often want to be in their own bubble, let’s say, but well, there are a lot of them that are pleased by the way that, “Okay, this is something that is not only doing research for research but actually something useful.” And what they also like is some kind of real use cases, some real world scenarios, or also data from the real war scenarios. For example, if their research is focused on code analyzers, they can download the code from GitHub, from open source projects, but these are not the real world scenarios in industry. So, we can bring them data from industry that they can work on and they explore, “Okay, so my solution was working on this small pieces of code, but would it work on large enterprise application?” And without this corporation, they wouldn’t have any opportunity to get this real world data.
Or another example would be research and graph databases that we also do. Again, they can play with some models, semantic models and so on. But again, we can give them real world data from customers describing their systems. And it’s much more fun to work with real world problems than something that you made up.
Shane Hastie: Thinking about careers and growth and so forth. You used the example, I think his name was Andre, who ended up in a leadership position of a small team team. Did you give him any leadership skills training?
Ensuring interns build leadership and people skills as well as technical skills [14:38]
Lukáš Hermann: Yeah, that’s definitely necessary. We have a program for team leaders that they can use and also, managers that help them to grow into this position. Obviously, it’s something different to really lead the research program, and then to lead the whole development team. So, this is still a little bit different, but we really want to encourage people to, no, don’t be afraid of leading and deciding.
Shane Hastie: And how do you grow leaders in your organization?
Lukáš Hermann: That’s always hard and especially for a company as we are, we are a young company, really fast growing. So, it’s a combination of finding already good leaders on the market that would fit into our philosophy, which is the one way. And the second way, is try to grow people that are inside our organization, but it takes time. So, it’s always about identifying those people that are interested in that and then providing them all the support to become a good leader.
Shane Hastie: And what does that look like? What does that support play out as?
Supporting people to become good leaders [15:42]
Lukáš Hermann: So, it’s about trainings, it’s about mentorship and coaching from leaders that are already within the company for a longer time, teaching them all the processes, supporting them with the way, how they plan, how they work with people. And it’s always, let’s say incremental. So, they will be responsible from the beginning for everything that a team leader is doing. They start with smaller projects, maybe tech leading at the beginning, and then we add more things to that. Okay, so now you need to also be responsible for a plan. Now you need to be responsible also for performance review and so on. So, it’s always incremental process.
Shane Hastie: What are the biggest challenges for leaders in the software environment today?
Lukáš Hermann: I believe that the biggest challenge is that you are somehow in the middle. So, you already have some responsibility for people, you need to hear them, you need to provide them all the support. And on the other hand, you have the responsibility to your managers that everything in the team work well. And if not, then you need to work on that with them. So, it’s a quite hard position, I believe, especially for good programmers, good technicians, and now they’re in this position that requires a different skillset.
Shane Hastie: And as an industry, how do we grow? How do we mature? How do we build better leaders for the future?
Lukáš Hermann: Yeah, so definitely, it’s about constant learning. You need to be able to provide them the support to learn and also the support for changes. So they know, “Okay, so now I see it in this way, but maybe this works for now, but maybe in future something else will work.” And especially with the growing organization, you need to change almost every year. You need to adapt. So, you need to be open to all the changes, to all the advises or all the experience from outside. And also, to accept that if you change something, you might fail and you might be wrong direction, but you need to identify it quite soon and try to learn from your mistakes.
Shane Hastie: Learning from mistakes is hard.
Lukáš Hermann: Yeah, it is hard.
Shane Hastie: Where do you think we’re going as an industry? What’s the future?
Thoughts on the future of software engineering [17:51]
Lukáš Hermann: What’s the future? Maybe I’m now a little bit impressed by the Chat AI that was released just last week. We were playing with that in our team for a week and we were thrilled by what it could provide. So that question was like, “Okay, so is a programmer someone who lose their job because any AI could do that?” It made us thinking about what is to be really good programmer. It’s obviously not just writing some code that someone already wrote. It’s always about the creativity, the innovation, the new ways of thinking. And that’s the only way how we can, as a programmers, how we can survive that, that we will be still more creative than this AI.
Shane Hastie: Lukas, some really interesting thoughts. Great to see bringing young talent in and … Well, I’m making an assertion that most of these people you’re bringing in are young, but bringing new talent into the industry and growing them within your organization and giving them a foothold and a starting point. If people want to continue the conversation, where can they find you?
Lukáš Hermann: So, thank you very much for the whole conversation. It was so a pleasure for me to talk to you. And if you want to contact me, just use my LinkedIn profile, it will be the best way.
Shane Hastie: Wonderful. And we’ll make sure that that’s included in the show notes. Thank you so much.
Lukáš Hermann: Thank you. Have a nice day.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Sergio De Simone

In a recent paper, researchers at Microsoft Autonomous Systems and Robotics Group showed how OpenAI’s ChatGPT can be used for robotics applications, including how to design prompts and how to direct ChatGPT to use specific robotic libraries to program the task at hand.
As Microsoft’s engineers explain, current robotics relies on a tight feedback loop between the robot and an engineer who is responsible to code the task, observe the robot’s behaviour, and correct it by writing additional code.
In Microsoft vision, ChatGPT could be used to translate a human-language description of the task to accomplish into code for the robot. This would make it possible to replace the engineer (in the loop) with a non-technical user (on the loop) only responsible to provide the original task description in human language, observe the robot, and provide any feedback about the robot’s behaviour, again in human language, which ChatGPT would also turn into code to improve the behaviour.
Using their experimental approach, Microsoft researchers created a number of case studies which include zero-shot task planning to instruct a drone to inspect the content of a shelf; manipulating objects through a robotic arm; searching for a specific object in an environment using object detection and object distance APIs; and others.
In all those cases, ChatGPT was able to generate the code to control the robot as well as to ask for clarifications to better carry the task through when it found user input ambiguous, say Microsoft.
Microsoft’s work to make ChatGPT usable for robotic applications focused on three main areas of investigation: how to design prompts used to guide ChatGPT, using APIs and creating new high-level APIs, and how to provide human feedback through text. Those three areas represents the keystones of a methodology to use ChatGPT for robotic tasks.
In a first step, the user defines a set of high-level APIs or function libraries that ChatGPT should use.
This library can be specific to a particular robot, and should map to existing low-level implementations from the robot’s control stack or a perception library. It’s very important to use descriptive names for the high-level APIs so ChatGPT can reason about their behaviors.
In the second step, the user provides a description of the task goal specified in terms of the available APIs or functions.
The prompt can also contain information about task constraints, or how ChatGPT should form its answers (specific coding language, using auxiliary parsing elements).
Finally, the user evaluates ChatGPT’s code, by using a simulator or inspecting the code, and provides feedback for ChatGPT to correct its code.
When the outcome is satisfactory to the user, a robot can be programmed using the generated code.
Microsoft is also launching a collaborative open-source platform for users to share prompting strategies for different robot categories, which at the moment includes all the prompts and conversations that the Microsoft team used for their research. Additionally, they also plan to add robotics simulators and interfaces to test ChatGPT-generated algorithms.
MMS • Steef-Jan Wiggers
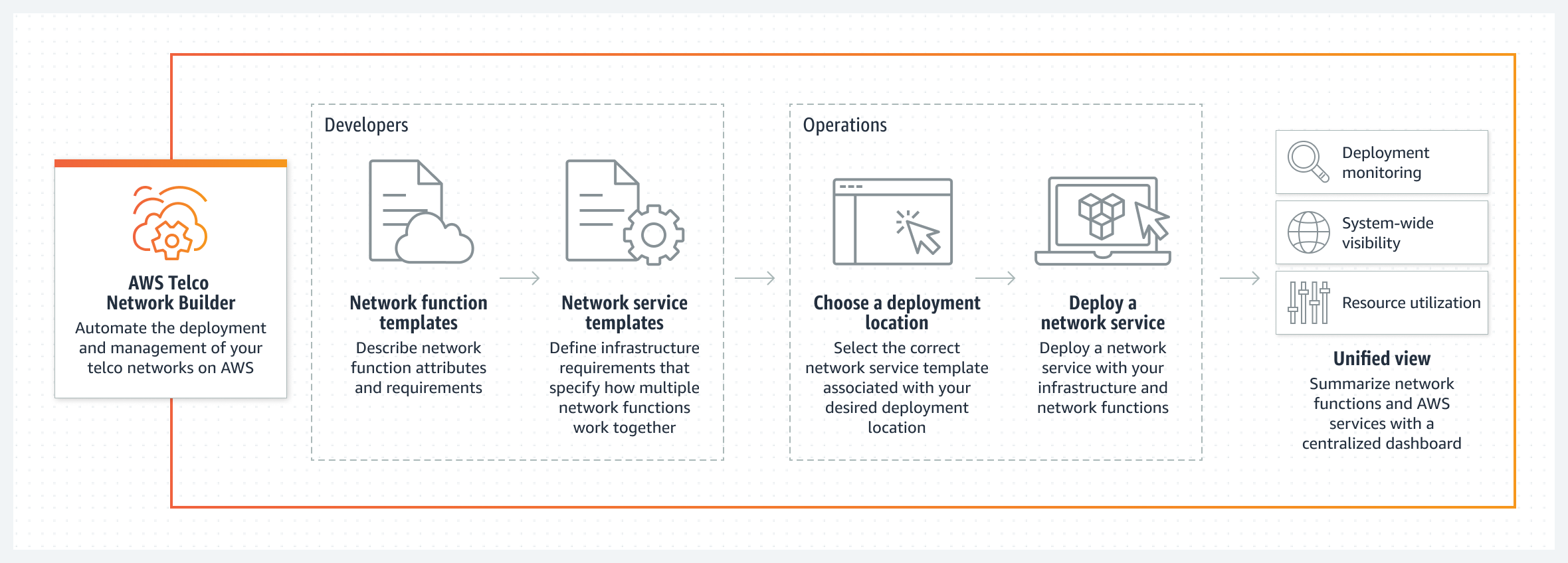
AWS recently announced a new service AWS Telco Network Builder (TNB), that enables customers to deploy, run, and scale telco networks on AWS infrastructure. It is designed for communication service providers (CSPs) who want to use AWS for their 5G networks.
AWS TNB offers a simplified solution for creating and scaling a telco network in the cloud, eliminating the laborious task of deploying hundreds of network functions (NFs) and managing separate monitoring tools. It supports telecom industry standards such as ETSI NFV MANO, 3GPP, and TM Forum. In addition, it integrates with AWS services such as Amazon EC2, Amazon S3, and Amazon VPC and can be deployed on networks on-premises or in AWS regions.
Furthermore, some of the other characteristics of AWS TNB are automation of the network deployment process using templates that map to network services and a centralized dashboard to monitor and manage the network performance and resources.
Source: https://aws.amazon.com/tnb/
According to the documentation, customers have various options to create, access, and manage their AWS TNB resources, including:
- An AWS TNB Console – a web-based interface allowing users to manage their network using an intuitive graphical user interface.
- An AWS TNB API that provides a RESTful API enabling users to perform AWS TNB actions programmatically.
- The AWS Command Line Interface (CLI), which offers a command-line interface for a broad range of AWS services, including AWS TNB.
- AWS SDKs providing language-specific APIs that simplify connecting to AWS TNB. The SDKs handle tasks like calculating signatures, request retries, and error handling.
Jeff Barr, a chief evangelist at AWS, states in an AWS news blog post on TNB:
Today, CSPs often deploy their code to virtual machines. However, as they look to the future, they are looking for additional flexibility and are increasingly making use of containers. AWS TNB is intended to be a part of this transition, and makes use of Kubernetes and Amazon Elastic Kubernetes Service (EKS) for packaging and deployment.
In addition, Jan Hofmeyr, vice president of Amazon Elastic Compute Cloud (Amazon EC2), pointed out the critical value of TNB for customers in an Amazon press release:
AWS Telco Network Builder removes the burden of translating a customer’s desired telco network into a cloud architecture, empowering them to easily modernize and quickly scale to meet demand while freeing time and capital to build new offerings, expand coverage, and refocus on invention.
Currently, AWS Telco Network Builder is available in the following AWS Regions: US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Europe (Frankfurt), Europe (Paris), and with availability in additional AWS Regions coming soon.
Lastly, AWS TNB pricing is determined by the number of Network Functions managed and the calls to the TNB APIs. However, the first 45,000 API requests per month per AWS Region incur no charges. In addition, there are extra fees for any AWS resources generated during deployment. More details of TNB are available on the pricing page.
MMS • Matt Campbell

HashiCorp has released version 1.5 of Nomad, currently in beta. Nomad is their orchestrator platform for deploying and managing both containerized and non-containerized environments. This release adds single sign-on and OIDC support as well as dynamic node metadata, job templates, and UI improvements.
With this release, it is now possible to sign into Nomad via single sign-on (SSO). Any OIDC-compliant identity provider (IDP) can be used. At the time of writing, this includes Okta, Auth0, Amazon Cognito, Google Identity Platform, Azure Active Directory, and HashiCorp Vault. This improves upon previous releases where ACL tokens were used to control permissions. The distribution and management of these tokens were left up to Nomad administrators.
This improvement also includes a new nomad login CLI command. This command can be used to exchange the provided third-party credentials with the requested authentication method to receive a Nomad ACL token. For example, logging in via an OIDC provider can be done as follows:
nomad login -type=OIDC -method=auth0
This release also improves setting and updating metadata on Nomad client nodes. Metadata can be configured on client nodes to help with scheduling decisions. For example, the spread block can be used to specify the node attribute that allocations should be spread over. Metadata can be used here to help specify which racks to place the allocations:
spread {
attribute = "${meta.rack}"
target "r1" {
percent = 60
}
target "r2" {
percent = 40
}
}
It is now possible to dynamically update and create metadata without having to restart the client. This can be done by the API, UI, or CLI. Updating via the CLI can be done as follows:
nomad node meta apply -node-id aws-t2-622 inodes=127126 custom-key=val
Mike Nomitch, Senior Product Manager at HashiCorp, notes that this feature can be useful in situations such as
Conditional scheduling based on changes to node-level dependencies, customized node health or resource checks, and scheduling in response to batch jobs that change the configuration of their client node.
A new Unix domain socket (UDS) has been added to simplify how Nomad tasks communicate with Nomad. The socket is mounted at ${NOMAD_SECRETS_DIR}/api.sock and requests to it require authentication. Tasks that can make use of the socket include autoscaling controllers, custom operator tasks, and modifying metadata.
New job templates have been included in this release. Designed to help new Nomad users get up to speed they cover use cases such as a simple service job, batch jobs, service discovery, and Nomad variables. The templates are available from the UI and the CLI.
This release also introduces a number of UI improvements including a new page where administrators can view, create, and update Nomad ACL policies. Additionally, task events are now shown in the logs sidebar. This can facilitate debugging as task failure information will be located here.
More details on the release can be found on the HashiCorp blog. Questions and feedback can be taken to the Nomad Community Forums or the community office hours. The open-source version of Nomad is available free for download.