Transcript
Turner: Do you find you have trouble with the APIs in your organization? Do services struggle to interact with each other because their APIs are misunderstood, or they change in breaking ways? Could you point to the definition of an API for a given service, let alone to a catalog of all of them available in your estate? Have you maybe tried to use an API gateway to bring all of this under control, but do you find it doesn’t quite feel like the right tool for this job? I’m Matt Turner. In this talk, I’m going to talk about some more modern techniques and tools for managing your APIs. We’re going to see what API gateways really do, what they’re useful for, and where they can be replaced by some more modern tooling.
Outline
In the first half of this talk, I’m going to talk about what an API is just very briefly, get us back on the same page. Talk about what an API gateway is. Where they came from. Why I’m talking about them. Then we’re going to look at sidecars, which I think are a more modern distributed microservice style alternative. Then get a look at some more tooling around the lifecycle of an API. Some of these stages you might be familiar with in the design and development of an API. I think API gateways have been pressed into helping us with a lot of these things as well. Actually, rather than using an API gateway or a sidecar, rather than using a component of the network, like an online active component at runtime, there’s a bunch of more modern tooling now that enables us to do this earlier in the dev cycle to shift these concerns left. I’m going to be covering that as well.
API Gateways and Sidecars
API gateways and sidecars. Let’s very briefly go over what I mean by API, at least for the purposes of this talk. Let’s start off easy, what isn’t an API? The definition I’ve come up with is that an API is the definition of an external interface of some service. Service is open to interpretation, your workload and point where you want to call it. There’s a way of interacting with it and talking to it from the outside. That’s what an API is. Wikipedia says that an API is a document or a standard that describes how to build or use a software interface. That document is called an API specification. It says that the term API may refer to either the specification or the implementation. What I really want us to agree on, for the purposes of this talk, an API is not a piece of code or a running process. People, I’ve heard them talk about deploying an API, and what they mean is deploying a pod to Kubernetes, deploying some workload to a compute environment. That’s either the fact that that service is not a batch processing service but it’s some daemon that has an API. I think we get confused if we start using the word API for that. An API by my definition, how do we define it? An API is defined by an IDL, an Interface Definition Language. You may have come across OpenAPI Specs, formerly called Swagger, or protobuf files, which include the gRPC extensions. There’s Avro, or Thrift, and a lot of those other protocols have their own IDLs as well. This is like a C++ header file, the Java interfaces, C# interface.
Very briefly, a workload, a running process, a pod can have an API that we can talk to. If you got more than one of those, you put something in front, that it spreads the work between APIs. This is your classic load balancer. You can have more than one different API on different workloads, and then your front-facing thing, whatever it is, can expose both of them. You can have a slightly fatter, more intelligent front-facing thing that can combine those backend APIs in some way. Think of this as a GraphQL resolver, or even a load balancer, or an API gateway doing path routing. It’s worth saying, a pod, a service, a workload can actually implement two different APIs, like a class having two interfaces, or maybe two versions of the same API, which is something that’s going to be quite relevant for us.
What Is an API Gateway?
What is an API gateway? They have a set of common features. They are network gateways. The clue is in the name with gateway. They do things like terminate TLS. They load balance between services. They route between services. They do service discovery first to find out where those services are. They can do authentication with cloud certificates, JWTs, and whatever. They can do authorization. That’s allow listing, block listing of certain hosts, certain paths, certain header compressions, whatever, because it’s at layer 7. They do security related stuff. An obvious example would be injecting calls headers. They can rate limit and apply quotas. They can cache. They can provide a lot of observability, because we send all traffic through them, so we can get a lot of observability for free. Then, some of the common features that get more interesting or more relevant to this talk that I’ve pulled out of a lot of those different product specifications is things like the ability to upload one of those IDL files, like an OpenAPI Spec, and have the API gateway build an internal object model of your API, hosts, paths, methods, and even down to a body schema, so enforcing the schema of bodies and request bodies coming in and going out. A lot of them also have some support for versioning APIs, different stages of deployment, so maybe a test, a staging, and a prod version of an API. A lot of them will also do format translations. That’s maybe gRPC to SOAP or gRPC to “REST,” JSON over HTTP. They can do schema transforms. They might take a structured body like a JSON document in one format, and rearrange some of the fields, rename some of the fields. They can manipulate metadata as well, so insert, modify, delete headers.
Why Am I Talking About This?
Why am I talking about these things? Back in the day, we had a network and we would probably need some load balancing. Since we got beyond a toy example, we’d have certain services. In this case, I’m showing a database where we need more than one copy running for redundancy, for load carrying ability. We’d have multiple clients as well that needed to talk to those things. We’d stick a load balancer in the network, logically in the middle. These were originally hardware pizza boxes, thinking F5, or a Juniper, or a NetScaler. Then there were some famous software implementations, something like HAProxy, NGINX is quite good at doing this. They balance load service to service, but you also needed one of at the edge so that external clients could reach your services at all, across that network boundary, discover your services. Then they would offer those features like load balancing between different copies of the service. Here, I’ve just shown that middle proxy copied, we’ve got another instance of it, because it’s doing some load balancing over. This is probably the ’90s or the early 2000s. This is your web tier, and then they got a load balancer in front of your database tier. Because this thing is a network gateway, because it’s exposed out on the internet, it’s facing untrusted clients on an untrusted network, it needs to get more features. Things like TLS termination, just offering a serving cert so you can do HTTPS rate limiting, authentication, authorization, and then more advanced stuff like bot blocking, and your web application firewall features like detecting injection payloads, and that kind of stuff. Although it’s a very blurry definition, I think all of these features made a load balancer into what we can nebulously call an API gateway.
Now that we’ve moved to microservices, our monoliths are becoming distributed systems, we need a bunch of those features inside the network as well, so observability doesn’t come from attaching a debugger to the monolith, it comes from looking at the requests that are happening on the wire. Things that were a function call from one class into another that were effectively infinite and infallible, are now network transactions that can fail, that can time out, that can be slow, that can need retrying. All of this routing, and, yes, we used to have dependency injection frameworks. You wanted to do your reads in different config or access a different database in test, you would just use dependency injection to do a different build profile. We can’t do any of that stuff anymore in the processes themselves, because they’re too small and too simple. A lot of that stuff is now being done on the network. That fairly dumb load balancer in the middle has gained a lot of features and it’s starting to look a lot like an API gateway. In fact, a lot of API gateway software is being pressed in to perform this function.
I think the issue with this is that it can do a lot. The issue is that it can maybe do too much, and that it’s probably extensible as well. You just write a bit of Lua or something to plug in. It’s very easy for this to become an enterprise service-plus thing from 2005. It’s this all-knowing traffic director that does all the service discovery, holds all the credentials for things to talk to each other. It’s the only policy enforcement point. All of those extensions, all of those things that we can plug in, even the built-in features like the ability to just add a header here or manipulate a body there, just rename a field, just so that a v1 request looks like a v2 request. All of that stuff strikes terror into me of ESPs, and makes me think of these systems that accreted so much duct tape that nobody really understood. Of course, that duct tape isn’t really duct tape, this is part of a running production system, so you’ve got to consider it production code.
It’s also not giving us the security we think it is, in this day and age. The edge proxy works. The edge proxy secures us from things on the internet, because it’s the only way in and out of the network. That’s fine as long as all of our threats are outside. Then that’s the only way in because the subnet is literally unroutable. Bitter experience shows us that not all threats are on the outside, compromised services attempting lateral movement, probably because they’ve had a supply chain attack or a disgruntled employee has put some bad code in, or just somebody on the internal network because Clee has plugged into an Ethernet port or somebody’s cracked the WiFi or something. There’s more of these devices on our networks now with Bring Your Own Device, and with cloud computing, and with one monolith becoming 3000 microservices, there’s just more units of compute, more workloads that we have to worry about that could be a potential threat. While an API gateway being used as a middle proxy might do authentication, it’s kind of opt-in, you’ve got to send your traffic through it with the right headers, if you don’t have the right headers, what’s to stop you going sideways like this?
Sidecars
Onto sidecars. The basic sidecar idea is the idea of taking this middle proxy that’s got a bunch of logic, and logic that I agree that we need, I just don’t think it should be here. What a sidecar does is it moves it to each of the services. Some of them are maybe a little bit obvious, like rate limiting. Each one of those sidecars can rate limit on behalf of the service it’s running on. Load balancing is one people often get a bit confused about. You don’t need a centralized load balancer. Each service, in this case, each sidecar can know about all of the other potential services and it can choose which one to talk to. They can either coordinate through something called a lookaside load balancer to all make sure that their random number generators aren’t going to make them all hit the same one basically. They can look at the lookaside load balancer to find out which of the potential backends has the currently least connections from all clients. Client-side load balancing is actually perfectly valid and viable for those backend services, for internal trusted services where we have control over the code.
I’ve said sidecar a few times, I should actually have talked more generally about that logic. The first thing we did with that logic, that stuff that the API gateway was doing for us on the network, retries, timeouts, caching, authentication, rate limiting, all that stuff, the first thing we did was we factored it out into a library. Because like that Kong slide showed earlier, we don’t want every microservice to have to reimplement that code. We don’t want the developer of each service to have to reinvent that wheel and type the code out, or copy and paste it in. We factor it out. There are a couple of early examples of this. We’ve got Hystrix and Finagle, which are both very full featured libraries that did this stuff. The problem with those libraries is that they’re still part of the same process. They’re still part of the same build, so deployments and upgrades are coupled. They’re reams of code. They’re probably orders of magnitude more code than your business logic, so they actually have bug fix updates a lot more often. Every time they do, you have to roll your service. You also, practically speaking, need an implementation in your language. Hystrix and Finagle were both JVM based languages. If you want to do Rust or something, then you’re out of luck unless there’s a decent implementation that comes along. We factored it out even further, basically, to an external process, a separate daemon that could do that stuff, and another process that can therefore have its configuration loaded, be restarted, be upgraded independently.
What software can we find that will do that for us? It turns out, they’ve already existed. This basically is an HTTP proxy, running as a reverse proxy. Actually, I could be running as a forward proxy on the client side and then a reverse proxy on the server side on the Kotlin side. Even Apache can do this, if we press it, but NGINX, HAProxy are better at it. The new goal is a cloud native HTTP proxy called Envoy, which has a few advantages, like being able to be configured over its API in an online fashion. If you want to change a setting on NGINX, you have to render out a config file, put it on disk, hit NGINX with SIGHUP, I think. I don’t think you actually have to quit it. You do have to hit it with a signal and it will potentially drop connections while it’s reconfiguring itself. Envoy applies all of that stuff live. This is the logo for Envoy. Envoy is a good implementation of that, and we can now use nice cool modern programming languages, any language we want, rather than being stuck in the JVM.
This is great for security, too. I talked before about how that API gateway middle proxy was opt-in, and it could be bypassed fairly easily. If you’re running Kubernetes and each of these black boxes is a pod, then your sidecar is a sidecar container, so a separate container. It’s in the same network namespace. The actual business logic, the application process is unroutable from the outside. The only way traffic can reach it is through the pod’s single IP, and therefore through the sidecar because that’s where all traffic is routed. These sidecars are also going to be present in all traffic flows in and out of the pod. Whatever tries to call a particular service, no matter where on the network it is, or how compromised it is, it’s going to have to go through that sidecar, they can’t opt out. We therefore apply authentication, authorization, rate limit to everything, even stuff that’s internal in our network that it would have just been trusted, because it’s on the same network, in the same cluster, it came from a 192.168 address. We don’t trust any of that anymore, because it’s so easy for this stuff to be compromised these days. This is an idea called zero trust, because you trust nothing, basically. I’ve put a few links up for people who want to read more on that. They can also cover the egress case. You’re trying to reach out to the cloud, all traffic goes through the cloud. You’re trying to reach out to things on the internet, again, all traffic out of any business logic has to go through the sidecar.
These sidecars, they can do great things, but they can be quite tricky to configure. NGINX config files can get quite long, if you wanted to do a lot. Envoy’s config is very long and fiddly. It’s not really designed to be written by a human. Each of these sidecars is going to need a different config depending on the service that it’s serving. Each one is going to have different connections that it allows and different rate limits that it applies on whatever. Managing that configuration by hand is a nightmare. We very quickly came up with this idea of a control plane. A daemon that provides a high-level simple config API, and we can give it high level notions like service A can talk to service B at 5 RPS. It will then go and render the long-winded, individual configs needed for the sidecars, and go and configure them. This control plane in addition to the sidecar proxies gives us what’s called a service mesh. Istio is probably the most famous example. There’s others out there like Linkerd, or Cilium, or AWS’s native App Mesh. If you’re running your workloads in Kubernetes, then you could get this service mesh solution quite easily. Using various Kubernetes features, you can just make container images that contain just your business logic. You can write deployments that deploy just your business logic, just one container in a pod with your container image in. Then using various Kubernetes features, you can have those sidecars automatically injected. The service mesh gets its configuration API and storage hosted for free in the Kubernetes control plane. It can be very simple to get started with these things if you’re in a friendly, high-level compute environment like Kubernetes.
Just to recap, I think we’ve seen what an API gateway is as a piece of network equipment. What features it has. Why they used to be necessary. They are still necessary, but why in a microservice world having them all centralized in one place is maybe not the best thing. How we can move a lot of those features out to individual services through this sidecar pattern.
API Lifecycle
I want to talk about some of the stuff we haven’t touched on. Some of those API gateway features like enforcing request and response bodies, like doing body transformation, and all that stuff. Because, as I was saying, API gateways, some of them do offer these features, but I don’t think it’s the right place for it. I don’t think it should be an infrastructure networking. I don’t think it should be moved to a sidecar. I think it should be dealt with completely differently. I’m going to go through various stages of an API’s lifecycle and look at different tooling that we can use to help us out in all of those stages.
We want to come along and design an API. The first thing is you should design your API upfront. This idea of schema-driven development, of sitting down and writing what the API is going to be, because that’s the services contract, is really powerful. I found it very useful personally. It can also be great for more gated development processes. If you need to go to a technical design review meeting to get approval to spend six weeks writing your service, or you need to go to a budget holder’s review meeting to get the investment, then going with maybe a sketch of the architecture and the contract, the schema, I’ve found to be a really powerful thing. Schema-driven development I think is really useful. It really clarifies what this service is for and what it does, and what services it’s going to offer to whom. If you’re going to be writing the definitions of REST interfaces, then you’re almost certainly writing OpenAPI files. That’s the standard. You can do that with Vim, or with your IDE with various plugins. There’s also software packages out there that support this, first-class. Things like Stoplight, and Postman, and Kong’s Insomnia. If you’re writing protobuf files describing gRPC APIs, which I would encourage you to do. I think gRPC is great. It’s got a bunch of advantages, not just around the API design, but just around actual runtime network usage stuff. Then you’re going to be writing proto files. Again, you can use Vim, you can use your IDE and some plugins. I don’t personally know of any first-class tools that support this at the moment.
Implementation
What happens when I want to come to implement the service behind this API? The first thing to do I think, is to generate all of the things: generate stubs, generate basically an SDK for the client side, and generate stub hooks on the server side. All of that boilerplate code for hosting a REST API where you open a socket and you attach a HTTP mux router thing, and you register logging middleware, and all that stuff. That’s boilerplate code. You can copy and paste it. You can factor it out into a microservices framework, but you can also generate it from these API definition files. Then they will leave you with code where you just have to write the handlers for the business logic. Same on the client side, you can generate your client libraries, SDKs, whatever you want to call them, a library code where you write the business logic. Then you make one function call to hit an API endpoint on a remote service. You can just assume that it works because all of the finding the service, serializing the request body, sending it, retrying it, timing it out, all of that kind of stuff is taken care of. Again, you can just focus on writing business logic.
One of the main reasons I think for doing this is, I often see API gateways used for enforcing request schemas on the wire. Perhaps service A will send the request to service B. The API gateway will be configured to check that the JSON document that it’s sending has the right schema. This just becomes unnecessary if all you’re ever doing is calling autogenerated client stubs to send requests and hooking into autogenerated service stubs to send responses. It’s not possible to send the wrong body schema, because you’re not generating it and serializing it. Typically, in an instance of a class, you’ll fill in the fields, so you’ll have to fill in all of the fields and you can’t fill any extra fields. Then the stubs will take it from there, and they’ll serialize it, and they’ll do any field validation or non-integer size, or string length, or whatever. By using these client stubs, just a whole class of errors just goes away and it gets caught a lot earlier.
Generating stubs from OpenAPI documents for REST, there’s a few tools out there. There’s Azure AutoRest, which gets a fair amount of love, but only supports a few languages. There’s this project called OpenAPI Generator. Its main advantage is that it’s got templates for like a zillion languages. In fact, for Python, I think it’s got four separate templates, so you choose your favorite. I do have to say from a lot of bits of practical experience that most of those templates aren’t very good. The code they emit is very elaborate, very complicated, very slow, and just not yet idiomatic at all. Your mileage may vary, and you can write your own templates, although that’s not easy. It’s a nice idea. I’ve not had a great amount of success with that tool. Even the AWS API Gateway can do this. It’s not a great dev experience, but if you take an OpenAPI file, and you upload it into AWS API Gateway, which is the same thing as clicking through the UI and making paths and methods and all that stuff, there’s an AWS CLI command that’ll get you a stub. It only works for two languages, and they seem pretty basic, doing the same for gRPC. Then there’s the original upstream Google protoc compiler, and it has a plugin mechanism. There needs to be a plugin for your language. There’s plugins for most of the major languages. It’s fine, but there’s this new tool called Buf, which I think is a lot better.
When we’ve done that, we really hopefully get to this point of just add business logic. We can see this service on the bottom left is a client that’s calling the service on the top right, which is a server. That distinction becomes irrelevant in microservices often, but in this case, we’ve got one thing pointing another to make it simple. That server side has business logic, and that really can just be business logic, because network concerns like rate limiting and authentication or whatever are taken care of by the sidecar. Then things like body deserialization, body schema validation, all of that stuff are taken care of by just the boilerplate, like open this socket and set the buffer a bit bigger, so we can go faster. All of that stuff’s taken care of in the generated service stub code. Likewise, on the client, the sidecar is doing retries and caching for us. Then the business logic here can call on three separate services, and it has a generated client stub for each one.
Deployment
When we want to deploy these services, schema validation that we use to configure on an API gateway. I’m going to say, don’t, because I’ve talked about how we can shift that left, and how we don’t make those mistakes if we use generated code. I’ve actually already covered it, but the IDLs tend to only be expressive to the granularity of the field email is a string. There are enhancements and plugins, I think for OpenAPI, certainly for proto where you can give more validation. You can say that the field email is a string. It’s a minimum of six characters. It’s got to have an ampersand in the middle. It’s got to match a certain regular expression. That fine-grained stuff can all be done declaratively in your IDL, and therefore generated into automatic code at build time.
Publication
What happens when we want to publish these things? Buf is just one example, Stoplight and Postman all offer this as well, I think, but Buf has a schema registry. I can take my protobuf file on the left and I can upload it into the Buf schema registry. There’s a hosted version or you can run your own. You can see that it’s done, sort of Rust docs, or Go docs, it’s rendered this nicely in terms of documentation with hyperlinks. Now I’ve gotten nice documentation for what this API is, what services it offers, how I should call them, and I’ve got a catalog by looking at the whole schema registry. I’ve got a catalog for all the APIs available in my organization, all the services I can get from all the running microservices. This is really useful for discovering that stuff. The amount of time in previous jobs I’ve had people say, “I’d love to write that code but this piece of information isn’t available,” or, “I’m going to spend a week writing the code to extract some data from the database and transform it,” when a service to do that already exists. We can find them a lot more easily now.
There’s this idea of ambient APIs. You just publish all your schema to the schema registry, and then others can search them, others can find them. You could take that stock generation and you can put it in your CI system. When you’re automatically building those stubs, you automatically build those stubs in CI every time the IDL proto definition file changes. Those built stubs are pushed to pip, or npm, or your internal Artifactory, or whatever, so that if I’m writing a new service that wants to call a service called foo, if I’m writing in Python, I just pip install foo-service-client. I don’t have to go and grab the IDL and run the tooling on it myself and do the generation. I don’t have to copy the code into my code base. I can depend on it as a package. Then I can use something like Dependabot to automatically upgrade those stubs. If a new version of the API is published, then a new version of the client library that can call all of the new methods will be generated. Dependabot can come along and suggest or even do the upgrade for me.
Modification
I want to modify an API. It’s going through its lifecycle. We should version them from day one. We should use semver to do that. Probably sucking eggs, but it’s worth saying. When I want to go from 1.0 to 1.1, this is a non-breaking change. We’re just adding a method. Like I’ve already said, CI/CD will support the new IDL file, generate and publish new clients. Dependabot can come along and it should be safe to automatically upgrade the services that use them. Then, next time you’re hacking on your business logic, you can just call a new method. You press clientlibrary. in your IDE, and autocomplete will tell you the latest set of methods that are available because there are local function calls on that SDK. When I want to go to v2, so this is a breaking change, say I’ve removed a method, renamed a field. Again, CI/CD can spot that new IDL file, generate a new client with a v2 version on the package now, and publish that. People are going to have to manually do this dependency upgrade because the API changes on the wire, then the API for the SDK is also going to change in a breaking way. You might be calling the method on the SDK that called the endpoint on the API that’s been removed. This is a potentially breaking change. People have to do the upgrade manually and deal with any follow in their code. The best thing to do is to not make breaking changes, is to just go to 1.2 or 1.3, and never actually have to declare v2. We can do this with breaking change detection, so the Buf tool. This is one of the reasons I like it so much, you can do this for protobuf files. Given an old and a new protobuf file coming through your CI system, Buf can tell you whether the difference between them is a breaking change or an additive one. That’s really nice for stopping people, making them think, I didn’t mean for that to be a breaking change. Or, yes, that is annoying, let me think if I can do this in a way that isn’t breaking on the wire.
Deprecation
How do we deprecate them? If I had to make a v2.0, I don’t really want v1.0 to be hanging around for a long time, because realistically I’m going to have to offer both. It’s a breaking change. Maybe all the clients aren’t up to date yet. I want to get them up to date. I want to get them all calling v2, but until they are, I’ve got to keep serving v1, because a v1 only client is not compatible with my new v2. As I say, keep offering v1. A way to often do this is you take your refactored, improved code that natively has a v2 API, and you can write an adapter layer that will keep serving v1. If the code has to be so different, then you can have two different code bases and two different pods running. Then the advantage of the approach I’ve been talking about is you can go and proactively deprecate these older clients. The way you need to do that is you need to make sure that no one’s still using it. We’ve got v2 now where we want everybody to be using v2, we want to turn off v1, so we want to delete that code in the pod that’s offering v1. I’ll turn off the old viewer pods, or whatever it is. We can’t do that if people are still using it, obviously, or potentially still using it. The amount of people I’ve seen try to work out if v1 is still being used by just looking at logs or sniffing network traffic. That’s only data from the last five minutes or seven days, or something. I used to work in a financial institution, it doesn’t tell you whether you turn it off now, in 11 months, when it comes around to year-end, some batch process or some subroutine is going to run that’s going to expect to be able to call v1, and it’s going to blow up and you’re going to have a big problem.
If we build those clients stubs into packages, and we push them to something like a pip registry, then we can use dependency scanners, because we can see which repos in our GitHub are importing foo-service-client version 1.x. If we insist that people use client stubs to call everything, and we insist that they get those client stubs from the published packages, then the only way anybody can possibly ever call v1, even if they’re not doing it now is if their code imports foo autogenerated client library v1. We can use a security dependency scanner to go and find that. Then we can go and talk to them. Or at least we’ve got a visibility at least even if they can’t or won’t change, we know it’s not safe to turn off v1.
Feature Mapping
This slide basically says for all of the features that you’re probably getting for an API gateway, where should it go? There are actually a couple of cases where you do need to keep an API gateway, those kinds of features. Things like advanced web application firewall stuff, advanced AI based bot blocking, or that stuff. I haven’t seen any sidecars that do that yet. That product marketplace is just less mature. It’s full of open source software at the moment. These are big, heavy R&D value adds. You might want to keep a network gateway. For incidental stuff, this is talking about whether you want to move that code actually into the service itself, into the business logic, whether you want to use a service mesh sidecar or whether you want to shift it left.
Recap
I think API gateways is a nebulous term for a bunch of features that have been piled into what used to be ingress proxies. These features are useful. API gateways are being used to provide them but they’re now being used in places they’re not really suited like the middle of microservices. Service meshes, and then this shift left API management tooling can take on most of what an API gateway does. Like I said, API gateways still have a place, especially for internet-facing ingress. You actually probably need something like a CDN and regional caching even further left than your API gateway anyway. In this day and age, you probably shouldn’t actually have an API gateway exposed to the raw internet. These patterns like CDNs, and edge compute, and service meshes are all standard now. I wouldn’t be afraid of adopting them. I think this is a reasonably well trodden path.
Practical Takeaways
You can incrementally adopt sidecars. The service meshes support incremental rollouts to your workloads one by one, so I wouldn’t be too worried about that. I think sidecars will get more of these API gateway features like the advanced graph stuff over time. I don’t think you’re painting yourself into a black hole. You’re not giving yourself a much bigger operational overhead forever. Check out what your CDN can do when you’ve got those few features left in the API gateway. CDNs can be really sophisticated these days. You might find that they can do everything that’s left, and you really can get rid of the API gateway. That shift left management tooling can also be incrementally adopted. Even if you’re not ready to adopt any of this stuff, if I’ve convinced you this is a good way of doing things and you think it’s a good North Star, then you can certainly design with this stuff in mind.
Questions and Answers
Reisz: You’ve mentioned, for example, what problem are you trying to solve. When we’re talking about moving from an API gateway to a service mesh, if you’re in more of something where the network isn’t as predominant. You’ve got more of like a modular monolith, when do you start really thinking service mesh is a good solution to start solving some of your problems? At what point like in a modular monolith, is it a good idea to begin implementing a service mesh?
Turner: I do like a service mesh. There’s no reason not to do that from the start. Even if you have, in the worst case, where you have just the one monolith, it still needs that ingress piece, that in and out of the network to the internet, which is probably what a more traditional API gateway or load balancer is doing. A service mesh will bring an ingress layer of its own that can do a lot of those features. Maybe not everything, if you’ve subscribed to an expensive API gateway that’s going to do like AI based bot detection and stuff. If it satisfies your needs, then it can do a bunch of stuff. Then, as soon as you do start to split that monolith up, you don’t ever have to be in a position of writing any of that resiliency code or whatever, or suffering outages because of networking problems. You get it there, proxying all of the traffic in and out. You can get a baseline. You can see that it works. It doesn’t affect anything. Then, as soon as you make that first split, split one little satellite off, implement one new separate service, then you’re already used to running this thing and operating it, and you get the advantages straight away.
Reisz: One of the other common things we hear when you first started talking about service mesh, particularly in that journey from modular monoliths into microservices, is the overhead cost. Like we’re taking a bunch of those cross-cutting features, like retries, and circuit breakers out of libraries and putting them into reverse proxies that has that overhead cost. How do you answer people, when they say, I don’t want to pay the overhead of having a reverse proxy at the ingress to each one of my services?
Turner: It might not be for you if you are high frequency trading or doing something else. I think it’s going to depend on your requirements, and knowing them, maybe if you haven’t done it yet, going through that exercise of agreeing and writing down your SLAs and your SLOs to know, because this might be an implicit thing, and people are just a bit scared. Write it down. Can you cope with a 500-millisecond response time? Do you need 50? Where are you at now? How much budget is there left? That code is either happening anyway in a library, in which case, there are going to be the cycles used within your process, and you’re just moving them out. Or maybe it’s not happening at all, so things look fast, but are you prepared to swap a few dollars of cloud compute cost for a better working product? Yes, having that as a separate process, there’s going to be a few more cycles used because it’s got to do a bit of its own gatekeeping. They do use a fair amount of RAM typically. That’s maybe a cost benefit thing. They do have a theoretical throughput limit. What I’d say is that’s probably higher, these proxies do one job and they do it well. Envoy is written in C++. The Linkerd one is written in Rust. These are pretty high-performance systems languages. The chances of their cap on throughput being lower than your application, this may be written in Java, or Python, or Node, is actually fairly low. Again, depends on your environment. Measure and test.
Reisz: It’s a tradeoff. You’re focusing on the business logic and trading off a little bit of performance. It’s all about tradeoffs. You may be trading off that performance that you don’t have to worry about dealing with the circuit breakers, the retries. You can push that into a different tier. At least, those are some of the things that I’ve heard in that space.
Turner: Yes, absolutely. I think you’re trading a few dollars for the convenience and the features. You’re trading some milliseconds of latency for the same thing. If it’s slowing you down a lot, that’s probably because you’re introducing this stuff for the first time, and it’s probably well worth it. The only time where it’s not a tradeoff, or it’s a straight-up hindrance is probably that cap on queries per second throughput. Unless you’ve got some well optimized C++, you’re writing like a trading system or something, then the chances are, it’s not your bottleneck and it won’t be, so there really isn’t a tradeoff there.
Reisz: If there is a sidecar or not sidecar, like we’ve been talking in Istio, kind of Envoy sidecar model. There are interesting things happening without sidecars, and service meshes. Any thoughts or comments there?
Turner: It’s a good point. This is the worst case. The model we have now gets things working. The service mesh folks have been using Envoy. It is very good at what it does, and it already exists. It’s a separate Unix process. Yes, I think things aren’t bad at the moment. With BPF moving things into the kernel, there’s this thing called the Istio CNI. If you’re really deep into your Kubernetes, then the Istio folks have written a CNI plugin which actually provides the interface into your pod’s network namespace so that you don’t have to use iptables to forcefully intercept the traffic, which means you save a hop into kernel space and back. Yes, basically technological advancement is happening in this space. It’s only getting better. You’re probably ok with the tradeoffs now. If you’re not, watch this space. Go look at some of the more advanced technologies coming out of the FD.io VPP folks, or Cilium, or that stuff.
Reisz: Any thoughts on serverless? Are these types of things all provided by the provider? There isn’t really like a service mesh that you can implement, is it just at the provider? What are your thoughts if some people are in the serverless world?
Turner: If I think of a serverless product, like a Knative serve or an OpenFaaS, something that runs as a workload in Kubernetes, then as far as Kubernetes is concerned, that’s opaque and it may well be hosting a lot of different functions. If you deploy your service mesh in Kubernetes, then you’re going to get one sidecar that sits alongside that whole blob, so it will do something, but it’s almost like an ingress component into that separate little world that may or may not be what you want. You may be able to get some value out of it. You’ll get the observability piece, at least. I don’t personally know of any service meshes that can extend into serverless. I don’t know enough about serverless to know what these individual platforms like a Lambda or an OpenFaaS offers natively.
Reisz: Outside of Knative, for example, they can run on a cluster.
Turner: Yes, but Knative is maybe its own little world, so Kubernetes will see one pod, but that will actually run lots of different functions. A service mesh is going to apply to that whole pod. It’s going to apply equally to all of those functions. It doesn’t have too much visibility inside.
See more presentations with transcripts












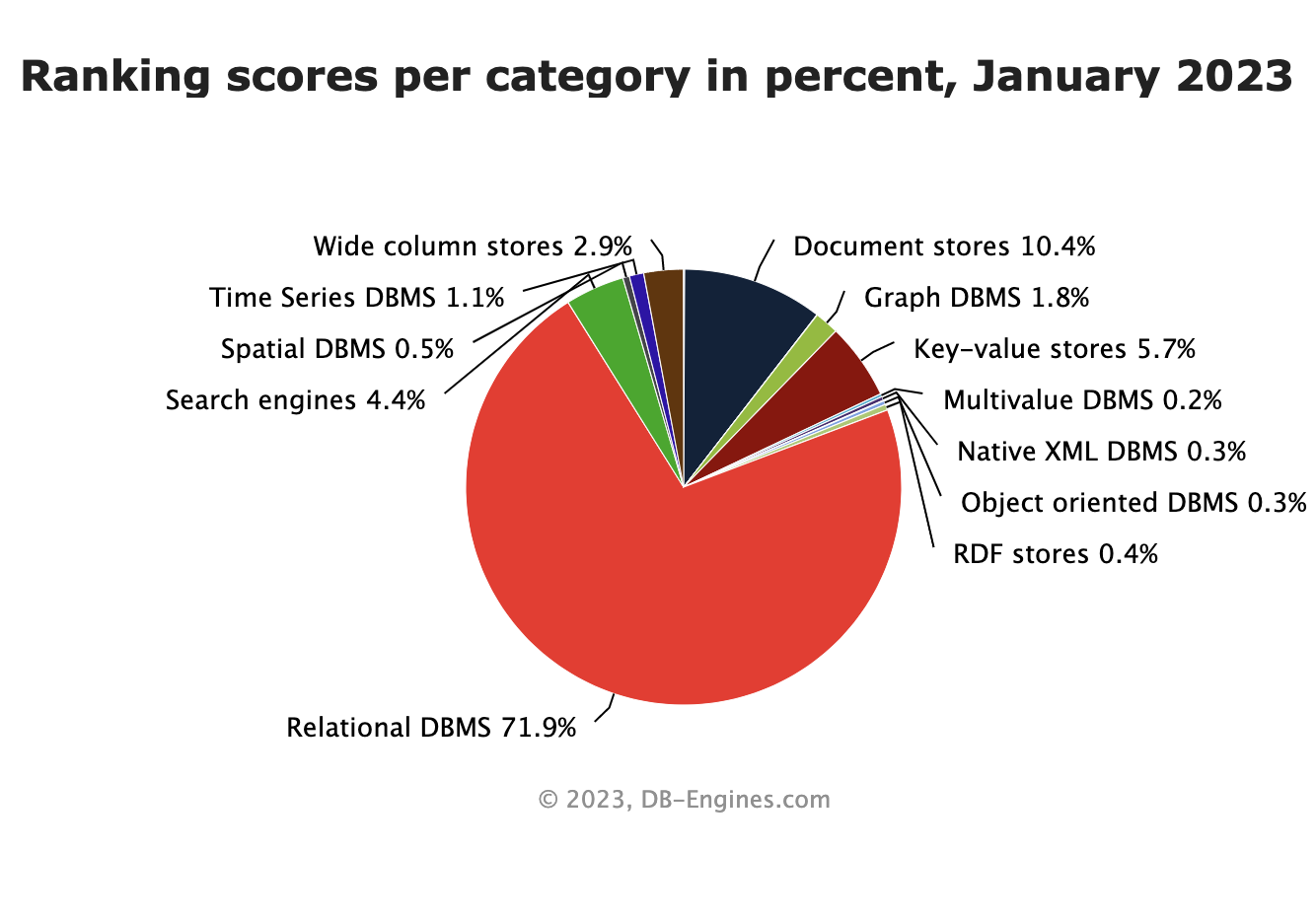 As you can see, relational databases are still the most used type of database despite all the hype around NoSQL databases. However, if we look at recent trends, the ranking tells a slightly different story.
As you can see, relational databases are still the most used type of database despite all the hype around NoSQL databases. However, if we look at recent trends, the ranking tells a slightly different story.