Month: February 2023

MMS • Robert Krzaczynski

Microsoft recently released another control for the .NET MAUI platform: MediaElement. This is one of the components of the .NET MAUI Community Toolkit that allows audio and video playback within .NET MAUI applications.
MediaElement gives you control over media playback in your .NET MAUI application and is a continuation of MediaElement from the Xamarin Community Toolkit, created by community member Peter Foot. The version of MediaElement moved to .NET MAUI was redesigned from scratch. This kept certain elements and improved some other parts, especially on Android.
In the case of Android, it uses ExoPlayer as the platform equivalent, replacing the Android MediaPlayer that worked with Xamarin. This automatically gained a lot of additional functionality right out of the box, such as HTTP Live Streaming (HLS) video playback.
iOS and macOS leverage the AVPlayer platform, as on the Xamarin platform. Tizen is also unchanged using Tizen.Multimedia.Player.
In order to start using MediaElement, it is necessary to install the CommunityToolkit.Maui.MediaElement NuGet package, which is a separate package from the main Community Toolkit package. Once the installation is complete, the developer should navigate to the MauiProgram.cs class and add the following initialisation line to MauiAppBuilder:
public static MauiApp CreateMauiApp()
{
var builder = MauiApp.CreateBuilder();
builder
.UseMauiApp()
.UseMauiCommunityToolkitMediaElement()
return builder.Build();
}
In a comment on the release announcement, Abdelmounaim Elhili asked if it is possible to use this control in a .NET MAUI Blazor application. Gerald Vesluis, software engineer at Microsoft on the .NET MAUI Team, answered:
You can’t mix a .NET MAUI component into Blazor, what you could do however is navigating to a .NET MAUI page which then has the MediaElement to play the actual media. I have a video about mixing Blazor Hybrid and .NET MAUI here that should give you some idea.
The announcement of this control received a positive response from the community. Among others, Gagik Kyurkchyan, Xamarin/.NET MAUI consultant, wrote:
Thank you so much!! That’s a major achievement! I remember the time when we needed a good media player in Xamarin.Forms, we had to go commercial. So, it’s a significant achievement indeed, I can’t wait to try it!
All current MediaElement features are available on the documentation page. Vesluis also published a video outlining the basics of how to get started with MediaElement.
MMS • Einat Orr

Transcript
Orr: I’m Einat Orr. This is data versioning at scale, chaos and chaos management. When I was 23 years old, I was a master’s student. I held a student position in an Israeli networking company called Telrad. I was a BI Analyst within the operations department and I was working on modeling the company’s inventory. Inventory comes with very high costs, and it was very important to optimize. It so happened that I was invited to observe a meeting that included the company’s management together with a few consultants, and of course, in the presence of the CEO. I didn’t have a seat at the table, I was just sitting with my back to the wall with all kinds of people sitting in front of me, and I was listening to the meeting. At some point, the CEO said something about, since our inventory costs are mainly due to extremely high cost components. That is something that I knew to not be true, so I just stood up and said, “I’m afraid, 80% of our costs are actually from low cost, high quantity items.” He looked at me, he didn’t know who I was, of course, and said, “I believe you’re wrong.” To which I replied, “I believe I’m not.” He said, “I’ll bet you a box of chocolates.” I said, “Fine. As long as it’s dark chocolate with nuts, I’m going for it.” We sealed the deal. He did not take a decision according to the data that he had at that moment. He checked the data. Two days later, he changed his decision, and I had a lovely box of chocolates on my desk.
I’m telling you that because that was a moment where I realized how important it is to understand the data and to be able to bring the right data at the right moment to the people who take the decisions. I’ve never left the world of data since. I have seen the world of data evolving from 10, 15 datasets on a relational database, which is what I had then, to petabytes of data over object storages, distributed compute, and so on. I have realized that when we had those small datasets in relational database, we had the safety of managing complexities in data, such as the transient nature of data in a much better way than we have today. Since data is transient, and we’re having a lot of data, our world today is extremely chaotic. Let’s talk about how we stabilize that world and make it manageable.
Brief History
I was at my master’s then, I have finished a PhD in mathematics at Tel Aviv University. I started my career as an algorithms developer, and later on moved to managing people. Four times VP R&D and CTO with Israeli startup companies, the last of which is SimilarWeb that was a data company. I am now the CEO of Treeverse the company behind the open source project, lakeFS.
The Complexity of Transient Data
I would like to talk about the complexity that comes with the fact that the data is transient. As I mentioned earlier, the amount of data grew, the computation is distributed that comes with a lot of complexity. There are a lot of complexities in the world of data now in the modern time, but something stays the same, and that is that the data changes. If you are now thinking, of course, the data changes, there is additional data every day, then this is not what I mean. The historical data that we have accumulated might change. It might change once. It might change many times. This complexity is something that is becoming harder to manage with the amount of data and the amount of data sources that we have.
Let’s look at a few examples so that I can convince you that the data indeed changes. The first one is that at the time of the first calculation, as you can see on the left-hand side, some of the data is missing. You can see the null values in the price column. We did not have the prices of those products at the time that we have done the calculation. This data was late, but after a few days or a few weeks it had arrived with the right value that was true in the history where we actually recorded the table. We can now go back and backfill this information, and instead of the null values, have the values that we have missed earlier. This means that the data has changed from the original version that we had of it.
Another example would be the case where we are fixing a mistake. We knew of values to the data, but for some reason, those values were incorrect, either a human error, someone typed the wrong value. Maybe a wrong calculation, maybe a bug in the logic that collects the data. Once we have fixed that, we will be able to also fix the values that were incorrect. Some of the values were correct, they would stay the same, and other values would be replaced by the correct values because they were influenced from the bug. Another example would be a case where the data that we had originally doesn’t come from collecting data, but rather from a certain calculation. Maybe an estimation of a sort. We have estimated the price using a certain algorithm, and then we realize there’s a better logic of estimating the price, and we will implement that logic back on historical data to get better estimations of the past as well. Once we do that, the entire dataset we had will now change and be a different, hopefully better version of the data. Those are examples.
If we want unstructured data examples, which is extremely important, we do a lot of work on semi-structured and unstructured data. Think, for example, about pictures. You had a training set for a computer vision algorithm, and you were using a set of pictures that represent a good sample of the world that you would like to develop the machine learning model over. Right now you have decided to replace some of those pictures with other pictures that represent the same point in the space you wish to create, but they do it in a better way. Some of the pictures remain the same, and some you have decided to replace. Another case would be that you may have decided to look at the problem from a different resolution, same picture, but different properties of the picture, and so on.
All these changes that happen in the data make it challenging for us to do the simplest things that we need to do when we work with data. First, we want to collaborate. If we want to collaborate, we need to be able to talk about a single source of truth. If we changed historical data, we now need to talk about, which version of the data are we discussing? If we need to understand what dataset created what result in the past, we have to have lineage. If data changes over time, then lineage becomes more complex. We want to have reproducibility. If we run the same code over the same data, we expect to get the same result. We need to know, what was the dataset? We need to have it available for us in order to run this and get reproducibility. We need to have cross-collection consistency, so if we updated one table with better historical data or different historical data, we would want to make sure that all tables that are lineage to it or depend on it are also immediately and atomically influenced by that change in a way that allows us to view the history in a consistent way. All those things are things that we expect to do. If we do not have the right infrastructure, it would be extremely painful, manual, and error prone to do.
Version Control
The world had already solved the problem of how to deal with sets of data that changed by a lot of people, it is called version control. Yes, it was built for code. It wasn’t built for data. It means that if we’re going to try and use Git over our data, we would probably fail. The notion of version controlling our data the way we version control our code, would take this chaos of the transient data that I hope I’ve convinced you exists, and really manage it properly. We are looking to have alternatives to Git, but for data. The 23-year-old me would probably tell you, I’m not sure what the problem is. Remember I was managing five tables in a relational database. I would just add to each row in my table, the time where it was relevant for. This value I have received in the date that is specified in the, from column, and it had stopped being relevant on the date that I would put into the, to column. This is referred to in literature as the by temporal method. It allows us to know for each row of the data, for what time it was relevant. It seems simple, but even in five tables it’s quite annoying. Because if the tables are connected to one another, and they’re not independent, then if we have relevance of time to enroll in one table, we need to be able to drag that all along our process of building the tables in the views that depend on that table to make sure that everything is updated according to certain dates. Of course, the date would now become the minimum, the maximum, the whatever is needed between all the timestamps that we have on all the tables and all the values. It is not simple at all to cascade that information into a more complex logic that runs with the tables, but it is possible if you have a handful of tables and a handful of processes. The larger things get, the more complex it is, and the better it is to try and use an infrastructure such as Git.
Let’s review a few of the solutions that exist today that provide the ability to version control data the way Git version controls code. Let’s start really with the database option. Let’s say I do run my data over a relational database. Now I would like to make that relational database version-aware, so I’ll be able to manage the tables, or the views, or a set of tables as a repository, and version everything, allowing me to use Git-like operations, such as branching, merging, commits. All that would happen naturally as an interface to the database. What do I need to actually change in the database? The answer basically is everything. If you want to have a very simple abstraction of a database, let’s say that it is structured with two main components. One is the storage engine. This is where we keep the data. We keep it in a data structure that allows us to retrieve and save data into the database with decent performance. In our case, we also wanted that storage engine to allow us Git-like operations. On the other hand, the other part of the application would be the parser that parses the SQL queries and the executor that executes them, and of course, the optimizer that makes sure they would happen as fast as possible. Those three components are the ones that build the server of the database, and it is usually optimized for the storage engine that the database has. If we want to make the storage engine version-aware, we need to make the application version-aware, and then the entire database actually changes.
The Dolt Database
A very beautiful example of an open source project that is a versioned database is Dolt. Dolt is based on a storage engine called Noms, also open source. It provides Git-like operations. Our use case is I’m using a relational database for my data. I wish to continue using a relational database, but I want to be able to have version control capabilities, and the answer to that is, for example, Dolt, a version controlled database. How does that work? I’ll try and explain the most important components in my opinion of the Dolt database, which is the Noms storage engine. It relies on a data structure called Prolly Trees. A Prolly Tree is actually a B-Tree and a Merkle Tree having a baby. It was born, it’s called Prolly. Why is it important to merge those two logics? A B-Tree is a tree that is used to hold indices in relational databases, because the balance or the way you structure it allows a good balance between the performance of reading and writing from a database. Clearly, if you want to write very quickly, you would just throw all your tuples into a heap. Then if you want to read them, you would have to scan everything and work pretty hard. While if you save them into a B-Tree, you will have an easier way to logically go through the structure of the tree and allocate the values that you wish to retrieve. Then the retrieval would be in higher performance. This is why B-Trees are used. We have to keep that property because Dolt wants to be a relational database with decent performance.
On the other hand, we want the database to support Git-like operations, so we want this tree to resemble a Merkle Tree, which is the data structure that we use in Git. The logic would be that we would want to save data according to a hash of its content. The data would still be pointed to from the leaves of the tree. We would have sets of actual data that we calculate the hash from, but then the mid and root of the tree would actually be addresses that are calculated from the hash of the content of the values below, so we would be pointing at addresses. That would help us, because if a tuple changes, if this tree represents a table and a row in a table changes, then, of course, the hash of its content changes. Then the calculation going up with hashing the values would change the value of the root of the tree. We would have that tree representing the table and a different hash representing this change in its content. Since other rows haven’t changed, their hash didn’t change, and then the pointers to them are the same as in the Prolly Tree that represents the table from before the change. We can imagine that it would be easier to calculate diffs between such trees, calculate and implement merges and so on. This is how a Prolly Tree helps us actually combine B-Tree and Merkle Tree into an efficient way of versioning tables within a relational database.
To sum it up, when we have data that is saved in a relational database, then it’s probably operational data that is saved there. Usually, this is how you use MySQL. Dolt is consistent with MySQL from an interface perspective. You could think about operational data. You can also think about feature store because features are, at the end of the day, rather small data, could be kept in a database, but should be versioned because they change over time. In general, it means that you are willing to either lift and shift your existing MySQL, or you’re willing to lift and shift data into a database. You have all the guarantees of a database, so ACID guarantees and so on, which is extremely important. Of course, you have tabular data because we are dealing with a relational database. It won’t help you if you don’t want to lift and shift, if you need to keep your data in place. It will probably be harder to manage in petabyte scale. If you are in real need of higher performance in OLAP, then this structure would be less efficient for you. Of course, if you rely heavily on unstructured data, then you would need a different solution. There are different solutions. Let’s see what’s out there for us, if we don’t want to use a relational database.
Git LFS
When we started, we said Git would have been a good idea, it’s just that Git doesn’t scale for data, and we can’t use Git for data. We can use an add-on for Git that is called Git LFS that will help us combine the management of data, actually, together with the management of code. Where does this idea come from? It doesn’t come from the world of data, it comes from the world of game development. Game developers had their code, the code of the game that they had to manage. They also had tons of artifacts, mostly binaries that were influencing the way the game looked like. They had to manage those assets together with the code, so the repositories became very strange and extremely heavy, because they were checking in and checking out in Git those very large binary files, and it made their work very hard. They have built an add-on to Git that allows them not to do that if they don’t have to. The logic behind it is extremely simple, it relies on managing metadata. This use case that comes from game development grew on people who do machine learning and research. Because they said, we also have files that are not code that we want to version, but they’re also a little larger than what you would expect, or there are many of them, from files that are managing code. Still, we want to do that together because we have a connection between the model and the data that it was running on. It’s the same use case, why don’t we just use the same solution? This is how Git LFS found its way into the world of data. Let’s see how it works.
Basically, it’s Git, so you have the large file storage that is added to the actual Git repository. The large file storage saves those large binary or those data files, or whatever it is that we want to manage with Git LFS. We then calculate a pointer to this data. When we check out the repository, we do not check out those files, we only check out the pointers to the files. Only when we decide we want those files locally, do we then call them and actually create a local copy of them. If they already exist, of course, they’re not called again. Then the back and forth between the large file storage and your local installation of the code and the artifacts is not updated every time. It’s a very simple idea, and it makes it easier to manage large files. Same of course would go for data files that you want to manage.
This is definitely good for game developers or repos of others who have additionally to code, either data that they would like to manage, for example, data science repos. The whole thing is format agnostic since we simply create this path or pointer to the file, to the large file, we don’t care what format it has. We do care that Git manages your code. It means that the repository of the code is the Git repository, or if you’re using a service, then the code is hosted there. It means that those files would also be hosted there, meaning you have to lift and shift your data to coexist with your code wherever it is. Of course, since you’re using Git, all changes are in human scale, so this supports up to a certain size of files, up to a certain amount of files depending on the configuration or the hosted solution. Of course, not structured to manage data in place, or have petabyte scale of data. Of course, doesn’t support high performance in data writing or reading. This is not something that Git or Git LFS at all optimizes for.
DVC (Data Version Control)
That’s optimized. As we continue, there are other solutions we can use. Let’s see, what is the next solution? DVC, Data Version Control is a project that was built on the inspiration of Git LFS, but having the data scientists and the researchers in mind. Say, I want Git LFS, but I wrote my own Git LFS that is actually providing additional capabilities that are suitable for my specific use case as a data scientist. I need to keep my data where it is because I have large amounts of data or I have large files, or I can take the data out of the organization, and very many other excuses. Data must stay in place. In place might be in an object storage, or in a local storage, or anywhere. Also, I am working in a team and the retrieval of data, because the files are pretty big, can take some time. I prefer having a caching layer that is shared between me and my coworkers, so that when we retrieve a file we all need, it would be cached and very quickly be able to be used by us, rather than each one of us needing to load the file into our local Git repository, as in Git LFS. Of course, there are other subtleties of what a commit would look like, if I am a data scientist, and what a merge would look like, what are the metadata fields that I would want to save? We want to create here a solution that is targeted really well to the needs of data scientists, and even more specifically, ones that are dealing with ML. This is the premise with DVC. This is why its architecture looks very much like the Git LFS one, but with the required improvements to answer those requirements that we have just specified.
This is what it would look like. We have a remote code storage that is actually a Git server, and this is where the code is kept. We also have a remote storage for the data, which could be any object storage on any cloud provider, or hosted, or on-prem, and of course SSH access that allows us to access file systems, and local storage. Now the data stays in place, and I can edit and see it as part of my repository. I also have a caching layer here mentioned as local cache, so when I would like to read a file that is a data file, in this case, a pkl file that is holding a model. When I would get that file, of course, usually I manage the path, but if I decide to actually pull out this file, it would also be kept in the local cache so that when others are looking to pull that file, the performance would be much better for them. This is a very short version of how DVC is more adequate to data science than Git LFS.
As we said, data science, machine learning use cases. We can support both structured and unstructured data. Data can stay in place. Still, we are using Git infrastructure underneath. This is human scale of changes both in data and in the Git-like operations such as merge, branch, and commit. It allows collaborative caching. What would be missing? If you are a relational database person, then this solution is less adequate for you. If you are with petabyte scale, and you would be using hundreds of millions of objects, caching becomes something that is unrealistic stuff at machine scale. All operations that happen might need to happen in thousands or tens of thousands a second, then this would not be a suitable solution for you. You would have to move to the next solution.
lakeFS
The last solution that I’m going to talk about refers to a world where the architecture looks like this. We have actually very many data sources that are saving data into an object storage. We have ETLs that are running on a distributed computer such as Spark. Those could be ETLs that are built out of tens or hundreds or thousands of small jobs running in an order that is dictated by a directed acyclic graph that is saved somewhere in an orchestration system. Then we have a bunch of consumers consuming the data. Those could be people who are developing machine learning models, those could be BI analysts, or they could be simply the next person to write an ETL over the data for some use that the company has with the data. For this world, which is the world most of us are either already living or would probably live, in the next couple of years, since the amount of data keep on growing. For this one, we would need a slightly different solution. We would want something like lakeFS that allows us first to keep the data in place, so data would stay in the object storage. We’re not going to lift and shift it anywhere. That is one. The second would be, we would have to be compatible with all the applications that can now run over an object storage and serve the data to the organization. We would have to impact performance as less as possible. Also, work in extremely high scale when it comes to the amount of objects that we are managing. It could be hundreds of millions or billions of objects. Also, the Git-like operations would have to be extremely efficient so that we can have very many of those a second, according to our architecture and our needs, or the logic by which we want to create commits and manage versions in our data.
How would we build something like that? First, from a logical perspective, since the data stays in place, look at the right-hand side, it says S3, but it means S3 as an interface. It also supports Azure and Google Cloud Storage. Basically, any object storage that you can think of. We can see that both the data itself in pink and the metadata that describes it, those are both saved into the object storage, so the system is extremely reliable. In the middle runs the lakeFS server. Let’s look at the top part of the screen. In the top part, we’re looking at a case where you would have an application running on Spark. In Java, in Scala you might be running your own Python application, whatever it is that you’re using. You can then use a lakeFS client together with your code that would allow you to use Git-like operations. When you use a lakeFS client, your client would be communicating with the lakeFS server to get the lakeFS metadata, while your application would be the one accessing the data for reading and writing. That would be done directly by your application as it is done today. This allows us to work with all the applications, so this allows lakeFS to work with all the applications and be compatible with the architectures that we all have today.
The other options would be to run through our lakeFS gateway that would be saved for cases where you can’t use a client, and then your data would go through lakeFS servers. That is an architecture that is useless but it is possible to use. We now understand that this is a wrapper around the parts of our data lake that we would like to version control. The storage status and object storage, and we are adding an additional layer that provides Git-like operations over it, it’s somewhat similar to what Noms has done for Dolt with the storage engine. We put an application into the storage that allows us to have versioning. In this case, we don’t change the storage, we wrap it, and this interface that was created with now lakeFS to version control the data using a set of metadata that it is creating, once you’re using lakeFS and using the data.
When we look under the hood, it beautifully looks like a different version of Prolly Tree. We don’t manage lines in tables in lakeFS, we manage objects in an object store. An object can have a hash of its content, just like a tuple in a database has a hash of its content. Then what we have is a two-layered tree. The first layer actually holds a range of objects. The layer on top of it holds the range of ranges, it’s called the Meta range. Then just like in a Prolly Tree, if you want to access quickly, or to compare quickly only a small portion of the data that the tree represents, you can do that by allocating the changed ranges of data, compare only them, and get the diff. Also, of course, the same logic would then work for merging or committing data. This is how those data structures are similar, although lakeFS is located in a completely different scenario, and actually relies on Pebbles that is a version of RocksDB.
To sum up what lakeFS can provide us. It is useful if you want to develop and test in isolation over an object storage, if you want to manage a resilient production environment through the versioning. It allows collaboration, so very much what version control gives us in all cases. It supports both structured and unstructured data, so it is format agnostic just like Git LFS, but your data stays in place. It is built to be highly scalable and to keep higher performance. It is of course compatible with all compute engines that exist out there in the modern data stack over in object storage. What wouldn’t you do with lakeFS? Really, if you don’t have an object storage, lakeFS won’t be the right solution for you. Of course, in data diffs and merges, lakeFS only provides information about the objects lists, rather than going into the tables, or if it’s unstructured data, the bytes themselves tell us exactly where the diff is. This does not exist. There is a place to contribute code to do that for specific formats of data.
Summary
Here is me at 23. I can go back to being 23 if we use the right data version control tool, to allow us to take this chaos that is created by the amount of data, the complexity, and the transient nature of the data, and turn it from this chaotic environment that is hard to manage into a manageable environment where we have full control. Then we know exactly where the data comes from, we know what had changed and why. We can go back to being the person in the room that corrects the CEO when they’re about to take the wrong decision based on the wrong data. Here you have the full advantages of each one of those systems, and you can use them whenever you need them. Please use them to make your life easier and to manage the chaos of data. Or as one of my team members loves to say, you can mess with your data, but don’t make a mess of the data.
Questions and Answers
Polak: How does lakeFS relate to existing columnar formats such as Parquet and ORC?
Orr: lakeFS actually is format agnostic. What it manages and versions is the objects within the object store, and those could be in any data format. It basically allows you over whatever it is that the format provides, the ability to treat a set of tables as a repository and manage those together, and travel in time within all those tables together as a repository. It is actually a layer over the actual storage format that you’re using. The same answer goes to more advanced formats, such as Delta, Hudi, and Iceberg that provides a bit more of mutability capabilities that are lacking in object storages that are immutable. This is the strength of the format. Again, lakeFS works over that and allows the treatment of very many tables as one repository.
Polak: What grain is in object, single file, Parquet file?
Orr: A single file, yes.
Polak: Single file that exists on object store.
Orr: If you’re using some virtualization such as Hive Metastore, you will be able to see a collection of files as a table within Hive, and then lakeFS, and also DVC can work together with Hive Metastore with the table representation of it.
Polak: What does lakeFS do when there is a conflict between the branches?
Orr: It does what Git does. When lakeFS looks at a diff between the main and a branch, it would look at the list of objects that exist in both. If we would see a change that happened in an object that exists in both, that would constitute a conflict. This conflict would be just flared for the user to decide what logic they would like to implement in order to resolve that conflict. That could be done by using one of the special merge strategies that allow you to maybe ignore one of the copies. Or if you have another type of logic that you would like to use, you can always contribute that to the set of logics that already exists within lakeFS.
Polak: Does version control increase storage cost because we now save several versions of the same dataset?
Orr: It does seem like that intuitively at the beginning, because instead of just saving the one latest copy, I will be saving a history of my data and that might create a situation where I am saving way more data than I did before. In actuality, in order to manage ourselves properly, and to have isolation, we copy a lot of data. When you use solutions like lakeFS that are actually soft copies, so it’s a very small set of metadata that is created instead of copying large amounts of data. When you look at the overall influence, then actually lakeFS reduces the amount of storage that you use in around 20%, from what we see from our users. If you add to that the fact that lakeFS provides an ability to actually control the data that you decide to delete in a way that is optimal from a business perspective, you get a really powerful result. Except for having the deduplication, you also have the ability to say, I don’t want to save more than two months of versions for some datasets, I want to save seven years in cases where I have to because of regulation. Of course, I can decide branches that are given to R&D people for just short tests, are short-lived and would always be deleted after 14 days, for example. You have full control that is actually based on business logic, to make sure that you only have or you only keep the data that you actually need.
Polak: It completely makes sense. I’ve been seeing people copying data again and again in production, in staging environments, so it completely resonates, also makes sense to keep track of who copied, and where the data is.
Can Git LFS be used on managed services such as GitHub or GitLab?
Orr: Yes, definitely. They both support that. You do have some limitations of the amount of storage that you can use if you’re using it within a managed service. It’s just a click of a button and you get Git LFS running for you, whether you’re using Bitbucket, GitHub, GitLab, any of those solutions.
See more presentations with transcripts
MMS • Luca Palmieri

Transcript
Palmieri: We’ll be speaking about TrueLayer’s journey into adopting Rust. Why we did it, how it started, and how it played out. My name is Luca Palmieri. I’m a Principal Engineer at TrueLayer. I’ve been in the Rust community for roughly four years, and I’m best known for being the author of, Zero to Production in Rust – An Introduction to Backend Development using the Rust Programming Language. Apart from the book, I contribute to a variety of open source projects, some of which are listed on this slide. HTTP mocking, Docker builds, plus some workshops to get people introduced to the language.
Outline
The talk is divided into three sections. We’re going to look at the timeline of Rust adoption at TrueLayer. How it came to be, what were the significant turning points, and why it took the time it took. Then we look at adoption of new technology in general. What are the risks? What should you consider? What are the specifics of adopting programming languages? In the end, we’re going to zoom in on Rust. What convinced us about Rust, specifically? What moved us beyond the doubt phase into actually deciding to give it a shot? We’re going to give specific examples of risks and pros that we saw adopting Rust for our specific use cases.
Rust at TrueLayer: Key Milestones, Current Usage, and Trends
In 2020, TrueLayer was very much a startup, it had roughly 30 developers, none of which were using Rust on a daily basis. There was a single service using Rust running in production, roughly 4000 lines long. No internal ecosystem whatsoever, we were always relying on external crates. We’ll be talking about this microservice a little bit more going further. If we go to December 2021 instead, so a year and a half later, the company is a lot bigger, so we have 100 developers. Roughly one-fourth of the development workforce is using Rust on a daily basis. The same ratio we find in terms of microservices, 44 out of 164 are written in Rust and are running in our production cluster. The lines are now over 200,000, over 86 crates in our internal ecosystem. Much bigger, much more established. Definitely there is an internal ecosystem for it.
A year and a half is not a long time span. What happened? In H2 2020, TrueLayer started working on an entire new product line centered around allowing merchants to settle funds with us, so us holding funds in merchant accounts and giving them information around their settlement times. This project was spearheaded by six engineers who wrote the first version of payouts API and core banking, the two subsystems underpinning this new product offering. These systems were written in Rust, they were the first product systems written in Rust. The product happened to be successful commercially. Over the following quarters, we scaled it up both in terms of capabilities and in terms of engineers working on the systems, getting up to 23 engineers around December 2021. In H1 2022, we’ve hired more, and we’re working on more projects.
This is not really the journey that got us into Rust, though, this is the outcome. If you want to look at the journey, you need to go back further in time. We need to go as far back as Q3 2019. TrueLayer was a much smaller company, very much a startup. We were transitioning from being a startup to being a scaleup. We had one product at the time called Data API to allow customers to access banking data securely. That product was starting to attract more customers, more enterprise customers with higher demands both in terms of quality and reliability. In particular, that API was suffering when it came to latency percentiles. We were supporting a concept called asynchronous operations, so customers could tell us to go and fetch some data. We would respond with a tool to accept it, and then send them a webhook when the data was ready to be fetched. This allows us to scale during the night and perform backup operations in an efficient fashion.
The MQ operation was supposed to be very fast, just authorization, authentication using JWTs, and then pop a message onto a queue that will then be processed asynchronously by other workers. Unfortunately, things were not quite working as smoothly as they should have been. We were experiencing very high p95 and p99 percentiles on this MQ endpoint, for really nothing that was immediately discernible to us. It was supposed to be extremely fast. The latency to talk to Redis, which was a queue at that point in time, was not experiencing the same spikes. After further investigations, this was nailed down to be a garbage collection issue. The details of it are a little bit gnarly and have to do with the specifics of .NET Core 2.2 and Linux cgroups.
It’s suffice to say that some of us were quite frustrated throughout the investigation. In anger, a couple of engineers, myself included, decided to write a POC. We’re having issues with garbage collection, what happens if we use a language that doesn’t have GC? That’s how our Rust POC of Data API was born, addressing just the parts that was experiencing latency issues. Prototype was much faster. It could handle a lot more throughput. The latency profile was extremely flat. As it happens in life, that prototype was never deployed. We were not ready at that point in time to embrace a new programming language. C# was definitely the language we were using for all of our backends, and we were a fairly small startup. Rust also was a lot younger in 2019, than it was in second half of 2020. There was no async/await at that point in time. The ecosystem for doing backend development was a lot younger.
What we did though is we started to pay attention to Rust. We started to play around with the language outside of the critical path. We started to write some Kubernetes controllers to send notifications where things were happening. We started to write some CI/CD tooling, some CLIs were operational concerns. All of these was outside of production, product traffic, but allows us to get exposed to the language, to play around with it, to get a feel, to understand if we liked it or not. At the same time, we tried to get engineers who could not work on the side projects to be more exposed to the community. We started to host the Rust London User Group, so the Rust London meetup, which is something we still do to this very day. We also brought in Ferrous Systems to carry out a training workshop for TrueLayer engineers who wanted to get started with Rust, so three days to get them tinkering the ground and getting their hands on the compiler. All these things put us in a position where in H2 2020, it was actually possible to have a serious conversation about, should we use Rust for this new system? The answer turned out to be yes.
Adopting New Technology – How Should We Approach It?
The conversation though was quite an interesting one. That’s the second part of this talk. How do you think when it comes to adopting new technology? In general, when it comes to TrueLayer, we frame it in terms of risks. When you think about the product and how a product is done, it’s a combination of many different types of technologies. You have operating systems, programming languages, several libraries, databases, all working together to produce an artifact that actually satisfies a need. Which is why I think some of us think of technology as magical from time to time. Because if you just try to picture how many different independent pieces are required to work together productively to actually ship something that works, it’s amazing that anything works at all. When you want to introduce a new tool, of course, you’re coming with the aspiration of improving things, or making a certain workflow easier or less painful, making certain parts of the product faster, or to be able to add a certain feature. What is also true is you appear to be adding an equilibrium. All those tools that compose your toolkit, and now you know how to combine together, are they going to interact with the new thing that you’re actually putting into the picture? How is that combination going to turn out? That’s where the risks come from. In terms of risk, we usually identify four categories that we care about: hidden facts, unforeseen risks, requirements, and known risks. Requirements are the easy ones. You need to build a product, this product comes with a set of demands in terms of functionality and non-functional requirements. You know you’re going to have to put in some work to make sure that it satisfies all of those. That’s the type of risks around, can we execute on this?
Then you have known risks, which are risks you’re aware of, because you’ve worked with this technology before. You can assess the impact, but you’re not going to solve immediately. You might, for example, know that if you move from 10 requests per second to 100 requests per second, your database schema will require some work. Perhaps you’re going to need to introduce some new indices to be able to support for it at that level of throughput. Your engineers know this. They roughly have a plan the thing can work, but they’re not actually going to action that plan at this point in time. That’s something for the future whenever that comes. You then have unknown knowns. Risks which are deep in your technology stack that your engineers are not aware of. They might not know what happens when a table in Postgres goes beyond a billion records. That is the good thing, somebody in the community does, because somebody actually has managed tables in Postgres with more than 1 billion records. When the point comes, or if your engineers spend more time to actually study the technology, they can become aware of these risks, and they become known risks. This is still in the realm of risks that can be managed proactively. The last category instead, is where stuff goes down badly. Risks that you’re not aware of, and nobody else is aware of. That’s because nobody has used that technology in the specific circumstances that you’re about to use it. There’s only one way to find out, which is to actually do it, and then debug it, assuming you can. Sometimes you’re going to find out that it’s just not possible to do what you want to do. You’re going to find out after you put in a month, two months, three months, six months, perhaps a year of effort. That’s an extremely painful circumstance to be in.
How do we mitigate unknown unknowns? There was a talk a few years back by Dan McKinley around Choose Boring Technology. The fundamental thesis of the talk is, the only way you can mitigate unknown unknowns is by waiting a long time. Thanks to the fact that people are going to use the technology, and they’re going to find out about these unknown unknowns, and document their experience and feed that knowledge back into the community, so that they become, at worst, unknown knowns, at best, they become instead known risks. The way Dan of course advises you is you want to be using very few pieces of technology, that they’ve not fully understood failure modes. You want to minimize the number of unknown unknowns. The way you do it is by using a concept called innovation tokens. At the time you’re starting a new project, you can use up to three innovation tokens to use a piece of technology that you do not have experience with, or a piece of technology that is very new. Once you run out of innovation tokens, you need to make boring choices for all the other pieces of technologies you need, where boring means very well understood piece of tech with very well understood failure modes. The question engineers usually ask when we use this metaphor is, what can I buy with an innovation token? How much is an innovation token worth? We usually refer to a technology pyramid to explain the answer to this question. The technology pyramid is oriented in terms of increasing risks. Libraries is where the risk is the lowest. Cloud providers and orchestrators is where the risk is the highest, where risk means, how big is the blast radius if something goes wrong? If your Kubernetes orchestrator goes down, probably most of your applications are going to be down.
The second dimension is how easy it is to swap something out for something else. Replacing a library in a specific application can take some time, but it’s a finite task. Migrating all your applications to a new cloud provider, that can take years depending on how complex your stack is. Ideally, the higher you go in this pyramid, the more innovation tokens it actually takes to do something innovative. Probably, if you want a new database, that’s all of your innovation tokens, just right there. Some jobs, as one might argue, a team cannot do in isolation, they don’t have enough innovation tokens alone to bet on a new cloud provider. Because those choices actually have a ripple effect for the entire company. Therefore, they need to be taken collectively by other combinations of teams, or the entire engineering organization. Programming languages in particular are a little bit of where the line gets blurry. Most of our stacks, including TrueLayer’s, are microservice architectures, therefore, the different applications communicate over the network. One might argue, anybody can use whatever they want to write their services, they just communicate over network.
The truth is also that programming languages have implications that go beyond the service itself. They have implications around who you can hire. How your organization can be structured. How malleable your organization structure is, and how easy it is for people to move around. If you choose a new programming language, you’re going to have multiple ecosystems within your company. If you need to write a library to address a certain cross-cutting concern, like tracing, you now need to write two or three or four, one for each ecosystem. That’s probably why we’ve seen so many sidecar patterns in the recent years. People understand the problem, they have too many programming languages, cannot bother to write libraries, and so they move that interaction into a microservice that sits next to the application. You then have hiring. Can we find people who know this stack? Can we train them up? Are they willing to work for us? You have internal mobility. Somebody is moving from a team to another team, usually they need to upskill on the domain. Now they also need to upskill on the tech stack. Is it something we want? Does it make it more difficult to move people around, which in turn means that we’re going to have silos? All these considerations very much affect the global landscape of an engineering organization. Therefore, they do require some level of global buy-in. In an organization such as TrueLayer, that means engineering as a whole, and the CTO, actually, they suddenly want to take a bet on a new programming language.
Assessing Rust – Why Did We Bet On a New Programming Language?
So far we have discussed technology adoption in general. Let’s now get specific. Let’s look at Rust. Why did we choose to adopt Rust? What did we see there that we thought was valuable, overcoming all the risks?
Pros – Composition without Surprises
It starts with composition without surprises. This is by far the most important thing. All the others are very far second. If you’re writing any piece of software, you’re combining so many different layers. It’s like a wedding cake, a very tall wedding cake. You have a library that builds upon another library that builds upon another library all the way until you actually get to the metal. We can only be productive insofar as we can ignore the layers below. The only thing we should be caring about is the interfaces that we use. We shouldn’t be caring about the complexity that is hidden beneath those interfaces. That’s the magical thing about modularity. You look at the module interface, and hides a lot of very complex things that are going underneath, way more complex than the interface itself. In software, in particular, when it comes to business software, this is even more accentuated. Because you really have incentives to spend time working on your business logic, working on the parts of your application that are actually going to give you an edge against the competition. You don’t want to be spending time rewriting an AWS client or rewriting a web framework that is all undifferentiated lift. In Rust, this is actually easier to do, we have found, than in other languages we have used.
Let’s start with an example. We have a function defined called verify_signature. This is Python. This function has some security aspect, takes this input, a token, and it’s asynchronous. By looking at the definition, what can we say? The only thing we can really say is that it might perform some kind of input/output. That’s the extent of what we know. Like verify_signature as a name tells us something about the fact that it has to do with security. Token, was that a JWT? We don’t really know what to expect in terms of data. Even verify is ambiguous. Does this return like a Boolean, verified, yes or no? Does this return an exception if it fails, but some data if it succeeds. We don’t really know. The only way to know is to peel away the abstraction layer. You actually need to go inside and look in the implementation, so that you can find out what exceptions it can throw, what data it actually needs. Even when it comes to exceptions, sometimes it’s not enough to peel away one abstraction layer. You might have to peel away multiple, because this function might be calling another function that can in turn raise exceptions. Unless verify_signature wraps everything in a try-catch and recasts exceptions, we need to recursively introspect all the layers that are being used, without even considering how those layers are stable over time when the library gets updated. We have tons of questions and very few answers, just by looking at the interface, which is not ideal if we need to build a very tall tower of abstractions.
Now let’s look at Rust. Same function, but there’s a lot more in the signature. Once again, it’s asynchronous. We know it might perform some input/output. We now know what’s the structure of the input. It’s a JWT token. We can check the types if we want to know what it actually looks like. We know it’s not going to be mutated because it’s taking a shared reference, and by checking the type we know it’s not going to have interior mutability. We know it can fail, and when it fails, we know how, so we can look at VerificationError. If it’s an enum, for example, we have all the failure modes right there. Then we have the data returns if the function was successful, so it returns the claims inside the JWT token. All these things we can tell without actually looking at the implementation, and without having to rely, for example, on documentation, which might or might not be up to date. Everything or most of the things we care about are encoded in the type system, and so they’re checked at compile time by the compiler. They’re robust when the library is updated. They’re robust when our code changes. This actually allows us to scale that abstraction layer, because we can go higher, because we’re built on a foundation that is robust, and it’s not going to shake under our feet without us noticing.
Pros – State Machines
Which brings us to the second topic, which is state machines. If you’ve done enterprise software, you know that it’s mostly entities that can be in a finite number of states, with a certain number of transitions between states, which correspond to precise business processes. Let’s make an example, users. You have a platform, you launch. You have users and there are two kinds. There are the pending, so they’ve signed up, but they have not yet clicked on the confirmation link. Or they’re active, they’ve signed up, and they clicked on the confirmation link. Rust does support for enumeration with data, also called algebraic types. We can encode the user in the pending state, the only thing we know about is the email. For a user in the active state, we also know the confirmation timestamp. The nice thing about algebraic types is that you cannot use them without actually matching and first determining which variant you are actually working with. The compiler forces you to have a match statement. Then once you get into the pending variant, you can do things assuming that you’re in the pending variant. The same applies for active. You cannot just assume that a user is active and try to grab the confirmation timestamp. That’s not going to work.
The second thing that is very nice is that your domain evolves over time, this happens continuously. You find out that your state machines have more states than you have actually anticipated, or that you need more data, and you need to do different things. We can change the enum to add a new state, suspended. We launched. We found out that some users can be naughty, so we want to be able to suspend them. This state is going to have its own amount of data. We have a lot of code that we have already written assuming that the user could be in pending and active state, what’s going to happen now? In another language, you might have to do the things that your software design suggests you. You might have to use comments to document all the different places that you’re using this enum from, so that when you add a new enum, you remember that you actually need to modify all those different parts. Through this, this approach doesn’t scale. This approach doesn’t scale to complex software, which has tens of thousands of lines. Somebody is not going to modify all the places. Somebody is going to add one more usage without actually updating the comment, this is very brittle.
Rust instead, once again, lets you rely on the compiler. Match statements need to be exhaustive if the enum has not been marked as non-exhaustive. What this means is that as soon as you introduce a new variant, all the locations where you’re using the enum, the compiler is going to float them to you and say, I cannot move forward unless you tell me what I need to do with this other variant, which is currently not handled by the match statement. You can do a classic follow the compiler refactoring. You go case by case, line by line. In every single case you specify what needs to happen until you’ve handled all of them, and then the compiler is happy. You know, you’re certain that nothing slipped past you. That’s the way it should be, because this allows us to offload complexity from the brain of the developers, so they don’t need to be worried about it, they don’t need to keep in mind all these little bits and pieces. They can offload all of that to the machine, and they can focus on other things. That means they can be more productive, and they can make less mistakes.
Pros – Predictable Performance
Many of you have a very strong association when you hear the word Rust. It’s like Rust, system programming, performance. Which often leads to conversation along the lines of, you are not doing system software. You don’t need to be so performant. Why are you using Rust? Why don’t you just use Java, C#, whatever language? There is truth to that. In business software, you don’t need to squeeze the millisecond, necessarily. You care about performance in general. It’s nicer to use applications which are responsive, which are fast, which don’t hang, which don’t have a lot of errors. That’s a very nice feeling. You want to have that feeling, but you’re not optimizing like the half milliseconds unless there’s a very compelling need for that optimization. Still, there’s one thing we care about, which is predictability of performance. The software you’re writing is still going to run inside a production environment, which means that it’s going to have spikes. There’s going to be incidents. You might have to scale it up and down depending on load. If the performance profile is predictable, this is a lot easier.
Let’s look at an example. This is an article that came out in 2020 from Discord, when they rewrote part of their systems from Go to Rust. You can see Go in purple and Rust in blue. It doesn’t matter which one is faster. That’s not really the point of this conversation. The point of this conversation is, look at the shape of that profile. The Rust one is very flat. It takes an average fixed amount of effort or time to fulfill those requests. If I look at that flat profile and I see a spike, I know I need to be worried. Something unusual has happened. If I look at the Go one instead, I’m like, there’s going to be spikes, Redis or GC. Is this a particularly bad GC spike? Do I need to get worried? Should I page someone? How do I scale it up and down? All these things become easier if the performance profile is flat. Because you know predictably, how much resources are needed to do work. Performance or consumption are not going to change. A lot of conversations become a lot more trivial, which is a good thing. We want software in production to be boring, and that makes it more boring.
Pros – Community
The three things that I listed so far, they’re all technology related. That’s not where it ends. When you actually choose a new technology, something as big as a programming language, you’re also choosing a community, because you’re going to be hiring people from that community into your organization. The question you need to ask yourself is, do I like that idea? Do I want those people in my company? It comes down to culture and values. Those people are going to bring some values into your company. If they are not aligned with yours, then you’re going to have problems. Either they are not going to survive long inside the organization, or the organization culture is going to change under their influence. That’s why it was so important for us to become hosts of the Rust London meetup. Because this gave us an opportunity to many engineers who were interested to actually talk to people in the Rust community, have interactions, and experience what it feels like to be part of the Rust community. The Rust community does a lot of things right, a lot of things that we care about. Sometimes they do it better than we do. It’s an inclusive community. It’s a respectful community. A community that value the input of beginners and tries to make it easier for people to contribute. These are all things that we want to do as an organization. By hiring people from this community, we give ourselves a better shot at actually making it possible. Which is not to say this is a community without fault, there’s going to be incidents. There have been, there are going to be more, but it all depends on how you handle them. That’s where you actually see what the community stands for. So far, it’s one of the best communities I’ve had the chance to be in.
Pros – Growth Trajectory
Once again, on the social side, there’s growth. You don’t want to be in a programming language that is likely to die, because that means that you’re going to be left with hundreds of lines of software, where you not only need to maintain your own software, you also need to maintain the compiler that you’re using and a bunch of the ecosystem. 2020 and 2021 were inflection points for Rust: language adoption, skyrocketing in the industry, major projects being announced by a variety of different companies, and also open source initiatives like Rust in the Linux kernel. There was really little doubt that Rust was going to die. I think it was quite clear that we were boarding a train that was not going to stop in two years’ time. That gave us a little bit of peace.
Risk – Learning Curve
Not everything is roses and rainbows. There were also risks that we were concerned about, and gave us a little bit of trouble. The first one was the learning curve. Rust has quite a reputation for being a little bit of a difficult language, more difficult than your average programming language. Some of this is justifiable by the introduction of concepts that you just don’t find in other programming languages: ownership, borrows, lifetimes. Most developers who work with typical mainstream languages have never had to worry about any of this. You also have concepts that come from typical functional programming languages, so algebraic types, options, results, which once again are not part of the background of your average Object Oriented Developer. When they come to Rust, all of these things need to be learned. It can feel a little bit overwhelming. The way we de-risked this was trying to make sure that in our first major Rust project, we staffed people at different levels of Rust expertise, people who knew the language very well, but also people who’d never used it before. Because for us to succeed, we needed to know that we could train people effectively. That has gone quite well. We got people from C# picking up Rust. We got people from JavaScript picking up Rust, becoming very proficient, very good Rust developers in just a handful of months. I think the trick, the thing that is often overlooked is that you don’t need to learn the entire language. Rust is a very big language. There’s a lot of API surface. The truth is, depending on the application you’re trying to write, you only need a subset of that language. You can get very productive in that subset relatively quickly if you focus on it and you don’t get overwhelmed by all the rest. By guiding people and giving them learning resources that were tailored to the type of things they were trying to do, so writing backend services, was actually able to get them to be confident enough to be productive very early on. Then just growing them over time into exploring the rest of the language, which was not as core to their day-to-day, but still important for them to learn and to get a sense of.
Risk – Ecosystem Readiness
The second risk was ecosystem readiness. Rust still is a young programming language. Async/await has been around for a year or two, and so, are we going to have to write our own web framework? Are we going to have to write our own HTTP server? These were all things we were worried about, because these are all very complex projects that take time away from doing work on the product. To de-risk this, what we did was we brought a very and completely functional demo called Donate Direct. This was during COVID, before we actually chose to use Rust for our next big product. Donate Direct uses Payments API from TrueLayer to donate money to charities for helping communities impacted by COVID. Donate Direct is a very typical TrueLayer application. It’s a backend API, has a bunch of message consumers, interacts with RabbitMQ, interacts with Redis, interacts with Postgres. It gives us an opportunity to try out all the different bits and pieces that we’re going to need on a daily basis. We could try out that web framework, that RabbitMQ client, that AWS client, and get a sense of, are they actually usable? Can we rely on these things? The outcome was overwhelmingly positive. All the things we tried were very solid. Obviously, perhaps not as solid as what you would have found in Java, but good enough to use, assuming you are ok from time to time to submit an issue about a bug or just upstream a patch, which we’ve done several times. It was clear that we wouldn’t know that to move mountains to use Rust. We would have to be good citizens and write small utilities from time to time that in other ecosystems you would find ready packaged for you to use. Overall, Rust is a language ready for productivity when it comes to backend development. It was a very good discovery early on that gave us motivation into moving forward.
Risk – Talent Pool
Then we had the talent pool. Rust is young, which means you will not find a lot of engineers who have experience using the language, or many years of experience using the language in a production setup. You need to make peace with the fact that you’re going to have to hire people who want to learn Rust, but don’t know Rust yet. If you can do this, and this goes back to point one around the learning curve, if you establish that you can train people into Rust effectively, then hiring is going to be very easy. This has been confirmed in almost two years of using Rust. There’s a massive pool of people who are very keen to use Rust as a programming language, and we’ve been able to hire very effectively extremely talented engineers for that pool. We’ve been able to train them, and they’ve been happy with us ever since, maybe all of them, I think. This was one of the most important successes as an organization. It actually made it a lot easier for us to hire, which is a boost for an organization that is scaling as fast as TrueLayer is. You’ve seen the number from 30 to 100, to 150 at this point. We’ve turned the risk into an opportunity.
Risk – Bus Factor
Last, and this was probably the risk where no real mitigation was possible, you have bus factor. Once you are starting adoption of a new technology, you’re going to have just a few engineers who are actually experienced in that technology. What this means is that if those engineers leave, you’re going to be left holding a system written in a technology that you don’t have institutional knowledge for. That is not a nice situation to be into. Our adoption plan was designed to get us away from the bus factor as fast as possible, so to upskill as many people as possible to make the Rust community inside TrueLayer self-sufficient. There still is a window of risk: three months, six months, whatever that is. It all comes down to a judgment call from the CTO or the person who’s responsible in your organization. Do we trust those developers to stay around to see this project through? Are we ok with taking this risk? You need to say either yes or no. TrueLayer’s CTO decided to say yes. I think today, this is no longer an issue. It definitely was when we were discussing adoption.
Summary
It was a very quick overview into TrueLayer’s experience adopting Rust. In December 2021, we had 23 developers using Rust, and 44 microservices. I’m very curious to see the numbers in December 2022. I know the numbers as of April 2022. I know that the trend keeps going strong. I think momentum for us both inside and outside the company still keeps going very strong. I do expect to see more growth in this year.
Questions and Answers
Eberhardt: 164 microservices, 100 developers? If you’ve got any comments on that. There are lots of people who debate how many microservices you should have, how many is too many. You’re in a position where you’re happy with more microservices than people. I wonder if that’s something you could elaborate on.
Palmieri: You really need to qualify then the numbers and what those services are doing. The real metric that we care about usually is the number of services in the critical path. How many do you need to hop from in order to fulfill a request at the edge? That’s definitely not in the 20s, 30s. Is it probably a bit higher? Yes and no. Some services have a shared core and just are deployed as multiple units, perhaps because that makes scaling easier. It’s a complicated conversation, really need to go into what the numbers mean. We’re actually quite happy with the way the fleet looks.
Eberhardt: I’m going to guess that you’ve invested quite heavily in lots of automation to support all of that.
Palmieri: Yes we did.
Eberhardt: How do you see Rust’s maturity for backend web applications nowadays?
Palmieri: Much stronger than it was when we started. There’s a lot more frameworks. The frameworks are getting more polished. A lot of supporting applications, supporting libraries are being written. Web framework, that’s really like one piece of backend web applications. You have databases. You have clients for various APIs. You have caching. You have rate limiting. A couple of years ago, I think you had to build with the backbones. It was viable, but required a little bit of effort. Nowadays, we really don’t find ourselves writing a lot of stuff from scratch, unless we have some very peculiar requirements that obviously you’re not going to find implemented in the ecosystem. Obviously, you need to distinguish between what you mean by backend. One thing is writing an API that is part of a microservice architecture, and is running inside the system, and so it’s not an edge API, which is different from a backend for a frontend, which has different kinds of requirements and different kinds of libraries.
Eberhardt: By asking about a backend web application, I’m assuming they’re talking about the equivalent to Ruby on Rails.
Palmieri: Rails, or a Django.
Eberhardt: Yes, exactly. That sort of thing.
Palmieri: From that point of view, I think things are moving forward. You don’t really have at this point in time an equivalently, fully-fledged framework. Something that takes a very opinionated stance in what it means to do a web backend in Rust. I think that may be coming. I think it’s a matter also of philosophy. Some people have been burned in the past by large frameworks that are largely opinionated. It still requires you to assemble the pieces yourself. My point of view is the pieces are there, but you need to choose your toolkit. You’re not going to find something that you can take off the shelf, and pretty much just plug and go. The closest you can find in the ecosystem to something like that is probably the Poem framework. They’ve taken more of a battery-included approach to developing a web backend framework. I suggest you do check it out, if that is the type of thing you’re looking for.
Eberhardt: In contrast, C#, .NET, there are going to be multiple, very mature web application frameworks that you could choose from. That’s the difference.
How have you been dealing with Rust evolving quickly, particularly with upskilling and the steeper learning curve? If we start with the first one, dealing with Rust still evolving quickly. What are the challenges and how do you tackle it?
Palmieri: I think that very much depends on your perception and what quickly means. I think sometimes people confuse the release cadence they have for Rust as a project and actually how much the Rust programming language changes. It is true that Rust ships a new compiler version every six weeks. Most of those releases are just a little meddle here and perhaps a better implementation there, a little bit of performance boost there. There’s not really many major language changes that ship with Rust on a six week’s basis. If I look back at the last two years, so if I look back at major new Rust capabilities that have been shipped after async/await, which was the major one we were interested into, the only one that comes to my mind is constant generics. Even then, constant generics is like, it’s there but it’s not really necessarily relevant for the type of code that we’re writing. You actually don’t find it much in backend applications, because it’s something that is more interesting, perhaps, to an extent, to people working on embedded and different kinds of environments. That’s because constant generics is not quite where it needs to be yet to be useful in different contexts.
The reality is, you don’t need to know the entire language to actually be effective on a daily basis, so we don’t actually end up doing a lot of upskilling insofar as updating people’s knowledge of Rust. We’re much more concerned with the Rust ecosystem moving, and not really with the Rust language moving. The Rust language to our consensus has been pretty stable, but can really change the way we write a lot of things. We keep up with lints and a little bit of what language conventions are, but that’s not the major source of churn. The major source of churn is libraries changing and breaking changes into libraries we depend upon. Those have been much quicker than the language problems. We usually coordinate, so we pick a toolkit across the company, so some foundational libraries that we use consistently. Then we decide to do waits or updates, when the time comes. This again has been getting better over the past year or so especially since Actix finally shipped version 4, and we got that with a better situation. It feels like the ecosystem is settling a little bit more. We don’t find ourselves doing a lot of those anymore. It’s less of a pain point than it used to be a year ago.
Eberhardt: Do you as an organization keep up with the Rust compiler release cycles? Is there a need to? Is it easy to do that? What’s your strategy?
Palmieri: We do. This is a language policy that goes also beyond Rust. We try to be on compiler versions that are at most six months old. This is usually because standard libraries can have CVEs, just like normal libraries. This has actually happened in Rust I think it was 1.56 or 1.57. By making sure that our code can run without any issues on the latest compiler, we know that at any point in time, if a security vulnerability pops up, we’re actually able to get the fix as fast as possible. Also, we get improvements with performance boosts.
Eberhardt: With Rust, as you compile to a binary, you have quite an advantage over languages like Java, because the limiting factor in Java is not the desire to move to the next Java version. It’s waiting until all of your clients have updated their runtime to match the Java version. I’m guessing in Rust, that’s not a challenge.
Palmieri: The difference is that, for example, C# also has new versions. If you want to move from .NET 5 to .NET 6, you have breaking changes. Rust doesn’t do that. The library gives you this. If you compile it in Rust 1.40, you should compile on any versions of Rust after that. They might ship new lints, which are optional and we usually enforce in our CI environments, because we want to keep the code to a certain standard. There should really be no problem in us compiling on the latest compiler version. It’s a much easier sell.
Eberhardt: Are there any features that Rust lacks, that are present in other languages like Java and C#? Because I know there are a lot of things that Rust will do differently. Is there anything that you think is fundamentally lacking compared to Java and C#?
Palmieri: Nothing fundamental. Obviously, I have my pet list of things I’d like to see inside the language that are not quite there yet. I wouldn’t qualify many of them as being fundamental limitations, so nothing that prevents me from doing things I would like to be able to do. They are mostly things that make some things I want to do more cumbersome than they need to be sometimes.
Eberhardt: Sometimes I’ve found in languages like C# and Java, I’ve, on occasion, thought, I wish I had macros. There are some fundamental limitations in some of these older languages anyway.
Palmieri: No, that is true. The fact that you can do a lot of stuff at compile time, obliviates, for example, like I think that many people bring up when they look at Rust is there’s no runtime reflection.
Eberhardt: Yes, reflection. How often do you use that?
Palmieri: We use it in places where you use that in C#. Actually, in most cases you can do that with compile time reflection, which is macros. That works.
Eberhardt: Yes, you might use it for things like database access models, O/R mappers.
How do you estimate if we’re moving over to a completely new language, learning curve challenges? How do you get the backing from the business to go with something as drastic with so many unknowns? How do you get business backing for a full scale migration to another language?
Palmieri: We’re talking about two different things. One thing is, you want to do a full scale migration, which is, let’s take everything we have and rewrite everything in a different language. That’s a very specific type of conversation. Another one is we want to start using a new language for potentially new parts of the stack. We didn’t do a language migration. We didn’t take the 60 AD services we have built in C# and decided, we’re going to stop doing anything else and rewrite everything to Rust. That will make no sense. What we did was, we think this language is good, and quantified the type of improvements that we wanted to see mostly around reliability and faults, and managed to justify the much smaller effort, which is, we want to support two languages side to side. If you want to do a rewrite, then you need to have a different type of conversation, which is around a complex application that you want to rewrite is, what benefits do you expect to see from the other programming language?
Usually, my suggestion is to break their nodes. If you want to do a massive project that involves a new programming language, that shouldn’t be the first project you do with a programming language. You should be mitigating a lot of those risks in lower stakes opportunities that give you the opportunity to build expertise, understand that you’re actually capable of pulling off what you want to pull off. To the point that when you actually want to evaluate, for example, a rewrite, the fact that you have competence in the new technology is not one of the risk points. The risk point is simply like, is it the right call to do a rewrite? Are we going to see the benefits we think we’re going to see? How long is it going to take? What’s the opportunity cost of doing a rewrite?
Eberhardt: My advice to anyone, and I’ve seen this done a number of times, never go to business and say, we want to take our product which is written in technology A, rewrite it in technology B, it will do exactly the same thing, and it will cost you a million pounds or dollars. The answer is going to be no. You never get a good response. From my perspective, if you want to migrate, you have to find business value in that migration. I always recommend that, don’t look at migrating the entire platform, look at where you can add value to your clients early on throughout the process of migration. If you’re implementing some new features that you think you can implement better, faster, sooner with a different language, that’s the way to start the journey of a migration. Don’t look at the full ticket cost because that’ll never fly.
See more presentations with transcripts
MMS • Chris Rutter

Key Takeaways
- We can move away from asking security teams, “Is my product secure?” to telling them, “I know it’s secure as I’ve built it using requirements we’ve already agreed on”
- It’s possible for delivery teams to proactively build agile security workflows that speed up delivery, and compliment Infosec compliance needs
- Shifting left doesn’t just mean automation, it means developing new workflows to empower product teams to build securely and provide assurance
- By analysing where we spend time expensively retrofitting security controls, we can build capabilities to design these controls into products cheaply or for free
- Security teams usually aren’t against agile or rapid releases, as long as they receive enough assurance, and delivery teams are the best people to provide it
The software delivery process has been transformed in the last decade; we’ve adopted well-understood workflows around functions such as testing, release management and operational support.
These changes have enabled organisations to speed up time to market and improve service reliability. So why does security still seem so far behind? And why does it still feel so hard for so many product teams?
In this article we’ll explore the impact that typical security workflows have on software delivery, explain the root causes and share battle-proven techniques through case studies to show how we can make delivering secure software easier.
A typical security workflow
First of all, let’s look at a typical secure delivery workflow and identify some common issues. If you’re nodding your head along to these, then this article is for you.
Workflow purpose
Most organisations have risk assessment and security programs that directly relate to regulatory standards; they’ve been designed to ensure that all software is subject to industry-standard security checks, ensure that any risks that end up in production are classified, and that somebody is held accountable.
This is all good stuff which most people would agree with, however in practice we often see security workflows that were designed to service waterfall-based projects with infrequent bing-bang releases, which haven’t evolved to support modern software delivery and make regularly releasing small chunks of software difficult.
What happens in practice
Using these workflows, a product delivery team will often develop a system without technical security standards or requirements, then when they’re just about ready to release they begin to review their system architecture with a risk assessor who tries to spot any security concerns in the design and recommends more effective security controls.
When reviewing architecture at a high level, any security concerns are usually big-ticket items that require considerable effort to retrofit, and sometimes even the redesign of a critical feature of a system like authentication.
Lower-level threats and vulnerabilities are often found by outsourcing deeper technical security knowledge from an external penetration testing company, who are engaged to attack the system and highlight any serious issues.
After these activities are complete, we usually see a fractious negotiation around risk and resources, with the engineering team pushing back on making expensive, time-consuming changes to their system architecture and operational processes just before their release deadlines, and the system owner pushing for risk acceptance for all but the most serious risks.
Overall, security can be seen as something that’s owned by the security team and not an attribute of a system’s quality that’s owned by engineers, like performance or reliability. The result is often a system which has sub-optimal security controls and a growing risk register of known issues which are rarely re-examined.
What is the impact?
When teams use the workflows detailed above, we commonly observe the following negative impacts:
- Security activities slow down delivery and reduce release cadence – Time-consuming workflows to initiate and perform big bang security reviews encourage larger, less frequent and higher risk software releases.
- Improving security involves lots of duplicated effort across many teams – Each team performing the same assessments or penetration tests on every release which produce similar findings.
- Large chunks of security work just before release – Sudden demand for large architectural system changes to implement new security controls based on an end-of-project risk assessment.
So now that the problems are clear, how can we improve?
Break up the big bang security review and do the right activities at the right time
Delivery teams can proactively use their skills and agile experience to break up the large, waterfall security risk assessments into more manageable, granular security review activities that can fit modern workflows and rapidly changing systems.
Case study
While working with a regulated financial services institution on a new customer-facing product, each software release was subject to a full risk assessment and penetration test which forced big-bang releases with a cadence of around three months, which severely impacted the quality of the product as releases were full of bugs and user feedback was incredibly slow.
Categorising releases
We first worked with InfoSec teams to categorise different types of releases, based on the scope of architectural changes, whether they related to security sensitive controls like authentication, whether the change introduced new classifications of data with different protection requirements, or whether they were small incremental changes to functionality.
Sensible review activities at the right time
Once we agreed on these release categories, we were able to introduce a process where each user story was self-assessed by a security champion at the backlog refinement sessions (with the result added to the JIRA ticket) and based on the agreed release criteria we established the type of security activities that were required.
The range of activities were Peer Code Review, Static Code Scan, and Threat model, Risk Assessment / Penetration test.
Provide assurance
Thanks to linking evidence of each self-assessment decision to each user story, and providing links to security scans, pull request reviews or threat models, delivery teams could use Jira Query Language to provide an instant report that demonstrated all releases had undergone the right levels of security review, and when audit time came along it was easy to show specific examples for any chosen release.
Reap the benefits
By self-assessing each user story and performing the most applicable security activities for each release based on agreed criteria, we were able to realise the following benefits:
- Increase our release cadence to weekly releases, delivering value faster and reducing the number of bugs
- Avoid expensive retrofitting work near the end of a project
- Improve the security of our products as each small change had the benefit of security input while in development, rather than as a big bang at the end of three months of work
Scale out common and expensive security controls
Product delivery teams can pre-define common security requirements, develop approved patterns and build shared security capabilities, allowing them to easily design effective security controls into their systems (or get them for free).
Case study
While working with a PCI-regulated organisation during a transformational period, several product delivery teams were actively building brand-new products using a microservices architecture.
Mandatory architectural security reviews were carried out once development was complete, with important security requirements around areas like data protection, authentication and authorisation, and secrets management frequently surfacing once systems were functionally ready for release. Each team would build their own implementations of these controls and re-submit them for review, causing extensive project delays and large amounts of duplicated work.
Identify common security-critical components
We reviewed all previous security assessments, finding the common areas which required intensive security review and led to expensive retrofitted security controls. The areas we noticed were causing repeated problems for multiple teams were:
- Secrets Management
- Application Security Logging
- Client Authentication / Authorization
Choose a practical method to standardise and scale
Depending on how a product delivery function is structured, the technology they use and their architectural ethos, several different techniques can be used to help standardise security controls and make them cheaper for teams to implement early:
- Pre-agreed technical security requirements
- Shared code libraries or infrastructure-as-code modules
- Fully supported security cross-cutting capabilities
Technical security requirements
Many new products implemented different authentication and authorization schemes based on the needs of various backend third-party integrations. Technical security input was not available throughout product delivery, and any security issues were usually identified after pre-go-live risk assessment or third party penetration test.
The product delivery teams reviewed all previous penetration test findings and worked with a security subject matter expert to work on defining a set of core requirements that teams could use when designing their authentication schemes. We built out technical requirements documents around areas like approved crypto algorithms, password hashing strategies, rate limiting and key rotation, and these standards were used during the design phase for all further projects, saving large amounts of retro-fitting and re-design.
Shared code libraries
We realised that each delivery team was subject to a drawn-out process of identifying security-relevant events in their applications, implementing specialised logging to capture these events and then working with security teams to test their effectiveness in a centralised SIEM (Security Information and Event Management) tool.
We worked with security teams to define a general set of useful security events (For example: Failed login, Rate limit reached, Signature verification failure), and implemented a shared code library which teams could import into their applications that provided a standardised way of logging these events which the SIEM understood. We released the library with easy-to-understand documentation that allowed teams to build in the required logging while building their applications, and saved weeks of project delay in many projects.
Cross-cutting capabilities
One of the largest areas of risk present in the new microservices was around secrets management. Many delivery teams had developed their own secrets management mechanisms, ranging from encrypted values in source control to basic encrypted cloud object storage. The lack of standardisation meant each team spent weeks working back-and-forth with InfoSec teams to reach a security compromise, and responding to any incidents regarding secrets was disjointed and often required key individuals’ knowledge.
We implemented a generic and secure secrets management mechanism which could be used by any deployment, so teams could inject secrets using placeholder values in config files backed with a secure cloud-based secrets storage mechanism. Protecting secrets was much easier given the standardised cloud logging and access management capabilities, teams spent almost zero time building secrets management into new products and demonstrating that secrets were securely managed for audit and compliance reports was incredibly easy.
Conclusion
If waterfall-based security workflows are slowing your delivery down, or you realise that large chunks of your valuable development time is spent retrofitting security controls, you can treat these issues as just another value stream problem to solve and invest in using these techniques to develop the workflows, knowledge and capabilities required to build software securely and at pace.
MMS • Matt Campbell

Grafana has released Grafana Tempo 2.0 which introduces the new TraceQL query language and support for the Apache Parquet format. Grafana Tempo is an open-source tracing backend that works with object storage. The new TraceQL query language works with the Apache Parquet format to provide improved search times and queries aligned to traces.
The TraceQL query language is based on existing languages like PromQL and LogQL. It allows for selecting traces based on span and resource attributes, timing, and duration. A TraceQL query is an expression that is evaluated one trace at a time. Queries are comprised of a set of expressions chained together into a pipeline. Each expression in the pipeline will select or discard spansets from being included in the results. For example, the following query will select traces where the spans have an http.status_code between 200 and 299 and the number of matching spans within the trace is greater than two:
{ span.http.status_code >= 200 && span.http.status_code 2
A trace represents the journey of a request through the system under observation. They are composed of one or more spans that represent a unit of work within a trace. Spans have a start time relative to the start of the trace, a duration, and an operation name.
TraceQL differentiates between two types of span data: intrinsics and attributes. Intrinsic fields are fundamental to spans and include things like the status, duration, and name of the span. Attribute fields are derived from the span and can be customized. For example, the query { span.http.method = "GET" } uses attribute fields on the span to return traces with the HTTP GET method.
Comparison operators are supported and can be used to combine spansets. To find traces with spans that traverse two regions the following query could be used:
{ resource.region = "eu-west-0" } && { resource.region = "eu-west-1" }
This release also includes the aggregators count and sum. count can be used to return a count of spans within a spanset whereas average is used to provide an average of a given attribute or intrinsic for a spanset. The following query could be used to find traces that have more than three spans with an HTTP status of 200:
{ span.http.status = 200 } | count() > 3
This release also introduces Apache Parquet as the default backend storage format. Apache Parquet is an open-source, column-oriented data file format. Joe Elliott, Principal Engineer at Grafana, does note that this change may have performance implications:
Previous iterations of Tempo used a format we call v2 that was incredibly efficient at storing and retrieving traces by ID. Parquet is more costly due to the extra work of building the columnar blocks, and operators should expect at least 1.5x increase in required resources to run a Tempo 2.0 cluster.
However, the Tempo release notes indicated the Tempo team saw a substantial search speed increase with the new Parquet format:
With our previous block format, we’d seen our ability to search trace data cap out at a rate of ~40-50 GB per second. Since switching to Parquet, we’re now hitting search speeds of 300 GB/s on common queries and doing so with less compute.
This new Parquet block is enabled by default in Tempo 2.0 and is required to make use of the new TempoQL query language. Once enabled, Tempo will begin writing data in the Parquet format but will leave existing data as-is. The Parquet format can be disabled to instead use the original v2 block format.
Tempo 2.0 is open-source and available under the AGPL-3.0 license. Elliot notes that the best TraceQL experience is found with Grafana 9.4.
MMS • RSS

(phive/Shutterstock)
DataStax is giving users of its AstraDB cloud service free access to entire blockchains, starting with Ethereum, with the goal of making it easier for developers to create new Web3 applications.
DataStax noticed that some of its customers were trying to host Ethereum themselves as part of crypto currency analytics offerings. Company saw the customers struggle to make it work, which is when they realized DataStax was in a position to alleviate a lot of administrative overhead by building support for Ethereum directly into the platform.
Astra Block, as the new service is called, is a feature available to all users of AstraDB, the Cassandra-database-as-a-service that DataStax originally launched back in 2019 (when it was called Constellation).
Currently, Astra Block hosts the entirety of Ethereum, which is the considered to be the largest blockchain, currently consisting of more than 1 TB of data, according to Alex Leventer, a Web3 developer at DataStax.
“It’s a heavy lift,” Leventer tells Datanami. “It’s especially a heavy lift for the real-time aspect. A lot of our users were running batch jobs, so the data is always out of date until you run the next job. So the real time aspect is hard to do. All the data modeling, all the management of the database–all that we’re taking care of for users.”
In addition to providing a copy of the blockchain, Astra Block exposes blockchain data via REST and GraphQL APIs or existing Cassandra drivers. The company has also built new indexes to speed up access to frequently used data.
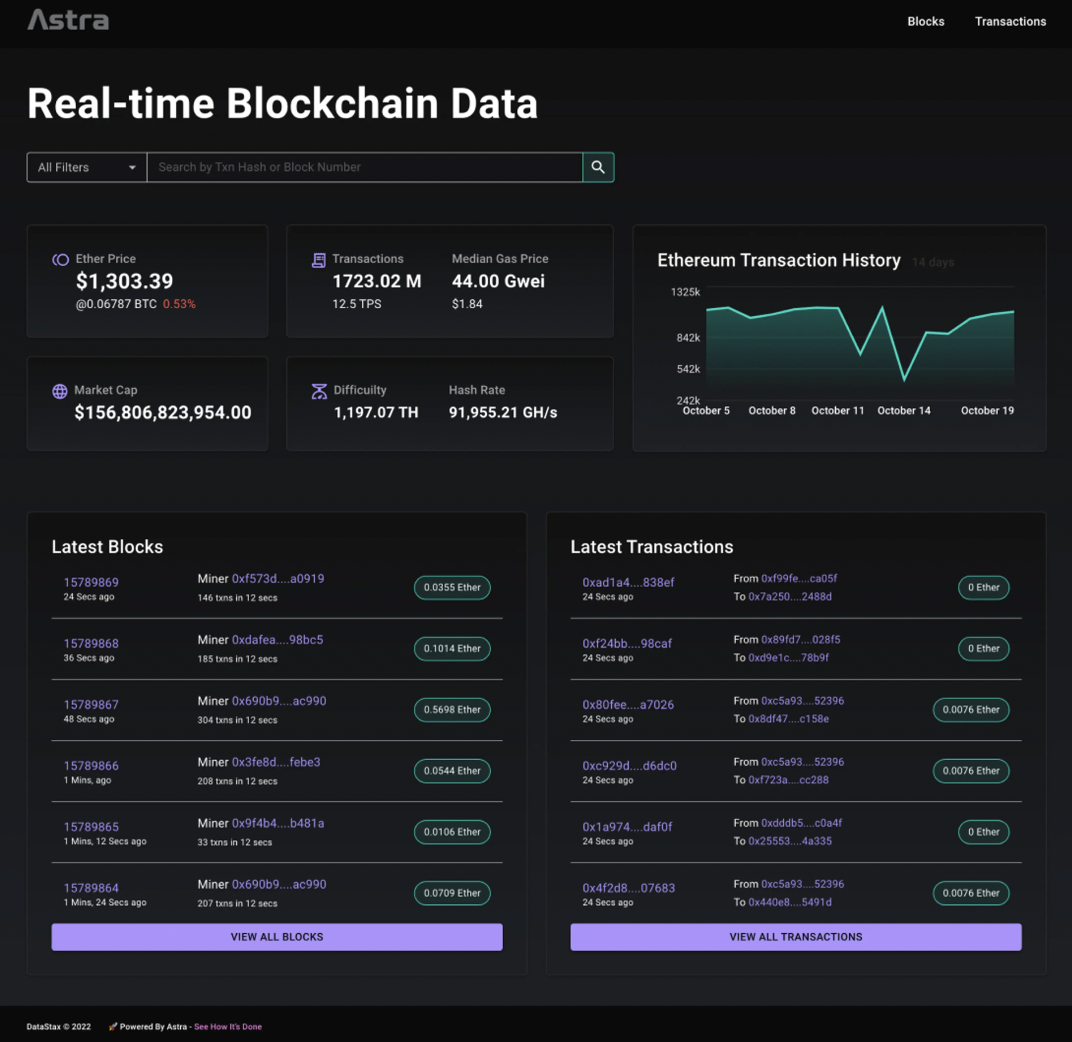
Astra Block includes the entirety of the Etherum blockchain (image courtesy DataStax)
The current state of blockchain development is not simple, and so the overarching goal with Astra Block is to simplify life for developers using the blockchain to build the next generation of Web3 applications, says Mike Hulme, vice president of marketing for the Santa Clara, California database and blockchain company.
“You’re asking developers to work with hundreds of API connections” without Astra Block, he says. “You’re asking them to build their own indexers. You’re having to manage their own infrastructure. And that’s taking away the time of actually building the app, delivering the app and doing the thing that’s valuable.”
A blockchain, of course, is a distributed ledger of transaction records stored in encrypted hashes. Blockchains are unalterable and open, features that enable them to form a trusted chain of record.
Crypto currencies such as Ethereum and Bitcoin use blockchains as the underlying technology that keeps everybody honest. The company plans to add support for additional blockchains in the future beyond Ethereum, including Bitcoin, Polygon, Solana, and Binance, DataStax officials say.
While cryptocurrency is the most visible application for blockchain technology, it’s not the only one. Many technologists have visions of using blockchains to displace institutions that currently function as the trusted middlemen in various industries, from finance and real estate to healthcare and entertainment.
Blockchain is still in its infancy in terms of adoption, but the upside for development of so-called Web3 applications is tremendous, Hulme says.
“We want developers of all skill sets to have access to this,” he says “So by giving them the flexibility of working in whatever language they want, using the right kind of APIs, using the right kind of models, they can actually bring their own skills to this thing that has really changed the way that applications are being built. We think that makes it much more accessible and we’ll give it broader appeal to some industries that maybe haven’t been able to take advantage of blockchain today.”
One company that’s currently developing Web3 applications on AstraDB is Blockscope. The Y Combinator company offers additional services on top of blockchains, including “no code” event listeners that monitor for transactions and events. When it detects an event of interest, it can trigger a webhook to take additional actions.
The future of blockchain has yet to be written, but DataStax wants to be part of the action, Hulme says.
“There’s a whole set of use cases that are coming out in different markets for blockchain. Crypto is the one that I think a lot of people associate with it, but we’re seeing a lot more interest around like healthcare or real estate for different types of transactions and historical data,” he says. “Cassandra is built for speed scale. There’s nothing that compares to it. And so when you’re working with data sets that are this large that have to be accessed in real time, there’s no better combination of technologies than Cassandra and blockchain.”
Related Items:
DataStax Bolsters Real-Time Machine Learning with Kaskada Buy
DataStax Nabs $115 Million to Help Build Real-Time Applications
DataStax Taps Pulsar for Streaming Data Platform
MMS • RSS

A multi-model NoSQL document database is powering a new public-facing court judgement portal, designed to offer free access to important legal decisions for the public.
The new system, Find Case Law – currently in alpha, but operational since April 2022 – is a new cloud service running on AWS provided by the official UK preserver of all government and records of national importance, The National Archives.
Based out of its Kew, London, main headquarters, the Archives looks after 11 million important historical documents and treasures.
Many of these valuable items are secured deep underground in the British countryside, as well as in its 200 kilometers of physical shelving.
The recent rise in importance of digital records also means the body must secure documentation in digital form – a trove which is already over 2 Petabytes, says the organization’s Digital Director, John Sheridan.
But a directive from right at the top of the British legal system in 2020, in the wake of The Digital Justice Report, forced Sheridan and his team to look for new ways of making some of the key information coming into the archive from British courts easier for third parties to work with.
He says:
Before Find Case Law, there was no route for judgments to come to the archive straight away – we might eventually get them decades down the line. You could access this information if you were prepared to pay for it through things like the British and Irish Legal Information Institute (BAILII) – but even then, it wasn’t easy.
This was a big hurdle for several users, says Sheridan: citizens interested in the latest findings from the High or Supreme Court, other non-UK legal systems that base possible changes in their laws by UK legal precedent, and the providers of specialist third-party commercial legal support databases.
He says:
If you are an innovator wanting to obtain access to this information, there was no publicly funded service providing access to the material.
Plus, while from an archive perspective the decisions that a court makes is just a record, from a legal perspective all courts develop the law through making decisions in particular cases and setting precedents, and a judgement is where you find that out.
Also, important information doesn’t keep itself and the technologies we use for keeping digital information are here today and gone tomorrow – so if you want the information to survive, someone needs to do some work. And that’s what we’re for.
Therefore, Sheridan needed to share judgements with not just the public and legal professionals, but also users of the data who need it for their own products or service, and AI researchers who want to build predictive models of how a court makes decisions.
Sheridan’s colleague, Nicki Welch, a Service Owner for Access to Digital Records at the institution, explains that the output needed to be both easy for website and mobile visitors to handle but also for this large body of data users, too.
She says:
The judgments we deal with can be hundreds of pages long, and often at least 20 to 30 pages. We have to be aware of the size of the document, and not just how it’s going to look on the web to users, but how people are going to navigate through them.
So, our documents have a bit of a complicated shape, but you also want to pass on a lot of quite rich metadata to do stuff with.
That meant that a standard business relational database approach for all this semi-structured documentation would not be ideal as a basis for a new system, she says.
Semi-structured, with rich metadata
National Archives was already using the data software it eventually applied to deal with these problems in publishing legislation, says Sheridan.
Welch adds:
We built a transformation tool ourselves that converts the Word files we get straight from places like the Privy Council Supreme Court and High Courts into a particular standard of XML called legal document markup language.
That’s available on the website, should you want it via our API, and then we transform it into HTML5, which is what we feel the public should expect from a modern digital service. And then we also provide the PDF as well, just in case users want to be able to download or print out the judgement.
Sheridan points out that the service is believed to be the first live service based on the current legal document markup language standard.
Welch says that the system has quickly become popular, with over 3000 judgments published since launch. Access is also strong on mobile, he says, with 42% of users visiting the service from devices other than desktops. She says:
We don’t publish every judgement from every court; we take judgments from the Courts of Record, but we’re up to at least 15 or so 20 judgments a day when those highest courts are in session.
Summing up the impact of Find Case Law, Sheridan says:
We had three main targets for the service: one, accessibility – and that’s not just access, but true accessibility, so making this content easier to read for everyone; a judgement looks great on your mobile phone, which no one had really done before. Two, to fulfil our obligation on long term preservation, as our job is to preserve what’s important; and three, enable reuse – that you can take this data and do things with it, as it’s not just a bag of Word documents, but well-modelled data.
Improving the quality of British justice system data
Once fully bedded in, the eventual aim is to fully meet The Digital Justice Report’s call to improve the quality and accessibility of justice system data across the British legal system.
Eventually, all Judicial Review rulings, European case law, commercial judgments and many more cases of legal significance from the High Court, Upper Tier Tribunal, and the Court of Appeal will be made available through the service, say the team.
Beyond that, intriguing potential next steps for NoSQL document database and metadata at National Archives, says Sheridan, include the first steps to a knowledge graph. He says:
One of the nice things about the software we’re using is that it allows us to store documents in a standard document format but also useful information in a knowledge graph alongside that document. So where one judgement refers to another or where it refers to a piece of legislation, we’d like to turn all those references and citations into a graph alongside other information, like which court this was from, and who the parties were.
A graph like that will be very interesting because it might tell you what the most influential judgments have been, or what the most litigated pieces of legislation are, and so on.
In the shorter term, adds Welch, as her team is already marking up the XML to connect to references to other cases.
MMS • RSS
SAN MATEO, CA / ACCESSWIRE / February 9, 2023 / The complexity of data management and data analytics increases day by day as the amount of data grows significantly. One of the serious issues faced by organizations is the decreasing productivity of data analysis due to the fast-growing volume of complex non-flat data, such as JSON or XML. In response to this challenge, Keyark, a Silicon Valley software and technology development firm, has developed the novel KeySQL technology.
According to the company, KeySQL technology is a breakthrough in the handling of non-flat data comparable to the breakthrough achieved by the relational model developed by E.F. Codd for flat data. In 1970, Codd introduced the relational model of data, which brought about a multi-billion dollar industry of SQL databases. This happened because SQL (Structured Query Language) created a disruptive productivity jump in data management. SQL enabled thousands of business analysts and other non-programmers to assemble data and create reports and dashboards. Prior to relational systems, business users needed the help of programmers in data manipulation and creating even simple business reports. The main advantage of the relational model, underlying SQL, is that it forces data into the confines of simple tables and employs relational algebra operations to produce new tables from the existing ones. Codd called it Spartan Simplicity.
However, the advantage of the relational model turned into a critical shortcoming in the internet era. The massive amount of non-flat data generated by businesses became hard to manage using SQL. This gave rise to the NoSQL movement, which offers greater flexibility than Codd’s relational model, however it suffers from the lack of a common NoSQL language, and the lack of a solid mathematical basis and operations closure. Therefore, while being more efficient in supporting business operations with non-flat data, NoSQL systems turned out to be not at all friendly for use by non-programmers.
“We have gone full cycle, literally returning to the pre-relational age when business users needed the assistance of programmers to perform analytical data processing functions. In lieu of programmers, businesses now depend on difficult-to-hire data scientists supposed to have the technical skills for extracting information from complex NoSQL data. Instead of a business analyst using SQL, two people are needed, a business analyst and a data scientist proficient in Java, Scala, Python, or other programming languages to speak natively to NoSQL systems. However, KeySQL technology enables an order of magnitude productivity breakthrough in the handling of non-flat data,” says Mikhail Gilula, President and CEO of Keyark.
KeySQL makes the bulk of NoSQL data accessible to non-programmers using a still spartan but more flexible data model. It comprises the same high-level data manipulation statements SQL does. At the same time, it can handle data of any complexity. According to the company, KeySQL language is easy to learn yet fully expressive for handling both flat relational data and non-flat NoSQL data. The KeySQL data model is based on the mathematical structure of hereditarily finite sets. Data definition is performed using a single construct called composition. It is the only one needed for producing new data objects from the existing ones. In this sense, it is even more spartan than the relational model.
Commenting on the advantages of this new data model, David Golden, growth engineer at Keyark said “Business users fluent in SQL can grasp the bulk of KeySQL in just a couple of days. Because of the hereditarily finite set foundation, KeySQL uses business friendly bottom-up data definition. In SQL data definition is top-down. Columns exist only within the context of the tables, and a column with the same name in another table can have a different meaning. The construct of composition allows the creation of data objects of any complexity. The flexible schema approach allows the data with different structures to be accessed with a single query.”
According to Keyark, complex business objects which would correspond to one or more SQL tables are treated on equal basis with elementary objects and can be retrieved, updated, or deleted by using their names in the corresponding KeySQL statements. KeySQL provides a powerful means of producing new data structures from existing ones. The structural data transformations enable precise targeting for data of interest. In particular KeySQL supports grouping of objects of any complexity by other objects.
About Keyark
Keyark is a software development company headquartered in San Mateo, California, United States, and was founded in 2019. Keyark develops KeySQL technology enabling a productivity breakthrough in NoSQL data analytics. According to the company, this is the most significant innovation in data management since the introduction of relational databases and the SQL language over 50 years ago.
Media contact:
Name: David Golden
Email: david.golden@keyark.com
SOURCE: Keyark
View source version on accesswire.com:
https://www.accesswire.com/738776/Simplifying-Big-Data-How-Keyark-Allows-Non-Programmers-to-Analyze-Complex-Data
MMS • Ben Linders
Having an agile mindset is not enough; we need to change behavior for adopting agile. With the Antecedent Behavior Consequence (ABC) Model, you can analyze the behavior, figure out what triggers it, and think about strategies to drive behavioral change.
Evelyn van Kelle and Chris Baron spoke about behavior change for adopting agile at Better Ways 2022.
Van Kelle started by mentioning that we are not changing people:
Unfortunately, we are not magicians who can put a spell on people and make them show desired behavior or stop unwanted behavior.
We can only change the environment of people so they can and are willing to show the desired behavior. And that requires a lot of observation to begin with, Van Kelle said.
Baron and van Kelle mentioned the Antecedent Behavior Consequence (ABC) Model which can help us to influence and drive behavior change:
- A = Antecedent or a trigger
- B = Behavior
- C = Consequence
When performing the analysis, you start by specifying the behavior you want to analyze. The overall goal here is to identify the behavior (B) you want to analyze, the antecedents (A) or triggers that provoke the behavior, and the consequences (C) of the behavior, Baron explained:
You want to identify what comes before the behavior takes place and what happens after the behavior takes place. Always seen from the perspective of the person that is showing the behavior.
Analyzing the information provides you new insights into why the behavior takes place so you can think of strategies to try and change this, Baron said.
Van Kelle mentioned that it’s important to take a close look at the consequences of people’s behavior since this tends to influence future behavior the most:
When behavior leads to positive consequences, we’re likely to show the same behavior in the future. When it leads to negative consequences, we’ll be less likely to do so. When influencing behavior, it’s crucial to know what are positive consequences for the person showing the behavior.
The behavior to analyze can be desired behavior, but usually, we want to start analyzing undesired behavior because we want to change it, Baron mentioned. But we can also try to find out what triggered the positive behavior, and what we can do to have more of such triggers.
InfoQ interviewed Evelyn van Kelle and Chris Baron about behavioral change.
InfoQ: How can we influence human behavior?
Evelyn van Kelle: Behavioral change is always about the person showing the behavior, not about the person trying to influence the behavior. It’s about discovering what triggers the behavior and what consequences are related to certain behavior.
More specifically, which consequences are most powerful. Meaning that not all consequences are equally powerful. Some are more important for someone than others. And that’s on an individual level.
If you know which consequences are most powerful to someone, you know where to start with making changes to their environment. There’s no shortcut you can take to make universal changes to an environment that works for a big group. You’ll have to put in the time, effort and work to analyze this on an individual level. There are concepts and techniques that can help you with that.
Chris Baron: With the ABC model, you can do an analysis to try and figure out “why” certain behavior occurs and what factors keep this behavior in place. With the outcomes you can think of new triggers and consequences to add to the environment of people, so they want to show different behavior themselves.
InfoQ: How can we change the environment in order to enable people to show desired behavior and achieve results?
Van Kelle: Once you’ve done the ABC analysis, you have a better understanding of what triggers certain behavior, and which consequences are related to it. You also know which consequences are most powerful.
For example, you analyzed “looking at a phone every five minutes during a refinement session”, and you found out that “not being bored for a while” is one of the most powerful consequences. You can use this to make changes to the environment. If “not being bored for a while” is an important consequence, then what can you change to the refinement session that will also lead to that consequence? It might mean you have to change something to the meeting structure, or to the list of people invited, or maybe you have to step up the preparation of stories before the session so there’s no time wasted on trivial stuff. What you get from this example is that it’s not about changing people, but about changing their environment.
Baron: This is very challenging to make happen. Improving your knowledge of how behavioral change works and unraveling the complexity in your own organization is a great way to start.
MMS • Steef-Jan Wiggers
Microsoft recently announced the general availability of Azure Load Testing, a fully-managed load-testing service allowing customers to test the resiliency of their applications regardless of where they are hosted.
In December 2021, the company released a preview of the service as a successor to their Azure DevOps cloud-based load testing service and Visual Studio 2019 load testing capabilities, which are no longer supported.
Since the preview, Microsoft has enabled several capabilities, such as additional metrics for pass/fail criteria, support for authenticating with client certificates, support for user-specified JMeter properties, load engine metrics views, and private endpoint testing based on customer feedback.
The Azure Load Testing service allows users to generate high-scale loads without managing complex infrastructure. It integrates with Azure Monitor, including Application insights and Container insights, to capture metrics from the Azure services. As a result, users can leverage the service for use cases such as:
- Optimize infrastructure before production by planning for the expected traffic and unplanned increase in loads.
- For Azure-based applications, the service collects detailed resource metrics to help identify performance bottlenecks across your Azure application components.
- Automate regression testing by running load tests as part of your continuous integration and continuous deployment (CI/CD) workflow.
- Leveraging JMeter, a popular open-source load and performance tool, by creating a JMeter-based load test.
Source: https://azure.microsoft.com/en-us/blog/microsoft-azure-load-testing-is-now-generally-available/
Furthermore, with the GA release, Microsoft also released several Azure SDK Load Testing libraries for .NET, Java, JavaScript, and Python programming languages.
Mandy Whaley, partner director of product, Azure Dev Tools, at Microsoft, told InfoQ:
I’m thrilled that Azure Load Testing is now generally available. Every company and developer can use it to ensure their apps and services are responsive and resilient in real-world conditions.
In addition, she added:
Developers can use load testing early in the development process to make sure they’re picking the right tier of cloud resources for their apps so cloud investments match traffic, and they only pay for the resources they need. We’re seeing a range of customer adoption from small businesses to Fortune 500 companies. Azure Load Testing is scalable enough for the biggest team and accessible enough for smaller organizations and individuals.
Currently, Azure Load Testing is available in 11 regions, and the pricing details are available on the pricing page. In addition, more information about Azure Load Testing is available on the documentation landing page.