Month: March 2023

MMS • RSS

Sponsored Feature Welcome to the new development team. It’s a lot like the old development team, but with two main differences: managers are asking devs to work in more joined-up ways. They finally understand that they must unlock the data across disparate systems in their organization so that they can use it to whip up new digital services for customers and increase internal efficiencies.
That’s easier said than done, argues Sahir Azam, chief product officer at MongoDB. Developers are crucial in creating those new services, but it’s difficult for already-stretched teams to suddenly become data architects.
“The scarcest resource in modern business is developer talent,” says Azam. “Every organization is going through some sort of digital transformation, and the demand for developers to help with that has taken off.”
This transformation places increasing demands on developers during a period when their skills are hard to find. So with IDC predicting a shortage of 4m developers by 2025 (up from 1.4m in 2021), it’s important to make coders as productive as possible.
One of the biggest hurdles to productivity is data fragmentation. “A lot of these modern applications don’t use just a single database,” Azam explains. Instead, they rely on several technologies from multiple online transaction processing databases of different types through to streaming, analytics and search systems. Historically, those different technologies have been isolated across different platforms that require different development skills to build applications . “A lot of cost goes into operating and managing and duplicating all those environments” Azam adds.
How about a unified data platform?
Over the last few years, MongoDB has moved to solve that problem by bringing in not just more of the things that developers have grown to know and love about the database, but also capabilities that they need as their remit expands and stretches – essentially creating a developer data platform. At its MongoDB World event last June and over the course of the year, the company has since doubled down with a slew of additional new features.
MongoDB hopes that developers will find this platform familiar and comfortable – after all MongoDB is at the heart of it. But they should also be able to expand the use cases that it caters to and the applications it supports. “This has the capability to replace a lot of those disparate data tools” Azam says.
The data platform should also help companies to consolidate vendors, saving in software licenses and support costs, MongoDB believes. It will consolidate organizations’ data footprints for example, make their skill sets more adaptable, and generally help them to do more with less.
Better search and support for time series data
Three years ago, MongoDB launched Atlas Search, an embedded full-text search solution in the Atlas multi-cloud database service. Previously, many organizations would have defaulted to a separate search engine to address their search needs, and then figured out the plumbing between the systems themselves. But the developer data platform integrates the database, search engine, and sync mechanism so that developers can build relevance-based search directly into applications.
Atlas Search is based on Apache Lucene, a popular library underpinning several of the most widely used search engines. Because it’s integrated into the developer data platform, developers can leverage a single query language for both database and search operations. Atlas Search provides a full suite of features to help developers deliver search experiences to their users, including autocomplete, fuzzy matching, relevance scoring, geospatial queries, and faceted search, among others.
One customer is real estate company Keller Williams, which has been honing its use of Atlas Search to power its customer-facing search experience. It implemented auto-completion of user searches for ease of use, and then went one step further. Location-based search is important to users looking for properties, so the company built geolocation features into its Atlas Search-based implementation that change the auto-completion results based on where customers are searching. Keller Williams has also included a form of fuzzy searching capability that returns results based on incorrect spelling, along with synonyms for search terms.
MongoDB Time Series is another platform addition that helps developers avoid data silos. Time series data is common across industries, but can be challenging to work with due to its enormous storage footprint and the difficulty of unlocking real-time insights. Time Series empowers developers to handle this directly within MongoDB with native support for the entire data lifecycle, including storage optimization and performant data analysis. One customer, Norwegian startup and industrial IoT-as-a-service provider DigiTread Connect, leverages the simplicity and performance of Time Series to deliver solutions for their customers faster.
Application-driven analytics and queryable encryption
In its quest to build a unified data platform for both analytic and transactional workloads, MongoDB has also included a wide range of capabilities to help development teams build richer application experiences that rely on automatic, low-latency processing of live data. This includes rich aggregations and indexing strategies, as well as dedicated analytics nodes for workload isolation. The company has also added capabilities that help teams better manage their entire data lifecycle. Atlas Data Lake now allows developers to cost-effectively store large amounts of historical data without the need for complex extraction, transformation, and loading tools.
Developers can set up automated pipelines that extract data from Atlas clusters to provide consistent copies of their cluster data for analytical queries. When used in conjunction with Atlas Data Federation, developers can create a virtual database that queries across various sources, including data lake datasets, multiple Atlas clusters, HTTPS endpoints, and Amazon S3 storage buckets.
Azam also singles out another technology – queryable encryption – a feature which allows database users to search their data without decrypting it. The system is based on work with experts from Brown University who formed a company called Aroki that MongoDB acquired. It uses a token-based approach known as structured encryption to find the appropriate information while leaving it encrypted, enabling companies to query sensitive data for everything from insurance claims to healthcare without having to see and be liable for that data.
This is different from the homomorphic encryption that some companies have pursued in the past. That approach focuses on conducting calculations with encrypted data. Structured encryption concentrates on finding it, but the Aroki approach can handle more complex queries than other databases’ attempts to query encrypted data on the client side, Azam says.
“Queryable encryption allows us to make that data use much more powerful,” he says. “You can start to move beyond point queries towards range, prefix, and suffix-based queries across multiple values, which has previously been impossible.”
Queryable Encryption is still not generally available at the time of writing, but the reasons for that are sound; MongoDB has open-sourced parts of the technology so that third parties can validate it. Initial feedback from academics has been positive but the company wants to be thorough, so that customers can be confident in it when it goes live later in 2023.
You’re speaking my language
The developer data platform also incorporates capabilities covering a range of different areas, including the general availability of Atlas Serverless, a version of the cloud-based MongoDB Atlas database that will expand and contract based on workload all without interaction from a developer or ops personnel. That’s now part of a broader technology stack encompassing everything from security tools and advanced search through to new performance features.
One of these performance features is columnar indexing. This allows developers to create their own indexes across columns of data rather than rows. The advantage here is speed. Unlike row-based indexes, columnar ones need not retrieve each core document to extract and index its data, which speeds up the aggregations necessary for analytical queries. The company claims up to a 15-fold performance increase compared to conventional row-based indexes in some cases.
While MongoDB is a NoSQL database, that doesn’t mean that it can’t play nicely with SQL-based tools. After all, many companies are likely to straddle both environments. While their developers are likely to prefer MongoDB’s document data platform to build applications, their business analysts may choose to use relational business intelligence tools like Tableau or Power BI for data analysis, for example.
Last year, MongoDB declared its Atlas SQL Interface available for public preview, serving to create an endpoint to easily connect SQL-based analytics tools to Atlas using custom MongoDB Connectors for select programs (eg Tableau and Power BI) or drivers (JDBC/ODBC) that provide connection to a broad range of other tools.
Built with MongoSQL, a SQL-92 compatible dialect optimized for the document data model, analysts can use custom SQL commands and native BI tool features to control their data visualization directly from their analytics dashboards; the Atlas SQL Interface, Connectors, and Drivers eliminate the need for data replication and ETL, preserving the richness of the document model while facilitating faster time to insights on live application data.
This support for SQL access tools eases the transition and learning curve for developers whose companies Azam hopes will eventually transfer their relational database assets to MongoDB. And to help these teams with mapping and moving relational data to documents, MongoDB launched Relational Migrator.
“It’s easy to rush into using MongoDB quickly,” he says, though warning that you can trip up unless you think about the right way to model the relationships between data elements to take advantage of the document format. “This tool makes mapping rows, tables and their foreign key relationships to documents a very visual experience that’s easier to understand. And when teams are ready to start migrating data and changing application code, the tool helps there too.”
Today’s developers don’t just code algorithms; they manipulate complex data from multiple sources that feed their programs for optimal results. If the software is the engine, then the data is the fuel that makes it go. MongoDB seems set on combining the two, honing its expanded tech stack along with educational resources so that organizations can continue their digital transformation journey.
Sponsored by MongoDB.
MMS • RSS
Version 4.1 of Apache Cassandra, the open source NoSQL distributed database, has been released. The team says this release paves the way to a more cloud-native future for the project by externalizing important key functions, extending Apache Cassandra, and enabling an expanded ecosystem without compromising the stable core code.
Apache Cassandra handles massive amounts of data across load-intensive applications with high availability and no single point of failure.

High-profile users include Apple, which has over 160,000 instances storing over 100 petabytes of data across 1,000+ clusters, Huawei and Netflix, where Cassandra handles over 1 trillion requests per day.
Cassandra’s plugability has been a focus in this release, and the team says that as frameworks are added, they are establishing a straightforward interface to Cassandra internals and an understood contract when using outside code. Work has also been done on features to provide better control, improved ease of use, and flexibility.
Cassandra’s Paxos consensus protocol is another area to have received attention. Cassandra uses a Paxos consensus protocol implementation for consistency using quorum reads to ensure a single value is selected and executed from all the proposed updates at any given time. The work this time has been on Lightweight Transactions, which are used where an action needs to persist based on the current state of the system, such as selling tickets for seats. In the past, Lightweight Transactions have suffered from poor performance, so the developers have worked to optimize Paxos to improve the performance of these transactions by 50%, improving latency, and halving the number of required round-trip to achieve consensus.
There are also a number of new Cassandra Query Language features, including the ability to group by time range and to use Contains and Contains Key conditions in conditional updates.
There’s also new support for Exists in Alter statements, and Group By can now to use to output row sets that are the same into a single grouped row. Support has also been added for pre-hashed passwords in CQL.
Cassandra 4.1 is available now.
More Information
Related Articles
Cassandra 4 Improves Performance
DataGrip Adds Cassandra Support
Instaclustr Releases Cassandra Tools
Cassandra 1.0 with Increased Performance
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.


Comments
or email your comment to: comments@i-programmer.info
MMS • RSS

Image by Author
In the 1970s, Edgar F. Codd proposed the relational database model, commonly known as SQL databases. These databases are mainly designed for handling structured data having relational models. They can handle transactional data, which involves storing and manipulating data in tables with predefined schemas. Famous examples of SQL databases are MySQL, PostgreSQL, and Oracle Server.
In the 1980s, they gained immense popularity, but after that, the demand and volume of data increased, and the need for different data types became more diverse to the point where SQL databases struggled. In addition to that, they are complicated for horizontal scaling, which makes them not suitable for handling large amounts of data.
To cater to these limitations of SQL databases, in the early 2000s, NoSQL databases came into the picture. They are document-oriented databases and use fast key-value pairs to store data. They are capable of parsing data from the documents and storing that data under keys rather than defining strict tables of information, unlike SQL databases.
NoSQL databases have now become mainstream and provide various advantages over SQL databases. But it does not necessarily mean that NoSQL databases are better than SQL. Both SQL and NoSQL databases serve different purposes and use different approaches to data management. One is used for relational data, and the other is for non-relational data. SQL databases are still in use where there is a need to run complex queries, and the database schema is well-defined. Famous examples are MongoDB, Cassandra, Neo4J and Redis.
But NoSQL databases are better than SQL databases in certain areas discussed below.
Below are some key features where NoSQL databases perform better than SQL databases.
- Flexibility:
It means that data can be dynamically added or removed without changing the structure of the original database. It means unlike SQL databases, they don’t require rigid schemas. They are designed to handle any data format structured, semi-structured or unstructured. This gives freedom for the developers to focus on the application development rather than worrying about the database schema.
- Scalability:
NoSQL databases support horizontal scaling, which means we can scale it by adding more servers instead of increasing the capacity of a single server. This makes it more powerful to handle large numbers of requests.
- High Availability:
Due to its feature of replicating its database across multiple servers, it provides very low latency and almost zero downtime to its users. Also, they divide the traffic among themselves to reduce the burden on a single server.
- Performance:
They are designed to optimize the read and write performances, making them suitable for real-time data processing applications where daily tera-bytes of data are generated. They have a faster query response time and support database sharding, improving their overall performance.
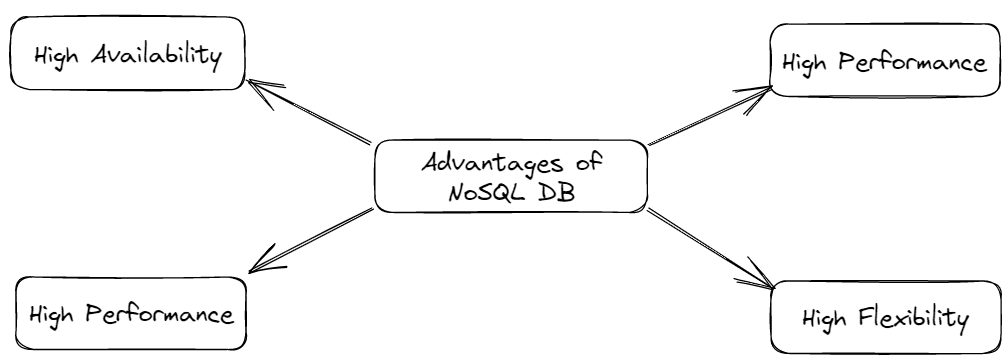
Image by Author
These are some points where NoSQL databases perform better than SQL databases. The following section will discuss the types of NoSQL databases and their use cases.
There are various types of NoSQL databases, each having its own benefit and limitations. Below we have discussed some popular ones:
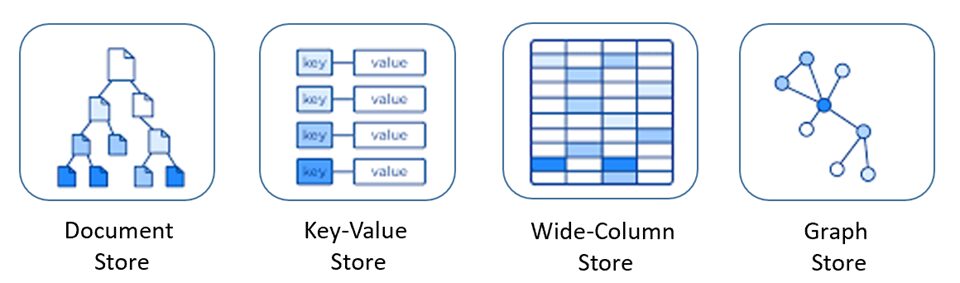
Key-Value
This is the most flexible NoSQL database. It requires a key-value pair for storing data. A key can be a unique attribute, like an id, that corresponds to a particular value. The application has control to store any type of data in the value field. These are suitable for real-time applications, caching, or session management. Redis and Riak are famous examples of key-value databases.
Use Case:
This database is best suited for e-commerce platforms where large amounts of customer-related data like orders, user profiles, and product catalogs are generated daily. Due to its low latency and quick processing, it is suitable for real-time inventory management and handling high traffic.
Document-Oriented
These databases store data in documents, mainly in the form of JSON objects. This is most suitable for storing semi-structured or unstructured data, where there is no need to specify the document’s fields explicitly. MongoDB is a famous example of a document-oriented database.
Use Case:
This is best suited for Content Management Systems, for example, a blogging website. Data in the form of articles, comments, categories, and tags can be stored and retrieved quickly. Document-based data is suitable for storing unstructured data like texts, images, links, etc. Also, its flexible schema behaviour allows easy changes in the data model.
Graph Databases
This type of NoSQL database is most suitable for data that are strongly interconnected to each other. They store data in the form of nodes and edges and are used to represent complex relationships between objects. It is best suitable for social media applications and for creating recommendation engines. Famous examples are Neo4J and InfoGrid.
Use Case:
They are most suited for creating recommendation engines. Take the example of Youtube, which recommends videos to users based on their viewing history. Graph databases can store and process interconnected data and quickly deliver relevant content.
Column-based Databases
In this type of NoSQL database, the data is stored in column families. Similar types of data are grouped into cells and stored in columns of data instead of rows. A column can even contain multiple rows and columns inside it, which have their own unique id.
In a traditional SQL database, the query executes row by row. But in the columnar database, the query executes only for the specific column we want. This saves time and makes it suitable for handling large datasets. They may look like a SQL database, as they involve some form of schema management and function the same way as relational table works. But they are far more flexible and efficient than SQL databases, making them in the NoSQL databases category.
Popular examples of columnar databases are Apache HBase and Apache Cassandra. You can read this article by Alex Williams for more information about this topic.
Use Case:
Column-family databases are best suited for data warehousing applications. These applications require analyzing large amounts of data for business intelligence with a high write throughput, and column-family databases completely take charge of it.
Different types of NoSQL Databases | Image by Author
In this article, we have learnt what NoSQL databases are and a glimpse of the fundamental difference between SQL and NoSQL databases. Then, we discussed the popular types of NoSQL databases along with their use cases.
There is always a What to Choose? between SQL and NoSQL databases. To make the proper selection, first, you must understand your application’s use case, data model, scalability, and performance, and then decide.
I hope you enjoyed reading the article. If you have any comments or suggestions, please contact me on Linkedin.
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.
MMS • Ben Linders

Proper programming foundations can improve your test automation, making it easier to maintain testing code, and reduce stress. A foundation of the theory and basic principles of coding and programming can help to bring test automation to the next level. Object-oriented programming principles can help to overcome code smells.
Christian Baumann spoke about test automation at Agile Testing Days 2022.
Baumann mentioned that a lot of testers are “thrown” into test automation without a profound background in programming, or without having received any proper training. These people have some idea of what tool to use and managed to create some automated tests with it. At a certain point, they suspect that something is not quite right with their automation, Baumann said. The code feels messy, maintaining it costs a lot of time, and it’s very frustrating.
It would be great if everybody doing test automation would get a proper foundation in terms of the theory and basic principles of coding and programming, Baumann stated. This in order to also produce high quality automation code.
Baumann gave an example of how to use object-oriented programming principles in our test automation:
We can use the object mother pattern which uses the object-oriented principle of “abstraction”. This means, it hides internal implementation details, and reveals only methods that are necessary to use it. How test objects are created in detail, how they are deleted from the database, how they are modified during a test – all of that is not necessary for the user to know; all that the user needs to know is that these methods exist and can be called.
Using object-oriented programming principles can also help to overcome code smells, as Baumann explained:
Eliminating code smells means, to change the code, without changing the code’s behaviour, which basically is the definition of refactoring; and for refactoring, we need unit tests as a safety net, so we know that with our changes we did not break anything and the code is still working as intended.
Baumann suggested that test automation code should be valued and treated as the production code of the applications we are building, to prevent running into similar problems.
InfoQ interviewed Christian Baumann about programming foundations for test automation.
InfoQ: What benefit can object-oriented programming principles bring?
Christian Baumann: Applying object-oriented programming principles in test automation code is of great help, by making the code less prone to errors, and also making it easier to read, understand and maintain.
InfoQ: What can be done to take good care of our test data?
Baumann: In the context of test automation, I believe the best approach to deal with test data is that each test is responsible for its very own data. This means that each test creates the test data it needs as part of its test setup. At termination of the test, the data is being deleted again from the system, leaving the test environment in a clean state.
The object mother pattern can be of great help in doing so. It starts with the factory pattern and provides prefabricated objects that are ready to be used in tests via a simple method call. But it goes far beyond the factory pattern, because the created objects can be customised; also test objects can be updated during the test, and furthermore -if necessary- at the end of the test, the object is being removed again from the database.
InfoQ: How can we recognize and eliminate code smells?
Baumann: In order to recognize code smells, one needs to know them. Therefore, as a programmer (what we are if we write test automation code), we need to learn and study them.
For certain code smells, certain “recipes” can be used to eliminate them; for example, applying the OOP principle “polymorphism” helps to eliminate the “switch statement” code smell as well as the “too many arguments” smell.
Google AI Updates Universal Speech Model to Scale Automatic Speech Recognition Beyond 100 Languages
MMS • Daniel Dominguez

Google AI have recently unveiled a new update for their Universal Speech Model (USM), to support the 1,000 Languages Initiative. The new model performs better than OpenAI Whisper for all segments of automation speech recognition.
A universal speech model is a machine learning model trained to recognize and understand spoken language across different languages and accents. USM is a family of state-of-the-art speech models with 2B parameters trained on 12 million hours of speech and 28 billion sentences of text, spanning 300+ languages. According to Google, USM can conduct automatic speech recognition (ASR) on under-resourced languages like Amharic, Cebuano, Assamese, and Azerbaijani to frequently spoken languages like English and Mandarin.
The initial phase of the training process involves unsupervised learning on speech audio from a vast array of languages. Subsequently, the model’s quality and language coverage can be improved through an optional pre-training stage that employs text data. The decision to include this stage is based on the availability of text data. When the second stage is incorporated, the USM achieves superior performance. In the final stage of the training pipeline, downstream tasks such as automatic voice recognition or automatic speech translation are fine-tuned using minimal supervised data.
According to the research, the two significant challenges in Automatic Speech Recognition (ASR) are scalability and computational efficiency. Traditional supervised learning methods are not scalable because it is challenging to collect enough data to build high-quality models, especially for languages with no representation.
Nevertheless, self-supervised learning is a better method for scaling ASR across numerous languages since it can make use of more accessible audio-only data. A flexible, efficient, and generalizable learning algorithm that can handle large amounts of data from various sources and generalize to new languages and use cases without requiring complete retraining is required in order for ASR models to improve in a computationally efficient manner while increasing language coverage and quality.
A large unlabeled multilingual dataset was used to pre-train the model’s encoder and fine-tune it on a smaller collection of labeled data that makes it possible to recognize underrepresented languages. Furthermore, the training procedure successfully adapts new data and languages.
Universal speech models play a crucial role in facilitating natural and intuitive interactions between machines and humans, and can serve as a bridge between diverse languages and cultures. These models hold immense potential for various applications, such as virtual assistants, voice-activated devices, language translation, and speech-to-text transcription.
With this new update, the USM is now one of the most comprehensive speech recognition models in the world. This development is a significant step forward in Google’s efforts to create a more inclusive and accessible internet, as it will allow people who speak minority or lesser-known languages to engage with technology in a more meaningful way.
AWS Application Composer to Visualize and Create Serverless Workloads Now Generally Available
MMS • Steef-Jan Wiggers
AWS Application Composer, a visual builder that enables users to compose and configure serverless applications from AWS services backed by deployment-ready infrastructure as code (IaC), is now generally available (GA).
The GA release follows the service preview during the AWS re:Invent conference last year, including several improvements based on customer feedback. These improvements are:
- UI improvements with the size of resource cards that have been reduced and allowing users to zoom in and out and zoom to fit buttons to show the entire screen or the desired zoom level
- enhanced integration with Amazon Simple Queue Service (SQS)
- a Change Inspector feature that shows a visual breakdown of template changes between two resources connected on the canvas
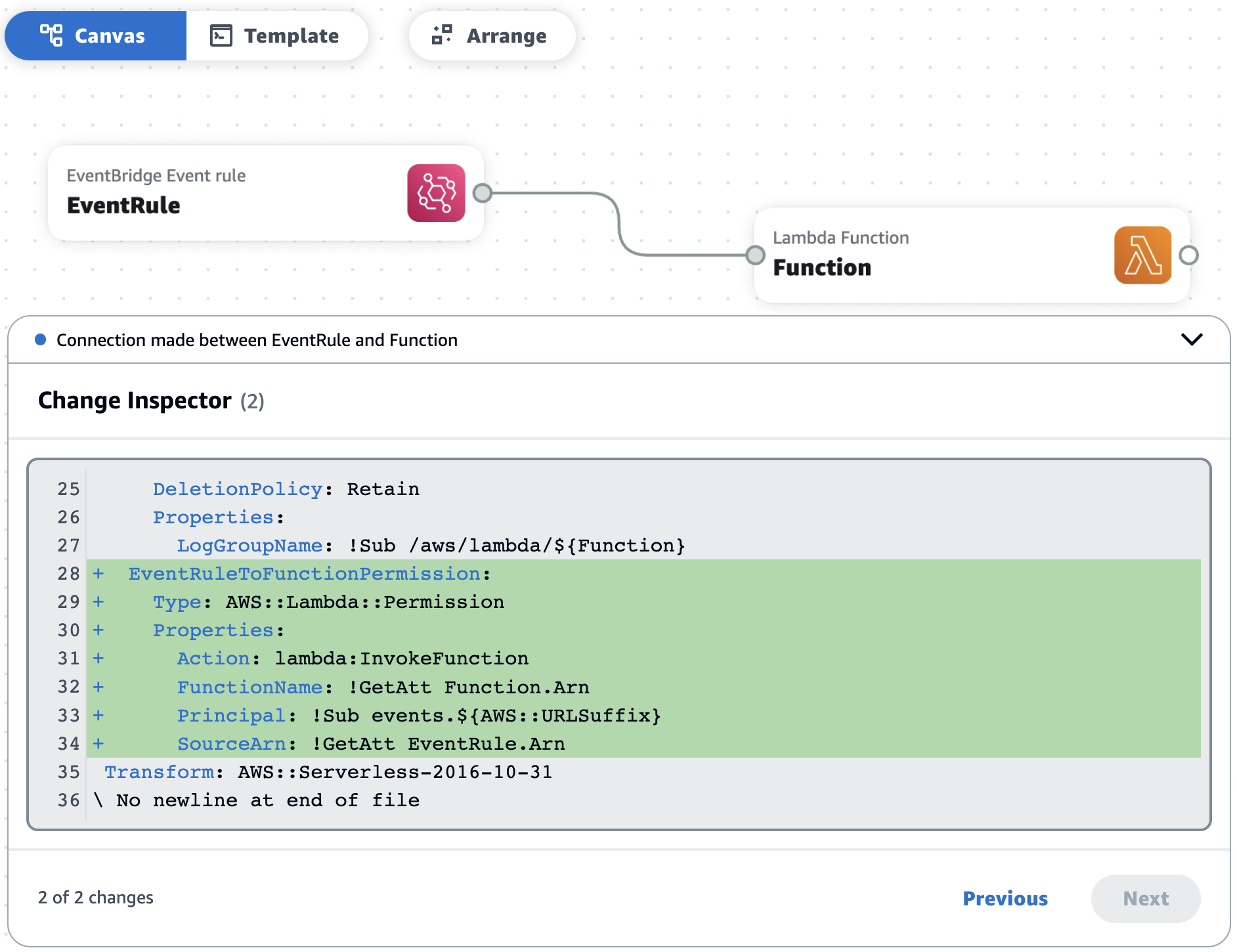
Users can start with AWS Application Composer by choosing Open demo in the AWS Management Console, which shows a simple cart application with Amazon API Gateway, AWS Lambda, and Amazon DynamoDB resources. In addition, the AWS Application Composer works with the AWS Serverless Application Model (SAM) CLI for application deployment, which allows an application to be created through AWS Application Composer and then deployed using the SAM CLI.
Channy Chun, a principal developer advocate for AWS, outlines several real-world scenarios for AWS Application Composer in an AWS news blog post, such as:
- Building a prototype of serverless applications
- Reviewing and collaboratively evolving existing serverless projects
- Generating diagrams for documentation or Wikis
- Onboarding new team members to a project
- Reducing the first steps to deploy something in an AWS account
Banjo Obayomi, a senior developer advocate at AWS, concluded in a BuildOn.AWS blog post:
By leveraging AWS Application Composer and AWS SAM, developers can focus on creating code instead of writing YAML and fiddling with IAM policies and other tedious “grunt work.”
Regarding the GA release Matthew Bonig, a chief cloud architect at Defiance Digital, tweeted:
App Composer is GA but doesn’t support reading .json CloudFormation files.
Or does it!? Just rename your file to .yml, and it works.
Ryan Coleman, an AWS PM for AWS Application Composer and AWS SAM, responded:
🙂 classic case of tech outpacing the DX. We’re certainly planning to clean this up, so json/yaml template interop just works intuitively, but I don’t have a date yet.
Currently, AWS Application Composer is available in the US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm) regions, adding three more regions to the six regions available during preview. More details on working with AWS Application Composer is available in the developer guide.
MMS • RSS

Where is the edge of your organization? It might have been relatively straightforward to answer this question a few years ago, when the perimeter was somewhere between your internal IT systems, a handful of managed remote devices, and possibly a cloud provider storing some of your data.
Today, the landscape is different. Remote devices and workers are abundant, Internet of Things (IoT) connectivity is unprecedented, multi-cloud environments are becoming the norm, and users interchangeably perform data-driven work both on and off corporate devices and networks.
Couchbase, a provider of next-generation cloud and NoSQL databases, responds to the challenges of this new operating environment by giving customers a flexible, mobile-friendly, and scalable platform for managing their data. Couchbase is on our Top 10 Shortlist of Data Modernization Enablers.
Jeff Morris, Vice President of Product and Solutions Marketing at Couchbase, explained the Couchbase approach to Acceleration Economy. “Our story is so competitive right now,” he says. “I can help you save a ton of money. I can help you make money by going mobile. I can simplify your environment by taking out other databases, which makes your developers happier and the system easier to maintain and constantly drops costs.
“When I survey customers, I hear, ‘I bought you for performance; I needed you for the flexibility. I needed you for mobility, and I was psyched that you lowered my TCO all the way around’.”
Who Is Couchbase?
Couchbase was born out of a merger between Membase and CouchOne in 2011. Headed up by CEO Damien Catz, CouchOne was focused on issues around mobile, data synchronization, and offline use cases, while Membase technology was focused on performance and scalability. Once combined, the companies directed their efforts at building a scalable, NoSQL database platform.
Over nine funding rounds as a private company, Couchbase raised $251 million, and the company went public on the NASDAQ in 2021. Couchbase announced its fourth quarter and fiscal 2023 financial results last week. Total revenue for the year was $154.8 million, an increase of 25% year-over-year.
Current Chairman, President, and CEO Matt Cain has held the position since 2017. Before Couchbase, Cain was President of Worldwide Field Operations at Veritas.
Senior Vice President and CFO Greg Henry came to Couchbase after serving as Senior Vice President of Finance at ServiceNow. Before ServiceNow, Henry was CFO of GE’s Healthcare IT unit. Ravi Mayuram, former Senior Director of Engineering at Oracle, is Couchbase’s CTO.
What Does Couchbase Do?
Couchbase Capella, a Database-as-a-service (DBaaS) offering designed for rapid, scalable, and flexible deployment, is the company’s flagship product.
As a distributed cloud database, there is no single point of failure. This ensures high availability, while nodes can be scaled up or down on demand. Communication is secured through end-to-end encryption. The query language for Couchbase is SQL++, a SQL for JSON language; that’s important because most database developers share a common knowledge of SQL databases. Support for the JSON data interchange format means customer data can adapt to agile workflows and changing requirements. Multi-model support means customers can consolidate multiple data types into one Couchbase database.
Built-in search capabilities make it easy for developers to add this function to applications while vendor sprawl is minimized through various out-of-the-box functions such as Analytics Services, Query Services, and Backup Services.
Morris explained how Couchbase mitigates sprawl in data management, especially when compared to a multi-vendor data ecosystem: “I can help you reduce your infrastructure footprint. I’ve got the speed that you need, the capabilities that you need, and as you’re transforming and going more mobile, I’ve got the best mobile capabilities.”
He added: “We have the performance of [Amazon] ElastiCache and DynamoDB key value capability. We have the transactions covered in place of [Amazon] RDS. We have the speed of in-memory processing vendors, the flexibility of MongoDB and other document databases, and the search capability of vendors like Elasticsearch.”
“I can help you save a ton of money. I can help you make money by going mobile. I can simplify your environment by taking out other databases, which makes your developers happier and the system easier to maintain — and it constantly drops costs’.”
Jeff Morris, Vice President of Product and Solutions Marketing at Couchbase

Differentiating features of Capella include its managed mobile and synchronization capabilities. Capella App Services enables developers to build serverless applications that operate on and offline and synch from the cloud to edge devices. The technology allows developers to sync data between devices and the cloud, or between devices via peer-to-peer sync.
“Having a mobile client that works the same way as the server-side database, we can create a data mesh so you get the data that you need inside an application at exactly the right time and place, right to the consumer, let them process it and then bring it back into the rest of the environment,” Morris says.
All back-end processes are fully managed by Couchbase, so developers need only focus on developing and delivering applications. Capella also supports the storage of user-generated content such as images and videos.

“Couchbase is a great example of a modern database. It runs where you want it to run — cloud, on-prem, even edge/IoT — supports legacy and modern data types, handles both transactional and analytics workloads, and performs even complex data synchronization right out of the box. Couchbase solves many problem categories.”
Wayne Sadin, CXO and Acceleration Economy Data Modernization analyst
Customers Couchbase Has Dazzled
Well-known Couchbase customers include Marriot International, Pepsico, and Cisco. One especially noteworthy customer based on its use case is the UK fintech company Revolut. Using Couchbase, Revolut reports a financial impact of over $3 million.

Revolut struggled to combat the evolving ways fraudulent users were flouting existing detection mechanisms. They needed an application to respond to the threat, but it had to have high availability and high throughput to meet the demand of Revolut’s fast-growing customer base.
Revolut used Couchbase to develop its Sherlock fraud prevention application. The autonomous system consistently monitors transactions, and if any unusual activity is detected, customers are sent a push notification to approve a transaction in question.
Powered by machine learning (ML), Sherlock constantly updates rules and evaluates transactions in under 50 milliseconds. The system quickly caught 96% of fraudulent transactions, and within year one, Revolut saw a 75% improvement above industry standards, saving more than $3 million.
“For our customers, the loss of $100 can mean the difference between a pleasant holiday and an experience filled with frustration and resentment. Couchbase has never failed us or our customers,” says Revolut’s Financial Crime Product Owner, Dmitri Lihhatsov, in a Couchbase case study.
Why Couchbase Is a Top 10 Data Modernization Enabler
Couchbase enables developers to consolidate their data technology ecosystem, while providing fast, flexible platform that delivers major benefits to customers such as Revolut. Our practitioner analysts selected Couchbase for inclusion on our Top 10 Shortlist of Data Modernization Enablers because:
- Couchbase has a market-leading approach to mobile and IoT database management
- The company’s ability to support on- and off-line processing, as well as various synchronization processes, enables high flexibility and agility
- It enables users and developers to query in the industry-standard SQL language, streamlining app development
- Couchbase’s cloud-first, distributed database model directly addresses the core architectural preferences of today’s modern digital organizations
- It is delivering quantifiable benefits to leading-edge customers including Revolut, which in turn is supporting strong growth in Couchbase’s business
Which companies are the most important vendors in data? Click here to see the Acceleration Economy Top 10 Data Modernization Short List, as selected by our expert team of practitioner-analysts
MMS • Steef-Jan Wiggers
ChatGPT is now available in preview on Microsoft’s Azure OpenAI service allowing developers to integrate ChatGPT directly into a host of different enterprise and end-user applications using a token-based pricing system.
Microsoft first launched the Azure OpenAI Service at Ignite in 2021 with access to OpenAI’s powerful GPT-3 models. After that, the company continued expanding access to more models like Codex and Dall-E before they became generally available in January of this year.
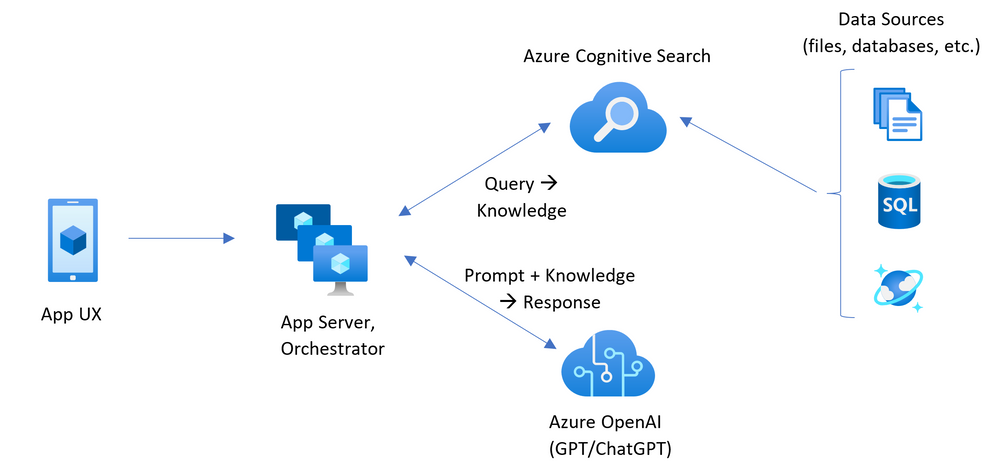
With the inclusion of ChatGPT in the Azure OpenAI Service preview, developers can integrate tailored AI-driven interactions into their applications seamlessly. For example, Pablo Castro, a distinguished engineer at Microsoft, outlines a scenario in a Tech Community blog post combing Azure Cognitive Search and Azure OpenAI Service:
Azure Cognitive Search and Azure OpenAI Service integrate Azure’s enterprise-grade characteristics, Cognitive Search’s ability to index, understand, and retrieve the right pieces of your own data across large knowledge bases, and ChatGPT’s impressive capability for interacting in natural language to answer questions or take turns in a conversation.
In general, Microsoft utilizes Azure OpenAI to drive various services, including but not limited to GitHub Copilot (Visual Studio 2022), Power Apps, Microsoft Teams Premium, Viva Sales, and the advanced Bing chatbot.
Eric Boyd, corporate vice president, AI Platform, Microsoft, stated in an Azure blog post:
With Azure OpenAI Service, over 1,000 customers are applying the most advanced AI models—including Dall-E 2, GPT-3.5, Codex, and other large language models backed by the unique supercomputing and enterprise capabilities of Azure—to innovate in new ways.
In addition, Valentina Alto, Azure specialist Data&AI at Microsoft, concluded in her medium blog post on querying structured data with Azure OpenAI:
Azure OpenAI has so much potential for enterprises. Imagine using its powerful generative models as a support tool for producing financial reports on ERP data, analytical insights on Sales data, and any other kind of analysis.
Currently, in preview mode, access to the Azure OpenAI Service is restricted to Microsoft managed customers and partners. Developers must apply to use it, as registration is required to prevent abuse. Additionally, the service will be priced at $0.002 for every 1,000 tokens. OpenAI’s pricing for their diverse AI models is token-based, with each token representing a word fragment, meaning roughly 750 words equivalent to 1,000 tokens.
Lastly, more of Azure’s OpenAI service details are available on the documentation landing page.
MMS • Liav Yona

Key Takeaways
- Infrastructure as code has become the backbone of modern cloud operations, but its benefits in configuring systems are just the tip of the iceberg.
- Serverless is a common infrastructure choice for growing SaaS companies, as it’s easy to get started, provides minimal overhead, and complements IaC practices.
- As ephemeral runtime, serverless breaks down with overly complex and high-scale systems and also has a high-cost tradeoff.
- Our IaC backbone provided an added layer of portability and extensibility, and exploring new systems to migrate to became less daunting (starting with Elastic Container Service and then Kubernetes).
- Kubernetes eventually afforded us the cost, scale visibility, and portability we needed to maintain the high throughput, volume, and scale our systems required.
The world of Infrastructure as Code has taken cloud native by storm and today serves as a general best practice when configuring cloud services and applications. When cloud operations grow exponentially, which happens quite rapidly with today’s SaaS-based and cloud-hosted on-demand applications, things quickly start to break down for companies still leveraging ClickOps, which creates drift in cloud apps through manual configuration.
It’s interesting to note that while IaC is a best practice and provides many benefits (including avoiding drift) we witnessed its true value when we needed to undertake a major infrastructure migration. We found that because we leveraged the power of IaC early, and aligned ourselves to best practices in configuration, formerly complex migration processes became much simpler. (Remember companies like VeloStrata and CloudEndure that were built for this purpose?) When we talk about cloud and vendor lock-in, we have now learned that how we package, configure, and deploy our applications directly impacts their portability and extensibility.
In this article, I’d like to share our journey at Firefly on a great migration from serverless to Kubernetes jobs, lessons learned, and the technologies that helped us do so with minimal pain.
Station I: Our Lambda Affair
Serverless is becoming a popular architecture of choice for many nascent and even well-established companies, as it provides all of the benefits of the cloud––scale, extensibility, elasticity––with the added value of minimal management and maintenance overhead. Not just that it was fast and scalable, but it was also quite fun to build upon.
Lambdas, functions, the services that connect them, and event-based architecture are a playground for developers to experiment in and rapidly iterate formerly complex architecture. This is particularly true with Terraform and Terraform Modules built for just this type of job. It was suddenly possible to build infrastructure to support large-scale concurrent operations, through lambda runners, in hours––something that used to take days and weeks.
Over time though, we started encountering issues due to our event-driven architecture and design. With the diversity of services required to have our data and flow work properly––API gateway, SQS, SNS, S3, event bridges, and more, the number of events and their inputs/outputs started to add up. This is where we started to hit the known serverless timeout wall. As serverless is essentially ephemeral runtime, it largely has a window of 15 minutes for task completion. If a task does not complete in time, it fails.
We started to realize that the honeymoon might be over and that we needed to rethink our infrastructure choice for the specific nature of our use case and operation. When you go down the microservices route––and in our case, we chose to leverage Go routines for multi-threaded services (so we’re talking about a lot of services), you often start to lose control of the number of running jobs and services.
Our “microservices to rule them all!” mindset, which we formerly took as a sign of our incredible scalability, was also ultimately the source of our breakdown. We tried to combat the timeouts by adding limitations, but this slowed down our processes significantly (not a good thing for a SaaS company), certainly not the outcome we hoped for. When we increased our clusters, this incurred significant cost implications—also not ideal for a nascent startup.
The technical debt aggregated, and this is when we started to consider our options––rewrite or migrate? What other technologies can we look at or leverage without a major overhaul?
Station II: A Stop at ECS (Elastic Container Service)
The next stop on our journey was ECS. Choosing ECS was actually a byproduct of our initial choice for packaging and deploying our apps to serverless. We chose to dockerize all of our applications and configure them via Terraform. This early choice ultimately enabled us to choose our architecture and infrastructure.
We decided to give ECS a try largely because of its profiling capabilities and the fact that there are no time limitations on processing tasks, events, and jobs like with serverless.
The benefit of ECS is its control mechanism––the core of its capabilities, where AWS manages task scheduling, priority, what runs where, and when. However, for us, this was also a double-edged sword.
The nature of our specific events required us to have greater control when it comes to task scheduling––such as finer-grained prioritization, ordering of tasks, pushing dynamic configurations based on pre-defined metrics and thresholds––and not just programmatic limitations, ones that are more dynamic and leverage telemetry data. For example, if I have a specific account or tenant that is overloading or spamming the system, I can limit events more dynamically, with greater control of custom configurations per tenant.
When we analyzed the situation, we realized that what was lacking was a “computer,” or an operator in the Kubernetes world. (And this is a great article on how to write your first Kubernetes operator, in case you’d like to learn more).
Station III: Our Journey Home to Kubernetes Jobs
Coming back to our choice of using containerized lambdas, we realized we are not limited to AWS-based infrastructure as a result of this choice, and suddenly an open and community standard option started to appear like the right move for us and our needs.
If we were to look at the benefits of migrating to Kubernetes, there were many to consider:
- With Kubernetes jobs, you have an operator that enables much more dynamic configuration
- As an IaC-first company, Helm was a great way to configure our apps
- Greater and finer-grained profiling, limitations, and configurations, at infinite scale
For us the benefit of being able to manually configure and manage CPU and memory allocation, as well as customize and automate this through deep profiling, was extremely important. Particularly when we’re talking about scale comprising a diversity of clients with highly disparate usage behavior, where one tenant can run for two hours, and others run for only three seconds. Therefore, this customizability was a key feature for us and what eventually convinced us the move was necessary.
Next was examining the different layers of our applications to understand the complexity of such a migration.
How Do You Convert Lambdas to Kubernetes Jobs?
Now’s our moment to get philosophical. Eventually, what’s a lambda? It’s a type of job that needs to be done a single time with a specific configuration that runs a bunch of workers to get the job done. This brought us to the epiphany that this sounds a lot like…K8s jobs.
Our containerized lambdas and fully-codified configurations enabled us to reuse the runtime and configurations, with very minimal adjustments when moving between environments. Let’s take a look at some of the primary elements.
Networking
The large majority of the networking elements were covered via containerization, including security groups and much more. The flip side is that if your networking is not configured as code and well-defined––then you can find your communication between services crash. Ensuring that all of your security groups and their resources, from VPCs to anything, are properly configured ensures a much more seamless transition and essentially is the backbone to democratizing your infrastructure choice.
Permissions and External Configurations
Another critical aspect that can make or break this transition is permissions and access control. With serverless (AWS), ECS, and Kubernetes working with IAM roles, it’s just a matter of how you design your roles so that flows don’t break, and then you can port them quite easily across environments. This way, you ensure your flow does not break in such a transition. There are minor changes and optimizations, such as configuration trust relationships; however, this beats configuring all of your permissions from scratch.
Changing your IAM Role’s Trust relationship from this:
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
To this—makes it portable and reusable:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::123456789:oidc-provider/oidc.eks.us-east-1.amazonaws.com/id/XXXXXXXXXXXXXXXXX"
},
"Action": "sts:AssumeRoleWithWebIdentity"
}
]
}
Other changes you need to ensure you cover are converting environment variables to the configmap format in Kubernetes deployments. Then you are ready to attach to your preferred runtime and environment.
The Unhappy Runtime Flow
This doesn’t mean there can’t be unhappy flows. Docker is not a panacea, and there are situations where there are compatibility issues, such as the base image that can change from service to service, or between different OS distributions, alongside Linux issues, such as dependencies in file directories.
However, you can overcome these challenges by building your own Docker images and dependencies with as much abstraction as possible. For example, compiling our Golang app in a separate builder image and using it in our target image or managing our environment variables in a struct with explicit references to avoid relying upon any runtime to inject them for you are good practices to avoid runtime issues.
Blue/Green >> GO!
So what does the final rollout look like? Although there was some downtime, it wasn’t significant. Our team chose the blue/green method for deployment and monitored this closely to ensure that all the data was being received as it should and the migration went smoothly.
Before we dive into this further, here is a brief word about monitoring and logging. This is another aspect you need to ensure you properly migrate before you deploy anything. When it comes to monitoring, there are elements you need to ensure you properly convert. If you were previously monitoring lambdas, you now need to convert these to clusters and pods. You need to validate that logs are shipping and arriving as they should––CloudWatch vs. fluentd.
Once we had all of this in place, we were ready to reroute our traffic as the blue/green rollout. We routed some of our event streams via SQS to the new infrastructure and did continuous sanity checks to ensure the business logic didn’t break, that everything was transferring, and that the monitoring and logging were working as they should. Once we checked this flow and increased the traffic slowly from our previous infrastructure to our new infrastructure without any breakage, we knew our migration was complete.
This can take hours or days, depending on how large your deployment is and how sensitive your operations, SLAs, data, and more are. The only obvious recommendation is to ensure you have the proper visibility in place to know it works.
MMS • RSS

Nosql Market
The NoSQL database industry is driven by an increase in demand for e-commerce and online applications, which adds to total market demand.
PORTLAND, UNITED STATE, March 15, 2023 /EINPresswire.com/ — Allied Market Research published a new report, titled, “NoSQL Market Expected to Reach USD 22,087 Billion by 2026 | Top Players such as – AWS, DataStax and Couchbase.” The report offers an extensive analysis of key growth strategies, drivers, opportunities, key segment, Porter’s Five Forces analysis, and competitive landscape. This study is a helpful source of information for market players, investors, VPs, stakeholders, and new entrants to gain thorough understanding of the industry and determine steps to be taken to gain competitive advantage.
The NoSQL market size was valued at USD 2,410.5 million in 2018, and is projected to reach USD 22,087 million by 2026, growing at a CAGR of 31.4% from 2019 to 2026.
Download Sample Report (Get Full Insights in PDF – 266 Pages) at: https://www.alliedmarketresearch.com/request-sample/640
Increase in unstructured data, demand for data analytics, and surge in application development activities across the globe propel the growth of the global NoSQL market. North America accounted for the highest market share in 2018, and will maintain its leadership status during the forecast period. Demand for online gaming and content consumption from OTT platforms increased significantly. So, the demand for NoSQL increased for handling huge amount of data.
The report offers a detailed segmentation of the global NoSQL market based on type, application, industry vertical, and geography. Based on application, the web apps segment held the largest share, with more than one-fourth of the total share in 2018, and is estimated to dominate during the forecast period. However, the mobile apps segment is projected to manifest the highest CAGR of 33.5% from 2019 to 2026.
Enquiry Before Buying: https://www.alliedmarketresearch.com/purchase-enquiry/640
Based on vertical, the IT sector contributed to the highest market share in 2018, accounting for more than two-fifths of the total market share, and is estimated to maintain its highest contribution during the forecast period. However, the gaming segment is expected to grow at the highest CAGR of 34.8% from 2019 to 2026.
Based on type, the key value store segment accounted for more than two-fifths of the total market share in 2018, and is estimated to maintain its lead position by 2026. Contrarily, the graph based segment is expected to grow at the fastest CAGR of 34.2% during the forecast period.
For Report Customization: https://www.alliedmarketresearch.com/request-for-customization/640
Based on region, North America accounted for the highest market share in 2018, contributing to more than two-fifths of the global NoSQL market share, and will maintain its leadership status during the forecast period. On the other hand, Asia-Pacific is expected to witness the highest CAGR of 35.5% from 2019 to 2026.
Leading players of the global NoSQL market analyzed in the research include Aerospike, Inc., DataStax, Inc., Amazon Web Services, Inc., Couchbase, Inc., Microsoft Corporation, MarkLogic Corporation, Google LLC, Neo Technology, Inc., MongoDB, Inc., and Objectivity, Inc.
Procure Complete Report (266 Pages PDF with Insights, Charts, Tables, and Figures) at:
Covid-19 Scenario:
● With lockdown imposed by governments of many countries, demand for online gaming, content consumption from OTT platforms, and activity on social media increased significantly. So, the demand for NoSQL increased for handling huge amount of data.
● With organizations adopting “work from home” strategy to ensure continuity of business processes, NoSQL databases would be needed to store and retrieve data.
Thanks for reading this article; you can also get an individual chapter-wise section or region-wise report versions like North America, Europe, or Asia.
If you have any special requirements, please let us know and we will offer you the report as per your requirements.
Lastly, this report provides market intelligence most comprehensively. The report structure has been kept such that it offers maximum business value. It provides critical insights into the market dynamics and will enable strategic decision-making for the existing market players as well as those willing to enter the market.
Other Trending Report:
1. Database Monitoring Software Market
About Us:
Allied Market Research (AMR) is a market research and business-consulting firm of Allied Analytics LLP, based in Portland, Oregon. AMR offers market research reports, business solutions, consulting services, and insights on markets across 11 industry verticals. Adopting extensive research methodologies, AMR is instrumental in helping its clients to make strategic business decisions and achieve sustainable growth in their market domains. We are equipped with skilled analysts and experts, and have a wide experience of working with many Fortune 500 companies and small & medium enterprises.
Pawan Kumar, the CEO of Allied Market Research, is leading the organization toward providing high-quality data and insights. We are in professional corporate relations with various companies. This helps us dig out market data that helps us generate accurate research data tables and confirm utmost accuracy in our market forecasting. Every data company in the domain is concerned. Our secondary data procurement methodology includes deep presented in the reports published by us is extracted through primary interviews with top officials from leading online and offline research and discussion with knowledgeable professionals and analysts in the industry.
David Correa
Allied Analytics LLP
+1-800-792-5285
email us here
![]()