Month: March 2023
Integrating Azure Database for MySQL – Flexible Server with Power Platform and Logic Apps

MMS • Steef-Jan Wiggers
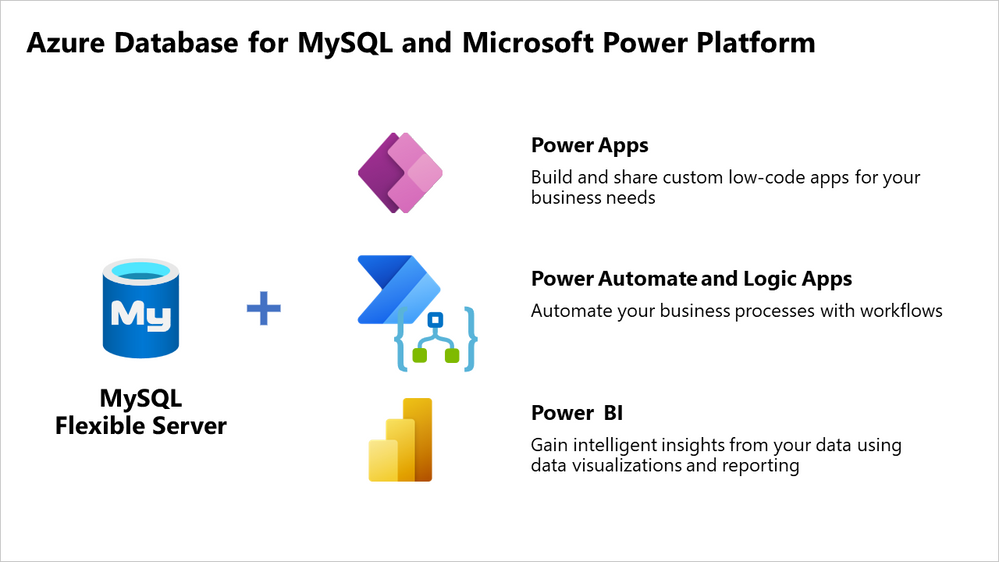
Microsoft recently announced a new set of integrations with Azure Database for MySQL – Flexible Server and the Microsoft Power Platform and Azure- making it easier to develop solutions for analyzing data, automating processes, and building apps. These new integrations include PowerBI, Logic Apps, PowerApps, and Power Automate.
Azure Database for MySQL – Flexible Server is a deployment mode generally available since November 2021 that provides more control and flexibility over database management functions and configuration settings than the Single Server mode. Users can use it as a managed service to run, manage, and scale highly available MySQL servers in the cloud. It supports MySQL 5.7 and 8.0 versions.
Earlier this year, the company released the public preview of the Azure Database for MySQL – Flexible Server connector for Power Automate and Azure Logic Apps. Power Automate can be used to build automated processes using low-code, drag-and-drop tools. At the same time, Azure Logic Apps is a cloud-based platform for creating and running automated workflows that integrate your apps, data, services, and systems. Both provide a connector that allows users to connect to and query data from a MySQL flexible server.
Sunitha Muthukrishna, a senior program manager at Microsoft, Azure OSS databases team- MySQL, PostgreSQL, and MariaDB, explain some use cases regarding the connector in a Tech Community blog post:
You can use Power Automate or Logic Apps to automate processes such as employee onboarding, access management, purchase order/expense approval, organizational communications, request intake, etc. The Power platform helps improve and streamline organization processes for various departments within the organization, such as:
• Human resources
• IT
• Finance
• Sales
• Customer relations management
Microsoft Power Apps is a no-code developer platform for generating mobile and tablet apps that can be connected to MySQL data. The same connector for Power Automate and Logic Apps is also available for Power Apps. With the connector, users can perform data operations such as list rows, update, and add or delete rows in their apps using Azure Database for MySQL – Flexible Server.
Next to integrations with Power Apps, Power Automate, and Logic Apps, there is an integration with Power BI. This platform allows users to connect to, visualize, and analyze any data and embed the insights into their apps. The integration with PowerBI directly with Azure Database for MySQL – Flexible Server is generally available. Users can now import data from Azure Database for MySQL – Flexible Server to Power BI Desktop from the Azure portal. In addition, the Power BI Desktop lets users create reports with a drag-and-drop canvas and modern data visualizations.
In the next few months, Microsoft will enhance Azure for MySQL – Flexible service in terms of performance, availability, security, management, and developer experience by making the following features available:
• Autoscale IOPS (GA)
• Cross-region read replicas in paired regions (GA)
• Private Link (Public Preview)
• MySQL Extension for Azure Data Studio (GA)
A Microsoft spokesperson told Info:
Our goal is to provide our customers with tools to increase developer productivity and automate business processes more efficiently. MySQL is a popular structured database for web and mobile app developers, and this integration directly reflects our customers’ needs.
Lastly, Service details are available on the Azure Database for MySQL documentation landing page and pricing on the pricing page. In addition, there is a free account available to try out the service.
MMS • Sabri Bolkar

Zero-copy and in-memory data manager Vineyard (v6d) has recently released version 0.13.2 which brought improved features for Python/C++ development, and Kubernetes deployment. It is maintained as a CNCF sandbox project and provides distributed operators that can be utilized to share immutable data within or across cluster nodes. V6d is of particular interest for deep network training (e.g. large language and graph models) on big (sharded) datasets. Its development is currently led by an Alibaba engineering team.
Zero-copy and in-memory data distribution is a central problem for many real-time applications. From image processing pipelines to deep learning models such as LLM and graph mining algorithms, many data-crunching applications require to ingest large data from many independent processes. In machine learning engineering, this bottleneck has become more evident as deep networks are getting larger and distribution of model parameters mandate access to shared state and data. As an early-stage project, V6d aims to bring a high-level API for such use cases.
Architectures of real-time applications generally exploit in-memory key-value storages/caches (e.g. etcd, Memcached, Redis) for storing and interchanging frequently reached data. According to service type, engineering teams have to consider related trade-offs that come with these tools. V6d consists of two main components: Apache Arrow Plasma-derived shared-memory data manager (within a node) and a metadata server backed by etcd (between different nodes). While the Plasma-derived service allows zero-copy data transfer, etcd service handles the global distribution of (possibly partitioned) data’s properties.
V6d places itself within the Python community. In a way, it can be considered to scale Python’s native multiprocess shared_memory to multiple machines for immutable blobs. V6d offers two different Python client interfaces IPCClient and RPCClient for manipulating local and remote objects respectively. Both client APIs permit uniform data insertion and retrieval patterns that are based on object IDs. However, v6d does not automatically move data between cluster nodes unless instructed to do so due to the high network cost of such operations.
We could present a simple example that can be run on a local machine, let’s start with creating a local v6d instance:
python -m vineyard --socket /tmp/vineyard.sock --size 16733650944
As the first step, let’s show how we can utilize Python’s native API. For this purpose we will create a dummy 10k resolution RGB image using NumPy and share it quickly using the shared_memory() interface:
import numpy as np
from multiprocessing import shared_memory
shape_, dtype_ = (3, 10000, 10000), np.uint8
array_to_share = np.random.randint(0, high=255, size=shape_, dtype=dtype_)
# Create shared memory
shm = shared_memory.SharedMemory(create=True, size=array_to_share.nbytes)
array_shm = np.ndarray(shape_, dtype=array_to_share.dtype, buffer=shm.buf)
array_shm[:] = array_to_share[:] # Here we need to copy as we use existing array
# Use the shared memory name, size and type info to retrieve data in another process
existing_shm = shared_memory.SharedMemory(name=shm.name)
array_retrieved = np.ndarray(shape=shape_, dtype=dtype_, buffer=existing_shm.buf)
Here, we could carry out the same operation using v6d:
import vineyard
client = vineyard.connect('/tmp/vineyard.sock')
array_id = client.put(array_to_share)
# Retrieve the previous array_to_share in another process
array_retrieved = client.get(array_id)
As shown above, the API is quite easy to use and propagates the dtype and array shape to the retrieved object. Because of the common array protocol (aka buffer protocol), the NumPy interface also accepts zero-copy operations on PyTorch, TensorFlow, and MxNet tensors. In addition to that, v6d enables same operations on Pandas/Arrow dataframes. Further information on library integrations can be reached in the related documentation page. An example machine learning training tutorial can also be found in the webpage.
For multi-node settings, V6d allows deployment of vineyard operators on Kubernetes clusters via the Python API and Helm charts. A more detailed overview of the architecture is also provided in the official documentation.
Road to Quarkus 3: Improved Dev UI, Steps Towards Diataxis Documentation and Performance Bumps
MMS • Olimpiu Pop

In our previous conversation with Max Rydahl Andersen, Quarkus co-lead and distinguished engineer at Red Hat, we focused on the technical changes that they consider to be the following steps to deliver on their mission. More than speed and cloud nativeness, developer joy and support for both reactive and imperative coding styles that are part of Quarkus’ mission statement, Developer Experience (DX) and the focus on productivity were also an important part of each of the previous major releases. To find out whether version 3.0 will follow this tradition, InfoQ continued the conversation with Andersen.
InfoQ: Quarkus 2 delivered continuous testing as part of your promise for a joyful Developer Experience. Is there anything prepared for 3.0?
Andersen: Quarkus has three capabilities that enhance the developer’s productivity:
They allow you to explore and try things out without complex setup, restart and still apply TDD. Next, we focus on improving their integration as well as their visual experience.
The Dev UI is built around the Qute template concept, which is “tiles” that provide development-relevant information. Even though it was easy to add content, it required a lot of duplication and some workflows were just impossible to implement. We intend to have a more common structure and also use more advanced client-side technologies for a richer experience.
To enable an improved update flow, we explore the idea of a plugin mechanism for the CLI to allow integration of externally provided tooling to help during development.
InfoQ: Is Kotlin’s growing popularity reflected in Quarkus’ user habits? How about Scala?
Andersen: Each reported issue requires a reproducer project: Java leads the pack while Scala has just a few patches (for Scala 3 for instance). Kotlin has increased traction, enough to allocate dedicated engineering time to improving the experience. For example, hot-reload was improved. Also, we explore ways of improving the usage of coroutines and reactive code in Kotlin.
InfoQ: How about imperative vs. reactive programming?
Andersen: Technically, everyone uses reactive indirectly: the framework was built on a reactive core. Users can choose to write the business logic imperatively (AKA blocking) or reactively either with SmallRye Mutiny or Kotlin Coroutines. In the foreseeable future, the three models will be available. Rather than an ideology or preference, you should approach it pragmatically depending on the type of application. For instance, a primarily event-driven application has more sense to be reactive, whereas a traditional CRUD REST microservice may only use it for specific calls perhaps around 15-30%.
Starting with 2.x, Quarkus’ default REST stack is reactive, but users can opt for imperative for their business logic.
A similar hot topic is the use of virtual threads. The output of Project Loom promises to have the simplicity of imperative with performance similar to reactive without the mental overhead of reactive programming. We have limited early support for virtual threads – limits in the Java Development Kit keep virtual threads from being a drop-in replacement.
InfoQ: Does Quarkus 3.0 take further steps on the super-sonic start-up time promise?
Andersen: We continuously aim to improve the performance. But, we recently hit a plateau – the improvements were not showing up as we had expected. We started investigating when we realized that other non-JVM solutions don’t have similar problems. That led to Francesco Nigro’s (re)discovery of a long-time bug related to JVM optimization of
instanceofchecks. We’ve applied many updates to libraries used by Quarkus to reduce the impact. We worked with the OpenJDK team to get it fixed and hopefully also backported to future Java releases.We target to support
io_uring, a feature using modern OS kernels that allows having shared ring buffers between the kernel and application avoiding expensive copy operations. It is a game changer for improving response time and reducing latency.Finally, the upgrade to Hibernate 6 allows us to renounce the workarounds in Hibernate 5 related to startup and native image improvements. With Hibernate 6, we can use the “plain” version which comes with its own set of new features and Hibernate-specific improvements.
More than just features and tools, Quarkus’ third milestone brings changes to the documentation as well as following the Diataxis framework principles. And, to make the migration for existing users, tooling for migration is also available. As the current version is 3.0.0.Alpha5, developers are encouraged to experiment and share feedback with the team.
MMS • Chris Swan Sarah Wells Srini Penchikala Werner Schuster

Subscribe on:
Transcript
Thomas Betts: What makes QCon software conferences stand out from other events? The top reason has to be the content which focuses on innovator and early adopter trends and presenters who are expert practitioners sharing their real world stories.
Deciding what topics to include in the conference starts with the QCon programming committee and today I’m joined with some of its members. We’re going to go backstage to get an understanding of how QCon London came together and why the trends that are being featured this year are important. So we’ve got a few people joining us today. I’m just going to let them all introduce themselves. We’ll start with Chris.
Chris Swan: So hi folks. I’m Chris Swan. My day job is an engineer at Atsign where I’m helping to build a platform for end-to-end encryption and I’m back on the program committee after quite a long break because my last job wouldn’t let me do it. But I was on the program committee before for a few years.
Thomas Betts: And the next one is Srini.
Srini Penchikala: Hi Thomas. Hi everybody. It’s great to participate in this podcast and share what’s coming up at QCon London 2023 conference. About myself, I currently serve as the lead editor for data engineering and AI and ML community at InfoQ website. I have the opportunity to work with great members and great speakers in this capacity. Outside of that, I focus on data engineering and data processing areas as my main focus of expertise. Back to you, Thomas.
Thomas Betts: Then, Sarah Wells.
Sarah Wells: Hi. I’m currently writing a book about microservices. Before that, I was a tech director at the Financial Times. I’ve been involved with QCon for good few years, speaking, track hosting and on the program committee for the last couple of years.
Thomas Betts: And finally, Werner.
Werner Schuster: Hi. Yeah. I have been on a few of these committees. I think the last count was above 20 or so. So it’s been fun. And in my day job, my job title is cloud plumber at Wolfram, so whenever developers create leaks, I find them and tell them how to fix them. That’s it for me.
What makes QCon different from other software conferences? [02:03]
Thomas Betts: So let’s start with how QCon is different from other software conferences. What are the things that Qcon does differently than the other conferences that people can attend out there?
Chris Swan: I think it starts with us getting together and essentially creating a framework for the conference that we want to attend ourselves. I’ve been going to QCon since the earliest days and I think it’s always been one of my favorite conferences. And so now that I get to help shape it, I’m kind of thinking what do I want and what do I think people like me that come to conferences want to have? And that gets us to sort of the themes for the tracks. And then we go off and find great track hosts who are going to go and find the individual speakers to fit into those themes. Like good software development, there’s a lot of iteration goes on in the early days to refine that as well.
Thomas Betts: Yeah. And I know QCon’s one of the conferences that doesn’t do a big open call for papers to have the speakers show up. How does that make a difference?
Sarah Wells: A lot of it comes from the track host. One of the things I really love about having track hosts is you get a very opinionated view on a particular topic. They get to shape the track. We’ll have come up with a theme in the program committee, but the track host can find their take on that and they go to their own connections. And also they can draw on the whole of the committee’s connections. You tend to have a mix of experienced good speakers and some rising stars where you want to encourage people who maybe haven’t spoken before. So I think that’s one of the things.
The other thing that is really interesting about the kinds of talks that get scheduled at Qcon is that it’s very much about practitioners. You want to hear people talking about something they’ve actually done. As with Chris, I was an attendee… Well, so I was an attendee at QCon way before I was on the program committee. I always knew that I was going to learn about things that I’d been hearing a little bit about that I wasn’t quite sure about. I’d get that exposure by coming to QCon.
Thomas Betts: And I think some of us have been in that track host role and the program committee. And what are the tracks at Qcon like? I’ve heard it described as sort of a mini conference within a conference. Is that how you think of that, Srini?
Srini Penchikala: Absolutely. Each track can be its own conference because again, like Sarah mentioned earlier, we want to focus on the attendee as our target audience, what’s best for the attendees. I mean not only technologies, but also what should they be aware of in terms of leadership contributions in their companies. Also, the process improvements. So it’s kind of a holistic experience when they come to the conference and QCon actually provides that. So it can be seen as a multiple mini conferences. But again, I think all of those gel together because of the programming committee efforts. So if somebody’s looking for technology expertise, innovations and the process improvements and not only what they are doing right now but what they should be familiar with going forward. It’s all kind of provide in one stop conference.
Thomas Betts: And I think Sarah made a good comment about we’ve all been attendees before we were involved with QCon. I don’t know if that was your case as well, Werner. Were you an A attendee and what do you think the attendees get out of QCon that they don’t see at other conferences? Everyone says they love them so much, but what is it that QCon is different for the attendee perspective?
Werner Schuster: Well, at QCon you hear practitioners speak. You don’t hear people who just selling something or who are just telling other people, “This is the great solution,” but they have never actually used it. And that builds a certain trust where that person that tells me to use this language, they’ve suffered for that, right? They have the scars and they can show them and say, “Okay, you showed me… Use this language and these are the pitfalls to avoid and so on.” So this is one of the big selling points. And of course with QCon, you get to meet people like creators of languages, creators of frameworks that where you think, “I’ve been using this language for so long, I can get to ask Rich Hickey, “Why Clojure? Why Lisp?” And stuff like that. And he’ll answer, “These people are very nice actually. You can talk to them and these are just real people like me.” So that’s one of the setting points I think.
Thomas Betts: I know at other QCons I’ve seen people doing the selfies, like meeting your heroes. Like, “I can’t believe I get to see that person.” And not just up on a stage, but you run into everyone in the hallways and discussing things over lunch.
Architectures You’ve Always Wondered About [06:00]
Thomas Betts: So QCon does have some recurring tracks. So we talked about how we break up QCon into the separate tracks, but there are some that always show up and there’s some that always show up in London specifically. One that I know is a big hit has been around for at least a decade, is the architectures you’ve always wondered about. And you said, Werner, the chance to… How did they build that thing? How did they hear about… What’s in the architectures you wanted to know about this year?
Sarah Wells: I should probably talk about that because I’m the program creating member for that. So the Architecture You’ve Always Wondered About, it’s absolutely the marquee track. We do it on the first day, generally. It’s giving you that exposure to tech leaders from leading companies talking about scale. And this year we have talks from Google talking about how they scale their global cloud L7 Load Balancer. We’ve got CloudFlare talking about handling 1 trillion messages in Kafka. Zoom should be really interesting to hear about how they scaled up in response to the mass move to working from home with the pandemic. And Monzo on serving 7 million customers daily with a huge number of microservices that they deploy hundreds of times a day.
Data and ML/AI tracks [07:02]
Thomas Betts: So Sarah’s in charge of that track. Let’s go to Srini. What’s your track that you’re most looking forward to?
Srini Penchikala: Most looking forward to? I have to start with the two tracks that I am serving as the PC champion, the programming committee champion. The first one is innovations in the data engineering, and the second one is AI/ML trends. So I think the attendees are going to get a lot out of these two tracks. They can say that if there is one area that has seen exponential growth in last couple of years, especially last year, would be the data engineering side and the artificial intelligence and machine learning. So there are so many things to share with the audience. And we have the speakers and topics to reflect those developments and innovations happening in these two areas.
So if I can summarize, Thomas real quick, the data engineering track kind of provides a overview of all the different phases involved in a typical data engineering process. We have the data storage topic to show how to store objects on the cloud using Apache Pinot database by Neha. I know that’s going to be an interesting topic and how to kind of balance between scalability and performance and the typical cross-functional requirements that all data architects have to experience. We also have streaming data processing talk. Data streaming has been a big topic for last several years, so that’s going to stay even more popular for some time to come. And we also have Change Data Capture, CDC when using microservices. So this is an interesting use case when you are using microservices. When they talk to each other, how do you actually manage the data behind the microservices or how do you replicate, how do you reconcile? So we are looking forward to Gunnar Morling is a speaker. So he’ll be talking about a couple of different interesting design patterns involving the CDC for microservices. Then we also have the data analytics as well as how to implement these solutions in the cloud also. So those are definitely some of the talks that will be of interesting.
On the machine learning side, again, no other industry has gone through the same growth that machine learning has seen in last year… Chat GPT for example, right? We hear that a hundred times every day. So yeah. There are a lot of good things happening here, whether it’s the transformers that are shaping out the machine learning space or the NLP, natural language processing innovations or the infra security itself for AI/ML, how to deploy ML programs on the cloud and ML ops. How to support ML after going to production. So we have these speakers and topics kind of representing all of these different innovations, including the realtime ML pipelines, presentation, Graph Neural Networks, how to apply machine learning techniques on graph data. And we all know graph data is everywhere. Whether it’s collaboration platforms in the corporations or those on social media, the connected data is everywhere. So how do we apply machine learning to that type of data will be the focus of this Graph Neural Network presentation.
And we also have ML ops. How to operationalize ML programs in production. This will be actually showcasing the DoorDash real world use cases, which should be very interesting. And also we have a digital twins topic, which is getting a lot of attention in the industry, especially in the manufacturing supply chain and healthcare industries. How to virtualize the business processes where it is very expensive to create the simulated environments in the real world. So can we do that in the digital world? So create a digital twin whether for a car or for a supply chain process. So we have a presentation on that. And finally, probably most importantly, the presentation on responsible and ethical AI by the track host, Mehrnoosh. Will highlight the importance of ethics and doing the AI/ML the right way and show us how to put these ethical practices into real projects and applications. So to summarize, we have great speakers and we have great topics lined up for our attendees this year. The attendees can expect and look forward to learning about the modern data architecture stack as well as the transformative innovations happening in the mission learning space.
Thomas Betts: I appreciate that. That sounded like an entire data software conference all by itself. But that’s just two tracks you talked about. The ML and AI and the emerging AI and ML trends and innovations in data engineering. They overlap a lot. So somebody might go to all those sessions or they may say one session’s alright. And they go to other things so you can pop on and get what you personally need.
Srini Penchikala: And also we made sure that they are on two different days, Thomas. So if somebody wants to attend all of the data engineering talks and all of the machine learning talks, they can still do that. And that’s really good problem to have, right? So which one to attend at any point in the day, also.
Thomas Betts: There’s always the problem of there’s too many sessions you want to go to. There’s only five tracks or six tracks in a day. But you always have two sessions that are at the same time. And I always look for which one can I watch on the recording as soon as possible afterwards.
Tech of FinTech [11:31]
Thomas Betts: I wanted to back up. So one of the topics that usually shows up in London is FinTech and there’s a FinTech track this year, is that correct?
Chris Swan: So we’re calling it Tech of FinTech. And if I look at previous sort of iterations of the finance track for QCon London, it’s been very focused on, I would say kind of traditional financial services. So talks from people working in the big banks, et cetera. And normally there would be sort of one or two more FinTech talks sprinkled in there. And to liven things up, what we’ve tried to do is sort of flip it this year. So the idea of The Tech of FinTech track as we’re calling it, is to get people from FinTech startups, but also to get people that have adopted the same technology platforms as the FinTech startups. And so we’ve seen that going on with some cases, banks kind of having a newly launched name and a new engineering team to go with that. But sometimes it is just engineers within a particular team are picking up new approaches and applying them to the stuff that they’re building.
So we’ve been rooting those out as well. I’d particularly call out open source in banking is going to be one of the topics we’re touching on. This has been I think a theme where there’s been various attempts in the past to do stuff and kind of say, “Well, all of the banks are building kind of all of the same stuff, so why don’t we open source it and mutualize it?” And maybe that’s now an idea where the time’s finally come for it.
Thomas Betts: That’s an interesting idea to talk about the technology, not just the companies and what they’re doing. Looking forward to some of those.
Architecture for Sustainability [13:02]
Thomas Betts: So we talked about the headline track, the Architectures You’ve Always Wondered About and we got all the data and ML. What else for architecture focus? Because a lot of people that attend QCon are either senior engineers or architects or have that technical experience. It’s not for the beginner entry level roles. So there’s a lot of architecture focus. What’s on the architecture track this year?
Chris Swan: So another new one for this year is Architecture for Sustainability. And we’ve previously had tracks that have been dedicated to sustainability but with a sort of broader approach. So they haven’t been focused on architecture. So this time around we’re actually focusing on the architectures involved in sustainability. And I think that’s been a little more challenging in terms of finding stories, but I think we’ve found some excellent stories and the track hosts have done a really good job of getting speakers who can come along and talk about real world implementations of stuff in the architectures that lie behind them.
Thomas Betts: So what does the Architecture for Sustainability mean? Because sustainability has a couple different interpretations. There’s the sustainable software that’s going to live for a while and be maintainable and you can operate. But this is I think is the green environment, the green software principles and how do you make software that doesn’t consume more electricity and more energy and carbon than the entire airline industry, for example.
Chris Swan: It’s more about the latter. Absolutely. And we find that that flows over into a lot of considerations around performance because if you’re using your underlying hardware thoughtfully than that tends to be good from a carbon footprint perspective as well. And so the story that we’re getting from Goldman Sachs is really about how they’ve gone about systematically optimizing their estate so that it’s got less of a carbon footprint, but that also means that it’s got less of a dollar footprint. And I think that’s something that all organizations are interested in. It’s not just about environment and social responsibility concerns, it’s about the financial concerns that go along with those as well.
Thomas Betts: That sounds easier to project to the shareholders. We’re going to increase our bottom line because we’re going to spend less on our cloud footprint. Also, our software runs better and we’re having less of an environmental impact. So win-win for everybody. Right.
Architecture in 2025 [15:13]
Srini Penchikala: Thomas, I want to highlight one more track on the architecture. The title is Architecture in 2025. So this will be about what does architecture look like in the future? What is the role of software architect, which is I know one of your areas of passion as well.
Sarah Wells: I think he’s speaking on the tracks really.
Thomas Betts: Yes, that’s my talk. And again, the idea of not just what is architecture, but Architecture in 2025. It is very clearly that opinion of how do we look forward to the future, where are people heading, how are things changing? So how has the role of an architect evolved? Which saying, I’ve definitely talked about. We’ve covered things about this on the in InfoQ Trends Report for the last several years. So there’s going to be a lot of things that you see on those trends reports that I’m hearing you guys talk about as topics for the conference, the AI trends, the data engineering trends, the sustainability trends. So it’s been top of mind for us as innovator and early adopter for the last few years and that’s why they are topics at QCon.
Sarah Wells: I think it was interesting when we were thinking about the themes was that we decided that there really wasn’t a space for a microservices track. So where we probably would’ve had microservices as an architectural thing in previous QCons. Now it’s like, well, that is just something people do. Where do you go? What do you talk about with the architecture? What’s coming next?
Debugging in Production [16:21]
Thomas Betts: So Werner, we haven’t heard from you yet. What’s one or two of the tracks that you’re most looking forward to?
Werner Schuster: I’m biased because the ones I’m looking forward to are the ones I’m managing. And talking about microservices. The one I’m looking forward to is debugging in production. And one of the problems with microservices is of course always you can’t just attach debugger to 50 services and then step through all of them. So you need some better ways. In this track, we are looking at observability and tracing and things like that. And just generally how do you debug a system with all of these things happening at the same time? I’m not going to go into details. We have a great website and there’s some really exciting stuff on there.
Performance: Designing and Tuning [17:00]
Werner Schuster: And then the other track is somewhat related. It’s sort of our second sustainability track except we call it performance because we’re old school. Because as Chris just mentioned, to be green, he can just do less or do it with fewer cycles. And we have a really exciting track. It’s hosted by Justin Cormack. He found some amazing speakers there. Just to highlight one talk, we have speakers from Red Panda, which is a re-implementation of Kafka with a strong, strong focus on… I guess, as Martin Thompson calls it mechanical sympathy. Really writing the software so that it works with the hardware. It maximizes the hardware. And that’s just one of the exciting developments recently to see people really focusing on this. Yeah. The performance track is another one that I’m really looking forward to here.
Socially-Conscious Software [17:48]
Thomas Betts: Chris, you already mentioned the architecture with sustainability, there’s another socially-conscious software. I think Srini mentioned ethics a little bit. That’s one of those topics that has been at QCon for several years. We’ve always had this kind of nebulous, maybe one talk, maybe whole track. Is that what the socially-conscious software is getting into?
Chris Swan: Yes. And I think that track from a sort of title and abstract perspective gave us scope to go beyond just ethics. So we have previously had an entire track of ethics and I think that was an interesting approach, but also we don’t want to be having the same people doing the same talks again and again. So we’ve changed it a little and given ourselves scope to get some different speakers telling some different stories.
Culture & Methods tracks [18:33]
Thomas Betts: And then the last category of QCon, and InfoQ has these same topics across the personas, is the culture and methods track. I know people are probably familiar with Shane Hastie as the other InfoQ podcast. He’ll be there running the on conference. But there’s two tracks that I thought were under that culture and methods is one is the staff+ engineering and the other one is remote and hybrid work. And again, these have been around for a couple years. What’s the current trends that we’re expecting to see and why are those two topics important at QCon?
Sarah Wells: So staff plus, it’s interesting because I think it’s still… Particularly in the UK, perhaps individual contributor path hasn’t been talked about as much. People last year who came to the talks on that track were really interested to work out what does it mean? How do I shape a career that doesn’t involve going into management or leadership? So I think that it’s still early and I’m not actually overseeing that. But the talks I think will cover a variety of things around what skills do you need to stay on the technical track and what can you expect? Where are the challenges that you’re going to have as a result of doing that? And a lot of that comes down to how do you influence when you are not actually someone’s manager? You don’t get to tell someone that they need to do something. How do you as an individual contributor effect change?
And then the other one was remote and hybrid work. Well, that’s just interesting at the moment every year because two years ago, three years ago it was how do we all work from home? Well, but now it’s like, “What’s come next?” And you’ve got lots of companies that were doing fairly remote work and starting to look at hybrid, starting to call back people back into the office some part of the week. I think that’s incredibly difficult to do. So it’s really interesting to hear from people about how they’ve made something like that work.
Thomas Betts: I don’t know if anyone else had this experience at the QCon San Francisco last year and some of the QCon Plus that have been online. The remote and hybrid work sessions, the talks have been the most surprising. I think I go to the technical talks and I have a sense of what I can expect. I’m going to gain some knowledge about a tool or technology I don’t know. Those talks have the power to surprise you because you don’t know what is going on and I think you can also take it back and use it the next day. I might not be able to implement Kafka next week, but I can say, “Hey, we can try this out.” Bring it up in a retro and say, “Why don’t we try this idea that I heard about at Qcon?” So that’s a great opportunity that the audience can take right back to work with them.
Sarah Wells: I agree. I think it’s one of the really nice things about QCon is that it’s a conference that covers those kinds of people and culture and process topics as well. And we aim to have one track of that for each day. So if you wanted to spend your time digging deep into culture and methods, you can do it. If you’re going to a conference that’s about particular technologies, you don’t necessarily get that opportunity. So I think it is… Yeah. Totally. People should at least dip into some of those talks because it’ll be a different perspective potentially.
Security [21:16]
Thomas Betts: I think that covered all of the main tracks. Is there anything else people wanted to bring up that we didn’t talk about for the specific tracks and themes of QCon?
Chris Swan: So we didn’t talk about security.
Thomas Betts: We never talked about security until it’s too late, do we?
Chris Swan: We brought security back onto the menu and specifically we’re talking about building security in earlier. So this whole concept of shifting left and getting some practitioners to talk about how they’ve done that and what they’ve accomplished in doing that. And I’m really looking forward to some of those stories myself because I think security’s one of those things where if you don’t focus on it early in the cycle, then it comes back to bite you later on and it can be annoying and expensive.
Paving the Road [21:58]
Sarah Wells: We also didn’t talk about the other track that I’m the champion for, which is about paving the road. So this is about developer productivity and experience. And this is coming at it from an engineering point of view, but obviously it’ll talk about culture methods as well. And the host, Nayana Shetty has really focused on user-centric approaches to engineering enablement. So how do you treat your platform as a product? We’ll hear from companies like Netflix and the BBC about the ways they’ve approached that. It’s a topic I’m really interested in and I think it’s going to be a great track.
Thomas Betts: We’ve talked about the paved road in the past and how it’s good, but this is actually how to go and pave the road and the benefits you get.
Sarah Wells: And to get that product mentality for teams that have other developers as customers. And this is my background, I was a tech director for engineering enablement at the Financial Times. It’s like how do you manage to get that product view on things? I think that’s an important development for people.
Thomas Betts: I think it started off with a few people saying, “I’m going to write a script to make my life easier.” And then that became a Jenkins job or something else and it’s just evolved into, now we need, that is a product that people need specific to your company and it’s not something you can just buy off the shelf and have exactly what you need. You have to put some time and effort into making it. What your organization needs. Right?
Sarah Wells: I mean, I’d argue you should buy at least parts of it off the shelf.
Thomas Betts: Oh. yes. Yeah. You can’t build the whole thing.
Sarah Wells: It needs to be in the context of your organization to make it really work.
Thomas Betts: You need to be able to pave your own road. But yeah. Hire the trucks to bring over the asphalt.
Sarah Wells: Yes.
In-person and online [23:24]
Thomas Betts: I did want to wrap up with some of the logistics of QCon. So I know this is the first one where we’re doing in-person and online at the same time. The last few have been staggered by a month. So how does that work for people who might not be able to make it to London but still want to get the content?
Sarah Wells: Well, I believe that the videos for online will go up at the same time as the conference starts, which is a challenge for speakers because that means they have to get their talks ready ahead of time. But should make for a really great experience for whether you’re coming in person or online.
Thomas Betts: I’m assuming there’ll be online discussions as well, that people can then engage afterwards.
Srini Penchikala: And also there won’t be any online disruptions because the recorded video will be available.
Thomas Betts: That’s right. It’s pre-recorded videos for all of the sessions so you can watch it, but it won’t have the… I couldn’t turn my camera on and technical difficulties. QCon has done a pretty good job of the online presentation of making sure that those sessions all run smoothly.
Srini Penchikala: I think we can say we have followed a shift left approach for the conference as well, so we’re organizing the talks.
Thomas Betts: I think that same plan of the online at the same time is what’s going to happen in QCon New York in June and then QCon San Francisco in October. Two more coming up if you can’t make it to London. Think about those.
Well, I want to thank all of my guests today, Chris, Srini, Sarah and Werner. And if you enjoyed this discussion of software trends, please leave a comment on the podcast either on the InfoQ page or wherever you get this, because we want to know if we want to have similar conversations like this with the future QCon organizers.
So if you want to know more about QCon London, there’s still time to register for the conference, either in person or online@qconlondon.com. And registration is open, as I said, for QCon New York and QCon San Francisco. So thanks again for listening to another episode of the InfoQ podcast.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Java News Roundup: Sequenced Collections for JDK 21, Vector API for JDK 20, Gen ZGC, Hilla 2.0
MMS • Michael Redlich

This week’s Java roundup for March 6th, 2023 features news from OpenJDK, JDK 20, JDK 21, Spring Cloud Data Flow 2.10.2, Spring Modulith 0.5, Quarkus 2.16.14 and 3.0.0.Alpha5, Open Liberty 23.0.0.2, Micronaut 3.8.7, Helidon 2.6.0, Apache Tomcat 11.0.0-M4, Apache Camel-4.0.0-M2, JobRunr 6.1.1, Jarviz 0.3.0 and Hilla 2.0.
OpenJDK
After its review had concluded, JEP 438, Vector API (Fifth Incubator), was promoted from Proposed to Target to Targeted status for JDK 20 this past week. This JEP, under the auspices of Project Panama, incorporates enhancements in response to feedback from the previous four rounds of incubation: JEP 426, Vector API (Fourth Incubator), delivered in JDK 19; JEP 417, Vector API (Third Incubator), delivered in JDK 18; JEP 414, Vector API (Second Incubator), delivered in JDK 17; and JEP 338, Vector API (Incubator), delivered as an incubator module in JDK 16. JEP 438 proposes to enhance the Vector API to load and store vectors to and from a MemorySegment as defined by JEP 424, Foreign Function & Memory API (Preview).
JEP 431, Sequenced Collections, has been promoted from Candidate to Proposed to Target status for JDK 21. This JEP proposes to introduce “a new family of interfaces that represent the concept of a collection whose elements are arranged in a well-defined sequence or ordering, as a structural property of the collection.” Motivation was due to a lack of a well-defined ordering and uniform set of operations within the Collections Framework. The review is expected to conclude on March 16, 2023. Further details on JEP 431 may be found in this InfoQ news story.
JEP 439, Generational ZGC, was promoted from its Draft 8272979 to Candidate status this past week. This JEP proposes to “improve application performance by extending the Z Garbage Collector (ZGC) to maintain separate generations for young and old objects. This will allow ZGC to collect young objects, which tend to die young, more frequently.”
Dalibor Topic, principal product manager at Oracle, had proposed to dissolve and archive the JDK 6 project due to: no defined project lead or mailing list traffic for the past two years; and not a single push into its forest for the past four years. InfoQ will follow up with a more detailed news story.
JDK 20
JDK 20 remains in its release candidate phase with the anticipated GA release on March 21, 2023. Build 36 remains the current build in the JDK 20 early-access builds. More details on this build may be found in the release notes.
JDK 21
Build 13 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 12 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 20 and JDK 21, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
The release of Spring Cloud Data Flow 2.10.2 ships with bug fixes, library upgrades to Spring Boot 2.7.9 and Spring Cloud 2021.0.6, and dependency upgrades to sub-projects such as: Spring Cloud Dataflow Build 2.10.2; Spring Cloud Dataflow Common 2.10.2; Spring Cloud Dataflow UI 3.3.2; and Spring Cloud Deployer K8S 2.8.2. More details on this release may be found in the release notes.
The release of Spring Modulith 0.5 delivers library upgrades to Spring Boot 3.0.4 and jMolecules 2022.2.4, and improvements such as: renaming the property to trigger JDBC database initialization, spring.modulith.events.schema-initialization.enabled, to spring.modulith.events.jdbc-schema-initialization.enabled. Further details on this release may be found in the changelog.
Quarkus
The fifth (and final) alpha release of Quarkus 3.0.0 features support for: Hibernate ORM 6.0 and the StatelessSession interface; a new Dev UI; Gradle 8.0; custom redirect handler in REST Client Reactive via the @ClientRedirectHandler annotation; and time zones for cron-based schedules via @Scheduled annotation. More details on this release may be found in the changelog.
Quarkus 2.16.14.Final, the fourth maintenance release, delivers notable changes such as: propagate Quarkus-related failsafe system properties; return a null InputStream from REST Client when the server response is 204, No Content; and improved logging in the DevServicesKubernetesProcessor class. Further details on this release may be found in the changelog.
Open Liberty
IBM has released Open Liberty 23.0.0.2 ships with new features such as: testing database connections with the Admin Center; a new a --timeout command line option for the server stop command; and a fix for CVE-2022-45787, a vulnerability in which improper lazy permissions on the temporary files used by the TempFileStorageProvider class in Apache James Mime4J that may lead to information disclosure to other local users.
Micronaut
The Micronaut Foundation has released Micronaut 3.8.7 featuring bug fixes, improvements in documentation and updates to modules: Micronaut Serialization, Micronaut CRaC, Micronaut Kafka, Micronaut AOT and Micronaut GCP. There was also an update to SnakeYAML 2.0, that addresses CVE-2022-1471, a vulnerability in which the deserialization of types using the SnakeYAML Constructor() class will allow an attacker to initiate a malicious remote code execution. More details on this release may be found in the release notes.
Helidon
Oracle has released Helidon 2.6.0 with notable changes such as: register the OciMetricsSupport service only when the enable flag is set to true; a dependency upgrade to SnakeYAML 2.0; cleanup the Helidon BOM by removing artifacts that are not deployed; and remove the claim that metrics are propagated from server to client in the documentation.
Apache Software Foundation
The fourth milestone release of Apache Tomcat 11.0.0 that delivers: restore the original system property-based approach to load the custom URL protocol handlers; provide an implementation of the subset of JavaBeans support that does not depend on the java.beans package; and restore inline state after async operation in NIO2 to address unexpected exceptions being thrown by the implementation. Further details on this release may be found in the changelog.
The second milestone release of Apache Camel 4.0.0 features bug fixes, dependency upgrades and new features such as: pre-signed URLs in the camel-minio component for connections to cloud services; add health checks for components that has an extension for connectivity verification in the camel-health component; and catalog output is now in JSON format with the camel-jbang component. More details on this release may be found in the release notes.
JobRunr
JobRunr 6.1.1 has been released featuring two bug fixes: an error executing a recurring job with the JobLambda interface; and a NullPointerException due to missing property at job JSON when using Yasson.
Jarviz
Version 0.3.0 of Jarviz, a new JAR file analyzer utility, has been released by Andres Almiray to the Java community. This new version ships with bug fixes and new features such as: a new command, extract, to extract JAR entries by name or pattern; a new command, validate, to validate package names; and a new --output-format command-line option to specify a desired output.
Hilla
From the makers of Vaadin, version 2.0 of Hilla, an open source framework that integrates a Spring Boot Java backend with a reactive TypeScript frontend, has been released. This new version features support for: JDK 17; Jakarta EE 10; Spring Boot 3.0; reactive nedpoints; native image compilation with GraalVM; and an SSO Kit for quickly adding single sign-on capabilities to Hilla apps. Further details on this release may be found in the release notes and in this InfoQ news story.
JetBrains Releases Rider 2023.1 EAP 6 with Improvements of UI and Debugging Experience
MMS • Robert Krzaczynski

Recently JetBrains released Rider 2023.1 EAP 6. This new release contains some UI improvements: adding Compact Mode, project tabs for macOS users and the option to split the tool window area. Additionally, EAP 6 improves the debugging experience for developers.
The development of Rider 2023.1 is progressing rapidly. A few weeks ago, versions EAP 4 and EAP 5 were published consecutively.
In order to enable UI improvements, go to Settings/Preferences | Appearance and Behaviour | New UI, and then restart the IDE.
The first enhancement is about adding the option to split the tool window area to conveniently place all windows. For adding a tool window to this area and placing it at the bottom, drag its icon along the sidebar and drop it under the separator. Alternatively, it is possible to right-click the icon to bring up the context menu and assign a new position for the tool window using the Move To action.
There is also Compact Mode, which provides a more comfortable experience on smaller screens. This is achieved through the reduced height of toolbars and tool window headers, reduced spacing and complements, and smaller icons and buttons. Compact Mode can be activated by going to the View menu and selecting Appearance | Compact Mode.
Another feature is dedicated to developers working on macOS – the project tabs. When a user has several projects open, they can now switch between them using the project tabs displayed below the main toolbar.
The EAP 6 version also introduces an improvement to debugging. Starting a debugging session for an ASP.NET Core application in Rider causes the IDE to open a new browser window or tab. Until now, starting multiple debugging sessions left multiple tabs open, which then need to be closed manually. Starting with EAP 6, whenever debugging an ASP.NET Core application with the JavaScript debugger enabled, Rider will close the corresponding browser tab when the process is stopped.
Below the release post, Jonathan Dunn wrote the following comment:
Hi, I love most of the new changes, but one thing that was annoying was the automatic switch to the new ‘Dark RC’ colour scheme. It’s nice, but some of the font colours were not to my liking.
Sasha Ivanova, a marketing content writer in .NET tools at JetBrains, answered that will share this feedback with the team. Sasha also suggested a short-term solution:
In the meantime, what do you think of the colour scheme options available through the plug-ins? There is one called Darcula Darker and it provides more contrast to the familiar palette.
The entire changelog of this release is available on YouTrack.
MMS • Sergio De Simone
Ngrok-go is an idiomatic Go package that enables Go applications to securely receive network requests through ngrok’s ingress-as-a-service platform as if they were listening on a local port.
ngrok-go aims to simplify the creation of network ingress by taking care of a number of low-level network primitives at different layers of the network stack that developers are responsible to set up today to enable network ingress. That includes DNS, TLS Certificates, network-level CIDR policies, IP and subnet routing, load balancing, VPNs and NATs.
ngrok-go can be seen as a way to package the ngrok agent and embed it into a Go app, thus removing a significant complexity for apps that used to bundle ngrok to create network ingress, such as IoT devices, CI/CD pipelines, and others.
ngrok-go lets developers serve Go apps on the internet in a single line of code without setting up low-level network primitives like IPs, certificates, load balancers and even ports!
To embed ingress through ngrok into a Go app, all developers need to do is calling the ngrok.Listen primitive provided by ngrok-go. If your environment has an ngrok authtoken, the call to Listen will initiate a secure and persistent connection to ngrok and transmit any configuration requirement you specified, including URL, authentication, IP restrictions, and so on, for example:
ngrok.Listen(ctx,
config.HTTPEndpoint(
config.WithDomain("my-app.ngrok.io"),
config.WithAllowCDIRString("192.30.252.0/22"),
config.WithCircuigBreaker(0.8),
config.WithCompression(),
config.WithOAuth("github")
),
ngrok.WithAuthtokenFromEnv(),
)
All the policies specified when calling Listen are enforced by ngrok, which rejects all unauthorized requests at the edge, which means that only valid requests will ever reach the Go app.
Another advantage of using ngrok-go is its “portability” with respect to ingress. This means an app using it will just run the same way independent of the underlying platform, be it bare metal, a virtual machine, AWS, Azure, Kubernetes, and so on.
While ngrok chose Go as the first language to support, support for other languages is already in the works, including Rust and JavaScript. Other languages like Java, C#, Python and Ruby are expected to be included in the roadmap soon, also based on users’ feedback.
If you are interested to try it out, ngrok-go is available on GitHub and a good place to start is it official getting started guide.
MMS • RSS

We published a new industry research that focuses on NoSQL Database market and delivers in-depth market analysis and future prospects of Global NoSQL Database market. The study covers significant data which makes the research document a handy resource for managers, analysts, industry experts and other key people get ready-to-access and self-analysed study along with graphs and tables to help understand market trends, drivers and market challenges. The study is segmented by Application/ end users [Laboratory, Industrial Use, Public Services & Others], products type and various important geographies like North America, Europe, Asia-Pacific etc].
Get Access to sample pages @ marketreports.info/sample/366356/NoSQL-Database
The research covers the current market size of the Global NoSQL Database market and its growth rates based on 5-year history data along with company profile of key players/manufacturers. The in-depth information by segments of NoSQL Database market helps monitor future profitability & to make critical decisions for growth. The information on trends and developments, focuses on markets and materials, capacities, technologies, CAPEX cycle and the changing structure of the Global NoSQL Database Market.
The study provides company profiling, product picture and specifications, sales, market share and contact information of key manufacturers of Global NoSQL Database Market, some of them listed here are DynamoDB, ObjectLabs Corporation, Skyll, MarkLogic, InfiniteGraph, Oracle, MapR Technologies, he Apache Software Foundation, Basho Technologies, Aerospike. The market is growing at a very rapid pace and with rise in technological innovation, competition and M&A activities in the industry many local and regional vendors are offering specific application products for varied end-users. The new manufacturer entrants in the market are finding it hard to compete with the international vendors based on quality, reliability, and innovations in technology.
Further the research study is segmented by Application such as Laboratory, Industrial Use, Public Services & Others with historical and projected market share and compounded annual growth rate.
Geographically, this report is segmented into several key Regions, with production, consumption, revenue (million USD), and market share and growth rate of NoSQL Database in these regions, from 2022 to 2030 (forecast), covering North America, Europe, Asia-Pacific etc and its Share (%) and CAGR for the forecasted period 2022 to 2030.
Read Detailed Index of full Research Study at @ marketreports.info/industry-report/366356/NoSQL-Database
Following would be the Chapters to display the Global NoSQL Database market.
Chapter 1, to describe Definition, Specifications and Classification of NoSQL Database, Applications of NoSQL Database, Market Segment by Regions;
Chapter 2, to analyse the Manufacturing Cost Structure, Raw Material and Suppliers, Manufacturing Process, Industry Chain Structure;
Chapter 3, to display the Technical Data and Manufacturing Plants Analysis of NoSQL Database, Capacity and Commercial Production Date, Manufacturing Plants Distribution, R&D Status and Technology Source, Raw Materials Sources Analysis;
Chapter 4, to show the Overall Market Analysis, Capacity Analysis (Company Segment), Sales Analysis (Company Segment), Sales Price Analysis (Company Segment);
Chapter 5 and 6, to show the Regional Market Analysis that includes North America, Europe, Asia-Pacific etc, NoSQL Database Segment Market Analysis (by Type);
Chapter 7 and 8, to analyse the NoSQL Database Segment Market Analysis (by Application) Major Manufacturers Analysis of NoSQL Database;
Chapter 9, Market Trend Analysis, Regional Market Trend, Market Trend by Product Type, Market Trend by Application [Laboratory, Industrial Use, Public Services & Others];
Chapter 10, Regional Marketing Type Analysis, International Trade Type Analysis, Supply Chain Analysis;
Chapter 11, to analyse the Consumers Analysis of Global NoSQL Database;
Chapter 12,13, 14 and 15, to describe NoSQL Database sales channel, distributors, traders, dealers, Research Findings and Conclusion, appendix and data source.
What this Research Study Offers:
Global NoSQL Database Market share assessments for the regional and country level segments
Market share analysis of the top industry players
Strategic recommendations for the new entrants
Market forecasts for a minimum of 5 years of all the mentioned segments, sub segments and the regional markets
Market Trends (Drivers, Constraints, Opportunities, Threats, Challenges, Investment Opportunities, and recommendations)
Strategic recommendations in key business segments based on the market estimations
Competitive landscaping mapping the key common trends
Company profiling with detailed strategies, financials, and recent developments
Supply chain trends mapping the latest technological advancements
Buy this research report @ marketreports.info/checkout?buynow=366356/NoSQL-Database
Reasons for Buying this Report
This report provides pin-point analysis for changing competitive dynamics
It provides a forward looking perspective on different factors driving or restraining market growth
It provides a six-year forecast assessed on the basis of how the market is predicted to grow
It helps in understanding the key product segments and their future
It provides pin point analysis of changing competition dynamics and keeps you ahead of competitors
It helps in making informed business decisions by having complete insights of market and by making in-depth analysis of market segments
Thanks for reading this article; you can also get individual chapter wise section or region wise report version like North America, Europe or Asia.
About Us:
Marketreports.info is the Credible Source for Gaining the Market Reports that will provide you with the Lead Your Business Needs. The market is changing rapidly with the ongoing expansion of the industry. Advancement in technology has provided today’s businesses with multifaceted advantages resulting in daily economic shifts. Thus, it is very important for a company to comprehend the patterns of the market movements in order to strategize better. An efficient strategy offers the companies a head start in planning and an edge over the competitors.
Contact Us
Market Reports
Phone (UK): +44 141 628 5998
Email: sales@marketreports.info
Web: https://www.marketreports.info
MMS • Omar Sanseviero

Transcript
Sanseviero: My name is Omar Sanseviero. I will talk about open machine learning. I would love to begin talking a bit about the history, at least over the last few years. Three years ago, OpenAI released GPT-2. GPT-2 is a large language model. It has 1.5 billion parameters. It was trained on 8 million webpages, and GPT-2 is trained with a single simple objective, predict which is the next word. OpenAI iterated on GPT, they launched GPT-3. GPT-3 was extremely impressive, it was able to generate entire website layouts. Also, it was able to generate code based on network strength. If you’ve played with Copilot, this is the technology backing it up. Although the results are quite impressive, OpenAI decided not to release the model due to concerns about malicious applications of the technology. This is understandable, but at the same time, this caused a big issue in the science world. You cannot reproduce the results. This lack of reproducibility makes it extremely challenging to scientifically, rigorously evaluate the model.
Two years ago, a community called EleutherAI, it’s a collective of volunteers, they decided to build an open source GPT. You would expect that’d be a group of academics, but this was actually a Discord server, and the initiative started as a joke. Then it turned out to be serious. EleutherAI has been able to do very interesting open science and open source work. They have released large GPT models such as GPT-J and GPT-NeoX. They have been able to open source huge datasets, such as The Pile, and there are projects around art generation and much more. It became a huge collaboration. They have published over 10 papers. It has been a quite exciting alternative for open science, compared to GPT-2 or GPT-3.
BERT 101 – State of the Art Model Explained
Another very famous language model is BERT. BERT was created and was publicly released by a research lab at Google. Bringing a large BERT model from scratch was a quite compute intensive task and required lots of data and lots of compute resources, that is money. Although Google released the code for training the model, very few institutions were able to have resources to do a training from scratch. Something interesting happened then, BERT was considered state of the art, so, many research groups were training a BERT model to have a baseline to compare their new research proposals. Each time a research lab wanted to do these baselines, they weren’t training a BERT model from scratch. This led to a lot of issues. For example, people sometimes used different languages, different scripts, different hyperparameters, so it was hard to reproduce the exact same results as the ones published in the original paper. This also has ecological and financial impact. If you’re training the model again and again, you are, at the end, having direct impact. This also means that just the research labs that have significant compute resources can actually create these baselines, so if you’re talking about universities that don’t have the amount of compute resources to train a BERT model from scratch, they couldn’t do it.
Transformers
There was an open source alternative created after some time. At Hugging Face, we created a library called Transformers with the idea of easily sharing pre-trained Transformer models. Transformer is the architecture of BERT. GPT-2 is also a type of transformer model. The idea with the library is quite powerful. It enables people to load models from a shared place with only a line of code, hence solving the reproducibility issue and making transformers available in the hands of everyone. The project was launched almost three years ago, it was launched in 2018. The open source adoption has been extremely wild. Right now, it has almost 60,000 stars in GitHub, thousands of organizations and users are using transformers to share their work.
News Summarizer
Let’s say you want to build a news summarizer. The summarization task is quite simple. The idea is that provided a large text you can think a news article, a blog post, any large text. The machine learning model will make a summary of it, that is a small summarization of the original text. Before going and training a large model for this, the first thing you will want to do is collect and clean a dataset. There you go, you might have to use hundreds of thousands of dollars to collect, clean, correct the dataset, explore it. Then after that you can use the dataset to train the model. How do you train the model? You need to pick the right one. There might be many different architectures. You might need different teams trying different explorations. You might want to train a model from scratch. Even then, if you get the model after, the metrics might not be good enough and you might need to go and collect more data.
Is There an Easier Way?
Similarly, can we do better? Can we do any alternative that is out there in the open? What I just described before in this news summarization use case can be quite simpler. If you’ve used GitHub before, your approach when doing software related projects most likely to explore, find repositories with tools to solve some of the problems you have. You don’t want to reinvent the wheel. You will collaborate with your team by having a shared repository. Once you’re ready, once you have a project that might depend on other open source projects, you might open source your work for the whole ecosystem to use. We can do exactly the same with machine learning. Why do we have hundreds of people training the same model for the same thing, again and again, how many summarization models there might be out there? What if we could instead have a central platform through which people could collaborate, explore, and discover models and datasets? That’s where Hugging Face comes in. The Hugging Face Hub is a free open source platform with over 30,000 models and 3,000 datasets in which people can easily collaborate in their machine learning workflows.
Transfer Learning
Before going a bit more in this, something that is quite important in the transformers world is transfer learning. Transfer learning has been actually quite impactful in the last few years, not just for NLP, but also for computer vision and other domains. What’s the whole idea in transfer learning? In the classic supervised learning, an example of machine learning, that’s probably the most common one, you will grab a dataset with labeled queries or labeled samples, and you will train a model to generate the predictions. Let’s say now that you have a second domain, you will now again train a model from scratch to solve this particular task. With transfer learning, the idea is to extract knowledge from a source task, from a domain A, and then be able to apply it to a different task. For example, let’s say that you will train a large language model that will get a statistical understanding of a language, let’s say in Spanish, then you can fine tune-this model to solve a particular Spanish related task, let’s say summarization. Right now, since you are using transfer learning, you will transfer the knowledge of this base, original, large model. Then, since you already have this pre-trained model, you don’t need that much data, you don’t need as much compute resources. It’s actually much cheaper, takes very few minutes or a few hours at most. It can be quite powerful. This is not just for NLP, this is also for computer vision. This is what Convolutional Neural Networks are doing. You can also do it for speech, biochemistry, time series. Reinforcement learning is starting to use Decision Transformers as well. We don’t know yet but there will likely be other domains in which people can apply transfer learning and transformers.
Brief Tour Through Open Source Family
We’ll take a brief look at the open source ecosystem, you can observe some of the GitHub repositories that we have. We’ll dive into some of this. Across our libraries we have over 1000 different contributors without which the libraries wouldn’t exist. That’s very important, because this is not a couple of libraries maintained by a single company, but by a huge community of different contributors. Across all of these libraries, we have over 60,000 stars in GitHub. Let’s go with the first important pillar of this platform, of the hub. One key aspect is sharing models. The model hub is a free open source central repository for models across different frameworks. People can share transformer-based models here, but also from other NLP frameworks. If you use AllenNLP, Flair, or spaCy, or vision frameworks such as timm, or PyTorch Image Models, or even other fields, from speech, ESPnet, SpeechBrain, PyAnnote, all of these are different open source libraries. The hub actually just passed a milestone, there are 30,000 models shared by the community. The hub serves as a central sharing point for all these models. It shines in multiple aspects. It enables reproducibility. With just a single line of code, people can go and load one of these models. By sharing checkpoints, users can simply load the model, test, and evaluate models. This enables people to actually reproduce the results sharing their inner papers. Then, with the concept of transfer learning or fine-tuning, people can easily pick a model from one domain for a certain task, and adapt it for their own particular needs. This is not just for English, there are over 180 languages on the hub.
A Small Tour Through the Features
Let me just quickly show you a bit of this. This is going to the Hugging Face website. As you can see, on the left, people can filter for things such as question answering, summarization, Fill-Mask, which are different tasks that machine learning models can solve. If you click the +14, you can find the different domains for which you can apply these models. You can search for image classification models or reinforcement learning models or translation. Then, you can also filter based on the library, based on the dataset, based on the language. Here at the right, you can see the different models out there. I see this one, GPT-2. Actually, OpenAI released a small version of GPT-2. It was not a huge model, but a smaller version of it. What you are seeing here is the model repository. The concept is quite similar to GitHub, you have Git based repositories that have version control. If you click files and versions here, you can see all the files in this repository. You can click here the history, and you will be able to explore all the history of this model repository.
Then, going back to the model card. What’s the model card? A model card is an excellent way in which people can document what the model does. It has things such as the model description, which are the intended use cases and limitations. It might have snippets of how to use this model. Even a section on limitations and biases. These models were trained many times with lots of data from the web, such as unfiltered content from Reddit. The models can have, of course, many biases and generate very concerning quirks. You need to be very careful in how you use these models. It has model data on how the model was trained, which data was used for training, which are the evaluation results. All of this is actually quite exciting. This is a way in which anyone can go here, read this, understand the model. They can go and see the actual files for this. Or if they want, they can click here, using transformers, and with these three lines of code, they can load this model in the transformers library.
This was the first thing mentioned here, model card, version control. The third one is interactive widgets. You can actually play with the model directly in the browser. It may take a few seconds the first time because it’s loading the model. You can actually play with the model directly in the browser without having to run a single line of code. This is quite powerful, especially if you are exploring which model to use. It has things such as TensorBoard hosting, so if people share TensorBoard logs, they can freely host their TensorBoard logs directly in the browser. This is a nice way to track how different models have been. The last example I would like to show is the evaluation results. Evaluation results allow people to self-report metrics on a specific dataset. Thanks to a nice integration with Papers With Code, you can actually compare all of the different models for a given dataset for a certain task. This is quite powerful. People can even do things such as report CO2 emissions. You can use this with any library that you love. If you’re a TensorFlow user, if you are a PyTorch user, if you are using a higher-level library or a more specialized library, you can use this as well.
The usual workflow is that you can go, you can find an open source model in the model hub, which was published either by a practitioner or by a researcher. You can find and pick this pre-trained model. You can then go and take a dataset. You can go and search for a dataset that will be interesting for your use case. Then you can do the fine-tuning of your model with this particular dataset. The open source philosophy is that once you are done with this, you will open source your model for anyone else to use. This will contribute back to the community that helped you by having pre-trained models that you were able to use.
Datasets Hub
We were talking about datasets. The next question is, how do you get these datasets? Actually, the hub also contains datasets. It is a catalog of datasets shared by the community which you can as well load with a single line of code. It contains well known datasets such as SQuAD or the GLUE benchmark, as well as many other datasets for classification, question answering, summarization, language modeling, and more. As of now, the Dataset Hub has over 3000 datasets. As for the model hub, each dataset comes with versioning using Git, so you can do reproducibility, you can load different versions of the dataset and more. There are two key components to the Datasets Hub. There is the platform, the web UI, which has the largest hub of ready-to-use datasets for hundreds of languages and different tasks. There’s also a Python open source library called datasets, which allows you to load a dataset with a single line of code. There are no RAM limitations, so if there is a huge dataset, which is terabytes, there is something called streaming that allows people to just load the data as needed. It allows to have very fast iterations and querying. If you don’t want to share your dataset with the whole world, you might want to host your datasets through Amazon Web Services, or other places. This is also enabled, so people can also use the datasets library or datasets that are not hosted on hub. That’s totally fine.
Demos
I would like to talk about the third last pillar, which are probably the most interesting. By using open source libraries such as Streamlit or Gradio, people can easily create interactive demos that allow anyone to try out a machine learning model. This increases the reproducibility of research. By having them share in the web, anyone can just go and try this out. Here you can see a small gif of a demo in which the user selects an image, clicks submit. Finally, they get that classification result that says it’s an alligator. How do you build such a demo? How do you share your model as a web app? Until recently, people had to learn some new tools. Many of our engineers actually don’t have that much experience in web technologies, for example, or you cannot probably expect people that are focused on writing papers, being able to know about Flask, Docker, or JavaScript, CSS, and more. This can actually discourage people that don’t know how to use these technologies. For each part of this stack, there are different tools. This makes things even more complicated. After you train a model, you need to deploy it with tools such as Docker. Then, you might want to store incoming samples with SQL. Then you will want to build an interactive user interface with frontend technologies such as HTML, JavaScript, CSS, or Svelte, or any other advanced frontend framework.
Gradio is an open source Python library that allows to take each of these steps in a single path, in a single pipeline, which makes things extremely easy. You might expect the code to be actually super-complicated, but what you see at the left has the three key components. There are three parts. The first one is this classify_skin_image, that’s a prediction or classification function. The idea is that this function will take an input and will output an output. Then you will have the types of the input and the types of the output. In this example, the input is an image and the output is a label. Then once you have this, you can launch this interface from anywhere you want. This can be from the command line. This can be from a Jupyter Notebook. This can be from a Colab notebook. The result can be seen here at the top right. You have a web interface that anyone can go and try it out. You put an image, you click submit, and then you get this image response to a benign or cancerous skin photo issue.
Let’s build a Gradio demo ourselves, actually. This is really quite simple. I will do this right now live. Here, let’s see these three first parts. First, we will install Gradio. That’s already done. Then you will have a prediction function. In this case, I’m not loading any ML model. I’m just doing a Hello World or Hello name. The idea is the same. You have a function that takes an input and has an output. Then the last part is the interface, which does all the UI. Let’s see first, what is that? My name is Omar. I will click Submit, and I get Hello Omar. What’s the code for this? First, you have a Gradio interface that’s actually quite simple. You have this prediction function, in this case, it’s greet. This prediction function takes an input and an output. The input in this case is a single text. The output is, again, another text. That’s it. Once you click launch, you get this. You can take screenshots, if you want. You can clear. You can do many things. You can adapt the UI if you want something fancier. You can have multiple inputs, multiple outputs. You can run many models in parallel. There are actually quite a few alternatives you can do within this. This is the simplest example. What is very nice is that at the end, the syntax is extremely simple. All the complexity relies in this prediction function. Let’s say that you have a TensorFlow model. What you can do is just load the model before. You can load a model here. Then you can just write the inference within the prediction function. This shows you how generic or how flexible this is. No matter if you have a spaCy model, a TensorFlow model, a PyTorch model, no matter what you are using in the Python world, you can very easily use a prediction function to create a nice web interface.
Let’s see a very quick second example. This example is actually using GPT-J, which is this model from EleutherAI. The interface is a bit nicer. As you can see, it has a title. At the bottom, you can see a couple of examples. For example, I can click here. “The moon’s orbit around Earth has,” you can click Submit, and then at the right I will get which is the output of this interface. The moon’s orbit around Earth has one of several shapes. Then after this, all of the text is completely generated by the GPT-J model. In terms of how this works, this specific syntax is using an already existing model in the hub. It’s using something which is called the inference API. It is using that under the hood. The idea is pretty much the same, you have an input, you have an output, and we’ll have a prediction function that will take care of everything in between.
Let me show you a couple of demos to have an idea of what things you can do, because this is not limited to text. You can do things such as face stylization with JoJoGAN. JoJoGAN is a one face stylization. In this case, you’re seeing a picture of me being stylized as a Disney feature. This is the demo that we were talking in the third use case. Let’s say that you want to do a summarization of a news article. What you can see is that at the right, the user can paste a URL for a news article. At the right the output will be a short summary of the article from the link. This third one is a voice authentication model and demo from Microsoft. This is using WavLM plus X-Vectors. The idea here is quite fun. You will upload two different audio files. Then the model will determine if this is the same person speaking in the two audio files, or if these are different persons. This is quite nice. This shows you that these demos are not limited to NLP or to computer vision but also extend to things such as audio. This is the last example I would like to show. This is GLIDE from OpenAI demo. This allows people to write the text and the image on the right is fully generated by this model called GLIDE.
The Spaces Platform
We’ve been able to create demos. We’ve been able to run them in Colab. All of this is quite nice. We built a demo. Now the question is, how do you share this with the community? For this, there is the third pillar in Hugging Face, which is called Spaces. Spaces is a central platform through which people can upload their own machine learning demos and share them with the rest of the ecosystem. It was launched in October of last year. Again, all of this is open source and free. This has, by today, over 2000 different spaces created and shared by the community. Let’s say that we want to create our own space, so we can just create a new space. You can put any name you want. You can use Streamlit, which is another Python library for creating demos. You can use Gradio, or if you want to go a bit hardcore, and you do want to use HTML and JavaScript or something such as TensorFlow.js, you can go with Static, which is just custom HTML and JavaScript. You can make this public or private.
Again, all of this is based in Git, so you can actually go and do git clone in your computer. Here are some instructions of how you can do it. If you don’t want to download them, you can do everything directly in the web browser as well. You can just create a file, which is something like app.py. Let’s do the same demo we had over here. Let me copy these lines, so the prediction function. Let me import Gradio. Finally, let’s copy the interface. As you can see, the code is exactly the same. I have not changed anything. You have the import gradio. You have the prediction function. Finally, you have the interface which specifies the prediction function, the input, and the output. This takes a couple of seconds the first time because this is loading. At the end, you have this web interface that you can try it out. My name is Omar. We have the exact same result as we were having before. You can do things, again, since this is based in Git, you have version control. You can see the logs if you want to see the logs. You can make it public or private. You can even automatically embed this in other websites, if that’s something that you would be interested in. As you can see, this was quite easy to do. You can even specify your own requirements, so if you’re using other third-party dependencies, you can use that without any issue.
The Machine Learning Turning Point
We have seen that these demos have become quite popular, and have enabled people that are not from the machine learning world necessarily, to access and play out with these models. For example, a couple of months ago, there was a new space for AnimeGanv, and everyone in social media, in TikTok, in different places, were trying out AnimeGanv. This was quite interesting because this increased the audience of the machine learning model. We think we are in a turning point in usage of machine learning. Until now, people that wanted to try out a model were normally ML engineers, ML researchers, software engineers, and if people were sharing models, or let’s say scripts, people had to go to GitHub, people had to open Colab, people had to run actual code. This was already a huge barrier of entry for other people. Now with Spaces and with these nice demos, anyone who can use a graphic user interface, or a browser can access these demos. This is quite powerful. If you have a model that might have some biases, this open, transparent, public open source approach will enable the community and a more diverse set of users to try out your model. This will allow you to find biases in your model, issues, and other things.
From a research perspective, this will also make your work public to everyone to try out. If you compare just a paper, or a paper with a nice, open interactive demo that anyone can use, the interactive demo with the paper will be potentially much more impactful and will help people understand what the model is doing. This will also help avoid cherry picking, increase reproducibility, and much more. Through these three pillars, models, datasets, and demos or Spaces, this enables anyone in the community to share their work, collaborate with others, work in a team, just with the same Git-based workflows that people are used to for software engineering with things such as GitLab, or GitHub. People can do this for machine learning as well and share their models with the ecosystem. There won’t be a single company that will solve NLP or computer vision, it will be a community thing. These are things in which everyone needs to get involved. I hope you were able to learn a bit more about the open source alternatives and tools that you can use right now to share the amazing work that probably many of you are doing.
Questions and Answers
Breviu: Why is OpenML so important? You’ve talked a little bit about the history and a lot of the challenges and things that Hugging Face has really made so easy that used to be so hard. I’m curious like more of your perspective on OpenML and where this is going.
Sanseviero: Our goal as a company is to really enable collaborative machine learning. This is very ingrained in the vision of the founders and other team members. That sounds extremely broad, and maybe a bit ambiguous. What we want to do is to really enable anyone to work and collaborate in machine learning. What that means is that if you want to use models, you can easily share your models with others and others can easily use your models, which is extremely important for transfer learning. This also means that if you want to access datasets, they should be public, and you can use them. This is not a rule that everything should be open source, or not all datasets should be open source. There’s, of course, medical datasets that have lots of very sensitive data. The idea is that, for example, there’s lots of research that might publish datasets, or very interesting models, but it’s very hard to actually use this data, or very hard to replicate the results of these papers. What we’re doing is really making this extremely accessible to everyone. Then we launched Spaces which also makes it extremely easy to access demos and to show demos to people that might not have a technical background even, or a ML background.
Now we are starting to explore not just a technical audience, but also audio-visual, non-technical people to understand what machine learning is. For example, something that we did a couple of months ago is this thing which is called Task Pages. Task Pages are a very nice way to understand different tasks. This is more for non-ML people. For example, what is question answering? You can go here and you’ll get a small schema of what question answering is. I think we are starting to increase our scope. Originally, we were mostly focusing in NLP. Now we are focusing in really, all the machine learning ecosystem, which is huge. Now we are doing computer vision, and audio, and speech, and reinforcement learning, and other things.
Breviu: I love that you have that task, because most models are like they’re trying to answer a question. Every model ends with a question, a pointed question. The democratization of it where people can come in, and you don’t really have to know what you’re doing, you can do this implied AI thing where you can grab these models and just start using them. It’s so powerful. You talked about all those issues, and how you’ve gotten over those with these tooling.
Are the biases declared upfront as a model is checked in? How do you make sure they are ethically sound?
Sanseviero: There is this tool called model cards. Model cards might show sections such as intended uses and limitations, how to use, they might have a few other things. These files under the hood, they are really just Markdown files. This is just plain Markdown, it’s not any fancy text. Right now, we don’t have any automatic validation, but we do have a few projects ongoing on how to do automatic bias evaluations. We are starting to work in those to analyze, which are the biases that models might have. Right now, what we do is that we encourage everyone to add these kinds of sessions such as intended uses and limitations. Meg Mitchell is one of the most prominent researchers in the ethics for machine learning field. She joined the company a couple of months ago. We are doing both technical work and also research in the more high-level aspects of this. Again, we don’t have any automatic thing. Right now, anyone can share ML models. What usually happens is that people just use models that are purely documented. Similar with code, you don’t go and take any Python library, but instead you really look for documented code and documented models. Most researchers nowadays when they publish any model, they are already creating nice model cards that document the biases that they might have.
Breviu: I like that there was a talk about ethics too, because I think so frequently in machine learning ethics were an afterthought. If you think about all the issues that have happened, it’s like, look what we can do, but we didn’t really think about, who could this hurt? What do we need to consider there with our models? There’s actually a talk on this track where we’re going to talk about different tooling, where the person developing the tool, or the model can actually look into the ethics of the model and take on that ownership because you are posting it. It’s almost like a GitHub, like you’re posting your model, your code, and everything out there for other people to use. When you do that on GitHub with regular code versus this is machine learning, you do that same thing. You put a ReadMe in. You have information on how to use it, and those types of things. It’s your code. It’s on your user name too. I feel like putting that ownership on the people that are submitting things is part of it too. You guys are creating this platform for awesomeness. I think it’s great to think that you guys are hiring ethics people to make sure that you can automate some of that, but then it’s also on, I feel like the individual as well.
Sanseviero: You could say something a bit similar with GitHub. It’s not like all the repositories uploaded by the users are being analyzed if they are meeting ethical criteria. We are working very practically right now in having very clear guidelines on what things can be shared. How should people document these biases, because it’s extremely frequent at least most of the time that models will have biases. It’s extremely important to have very clear documentation to really help users to easily create a better documentation for their own models.
Breviu: Can you compare OpenAI with OpenML?
Sanseviero: OpenAI is a company. It’s a very large company that has been creating some very powerful models. GPT-3, for example, the inferencing that GPT-3 has. Very popular in the last couple of weeks is DALL·E. The DALL·E 2 model that has been creating these extremely amazing images. This is OpenAI, which is a company that was founded a couple of years ago. What they did, when they began, they did open source some of their models at the beginning. The original GPT was open source, but after that, with GPT-2 they decided to not release the models due to concerns with ethical issues. That was the public explanation given by OpenAI. What they have been doing, though, is that they have been making all of the research public at least, so that means that the paper to reproduce the results are out there. This has many issues, because this means that the research is out there, but you cannot reproduce it unless you’re willing to spend a couple of millions of dollars. At least from the more research perspective, it’s at least an improvement to previous methods in which no one was open sourcing anything at all, nor making their research public.
There are, though, efforts from the community to replicate things. For example, with GPT, I mentioned GPT-J, now there’s OPT, which was launched by Meta, which is a very large GPT model as well. Similarly with DALL·E, it’s an ongoing effort, which is called DALL·E mini by a community member called Boris. This is pretty much the same concept that you write an input, for example, astronaut riding horse in the moon, and these images are generated by the model. This is a smaller version of DALL·E. Right now, there are two very large efforts in the community to create a DALL·E model on the same scale as the DALL·E from OpenAI. I think OpenAI is a company, OpenML is really a culture of making things open. It’s making open source code, open source models, and really a collaborative mindset.
Breviu: I think that the DALL·E model is super cool. Then using large language models in the computer vision space, I also think is really interesting because CNNs or Convolutional Neural Networks have really been the main way to do computer vision for so long. Then, now the way that they’re starting to use transformer models to solve computer vision problems, or create computer images is just so cool.
Sanseviero: We’re starting to see transformers being used. Vision transformers are for computer vision, so we transformers models being used for image classification, object detection, but also for reinforcement learning. There are Decision Transformers, and there is also for audio and speech. Wav2Vec 2.0, for example, is a very good model to do automatic speech recognition, which means taking an audio and then outputting the text, even in tabular data and time series. There are very interesting efforts in applying these large transformer models in other domains.
Breviu: If we use pre-trained models, can we get good results in a specific domain with more limited data, like fine-tuning a large model with a small or medium sized dataset in a specific domain?
Sanseviero: Yes, that’s exactly what transfer learning tries to achieve. Actually, transformer models are extremely good at least in NLP. If you pick BERT, for example, which is a very large language model, and then you fine-tune it with your own dataset, even if you just have a couple of hundreds of samples, it’s really very little data, you can already get some very cool results. Even then, if you don’t have any data at all, there is one model called zero-shot classification. This model, you can see here on the right, there is this small widget. What zero-shot classification does is that you input a text, so, for example, I have a problem with my iPhone that needs to be resolved as soon as possible. This model was not trained to classify based on a fixed set of labels. It was not trained with these labels. For example, urgent, not urgent, phone, tablet, computer. The model was never trained to label based on this. What you can do with zero-shot classification models is that you can specify the labels that you want in the inference time. You never trained the model directly with these labels, but instead now they’re able to do it in inference with zero-shot classification. That’s really just an extra piece of information, but what you said is perfectly correct. That’s what most people are using transformers nowadays for. They pick these large transformer models, they do fine-tuning with their own small or medium dataset, or their own specific domain. For example, now I want to use BERT for research, or now I want to use this even for code. There are some large pre-trained models for code that you can do fine-tuning for your own specific programming language, for example.
Breviu: That’s actually the demo that I did, I used Hugging Face Hub, and I used a model that Microsoft open sourced, that was a distilled BERT model. It was very much smaller, but it was task agnostic. Then I used a dataset to actually train it into a sentiment analysis model. You could take this distilled, much smaller model, fine-tune it with that dataset. Then I use quantization to actually make it smaller, and then deploy it to web. I actually used the Hugging Face tooling that they have to do exactly that. It’s so powerful. Because before, you’d have to start with nothing, and it would take so much longer, you’d have to have so much more tooling. Then, also, the model that was trained is now open source. You could just go grab that model, and use it again. I think having these model zoos, where you can just go and grab pre-trained models, makes the applied AI space grow even more too. Because you can just go in there and use what’s there and apply it to your problem without having to understand all the different operators and machine learning frameworks.
Is it better to fine-tune the word embedding, or just take the general word embedding and train just the transformer?
Sanseviero: When you train the whole transformer, you are also training the embeddings. You just input the text or the tokens, and the model then will learn both the embeddings. It will learn how to compare the text to an embedding space. This actually opens some very interesting applications. There’s a very famous library called SentenceTransformers, which allows us to map sentences or to create embeddings not just for words, for tokens, but for whole sentences. What this means is that now you can map directly one full sentence, or paragraph, or document, or essay into embedding of 256 or 512 numbers. This is really a vector, and now you can do comparison between vectors. This is extremely powerful because if you want to do semantic search, for example, people are using this in production systems right now. Or if you want to do retrieval, or clustering, or paraphrase mining, or image search, this kind of stuff, it’s something very interesting. In any case, the transformer models are the ones that learn the embedding while you’re training it. It’s not something that you need to pre-train before.
See more presentations with transcripts
MMS • Ismael Mejia

Transcript
Mejía: We’re going to talk about taming the database. We’re going to talk about how not to be overwhelmed by the data landscape. There are many systems, and we have to choose from them, so it’s difficult. My name is Ismaël Mejía. I’m a Microsoft Advocate for Azure.
I got interested in this subject, because I had a new job opportunity, and this can be the case for many of you for different things. This can be for example, for a new project that starts from a new perspective for creating or integrating a new system. In my background, I have been doing open source for many years. I have worked with the Apache Software Foundation. I worked with Hadoop and Spark first as a client, creating jobs and data transformation pipelines, and then I moved deep into open source, working in Apache Beam and doing many other things. In both cases, I was working with AWS’s infrastructure, and then afterwards with Google Cloud. When I got an opportunity to work at Microsoft, it was really interesting, because I was not so knowledgeable about the technology. I was presented with Azure, and I was like, this is really nice. This is a cloud infrastructure from Microsoft. They welcomed me with this little diagram of the fundamental services that we have in Azure. Of course, I quickly found some similarities, like the data services, like databases like Cosmos DB, or with Synapse that integrates Apache Spark, so it was an easy place to fit well. Then I realized the platform was quite big. As you can see, you can easily become overwhelmed with the big size of the things. Then I started to discuss with people and they asked me questions about security or about networking issues that they had while integrating with data systems. It’s a feeling of being overwhelmed, because I had to ramp up in so many technologies and understand everything to explain it. I had this feeling that I have already lived this, this was not the first time I have to deal with this system, lack of experience, like I have already in the past been confronted with other systems like that, like when you saw in the old times the Hadoop ecosystem, tools was a little bit like that.
The Data Landscape
Then the real point that triggered my attention some years ago was this image. This image is the data landscape produced by Matt Turck. This image is quite overwhelming, because you’ve seen many of the different systems and frameworks and databases and companies that produce all of this. It gives a broad view of all the things that we can integrate in our architectures. When we zoom in just in a little part of this diagram, we can see that there are many things that we will have to choose from to create our architectures or solutions. It’s the moment of despair when we get to the real question is how we can choose the right project or the right service, the right product, or the right platform with so many options. This happens to everyone. Of course, there is this big element that they call fear of missing out that is this feeling that if I’m not in the latest thing or the latest family of systems, I probably am missing something that can help me have an advantage in my company. With those two in mind, even with all of these, nobody can learn or even evaluate all of these. There are so many solutions that you can sit all day and not produce any work just by trying to decide from so many options.
This happens because there is a lack of consolidation. We can arguably hope and be optimistic about this, like, in the future systems we’ll consolidate, so why should I care about this? There are many reasons why this has not happened. One is business wise, of course. There is many people at companies who are putting money outside, like venture capitalists who give money just to create the next new big data thing, because there is a lot of money in data. Of course, there is this legislation part also, there is nothing that oblige any of these companies to interact between all of them. Of course, in a more optimistic way, there is also the technology aspect of it, we are creating new systems that were not possible 15 or 20 years ago. All of this opens new opportunities, and there is innovation. We have to live with this. This is the message we have to deal with, so all this variety.
Current Data Trends
In the end, if we want to tackle this, we come to the critical problem of decision making. I am not an MBA, so I’m not an expert on decision making, or a person who’s certified on IT along with these problems. I got interested in all of these from the perspective of a data engineer, or a data architect. To understand how we can do choices, we probably first need to understand what is the current data landscape trends. In the batch family of systems, let’s say, we have two big families. We have operational data. Operational data corresponds to all the databases that we know, like the Postgres and the SQL servers, and Oracle’s from the old time. All of this is quite mature. Now we have many of those who have cloud versions. This is the more developed area. Then we have the analytical data part was when we used to produce reports and do data analysis. Even more recently, to start with all these annual trends. In this, we have two subfamilies that were appearing because of the cloud. We have the data lake part. Basically, we use the data storage part of the cloud vendors, and we use a distributed file system because this can be done on-premise too. We put files there and we create an open system that we can access. Of course, there’s data warehouses that come from a long time ago, but now there are the cloud versions of those. These are more closed systems that give you a more consolidated experience, mostly around SQL to do all these operations. This is one part. Then we have the recent appeal of streaming data. The idea of streaming data is that we are going to deal with data at the time it happens, so we want to reduce latency and produce results and integrate results as fast as possible. Streaming data is like the Year of Linux Desktop of the data engineering world. Why is this? Because in the Linux desktop community, there’s always people saying, the next year is going to be the year of world domination for Linux, but this never happens. In the data engineering world, something like this, every year we say, streaming is going to be mainstream now. Everybody’s going to use streaming data. We’re getting there slowly, but we are not fully there. Of course, there have been a lot of progress because most companies now have a replicated log like Kafka. There is all this event streaming and change data capture things going on. More recently, there’s this trend around SQL over Streams, and to have real-time materialized views of what’s going on. That’s another big set of products and tools that we can integrate in our systems.
More recently, we have data mesh. Data mesh is a set of concepts that came from a problem that appeared because of data lakes and poorly integrated data ownership. It’s not because of data, it’s because infrastructure became complex, and really specialized people took control of data. What data mesh proposes is just to have a more decentralized view of data. This is not 100% about tools, but tools help you to get there. We can bring data back to the people who have the domain knowledge. It’s a question of access and ownership.
Of course, now also with the big different scenarios for data that we can have like batch and maybe using notebooks, or maybe using SQL, and maybe also some parts with streaming. This has given rise to what we call the cloud data platform. These are fully integrated vendors. Some of them are cloud vendors. Things like Snowflake, or Databricks. We’re going to put both and fully integrated solution for data. That’s another thing. The opposite of this is the so-called modern data stack movement. These are tools that mostly are service oriented. They’re cloud first, so there’s low configuration, very easy to set up. Their goals are more focused into specific problems. The good part of this is that I would call this the second-generation tools somehow. Because in the previous 10 or 15 years, we have been really dealing with the problem of scale with data, how we scale data and get it faster. How will you scale data for shipping? All of this is really important. A really big part of the promise that data engineers have are around different things like governance. How do I govern these data accesses? How can I trace those? How can I do the data lineage? How can I create better catalogs? All of these are things that were not immediately solved but now there are many companies and services that are trying to solve those. Again, another set of things that we can integrate. Of course, we have the ML and AI systems. The recent trend is that data supports ML, is basically one big thing. The other thing is that we also can use ML to improve our data system, so its implementations. Again, many things we can choose from. When we are going to choose, we need some approach to choose. That’s the real question, how we can choose with so many tools, with so many trends? What is the correct approach?
Strategy
I came with a small framework of three things that we can take into account to choose. The first one is the strategy, because the strategy of the companies, or the project we’re working on is the main area we should focus on. Then we have the technology, of course, because technology constrains the relation of our choices. Then we have the people, because people matters, and it’s something that we engineers let for a second thought.
If we go with our first one, with the strategy, the first step we have to check is, what are our current systems now? What is the legacy we have as a company? Also, what are our business priorities? Why are we doing this? What results do we want to have first? Maybe there’s this report that we want to have first, and with different requirements. Of course, none of this can be done without paying for this in one way or another. We have to take into account cost, how much we pay for licenses, but how much also we pay for engineers, and how much we pay for operations, all of these things. We have to also bring into account support. That’s something that we tend to forget. When I say support, this is how fast your vendor is going to answer your questions and help you get there. This is something that Microsoft does well in Azure. Of course, another important dimension is knowledge and experience. If you have a team, does this team have knowledge on this particular tool we want to use? That’s something that’s interesting. For example, when you’re recruiting, you’re going to recruit someone, but this next thing we want to integrate, that’s pretty good. Of course, all these decisions have an impact in the future of what we do, we have to take into account this. Is choosing this tool maybe solving the problem right now but bringing me more issues in the future? That’s another thing we have to analyze.
One common thing that happens is that people get pressed a little bit because of marketing or because of buzz of the peers about what is the next nice thing everybody’s using? Sometimes this is not appropriate for the problems you have. This is something that happened to me with a friend a long time ago, who asked me, “You see there is these companies. Now we’re hearing a lot about this thing called feature stores, and we want to do machine learning in our company. This is a little startup. Maybe I need a feature store to this.” That’s not the right way to approach this problem. The first question I asked was, do you already have data available and is this data clean and of good quality? Do you have processes to keep it like that? Because it’s not only a one-time shot, you have to keep these things going on. More important, is that data already used in your business? Do you have reports, or things like that? This is all the steps that were pretty important, even before thinking about machine learning and stuff like that. Even if we go into some machine learning specific project, like text recognition, for example, do you have to do this by yourself or can you use a managed service to do that? That’s another thing you have to consider. In general, marketing new projects and ideas are really good and exciting, but you have to take things with a grain of salt.
Another thing that is common is that we have cognitive biases. Cognitive biases happen when we saw our first image of something and we get a little bit assuming that, that’s the way it is. One common approach on these four data systems is performance. Everybody talks about, my system is the most performant, the fastest than all the others, or beat this benchmark. Performance is just only one dimension of so many things you have to take into account when you choose a data system. This is a photo of the countryside in Scotland, which is really beautiful. As you can see, this is a pretty day with sun and not so many clouds. In general, this can be quite a different experience, if you go during the winter and it’s raining. Don’t let yourself be anchored by the things that they show you first.
Another thing that matters is when we do these decisions, this timeliness, for example, that we use to decide if we go with some new, more experimental technology or we wait until we jump into something, matters. That’s something that we as engineers have to play, or decision makers, we have to play a little bit of distance before taking this decision. We cannot do it immediately. We have to think a little bit more. Of course, even with all of these into account, we end up having to deal with things that are not set in stone. We have to have faith on many things like, for example, is your tech provider going to be there in three or four years, or maybe is going to change price or strategy, and how this will impact you? We can say, but this is for vendors and all this stuff, but what about open source? This will be a guarantee for the future? It can be, but you don’t know if this open source project will be maintained in the future. This is something that happened recently with a workflow system for data that a big company open sourced and now they say they’re not going to maintain it anymore. If your company is dependent on the system, you have to be ready. All of this is to say that part of the strategy is to be ready for changes. This is what we have to do.
Technology
What about the technology? The technology part is something that we always are quite strong about. We always say, our systems are bad. There’s this negativity about the current solutions. We have to be realistic. We have to deal with what we have, and every company has a mess somewhere. If you want to change all your architecture or these things that are done very well, this is what it is and you have to deal with it. We can incrementally fix things. This is something that we have to consider first. Part of choosing new technologies or dealing with all these products in the landscape, it’s exciting, and get us the possibility to experiment with new things. Sometimes we have to play a little bit conservative now, and choose the technologies that are in the proven path for this critical operation, because nobody wants to be called in the night because something’s not working because of some experiment. We are now open to experimentation in many areas, but we also have to be conservative. This is a common tension and tradeoff when choosing systems. Of course, cloud services are a fantastic thing because they let us experiment with an easy setup. Sometimes with a really affordable cost at least for the exploration part when you’re still doing a proof of concept. Doing proof of concept is also something that helps your engineers to be interested. It’s something that we should consider.
Another technology that we can arguably say is good is to choose open source tools, because open source tools gives you the control of the tool. You can adapt the tool for your needs. That’s attractive, of course. Open source has to be looked in detail in one sense, because there are always incentives in the tool that are open source. One thing you have to check first is who open sourced this tool and why? More importantly, is to check if there is a healthy community around the project that you are going to choose. Of course, the question of licenses. More important is to also see if there are multiple actors, there are people who are interested in this tool, or it’s going probably to disappear tomorrow if someone does not maintain it anymore. If you choose open source tools, and you say, ok, but we can take care of it, look that you have the resources to take care of it. This is something that matters. Of course, a part of open source recently, we also have open data formats, and table formats that are ways we could present the data, we store the data into our data lakes. Since you control the data, you control the format, and you control how you modify the data, or how can you access the data. The good thing here is to choose formats that have a healthy ecosystem. There is a new family of table format tools like Apache Iceberg, or Delta, that allows to do new nice things. If you control the data, take care that the data is in an open format that you can access in the future, you need to have the guarantee, in time. Of course, a good table format also allows you to control schema evolution, allows you to time travel in between different versions of the data, which is really nice and a recent feature of these systems.
Of course, when you choose a tool, probably you also need to decide how you integrate with other tools that you already have, or systems. Then we have to check about the compatibility, we have API compatibility, which is really important, and is something that is happening more. In the case of data, sometimes the concrete API is like the MongoDB API that is supported by Cosmos DB, for example, or sometimes that are like SQL flavors, like is the SQL flavor supported? That can be another way to check this out. More recently, there are tools that are supporting data at the level of the wire compatibility. For example, they support, let’s say, for Postgres compatibility. The nice thing with this is once you support the DB protocol, the tools that integrate with this database will integrate with your tool too. For example, this new database like CockroachDB, for example, supports Postgres and the Postgres mode of connection. You can just, in theory, at least replace them easily. Of course, all the existing tools that you have are supported, all your Power BIs, and Tableau, and all these things are already something that you can integrate with the new system. That’s another question you have to ask when you choose technology.
Another thing we have to choose when we choose technology is to choose how we’re going to operate it. I realized with the proposed images, that operations are something that has three traits. One is that operations are critical. Operations are hard, and are done mostly by experts. As you can see in these different domains, from the control center, to the surgery, to the military operation, these are things that have these patterns. Let’s not forget that we also have to do this for software. Operations in software are critical, so if you can go cloud and deal less with this, probably it’s a good idea. You have to be prepared to deal with the complicated part.
Of course, when we choose technology, we have the issue of risk planning. Will I be locked with this vendor and why? Especially, what is the tradeoff because being locked with a vendor can have some advantages, but also can have some hidden costs. One common in the cloud, for example, is the cost of data egress. Is data egress something we care about in the long term? If we’re going to get all this data out it’s going to be really expensive, so we have to think in advance what’s going to happen in two or three years. Of course, another part that we usually don’t consider a risk but is important is the user experience of these different tools. Do our developers like them? Why I say this is critical, because if people don’t like these things, they don’t use them. If they don’t use them, we are losing the advantages. Of course, part of this experience was about documentation, is documentation good and sufficient? Of course, the different support channels. It’s easy to find a community, find answers to my questions, all of this is part of the technology choice.
Of course, we can use one advantage that we also sometimes forget is communication. Before choosing these tools you can discuss with your peers and ask them, why would you use this tool? What do you think about this tool? Commonly, people are really enthusiastic and tell you what’s going on, what’s good, and what is bad. What is bad is really important also to take your decisions. You can, of course, start with the providers who will give you an overview of things. You can engage with the communities. This is especially important for open source tools. When you decide to use an open source tool, you can check the community, check the GitHub, see how many people are active in the project. You can ask a question and see how easily they answer to, or they go into their Slack, and of course, read technical information about all these things.
People
The last aspect is the people dimension. The people dimension, something that is important is that people happiness matters. This is important. We need to balance stability and innovation. Sometimes people are happy because they’re going to do something new and it’s pretty cool, and it’s different. Sometimes people are happy because they can sleep at night and they’re not bothered because of production issues. We have to make happy bugs counts. One thing that’s important for people is the expertise, what are the things that engineers know, and how they can do things with their tools. Sometimes when someone knows a tool pretty well, maybe it’s not the right tool to do the job, but sometimes it’s the right tool for the person. Use the right tools. Of course, when you’re working, for example, repair your home or do something like that, and you don’t have enough tools to do the actual work, you learn. You can decide how critical some tool could be for you. This can be something we can use to decide what is the more critical thing we need when we choose all of these tools in the landscape.
No amount of data and ML technology will solve issues for any project without domain knowledge. We have to know what we are talking about. This domain specialist knowledge is something that really matters. We used to say that data is the new gold. This is a very nice expression, so I decided I’m going to search for this in the internet. I put this, data is the new phrase, and then Bing gave me, as a result, data is the new bacon. I was like, maybe this is because of Bing. Then I decided to Google it, and data is the new bacon was also there. What matters with this data is the new bacon especially that some data should be something we care about, is the new oil, is the new gold, call it as you want. More critical than this is that data must be part of our culture. Data must be part of our culture. This is not only for companies and software projects, this is for all of our culture. You have seen all the things that have happened in recent years with politics and all this stuff, and fake news, and all this. If we have an indication about data, we can be aware of so many things. Data matters for everything.
Sometimes it’s not only about technology, and I want to tell this little story about a recent project I was part of. In Microsoft there is this thing that is called Microsoft Docs. Microsoft Docs is all the people who produce the websites with the documentation and the examples, and then modules. This is huge. You think about the whole complete Microsoft, this is huge. They did this hackathon project where they wanted to integrate all the data that users produce from all these systems. This is like an analytics project, when you start clicking a link, or you do a module, or you read documentation, all of these is tracked and stored in some datastore. They wanted to call different stakeholders that’d be interested on data to be part of this. There were many people who were interested in this. I was interested because I wanted to know what were the trends, what people are looking for on particular products? There are also product managers who are interested in this, advocates, the people who are producing the content too.
I participated in this hackathon. The idea was to consolidate also the queries we have. What is interesting is that this hackathon first made us, especially the ones who were not aware of, I was not aware of the data catalog we had internally for this. Then we could contribute to this with our own queries for analytics. We had this consolidated shared library, of course, that was produced because of this. Of course, because some of us were new, and we were dealing with how to get into this, this also produced an onboarding guide for all of this data analytics. There were discussions about the future strategy. How can we integrate all this? How can we produce more data queries that are part of these? Are we using the right technology? There was the critical point that is this the right language we have to use for this. All we did here did not require any tool. Of course, they required some tools that were already in place, but we didn’t have to buy a new solution for this. The return for the company is interesting, because a lot of us who were not aware of data became aware of the data for some of the parts of the task we have to do now. This is an interesting project. This reminds me that there is this company mandated compliance trainings, you probably have seen those. Does your company have those four data processes? We talk about data is the most important thing. Data is the new gold or the new bacon, but we’re not giving data the importance it should have in your company. As you’re learning already about the data use in your company, that’s something that probably everyone cares about. Even as a normal software engineer, you want to know how your company is growing, or are we really growing? This data that we can have access to, it’s important to know. If data is the new gold, we probably need more miners, so this is, data matters.
Another approach we can have to get this control of data is to have some role rotation. So many times, there is the tension between data analysts who are producing the reports or analyzing the current data, and data engineers who are in many cases dealing with infrastructure. Sometimes, the other parts of the organization don’t know the struggle they have, so for example if you’re doing just frontend or backend engineering. Maybe an interesting approach would be to have a rotation program like DevOps people have, you can just put someone who does not normally do this data analytics or engineering job and put it there just to see how it works. Definitely, this will create empathy about the different issues that one or the other have. This is another good idea.
Recap
There are many things which are not white or black. They are always not in the extremes. There are always tradeoffs, and we have to choose our tradeoffs wisely. Of course, probably the most easy way to approach things is to do it step by step, don’t jump into the next product that is going to solve everything for you, because you can hit the wall with this this product as opposed to doing a step by step adoption, seeing what we need or what we care about, and take a little bit of it, step by step. Don’t focus on magical solutions because magical solutions basically don’t exist, especially these. If it was at x company, especially because big companies don’t have the same problems, the dimension is different and what they are doing is different, so focus in your own. Of course, focus on the three main issues or the [inaudible 00:35:09] aspects to take the decision: strategy, technology, and people. If you have doubts, people are normally always more important than technology, you can find your way with technology easily than with people.
Data engineering is still exciting. There is a lot of things that feel like we have not completed, and the way this is integrated in companies, the approach is changing and there is a lot of opportunity. There is a lot of things to do.
Questions and Answers
Polak: One of the things that you mentioned was actually about opportunities in the ecosystem. Also, why the data engineering ecosystem is so diverse, because you mentioned that it’s existed for more than 60 years, which is incredible. How are those opportunities in particular in the data ecosystem so diverse?
Mejía: A thing that jumped to my mind when I prepared this presentation was the fact that we don’t really reflect much on the past. Because the past, let’s say, had simpler systems, we think today, because we have the old databases that come from the ’60s, but in reality in the industry, we’re in this ’80s somehow. If you think about it, many things have not changed, we are doing the full cycle, many systems are going back to standard SQL. We are getting into Postgres as a standard binary protocol. All these things show that there is something standard that we can find. This standard is born not only in technology, but also in processes. I think there is a huge opportunity there. The whole data mesh movement, I think is a really right step in that direction. Like we’re thinking about, what’s critical and why. It’s not only technical, of course, there are technical challenges, but we have also evolved a lot in the technical aspect. We have now achieved data storage so we can have data lakes. We have immutability, first principles, reproducibility with containers, we’re almost getting to a point when maybe we can create a data architecture to data that can stamp on the time.
Polak: You mentioned data mesh, I remember when it was discussed in QCon, in 2019 in San Francisco, where Zhamak went on stage and shared her vision for data mesh. I remember I created a lot of question marks with people. Because sometimes we tend to focus so much on technology aspects we forget about people and strategies, and how to scale that beyond just the scalability of technology, which I think is fascinating. What do you think about this aspect of decentralizing the data architecture that data mesh suggests?
Mejía: I think decentralization matters. It’s a little bit like in microservices, if you know somehow like the equivalent in the data world. I think decentralization matters, if you want to scale in the sense that responsibilities, people who are responsible for these data products are the ones who have the knowledge. This definitely is a step in a good direction. Of course, this requires that there are systems also that help do that. It is not only the systems but you need both, you need the technology and you need knowledge from people.
Polak: Usually in companies there are compliance training for different aspects, for example, security. How do you stay secure? How do you secure your system and laptops? How can we actually build a compliance training around data? Can you share a little bit more about the thought process around this?
Mejía: I heard already long time ago one compliance on GDPR stuff, the European law. At the point when I do this, it’s interesting because we are learning about something really generic, but we are not learning about data in our companies, like what is happening, what data we produce. That’s probably one of the reasons why we always end up with the domain expert, who only knows the dataset and knows what to do. Nobody knows about it, because the other people are maybe just plumbing the data back into the place but not learning about the data. I think this is something that should change with the new more domain-oriented mindset that comes also from data mesh. When I mentioned this role rotation, I think that’s interesting, especially for junior engineers. You want to touch many things to see, what’s the area that you like the most? One of these things you can do is just go play with this area and learn about it. I think we need diversity. That’s the point that is different, for example, from infrastructure, that data is a way bigger branch of people, like for really analytics people, pure business people to infrastructure. You have to think wider also.
Polak: I remember when being data driven just started, there was a whole conversation on how do you make data driven decisions? Where’s the data? Can you trust that data? How can we collect the data in a safe manner? You mentioned also GDPR. There’s a lot of compliances that we need to adhere to as data engineers, as people that work with data. How do you see the trend of doing data driven decisions in the industry compared to what it was before it started. People did data driven decisions, or it’s more a gut feeling?
Mejía: I think we all love the idea of having data driven decisions, but there is still a lot of gut feeling out there now. The good part somehow is that we are maturing into this and we are realizing as software engineers in general. Sometimes we always have this analogy of, software architectures like normal architectures, let’s say, [inaudible 00:42:48]. We are not at all like this. We are always evolving. That’s something that is recent. It’s recent that everybody has this realization, I didn’t do my big application, I never touch it again. No, it doesn’t work like that. You should continue iterating on this, especially now with the cloud, you’re still in that live system. Your machine that you turned off is now a live system. I think slowly we’re getting into this with data processes, and data knowledge that will hopefully help us solve this issue.
Polak: You said some of the strategies that you presented around technology is making sure that you manage the tradeoffs, that you have a clear understanding of tradeoffs. However, one of the challenges is actually that it is a complicated world. How do you manage these tradeoffs in such a complicated world where there are many moving parts, and you have to decide on adopting a new technology or a new paradigm?
Mejía: It’s definitely a question of balance, of risk. Sometimes being an early player is an advantage for you, sometimes, maybe you are paying the price like people who adopted early Hadoop, for example, is one of the good examples. It was really interesting as a technology but it was too early for many people to adopt, even Kubernetes is arguably the same. We cannot create a rolling stone, it’s case by case. You also have to be consistent that sometimes things are shiny in the exterior, but they are not the thing that you need. You have to know how to prioritize them.
See more presentations with transcripts