Month: March 2023

MMS • Aditya Kulkarni

DevZero is a platform that provides developers with an efficient way to create and manage development environments. It’s a cloud-based service that replaces the traditional local development environment with a scalable alternative.
Debosmit “Debo” Ray, co-founder and CEO of DevZero, discussed the benefits of using cloud computing to increase developer productivity. Ray stated that developers want to focus on solving problems for users and creating quality code but are often hindered by slow build times and limited resources on their laptops. Additionally, developing on a laptop different from production can lead to errors and inefficiencies during the testing phase. By merging local tools with remote computing capabilities, a favorable return on investment is achievable.
When discussing the pattern of cloud (or remote) development environments, Ray noted that these environments would mean hosting a runtime for the development environment in the cloud, that contains all necessary source code, secrets, artifacts, and build tools. A remote development environment can also mean an IDE inside a browser that contains source code, build tools, and an execution environment that usually runs on some cloud VM or container.
The DevZero platform comprises a management plane that contains a group of micro-services hosted in DevZero’s private cloud, as well as developer environments hosted either on the customer’s cloud or DevZero. Developers can use their local tools with DevZero environments by utilizing the dz CLI.
Illustrating the benefits, Ray said that remote development environments offer flexibility as the developer can get a fresh copy of the whole environment in seconds. There can be sandboxed, forked copies of relevant databases for development with enough computing power to debug multiple microservices. At an organizational level, remote development environments allow organizations to focus on generating revenues instead of building internal development environments. The time saved by developers not having to manage their environments can be spent on serving their users.
We are seeing that remote development environments are gaining traction at a steady pace. During the last year, tech organizations like Slack and Uber also adopted remote development environments, improving the developer experience. Similarly, in one of the InfoQ podcasts with Shawn “Swyx” Wang, we noted that the cloud may reduce the dev machine to a poorly maintained set of environment mocks.
However, Ray said that cloud-based software development is not yet the status quo due to timing and the need for security reviews. While there has been increasing emphasis on cloud-based development over the past five years, it still requires a shift in mindset and an investment in resources.
Interested readers can get started with DevZero or refer to the documentation and understand where DevZero fits in the software development lifecycle.
Podcast: How to Become an Effective Communicator as an EngineerEffective Communicator as an Engineer
MMS • Neil Thompson
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie from the InfoQ Engineering Culture Podcast. Today I’m sitting down with Neil Thompson.
Neil, welcome. Thanks for taking the time to talk to us today.
Neil Thompson: Thanks for having me.
Shane Hastie: My first question to all my guests is, who’s Neil?
Introductions [00:31]
Neil Thompson: Well, it’s not that complicated of an answer really. I was somebody who ended up as an engineer because my father said that I probably should. It was never really something that I thought to do really. When I finished high school, I was pretty good at math and science. And he said, “Become an engineer,” and I said, “Okay.” I used to lie about the reason I became an engineer, too, because I was embarrassed by the reason. Oftentimes when you hear people answer that question, they’ll say something like, they were in robotics club. Maybe ever since they were kids, they played with Legos. I don’t really remember playing with Legos as a kid. And I certainly wasn’t a member of a robotics club. My high school didn’t even have one. I solely became an engineer because my father said I should. And luckily, it worked out okay. So, I have got a degree in materials engineering.
And then my father said, “Go to graduate school and get a master’s degree.” And I said, “Okay.” and I got a master’s in engineering, as well, in biomedical engineering. And then he said, “Go get a PhD.” I said, “Okay.” So I started a PhD program. But that’s why, I guess, the agreeing with my father ended. When I was 18 is when I started undergrad. And by this time, starting the PhD, I’m 24 years old. So that’s six years later. At some point, you got to start making decisions for yourself, not for the wants of others, your parents included. And I really didn’t see myself going through a PhD program for however long it was going to take to get this PhD if I really wasn’t passionate about getting the PhD. So, after a year in the PhD program, I left, and I spent about seven months looking for a job, living in my father’s condo. He certainly wasn’t happy about the fact that I was back in his condo.
But luckily, after a few months, I was able to find a job and I kind of got off to my career that way. Actually, with my second job that I even thought about, what I needed to do to move up within an organization. With that first job, I was just kind of feeling my way out, just trying to figure things out, I suppose. But with that second job, I was put on a project as a project lead. And what’s a project lead? Well, the company that I was working for was too cheap to hire project managers, they pushed that responsibility onto the engineers. And one of them was giving presentations on a monthly basis to senior management. So we’re talking the CEO, COO, CTO, C-fill-in-the-blank-O, all the C’s, all these people in this conference room, with myself and all the other project leads talking about project-status updates for their projects.
The fear of public speaking [02:50]
And those first two presentations that I had to give were absolutely horrendous. I didn’t even know it was that possible to sweat that profusely from one’s body, but there I was, like I came out the shower, just completely coated with water. But I realized, ultimately, that giving presentations in front of these people, many of whom were not technical, was something that I should probably get better at because I really didn’t want that feeling of just being completely covered in sweat before, during, and after presentations. I really wanted to get better at it. That coupled with the fact that the project that I was working on at that second job, the project that I was actually brought in to do was cancelled. And I firmly believe that perhaps if I was better at communicating the updates to the senior management types, maybe I could have saved it. And that was almost 13, maybe 14 years ago, and I still think that.
So, eventually, I did get better at giving presentations in front of others. I joined Toastmasters. For those of you that don’t know, it’s a international organization that helps people, like myself or just anyone, with their public-speaking skills. It’s a great forum to do that. And then, now I was looking for opportunities to speak in front of others. Basically, I took everything that I learned in getting better at communicating with others, and I built an online course called Teach the Geek to Speak. And it was geared towards people like myself, people in technical fields who want to get better at communicating their technical expertise, especially to non-technical people. I eventually turned it into a membership, and the membership comes with the course and then an online community and then also monthly calls, where people can talk about the issues that they’re facing and get real-time advice on how to overcome any hurdles that they may have. So, that’s essentially who Neil Thompson is.
Shane Hastie: Cool. So, Teach the Geek to Speak. You gave us an eloquent description there of why being able to speak in public is a good thing.
There are the stories, but there’s also some clear studies that for some people are more afraid of public speaking than they are of dying. How do we help naturally-introverted people overcome that?
The benefits of building better communication skills [04:52]
Neil Thompson: Well, I’m naturally introverted myself, so I definitely can answer that or have some thoughts on that. At least for me, it was just seeing the benefit of what getting better at public speaking can do for you. When I was in undergraduate and even in graduate school, we focused mainly on the technical aspects of becoming an engineer, not nearly enough time, in my opinion, on the soft skills. Because once you start working at a company, you can have all the technical expertise you want, but if you’re not able to communicate it, a lot of the times, you won’t even be listened to because people won’t even understand you. So, even if you have that fear, like I did even, of giving presentations in front of these people, really focus on “Why should I get better at it” and see all the benefits. As I mentioned, the people who move up in organizations, those are the ones who are great at communicating with others, with networking with others, just talking to people. And if you keep that in mind, well, at least in my opinion, that will push you past that fear.
Shane Hastie: What makes an engaging talk? Let’s take the technical architect having to explain their architecture to a group of non-technical people. So these are people that need to approve the funding or approve some significant decisions. How does the architect get the message across?
Meet people where they are at and tell stories [06:25]
Neil Thompson: Well, firstly, you have to figure out where the audience that you’re speaking to is, what is their level of expertise. If you’re an architect and want to talk about architecture to a non-architect, it’s really important for you to figure out what level of expertise that they have. Are they novices? Are they maybe more advanced than you may have thought? If you could figure that out, then you can tell your presentation to those people. So, let’s just say that they’re novices. They know very little about architecture. You certainly want to use words that they’ll understand. So you want to minimize the amount of technical jargon you might use with other architects and use more commonly-used words.
I remember, when I was working as an engineer at that second job, when I had to give project-status updates, I was working in a group called orthobiologics. So if I were to continue talking about orthobiologics right now, you probably would have no clue what I’m talking about, unless you’re from that field. Essentially, orthobiologics is implants that are made out of human cadaver bone. I worked at a spinal-implant company. And implants can be made out of ceramics, they can be made out of metals, but they can also be made out of human bone. And I worked in the group that designed the implants made out of human bone. If I continued using that word orthobiologics, people wouldn’t know what I’m talking about. But if I talk about human cadaver bone and implants being made out of them, well, I know what a human cadaver bone is. I know dead people’s bones, I know what that is. I know implants, I know what those are. So now I’m using words that people can actually recognize. So, that’s another thing.
And one other thing is the use of storytelling. I never realized how important that was in presentations until I really thought about it and heard other people giving technical presentations doing it, too. In fact, I used to think it was rather inappropriate to tell stories in a technical presentation. I thought it was more important to get the data and the facts out there and that was it. But if you’re talking, especially to a non-technical audience, storytelling is even more important, because they already are at a deficit when it comes to your knowledge, so you have to fight that uphill battle. If you’re able to couch whatever data and facts that you have in stories, they’re way more likely to listen. I mean, I just told a story about orthobiologics. That’s completely off the radar for many people. But just even explaining what it is, I mean, hearing that word and getting the explanation of what that word means, people are more likely to listen as opposed to me just babbling on about orthobiologics.
So, those are the things that I would say. Know who you’re talking to and know their level of expertise. And then also, using words that they’re more commonly known, so they’re more likely to listen. And then also, the use of storytelling. I think that all three can be really helpful in engaging an audience.
Shane Hastie: I am now fascinated by orthobiologics. Thank you. That was a really great example of putting those ideas into practice.
What other advice would you have for the person moving into that technical-leadership role?
Techniques to engage an audience [09:11]
Neil Thompson: Well, when it comes to just communicating what you need to with others, I think less is more. I have been on the receiving end of being in presentations at conferences. When I worked as an engineer, I used to have to go to conferences. And being in the audience of those technical talks, you don’t want to be in that audience if you don’t have a cup of coffee with you, or a Red Bull, something, some smelling salts, or else you’re falling asleep hard, because I used to, all the time.
And one of the issues, I think, that a lot of these technical-type peoples, especially technical leaders, whomever was giving presentations, was that they would read their slides, they wouldn’t look at the audience. It was almost as if they were there just to be able to say that they gave the presentation as opposed to “I want to engage these people. I want them to come away with something that they didn’t know before.” But if you’re just reading slides, you’re not looking at people, obviously, because you’re looking at the slides as opposed to the people. And if you do that, that’s a very easy way to lose others.
So, if you’re a technical person, I’m a big fan of minimizing the amount of words that you use on slides when you give presentations. And then also, I’m a big fan of having images on the slides as opposed to a lot of texts, because what that does is it eliminates the ability of the audience to read. So now they only have two options: they either listen to you or ignore you. And then it also, for the person who’s speaking, the leader, it eliminates the crutch of being able to read the slides. So now either you have to look at the audience or look at your shoes.
Shane Hastie: Hey, certainly, all of the presentation training and stuff that I’ve done over my career has taught that, using images, not words, the seven bullet points of seven words each is a nightmare scenario. But how do I make the image that I’m putting up on the screen meaningful to connect to the audience?
Neil Thompson: Well, it certainly should have something to do with what you’re talking about. And what that does is it helps jog your memory, even, of what you’re going to talk about to the audience. I recognize that it’s difficult to give a presentation and you don’t have those words on the screen that can help you really jog your memory as to what you want to say, especially if they were sentences, because it’s easy to be able to read a sentence and then communicate that way to the audience. But as I mentioned, it’s a terrible way to engage people because you’re not able to look at them. So, as long as the image that you’re using has something to do with what you’re talking about, that’s helpful.
And then another thing I would like to say is, if you have graphs or tables on your slides, give those graphs and tables titles that convey what you want the people to take away from those graphs and tables. You don’t want them to have to think too hard about what that graph and table means. If the title says essentially what they’re supposed to take away from that graph or table, that’s really helpful, in especially a non-technical audience listening to what you have have to say, so they don’t have to think too hard about what you’re trying to convey.
Shane Hastie: What about the panel discussion? How do I engage my audience when I’m part of a panel?
Engaging an a panel discussion [11:44]
Neil Thompson: That can be quite difficult, especially given… if there’s several people on this panel and there’s only a certain amount of time for the panel, you have to be able to say whatever you need to say, in as efficient a manner as possible, to make sure that everyone else has time to talk about what they want to talk about. If it is, at all, possible to find out essentially what the scope of the discussion is going to be beforehand, before the actual panel discussion, you can already have some stories available, ready at the go, so that you can save them during your panel discussion. So, that’s really helpful.
And then, as I mentioned even earlier, being able to distil what you have to say in as few words as possible. That’s something actually that comes rather easy to me. And I never realized that until it was brought up by others. I’ve been told I’m economical with my words. And I like that. I like being able to say as much as I possibly can in as few words as possible, because what it does is it makes it so that people don’t have to think too hard about what you’re saying. The more words you use, the more they have to think about it. I can even remember reading, reading just in school, just reading generally, technical books, and if you have a long sentence, it’s way more difficult to take in what that sentence says as opposed to a shorter one. Even if you break up that long sentence into a couple or a few shorter sentences, it’s much easier to really take in what that initial long sentence was trying to convey. So, if you’re on a panel discussion, try to be short and sweet with your answers to give time for the others to answer the questions that they’re asked. And hopefully, they’re short and sweet with their answers, too.
Shane Hastie: If I’m not just presenting but I’m trying to convince somebody to make a decision or go down a path, what’s different?
Persuading and convincing rather than just communicating [13:21]
Neil Thompson: Well, when it comes to persuasion, it’s presenting options, but then also presenting the option that you think is the best option, and telling the person using the data and the facts that you have. And then also by using stories, I mentioned earlier, why you think that the option you think is the best option is the best option.
It’s certainly something that I wish I was better at back when I was giving those presentations in front of management. I did mention that project was cancelled, and perhaps the reason… I truly think the reason it was cancelled is because I didn’t have those persuasion skills. “Why should we add more money to this project deal?” “Why should we add more people to this project deal?” I didn’t have any answers to those questions. I was trying to get out there as quickly as possible. I was up there reading slides, sweating bullets, trying to get out there as quickly as possible, but I never got out of there as quickly as possible, Shane. What ended up happening is I’d get questions that I thought I had answered during the presentation, but now I’m sweating even more because I thinking I really messed up by getting these questions.
So, when it comes to just being able to convince or persuade people and taking a path, they certainly want to know what the options are, but they also want to know what the best option is. And the use of storytelling to be able to convince them or to tell them why that option is the best option, I think it’d be quite helpful.
Shane Hastie: Changing tack, one of the things that we mentioned before we started recording was you’ve also written a children’s book. Tell us about that.
Writing STEM books for children [14:43]
Neil Thompson: Sure. The book is called Ask Uncle Neil: Why is My Hair Curly? It’s about my nephew asking me why his hair is the way it is, and I use science to answer the question. Ultimately, I’d like to make it a series where my nephew asks me a question and I use science to answer it. The goal for me writing that book was to encourage children to be curious. I mentioned earlier that I grew up in a house where my father was telling me what to do. He told me to go into engineering, and as I said, it worked out okay, but it was quite possible that it might not have. I mean, I could have hated being in engineering and hated being an engineer and resented my father for telling me to go into engineering and all of that. But luckily, as I mentioned, it worked out.
What I really want to encourage in kids is to be curious and be okay asking questions. When I was a kid, I wasn’t okay asking my father “Why should I do engineering?” I just did what he told me to do. I want kids at a young age, this book is geared to kids up to about eight years old, to be comfortable asking questions about themselves, asking questions about others, just asking questions about the world around them, and being okay with getting answers from others and even finding the answers themselves, because, ultimately, the question askers of today are the problem solvers of tomorrow. And I want them to be able to see themselves in the future as the people who are solving the problems that they questioned back when they were young.
Shane Hastie: Anything else you’d like to explore?
Neil Thompson: Well, we talked about Teach the Geek. We talked about my children’s book, other things that I do. So, I became a patent agent about 10 years ago. For those of you all that don’t know what that is, it is a person who drafts patent applications and files them with the patent office. And what’s a patent? It is an instrument used to keep others from making, using, and stealing your invention idea. I became a patent agent because the boss that I had at the time said that I should.
I don’t know if you noticed the pattern. My father told me to go into engineering. My boss told me to become a patent agent. When am I going to start making a decision for myself? But luckily, that decision actually worked out pretty well, too. So, even to this day, every now and then, I’ll draft patent applications for select clients. I do contract work with a patent shop here in the San Diego area, where I live.
And I used to work in medical devices, more specifically spinal implants, as a product-development engineer. So a couple of former coworkers and I do work with typically smaller medical-device companies on their packaging. A lot of these companies, they have a lot of work to do on the product themselves, and they have that expertise in-house. They don’t often have the expertise of what the packaging is supposed to be in-house. And there’s quite a lot of regulations that need to be followed for the packaging that the product has to go into. So we assist those type of companies with developing and design the packaging.
Shane Hastie: So, as you mentioned, a bit of a pattern of doing what people tell you, but it’s worked out all right. And it’s an interesting career and an interesting journey so far. Where’s your journey going next?
Neil Thompson: As I mentioned with the children’s book, I plan on making it a series, the Ask Uncle Neil series. My nephew asks me a question and I answer it with science. And hopefully with that, always trying to do more author visits so I can go to libraries and schools to expose children to the book, and then also to just get out the message that curiosity is a good thing. I remember being a kid and asking too many questions and your parents tell you, “Stop asking so many questions.” I really want to even tell adults and get that message to adults that: Please, don’t do that. Really foster the curiosity within children. So, there’s that.
And then also with Teach the Geek, I mentioned I started it off as a course and it evolved into a membership, and now it’s evolved even into trainings going into companies and organizations, associations that hire or work with people like myself, technical professionals, on improving their presentation skills so they’re not the sweaty engineer that I was early on in my career, having to give presentations in front of others. So, there’s that.
And then there’s always… looking to do more with drafting patent applications. That’s always fun to do. And just whatever I find interest in, I just want to be able to have the flexibility to go down that path. It’s the reason that I stopped being an employee about seven years ago. It wasn’t because I was necessarily disgruntled being an employee, it’s just that I wanted to work on the things that I wanted to work on. My father told me to study engineering. The boss that I had told me to be a patent agent. Now I want to work on things that I want to work on and not be told what to do.
Shane Hastie: Neil, some really interesting stories there. If people want to continue the conversation, where do they find you?
Neil Thompson: They can go to teachthegeek.com. I also have a podcast that’s affiliated with Teach the Geek, called the Teach the Geek Podcast, where I interview people with technical backgrounds about their public-speaking journeys. That’s been really interesting finding out more about people that got these technical degrees and, in many instances, ended up doing something completely different. One of my former guests, she started off as a civil engineer, never worked as one though, but she got a degree in civil engineering. Then she went to law school, worked at a lawyer for about five years. Then she was a stay-at-home mom for about a decade. And now she works as a personal stylist. This is not somebody that I would’ve just come across in my normal travels. Civil engineering to law, to stay-at-home mom, to personal stylist, helping people with their clothes. It’s been really interesting learning about the journeys of people like that.
So, you can learn more about that at podcast.teachthegeek.com. And if you care to check out the YouTube channel, it’s youtube.teachthegeek.com. And then also, if you want to learn more about the children’s book, you can go to askuncleneilbooks.com.
Shane Hastie: We’ll make sure to include those links in the show notes. Thank you so much.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
.NET MAUI Community Toolkit 5.0.0: Enhancing User Experience with New Features and Bug Fixes
MMS • Almir Vuk

The latest release of the .NET MAUI Community Toolkit version 5.0.0, brings a range of new features and improvements, including enhancements to accessibility, bug fixes, and some breaking changes.
One of the most significant updates is the reintroduction of SemanticOrderView, which is ported from the Xamarin Community Toolkit. SemanticOrderView provides users with the ability to control the order of visual elements for screen readers, thus improving the accessibility of an application. This component is crucial for users who depend on screen readers to access digital content, such as those with visual impairments. The documentation for SemanticOrderView is ready for developers to explore.
Another notable update is introduced for the FileSaverResult and FolderPickerResult. Previously, when a user canceled a file save or folder pick an action, an exception was thrown. With the new changes, these two objects provide more information and control when this happens, enabling users to manage the situation more effectively. In addition, the selection of the initial folder on Android has been fixed.
Regarding the FileSaver API, in addition to the official release note, Gerald Versluis one of the core team members of the project has published the video named: “Save Files With Just 1 Line of Code with .NET MAUI FileSaver!”. In this video, Gerald shows the usage of FileSaver API in the .NET MAUI project.
The release note also mentions that StateContainer has received significant improvements in this version. Firstly, a bug that caused crashes has been fixed, and secondly, the introduction of StateContainer.ChangeStateWithAnimation() has enabled developers to customize the behavior or animations whenever the state changes. The documentation has been updated to reflect these changes, and developers are encouraged to check it out.
Other notable changes in the release include improvements for EmailValidationBehavior, support for custom fonts in Snackbar, and updates to the Expander and DrawingView. The Expander now supports CollectionView, while DrawingView appropriately sizes the image while using the GetImageStream() method.
This release introduces several breaking changes in this release. For example, the StateContainer.ShouldAnimateOnStateChange property has been replaced with the StateContainer.ChangeStateWithAnimation() method. Similarly, the IFileSaver.SaveAsync() and IFolderPicker.PickAsync() methods now return the FileSaverResult and FolderPickerResult objects, respectively, instead of a string.
This version also includes updates to several dependencies, such as Microsoft.Windows.SDK.BuildTools, FluentAssertions, and AutoFixture.Xunit2, Microsoft.CodeAnalysis. The docs for all the changes and features have also been updated, so developers can explore and learn how to use the new features effectively.
Overall, the latest release of the .NET MAUI Community Toolkit, version 5.0.0 includes several updates aimed at improving accessibility, functionality, and user experience. The new features, such as the SemanticOrderView and the FileSaverResult, and FolderPickerResult objects, provide users with more control and flexibility when using an application. Meanwhile, the StateContainer update and bug fixes ensure that the application runs more smoothly and efficiently.
Based on all the reactions and feedback, this release has a lot of interest in the community. More details and the complete changelog for this version are now accessible through the official release notes on GitHub.
In addition, developers who are interested in tracking the .NET MAUI Community Toolkit project’s roadmap and general progress can find detailed information on the official GitHub repository.
Introducing Hilla 2.0: Reactive Endpoints, Native Image, Simplified Theming, SSO Kit, and More
MMS • A N M Bazlur Rahman

Hilla, the type-safe web framework for Spring Boot, has announced the release of version 2.0. This latest release utilizes Spring Boot 3, Java 17, and Jakarta EE 10, providing access to the latest features and improvements in the Java ecosystem. Hilla 2.0 also includes an improved TypeScript generator, web socket support for reactive endpoints, support for GraalVM native images, a simplified theming mechanism, and a new SSO Kit.
With Hilla’s new reactive endpoints feature, developers can send data to clients in a stream without using the usual HTTP request-response pattern. This feature uses Reactor to stream data and needs the hillaPush feature flag to be turned on. With Hilla’s reactive endpoints, server push allows developers to push data to the frontend in a sequence of 0-N items that can be transformed, connected to other fluxes, and have multiple subscribers. To learn more about reactive endpoints, and reactive programming, developers can explore the blog post by the CTO at Vaadin, Artur Signell and Project Reactor reference guide.
Another significant addition to Hilla 2.0 is GraalVM Native image support. This feature includes AOT compiler hints required by Spring Boot to build a native GraalVM image. Native images offer faster startup times and lower memory usage compared to JVM-based applications. Developers can build a native image locally through Maven, and leverage buildpacks to create a container for production deployment.
Nevertheless, Hilla 2.0 also includes simplified theming, a new SSO Kit for quickly adding single sign-on capabilities to Hilla apps, and an improved TypeScript generator. The SSO Kit allows integration with third-party identity providers like Okta, Keycloak, and Azure Active Directory, and provides all the necessary configuration for adding single sign-on capabilities to Hilla applications based on OpenID Connect.
Spring Developer Advocate at VMware Tanzu, Dan Vega expressed his enthusiasm about the Hilla 2.0 release by tweeting:
This is super exciting to see. Hilla is on the short list of projects I need to check out.
Developers can upgrade to Hilla 2.0 by replacing the version number with 2.0.0 in their pom.xml file and updating jakarta.servlet:jakarta.servlet-api instead of javax.servlet:javax.servlet-api, and import statements to use jakarta packages instead of javax. Hilla’s next feature release, Hilla 2.1, is expected to include an enhanced SSO Kit, improved Form binding in Hilla + React, better starters and documentation, and more.
Developers who are interested in trying out Hilla 2.0, can make use of the documentation to get started.
MMS • RSS
A database management system (DBMS) is a tool we use to create and manage databases. A DBMS requires several components to come together. Firstly, we need data, which is the information stored in a database. Text, numbers, booleans (i.e. true/false statements) and dates typically represent our data. Once we gather an organized collection of data we can refer to it as a database. We can think of the schema as the blueprint of a structured database that explains the type of data stored in a database and how the data is related.
Finally, a database engine is one the most important pieces of software behind a DBMS because it’s responsible for accessing and managing the database.
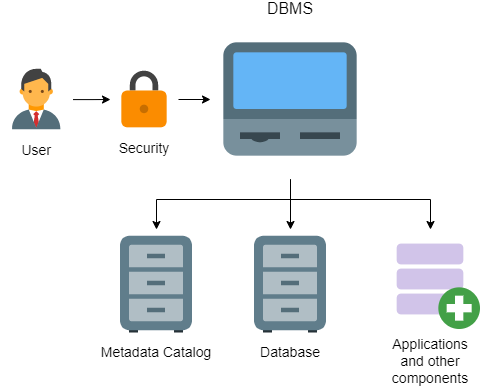
What Does a Database Management System (DBMS) Do?
A DBMS acts as an interface between users and data stored in a database, thereby allowing users to create, read, update and delete data in a database. A DBMS manages the database engine, policies and schema needed for users to extract any data they may need.
Components of a DBMS
In addition to a database engine, there are several other components and tools normally contained within a DBMS.
- Database engine
- Query language
- Query processor
- Optimization engine
- Metadata catalog
- Monitoring tools
- Quality assurance tools
Database Engine
A database engine is the core of any DBMS. It’s the software that interacts with the data, database users and the query processor.
Query Language
A DBMS requires a database access language in order for users to interact with a database. A query language defines a set of commands and rules that allow a DBMS to know when users want to create databases, as well as insert, update or delete data. The most popular and commonly used database query language is Structured Query Language (SQL). Some database management systems inherit or extend SQL while adding their own features such as PostgreSQL or MySQL.
Query Processor
A query processor uses the established query language to interpret the queries executed by users and converts them into proper, compatible commands for the database. A query processor parses, translates, optimizes and evaluates a query.
Metadata Catalog
In simple terms, a metadata catalog is a collection of all the data about your data. All data stored in a database has some information regarding its lifetime and journey, such as the creation timestamp or the user who inserted the data. All this information is known as metadata and it is stored in the DBMS metadata catalog. A metadata catalog’s main function is providing an overarching view and deeper visibility into all of the data managed by a DBMS.
Monitoring Tools
Monitoring a DBMS helps to optimize performance, protect our databases and reduce downtime. There are a variety of metrics we can monitor in a DBMS such as CPU, memory performance or system downtime. There is a whole market of tools available out there such as SolarWinds, SQL Power Tools and Datadog to do this work within a DBMS.
Quality Assurance Tools
To ensure that our DBMS manages data correctly, it is important to monitor the veracity of the data populating our databases. DBMS software has its own built-in software quality assurance tools for data integrity checks, database repair and data validations.
Advantages of Using a Database Management System
Improved Data Security
A DBMS acts as the middleman between databases and users. The more often we need to access a database, the higher the risk of a security breach. With a DBMS, we can implement security policies that define permissions regarding who can access what and where data is allowed to be stored. A DBMS allows us to have strict control over the data’s journey within our system.
Privacy Compliance
A DBMS provides a framework for compliance with privacy policies, which allows companies to manage privacy and security in a centralized manner. Privacy compliance is all about using data responsibly, whereas data security is simply about protecting all our data from malicious threats. Ultimately data privacy comes down to following regulations to clearly establish what data is protected, how it’s protected, from whom it’s protected and who is responsible for that protection.
Data Integrity
The term data integrity refers to the accuracy and consistency of data. A DBMS imposes policies on its databases that optimize data integrity. One fundamental policy for data integrity is ensuring that correct data types are stored in each column. For example, we don’t want numeric values stored in columns meant for alphabetic data.
Types of Database Management Systems
Databases tend to be relational or non-relational and this is based on the type of data they handle. Relational databases store data in tables whereas non-relational databases store data in JSON documents or key-value pairs. Additionally, graph databases store nodes and their relationships.
Just as we have relational, non-relational and graph databases, in the same way, we can have relational database management systems (RDBMS), document database management systems (DoDBMS) or graph database management systems.
Relational Database Management Systems (RDBMS)
We use relational databases to store structured data, which is based on tables that contain rows and columns. Data is stored in rows that contain a unique ID known as the primary key. We can then link multiple tables with each other based on common values such as product ID or customer name.
We use an RDBMS to manage relational databases — sometimes called SQL databases. This is because we use SQL to interact with relational database management systems. Some popular RDBMSes include MySQL and Microsoft SQL.
It is worth noting that many people may refer to MySQL as a database when, in reality, it is a DBMS.
Another popular example of an RDBMS is a data warehouse. A data warehouse is a relational database management system used to manage databases that store data in columns rather than rows. Columnar databases are a good choice for data analytics. Some examples of cloud-based data warehouses that used columnar data are BigQuery from Google Cloud Platform or Redshift from Amazon Web Services.
Document Database Management Systems (DoDBMS)
Non-relational databases normally contain JSON-like structures that we consider objects or documents. Unlike relational databases, data in non-relational databases have no set structure or relationship and are powered by services such as MongoDB (one of the most popular NoSQL platforms) or DynamoDB.
We use DoDBMSes to manage non-relational databases, which rely on NoSQL languages to interact with its databases. For this reason, we sometimes call non-relational databases NoSQL databases.
Graph Database Management Systems
A graph database management system provides specific support for the deployment and maintenance of graph databases. A graph database is used to store data in the form of nodes and connections. This is a great option to navigate deep hierarchies and to find hidden connections between items of a network. We can use graph databases to model transport networks, recommendation engines and fraud detection systems.
Some popular choices of graph database management systems are Neo4j, ArangoDB, GraphQL and OrientDB.
MMS • Michael Redlich

JDK 20, the third non-LTS release since JDK 17, has reached its initial release candidate phase as declared by Mark Reinhold, chief architect, Java Platform Group at Oracle. The main-line source repository, forked to the JDK stabilization repository in mid-December 2022 (Rampdown Phase One), defines the feature set for JDK 20. Critical bugs, such as regressions or serious functionality issues, may be addressed, but must be approved via the Fix-Request process. As per the release schedule, JDK 20 will be formally released on March 21, 2023. It is worth noting that JEP 438 was added to the feature set in early March 2023.
The final set of seven (7) new features, in the form of JEPs, can be separated into two (2) categories: Core Java Library and Java Specification.
Five (5) of these new features are categorized under the Core Java Library:
Two (2) of these new features are categorized under the Java Specification:
We examine these new features and include where they fall under the auspices of the four major Java projects – Amber, Loom, Panama and Valhalla – designed to incubate a series of components for eventual inclusion in the JDK through a curated merge.
Project Amber
JEP 432, Record Patterns (Second Preview), incorporates enhancements in response to feedback from the previous round of preview, JEP 405, Record Patterns (Preview). This proposes to enhance the language with record patterns to deconstruct record values. Record patterns may be used in conjunction with type patterns to “enable a powerful, declarative, and composable form of data navigation and processing.” Type patterns were recently extended for use in switch case labels via: JEP 406, Pattern Matching for switch (Preview), delivered in JDK 17; and JEP 420, Pattern Matching for switch (Second Preview), delivered in JDK 18. Changes from JEP 405 include: added support for inference of type arguments of generic record patterns; added support for record patterns to appear in the header of an enhanced for statement; and remove support for named record patterns.
Similarly, JEP 433, Pattern Matching for switch (Fourth Preview), incorporates enhancements in response to feedback from the previous three rounds of preview: JEP 427, Pattern Matching for switch (Third Preview), delivered in JDK 19; JEP 420, Pattern Matching for switch (Second Preview), delivered in JDK 18; and JEP 406, Pattern Matching for switch (Preview), delivered in JDK 17. Changes from JEP 427 include: a simplified grammar for switch labels; and inference of type arguments for generic type patterns and record patterns is now supported in switch expressions and statements along with the other constructs that support patterns.
Project Loom
JEP 429, Scoped Values (Incubator), an incubating JEP formerly known as Extent-Local Variables (Incubator), proposes to enable sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads.
JEP 436, Virtual Threads (Second Preview), proposes a second preview from JEP 425, Virtual Threads (Preview), delivered in JDK 19, to allow time for additional feedback and experience for this feature to progress. This feature provides virtual threads, lightweight threads that dramatically reduce the effort of writing, maintaining, and observing high-throughput concurrent applications, to the Java platform. It is important to note that no changes are within this preview except for a small number of APIs from JEP 425 that were made permanent in JDK 19 and, therefore, not proposed in this second preview. More details on JEP 425 may be found in this InfoQ news story and this JEP Café screen cast by José Paumard, Java developer advocate, Java Platform Group at Oracle.
JEP 437, Structured Concurrency (Second Incubator), proposes to reincubate this feature from JEP 428, Structured Concurrency (Incubator), delivered in JDK 19, to allow time for additional feedback and experience. The intent of this feature is to simplify multithreaded programming by introducing a library to treat multiple tasks running in different threads as a single unit of work. This can streamline error handling and cancellation, improve reliability, and enhance observability. The only change is an updated StructuredTaskScope class to support the inheritance of scoped values by threads created in a task scope. This streamlines the sharing of immutable data across threads. More details on JEP 428 may be found in this InfoQ news story.
Project Panama
JEP 434, Foreign Function & Memory API (Second Preview), incorporate refinements based on feedback and to provide a second preview from JEP 424, Foreign Function & Memory API (Preview), delivered in JDK 19, and the related incubating JEP 419, Foreign Function & Memory API (Second Incubator), delivered in JDK 18; and JEP 412, Foreign Function & Memory API (Incubator), delivered in JDK 17. This feature provides an API for Java applications to interoperate with code and data outside of the Java runtime by efficiently invoking foreign functions and by safely accessing foreign memory that is not managed by the JVM. Updates from JEP 424 include: the MemorySegment and MemoryAddress interfaces are now unified, i.e., memory addresses are modeled by zero-length memory segments; and the sealed MemoryLayout interface has been enhanced to facilitate usage with JEP 427, Pattern Matching for switch (Third Preview), delivered in JDK 19.
JEP 438, Vector API (Fifth Incubator), incorporates enhancements in response to feedback from the previous four rounds of incubation: JEP 426, Vector API (Fourth Incubator), delivered in JDK 19; JEP 417, Vector API (Third Incubator), delivered in JDK 18; JEP 414, Vector API (Second Incubator), delivered in JDK 17; and JEP 338, Vector API (Incubator), delivered as an incubator module in JDK 16. This feature proposes to enhance the Vector API to load and store vectors to and from a MemorySegment as defined by JEP 424, Foreign Function & Memory API (Preview).
JDK 21
Scheduled for a GA and next LTS release in September 2023, two (2) JEPs are currently Proposed to Target for JDK 21.
JEP 430, String Templates (Preview), a feature JEP type, proposes to enhance the Java programming language with string templates, which are similar to string literals but which contain embedded expressions that are incorporated into the string template at run time. This feature has been classified as Proposed to Target for JDK 21, but has not yet been formally announced with a review date.
JEP 431, Sequenced Collections, proposes to introduce “a new family of interfaces that represent the concept of a collection whose elements are arranged in a well-defined sequence or ordering, as a structural property of the collection.” This is motivated by the lack of a well-defined ordering and uniform set of operations within the Collections Framework. This feature has been classified as Proposed to Target for JDK 21, but has not yet been formally announced with a review date.
We can surmise which additional JEPs have the potential to be included in JDK 21 based on a number of JEP drafts and candidates.
JEP Draft 8303358, Scoped Values (Preview), submitted by Andrew Haley and Andrew Dinn, both distinguished engineers at Red Hat, evolves JEP 429, Scoped Values (Incubator), delivered in the upcoming release of JDK 20. Formerly known as Extent-Local Variables (Incubator) and under the auspices of Project Loom, this feature proposes to enable sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads. And while this draft has not yet reached Candidate status, the description explicitly states that this JEP will be added in JDK 21.
JEP Draft 8277163, Value Objects (Preview), a feature JEP under the auspices of Project Valhalla, proposes the creation of value objects – identity-free value classes that specify the behavior of their instances. This draft is related to JEP 401, Primitive Classes (Preview), which is still in Candidate status.
JEP 435, Asynchronous Stack Trace VM API, a feature JEP type, proposes to define an efficient API for obtaining asynchronous call traces for profiling from a signal handler with information on Java and native frames.
JEP 401, Primitive Classes (Preview), under the auspices of Project Valhalla, introduces developer-declared primitive classes – special kinds of value classes – as defined in the aforementioned Value Objects (Preview) JEP Draft – that define new primitive types.
JEP Draft 8301034, Key Encapsulation Mechanism API, a feature JEP type, proposes to: satisfy implementations of standard Key Encapsulation Mechanism (KEM) algorithms; satisfy use cases of KEM by higher level security protocols; and allow service providers to plug-in Java or native implementations of KEM algorithms. This draft was recently updated to include a major change that eliminates the DerivedKeyParameterSpec class in favor of placing fields in the argument list of the encapsulate(int from, int to, String algorithm) method.
JEP Draft 8283227, JDK Source Structure, an informational JEP type, describes the overall layout and structure of the JDK source code and related files in the JDK repository. This JEP proposes to help developers adapt to the source code structure as described in JEP 201, Modular Source Code, delivered in JDK 9.
JEP Draft 8280389, ClassFile API, proposes to provide an API for parsing, generating, and transforming Java class files. This JEP will initially serve as an internal replacement for ASM, the Java bytecode manipulation and analysis framework, in the JDK with plans to have it opened as a public API. Brian Goetz, Java language architect at Oracle, characterized ASM as “an old codebase with plenty of legacy baggage” and provided background information on how this draft will evolve and ultimately replace ASM.
JEP Draft 8278252, JDK Packaging and Installation Guidelines, an informational JEP, proposed to provide guidelines for creating JDK installers on macOS, Linux and Windows to reduce the risks of collisions among JDK installations by different JDK providers. The intent is to promote a better experience when installing update releases of the JDK by formalizing installation directory names, package names, and other elements of installers that may lead to conflicts.
We anticipate that Oracle will start targeting additional JEPs for JDK 21 very soon.
MMS • Ben Linders

Whether working remotely or in a hybrid environment, the way in which we work with one another is changing, and can impact mental health and well-being. Personality characteristics can influence how we may respond differently to remote or hybrid working environments. Organizations can foster a sense of psychological safety at work by focusing on culture, transparency, clarity, learning from failure, and supportive leadership.
Helen Bartimote will speak about the interaction between hybrid or remote working and maintaining our mental health at QCon London 2023. This conference is held March 27-29.
According to Bartimote, to understand how hybrid and remote working impact mental health and well-being, you need to consider the relationship between the individual employee and the system of work they are functioning within. Maintaining mental health and well-being and staying resilient is a complex interaction between four areas: personality, coping mechanisms, personal history and the environment someone is in:
The way in which a person is interacting with a hybrid and remote system and how that impacts their mental health and well-being in a positive or negative way is determined by considering those four areas.
Our individual personality traits will moderate our experience of pressure. They will also determine what we need to feel psychologically healthy at work. According to Bartimote, how well someone understands themselves and how much control they feel they have within work is vital to their sense of wellbeing and ultimately their mental health.
Bartimote suggests that organizations focus on five key areas to foster a sense of psychological safety at work:
- Establish an open and respectful communication culture. Individuals feel able to take interpersonal risks by having candid conversations knowing they are safe to do so.
- Ensure the organization is as transparent as it can be, and that leaders show active support for the psychologically safe culture. They act as role models by showing great skill in having candid conversations.
- Ensure there is clarity in roles and responsibilities. Ensure there is no confusion regarding the expectations everyone has for each other in the organization.
- Ensure that failure is discussed and mistakes are used as opportunities for learning and growth, as much as possible.
- Leadership practices follow a supportive and consultative approach with high emotional intelligence displayed.
InfoQ interviewed Helen Bartimote about mental health in remote or hybrid working environments.
InfoQ: How can our personality characteristics influence how we respond to remote or hybrid working environments?
Helen Bartimote: For example, let’s take the extroverted person who is living alone and working remotely. If the environment they are in does not enable them to make new connections and spend time with work colleagues socially online, or create opportunities for physical meet ups throughout the year, they will experience a sense of feeling deprived of social energy that helps them stay happy. If this is further compounded with difficulties sustaining connections outside of work, due to maybe workload or other factors – the outcome could lead to decreased mental health and wellbeing.
Similarly – consider the introverted person who works for an organisation remotely but feels little autonomy or control over their work. They may be in back-to-back zoom calls with no time to be alone with their thoughts and re-energise. Furthermore, if the system of work does not promote feedback or candid communication, then they may be unable to express this experience to their manager in a psychologically safe way.
These are just a few examples of how personality traits can interact with the system of remote or hybrid working.
InfoQ: What have you learned at Container Solutions?
Bartimote: We have learnt many things over the years, and the psychologically safe culture is something we continue to develop our understanding of and how to continually reinforce this message. Feeling a sense of autonomy, belonging and competence are three core pillars that we try to ensure employees experience during their time in Container Solutions and we have a range of systems and processes which also support this.
MMS • RSS

Apache Cassandra 4.1 was a massive effort by the Cassandra community to build on what was released in 4.0, and it is the first of what we intend to be yearly releases. If you are using Cassandra and you want to know what’s new, or if you haven’t looked at Cassandra in a while and you wonder what the community is up to, then here’s what you need to know.
First off, let’s address why the Cassandra community is growing. Cassandra was built from the start to be a distributed database that could run across dispersed geographic locations, across different platforms, and to be continuously available despite whatever the world might throw at the service. If you asked ChatGPT to describe a database that today’s developer might need—and we did—the response would sound an awful lot like Cassandra.
Cassandra meets what developers need in availability, scalability, and reliability, which are things you just can’t bolt on afterward, however much you might try. The community has put a focused effort into producing tools that would define and validate the most stable and reliable database that they could, because it is what supports their businesses at scale. This effort supports everyone who wants to run Cassandra for their applications.
Guardrails for new Cassandra users
One of the new features in Cassandra 4.1 that should interest those new to the project is Guardrails, a new framework that makes it easier to set up and maintain a Cassandra cluster. Guardrails provide guidance on the best implementation settings for Cassandra. More importantly, Guardrails prevent anyone from selecting parameters or performing actions that would degrade performance or availability.
An example of this is secondary indexing. A good secondary index helps you improve performance, so having multiple secondary indexes should be even more beneficial, right? Wrong. Having too many can degrade performance. Similarly, you can design queries that might run across too many partitions and touch data across all of the nodes in a cluster, or use queries alongside replica-side filtering, which can lead to reading all the memory on all nodes in a cluster. For those experienced with Cassandra, these are known issues that you can avoid, but Guardrails make it easy for operators to prevent new users from making the same mistakes.
Guardrails are set up in the Cassandra YAML configuration files, based on settings including table warnings, secondary indexes per table, partition key selections, collection sizes, and more. You can set warning thresholds that can trigger alerts, and fail conditions that will prevent potentially harmful operations from happening.
Guardrails are intended to make managing Cassandra easier, and the community is already adding more options to this so that others can make use of them. Some of the newcomers to the community have already created their own Guardrails, and offered suggestions for others, which indicates how easy Guardrails are to work with.
To make things even easier to get right, the Cassandra project has spent time simplifying the configuration format with standardized names and units, while still supporting backwards compatibility. This provides an easier and more uniform way to add new parameters for Cassandra, while also reducing the risk of introducing any bugs.
Improving Cassandra performance
Alongside making things easier for those getting started, Cassandra 4.1 has also seen many improvements in performance and extensibility. The biggest change here is pluggability. Cassandra 4.1 now enables feature plug-ins for the database, allowing you to add capabilities and features without changing the core code.
In practice, this allows you to make decisions on areas like data storage without affecting other services like networking or node coordination. One of the first examples of this came at Instagram, where the team added support for RocksDB as a storage engine for more efficient storage. This worked really well as a one-off, but the team at Instagram had to support it themselves. The community decided that this idea of supporting a choice in storage engines should be built into Cassandra itself.
By supporting different storage or memtable options, Cassandra allows users to tune their database to the types of queries they want to run and how they want to implement their storage as part of Cassandra. This can also support more long-lived or persistent storage options. Another area of choice given to operators is how Cassandra 4.1 now supports pluggable schema. Previously, cluster schema was stored in system tables alone. In order to support more global coordination in deployments like Kubernetes, the community added external schema storage such as etcd.
Cassandra also now supports more options for network encryption and authentication. Cassandra 4.1 removes the need to have SSL certificates co-located on the same node, and instead you can use external key providers like HashiCorp Vault. This makes it easier to manage large deployments with lots of developers. Similarly, adding more options for authentication makes it easier to manage at scale.
There are some other new features, like new SSTable identifiers, which will make managing and backing up multiple SSTables easier, while Partition Denylists will make it easier to either allow operators full access to entire datasets or to reduce the availability of that data to set areas to ensure performance is not affected.
The future for Cassandra is full ACID
One of the things that has always counted against Cassandra in the past is that it did not fully support ACID (atomic, consistent, isolated, durable) transactions. The reason for this is that it was hard to get consistent transactions in a fully distributed environment and still maintain performance. From version 2.0, Cassandra used the Paxos protocol for managing consistency with lightweight transactions, which provided transactions for a single partition of data. What was needed was a new consensus protocol to align better with how Cassandra works.
Cassandra has filled this gap using Accord (PDF), a protocol that can complete consensus in one round trip rather than multiple transactions, and that can achieve this without leader failover mechanisms. Heading toward Cassandra 5.0, the aim is to deliver ACID-compliant transactions without sacrificing any of the capabilities that make Cassandra what it is today. To make this work in practice, Cassandra will support both lightweight transactions and Accord, and make more options available to users based on the modular approach that is in place for other features.
Cassandra was built to meet the needs of internet companies. Today, every company has similarly large-scale data volumes to deal with, the same challenges around distributing their applications for resilience and availability, and the same desire to keep growing their services quickly. At the same time, Cassandra must be easier to use and meet the needs of today’s developers. The community’s work for this update has helped to make that happen. We hope to see you at the upcoming Cassandra Summit where all of these topics will be discussed and more!
Patrick McFadin is vice president of developer relations at DataStax.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.
MMS • Steef-Jan Wiggers
Microsoft recently announced the release of the Public Preview Enhancements for Logic Apps Standard in Application Insights. These enhancements provide developers with more in-depth insights into the performance and health of their standard Logic Apps, making it easier to diagnose issues and optimize performance.
Logic Apps are Microsoft’s automated workflow offering, and its Logic App Standard tier allows developers to run workflows anywhere. Standard has generally been available since June 2021.
Application Insights is an Azure service that allows users to monitor the performance and usage of their applications. With the Public Preview Enhancements for Logic Apps (Standard), developers can gain deeper insights into the performance of their Logic Apps, including the ability to monitor and analyze the execution of individual actions within a Logic App.
With the new feature, developers can enable Application Insights integration for their Logic Apps (Standard) projects from the Azure Portal or by modifying the Application Settings. The feature requires the Functions V4 runtime, automatically enabled for new Logic Apps (Standard) instances.
Once enabled, developers can view various metrics and logs for their Logic Apps (Standard) workflows, such as the number of runs, failures, triggers, actions, and custom events. In addition, they can also use the Application Insights query language (Kusto) to analyze and visualize the data.
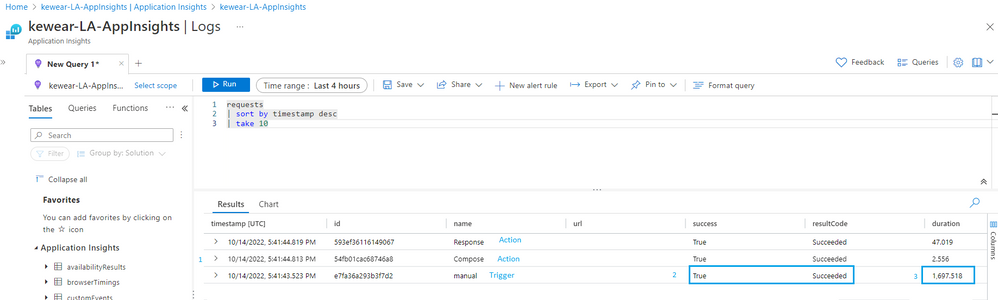
Furthermore, users can leverage the distributed tracing feature of Application Insights to track the end-to-end flow of their Logic Apps (Standard) workflows across multiple services and components. This feature provides a graphical representation of the workflow execution and each step’s duration, status, and dependencies.
Kent Weare, a Principal Program Manager of Logic Apps at Microsoft, told InfoQ:
We have enhanced how Azure Logic Apps (Standard) emit telemetry based on customer feedback. Customers are looking for more control over how events are emitted and the schema used to do so. Application Insights storage is a cost that customers have to absorb, so we wanted to be as efficient as possible and give them control over what telemetry is filtered at source.
In addition, he added:
One feature I am particularly excited about is including connector metadata within our events that are being emitted. Connectors are a big part of our value proposition, and organizations want to understand what connectors are being used and by which workflows. Providing this type of inventory data in a simple query makes governance and maintenance much more straightforward for customers.
The new feature is currently in public preview and is available for all regions that support Logic Apps (Standard). In addition, Microsoft encourages developers to provide feedback and suggestions for improvement through the Logic Apps User Voice.
Great Graph Database Debate: Abandoning the relational model is ‘reinventing the wheel’
MMS • RSS
Register Debate Welcome back to the latest Register Debate in which writers discuss technology topics, and you the reader choose the winning argument.
The format is simple: we propose a motion, the arguments for the motion ran on Monday and today, and the arguments against on Tuesday and tomorrow. During the week you can cast your vote on which side you support using the poll embedded below, choosing whether you’re in favor or against. The final score will be announced on Friday, revealing which argument was most popular.
It’s up to our writers to convince you to vote for their side.
This week’s motion is:
Arguing FOR the motion once again, with a counterpoint to yesterday’s assertions from Jim Webber, is Andy Pavlo, associate professor of databaseology at Carnegie Mellon University.
It’s all fun and games until things get … Relational
My esteemed colleague is being coy in claiming that he does not know what a “well-architected” DBMS means. Nevertheless, allow me to remind him of the key characteristics of such a system. I will focus on analytical queries over graphs, as this is what graph DBMSs claim to be better at than relational DBMSs. My list below is also inspired by this CIDR 2023 paper [PDF] by researchers at CWI.
- Fast Scans on Typed Data – The NoSQL movement misguided developers in thinking that a schemaless (i.e., schema-optional) database is a good idea. It is necessary for some scenarios, and most relational DBMSs now support JSON data types. But for ripping through data quickly, if the DBMS is aware of the schema and the data’s types, it removes indirection and improves scan performance.
- Columnar Storage – Storing data in a column-oriented manner has several benefits, including reducing disk I/O and memory overhead due to skipping unnecessary columns for a query. Columnar data also has lower entropy than row-oriented data, making it more amenable to compression schemes that do not require the DBMS to decompress it first.
- Vectorized Query Execution – Using a vectorized processing model [PDF] (as opposed to a tuple-at-a-time model) improves DBMS performance for analytical queries by 10-100x. Processing data in batches also allows the DBMS to leverage vectorized CPU instructions (SIMD) to improve performance further.
- Explicit Control of Memory – The DBMS needs complete control over its memory allocations. This means not using a “managed” memory runtime (e.g., JVM, Erland) where fragmentation and garbage collection will cause performance problems, nor should it allow the OS to determine what data to evict from the cache (e.g., MMAP). The DBMS must also have fine-grained data placement to ensure that related information is located close to each other to improve CPU efficiency.

Andy Pavlo: “The mistake they made was to ignore database history and try to reinvent the wheel by abandoning the relational model”
There are some additional optimizations that are specific to graphs that a relational DBMS needs to incorporate:
- Graph-centric Query APIs – The SQL:2023 standard introduces Property Graph Queries (SQL/PGQ) for defining and traversing graphs in a relational DBMS. SQL/PGQ is a subset of the emerging GQL standard. Thus, SQL/PGQ further narrows the functionality difference between relational DBMSs and native graph DBMSs.
- Query Execution Enhancements – A well-architected relational DBMS will want to include enhancements specifically for optimizing graph queries, including multi-way worst-case optimal joins (WCOJ), compact ephemeral data structures (e.g., compressed sparse rows), and factorized query processing. Although adding these requires non-trivial engineering, such enhancements fit nicely with existing relational DBMS execution engines and do not require a new engine to be written from scratch.
As evidence for how a well-architected relational DBMS performs against a graph DBMS, I refer to the CIDR 2023 paper from CWI [PDF]. They extended the DuckDB embedded analytical relational DBMS to add support for SQL/PGQ and the above enhancements. Then, they compared it against a leading graph DBMS on an industry-standard graph benchmark. Their results show that DuckDB, with the above extensions, outperforms the native graph DBMS by up to 10x. These are state-of-the-art results from January 2023 and not from five years ago.
And although the CWI team includes some of the best database systems researchers in the world, they have not raised hundreds of millions of dollars to achieve these results.
Regarding my colleague’s reference to Stonebraker’s seminal 2006 paper that refutes “one size fits all” DBMS architectures, their anecdote that Neo4j arose from their attempt to use a relational DBMS in the 2000s for graph-centric workloads is evidence of Stonebraker’s argument. But the mistake they made was to ignore database history and try to reinvent the wheel by abandoning the relational model. I encourage interested readers also to read Stonebraker’s 2006 treatise [PDF] on the failure of alternative data models to supplant the relational data model since its invention in 1969. Graph databases are just another category of non-relational DBMSs that will eventually decline in popularity as relational DBMSs adopt the best parts of them (as they have with others in the past).
Lastly, I stand by my 2021 public wager about the future of the graph database market. I will replace my official CMU photo with one of me wearing a shirt that says “Graph Databases Are #1”. I will use that photo until I retire, get fired, or a former student stabs me. ®
Cast your vote below. We’ll close the poll on Thursday night and publish the final result on Friday. You can track the debate’s progress here.