Month: March 2023
High-Performance Computing for Researchers and Students with Amazon Lightsail for Research

MMS • Steef-Jan Wiggers
AWS recently announced the general availability (GA) of Amazon Lightsail for Research, a new offering designed to enable researchers and students to easily create and manage high-performance CPU or GPU research computers on the cloud.
Amazon Lightsail for Research is an ideal solution for students and researchers who may not have access to dedicated computing resources or the technical expertise required to set up and manage a high-performance research environment. This new offering provides a simple and cost-effective way to leverage the power of the cloud for research and experimentation.
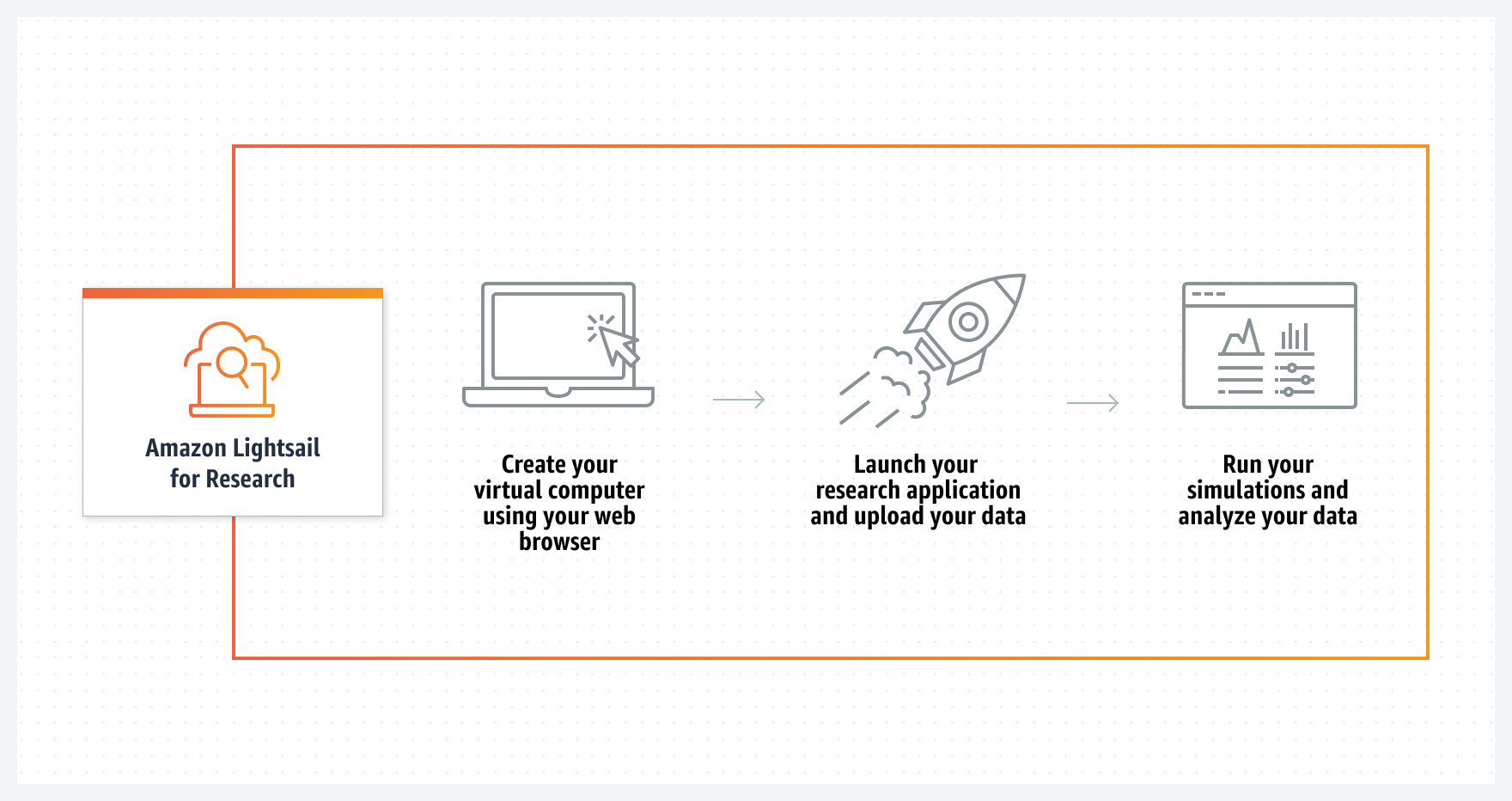
For instance, through the Lightsail for Research console, users can choose to create a virtual computer and create a new research computer. In addition, they can select which software to have preinstalled on their computer and what type of research computer. The service supports Jupyter, RStudio, Scilab, and VSCodium, and users can install additional packages and extensions through the interface of these IDE applications.
Next, users can choose the desired virtual hardware type, including a fixed amount of compute (vCPUs or GPUs), memory (RAM), SSD-based storage volume (disk) space, and a monthly data transfer allowance. After that, bundles are charged on an hourly and on-demand basis.
And finally, after naming the computer, users can create a virtual computer, and once completed, click Launch application to start working.
Besides using the console, users could alternatively use the AWS Command Line Interface (CLI) or AWS SDKs to create a computer with preinstalled software and configuration.
Source: https://aws.amazon.com/lightsail/research/
Channy Yun, a Principal Developer Advocate for AWS, explains in an AWS news blog post the benefits of Amazon Lightsail for Research:
You pay only for the duration the computers are in use and can delete them at any time. You can also use budgeting controls that can automatically stop your computer when it’s not in use. Lightsail for Research also includes all-inclusive prices of compute, storage, and data transfer, so you know exactly how much you will pay for the duration you use the research computer.
In addition, Swapnil Bhatkar, a Cloud engineer at National Renewable Energy Laboratory, U.S Department of Energy, tweeted in response to the GA release of Amazon Lightsail for Research:
We built Stion a few years ago for the #cryoem community just for this purpose. Glad that AWS extended this concept of ‘one-click button to get a GPU machine’ for broader research community.
Currently, Amazon Lightsail for Research is available in the US East (Ohio), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), and Europe (Stockholm) Regions.
Lastly, more details on Amazon Lightsail for Research are available on the documentation pages.
MMS • Ramsay Ashby Laz Allen

Key Takeaways
- Data has been used to drive organisational improvement for decades. More recently, new metrics, such as DORA, have started to emerge to improve the pace of software delivery, but adoption is not straightforward and can easily result in fear and rejection from team members and their leaders.
- Focusing on culture change rather than tool-use produces better and longer lasting results, and requires a fundamentally different approach.
- In culture change, initiatives being ready to change the approach at short notice is vital. Being prepared from the start is therefore key.
- Thinking about who the primary users of the tool would be and how they would want to use it clearly favoured some vendors over others. We selected one that would enable our team and reinforce the cultural change that was the fundamental goal of the exercise.
- Focusing adoption on a small subset of metrics enables us to circumvent the barriers to ensure we made the most impactful improvements.
Team metrics are in vogue: there are a plethora of companies offering tools to support our agile practices and there is no shortage of books espousing the value of various combinations of metrics that will lead your team(s) to delivery stardom. In this article we will share our journey, starting from the point of realising this could enhance our competitive advantage and the signs that indicated change was needed. We explain why we choose not just to deploy a tool, but to think about this as changing our engineering management culture to being one that values and utilises these metrics to drive greater improvement at scale.
We will explain how our understanding of what we needed evolved throughout the exploration process and how we ran trials with teams to understand this better. We will share our interpretation of the most important metrics, the sources we were inspired by and how we expected to need to augment them. Then, we’ll explore the challenges we discovered with adoption, those we predicted and how we altered our plans to adapt to them. The piece will then take a look at the values we created to assess the various tool providers to find one that we felt would enable our team, and more importantly, reinforce the cultural change that was the fundamental goal of this exercise.
At the time of writing, Skyscanner was guiding 85 squads (~700 engineers) through this change and we have been seeing good levels of adoption and insights being acted on, having created cross-organisation communities of practice to support this change and bed it in for the long term. We will talk about the principles we have used to drive this adoption.
Exploring Metrics
Skyscanner is an organisation that continually strives to improve and knows that we need to keep adapting as opportunities change around us. To that end, we need to continually strengthen our approach to ensure continuous improvement at all levels. We already use data to inform our strategic and day to day product development decisions, so it made sense for us to achieve the former by thinking more deeply about the latter. The space here has been maturing for some time with works like Accelerate, Agile Management and Project to Product, so we decided to explore how we could apply these concepts and practises across the organisation.
Travelling back in time a decade or so, Skyscanner released an update to its monolithic codebase on a six-weekly release train. This train made it very easy to understand how much ‘value’ we were able to release in a given period and also to get a good read on the overall health of our code and engineering org because it was easy to compare the contents of one release to the next, and what was expected to ship.
But in a world where teams are potentially deploying changes multiple times each day, we don’t have that same implicit view of how long new features take us to build – because each deployment usually contains just a tiny part of a more significant piece of work. We recognised that our CI & CD practices had matured to a point where we needed to explicitly seek out some information that would once have been fairly obvious.
We knew that helping our teams have visibility of the right metrics would enable them to identify and act on the most impactful improvements to how they worked together. We also recognised that we could aggregate these metrics in some cases to identify organisation-wide improvements.
Selecting Metrics
We started from two places. The DORA metrics were already well understood as a concept in our engineering organisation so there already was an appetite to explore using them more sustainably and consistently across our 85 squads. These metrics are reasonably well understood to assist in the improvement of DevOps practices. That said, we knew we needed more than that as DevOps practices; integration and deployment only count for a small part of the overall value stream. Additionally, they are also the most automatable parts of the process and are often optimised in isolation of the rest of the value streams.
So we began looking at the Flow Metrics that Mik Kirsten describes in his book, Project to Product. These metrics resonated strongly with us, and the journey that the book described also felt fitting. These are termed, flow time, flow load, flow distribution, flow efficiency, and flow velocity.
But when we started talking about these metrics with our trial group, we found that the new novel vocabulary increased confusion and hindered adoption. Within the software industry, terms like “cycle time” and “work in progress” are already well understood, so we opted to stick with them to make a gentler learning path over the vocabulary that Kersten uses in the book.
The core set of metrics that we went with were:
- Cycle time for epics, and stories – how long it takes us end-to-end, including all planning, development, testing, deployment, etc. to get a piece of work live in production
- Work in progress – how many concurrent work items are in any “in progress” state (i.e. not “to do” or “done”) on a team’s board at any given time
- Waiting time – the amount of time that a piece of work spends in an idle state, once work has begun. The time spent waiting for a code review is one of the most significant contributors to this metric
- Distribution of work (across different categories) – tagging each work item as one of “defect”, “debt”, “feature”, or “risk” and tracking the overall distribution of these categories (expecting a healthy mix of each)
Our initial trial included two squads, and involved the two capturing these metrics manually in Excel and discussing them regularly in their retrospectives. This allowed us to very quickly prove that we could drive meaningful improvements to team delivery. We saw a >37% reduction in epic cycle time just from limiting work in progress and small tweaks to a team’s way of working, such as better prioritising code reviews, which was far beyond our expectations.
Evaluating Tools
We started from the position that we wanted to have all our value stream and productivity measures in the same place. At Skyscanner, we have a lot of tools so only introducing one new one rather than multiple was very important. It would also make rollout and communication much easier too.
From there we started reviewing the available tools and speaking to the teams building them; a few key deciding factors become clear to us:
By looking at the underlying ethos of the tools, we identified that some were aimed at managers, heads of departments and CTO’s, others were aimed at being most useful to teams themselves. These two approaches produced quite different user experiences; the product looked different and you could tell which audience they were mainly aimed at. We felt fairly safe in predicting that a tool that did not put use by teams first would not be used by our teams, and also that a tool that was not used by our teams would not produce meaningful data for anyone else. So that use case became our primary focus.
We also looked at how “opinionated” the tool was about the team’s ways of working. Some of the tools required teams to work in defined ways in order for them to produce meaningful data, whilst others were much more adaptable to different ways of working. At Skyscanner we encourage teams to adapt and refine their ways of working to best fit their needs, so we didn’t want to introduce a tool that forced a certain convention, even if the data would ultimately lead teams to make some changes to how they worked.
After going through this process and trialling a few of the tools, we settled on using Plandek to actually gather the metrics and present the data and the insight to our teams. The team at Plandek has been great, working with us throughout, understanding our needs and giving us relevant advice and in some cases making additions to the product to help us get to where we want to be.
Changing Culture
This was probably the part that we put the most effort into, because we recognised that any mis-steps could be misinterpreted as us peering over folks’ shoulders, or even worse, using these metrics intended to signal improvement opportunities to measure individual performance. Either of those would be strongly against the way that we work in Skyscanner, and would have stopped the project in its tracks, maybe even causing irreversible damage to the project’s reputation. To that end we created a plan that focused on developing a deep understanding of the intent with our engineering managers before introducing the tool.
This plan focused on a bottom-up rollout approach, based on small cohorts of squad leads. Each cohort was designed to be around 6 or 7 leads, with a mix of people from different tribes, different offices, and different levels of experiences, covering all our squads. The smaller groups would increase accountability, because it’s harder to disengage in a small group, and also create a safe place where people can share their ideas, learnings, and concerns. We also endeavoured to make sure that each cohort had at least one person who we expected to be a strong advocate for team metrics, and no more than one person that we expected to be a late adopter or detractor. This meant that every cohort would generally have a strong positive outlook, with a minimal risk of collectively building a negative sentiment.
Cohorts would meet every 2-4 weeks, where we’d take them through a little bit of structured learning – perhaps explaining what a particular metric means and why that is useful, as well as some tips for improving it – followed by a healthy amount of discussion and knowledge sharing. Between sessions we’d encourage people to try things out, take data back to their teams to discuss in retrospectives, etc. and then bring any insights back to the next cohort session.
Whilst with hindsight we’d make some minor tweaks to the exact composition of some cohorts where perhaps some advocates weren’t as strong as we’d expected, overall this approach has worked very well for us, and we intend to follow this pattern for similar rollouts in the future. As we progress through Q1 in 2023, we will re-balance the cohorts to reflect the different levels of understanding that people have and to enable us to onboard new managers.
Outcomes
We’re very happy with the level of engagement that we’ve seen from most of our engineering managers. The usage data that Plandek shares with us shows a healthy level of regular engagement, with most managers logging in at least once a Sprint. Our most engaged team members are setting an incredibly high bar with potentially dozens of sessions each Sprint, showing just how engaging team data like this can be.
With this, we’ve seen an increase in awareness of work-in-progress and cycle time across all levels of the organisation, and the outcomes we’d expect from it; teams are feeling less stressed, have more control over their workloads, and all those other great things. The benefits are yet to fully filter through to visible impacts on the wider delivery picture, but these things take time and are relatively well understood, so we’re happy being patient!
One of our squad leads noted: “Having clear visibility of the cycle time also allowed the team to be more aware of the way that we split the tickets, the type of tickets that are of the type spike”. This is a great example of awareness of the data leading naturally to the right kind of (agile) change without having to educate people about it.
The initiative has also helped to raise the profile of these metrics such that people naturally talk about them in different contexts, and without any prompting. It’s great to see epic cycle time being a consideration when teams are weighing up options in their system design reviews. Similarly, our executive and senior leadership teams have started to adopt the same vocabulary which is both a great sign and further accelerates adoption. Before these were only concepts; now they are actual tangible measures people can understand them much better, and action follows understanding.
Adoption Challenges
Naturally, it hasn’t all been perfect or easy, though. The two greatest challenges were competing for people’s time, and people’s engagement being variable.
First, everyone sees themselves as “busy”; some, as the saying goes, “too busy to improve”. That meant positioning this as something relatively lightweight that can help them make more space for thinking quickly was a priority. We did this by cutting the dashboard of metrics we asked people to look at down to what we thought was the absolute minimum that was useful. Plandek has over 30 different metrics, but we’ll get to more in time. As people started exploring the subset we started with they naturally started experimenting with the other insights on offer.
Second, as we moved forward with the cohorts, not everyone in each cohort was moving at the same speed, which sometimes led to disjointed conversations. As mentioned above, we’re going to rebalance the cohorts as we progress through Q1 2023 to realign people with the level of support they will benefit most from. We still think starting off with the highly mixed cohorts was the right thing to do to align with the message that this was not about oversight; now that this has been somewhat proven we can think about how we move forward.
Learnings
Our biggest learning was undoubtedly just how critical the underlying culture enhancements were. From the outset, we were conscious and explicit that we didn’t want to “roll out a tool,” but instead the “thinking process” around team metrics. But it was only after our first proof of concept that we realised that we needed to dig even deeper and focus on the foundations and build the notion of delivery metrics into our culture, as we have with service and product metrics.
We did this mainly by being clear about what we called the initiative (that is not “Plandek roll out”) and then front loading the cohort sessions with theory and explorative discussion before we got to using the tool. The small frequent cohort groups allowed people to become comfortable with the concepts. Had we approached this as a tool rollout rather than culture change, we could have easily just had a few large one-off training sessions to “get people started on the tool”.
From there, it all takes more time and effort than we had assumed. There is value in making things simple; it’s not about having many metrics and many advanced ways of using them, it’s about getting smart people to understand the why, the value, and giving them easily accessible tools, arming them with enough understanding to get started then supporting them and getting them to share their successes.
MMS • Johan Janssen
The Adoptium Working Group has published their Eclipse Adoptium: 2022 in Review and 2023 Roadmap document that provides a retrospective for their accomplishments in 2022 and what developers can expect in 2023. Eclipse Adoptium provides Eclipse Temurin JDK and JRE binaries and introduced the Adoptium Marketplace in 2022 for third party runtimes. Adoptium produced 166 releases last year, each one verified by thousands of tests for the various supported platforms.
The AdoptOpenJDK project, introduced in 2017, joined the Eclipse Foundation in 2020 and was rebranded as Eclipse Adoptium. The first Temurin JDK builds were released in 2021 and supports the (Alpine) Linux, Windows, macOS, AIX and Solaris operating systems for various architectures such as x64, x86, aarch64 and arm.
Adoptium Quality Assurance (AQAVit), an open source test suite, was improved last year with features such as new tests, new test pipelines with remote triggers and Jenkins auto-rerun. The Java Test Compatibility Kit (TCK) is a set of tools and documentation used to verify whether a Java implementation is compatible with the Java specification. Adoptium introduced the Adoptium Marketplace in 2022 which provides TCK- and AQAVit-verified runtimes from organizations such as Red Hat, Microsoft, Azul, IBM, Huawei and Alibaba Cloud. In the past AdoptOpenJDK also offered binaries for other projects such as Eclipse OpenJ9.
Google and Rivos joined founding members Alibaba Cloud, Microsoft, Red Hat, Azul Systems, Huawei and Karakun as Strategic Members of the Adoptium Working Group. The organizations view Adoptium’s solutions as critical to their future. The members may be part of the steering committee or other subcommittees such as marketing, branding, quality assurance or infrastructure. Together they ensure that Adoptium Temurin continuous as a secure, trusted and high quality distribution for organizations and developers which is available for free and supported for a long time.
The Secure Software Development Framework (SSDF) is a set of development practices to establish secure software development processes to reduce vulnerabilities. This is published by the National Institute of Standards and Technology agency of the US Department of Commerce’s Computer Security Resource Center division. Eclipse Adoptium already uses the OWASP CycloneDX Bill of Materials (BOM) standard which reduces the risk in the supply chain. The standard includes the Software Bill of Materials (SBOM), which are produced as JSON files for the Temurin builds. A GitHub issue is still open to discuss future improvements for the SBOM. Adoptium started working on reproducible builds, which are binary identical and may be built by third parties. This verifies that Adoptium built the binaries in a correct way and the build and distribution process hasn’t been compromised. GPG signatures were introduced, next to the already existing SHA checksums, for each build which may be used to verify that the artifacts weren’t changed after being built by Jenkins. Two factor authentication and two person reviews are now activated for all critical repositories on GitHub.
Supply chain Levels for Software Artifacts (SLSA) is a security framework that includes a check-list of standards and controls to improve the integrity of artifacts. Eclipse Temurin reached SLSA level 2 compliance which means the project started to prevent software tampering and added minimal build integrity measures. There are four levels in total, where the fourth level assures the highest build integrity and measures for dependency management should be in place.
For 2023, the focus is on growth as less than a hundred people currently work on the projects which have millions of downloads per week and thousands of users on Slack. Eclipse Adoptium plans more community involvement especially to collect feedback, for example, via the Slack channel. The project also wants to encourage users of open source solutions to consider Eclipse Adoptium which hopefully results in usage of other Adoptium projects. Lastly, they aim to increase collaboration with other Eclipse projects to increase the Adoptium community and receive more feedback. This hopefully also results in support from the community in order to improve infrastructure components, such as the automation with AQAvit.
The Adoptium website offers Temurin binaries as well as Marketplace binaries for various other projects and their documentation provides more information.
More information about the results for 2022 and the plans for 2023 can be found in the blog Eclipse Adoptium: 2022 in Review and 2023 Roadmap.
Road to Quarkus 3: Bets on the Flow API for Mutiny 2.0, Updates to Jakarta Namespace and More
MMS • Olimpiu Pop

First introduced to the Java community in 2018 and 2019, Quarkus, Helidon and Micronaut embarked on a journey to provide alternatives in a market dominated by Jakarta EE and Spring. Their main differentiator: the cloud-native promise in a world that has been rapidly moving to the cloud. In 2022, Java’s intent to be cloud-fit was underlined: Project Leyden was resurrected to continue its mission to have a Java presence in the cloud, and the release of Spring 6.0 made the first steps towards supporting native Java.
Quarkus seems to have a head start, as its guiding principles, stated on its website, include:
- Framework Efficiency: “promising supersonic, subatomic with fast startup and low memory footprint”
- Kube-Native: “enabling Java developers to create applications that are easily deployed and maintained on Kubernetes”
Quarkus’ continuous evolution seems to be confirmed by its “Early Majority” classification, according to the December 2021 InfoQ Java Trends Report, and by being shifted to the “Trial” bracket, according to October 2021 ThoughtWorks Technology Radar. Following its traditional major release every 18 months, the framework has reached its next major version promising additional improvements towards its stated mission.
To get a deeper understanding of what developers can expect in the final version 3.0 release targeted in the next couple of months, InfoQ reached out to the team behind the project led by Max Rydahl Andersen, Quarkus co-lead and distinguished engineer at Red Hat. This is the first of a two-part news story that discusses the road to Quarkus 3.0.
InfoQ: Thank you for taking the time to answer the questions for our readers. To start: what are the major themes for Quarkus 3.0?
Andersen: This is an ever-evolving list that changes based on the community’s feedback while getting closer to the final version. Currently, the major themes are the integration of Hibernate ORM 6, Eclipse MicroProfile 6, virtual threads and structured concurrency following the learnings from the initial integration. Also, we target some core changes to improve performance like bringing io_uring (next generation async IO) and moving from Reactive Streams to using the Flow API.
InfoQ: Why does Quarkus 3 switch from Reactive Streams to Java’s Flow API?
Julien Ponge: We created SmallRye Mutiny for reactive programming, initially being developed on top of the Reactive Streams API. The implementation decisions were made when Java 8 was still supported and the Flow API was not part of the JDK. That is no longer the case, so we decided to embrace modern APIs. Mutiny 2 was conceived with this thought in mind. However, as that larger migration in the ecosystem may take time, Mutiny provides no-overhead adapters to bridge between Java Flow and the legacy Reactive Streams APIs. To make the transition smoother, Resteasy Reactive and Reactive Messaging work with both.
InfoQ: Project Leyden plans to optimize Java with jlink enhancements. Does Quarkus plan to support the Java Platform Module System (JPMS)?
Andersen: The limits applied by JPMS hinder the experience frameworks and users have. Therefore we hesitate to support JPMS fully as it hurts both usability and performance.
We are happy to see ideas being explored around the condenser notion in Leyden. This would allow the JDK and third-party libraries and frameworks to participate in various phases of the creation of an optimized Java application and eventually native image generation. Nevertheless, it is proposed to be done via jlink. We are working with OpenJDK and GraalVM to find a solution not to exclude the vast majority of the java ecosystem relying on classpath-based libraries.
GraalVM native images have shown that dead code elimination works remarkably well to decrease storage and provide runtime savings; without being limited to JPMS boundaries.
InfoQ: Are there any particular features that you would encourage developers to use with care?
Andersen: In general, we expect everything to work after the initial migration step, but when using Apache Camel, it is recommended to wait for version 4 when the Jakarta namespace will be supported.
We wish that would not be a necessity, but that ship has sailed, and now we focus on a smooth transition. We focus on having minimal breakages in our core and providing migration tooling.
InfoQ: What was the most challenging technical aspect while developing this version?
Andersen: Even though “boring”, the Jakarta namespace migration was a multi-year effort that involved close collaboration with multiple Red Hat Runtimes teams. Before even considering moving Quarkus to the Jakarta namespace, we ensured that the underlying stack was ready. Once the releases started happening, we started working on a semi-automated way to have our current Quarkus release and validate as many extensions as possible.
According to Andersen, Quarkus was created to enable the use of Java in container-native applications and, in doing so, rethink the approach the Java ecosystem has taken over the last quarter of a decade. More than just efficient running, Quarkus focused on Developer Experience (DX) as well: hot code replacement, continuous testing and developer services. All in all the effort to make a cleaner API to deliver business applications faster. As they try to work closely with the community, developers are encouraged to try it and provide feedback.
WireMock Spring Boot Simplifies the WireMock Configuration for Spring Boot Applications
MMS • Johan Janssen

WireMock, a flexible tool for building API mocks, and the new WireMock Spring Boot utility simplifies the WireMock configuration for JUnit-based integration tests in Spring Boot applications.
Maciej Walkowiak, freelance architect & developer, released the first version of WireMock Spring Boot in February 2023. The project automatically configures the Spring environment properties and provides a fully declarative WireMock setup. Multiple WireMockServer instances may be used, one per HTTP client. Lastly, this new utility doesn’t publish extra beans to the Spring application context, but keeps them in a separate store associated with the application context.
WireMock Spring Boot may be used after adding the following Maven dependency:
com.github.maciejwalkowiak.wiremock-spring-boot
wiremock-spring-boot
0.1.0
test
Currently, the dependency is not yet available on Maven Central, but may be used via the JitPack package repository for Git. JitPack downloads the code from the Git repository after the first request and builds the code to provide the build artifacts, such as JAR files. More information can be found in the JitPack documentation.
The following JitPack repository should be configured in the pom.xml, until the artifact is available in Maven Central:
jitpack.io
https://jitpack.io
Tests annotated with @SpringBootTest, and other annotated tests using the SpringExtension class, may be annotated with the @EnableWireMock annotation which enables the WireMockSpringExtension and adds the test context customizer. The mock is configured with the @ConfigureWireMock annotation which creates a WireMockServer and uses the name specified by the property as the name of an environment property which can be used to retrieve the WireMockServer:
@SpringBootTest
@EnableWireMock({
@ConfigureWireMock(name = "studentservice", property = "studentservice.url")
})
class StudentControllerTest {
@Autowired
private Environment environment;
@WireMock("studentservice")
private WireMockServer wireMockServer;
@Test
void studentTest() {
environment.getProperty("studentservice.url");
wireMockServer.stubFor(get(urlEqualTo("/student"))
…
}
}
The previous example uses the environment.getProperty("studentservice.url") method to retrieve the URL of the WireMockServer instance.
WireMock extensions may be configured via the extensions parameter in the configuration annotation:
@ConfigureWireMock(extensions = { … }, …)
By default, the classpath directory containing the mapping files is set to wiremock/{server-name}/mappings, but may be changed via the stubLocation parameter in the configuration annotation:
@ConfigureWireMock(stubLocation = "customLocation", …)
Automatically-set Spring properties and the declarative configuration of multiple WireMockServer instances are advantages of WireMock Spring Boot compared to Spring Cloud Contract WireMock. However, the latter supports contract testing, REST docs and other features.
WireMock Spring Boot uses the concepts and ideas from the Spring Cloud Contract WireMock and Spring Boot WireMock projects and the article Spring Boot Integration Tests With WireMock and JUnit 5. More information about the project can be found on GitHub.
MMS • Almir Vuk

A new available extension makes it possible to update any .NET application to the most recent .NET version within Visual Studio. Applications built using .NET Core or .NET Framework can now be upgraded using the upgrade tool, within Visual Studio. Several project types, are still in development and will also be available soon.
The .NET Upgrade Assistant is a Microsoft tool that helps developers upgrade their .NET Framework apps to .NET 5 or later by analyzing code and dependencies, generating a report of issues, and providing code fixes. The tool simplifies the upgrade process and ensures compatibility with the latest .NET runtime.
Microsoft has been working on simplifying the process by developing new tools, including the Upgrade Assistant CLI and Microsoft Project Migrations. After receiving feedback from users through surveys, comments, and feature requests, Microsoft concluded that a unified upgrade experience for all project types within Visual Studio was needed. By doing so, Microsoft aims to make the upgrade process more straightforward and accessible for developers.
According to the .NET blog post, the upgrade tool within Visual Studio is planned as a lasting solution to keep applications up-to-date with the latest .NET runtime. Additionally, aside from changing the target framework version, the upgrade assistant is also set to address some of the breaking changes by modifying the code.
The extensions support several project types, including ASP.NET, class libraries, console applications, WPF, and WinForms. These project types are similar to what the Upgrade Assistant CLI tool supports. In the future, the tool will add support for migrating Xamarin to .NET MAUI, migrating UWP to WinUI, and migrating WCF to WCF Core.
For not supported types Microsoft recommends:
If you need to migrate these project types today, we recommend using the existing Upgrade Assistant command line tool, which already has code fixers. The Visual Studio extension will get them soon too.
The Upgrade Assistant has three upgrade types available: in-place, side-by-side, and side-by-side incremental. Each type will be recommended for specific project types. While using it developers will only be presented with options that are suitable for their particular application.
In-place upgrades the original project all at once, while Side-by-side adds a copy of the project to the solution containing the upgraded code. Side-by-side incremental is ideal for web applications and allows the gradual upgrade of items to .NET 6/7 without breaking the app.
On the official post by Microsoft, you can find the status of all upgrade types by project type in the table form and the walkthrough steps of an upgrade of the class library with the In-place type of upgrade.
In addition to the blog post, the official dotnet YouTube channel provides the video named: Upgrade Your .NET Projects Faster with Visual Studio;. In this video, Olia shows you how to get the extension and start to update your projects to the latest version of .NET in minutes.
A survey is also available, to gather feedback on the newly available feature for upgrading .NET projects from within Visual Studio. Users are encouraged to share their experiences and suggest improvements by participating in the survey More info and details about .NET Upgrade Assistant can be found on the official Microsoft dotnet website.
Couchbase beats earnings and revenue targets and its stock inches higher – SiliconANGLE
MMS • RSS

Shares of the database company Couchbase Inc. were trading higher after-hours today, after it posted fourth-quarter financial results that beat Wall Street’s expectations.
The company reported a loss before certain costs such as stock compensation of 18 cents per share, well ahead of Wall Street’s forecast of a 34-cent loss. Revenue for the period rose 19% from a year ago, to $41.6 million, beating the analyst forecast of $38.25 million. Despite the earnings beat, Couchbase was unable to avoid going deeper into the red, as it reported a net loss of $18.5 million for the quarter, up from a $12.7 million loss one year earlier.
Couchbase Chairman, President and Chief Executive Matt Cain (pictured) said his company delivered another strong quarter of sustained growth, while making substantial operational progress in fiscal 2023 overall. “This is a direct result of great execution across the company, which we are particularly pleased with despite this more challenging macro environment,” he added.
Couchbase’s revenue for the full year rose 25% from a year earlier, to $154.8 million, resulting in a net loss of $69.3 million, up from a $56.3 million net loss in fiscal 2022.
The company is the developer of the popular Couchbase NoSQL database that’s used by enterprises to power an array of business applications. The big advantage of Couchbase is that it can accommodate both structured and unstructured data at the same time, in contrast to traditional databases such as Oracle’s that can handle only one type.
Thanks to this capability, it also can function as a data cache, which means enterprises can use one system to accomplish what would previously have required three. In recent months, Couchbase has been focused on the emerging “database-as-a-service” niche with Couchbase Capella, a cloud-hosted version of its database that launched last year on Amazon Web Services. During the previous quarter, Couchbase expanded its database-as-a-service offering by launching Capella on Microsoft Azure too.
There were other positive numbers for Couchbase as well. Its subscription revenue for the quarter rose 16%, to $38.1 million, suggesting decent growth with the Capella service. The company also reported annual recurring revenue of $163.7 million at the end of the quarter, up 23% from a year ago. Remaining performance obligations came to $165.9 million, up 3% from a year earlier.
Constellation Research Inc. analyst Holger Mueller said Couchbase delivered on another good quarter, though he noted that its growth has dipped slightly from over 20%, to just under. Still, he said he’s optimistic that the company may be able to accelerate its growth again.
“By bringing Capella to more clouds with its launch on Azure, Couchbase’s offerings will become more attractive to companies that are building next-generation applications,” Mueller said. “The company has made some progress on the cost management side too, with its loss per share down by a third from the previous year. For Couchbase, 2023 will be all about maintaining growth.”
Despite its encouraging growth, Couchbase was somewhat cautious regarding guidance for the coming quarter and full year. It said it sees first-quarter revenue of between $39.5 million and $40.1 million, just below Wall Street’s consensus estimate of $40.6 million. For fiscal 2024 overall, Couchbase expects revenue to fall somewhere between $171.7 million and $174.7 million, versus Wall Street’s $176.6 million forecast.
Couchbase’s stock, which stayed flat during regular trading, gained almost 3% in the after-hours session.
Photo: Couchbase
Show your support for our mission by joining our Cube Club and Cube Event Community of experts. Join the community that includes Amazon Web Services and Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger and many more luminaries and experts.
MMS • Matt Raible
The JHipster Mini-Book is a guide to getting started with hip technologies today: Angular, Bootstrap, and Spring Boot. All of these frameworks are wrapped up in an easy-to-use project called JHipster. JHipster is a development platform to generate, develop and deploy Spring Boot + Angular (or React/Vue) web applications and microservices. This book shows you how to build an app with JHipster, and guides you through the plethora of tools, techniques, and options you can use. Then, it shows you how to secure your data and deploy your app to Heroku. Furthermore, it explains the UI and API building blocks so you understand the underpinnings of your great application.
The latest edition (v7.0) is updated for JHipster 7. This edition includes an updated microservices section that features WebFlux and micro frontends with React.
Purpose of the book:
To provide free information to the JHipster community. I’ve used many of the frameworks that JHipster supports and I like how it integrates them. I think building web and mobile applications with Angular, Bootstrap and Spring Boot is a great experience and I’d like to encourage more developers to try it.
Free download
MMS • Steef-Jan Wiggers
Microsoft Azure recently announced the general availability of Azure Communications Gateway. This product lets operators connect their fixed and mobile voice networks to Teams Phone, Microsoft’s cloud-based system.
Azure Communications Gateway is a managed, cloud-based voice gateway that simplifies the integration of operator networks with Teams Phone. It combines a high-availability, Teams-certified, and mobile-standards-compliant Session Border Controller (SBC) with API mediation function—removing the need for disruptive voice network changes or costly hardware deployments.
According to Microsoft, Azure Communications Gateway allows operators to provide enhanced enterprise calling solutions to Teams users, such as Operator Connect (for fixed-line networks) and Teams Phone Mobile (for mobile networks). For example, operator Connect enables enterprises to use their existing operator contracts and phone numbers with Teams Phone. At the same time, Teams Phone Mobile allows mobile operators to offer native dialing and calling features within the Teams app on mobile devices.
Azure Communications Gateway sits at the edge of an operator’s network, where it functions to secure, normalize, and interwork both voice and IT traffic between the operator and Microsoft Teams. In addition, it supports various interoperability scenarios, such as SIP trunking, number portability, emergency calling, media transcoding, and codec negotiation.
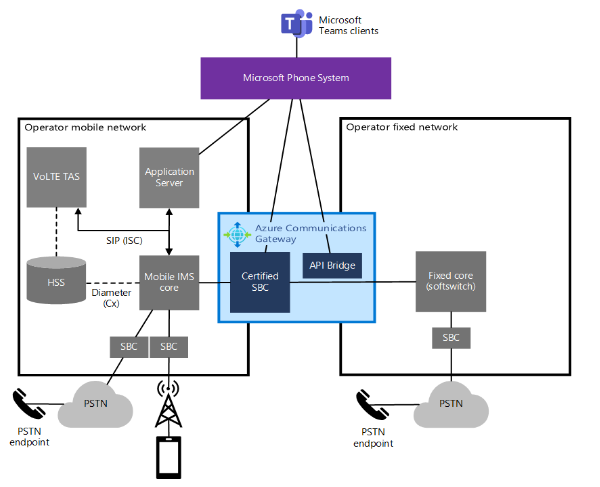
According to the documentation Azure, Communication Gateway ensures availability by deploying it into two Azure Regions within a given Geography. In addition, it supports active-active and primary-backup geographic redundancy models to fit the customers’ network design. Furthermore, the customers’ network must follow the Microsoft Teams Network Connectivity Specification and use Azure Peering Service. And finally, sites must also be able to route to both Azure Regions.

Source: https://learn.microsoft.com/en-us/azure/communications-gateway/overview#architecture
Microsoft claims Azure Communications Gateway offers several benefits for operators and enterprises. For operators, it reduces time-to-market and operational costs by eliminating the need for on-premises SBCs or complex network configurations. It also enables them to leverage Microsoft’s global cloud infrastructure and scale their services according to demand. For enterprises, it enhances their communication experience by allowing them to use Teams Phone with their preferred operator service plans and phone numbers. It also improves their security and compliance by encrypting all voice traffic between their network and Microsoft’s cloud.
Details of the Azure Communication Gateway are available on the documentation landing page. And lastly, Azure Communication Gateway has a tiered pricing structure and per-subscriber billing; customers only pay for what they use. More details on pricing are available on the pricing page.
MMS • Alen Genzic
Entity Framework Core 8, scheduled to release in November 2023, brings new features and improvements to features already introduced in EF Core 7. Notable features include support for raw SQL queries for unmapped types, lazy-loading improvements, and support for TimeOnly and DateOnly SQL Server data types.
EF7 already introduced Raw SQL queries for scalar types, however, in EF8, raw SQL queries can now return any mappable CLR type that is not included in the Entity Framework model. Queries executed in this way support Entity Framework features such as parametrized constructors and mapping attributes. Notably, relationships between the un-mapped type and other types in the model are not supported, since the un-mapped model cannot have foreign keys defined.
SQL views and functions can also be queried using this method, and can be mapped to any CLR type in the same way tables can be mapped.
Entity Framework 8 added support for lazy-loading of navigation properties in un-tracked queries. Lazy-loading properties on un-tracked queries work for both lazy-loading with proxies and without proxies.
There are some caveats to this approach though. Lazy-loading works only until the DbContext used to execute the no-tracking query is disposed of. Lazy loading will likewise not work for entities detached from the DbContext. Additionally, lazy-loading will always use synchronous I/O since there is no way to asynchronously access a navigation property.
The lazy-load feature would silently not run when the navigation property did not have the virtual keyword in EF6 applications, causing bugs.
In EF Core, to avoid the common bug, the proxies throw an exception when the virtual keyword is not present on the navigation property. Due to this new EF Core behavior, EF Core 8 introduces an opt-out feature that you can use to eagerly load only specific navigation properties you explicitly set to load in such a way.
The DateOnly (mapping to a date type column) and TimeOnly (mapping to a time type column) data types are now natively supported by EF Core 8 for SQL Server. Until now (In EF Core 6 and 7), you could use these types only by installing a community NuGet package. The two new types can also be used in SQL JSON columns.
A medium-impact breaking change is related to these types as well. In previous versions of EF, the date and time column types are scaffolded as DateTime and TimeSpan types respectively. In EF8, the new DateOnly and TimeOnly type mappings are used instead. This only affects users that use a database-first approach and regularly re-scaffold their code model. A mitigation strategy is available for users affected by this change.
You can read more about plans for EF8 from official Microsoft sources and vote on features you would like to see implemented on the EF Core GitHub issues page.
You can download the latest preview of EF Core 8, released on 21st February 2023 as a NuGet package. It supports .NET 6 and .NET 7 projects.