Month: May 2023

MMS • RSS
Blockchain and database technologies have numerous similarities and differences and are often compared against each other.
While the two technologies can serve similar purposes and be used together, they work in different ways. Understanding how blockchain and traditional database technologies work is critical to understanding where each technology can best be used in an application deployment or service.
What is a blockchain?
A blockchain is a decentralized, distributed database or ledger that is replicated and synchronized across computers on a network. Since each computer holds a current copy of the ledger, the data isn’t vulnerable to a single point of failure. The copies are updated and validated in parallel by every participant.
Blockchain is a type of distributed ledger technology. It is designed to allow the secure recording of data in an immutable ledger, which means the data theoretically can’t be tampered with. Data is cryptographically hashed — that is, converted to strings of characters that can’t be easily decoded — and stored in blocks that are chained together, which is where blockchain gets its name.
Blockchain isn’t just used for storing data. It also enables cryptocurrencies such as Bitcoin and Ethereum’s Ether. Blockchain technologies are also foundational to Web 3.0 (aka Web3) platforms, which often also rely on cryptocurrency and are touted as the building blocks of the next generation of the web. Blockchain enables the decentralized, peer-to-peer network approach that is a critical to the operations of Web 3.0 technologies, among them decentralized finance, non-fungible tokens and distributed applications.
What is a database?
A database is software that is used to store and retrieve data.
There are many types of databases, including relational databases, which use rows and columns to organize data. Relational databases commonly rely on SQL to let users query and access data. Among the most widely deployed relational databases are Oracle Database, Microsoft SQL Server and the open source PostgreSQL.
Another common type of database is the NoSQL database, which is actually not a single technology but can refer to nonrelational document databases and graph databases. Commonly deployed NoSQL databases include Couchbase, MongoDB and Neo4j.
Databases can serve as a system of record for financial transactions, product catalogs, healthcare systems and supply chain management, among many business uses. Databases are also commonly part of the application stack for applications such as data analytics, ERP, mobile applications and content management systems.
The difference between blockchain and database technology
The two technologies share many overlapping capabilities and can be used for some of the same uses.
Among the similarities of blockchain and databases are the following:
- Data storage. Both allow users to store information.
- Data queries. The ability to query data is common to both technologies.
- Concurrency. The ability of multiple users to execute queries at the same time is a core feature.
- Integrity and consistency. A hallmark of both technologies is a focus on maintaining data integrity and consistency.
- Powering applications. Applications of all types use both blockchain and databases as a foundation.
- Enabling transactions. Blockchain and database technologies are both commonly used to enable transactions, such as product purchases.
Nevertheless, there are important differences between the typical blockchain deployment and a traditional database.
Most databases are controlled and managed from a central location, while those functions are decentralized and distributed in blockchain.
While a traditional database can use encryption for security, it’s not an integral part of the database or included by default. In contrast, a blockchain, by definition, includes a cryptographic hash. Cryptography is included by default and is what makes the blockchain ledger immutable.
Modern relational databases use four attributes of transactions — atomicity, consistency, isolation and durability (ACID) — which help to ensure that transactions are executed correctly. With blockchain, consistency comes from the consensus algorithms that synchronize data across the nodes on a chain.

Advantages of using blockchain
Blockchain potentially provides significant advantages to application developers and users. Among the advantages are the following:
- Web 3.0 integration. As a foundational element of Web 3.0, blockchain enables developers to build the decentralized applications that are expected to be a defining aspect of Web 3.0.
- Immutable data. Each transaction in a blockchain is cryptographically hashed to keep it from being tampered with.
- Privacy. Blockchain helps improve privacy by not requiring users to authenticate with anything more than a combination of public and private keys.
- Fault tolerance. The distributed structure of most blockchains minimizes the risk of a single point of failure.
Advantages of using traditional databases
Traditional databases are a standard technology that has existed for decades and has many advantages, including the following:
- Familiarity. Developers and users are likely to be far more familiar with deploying and using a traditional database. It is a tried-and-true technology that has stood the test of time.
- Compatibility. Traditional databases are compatible with a massive array of enterprise and consumer applications developed over decades.
- Skills. Traditional database technology has been in use for a long time in critical business processes, and the talent pool of trained database administrators is large.
- SQL queries. SQL provides developers, data analysts and database administrators with an expansive set of capabilities to access, query and manipulate data.
Blockchain tables integrate blockchain with traditional databases
Is blockchain better than a traditional database? The question calls for a nuanced answer, in part because it’s not an either-or choice.
Blockchain is considered by some observers to be one type of distributed database, much like a document database is a type of NoSQL database. For organizations that want to deploy a distributed database instead of a traditional one, blockchain is a highly secure and encrypted option.
To make matters even more interesting, traditional databases can also integrate blockchain. An increasingly popular approach to database product development is to have what is known as a multimodel database. In the multimodel approach, relational, document, graph database and other models — including blockchain — are all available in a single database.
Traditional database vendor Oracle, for example, began to integrate blockchain into its multimodel approach with the Oracle Database 21c update that came out in January 2021. With the Oracle approach, a blockchain table — an immutable, cryptographically assured set of data stored in table format — is available. It isn’t the same fully decentralized approach that normally typifies blockchain, but it is blockchain nonetheless.
Oracle isn’t the only traditional database vendor to embrace some of the concepts of blockchain. Microsoft introduced a distributed ledger with blockchain-type functions in its Azure SQL database in May 2021.
MMS • Jason Harmon

Key Takeaways
- Define consistent language and terminology across your API team to ensure consistency and avoid confusion later on.
- Apply shared style guidelines and linting rules to enable better governance and standardization.
- Establish your API design review team early on, accounting for all stakeholders and not just the technical ones!
- Create an API catalog that actually reflects the scope and depth of APIs in your organization to improve discoverability and visibility.
- Whenever possible, maximize your use of shared components and models to help your developers scale and replicate with ease.
In the course of designing APIs at scale, it takes deliberate effort to create consistency. The primary difference between a bunch of APIs and something that feels like a true platform is consistency. In this case, consistency simply means that if you use multiple APIs, factors like naming conventions, interaction patterns like paging, and auth mechanisms are standard across the board.
Traditionally, review committees have traumatized API developers with delay-inducing discoveries when development is thought to be complete. Worse, design by committee can take over, stalling progress or encouraging developers to find ways to sidestep the process to avoid the pain altogether.
To truly unlock a modern platform, enablement through decentralized governance is a much more scalable and engaging approach. This simply means that each domain or functional area has a subject matter expert who has been educated on the standards and overall architecture to be a well-enabled guide for API developers.
More importantly, agreeing on API design before the bulk of development is complete can largely avoid last-minute discoveries that put delivery timeframes in jeopardy (often referred to as a design-first approach). Using a spec format like OpenAPI (the de facto standard for HTTP/”REST” APIs) provides the ability to define an API before any development, which enables much earlier alignment and identification of issues.
With this context in mind, let’s take a closer look at how to conduct API design reviews, and how to develop processes and prepare the organization to avoid protracted timelines and a lack of developer engagement.
Here are some key prerequisites to ensure a smooth process:
1. Define consistent language/terms
APIs usage is a very distilled experience, and as such, the impact of language is disproportionately higher than most other design realms. Each team member may have a slightly different way of defining and describing various terms, which manifests in confusion and decreased productivity for API teams.
While API portals/documentation are essential to a great developer experience, well-designed APIs should tell most of the story without having to think about it much. If terms are familiar to the consumer, and interaction patterns are obvious, then the experience can be quick and painless. Consistency is the primary difference in experience between a bunch of APIs and something that feels like one platform.
When establishing your API program and governance process, start with shared language. While it can seem impossible at first, defining a customer-centric shared vocabulary/grammar for your platform is essential, and an overall accelerator for an organization. Many terms can have varied meanings inside of a company, and to make things worse, these are often terms that end-consumers wouldn’t even recognize.
Doing this homework upfront avoids conflicts over naming in the midst of designing APIs. Work through each domain with relevant stakeholders to define shared terminology, and ensure wide availability and awareness to API designers. And once you’ve settled on internal standardization of terms, don’t forget to check if it fits with your external needs as well. Using customer language and having a customer-centric view of API development helps teams avoid confusing their customers with unfamiliar technical terms, so ensure there’s synchronization between your internal understanding and external understanding.
2. Define Shared Components
When API consumers encounter models or parameters that vary between APIs, it can be a confusing, frustrating, and time-consuming process. For example, if you use one API which refers to contact information, and the next API in the same platform uses a completely different model, consumers often have to resolve these differences. Worse, systemic differences in handling this data can unfold, creating functional differences.
As early as possible, identify common components (models, parameters, headers etc) and the systems that support them. Linking to shared components in API definitions ensures that future changes to those components are easier to roll out across the platform, as well as reducing undue cognitive burden on API consumers.
The more common components you have, the better opportunity for increased consistency, reusability, further collaboration opportunity and enhanced efficiency. All of us in the developer world love the ‘DRY method’ (Don’t Repeat Yourself), and the more shared components there are, the easier it is to innovate without having to make the same thing from scratch over and over again. Shared components also allow your team to scale quickly, training up new developers or stakeholders outside of the API team with ease.
3. Apply Shared Style Guides and Linting Rules
For the vast majority of simple naming conventions, interaction patterns, and auth mechanisms, automation with style guides can be provided to flag inconsistencies as early as possible.
The first style guides were developed between 2013-2015, setting expectations for look and feel (aka DX) for API development teams. The need for design consistency was apparent from the outset of API platform development, and early efforts by Paypal (I was a part of this team back in the day actually!) and Heroku resulted in some of the first style guides from successful programs to be shared publicly.
While there are a variety of automation tools available to help with style guides, the open-source tool Spectral has emerged as a standard for defining API linting rulesets. Aligning upfront on the conventions for paths, parameters, and more, and defining automated linting rules will avoid delays from conflicts over which conventions are ‘correct’. Have the discussion once, and define rules … try not to talk about it again; just make the lint errors go away!
For the design standards that can’t be automated, these should be documented and made easily available to API designers. Training that explains the importance of automated and manually verified rules can build motivation from developers to fully support the initiative, and avoid surprises and friction.
4. Establish API Design Reviewers Across the Org
While an API enablement team should exist to curate these design standards and foster community, authority should be enabled in each functional area or domain.
Although API standards are important, domain knowledge of systemic constraints, specific customer needs, and organizational strengths and weaknesses are best handled by an expert who is part of that world. If centralized API enablement team members are expected to know about everything in the company, bottlenecks leading to delivery delays and developer disengagement are nearly guaranteed.
Training workshops can be a powerful technique for spreading awareness of the importance of API standards. Additionally, you’ll often discover the right SMEs to provide governance authority. Look for individuals who express a passion for APIs (I often refer to these as a ‘band of rebels’), exhibit an awareness of the relevance of consistency and standards, and have the technical respect of their peers and/or reports.
Developing a successful API will involve many folks across your organization, often with contrasting skill sets, some who will build and deploy the API, and others who will be on the strategic side of the business problem identifying the value of your API. Don’t forget the business stakeholders as well when it comes to who to involve in the design review. Often, we only include the technical side, and that can result in failure later on. The more perspectives, the better!
5. Ensure Portfolio/API Catalog Alignment
Your platform should have product managers who agree on the overall composition of the API portfolio/catalog. Catalogs come in many different forms, and they organize your APIs to make it easier to find what you need without needing to know exactly what you’re looking for. It allows potential users to browse through available APIs grouped by functionality or other user concerns.
Good catalogs are searchable or filterable so that developers can easily narrow down the options, and they offer comparable, digestible detail for each API in the catalog that offers a clear path forward.
For any new API proposed, a functional overview with use cases and basic naming should be reviewed as early as possible. This ensures language alignment, reusability, and overall “fit” of a new API against the larger platform perspective.
Your enablement team should have product managers who own the portfolio alignment process, and each should own a manageable collection of domains. At the very least, a regular venue for domain-specific PMs to have alignment discussions is key.
While that can seem like a lot, remember that API standards should evolve through iteration. As each API is designed, you’ll recognize opportunities to refine standards. With that in mind, make sure the basics are covered in your upfront homework, and make sure API governors have a clear understanding of how to propose and adopt changes to standards.
Conducting API Design Reviews
If you’ve completed the above prerequisites, there’s not much to do in API design review! If domain-centric SMEs are involved, design review can often be largely integrated into ongoing design efforts. If “fit” in the platform is aligned early, design reviewers should have the confidence that this API belongs in the bigger picture. Additionally, if API designers see linting errors as they’re iterating, there should be no discussions about basic conventions beyond educating developers on the relevance of various linting rules, or simply how to resolve lint errors.
Not everything can be automated, and sometimes product and architecture needs can conflict. Make your API design review a time where manually enforced conventions are checked, customer language is validated (as this is hard to automate), and final alignment is solidified. With that scope in mind, meetings can often be bypassed, and asynchronous discussions can often suffice.
Most importantly, keep a close eye on API design review cycle time … it should drop distinctly over time as more decentralized SMEs get more comfortable with existing standards and how to adopt new standards.
MMS • Mehrnoosh Sameki

Subscribe on:
Transcript
Introduction [00:44]
Welcome everyone to the InfoQ podcast. My name is Roland Meertens, your host for today, and I’ll be interviewing Mehrnoosh Sameki. She is the Responsible AI Tools lead at Microsoft and Adjunct Assistant Professor at Boston University. We are talking to each other in person at the QCon London conference where she hosted the track Emerging AI and Machine Learning Trends. She also gave the presentation, Responsible AI from Principle to Practice. Make sure to watch her presentation as she both delivers tremendous insights into responsible AI and also gets you the tooling needed to get started with it yourself. During today’s interview, we will dive deeper into the topic of responsible AI. I hope you enjoy it, and I hope you can learn from it.
Welcome Mehrnoosh to the InfoQ podcast. We are here at QCon London, you are giving a talk tomorrow. Do you want to maybe give a short summary of your talk so people who haven’t watched it online yet can watch it.
Mehrnoosh Sameki: Absolutely. So first of all, thank you so much for having me. It’s so wonderful to be in this venue and also in London in general. I feel like I’m here as a part of history. It’s so beautiful here. My name is Mehrnoosh Sameki, I’m a principal PM lead at Microsoft, and I’m also an Adjunct Assistant Professor at Boston University. And my focus and passion is to help operationalize this buzzword of responsible AI in practice. So I lead a product team who is on a mission to essentially help you with the tools that you can incorporate in your machine learning lifecycle to operationalize concepts like fairness, transparency, and interpretability, reliability, and safety. And so it’s so wonderful to be here among the practitioners and understand their concerns or challenges, and see how we can support them in their ML lifecycle.
Defining responsibility and fairness [02:30]
Roland Meertens: You mentioned concepts like fairness. What do you mean with fairness? What do you mean by responsible?
Mehrnoosh Sameki: Great question. So responsible AI in general is a term that we very generically use to talk about the right approach of developing and deploying artificial intelligence systems. And it consists of many different aspects. So one possible enumeration is Microsoft’s six different responsible AI principles of fairness, inclusiveness, reliability and safety, privacy and security, underpinned by two more foundational principles of transparency and accountability. And so during this podcast, I could double-click on each one of them, but specifically this aspect of fairness is very interesting because in general fairness is a concept that has been studied by philosophers, or psychologist, many different sociologists, and also computer scientists for decades, maybe even more than that. And so we cannot suddenly come from the tech world and come up with one great definition for it. It’s truly a hugely multifaceted concept. However, the way that we refer to it in the space of AI is, AI systems should treat similarly situated people the same regardless of their protected attributes or sensitive attributes like gender, sex, sexual orientation, religion, age, or whatever else that might be.
And my possible way to simplify fairness for teams is to help them think through the harms, because harms make it very real. So think through what type of fairness harm you are envisioning your AI could have. Is that a harm of allocation where AI is allocating opportunities or information differently across different groups of people? Is that harm to the quality of service when AI is providing different quality of service across different groups of people? Is that representational harm like your AI is stereotyping, or using demeaning language or derogatory language, or possibly even erases a population from its answers or from the population that it’s serving? So thinking through the harms would help just make this concept of fairness a little bit more real, and help you with picking the right measurements and mitigation techniques to resolve it.
Roland Meertens: And how do you then determine that two users have the same background or are essentially in a similar situation?
Mehrnoosh Sameki: You need to have something in your data that is considered as your sensitive attribute. So you need to have that type of information. And usually a lot of our customers, a lot of users that I’m seeing, they do have some notion of even if they haven’t used some sensitive attributes like a gender during their model training, they still have access to them. And those are the angles that we use in order to see how the model is treating different groups defined in terms of those angles. For instance, female versus male versus non-binary.
Sometimes customers come and say, “We don’t have access to sensitive attributes at all because we’re not allowed to even collect that.” In such scenarios, what we really recommend to them is a tool that I’m presenting in details in my presentation called error analysis, which at least provides you with the blind spots of your AI. So it says, “Oh, marginally, a lot more people of this particular cohort are getting erroneous responses.” So it automatically puts those blind spots in front of you and even though you don’t have access to those sensitive attributes and these cohorts might not be defined in terms of sensitive attributes, still knowing those blind spots and improving the performance of the model for them would hopefully help raise the overall performance of the model for everyone. And you never know, maybe there is a correlation between those blind spots features, and some sensitive attributes that you haven’t even collected.
Using sensitive attributes [06:13]
Roland Meertens: Would you then recommend people to explicitly gather these maybe sensitive attributes for model evaluation or maybe even model training, or would you rather recommend people to not collect at all and not use it at all?
Mehrnoosh Sameki: Great question. So you are now alluding to the question that is asked a lot that if we don’t collect and the model never knows, then what is the risk for fairness? Essentially, it’s like we are completely closing our eyes to these sensitive attributes with the best intent. The challenge here is often there are other factors that leak information about sensitive attributes. So even if you haven’t used sensitive attributes in your machine learning model, there might be another factor that seems very non-sensitive, like neighborhood for instance, or I was working on a hiring scenario, and something that we saw was time outside the work market, and that might be an interesting feature for the model, but then we realized that that’s leaking information about gender because there are a lot of women who might take more time off because of maternity leave, because often maternity leave periods are longer than paternity leave.
And so in such cases I really recommend for them, if they could legally collect it, they could omit it from the model training, they could just pretend they don’t have it, but still bring it as metadata to the evaluation phase just to make sure that no other nonsensitive factor has leaked information about that sensitive factor.
Roland Meertens: And would you then, during your evaluation step, do something like demographic pairing where you’re comparing all the different people from different domains with different backgrounds?
Mehrnoosh Sameki: That is a great question again. So there are many different ways that you could enhance and improve the fairness of an AI system. You could never guarantee fairness, but you could improve the fairness with information you have at hand. And the demographic parity is one of them. So there are other things like equalized odds, or equal opportunities, stuff like that, and so the way that I look at it is, when we sit down with a team who is interested in fixing, or mitigating, or improving fairness of their AI, we try to understand, what is the thing that it’s very top of mind for them? In other words, what disaster would look like to them.
Some companies might say, “I want my distribution of favorable outcome to be exactly the same across different demographic groups.” So then we go with that approach. We try to, exactly as you mentioned, look into different demographic groups, look at what is the percentage of the favorable outcome distributed by the AI across those. Some people say, for instance, in a HR scenario, “I want to make sure that I’m making the errors in a systematically similar way for women, men, non-binary people. So imagine these people apply for my job, I want to make sure that the qualified ones based on ground truths are getting the same acceptance rate to my job, and the unqualified ones getting the same rejection rate.” In other words, you want to get deeper in each demographic and even divide them into more buckets and then compare them. So it really depends on what your goal is. And demographic parity is definitely one of the top ones we see with the customer.
Trade Offs between performance and fairness [09:24]
Roland Meertens: Do you then ever get difficult trade-offs where, for example, you manage to improve the overall performance of your system except for one group? What do you do in such a case?
Mehrnoosh Sameki: So let me just first acknowledge that the concept of responsibility is very tough, and often we have to approach that with a very, very open mind, growth mindset and empathy, and always acknowledge that with the best, best, best intentions, still mistakes will happen in the real world. And so that’s where the great feedback loops, and monitoring loops comes into the scenario that at least be very fast to respond. So to your point, yes, we see trade-offs all the time. We see trade-offs in two different facets when it comes to fairness. Sometimes you choose a couple of fair criteria and perfecting one to the knowledge that you have is essentially like tackling the other one or taking it to the negative side, or sometimes it’s the fairness versus performance. I should say doesn’t happen all the time. So sometimes you see that, “Wow, I improved the fairness of my model, and overall it brought up the performance for everyone.”
But sometimes we see that challenge, and then the way that we tackle it is we try to provide different versions of a model. One of our mitigation techniques that is in the opensource under the package called Fairlearn tries to provide you with different model candidates. Each one has a fairness metric attached to it and a performance, and then it puts it on a diagram. And essentially, you’re looking at a performance versus fairness trade off. And you might say that I am okay losing performance by five percent at the expense of getting this much improvement in the fairness. So these type of decisions are very, very dynamically being taken with the stakeholders in the room.
Roland Meertens: It’s like an ROC curve, but then fairness versus performance.
Mehrnoosh Sameki: Exactly. And so you could take a look, you could see, “Okay, for this particular use case, am I okay losing the performance a little bit?” So you are trying to look at your losses. If I lose the performance, how much loss? But then fairness, the loss is beyond words, right? So if you lose the trust of, say, a certain group in the society, then I would say gradually your business is going to go out of the way with all the competition that is happening. So people these days are very aware and educated about these concepts, and I’m so proud of every single customer communication that we have, they genuinely care about making sure that everyone is getting served by this AI system.
Tools to help [11:50]
Roland Meertens: And you mentioned you have a tool which can give you insights into your data. How does this work?
Mehrnoosh Sameki: That’s a great question. So we have built several open source tools that are absolutely free to use. People could just install them with a pip install. The three of these tools that we first started with are individual tools, each one focusing on one concept. So one of them was called InterpretML. That was a tool that you could pass your machine learning model to and it is providing explainability, or feature importance values, both on the overall level, the explainer says, “What are the top key important factors impacting your model’s prediction?” And also on the individuals, say for Mehrnoosh, what are the top key important factors impacting models’ predictions? So that was one tool for transparency specifically.
Then we worked on Fairlearn with the focus on the concept of group fairness. So exactly as you said, how different demographics, different sensitive groups are getting treatment from the AI. And so that one has a collection of fairness measurements and unfairness mitigation techniques that you could incorporate in your ML lifecycle. The third tool we worked on is called Error Analysis, and that is with this goal of giving you the blind spots of your AI, because often people use aggregate metrics. For instance, they say, “My model is 95% accurate.” That is a great proxy to build trust with that AI, but then if you dive deeper and you realize that, “Oh, but for, say, Middle Eastern people whose age is less than 40 and they are women, the model is making 95% error.” But because they’re a small portion of the data set, then in the aggregation you don’t see it. So Error Analysis puts those blind spots in front of you, and once you see it, you can’t miss it.
And very lately we brought them all together under one roof, what’s called the Responsible AI Dashboard, again open source, and now it gives you interpretability, transparency, and fairness, and error analysis, and other concepts like even causal analysis, so how you would use the historic data to inform some of your real world decisions and do real world intervention. It also has another capability for counterfactual analysis, which is, show me the closest data points with opposing predictions, or in other words, what is the bare minimum change you could apply to the features so that the model would say the opposite outcome. And so all of these tools under this Responsible AI Dashboard are aiming to give you the ability to identify your model issues, and errors, and fairness problems, and diagnose by diving deeper. And then we have a set of mitigation techniques to help you either augment your data, or mitigate the fairness issue that you just identified.
Roland Meertens: And so for solving this, is it a matter of collecting more data? Is it a matter of balancing the data during training? How does one go at solving this?
Mehrnoosh Sameki: It could look like 20-plus things, so I just categorized a few of them for you. So sometimes it is, wow, you’re really underrepresenting a certain group in your training data, that’s why the model never learns how to even respond for that group. Sometimes it is, you do have a great representation about that demographic group, but in your training data it’s always associated with negative results. So for instance, imagine you collected the loans data and in your dataset you only have young people getting rejection under their loans. And obviously the model then probably picks a correlation between age, the lower the age, the higher the rejection rate.
So sometimes it’s about augmenting data, collecting more data on a completely erased population, or collecting better high quality diverse data on some particular population.
Sometimes you take a look at model explanation, and you’re like, “For some reason I don’t see, based on my common sense and my domain expertise, I don’t see any top factor showing up among the top important factors. So maybe I don’t have the right features, or I have a very simple model, I don’t have the right model that is picking on the complexity of the features that I have.” So in those cases, maybe you chose the overly simple model, you go with the more advanced model, or you go and augment your feature set to come up with a better feature set. So all of those are possible and depending on what you’re diagnosing, you can take the target at mitigation.
Roland Meertens: Do you know if it’s often better to have a more advanced model such that your model can maybe capture the complexity of the different uses you have, or is it sometimes better to have a more simple model such that the model is not able to discriminate maybe between people?
Mehrnoosh Sameki: That is a great question. I don’t think I do have an answer of when to go with which model. What I would say is, always start with the simpler model though. Try to look at maybe the performance of the model, like the error blind spots, and then go with the complex. I feel like everyone is defaulting on super advanced technology in terms of, say, the most sophisticated architecture for deep learning or whatever from the very get-go. And sometimes the notion of the problem is very simple. So I always recommend people to start with a simple model and experiment, and it’s okay if they end up obviously with a more complex model, it’s okay because now we have these interpretability techniques that could sit on top of it and treat it as a opaque box model, and take out explanation using bunch of heuristics. So they won’t lose transparency anymore by using more complex models. But always start from a simple model.
Roland Meertens: And do you have specific models for which this toolbox is particularly suited or does it work for everything?
Mehrnoosh Sameki: For this particular open source toolbox, we cover essentially any Python model or necessarily even if the model is not in Python, you can wrap the prediction function in a Python file, but it needs to have a .predict or .predict_proba conforming to SciKit convention. And if you don’t have it, if you’re using a model type that doesn’t have predict or predict_proba conforming to SciKit, it’s just a matter of wrapping it under a .foo.bar prediction function that is transforming the format of your prediction function to predict, predict_proba. So because of that we support any SciKit learn model PyTorch, Keras, TensorFlow, anything else, just because of that wrapper trick that you could use.
Large Language Models [17:59]
Roland Meertens: That sounds pretty good. So nowadays one of the more popular models are these ChatGPT models, these large language models. Do you think it’ll democratize the field because now more people can use these tools or do you think it will rather maybe drive people further apart and introduce more bias?
Mehrnoosh Sameki: I absolutely think it is going to put AI in every single person’s hands. I personally see literally everyone from the tech world or outside tech world talking about these models. I have friends outside tech world using it on a day-to-day basis for anything they’re doing right now. So they’re like, “Oh, how was life before these models?” And so now we see this huge move of companies wanting to use such models in their ML life cycle. So the answer is absolutely yes. One thing that I have to say though is the challenges that we have for use of such models is fundamentally very different from what now I can say more traditional ML, and with more traditional ML, I’m also putting deep learning on their that now. So previously we were seeing a lot of people wanting the tools that we have, fairness, interpretability, error analysis, causal analysis, stuff like that, the concerns are still the same, I can talk a little bit about what challenges happen in generative AI, but it needs fundamentally different tools because the nature of the problem is completely different.
Roland Meertens: So do you think that now that more people are going to use it, is that a danger you see?
Mehrnoosh Sameki: The only danger that I’m seeing is I think the mindset should be not having over-reliance on generative AI. So previously when we had machine learning models, there was a lot more focus on assessment of such models. So I’m going to evaluate it, I’m going to even collaborate with a QA team on the results of it, stuff like that. And because the generative AI models are super, super smart, and we are all super excited about them, but also surprised by their capability, I see the challenge of over-reliance sometimes. So that’s the part that I’m hoping to work with my team on, on better tools or new set of tools essentially for this space of measuring generative AI issues, or errors, or harms, and then helping them mitigate that. And so I think if we can change our mindset from, “Wow, these are literally replacing all of us,” to, “These are our pets, our toys, and we are not going to overly on them, we still need the right assessment, the right mitigation, the right monitoring, and the right human in the loop with them, then I think if there’s so much potential and we can minimize the harm state could cause.”
Roland Meertens: Yeah, especially if you are using them as a zero shot inference where exactly you can basically deploy any application in minutes if you want.
Mehrnoosh Sameki: Absolutely. In fact, originally when they came out I was like, “Oh, people are going to really fine-tune them on some data.” And then it turned out because fine-tuning is quite expensive in such scenarios, all people are doing is zero shot or few shots. So it becomes even more important to test than how they’re going to do in a real world scenario.
Roland Meertens: Do you then recommend people to maybe take the output of these models and then train the model on top of that again such that you still control the entire training data pipeline or the information pipeline?
Mehrnoosh Sameki: I don’t think that might be the approach, but the approach might be, for instance, Microsoft has worked on content moderation capabilities that we are exposing on top of these models. So they automatically sit on top of your outcome of large language models and they filter sexist, racist, harmful, hateful language for you. But there is so much work that is needed to happen in terms of the evaluation life cycle, and necessarily it’s not about training a new model on top of it, but there should be a mechanism to make sure that the answers are measured before it’s even deployed, that the answers are grounded in the reality, whatever context it is, there is no leakage of PII, so things like email addresses, social security numbers, any other personally identifiable information, there needs to be also some filters put in place to measure things like stereotyping, or hate, or demeaning, the content moderation capability that I mentioned definitely going to help with that. There needs to be work happening around inaccurate text, which I mentioned as groundedness.
I think we as the tooling team need to step up and create a lot of different tools that people could incorporate in their ML lifecycle and then we could help them with the right red teaming. So obviously one challenge that we have here is with the traditional models, people usually had test data set aside, so that was coming with ground truths, which is the actual source labels. Then they would hide those ground truths labels and then they would pass the test data to their model, get the answers and they would compare. This is not true anymore for generative AI, so it fundamentally requires things like bringing the stakeholders in the room to generate that data set or automate that generation of the data set for them. So there’s so much work that needs to happen to make that happen so that people don’t have to train another model on top of generative AI, which defeats the purpose of that superfast deployment of it.
Roland Meertens: And so for example, you mentioned the red teaming, and the security boundaries for ChatGPT, we see that as soon as you try to do something unethical or which leads toward towards unethical, it starts with this whole rant about it being a large language model and not it being able to do it, but we also see that people immediately defeat it. What do you think about the current security which is in place? Do you think that’s enough? Do you think it’s too little? Do you think it’s a perfect amount?
Mehrnoosh Sameki: Definitely a lot could happen more because we saw all these examples of… What you’re referring to is known as jailbreak essentially, or manipulation. So when you are providing an instruction to a large language model, and then you immediately see that, not immediately, but through some trials of putting it in essentially the hands of users, you see that people went around that instruction. So I think there are ways that we could also detect things like jailbreak. The very first stage of it is to understand why it’s happening, in what scenarios it’s happening. So that’s why I think the red teaming is extremely important because people could attack the same model that the company is working on, and try to figure out what are some of the patterns that are happening. And then with those patterns, they could go and generate a lot more data and try to understand whether they could either improve their prompt instructions to the model, or they could write post-processing techniques on top of the outcome of the model. But even in that case, I think red teaming and figuring out patterns and see whether those patterns could help with some more reliable and less manipulative prompt instructions, whether that could lead to those instructions.
Roland Meertens: That would be great. And so if I want to get started with responsible AI, what would you recommend someone who is maybe new to the field or if someone already has models they are deploying on a daily basis, what would you recommend them to do?
Mehrnoosh Sameki: There are so many amazing resources out there, mostly by the big companies like, for instance, Microsoft, I saw many other cloud providers and many other consulting companies also have their own handouts about what responsible AI in practice means. So one great place to start is looking at the responsible AI standard that Microsoft publicly released, I think it was June or July last year. It walks you through the six principles that I mentioned at the very beginning and what are the considerations that you need to have in place around each of these areas. So when it comes to fairness, what are the concerns, what checks and balances you need to put in place? Same for transparency, reliability and safety, privacy and security, inclusiveness, accountability. And then there are so many great papers out there if you search for fairness in AI, interpretability and transparency in AI, there are so many fundamental papers that explain the field really well.
And then one great place to start maybe is from the open source tools. As I said, something like Responsible AI Dashboard or Fairlearn, or Interpret ML or Error Analysis, they’re all open source. I’ve seen many great tools by other either research groups or companies as well. So what I would say is start with reading one of these standards by the companies, and educate yourself about the field. Look into an impact assessment form. Again, Microsoft also has a PDF out there which you could access and see what are the questions you should ask yourself in order to identify what challenges might be happening around your AI, or what demographic groups you need to pay attention to. And then going through that impact assessment form, that will educate you or at least inform you, bring that awareness to you that, “Okay, maybe I should use a fairness tool. Maybe I should now use a reliability tool.” And then there are so many open source, the ones that I named, and many more out there that could help you get started there.
Roland Meertens: Thank you very much for joining the InfoQ podcast.
Mehrnoosh Sameki: Thank you so much for having me.
Roland Meertens: And I really hope that people are going to watch your talk either tomorrow or online.
Mehrnoosh Sameki: Thank you. Appreciate it.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Java News Roundup: Azul Zulu Support for CRaC, Spring Boot Updates Mitigate CVEs, OpenJDK JEPs
MMS • Michael Redlich

This week’s Java roundup for May 15th, 2023 features news from OpenJDK, JDK 21, Azul Zulu, point releases of Spring Boot, Spring Security, Spring Security Kerberos, Spring Integration, Spring Batch, Spring for GraphQL, Spring Authorization Server, Spring LDAP, Micronaut, Open Liberty, TornadoVM, Hibernate ORM, Apache TomEE, Apache Tika, OpenXava, JBang, JDKMon and Spring I/O conference.
OpenJDK
JEP 449, Deprecate the Windows 32-bit x86 Port for Removal, has been promoted from Proposed to Target to Targeted for JDK 21. This feature JEP, introduced by George Adams, senior program manager at Microsoft, proposes to deprecate the Windows x86-32 port with the intent to remove it in a future release. With no intent to implement JEP 436, Virtual Threads (Second Preview), in 32-bit platforms, removing support for this port will enable OpenJDK developers to accelerate development of new features.
JEP 445, Unnamed Classes and Instance Main Methods (Preview), has been promoted from Proposed to Target to Targeted for JDK 21. This feature JEP, formerly known as Flexible Main Methods and Anonymous Main Classes (Preview) and Implicit Classes and Enhanced Main Methods (Preview), proposes to “evolve the Java language so that students can write their first programs without needing to understand language features designed for large programs.” This JEP moves forward the September 2022 blog post, Paving the on-ramp, by Brian Goetz, Java language architect at Oracle. Gavin Bierman, consulting member of technical staff at Oracle, has published the first draft of the specification document for review by the Java community. InfoQ will follow up with a more detailed news story.
JEP 443, Unnamed Patterns and Variables (Preview), has been promoted from Proposed to Target to Targeted for JDK 21. This preview JEP proposes to “enhance the language with unnamed patterns, which match a record component without stating the component’s name or type, and unnamed variables, which can be initialized but not used.” Both of these are denoted by the underscore character as in r instanceof _(int x, int y) and r instanceof _.
JEP 404, Generational Shenandoah (Experimental), has been promoted from Proposed to Target to Targeted for JDK 21. This JEP proposes to “enhance the Shenandoah garbage collector with generational collection capabilities to improve sustainable throughput, load-spike resilience, and memory utilization.” Compared to other garbage collectors, such as G1, CMS and Parallel, Shenandoah currently requires additional heap headroom and has a more difficult time recovering space occupied by unreachable objects. InfoQ will follow up with a more detailed news story.
JEP 452, Key Encapsulation Mechanism API, has been promoted from Candidate to Proposed to Target for JDK 21. This feature JEP type proposes to: satisfy implementations of standard Key Encapsulation Mechanism (KEM) algorithms; satisfy use cases of KEM by higher level security protocols; and allow service providers to plug-in Java or native implementations of KEM algorithms. This draft was recently updated to include a major change that eliminates the DerivedKeyParameterSpec class in favor of placing fields in the argument list of the encapsulate(int from, int to, String algorithm) method. The review is expected to conclude on May 26, 2023. InfoQ will follow up with a more detailed news story.
Ron Pressler, architect and technical lead for Project Loom at Oracle, has announced several changes to JEP 453, Structured Concurrency (Preview). Still in Candidate status, changes in this feature include: the TaskHandle interface has been renamed to Subtask; a fix to correct the generic signature of the handleComplete() method; a change to the states and behavior of subtasks on cancellation; and a new currentThreadEnclosingScopes() method defined in the Threads class that returns a string with the description of the current structured context.
JDK 21
Build 23 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 22 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 21, developers are encouraged to report bugs via the Java Bug Database.
Azul
Azul has announced that Zulu, their downstream distribution of OpenJDK, now supports Coordinated Restore at Checkpoint (CRaC) to reduce Java application startup and warm up times. InfoQ will follow up with a more detailed news story.
Spring Framework
The release of Spring Boot 3.1.0 delivers notable new features such as: support for managing external services at development time using Testcontainers and Docker Compose; simplified configuration of Testcontainers in integration tests; centralized and expanded configuration of SSL trust material for connections; and auto-configuration for Spring Authorization Server. There were also dependency upgrades to Spring Data 2023.0, Spring GraphQL 1.2, Spring Integration 6.1, Spring Security 6.1 and Spring Session 3.1. More details on this release may be found in the release notes.
Versions 3.0.7, 2.7.12, 2.6.15 and 2.5.15 of Spring Boot have been released featuring bug fixes, improvements in documentation and dependency upgrades and resolutions to mitigate: CVE-2023-20883, Spring Boot Welcome Page DoS Vulnerability, a vulnerability in which there is potential for a denial-of-service (DoS) attack if Spring MVC is used together with a reverse proxy cache; and CVE-2023-20873, Security Bypass With Wildcard Pattern Matching on Cloud Foundry, a vulnerability in which an application deployed to Cloud Foundry could be susceptible to a security bypass with requests that match the /cloudfoundryapplication/** endpoint. Further details on these releases may be found in the release notes for version 3.0.7, version 2.7.12, version 2.6.15 and version 2.5.15.
The release of Spring Security 6.1.0 delivers new features: a more comprehensive explanation for deprecating the and() method in favor of lambda DSLs for configuring Spring Security; and improved documentation for Cross-Site Request Forgery (CSRF). More details on this release may be found in the release notes.
The first release candidate of Spring Security Kerberos 2.0.0 features improvements in documentation and a re-implementation/migration of the utilities in spring-security-kerberos-test as the Apache directory server libraries have undergone many refactorings. Further details on this release may be found in the release notes.
The release of Spring Integration 6.1 delivers notable changes such as: additional diagnostics for testing the SftpRemoteFileTemplateTests class; fix memory leak in the FluxMessageChannel class; improvements and cleanup of the ImapMailReceiverTests class; and a new PartitionedChannel class for partitioned message dispatching. More details on this release may be found in the release notes.
Spring Batch 5.0.2 has been released featuring bug fixes, improvements in documentation and new features such as: allow the StaxEventItemReader class to auto-detect the input file encoding; a change in which the JobParameters class now uses an instance of LinkedHashMap instead of HashMap in the constructor and the getParameters() method to guarantee input order; and a reduction in the use of deprecated APIs. Further details on this release may be found in the release notes.
Spring for GraphQL 1.2.0 has been released with new features such as support for: the @GraphQlExceptionHandler annotation methods in the AOT processor; nested paths in GraphQlTester interface; schema mapping inspection for the @BatchMapping annotation methods. More details on this release may be found in the release notes.
Similarly, Spring for GraphQL 1.1.4 has also been released to provide bug fixes, dependency upgrades, improvements in documentation and a new feature in which the ClientGraphQlRequest interface passes attributes to a request from the WebClient interface. Further details on this release may be found in the release notes.
The release of Spring Authorization Server 1.1.0 ships with dependency upgrades and new features such as: a simplified federated login and updated UI design in the demo sample; the addition of a logout success page to default client sample; and a revocation of tokens if authorization code is used more than once. More details on this release may be found in the release notes.
Versions 3.1.0 and 3.0.3 of Spring LDAP 3.1.0 have been released featuring: dependency upgrades such as Spring Security 5.8.3 and 5.7.8 and Jackson 2.15.0 and 2.14.3, respectively; and a new feature in version 3.0.3 in which there was calcification on the use of attribute mapping with the @DnAttribute annotation. Further details on these releases may be found in the release notes for version 3.1.0 and version 3.0.3.
Micronaut
The Micronaut Foundation has released Micronaut Framework 3.9.2 featuring bug fixes and updates to modules: Micronaut Azure, Micronaut AWS, Micronaut GCP, Micronaut OpenAPI, Micronaut SQL and Micronaut Kubernetes. More details on this release may be found in the release notes.
Open Liberty
IBM has released Open Liberty 23.0.0.5-beta featuring: continued enhancements to InstantOn, their new feature that provides faster startup times for MicroProfile and Jakarta EE applications; and the latest updates to the preview for the Jakarta Data specification.
TornadoVM
TornadoVM, an open-source software technology company, has released TornadoVM version 0.15.1 that ships with delivers bug fixes and notable improvements such as: improved compatibility with Apple M1/M2 through the OpenCL Backend; introduction of a device selection heuristic based on the computing capabilities of devices; integration and compatibility with the Graal 22.3.2 JIT compiler; optimisation of removing redundant data copies for read-only and write-only buffers from between the host (CPU) and the device (GPU) based on the Tornado Data Flow Graph; improved integration of GraalVM/Truffle programs; and the option to dump the TornadoVM bytecodes for unit tests. Further details on this release may be found in the release notes.
Juan Fumero, research associate, Advanced Processor Technologies Research Group at The University of Manchester, introduced TornadoVM at QCon London in March 2020 and has since contributed this more recent InfoQ technical article.
Hibernate
Hibernate ORM 6.2.3.Final has been released featuring bug fixes, performance improvements and HQL support for the native PostGIS distance operators. More details on this release may be found in the list of changes.
Apache Software Foundation
The release of Apache TomEE 8.0.15 features bug fixes, dependency upgrades and resolutions to mitigate: CVE-2022-1471, a vulnerability in which the deserialization of types using the SnakeYAML Constructor() class will allow an attacker to initiate a malicious remote code execution; CVE-2023-28708, a vulnerability in which using the RemoteIpFilter class, with requests received from a reverse proxy via HTTP that include the X-Forwarded-Proto header set to HTTPS, session cookies created by Tomcat did not include the secure attribute. This vulnerability could result in an attacker transmitting a session cookie over an insecure channel; and CVE-2023-24998, a vulnerability in Apache Commons FileUpload such that an attacker can trigger a denial-of-service with malicious uploads due to the number of processed request parts is not limited. Further details on this release may be found in the release notes.
Apache Tika 2.8.0 has been released delivering new features such as: enable counting and/or parsing of incremental updates in PDFs; enable optional extraction of file system metadata in the FileSystemFetcher class; allow pretty printing from the FileSystemEmitter class; and improve embedded file extraction from PDFs. More details on this release may be found in the release notes.
OpenXava
OpenXava 7.1 has been released that ships with bug fixes, dependency upgrades and new features such as: the calendar in list mode; enhancements to web security that include mitigating CVEs; the ability to annotate properties to indicate a data input mask with the new @Mask annotation; and a rich new text editor. Further details on this release may be found in the release notes.
JBang
The release of JBang 0.107.0 provides support for JDK 21 with a new --enable-preview flag and notable fixes such as: export will now create the missing output folders; PicoCLI no longer throws exceptions for certain configuration values; and a resolution to unnecessary lookups in the JBang alias list.
JDKMon
Version 17.0.59 of JDKMon, a tool that monitors and updates installed JDKs, has been made available this past week. Created by Gerrit Grunwald, principal engineer at Azul, this new version provides changes such as: improved support on Linux; and fixes related to CVE detection.
Spring I/O Conference
The 10th annual Spring I/O conference was held at the Fira de Barcelona at Montjuïc in Barcelona, Spain this past week. Celebrating their 10th anniversary, speakers from the Java community presented sessions and workshops on Spring projects, GraalVM, native Java, enterprise security, domain-driven design and cloud computing.
Jetpack Compose Brings Performance Improvements, Better Tooling Integration, and Updates Material 3
MMS • Sergio De Simone

At its Google I/O conference, Google has announced a new iteration of its Jetpack Compose UI toolkit for Android. Among its many improvements, Jetpack Compose has now better performance, extended support within Android Studio, a new Material 3 library, and more.
Google says it is been working on Compose performance by migrating modifiers to a new more efficient implementation. Modifiers in Compose are what you use to decorate or augment a composable, for example to modify its appearance, making it scrollable, draggable, and so on. According to Google, the new system brings a 22% performance improvement on Text and TextField composables, but the hole toolkit benefits from its adoption.
Jetpack Compose includes also new UI features, including a new pager component to flip through a list of items and new FlowRow and FlowColumn layouts to automatically arrange a list of items into a vertical or horizontal layout.
Compose integration in Android Studio has also made progress by including support for live edit and extended animation preview in Android Studio current beta. More features have been packed into Android Studio canary, dubbed Hedgehog, such as displaying which parameters have changed in the debugger to inspect what is causing re-rendering, support for a new Espresso Device API that enables applying rotation changes, folds, and other synchronous configuration changes to virtual devices, and more.
Jetpack Compose also updates the implementation of Android official design system Material Design 3, which reaches version 1.1. Compose Material 3 1.1 brings new components, improved APIs and a number of enhancements. New components include bottom sheets, either standard or modal, which overlap the main UI; new DatePicker and DateRangePicker; a new TimePicker supporting two different layouts, horizontal for keyboard-based time input and vertical for gesture-base time input; revamped search bar and docked search bar, which differ in the way they show search results, either full screen or in a smaller window; and support for tooltips.
The new Jetpack Compose also extends support for large screens, foldable devices, and wearables. In particular, a new Glance library aims to make it easier to develop homescreen, responsive, interactive widgets. Compose for WearOS 1.2 has reached alpha, bringing improvements like loading animations, long list and text folding, enhancements to rotary inputs to navigate through lists, and better preview integration in Android Studio.
For a full list of changes included in the last version of Compose, check the official release notes.
MMS • Ben Linders
Software developers are constantly learning new languages, frameworks, tools, and techniques. It can be challenging to decide which topic to learn, estimate our competence level, prevent becoming overwhelmed, and keep our learning effective.
Tav Herzlich will give a talk about learning for software developers at NDC Oslo 2023. This conference is held May 22-26 in Oslo, Norway.
According to Herzlich, the AI revolution that we’re going through is going to accelerate the rate of change in the industry. This is expected to make learning and adapting to new circumstances an even more important skill.
Challenges software developers face when trying to learn new things are figuring out which topics are actually worth our time and estimating our true level of competence.
To make better decisions on what to learn, Herzlich points out that theoretical concepts stick with us way longer than tools:
Every tool we will encounter is based on deeper patterns. For example, spending time on learning about relational databases will make it much easier to learn how to work popular tools such as: PostgreSQL, SQLite, MySQL, etc…
Herzlich suggests using the “Dreyfus model” for estimating your level of competence:
It’s a model that pinpoints what makes one competent at a certain topic by asking questions like “How much can you keep focus on what matters?” or “How strictly do I need to follow well defined rules to complete a task?”.
For better learning, Herzlich suggests breaking down our learning to realistically sized phases, and allowing ourselves to repeat the same topic several times to really get to experience it properly.
InfoQ interviewed Tav Herzlich about learning.
InfoQ: What does your philosophy on learning look like?
Tav Herzlich: The same as the philosophy I try to follow around any other area of life: being aware of my own limitations as a human being. When we’re aware of our weaknesses, we become less frustrated, more eager to learn from others and realise that the only person we can compare ourselves to is who we were a week ago.
InfoQ: How can developers identify their level of knowledge of a topic or technology?
Herzlich: The “Dreyfus model” model suggests that a junior will have a need to follow rigid and definitive rules, which might lead them to come to dichotomic conclusions that will often hinder their progress, while a senior will be able to ask relevant questions and understand that different solutions fit different problems.
An example would be programming languages. A novice might declare “Python is always the best” while a senior will address the topic of which language is right for a project only when it’s the right question to ask.
InfoQ: What about cognitive load, how can we prevent becoming overwhelmed and keep our learning effective?
Herzlich: Circling back to understanding our limitations, being aware that some forces can affect our ingestion of information is crucial to our learning process. Examples of this are: identifying quality information, making sure we’re well rested and calm, and of course being in a quiet and friendly environment.
However, we should also remember that perfect conditions are too rare to rely on and that there are always trade-offs we have to make. A good example would be the recent trend of remote work as it offers a peaceful environment but on the other hand, has made learning from our peers more difficult.
InfoQ: What suggestions do you have for managing our time and energy when learning new things?
Herzlich: Remembering that while learning is important, we have duties to ourselves and other people to attend to. Trying to spend all our time on learning and improving our career is great, but it shouldn’t cost us our relationships, mental health and hobbies.
A great approach that worked for me is working in the evenings as a programming course instructor. Being an instructor includes a fair share of learning, and the nature of the role made it so that I could socialise, give back to the industry and earn some extra cash along with that.
Sometimes we should allow ourselves to learn less in favour of quality of learning and keeping our precious sanity.
I learned to make compromises when I figured out how difficult it was to master a language like C++. I wanted to play around with computer graphics but getting familiar with such complex technology was just too taxing on my time. This made me stick with good old Java to achieve the same goal (Even though C++ is the industry standard when it comes to developing graphics).
MMS • Chris Richardson

Transcript
Richardson: Welcome to my talk on dark energy, dark matter, and the microservice architecture. I’m sure many of you watching this presentation are architects. When you’re not fighting fires, or developing features, your job is to define and evolve your application’s architecture. An application architecture is a set of structures, elements, and relations that satisfy its non-functional requirements. These consist of development time requirements such as testability, and deployability, and runtime requirements such as scalability and availability. These days, one key decision that you must make is deciding between the microservice architecture and the monolithic architecture. Naturally, you ask Twitter, as you might expect, there are lots of opinions, some are more helpful than others. In reality, the answer to this question is that it depends, but on what? What are the criteria that you should consider when selecting an architectural style? In this presentation, I describe how the choice of architecture actually depends upon dark energy and dark matter. These are, of course, concepts from astrophysics, but I’ve discovered that they are excellent metaphors for the forces or the concerns that you must resolve when defining an architecture, both when deciding between a monolithic architecture and microservices, but also when designing a microservice architecture.
Background & Outline
I’m Chris Richardson. I’ve done a number of things over the past 40 years. For example, I developed Lisp systems in the late ’80s, early ’90s. I also created the original Cloud Foundry back in 2008. Since 2012, I’ve been focused on what eventually became known as the microservice architecture. These days, I help organizations all around the world use microservices more effectively. First, I’m going to explain why you should use patterns rather than Twitter to make technology decisions. After that, you will learn about dark energy and dark matter, which are the metaphors for forces or concerns that you must resolve when making architectural decisions. Finally, I’m going to show how to use dark energy and dark matter forces when designing an architecture.
Suck/Rock Dichotomy vs. Patterns
The software development community is divided by what Neal Ford calls the suck/rock dichotomy. In other words, your favorite technology sucks, my favorite technology rocks. Much of the monolith versus microservices argument is driven by this mindset. A powerful antidote to the suck/rock dichotomy are patterns. They provide a valuable framework for making architectural decisions. A pattern is a reusable solution to a problem occurring in a context and its consequences. It’s a relatively ancient idea. They were first described in the ’70s by the real-world architect, Christopher Alexander. They were then popularized in the software community by the Gang of Four book in the mid-90s. Christopher Alexander was surprised to find himself invited to speak at software conferences when that happened. What makes patterns especially valuable is their structure. In particular, a pattern has consequences. The pattern forces you to consider both the drawbacks and the benefits. It requires you to consider the issues, which are the subproblems that are created by applying this pattern. A pattern typically references successive patterns that solve those subproblems. Then, finally, a pattern must also reference other patterns, alternative patterns, which are different ways of solving the same problem.
Later on, I will describe some specific patterns. Patterns that are related through the predecessor/successor relationship, and the alternative relationship often form a pattern language. A pattern language is a collection of patterns that solve problems in a given domain. Eight years ago now, I created the Microservices Pattern Language with the goal of helping architects use microservices more appropriately and effectively. On the left are the monolithic architecture and microservice architecture patterns. They are alternative architectures for your application. Every other pattern in the pattern language is the direct or indirect successor of the microservices architecture pattern. They solve the problems that you create for yourself by deciding to use microservices. The pattern language can be your guide when defining an architecture. The way you use it to solve a problem in a given context is as follows. First, you find the applicable patterns. Next, you assess the tradeoffs of each of those patterns. You then select a pattern and apply it. This pattern updates the context and then usually creates one or more subproblems. You repeat this process recursively until you’ve designed your architecture.
Monolithic and Microservice Architecture Pattern
I now want to describe the first two patterns, the monolithic architecture pattern, and the microservice architecture pattern. These two patterns are alternative solutions to the same problem. They share the same context and the same forces. Let’s start by looking at the context. The context is the environment within which you develop modern applications. Today, software is eating the world. It plays a central role in almost every business in every industry. The world is crazy, or more specifically, it’s volatile. It’s uncertain. It’s complex and ambiguous. In order to be successful, a business must be nimble.
This means that IT must deliver the software that powers the business rapidly, reliably, frequently, and sustainably. IT needs to be structured as a loosely coupled network of small teams practicing DevOps. This has big implications for architecture. In order for a network of small autonomous DevOps teams to deliver software rapidly, frequently, reliably, and sustainably, you need an architecture with several key qualities. For example, the authors of “Accelerate” describe how testability, deployability, and loose coupling are essential. In addition, if you are building a long-lived application, you need an architecture that lets you incrementally upgrade its technology stack.
How to Define an Architecture
I now want to talk about the dark energy and dark matter forces which are a refinement of these architectural quality attributes. These forces are central to the process that I like to use to design a microservice architecture. The first step distills the application’s requirements into system operations. A system operation models a request that the application must handle. It acts upon one or more business entities or DDD aggregates. The second step organizes those aggregates into subdomains. A subdomain is a team-size chunk of business functionality. You might also call it a business capability. For example, in a Java application, a subdomain consists of Java classes organized into packages. Each subdomain is owned by a small team. The third step groups the subdomains to form services and designs the system operations that span multiple services. This design process group subdomains to form services. The key decision that you must make is whether a pair of subdomains should be together or separate. I use the metaphors of dark energy and dark matter to describe the conflicting forces that you must resolve when making this decision. Dark energy is an antigravity that’s accelerating the expansion of the universe. It’s a metaphor for the repulsive forces that encourage you to put subdomains in different services. Dark matter is an invisible matter that has a gravitational effect on stars and galaxies. It’s a metaphor for the attractive forces that encourage you to put subdomains together in the same service. These forces are actually a refinement of the architectural quality attributes I described earlier, deployability, testability, along with loose coupling, and so on.
Repulsive Forces – Subdomains in Different Services
Let’s first look at the repulsive forces that encourage decomposition. The first dark energy repulsive force is simple services. Services should be as simple as possible and have as few dependencies as possible. This ensures that they are easier to understand, develop, and test. We should therefore minimize the number of subdomains that are grouped together to form a service. The second dark energy force is team autonomy. Team autonomy is an essential aspect of high-performance software delivery. Each team should be able to develop, test, and deploy their software independently of other teams. We should therefore avoid colocating subdomains that are owned by different teams together in the same service. The third dark energy repulsive force is fast deployment pipeline. Fast feedback from local testing from the deployment pipeline and from production is essential. The deployment pipeline should build, test, and begin deploying a service within 15 minutes. It must be possible to test services locally. We should therefore minimize the number of subdomains that are grouped together to form a service. We should avoid mixing subdomains that can’t be tested locally with those that can.
The fourth dark energy force is, support multiple technology stacks. An application often needs to use multiple technology stacks. For example, a predominantly Java application might use Python for machine learning algorithms. The need for multiple technology stacks forces some domains to be packaged as separate services. What’s more, it’s easier to upgrade an application’s technology stack if it consists of multiple small services. That’s because the upgrade can be done incrementally, one service at a time. Small upgrade tasks are less risky, and much easier to schedule than a big bang upgrade. In addition, it’s much easier to experiment with new technology stacks if the services are smaller. The fifth dark energy repulsive force is, separate domains by their characteristics. It’s often beneficial to package subdomains with different characteristics as separate services. These characteristics include security requirements, regulatory compliance, and so on. For example, it’s often easier and cheaper to scale an application if subdomains with very different resource requirements are packaged as separate services. For example, a subdomain that needs GPUs must run on an EC2 instance type that’s eight times the cost of a general-purpose instance. You do not want to colocate it with services with different resource requirements. It could be extremely costly and wasteful if you did. Similarly, you can increase availability and make development easier by packaging business critical subdomains as their own services that run on dedicated infrastructure. For example, in a credit card payment application, business critical operations are those for charging credit cards. That’s how money is made. Functionality such as merchant management, while it’s important, is far less critical. You should therefore avoid packaging those subdomains together. Those are the dark energy forces that encourage decomposition.
Attractive Forces – Subdomains in Same Service
Let’s now look at the dark matter forces that resist decomposition. They are generated by the system operations that span subdomains. The strength of those forces depends on the operation and the subdomains that it references. The first dark matter attractive force is simple interactions. An operation’s interactions should be as simple as possible. Ideally, an operation should be local to a single service. That’s because a simple local operation is easier to understand, maintain, and troubleshoot. As a result, you might want to colocate subdomains in order to simplify an operation. The second dark matter force is efficient interactions. An operation’s interactions should also be as efficient as possible. You want to minimize the amount of data that’s transferred over the network, as well as the number of round trips. As a result, you might want to colocate subdomains in order to implement an operation efficiently. The third force is, prefer ACID over BASE. System operations are best implemented as ACID transactions. That’s because ACID transactions are a simple and familiar programming model. The challenge, however, is that ACID transactions do not work well across system boundaries. An operation that spans services cannot be ACID, and must use eventually consistent transactions, which are more complicated. As a result, you might want to colocate subdomains in order to make an operation ACID.
The fourth dark matter force is, minimize runtime coupling. An essential characteristic of the microservice architecture is that services are loosely coupled. One aspect of loose coupling is loose runtime coupling. Tight runtime coupling is when one service affects the availability of another service. For example, service A cannot respond to a system operation request until service B responds to it. As a result, you might want to colocate subdomains in order to reduce the runtime coupling of an operation. The fifth dark matter force is, minimize design time coupling. The other aspect of loose coupling is loose design time coupling. Tight design time coupling is when changes to one service regularly requires another service to change in lockstep. Frequent lockstep changes are a serious architectural smell, because it impacts productivity, especially when those services are owned by different teams.
Some degree of coupling is inevitable when one service is a client of another. The goal should be to minimize design time coupling by ensuring that each service has a stable API that encapsulates its implementation. However, you cannot always eliminate design time coupling. For example, concepts often evolve to reflect changing requirements, especially in a new domain. If you put two tightly coupled subdomains in different services, then you will need to make expensive lockstep changes. For example, imagine that the customer service API regularly changes in ways that break the order service. In order to support zero downtime deployments, you will need to define a new version of the customer service API and support both the old and the new versions until the order service and any other clients have been migrated to the new version.
One option for handling tightly coupled subdomains is to colocate them in the same service. This approach avoids the complexities of having to change service APIs. The other option is to colocate the two services within the same Git repository. This eliminates the complexity of needing to make changes across multiple repositories. However, you might still have issues with service API management. As you can see, the dark energy and dark matter forces are in conflict. The dark energy forces encourage you to have smaller services. The dark matter forces encourage you to have large services, or in fact a monolith. When you are designing a microservice architecture, you must carefully balance these conflicting forces. Some operations as a result will have an optimal design, whereas others might have a less optimal design. It’s important to design your architecture starting with the most critical operations first, so that they can have the optimal design. The less important operations might perhaps have lower availability, or higher latency. You must make these tradeoffs.
Dark Energy and Dark Matter in Action
Now that you’ve had a tour of the dark energy and dark matter forces, I want to look at how well the monolithic architecture and the microservice architecture resolve these forces. The monolithic architecture is an architectural style that structures the application as a single deployment unit. A Java application would, for example, consist of a WAR file or an executable JAR. There are two main ways to structure a monolith. The first is a traditional monolith, which has a classic three-layer architecture. While the structure is simple and familiar, it has several drawbacks. For example, ownership is blurred and every team works on every layer. As a result, they need to coordinate their efforts. The second option is a modular monolith, which is shown on this slide, each team owns a module, which is a vertical slice of business functionality, presentation logic, persistence logic, and domain logic. A major benefit of the modular monolith is the code ownership is well defined, and teams are more autonomous.
The microservice architecture is an architectural style that structures the application as a set of loosely coupled, independently deployable components or services. Each service in a Java application would be a WAR file or an executable JAR. Since a service is independently deployable, it typically resides in its own Git repository, and has its own deployment pipeline. A service is usually owned by a small team. In a microservice architecture, an operation is implemented by one or more collaborating services. Operations that are local to a single service are the easiest to implement. However, it’s common for operations to span multiple services. As a result, they must be implemented by one of the microservice architecture collaboration patterns, Saga, API composition, or CQRS.
Choice of Architectural Styles
Let’s look at how these architectural styles resolve the dark energy and dark matter forces, starting with the monolithic architecture. Because the monolithic architecture consists of a single component, it resolves the dark matter attractive forces. Whether it resolves the first three dark energy forces depends on the size of the application, and the number of teams that are building the application. That’s because as the monolith grows, it becomes more complex, and it takes longer to build and test. Even the application startup time can impact the performance of the deployment pipeline. Also, as the number of teams increases, their autonomy declines, since they’re all contributing to the same code base. For example, even something as simple as Git pushing changes to the code repository can be challenging due to contention. Some of these issues can be mitigated through design techniques such as modularization, and by using sophisticated build technologies, such as automated merge queues, and clustered builds.
However, ultimately, it’s likely that the monolithic architecture will become an obstacle to rapid, frequent, and reliable delivery. Furthermore, the monolithic architecture cannot resolve the last two dark energy forces, it can only use a single technology stack. As a result, you need to upgrade the entire code base in one go, which can be a significant undertaking. Also, since there’s a single component, there’s no possibility of segregating subdomains by their characteristics. The monolith is a mixture of subdomains with different scalability requirements, different regulatory requirements, and so on. In contrast with the microservice architecture pattern, the benefits and drawbacks are in some ways flipped. The pattern can resolve the dark energy repulsive forces, but potentially cannot resolve the dark matter attractive forces. You need to carefully design the microservice architecture, the grouping of subdomains to form services, and the design of operations that span services in order to maximize the benefits and minimize the drawbacks.
Let’s look at an example of the architecture definition process. In the architecture definition process that I described earlier, you first rank the system operations in descending importance. You then work your way down the list, grouping the subdomains into services, and designing the operations that span services. Let’s imagine that you’ve already designed the createOrder operation, and you end up with an architecture looking like this. The next most important operation on the list is acceptTicket, which is invoked when the restaurant accepts the ticket. It changes the state of the ticket to accepted, and schedules the delivery to pick up the order at the designated time. The first step of designing this operation is to group its subdomains to form services. However, the kitchen management subdomain is already part of an existing service, but you still need to determine where to place the delivery management subdomain. There are five options. You could assign delivery management to one of the four existing services, or you could create a new service. Each option resolves the dark energy and dark matter forces differently.
For example, let’s imagine that you colocated delivery management with kitchen management. This operation makes acceptTicket local to the kitchen service, which resolves the dark matter forces. However, it fails to resolve the dark energy forces. In particular, delivery management is a complex subdomain that has a dedicated team. Putting that team subdomain in the kitchen service reduces their autonomy. Another option is to put delivery management in its own service. This option resolves the dark energy forces. However, it results in the acceptTicket operation being distributed. As a result, there is a risk that this design option might not resolve the dark matter forces. In order to determine whether this option is feasible, we need to design the acceptTicket operation.
Classic Two-phase Commit/XA Transaction, and Saga
When implementing a distributed command, there are two patterns to choose from. The first pattern is a classic distributed transaction, also known as two-phase commit. This pattern implements the command as a single ACID transaction that spans the participating services. The second pattern is the Saga pattern. It implements the command as a sequence of local transactions in each of the participating services. It’s eventually consistent. These two patterns resolve the dark energy and dark matter forces differently. 2PC has ACID semantics, which are simple and familiar, but it results in tight runtime coupling. A transaction cannot commit unless all of the participants are available. It also requires all of the participants to use a technology that supports two-phase commit. On the other hand, Sagas have loose runtime coupling. Participants can use a mixture of technology. However, Sagas are eventually consistent, which is a more complex programming model. Interactions are potentially complex and inefficient. The participants are potentially coupled from a design time perspective. Consequently, we need to design the Saga in a way that attempts to resolve the dark matter forces.
There are several decisions that you must make when designing a Saga. You need to define the steps, their order, and compensating transactions. You need to choose a coordination mechanism: choreography or orchestration. You must also select countermeasures which are design techniques that make Sagas more ACID. These decisions determine how well a given Saga resolves the dark matter forces. For example, sometimes orchestration is a better choice because the interactions are simpler and easier to understand. Similarly, one ordering of steps might be more ACID than another. Of course, for a particular grouping of subdomains, it might not be possible for a Saga to effectively resolve the dark matter forces. You must either live with the consequences or consider changing the grouping of subdomains. The acceptOrder operation can be implemented by a simple choreography-based Saga. The first step changes the state of the ticket. It then publishes the ticket, accepted event. This event triggers the second step in the delivery service, which schedules the delivery. What’s nice about this design is that it effectively resolves the dark matter forces. For example, it’s sufficiently ACID despite consisting of multiple transactions.
Summary
The answer to almost any design question is, it depends. If you’re deciding between the monolithic architecture and the microservice architecture, or in the middle of designing a microservice architecture, very often, the answer depends on the dark energy and dark matter forces.
Questions and Answers
Reisz: A lot of times when I’m talking with people, customers, clients, they’ll often want to have this desire for a microservice environment. As I start talking to them, there are smells, there are signals, there’s things that are pulling them towards or away from microservices, that may not align with what their goal was. How do you talk to them like, top-down, for example, a very top-down directed low autonomy environment? How do you start to talk to companies about some of the organizational changes, cultural changes that come with microservices versus a monolithic architecture?
Richardson: There’s just so many different things that can go wrong. Even years ago, I just recognize that one of the antipatterns of microservice adoption was trying to do microservices without changing anything else about your organization. One extreme example of that was you still could only release on a Saturday night, fourth Saturday night. I call that the Red Flag Law. That name comes from the fact that, apparently, in some jurisdictions, when automobiles started appearing in the early 19th century, someone had to walk in front of them with a red flag. It was like a car slowed down to the pace of a pedestrian. Though I’m not sure whether in reality the cars could actually go much faster anyway.
Reisz: Yes, faster horses, not cars.
Richardson: There’s a lot of antipatterns. Another example of this is adopting cloud. I think this comes up too where people don’t change their organization or their processes, when they adopt cloud, and then they get unhappy about cloud because it’s not fulfilling the promise. I see a lot of analogies there.
Reisz: How do you, in your mind, decide when you should use choreography versus orchestration when it comes to services?
Richardson: The tradeoffs, in many ways, are specific to the situation. I even touched on this, where orchestration and choreography can resolve the dark energy, dark matter forces in different ways. One example of that is, with choreography, you can have services listening to one another’s events. There’s cycles in the design in terms of the dependency graph. Whereas with orchestration, it’s like the orchestrator is invoking the APIs of each one of the participants. The dependencies are in a different direction. In many ways, you just have to apply the dark energy, dark matter forces to a given situation and just analyze and figure out what the consequences are.
Reisz: Randy Shoup talks about what got you here won’t get you there. He’s basically talking about technology and how it evolves through an organization’s lifetime, like early startup versus a more enterprise that may evolve their architecture. Are there patterns that you might talk about or identify that companies see in that stage, as going from startup to scale-up, to a larger company, when it comes to microservices and monoliths?
Richardson: The key point there is that, over time, the application’s non-functional requirements evolve. The job of the architect is to come up with an architecture that satisfies those non-functional requirements. I think one of the key points to make is that an organization should have architects doing actual architecture on an ongoing basis, and make sure that their architecture is evolving as necessary to meet those non-functional requirements. I think a problem most organizations do run into is they neglect their architecture.
Reisz: Keeping in mind Conway’s Law, like the ship your org chart, how does company size affect decisions towards monoliths versus microservices, or does it?
Richardson: Yes. One of the big motivations for using microservices is to enable teams to be autonomous. The general model is each team could have their own service, and then they’re free to do whatever they want. If you only have one team, you’re a small company with just 6, 8, 9, 10 developers, you don’t have an issue with autonomy. You most likely don’t need to use the microservice architecture, from a team perspective.
Reisz: What problem are you solving? If teams are stepping on each other in velocity, that’s a time you may want to solve it with microservices. There’s other reasons you might use it, but not necessarily the team or org structure.
Richardson: I actually tweeted about this, revisiting the Monolith First guideline, which I think is, in general, a good one. If you then look at some of the dark energy forces, there are reasons why you might want to use microservices from the beginning. One very tangible example of that is where you need to use multiple technologies. At least then you’d need a service, at least one service for each of the technology stacks that you’re using. Then, if you look at some of the other dark energy forces, there are other arguments to be made possibly for using microservices from the beginning.
Reisz: Cognitive load is a topic that comes up quite a bit in Team Topologies. It comes up with Simon Wardley in Wardley maps. It comes up all over the place when we talk about microservices. When I think about it, I’m trying to phrase the question around dark energy and dark matter and cognitive load. My first inclination was to ask, is cognitive load a force for dark energy, dark matter? I didn’t really have an answer. How do you think about cognitive load when it comes to microservices or to a monolith?
Richardson: There’s the dark energy force, which is simple components. Then there’s the dark matter for simple interactions. Cognitive load, more or less, fits into those two components. If you break your system up into services, and the world of a developer becomes just their service, then, in theory, you’ve reduced their cognitive load considerably.
Reisz: What are your thoughts on platform teams today and their cognitive load?
Richardson: I think having a platform team is a good idea, in the sense that, say, you’re stream-aligned teams. You’re implementing actual business logic, can just use the platform to get certain things done. That just seems like a good idea.
Reisz: In self-service, yes. Absolutely.
What are your thoughts with the dark energy, dark matter forces when you apply it to frontends, or microfrontends? Any thoughts on that?
Richardson: It’s possible that some of the same considerations apply. My focus is more on the backend, rather than the frontend.
Reisz: Similar concepts, I would think, though, as you break it down.
Do you have any thoughts on Federated GraphQL being used to automate API composition?
Richardson: GraphQL is a good API gateway technology. Because in a sense, it’s just API composition on steroids: flexible, client driven. That’s quite good. Federated GraphQL is maybe something a little different. I think that’s implying that the services themselves actually have a GraphQL API. Maybe there are situations where there’s value in a service actually having a GraphQL API. I don’t think that should be the default. At least that’s how I’m interpreting Federated GraphQL in this context.
Reisz: How do you balance getting quick wins versus starting with the most critical operations first? Is it always, start with the most critical, go for the value first, is that your mindset?
Richardson: This is in the context of the design process for microservices, so the on-paper activity, which actually itself should not be a massive, lengthy process.
Reisz: Any final thoughts, or how would you like to leave the audience as they’re going through these exercises. What would you like to leave them as your final thoughts.
Richardson: I think if you’re an architect or even just a developer, anyone who actually has to make a decision, the first thing to know is that it depends. Usually, the answer, it depends. Then the second thing you need to know is, what are the criteria that you should use to evaluate the differing options? Sort of like the first two steps towards enlightenment as a software architect. That’s one, just general thought. Then in the case of monolith, microservices, I think the dark energy, dark matter forces are what it depends on. Those are the factors to consider primarily. This has been on my mind a lot, just based on recent conversations is, don’t automatically assume that you need a microservice to accomplish something. Sometimes just a JAR file, or, quite often, a JAR file is all you need, just the library jump.
See more presentations with transcripts
Presentation: Unraveling Techno-Solutionism: How I Fell Out of Love with “Ethical” Machine Learning
MMS • Katharine Jarmul

Transcript
Jarmul: Welcome to my talk, unraveling techno-solutionism, or otherwise known as, how I fell out of love with ethical machine learning. I’m Katharine Jarmul. I am a privacy activist and a principal data scientist at Thoughtworks. I’m excited to talk with you about how we can pull apart techno-solutionism. Where we’re going to start, though, is how I fell into love with ethical machine learning. Here’s me. It was my first ever keynote I was invited to present, which was a really amazing experience, at PyData Amsterdam. I had started thinking and working in the space of ethical machine learning due to the changes that we had seen in natural language modeling. I was primarily working in NLP or natural language processing, and modeling. This was the point in time when we were moving to word vectors and to document vectors, and to then also try to place those together in new ways and think through problems. I had been spending some time investigating word vectors and finding really problematic stuff. Then I found, of course, the work of ethical machine learning, of FAT ML, so fairness, accountability, and transparency in machine learning. I was really inspired by all this work.
I thought to myself, way more people just need to hear about this work. If more people hear about this work, and they’re aware of this work, then maybe we’re going to have some fundamental questions about the data we use. We’re going to have some fundamental questions about the way that we process that data, the way that we train with that data. We’re going to end up solving the problem. Maybe not solving the problem, we’re going to at least make some progress. Here’s me presenting just really thinking, this is a really amazing, cool field. How are we going to get there? This is it now, basically, nearly six years later from when I wrote the talk. We’re generating dashboards with YAML and Python. This isn’t what I expected or wanted. I don’t think this is what anybody in the field of responsible AI expects or wants. This is what we’re going to talk about, is how do we actually keep to the core principles of maybe some of the inspiration for techno-solutionism, without actually falling into the trap of techno-solutionism. This is not to say that the responsible AI work that lots of folks are doing, whether at Microsoft Research and many other places, is in any way not useful. It is to say that a dashboard is not going to solve ethical machine learning.
What Is Techno-Solutionism?
First, we need to figure out, what is techno-solutionism? If we can’t identify it, we probably can’t find it. Let’s cover what it is. Here’s a good graphic that I think breaks it down to the simplest of ways. We have a bad state. Then we have a magic technology box. When we push the bad state through the magical technology box, it comes out to a very nice happy state. This can be people. I think we should often think about it in people even if what we’re doing is we’re optimizing a service, we’re optimizing a product or something. It’s going to affect people. This is one of the things that we need to think about when we talk about techno-solutionism, is with the bad people problem that is going through the magic technology and becoming a better one. This is the view of the world as a techno-solutionist.
Another thing that you’ll often see or hear or know about, if you’re thinking about, or you’re talking with, or you yourself are in the depth of techno-solutionism is this mythos, that technology equals progress. That of course progress is good. Progress has this notion that it’s positive or good, or that technology in and of itself is completely neutral. We can never criticize technology because technology is neutral, but it is the people that are bad or good, or something like this. Here, I have the first written formula for gunpowder, which was actually discovered by Chinese researchers who were trying to discover the elixir for life. I think that is just like a really great example of techno-solutionism. It’s like we want to find the elixir of life, because we want life to be good forever. If you can just find the way to have life, it’d be great. Then everything’s going to be awesome. Ended up inventing gunpowder, which, of course, changed the history of quite a lot of the world. Mainly, most people would agree in quite a negative way, killed a lot of people, still kills a lot of people. Essentially, was a technology that was able to be used by colonialism, and so forth, to consolidate power and oppress people, and to perform genocides and hostile takeovers of entire areas of the world.
We can clearly see here that gunpowder is neither neutral, nor is it necessarily progress if we’re affiliating that with societal change, that means that people are happy and benefiting. It’s a great example, because when you actually take a look back at the scientific process, and how technologies developed and so forth, it’s often more like this. There’s a technology that we found, discovered, invented, figured out a new use for. Then that technology creates winners and losers, and potentially lots of other things as well. The technology is going to hurt some people and it’s going to help some people. The technology, therefore, is not neutral. Yes, of course, it depends how you use the technology, and who has the technology in the end. It is not like it’s some magical vacuum that has neutral effects, or that it inherently means progress that is positive in any way, shape, or form. Once we start looking at the world like this, we can start to question the techno-solutionism. This is a real narrative that counters the fake narrative.
Early Mythology
How did the fake narrative even start? There’s a lot of mythology in it. There’s also a lot of history in it. We can get into a long debate about the greater span of technology over human history, at least of what we know, and so forth. I think there’s a lot of really amazing research on the intersection of technology and consolidation of power on technology, and colonialism, and feudalism, and so forth. We’re going to zoom in on technology in our field, which particularly starts with computer science, and maybe data, and machine learning, and so forth. When we zoom into that, we often end up in the buzz of Silicon Valley. This early mythology, and here we have Jobs and Wozniak, centers around the culture or the subcultures that existed in Silicon Valley, at the start of personal computing, as well as the expansion of data centers and the internet and so forth.
We’re in this era, from the late ’70s till the mid-90s. We’re in this area, this period here. In that time, this mythology allowed people to combine the movements, or the history at the time allowed people to combine the movements of hippie activism, and revolutionize things, and don’t do the way that it was done before. Think outside the box. Fight the power. You’re the underdog. You’re going to conquer and create a new paradigm, and all this stuff. This was like a lot of the language at the time. Then, Silicon Valley in particular combined that hippie revolutionary spirit with entrepreneurialism and essentially like a yuppie search for wealth. This idea that the best idea will always win. This idea that it’s genius, and therefore, you should be able to get paid a lot of money for it, and this ethos. Those two things clashed to create this rugged individualism, technology as part of social change, and we’re going to get rich. That was the era of this, and I think also a big play into some of the core beliefs or philosophy around techno-solutionism.
California Mentality
Part of why this was able to be done, and part of what made Silicon Valley so special for this is the California Mentality. I am a native Angeleno from Los Angeles. I deeply know this California Mentality. Let me tell you a little bit about the California Mentality. Here’s a picture of the Gold Rush which brought a whole bunch of new different population to California, in the search for wealth. I think you can’t remove the Gold Rush and also the pioneer mentality from California. It was the idea that here’s this rugged wilderness, as if it was unoccupied. This place where if we could only tame it and use it, it would make us rich. It would bring us happiness. We could start a new life, all of these things. These were primarily white settlers who were coming from the Midwest, who were coming with this dreamer idea of Manifest Destiny. That it is America’s destiny from some religious aspect almost, to control the entire North American continent. Of course, it’s the idea of, we’re bringing progress and technology and civilization. We’re then changing the nature of the place, and of course, also changing the people of the place. Let us not forget that there was many First Americans who were already there, and who were killed and displaced. Genocide was committed as part of “settling” California. This California Mentality, it plays into the techno-solution, because it is this idea that if you have a better way of doing your thing, you can just displace people, and you can take things. Also, this idea of like, the gold is everywhere, the gold is in the earth, but if you can find it, it’s yours.
Echoes of Colonial Pasts
That’s important to remember, because this is also part of the story of the way that we see numerous ideas of techno-solutionism in our world today, is the idea that there are resources out there that we just need, if you have a better way to do it, you’re going to win, you’re going to get rich, and it’s yours for the taking. These are, of course, echoes of the colonial past, of not only California, but numerous other places. Where if you can be the most powerful one to command those resources, and if you can use technology to control that, then you deserve the benefits of that, and so forth. Kate Crawford is an amazing computer scientist and also a thinker. She has a massive piece of work that she worked on, one that artists called Atlas of an AI. It’s fantastic because it’s really starting to go against this narrative of techno-solutionism, because it looks at the entire AI system. It looks even from the start of taking precious metals from the ground in Central Africa, often with the help of child labor, or at least minimally, and soldiers, and so forth, and then turning that into chips, like TPUs, and GPUs, and so on. Then through the entire actual data collection, classification, training process, and then the deployment of these systems and how they’re used.
This is a little zoom into some of the middle, but I want to point it out here, because data exploitation is not that dissimilar from the gold mining exploitation. It’s not that dissimilar of saying, let’s take some technology plus an idea. Let’s take also cheap labor, and let’s turn it into value. What we see here is also the hierarchical nature of the labor that is related to an AI system as well. When we think about this in the concept of how the data ecosystem works today, we can often also compare it quite easily to a feudalistic society, in which we can think of the top, the kings giving out the money to ideas, or the VCs. We go all the way down, knowledge workers, those of us that are machine learning engineers, and so forth, maybe data collection workers, data engineers, systems that support that. Then all the way down to the data producers, or those that have to answer to these systems, which we could compare to gig workers, for example. We can essentially see the colonial nature of quite a lot of the technology that we have.
Joseph Weizenbaum’s Work
There wasn’t only that narrative. It seems pretty silly. There’s got to be alternative narratives, this whole mythos of Silicon Valley, and it providing something, and this idea of, if I have the technology, then I deserve to take it and make value of it. That’s not the only voices. It’s not even the only voices when we look at the history of data and machine learning in our world. I like to talk about Joseph Weizenbaum’s work, because he’s a great example of somebody that was not buying into the techno-solutionism narrative of his time, or of the times that he saw after he left the act and field of programming. Here he is, SSH-ing or teleporting into his computer at MIT. He was a professor for a long time. Before that he built actually the first OCR, the first automated character recognition system. He also built what many consider the first NLP model. He saw the impact of that on the world. He saw the impact of automated check reading, which is what he built for Bank of America, many decades ago. He saw that that actually allowed Bank of America to expand very quickly in comparison to its competition.
What did he think about technology? One interview in the ’80s, around the time that the mythos of Silicon Valley was deeply churning out new ways that computers are going to “revolutionize” the world, Joseph Weizenbaum had already seen a bunch of that. He says, “I think the computer has from the beginning been a fundamentally conservative force. It has made possible the saving of institutions pretty much as they were, which otherwise might have had to be changed.” A stark difference we see here. We do not see computers as progress. We see computers as consolidations of power and resources. We see computers as being in the hands of institutions that always have been and always will be, rather than in the hands of a “revolutionary.” There’s a whole bunch of technologists and ethicists and thinkers and people who have been calling out techno-solutionism and calling out what they see in this, for decades. Hopefully you’re here. You’re not alone. We’re not alone. We want to find Weizenbaum’s of our time. We want to support them. We want to maybe be part of that. How are we going to do it?
How To Spot Techno-Solutionism
First off, we need to first spot techno-solutionism. I made some test here. It’s guaranteed an incomplete list. These are some things that I’ve definitely seen that I know I’ve also fallen for myself. I’ve fallen for thinking, yes, if we just put for good at the end, like it’s data for good. Then, definitely, it’s going to be good data stuff. We should just do only data for good. That means that we solve the problem, and other things like this. Because it’s quite seductive when we think of techno-solutionism, because, of course, I think a lot of us, we want to contribute something positive to the world. We love math, or computers, or technology, whatever it is that drew you to this field. You want to feel like that combination is almost inherent. That’s why the techno-solutionism story gets so intoxicating, because it basically says, just keep doing technology, because it is good. If you just keep doing that, then you’re going to be positively changing it. It’s easy to do, everybody along. A lot of us have done it. Totally understandable from a psychology point of view.
Here are some tests. One test, are you optimizing a metric that you or somebody else made up? If you’re in meetings, and you’re planning something, you’re researching something, you’re building something, and every single person agrees how awesome it’s going to be, how much it’s going to change the world for good, and then that. If you can reformulate the problem statement as, if we only had blank, it would solve everything. If you find yourself using this mythology speak, revolutionize, change, progress, and so on. If you notice when people are bringing up issues, or they’re questioning something, or they’re pushing back, not on a simple technology choice, but maybe on the impact of things, and you realize that those people were being therefore then excluded to the conversation. Maybe this was you at some point in time as well. If you realize that nobody on the team has even tested or thought about a non-technical solution to the problem, to even just essentially have a counternarrative. If you said yes to any of these, you might be in techno-solutionism. There’s probably some other tests you can think about. Let’s create a really nice list for us to think about and notice when we’re there.
Lesson 1: Contextualize the Technology
If you notice you’re in techno-solutionism, what I’m hoping is, you’re here on the staff-plus track, which means that you understand a lot about technology. You probably also understand a lot about businesses and companies. You’ve been around a few different ones most likely at some point in time, and you understand maybe that side of technology as well. You potentially also have a lot of power in the organization. When you realize it’s happening, there’s some things that can be done that can help shift the entire conversation. This may end up with all different sorts of outcomes. I think shifting the conversation is the most crucial and important step in actually countering techno-solutionism. The first lesson that I can tell from hard-learned experience is, first take a step to contextualize the technology in terms of society and the world and the larger space of history. We have a technology that we found or discovered or invented or created a new use for and so we’re optimizing whatever we did. Where we want to first look at is, where are we in the course of history on this problem, and also on this solution, and also on this technology? I would very much recommend expanding the connections that you have in the world beyond the tech world, and finding ways to connect and talk to researchers in other fields, to talk to historians and librarians and scientists in all other areas. To start figuring out and learning about what happened before this technology, and what even happened with this technology before, and really immerse in that search. You might not have the time or capacity to do this. If it’s not you, it needs to be somebody that’s doing this, or it needs to be a group of people that are doing this.
Then I would say, think about the null hypothesis. If this technology was never released and never available, what would be the same? What would be different? Then, I also want you to start mapping and thinking about the non-technical competitive landscape. Other than this technology, what are solutions to this problem? I want to give you a really clear example here so that you have something, or how you can look at this. Because usually when we have a competitive landscape, especially if you’ve formed a startup, you just throw a bunch of other startup names that are in the space, and you put them on the chart, and you’re like, we’re better because, whatever. That’s really deep into techno-solutionism there. When you’re thinking of a non-technical competitive landscape, you want to figure out, how are people solving the problem not using technology today, or in the past? Then you also think about new, creative ways to combat that problem. This is also going to involve the 5 why’s, and really asking why.
There was a startup here in Berlin for a little moment, that promised to deliver medicine to your house in less than 10 minutes. Medicine here in Germany is a lot of times at like little pharmacies, and there’s quite a few, usually, in most neighborhoods and so forth, in a large city like Berlin. I was wondering, when I saw the advertisements, like what problem is this solving? Most neighborhoods have these small pharmacies, and there’s usually a pharmacist there, and of course, they have medicine and so forth. Might be the case that you have to walk more than 10 minutes, or take a bus more than 10 minutes. Also, unlikely, I would be surprised, then you’d have to go outside of the city maybe quite far. That wasn’t where the startup was. Then I started thinking, some of these pharmacies, sometimes they close at like 6:00 or 7:00 in the evening. Maybe the problem is that somebody wants medicine delivered late in the evening or something like this, and they don’t want to go to a hospital or something like this. Then I thought to myself, did they not know that they needed medicine before? Could they have gotten off work 20 minutes earlier, or 30 minutes earlier and gone to the pharmacy? Then you start to figure out there’s all these other potential ways to solve this problem. It also makes you question, what even is the problem that we’re actually solving? Both of those are really important.
Lesson 2: Research the Impact, Not Just the Technology
As you’re figuring out the context, and now you have a better understanding of the landscape, you can also start to figure out what’s the impact. Only when you have the context, can you also start researching the impact. You’re going to have the short-term impact. This means finding people that are going to be harmed by the technology, and finding people that are going to be helped by the technology. You’re probably already talking to those people. Probably some of them are your customers. If it’s hard for you to figure out the harmed part, then you probably need to go back to the context, and talk with more people outside of the field, and get some more context of how this technology could harm people. Make sure that you get those voices and document those short-term impacts. It’s also beyond thinking of the short term. It’s not the year after you release the technology. It’s the five years after you release the technology. Let’s say the technology does all of the dreams that you want it to do, and it starts actually changing the way people behave, or the way that certain community things happen, or the way that traffic patterns happen, or whatever it is.
Then you need to start thinking about, what’s the human impact? What’s the impact on schools, the education system? What’s the impact on the transportation industry? What’s the impact on the government? What’s the impact on logistic networks? What’s the impact on the critical infrastructure of a place? What’s the impact on the workers, both the workers at the company you work at but also workers at other places? What’s the impact on the supply chain? What’s the impact on factories and the production of things? That’s your mid-term impact. Then as you think of the long-term impact, you’re thinking, what’s this interaction? How does this interact with other systems and processes in the world? How does this affect people in other regions of the world? Particularly when you’re thinking of these, and you’re looking in a North American context or something like this, you need to think about, how does this impact humans and people and communities and work in the Global South? How does this impact other entire areas and regions that you may not even have imagined will use the technology, if they do use the technology or if a competitor in your space starts using the technology in another place? What does that impact? You’re not going to know all the answers. You’re going to need to get that outside help. That’s why it’s good to start with the context because you start to have people that you can rely on and have these conversations with, and potentially even start communities at your company or organization that can actually have a more in-depth and educated conversation about this, with experts from other fields with knowledge, and ideas, and work from other spaces. Also, how it’s the interaction effect on the wealth distribution, and capital systems in the world, and so forth.
Lesson 3: Make Space for and Learn from Those Who Know
Now you have a good idea of the impact. Hopefully, along the way, you ran into some really interesting organizations. When I use the term expert, I don’t mean that they have to have a PhD after their name. Nobody is an expert in another person’s experience, other than that person. You can’t be an expert on somebody else’s experience. They’re the expert. This means that when you’re thinking particularly about potential harm, so when you’re thinking of harms on a community, or societal or institutional level or system level, you need to start thinking about oppressed folks in the world and how it works with systems of oppression. How folks that are undervalued or underrepresented, and under-accounted for often in technology systems, how that’s going to impact them. When I stepped away from ethical machine learning, because not only was I realizing, I don’t feel like this is a place where I feel like I can contribute.
Because I think there’s quite a bit of noise, and I don’t feel like I’m fundamentally essential to helping improve this. I also see a lot of techno-solutionism, and that makes me upset. I started thinking about, what are smaller slices of ethical machine learning that I really want to focus on? What I eventually focused on is privacy in machine learning, and data science. A lot of that was inspired by making space for and learning from people who have been affected by machine learning systems.
I came across the work of Stop LAPD Spying, near and dear to my heart of being an Angeleno, and seeing up close and personal the oppression of the Los Angeles Police system. Their work started with documentation of not only the surveillance infrastructure, such as the drones that the LAPD were deploying primarily in lower income, communities of color, primarily black and Latinx communities in LA, and how that was creating a reinforcement system where more were deployed. Of course, then, if crime was found, then they deployed more. This was, of course, a way to do more automated surveillance and automated policing, and so on. They’ve been working against that and many other things, and they have weekly meetups, and you can donate to them, and so on. When you find groups like this, that have already been working on the impacts of these systems, make space for them, learn from them, listen. Hopefully, you still have that idea of the beginner’s mindset, even though you’re a staff-plus. You hopefully have learned that there’s nothing better than keeping your mind open to learn. When I say make space, I mean make space for them in the conversation. Bring them into the room. Hold the space for them. Use your own privilege and your own space at the table to lift up those voices. If needs be, create a permanent space for them, or step away and give up your space for them. This is the ways that we can use the power and the progress that we have in this world to make sure that the right voices, the most affected voices, and the often underheard voices are a part of the conversation.
Lesson 4: Recognize System Change and Speak to it Plainly
As you’re doing that, you’re probably going to start to change if you haven’t already changed your idea of system change. It’s going to look less like the Amazon Go of the world, that Amazon Go is going to revolutionize retail convenience. It starts to sound confusing, because revolution is a group of humans that can come together, and that can change a system that is usually oppressing them, for a better outcome. Amazon Go has very little people and these people that are shopping, and there are systems that are tracking them. Then there’s almost no people working, because that’s the point of Amazon Go. You stop thinking revolution in these terms, and you start maybe thinking of revolution in these terms. You start recognizing the Amazon Labor Union and the work that they’ve been doing, and the work that they have continued to do to try to change a system that is actively oppressing them. Speak to revolution in words like that, very plainly. Speak to them in a way that doesn’t take an asocial and ahistorical view, because you can’t have revolution without people.
Lesson 5: Fight About Justice, not just about Architectures
Finding the Weizenbaum’s of your fields and of your world, and making sure that their voices are uplifted, are going to make sure that there’s arguments about justice at work, not just about architectures. This means you don’t have a homogeneous team because you made space and you created a space for brilliant minds like the two here. Timnit Gebru and Margaret Mitchell were fired from Google for literally doing their job as ethical AI researchers. They were hired to do ethical AI research. When they did it, and criticized the company’s own machine learning practices, they were unceremoniously fired. Make sure that you make space for fighting about justice and make sure you try to create safe space, psychologically safe, and also literally from firing safe justice, ways to talk about justice and change in your organization. If you do these things, you might find a field, an area, a product, or technology that you really, truly believe in. I did. I found data privacy. I found privacy technology. It’s both intellectually enthralling and extremely inspiring in terms of the way that it can change the way that we work with data, and how we collect it, and how we use it.
Conclusion
I’m going to leave you with some questions, because I’ve given you a lot to think about. Now you know maybe some ways and maybe you go through those steps, and maybe you realize, I don’t really feel connected to what I’m working on right now. Awesome if you do, and awesome if you can continue doing this in a way that’s not techno-solutionist thing. Keep on keeping on. I want you to think, and if you turn out like me that you realize, maybe you’re not working on the right part of the problem. Then I want you to ask, what could you be doing if you weren’t building what you’re doing now? I want you to think about, what could you change if you focused on the change, and not the technology? The change itself, was it the change that you want to see? I want to think this is a room full of brilliant technologists with many years of technology experience, and therefore a lot of collective power and a lot of collective responsibility, at probably many different technical organizations. What if we collectively took responsibility for the future of the world instead of the future of technology? What if we use the engineering brilliance that we all have to actually think about, what is the future of the world that we want? The technology is a second-hand question that we deal with later.
Questions and Answers
Nardon: We are in the staff-plus engineer track, which means a track where we discuss the choices and skills you need to have if you want to stay in the technical path. In your field of work, data science, I see many problems in this field, like data privacy bias, and things like you talked about. If we don’t have more experienced engineers in this field, specifically, maybe it’s going to be hard even to detect that these problems are happening. I want to hear your thoughts on the importance of having more staff-plus engineers, or more experienced engineers stay in the technical track, to be able to solve these complex problems we have. What skills do you think these people should have, in order to even convince their bosses that this is a problem, because you probably need not only technical skills, but also soft skills to be able to have these conversations?
Jarmul: I think you know also from your work in the field, how difficult it is in the beginning of your career in data, and machine learning, and so forth, to even see that problems are happening. I think also, like one thing that I’m noticing, and you’re probably noticing too, also from the field is like machine learning is now becoming just easier to do. There’s a lot of models that are available, where maybe the danger is not understood of how a model could be used, or how it could be deployed, or what even are the dangers or the risks. Just a quick example, from recent events, Stable Diffusion is out. Everybody is excited about it. There’s actually prompts that you can give Stable Diffusion where you can see ISIS executions. There’s prompts where you can give Stable Diffusion where you can see non-consensual pornography, and other things like this. Even experienced teams, even experienced researchers end up making mistakes. That’s normal.
I think what you’ve noticed, and what I’ve noticed in the field, and probably some people also, is that if you’ve been in this field for a while, and you have a critical eye towards problems that can happen. It can become easier to predict that these things will happen and therefore your expert opinion and your input to those conversations of analyzing risks is even more essential. I think the reason why I keep saying the word risk is I think that’s actually the best approach that we can use as technologists, is we’re asked to be the experts on not only the technology but the risks and rewards of using that technology. Being therefore the owner of the risks of the technology that you choose to implement in products can help position you to have the power in a conversation to highlight that to upper management and so forth. That means taking time to sit, outline them all, educate your team, speak with management about it. Sometimes some teams are better at that than others. I think practicing, even if you’re not a team that currently uplifts technological voices to management level, at least trying it, is a good start.
Nardon: I think that part of this movement of having more experienced people stay in the technical field is a win. It’s not just for people that don’t have management skills and they want to stay in the technical field. It’s more about having more experienced people having a voice in companies. I see that many companies are realizing that they need to have more experienced people stay in the technical field, to solve better their problems. Also, to have these voices with status in the company that allow them to provide a technical vision that can avoid many problems in data. I work in data as well. Usually, it can be a huge problem for companies if they don’t do things in the right way. I imagine that many other fields are having someone that’s very experienced in technology, being able to go to the management and saying, “You shouldn’t do this, because this is going to have these problems.” It’s probably going to be even financially interesting for the companies. I think this is part of what we have to do as staff-plus engineers is to create more awareness of how these people are important for the company, and giving them the right status is important as well. That’s a good conversation to have.
What is the most important lesson that you learned when you became a staff-plus engineer?
Jarmul: I think probably the most important thing that I’ve learned is learning when to make space. Knowing that there’s probably other people that are thinking the same thing as me, and knowing when to make space for the more junior engineers on the team to shine as well. I think that that has helped my life a lot. It’s helped, hopefully, some of the juniors that I’ve had a chance to mentor and coach. It also gives space for new ideas. I think often as staff-plus we’re asked for the solution, and it’s fine, you probably already know the solution when you’re asked for it. There can be this very critical point of leaving some silence and potentially learning at the same time. I give myself little reminders on my calendar so I remember that, because it can be very easy to get used to hearing your own ideas. It’s important to remain somewhat humble and open and beginner in your approach even after many years. It’s hard, but it’s something that I think is useful.
See more presentations with transcripts
MMS • RSS

(theromb/Shutterstock)
Tigris Data has beta launched a new vector search tool for building personalized recommendations and search applications. Available now as a free beta, Vector Search is meant for use cases like retail and e-commerce, as well as financial applications and event stores.
Vector search leverages deep learning to provide search results based on similar semantic meanings and is an alternative to keyword-based searches that rely on direct matching of keywords. Instead, a vector search engine matches an input term to a vector, which is an array of features generated from an object catalog. Each vector contains tens to hundreds of dimensions that each describe aspects of an item in a catalog, resulting in context-based search results. Companies like Home Depot are using vector search algorithms on their websites to make it easier to search for products and receive recommendations on related products.
Another feature in beta is a Database to Search automatic synchronization that the company says allows users to automatically create search indexes and synchronize data from Tigris Database to Tigris Search. Additionally, Tigris has also released a tutorial on how to use the OpenAI Embeddings API to generate embeddings for documents and use Tigris to index the embeddings to build a vector search engine.
![]() Vector Search is part of the Tigris Data platform, which is an open source, NoSQL, multi-cloud database and search platform that the company claims is 4x less expensive than DynamoDB, the NoSQL database offered by AWS.
Vector Search is part of the Tigris Data platform, which is an open source, NoSQL, multi-cloud database and search platform that the company claims is 4x less expensive than DynamoDB, the NoSQL database offered by AWS.
Tigris says its distributed, cloud-native architecture allows developers to leverage cloud infrastructure services such as auto-scaling and automatic backups without the need for infrastructure management. The platform has a single API that spans search, event streaming, and transactional document store while supporting multiple programming languages and frameworks. Tigris is based on FoundationDB, a distributed database open sourced by Apple in 2018 under the Apache 2.0 license.
Tigris Data launched with $6.9 million in seed funding in 2022. The company’s investors include General Catalyst and Basis Set Ventures, along with Guillermo Rauch, CEO at Vercel, and Rob Skillington, CTO and Co-Founder of Chronosphere.
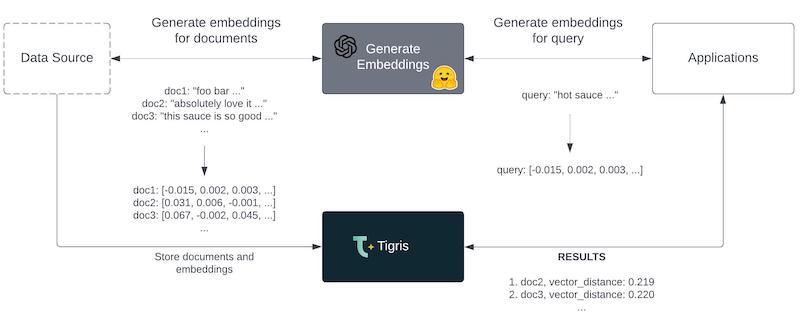
The vector search workflow with OpenAI and Tigris. (Source: Tigris)
The company was founded by Ovais Tariq, Himank Chaudhary and Yevgeniy Firsov, who led the development of data storage and management at Uber. The team’s experiences with data growth and infrastructure sprawl led to its creation of a developer data platform that could simplify data applications without sacrificing speed or scalability, according to a prior release. CEO Tariq previously commented that the goal of building Tigris was to develop a single approach to data management in a developer-friendly environment that lets developers focus on building instead of managing infrastructure. He also noted that building Tigris as an open source platform was important to the team to ensure developers can avoid lock-in.
“With Vector Search, Tigris Data gives developers the ability to deliver fast, accurate, and personalized recommendations to their users,” said Tariq in a release. “This powerful tool is designed to help companies unlock the full potential of their data by making search and recommendation applications more effective and customer-centric.”
Related Items:
Home Depot Finds DIY Success with Vector Search
Vector Databases Emerge to Fill Critical Role in AI
A New Era of Natural Language Search Emerges for the Enterprise
MMS • Shiva Nathan
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today, I’m sitting down with Shiva Nathan. Shiva is the founder of Onymos and has a background working in high security environments. Shiva, welcome. Thanks for taking the time to talk to us today.
Shiva Nathan: My pleasure being here, Shane. It’s a great time to be talking about security and privacy and such.
Shane Hastie: Thank you so much. So, probably a useful starting point, who’s Shiva?
Introductions [01:26]
Shiva Nathan: I’m the founder and CEO of a company based out of Silicon Valley here in the San Francisco Bay Area in California. We are a company that’s trying to invent the next technology abstraction when it comes to enterprise applications. So, you can look us up at onymos.com O-N-Y-M-O-S.com. The name itself came about to be the antonym of anonymous, so we wanted the antonym of word to know about us. That’s how the name Onymos came about. That’s a fun fact for you there.
Shane Hastie: And now, chatting earlier, we were talking about the importance of privacy in particularly data privacy, personal privacy. Your background working in that high security space, what have you seen and what should we be thinking about as technologists working in that space?
Data privacy and retention needs to consider the implications over multiple decades [02:11]
Shiva Nathan: As technologists, we are to start doing everything that we do with a very, very long-term time horizon in mind, and I’m not talking about 15 years, 20 years, or something. I’m actually literally talking about what is the data or information that you are leaving behind today that might affect your great-great,-great-grandchild. If you start to think, it’s a very different view of security and privacy, and I’ll give you a particular specific example. It might be out there, but I’ll still give you a specific example. Imagine five generations from now, your great-great-grandchild cannot get insured because you actually put out there about something that you did or did not do for your health, and your great-grandchild gets denied his or her insurance because of that information that you put out there. You are long gone. You are in your grave rolling probably, and your great-grandchild is doing that. That’s on the personal side.
But on your work side, the stuff that we are building right now are probably going to be lingering around in some fashion for 30, 40, 50 years being used. With people that are using it, not even thinking about who built it or how it was built or under what conditions it was built. And if they run into a problem, it was caused by you, and you’re probably long gone and retired from your day job and still that can linger on. So, if you approach every single problem with this long-term vision in mind as a technologist, it’ll actually help make the right decisions and do the right things when it comes to either of these aspects, when it comes to security and privacy.
Shane Hastie: Organizations don’t think long term.
Shiva Nathan: Very true, they don’t, and that’s unfortunate in some sense. But then, if you actually look at organizations paying for problems that’s created, and if you actually go do a root cost analysis of the problem that organizations have created, you’ll actually find the origin of it, the decision or the non-decision of it from years back. So, all of us are familiar with the Boeing problem and the Boeing planes crashed killing people because of some application software that took control of the plane and plummeted them into land and oceans, right? Go back and do a root cause analysis for that problem, and you’ll find that that particular decision or non-decision was made years back, and it slowly percolates up, and then infects itself into the organization. And then, finally comes to literally killing people years after such decisions are made. Security and privacy are privacy averse.
Shane Hastie: What are some practical things I can do as a technologist?
Be very deliberate about what data is collected and how long it needs to be retained [04:38]
Shiva Nathan: Start with thinking data. What data do I really need, and what data do I not need? We are at a point in inflection in the technology where storage is cheap, and analytics is the biggest thing that everyone wants to do. And since storage is cheap, analytics is good, I want to capture each and every piece of information and data out there to store it, not even knowing whether I’m going to use it or not.
Let’s take this one particular podcast for example. So, as people that are going to be listening to this podcast are thinking that “Okay, let’s save this podcast. Let’s save Shiva’s voice and Shane’s voice somewhere, and let’s store this information whether we want it or not. Let’s store other information about Shiva and Shane whether we want it or not.” Such storing of information “Where is Shane speaking from? Where is Shiva speaking from? Is it even relevant to the conversation that we are having?” But all that information is being stored in the podcast. And that data collection, what I call as unnecessary data collection, is what is going to do technologies in. So, you are collecting data without even having a current use for it, thinking, and hoping that “Hey, that might be a time when I might need it, and I should be able to go back to it.” And capturing the data is the one that’s going to do you in when people hack into the data and find out and stitch where Shane lives, how old is he, and how many children he has, and all of this different stuff to do a technology attack on Shane and Shane’s bank accounts. And all of that was caused by some innocuous data collection to begin with.
And then, the second thing is write one data. Let’s say you do have to collect this data. Start to think from day one in terms of “How long do I really need this data?” Okay. I’m collecting a data about a particular person or a particular enterprise. How long? Think about the expiry of the data when you collect the data. Not many enterprises are very disciplined about doing that. If you put an expiry tag onto the data when you collect it, you would, and if you have a process in place to go delete the data on that expiration date, it’ll do your world of good.
And the third thing that I talk about is if you don’t do that is you start to get nostalgic about data, and the nostalgia of data is a bigger problem.
Well, the first part is that don’t collect unnecessary data. Second is put an expiration on the data, and do not get nostalgic about data. So, as technologists, if we follow these three principles, I think you’ll be in a much better place when it comes to data security. Then, there are a lot of other aspects of security and privacy.
Shane Hastie: So, thinking of your experience working in high profile organizations where they were the target of, as you mentioned, state and non-state actors, how do you build platforms to be secured?
Shiva Nathan: Building secure systems starts with attitude and mindset
Start with the people. Again, it might be the different way of thinking. Start with the people first, the people that are actually building these platforms. What I’m going to tell in you this podcast is not about, “Oh, buy this tool, buy that tool. Implement this, implement that, implement the process and stuff.” It all comes boiling down to the people that are building this stuff. People and their abilities and in many a times their lack of imagination is what is the Achilles heel for secure platforms.
In my previous job and in my current job, when we are building platforms that enterprise applications are going to be built in, the first thing that we start with is how much of the time and their mental focus are my engineers focusing on privacy and security? How much are they diligent about following the process that we lay around? How much are they proficient in the tools that we’re going to give them? It all starts with the people. So, once you have the people area covered, and you know that if every engineer in your team is first of all have their mindset on doing it the highest private way and highest secure way, if you have those two aspects covered, then, you go tell them about the process, you go tell them about using of the tools, then, you go up, tell them about other aspects and other vulnerabilities that they’re going to put in all kinds of testing that they have to do, everything comes easy from there. It flows from there.
Shane Hastie: And what do we build on top of that?
Building for security starts with data at the centre [08:33]
Shiva Nathan: Once you have the people in place, then, start with data at your centre. So, you have the people as your rock bottom foundation, people and the mindset. And then, once you have the people as your rock bottom foundation, then, start with the data, and I’ve already touched upon this data. So, data, very simply think about what is absolutely necessary, what is not relevant, and collect only what is absolutely necessary. Do not collect data that you think you might need it one year from now, two years from now. Do not do that. Then, once you collect the data right at the time of collection, put an expiration tag on the data.
And then, the third thing is do not get nostalgic about data. When the expiration clock ticks in, go delete the data subject to federal regulations, data collections, whatever regulations you have, go delete that data. Once you have the data in place, then, the second thing is your engineering practices. In terms of development, testing and such, right from the beginning, make them super robust. Find out secure coding practices. All your engineers should be proficient in secure coding practices. Then, your CI/CD pipeline, continuous integration/continuous delivery pipeline, they need to be set up to catch security vulnerabilities.
Then, go look at tools that you have already in place and tools that you can augment that continuously keep checking your security vulnerabilities and stuff. Then, go into your release and deployment process, and follow the same thing in terms of how secure and stuff. And more important thing is that most companies do this one time, and the thing is like one and done. It’s never about one and done. It’s continuous evolution. If you’re still running your iPhone on iOS 15, you are in bad shape because there are a lot of security updates that have come up.
Keep platforms and tools up to date [10:11]
Imagine an enterprise running an application on the latest and greatest releases of everything that their stack depends on. It’s a lot of hard work. It’s a lot of hard work to make an application that you’re developing to be running on the latest and greatest. Most of the times, the latest and greatest don’t even work with each other. Finding that denominator that makes things work will bring you down in security levels multiple fold.
Think about what are the things that you can do. Let’s say there are two components that you’re depend on. One is on version two, one is on version three, and you want to upgrade one of them up one version and those two don’t get along. What are the security fixes that I can at least bring in to make them work along so that I’m not open security wise?
To summarize, start with the people, think about the data, think about the entire process, and keep thinking about it continuously, and always stay on the latest and greatest of technologies because that’s what is going to keep you safe.
Shane Hastie: So, let’s go right to the base then and start with the people. How do you create an environment where the safety security thinking is pervasive, and the culture is generative and engaging?
Enabling a security conscious culture [11:16]
Shiva Nathan: All of us as human beings have grown with biases and such. Especially, a newer generation that has grown with social media and such. It is second nature for them to expose most of the lives onto the social forums, that many that are born 40, 50 years back would not even think about doing. Whether or not someone is interested, people start to post attributes about their life in terms of what they ate for breakfast, where they went on vacation and such. I’m not saying don’t go tell your engineers that now you work for the CIA, and you’re not supposed to do all of that particular stuff, but make them start to think in terms of, “This information that you are really sharing with the world, do you understand the ramifications?” Once you understand the ramifications and once you put out your data out there, then, if you’ve gone to the thought process, then you go to whatever you want.
Once you build that particular culture where you educated your team, in terms of what is data, what is data privacy, what is data security, and then, you make them work on your application development as a technologist and such. And then, giving them more time and praising them for the efforts that they put in to be security focused, to be privacy focused. As leaders, we need to walk the walk and talk the talk or rather walk the talk to be sure, to be able to say, “I have really acknowledged and appreciated an engineer in my team that took the extra effort to make something a little bit more robust and a little bit more secure.” So, that’s how you build that culture within the company.
Shane Hastie: We were talking earlier about what makes a good leader, and you had some counterintuitive advice in terms of what comes first.
Employees come first, customers second and investors third [12:50]
Shiva Nathan: Employees come first any day. I have this fundamental belief that I’ve got it from my previous employers and stuff. The employees come first, customers come second, investors come third. With extreme pride, I tell my investors that they come third, and when you make employees come first, if you take really good care of your employees, your employees will do the right thing for the customers. And if your customers have taken really good care of, they automatically will take care of your bottom line and investors.
You try to put this in any other order, employees, customers and investors. And selfishly, I’m an employee as well, so it actually bodes well for me too. So, if you put employees first, customers second and investors third, the system all works diligently. If you try to put customers first, a lot of companies out there that actually go out and say, “Customers first,” and do substandard decisions for their employees, what happens is that unhappy and discredited employees don’t always go the extra mile to make the customers happy. And when your customers are not made extremely happy, your investors suffer. There are some people out there say they are looking for the next fundraising and go, “I’m going to put my investors first”. You can build a rocket ship or a meteor that actually launches and grows very fast for the investors for the next three, five years, and then crashes and burns because you are not taking care of your customers, because you’re making suboptimal decisions for your customers, because you put your investors first. And if you make suboptimal decisions for your employees, they don’t take care of the customers.
Going by this logic of employees first, customer second, investors third, always, always is the right approach in my mind to build a long-lasting company that really succeeds and takes care of all of these three stakeholders.
Shane Hastie: If we look around the tech industry at the moment, we’re recording this in March 2023. See a lot of behavior that has definitely not been putting employees first. The massive layoffs. And I can understand that layoffs at times are necessary in economic climes, but what has worried me in this round is the inhumane way that that has been dealt with or certainly what has been reported on the social media. We arrive at work and can’t log in, or I’m working remotely, and my ID no longer works, and that’s how I know I was let go. What happened that organizations got it so wrong?
The impact of the way layoffs are handled [15:08]
Yes. It is unfortunate what we are going through in the economic climate. Although, I would not say that the company making a layoff makes it a non-employee first company or anything. Layoffs are a necessary part of an economic cycle, but how that is handled is what is important. If you have an employee or a particular division that is not got attraction for no fault of a single employee. So, let’s say there’s a division within a large company try to introduce a product. The product did not get attraction, and the company decides to lay off the entire department, that is the right thing for the company. But how you treat the employees when you are going to lay them off speaks a ton about the culture, and tells the current existing employees, the existing employees how they’re going to be treated going forward.
The particular example that you talked about where a person wakes up in the morning, finds out that they are no longer able to log into the system, and that’s how they get to know that they’re laid off. In this day and age, that to me is horrendous. It could have taken just one email to the person. Even if the company’s laying off 10,000 people and they don’t have an HR that can sit across a table from 10,000 people and have the conversation to tell them gracefully that “Yes, you got laid off.” A simple email would have been understandable. A simple email informing very clearly and nicely that, “Sorry, we have to make this hard decision to let you go,” would have served those companies really well, and that is unfortunate.
And then, there are companies where HR got laid off along with the people that there was no one to do it, but it’s on their leaders then. It’s on the leaders to be able to be upfront. And let’s say, I’m running a company where I would let go of 10,000 people. Let’s say I would let go 99, but I hope I’d never come to that situation ever in my life, but let’s say the entire company has to be shut down. As long as a leader comes out and send out a mass email even saying why that leader is shutting down that company, and what are the reasons, and then also explaining “Why am I sending a mass email because I cannot afford to send 10,000 emails one by one and for the sake of time, I am doing that through a mass email,” that will go a long way. Being upfront, being a person of high integrity and showing leadership, that will go a long way. Then, employee waking up in the morning and finding out that they cannot access their corporate system and that’s why they know they’re laid off.
Shane Hastie: These are not difficult concepts, but we see them breached all too often. What does this tell us, I wonder about our industry or elements of our industry? That’s getting into philosophy, and we might not go too far there.
Human connections got reduced through the pandemic [17:33]
Shiva Nathan: No. I think what the pandemic did to the world is that it actually reduced the level of human connections for people in the last two years that people were hunkered down in the homes. So, there are some managers that I know I’ve never met their employees in person ever. So, if I’ve never met you in person, I’ve always seen you as a two-dimensional object on a Zoom or a Microsoft Teams call, that personal connection doesn’t get formed, so it’s easy for you to wake up and find out that your employee access is not working anymore, and it does not affect me personally. The interpersonal connection is gone because of the pandemic.
I’m getting into the philosophical realm now. I think we as human beings, like what we did, Shane, before this podcast started, to be able to talk about each other’s personal lives a little bit. Not go too much into it, but at least establish that human to human connection, and you offering to tell me, “Hey, if you’re in my neighborhood, come by and say hi,” that’s a good human interpersonal connection, and I’ll remember that for months and years to come. And when I’m ever in your neighborhood, I’ll be like, “Yes, I know a person, Shane, that I can come by and say hi, and meet you all for lunch.” And that only happens when we take the extra effort as human beings in every interaction that we have to go about “Why am I here? Oh, I’m here to do this podcast. Shane’s here to record the podcast,” and just have the conversation go away. That’s not the case.
I really appreciate the time that you took to get to know me as a person and for offering for me to get to know you as a person. We have take the extra effort. If you are scheduled this to be like a 30-minute thing, 20-minute I’m off to my next thing, we won’t have been able to make that connection. I think every human being has to do that in this world.
Shane Hastie: Build in the time to be human.
Shiva Nathan: Yep. You said that lot succinctly than I did.
Shane Hastie: Shiva, thank you so very much for taking the time to talk to us. If people want to continue the conversation, where do they find you?
Shiva Nathan: I’m on Twitter @_ShivaNathan, and they can also follow my company Onymos, O-N-Y-M-O-S on Twitter as well. And I’m also on LinkedIn, so people can connect with me on LinkedIn. You can look me up as Shiva Nathan on LinkedIn.
Shane Hastie: Wonderful. Thank you so much.
Shiva Nathan: Thank you so much, Shane. Thanks for having me. My pleasure.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.