Month: May 2023

MMS • RSS

With less than six months to go before support for version 5.7 of relational database MySQL runs out, it appears users are ignoring recommendations to upgrade.
Figures from Percona Monitoring and Management show that between 40 and 50 percent of MySQL users remain on version 5.7 despite mainstream support ending on 31 October, 2023.
Users who feel version 5.7 is not broken so doesn’t need fixing could be in for some nasty shocks in the long term, said Dave Stokes, technology evangelist at Percona.
“It is like the people who don’t brush and floss every day: eventually they’re going to get abscesses. It’s going to be a lot more painful down the road even if the intermediate results may not be apparent,” he told The Register.
According to marketing and sales research company 6Sense, MySQL has about 45 percent share of the relational database market, with around 176,000 customers. It sits second only to Oracle on the DB Engines ranking, above Microsoft’s SQL Server.
For users considering the upgrade, there are some technical differences between the 5.7 and 8.0 (the next iteration) that users should be aware of, Stokes said. “The ‘group-by’ statement was rewritten. A lot of customers struggle with rewriting those. The original version of MySQL didn’t really follow the SQL standard. It kind of on its own made some assumptions that weren’t always true. Now, if you’re making those old assumptions, and they’re not true anymore, and some of you are getting different results, that’s kind of a shock,” he said.
He recommended customers use MySQL Shell and the util.checkforserverupgrade function checks to flag out-of-date features or settings.
“Sticking with 5.7 is OK, but it is a technical debt you really don’t have to sign up for and 8.0 features are more than enough to make you want to switch over,” Stokes said.
MySQL was authored by Swedish computer scientist Michael “Monty” Widenius in 1995. It became part of Sun Microsystems in 2008 and then moved to Oracle when it bought Sun in 2010. Oracle has declined the opportunity to take part in this piece.
Peter Zaitsev was an early MySQL employee who went on to found Percona. He has literally written the book on high-performance MySQL, working with high-profile users including Facebook. Other prominent MySQL fans include Uber, Twitter and Netflix.
“In recent years, security scares around unsupported versions, saying that it can be a serious problem, get a lot of attention among high-end from enterprises,” said Zaitsev. “But a lot of other users seem to feel free to lapse. They start thinking about upgrades months, even years after the software has gone past its end of life. It is not very good, but that is reality. But with MySQL 5.7, unfortunately, that is going to be even worse because the lift to upgrade to eight is kind of higher.”
The differences are, compared with moving from 5.6 to 5.7, that MySQL will allow more incompatibility and remove more features. It also changes whether users can revert back to earlier iterations should something go wrong.
“MySQL 5.7, it was unlikely there are any breaking changes in the minor release,” Zaitsev said. “But that is not the case with MySQL 8. You may find certain things which were there before don’t work or work differently. As you upgrade to MySQL 8, you not only have to do the upgrade in terms of software, you also need to upgrade your processes to deal with that situation.”
Carl Olofson, research vice president at IDC, said users looking to shift from MySQL 5.7 to 8 might present an opportunity for MariaDB, the MySQL fork.
“Any kind of change like that, no matter how trivial it may seem, it’s going to involve installing the new version on parallel servers, running parallel testing, checking to see if there’s any data conversion that needs to be done. That’s a lot of work. If you’re going to go through that much work, it’s not that much more work to shift providers,” he told The Register.
Inevitably, MariaDB agreed. Manjot Singh, field CTO, said: “We’re probably the most compatible alternative database. But I would differentiate us and say we haven’t been a fork [of MySQL] for a very long time.”
He said the company had won customers through the migration but was getting them equally from AWS Aurora, from Oracle and Microsoft SQL Server. MariaDB’s SkySQL DBaaS could back up MySQL databases during the transition, he pointed out.
On the other hand, Zaitsev said he was not expecting a lot of SQL users to shift from 5.7 to MariaDB instead of MySQL 8.0.
Whoever is right, the deadline is unlikely to change, so users have a decision to make or risk experiencing some painful decay. ®
MMS • Daniel Dominguez

Hugging Face and ServiceNow, have partnered to develop StarCoder, a new open-source language model for code. The model created as a part of the BigCode Initiative is an improved version of the StarCoderBase model trained on 35 billion Python tokens. StarCoder, is a free AI code-generating system alternative to GitHub’s Copilot, DeepMind’s AlphaCode, and Amazon’s CodeWhisperer.
StarCoder was trained in over 80 programming languages as well as text from GitHub repositories, including documentation and Jupyter programming notebooks, plus it was trained on over 1 trillion tokens and with a context window of 8192 tokens, giving the model boasts an impressive 15.5 billion parameters. This has outperformed larger models like PaLM, LaMDA, and LLaMA, and has proven to be on par with or even better than closed models like OpenAI’s code-Cushman-001.
StarCoder will not ship as many features as GitHub Copilot, but with its open-source nature, the community can help improve it along the way as well as integrate custom models, said Leandro von Werra, one of the co-leaders on StarCoder to TechCrunch.
The StarCoder LLM was trained using code from GitHub, therefore it might not be the optimal model for requests like requesting it to create a function that computes the square root. Nevertheless, by following the on-screen instructions, the model might be a helpful technical aid. Tokens are used in the model’s Fill-in-the-Middle method to determine the prefix, middle, and suffix of the input and output. Only content with permissive licenses is included in the pretraining dataset that was used to choose the model, enabling the model to produce source code word for word. However, it is crucial to follow any attribution requirements and other guidelines set forth by the code’s license.
The new VSCode plugin is a useful tool to complement conversing with StarCoder during software development. Users can check whether the current code was included in the pretraining dataset by pressing CTRL+ESC.
While StarCoder, like other LLMs, has limitations that can result in the production of incorrect, discourteous, deceitful, ageist, sexist, or stereotypical information, the model is available under the OpenRAIL-M license, which sets legally binding restrictions on its use and modification. Also, researchers evaluated StarCoder’s coding capabilities and natural language understanding by comparing them to English-only benchmarks. To expand the applicability of these models, additional research into the effectiveness and limitations of Code LLMs in various natural languages is necessary.
AI-powered coding tools can significantly reduce development expenses while freeing up developers to work on more imaginative projects. According to a University of Cambridge research, engineers spend at least half of their time debugging rather than actively working, which is projected to cost the software industry $312 billion annually.
MMS • Ben Linders

Nudging gives us opportunities to positively influence our behavior. Its principles can be applied in testing to increase attention or to enhance the product’s quality. Ard Kramer will give a talk about nudging in agile testing at the Romanian Testing Conference 2023.
The principle of “nudging” is described by Richard Thaler and Cass Sunstein in the book Nudge: Improving Decisions on Health, Wealth, and Happiness:
A nudge is any form of choice architecture that alters people’s behavior in a predictable way without restricting options or significantly changing their economic incentives.
According to Kramer, nudging makes use of something that is well-known to us as humans: our biases. This term may cause concern for testers as it poses a risk to delivering useful software. However, scientists have also recognized its potential to positively influence our behavior.
Kramer gives an example of how nudging can be used to support testing:
A risk session is a vital starting point for testing. How can we get stakeholders in the right mindset to consider product risks thoroughly? What if we place them in a room with pictures of natural disasters such as typhoons, volcanoes, and earthquakes on the walls? The unconscious behavior will hopefully activate them. They can come up with all kinds of product risks that can occur during the development of that new product. Risks that need to be monitored or mitigated to reach for a better and more reliable product.
To apply nudging in testing, Kramer suggests considering the situations in which you want those around you to increase the attention to testing or to enhance the product’s quality. Then think about which principle will be appropriate and useful to nudge people towards better testing or higher quality. Such an exercise can be enjoyable and valuable.
InfoQ interviewed Ard Kramer about nudging.
InfoQ: Where does nudging come from?
Ard Kramer: Nudging has been in existence since humans started living as social beings, attempting to influence and modify each other’s behavior within groups. However, the awareness of how it works and its applications originated in the social sciences, such as behavioral economics and political theory. Behavioral economists moved away from the concept of homo economicus, recognizing that humans are not always rational (as evidenced by the quality of code).
It is not surprising that marketing and sales have utilized this knowledge to influence people, for example to purchase more of a particular product. In addition, politics has identified opportunities to improve the quality of our society, such as encouraging safe driving or reducing the amount of money students borrow from the government to pay for their education.
InfoQ: How do you apply nudging in testing to improve the quality of software?
Kramer: An interesting example is the principle of “the default option”: a bias that we encounter many times a day when they ask you to accept a cookie to enter a website. Because you want to proceed as fast as possible, you don’t look at the different options that are offered to you. And you know what: the default option is often the option with the most interesting cookies for the people of the website. So if we have limited time, we often choose the default option (and sales people know that).
How to apply this to testing? A very simple example is setting the default option if you report a bug to “blocking”. If people don’t have much time in reporting, all bugs will be blocking, because they will choose the default option. With this action, you will get attention because there will be a full list of blocking bugs. This will help you, as a tester, to have people around become aware of how many bugs there are that need attention.
This is just an example of one principle, however there are over 15 others, such as “keep it simple,” the generation effect, and reciprocity, that can be utilized to nudge people in a particular direction.
InfoQ: What about ethics, is it ok to nudge people to make better choices to improve quality and testing?
Kramer: The foundation of ethics is to determine one’s intentions, and the same holds true for nudging. My reason for utilizing nudging is to improve the quality of testing, thereby increasing the value that a tester can bring. I don’t believe many people would object to this intention.
MMS • Almir Vuk
Microsoft has released a new version of .NET Upgrade Assistant in Visual Studio, which provides a set of new enhancements and support for different platforms and frameworks. The tool now supports .NET 8, enabling developers to utilize the latest features and improvements of .NET. Also, the new version brings the enhancements like an upgrade for Azure Functions, alongside .NET MAUI, WinUI and support for ARM64.
The latest release of the .NET Upgrade Assistant comes with a new feature – Azure Functions upgrade. The tool will now automatically upgrade the version of Azure Functions to v4 isolated when upgrading an Azure Functions project to the latest .NET version. This upgrade is recommended by Microsoft as it is considered to be the best version currently available. Developers can easily upgrade their Azure Functions project, similar to upgrading any other project, by right-clicking on the project in the Solution Explorer and selecting the Upgrade option.
By following the reported upgrade steps in the tool, developers can ensure that both the project file and the Azure Functions version are updated to the latest available versions. However, this upgrade process goes beyond just updating the project file to target the latest .NET version and Azure Functions version. The tool also updates the body of the functions to utilize new APIs, ensuring that the upgraded project is optimized for the latest technology and functionality.
Furthermore, regarding the upgrade from .NET Core or later to .NET 6, 7 or 8. The tool now upgrades all packages referenced by the application to a cohesive set of packages that correspond to the target .NET version, in addition to upgrading the target framework.
Regarding the package upgrades, Olia Gavrysh Senior Product Manager, .NET, author of the blog post states the following:
Here is how the package upgrades work:
For standard .NET runtime or ASP.NET Core packages the version will be set to the latest matching target framework 6, 7, or 8. For example, if you are upgrading your app to .NET 6, you’ll get the corresponding .NET 6 release package version, and if you are upgrading to .NET 8, your packages will be updated to the latest pre-release versions.
For all other packages the tool checks if this package already supports target framework, in that case the package remains unchaged. If not, the tool will check if the latest version of the package support the target framework to wich the app is upgraded. In case even the latest package version does not support the target framework, this package will be removed.
In addition to this enhancement, the latest version of the .NET Upgrade Assistant also includes a new feature that allows developers to upgrade from older preview versions to the most recent ones.
Worth mentioning is that the original announcement blog post provides tutorial-based steps on how to do upgrades from Xamarin.Forms to .NET MAUI and upgrades for Azure Functions.
Also, in the official announcement blog post, the team behind the .NET Upgrade Assistant shared their plans for future development and the focus for the next phase will be on improving the quality of upgrades, stabilizing the tool, and addressing bugs based on user feedback. Another stated priority is updating the existing Command Line Interface (CLI) tool to communicate with the same engine as the Visual Studio extension. This enhancement will ensure that the CLI tool includes all the new features available in the Visual Studio Extension. This update will offer developers a choice between Visual Studio and CLI experiences.
Lastly, a survey is also available, to gather feedback on the newly available feature for upgrading .NET projects from within Visual Studio. Users are encouraged to share their experiences and suggest improvements by participating in the survey. More info and details about .NET Upgrade Assistant can be found on the official Microsoft dotnet website.
MMS • Vivian Hu
During the KubeCon + CloudNativeCon EU 2023 event, Huawei announced that it had open-sourced Kuasar, a Rust-based container runtime that supports multiple types of sandboxes, including microVMs, Linux containers, app kernels, and WebAssembly runtimes.

(Kuasar was open sourced on KubeCon EU 2023. Source)
At KubeCon EU 2023, over 50% of attendees attended the flagship Kubernetes conference for the first time. Kubernetes and the cloud-native application paradigm it empowers appear to be crossing the chasm into mainstream IT organizations. As Kubernetes gains popularity, developers are increasingly applying cloud-native architecture beyond traditional data centers, such as edge data centers, data streaming applications, blockchains, autonomous vehicles, and even IoT devices.
These new cloud-native applications need to handle diverse workloads. The one-size-fits-all Linux container approach is no longer sufficient. For example, some applications require VM-level security and isolation, while others need to run lightweight isolation sandboxes such as WebAssembly (Wasm).
In the past, numerous efforts have been made to enable VM and Wasm workloads to run side by side with Linux containers in the same Kubernetes cluster. For example, the KubeVirt project can manage both VMs and containers. The crun project supports both Linux containers and Wasm runtimes at the OCI level. With the help of runwasi, the containerd project can manage Wasm runtimes, such as WasmEdge, and Linux containers side by side. However, those projects use the Linux container framework to support other sandboxes and hence have numerous inefficiencies and unexpected behaviors when using VM or Wasm sandboxes. To see the complexity of running Wasm containers in traditional Kubernetes environments, several tutorials can be consulted.
Kuasar is designed to support multiple types of sandboxes and containers from the ground up. Built on top of containerd’s Sandbox API, Kuasar introduces a unified approach for sandbox support and management. The Sandbox API is a low-level target for resource management of multiple containers, which is implemented and orchestrated independently without any Go dependencies. That allows Kuasar to be implemented in Rust, which provides additional safety and performance benefits at the infrastructure level. Chris Aniszczyk, CTO of CNCF, tweeted about the announcement of Kuasar:
new open source project taking advantage of sandbox API to run containers, wasm etc – planning to contribute to CNCF! look forward to see how the sandbox API evolve in cri/containerd land this year!
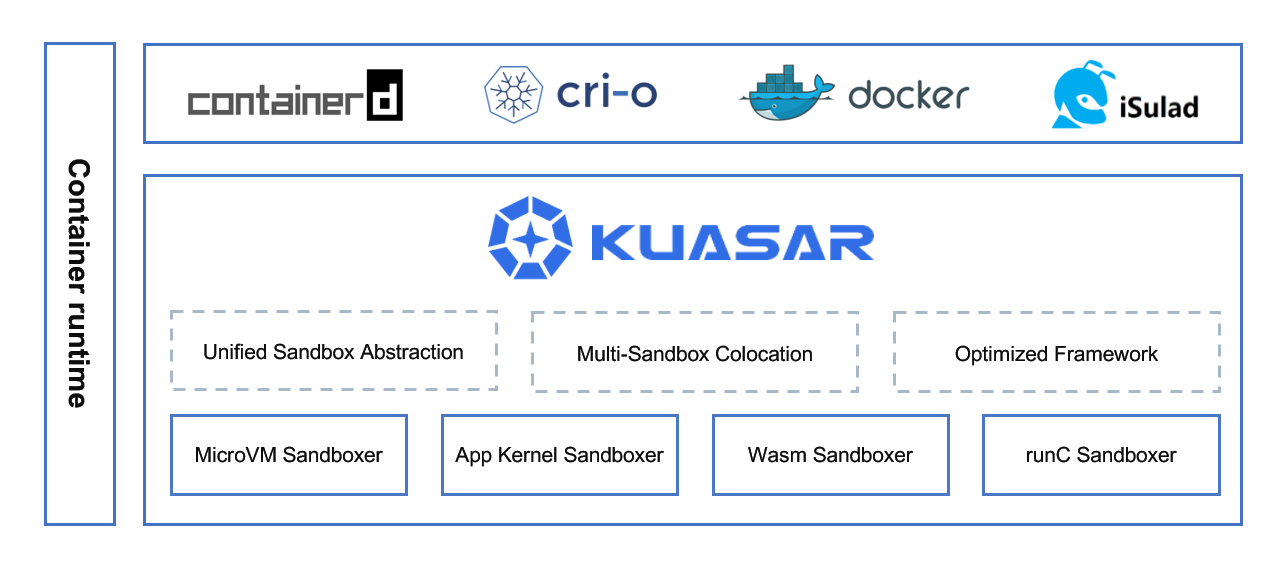
(The architecture of Kuasar. Source)
Compared with Kata, which is another secure container runtime, Kuasar starts up within half of the time and consumes less memory. Such performance gains are achieved by:
- Using the Rust programming language.
- A re-design to remove all pause containers.
- A re-design to replace shim processes with a single resident sandboxer process.
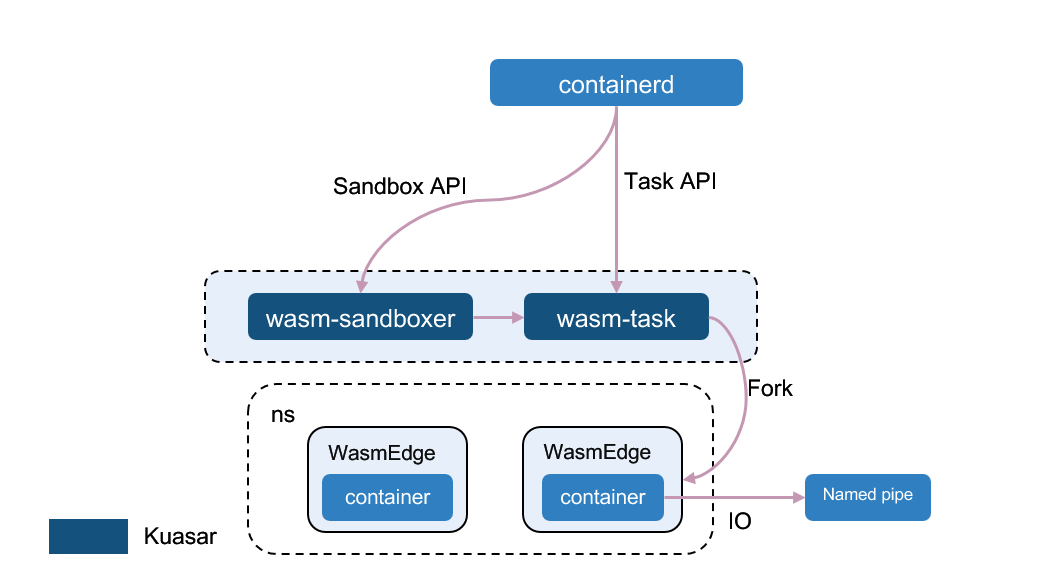
(Kuasar’s support for WasmEdge Source)
As a unified container runtime, Kuasar already supports MicroVM sandboxes such as Cloud Hypervisor, StratoVirt, and QEMU, app kernel sandboxes like Quark, and Wasm sandboxes like WasmEdge. Kuasar can seamlessly integrate into high-level CRI container management tools, such as containerd, cri-o, docker, and iSulad. Bill Ren, a CNCF board director, shared his vision and hope for Kuasar at KubeCon EU:
The open-source Kuasar will provide developers with more choices and support, offering users a more efficient, complete, and flexible cloud-native container solution for their scenarios.

(The ecosystem of Kuasar. Source)
Kuasar is jointly developed by multiple commercial and open-source organizations, including Huawei Cloud, the Agricultural Bank of China, WasmEdge (Project under CNCF), and the openEuler community.
Kuasar is an open-source project under Apache 2.0. The source code is available at GitHub. If you are interested in container runtime, check it out and make a contribution.
MMS • Sergio De Simone

Google has begun rolling out support for passkeys across Google Accounts on all major platforms. Passkeys will be available as an additional authentication option alongside pre-existing mechanisms, including passwords, 2-step verification, and so on.
According to Google, passkeys provide an easier and more secure way for an user to get authenticated.
Passkeys let users sign in to apps and sites the same way they unlock their devices: with a fingerprint, a face scan or a screen lock PIN. And, unlike passwords, passkeys are resistant to online attacks like phishing, making them more secure than things like SMS one-time codes.
Passwords are notoriously hard to manage for users, who need to create and remember a multitude of strong passwords, distinct for each service they use. In fact, as strong as they may be, passwords do not protect users from the possibilities of phishing and are ever more frequently used along with an additional mechanism, two-factor authentication (2FA), which has its own drawbacks.
Under the hood, passkeys are cryptographic private keys that are stored on users’ devices, while the corresponding public keys are uploaded to Google. When a user attempts to sign in to Google using a passkey, Google will ask their device to sign a challenge using the private key.
The signature proves to us that the device is yours since it has the private key, that you were there to unlock it, and that you are actually trying to sign in to Google and not some intermediary phishing site.
The challenge can only be signed if the user unlocks their device, a step which can leverage advanced biometric hardware available on many devices, including fingerprint and face recognition. Alternatively, a more traditional PIN can be used. According to Google, any biometric data is not shared outside of the signing device, which only sends out the public key and the signature.
Google has also defined a mechanism to use your phone to sign in on another device, which is crucial when you need to access your account from a shared device. In this case, the device will first check that the phone is nearby using Bluetooth, then it will show a QR code that the phone scans and uses to generate a one-time passkey signature, if the user authorizes it. The new device does not receive either the passkey nor any biometric information.
A passkey resides on an individual device and each device will need to get its own passkey, which can become cumbersome. To circumvent this, passkeys can be shared across all of your devices. Google does not provide a universal mechanism for this, but users can rely on iCloud Keychain for Apple devices and on Google Password manager for Android and Chrome devices for a seamless experience. Unfortunately, this does not enable sharing a passkey across, say, iPhone and Android devices, unless a third-party SSH key manager is used. Notably, Microsoft does not provide yet an official solution to share secrets across Windows devices.
To create a passkey for your Google account, you need to use a dedicated domain for the time being.
Google has been working with Apple and Microsoft for the last year to define standard approaches, including FIDO and W3C WebAuthn for passwordless authentication that can be adopted industry-wide.
MMS • Anthony Alford

OpenAI recently announced plugin support for ChatGPT, allowing the language model to access external tools and databases. The company also open-sourced the code for a knowledge retrieval plugin, which organizations can use to provide ChatGPT-based access to their own documents and data.
Although large language models (LLM) like ChatGPT can answer many questions correctly, their knowledge can become out of date, since it is not updated after the LLM is trained. Further, the model can only output text, which means it cannot directly act on behalf of a user.
To help solve this problem, researchers have explored ways to allow LLMs to execute APIs or access knowledge databases. ChatGPT’s plugin system will allow the model to integrate with external systems such as knowledge bases and 3rd party APIs. The retrieval plugin allows the model to perform semantic search against a vector database. Because the plugin is self-hosted, organizations can securely store their own internal documents in the database, which lets their users interact with the data via ChatGPT’s natural language interface.
The plugin supports several commercial and open-source vector databases, including one developed by Pinecone, who contributed to the open-source plugin code. InfoQ spoke with Roy Miara, an Engineering Manager at Pinecone, about their contribution to the plugin.
InfoQ: What is a ChatGPT plugin, and in particular, what is the Retrieval Plugin used for?
Miara: ChatGPT plugins serve as supplementary tools that facilitate access to current information, execute computations, or integrate third-party services for ChatGPT. The Retrieval Plugin, in particular, empowers ChatGPT to obtain external knowledge via semantic search techniques. There are two prevalent paradigms for employing the Retrieval Plugin: 1) utilizing the plugin to access personal or organizational data, and 2) implementing the plugin as a memory component within ChatGPT. Both are using semantic search as a way for the model to rephrase user prompts as queries to a vector database such as Pinecone, Milvus, or Weaviate.
InfoQ: What are some advantages a ChatGPT plugin has over other LLM integrations such as LangChain?
Miara: Although LangChain enables an “agent” experience with tools and chains, ChatGPT plugins are more suitable for AI app development. The advantages of ChatGPT plugins include: 1) a more sophisticated implementation that leverages OpenAI’s internal plugin capabilities, as opposed to LangChain’s approach of concatenating plugin information as a prompt to the model, and 2) the support for security and authentication methods, which are essential for AI application development, particularly when accessing personal data or performing actions on behalf of a user. These features are not present in Langchain’s current offerings.
InfoQ: Can you describe your contributions to the retrieval plugin open source project?
Miara: Pinecone datastore implementation was contributed to the project, alongside some other internal improvements of testing and documentation. The overall base implementation follows Pinecone’s upsert/query/delete paradigm, and we are currently working on hybrid queries and other advanced query techniques.
InfoQ: Can you provide some technical details on how a typical ChatGPT plugin works?
Miara: A ChatGPT Plugin is a web server that exposes an “instruction” manifest to ChatGPT, where it describes the operation of the Plugin as a prompt and the API reference as an OpenAPI yaml specification. With those, ChatGPT understands the different API calls that are possible, and the instructions it should follow.
So in order to build Plugin, one should build the application logic, implement a web server that follows OpenAPI specification, and deploy the server such that ChatGPT is able to access it. Although there is no limit to the application logic that one can implement, it is not recommended to construct a complex API server, since this might result in undesired behavior, confusion etc.
We have found that the “description_for_model” part of the manifest, which is essentially a prompt that is injected before the context retrieved, is a key for a successful plugin. OpenAI are providing some guidelines, but in the end of the day, it’s in the developer hands to find the right prompt for the task.
InfoQ: OpenAI mentions that plugins are “designed specifically for language models with safety as a core principle.” What are some of the safety challenges you encountered in developing your plugin?
Miara: Firstly, enabling ChatGPT to access personal or organizational data necessitated the implementation of both security and data integrity features. The plugin is designed to handle API authentication, ensuring secure data access for both reading and writing purposes.
Secondly, generative language models often grapple with hallucinations and alignment issues. We observed that earlier versions of plugins occasionally provided incorrect responses to queries, but subsequent iterations demonstrated improved accuracy while also admitting when certain questions were beyond their scope. Moreover, by running plugins in an alpha stage for an extended period, OpenAI can better align the results before releasing them to a broader audience.
Additionally, it’s important to note that the plugins feature is designed with complete transparency for users. First, users explicitly select the plugins they wish to enable for use with ChatGPT. Secondly, whenever ChatGPT utilizes a plugin, it clearly indicates this to the user, while also making it simple to view the specific results that the plugin service has provided to ChatGPT’s context.
MMS • Kristen Tronsky
Key Takeaways
- Align the company culture externally and internally: The best way to express your values is to live them with clients as well as employees.
- Measure everything and share the results: Customer and employee surveys, quarterly OKRs, real-time performance check-ins of employees and leadership.
- Open doors, always: Make sure employees have access to everyone, and feel empowered to use it. Employees can’t grow unless they speak up, and they won’t speak up unless they feel comfortable with the people they’re speaking to.
- Take professional development seriously: Employees that can make the most of expanding the breadth and depth of their skills on the job will be more engaged, more productive and less prone to burnout.
- Feedback loops go both ways: One-way feedback creates a culture of fear and approval seeking. Employees should guide the company’s growth and development as much as the other way around, and formal and informal touchpoints are essential to gather that direction.
In a startup’s world, the economy is driven by employee skills and talents, and people are an organization’s primary source of competitive advantage. Successful startups tend to have strong cultures where they are literal communities with shared goals, values, objectives and rules. These businesses have proven much more likely to survive and thrive in both good and bad economies, largely due to their sustaining cultural strength rooted in core values, transparency and pragmatism.
The following looks at the current reality of people management in startups, how to build a culture, and most importantly, how to make it last with “radical transparency.”
The talent tightrope
Startups must be adept at walking a tightrope that requires balancing workforce demands and culture, regardless of shifting economic winds and scale. This begins by candidly looking at the landscape of your organization’s hiring needs and putting a plan together that will support where the business is going to be 18 months out at all times. If not, short-sighted decisions can occur that will need to be corrected or evolved before you know it – and at a much greater cost.
With fewer employees, it’s crucial for startups to attract resilient talent capable of scaling their own skill sets as the company rapidly changes, while also taking care to align employee development plans to anticipate and support future business needs wherever possible.
If a startup is in a hot industry segment or a product suddenly takes off, it could experience hypergrowth and need to acquire more talent, fast. Some organizations, ours included, are experiencing just that in spite of the current economy.
Navigating these periods of high demand with a methodical approach to healthy growth is an essential part of ensuring longer term sustainability, efficiency and financial health. It can be tempting to skip these sometimes challenging discussions in the face of business urgency, but the consequences of poor planning and execution can be disastrous to a company’s culture, reputation and overarching business momentum.
Sustainable organizational development
Our organization follows both top-down and bottom-up organizational development models, encompassing the vision of leaders, employee feedback and facets of business practices. On the technical side we use detailed models to determine the coverage ratios needed in order to scale effectively and serve our customer base. This helps us understand such things as the number of cloud architects and consultants that would be needed to support expansion plans, and then we review actual performance against our models and iterate along the way.
The sales department takes a top-down approach to model out how many new team members we might need based on the addressable market, established quotas and the number of customers we need to bring on over the span of the next 12 months to hit proposed revenue targets based on average deal sizes. Simultaneously, the bottom-up component looks at historical sales attainment by rep, ramp speed, pipeline creation and conversion rates, all to reverse engineer how best to build up to the top line revenue goal across the broader team.
With this data-driven approach, we’ve reached an appropriate middle ground and established a trigger-based hiring plan to ensure we’re at the right capacity at all times. Equally important is the ability to protect and foster a hard-built culture that has enabled us – as a company and as employees – to handle peaks, valleys and future plans, comfortably and with continuity.
A radical approach to sharing information
Culture is a reflection of a company’s core values in action. If you know what you want your company to be, the people you want to attract and the type of service you want to be known for, you can define a base set of principles to act as a guiding light. This can keep a company on track and create a body of highly motivated overachievers that are not only incredibly driven, they’re personally invested and incentivized to bring the company and their teams along with them for the ride as they build the business together.
Key to this for us has been embracing radical transparency, internally and externally. This enables us to show, not just tell, their true values across every aspect of a company and team. While not easy, it’s an investment that employees and customers appreciate, reward and reciprocate.
For example, we allow employees to fully access just about all company data no matter if it relates to customer support, finances or any other area. This is the foundation of a business model that has existed from our outset. The reason for doing so? We realize there is no way to know how the information might be used beneficially unless it’s put into the hands of the people who give it value – employees.
It’s easy for a business to fall into the trap of simply safeguarding data, releasing just enough so employees can perform their specific functions and nothing more. By doing so, however, employees work with virtual blinders on, never knowing how their role fits into a company’s broader vision or even if they’re having a positive or negative impact. It can also create knowledge silos, and in a startup, shared information is what builds content and perspective needed to iterate and innovate.
The more that startups share with their people, the more aligned they’ll be with company vision, resulting in greater productivity and innovation. An entire organization’s focus is sharper when both individual and collective business objectives are at the forefront and all are moving in the same direction. By being transparent, teams share candid details on what is and isn’t working, and their ability to collaborate openly and comfortably can unearth opportunities that otherwise would be missed. Also, employees will better understand the skills needed for a given project, and with full transparency, they’ll know where in the organization they can find them. (They will also have a clearer understanding of why some projects are deprioritized in favor of other initiatives when there are difficult decisions to make.)
Tips for transparency
Keep in mind, the goal of transparency is not simply about metrics like achieving the highest operational cost efficiency possible or forcing information overload. Radical transparency is about cultivating trust among your workforce, making them aware of company expectations and supporting their ability to carry them out with as much impact as possible. This ultimately benefits your staff, customers and the company.
The following tips can help you ensure your startup is as transparent as possible:
- Align culture internally: The best way to express your values is to live them. The work you ask your employees to do should be reflective of the culture that they signed onto. For example, don’t profess to be a progressive organization and then expect employees to do regressive work. If a core value of your team is autonomous achievement, give them the independence to work undisturbed. And if one of your values is collaboration, invest in tools and technologies that inspire and enhance it.
- Align culture externally: Customers seek business partners who are trustworthy and true to themselves. Being an open book about your data and metrics is a surefire way to build it. For us, that means publishing service stats in real time, giving customers (and employees) a live, down-to-the-second look at performance metrics. Emphasizing transparency to customers doesn’t just build trust, it attracts like-minded ones whose values align well with your own. Also, with full visibility, there’s a pressure and motivation to continue evolving and provide a better, more client-friendly solution.
- Measure and share: Customer and employee surveys, objectives and key results (OKRs), real-time performance check-ins of employees and leadership – all should be measured and shared. We survey our employees on a quarterly basis, alternating between two formats. For example, we use the Q12 format from Gallup, as well as a “start, stop, continue” feedback format. Each one of those also includes an employee Net Promoter Score question. Not only does this yield great insight, it’ll keep your startup honest.
- Open door policy: Make sure employees have access to everyone and feel empowered to reach out. Employees won’t grow unless they speak up and they need to feel comfortable doing so, regardless of title. We create a number of touchpoints for employees to connect with leadership, from introductions the moment they walk in the door all the way through feedback, discussions and more. But as much as these are vehicles for discussion, they’re especially effective in building comfort for employees with the radical idea that leadership’s doors are truly always open. In making leadership accessible, be sure employees trust they can be candid, even when reaching out to the CEO with a quick question or idea. This can be particularly critical for building trust in fully remote startups.
- Take professional development seriously: Employees that can make the most of expanding the breadth and depth of their skills on the job will be more engaged, productive and less prone to burnout. The important part is to make sure you understand what every single person on your team is looking to get out of their employment opportunity and that they’re continuing to grow in that direction. If you’re being authentic with the people that you manage – and understand what their wishes, hopes and dreams are within your company and beyond – you can facilitate their growth and satisfaction.
- Keep everyone in the loop: Feedback loops should go both ways. Employees should guide the company’s growth and development as much as the other way around, and formal and informal touchpoints are essential to gather that direction. Additionally, forget those lengthy annual, archaic, exhausting performance reviews and focus on continuous management with regular performance feedback and goal alignment discussions. We use a quarterly OKR system that evolves with our priorities and can be adjusted along the way. You want people to get feedback, good or bad or constructive, in real time. That way they can make real-time adjustments and eliminate performance review surprises down the road.
Honesty as a policy
Radical transparency isn’t a business model for every company. However, with technology startups, you’re typically dealing with highly skilled experts that require a lot of independence to do their job. And when collaboration is necessary – and it always will be – employees understand the skills needed for a given project. With full transparency, they’ll know where in the organization to quickly and easily find them, and that’s just another in a list of competitive advantages that can be gained.
Always remember, though, you have to deliberately maintain and cultivate that kind of honest, open connection or it’s a futile exercise. You need to be accessible, honest, consistent and transparent. You must be willing to engage in thoughtful, open dialogue. The moment you deviate, you undermine your progress.
Honesty, as a policy, is much easier to handle from an HR perspective, too. Not only does it simplify and clarify objectives and expectations, it creates more personally satisfied, cohesive and highly motivated teams that can produce results regardless of economic shifts. And a win for everyone always makes for a better story.
Quarkus 3.0 Released: Improving Cloud-Native Java Development with Jakarta EE 10 Support
MMS • A N M Bazlur Rahman

Following six alpha releases, a beta release, and two release candidates, Red Hat has launched the highly anticipated Quarkus 3.0 release this past week. This update brings a host of new features, including support for Jakarta EE 10, MicroProfile 6.0, Hibernate ORM 6.2, and Hibernate Reactive 2.0. Furthermore, the Dev UI has been revamped to be more extensible and user-friendly, showcasing a modernized look and feel. In addition, Quarkus 3.0 introduces an upgrade to SmallRye Mutiny 2.0.0, which now utilizes the Java Flow API instead of Reactive Streams.
The development process began on March 18, 2022, with the ambitious goal of rewriting the entire tree to migrate to the new jakarta.* packages and adopt Jakarta EE 10. The shift to Jakarta EE 10 offers two major benefits: it aligns with the broader Java ecosystem’s move to Jakarta dependencies, enabling easier sharing and compatible implementations; and it introduces CDI Lite and Build Compatible Extensions (BCE) for standard extensions compatible across CDI implementations, benefiting from Quarkus build time optimizations.
Quarkus 3.0 debuts a revamped Dev UI, providing a more extensible and user-friendly experience with an improved look and feel. While not all extensions have migrated to the new Dev UI, the old Dev UI can still be accessed at /q/dev-v1, but it is slated for removal in a future version. A Quarkus YouTube channel playlist demonstrates the new Dev UI, highlighting its features and how to use and extend it.
Quarkus 3.0 upgrades Hibernate ORM from version 5.0 to version 6.2, which brings numerous changes, some of them breaking. The upgrade to Hibernate ORM 6.0 requires some effort and testing, and developers are advised to consult the Hibernate ORM 6.2 update guide for guidance. Hibernate Reactive has also been updated to version 2.0 to maintain compatibility with Hibernate ORM 6.
Quarkus 3.0 enhances the developer experience with improvements to the CLI, Maven and Gradle plugins, including the ability to deploy Quarkus applications to platforms like Kubernetes, Knative, and OpenShift without requiring changes to project dependencies or configuration. It now supports Maven 3.9 and Gradle 8.0, and Maven 3.8.2 is the minimum requirement for Quarkus 3 projects. Examples of CLI commands follow:
$ quarkus deploy
$ mvn quarkus:deploy
$ gradle deploy
Eclipse MicroProfile 6.0 now aligns with Jakarta EE 10 Core Profile and replaces MicroProfile OpenTracing with MicroProfile Telemetry. RESTEasy Reactive, the default REST layer for both reactive and blocking workloads, has been updated with usability enhancements, including the ability to retrieve all multipart parts. Additionally, the OpenTelemetry extension has been revamped to support SDK autoconfiguration, with its configuration namespace changed to quarkus.otel.*. This update simplifies enabling OpenTelemetry for JDBC by only requiring users to set the quarkus.datasource.jdbc.telemetry property to true, without needing to modify JDBC connection URLs.
As active support for Java 11 will end in September 2023 by the OpenJDK community, Quarkus has marked it as deprecated. While core Quarkus functionality will continue to support Java 11 past that date, developers are encouraged to upgrade to Java 17 or later for the best Quarkus experience.
To assist developers in updating their projects to Quarkus 3.0, a comprehensive migration guide has been provided, along with a dedicated Hibernate ORM 6.2 update guide. Quarkus 3.0 also introduces an update tool that can automate most of the tedious work involved in updating projects, including adjusting package names, updating dependencies and configuration files, and upgrading Quarkiverse extensions to be compatible with Quarkus 3.0.
In conclusion, the release of Quarkus 3.0 signifies a major step forward for the Java ecosystem, offering developers an enhanced experience and a myriad of new features and improvements. With a focus on developer experience, performance, and extensibility, Quarkus 3.0 is well-positioned to solidify its place as a top choice for Java developers looking to build resilient and efficient applications in a rapidly evolving technology landscape.
MMS • RSS

Remult is a full-stack CRUD library that simplifies development by leveraging TypeScript models, providing a type-safe API client and query builder.
In software development, two data models must be managed and synchronized to ensure proper system functionality: server and client models. Server models specify the structure of the database and API, while client models define the data transmitted to and from the API.
However, maintaining separate sets of models and validators can result in redundancy, increased maintenance overhead, and the potential for errors when the models become out of sync.
Remult solves this problem by providing an integrated model that defines the database schema, exposes simple CRUD APIs, and supports client-side integration that enables developers to query the database, all while maintaining type safety easily.
Defining Entities
Remult utilizes decorators to transform basic JavaScript classes into Remult Entities. Developers can accomplish this easily by adding the Entity decorator to the class and applying the relevant field decorators to each property.
Using decorators, Remult simplifies the process of creating entities and their associated fields, making it more efficient and intuitive for developers.
import { Entity, Fields } from "remult"
@Entity("contacts", {
allowApiCrud: true
})
export class Contact {
@Fields.autoIncrement()
id = 0
@Fields.string()
name = ""
@Fields.string()
number = ""
}
Server Side Setup
To start using Remult, register it alongside the necessary entities with the chosen server.
Fortunately, Remult provides out-of-the-box integrations for several popular server frameworks, including Express, Fastify, Next.js, Nest, and Koa.
import express from "express";
import { remultExpress } from "remult/remult-express";
import Contact from "../shared/Contact.ts";
const app = express();
app.use(
remultExpress({
entities: [
Contact
]
})
);
Client Side Integration
After configuring the backend and entities, the next step is integrating Remult with the application’s front end.
Fortunately, Remult’s client integration is designed to be library agnostic, meaning it can operate using browser fetch capabilities or Axios.
To illustrate this functionality, consider the following example:
import { useEffect, useState } from "react"
import { remult } from "remult"
import { Contact } from "./shared/Contact"
const contactsRepo = remult.repo(Contact)
export default function App() {
const [contacts, setContacts] = useState([])
useEffect(() => {
contactsRepo.find().then(setContact)
}, [])
return (
Contacts
{contacts.map(contact => {
return (
{contact.name} | {contact.phone}
)
})}
)
}
This example demonstrates the ease and flexibility with which Remult can be incorporated into the front end of an application, allowing developers to seamlessly leverage the power and functionality of Remult across the entire stack.
Remult is open-source software available under the MIT license. Contributions are welcome via the Remult GitHub repository.