Month: June 2023

MMS • RSS

Sundry Photography
With the Fed not quite committing yet to lowering or even pausing interest rate hikes, many investors are wondering if the sharp rally that we’ve seen in the markets since the start of May can be sustained. The gains have been especially notable in tech stocks, which shook off a very weak second half of 2022 to rebound.
MongoDB (NASDAQ:MDB), in particular, has nearly clawed its way back to 2022 levels. Up more than 100% year to date, the gains started accelerating in June as MongoDB reported excellent Q1 results. The question for investors now is: can the rally keep going?
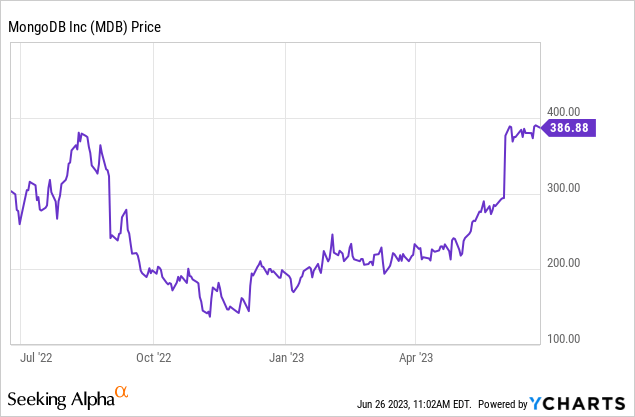
I made a fortunate bullish call on MongoDB at the start of this year that has, needless to say, paid off handsomely. It’s tempting to look at the strength of MongoDB’s price chart over the past two months and say the stock has reached a cliff, but now is not the right time to be greedy – especially with so much uncertainty over interest rates. Owing primarily to valuation, I’m pivoting to neutral on MongoDB and locking in the gains on my trade.
It would be remiss not to acknowledge the fact that MongoDB is still a fantastic company, fundamentally speaking. I still see a number of tailwinds driving the bull case for MongoDB:
-
Growth at scale. Very few companies that have reached a >$1 billion annual run rate are still growing revenue north of >50% y/y, and MongoDB is one of those few. That’s a testament to the all-encompassing, horizontal nature of MongoDB’s product. Almost all companies now have a use for managing unstructured data, and its technology is broadly applicable across a wide variety of use cases.
-
Secular tailwinds. More and more these days, companies and brand marketers want to capture consumer data coming from “unstructured” sources – Tweets, social media posts, and the like. Traditional databases which store data in a columnar format are not equipped to handle this. MongoDB’s generous growth rates are a reflection of the largesse of the company’s space.
At the same time, however, at higher prices I’m more cognizant of several risks:
- GAAP losses are still large. Though MongoDB has notched positive pro forma operating and net income levels, the company is still burning through large GAAP losses because of its reliance on stock-based compensation. In boom times investors may look the other way, but in this more cautious market environment MongoDB’s losses may stand out.
- Competition. MongoDB may have called itself an “Oracle killer” at the time of its IPO, but Oracle (ORCL) is also making headway in autonomous and non-relational databases. Given Oracle’s much broader software platform and ease of cross-selling, this may eventually cut into MongoDB’s momentum.
The biggest thing we have to watch out for, however, is MongoDB’s enormous valuation. At current share prices near $390, MongoDB trades at a market cap of $27.33 billion. After we net off the $1.90 billion of cash and $1.14 billion of convertible debt on MongoDB’s most recent balance sheet, the company’s resulting enterprise value is $26.57 billion.
Meanwhile, for the current fiscal year MongoDB has guided to $1.522-$1.542 billion in revenue, representing 19-20% y/y growth:

MongoDB outlook (MongoDB Q1 earnings release)
Taking even the high end of this guidance range at face value (as MongoDB has had an unbroken tendency to “beat and raise”), the stock’s valuation stands at 17.2x EV/FY24 revenue. Let’s not even mention that from a P/E basis (though as EPS growth is still in its nascent stages, this isn’t an entirely fair valuation either) MongoDB is trading at a >200x P/E ratio.
The bottom line here: I view MongoDB as one of the few tech stocks to have returned very close to pandemic-era mania levels. While I can’t argue that the company’s fundamentals and market opportunity is very strong in a vacuum, it’s difficult to see any further upside at MongoDB’s high-teens revenue multiple.
Q1 download
Let’s now go through MongoDB’s latest quarterly results in greater detail. The Q1 earnings summary is shown below:
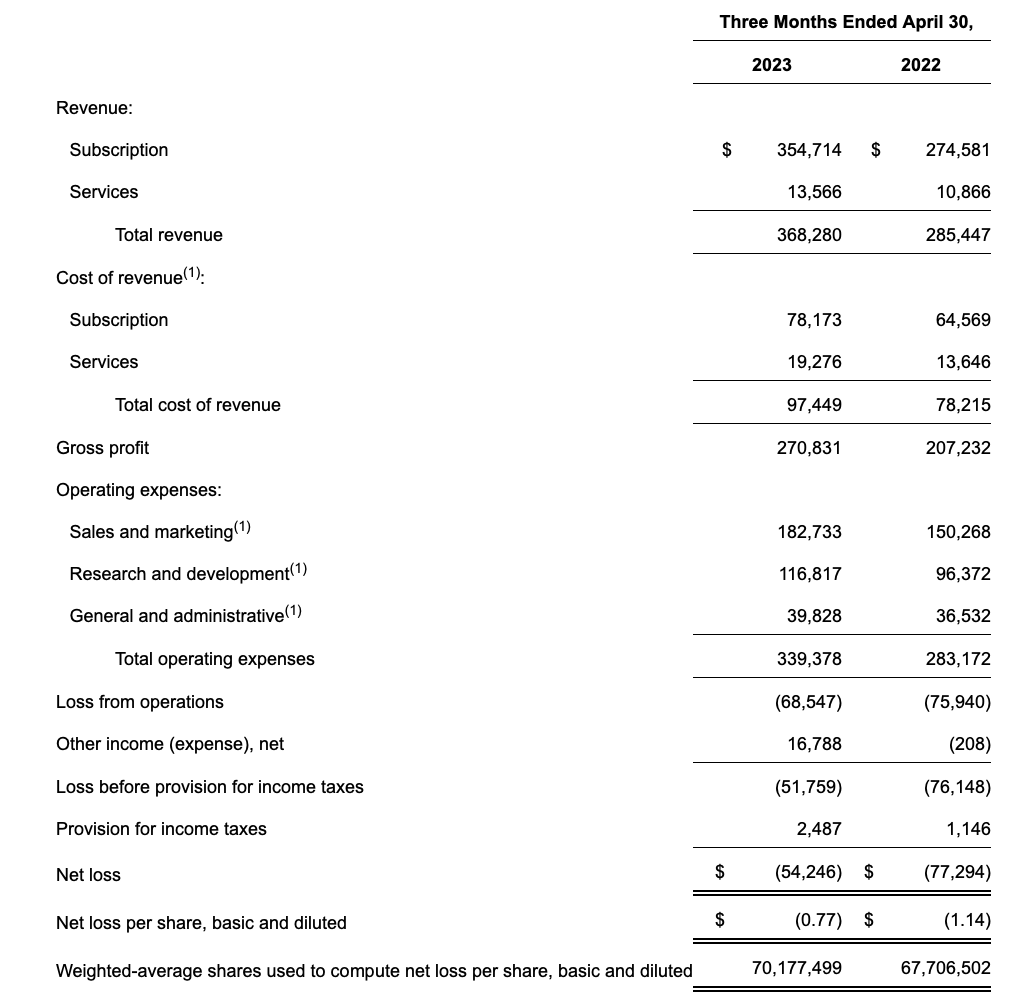
MongoDB Q1 results (MongoDB Q1 earnings release)
MongoDB’s revenue grew 29% y/y to $368.3 million, beating Wall Street’s expectations of $347.1 million (+22% y/y) by a seven-point margin, but also decelerating seven points from Q4’s growth rate of 36% y/y. Subscription revenue also grew at 29% y/y, while the smaller slice of professional services revenue grew 25% y/y.
Where MongoDB also exceeded expectations was on net customer adds, adding 2.3k net-new customers in the quarter to end with 43.1k total customers. As the company has focused more on its direct-sales business, it has been able to bring in a wider net of smaller self-service customers. That being said, MongoDB also added 110 net-new customers with greater than $100k in ARR, up 28% y/y.

MongoDB customer metrics (MongoDB Q1 earnings release)
Management noted that customer consumption trends are above expectations, driven by higher-than-expected underlying application usage. That being said, consumption growth levels are still lower than where they were when MongoDB entered into the macro-driven slowdown in Q2 of last year. Net ARR expansion rates were 120%, indicating that a typical installed base customer spends 20% more in the following year.
Additional investor enthusiasm poured into MongoDB as the company highlighted that customers are choosing the MongoDB platform to build and deploy AI-driven applications. Per CEO Dev Ittycheria’s remarks on the Q1 earnings call:
Moreover, the shift to AI will favor modern platforms that offer a rich and sophisticated set of capabilities, delivered in a performance and scalable way. We are observing an emerging trend where customers are increasingly choosing Atlas as a platform to build and run new AI applications. For example, in Q1, more than 200 of the new Atlas customers were AI or ML companies. Well finance startups like Hugging Face, Tekion, One AI are examples of companies using MongoDB to help deliver the next wave of AI-powered applications to their customers. We also believe that many existing applications will be re-platformed to be AI-enabled. This will be a compelling reason for customers to migrate from legacy technologies to MongoDB.
To summarize, AI is just the latest example of the technology that promises to accelerate the production of more applications and greater demand for operational data stores, especially the ones best suited for modern data requirements such as MongoDB.
From a profitability standpoint, MongoDB’s pro forma gross margins lifted one point y/y to 76%. Pro forma operating margins clocked in at 12%, six points richer than 6% in the year-ago Q1.
Key takeaways
In my view, the ~2x gain in MongoDB since the start of the year has been a generous run. Yes, a good chunk of that is justified by fundamentals as MongoDB continues on a path of ~30% y/y growth alongside substantial margin expansion, fueled by potential further tailwinds from AI workloads migrating onto the platform – but it’s difficult to justify a ~17x forward revenue multiple. Retreat to the sidelines here.
MMS • Renato Losio

The Microsoft security team recently released AzDetectSuite, a collection of KQL queries and detection alerts against security threads on Azure and AzureAD. The open-source project provides basic detection capabilities at a low cost, targeting small environments within the Microsoft cloud platform.
AzDetectSuite is an open-source library designed to help developers detect and understand tactics, techniques, and procedures used in cyber-attacks on Azure networks.
Written to match the Azure Threat Research Matrix (ATRM), a knowledge base built to document known TTPs within Azure and Azure AD, the detections are grouped according to the different tactics involved: reconnaissance, initial access, execution, privilege escalation, persistence, credential access, and exfiltration. Ryan Hausknecht, senior security researcher at Microsoft, explains:
AzDetectSuite is a project created to allow Azure users to establish a basic defense within Azure by giving pre-built KQL queries for each technique within ATRM that are deployable Alerts to Azure Monitor. In ATRM, most (85%+) techniques will have a KQL query and a button that will deploy the query to their Azure subscription.
For example, AzDetectSuite supports detections for attacks like Azure Key Vault dumping, account creation or manipulation, or password spraying. The detections are written using the Kusto Query Language (KQL), a language designed to explore data and discover patterns, identify anomalies and outliers, and create statistical modeling.
The new library relies on Azure Monitor, the centralized service that ingests data from different log sources, including general Azure Log (AzureActivity) and more detailed logs, such as Service Principal Sign-Ins (AADServicePrincipalSignInLogs).
AzDetectSuite is not the main option available for TTPs on Azure and AzureAD. Hausknecht warns:
AzDetectSuite (ADS) is not meant to compete with Microsoft Defender for Cloud (MDC). MDC provides advanced detections based on your subscription plan and will give more granular control based on the telemetry in a tenant. ADS is meant to be an open-source suite of basic detections for techniques found within ATRM.
The announcement explains how to build alerts for anomalous behaviors and how to handle baselining in KQL. On Twitter, Hausknecht adds:
The goal of this is to continue releasing OSS tooling that will benefit Azure users. It definitely goes against some of the mentality I’ve come across internally, but I’m firm in my belief that people should be able to have a security baseline for free.
The project’s GitHub repository contains the KQL queries and the PowerShell script Invoke-AzDetectSuite.ps1 to import detections for all or specific tactics. The detections are available for free but customers might still be charged for alert fees.
MMS • RSS
On June 26, 2023, the options scanner of a leading financial news outlet detected 15 unusual options trades for MongoDB. The traders who made these trades were divided in their sentiment, with 26% being bullish and 73% bearish. The options uncovered included 6 puts, worth $303,072 in total, and 9 calls, worth $605,197 in total. These trades suggest that large investors, or “whales,” have been targeting a price range of $70.0 to $650.0 for MongoDB over the last three months.
In other news, Capital One recently initiated coverage of MongoDB with an Equal-Weight recommendation on June 26, 2023. The average one-year price target for the company, as of June 2, 2023, is $266.84, with forecasts ranging from $181.80 to $383.25. This represents a decrease of 31.58% from the latest reported closing price of $389.99.
Meanwhile, Victory Capital Management Inc. has reduced its stake in MongoDB by 50.9% during the fourth quarter. As of June 21, 2023, the stock is trading at $371.25, a drop of $8.53 or 2.25% from the previous closing.
MongoDB, Inc.
MDB
Buy
Updated on: 26/06/2023
MDB Stock Analysis: Significant Increase in Earnings and Revenue Growth in 2023
On June 26, 2023, MDB stock opened at $388.00, up from the previous day’s close of $379.85. Throughout the day, the stock’s range fluctuated between $375.31 and $393.60, with a volume of 78,699 shares traded.
MDB has a market capitalization of $27.5 billion, and its earnings growth over the past year has been -5.89%. However, the company has seen a significant increase in earnings growth this year, with a growth rate of +92.12%. Over the next five years, the company is expected to see a steady growth rate of +8.00%.
In terms of revenue growth, MDB has seen a significant increase of +46.95% over the past year. The company’s P/E ratio is not available, but its price/sales ratio is 11.45, and its price/book ratio is 36.88.
MDB’s next reporting date is August 31, 2023, with an EPS forecast of $0.46 for this quarter.
Overall, MDB has seen a significant increase in earnings growth this year and revenue growth over the past year. However, its net profit margin remains negative, and the company’s stock price experienced significant fluctuations throughout the day. Investors should continue to monitor the company’s financial performance and market trends to make informed investment decisions.
MongoDB Incs Stock Shows Bullish Sentiment with Strong Financial Performance and Growth Prospects
On June 26, 2023, MongoDB Inc (MDB) was trading at a price of 379.85. The 22 analysts offering 12-month price forecasts for the company had a median target of 420.50, with a high estimate of 445.00 and a low estimate of 210.00. The current consensus among 27 polled investment analysts was to buy stock in MongoDB Inc. The company had reported earnings per share of $0.46 in the current quarter, with sales of $393.9M. The bullish sentiment was driven by the company’s strong financial performance and growth prospects.
Revolutionizing developer platforms: MongoDB’s journey to AI integration – SiliconANGLE
MMS • RSS

The developer-led data platform isn’t new at MongoDB Inc., but what is new is the advent of artificial intelligence — something that led the company to spring to action.
But in some ways, the company’s developer data platform was “prescient,” according to Mindy Lieberman (pictured, right), chief information officer of MongoDB.
“It’s all about data, and applications on top of data,” she said. “I look at it, for IT, as a portfolio. There’s some that is built; there is some that is bought. When you can’t go to the market and find things that are fit for purpose, you have to build. And to have a developer platform available, and I get good pricing, that can’t be beat.”
Lieberman and Tara Hernandez (left), vice president of developer productivity at MongoDB, spoke with theCUBE industry analyst John Furrier at the MongoDB .local NYC event, during an exclusive broadcast on theCUBE, SiliconANGLE Media’s livestreaming studio. They discussed how to approach security, the role of AI and how developers are driving things forward. (* Disclosure below.)
Data in everything
These days, data is ubiquitous across entire enterprises, and companies need to be careful about how they manage it, according to Lieberman.
“You have to figure out ways to gather [data], to disseminate it, to cleanse it. So it’s all about the data,” she said.
On the developer side of things, whether it comes to testing or analysis, it’s critical to be mindful of how customer data is managed and how to build guardrails so developers aren’t looking at anything they aren’t supposed to, according to Hernandez. That also goes for ensuring that data is saved in a safe way, without getting in the way.
“That’s what DevSecOps is. That idea of a shift left is interesting, not because it’s making the develops more acutely aware of security — I mean, that’s a little part of it — but it’s that we ideally have created a platform where they don’t have to worry about it,” Hernandez said. “But they get the benefit of the protections that were built into how they do their development.”
Open-source has proven that developers are driving the bus. So, what are the operations good enough to enable developers and not foreclose them from being curious, experimental and playful with code? Aside from providing developer tooling to experiment with and figure out what works versus what is hype, MongoDB’s goal is focused on collaboration and a “very light touch” on coordination, according to Lieberman.
“Basically, we are saying yes to safe cases. We are trying to shorten the process to make sure that people can get their hands on things early and often. We test, and learn, and then expand,” she said.
MongoDB is based on open-source technology at its heart, which enables people to grab the community build or go to GitHub to grab the source, according to Hernandez. That applies to technology like ChatGPT too.
“One of the first things we said is, we took a quick pass and like, ‘You want to play with ChatGPT?’” Hernandez said. “Point it at the public repos, because the guardrail is already public.”
The internal stuff can be worked on as fast as possible, but there’s no reason that the company couldn’t have a reasonable set of policies to get started, Hernandez added.
Here’s the complete video interview with Mindy Lieberman and Tara Hernandez, part of SiliconANGLE’s and theCUBE’s coverage of the MongoDB .local NYC event:
(* Disclosure: TheCUBE is a paid media partner for the MongoDB .local NYC event. Neither MongoDB Inc., the sponsor of theCUBE’s event coverage, nor other sponsors have editorial control over content on theCUBE or SiliconANGLE.)
Photo: SiliconANGLE
Your vote of support is important to us and it helps us keep the content FREE.
One-click below supports our mission to provide free, deep and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger and many more luminaries and experts.
THANK YOU
Enterprise Database Management Suite Market in-Depth Analysis with Leading Key players
MMS • RSS
PRESS RELEASE
Published June 26, 2023

Enterprise Database Management Suite Market is growing at a +6% CAGR during the forecast period 2023-2030. The increasing interest of the individuals in this industry is that the major reason for the expansion of this market
An enterprise database management suite is a suite of software tools used to manage a large collection of databases in an enterprise. It typically includes database management systems, data integration and transformation tools, query and reporting tools, database security and access control tools, and data warehouse and analytics tools. Enterprise database management suites provide a single unified platform for managing complex and large data stores and may also include application development, database maintenance, and data analytics and visualization features.
Get the PDF Sample Copy (Including FULL TOC, Graphs and Tables) of this report @: https://www.researchcognizance.com/sample-request/212980
Enterprise Database Management Suite market research is an intelligence report with meticulous efforts undertaken to study the right and valuable information. The data which has been looked upon is done considering both, the existing top players and the upcoming competitors. Business strategies of the key players and the new entering market industries are studied in detail. Well explained SWOT analysis, revenue share and contact information are shared in this report analysis.
Top Companies of this Market includes: Oracle, Microsoft, IBM, SAP, AWS, MongoDB, Google, Broadcom, MarkLogic, MariaDB, InterSystems, Cloudera, Teradata, Vertica, Alibaba Cloud, Knack
This report provides a detailed and analytical look at the various companies that are working to achieve a high market share in the global Enterprise Database Management Suite market. Data is provided for the top and fastest growing segments. This report implements a balanced mix of primary and secondary research methodologies for analysis. Markets are categorized according to key criteria. To this end, the report includes a section dedicated to the company profile. This report will help you identify your needs, discover problem areas, discover better opportunities, and help all your organization’s primary leadership processes. You can ensure the performance of your public relations efforts and monitor customer objections to stay one step ahead and limit losses.
The report provides insights on the following pointers:
Market Penetration: Comprehensive information on the product portfolios of the top players in the Enterprise Database Management Suite market.
Product Development/Innovation: Detailed insights on the upcoming technologies, R&D activities, and product launches in the market.
Competitive Assessment: In-depth assessment of the market strategies, geographic and business segments of the leading players in the market.
Market Development: Comprehensive information about emerging markets. This report analyzes the market for various segments across geographies.
Market Diversification: Exhaustive information about new products, untapped geographies, recent developments, and investments in the Enterprise Database Management Suite market.
For Any Query or Customization: https://www.researchcognizance.com/inquiry/212980
The cost analysis of the Global Enterprise Database Management Suite Market has been performed while keeping in view manufacturing expenses, labor cost, and raw materials and their market concentration rate, suppliers, and price trend. Other factors such as Supply chain, downstream buyers, and sourcing strategy have been assessed to provide a complete and in-depth view of the market. Buyers of the report will also be exposed to a study on market positioning with factors such as target client, brand strategy, and price strategy taken into consideration.
Global Enterprise Database Management Suite Market Segmentation:
Market Segmentation by Type:
- Relational Database
- Nonrelational Database
Market Segmentation by Application:
- SMEs
- Large Enterprise
Reasons for buying this report:
- It offers an analysis of changing competitive scenario.
- For making informed decisions in the businesses, it offers analytical data with strategic planning methodologies.
- It offers seven-year assessment of Enterprise Database Management Suite
- It helps in understanding the major key product segments.
- Researchers throw light on the dynamics of the market such as drivers, restraints, trends, and opportunities.
- It offers regional analysis of Enterprise Database Management Suite Market along with business profiles of several stakeholders.
- It offers massive data about trending factors that will influence the progress of the Enterprise Database Management Suite
Table of Contents
Global Enterprise Database Management Suite Market Research Report 2023
Chapter 1 Enterprise Database Management Suite Market Overview
Chapter 2 Global Economic Impact on Industry
Chapter 3 Global Market Competition by Manufacturers
Chapter 4 Global Production, Revenue (Value) by Region
Chapter 5 Global Supply (Production), Consumption, Export, Import by Regions
Chapter 6 Global Production, Revenue (Value), Price Trend by Type
Chapter 7 Global Market Analysis by Application
Chapter 8 Manufacturing Cost Analysis
Chapter 9 Industrial Chain, Sourcing Strategy and Downstream Buyers
Chapter 10 Marketing Strategy Analysis, Distributors/Traders
Chapter 11 Market Effect Factors Analysis
Chapter 12 Global Enterprise Database Management Suite Market Forecast
Buy Exclusive Report @: https://www.researchcognizance.com/checkout/212980/single_user_license
If you have any special requirements, please let us know and we will offer you the report as you want.
Get in Touch with Us:
Neil Thomas
116 West 23rd Street 4th Floor New York City, New York 10011
+1 7187154714
https://researchcognizance.com
Market Reports
MMS • RSS

Credit: Dreamstime
After trying to broaden its user base to include traditional database professionals last year, MongoDB is switching gears, adding features to turn its NoSQL Atlas database-as-a-service (DBaaS) into a more complete data platform for developers, including capabilities that support building generative AI applications.
In addition to introducing vector search for Atlas and integrating Google Cloud’s Vertex AI foundation models, the company announced a variety of new capabilities for the DBaaS at its MongoDB.local conference in New York Thursday, including new Atlas Search, data streaming, and querying capabilities.
“Everything that MongoDB has announced can be seen as a move to make Atlas a more comprehensive and complete data platform for developers,” said Doug Henschen, principal analyst at Constellation Research. “The more that MongoDB can provide to enable developers with all the tools that they need, the stickier the platform becomes for those developers and the enterprises they work for.”
Henschen’s perspective seem reasonable, given that the company has been competing with cloud data platform suppliers such as Snowflake, which offers a Native Application Framework, and Databricks, which recently launched Lakehouse Apps.
Vector search helps build generative AI apps
In an effort to help enterprise build applications based on generative AI from data stored in MongoDB, the company has introduced a vector search capability inside Atlas, dubbed Atlas Vector Search.
This new search capability, according to the company, will help support a new range of workloads, including semantic search with text, image search, and highly personalised product recommendations.
The search runs on vectors — multidimensional mathematical representations of features or attributes of raw data that could include text, images, audio or video, said Matt Aslett, research director at Ventana Research.
“Vector search utilises vectors to perform similarity searches by enabling rapid identification and retrieval of similar or related data,” Aslett said, adding that vector search can also be used to complement large language models (LLMs) to reduce concerns about accuracy and trust through the incorporation of approved enterprise content and data.
MongoDB Atlas’ Vector Search will also allow enterprises to augment the capabilities of pretrained models such as GPT-4 with their own data via the use of open source frameworks such as LangChain and LlamaIndex, the company said.
These frameworks can be used to access LLMs from MongoDB partners and model providers, such as AWS, Databricks, Google Cloud, Microsoft Azure, MindsDB, Anthropic, Hugging Face and OpenAI, to generate vector embeddings and build AI-powered applications on Atlas, it added.
MongoDB partners with Google Cloud
MongoDB’s partnership with Google Cloud to integrate Vertex AI capabilities is meant to accelerate the development of generative AI-based applications. Vertex AI, according to the company, will provide the text embedding API required to generate embeddings from enterprise data stored in MongoDB Atlas.
These embeddings can be later combined with the PaLM text models to create advanced functionality like semantic search, classification, outlier detection, AI-powered chatbots, and text summarisation.
The partnership will also allow enterprises to get hands-on assistance from MongoDB and Google Cloud service teams on data schema and indexing design, query structuring, and fine-tuning AI models.
Databases from Dremio, DataStax and Kinetica are also adding generative AI capabilities.
MongoDB’s move to add vector search to Atlas is not unique but it will enhance the company’s competitiveness, Aslett said. “There is a growing list of specialist vector database providers, while multiple vendors of existing databases are working to add support to bring vector search to data already stored in their data platforms,” Aslett said.
Managing real-time streaming data in a single interface
In order to help enterprises manage real-time streaming data from multiple sources in a single interface, MongoDB has added a stream processing interface to Atlas.
Dubbed Atlas Stream Processing, the new interface, which can process any kind of data and has a flexible data model, will allow enterprises to analyse data in real-time and adjust application behavior to suit end customer needs, the company said.
Atlas Stream Processing bypasses the need for developers to use multiple specialised programming languages, libraries, application programming interfaces (APIs), and drivers, while avoiding the complexity of using these multiple tools, MongoDB claimed.
The new interface, according to Aslett, helps developers to work with both streaming and historical data using the document model.
“Processing data as it is ingested enables data to be queried continuously as new data is added, providing a constantly updated, real-time view that is triggered by the ingestion of new data,” Aslett said.
A report from Ventana Research claims that more than seven in 10 enterprises’ standard information architectures will include streaming data and event processing by 2025, so that they can provide better customer experiences.
Atlas Stream Processing, according to SanjMo’s principal analyst Sanjeev Mohan, can also be used by developers to perform functions like aggregations, as well as filter and do anomaly detection on data that is in Kafka topics, Amazon Kinesis or even MongoDB change data capture.
The flexible data model inside Atlas Stream Processing can also be modified over time to suit needs, the company said.
The addition of the new interface to Atlas as a move to play catchup with rival data cloud providers such as Snowflake and Databricks, which have already introduced features for processing real-time data, noted Constellation’s Henschen.
New Atlas search features
In order to help enterprises to maintain database and search performance on Atlas, the company has introduced a new feature, dubbed Atlas Search Nodes, that isolates search workloads from database workloads.
Targeted at enterprises that have already scaled their search workloads on MongoDB, Atlas Search Nodes provides dedicated resources and optimises resource utilisation to support performance of these specific workloads, including vector search, the company said.
“Enterprises may find that dedicating nodes in a cluster, specifically to search, can support operational efficiency by avoiding performance degradation on other workloads,” Aslett said, adding that this is a capability that was being adopted by multiple providers of distributed databases.
MongoDB’s updates to Atlas also include a new time-series data editing feature that the company claims is usually not allowed in most time-series databases.
The company’s Time Series Collections features will now allow enterprises to modify time-series data resulting in better storage efficiency, accurate results, and better query performance, the company said.
The feature to modify time-series data will help most enterprises, according to Mohan.
Other updates to MongoDB Atlas include the ability to tier and query databases on Microsoft Azure using the Atlas Online Archive and Atlas Data Federation features, the company said, adding that Atlas already supported tiering and querying on AWS.
MongoDB Atlas for financial services and other industries
As part of the updates announced at its MongoDB local conference, the company said that it will be launching a new industry-specific Atlas database program for financial services, followed by other industry sectors such as retail, healthcare, insurance, manufacturing and automotive.
These industry-specific programs will see the company offer expert-led architectural design reviews, technology partnerships via workshops and other instruments for enterprises to build vertical-specific solutions. The company will also offer tailored MongoDB University courses and learning materials to enable developers for their enterprise projects.
While the company did not immediately provide information on the availability and pricing of the new features, it said that it was making its Relational Migrator tool generally available.
The tool is designed to help enterprises move their legacy databases to modern document-based databases.

MMS • Jim Highsmith
Subscribe on:
Transcript
Introductions [00:05]
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today, I have a great privilege. I’m sitting down, across many miles, with Jim Highsmith. Jim, one of the great names in our industry, has been incredibly influential over the last six decades and more. I’ve had the privilege of working with Jim a few times over the years, and every time it’s been a joy. So I’m really looking forward to our conversations today.
Jim, welcome. Thanks for taking the time to talk to us.
Jim Highsmith: Thanks, Shane. It’s really nice to be here back in New Zealand.
Shane Hastie: Some of our audience probably haven’t heard of you before, so let’s go right back. Tell us a little bit, the super fast version, of the Jim Highsmith story.
Foundations of agile software development and the agile mainifesto [00:50]
Jim Highsmith: Well, it’s nearly 60 years, so let me hone in on the last 20 or so first, because what I’m best known for is part of the agile movement as one of the signatories of the Agile Manifesto, and I’ve written several books on agile development. My book, Adaptive Software Development, came out about the same time Kent Beck’s Extreme Programming came out, at the end of 1999. And those were two of the initial books that sort of launched the movement in a way.
And of course, others came along really quickly and I was part of the group that wrote the Agile Manifesto. I was heavily involved in the Agile Alliance, the formation of the Agile Alliance, the Agile Project Leadership Network. I did a lot of writing of articles right after the manifesto promoting Agile Software Development or agility and the Agile Manifesto. And so I’ve been involved in that quite a bit.
In mid-century, I wrote a book called Agile Project Management, which is still selling a few copies now and then today, and I hope that it did with a second edition in about 2009. In the agile period that I have the book, I break the agile era into three subunits. The first is the rogue team era, the second one is the courageous executive era, and the third is the digital transformation era. And each of those have sent slightly different characteristics, and so I’ve written them books in each of those different areas over the years.
And as I got to look back over my career a year and a half ago or so, I started to think about all of the things I’d been involved in. And I really have this idea that a lot of people today didn’t have much history of the agile movement, much less the evolution of software development. There’s very little out there written about the history of software development, software engineering. So my history goes back about 60 years to the mid-’60s and I kind of started there and moved and came forward.
Shane Hastie: Thank you. And yes, well known for being a signatory of the Agile Manifesto. I will confess that your book, Adaptive Software Development, was for me one of the absolutely foundational ideas when I was working in the early 2000s, late 1990s with teams bringing these ideas to the fore. So hugely influential and just wanted to acknowledge that. But let’s step right back, what was software engineering like in the 1960s?
The beginning of software engineering [03:12]
Jim Highsmith: It wasn’t. At an engineering conference, an IEEE conference in about ’67 or ’68, software engineering got its name, but when I started working and developing in COBOL, there really wasn’t any engineering about it. You’d basically learn from experience from working with mentors and from reading the COBOL manual. That was about it, and so it was very difficult back then.
And then you had things like computers back then were really slow and not much memory. I’ve got a picture in the book of the guy sitting down at the end of a big honking computer, feeding card decks in and getting printouts on the other end. And it would be like today sitting down to a terminal to write a program hitting the enter key and having a 12-hour delay. And so that’s what I call the wild west.
We had a guy that worked beside me at Exxon. He was one of my mentors, and his office was full of card decks and printouts. I mean just every shelf, every piece on the floor, every chair had card decks and printouts. He had some special card decks that he ran at the end of the year, to close the financial books. If Ed wasn’t there, you didn’t close the books, there was that little backup. If he lost those decks, we were out of luck.
So that’s the kind of stuff that went on back then. And then I was thinking about testing tools that we had back then too. The testing tool we had was a core dump of the entire memory in hexadecimal. And so you had to read hexadecimal, find out where the program started and go from there. Just to kind of give you an idea of what we were looking at back then, in 2021, a gigabyte of memory cost about $10. In the Wild West era, if you could have gotten that much memory, it would’ve cost $734 million.
Shane Hastie: Things have changed.
Jim Highsmith: And so people wonder why we had the Y2K problem. The reason we had the Y2K problem is a bunch of idiots like me had to delegate date field because memory and storage was so expensive back then. And even in the last 10 years, the cost of storage has plummeted so that you now have petabyte data warehouses. And so it’s a lot different than it was back then.
And so from that early years, it sort of evolved, and so the three eras that I talked about before agile. One is the wild west which is the ’60s and part of the ’70s, structured methods and monumental methodologies which was basically the ’80. And then as things started to change, I called the ’90s the roots of agile. And each of those eras had certain business things that were going on that sort of shaped software development and some technology that shaped software development. So technology both enhanced and constrained what you could do in software development.
Shane Hastie: Structured methods, I certainly remember playing with case tools and structured systems analysis. So I’m aging myself here. I came into this in the 1980s. What did structure methods bring us compared to that wild west of the 1960s?
Structures methods and monumental methodologies [06:07]
Jim Highsmith: I think it brought a little discipline to the industry and it also brought some tools, some analytical tools that you could use to do data flows, to look at processes within an organization. And one of the things that people need to remember is back then, what we were automating was internal business processes. We were automating accounting and order processing and manufacturing, and all of those in internal things is what was going on in the 1980s.
And so having things like data-flow diagrams was a great advantage because you could actually map out the flow of processes within the organization. And so it was a good tool for the time. And people are still using data-flow diagrams. In fact, Tom DeMarco was one of the gurus at the time, and I’ve interviewed him for the book. One of the funny things that he talked about when I was interviewing him was that he actually ran into a piece of code way back then, and basically this program for data names used vegetable names.
And he was talking about the need to eliminate comments so that the code told your story. And so what happened, these structured tools, interrelationship diagrams, structured charts, data-flow diagrams started being used by people like Ken Orr and Tom DeMarco and Tim Lister and some others. And then in about the middle of the decade, the other thing that was advancing at the same time was the project management profession. And so you’ve got the rise of PMI, Project Management Institute, during that period of time, more emphasis on project management.
And so the structured tools and project management sort of intersected. And what happened was people decided, “Ah, a little bit of structure is good, but a lot of structure is better.” And so we started having what I called monumental methodologies. At that point in time, they were in big four ring or three ring notebooks, four inch notebooks. There’d be five or six of them, and they would do forms and processes and checkpoints and a lot of different documentation.
So all that documentation became fairly burdensome. So aha, what do you do? Well, you automate it. And so that’s when CASE tools came along. And so the CASE tool era hit in the late ’80s, early ’90s and drove into the next era. But we were still using sort of the philosophy of the mindset of the structured era and CASE tools didn’t change that.
In fact, one of the reasons CASE tools ran into trouble, and there were a lot of reasons it did, is there was an idea back then that once you got the diagrams done, you could generate code from them and you wouldn’t have to have any coders or programmers. And that didn’t turn out to be true.
Shane Hastie: Yeah, we’ve been trying to do that for a few decades and hasn’t happened yet. Well, maybe Copilot and ChatGPT, but we’ll see.
The advancement of tools changes the level of abstraction needed to develop software [08:47]
Jim Highsmith: If you look back when I just talked about the ’60s, we had zero tools. Our tools were a compiler. And so as we moved through time, we got more and more tools, which made the job of a developer different, but it made it at a different level. So for example, today, one of the jobs that a developer, a team of developers has to go through is they’ve got a software stack that may be 15 or 20 items deep, and they’ve got to figure out at each level what kind of software they need at that part of the stack.
So there’s an enormous amount of analysis before you ever get to coding. And so what happened is what we do has changed and the job has changed. So maybe it’s not quite as much coding as it was before, but it’s still a software engineering-software development job.
Shane Hastie: Coming through that period of the ’80s into the ’90s, you talk about the roots of agile, what was happening there?
The roots of agile in the 1990’s [09:40]
Jim Highsmith: Well, let me give you an example. So about mid-decade, I was called in to do some work at Nike up in Beaverton, Oregon. And they had a project that they were working on and they had spent 18 months producing a requirements document. And the VP of the customer area was not too pleased because after 18 months, all they had was a document and it was out of date.
And so what happened was a friend of mine was working for Nike, actually he was a guy that I used to go mountaineering with a lot. And so he knew what I was doing a little bit, but I had a rapid development method, a RAD method they called it back then. And so he set me up with a meeting with the VP of IT for Nike. And my big question going into that first meeting was what to wear?
Because I knew that at Nike, you didn’t want to wear a suit and tie and a button down jacket. So I went in with a nice pair of slacks, nice shirt and red Nike running shoes. And he recognized the shoes, and I got the job. And so what this was all about was this was sort of the result of monumental waterfall type methodologies. You got into this kind of business where you had 18 months and all you had was a requirements document.
And so the mantra that we kept hearing from IT managers during the ’90s was, takes too long, costs too much, doesn’t produce what I need. We heard that kind of thing over and over again. Then what happened is you also during that period of time had a technology revolution. For example, I used to trade stocks once in a while. Before the mid-’90s, what I would do is I would call the broker, place an order, talk to him or her for a few minutes about the stock, place an order, they would enter it into their terminal, it would get sent to New York or to Chicago to get traded. The confirmation would come back and then they would call me and let me know what it was. And I would get a slip of paper.
In the mid-1990s, I could log on, go directly to my account, trade stock without another human being being in the process. And I’m not sure that people understand how big a change that was because what happened in the mid-’90s is we went from building internal systems for internal people to building external systems for external people. And that was a huge change, particularly as it related to user interface design, because what you could use for internal people with the old character screens and what you could do for external people with the new GUI interfaces was very, very different. And it was a difficult transition for a lot of people.
And the things that made it possible were the internet, object-oriented programming and GUI interfaces. But that whole technology changed drastically in the mid-’90s, and that’s why you had the dotcom bubble and the dotcom bust during the ’90s. The other thing that was going on at that period of time was the culture of business was changing. In the ’80s and part of the ’90s, it was very command control, very deterministic. What I like to say, it was an era of plan-do, plan it out in detail and then do it.
And what happened is as the agile movement came about is you move from that to an envision-explore. You envisioned where you wanted to go in the future and you explored into that vision, which is a very different paradigm from a plan-do paradigm. And so the ’90s were all of these things were sort of turning. Scrum got started in the mid-’90s. The SDM got started in the mid-’90s. My approach, the RAD got started in the mid-’90s, feature-driven development got started down in Australia. So there were a number of these things that were sort of simmering from the mid to the late ’90s.
Shane Hastie: That management approach I think of people where, like Tom DeMarco, I think of Larry Constantine, I think of Jerry Weinberg. You know and knew all of these folks. What was it like working with them and collaborating with them?
Jim Highsmith: It was a blast. I mean, talk about Tom DeMarco. How often do you get to work with one of your heroes? And so during the ’80s, he was really a hero of mine. And during the ’90s, I got to work with him quite a bit. And so that was wonderful.
Larry Constantine may have been the person that set me on the path to rapid development and then agile. In the early 1990s, I got a call from Larry. He barely remembers this, but I do. And he had a job that people at Amdahl Computer company, it was a big computer company back then. They had something they needed done and Larry couldn’t do it because he was working for IBM at the time and doing some consulting work for IBM. So he asked me if I wanted a job, and it was a job to build a rapid application process.
It would help them sell their rapid application tool. So it was a process to go with their tool that I came up with, became good friends with their marketing head, who was Sam Bayer. And we worked on a process and we would go into one of their clients, one of their prospects, and we would do one-month projects with one week iterations. And this was in the early ’90s, and we must have done 20 or 30 or 40 of them. I wish I’d counted them at the time. But we did a number of those over the next few years, and that’s really got me started into the rapid application development. So that was my interaction with Larry Constantine.
I spent a lot of time with Jerry Weinberg. I went to several consultants camps that he ran during the summer. So Jerry was a big influence on me from the standpoint of collaboration and open style meetings and a different management style, as I was thinking about the type of management style that needed to go along with rapid application development, adaptive development, agile development. Jerry was modeling those kinds of leadership in his workshops and in his consultants camp. So I got to know Jerry pretty well too.
Shane Hastie: I had the privilege of meeting him twice. Amazing, amazing man.
Jim Highsmith: The guy that I worked with the most, and it really changed my career was Ken Orr. And so one of the reasons I wanted to write this book or one of the things that came out of this book was to really recognize some of these pioneers in a number of different areas, both the structured era and the agile era. Because I would talk to people today and I’d say, do you know Tom DeMarco or do you know who he is? Or do you know who Larry Constantine is? Or do you know who Ken Orr is? And they’d say, “No, I know Azure, but I don’t know Ken Orr.”
Shane Hastie: Yeah, we stand truly on the shoulders of giants. And then in late 2000, early 2001, there were 17, went up a mountain. What brought that about?
Authoring the agile manifesto [15:49]
Jim Highsmith: Yeah. Well, actually there was a pre-manifesto meeting that Kent Beck called in Oregon. And so in 1997, I met Martin Fowler in New Zealand, and that was the first time we’d ever met each other. And he went to one of my sessions and said, oh, because he’d been involved with XP and Kent Beck at that time. He said, this guy’s really on somewhat the same path.
So Martin and I met each other in New Zealand, and then Martin, we think as much as we can nail down, introduced me to Kent Beck. And then Kent Beck and I exchanged manuscripts before our two books were published, Adaptive Software Development and Extreme Programming. And Kent had a meeting in Rogue River, Oregon in the early 2000 or the fall of 2000, I don’t remember exact date. And it was basically to bring XP people together to see what the future of XP could be.
And he invited a couple of outsiders, and I was one of them that went to this XP meeting where I met Ward Cunningham and Bob Martin and some other people. And that meeting then precipitated Bob Martin sending out the call, so at six months later to do the manifesto meeting. So I find that pre-meeting was how I got involved and really got involved with the XP people during that period of time.
Shane Hastie: And that snowbird meeting, I’ve been fortunate. I’ve met all 17 of you that were there, and I’ve heard some stories, but from your point of view, what was so special? Why did that work?
Jim Highsmith: Well, a little bit of lead up. The meeting was held using open space principles. When we started, we didn’t have an agenda. We didn’t have a goal. Our thing was we knew that there were some people that were doing similar kinds of things, and we knew we didn’t like being called lightweight methodologist. And that was the label for us at the point in time.
And so we wanted to get together and just kind of see what happened, see if we had some common ground, see if we wanted to do something with that common ground. And besides the results that came out, I think one of the things that people don’t realize, they sort of know it but they don’t realize what it took. We had 17 people. They were all type A’s. They were all non-conformists, they were all adventurers, all 17 signed the manifesto.
And the way that happened is, there was an incident that Alistair Cockburn told me about. He and Ron Jeffries and Steve Miller had a side conversation during the conference. Now, I don’t know if you ever knew Steve, but he was not an agile methodologist. He was not a lightweight methodologist. And when he introduced himself at the meeting, he said, “I’m a spy from the structured methods”.
And so everybody got to wondering why was Steve there, and was he going to be the only nay vote when we came to doing the manifesto? And Ron, Alistair and Steve got together, and Steve started explaining what it was that he was trying to do. And Alistair and Ron listened to him and they listened to what he had to say, and they kept saying, “Well, we don’t think you can do it, and we think you got a problem because you want to do diagrams and then code, and then you got to maintain the diagrams and maintain the code, and that’s liable to get out of sync.”
And Steve said, “No, that’s not my intent. My intent is to have the diagrams generate the code and you maintain it in one place.” And Alistair said, “Oh, well if that’s true, then your intent is the same as our intent. We don’t think you can do it, but the intentions are the same.” And it was those kinds of conversations and good listening among these people that really got us to the point where we could agree on the four values at the meeting and then the principles later on. So it was a type of back and forth really trying to listen, really trying to understand that made that a very unique meeting.
Shane Hastie: And from there, the manifesto was published. I understand that there was a distributed work on the principles and how did you bring it to the world?
Jim Highsmith: That’s an interesting question because there were several different things, and of course, it took off faster than any of us imagined and grew to a size that none of us had ever dreamed of when we had the meeting. So that really happened. So we went away, and for example, Martin Fowler and I wrote an article that was in Software Development magazine that was the cover article that came out in like September of the next year. Alistair Cockburn and I wrote some articles. There were other people that wrote articles as to what was going on.
One of the best things that happened, and it was completely Ward Cunningham’s doing, is he put the manifesto and the principles up on a website and he added something that none of us had thought about but Ward thought about it. He added a place where people could sign on as signatories to the manifesto, and it took off. And people just kept signing up for that and basically saying, “This is great. This is wonderful.” Some people didn’t like it, of course, but some people would just put their names down there. Some people would write paragraphs about why they liked the manifesto or what they were doing. They finally found somebody of a kindred spirit.
And over the next 10 or 12 years, the last number I had was from 2013, 15,000 people had signed up. So the manifesto touched people in a way that structured methodologies had not. It really touched them at a gut level. It got them where they worked and said, “We want you to develop excellent software and we want you to work in an environment where you’re empowered and excited about going to work.” And those two things, I think are the core of the manifesto’s message.
Shane Hastie: I’m one of those 15,000 people. I think I signed the manifesto in 2003, which is about when you and I met. I certainly found it an inspiration, and the opportunities to talk with yourself and Alistair and some of the others in those SDC conferences at SoftEd in New Zealand.
Agile has almost become passé today. And the state of agile surveys tell us 96%, 98% of organizations claim to be doing agile. But I don’t see the difference. There are some organizations that really get it right, that are doing well. But there’s a whole lot where, “we’ve been scrummed before” was a comment I got from somebody when we were talking about let’s bring in some new ways of working. There was this fierce resistance to, oh no, not another organizational disruption. How come?
Jerry Weinberg’s Law of Strawberry Jam [22:10]
Jim Highsmith: Well, I go back to Jerry Weinberg’s Law of Strawberry Jam, which is the further you spread it, the thinner it gets. And so I think that happens with any movement, any type of management or software development or technology movement is as you spread wider and wider, it gets out to more and more people, they interpret it in different ways and they don’t go into it in any depth. They look at it at a very narrow place.
And one of the questions I always have for people is, how many organizations do you think should do this really, really well? What’s your target? And I would say that most organizations are not going to do anything very well, much less agile. And one of the things I tell people over my 60 year career, I’ve seen every single methodology succeed, and I’ve seen every single methodology fail.
And one of the things that I’ve been doing in some of my writing recently in some of my presentations, I’ve been sort of challenging the agile community, this next generation of agileists. And one of the ways that I want to prepare them for this, and that’s one of the reasons I wrote the book or has come out of the book, history’s role is not to help us predict the future but to help us prepare for it. So I want to prepare people for the future by giving them some history about what happened before.
And then I’ve got two questions that I want to ask. How do we continue to instill agility and adaptive leadership into our enterprises at all level? So I’m not talking about agile methodologies, I’m talking about the characteristics of agility and adaptive leadership. How do we go back and extract the good things out of agile or Kanban or Lean and move forward in the future? And then secondly, how do we rekindle the inspiration, the passion, and the excitement of agile? I think we’ve lost some of that excitement and we’re now battling some wars between the various different factions.
But I don’t see any of the new factions that have excited people the way the manifesto excited people. And that’s what I’m looking for and I’m looking for somebody to do that.
Shane Hastie: What will that look like?
Looking forward into the future [24:05]
Jim Highsmith: I don’t know. I know that people have done several attempts at it, but I don’t know exactly what it’ll look like. But one thing it’ll look like is taking the stuff from the Agile Manifesto and figuring out what’s still valid. So for example, the focus on people and their skills and abilities and interaction, do you think that’ll ever go away?
Shane Hastie: I hope not.
Jim Highsmith: The idea of exploring into the future or exploring into a project or product and envisioning and then exploring in today’s high change environment, that’s not going to go away, the idea of exploration and innovation and creativity. The idea of working together in collaborative groups is probably not going to go away given the challenges we face today. And this idea of emergence, of getting teams together and having them come up creatively with innovative ideas and innovative solutions, we need that today with all the issues and problems we have. So I don’t think that’s going to go away.
So if I look at the core attributes or behaviors or core pieces of the Agile Manifesto, I see that they have some applicability for the future. Maybe they need to be rewritten, maybe they need to be enhanced, but the core ideas are still valid, and I’d like to see people take that and then go on to the next thing.
Methods, methodology and mindset [25:22]
One of the things that I did in the book as I talk about methods, methodology, and mindset. The methods are things like structured programming or refactoring methodologies are stringing these things together into some sort of life cycle of how you go about doing stuff. And then the third one is the mindset. And I think the mindset piece of it is one of the things that people talk about a lot and that they are complaining that people don’t have the right mindset. But I don’t think we’ve figured out the best ways to try to encourage that mindset.
So, one of the things that I talk about in the book is this idea of an adventurous mindset. You’ve got to have some adventurous, non-conforming people in your organization or you’re not going to be able to do agile. So you’ve got to find those people. You’ve got to find those people that go out and climb mountains in their off time. You’ve got to find those people that go off and do century bike rides on their off time. You’ve got to find those people that are willing to take a chance at some new idea at work. And those are the people you’ve got to have lead your agile transformation.
I had a client one time and we had done a pretty good job of doing some agile implementation and transformation in the company, and we left. And they brought in a guy to manage the rest of the transition, who was a micromanager, who had completely the wrong mindset to implement agile. So those are the kinds of things that we’ve got to identify, those kinds of activities or actions that are agile or adaptive in nature, and make sure we find enough of those people in our organizations to carry through the transformation.
Shane Hastie: Transformation, you talk about in the book, that third era of agile is digital transformation. What are we doing there and what’s happening there?
The current era of digital transformation [26:58]
Jim Highsmith: Well, what’s trying to happen there, and a lot of people are talking about that today, is this idea of a digital organization or a digital company that it is really wired into how to use the technology. And I just had a very interesting example of that. I’m reading a memoirs by Bob Iger, who’s the CEO of Disney, and he talks about their acquisition of Pixar a number of years ago. And that one of the things that Pixar did is they were way upfront in terms of the technology they were applying to animation, whereas Disney animation studios had gotten behind the times. They were still using the old technology just about back to the flipping the pages as their tools. So they weren’t up to using the technology to the greatest extent possible, whereas Pixar was.
And it’s those kinds of differences between companies that I think is going to be even more important in the future as we move into a time of what I’ll call punctuated equilibrium. It’s a biologist term. So about 225 [million] years ago during the Permian extinction, 96% of all species on the face of the earth perished just kind of like the dinosaurs did it 65 million years ago where everything changed. So it’s called a punctuated equilibrium in biology.
And I think a similar kinds of things when you think about COVID and the climate situation and the geopolitical situation and the war between Ukraine and Russia, and all of those big problems that you got to have a different way of attacking those problems. And I think we’ve got to grow the kind of new leaders that can do that.
Shane Hastie: What are the skills that those new leaders are going to need to bring to the world?
Jim Highsmith: I think one of the things that they’re going to have to do is they’re going to have to look hard at a couple of different things, one of which is their sense of what’s going on in the world. An example, who developed the digital camera? It was a guy that worked for Kodak. But Kodak didn’t sense they were in big trouble for years and years and years. They should have seen it coming, but they didn’t. And finally, the digital cameras overwhelmed their film business, their film processing and film selling business.
So I think one thing that you’ve got to be able to do is you got to be able to look at what’s going on in the world through a different lens. And a woman by the name of Rita McGrath, who’s at the Columbia Business School wrote a book basically on sensing the future or sensing and how you go about, it’s called looking around corners or something close to that.
So I think sensing is one of those things. You’ve got to be able to adapt as you move forward. Your iterations give you different information or new information. You’ve got to be willing to adapt rather than try to go to some pre-planned place, which is what we used to have to do when you now need to go towards the place that evolves as we move forward. And so I think that’s a really important piece.
And I think another important piece, I’m just kind of taking these off the top of my head, is talent acquisition and management. We’re in an era that’s beyond the knowledge worker. We’re into an era that’s what I call the innovation worker. And if you want to get enough innovation workers into your company, you’ve got to have a really outstanding talent acquisition and management plan, or you’re just not going to make it.
Shane Hastie: Who’s doing this will?
Jim Highsmith: I have not worked with the science very much over the last few years, so I don’t have a lot of hands-on with clients that give me that kind of information. In the mid-2000s, I think the one that stands out is Salesforce. They did a great job of bringing agile in not only to IT and to their software development, but into the whole organization.
And I think there are other companies that are doing it maybe not as rapidly. A company that’s actually doing a pretty good job, I think at least in some aspects of it is IBM, believe it or not. And I take a lot of that from this book that I’ve just read by Ginni Rometty, who’s CEO at IBM for eight years. To me after reading this book, she’s the epitome of an agile leader, those kinds of things. And so if you want to see what a leader should be able to do, read that book. It’s at a CEO level.
I think a lot of pundits like myself, talk a lot about leadership, but I’ve never sat in the CEO seat of a big corporation. Ginni Rometty did, and so I think it behooves us to listen to some of those people from time to time.
Shane Hastie: And to round us out, what’s your one important message for the InfoQ community?
One important message [31:10]
Jim Highsmith: Well, I think one is to quit worrying about factions of agile methodologies, whether it’s scrum or scrum fast or scrum slow or whatever the different ones are, and realize that we’ve got some common ground and we’ve got some common problems to solve and we need to get on with it.
The other thing that I would say is that I would talk to people who are kind of up and coming, so some of the newer agileists or newer software developers that are out there, and think about their career in terms of what is their purpose in life? Why are they doing what they do? What do they think is some of the goals that they want their life to achieve?
And don’t try to plan it. One of the things I realized, and I wish I’d done this earlier in my career, is I didn’t plan stuff, but I had a purpose of what I was trying to do. And so I changed the plans as they went along to fit the purpose. And really, if you look back a long ways, the two things that I had in mind were building better software and building better work environments. That’s been a sort of catchword or a catch purpose for me for a long time, and it’s only within the last 20 years that I’ve been able to articulate it to any degree.
But that’s one of the things I talk about in the book, and I think that’s something that I would try to pass along to the newer people in the field.
Shane Hastie: Jim, thank you so much for taking the time to talk to us today. It’s been an absolute pleasure and truly a privilege to catch up with you.
Jim Highsmith: Yeah, it’s really nice to have an opportunity to talk some more and catch up.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
Microsoft has recently unveiled several new features for Azure Cosmos DB to enhance cost efficiency, boost performance, and increase elasticity. These features are burst capacity, hierarchical partition keys, serverless container storage of 1 TB, and priority-based execution.
Azure Cosmos DB is Microsoft’s globally distributed, multi-model database service that offers low-latency, scalable storage and querying of diverse data types. The burst capacity feature for the service was announced at the recent annual Build conference and is generally available (GA) to allow users to take advantage of your database or container’s idle throughput capacity to handle traffic spikes. In addition, the company also announced the GA of hierarchical partition keys, also known as sub-partitioning for Azure Cosmos DB for NoSQL, and the expansion of the storage capacity of serverless containers to 1 TB (previously, the limit was 50 GB).
Beyond Build, the company also introduced the public preview of priority-based execution, a capability that allows users to specify the priority for the request sent to Azure Cosmos DB. When the number of requests exceeds the configured Request Units per second (RU/s) in Azure Cosmos DB, low-priority requests are throttled to prioritize the execution of high-priority requests, as determined by the user-defined priority.
Richa Gaur, a Product Manager at Microsoft, explains in a blog post:
This capability allows a user to perform more important tasks while delaying less important tasks when there are a higher number of requests than what a container with configured RU/s can handle at a given time. Less important tasks will be continuously retried by any client using an SDK based on the retry policy configured.
Using Mircosoft.Azure.Cosmos.PartitionKey;
Using Mircosoft.Azure.Cosmos.PriorityLevel;
//update products catalog
RequestOptions catalogRequestOptions = new ItemRequestOptions{PriorityLevel = PriorityLevel.Low};
PartitionKey pk = new PartitionKey(“productId1”);
ItemResponse catalogResponse = await this.container.CreateItemAsync(product1, pk, requestOptions);
//Display product information to user
RequestOptions getProductRequestOptions = new ItemRequestOptions{PriorityLevel = PriorityLevel.High};
string id = “productId2”;
PartitionKey pk = new PartitionKey(id);
ItemResponse productResponse = await this.container.ReadItemAsync(id, pk, getProductRequestOptions);
Similarly, users can maintain performance for short, temporary bursts, as requests that otherwise would have been rate-limited (429) can now be served by burst capacity when available. In a deep dive Cosmos DB blog post, the authors explain:
With burst capacity, each physical partition can accumulate up to 5 minutes of idle capacity. This capacity can be consumed at a rate of up to 3000 RU/s. Burst capacity applies to databases and containers that use manual or autoscale throughput and have less than 3000 RU/s provisioned per physical partition.
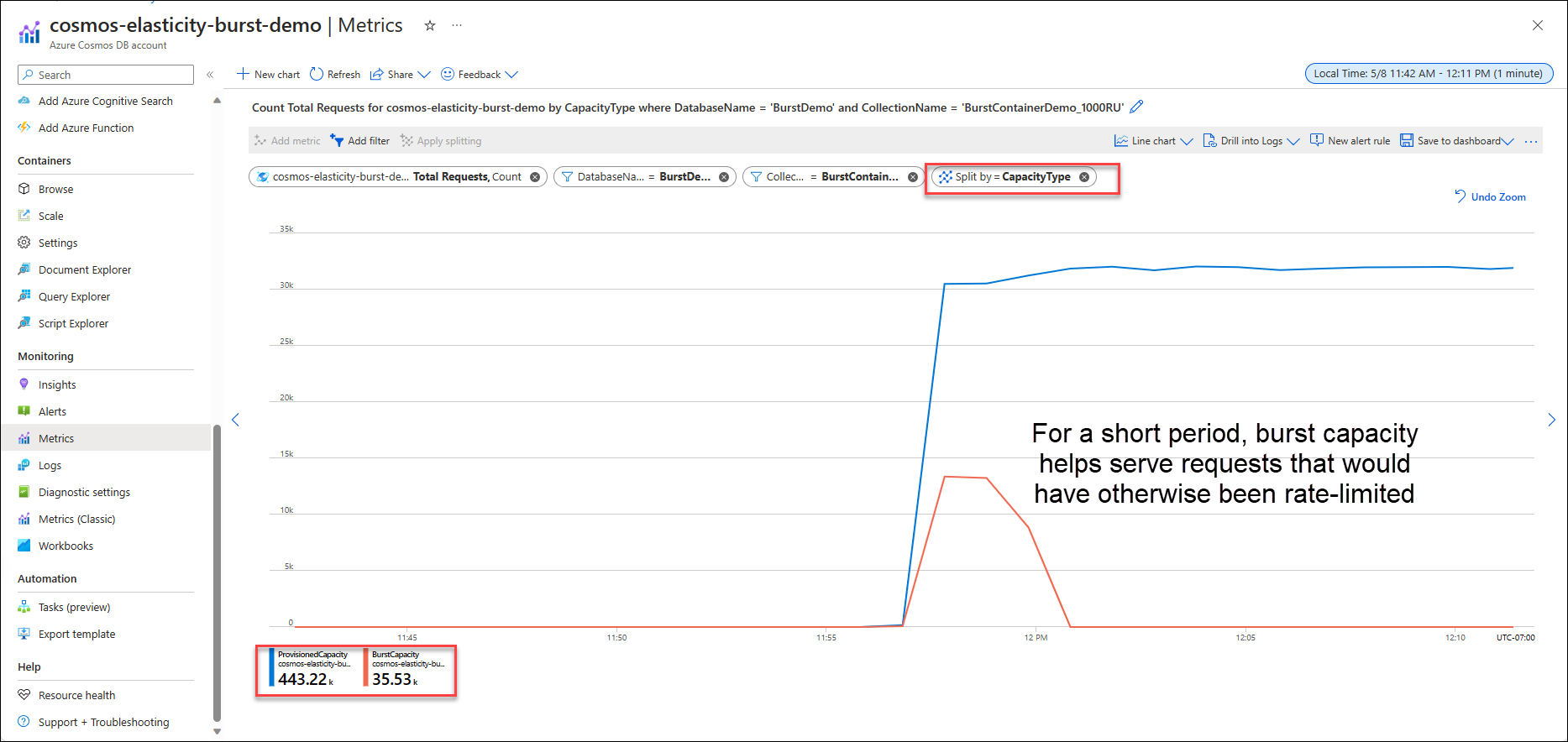
Source: https://devblogs.microsoft.com/cosmosdb/deep-dive-new-elasticity-features/
Next to optimizing performance, the hierarchical partition keys help in elasticity for Cosmos DB. The feature can help in scenarios where users leverage synthetic partition keys or logical partition keys that can exceed 20 GB of data. They can use up to three keys with hierarchical partition keys to further sub-partition their data, enabling more optimal data distribution and a larger scale. Behind the scenes, Azure Cosmos DB will automatically distribute their data among physical partitions such that a logical partition prefix can exceed the limit of 20GB of storage.
Leonard Lobel, a Microsoft Data Platform MVP, outlines the benefit of hierarchical keys in an IoT scenario in a blog post:
You could define a hierarchical partition key based on device ID and month. Then, devices that accumulate less than 20 GB of data can store all their telemetry inside a single 20 GB partition, but devices that accumulate more data can exceed 20 GB and span multiple physical partitions, while keeping each month’s worth of data “sub-partitioned” inside individual 20 GB logical partitions. Then, querying on any device ID will always result in either a single-partition query (devices with less telemetry) or a sub-partition query (devices with more telemetry).
Lastly, with the expansion of the storage capacity of serverless containers to 1 TB, users can benefit from the maximum throughput for serverless containers starting from 5000 RU/s, and they can go beyond 20,000 RU/s depending on the number of partitions available in the container. In addition, it also offers increased burstability.
MMS • Steef-Jan Wiggers
Microsoft has recently unveiled several new features for Azure Cosmos DB to enhance cost efficiency, boost performance, and increase elasticity. These features are burst capacity, hierarchical partition keys, serverless container storage of 1 TB, and priority-based execution.
Azure Cosmos DB is Microsoft’s globally distributed, multi-model database service that offers low-latency, scalable storage and querying of diverse data types. The burst capacity feature for the service was announced at the recent annual Build conference and is generally available (GA) to allow users to take advantage of your database or container’s idle throughput capacity to handle traffic spikes. In addition, the company also announced the GA of hierarchical partition keys, also known as sub-partitioning for Azure Cosmos DB for NoSQL, and the expansion of the storage capacity of serverless containers to 1 TB (previously, the limit was 50 GB).
Beyond Build, the company also introduced the public preview of priority-based execution, a capability that allows users to specify the priority for the request sent to Azure Cosmos DB. When the number of requests exceeds the configured Request Units per second (RU/s) in Azure Cosmos DB, low-priority requests are throttled to prioritize the execution of high-priority requests, as determined by the user-defined priority.
Richa Gaur, a Product Manager at Microsoft, explains in a blog post:
This capability allows a user to perform more important tasks while delaying less important tasks when there are a higher number of requests than what a container with configured RU/s can handle at a given time. Less important tasks will be continuously retried by any client using an SDK based on the retry policy configured.
Using Mircosoft.Azure.Cosmos.PartitionKey;
Using Mircosoft.Azure.Cosmos.PriorityLevel;
//update products catalog
RequestOptions catalogRequestOptions = new ItemRequestOptions{PriorityLevel = PriorityLevel.Low};
PartitionKey pk = new PartitionKey(“productId1”);
ItemResponse catalogResponse = await this.container.CreateItemAsync(product1, pk, requestOptions);
//Display product information to user
RequestOptions getProductRequestOptions = new ItemRequestOptions{PriorityLevel = PriorityLevel.High};
string id = “productId2”;
PartitionKey pk = new PartitionKey(id);
ItemResponse productResponse = await this.container.ReadItemAsync(id, pk, getProductRequestOptions);
Similarly, users can maintain performance for short, temporary bursts, as requests that otherwise would have been rate-limited (429) can now be served by burst capacity when available. In a deep dive Cosmos DB blog post, the authors explain:
With burst capacity, each physical partition can accumulate up to 5 minutes of idle capacity. This capacity can be consumed at a rate of up to 3000 RU/s. Burst capacity applies to databases and containers that use manual or autoscale throughput and have less than 3000 RU/s provisioned per physical partition.
Source: https://devblogs.microsoft.com/cosmosdb/deep-dive-new-elasticity-features/
Next to optimizing performance, the hierarchical partition keys help in elasticity for Cosmos DB. The feature can help in scenarios where users leverage synthetic partition keys or logical partition keys that can exceed 20 GB of data. They can use up to three keys with hierarchical partition keys to further sub-partition their data, enabling more optimal data distribution and a larger scale. Behind the scenes, Azure Cosmos DB will automatically distribute their data among physical partitions such that a logical partition prefix can exceed the limit of 20GB of storage.
Leonard Lobel, a Microsoft Data Platform MVP, outlines the benefit of hierarchical keys in an IoT scenario in a blog post:
You could define a hierarchical partition key based on device ID and month. Then, devices that accumulate less than 20 GB of data can store all their telemetry inside a single 20 GB partition, but devices that accumulate more data can exceed 20 GB and span multiple physical partitions, while keeping each month’s worth of data “sub-partitioned” inside individual 20 GB logical partitions. Then, querying on any device ID will always result in either a single-partition query (devices with less telemetry) or a sub-partition query (devices with more telemetry).
Lastly, with the expansion of the storage capacity of serverless containers to 1 TB, users can benefit from the maximum throughput for serverless containers starting from 5000 RU/s, and they can go beyond 20,000 RU/s depending on the number of partitions available in the container. In addition, it also offers increased burstability.
Java News Roundup: JNoSQL 1.0, Liberica NIK 23.0, Micronaut 4.0-RC2, Log4j 3.0-Alpha1, KCDC, JCON
MMS • Michael Redlich

This week’s Java roundup for June 19th, 2023 features news from JDK 22, JDK 21, updates to: Spring Boot; Spring Security; Spring Vault; Spring for GraphQL; Spring Authorization Server and Spring Modulith; Liberica NIK 23.0, Semeru 20.0.1, Micronaut 4.0-RC2 and 3.9.4, JNoSQL 1.0, Vert.x 4.4.4, updates to: Apache Tomcat, Camel, Log4j and JMeter; JHipster Lite 0.35, KCDC 2023 and JCON Europe 2023.
JDK 21
Build 28 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 27 that include fixes to various issues. Further details on this build may be found in the release notes.
JDK 22
Build 3 of the JDK 22 early-access builds was also made available this past week featuring updates from Build 2 that include fixes to various issues. More details on this build may be found in the release notes.
For JDK 22 and JDK 21, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
Versions 3.1.1, 3.0.8 and 2.7.13 of Spring Boot 3.1.1 deliver improvements in documentation, dependency upgrades and notable bug fixes such as: difficulty using the from() method defined in the SpringApplication class in Kotlin applications; SSL configuration overwrites other customizations from the WebClient interface; and support for JDK 20, but no defined value for it in the JavaVersion enum. Further details on these versions may be found in the release notes for version 3.1.1, version 3.0.8 and version 2.7.13.
Versions 6.1.1, 6.0.4, 5.8.4, 5.7.9 and 5.6.11 of Spring Security have been released featuring bug fixes, dependency upgrades and new features such as: align the OAuth 2.0 Resource Server documentation with Spring Boot capabilities; a new section in the reference manual to include information related to support and limitations when working with native images; and a migration to Asciidoctor Tabs. More details on these versions may be found in the release notes for version 6.1.1, version 6.0.4, version 5.8.4, version 5.7.9 and version 5.6.11.
The release of Spring Vault 3.0.3 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: a refinement in logging to log the token accessor upon token revocation failure; AWS Identity and Access Management (IAM) authentication added to the EnvironmentVaultConfiguration class; and the inclusion of a key_version attribute to the encrypt() method in the VaultTransitOperations interface. Further details on this release may be found in the release notes.
Versions 1.2.1 and 1.1.5 of Spring for GraphQL have been released featuring bug fixes, dependency upgrades and new features such as: an enhanced GraphQL request body check to prevent a 500 Internal Server Error when a 400 Bad Request is expected; elimination of the IllegalArgumentException due to no defined ConnectionAdapter interface when using existing Java Connection types. More details on these versions may be found in the release notes for version 1.2.1 and version 1.1.5.
Versions 1.1.1, 1.0.3 and 0.4.3 of Spring Authorization Server have been released featuring bug fixes and dependency upgrades. Version 1.1.1 ships with a new feature in which there was a performance enhancement by simply replacing the replaceFirst() method with the substring() method from the String class while using the OAuth2AuthorizationConsent class. Further details on these versions may be found in the release notes for version 1.1.1, version 1.0.3 and version 0.4.3.
The first milestone release of Spring Modulith 1.0.0 ships with bug fixes, dependency upgrades and a new feature that propagates instances of the ExecutorService interface defined in an application into instances of the Scenario class by default. This project has been promoted from its experimental status yielding these breaking changes: a rename of the actuator endpoint from applicationmodules to application-modules; a rename of the group identifier from org.springframework.experimental to org.springframework.modulith; and the removal of the previously deprecated configuration properties, spring.modulith.events.jdbc-*, in the JDBC-based event registry. More details on this release may be found in the release notes.
BellSoft
BellSoft has released version 23.0 of their Liberica Native Image Kit (NIK) featuring: the integration of the ParallelGC garbage collector as an experimental feature; implementation of the JFR ThreadCPULoad event; a removal of type checks from JNI-to-Java call stubs that can break compatibility; and implementation of the user CPU time thread with the getThreadCpuTime() method in the LinuxThreadCpuTimeSupport class.
IBM Semeru Open Edition
IBM has released version 20.0.1 their Semeru Runtime, Open Edition 20.0.1 built on OpenJDK 20.0.1 and Eclipse OpenJ9 0.39.0. Further details on this release may be found in the release notes.
Micronaut
The second release candidate of Micronaut 4.0.0 was also released providing bug fixes, dependency upgrades and these improvements: use of unsafe setters for Jackson; a new UnsafeBeanInstantiationIntrospection interface, a variation of the BeanIntrospection interface that includes an instantiateUnsafe() method for allowing to skip instantiation validation; and support for the All-open compiler plugin for the Kotlin Symbol Processing API.
The Micronaut Foundation has released Micronaut Framework 3.9.4 featuring bug fixes and updates to modules: Micronaut Security and Micronaut Servlet. There was also a dependency upgrade to Netty 4.1.94. More details on this release may be found in the release notes.
Eclipse Foundation
More than six years after its inception in March 2017, version 1.0.0 of JNoSQL, the compatible implementation of the Jakarta NoSQL specification, has been released. New features include: a migration to the jakarta.* namespace, support for the Jakarta Data specification; an implementation of new methods that explore fluent-API for the Graph, Document, Key-Value and Document NoSQL database types; and new methods, count() and exists(), as default on the DocumentManager and ColumnManager interfaces. Before it became a compatible implementation in November 2019, JNoSQL was a project for developers to more easily create NoSQL database applications using Java.
Two months after MicroStream had announced that their Java-native persistence layer had become an Eclipse Project, the first release of Eclipse Store, formerly known as MicroStream Persistence, has been made available to the Java community. Current non-Eclipse integrations in the MicroStream code base, such as Spring Boot, Quarkus and Helidon, will remain open source and the code will be hosted in a new MicroStream repository after they have been refactored to make use of the Eclipse Store and Eclipse Serializer projects.
Eclipse Vert.x 4.4.4 has been released featuring an upgrade to Netty 4.1.94.Final to address CVE-2023-34462, a vulnerability in which an attacker can manipulate the SniHandler class, with no configured idle timeout handler, to buffer the maximum 16MB of data per connection that can quickly lead to an OutOfMemoryError error and potential for a distributed denial of service. Further details on this release may be found in the release notes.
Apache Software Foundation
The Apache Tomcat team has disclosed that versions 11.0.0-M5, 10.1.8, 9.0.74 and 8.5.88 are affected by CVE-2023-34981, a vulnerability in which a regression in the fix for Bug 66512 could lead to an information leak if a response did not include any HTTP headers, then no Apache JServ Protocol (AJP) SEND_HEADERS message would be sent for the response. This was fixed in Bug 66591 and developers are encouraged to migrate to minimal versions 11.0.0-M6, 10.1.9, 9.0.75 or 8.5.89.
The release of Apache Camel 3.20.6 provides bug fixes and improvements such as: ensure that the REQUEST_CONTEXT and RESPONSE_CONTEXT headers are mapped when populating a Camel CXF message from Camel Message; and enhancements to the Camel JBang module to support OpenAPI. More details on this release may be found in the release notes.
Similarly, the release of Apache Camel 3.14.9 ships with these bug fixes: use the createTempFile() method in the Files class within the FileConverter class instead of directly creating a file; and a potential NullPointerException when using XML Tokenize on an Woodstox XML namespace. Further details on this release may be found in the release notes.
The first alpha release of Apache Log4j 3.0.0 delivers notable changes such as: allow plugins to be created through more flexible dependency injection patterns; split support for Kafka, ZeroMQ, CSV, JMS, JDBC and Jackson to their own modules; and removal of support for the Serializable interface in several classes and interfaces that include Message, Layout, LogEvent, Logger, and ReadOnlyStringMap.
Apache JMeter 5.6.0 has been released featuring bug fixes and new features such as: use Caffeine for caching HTTP headers instead of the Apache Commons Collections LRUMap class; use the Java ServiceLoader class for loading plugins instead of classpath scanning for improved startup; and improved computation when many threads actively produce samplers by using the Java LongAdder and similar concurrency classes to avoid synchronization in the Calculator class. More details on this release may be found in the release notes.
JHipster
The JHipster team has released version 0.35.0 of JHipster Lite with bug fixes, improvements in documentation, dependency upgrades and an improved Sonar analysis that provides more error details and an option to wait. Further details on this release may be found in the release notes.
Kansas City Developer Conference
The 2023 Kansas City Developer Conference (KCDC) was held at the Kansas City Convention Center in Kansas City, Missouri this past week featuring speakers from the Java community who presented workshops and sessions on topics such as: Java, architecture, cloud, data science, JavaScript, project management and security. The conference also featured puppies available for adoption from the Great Plains SPCA.
JCON Europe
Also this past week, JCON Europe 2023 was held at the Cinedom in Kön, Germany featuring speakers from the Java community who presented sessions on topics such as: Java, developer productivity engineering, security, web components, microservices and cloud native.