Month: June 2023

MMS • Robert Krzaczynski

NET MAUI in .NET 8 Preview 5 is available and contains bug fixes and performance improvements for cross-platform application development. It includes changes to iOS keyboard scrolling, test improvements, performance enhancements to the {Binding} mechanism and Android label layout. The announcement provoked different reactions in the community.
Visual Studio 2022 on Windows offers .NET 8 platform previews and the .NET MAUI preview workload. In order to access them, it is necessary to download version 17.7 Preview 2, select the .NET Multi-platform Application UI workload and enable the optional ‘.NET MAUI (.NET 8 Preview)’ component. For macOS users, it is recommended to download the .NET 8 preview 5 installer and install .NET MAUI using the command line.
For upgrading a .NET MAUI platform project to version 8.0.0-preview.5.8506, it is necessary to first install the .NET 8 platform SDK in the preview version. Then proceed to update the .NET MAUI NuGet packages within the project. It is possible to use Visual Studio or Visual Studio for Mac to manage the NuGet packages or manually modify the project file.
The announcement blog post sparked a lengthy discussion in the comments. Eder Cardoso wrote that all of these fixes were supposed to be on .NET 7 releases. David Ortinau, a principal product manager at Microsoft answered:
Hi Eder, I hear you and wish we could ship all the fixes to all the versions. We are optimizing for fixing the most impactful issues and that means limiting the most all of our focus to ensuring .NET 8 is the best possible release.
Then, Eder Cardoso replied:
All bug fixes matter David. Bug fixes are what matters the most for us as .NET MAUI developers.
Please change this bug fix merge and delivery policy/process. Bugs damage the framework’s image a lot, especially for those who are touching MAUI for the very first time.
Jens Jahrig added:
Definitely, these fixes should have been in .NET 7.
The team does the same fairytale every year “everything will be so awesome with the next major release (5,6,7,8,9,10), we fixed so many bugs”.
But we always get a current broken version and a next version which fixes one thing and breaks another.
I see no positive change in this scheme in the last few years.
These questions and concerns show that developers are not satisfied with the development of the framework. Working with the .NET MAUI is challenging due to the number of bugs.
A full list of changes can be found in the release notes.
MMS • RSS

MongoDB, Inc. MDB shares are trading higher Thursday after the company announced several new product launches.
What To Know: The MongoDB AI Innovators Program provides organizations building AI technology access to credits for MongoDB Atlas, partnership opportunities in the MongoDB Partner Ecosystem, and go-to-market activities with MongoDB to accelerate innovation and time to market.
The MongoDB Atlas for Industries helps organizations accelerate cloud adoption and modernization by leveraging industry-specific expertise, programs, partnerships, and integrated solutions.
Five new products and features were announced for the company’s industry-leading developer data platform, MongoDB Atlas, that make it significantly faster and easier for customers to build modern applications, for any workload or use case.
General availability of MongoDB Relational Migrator, a new tool that simplifies application migration and transformation, was announced.
A new initiative in partnership was announced with Google Cloud to help developers accelerate the use of generative AI and build new classes of applications.
Also, new capabilities for the world’s most popular NoSQL database for building modern applications faster and with less heavy lifting were announced as well.
“Our long-term vision is to create a developer data platform that removes as much builder friction as possible and makes it easier for developers to do what they do best—build,” said Andrew Davidson, Senior Vice President of Product at MongoDB. “Developers choose MongoDB Atlas because it’s the best place to quickly build applications that can make the most out of their data.”
“We continually hear from developers that they want to be able to use even more tools seamlessly on MongoDB Atlas, so with these additional integrations and expanded features, we are taking another step in fulfilling our mission to meet developers where they are and to provide the best possible building experience with the least amount of friction.”
Related Link: What’s Going On With Palo Alto Networks?
MDB Price Action: Shares of MDB were up 3.60% at $386.38 at the time of publication, according to Benzinga Pro.
Image by RAEng_Publications from Pixabay
MMS • Ben Linders

Improving the feedback time of a continuous integration (CI) system and optimizing the test methods and classes resulted in more effective feedback for development teams. According to Tobias Geyer, CI systems are an important part of the development process and should be treated as such.
Tobias Geyer spoke about improving a continuous integration system as a tester at the Romanian Testing Conference 2023.
When Geyer started at the company, the continuous integration system was an old developer PC that had been put under a desk, and nobody was responsible for it, with no time to do maintenance. Being slow it resulted in very long feedback cycles and developers ignoring the feedback from the CI system altogether, he said.
A quick win mentioned to improve the feedback time was to skip build steps during business hours that weren’t needed all the time and limit them to a nightly build, Geyer said.
A problem that took more effort to fix was the disk I/O bottleneck. The build did read and write so much data that the hard disk couldn’t keep up. Geyer mentioned that he got in touch with their IT department and moved the CI system from the developer PC to virtual machines in the datacenter. That allowed them to fix the disk I/O issue and scale the system to two machines, enabling them to run more builds in parallel.
After figuring out which tests were fast and which were slow, they split them into categories and ran only a subset of the tests as part of their fast feedback CI builds. The slower tests were moved to a dedicated build that was run less frequently. That way they still got the full feedback but they got the majority of it way faster than before, Geyer explained.
Geyer described how they optimized the test methods and classes:
Once we identified which tests were slow, we treated them like technical debt. We created “test debt budgets” for developers to improve the tests, which they approached in different ways:
1. Test data got trimmed down so that only the relevant data was kept, which shortened the setup time for tests.
2. Mocking was introduced in the tests, making it obsolete to load any test data in the first place.
3. The product code was made more testable so that the same checks could be done as unit tests instead of integration tests.
Geyer concluded that it’s not necessary to have a deep understanding of the technical side of things to have an impact:
I can use my testing skills of measuring, experimenting and collaborating to make changes for the better happen, even if it means that someone else has to do the actual implementation work.
InfoQ interviewed Tobias Geyer about improving the CI system.
InfoQ: Can you give an example of a build step that was skipped?
Tobias Geyer: The most prominent example was our product obfuscation. Each product artifact gets obfuscated before it’s delivered to the customer, and obviously the obfuscated product needs to be tested. Unfortunately, the obfuscation takes at least 30 minutes. We’re skipping it during the day, at night the products get obfuscated and tested that way.
InfoQ: What major changes did you do to the building process and platform?
Geyer: We migrated our build system from Ant and Windows batch files to Gradle. That was done mostly by the developers in my team with me taking care of all the parts that had to deal with executing tests.
We made an obvious but important change by introducing a test CI system. This allowed us to prepare and test changes to the CI system (like plugin updates, new build nodes,…) without interrupting the normal development flow.
InfoQ: How did you encourage knowledge sharing about continuous integration among different teams?
Geyer: I looked for people in other parts of the company who worked with or on CI systems and had a similar tech stack. We had regular meetings where we discussed the latest changes and the problems we were facing. Quite often some team had already solved a problem and their solution could be re-used.
It was great to see what the others were doing and the results they had. There were cases where teams wanted to introduce a change but met pushback in their teams. Being able to say “This other team made good experiences with it” helped to convince people.
InfoQ: What’s your advice to teams that are unhappy with their CI solution?
Geyer: Approach it like any other software development project. Make a list of the issues that bother you and treat them like bugs. Which means: Prioritize them, analyze them and then collaborate on fixing them. I’d like to stress the “collaboration” point – talking to our IT department was crucial to get some of the issues fixed.
MMS • RSS

(Zapp2Photo/Shutterstock)
Aerospike this week rolled out new graph database offering that leverages open source components, including the TinkerPop graph engine and the Gremlin graph query language. The NoSQL company foresees the new property graph being used by customers initially for OLTP workloads, such as fraud detection and identity authentication, with the possibility of OLAP functionality in the future.
Aerospike initially emerged as a distributed key-value store designed to store and query data at high speeds with low latencies. Over time, it became a multi-modal database by supporting SQL queries, via the Presto support it unveiled in 2021, as well as the capability to store and query JSON documents, added last year.
When Aerospike executives heard that some of its financial services customers were spending their own time and money developing bespoke graph databases to handle specific compute-intensive tasks–such as detecting fraud in financial transactions–they decided it was a good time to add graph to the mix.
“We had this payment company that had done this at scale,” says Lenley Hensarling, Aerospike’s chief product officer. “And we looked around at other of our customers who are throwing bespoke graph code, hand-coding graphs in order to get the throughput and the scale of data for a real production application of graphs.”
The product developers at Aerospike realized they could take Apache TinkerPop, an open source graph query engine that also forms the heart of the AWS Neptune and the Microsoft Azure Cosmos DB graph database offerings, and integrate it into the Aerospike storage engine. JanusGraph’s Gremlin was selected as the initial graph language, although the company is aiming to support openCypher, which is the open source version of Neo’s graph query language.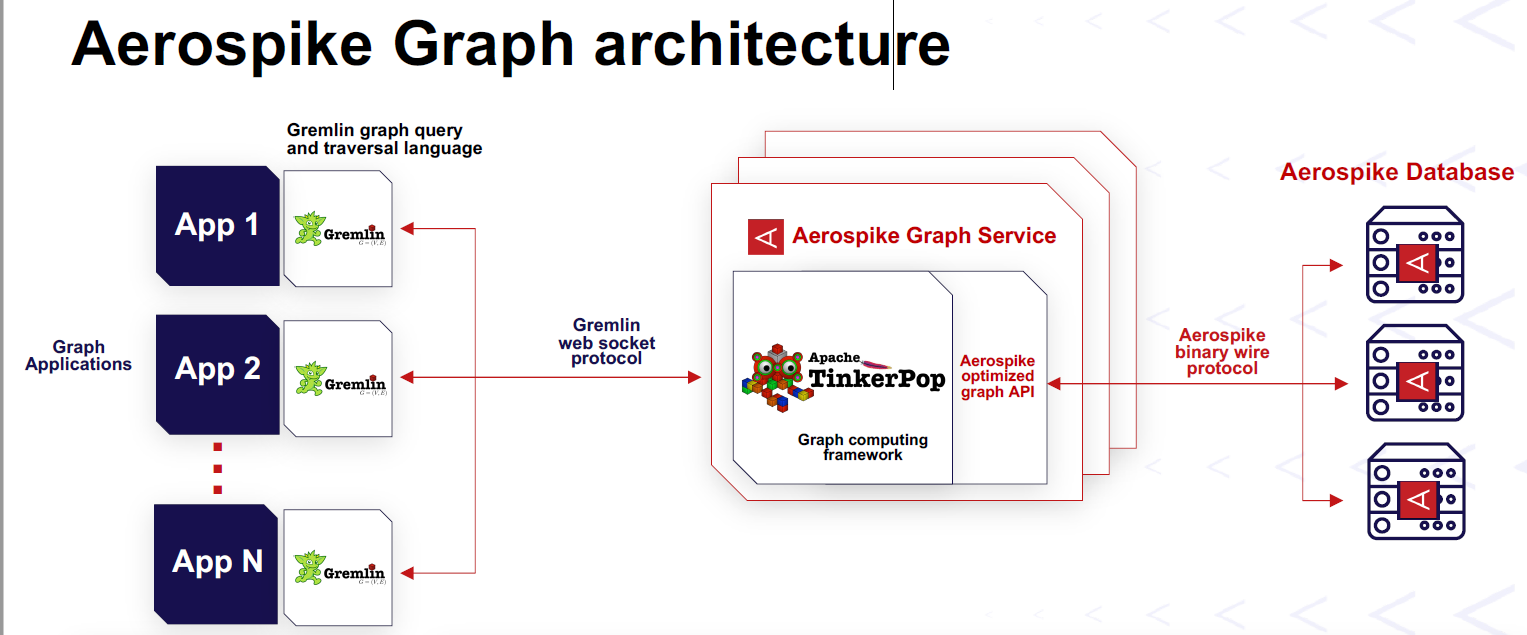
The combination of TinkerPop query engine, Gremlin query language, and Aerospike’s data management capabilities is a general-purpose property graph database that’s suitable for the types of transactional and operational use cases its customers require, Hensarling says.
“There’s just white space for graph solutions at scale,” he tells Datanami. “We believe there’s an unmet need. We can provide tens of thousands to hundreds of thousands to millions of transactions per second. It’s not going to be as fast as the key-value lookup, for sure. But it’s going to be over and over again, for many different applications.”
Fraud detection and identity authentication are the two main use cases that Aerospike sees customers using the graph database to build. Fraud detection, where connections to known fraudulent entities (people, businesses, devices, etc.) can be quickly discovered in real time, is a classic property graph workload.
But modern identity authentication methods today–in which multiple pieces of data are brought to bear to determine that yes, this person is really who they claim to be–are beginning to closely resemble that fraud detection workload, too.
Aerospike has optimized its database to deliver two to five “hops,” which is the number of traversals a query makes as it travels along vertices to find other connected nodes, within a short amount of time. Completing the graph lookup within about 20 milliseconds is the goal, Hensarling says.![]()
“It’s part of a longer transaction,” he says of the graph lookups. “They may use graph for part of it. They may use AI and ML stuff in another part. But they have seconds to do the whole chain of things and typically it’s like 20 milliseconds” for the graph component.
Aerospike worked with Marko Rodriguez, the creator of TinkerPop, to develop a connection to the Aerospike database, Hensarling says. That layer, which Aerospike developers called Firefly, enables OLTP workloads, but a similar layer could be adapted that leverages TinkerPop for OLAP and graph analytics workloads, he says.
The company has done a lot of development work in the past 18 months that prepared it for the move into the graph database realm, Hensarling says. That includes work on secondary indexes, as well as the support for predicate pushdowns, where data processing work is pushed into the database engine. “That has allowed us to do this at a much faster, scalable route than we could have previously,” he says.
For small deployments, all of the storage and query engines could sit in the same namespace, Hensarling says. But large Aerospike graph deployments will likely resemble large Aerospike Trino (or Presto) deployments, where the data is persisted on an Aerospike cluster while the TinkerPop query engine sits on a separate cluster. The TinkerPop cluster will run the queries against the Aerospike data, and will scale horizontally if necessary to handle bigger workloads.
“If you need more throughput, you can just stand up more nodes of TinkerPop,” Hensarling says. “And you can also take them down as you have bursts of transactions, because the data is held in Aerospike and it’s persisted, so you just connect it again and scale out. That’s something people have really responded to as well.”
The graph database has been in beta with Aerospike customers for several months. The largest deployment so far involved a financial transaction processing company that had a graph with billions of vertices and thousands of edges, with responses coming back in 15 milliseconds, Hensarling says.
Aerospike is confident that its new graph offering will resonate with customers, particularly among those that need to combine graph capabilities with other database capabilities.
“There’s an unmet need in the marketplace,” Hensarling says. “People don’t want yet another database all the time. If they can use the skills for operations and leverage them across more types of workloads, that’s good, as long as the performance and the semantic coverage is there.”
Related Items:
Aerospike Adds JSON Support, Preps for Fast, Multi-Modal Future
Aerospike’s Presto Connector Goes Live
Aerospike Turbocharges Spark ML Training with Pushdown Processing
MMS • RSS

New Jersey, United States – The Global NoSQL Software market is expected to grow at a significant pace, reports Verified Market Research. Its latest research report, titled “Global NoSQL Software Market Insights, Forecast to 2030“. offers a unique point of view about the global market. Analysts believe that the changing consumption patterns are expected to have a great influence on the overall market. For a brief overview of the Global NoSQL Software market, the research report provides an executive summary. It explains the various factors that form an important element of the market. It includes the definition and the scope of the market with a detailed explanation of the market drivers, opportunities, restraints, and threats.
Both leading and emerging players of the Global NoSQL Software market are comprehensively looked at in the report. The analysts authoring the report deeply studied each and every aspect of the business of key players operating in the Global NoSQL Software market. In the company profiling section, the report offers exhaustive company profiling of all the players covered. The players are studied on the basis of different factors such as market share, growth strategies, new product launch, recent developments, future plans, revenue, gross margin, sales, capacity, production, and product portfolio.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @ https://www.verifiedmarketresearch.com/download-sample/?rid=153255
Key Players Mentioned in the Global NoSQL Software Market Research Report:
Amazon, Couchbase, MongoDB Inc., Microsoft, Marklogic, OrientDB, ArangoDB, Redis, CouchDB, DataStax.
Global NoSQL Software Market Segmentation:
NoSQL Software Market, By Type
• Document Databases
• Key-vale Databases
• Wide-column Store
• Graph Databases
• Others
NoSQL Market, By Application
• Social Networking
• Web Applications
• E-Commerce
• Data Analytics
• Data Storage
• Others
Players can use the report to gain sound understanding of the growth trend of important segments of the Global NoSQL Software market. The report offers separate analysis of product type and application segments of the Global NoSQL Software market. Each segment is studied in great detail to provide a clear and thorough analysis of its market growth, future growth potential, growth rate, growth drivers, and other key factors. The segmental analysis offered in the report will help players to discover rewarding growth pockets of the Global NoSQL Software market and gain a competitive advantage over their opponents.
Key regions including but not limited to North America, Asia Pacific, Europe, and the MEA are exhaustively analyzed based on market size, CAGR, market potential, economic and political factors, regulatory scenarios, and other significant parameters. The regional analysis provided in the report will help market participants to identify lucrative and untapped business opportunities in different regions and countries. It includes a special study on production and production rate, import and export, and consumption in each regional Global NoSQL Software market considered for research. The report also offers detailed analysis of country-level Global NoSQL Software markets.
Inquire for a Discount on this Premium Report @ https://www.verifiedmarketresearch.com/ask-for-discount/?rid=153255
What to Expect in Our Report?
(1) A complete section of the Global NoSQL Software market report is dedicated for market dynamics, which include influence factors, market drivers, challenges, opportunities, and trends.
(2) Another broad section of the research study is reserved for regional analysis of the Global NoSQL Software market where important regions and countries are assessed for their growth potential, consumption, market share, and other vital factors indicating their market growth.
(3) Players can use the competitive analysis provided in the report to build new strategies or fine-tune their existing ones to rise above market challenges and increase their share of the Global NoSQL Software market.
(4) The report also discusses competitive situation and trends and sheds light on company expansions and merger and acquisition taking place in the Global NoSQL Software market. Moreover, it brings to light the market concentration rate and market shares of top three and five players.
(5) Readers are provided with findings and conclusion of the research study provided in the Global NoSQL Software Market report.
Key Questions Answered in the Report:
(1) What are the growth opportunities for the new entrants in the Global NoSQL Software industry?
(2) Who are the leading players functioning in the Global NoSQL Software marketplace?
(3) What are the key strategies participants are likely to adopt to increase their share in the Global NoSQL Software industry?
(4) What is the competitive situation in the Global NoSQL Software market?
(5) What are the emerging trends that may influence the Global NoSQL Software market growth?
(6) Which product type segment will exhibit high CAGR in future?
(7) Which application segment will grab a handsome share in the Global NoSQL Software industry?
(8) Which region is lucrative for the manufacturers?
For More Information or Query or Customization Before Buying, Visit @ https://www.verifiedmarketresearch.com/product/nosql-software-market/
About Us: Verified Market Research®
Verified Market Research® is a leading Global Research and Consulting firm that has been providing advanced analytical research solutions, custom consulting and in-depth data analysis for 10+ years to individuals and companies alike that are looking for accurate, reliable and up to date research data and technical consulting. We offer insights into strategic and growth analyses, Data necessary to achieve corporate goals and help make critical revenue decisions.
Our research studies help our clients make superior data-driven decisions, understand market forecast, capitalize on future opportunities and optimize efficiency by working as their partner to deliver accurate and valuable information. The industries we cover span over a large spectrum including Technology, Chemicals, Manufacturing, Energy, Food and Beverages, Automotive, Robotics, Packaging, Construction, Mining & Gas. Etc.
We, at Verified Market Research, assist in understanding holistic market indicating factors and most current and future market trends. Our analysts, with their high expertise in data gathering and governance, utilize industry techniques to collate and examine data at all stages. They are trained to combine modern data collection techniques, superior research methodology, subject expertise and years of collective experience to produce informative and accurate research.
Having serviced over 5000+ clients, we have provided reliable market research services to more than 100 Global Fortune 500 companies such as Amazon, Dell, IBM, Shell, Exxon Mobil, General Electric, Siemens, Microsoft, Sony and Hitachi. We have co-consulted with some of the world’s leading consulting firms like McKinsey & Company, Boston Consulting Group, Bain and Company for custom research and consulting projects for businesses worldwide.
Contact us:
Mr. Edwyne Fernandes
Verified Market Research®
US: +1 (650)-781-4080
UK: +44 (753)-715-0008
APAC: +61 (488)-85-9400
US Toll-Free: +1 (800)-782-1768
Email: sales@verifiedmarketresearch.com
Website:- https://www.verifiedmarketresearch.com/
NoSQL Market 2023 Segmentation Analysis, Key Players, Industry Share, and Forecast by 2031
MMS • RSS

The “NoSQL Market “ study has been updated and published by The Report Ocean, covering the prediction period of 2023-2031. This comprehensive report delves into how companies are capitalizing on market conditions to maximize their presence in the global market. It provides valuable insights and statistical estimations regarding the industry’s growth, measured in terms of value (in US$ Bn/Mn)
NoSQL (Not Only SQL) is a database mechanism developed for storage, analysis, and access of large volume of unstructured data. NoSQL allows schema-less data storage, which is not possible with relational database storage. The benefits of using NoSQL database include high scalability, simpler designs, and higher availability with more precise control. The ability to comfortably manage big data is another significant reason for the adoption of NoSQL databases. The NoSQL technology is emerging in the database market horizon and is expected to grow rapidly over the next few years.
Download Free Sample of This Strategic Report:https://reportocean.com/industry-verticals/sample-request?report_id=AMR855
According to data from the U.S. Bureau of Economic Analysis and the U.S. Census Bureau, the goods and services deficit increased by $1.9 billion from $68.7 billion in January 2023 to $70.5 billion in February. The increase in the goods and services deficit in February was due to a $2.7 billion increase in the goods deficit to $93.0 billion and a $0.8 billion increase in the services surplus to $22.4 billion. Compared to the same period in 2022, the goods and services deficit has dropped this year by $35.5 billion, or 20.3%. $49.5 billion or 10.8% more was exported. 2.2% or $14.0 billion more was spent on imports.
What our report offers:
— Comprehensive market share assessments for regional and country-level segments.
— Strategic recommendations tailored for new entrants in the market.
— Market forecasts spanning a minimum of 10 years for all mentioned segments, subsegments, and regional markets.
— In-depth analysis of market trends, including drivers, constraints, opportunities, threats, challenges, investment opportunities, and recommendations.
— Strategic analysis encompassing drivers and constraints, product/technology analysis, Porter’s five forces analysis, SWOT analysis PESTEL analysis, and more.
— Strategic recommendations for key business segments based on market estimations.
— Competitive landscape mapping highlighting key common trends.
— Detailed company profiling with strategies, financials, and recent developments.
— Mapping of supply chain trends, tracking the latest technological advancements.
Download Free Sample of This Strategic Report:https://reportocean.com/industry-verticals/sample-request?report_id=AMR855
KEY BENEFITS FOR STAKEHOLDERS
– The study provides an in-depth analysis of the current & future trends of the market to elucidate the imminent investment pockets.
– Information about key drivers, restraints, and opportunities and their impact analysis on the global NoSQL market size is provided.
– Porter’s five forces analysis illustrates the potency of the buyers and suppliers operating in the NoSQL industry.
– The quantitative analysis of the market from 2018 to 2026 is provided to determine the global NoSQL market potential.
KEY MARKET PLAYERS
– Aerospike, Inc.
– Amazon Web Services, Inc.
– DataStax, Inc.
– Microsoft Corporation
– Couchbase, Inc.
– Google LLC
– MarkLogic Corporation
– MongoDB, Inc.
– Neo Technology, Inc.
– Objectivity, Inc.
KEY MARKET SEGMENTS
By Type
– Key-Value Store
– Document Database
– Column-based Store
– Graph Database
By Application
– Data Storage
o Distributed Data Depository
o Cache Memory
o Metadata Store
– Mobile Apps
– Data Analytics
– Web Apps
– Others (E-commerce and Social Networks)
Request To Download Sample of This Strategic Report:–https://reportocean.com/industry-verticals/sample-request?report_id=AMR855
By Industry vertical
– Retail
– Gaming
– IT
– Others
ByRegion
– North America
o U.S.
o Canada
– Europe
o Germany
o France
o UK
o Rest of Europe
– Asia-Pacific
o Japan
o China
o India
o Rest of Asia-Pacific
– LAMEA
o Latin America
o Middle East
o Africa
Reasons to buy market research report:
Access to valuable information: The market research report offers access to valuable information and data that can assist in making well-informed decisions.
Gain competitive intelligence: By providing insights into the competitive landscape, including details about key players, their market share, and strategies, the market research report enables businesses to develop effective strategies for competition.
Make informed investment decisions: The market research report provides valuable insights for users, including an analysis of market trends, growth potential, and associated risks. This information aids in making informed investment decisions and minimizing risks.
Stay up-to-date on industry developments: The market research report ensures users are regularly updated on industry developments, such as new product launches, mergers and acquisitions, and regulatory changes. This helps users stay ahead of the curve and adapt to evolving market conditions.
Note: This statement highlights the company’s commitment to providing tailored services to its clients, including country segmentation and player additions that are aligned with the client’s specific business objectives. It should be noted that the extent of customization is contingent upon approval and feasibility. To access these personalized services, clients are encouraged to share their requirements with the company, prompting their executives to initiate further discussions and delve into specific details.
Key Questions Answered in the Report:
— What growth opportunities are available for new entrants in the industry?
— Who are the leading players operating in the marketplace?
— What key strategies are participants likely to adopt to increase their market share in the industry?
— What is the current competitive situation in the market?
— What are the emerging trends that may impact market growth?
— Which product type segment is expected to have a high compound annual growth rate (CAGR) in the future?
— Which application segment is projected to capture a significant share in the industry?
— Which region presents lucrative prospects for manufacturers?
MMS • Almir Vuk

Microsoft has released the second preview of Visual Studio 2022 version 17.7. Preview 2 brings a range of improvements and features aimed at enhancing developer productivity and improving performance and collaboration. It also includes enhancements for .NET development, as well as for C++ and game development. Preview 2 is available for download, and developers have the opportunity to explore and utilize its advancements in the preview version.
In terms of IDE Productivity & Performance, with Preview 2 developers can now simplify their workflow by creating a Pull Request directly within the Visual Studio. With the latest update, users can simply click the link provided in the notification banner after pushing their changes or navigate to it through the top-level menu by selecting Git > GitHub/Azure DevOps > New Pull Request. As it is reported in the release post, the development team plans to deliver more updates to improve the Pull Request experience in Visual Studio.
Productivity-wise, a new enhancement has been made to the file comparison feature introduced in Preview 1. Users now have multiple options to perform comparisons. They can either use the method of multi-selecting two files by holding down the Ctrl button, then right-clicking and selecting Compare Selected. Alternatively, they can right-click on a single file and choose Select for Compare from the context menu. Another option is to right-click on a single file and select Compare With… from the context menu, which will open File Explorer. From there, users can navigate to any file on disk and select it for comparison (introduced in 17.7 Preview 1).
Other productivity notable upgrades are related to Multi-branch Graph, Parallel Stack Filtering, F5 Speed on Unreal Engine, and updates regarding the optimization of editing speed like Enhanced Light Bulb performance in Roslyn, Optimized Hash creation for reduced CPU consumption, and C++ Unreal Engine – IntelliSense optimization.
.NET Development was also a part of the improvements and enhancements, and changes for this area were related to auto-decompilation for external .NET code and new auto Insights for the CPU usage tool. Regarding the first one, now inside Visual Studio, the debugger automatically decompiles and displays the execution point, simplifying the analysis of call stacks. Decompiled code is conveniently shown under the External Sources node in Solution Explorer during debugging, allowing easy browsing. To disable auto-decompilation, the user can clear the “Automatically decompile to source when needed (managed only)” option in Tools > Options > Debugging.
Also, the CPU usage tool now provides more detailed insights for specific methods and properties, helping developers optimize code and improve performance. Additionally, the new Ask Copilot feature offers explanations and suggested fixes for encountered issues, assisting developers in enhancing their code and avoiding common pitfalls.
Regarding C++ and game development, Build Insights has been incorporated into Visual Studio 2022. This integration brings much information for developers seeking to enhance their C++ build times. By generating a comprehensive diagnostic report, Build Insights enables users to identify costly includes and conveniently navigate to header files. Advanced users can also access Windows Performance Analyzer (WPA) directly from within the report, enhancing their optimization capabilities.
The new version also brings a significant enhancement for Doxygen comments, allowing shared comments to be displayed in overloads positioned away from the comments. Previously, Doxygen comments were only visible in the Quick Info section for immediate overloads. With this update, the Quick Info now includes the informative text Documentation from another overload when an overload is not directly beneath the Doxygen comments. In addition, unused parameters are now neatly grouped under the Unused Parameter heading, enhancing clarity and organization. Other C++ updates include updates for the Remote File Explorer and WSL Automatic Acquisition
Furthermore, regarding Enterprise Management, the latest installer allows users with limited permissions to update and modify the software. Although an administrator is still required for installation and configuration, standard non-administrator users can initiate and execute any installer function once enabled on the client machine. This enhancement simplifies software management for users with restricted access. Details about the required steps are available in the original release blog post by Microsoft.
In addition to the original release blog post, in the last paragraphs, Microsoft and the development team encourage users to provide feedback and share their suggestions for new features and improvements, emphasizing their commitment to constantly enhancing the Visual Studio experience.
Lastly, developers interested in learning more about this and other releases of Visual Studio can visit very detailed release notes about other updates, changes, and new features around the Visual Studio 2022 IDE.
MMS • Steef-Jan Wiggers
Microsoft recently announced the public preview of the Vercel and Azure Cosmos DB integration allowing developers to easily create Vercel applications with an already configured Azure Cosmos DB database.
Azure Cosmos DB is a globally distributed, multi-model database service provided by Microsoft that offers high scalability, low latency, and comprehensive data consistency across multiple data models and APIs. While Vercel is a cloud platform that simplifies the deployment and hosting of web applications, providing developers with a way to deliver fast and scalable websites. By integrating Vercel and Cosmos DB, developers can connect their web applications with a managed global distributed database hosted in Azure.
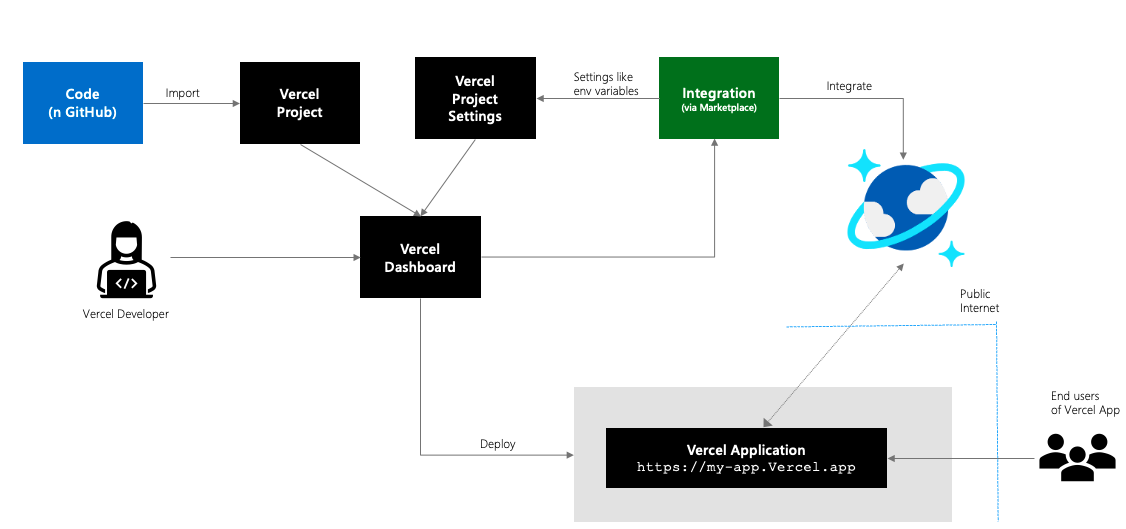
Source: https://devblogs.microsoft.com/cosmosdb/announcing-vercel-and-azure-cosmos-db-integration/
A developer can leverage Vercel Templates or Vercel Starter Projects, which are pre-configured boilerplate projects that provide a starting point for building web applications or static websites. Currently, an Azure Cosmos DB Next.js template is published on Vercel’s marketplace, which is a ready-to-use project structure and configuration. Furthermore, there is a starter app available on GitHub.
Vercel and Cosmos DB integration works with Azure Cosmos DB for NoSQL and Azure Cosmos DB for MongoDB. Furthermore, only existing Azure Cosmos DB accounts are supported. A developer can, after creating a Vercel project, start by adding the integration with a Cosmos DB account (note that the account needs to be set up earlier). In addition, the developer can also choose to have integration with Cosmos DB done through a command line.
On an Azure Reddit thread, a respondent commented on the integration of Vercel with Cosmos DB:
This might make things a little simpler, but they were simple before. I’d have to see the overhead of this solution to justify using it.
Currently, I build my backend in .NET and my front end in Nextjs. On a website that doesn’t get too much traffic daily, I can run my setup absolutely free every month by using Azure’s free server. I do pay $.02 cents for the blob storage, but that’s a cheap way to host.
If this new integration allows for the same inexpensive setup, I’d give it a shot, but having the backend and front-end separation is beneficial in its own ways.
More details on pricing and availability of Cosmos DB is available on the pricing page, while the pricing of Vercel can be found on their pricing page.
MMS • Yuliia Pieskova

Key Takeaways
- Sprint Reviews tend to be geared toward engineering teams reporting to management, rather than fostering an environment of creativity, exploration, and continuous improvement.
- Change agents starting a Sprint Review transformation should remain open-minded and focus on understanding the nuances of the organizational culture, while staying true to their own values and beliefs.
- To establish data-driven change goals and metrics, focus on facts over opinions, avoid broad generalizations, and identify recurring patterns. Ensuring that the initiative is aligned with the organization’s overarching business goals is a key success factor.
- To encourage continuous growth, it’s important to establish an improvement routine that moves forward with small but challenging steps, regularly educate the team about Sprint Reviews, and give them the skills they need to run them successfully.
- To create a more inclusive and engaging Sprint Review culture, change agents should consistently look for opportunities to bring in a broader spectrum of internal and external stakeholders.
In many instances, Sprint Reviews seem to function primarily as a platform for engineering teams to report to management. And it’s no wonder: reporting has been a fundamental approach for centuries. Yet, this is not why this practice was designed: Sprint Reviews should foster a dynamic environment of creativity, exploration, and continual refinement, where important product and overall business decisions are taken.
And you can feel the difference in a very distinct way. At the reporting Sprint Review you have a routine of the same participants going through the work done, often with praise or thanks at the end. No more, no less. At the ideation Reviews, you get to observe challenging discussions, rich takeaways, and behavioral changes. They are different because the product and its environment are changing. Such reviews may be followed not only by changes in product strategy, but also by updates to marketing campaigns, changes in sales strategy, new initiatives, or sometimes even creation of new departments. See how the influencing power differs?
In this article, we will explore the substantial mindset shift and routine change from a typical reporting-focused to interactive data-driven culture of Sprint Reviews.
Change Manager Mindset
Before we look at how to change the mindset of others, let’s explore the mindset of a change agent. Joining a new organization or team is a lot like the traveler’s experience: just as traveling to a foreign country can be an eye-opening and humbling adventure, so too can navigating a new organizational culture.
It’s useful to remember that our brains are wired to expect things based on what we’ve experienced before: it’s extremely helpful when the situation is similar, but it can also prevent us from being open to new but important nuances. The new corporate language, certain experiences and time spirits should be learned. There may be times when your attention can make a big difference. For example, you may share a seemingly mundane suggestion in a meeting, only to notice a distinct shift in the atmosphere of the room. It’s like walking into a bad neighborhood in a new country and instinctively feeling like an outsider. The level of danger is different, of course, but in both cases it’s important to investigate and learn from these new experiences.
Therefore, like a seasoned traveler, change agents should be extremely open-minded and strive to understand the culture they’re entering, while not blending in and staying true to their values and beliefs. It’s important to understand the value and function of the current Sprint Review processes, while resisting “it won’t work in our environment” and other skepticism. In coaching parlance, they need to “meet the client where they are” before helping them move forward. They will have to observe, learn, and respect the existing norms before they can effectively lead the organization to change.
Now that we have talked about the change manager mindset, we are ready to move on to the organizational assessment.
Organization Assessment
Typically, I kick off organization assessment by conducting a series of interviews and group discussions with individuals in various roles. By adhering to the adopted practices of product discovery interviews, I avoid general abstract questions and ask specifically about people’s experiences with Sprint Reviews, their preparations and takeaways. I am interested in the value they derived, how they applied this value in practice, what they found unhelpful, what was missing, and what was not asked. Observing a certain number of Sprint Reviews and getting first-hand experience is also important. When I notice distinct patterns and repetitive motives in the stories and situations I have collected, I know I have enough information to decide if the Sprint Reviews change would be timely and then move forward with implementing it.
One of the biggest challenges of organization assessment is how to make it as objective as possible and how to generate enough data to make evidence-based decisions on Sprint Review change. Fortunately, by today we have interviewing principles at our disposal that are proven to work well in similar situations: e.g. when making user interviews or sociological investigations.
Let’s review several of them:
- Ask for facts and not opinions. Opinions can be very subjective and it’s hard to judge them avoiding cognitive biases of both people who ask and answer questions. E.g. Once I was told that user feedback had a significant impact on product roadmaps. When I asked for specific instances of when and how this happened, I was given only one example to prove it. It’s normal for the human brain to overgeneralize, add our subjective perspectives, and it’s our job to dig into what actually happened.
- Avoid generalizations and ask for details. For example, if a person says it was difficult to give feedback, ask how they tried to do it to understand what they really mean by giving feedback. Also ask what happened next to get a more complete picture.
- Look for patterns: What are common challenges in all of your respondents’ stories? What happened frequently? We should check that the problem is not occasional, but systemic before addressing it. A good example of a pattern might be:for a year, there have been no changes to the product roadmaps based on the results of the Sprint Reviews.
When you are observing the Sprint Reviews, it’s important to define the areas you’ll pay attention to before you enter the room and reflect on the same list afterwards. For example, when documenting what the climate was, you may describe that there was an atmosphere of fear. Then, you document what observations brought you to this decision: e.g, it felt like a fearful environment, because when reviewing bugs, the team was in the “defensive” position naming excuses A and B and there was no search for new solutions.
Another example can be that you noticed the inclusive environment: representatives of the leadership team, engineers from other teams and users asked questions and gave feedback at the end.
Here are some key areas that I focus on when listening to the stories of the interviewees and examples of questions you can ask:
| Investigation area | Question Examples |
| Stakeholders, their personas, how different they are for different teams |
|
| Sprint Review Impact |
|
| Product Success Criteria |
|
| Sprint Review Climate |
|
| Recent experiments |
|
When conducting the assessment, it’s important to gather enough information to align your Sprint Review change initiative with organization strategy. We ensure that the timing is in line with the prevailing “currents” within the organization and supports the business strategy. For example, it may not be best to involve stakeholders in a department that is about to be reformed, or to start with the team that is about to take on a new function.
Goal-setting. As soon as we conducted the first iteration of Organization Assessment, it’s time to set change objectives. Our objectives should be based on the Assessment results. We’re data-driven in how we make decisions. It’s the only way we know that it’s not just the change we think is important, but the change that will drive significant business value and be worth pursuing.
Moving on, let’s address the next crucial stage of the process: establishing the direction and motivation for change.
Charting the Course: Rational and Emotional Factors in Change
Change theory suggests that successful change depends on two factors: rational reasoning and emotional motivation. As Daniel Kahneman articulated in his book Thinking, Fast and Slow, System 2, the rational mind, may decide that we go to the gym every Monday, but it’s System 1, the emotional mind, that may choose Netflix instead of the gym after a long day at work.
The rational goal is often to develop a Sprint Review practice where stakeholders and the development team can inspect and adapt their work in a safe environment, reducing the risk of waste. Understanding emotional motivation is just as important. We need to identify what drives colleagues and stakeholders to embrace change. Let’s explore some examples based on common motivations I’ve encountered:
| Role (persona) | Needs (rational drivers) | Motivation (emotional drivers) |
| Software engineers |
|
|
| Product management |
|
|
| Users |
|
|
There’s another thing to consider – the motivation of you and your team. I often look for successful and inspiring stories of change that the organization has already overcome and look for external examples. In the book Switch: How to change things when change is hard by Dan Heath and Chip Heath, there are examples of people making extraordinary changes, such as overcoming age-old superstitions about childcare in Vietnam. As someone who has experienced profound social change firsthand, these stories resonate with me and cheer me up in the most challenging times. They remind me that change is not only possible, but achievable with persistence and the right tools.
I encourage you to find something that will keep that spark of interest in your eyes and the eyes of your team. It’s usually a long journey and it’s better to enjoy it.
Implementation: from Small Steps to a Show-Case Environment
When conducting interviews and discussions with my team members and other parties involved, I transparently communicate that I am investigating the opportunities for a Product Review change. This open dialogue attracts interest and invites others to join. I am also looking for the teams with the most favorable environment to try the most disruptive and risky experiments.
Once I make sure the change is timely and I feel I know the people well enough, I start implementing the change. When practicing effective Sprint Reviews in various environments, I’ve found the following process universal:
- Sprint Reviews Workshop. This begins with a brief overview of Sprint Reviews practice as an integral part of user centric development and evidence-based culture. I explain their function, possible formats, and openly share my personal experiences, including both notable successes and significant failures. You can also consider watching or reading about some good examples to discuss together. Following the theory, we brainstorm as a team on our first step towards improvement – something that’s manageable yet slightly challenging in their context. As ideation may be difficult for the teams at first, I usually prepare potential first steps in advance, drawing ideas from the team members’ needs and pain points. I position them as examples of what can be done next, and it usually starts lively discussions.
- Individual and Team Coaching: This aims to enhance presentation skills and broaden the toolset required for Sprint Reviews. It’s essential for each team to be able to explain their work to non-technical individuals, understand their user and customer personas, manage potentially toxic comments, work on expectation setting, and establish an awareness of their teammates and stakeholders’ interests.
- Feedback loop as a team routine. Having the habit of implementing the improvements from the previously collected and sorted feedback, asking how to present better and who can be invited is extremely beneficial. Like any routine, it saves energy while enabling continuous improvement. From time to time, consider organizing retrospectives dedicated to Sprint Reviews. Moving forward with each of the next small but challenging steps has to become a habit.
- Celebrate Small Victories: Acknowledge your team’s accomplishments and spread the word within other parts of the organization. Balance these celebrations with learnings from failed or less successful experiments. These small wins don’t only motivate the team but also contribute to building the momentum for the change across the organization.
Now, we’ve reviewed the flow – as you can see, I haven’t mentioned any specific activities, just the direction and the procedures for finding the next step. I do believe that it’s important to treat each team and organization differently and to be driven by the data from their environment. However, I also notice that many teams find it difficult to come up with their own ideas of how to move forward. Therefore, I have prepared examples that have worked well in practice to inspire their creativity:
| Action | Format ideas | Recommendations |
| Training the presentation skills |
|
Use peer pressure:if you ask the group what to choose, there is a greater chance that the fear will be overcome and something will be chosen. Once one of your team members chooses to try something new, others are likely to join in. |
| Collect feedback at the end of the Review about how the meeting went |
|
Gathering feedback is important; you can insist on it, but let your team choose the ways that work best for them. |
| Casual talks with Individual stakeholder after the sprint review to gather more open feedback |
|
Talk to different people; do not make routines for such calls so people keep sharing feedback within the Review meeting. This is rather a “quality check.” |
| Creating a Demo Presentation Template |
|
Let the team choose the tools they feel comfortable with; don’t insist on innovative tools – that can come later, and it’s important not to let the inconvenience of using them discourage experimentation (for example, it’s better to have the next steps documented in a shared PowerPoint presentation than to insist on Miro and not have them documented at all). When collecting feedback, ask explicitly about the new parts that have been added: this is a way to measure success and, almost always, increases the team’s confidence in the new experiments, inspiring them to do more. |
| Trying out interactive formats or their elements |
|
Start with the structures that feel safe enough for the team to try. Listen carefully to what can go wrong and brainstorm ways to mitigate those risks. If you work for a large organization, ask your colleagues if they have tried anything and how it went. Experiment with new formats on a smaller scale or with internal stakeholders first. |
Broadening the Circle: Inviting New Participants
Taking the leap towards a more open and collaborative review process involves expanding the circle of participants. This isn’t merely about boosting numbers, but rather about integrating diverse perspectives to foster a richer and more fruitful discussion.
Consider inviting other internal stakeholders. Are there teams working on related functionality or willing to engage with your work? Their insights can be invaluable. Similarly, bringing in “observers” can be beneficial. Look for open-minded individuals who can provide valuable, skillfully communicated feedback. Don’t forget the other decision makers in your organization: who might be interested in the functionality you’re demonstrating? Maybe the marketing team would like to know more details, maybe customer success can help validate the workflow with early adopter customers, maybe sales can run your demo for several potential customers. Many companies have Reviews open to the entire organization; maybe this is an option for you too.
Now that you have experimented with Sprint Reviews with new internal participants, it may be a good time to consider inviting external stakeholders. Each company chooses its own working product discovery tools, and these may be some usage metrics or user interviews – not necessarily should there be externals at the reviews. However, especially in the B2B space, users and customers are often important invitees. Done well, Sprint Reviews can be one of the tools to upsell and generally strengthen your relationship with customers. When they see how their opinions are heard and how they can influence the product, it’s easy to become a loyal user and promote it internally.
Here are a few more recommendations:
- Continue to ask your team members for recommendations on who to invite. If you are successful and have candidates, take some time to learn about them and, if you can, check in with colleagues who have worked with them. With your team, review the personas they belong to, read their LinkedIn profiles, and understand their work pain points and interests.
- As you build this diverse participant list, prioritize stakeholders who are not only interested but also open to change. It’s crucial to foster positive associations with these initial experiments.
- When extending invitations, remember to align your agenda with the invitees and ask about their expectations. If certain expectations aren’t feasible, be transparent and communicate that up front.
- Don’t avoid small talks and introductions when you have newcomers at your Review. You can and you should keep it short, but establishing a personal connection and making people feel safe is essential.
Engaging users and other external stakeholders often requires a significant amount of preparation and follow-up. Remember, the goal isn’t merely to gather feedback; it’s to make these individuals feel invested in the experiment. Be grateful, show them the success their feedback has contributed to, follow up with them, and ask for their ideas, not just their opinions.
Moving away from a reporting culture in Sprint Reviews is like creating a beautiful mosaic. Each piece – from understanding your organization’s culture, to empowering your team with the skills they need, to engaging new stakeholders – plays an important role. It may seem overwhelming at first, but by addressing each aspect one at a time, mindset and culture change becomes manageable. As each piece finds its place, a bigger picture emerges, revealing a vibrant, creative and collaborative environment. My wish for you is that this journey, step by step, shapes into a masterpiece that reflects collaboration and innovation.
MMS • Matt Campbell

HashiCorp has released a number of new improvements to Terraform and Terraform Cloud. Within Terraform Cloud, there is a new CI/CD pipeline integration tool. Terraform has added support for Azure Linux container host for Azure Kubernetes Service. The HashiCorp Terraform AWS provider version 5.0 was released with improved support for default tags.
The new CI/CD pipeline tool has an associated command line tool called tfci. This tool automates Terraform Cloud runs via API and has support for Terraform Cloud operations that can be embedded into CI tools. tfci has commands for showing run details by Terraform Cloud Run ID, executing new plan runs, applying a run that is paused on confirmation after a plan, and returning the plan details.
Alongside the tfci CLI tool, there are templates provided for both GitHub Actions and GitLab CI. These templates showcase common actions that users may need to configure using tfci. For example, within GitHub Actions, the following snippet shows the runs portion of performing a new plan run using tfci:
runs:
using: docker
image: 'docker://hashicorp/tfci:v1.0.1'
args:
- tfci
## global flags
- -hostname=${{ inputs.hostname }}
- -token=${{ inputs.token }}
- -organization=${{ inputs.organization }}
## command
- run
- create
- -workspace=${{ inputs.workspace }}
- -configuration_version=${{ inputs.configuration_version }}
- -message=${{ inputs.message }}
- -plan-only=${{ inputs.plan_only }}
HashiCorp has also added support for deploying Azure Linux container hosts on Azure Kubernetes Service (AKS). Microsoft recently moved Azure Linux container host (previously called Mariner OS) in general availability. Azure Linux is designed to be a minimal, cloud-first Linux distribution.
The updates are within the azurerm Terraform provider. Provisioning Azure Linux container host for AKS can be done by setting the os_sku to Mariner:
resource "azurerm_kubernetes_cluster" "default" {
name = "aks-${random_string.suffix.result}"
location = azurerm_resource_group.default.location
resource_group_name = azurerm_resource_group.default.name
kubernetes_version = var.kubernetes_version
dns_prefix = "k8s-${random_string.suffix.result}"
default_node_pool {
name = "default"
node_count = var.aks_node_count
vm_size = var.aks_confidential_computing_enabled ? "Standard_DC2s_v2" : "Standard_D2_v2"
os_sku = "Mariner"
os_disk_size_gb = 50
}
confidential_computing {
sgx_quote_helper_enabled = true
}
identity {
type = "SystemAssigned"
}
tags = {
name = "demo-aks-${random_string.suffix.result}"
environment = "demo"
}
}
Version 5.0 of the HashiCorp Terraform AWS provider was released with improvements to default tagging allowing tags to be set at the provider level. This update solves a number of pain points with the previous defaulting tagging implementation. This includes addressing inconsistent final plans, identical tags between default and resource tags, and perpetual diffs within the tag configurations.
Default tags can be specified at the provider level using default_tags:
provider "aws" {
default_tags {
tags = {
environment = "Dev"
department = "WebEng"
application = "HashiCafe website"
cost_center = "8675309"
}
}
}
resource "aws_s3_bucket" "example" {
bucket = "example-bucket-aj-11122"
tags = {
environment = "Production"
created_at = timestamp()
}
}
The release also adjusts how attributes marked as deprecated or removed are reported. Previously users would receive a warning notification. Now an unsupported error will be shown to the user. EC2 classic functionality has also been fully removed as this functionality was deprecated by AWS back in August 2022.
The CI/CD pipeline integration tool and templates are available for users of Terraform Cloud and Terraform Enterprise. More details can be found on the release blog and within the GitHub repository. The Terraform AWS provider 5.0 release has an upgrade guide that provides more details on the release’s changes.