







What sets vector databases apart and how to select the right one for your project.
Jul 19th, 2023 6:16am by
Image from Shutterstock.
This is the second in a three-part series.
The emergence of ChatGPT signals the start of a fresh era of artificial intelligence (AI). AI is revolutionizing everything, with vector databases becoming an essential infrastructure in the new era. This trend is not surprising, given the increasing demand for AI-powered applications.
In the first post of our three-part series, we introduced unstructured data and its processing, analysis and querying. This post will delve into vector databases, their distinctions from traditional vector retrieval methods and how to select the optimal vector database for your project.
What Is a Vector Database?
Traditional relational databases store and process data with pre-defined formats in tables and usually perform accurate searches.
By contrast, vector databases store and retrieve unstructured data such as images, audio, videos and text through high dimensional values called embeddings. Vector databases are frequently used for similarity searches using the Approximate Nearest Neighbor (ANN) algorithm. This algorithm organizes data based on spatial relationships and enables finding the nearest neighbor of a given query point in a large dataset of points.
With the rise of ChatGPT, vector databases have become even more essential for addressing issues facing large language models (LLMs).
Vector Databases vs. Vector Search Libraries
Specialized vector databases are not the only stack for similarity searches. Before the advent of vector databases, there were many vector searching libraries, such as FAISS, ScaNN and HNSW, for vector retrieval. Both stacks can query vectors, but what are the differences?
Vector search libraries have limited functionality. They can only handle a small amount of data and struggle to scale with larger datasets and higher user demand. They don’t allow any modifications to their index data and cannot be queried during data import.
By contrast, vector databases are a more optimal solution for unstructured data storage and retrieval. They can store and query millions or even billions of vectors while providing real-time responses simultaneously; they’re highly scalable to meet users’ growing business needs.
Specialized vector databases also offer many user-friendly features, including CRUD (create, read, update and delete) support, disaster recovery, role-based access control and multitenancy. Many vector database providers, such as Zilliz, offer fully managed cloud services to help users eliminate the burden of maintenance work and concentrate on their business.
Moreover, vector databases operate on a different abstraction layer than vector search libraries, serving as full-fledged services rather than components for integration. To illustrate the significance of this abstraction, let’s examine the process of adding an unstructured data element to a vector database such as Milvus.
|
“` from pymilvus import Collectioncollection = Collection(‘book’)mr = collection.insert(data) “` |
As you can see, inserting unstructured data into Milvus is super easy with just three lines of code. However, it’s complicated when using libraries like FAISS or ScaNN. These libraries require manually recreating the entire index at checkpoints.
Vector Databases vs. Vector Search Plugins
As vector databases gain attention, many conventional databases and search systems such as Clickhouse, Elasticsearch, MongoDB and Databricks are rushing to integrate built-in vector search plugins. Elasticsearch 8.0, for example, has updated features such as vector insertion and ANN search that can be accessed through RESTful API endpoints.
However, it is important to note that vector search plugins do not offer a comprehensive approach to embedding management and vector search. They are merely add-ons to existing systems, which can limit their performance in terms of latency, capacity and throughput. Trying to build unstructured data applications on top of a traditional database is like fitting lithium batteries and electric motors inside a gas-powered car, which is not a great idea.
Vector Databases Are Essential for LLM Augmentation
With LLMs and AI applications thriving, vector databases are becoming a vital infrastructure for AI-related tech stacks.
Although LLMs are impressive in content generation, they have many limitations. For instance, they are susceptible to hallucinations due to the lack of up-to-date and domain-specific knowledge. What’s worse, LLMs’ token limit prevents you from adding extensive contextual information to prompts when making queries.
A vector database can serve as LLMs’ long-term memory and expand LLMs’ knowledge bases. It stores private data or domain-specific information outside the LLM as embeddings. When a user asks a question, the vector database searches for the top results most relevant to that question. Then, the results are combined with the original query to create a prompt that provides a comprehensive context for the LLM to generate more accurate answers. This solution is also known as a CVP stack (ChatGPT/LLMs + vector database + prompt-as-code).
LLMs charge for every token in queries. So if users ask similar or repetitive questions, they would be charged multiple times, resulting in high costs. During peak hours, responses can be very slow. To save time and effort, developers can integrate a vector database with GPTCache, an open source semantic cache that stores LLM responses. That way, when the user asks a question the LLM answered before, the vector database retrieves the answers from GPTCache and quickly returns them to users without calling the LLM.
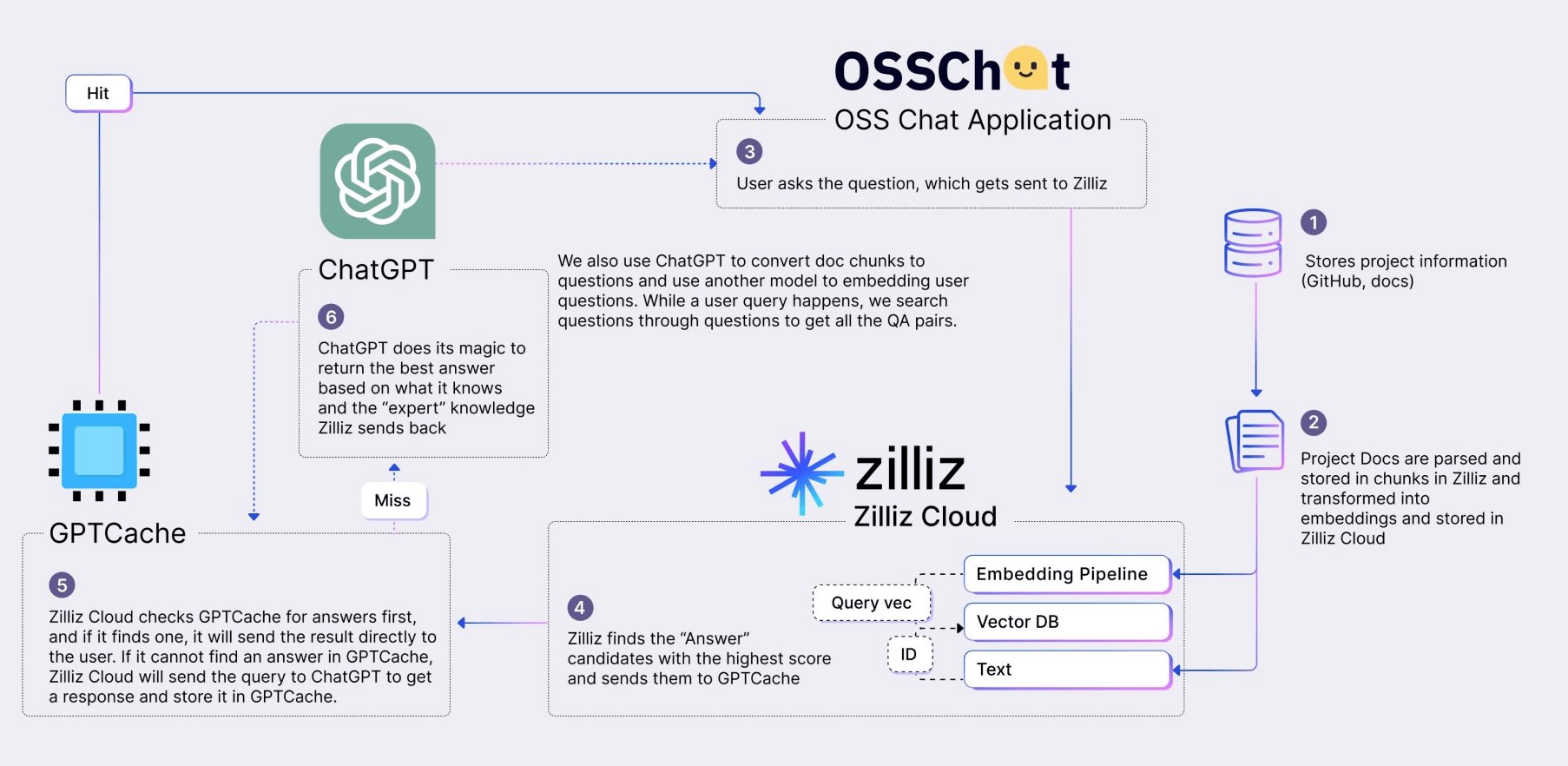
The architecture of OSS Chat that leverages Zilliz Cloud and GPTCache.
In addition to LLM augmentation, vector databases are valuable for many use cases, including recommender systems, image/audio/video/text similarity searches, anomaly detection, question-answering systems and molecular similarity searches.
How to Choose the Most Suitable Vector Database for Your Project?
Are you struggling to choose a suitable vector database for your projects? With numerous options available, it can be overwhelming. Luckily, there’s a solution to help you make an informed decision.
VectorDBBench is an open-source benchmarking tool for vector databases. It evaluates various vector database systems regarding QPS, latency, capacity and other metrics. It is written in Python and licensed under the MIT open-source license, so anyone can freely use, modify and distribute it.
With VectorDBBench, you can select the best vector database based on actual performance rather than marketing claims. To get started, see this tutorial.
Summary
This post provides an overview of vector databases, explaining how they differ from vector retrieval libraries and vector searching plugins on top of traditional relational databases. Most importantly, we introduce VectorDBBench, an open-source benchmarking tool to help users make informed choices.
In the following post, we will introduce Milvus, the world’s first and most widely used open-source vector database and walk you through how to get started with Milvus.
Created with Sketch.
