Month: July 2023

MMS • Ben Linders

Renewable energy is an important step on the way to fight climate change. The energy produced by burning fossil resources is one of the main drivers of carbon emissions. But running a datacenter on renewable energy all the time is difficult. Usually – with only a few exceptions – your workloads do not run on renewable energy.
Martin Lippert spoke about using running workloads on renewable energy at OOP 2023 Digital.
Most sources of renewable energy are not available all the time and do not produce energy at a constant level all the time, Lippert said. The amount of energy that wind and solar produce fluctuates over time, and this usually doesn’t fit well with the moments in time when we consume the energy, he added. It is a huge challenge to align the production and consumption of renewable energy as closely as possible so that you can relinquish other energy sources:
The sentence that the datacenter uses, “100% renewable energy,” usually only means that the operating company buys as much renewable energy as the datacenter consumes in total. It does not mean that the datacenter is fed all the time with enough renewables as it needs at that moment.
We don’t produce enough renewable energy for the overall energy needs, and the total energy consumption still goes up, Lippert said. Even if we dramatically increase the amount of renewable energy that is being produced, we might not get there fast enough.
Lippert suggested tackling the problem from multiple sides: more renewable energy production, less energy consumption, and more flexible workloads.
We need to think about workloads that are flexible with regards to when they run, where they run, and if they run at all, Lippert said. The more flexible the workloads are, the easier it is for a datacenter to save energy, the easier it is to align renewable energy availability with energy consumption, he mentioned:
Think about an option to automatically run a workload in the data center that has the most renewable energy available at a specific moment in time. Or to run batch workloads when renewable energy is available instead of at a fixed date and time. Or to not run workloads at all if they are not used.
A widely used technology stack for building business applications is Java and Spring Boot, Lippert said. While in the past, starting up those applications took many seconds, sometimes even minutes, this has changed dramatically, as he explained:
The GraalVM native image technology and the corresponding support for this technology in Spring Boot allows you to compile Spring Boot applications ahead-of-time into native executables that startup in milliseconds. This opens the door for probably millions of business applications around the globe to be more sustainable and more flexible with regards to scale-to-zero architectures and platforms.
The way you write and operate software has an impact on carbon emissions and climate change. Let’s not wait for others to solve the problem, let’s write greener software instead, Lippert concluded.
InfoQ interviewed Martin Lippert about handling zombie and idle workloads.
InfoQ: What problems do zombie workloads cause?
Martin Lippert: The term “zombie workloads” originates from the study zombie/comatose servers redux that analyzed a number of datacenters and their deployed workloads. In that study, they called workloads that were deployed, but never used, “zombies”. Interestingly, the study revealed that zombie workloads are not a niche problem. They found between 1/4 to 1/3 of all deployed workloads to be zombies. That is huge.
Zombie workloads consume energy and hardware resources. Identifying those zombie workloads and removing them could save huge amounts of energy. The cloud management software from VMware, for example, has features built-in to automatically identify zombie workloads. And you will find similar features in other offerings as well. Automation is key here. You can’t do that manually – at least not at scale.
InfoQ: The study also identifies idle workloads, those that are used only sometimes. What can we do about them?
Lippert: We can’t delete those idle workloads and for some of those workloads, we can’t even predict exactly when they will be used and when not. One approach here could be to adopt so-called “scale-to-zero” architectures and technologies that allow you to run those workloads on demand only.
This is obviously not very straightforward for many workloads that we have today. Imagine a workload that takes many seconds, if not minutes, to startup. You can’t start up such a workload on demand quickly enough to serve the users needs. But there are architectures and technologies in place that allow you to refactor applications into smaller pieces and to turn them into applications that indeed startup in milliseconds – which seems to me good enough for many on-demand approaches.
MMS • Steef-Jan Wiggers
Microsoft recently announced the preview of Azure Application Gateway for Containers – a new application (layer 7) load balancing and dynamic traffic management product for workloads running in a Kubernetes cluster. It extends Azure’s Application Load Balancing portfolio and is a new offering under the Application Gateway product family.
The company claims the Application Gateway for Containers is the next evolution of Application Gateway and Application Gateway Ingress Controller (AGIC). It introduces the following improvements over AGIC:
- Achieving nearly real-time convergence times for reflecting changes in Kubernetes YAML configuration, including adding or removing pods, routes, probes, and load balancing configurations.
- Exceed current AGIC limits by supporting more than 1400 backend pods and 100 listeners with Application Gateway for Containers.
- Provides a familiar deployment experience using ARM, PowerShell, CLI, Bicep, and Terraform or enables configuration within Kubernetes with Application Gateway for Containers managing the rest in Azure.
- Supports the next evolution in Kubernetes service networking through expressive, extensible, and role-oriented interfaces.
- Enables blue-green deployment strategies and active/active or active/passive routing.
Hari Subramaniam, a Cloud Solution Architect, tweeted:
Absolutely AGIC won’t be missed. I hope the glaring shortcomings with AGIC is addressed in this, and by the looks of it seems a lot of it will be addressed.
The Application Gateway for Containers consists of various components Application Gateway for Containers core, Frontends, Associations, and Azure Load Balancer Controller. In addition, deploying the gateway requires a private IP address, subnet delegation, and user-assigned managed identity.
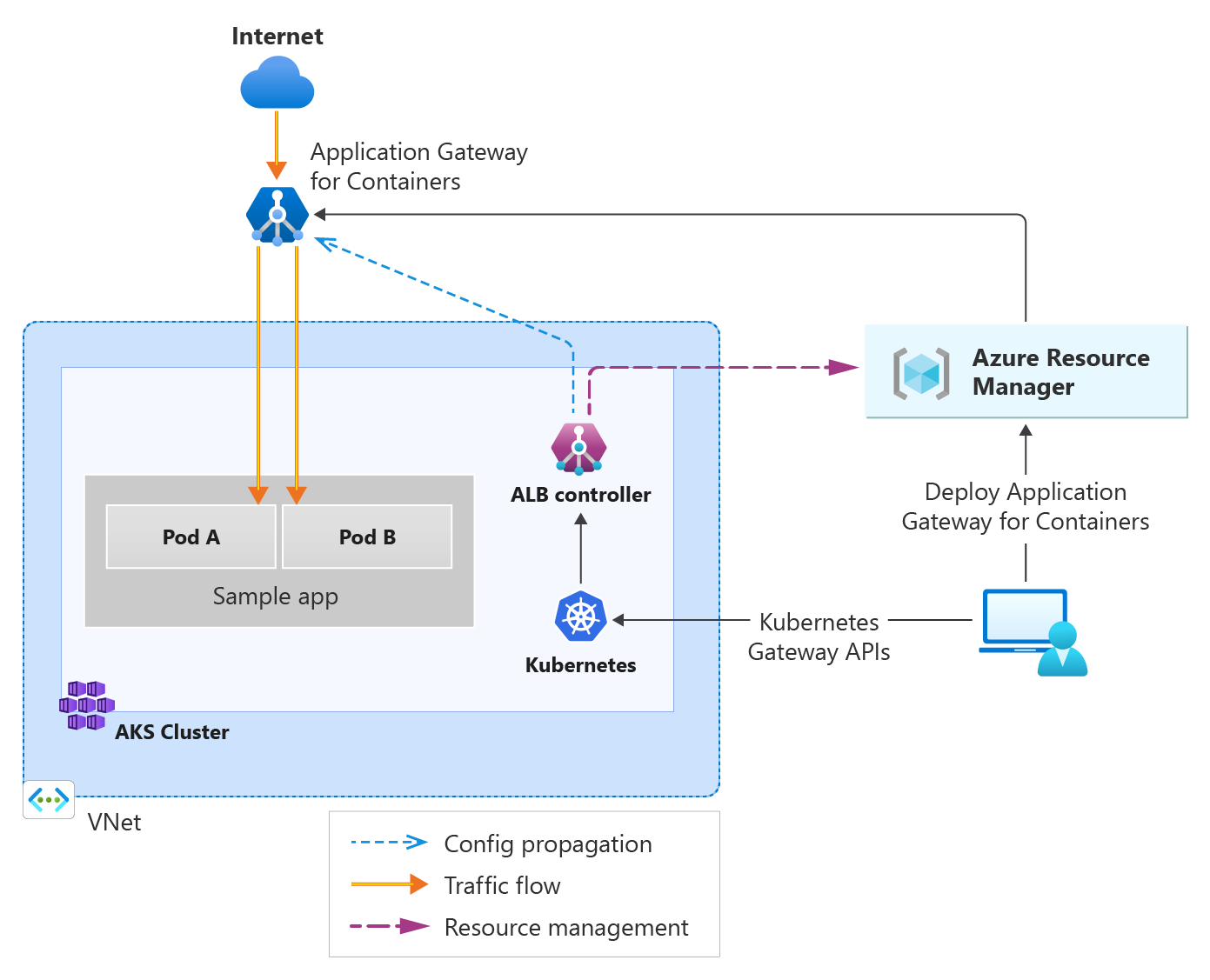
Diagram of the architecture of Application Gateway for Containers (Source: Microsoft Learn Documentation)
Camilo Terevinto, an Azure Solutions Architect Expert, tweeted in response to the preview announcement of Application Gateway for Containers:
This should be called “Azure Application Gateway for Kubernetes Service,” considering it doesn’t support Azure Container Instance (ACI) nor Azure Container Apps (ACA) – or is that planned for later?
With Azure Networking responding in a tweet:
Application Gateway for Containers is for Kubernetes workloads today, but we may consider extending the service to other container solutions in the future as well.
In addition, Dennis Zielke, a Global Blackbelt for cloud-native applications at Microsoft, outlined in a medium blog post a few design limitations:
Overall, the new service has very promising capabilities; however, there are a couple of design limitations today (which are being worked on):
- Limitation of exactly 1 ALB per cluster, 5 frontend per ALB
- Only supporting Azure CNI in the backend cluster
- No multi-region or multi-cluster support
Lastly, the Application Gateway for Containers is available in several Azure Regions globally, and no pricing details are available before the general availability according to the pricing page. In addition, more details and guidance is available on the documentation landing page.
MMS • Amy Tobey

Transcript
Tobey: My name is Amy Tobey. I’m a Senior Principal Engineer at Equinix. We’re here to talk about the endgame of SRE, which is what happens after you’ve done all of the things that SRE is supposed to do. We’ve built the best infrastructure that we can build, and yet, our teams still have reliability issues that they need to figure out. To do that, we need to go explore the sociotechnical space. To enable that exploration, we’re going to go into the town of Endgame. We’re going to do what you always do at the beginning of a new game, or in the beginning of a new journey through DevOps and SRE, we’re going to go talk to the people on the ground and find out what they’re feeling.
The Root Cause of Outages, in a Perfect Environment
Right away, we talk to hacker Dave, he’s in SRE. He set up the perfect Kubernetes environment for his people. Somehow, they still have outages, and this baffles him. He wants me to figure out why and I don’t really do root cause. We’ll just go around and talk to people to understand what’s going on. Right away, we meet Agi Lecoach, and she is somebody who works with a lot of software teams in this organization. She’s a great source of information about what’s going on here. Immediately, she keeps telling us about the leadership team, they hang out at a place called Mahogany Row. We’re going to talk about a lot of sociotechnical factors. That’s really what this is about, is how all these things come together. One of the first ones that I’ve noticed is a lot of people in, I see individual contributor positions, look at the leadership as like they should know all things. Really, they’re just people. There’s a team called Inferno. They deliver, but they have quality problems all the way through the process. We’re going to meet Team Marathon. Their velocity is smooth as can be. They make it look easy. They go home at night. I want to learn more about what works for them. Then there’s Team Disco. They work really hard, but their velocity is always going up and down. It’s hard to predict when they’re going to deliver something.
Another tip I like to give software engineers and SREs, and really anybody who’s trying to do this DevOps thing is, go make a friend in sales. We’ve made a friend in sales, Glenn Gary. He’s telling us right away, he’s having trouble selling the product, because when he demos it, it crashes. That’s like the worst case, because if we can’t sell the product, we can’t pay our bills. He says Team Inferno, they talk a big game. They never shut up about it. Their customers are stuck with us, so they haven’t really figured out their quality issues. That’s an interesting point. Team Marathon, it looks like again, that they’re just taking it easy. I’ve heard this for a different product, from actually a real sales guy before, and this is like the best case, when the whole product and engineering and the machine works together, the sales folks will complain. They’ll be like, “I’m basically just an order taker here. I don’t have to work to sell the product, people coming to me being like, just help me buy it.” That’s like the best case. Then again, Team Disco, they always deliver, but it’s never on time. Their releases are always dodgy. They’re always busy. That’s starting to tell me something. I think I smell what’s going on there. Then, Glenn tells us about Mahogany Row and how they’re always saying that everything is fine. This is the first concept I want to drop on you all, which is what I call Instagram leadership. This is when you got a leader, you get all the highlights, the best pictures of their organization, but you don’t really hear about the stuff that’s happening on the other side of the camera. I start to get curious when that happens, and be like, what do we not know about that they’re not talking about because we can’t help them as leaders, if we don’t know what they’re struggling with.
We meet Frau Barella. She is a UI engineer, or UX engineer, and is very proud of the style unification effort that her team went through. What she’s pointing out to us is that sometimes, like with quality, with reliability, with security, it seems like we have all of the elements. All the pieces are there, but it’s not coming together to create a great user experience. Again, this brings us back to the sociotechnical space. This is the story we’re going to go through with these teams is, all of the stuff that happens in that messy liminal space that we call sociotechnical between the products that we’re building, the technical bits, in the social space where all these humans are trying to do stuff is where these efforts tend to go sideways. With that, let’s go meet Team Disco. Right away, we meet Team Disco’s manager, Managear Greg. He comes right out of the gate telling me he’s doing a thing that we call the crap umbrella. A lot of managers, especially young managers think that this is a way to help their team, in that they make sure that all the bad news goes around them. That they don’t get hit with the worst of what’s coming from the rest of the organization. It’s a noble goal, but great people need context to do their best work. There’s something I’m probably going to have a further conversation with him about, do some coaching around. We know where this is coming from because when Managear Greg goes to his director, she tells him, and goes, “Don’t come to me with problems, come to me with solutions.” This is a useful phrase for really great managers, but a lot of middle-ish directors and things will say this. What they’re saying is, they don’t know what to do. They’re looking for that answer. The idea is, as a leader, your job is there to help your people succeed. It’s ok to ask for a plan, because sometimes your people will be stuck. They don’t know that they know the answer, and you lead them through it. Often, it’s also a way to bypass responsibility too. I think that might be what’s going on here.
We meet Polly Math who is all over the place. She’s working at kernels. She’s doing incidents. She’s fixing tests in kernels. She’s really doing a lot of things and probably a lot of glue work. This work is probably not being recognized. It might just be a matter of tracking it better. A lot of times, it’s more getting out into the sociotechnical space and making people realize that all these little kinds of things that people just take care of are what make our business function. Because it doesn’t show up on the books, and it’s not revenue facing a lot of times, it doesn’t get the credit it deserves. Here’s another opportunity for us to engage with this team and the teams around them and help them improve their communications. Next, we meet Isabella, who tells us, we’re so far behind, and they keep giving us more work. This brings up the law of stretched systems. The law of stretched systems says, if you add capacity to a system, it’s going to get consumed, basically. This is what we see happening on this team is that they’re never really getting their heads above water. Every time they find some capacity, it just gets hoovered up, and everybody is still complaining.
Next, we meet the tech lead, who says we love our work. Sounds like the team likes each other. Again, we know they’re having trouble with their velocity. They ran an experiment. They said, let’s split the work up, and as individuals, we can go faster as individuals than as a team. Let’s split it up, so we can go faster. Great idea, except as Polly Math predicted, business is just going to keep asking for more if you do that. Now your team is disconnected and people aren’t up to date on each other’s projects so it’s harder to communicate within the team. Also, you haven’t really gotten out of the hole. I don’t think this technique is really going to get them where they want to go. Probably give them advice to get back into that team sharing mode, if only to prevent burnout from people being too responsible for a single product. Cody is the senior engineer on the team. He brings up probably the most common, bar none, complaint that I’ve heard from various engineering teams, product teams. It’s usually like one saying one side or the other, is, they never give us enough detail in the product specs for us to do our job and to build the right stuff.
Product people often say the opposite. They’re like, we give them everything and they complain about it and we don’t know what they actually need because it’s in the technical space. There’s always opportunity here when you hear this old song to get involved and start figuring out where those communication breakdowns really are. Because usually once you get these folks together in a more constructive setup, sometimes you need a designer in the room, sometimes an SRE sitting in the room helps. It provides the opportunity for them to start communicating instead of just taking shots at each other over the fence.
This does happen, where product teams tend to want to protect the customer. They own the customer relationship. They’re very proud of it. This often could create barriers where engineers aren’t able to get face time with customers, and it’s harder for them to build empathy and build really great products when that happens. Then, finally, for Team Disco, we meet Devo Pestorius. She tells us another story I’ve heard before, which is, we have all this great CI/CD stuff, we’re doing DevOps. Why are we so slow when all of our vendors told us if we implement this stuff that we will be great at DevOps? Once again, the answer is, it’s not your tooling. It’s the sociotechnical system you exist within that creates the environment in which your team is performing poorly, so let’s go out and adventure more into that environment, and see if there is opportunity to change it and make it better for them.
Raising the Bar Leads to Burnout
Given what we learned about Team Disco, they’re a classic case of a team. Probably the most common thing I see with software teams is that they’re churning. They’re having a really hard time making progress, because something keeps pulling the rug out from under them, or their priorities are changing too fast so they never really get things over the finish line. We go meet the Bob’s. It’s what everybody calls him. This is why, is because he’s doing something that infuriates me, and I’ve seen this in the real world. It’s that he thought he could get more from the team by raising the bar. A lot of leaders and product managers, and so on, feel this way, is that they’re like, if I put pressure on the team, I will get more. The reality is, and most of us who are software developers and SREs, and so on, know that when that happens, it doesn’t necessarily get you more, it burns people out. When you see this, it’s a good time to bring people back to reality and remind them that velocity points are for your team, and they have no relevance outside of it. If I had my way, product managers would never be able to see story points. This is why I think it’s deleterious to do that, because it’s there for engineers to get better at estimating over time, not necessarily for people outside of the team to make predictions about how much capacity they can squeeze out of it. It’s like, whose line is it anyway? The points are made up.
We meet Directrix Tina. She is the director that says, come to me with solutions, not problems, but she doesn’t want to talk about that right now, because what she sees is an opportunity. She sees an SRE that knows how to code. She’s got teams that are behind. What if I add another person to the team? Maybe, Amy, can you go and write code and help us get this over the finish line? You’d be an asset to the team. A lot of us, especially as you get into staff, principal, SRE roles where you’re not directly in the line of revenue, there’s a temptation there to do this. Nobody succeeds without a support system. We’re the healers. We’re the back end of making things happen. I’m going to politely refuse again, for Directrix Tina. Maybe have a talk with her about this whole helping up Managear Greg. She recognized that Disco is struggling, but she really just wants me to talk to Inferno.
The Telephone Game
Another pattern that all of us have probably seen, is the telephone game. Pandora goes out and talks to a prospect, and shows him this new dark mode demo to get them excited. They want that before they’re going to sign a deal. Then that goes up and down the leadership tree. It’s gotten to the CEO. He recognized, we got a lead in front of us, we got to get that. He’s like, what if we could theme the whole site? It’s CSS, it’s so easy. Like this guy knows. He’s got the power, so he can make it happen. He went to his guy over in Team Inferno, and they started work on theming the whole site. I can only imagine how this is going to go. Getting back to the telephone game I mentioned, so we’ve already gone from dark mode to theming the whole site, and now we’re talking about a color wheel. I don’t know where that came from. You need a color wheel to theme the site. I don’t think you need it for dark mode. This guy is just trying to do his best. He’s trying to get that promotion, and so he wants to help. The intent is great, I suppose. The impact is that, now we have these multiple ideas in our organization about what we’re building. They’re going to conflict and they’re going to slow things down.
Pantone Values
We meet the Mistress of Scrum. She’s forming a tiger team to get ahead of this problem, and to implement the new Pantone values. We’ve gone all the way to Pantone values now, and we’ve covered the telephone game thing enough. What happens is, a lot of times, especially in command-and-control organizations, what you’ll notice is that communications tend to go up and down the chain of command. This is slow. Because of the telephone game, often you have information loss along the way. We know about information loss in analog systems if your Ethernet cord is too long or frayed, you might drop packets. The same thing happens in human networks, and it causes all kinds of problems, that we sit there scratching our head about, how did they come up with Pantone values? The other thing is the tiger team, it seems like a great idea. We’ll go get our best people from all the teams and put them together into a new team so we can knock out this new feature. Except that you completely screwed all those other teams by taking their best people away from them, and those people probably had a role to play in that team. I’m not a huge fan of tiger teams, unless there’s like a really existential business thing happening. Even then, we have to keep things moving, we have expectations to keep delivering. That often doesn’t get taken into account properly, I think when tiger teams are formed.
Water-Scrum-Fall
Then, I can’t go by without making a pass at water-scrum-fall, and what we see as a lot in our field. It’s inescapable in a lot of ways. These organizations that misunderstand what scrum is, or agile is and then they also want to keep holding on to waterfall. What we end up with is they plan all of the sprints out for months, which is completely missing the point of agile. They still have sprints, but they’re scheduled ahead of time and the plan never really comes together. We lose so much time and momentum in that. We don’t get the chances for the feedback to go back into making the plan continuously better. It’s one of those things that I look for, that tells me where to start talking to people and intervening in the sociotechnical realm. Finally, from Mahogany Row, we meet Desi Goner, she’s a designer. She was sent up here from Team Inferno to figure out the critical user journeys. As we were talking about, without a strong product process in place, if you go ask 7 leaders, what we’re supposed to build, you might get 8, 9, or 19.2 answers. That’s also a pattern I look for is when we just have these diverging opinions colliding with each other and preventing great communications.
Creating Room for Downtime
We were asked to go take a look at Team Inferno. Let’s go see what’s up with them. Immediately, I’m getting a vibe here, not just the red, but let’s go talk to this guy, he looks very boss like, and indeed, his name is The Boss. It used to be a joke I used to do when I was younger, and then I was working for a manager, I really liked it. I thought it would be funny to call him boss every once in a while. He stopped me and said, “I don’t like it when you call me that. I don’t like being a boss, I’m your leader. I’m trying to get you to understand where we’re going instead of telling you everything you’re supposed to do. I think that’s what bosses are and I don’t want that vibe.” It’s like, that was a good lesson for me. The other thing going on here with the boss is right away he’s coming at me complaining about the millennials. That’s right off the bat a problem. What he’s really complaining about is boundaries. There’s a little bit of a generational divide there. It’s fuzzy. I’m not going to make any claims about it. What we see happening with the quiet quitting debate or the quiet firing debate is people, those of us, the workers are setting boundaries. We’re saying, I need to have downtime to do my best work to continue doing this job for decades. I can’t just work 24/7. The boss says, he turned out ok through all that hustle, but I’m looking through the armor and I’m seeing red eyes. I’m seeing that maybe he didn’t turn out ok, after all. To just put a cherry on top of this guy’s problems, and I’ve seen a bit of this in the real world too, where people, especially an authoritarian style leader, will jump to being like, “If you guys write an exploit, I’m going to fire you, so don’t write any exploits.” I don’t really understand this line of reasoning, but I try to empathize with these people so I can understand them and fix what they do. A threat will keep somebody from writing a vulnerability. Those of us who write code that goes on the internet knows that’s bullshit. We know that it’s your state of mind, your ability to focus, your level of rest that determines the quality of the code that you produce on a regular basis over time. Lots of interventions already needed here. My recommendation would probably be to get a new manager for this team. Let’s see what else is going on before we come up with recommendations.
This guy, his name is Tenex. He clearly needs to work on his skincare routine. We’ve all probably worked with this person. I’ve been this person, earlier in my career where I liked working a lot. I liked what I was working on. I just never understood why people didn’t want to do what I did. It wasn’t till I got older and went through some burnout that I really started to understand. This is probably something worth addressing, because the standard he’s setting is unreachable for the rest of the team. That’s going to create problems. It could create problems with morale. If he’s working that much, I’ve got questions about the quality of his code. The other thing that’s happening is we’re bypassing the planning process. Any business that’s bigger than a few developers, we’ve really got to have some process to make sure that we can get into throughput mode, and crank out all that code that builds the business that we’re supposed to be building. When we keep churning, we end up like Team Disco, where we’re not actually making a lot of progress on each thing that we’re trying to build, and they all end up disjoint and low quality. Yes, planning is for nerds, but I like being a nerd and I respect nerds.
The Lead Dev is frustrated. When you have somebody who’s out doing 100-hour weeks and producing low quality code, and maybe he doesn’t have respect for their coworkers, somebody’s usually doing that cleanup job. It’s usually somebody with different socioeconomic backgrounds that usually end up with that work. She’s fed up with this. This team is looking at attrition, because who wants to work in an environment where you have to constantly chase this guy around and smell his lack of showers, when there’s a wide world of developer shops out there to go work at. When this happens, each time we have attrition, it’s easy to go like, Amy moved on. It’s not just that person going away in their capacity to produce the future. It’s also all the knowledge and implicit knowledge they carry about the systems that we’ve built, that they take with them, and that we no longer have access to. The people with our implicit knowledge is the unit of adaptive capacity. This is how we are able to get through turmoil and changes in the world around us. There’s a concern here with attrition. We’ll report that and move on. Then, this guy, it’s interesting when you’re trying to do the sociotechnical work, trying to engage with teams and help them get better. There’s usually some folks. I find them baffling. I have longed to understand the mindset that they can work in, where they’re in a mercenary mindset. They’re like, “I’m here. I get paid. Not my circus, not my monkeys, just, whatever man, I just do it.” I can’t do that. I’m like, I got to fix this. I got to fix that. These people are kind of inert. I want to try to help them and they will benefit if we make the team healthier. They’re probably not going to help us get there.
Shelly the Intern is also frustrated. She’s on a team that’s toxic. She’s unpaid. That’s a whole problem of its own, in that unpaid internships are only really available to people who can afford to not work. She’s mentioning that the Boss brought in a new developer metrics tool. These are very popular right now, to work on the quality problems. Immediately, he berated Shelly for having reviews that took a while. My feeling is that an intern’s code reviews, their PRs, should spend a little bit more time in scrutiny for it to get that opportunity to teach them. As a adaptive response to this, she got together with Leah Dev, and they decided just to stamp all their commits and not spend time on actually reviewing them. They’ll go off and do discussions on their own outside of the system, just so that the Boss doesn’t harp on mean time to review. This is where these metrics tools, especially when used naively can take your organization extremely sideways. The intent there from software managers is, yes, they got a lot of complexity to manage, they got to understand the health of their team and where it’s at, and it’s hard. There’s so much to look at, and so they reach for these tools. Then immediately metricism kicks in, and the target becomes the goal instead of the outcomes for your customers. Sometimes you can’t fight these things, but you can get involved and talk about these unintended consequences of the tools and the numbers. Often, that does have an impact.
Learned Helplessness
Finally, for Team Inferno, we talk to Kirito. He’s saying like, “I came from another job. I started here, it’s just weird. I’m here, these people are all crazy. I feel powerless.” It brings up a common situation, especially in toxic teams, or in larger teams that have toxic elements, is you get this effect I call learned helplessness. What that is, is when you go talk to a team, and they’re like, “We have this terrible stats tool. We have to stamp PRs, because if it goes over an hour, we all get in trouble. There’s nothing we can do about it.” That’s learned helplessness. Over time, humans, the thing we do best, is adapt. Adaptation isn’t good or bad, or evil or good. It’s just what it is. We will adapt to bad situations, and we will adapt to future situations. In learned helplessness, we adapt to that helplessness and it just gets under our skin. When you run into a team that has that, it really does take a leadership intervention to start to break out of that mode of learned helplessness. SREs often have a role in doing that in that we can provide tools, and access, advocacy with the leadership team. Breaking that is usually the first thing that needs to happen to get the team into a healthier place. Because if people don’t feel autonomous to go and make their environment better, how can we expect them to produce great products? I don’t think it’s really reasonable. Once again, we’re looking at some attrition. It’s pretty common for this to happen on a toxic team, where maybe it slides under the radar for a really long time. Because what’s happening is people join, they stay a year, almost exactly, and then they bail. Just the way things work out if you’ve been through enough interviews you know, there’s almost always that chronological reading of your resume. They go, “You were only at that job for six months. Why were you only there for six months?” Most people will try to stay at a job for a year, just to get past that hump, that perception. I think that’s what Kirito is doing. He doesn’t seem happy. He does see some hope. There is a team that seems like it might be better for him, but they almost never have openings, probably because they don’t have high attrition.
A Westrum Generative Culture
Let’s go see what Team Marathon is doing. Team Marathon, immediately when we come into it, it’s just a very different vibe, especially coming from Inferno. It feels cozy. People seem relaxed. We’ll talk to their manager, Nyaanager Evie. What I love right away is she’s just open about incidents. I’ve met teams where they’re shy about them. They’re like, we don’t want to talk about our incidents, because they feel bad. In a really healthy team, I feel, especially in internet live services and stuff, what we want is for them to be really curious about incidents, to talk about them, to learn from them. Because it’s one of the most powerful places we have to go and learn about the things we didn’t already know about our systems. Already getting a great vibe from Nyaanager Evie, and because of the incident and the drain it put on the team, she told them to take off for the day. It’s really nice. When we talked to Mahogany Row, it was pretty clear the leadership team maybe is, let’s say, still growing into their roles as leaders. What’s happening here is we have a team that’s fairly healthy with these other unhealthy teams around them. Then Mahogany Row distributing a caricature of all the worst leadership things I could think of. I see these teams all the time in large companies, small companies, where there’s that one team that’s pretty good, even when there’s other teams around that are trash fires. What usually is going on there is that weight of that, of the organization is putting that pressure on that manager. They’re the ones holding it back, maybe sometimes that crap umbrella I mentioned earlier.
I get the feeling that Nyaanager Evie is a little bit more straightforward with her team. There’s a real burnout possibility here. This pressure, whereas Nyaanager Evie wants to grow her career, but when she goes to the Mahogany Row folks and says, I want to grow into senior manager, or director, or whatever. She gets told, “You got to push your team harder, they’re making it look too easy.” To which I would respond, “We deliver on time. We deliver with high quality, and our customers are happy.” That’s what’s most important, more than how many features we put out. We all know this, but for some reason, we have to say it again and again. In effect, what we see going on with this team, is a Westrum generative culture. It is a framework for looking at cultures. It talks about a pathological mode, a bureaucratic mode, and then generative mode. Generative is in that fun space in a team. If you think of that team you were on, that was like the best, where you were having fun. You were cranking out code. You were delivering features, and it felt good. You start to look at that through this generative framework, I think a lot of things will start to look very familiar. Boba Jacobian has pointed it out to us, and I think we’re all on the hook to go learn about it.
Incidents and Soak Time
Next up, we’re going to go meet the Seventh Daughter of Nine. She’s really into incidents. She’s going to do the incident review. She’s only got the gist of it, but she’s going to wait till next week, to go and interview the team and find out what really happened. This is more of an incident thing. It comes any time we have a conflict or an adrenaline moment, or the team running really hard, is, you want to give people some soak time. We talk about this a lot in incidents, but it’s applicable across our domains. In that, we give somebody a bunch of information, and some of us are really good at processing that and can immediately work with it. Most folks need a day or two to really internalize it and start to understand, and be able to come up with a story, a narrative to tell us. This is a good sign that she understands the people around her and that they need some processing time. She also mentions that this guy over here, Xela, we’re going to talk to him next, was bragging about error budgets, that they use error budget alerts to find out about the incident. They’re comparing it to the incident timeline. This is an interesting thing we can do when we have SLOs and great metrics, is when we put together our incident timeline, we should be able to line up the dips at our traffic with the timeline. That’s cool that they’re collaborating and doing that work, while they’re waiting for the team to get their thoughts together.
Error Budget-Based Alerting
Hidaslo Xela, he’s a modest guy. Usually, he’ll tell you, he’s the most modest person you know, but he basically recently set up these SLOs and set up error budget alerting for the team. They’re feeling pretty good about how those error budget alerts fired. They found out about the problem well before the customers did. It seems like something pretty elementary to a lot of SREs that we should have really great alerting. The opportunity going forward is that with SLOs becoming more commonplace in our industry, with error budget-based alerting, we can start to clean up a lot of the noise in our alerts and focus on things that impact our customers and not the things that impact our computers. The stuff that impacts the computers, matters. At 4:00 in the morning, when I’ve been up maybe playing games all night, I stayed up too late, and I get woke up by the pager and it’s some stupid disk space alert, and my customers are fine. Do I really need to be getting out of bed for that? This is one of the problems that error budget-based alerting tends to solve. Going back to Westrum culture, he’s exhibiting something that we like to see in a healthy team, which is, when they discover a new technique that helps them succeed, they’re eager to share it with the organization. The organization would be eager to have it. I don’t know that this organization is ready for what Hidaslo Xela has to sell. I think he’s on the right track on how to help these teams improve. I’m probably going to buddy up with him. Be like, let’s go try to implement SLOs for these other teams. I think especially for Team Disco and that churn situation, the error budget will give them a tool to start to push back on the schedule, and say, our error budget is empty, we got to go spend some time on quality to get this service back on the road.
Learning from Incidents, and Minimizing Burnout
We meet Doctor McFire, who says, on-call is a rush, you’re typing away and next you’re incident commander. We have an on-call who went right from the SLO alert to the traces, immediately figured out that she screwed up and wrote a roll forward PR. What’s interesting about this is like when we have a really fast feedback cycle between, we cut the code, we merge the PR and it gets automatically deployed, and we immediately get alerted on it, all of that knowledge is still fresh in her mind from the code that she wrote. Doing a fix for it is super easy, because she doesn’t have to sit down and debug and figure out, so what did I do two weeks ago? It’s all just right there. That’s a really good sign. It’s a reference to a friend of ours. Dr. Laura Maguire wrote a paper about incident coordination. It’s very good.
Then the last character we’ll meet is Courage. He’s going to talk to us about something I like to see in individuals, which is, they still have some gas in the tank after work. When we run a team all the way to their capacity, we’re running people towards burnout. What we want to do is pull that back a little bit so they have a little capacity left at the end of the day. Because if you run out until you’re down at the bottom of the barrel, you’re not going to be writing your best code. You’re going to have more exploits, more reliability issues, and unhappy customers. This is a really good sign that he’s got this zeal to go write Rust. “It’s a full moon, the sky is clear, and I love coding.”
Conclusion
We visited three software teams. We visited one that is churning, and not really making progress. Another one that’s a toxic waste dump of ideas, and things that we don’t want to do. We met one team that’s functioning really well. In each one, there are interventions we can find when we start to understand the social-technical factors, and explain them to the people around us so that we can make these connections, and start to make our teams healthier. I think we will get better code out at the other side.
See more presentations with transcripts
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the target of some unusual options trading on Wednesday. Stock traders purchased 36,130 call options on the company. This is an increase of 2,077% compared to the typical volume of 1,660 call options.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the target of some unusual options trading on Wednesday. Stock traders purchased 36,130 call options on the company. This is an increase of 2,077% compared to the typical volume of 1,660 call options.
Insider Activity at MongoDB
In other news, Director Dwight A. Merriman sold 1,000 shares of the business’s stock in a transaction dated Tuesday, July 18th. The stock was sold at an average price of $420.00, for a total transaction of $420,000.00. Following the completion of the transaction, the director now directly owns 1,213,159 shares in the company, valued at approximately $509,526,780. The transaction was disclosed in a filing with the Securities & Exchange Commission, which is available through this link. In other MongoDB news, Director Dwight A. Merriman sold 1,000 shares of the company’s stock in a transaction that occurred on Tuesday, July 18th. The stock was sold at an average price of $420.00, for a total transaction of $420,000.00. Following the completion of the transaction, the director now owns 1,213,159 shares of the company’s stock, valued at approximately $509,526,780. The transaction was disclosed in a legal filing with the SEC, which is available at this hyperlink. Also, CAO Thomas Bull sold 516 shares of the company’s stock in a transaction that occurred on Monday, July 3rd. The stock was sold at an average price of $406.78, for a total value of $209,898.48. Following the transaction, the chief accounting officer now directly owns 17,190 shares of the company’s stock, valued at approximately $6,992,548.20. The disclosure for this sale can be found here. Insiders sold 116,427 shares of company stock valued at $41,304,961 over the last ninety days. 4.80% of the stock is owned by insiders.
Institutional Trading of MongoDB
Hedge funds have recently bought and sold shares of the stock. GPS Wealth Strategies Group LLC acquired a new stake in MongoDB during the 2nd quarter worth about $26,000. Capital Advisors Ltd. LLC lifted its stake in MongoDB by 131.0% in the 2nd quarter. Capital Advisors Ltd. LLC now owns 67 shares of the company’s stock worth $28,000 after purchasing an additional 38 shares in the last quarter. Global Retirement Partners LLC lifted its stake in MongoDB by 346.7% in the 1st quarter. Global Retirement Partners LLC now owns 134 shares of the company’s stock worth $30,000 after purchasing an additional 104 shares in the last quarter. Pacer Advisors Inc. lifted its stake in MongoDB by 174.5% in the 2nd quarter. Pacer Advisors Inc. now owns 140 shares of the company’s stock worth $58,000 after purchasing an additional 89 shares in the last quarter. Finally, Bessemer Group Inc. purchased a new stake in shares of MongoDB during the 4th quarter valued at approximately $29,000. Hedge funds and other institutional investors own 89.22% of the company’s stock.
MongoDB Price Performance
Shares of MongoDB stock opened at $405.14 on Thursday. The company has a quick ratio of 4.19, a current ratio of 4.19 and a debt-to-equity ratio of 1.44. The company has a market capitalization of $28.59 billion, a price-to-earnings ratio of -86.75 and a beta of 1.13. MongoDB has a 52 week low of $135.15 and a 52 week high of $439.00. The stock’s 50-day simple moving average is $365.22 and its 200-day simple moving average is $269.99.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Thursday, June 1st. The company reported $0.56 earnings per share for the quarter, topping the consensus estimate of $0.18 by $0.38. The company had revenue of $368.28 million for the quarter, compared to analysts’ expectations of $347.77 million. MongoDB had a negative return on equity of 43.25% and a negative net margin of 23.58%. The firm’s revenue for the quarter was up 29.0% on a year-over-year basis. During the same period in the previous year, the firm posted ($1.15) earnings per share. As a group, analysts expect that MongoDB will post -2.8 earnings per share for the current fiscal year.
Analyst Ratings Changes
MDB has been the topic of several analyst reports. Oppenheimer increased their target price on MongoDB from $270.00 to $430.00 in a report on Friday, June 2nd. VNET Group reissued a “maintains” rating on shares of MongoDB in a report on Monday, June 26th. The Goldman Sachs Group raised their price objective on MongoDB from $420.00 to $440.00 in a research note on Friday, June 23rd. Barclays increased their target price on MongoDB from $374.00 to $421.00 in a research report on Monday, June 26th. Finally, Piper Sandler raised their price objective on MongoDB from $270.00 to $400.00 in a research report on Friday, June 2nd. One investment analyst has rated the stock with a sell rating, three have issued a hold rating and twenty have issued a buy rating to the stock. According to MarketBeat.com, MongoDB has a consensus rating of “Moderate Buy” and a consensus price target of $378.09.
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • A N M Bazlur Rahman

JEP 451, Prepare to Disallow the Dynamic Loading of Agents, has been completed from Target status for JDK 21. This JEP has evolved from its original intent to disallow the dynamic loading of agents into a running JVM by default to issue warnings when agents are dynamically loaded into a running JVM. The goals of this JEP include: reassessing the balance between serviceability and integrity; and ensuring that a majority of tools, which do not need to load agents dynamically, are unaffected.
The primary goal of this proposal is to prepare for a future release of the JDK that will, by default, disallow the loading of agents into a running JVM. This change is designed to reassess the balance between serviceability, which involves ad-hoc changes to running code, and integrity, which assumes that running code is not arbitrarily changed. It is important to note that the majority of tools, which do not need to load agents dynamically, will remain unaffected by this change.
In JDK 21, the dynamic loading of agents is allowed, but the JVM issues a warning when it occurs. For example:
WARNING: A {Java,JVM TI} agent has been loaded dynamically (file:/u/bob/agent.jar)
WARNING: If a serviceability tool is in use, please run with -XX:+EnableDynamicAgentLoading to hide this warning
WARNING: If a serviceability tool is not in use, please run with -Djdk.instrument.traceUsage for more information
WARNING: Dynamic loading of agents will be disallowed by default in a future release
To allow tools to load agents without warnings dynamically, developers must run with the -XX:+EnableDynamicAgentLoading option on the command line.
Agents in the Java platform are components that can alter the code of an application while it is running. They were introduced by the Java Platform Profiling Architecture in JDK 5 as a way for tools, notably profilers, to instrument classes. This means altering the code in a class so that it emits events to be consumed by a tool outside the application without otherwise changing the code’s behaviour.
However, over time, advanced developers found use cases such as Aspect-Oriented Programming that change application behaviour in arbitrary ways. There is also nothing to stop an agent from altering code outside the application, such as code in the JDK itself. To ensure that the owner of an application approved the use of agents, JDK 5 required agents to be specified on the command line with the -javaagent or -agentlib options and loaded the agents immediately at startup. This represented an explicit grant of privileges by the application owner.
Serviceability is the ability of a system operator to monitor, observe, debug, and troubleshoot an application while it runs. The Java Platform’s excellent serviceability has long been a source of pride. To support serviceability tools, JDK 6 introduced the Attach API which is not part of the Java Platform but, rather, a JDK API supported for external use. It allows a tool launched with appropriate operating-system privileges to connect to a running JVM, either local or remote, and communicate with that JVM to observe and control its operation.
However, despite a conceptual separation of concerns between libraries and tools, some libraries provide functionality that relies upon the code-altering superpower afforded to agents. For example, a mocking library might redefine application classes to bypass business-logic invariants, while a white-box testing library might redefine JDK classes so that reflection over private fields is always permitted.
Unfortunately, some libraries misuse dynamically loaded agents, leading to a loss of integrity. They use the Attach API to silently connect to the JVMs in which they run and load agents dynamically, in effect masquerading as serviceability tools. This misuse of dynamically loaded agents by libraries has led to the need for stronger measures to prevent such actions and maintain the integrity of the JVM.
The proposal aims to require the dynamic loading of agents to be approved by the application owner, moving the Java Platform closer to the long-term vision of integrity by default. In practical terms, the application owner will have to choose to allow the dynamic loading of agents via a command-line option.
The impact of this change will be mitigated by the fact that most modern server applications are designed with redundancy, so individual nodes can be restarted with the command-line option as needed. Special cases, such as a JVM that must never be stopped for maintenance, can typically be identified in advance so that the dynamic loading of agents can be enabled from the start.
This change will allow the Java ecosystem to attain the vision of integrity by default without substantially constraining serviceability. It is a significant step towards ensuring the security and reliability of applications running on the JVM. The proposal is a clear indication of OpenJDK’s commitment to enhancing the integrity of the JVM and ensuring the secure operation of Java applications.
MMS • Diogo Carleto

Docker has released Docker Desktop 4.21. This version brings Docker Builds beta, support for new wasm runtimes, Docker Init support for Rust, Docker Scout dashboard enhancements, and more.
Docker Init Beta, which was released in Docker 4.18, is a CLI designed to make it easy to add Docker resources to any project by creating the required assets for the projects. In Docker 4.19 it added support for Python and Node.js, and now in Docker 4.21 they have added support for Rust, and at some point added support to Go. To create the assets automatically, it is only necessary to run the command docker init in a project, it will automatically create the dockerfiles, compose, and .dockerignore files, based on the characteristics of the project.
Docker Scout is a Docker product in early access designed to help to address security issues in images, allowing users to see all image data from local and remote images from both Docker Hub and Artifactory without leaving Docker Desktop. Initially released in Docker 4.19, it now brings dashboard enhancements which allows sharing the analysis of images in an organization with team members, aiming to help team members in security, compliance, and operations to identify vulnerabilities and issues in images.
Docker Desktop for macOs has received network, filesystem, and memory performance improvements. According to Docker, the container-to-host networking is 5x faster by replacing vpnkit with the TCP/IP stack from the gVisor project; this improvement can be noticed in scenarios where containers communicate with servers outside of the Docker network, such as workloads that download packages from the internet via npm install or apt-get; launching Docker Desktop is at least 25% quicker on Apple Silicon Mac compared with previous versions; VirtioFS is the default now on macOS 12.5+, which brings substantial performance gains when sharing host files with containers (example vi docker run -v), this gain can be noticed when building the Redis engine, where the time dropped from 7 minutes to 2 minutes.
Docker Compose has reached the end of life and will no longer be bundled with Docker Desktop after June 2023, and a warning is being showed in the terminal when running Compose v1 commands; for users who want to suppress this message, just set the environment variable COMPOSE_V1_EOL_SILENT=1.
Docker Builds view beta is a simple interface designed to give users the visibility of active builds currently running in the system enabling the analysis and debugging of completed builds; every build started with docker build or docker buildx build will automatically appear in the Builds view. From there it is possible to inspect the properties of a build invocation, including timing information, build cache usage, Dockerfile source, log access, etc.
The following Wasm runtimes are now supported in Docker Desktop: Slight, Spin, and Wasmtime. These runtimes can be downloaded on demand when the containerd image store is enabled.
More details about the news of the Docker Desktop can be found in the release notes.
MMS • Radia Perlman

Transcript
Perlman: I’m Radia Perlman. Welcome to the talk, Myths, Missteps, and Mysteries of Computer Networks. How do you understand network protocols? The way that it’s usually taught is as if just memorize the details of the current standards as if nothing else ever existed, no critical thinking about what’s good, or what’s bad, or alternate ways things could have been done. It’s important to understand that nobody would have designed what we have today. It’s just so grotesquely complicated. The only way to really understand it is to know how we got here. First, I’m going to talk about some layers 2 and 3 stuff. What is Ethernet exactly? It’s not what you think it is. How does it compare and work with IP? If I ask a network person, why do we have both Ethernet and IP? They’ll say Ethernet’s layer 2, and IP is layer 3. I’ll say, no, that’s not really true. What is all this layer stuff? First, we need to review network layers. ISO is credited with naming the layers, but it’s just a way of thinking about networks. Layer 1 is the physical layer, which is, what’s the shape of the connector? How do you signal a bit to a neighbor who’s on the same wire as you? Layer 2 is that you use the stream of bits that layer 1 gives you and somehow mark the beginning and end of a packet, maybe put in a checksum. It’s a way of sending a whole packet to a neighbor. Layer 3 has switches that connect to multiple links and forward packets from one link to another in order to deliver a packet across a network from a source to a destination.
What layer is Ethernet? Ethernet was intended to be layer 2, which should mean that it’s just between neighbors, which means it shouldn’t be forwarded, but we are forwarding Ethernet packets. How did that happen? Way back when I was the designer of layer 3 of DECnet, and the routing protocol I designed for DECnet was adopted by ISO and renamed IS-IS. It can route anything. It wasn’t really DECnet specific. Today, it’s widely deployed for routing IP. What’s a routing algorithm? Routers exchange information with their neighbors in order to compute a forwarding table. What’s a forwarding table? The forwarding table is a list of destinations and output ports. When the switch or router bridge, I use these terms interchangeably, it’s something that receives a packet. The packet contains a destination address. The switch looks in its forwarding table to decide which port to forward the thing on. Link state routing is what I did. Here’s a picture of a network. There are seven nodes. Again, I’m using nodes and switches and routers interchangeably. You’ll notice in this picture, like E has a neighbor B and the number here is the cost of the link. E has a neighbor F at a cost of 4. Each node is responsible for creating what I call a link state packet, saying who it is and who its neighbors are. C’s link state packet says I am C, I have a neighbor B at a cost of 2, and it does, F at a cost of 2, and it does, and G at a cost of 5. These link state packets get propagated to all the other switches, and so all the switches have the same database, which is the most recently generated link state packet from all the other switches. That gives you enough information to draw the picture of the network or compute paths. Each one uses this database to compute its own forwarding table.
The Invention of Ethernet
Back to history, I was designing layer 3, then along came the Ethernet with great fanfare. Originally, Ethernet, the invention of Ethernet was a way for a bunch of nodes to share the same wire. There was no leader to call on them. They were all peers. If two of them talk at the same time, the receivers just get garbage, so they have to somehow work it out by themselves so that they’re not always tripping over each other’s transmissions. The invention of Ethernet was known as CSMA/CD. CS stands for Carrier Sense, which is just polite, listen before you start speaking. If someone else is talking, you don’t start talking. MA is just lots of nodes share the same wire. MA is Multiple Access. CD is Collision Detect, which says that even while you’re talking, you listen in case somebody else started talking at about the same time, in which case, you should both stop, wait a random amount of time and try later. If you try to load the link with more than about 60% of the traffic, there’s too many collisions. This technology is fine, but it only works for a limited number of nodes, maybe hundreds, and a limited amount of distance. It’s ok for within a building, but it wouldn’t be ok for using for the entire internet. Ethernet addresses. Ethernet has a 6-byte address, but it only needs to identify nodes on a single link. I said there could only be a few hundred nodes on a link. Whereas IP has a 4-byte address, and it was intended to identify all the nodes in the internet. Why would the Ethernet designers use a 6-byte address when an Ethernet was only supposed to support a few hundred nodes. The reason is that it eliminated the need for users to configure addresses. When a manufacturer wants to manufacture a device that will plug onto an Ethernet, they purchase a block of addresses and configure a unique address into each device. A mild rant, for bizarre reasons, this built-in address is known as the MAC address. First of all, it’s not an address, because to me, my address should change if I move. Here, it’s something that’s built into the device and always stays the same. MAC is some weird jargon that nobody remembers what it is or cares. At any rate, they’re called MAC addresses.
Ethernet as a New Type of Link
I saw Ethernet as a new type of link. When I saw it, I said, I have to change the routing protocol in little ways to accommodate this new type of link. For instance, with the link state protocol, if you had a link with 500 nodes, all of whom are neighbors, and every one of them reported 499 neighbors, the link state database would get very large. I said, ok, instead of considering a 500-node Ethernet as fully connected, instead, think of it as having the Ethernet itself be a special node, called a pseudonode, and just have everybody report connectivity to it. Now it’s n links with n+1 nodes instead of n squared links. Instead of fully connected here, it’s one extra node and much fewer links. That was not a big deal. It was just, ok, Ethernet is a new kind of link. I wish they’d called it Etherlink, but because they called it Ethernet, a bunch of people said, this is the new way of doing networking. It’s easy to get confused. An Ethernet packet has data and a header with a destination and source. A layer 3 packet looks the same, it has this extra field of a hop count. The reason for the extra field is that when the topology changes, it takes a while for information about that to propagate. The switches will have inconsistent forwarding tables, and packets might go around in loops. If you have a hop count to count how many times a packet has gone round in a loop, if it’s looping, then the switches know to just throw it away. That enables the routing protocol to settle down more quickly rather than competing for bandwidth with all of these packets that are circulating.
It’s easy to confuse Ethernet with a layer 3 protocol because it looks the same. Ethernet has different type of addresses. Ethernet addresses are flat. Meaning there’s no way to summarize a bunch of addresses in a forwarding table because any particular address can be anywhere because it’s really not an address it’s an ID. Whereas a layer 3 protocol hands out addresses in such a way that you can draw a circle around a portion of the net, and anyone outside of the circle can just have a single forwarding entry that says, go to that circle. Ethernet doesn’t have a hop count field. It wasn’t because the Ethernet designers didn’t know about hop counts, it just never occurred to them that anyone would be forwarding Ethernet packets. Because, really, we shouldn’t be, it’s not a layer 3 protocol.
How Ethernet Evolved from CSMA/CD to Spanning Tree
How did it evolve from CSMA/CD to spanning tree? People when they heard about, Ethernet is the new way of doing networking, they built their applications on Ethernet without having layer 3 in their network stacks. A level 3 router can’t forward without the right envelope, the right header on there. I tried to argue with them and said, no, don’t take out layer 3, you still need it. They said, you’re just upset because no one needs your stuff anymore. I said, but you may want to talk from one Ethernet to another. They said, our customers would never want to do that. They were real heroes in the company because their applications were good, and so they made lots of money for the company. Their application would have been just as good if they’d done it correctly, which was including layer 3 in the step. I was in a bad mood about the whole thing. Around 1983, my manager called me in and said, “Radia, we need to design a magic box that will sit between two Ethernets and let someone on one Ethernet talk to someone on the other Ethernet,” which is what my step was all about. The constraint was without changing the endnodes to have layer 3. There were no spare fields in the Ethernet header, and there was a hard size limit.
The basic concept was the bridge just listens promiscuously, meaning it just listens to every single packet, stores it up. When some other port is free, because the ether is free, or it gets the token depending on what kind of comported as, the bridge forwards onto that port. This requires a topology without loops, because otherwise there’s no hop count, the packet will go around forever. Worse than that, if you have a bridge with five ports, it not only forwards it, but it forwards four copies because it forwards one on each one of its ports. What to do about loops? One possibility was just tell customers, “This is a kludge that’s only going to last for a few months. Don’t worry, we’re going to fix the endnode software so that it has layer 3, and then you can use a real router.” In the meantime, what if the customer just miscables something because that would be a total disaster, it brings down the entire bridge to Ethernet. The other thing is that a loop isn’t a bad thing. A loop says that there’s an alternate path in case something breaks. There was a desire for a loop pruning algorithm. As my manager explained the problem, allow any physical topology, no rules, just plug it together however you want. The bridges with zero configuration should prune to a loop-free topology for sending data. The other links that are not chosen to be in the loop-free topology are still there and you still run the spanning tree algorithm in case the topology changes. While the topology is settled down, you forward to and from all the links that are in the subset that’s the loop-free topology and you don’t forward data to or from links that are not chosen. This is the spanning tree algorithm. When he proposed this, I realized that night, it’s really easy, just create a tree.
The physical topology looks something like this. These round things are bridges and the blue things are Ethernets. After running the spanning tree algorithm, the bridges decide which ports are excess and don’t forward packets to or from those links. This is the loop-free topology. If you’ll notice, the path from A to B would go like this, A to X. You might think, that’s a silly spanning tree algorithm, if there had been a smarter spanning tree algorithm, you would have a better path from A to X. It really just has to go that way. The problem is, if you have a single subsetted, shared, loop-free topology, then you can’t get optimal paths. If you imagine that the topology is a big circle, the spanning tree algorithm has to break at some place, break the circle at some place, and people on either side of the break have to go around the long way.
About a year after spanning tree bridges, CSMA/CD died a long time ago. When people think, Ethernet is wildly successful. No, it isn’t. The main invention of Ethernet doesn’t exist anymore. It’s just point to point links, no shared links with running the spanning tree algorithm. My manager asked me to do this on a Friday. This was before people had cell phones or read email. He also said, and furthermore, just to make it more challenging, make it scale as a constant. No matter how many links and bridges there are in the world, the amount of memory necessary to run this in any bridge should be a constant, which is crazy. It’ll probably be n squared, but the best you can hope for is linear. That night, which was a Friday, and he was going to be on vacation the following week, I realized, “It’s trivial, I could prove that it works.” It was such a simple algorithm, that on Monday and Tuesday, I wrote the spec. It was about 25 pages long. It was in enough detail that the implementers got it working in just a few weeks without asking me a single question. This brings us to the end of Tuesday. The remainder of the week, I couldn’t concentrate on anything else, because I had to show off to my boss and he wasn’t reachable. I spent the remainder of the week working on the poem that goes along with the algorithm, and is the abstract of the paper in which I published the algorithm. The poem is called the Algorhyme, because every algorithm should have an Algorhyme. “I think that I shall never see a graph more lovely than a tree. A tree whose crucial property is loop-free connectivity. A tree which must be sure to span so packets can reach every LAN. First, the root must be selected, by ID it is elected. Least cost paths from root are traced, in the tree these paths are placed. A mesh is made by folks like me. Then bridges find a spanning tree.”
Then the interesting thing was, at first the implementers didn’t want to bother with the spanning tree, because they said, this is just a quick hack until people fix the endnode, so it’ll only last for a few months. Just tell the customers, don’t put loops in. I sympathized with that somewhat. Because even though the spanning tree is incredibly trivial, if you add that to the basic concept, it makes it more complicated. If really, we were going to fix all the endnodes to put in layer 3, it really didn’t have to be a fancy device. I didn’t want to argue because they would not listen to me anyway, because they’d assume I was biased. I let management argue about it. Management said, yes, we should put the spanning tree algorithm into the bridge. Then I knew, yes, we’d done the right thing when I heard about the very first bridge that we sold, which I only found out about after the patch. It was sold to the most sophisticated networking customer there was, and they had two Ethernets and one bridge. At the time, they were arguing with the sales guy saying, “But we’re doing all this fancy stuff with all these protocols.” He said, “It doesn’t matter. It’s just going to work.” They said, “We really need to talk to the engineers.” He said, “No, you don’t. It’ll just work.” They plugged it together and it didn’t work and they were really angry. When field service went to figure out what the problem was, they realized that the world’s most sophisticated customer had done this with the world’s simplest topology, which is that they plugged both ends of the bridge into the same Ethernet. Indeed, everything was working perfectly, the bridge said, I don’t need to forward packets, so I won’t. If the topology ever changes, and I need to forward packets, I’ll be happy to do that. I was glad that I had actually thought of this case. At any rate, everything was working fine. If that customer could get this topology wrong, it was right to make the product include the spanning tree algorithm.
Spanning tree Ethernet is a kludge, you don’t get optimal paths. The traffic gets concentrated on the links that are selected to be in the tree, and the other ones are unused. Temporary loops are incredibly dangerous, because the header has no hop count. Why was bridging so popular? Originally, there were lots of layer 3 protocols: IPX, AppleTalk, IP, DECnet. You would need a lot of different routers in order to let everybody on one Ethernet talk to the other. Or people did make multiprotocol routers, but they were very expensive and slow, whereas bridges just worked and they were cheap. Zero configuration was required. You just plugged it together and it worked. Bridges wound up helping IP be much more tolerable, as we’ll talk about later.
Why Do We Need Both Ethernet and IP?
Why do we need both Ethernet and IP, given that Ethernet is just point to point links today? Why not just interconnect everything with IP? The world has converged to IP as layer 3. You don’t have to worry about AppleTalk or IPX anymore. It’s in all of the network stacks. The original reasons for needing bridged Ethernet is gone. On a link with just two nodes, why do you need this extra header with the 6-byte source and a 6-byte destination when there’s no need for any source or destination? If you hear something, it’s for you. If you send something, it’s for whoever’s on the other side. Why can’t we just plug everything together with layer 3? There were other layer 3 protocols that would have worked, and we wouldn’t have needed the Ethernet header anymore. IP doesn’t work that way. If IP were designed differently, we could get rid of this, the world would be much simpler. What’s wrong with IP? IP is configuration intensive. Moving like a VM around from one side of a router to another, you’d have to change its address. Every link must have a unique block of addresses. If you have a block of addresses, you have to carve up the address space to have a different block on each link. Each router needs to be configured with which block of addresses are on which ports. If something moves, its address changes. You can’t have a cloud with a flat address space where people would like to have a cloud, like a data center where you can move things around without changing their address.
With IP, each link has a different address block. If you move from one side of this router to the other, you have to change your address. Layer 3 doesn’t have to work that way. For instance, a CLNP was a competing layer 3 protocol. When I was doing DECnet, when I started out, it had a 2-byte address, and we all realized, it needs a bigger address. Rather than trying to invent a new format, I looked at CLNP and said, this looks fine. It was a 20-byte address. With a 20-byte address, the way CLNP worked, the top 14 bytes was a prefix shared by all the nodes in a large cloud, and the clouds could support hundreds and thousands of endnodes and lots of links. The bottom 6 bytes were your specific node ID inside the cloud. For instance, your Ethernet address, you could use that and put that into the bottom 6 bytes. Inside the cloud, routers ignored this part. They just make sure, yes, it’s inside my cloud, and then they route to the specific endnode here. If it’s outside your cloud, then you route just like IP does but with a 14-byte address that can have as many levels of hierarchy as you want. In order to find the endnodes within the cloud, there was an extra protocol known as ES-IS where the endnodes periodically tell the router, I’m here in case anybody wants me.
With CLNP, the 14-byte prefix allows you to find the right cloud. Once you’re at that cloud, you route based on the bottom 6 bytes. If you’re using IP Plus Ethernet, in order to have a cloud that you can move around in, so Ethernet disguises a multi-link network to IP so that IP thinks it’s a single link, so you don’t have any IP routers inside of here. IP will get you to the destination link. Then, IP has to do ARP. It has to shout, who has this IP address inside of here? Whoever does will answer, it’s me, and my Ethernet address is alpha. Then this router can forward into the cloud by adding the extra Ethernet header. Inside the cloud, IP just depends on some other technology like CSMA/CD, or spanning tree, or TRILL, or VXLAN, in order to glue a bunch of links together so that it looks to IP like a single link. In contrast, with CLNP, the top 14 bytes get you to the cloud. Then you don’t need to do ARP or anything, or add an extra header, you just forward into the cloud, and routers inside the cloud know to route based on the bottom 6 bytes.
With hierarchy, if you have a block of addresses, you have to carve it up and configure everything with IP. With CLNP inside the cloud, zero configuration, you just plug it all together and it self-organizes. You don’t have to tell the routers anything except one router has to be told what the 14-byte prefix for the cloud is. Then it will tell everybody else. The worst decision ever was that in 1992, people said, IPv4 addresses, 4 bytes are really too small, why don’t we adopt CLNP with their 20-byte address. Somebody modified TCP to work on top of CLNP, and it was very easy for them to do it. It didn’t take them like a month or something at most. That meant that all of the internet applications automatically worked on top of CLNP. It was much easier to change the internet back then, to a new layer 3 protocol because the internet was much smaller, it wasn’t so mission critical, and IP hadn’t yet invented things like DHCP and NAT. CLNP gave understandable advantages. You don’t have to configure all the endnodes anymore, for instance. CNLP was much cleaner than IP. This level 1 of CLNP, level 1 routing was where you’re routing based on the bottom 6 bytes. It’s a cloud with flat addresses, and true layer 3 routing with a hop count and best paths.
The reasons given at the time not to adopt CLNP was it would be ripping out the heart of the internet and putting in a foreign thing. Or, we don’t like ISO layer 6, or we’re not immediately out of IPv4 addresses, and I’m sure we could invent something way more brilliant. The decision was, let’s do something new, and whatever it is, we’re going to call it IPv6. IPv6 is just a 16-byte version of IP with 8 bytes for the prefix and 8 bytes for the node ID on the last link. Eight bytes on top is inconveniently small for administering addresses, and 8 bytes on the bottom is way too much. For instance, once they did DHCP, where you have a node that’s handing out addresses, 3 or 4 bytes would be more than sufficient. Why didn’t they just do 6 bytes because Ethernet addresses were 6 bytes? At the time people were thinking, people might run out of the 6-byte addresses, so maybe they’ll convert to an 8-byte address, the unique ID. The 8-byte unique IDs I don’t think really caught on. IPv6 is technically inferior to CLNP, which is very frustrating even if we do wind up converting to it. Because IPv6 like IPv4 needs a different prefix on each link.
Some Other Protocol Observations, and Parameters
Some other protocol observations, parameters. I hate computers. I design things for people like me, which is just plug them together, and they work. Someone complained to me when I was at Digital that some customers found the bridge is boring, because they can’t do anything with it, you just plug it together and it works. Some customers like to fiddle with things. I said, fine, if they want knobs, I’ll give them knobs. They don’t have to touch the knobs. Even if they do, they can’t hurt themselves, because all settings will work. With parameters, if you do have parameters that people can set, of course, you need to do a sanity check to make sure they’re setting it to a reasonable value. For instance, if the only legal values are between 30 and 50, don’t let them set it to 70. That’s easy enough to do. Sometimes, A and B have reasonable settings, but they won’t interwork. An example of that is a protocol I was never able to explain to my otherwise bright college age son, which is that there’s no such thing as a reliable I am dead now message. You have to periodically call your mother. Here’s an opportunity for a parameter mismatch, which is how often you call your mother versus how long she waits before getting panicky and calling the police. What I did about that, was that in IS-IS, in the hello message where you say, “I’m still alive, link is still working.” I put in the Hello Timer. In the IS-IS, the hello message says, “I’m Radia. I’m your neighbor on this link. Expect to hear hellos from me every 30 seconds.” The neighbor says, “I’ll multiply that by three or so. If I haven’t heard from you for that amount of time, I’ll declare the link down.” OSPF pretty much copied IS-IS. They noticed the Hello Timer, and they put that in. What they did with it was that, when in OSPF if you receive a Hello Timer from your neighbor that says, “I’m Radia, expect to hear from me every 30 seconds.” OSPF looks at it and compares it with its own configured Hello Timer, and if it’s not identical, you refuse to talk. They haven’t fixed it as far as I know. When I complained, I said, why not just adjust your Listen Timer? They said, it’s just simpler, or something.
Latency, Fads, and Hype
Another short thing is latency. Suppose you care how long it takes to get a packet across the network? There’s two ways of forwarding a packet. One is known as store-and-forward where each switch receives the entire packet, and then forwards it to the next one, versus cut-through, which says that as it’s receiving the packet, once it can make a decision about what port to forward it on, assuming the port is free at the moment, it can immediately start forwarding. It’s forwarding while it’s receiving the packets. That will lower the latency across the network. What field do you need to see in order to make this forwarding decision? The destination address. Let’s look at the IP header. The IPv4 header has the destination address as the last thing. The IPv6 header also has the destination as the last thing. Another thing to rant about are Fads. Every once in a while, somebody invents some doodad. People then take it and run and they come up with doodad specific jargon, and they design packet formats without asking, how would this compare with how it’s done today? Is this useful in any sense? They convince someone in some funding agency that it’s the next big thing so it gets funding. There’s entire conferences about it. To get funding, people have to spin what they’re actually working on as some aspect of doodad-ism. An example of things like these are active networks, name-based networks, otherwise known as content-centric networks. These things usually die out.
Another thing to rant about is hype. Blockchain is a great example of something that just got so much hype. It started as the technology behind Bitcoin. People made money on Bitcoin. The more they hyped it, the more money got poured in, and the more money they made. Startups leveraged the hype to claim their product has something to do with blockchain, and the money rolled in. After hearing so much hype, it’s natural to assume blockchain must be important. There’s lots of talk about how it’s being considered for this and that, which is very different than it’s actually being used for this or that, and also very different from it was the best solution for this or that. Companies were convinced to throw money at consortiums because people show slides with the logos of all the other companies that have already thrown the money at the consortium, and they don’t want to miss out. People ask, how can I use blockchain in this application? Or, what can I build with blockchain? Instead, I say, no, start with, what problem are you solving? Look at various approaches and choose the best one. An engineer said to me, that sounds good, but what do I do? My manager really wants us to use blockchain. I said, fine, do what I said, which is start with what problem you’re solving, compare solutions, and choose the best one. Build that and then tell your manager, I used blockchain. They’ll never know the difference.
Theory vs. Practice
Theory versus practice. Secure communication on the internet. It’s so straightforward in theory. We do this every day. It obviously works. A client wants to talk to a website, let’s say, x.com. The client says, I want to talk to you. Prove that you’re x.com. The website sends a certificate with cool crypto and great protocols. It proves that it owns the name, x.com. Then you can have a cryptographically protected conversation. What could go wrong? Let’s look at reality. Usually, the user doesn’t start with the DNS name, and instead does a search and gets some sort of obscure URL string. That’s what a URL looks like. This is not something that humans really can deal with, even if the user finds the DNS name in the URL. I fell for a scam recently, so I understand the theory of all of this. I wanted to renew my Washington State driver’s license. I knew it could be done online, so I did an internet search for, “Renew Washington State driver’s license.” I got search results. I clicked on the top listed site. It didn’t occur to me that the top search wouldn’t be correct. This is the first one that I got, and I clicked on it. As it turns out, it did say, Ad. Even when you’re searching for things, often the one you want still gets promoted to the top because they paid money to the internet search people. I didn’t notice anyway. I clicked on it, and everything was as I expected. It was this very nice site. Look how happy all these people are. It couldn’t possibly be a scam. I clicked on renew driver’s license, and it asked me everything that I expected, like, what’s your address? What’s your license number? What’s your credit card number? I told it all of that, and success. I would have thought nothing of it, except probably in a month or two I would have started wondering why I wasn’t getting my new license. These guys were overly greedy and they kept charging more money, so eventually the bank fraud department called me up and said, “Are these legitimate charges?” At that point I realized, probably this was not a real site. I told them, no, it wasn’t legitimate. They disallowed the charges and gave me new credit card numbers. I wasn’t harmed in any way, and it gives me a great example.
This is quite shocking because, given that users don’t automatically know the right DNS name, and why should they? There is absolutely no security on the internet, even though we have all of this fancy crypto and wonderful protocols. Don’t blame the user. Scam sites can appear first after the search, either because they pay the search engine company, or because they understand the ranking algorithm and they can game the system. The particular scam I did now seems to have been shut down, but it had different names for all 50 states, washingtonlicensing.org, idaholicensing.org, or dmv.washington.org, dmv.ohio.org. They were all probably the same site, and just sitting there collecting credit numbers. At the time, once I realized it was a scam, I didn’t know what to do. How do you manage to alert the search engine, this thing is a scam. Somebody probably eventually figured out how to do it. I happened to know Vin Cerf, so I sent him an email saying, “Do you know how to report anything like this?” The site I should have gone to was dol.wa.gov. I claim I did nothing wrong. There’s no reason why I should be expected to have known that.
This is something I want everyone to take to heart. It’s something I wrote in our book, and once I wrote this paragraph I said, yes, this is absolutely true. Everyone should memorize it and take it to heart. I’ve seen it on quote words. “Humans are incapable of securely storing high-quality cryptographic keys, and they have unacceptable speed and accuracy when performing cryptographic operations. They are also large, expensive to maintain, difficult to manage, and they pollute the environment. It is astonishing that these devices continue to be manufactured and deployed, but they are sufficiently pervasive that we must design our systems around their limitations.” That’s a challenge for people. Don’t blame the users, figure out how to make things work.
See more presentations with transcripts
MMS • Guy Nesher
LangChain is a framework that simplifies working with large language models (LLMs) such as OpenAI GPT4 or Google PaLM by providing abstractions for common use cases. It supports both JavaScript and Python.
To understand the need for LangChain, we first need to discuss how LLMs work.
Under the hood, LLMs are statistical models that, given a set of chunks containing anything from a single character to a few words, can predict the next set of chunks.
The initial chunks of text are called Prompts, and Prompt Engineering is the art of fine-tuning the results received from an LLM by providing the most appropriate set of prompts.
While LangChain provides many tools, at its core, it offers three capabilities:
- An abstraction layer that enables developers to interact with the different LLM providers using a standardized set of commands
- A set of tools that formalizes the process of Prompt Engineering by enforcing a set of best practices
- The ability to chain the various components LangChain offers to perform complex interactions
The JavaScript example below demonstrates how to create and execute the simplest chain containing a single prompt.
const model = new OpenAI();
import { PromptTemplate } from "langchain/prompts";
const prompt = PromptTemplate.fromTemplate(`Tell me a joke about {topic}`);
const chain = new LLMChain({ llm: model, prompt: prompt });
const response = await chain.call({ topic: "ducks" });
Of course, using a chain of a single component isn’t very interesting. More complex applications usually use multiple components to generate the desired results.
We will use the SimpleSequentialChain to demonstrate that, which runs multiple prompts sequentially. In our case, after asking LangChain to write a joke about the provided language, we will ask it to translate it into Spanish.
const translatePrompt = PromptTemplate.fromTemplate(`translate the following text to Spanish: {text}`);
const translateChain = new LLMChain({ llm: model, prompt: translatePrompt });
const overallChain = new SimpleSequentialChain({
chains: [chain, translateChain],
verbose: true,
});
const results = await overallChain.run("ducks");
Note that by passing verbose: true to the SimpleSequentialChain, we can see the generation process, which is helpful for debugging.
Of course, LangChain can do much more than chaining several prompts. It includes two modules that allow developers to extend the interactions with LLMs beyond simple chats.
The Memory module enables developers to persist state across chains using a variety of solutions ranging from external databases such as Redis and DynamoDB to simply storing the data in memory.
The Agents module enables chains to interact with external providers and perform actions based on their responses.
The full documentation, alongside more complex examples, can be found on the official LangChain documentation site.
Developers should be aware that LangChain is still under active development, and use in production should be handled with care.
MMS • Steef-Jan Wiggers
Microsoft recently announced the public preview of deployment stacks in Azure, a new resource type for managing a collection of Azure resources as a single unit for faster update and delete (cleanup). In addition, it brings more granular capabilities for preventing unwanted changes to resources.
The company introduces deployment stacks to solve the current problem of handling the lifecycle (creation, updates, and deletions) of resources across various Azure scopes, such as Resource Groups, Management Groups, and Subscriptions, which can be complex and time-consuming. Furthermore, ensuring that essential resources are equipped with appropriate guardrails further contributes to the complexity of resource management.
With deployment stacks, developers and DevOps engineers have a way of managing a collection of resources across scopes as a single atomic unit. It enables 1-to-many CRUD operations and resource change prevention, providing the following benefits:
- Simple cleanup – delete or update resources across scopes with a single call to the deployment stack resource as a 1-to-many operation.
- Unwanted changes – block changes to managed resources with deny settings capability of a deployment stack.
Angel Perez, a program manager of Azure Deployments at Microsoft, explains in a Tech Community blog post:
A deployment stack is a resource that deploys a template file (ARM or Bicep) as a deployment object. Beyond the familiar capabilities of the deployments object, the resources a deployment stack creates are known as “managedResources” and can be easily updated/deleted with a single operation on the deployment stack. “managedResources” can be deleted directly via delete of a deployment stack or indirectly via updates to the template and “actionOnUnmanage” behavior of the deployment stack, specified via delete flags.
Developers and DevOps engineers can leverage Azure CLI, Azure PowerShell, the Azure portal, and Bicep files to create and update a deployment stack. Bicep files are transformed into ARM JSON templates, which are subsequently deployed as a deployment object by the stack.
To create a deployment stack at the resource group scope, the CLI command and parameters will look like:
az stack group create
--name ''
--resource-group ''
--template-file ''
--deny-settings-mode 'none'
Once a deployment stack is created, a developer can find it through the Azure portal by navigating to the correct scope.
Deployment stack resource in the Azure portal (Source: Tech Community Blog post)
Azure deployment stacks will provide features developers and DevOps engineers requested and anticipated in the past.
Stanislav Zhelyazkov, a Microsoft MVP and cloud infrastructure engineer, tweeted:
Something that I have pushed for years to be made is now available in preview. Thanks to all who all requested this as well and the people who made it happen.
One requested feature was the destroy feature similar to Terraform destroy command. Terraform is an infrastructure-as-code tool that enables the provisioning and management of cloud resources through declarative configuration files. It has providers for various cloud providers, SaaS providers, and other APIs – thus also for Azure and an option for developers and DevOps engineers.
Freek Berson, a Microsoft MVP, concluded in a blog post:
Deployment stacks unlock lots of great scenarios like removing resources from a deployment that reside across various different resource groups, subscriptions, and management groups providing similar functionality like the destroy option that e.g. Terraform has.
And:
Deployment stacks improve the overall life cycle management of Azure resources, it can prevent accidental deletion of a single resource that is part of a stack of resources that depend on each other and have the same life cycle, and it provides easy ways to roll back to a good known state.
Lastly, more details are available in the documentation and GitHub repo with samples and tutorials.
MMS • RSS
PRESS RELEASE
Published July 26, 2023

The NoSQL market was valued at $2,410.5 million in 2022, and it is expected to reach $22,087 million by 2030, growing at a compound annual growth rate (CAGR) of 31.4% between 2023 and 2030.
NoSQL databases are intended to store and retrieve structured and unstructured data through techniques other than tabular relations inherent in relational databases (RDBMS). They cover a wide range of database technologies designed to handle the increasing volume of data generated and stored as a result of variables such as the Internet of Things (IoT) and the internet. Because of the variety of data sources, dispersed data stores with high storage requirements frequently favour NoSQL solutions.
Download Free Sample Report- https://www.marketdigits.com/request/sample/744
The NoSQL market is anticipated to expand as a result of factors including rising demand from e-commerce, web applications, and social game development, among others. The study of NoSQL software, which includes revenue from the sale of commercial licences and upgrade fees of open-source NoSQL solutions, is part of the research done in this area. The difficulty of organising and testing complicated queries in comparison to conventional relational database strategies, however, continues to be a significant barrier to the mainstream adoption of NoSQL technology. However, NoSQL databases are anticipated to be quickly embraced in the coming years as awareness grows to handle the expanding commercial data, notably in the social networks, retail, and e-commerce industries.
Key Developments in Nosql Market
- Expansion of NoSQL Database Types: The NoSQL market has seen the emergence of various types of NoSQL databases, such as document stores, key-value stores, column-family stores, and graph databases. This expansion caters to diverse data management needs across different industries and use cases.
- Cloud-Based NoSQL Solutions: The adoption of cloud computing has led to the development of cloud-based NoSQL databases. Cloud-based NoSQL solutions offer scalability, flexibility, and cost-effectiveness, making them popular among enterprises seeking to leverage cloud infrastructure.
- Integration of NoSQL with Big Data Technologies: NoSQL databases are increasingly integrated with big data technologies, such as Apache Hadoop and Apache Spark, to handle large-scale and complex datasets. This integration enables real-time data processing and analytics at scale.
- Improved Security and Compliance Features: As NoSQL databases handle sensitive and critical data, there has been a focus on enhancing security and compliance features. NoSQL vendors are incorporating robust security measures, encryption, and auditing capabilities.
- Advancements in Data Modeling and Query Languages: NoSQL databases are continually improving their data modeling and query languages to offer more intuitive and developer-friendly interfaces. These improvements simplify data manipulation and enhance developer productivity.
Get a discount on report- https://www.marketdigits.com/request/discount/744
Major Classifications are as follows:
By Type
- Key-Value Store
- Document Database
- Column Based Store
- Graph Database
By Application
- DATA STORAGE
- MOBILE APPS
- WEB APPS
- DATA ANALYTICS
- OTHERS
By Industry Vertical
- Retail
- Gaming
- IT
- Others
By Region
- North America (U.S., Canada)
- Europe (Germany, UK, France, Rest of Europe)
- Asia-Pacific (Japan, China, India, Rest of Asia-Pacific)
- LAMEA (Latin America, Middle East, Africa)
Key Players
COUCHBASE, AEROSPIKE, GOOGLE LLC, OBJECTIVITY, INC., MARKLOGIC CORPORATION, NEO4J, INC., MICROSOFT CORPORATION, MONGODB INC., DATASTAX, AMAZON WEB SERVICES, INC.
Request for enquiry before buying- https://www.marketdigits.com/request/enquiry-before-buying/744
Key Questions Addressed by the Report
• What are the growth opportunities in the Nosql Market?
• What are the major raw materials used for manufacturing Nosql Market?
• What are the key factors affecting market dynamics?
• What are some of the significant challenges and restraints that the industry faces?
• Which are the key players operating in the market, and what initiatives have they undertaken over the past few years
Nosql Market Frequently Asked Questions (FAQs):
- What are the NoSQL databases available in the market?
- What makes NoSQL faster?
- What are the types of NoSQL databases?
- What are the advantages of using NoSQL databases?
About MarketDigits:
MarketDigits is one of the leading business research and consulting companies that helps clients to tap new and emerging opportunities and revenue areas, thereby assisting them in operational and strategic decision-making. We at MarketDigits believe that market is a small place and an interface between the supplier and the consumer, thus our focus remains mainly on business research that includes the entire value chain and not only the markets.
We offer services that are most relevant and beneficial to the users, which help businesses to sustain in this competitive market. Our detailed and in-depth analysis of the markets catering to strategic, tactical, and operational data analysis & reporting needs of various industries utilize advanced technology so that our clients get better insights into the markets and identify lucrative opportunities and areas of incremental revenues.
Contact US:
1248 CarMia Way Richmond,
VA 23235, United States.
Phone: +1 510-730-3200
Email: [email protected]
Website: https://www.marketdigits.com