Month: September 2023
Presentation: How Did It Make Sense at the Time? Understanding Incidents As They Occurred, Not as They Are Remembered

MMS • Jacob Scott

Transcript
Scott: With apologies to Beauty and the Beast, we’re kicking off with a tale of the oldest time, song as old as rhyme. An engineer hits return, and just like with the Ever Given container ship that launched a million memes when it got stuck in the Suez in 2021, what happens next is an incident. I learned on Wikipedia, of course, that the Ever Given can fit 20,000 containers on board. If anyone watching is responsible for operating Kubernetes, please let me know if this is the world’s longest and largest CrashLoopBackOff. I’m Jacob. I work as a staff engineer at Stripe.
Outline
I’m here to discuss the question, how did it make sense at the time? Specifically, I’m going to use examples of humans triggering incidents to explore the theory and practice of asking, how did it make sense at the time? With the goal of making users happy. I believe you should care about how it made sense at the time, because it will lead to happier users. There are many paths to happier users. Here’s one concrete example relevant to us, laid out backwards. Fewer HTTP 500s mean happier users. Better decisions in incidents means fewer 500s. Better learning in post incident activities means better decisions in incidents. Asking, how did it make sense at the time, means better learning in post incident activities? Of course, before we can ask, how did it make sense at the time? We need to understand what we’re asking. As I’ve highlighted, we’ll focus on the last two steps in this trend for the rest of the talk. Where we’ll spend our time is as follows. First, we have a few more preliminaries to run through to provide context and set the stage. Second, we’ll flesh out theory and concepts. Third, we’ll explore applying that theory in post incident activities. Finally, we’ll wrap up.
Incident Triggers (The Human)
Now I want to unpack incident triggers. Focusing on triggers means ignoring most of what happens during incidents. We’re only looking at how they start. I’m doing this because human triggers carry with them a common sense or intuition of, could they just have not pushed that button? This is strongly in tension with the perspective of, how does it make sense at the time? This tension in turn is fertile soil for those aha moments where everything clicks. We’re focusing narrowly to spend our time in that fertile soil. I’ve said, how did it make sense at the time, probably 10 times already. As a point of order, moving forward, I’m going to use the acronym HDIMSATT interchangeably with how did it make sense at the time, to have a little bit less of a word salad.
Caveats
First, I’m taking artistic license. We’ll be covering fragments of incidents to help us wrangle HDIMSATT, but we shouldn’t confuse that with a deep understanding of them, let alone how they were experienced by those involved at the time. Second, I’ll be critiquing some parts of publicly available incident write-ups. I can only do that because they were written about. It can be fraught to explain your failures to the world, especially to customers who pay you or prospective customers considering paying you. If none were published, our ability to learn from each other will be crippled. Courtney Nash gave a really great talk in the effective SRE track, where she presented research built on top of the VOID, an open repository of over 2000 incident reports from software organizations.
Salesforce’s May 11, 2021 Multi-Instance Service Disruption
Let’s explore the theory of HDIMSATT through the lens of human triggers of incidents. This is going to be the bulk of the talk. My goal here is to spark your curiosity and provide sufficient foundation to support discussion of HDIMSATT in practice. On May 11, 2021, Salesforce went down for 5 hours. This might have been a snow day for your go-to market organization, since many of them basically live in Salesforce. In my experience, engineering rarely has a good understanding of how others experience incidents. I challenge you to find a friendly account executive and ask them if they remember May 11th of last year, and if so, how it impacted them. Let’s look at what happened according to Salesforce’s public explanation of this multi-instance service disruption. The trigger for this incident was DNS. An engineer made a configuration change to Salesforce’s BIND DNS servers and hit an edge case in a long existing script where BIND didn’t restart cleanly. Basically, pushing the change to a DNS server shut it down. The engineer pushed the change globally via an emergency break fix process. Then, basically, all Salesforce globally went down. That’s the incident for our purposes, because, as we’ve said, we’re interested in the human trigger, which is the engineer running the script.
Now we can look at how Salesforce understood and explained what happened. This is a section of the document that they titled, Root Cause Analysis. I feel compelled to note here that I have problems with the term root cause analysis. Salesforce’s RCA has two findings that are interesting to us. First, the staggering canary change management policy was not followed or enforced. Second, the emergency break fix process was subverted. Again, subverted is the term used by Salesforce. That is, they consider the use of this process during this change to be against policy. We could lift the RCA findings into a human trigger centric version to explore as follows. An engineer applying a DNS change did not follow staggering canary process and subverted emergency break fix process, and Salesforce went down for 5 hours. Now we hit a major killer. People don’t show up to work to cause 5-hour outages. If there’s anyone watching, who could ask a coworker, are you planning to cause a 5-hour outage today, and get a serious yes back. People don’t show up to work intending to cause outages, but sometimes take actions which lead to outages. This is what motivates us to ask, how did it make sense at the time? Bringing this insight back to what happened to Salesforce on May 11th, we can ask, HDIMSATT to the engineer who triggered the incident to not follow and/or subvert these processes. Now we’ll dive into that question.
First off, what Salesforce’s write-up doesn’t touch on is how frequently the emergency break fix process is, “subverted” in this way without anything going wrong. The background here is of a woman jaywalking, because, until recently, jaywalking was against the law in California. Everyone jaywalks. I think we all understand that we jaywalk because it saves us time, and we look both ways first to establish that it’s safe. In my experience, I’m a lot more likely to jaywalk if I’m in a hurry because I’m late, or busy with a lot to do that day. If you have jaywalked before and especially if you jaywalk regularly, consider how it makes sense to you at the time to jaywalk, and how those considerations and motivations might translate to an engineer making a DNS change. In the academic discipline of modern safety science, which is where, give or take, the idea of just culture as used in our track title originates. The jaywalking intuition is formalized as the gap between work as written and work as done. That is to say, documents, runbooks, and rules are an abstraction which do not and cannot map exactly to work as it is actually done. For example, you won’t find a pictogram of a dad struggling to put together an IKEA crib in the official instruction guide. Ryan Reynolds is definitely having a chaotic time here.
Another thing that we can ask is what the purpose of this DNS change was. Who asked for it? What pressure the engineer making the change might have felt to complete it quickly. I don’t think that any of the folks pictured on this slide asked for the change. If a VP or director of XYZ was trying to do a demo that required the change and needed it in a tight timeframe, what do we expect, or what does Salesforce expect the engineer to do next? While Salesforce’s write-up didn’t include any information on this. Just like we did with jaywalking, we can consider how you might have responded to two different time sensitive requests, one from a teammate, the other from an executive in your reporting chain. Which request would you be more willing to cut corners in order to deliver on time? The point here is that pressure applied even implicitly, from those who hold power in an organization can impact decision making. I want to highlight why at the time, it’s so important. The late Dr. Richard Cook, was a seminal researcher in the field of modern safety science, and wrote an amazing short paper titled, “How Complex Systems Fail,” 22 years ago. One of the observations made in that paper is that all practitioner actions are gambles. Some of you may also be familiar with the business book, “Thinking in Bets,” by former professional poker player, Annie Duke. Unsurprisingly, given the title in this bestseller, Duke argues that considering decisions as bets is key to long-term business success. People generally do not gamble intending to lose. When someone gambles, just like when an engineer presses a button, they do not know the future. That is, they take actions which make sense to them at the time.
Atlassian’s April 5, 2022, 14-Day Cloud Downtime
Let’s talk about another incident. This time, in April of 2022, Atlassian’s cloud went down for 14 days. That’s 60 times longer than the Salesforce outage we just spoke about. What happened? An engineer was given a list of about 1000 IDs of a legacy plugin to delete as part of a migration related to an acquisition. They did a substantial amount of testing, including testing on staging, and taking a smaller sample of those IDs, running them on prod, and everything worked. Then they ran the rest of the IDs. It turned out that the folks who gave them those IDs, gave them 30 plugin IDs for the initial prod test, but then gave them site IDs for the other 900 IDs. Their script probably deleted 883 full installations. That’s not the unimportant legacy plugin they intended to delete, but installation of Atlassian products that you’ve heard of, like Jira and Confluence. Again, that’s the trigger of the incident. Again, an engineer pressed return. If we look at how Atlassian explained what happened, the two things that they called out were, one, the fact that the engineer running the script was given IDs of an unexpected type. Two, that the script didn’t provide any feedback or warning prior to deleting entire installation.
Even from this summary, I think we got a pretty good grasp of why it made sense for the engineer to press return. They got IDs. They followed a clear rollout process, and all of their preflight tests worked cleanly. To be honest, when I first read this incident report, and I got to the part where the first 30 IDs were app IDs and the rest were site IDs, I shivered. If I was doing that job that day, I do not think that there’s any way I would have done anything different. That said, there wasn’t much in the incident report about the folks who supplied the IDs, so there’s not much to say about HDIMSATT to them. Notice that HDIMSATT is often different for everyone, and divergence can be painful. The multi-agent version of this problem is out of scope for this talk. If you’re curious, what I recommend Googling is the phrase, Common Ground and Coordination in Joint Activity.
Salesforce vs. Atlassian
Boil down to the essentials, both Salesforce and Atlassian, or at least the shadow versions I’ve constructed for this talk, remember that I didn’t experience these incidents firsthand, had long painful outages after an engineer pressed return and a script did something surprising and unpleasant. At the same time, even skimming the surface of how these organizations publicly explained the trigger of these incidents shows real differences. After reading Salesforce’s incident report, I think that Salesforce believes that had the DNS change been assigned to a “better engineer” who followed the organization’s policy to the letter, the outage would have been completely avoided. After reading Atlassian’s incident report, I think that the organization believes that running the script made sense at the time to the engineer who hit enter, and that if another engineer was at the keyboard, it probably would have made sense to them too. From this difference in understanding and explanation, which organization is poised to have richer and more accurate learning in post incident activities? Atlassian.
If there’s a part of your brain that’s whispering, yes. Why could the engineer have just not have hit return, or is this simply nihilistic chaos where no rules matter? This slide is for you. From the same paper we touched on earlier, come two more observations. First, complex systems are heavily and successfully defended against failure. Salesforce and Atlassian both already have a tremendous amount of infrastructure, SREs, paging, automation, things that work well, and follow best practice architectural patterns. That’s how they got to be large businesses that are well known enough for me to select them as examples for this talk. All of that is for better or worse, table stakes for where we are, because the second point the paper makes is that catastrophe is always just around the corner. This is really uncomfortable but it’s fundamental. What keeps catastrophe around that corner is people taking actions, which make sense to them at the time. On the other hand, when catastrophe turns the corner, and visits our system, who is frequently involved? Again, someone taking actions which make sense to them at the time: pedestrians jaywalk, and engineers hit return. To learn and adapt, we need to understand not just what went wrong, but why we believed it would go right.
A Near Miss – Naomi’s Baby Monitor
I want to talk about one more very different non-incident. This is my baby daughter, Naomi, who’s 15 months old. Earlier this month, my wife and I accidentally left Naomi’s baby monitor off. Thankfully, unlike our previous examples, she slept through the night fine. Nothing bad happened. This is what modern safety science calls a near miss. It’s really just random chance that Naomi slept through the night fine when we forgot the baby monitor. She could just as easily have woken up and been fussy, in which case our time to respond would have been higher than usual. Near misses are interesting because the lack of a bad outcome tends to make them less fraught to explore. Just think about the difference between an incident that costs your employer $10 million, and a very similar one that almost cost your employer $10 million, maybe a feature flag disabled money movement on that latter incident. Which incident would you expect participants to be more nervous about? Which incident review meeting do you think you would learn more from?
Beyond the near miss, the other interesting thing here is that the trigger was not action but inaction. We basically didn’t hit enter, and we could have had an incident because of that. HDIMSATT. Like I imagine most parents watching, we don’t have a formal checklist for bedtime, like a surgeon might before operating, nor do we have paging configured for the baby monitor. Really, what happens is that during the past year that Naomi has been sleeping in her crib with plenty of fussing, we’ve come to understand intuitively that our bedroom is close enough to hers, that if something is really wrong, we’ll hear her regardless. With a little bit of hand waving, basically as the importance of the baby monitor being enabled decreased, so did our cognitive vigilance. Another thing I want to point out is that learning from and adapting to Naomi’s previous fussiness is what enabled our “high reliability baby ops.” Failure-free operations require experience with failure.
In Practice, HDIMSATT is Contextual
How do we take what we’ve just learned to market at our jobs? How do we have impact and make things better? What does this look like when things stop being concepts and start getting real? In practice, HDIMSATT is squishy. Success in practice really depends on the organization. We’ll go over some building blocks. The best high-level advice I have is to experiment, remix, and catch a wave. By catch a wave, I mean, for example, watch for something adjacent which spikes leadership’s interests, frequently this is an incident. Sneak in some HDIMSATT to what is already in progress. Practically, when’s the right time to bust out HDIMSATT? One thing you can do is look out for terms like these, which are frequently associated with actions that mostly make sense in hindsight. Given a failure, you can almost always find a test case, alert, or dashboard, which would have detected it. Of course, we build all of those things before the failure happens, so HDIMSATT to write or not write tests, before we knew that something had failed.
I love this figure. I think it does a great job of showing the dangers of hindsight. Whoever triggered the incident was faced with a very complex maze and made a number of decisions, but eventually ended up at a boom. If we don’t uncover how things made sense at the time, we are left with a view of the incident, which not only isn’t “correct,” but won’t be representative of how folks will engage with the world tomorrow. We can’t change what happened yesterday, but if we understand, how it made sense at the time, we might be able to do better tomorrow. An obvious place to HDIMSATT is existing post incident activities: post-mortem meetings, incident reports, and so on. There’s a wide range of options here. Starting with asking HDIMSATT in post incident meetings, or putting the term in templates next to root cause or similar sections. More complex, which means a larger investment, but also a larger reward might look like updating your post incident activities to follow modern safety science informed approaches like those found in Etsy’s debriefing facilitation guide, or Jeli’s How We Got Here, or Howie guide. Understanding HDIMSATT during post incident activities often means asking adjacent questions to tease insight out of participants. We touched on many of these questions earlier when talking about Salesforce’s outage. How does DNS work at Salesforce? What’s the genesis of the change, and so on? It turns out that they serve well as a starting point for many other contexts.
Modern safety science can sometimes seem like a deep rabbit hole. As you’ve seen, luckily for us, HDIMSATT is near the surface. Some resources, for example, the textbook, “Foundations of Safety Science,” by Sidney Dekker, are much deeper. In my opinion, perfect is the enemy of impact. I think you can almost certainly improve things in your organization without needing to venture too deep into this hole. I say that to dispel fear of the activation energy required for adoption. Let me be clear, this domain is fascinating. If you’re curious, I encourage you to spelunk.
How HDIMSATT Applies, Beyond Just Incidents
We’ve spent the talk zoomed in to incident triggers as a way to optimize for sparking intuition. Very little of what we’ve discussed is actually trigger specific. Since we can take that prompt and have framed HDIMSATT in terms of incidents, we can also show examples of how it applies beyond just incidents. One thing we can do is ask HDIMSATT about anything in the past. HDIMSATT to Steve Jobs and Apple, but not Blackberry, that the future of computing was full touchscreen smartphones. How did it make sense at the time for Softbank to invest in WeWork? The woman you see on the right is Dr. Katalin Karikó. Her research was considered so disappointing in the 1990s that she was demoted from a tenure track position at the University of Pennsylvania. Today, she’s famous and widely respected for her contributions to mRNA COVID vaccines. How did it make sense at the time?
HDIMSATT looking forward is perhaps the most tricky and most valuable. Because we’re looking at the future, we can work to align what makes sense with our desired outcomes. A canonical example I think of is break glass systems, which might allow you to deploy from a non-main Git branch in emergencies, even if it’s normally disallowed, or to Salesforce’s emergency break fix system that we saw earlier. These will be used via work as done in ways that make sense at the time. We have agency today to design them as a pit of success. We can also think about what we might ask in the future, about how what we’re doing now made sense and feel a bit more motivated to write down answers and context behind our decisions.
Resources
This talk is largely a work of synthesis. It really mixes many building blocks put together by researchers and practitioners, going back to the 1990s. You can find breadcrumbs for those building blocks, as well as citations, attributions, the full list of folks I need to thank, and so on, at qcon2022.jhscott.systems.
Conclusion
There’s a limit to the reliability of systems built on understanding failure as being caused by software bugs or human error. One way to get beyond it is to learn from how it made sense at the time. HDIMSATT helps us pierce the illusion of work as written, and consider work as done. Understanding the safety and reliability of complex systems is an exploration we’re on together, and you can help by sharing what you learn.
Questions and Answers
Brush: Let’s say you have some executive that keeps wanting to add counterfactuals to your incident report, why didn’t we just, or we should have? How would you suggest, politely or not politely, resetting back to, how did it make sense at the time?
Scott: One of the things that I’m most curious about today is adoption. I think it really depends, unfortunately, on your relationship with this leader, what other allies or other people you have in your orbit, how the rest of the organization is doing. I think there’s this question about whether it makes more sense to say, ok, we can do both, or to nudge them and say, do you have time to read how complex systems fail? Or engage with them, what are you really concerned about? Counterfactuals may not be that useful to what you’re trying to do. Actually, I submitted a panel discussion at the Learning From Incidents conference, I think in February 2023. The talk I submitted there was a panel on exactly this question, about learning from chances in failures, and adoption of learning from incident reports. It’s the same thing.
Brush: We all know that public incident reports aren’t exactly the same thing as internal ones, because, obviously, there’s a PR component and a legal component. Is there anyone that you’ve ever read that you thought, this company gets it.
Scott: Laura Nolan, who’s formerly a Senior Staff Engineer at Slack, if you go and look at Slack’s incident reports, many of them up until October or something, many of the trickiest ones were written by Laura Nolan. I think they do a great job of covering both what happens from a user perspective, and what happens from the perspective of folks participating in the incident, and overlaps with, how did it make sense at the time? The other person is Pete Shima, who I think has helped. He works in reliability at Epic Games, helping make sure that Fortnite stays up. There are some interesting incident reports out of Epic when there have been big Fortnite outages. I think that one is especially interesting. Learning from incidents or this perspective of modern safety science intersecting with software reliability can really be anywhere. You don’t have to be FAANG. You don’t have to be X, Y, or Z. The people keeping Fortnite up can also apply this and have increased learning and build trust, and all those sorts of things, including through public incident reports.
Brush: It’s interesting that you named two companies that are really what I would consider consumer based. I know Slack has enterprise customers and enterprise deals as well. I think we tend to think of them as a very consumer focused company. Do you think this is harder for enterprise?
Scott: For sure. This goes to adoption as well. Maybe you could compare it to, although it’s very different, but publishing demographics for engineering organizations. Like, why would you want to do that, if it’s bad, and the cultural sea change that had to happen. I think maybe it was Tracy Chou at Pinterest who drove a bunch of that. It’s the bar to release that information. I think, yes, particularly for enterprise companies, where if I simulate being an executive, it’s like, what’s the good? The good here is like secondary, it’s ephemeral. Like maybe he said, there’s some kudos, we helped the industry a little bit at a time. The potential downside is like someone at an important contract, takes this the wrong way, because maybe they don’t understand the differences between safety. It’s complicated. It’s complex. I don’t think you can expect everyone to do that. There’s a lot of apprehension, and the reward is qualitative. It all ties back. It’s one of these things with learning from incidents in complex sociotechnical systems. It’s particularly challenging for enterprise folks.
Brush: I was wondering if like, you have to have two versions of the learning. One is the one where your customers are mature enough, they’re ready to see. Then there’s one that is your organization that wants to do that.
Scott: For sure. I would point to, as you said, the differences between internal and external. The authority I would point to is Adaptive Capacity Labs, which is John Allspaw, Dr. David Woods, and the late Dr. Richard Cook, both of the former two being professors. They have a great blog post on the multiple audiences for incident reports and for post-mortems. That’s something interesting as an engineer to think about systems thinking or whatever. There are different audiences. This is why maybe the reports from Slack and Epic are so interesting. The more you can learn from the more people the better, but also some of those learnings are highly contextual. I’m going to learn a lot more from an incident report from an incident I’ve been in that’s written to engineers, because I know what systems they’re talking about. One of the things from Sidney Dekker is that complex systems are path dependent. The history matters. How these decisions were made years ago, which led to the systems that you depend on now having weird quirks. That’s not a thing that I think you can really expect to be in a public incident report. It’s like, what weird language choice, you have to hunt in the Google Drive. I really do think there are different audiences and different learnings possible in different settings. John Allspaw retweeted a meme he had made, which is the Pawn Stars, or something, where there’s like the dad and the father, and it’s like, it’s helpful. It’s like, it’s no good because it’s public. It’s like, but they have to start somewhere. Look at John Allspaw’s Twitter for a recent meme, well-said, on this very topic.
Brush: What is the most interesting thing you think you’ve ever learned by asking, how did it make sense at the time, that you don’t think you would have learned?
Scott: I had an incident where, by doing something incremental, we thought that we were taking a safer approach, but, in fact, there were rails for doing a larger chunk of work at a time that would have made it safer. It’s not exactly, how did it make sense at the time, but by continuing to ask and be curious, and think about, maybe how is this supposed to work? Or like, when other people did this migration, how did they not explode? Even though it wasn’t like directly a remediation. It was actually like, we had a discussion about the incident as a team, and a few days later, we followed up with the other team who built the infrastructure they were building on. It turned out that, yes, actually, maybe the docs we were looking at were not exactly as good as we thought. Like, it’d point us to a point in the code base, which actually had some of this dual read, dual write stuff built in, but only for this specific path, that if you chose a riskier path, you got a better outcome because there was protection for the risky path, but not for the safer path. If you back up from specifically, how did it make sense at the time, to sort of related like curiosity, systems thinking, whatever. That was pretty interesting. That was just in the past few months.
Brush: It seems like related, to me, like when folks sometimes slow down their deployments, so it doesn’t trigger the alerting anymore.
Scott: Yes, all of these unintended consequences. Just after Black Friday, Cyber Monday, many folks may have had code freezes. The classic one is like, you have a memory leak, because your code froze for a week, and normally you deploy multiple times a day, and so like your Java [inaudible 00:37:35]. Then you’re like, I had this thing I did that should have made me safer, in fact, made it worse.
See more presentations with transcripts
MMS • RSS
“
Open Source Big Data Tools Market report focused on the comprehensive analysis of current and prospects of the Open Source Big Data Tools industry. This report is a consolidation of primary and secondary research, which provides market size, share, dynamics, and forecast for various segments and sub-segments considering the macro and micro environmental factors. An in-depth analysis of past trends, future trends, demographics, technological advancements, and regulatory requirements for the Open Source Big Data Tools market has been done to calculate the growth rates for each segment and sub-segments.
Get the PDF Sample Copy (Including FULL TOC, Graphs, and Tables) of this report @:
https://www.researchcognizance.com/sample-request/221410
Some of the Top companies Influencing this Market include:
MongoDB Inc., AQR Capital Management, Apache, RapidMiner, HPCC Systems, Neo4j; Inc., Atlas.ti, Qubole, Qualtrics, Pentaho, Cloudera, Google, GitHub, Kaggle, Greenplum
This study provides an evaluation of aspects that are expected to impact the growth of the market in an undesired or constructive method. The Open Source Big Data Tools market has been consistently examined with respect to the corresponding market segments. Each year within the mentioned forecast period is concisely considered in terms of produce and worth in the regional as well as global markets respectively. Technical expansions of the Open Source Big Data Tools market have been examined by focusing on different technical platforms, tools, and methodologies. The notable feature of this research report is, it incorporates client demands as well as future progress of this market across the global regions.
The report provides insights into competitive samples, advantages and loss of products, and macro-economic policies of the market. It recognizes opportunities in competitive market conditions and provides information for decision-making and policies that will increase business growth. Driver and restraint for the growth of the Open Source Big Data Tools market are also included in this study. Production is done on the basis of area and application.
Global Open Source Big Data Tools market segmentation:
Market Segmentation: By Type
Language Big Data Tools, Data Collection Big Data Tools, Data Storage Class Big Data Tools, Data Analysis Big Data Tools, Others
Market Segmentation: By Application
Bank, Manufacturing, Consultancy, Government, Other
The report provides insights on the following pointers:
Market Penetration: Comprehensive information on the product portfolios of the top players in the Open Source Big Data Tools market.
Product Development/Innovation: Detailed insights on upcoming technologies, R&D activities, and product launches in the market.
Competitive Assessment: In-depth assessment of the market strategies, geographic and business segments of the leading players in the market.
Market Development: Comprehensive information about emerging markets. This report analyzes the market for various segments across geographies.
Market Diversification: Exhaustive information about new products, untapped geographies, recent developments, and investments in the Open Source Big Data Tools market.
Get a Special Discount of up to 30% on this Report @:
https://www.researchcognizance.com/discount/221410
An assessment of the market attractiveness with regard to the competition that new players and products are likely to present to older ones has been provided in the publication. The research report also mentions the innovations, new developments, marketing strategies, branding techniques, and products of the key participants present in the global Open Source Big Data Tools market. To present a clear vision of the market the competitive landscape has been thoroughly analysed utilizing the value chain analysis. The opportunities and threats present in the future for the key market players have also been emphasized in the publication.
Reasons for buying this report:
- It offers an analysis of changing competitive scenario.
- For making informed decisions in businesses, it offers analytical data with strategic planning methodologies.
- It offers a seven-year assessment of Open Source Big Data Tools Market.
- It helps in understanding the major key product segments.
- Researchers throw light on the dynamics of the market such as drivers, restraints, trends, and opportunities.
- It offers regional analysis of Open Source Big Data Tools Market along with business profiles of several stakeholders.
- It offers massive data about trending factors that will influence the progress of the Open Source Big Data Tools Market.
Table of Contents
Global Open Source Big Data Tools Market Research Report 2023-2030
Chapter 1 Open Source Big Data Tools Market Overview
Chapter 2 Global Economic Impact on Industry
Chapter 3 Global Market Competition by Manufacturers
Chapter 4 Global Production, Revenue (Value) by Region
Chapter 5 Global Supply (Production), Consumption, Export, Import by Regions
Chapter 6 Global Production, Revenue (Value), Price Trend by Type
Chapter 7 Global Market Analysis by Application
Chapter 8 Manufacturing Cost Analysis
Chapter 9 Industrial Chain, Sourcing Strategy, and Downstream Buyers
Chapter 10 Marketing Strategy Analysis, Distributors/Traders
Chapter 11 Market Effect Factors Analysis
Chapter 12 Global Open Source Big Data Tools Market Forecast
Buy Exclusive Report @:
https://www.researchcognizance.com/checkout/221410
Get in Touch with Us:
Neil Thomas
116 West 23rd Street 4th Floor New York City, New York 10011
+1 7187154714
Related Reports:
MMS • RSS

What is Apache Cassandra?
Welcome to our “DEFINITIONS” blog category, where we delve into various terms and concepts related to technology. In this post, we’ll be exploring the world of Apache Cassandra and uncovering what it is all about.
<!–
–>
<!–
–>
Apache Cassandra is an open-source distributed database management system designed to handle massive amounts of data across multiple commodity servers, providing high availability and fault tolerance. Now, you might be wondering why Cassandra stands out from other database systems. Let’s dive in and find out!
Key Takeaways:
- Apache Cassandra is an open-source distributed database management system.
- It offers high availability, fault tolerance, and handles massive amounts of data across multiple servers.
Cassandra was created at Facebook to handle the constantly increasing data needs of the social media giant. Eventually, it was released as an open-source project in 2008 and became a top-level Apache Software Foundation project in 2010.
So, what sets Cassandra apart? Here are a few notable features that make it a popular choice for modern data-driven applications:
Scalability:
Cassandra is horizontally scalable, allowing you to easily add or remove servers to accommodate changing data requirements. It can handle petabytes of data across thousands of nodes without compromising performance. As your application grows, Cassandra grows with it.
Distributed Architecture:
With Cassandra, data is distributed across multiple nodes in a decentralized manner. This architecture ensures high availability and fault tolerance, meaning your application can continue running even if some servers go offline. It also eliminates single points of failure, making it highly resilient.
Tunable Consistency:
Cassandra offers flexible consistency levels, allowing you to choose the level of trade-off between consistency and availability that fits your application’s requirements. This tunability enables you to optimize performance and ensure data integrity according to your specific needs.
NoSQL Schema:
Cassandra follows a schema-free, NoSQL data model. This means you can store and retrieve data in varying formats without rigid upfront schema constraints. You have the freedom to evolve your data structures as your application evolves, making it well-suited for agile development and Big Data use cases.
In summary, Apache Cassandra is a powerful distributed database management system that provides scalability, fault tolerance, and tunable consistency. Its NoSQL data model makes it a flexible choice for modern applications dealing with huge amounts of data.
Whether you are running a large-scale application handling massive data workloads or a smaller project that requires high availability, Cassandra might just be the right choice for you. Explore its capabilities, experiment, and unleash the full potential of this incredible database system!
Stay tuned for more informative posts in our “DEFINITIONS” category, where we break down technology jargon and help you navigate through the vast world of software and systems.
<!–
–>
MMS • Ben Linders

Emotions are at the heart of conflicts, influencing their initiation, escalation and dynamics. Effectively managing your own emotions and understanding those of others can greatly impact the outcome of a conflict. Two steps to be taken are to label emotions, and take control and determine which emotion you want to focus on.
Marion Løken spoke about handling conflicts in teams at NDC Oslo 2023.
It’s crucial to proactively handle your emotions, Løken said. The first step in dealing with your emotions during a conflict is to label them. Are you feeling stressed, worried, irritated, angry, or furious? Each of these emotional states has distinct origins and varying levels of intensity.
Once you have identified your emotional state, you can better manage your emotions, Løken said. This is particularly relevant when experiencing an amygdala hijack, where the primitive part of your brain takes over rational thinking and triggers flight, fight, or freeze responses. When you understand what’s happening, you can begin to self-regulate.
Refining your labelling of emotion can help prevent overreacting in situations, as Løken explained:
If you tend to use the term “irritated” for every situation and respond in the same manner, there’s a higher chance of overreacting frequently. However, if you’re simply feeling “peeved” or “slightly irritated,” it’s important to adjust your reaction accordingly. Often, just asking yourself, “Am I truly that upset?” can make a difference.
The second step in dealing with emotions is to take control and determine which emotion you want to focus on, Løken said. Humans can experience multiple feelings simultaneously. During conflicts, you may feel a combination of strong emotions like irritation and worry, fury and helplessness, or anger and focus. Instead of allowing yourself to be consumed by negative emotions, it’s beneficial to choose ONE emotion that can help you the most, Løken suggested.
A particularly useful emotion in most situations is feeling “surprised”. Being in a state of surprise (rather than shock) can truly make a significant difference in how you think and act during a conflict, as Løken explained:
Instead of asking yourself, “What, THE HELL, happened?” (shocked), try simply asking, “What happened?” (surprised) Notice the difference in how it feels? This slight reframing of your emotional state can positively impact your mindset and promote kindness in your behaviour.
If you manage to see a conflict as a learning opportunity, you have already won, Løken concluded.
InfoQ interviewed Marion Løken about handling conflicts.
InfoQ: What role does psychological safety play in dealing with conflicts?
Marion Løken: Psychological safety serves as the foundation for and is the result of good conflicts, Løken said. If you fear retaliation, you won’t address issues, express concerns, or generate your best ideas, she added. Trust, respect, and accountability are crucial for creating a team environment where individuals feel comfortable being vulnerable and speaking up.
When you take the risk (or chance) of being open with others, it reinforces trust within the team and contributes to psychological safety. Brené Brown, a researcher and author, proposes the idea that courage is contagious, generating a ripple effect.
Similarly, this concept can be applied to dissent. When an individual bravely raises a concern and the team effectively addresses it, it just gives everyone a boost of confidence and raises the trust level. It is then easier for the next conflict to be dealt with well.
InfoQ: What if it turns out that people don’t feel safe? How can we handle that?
Løken: You know, just declaring a space as “safe” doesn’t necessarily make people feel safe. It’s important for individuals to genuinely sense that safety.
I’m not entirely sure how we go about creating that feeling. Perhaps it involves people experiencing – and you demonstrating – signs or cues that contribute to a sense of security. So, one idea could be to encourage people to try it out with minor conflicts, and experiment “safely” to feel safe.
InfoQ: How can we hack our emotional response with curiosity?
Løken: Curiosity fuels both our sense of surprise and our desire for knowledge. It creates a positive mindset and fosters an eagerness to understand and learn. Both are critical for good conflict resolution.
In conflicts, curiosity can be summoned in various ways. Firstly, being curious about the root cause of our reactions is important. Why do we feel so upset? Were we aware that this subject would evoke such strong emotions? Which aspects of our identity, status, or autonomy are being challenged? Secondly, curiosity extends to seeking others’ perspectives and understanding why they perceive things differently.
MMS • RSS
“
Report Description:
The NoSQL Database Market Research report provides a detailed, in-depth analysis of global market size, share, regional and country-level Analysis, market segmentation, growth, NoSQL Database Market share, competitive landscape, and sales analysis. The NoSQL Database Market report first introduced definitions, classifications, applications and market overview, product specifications, manufacturing processes, cost structures, raw materials, etc. The research report is one of the best and most comprehensive, underlining the challenges, market structures, opportunities, driving forces, emerging trends, and industry competitive landscape.
The study gives a comprehensive knowledge of key players’ industry development plans, recent market conditions, growth data, and the scope of the respective NoSQL Database market in the future. The NoSQL Database market research is responsible for providing regional development, NoSQL Database industry driving aspects, and global sales revenue of the NoSQL Database market. This thorough study provides up-to-date and detailed information on the most recent technological breakthroughs, as well as SWOT and Porter Five Forces analysis and important market size data.
Download Sample Copy of the Report to understand the structure of the complete report@: https://globalmarketvision.com/sample_request/133867
Top Key Players:
DynamoDB, ObjectLabs Corporation, Skyll, MarkLogic, InfiniteGraph, Oracle, MapR Technologies, he Apache Software Foundation, Basho Technologies, Aerospike.
This NoSQL Database Market report includes a competitive landscape analysis, providing insights into prominent players with considerable market shares. With detailed data reflecting the performance of each player shared, readers can acquire a holistic view of the competitive situation and a better understanding of their competitors.
In today’s fast-paced digital era, the focused industry of Analytics has revolutionized the market with its innovative strategies. By utilizing market segmentation techniques, this industry has successfully tapped into various segments based on type, application, end-user, region, and more.
NoSQL Database Market by Type
Column, Document, Key-value, Graph
NoSQL Database Market by Application:
the market can be split into, E-Commerce, Social Networking, Data Analytics, Data Storage, Others
This comprehensive report provides in-depth coverage of various crucial aspects including revenue forecast, company ranking, competitive landscape, growth factors, and latest trends. It offers invaluable insights into the future prospects of the market, enabling businesses to make informed decisions. With accurate revenue forecasts, companies can plan their investments and resources efficiently.
Regional Outlook:
The following section of the report offers valuable insights into different regions and the key players operating within each of them. To assess the growth of a specific region or country, economic, social, environmental, technological, and political factors have been carefully considered. The section also provides readers with revenue and sales data for each region and country, gathered through comprehensive research. This information is intended to assist readers in determining the potential value of an investment in a particular region.
» North America (U.S., Canada, Mexico)
» Europe (Germany, U.K., France, Italy, Russia, Spain, Rest of Europe)
» Asia-Pacific (China, India, Japan, Singapore, Australia, New Zealand, Rest of APAC)
» South America (Brazil, Argentina, Rest of SA)
» Middle East & Africa (Turkey, Saudi Arabia, Iran, UAE, Africa, Rest of MEA)
Table of Content for Global NoSQL Database Market:
Chapter 1. NoSQL Database Market Overview
Chapter 2. Market Competition by Players / Suppliers
Chapter 3. NoSQL Database Market Sales and Revenue by Regions
Chapter 4. Sales and Revenue by Type
Chapter 5. NoSQL Database Market Sales and revenue by Application
Chapter 6. Market Players profiles and sales data
Chapter 7. Manufacturing Cost Analysis
Chapter 8. Industrial Chain, Sourcing Strategy and Down Stream Buyers
Chapter 9. Market Strategy Analysis, Distributors/Traders
Chapter 10. NoSQL Database Market effective factors Analysis
Chapter 11. Market Size and Forecast
Chapter12. Conclusion
Chapter13. Appendix
Continued….
If you have any requirements, let us know and we will customize the report according to your need.
Direct Purchase this Market Research Report Now @ https://globalmarketvision.com/checkout/?currency=USD&type=single_user_license&report_id=133867
The final report will add the analysis of the Impact of Covid-19 in this report NoSQL Database Market.
Adapting to the recent novel COVID-19 pandemic, the impact of the COVID-19 pandemic on the global NoSQL Database Market is included in the present report. The influence of the novel coronavirus pandemic on the growth of the NoSQL Database Market is analyzed and depicted in the report.
About Global Market Vision
Global Market Vision consists of an ambitious team of young, experienced people who focus on the details and provide the information as per customer’s needs. Information is vital in the business world, and we specialize in disseminating it. Our experts not only have in-depth expertise, but can also create a comprehensive report to help you develop your own business.
With our reports, you can make important tactical business decisions with the certainty that they are based on accurate and well-founded information. Our experts can dispel any concerns or doubts about our accuracy and help you differentiate between reliable and less reliable reports, reducing the risk of making decisions. We can make your decision-making process more precise and increase the probability of success of your goals.
Get in Touch with Us
Sarah Ivans | Business Development
Phone: +1 805 751 5035
Phone: +44 151 528 9267
Email: [email protected]
Global Market Vision
Website: www.globalmarketvision.com
”
MMS • Steef-Jan Wiggers
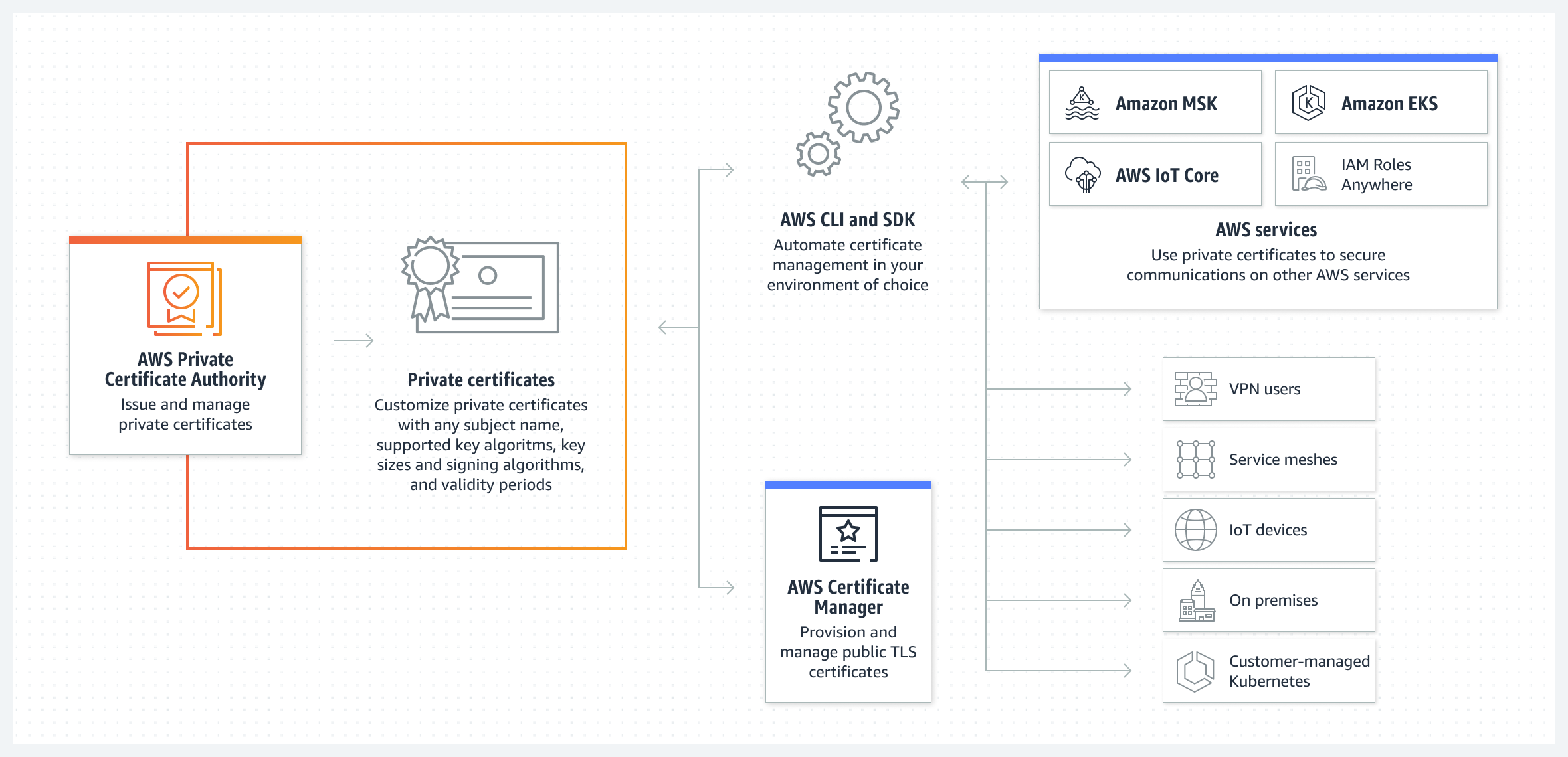
AWS recently launched the AWS Private Certificate Authority (CA) Connector for Active Directory (AD). It is a new feature that allows enterprises to use AWS Private CA as a drop-in replacement for self-managed enterprise certificate authorities without the need to deploy, patch, or update local agents or proxy servers.
AWS Private Certificate Authority (AWS Private CA) is a fully-managed, highly available CA that helps organizations secure their applications and devices using private certificates. In an AWS for Industries blog post, the authors explain:
With AWS Private CA, enterprise customers can build a PKI inside the AWS cloud for private use within an organization. AWS manages the undifferentiated heavy lifting of creating, managing, and securing CAs. With AWS Private CA, you can create your own CA hierarchy and issue certificates for authenticating internal users, computers, applications, services, servers, devices and signing computer codes.
AWS Private CA Diagram (Source: AWS Private CA Service)
The service now includes a Connector for AD pre-announced during the recent re:inforce 2023, allowing customers to replace on-premises enterprise or other third-party CAs with a managed private CA, providing certificate enrollment to users, groups, and machines managed by their AD.
In an AWS Security blog post on the key announcements and session highlights, the authors wrote:
AWS Private CA will soon launch a Connector for Active Directory (AD). The Connector for AD will help to reduce upfront public key infrastructure (PKI) investment and ongoing maintenance costs with a fully-managed serverless solution. This new feature will help reduce PKI complexity by replacing on-premises certificate authorities with a highly secure hardware security module (HSM)-backed AWS Private CA. You will be able to automatically deploy certificates using auto-enrollment to on-premises AD and AWS Directory Service for Microsoft Active Directory.
The first step is for users to create a connector through the console, command line (create-connector command), or API for AWS Private CA Connector for Active Directory (CreateConnector action). The request syntax for creating a connector using the API looks like:
POST /connectors HTTP/1.1
Content-type: application/json
{
"CertificateAuthorityArn": "string",
"ClientToken": "string",
"DirectoryId": "string",
"Tags": {
"string" : "string"
},
"VpcInformation": {
"SecurityGroupIds": [ "string" ]
}
}
Subsequently, users can follow other procedures, such as configuring templates and integrating with AWS Private CA and Active Directory.
When asked by InfoQ the benefits of the AD Connector, here is what Ken Beer, a general manager of Key Management Service at AWS, had to say:
AWS Private Certificate Authority (CA) Connector for Active Directory (AD) streamlines how customers manage Windows environments to cut private CA costs, reduce complexity, and secure private keys with hardware security modules. Customers can even pair the new feature with AWS Managed Microsoft AD to reduce their on-premises infrastructure dependencies and migrate AD and public key infrastructure to the cloud.
In addition, João Rodolfo Vieira da Silva, a Cyber Security Specialist at Banco Itaú, commented on a LinkedIn post on the AD Connector from AWS private CA general manager Todd Cignetti:
It’s opening up huge opportunities for the corporations. Keep it simple and easy for us!
Lastly, the Connector for AD is offered as a feature of AWS Private CA at no additional cost – customers only pay for the private certificate authorities and the certificates they issue through them. The pricing details for AWS Private CA are available on the pricing page.
MMS • Almir Vuk

Microsoft has recently announced the first Release Candidate version of the .NET Multi-platform App UI (MAUI) framework in the .NET 8 roadmap. As reported, this first release candidate version is focused on code quality, various UI improvements, and performance optimizations alongside Xcode 15 beta support for Apple SDKs.
The original announcement post starts with a very promising statement from David Ortinau, Principal Product Manager on .NET MAUI, which states the following:
.NET MAUI in .NET 8 release candidate 1 which comes with a go live license so you can confidently use this release for your production applications.
Regarding the quality part, in the recent development, significant improvements have been made to address memory leak issues in various user interface controls. As reported, these fixes aim to enhance memory management and boost application stability across the iOS platform. Specifically, memory leak issues have been resolved in key UI components such as the Editor, Entry, MauiDoneAccessoryView, RefreshView, SwipeView, TimePicker, Picker, and GraphicsView.
Additionally, several UI controls, including CheckBox, RefreshView, SwipeItem, Label, and Button, have undergone enhancements to improve overall app interaction, making it smoother for app users.
Platform-specific issues on iOS, Android, Windows, and macOS have also been addressed. These fixes ensure a consistent user experience by resolving issues related to border clipping, window glitches, and image-loading problems across various platforms.
Furthermore, performance optimizations have been implemented to reduce memory usage and improve resource generation. Notable improvements include better memory management in CollectionView, refined resource control, and the resolution of Android timer issues. These optimizations result in improved app performance and responsiveness.
In addition to quality improvements available with RC1, developers can now use Xcode 15 beta with Visual Studio for app development and simulator management. This compatibility will be part of the next Visual Studio release. Additionally, .NET 8 will introduce new APIs for Apple SDKs like iOS 17. This integration has been verified with Xcode 15 Beta 6, and it’s expected to work well with more recent releases.
Also, the comments section is active as usual, and it is based on multiple comments with disagreement around the quality and production readiness of .NET MAUI. The author of the announcement post and Principal Product Manager on .NET MAUI, David Ortinau was a part of the communication with community members. So it is recommended that developers take a look into the conversations to gain more insights and look for community feedback.
To get started developers can follow official recommendations and guidelines from the announcement post, stating the following:
Through the retirement of Visual Studio for Mac you can continue developing using Visual Studio for Mac after enabling the preview feature for .NET 8 in Preferences.
On Windows, update or install Visual Studio 2022 17.8 preview 2 to get .NET 8 RC1 with .NET MAUI. This version will ship soon, and we recommend waiting for this release on Windows if you are using Visual Studio 2022.
Lastly, in addition to an original release blog post, and as part of the development process, the development team calls on developers to test the new release and share feedback through the official GitHub issue tracker. The community members are also invited to visit the official GitHub project repository and learn more about this project and its future roadmap.
MMS • RSS
On September 13, 2023, it was reported that AM Squared Ltd has increased its holdings in MongoDB, Inc. (NASDAQ:MDB) by 33.3% during the first quarter of the year. According to the company’s most recent disclosure with the Securities and Exchange Commission, AM Squared Ltd now owns 1,200 shares of MongoDB’s stock after acquiring an additional 300 shares during the period. The value of these holdings was estimated to be $280,000 as of the most recent filing.
MongoDB, Inc. is a global provider of a general-purpose database platform. The company offers various solutions including MongoDB Atlas, which is a hosted multi-cloud database-as-a-service platform. This solution provides businesses with a convenient and scalable way to manage their data across multiple cloud platforms.
Another offering from MongoDB is MongoDB Enterprise Advanced, which caters to enterprise customers by providing them with a commercial database server that can be deployed in various environments such as the cloud, on-premise, or in hybrid setups. This allows organizations to have greater flexibility and control over their data management systems.
Additionally, MongoDB also offers Community Server – a free-to-download version of its database software. This version includes all the essential functionality that developers need to get started with MongoDB and serves as an entry point for individuals or organizations looking to explore and adopt this technology.
The increase in holdings by AM Squared Ltd showcases their confidence in MongoDB’s market potential and its ability to deliver value to investors. As companies increasingly recognize the importance of effective data management in today’s digital landscape, the demand for robust database solutions like those offered by MongoDB continues to rise.
Investors should note that this information is based on recent disclosures made by AM Squared Ltd with the Securities and Exchange Commission as at September 13, 2023; therefore, it may not reflect any subsequent changes or developments pertaining to their investment in MongoDB, Inc.
In conclusion, AM Squared Ltd has increased its stake in MongoDB, Inc. during the first quarter of 2023. MongoDB’s offerings, including its hosted multi-cloud database-as-a-service platform and commercial database server for enterprise customers, position the company as a significant player in the database industry. This development underscores the continued growth and demand for robust data management solutions in today’s technology-driven world.
MongoDB, Inc.
MDB
Buy
Updated on: 13/09/2023
Hedge Funds and Analysts Show Interest in MongoDB’s Stock
On September 13, 2023, it was reported that several hedge funds had recently bought and sold shares of MongoDB, Inc., a general purpose database platform provider. One hedge fund, abrdn plc, increased its stake in the company by 79.7% during the first quarter, acquiring an additional 5,331 shares. This brought abrdn plc’s total ownership to 12,019 shares worth $2,802,000.
Another hedge fund called Clarius Group LLC also raised its stake in MongoDB by 7.7% during the first quarter, purchasing an additional 97 shares. Clarius Group LLC’s total ownership now amounts to 1,362 shares valued at $318,000. Moody Lynn & Lieberson LLC entered the scene as well during this period by buying a new stake in MongoDB worth approximately $7,433,000.
Daiwa Securities Group Inc. and Principal Financial Group Inc. were two other hedge funds that increased their stakes in MongoDB. Daiwa Securities Group Inc.’s ownership rose by 3.5% with the acquisition of an additional 186 shares worth $1,273,000 during the first quarter. Similarly, Principal Financial Group Inc.’s stake grew by 12.3%, buying an extra 924 shares valued at $1,664,000 during the fourth quarter.
Overall, hedge funds and other institutional investors now own approximately 88.89% of MongoDB’s stock.
In terms of analyst reports on MDB stock from various equities research firms, Morgan Stanley raised their price target from $440 to $480 with an “overweight” rating on September 1st. JMP Securities also raised their price target from $425 to $440 with a “market outperform” rating on the same day.
Truist Financial joined in by increasing their price target from $420 to $430 with a “buy” rating for MongoDB on September 1st. The Goldman Sachs Group also raised their price target for the stock from $420 to $440, while 22nd Century Group maintained its rating of “Moderate Buy” on June 26th.
As for the company itself, MongoDB, Inc. offers a general purpose database platform known as MongoDB Atlas, which is a hosted multi-cloud database-as-a-service solution used globally. They also offer MongoDB Enterprise Advanced, a commercial database server designed for enterprise customers to run either in the cloud, on-premise, or in hybrid environments.
Additionally, they provide Community Server, a free-to-download version of their database that includes essential functionality for developers to start with MongoDB.
In recent news related to company insiders and stock transactions, Director Dwight A. Merriman sold 1,000 shares of MongoDB stock at an average price of $420 per share on July 18th. This transaction amounted to a total of $420,000 and reduced Merriman’s holding to 1,213,159 shares valued at approximately $509,526,780.
Director Hope F. Cochran also engaged in selling shares of MongoDB stock by disposing of 2,174 shares at an average price of $373.19 per share on June 15th. As a result of this sale, Cochran’s ownership decreased to 8,200 shares valued at around $3,060,158.
Overall, insiders have sold approximately 99,694 shares worth $39,991,889 over the past three months. As it stands now though, company insiders hold roughly 4.80% of MongoDB’s stock.
MongoDB’s stock opened at $374.57 on September 13th and has been trading within this range. The company has a debt-to-equity ratio of 1.29 along with a current ratio of 4.48 and quick ratio of 4.19.
With a market capitalization of $26.44 billion, MongoDB, Inc. has experienced significant growth in its valuation over the past year. The company’s stock performance has ranged from a low of $135.15 to a high of $439.00 during this period.
The stock currently has a 50-day simple moving average of $387.78 and a 200-day simple moving average of $313.60.
In conclusion, MongoDB, Inc., the provider of a general purpose database platform, has attracted attention from hedge funds and other institutional investors due to recent transactions involving its shares. Analysts have also expressed positive sentiments towards the company’s stock with buy ratings and raised price targets.
As for MongoDB itself, it continues to expand its services with offerings like MongoDB Atlas and MongoDB Enterprise Advanced while providing developers with its free-to-download Community Server version.
While insiders have sold shares in recent months, they still retain a small percentage of ownership in the company.
These factors combined contribute to the continuous growth and market capitalization of MongoDB as it remains an intriguing player in the database solutions industry.
MMS • RSS

Statsndata Big Data and Analytics Market research reports provide all the information. It fuels market growth by providing customers with reliable data that helps them make critical decisions. These documents encapsulate extensive studies and analyses conducted by experts in various fields, presenting findings and insights that are crucial for both businesses and individuals seeking to navigate the complexities of the Big Data and Analytics market.
You can access a sample report here:https://www.statsndata.org/download-sample.php?id=4013
The Big Data and Analytics report provides a comprehensive overview, including market definitions, applications, developments, and manufacturing technology. It meticulously tracks recent market developments and innovations while offering data on the challenges faced when starting a business, along with guidance on overcoming future obstacles.
Prominent companies influencing the Big Data and Analytics market landscape include:
• Microsoft
• MongoDB
• Predikto
• Informatica
• CS
• Blue Yonder
• Azure
• Software AG
• Sensewaves
• TempoIQ
• SAP
• OT
• IBM
• Cyber Group
• Splunk
This Big Data and Analytics research report spotlights the major market players thriving in the industry, allowing you to track their business strategies, financial status, and upcoming product releases.
To begin with, the Big Data and Analytics research report provides a market overview, encompassing definitions, applications, product launches, developments, challenges, and geographical considerations. The market is poised for robust growth due to increased consumption across various sectors. The report offers an analysis of the current market structure and other fundamental aspects.
Regional insights regarding the Big Data and Analytics market are primarily covered in the region-specific sections, including:
• North America
• South America
• Asia Pacific
• Middle East and Africa
• Europe
Market Segmentation Analysis is a crucial component, categorizing the Big Data and Analytics market based on type, product, end-user, and more, facilitating a precise market description.
Market Segmentation: By Type
• LoT, M2M
Market Segmentation: By Application
• Data Intergration, Data Storage, Data Presentation,
For customization requests, please visit: https://www. statsndata.org/request-customization.php?id=4013
The primary objectives of this report are:
- To provide qualitative and quantitative trend analysis, dynamics, and forecasts of the Big Data and Analytics market from 2023 to 2029.
- To employ analytical tools like SWOT analysis and Porter’s Five Competitive Skills analysis to assess the capabilities of Big Data and Analytics buyers and suppliers for profit-driven decision-making and business development.
- To conduct a thorough Big Data and Analytics market segmentation analysis to identify existing market opportunities.
- Ultimately, to save you time and money by consolidating unbiased information in one accessible source.
Conclusion
In conclusion, this report also delves into Big Data and Analytics market attractiveness assessments, exploring the competitive potential of new entrants and products for existing players. It highlights innovations, developments, marketing strategies, branded technologies, and products of key players in the global industry. A comprehensive analysis of the competitive landscape is conducted using value chain analysis, offering a clear vision of the market. The report also outlines future opportunities and threats for major Big Data and Analytics market players.
Table Of Content
Chapter 1 Big Data and Analytics Market Overview
1.1 Product Overview and Scope of Big Data and Analytics
1.2 Big Data and Analytics Market Segmentation by Type
1.3 Big Data and Analytics Market Segmentation by Application
1.4 Big Data and Analytics Market Segmentation by Regions
1.5 Global Market Size (Value) of Big Data and Analytics (2018-2029)
Chapter 2 Global Economic Impact on Big Data and Analytics Industry
2.1 Global Macroeconomic Environment Analysis
2.2 Global Macroeconomic Environment Analysis by Regions
Chapter 3 Global Big Data and Analytics Market Competition by Manufacturers
3.1 Global Big Data and Analytics Production and Share by Manufacturers (2023 and 2023)
3.2 Global Big Data and Analytics Revenue and Share by Manufacturers (2023 and 2023)
3.3 Global Big Data and Analytics Average Price by Manufacturers (2023 and 2023)
3.4 Manufacturers Big Data and Analytics Manufacturing Base Distribution, Production Area and Product Type
3.5 Big Data and Analytics Market Competitive Situation and Trends
Chapter 4 Global Big Data and Analytics Production, Revenue (Value) by Region (2018-2023)
4.1 Global Big Data and Analytics Production by Region (2018-2023)
4.2 Global Big Data and Analytics Production Market Share by Region (2018-2023)
4.3 Global Big Data and Analytics Revenue (Value) and Market Share by Region (2018-2023)
4.4 Global Big Data and Analytics Production, Revenue, Price and Gross Margin (2018-2023)
Continue…
Buy the full report: https://www .statsndata.org/checkout-report.php?id=4013
Contact Us
Related Report
MMS • RSS

What is Riak? A Comprehensive Definition and Explanation
Welcome to our “DEFINITIONS” category, where we provide in-depth explanations of different terms and concepts in the tech world. In today’s post, we will be diving into the world of Riak, a distributed NoSQL database that offers high availability, fault tolerance, and scalability. If you’ve ever wondered what Riak is and how it can benefit your business, you’ve come to the right place.
<!–
–>
<!–
–>
Key Takeaways:
- Riak is a distributed NoSQL database designed for high availability, fault tolerance, and scalability.
- It offers a flexible data model, allowing you to store and retrieve data in a schema-less manner.
So, what exactly is Riak?
Riak is a powerful distributed NoSQL database that is designed to handle large amounts of data across multiple nodes in a cluster. It provides a fault-tolerant and highly available storage solution, making it ideal for applications that demand high performance and reliability.
Unlike traditional relational databases, Riak does not use the traditional table structure with fixed columns. Instead, it offers a schema-less data model, which means you can store data with different attributes and structures without the need to define a rigid schema beforehand. This flexibility allows you to adapt to changing business requirements and easily scale your database as your data grows.
Why should you consider using Riak?
Riak offers a range of key benefits that make it a popular choice for businesses operating in today’s data-driven world:
- High Availability: Riak is designed with a distributed architecture that ensures high availability of data, even in the event of node failures. It automatically replicates data across multiple nodes, allowing for seamless failover and continuous access to your data.
- Fault Tolerance: With its distributed nature, Riak can handle failures gracefully. It provides built-in mechanisms to detect and recover from failures, ensuring that your data remains intact and accessible at all times.
- Scalability: As your data grows, Riak allows you to easily scale your database by adding more nodes to your cluster. This horizontal scalability ensures that your database can handle increasing data loads without sacrificing performance.
- Operational Simplicity: Riak simplifies database operations by offering auto-repair, automatic data rebalancing, and intuitive querying capabilities. This reduces the complexity of managing a distributed database and streamlines your development process.
Whether you are building a real-time analytics platform, a content management system, or any other data-intensive application, Riak can provide the foundation you need to handle large volumes of data and deliver fast, reliable results. Its flexible data model, combined with its fault tolerance and scalability, makes it a powerful tool for modern businesses.
So, if you’re looking for a distributed NoSQL database that can handle your data storage needs with ease, consider giving Riak a try. Its impressive features and ability to handle large datasets make it a solid choice for businesses of all sizes.
We hope this comprehensive definition and explanation of Riak has shed some light on this powerful database solution. Stay tuned for more informative “DEFINITIONS” posts right here on our blog!
<!–
–>