Month: September 2023
With the “summer of data” in the rear-view mirror, here are the key takeaways to remember

MMS • RSS

There’s no talking about the “Summer of Data” without including a significant addition about the year of artificial intelligence — the two are inextricably linked and will remain so in the months to come.
That’s because the rise of AI has led to the need for incredible amounts of data, and projections indicate that data centers are to become the world’s largest energy consumers, rising from 3% of total electricity use in 2017 to 4.5% by 2025. Indeed, more companies are seeing their data needs grow on a yearly basis, leading to the characterization that “every company is a data company.”
With an eye on approaching this challenge, various technological advancements have rolled out in 2023, including a necessity for data storage innovation. Next-generation storage solutions are estimated to be valued at more than $150 billion by 2032, according to a recent study from Global Market Insights Inc.
It’s also no surprise that every vendor offering data-related solutions are striving to secure a share of what’s estimated to be a total addressable market in the tens of billions of dollars when it comes to data platforms, noted Rob Strechay, lead analyst for theCollective from theCUBE, in an analysis for SiliconANGLE.
“The opportunities for storage platform vendors and data platform vendors lie in integrating data platforms as-a-service into their storage offerings,” Strechay wrote.
With all of these changes and demands in mind, some of the major players in data — including Snowflake Inc., MongoDB Inc., VAST Data Inc. and Databricks Inc. — spent the “Summer of Data” unveiling their strategies as data becomes even more important in support of AI’s evolution.
Though all of these companies and others like them are responding to the same challenges, their solutions differ. That’s why, with the “Summer of Data” in the rearview, it’s worth a recap of what we learned so far — and where these companies could be heading next.
This feature is part of SiliconANGLE Media’s ongoing series with theCUBE exploring the latest developments in the data storage and AI market.
Big ambitions, new evolutions
Before this year’s Snowflake Summit, the company’s stated target of $10 billion in revenue for fiscal year 2028 left plenty of open questions about how they might get there. Over the course of this year, meanwhile, theCUBE has produced a number of in-depth analyses, laying out a mental model for the future of data platforms.
In his post-summit analysis, theCUBE analyst Dave Vellante discussed the vision outlined by Snowflake during this year’s Snowflake Summit, from its keynote presentations to product announcements. The company’s intention was clearly to be the number one platform on which this new breed of data applications will be built, according to Vellante.
“This week’s Snowflake Summit further confirmed our expectations with a strong top-line message of ‘All Data/All Workloads,’ and a technical foundation that supports an expanded number of ways to access data,” Vellante wrote. “Squinting through the messaging and firehose of product announcements, we believe Snowflake’s core differentiation is its emerging ability to be a complete platform for data applications. Just about all competitors either analyze data or manage data.”
Other companies have also been weighing their strategies as the world of data storage evolves and as data and AI converge. For VAST, that looks like an evolution beyond being a storage company. In early August, VAST announced a new, global data infrastructure for AI called the VAST Data Platform, with an aim to unify data storage, database and virtualized compute engine services in a scalable system.
“By bringing together structured and unstructured data in a high-performance, globally distributed namespace with real-time analysis, VAST is not only tackling fundamental DBMS challenges of data access and latency but also offering genuinely disruptive data infrastructure that provides the foundation organizations need to solve the problems they haven’t yet attempted,” Market Strategy analyst Merv Adrian said at the time of the announcement.
Competitive environment, developers going next-level
Meanwhile, the realities of modern business — with challenges such as the skills shortage considered — mean developers must be kept happy. That has been good news for companies such as cloud database provider MongoDB.
The company recently saw its stock soar with blowout fiscal first-quarter earnings results, which posed an interesting question to watch in advance of MongoDB .local NYC in June: Was AI contributing to the surge in stock price?
DevOps democratization has surged over the past 20 years, but AI has posed a new wrinkle. AI isn’t the only thing to consider as developers seek to go next-level with their data, according to Mark Porter, chief technology officer of MongoDB, during an interview with theCUBE during MongoDB .local NYC.
“It is currently the thing that’s really exciting, and being able to build great apps that do great things with your core data is always going to be important,” he said. “But what’s happening is people are enhancing their apps with AI.”
With hundreds of people using MongoDB as the foundation of their AI apps, Porter pointed to the company’s developer data platform as key to this arrangement. Meanwhile, Databricks recently acquired Okera Inc., a data governance platform with a focus on AI with a stated goal to expand its own governance and compliance capabilities when it comes to machine learning and large language model AIs. Customers used to control access to their data using simple data controls that only needed to address one plane, such as a database.
“The rise of AI, in particular machine learning models and LLMs, is making this approach insufficient,” the Databricks team, including Chief Executive Officer Ali Ghodsi, explained in the announcement.
As an industry leader, many are watching what Databricks is doing closely, including Vellante. The big question for the company this summer was surrounding how it would execute its critical strategic decisions in the future as hype and confusion continued to swirl around the world of AI.
“Emerging customer data requirements and market forces are conspiring in a way that we believe will cause modern data platform players generally and Databricks specifically to make some key directional decisions and perhaps even reinvent themselves,” Vellante wrote in an edition of his Breaking Analysis series.
After the Data + AI Summit, those connections began to come into better view. In a new world where data is influenced by broader trends in AI, Databricks is back in its wheelhouse, according to Doug Henschen, vice president and principal analyst at Constellation Research Inc.
“I think generative AI for the last three years, they’ve been building up the warehouse side of their Lakehouse and making a case,” he said. “All this time data science has been their wheelhouse, and their strength and their customers are here, while others are making announcements of previews that’ll help eventually down the road on AI. This is where it’s really happening, and they’re building generative models today.”
What comes next?
The“Summer of Data” may be over, but it’s clear that the evolution of AI will continue to play into the strategy of major players in data for many months to come. That will lead to solutions such as the adoption of next-generation storage solutions and their valuation at over $150 billion by 2023.
Though the “AI-powered hybrid-multi-super cloud” comes with various demands on data, companies such as those mentioned above have laid out their plans during the “Summer of Data,” and the year ahead will be critical as those same companies are tasked to execute. So, too, will various data platforms continue to evolve.
Most traditional applications are built on compute, networking and storage infrastructure, but the future will see applications program the real world, George Gilbert, a contributor to theCUBE, wrote in a recent analysis.
In that world, data-driven digital twins representing real-world people, places, things and activities will be on the platform, Gilbert wrote, which explains the stakes at hand.
“On balance, we believe that the distributed nature of data originating from real-world things, combined with the desire for real-time actions, will further stress existing data platforms. We expect a variety of approaches will emerge to address future data challenges,” he wrote. “These will come at the problem starting from a traditional data management perspective (such as Snowflake), a data science view of the world (such as Databricks) and core infrastructure prowess (cloud/infrastructure-as-a-service, compute and storage vendors).”
Clearly, the challenges around data remain the same as AI continues its meteoric rise. The upcoming months will be critical as the needs of companies in this new world continue to be of paramount importance.
Image: Just_Super / Getty Images
Your vote of support is important to us and it helps us keep the content FREE.
One-click below supports our mission to provide free, deep and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger and many more luminaries and experts.
THANK YOU
MMS • RSS
MongoDB Inc (
MDB, Financial) has recently seen a daily gain of 4.11%, despite a 3-month loss of 12.79%. The company’s per-share loss stands at $3.46. But the question remains: is the stock significantly undervalued? Join us as we delve into a comprehensive analysis of MongoDB’s valuation, financial strength, profitability, and growth prospects.
A Snapshot of MongoDB Inc (MDB, Financial)
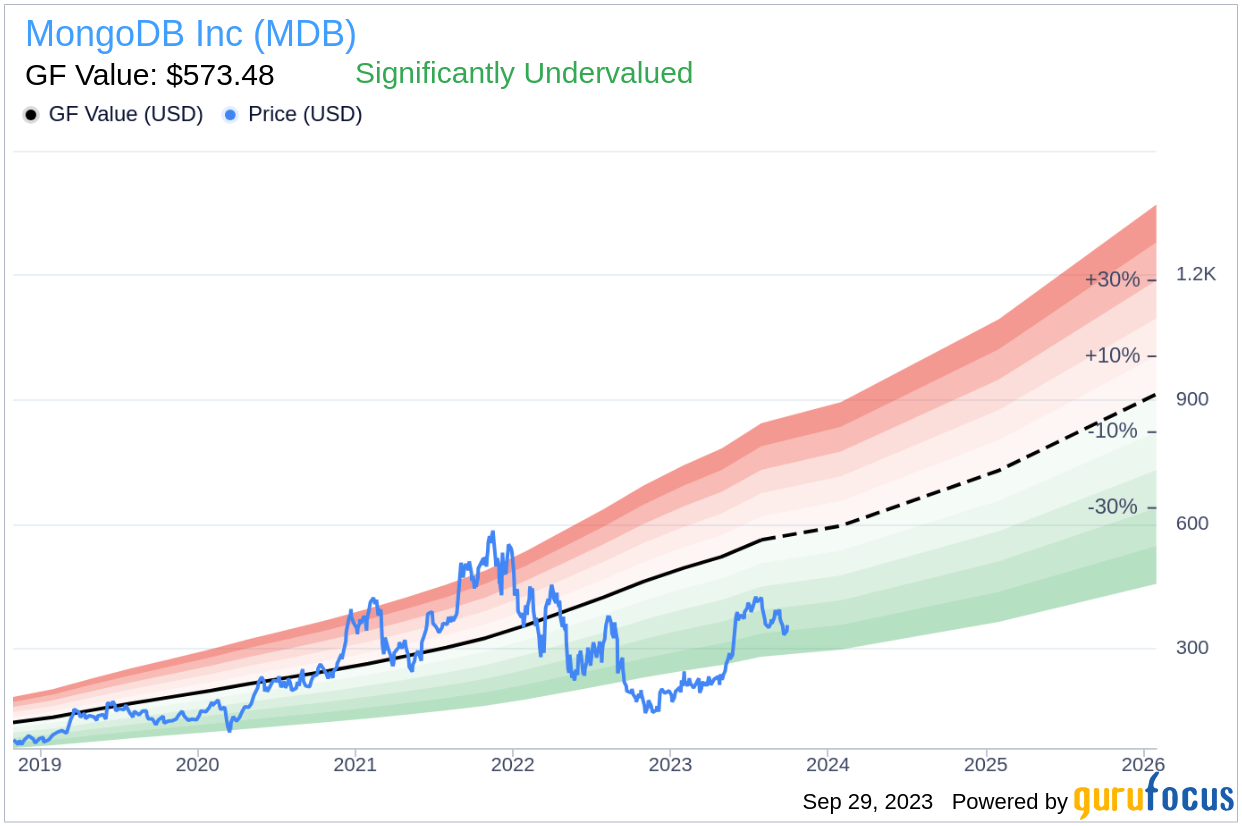
Founded in 2007, MongoDB is a document-oriented database company with nearly 33,000 paying customers and well past 1.5 million free users. The company provides both licenses and subscriptions as a service for its NoSQL database. Compatible with all major programming languages, MongoDB’s database can be deployed for a variety of use cases. The company’s current stock price is $357.21, with a market cap of $25.50 billion. However, our exclusive GF Value estimates MongoDB’s fair value at $573.48, indicating that the stock could be significantly undervalued.
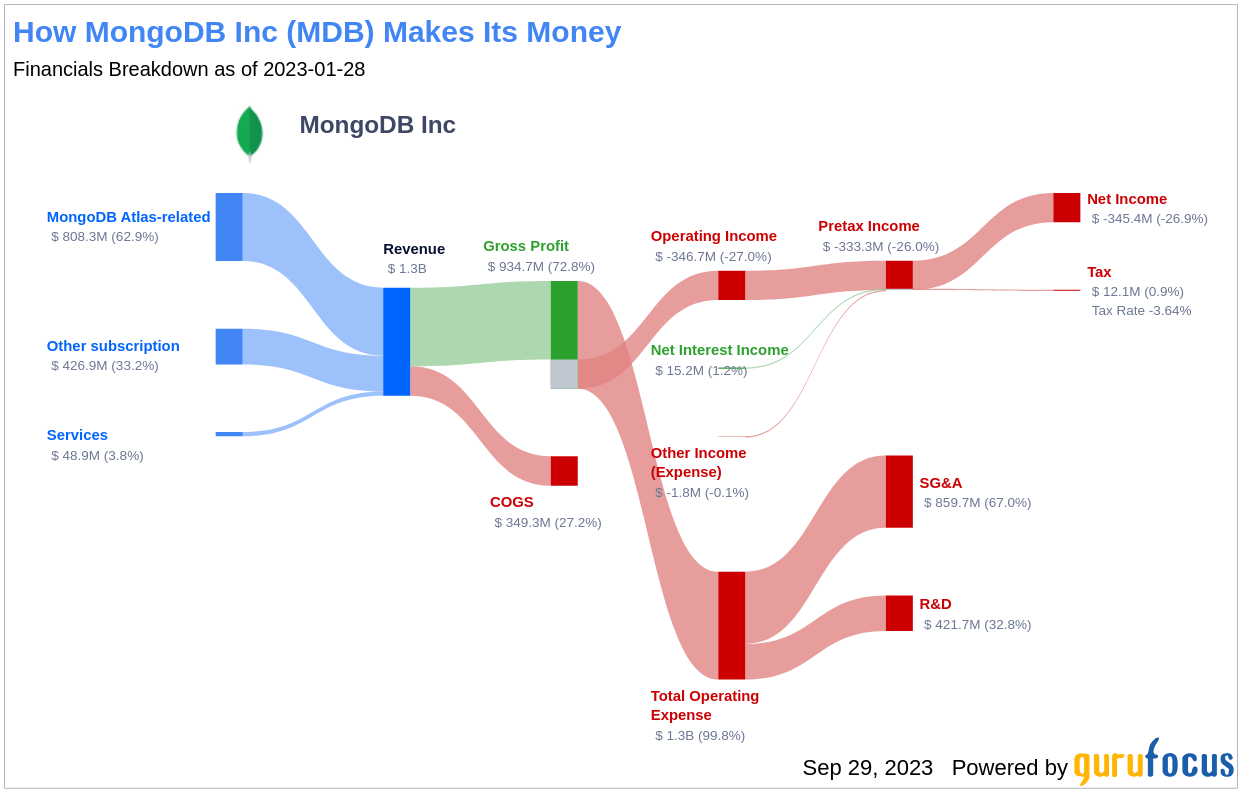
Understanding MongoDB’s GF Value
The GF Value is a proprietary measure that represents the current intrinsic value of a stock. It’s calculated based on historical multiples, a GuruFocus adjustment factor based on past returns and growth, and future estimates of business performance. If the stock price is significantly above the GF Value Line, the stock may be overvalued and its future return is likely to be poor. On the other hand, if the stock price is significantly below the GF Value Line, the stock may be undervalued and its future return will likely be higher.
Based on this analysis, MongoDB appears to be significantly undervalued. This implies that the long-term return of its stock is likely to be much higher than its business growth.
Link: These companies may deliver higher future returns at reduced risk.
MongoDB’s Financial Strength
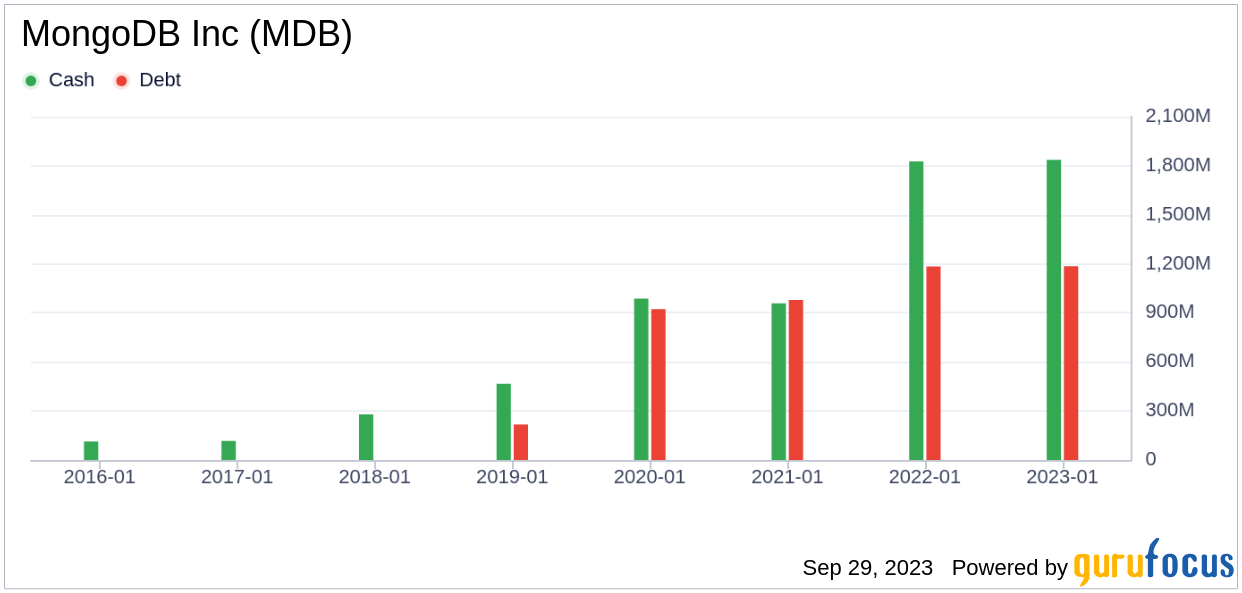
Investing in companies with poor financial strength can pose a high risk of permanent capital loss. To mitigate this risk, it’s essential to review a company’s financial strength before purchasing shares. Factors such as the cash-to-debt ratio and interest coverage can provide valuable insights into the company’s financial health. MongoDB has a cash-to-debt ratio of 1.6, which ranks worse than 57.99% of 2752 companies in the Software industry. The overall financial strength of MongoDB is 5 out of 10, indicating fair financial strength.
Profitability and Growth of MongoDB
Companies that have been consistently profitable over the long term offer less risk for investors. Higher profit margins usually indicate a better investment compared to a company with lower profit margins. MongoDB, however, has been profitable 0 over the past 10 years. Over the past twelve months, the company had a revenue of $1.50 billion and a Loss Per Share of $3.46. Its operating margin is -18.39%, which ranks worse than 72.78% of 2785 companies in the Software industry. Overall, the profitability of MongoDB is ranked 3 out of 10, indicating poor profitability.
Growth is a crucial factor in the valuation of a company. The faster a company is growing, the more likely it is to be creating value for shareholders, especially if the growth is profitable. MongoDB’s 3-year average annual revenue growth rate is 35.4%, which ranks better than 88.12% of 2415 companies in the Software industry. However, the 3-year average EBITDA growth rate is -21%, which ranks worse than 82.61% of 2007 companies in the Software industry.
Return on Invested Capital (ROIC) vs. Weighted Average Cost of Capital (WACC)
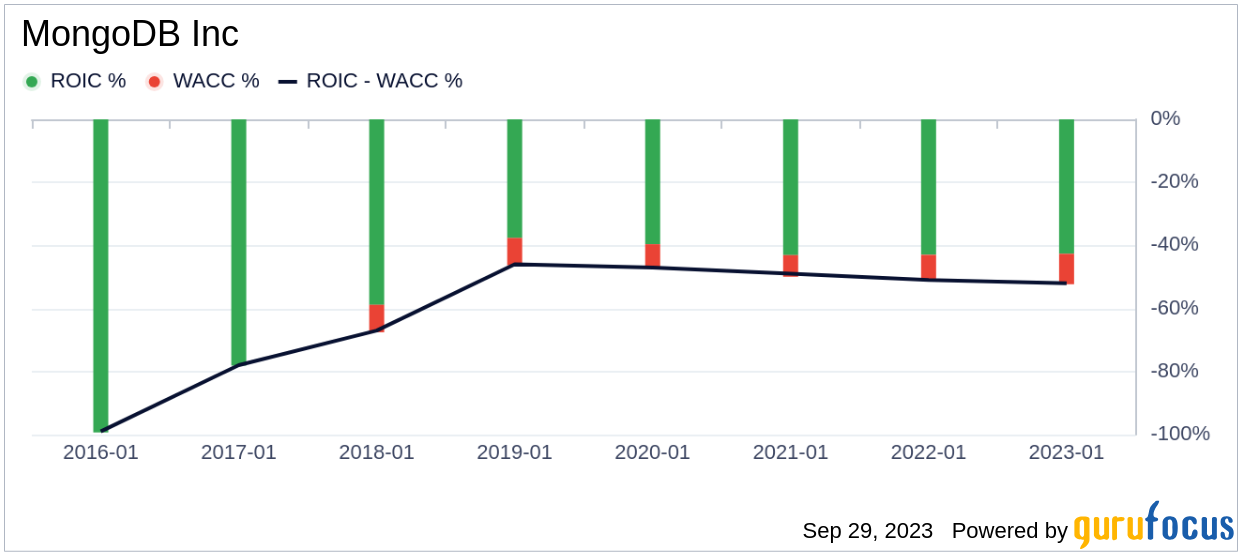
Comparing a company’s return on invested capital (ROIC) to its weighted average cost of capital (WACC) can provide insights into its profitability. ROIC measures how well a company generates cash flow relative to the capital it has invested in its business. WACC is the rate that a company is expected to pay on average to all its security holders to finance its assets. If the ROIC exceeds the WACC, the company is likely creating value for its shareholders. During the past 12 months, MongoDB’s ROIC was -35.46 while its WACC came in at 11.84.
Conclusion
In summary, MongoDB’s stock appears to be significantly undervalued. The company’s financial condition is fair, but its profitability is poor. Its growth ranks worse than 82.61% of 2007 companies in the Software industry. To learn more about MongoDB stock, you can check out its 30-Year Financials here.
To find out the high-quality companies that may deliver above-average returns, please check out GuruFocus High Quality Low Capex Screener.
MMS • RSS
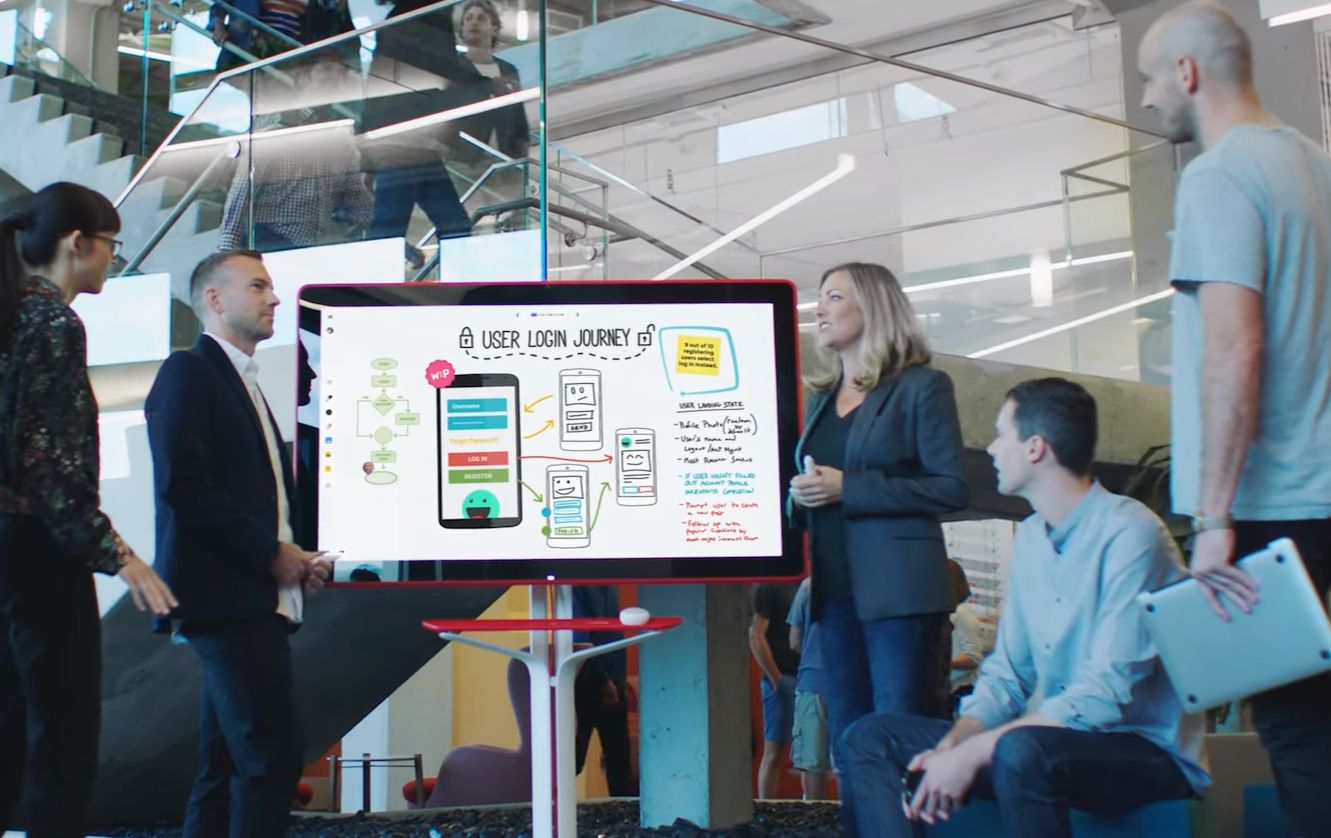
Google has added its Podcasts service and Jamboard whiteboarding application to the list of things “Killed by Google” this week alone.
“Starting October 1, 2024, you’ll no longer be able to create new or edit existing Jams on any platform, including the web, iOS, and Android…” Google said of the collaboration app, which launched in 2016.
Google’s associated Jamboard hardware (a $5,000 digital whiteboard with a $600/year fee) and software ecosystem are all getting the chop – in bad news for people who liked its native integration with G-Drive. (You could pull in data from Google Docs, Sheets, and Slides, and whiteboard work was saved in a filetype called “Jams” in Drive.)
“Over the past couple of years, we’ve heard from customers that whiteboarding tools like FigJam by Figma, Lucidspark by Lucid Software, and the visual workspace Miro help their teams work better together.
“As these tools have grown more capable, offering advanced features such as an infinite canvas, use case templates, voting, and more, we’ve decided to leverage our partner ecosystem for whiteboarding in Workspace and focus on core content collaboration across Docs, Sheets, and Slides” Google said on September 29 in a blog and email to admins.
It also revealed this week (September 26) that it was killing off Google Podcasts as a standalone proposition and migrating its features to YouTube Music.
The company earlier this year had revealed that YouTube Music would begin supporting podcasts in the US and insists that this will be a more natural home, with a focus on community and the ability to switch easily between audio podcasts and video; something Spotify is also working on.
In a blog on YouTube the company said: “This matches what listeners and podcasters are already doing: according to Edison, about 23% of weekly podcast users in the US say YouTube is their most frequently used service, versus just 4% for Google Podcasts.”
MMS • RSS
PRESS RELEASE
Published September 29, 2023
No. of Pages: [120] | 2023, “Cloud-based Database Market” Magnificent CAGR of 24.07% | End User (Large Enterprises, Small and Medium Business), Types (NoSQL Database, SQL Database), with United States, Canada and Mexico Region in what way to Growth and Advance Beneficial Insights from this Business Tactics, Customer Acquisition and Collaborations. A High-class Data Report Graph, which provides qualitative and quantitative perspectives on SWOT and PESTLE Analysis, Statistics On Industries, and New Business Environments. Global report Referring on governance, risk, and compliance, vertical classification, business revolution and progressions. As of 2022, the global Cloud-based Database market was estimated at USD 7614.33 million, and it’s anticipated to reach USD 27771.49 million in 2028, with a CAGR of 24.07% during the forecast years. | Ask for a Sample Report
Competitive Analysis: – Benefits your analysis after businesses competing for your main customers. Cloud-based Database Market Share by Company Information, Description and Business Overview, Revenue and Gross Margin, Product Portfolio, Developments/Updates, Historical Data and more…
Who are the Important Global Manufacturers of Cloud-based Database Market (USD Mn & KT)?
- Couchbase
- Cassandra
- Oracle
- Amazon Web Services
- Teradata
- Alibaba
- Rackspace Hosting
- Salesforce
- MongoDB
- Microsoft
- IBM
- SAP
- Tencent
Get a Sample PDF of report – https://www.industryresearch.biz/enquiry/request-sample/23067367
Cloud-based Database Market Overview 2023-2031
Market Overview of Global Cloud-based Database market:
According to our latest research, the global Cloud-based Database market looks promising in the next 5 years. As of 2022, the global Cloud-based Database market was estimated at USD 7614.33 million, and it’s anticipated to reach USD 27771.49 million in 2028, with a CAGR of 24.07% during the forecast years.
A cloud database is a type of database service that is built, deployed and delivered through a cloud platform. It is primarily a cloud Platform as a Service (PaaS) delivery model that allows organizations, end users and their applications to store, manage and retrieve data from the cloud.
This report covers a research time span from 2018 to 2028, and presents a deep and comprehensive analysis of the global Cloud-based Database market, with a systematical description of the status quo and trends of the whole market, a close look into the competitive landscape of the major players, and a detailed elaboration on segment markets by type, by application and by region.
Why Invest in this Report?
- Leveraging Data to Drive Business Decisions and Identify Opportunities.
- Formulating Growth Strategies for Multiple Markets.
- Conducting Comprehensive Market Analysis of Competitors.
- Gaining Deeper Insights into Competitors’ Financial Performance.
- Comparing and Benchmarking Performance Against Key Competitors.
- Creating Regional and Country-Specific Strategies for Business Development.
- And Many More…!!
Get a Sample Copy of the Cloud-based Database Report 2023
Why is Cloud-based Database Market 2023 Important?
– Overall, Cloud-based Database market in 2023 is essential for businesses to understand the market landscape, identify Growth Opportunities (Strategies, Services, Customer Base), Mitigate Risks (Economic Factors, Impact Business, Minimize Risks), Insight into Market Trend (Latest Trends, Developments, Consumer Preferences, Emerging Technologies, Dynamics, Top Competitive) make informed decisions, and achieve sustainable growth in a competitive business environment. Strategic Decision-Making (Data-Driven Insights, Pricing Strategies, Customer Satisfaction, Competitive Advantage), Validate Business Plans (long-term success of the business).
Market Segmentation:
The Global Cloud-based Database market is poised for significant growth between 2023 and 2031, with a positive outlook for 2023 and beyond. As key players in the industry adopt effective strategies, the market is expected to expand further, presenting numerous opportunities for advancement.
What are the different “Types of Cloud-based Database Market”?
Product Type Analysis: Production, Revenue, Price, Market Share, and Growth Rate for Each Category
- NoSQL Database
- SQL Database
What are the different “Application of Cloud-based Database market”?
End Users/Application Analysis: Status, Outlook, Consumption (Sales), Market Share, and Growth Rate for Major Applications/End Users
- Large Enterprises
- Small and Medium Business
Inquire more and share questions if any before the purchase on this report at – https://www.industryresearch.biz/enquiry/pre-order-enquiry/23067367
Which regions are leading the Cloud-based Database Market?
- North America (United States, Canada and Mexico)
- Europe (Germany, UK, France, Italy, Russia and Turkey etc.)
- Asia-Pacific (China, Japan, Korea, India, Australia, Indonesia, Thailand, Philippines, Malaysia and Vietnam)
- South America (Brazil, Argentina, Columbia etc.)
- Middle East and Africa (Saudi Arabia, UAE, Egypt, Nigeria and South Africa)
This Cloud-based Database Market Research/Analysis Report Contains Answers to Your Following Questions:
- How is Cloud-based Database market research conducted?
- What are the key steps involved in conducting Cloud-based Database market research?
- What are the sources of data used in Cloud-based Database market research?
- How do you analyze Cloud-based Database market research data?
- What are the benefits of Cloud-based Database market research for businesses?
- How can Cloud-based Database market research help in identifying target customers?
- What role does Cloud-based Database market research play in product development?
- How can Cloud-based Database market research assist in understanding competitor analysis?
- What are the limitations of Cloud-based Database market?
- How does market research contribute to making informed business decisions?
- What is the difference between primary and secondary market?
- How can Cloud-based Database market research help in assessing customer satisfaction?
- What are the latest trends and technologies in Cloud-based Database market?
- What are the ethical considerations in conducting Cloud-based Database market research?
- How can Cloud-based Database market help in pricing strategies?
- What is the future outlook for Cloud-based Database market research?
TO KNOW HOW COVID-19 PANDEMIC AND RUSSIA UKRAINE WAR WILL IMPACT THIS MARKET – REQUEST A SAMPLE
Detailed TOC of Global Cloud-based Database Market Research Report, 2023-2031
1 Cloud-based Database Market Overview
1.1 Product Overview
1.2 Market Segmentation
1.2.1 Market by Types
1.2.2 Market by Applications
1.2.3 Market by Regions
1.3 Global Cloud-based Database Market Size (2018-2031)
1.3.1 Global Cloud-based Database Revenue (USD) and Growth Rate (2018-2031)
1.3.2 Global Cloud-based Database Sales Volume and Growth Rate (2018-2031)
1.4 Research Method and Logic
1.4.1 Research Method
1.4.2 Research Data Source
2 Global Cloud-based Database Market Historic Revenue (USD) and Sales Volume Segment by Type
2.1 Global Cloud-based Database Historic Revenue (USD) by Type (2018-2023)
2.2 Global Cloud-based Database Historic Sales Volume by Type (2018-2023)
3 Global Cloud-based Database Historic Revenue (USD) and Sales Volume by Application (2018-2023)
3.1 Global Cloud-based Database Historic Revenue (USD) by Application (2018-2023)
3.2 Global Cloud-based Database Historic Sales Volume by Application (2018-2023)
4 Market Dynamic and Trends
4.1 Industry Development Trends under Global Inflation
4.2 Impact of Russia and Ukraine War
4.3 Driving Factors for Cloud-based Database Market
4.4 Factors Challenging the Market
4.5 Opportunities
4.6 Risk Analysis
4.7 Industry News and Policies by Regions
4.7.1 Cloud-based Database Industry News
4.7.2 Cloud-based Database Industry Policies
5 Global Cloud-based Database Market Revenue (USD) and Sales Volume by Major Regions
5.1 Global Cloud-based Database Sales Volume by Region (2018-2023)
5.2 Global Cloud-based Database Market Revenue (USD) by Region (2018-2023)
6 Global Cloud-based Database Import Volume and Export Volume by Major Regions
6.1 Global Cloud-based Database Import Volume by Region (2018-2023)
6.2 Global Cloud-based Database Export Volume by Region (2018-2023)
7 North America Cloud-based Database Market Current Status (2018-2023)
7.1 Overall Market Size Analysis (2018-2023)
7.1.1 North America Cloud-based Database Revenue (USD) and Growth Rate (2018-2023)
7.1.2 North America Cloud-based Database Sales Volume and Growth Rate (2018-2023)
7.2 North America Cloud-based Database Market Trends Analysis Under Global Inflation
7.3 North America Cloud-based Database Sales Volume and Revenue (USD) by Country (2018-2023)
7.4 United States
7.5 Canada
Get a Sample PDF of report @ https://www.industryresearch.biz/enquiry/request-sample/23067367
8 Asia Pacific Cloud-based Database Market Current Status (2018-2023)
8.1 Overall Market Size Analysis (2018-2023)
8.1.1 Asia Pacific Cloud-based Database Revenue (USD) and Growth Rate (2018-2023)
8.1.2 Asia Pacific Cloud-based Database Sales Volume and Growth Rate (2018-2023)
8.2 Asia Pacific Cloud-based Database Market Trends Analysis Under Global Inflation
8.3 Asia Pacific Cloud-based Database Sales Volume and Revenue (USD) by Country (2018-2023)
8.4 China
8.5 Japan
8.6 India
8.7 South Korea
8.8 Southeast Asia
8.9 Australia
9 Europe Cloud-based Database Market Current Status (2018-2023)
10 Latin America Cloud-based Database Market Current Status (2018-2023)
11 Middle East and Africa Cloud-based Database Market Current Status (2018-2023)
And more…………
Key Reasons to Purchase:-
– To gain insightful analyses of the market and have comprehensive understanding of the global Cloud-based Database Market and its commercial landscape.
– Assess the production processes, major issues, and solutions to mitigate the development risk.
– To understand the most affecting driving and restraining forces in the Cloud-based Database Market and its impact in the global market.
– Learn about the Cloud-based Database Market strategies that are being adopted by leading respective organizations.
– To understand the future outlook and prospects for the Cloud-based Database Market.
– Besides the standard structure reports, we also provide custom research according to specific requirements
Purchase this report (Price 3380 USD for a single-user license) – https://www.industryresearch.biz/purchase/23067367
About Us:
Market is changing rapidly with the ongoing expansion of the industry. Advancement in technology has provided today’s businesses with multifaceted advantages resulting in daily economic shifts. Thus, it is very important for a company to comprehend the patterns of the market movements in order to strategize better. An efficient strategy offers the companies a head start in planning and an edge over the competitors. Industry Research is a credible source for gaining the market reports that will provide you with the lead your business needs.
Contact Us:
Industry Research Biz
Phone: US +1 424 253 0807
UK +44 203 239 8187
Email: [email protected]
Web: https://www.industryresearch.biz
For More Trending Reports:
Smart Waste Bins Market Growth and CAGR 2023: Industry Size, Share, Trends and Segment Forecast 2030
PRWireCenter
MMS • Johannes Bechberger

Transcript
Bechberger: You probably all know the situation when you’re asked by others the question, aren’t you a software developer? Then, could you write me some awesome website? That’s what happened to me. I’m part of the organizing team of the Night of Sciences in Karlsruhe, where PhDs and professors can show their research to the general public at an evening in half an hour talks. It was during Corona, where everyone had to be at home and where we had the event held remotely, and so we had the problem that we wanted to have some interactivity there. Essentially, we wanted to ask participants or the viewers some questions in a quiz, like, how old is the universe? After a talk on astronomy. I was asked, and what I did, I just created a small website. Essentially, we had a client that regularly asked the server, is there any question? If yes, please give me the question. Of course, it could also answer the questions using this client. Then you had an admin interface with which you can set the question. Then you had the server that stored all the information, all the data in a simple JSON file, because I thought, ok, if I just use the file system, then the file system does the whole synchronization and consistency for me. I thought it’s because a premature optimization is the root of all evil, as Donald Knuth once wrote.
The event came, and I developed a software and was quite confident that it worked, because it’s a simple software, a couple of hundred lines of code. The client asks every 10 seconds the server for, is there any questions? That’s enough margin there. The event came in the evening, and the server was, of course, overwhelmed as one might expect, when I’m giving this example in historic. What was the problem? The problem was that the server just couldn’t handle that many connections, and that many participants that wanted to participate in the quiz. Now we come back to Donald Knuth’s original quote, which was a bit longer. It was originally, “We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.” He wrote further, “Yet we should not pass up our opportunities in the critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code, but only after that code has been identified.” We need to identify what went wrong, and profilers to the rescue, they are the tools that you use to see what went wrong, performance-wise. When you talk about profilers to someone who is not from computer science, you typically get a lot like, isn’t this something that people in crime shows do? Isn’t that something that Sherlock Holmes does, like a profiler solving crime mysteries? Essentially, that’s what we’re also doing here. We’re not solving crime mysteries, but we are solving the problem on why is this application so slow. Essentially, we are Sherlock Holmes and Watson digging into the depths of the performance data to see what went wrong.
Flame Graphs
One of the most common ways to visualize some performance data that you get is a flame graph. Here you see the flame graph building up in the bottom. You see that the main function takes all the time because it’s the main function, and on the top, you see the pseudocode building up of this. This is the simplified lookup but it’s essentially what the server is executing. The main function just calls some initialization code and then calls the serverLoop. The serverLoop takes most of the time of the main function. The serverLoop has a wide bar. The width of the bar is proportional to the amount of time that it takes to execute this function. Then the serverLoop is just a simple loop that waits for a new request, gets it, and checks whether this is a QuestionRequest, and then calls the handleQuestionRequest method, and then handles also some other requests that’s not important here. You see in the flame graph that the handleQuestionRequest takes a lot of time. Then, what does the handleQuestionRequest do? It just checks, is there any question enabled? Then it emits the current question. These methods shouldn’t take that much time, but why do they? The flame graph also gives us this answer, essentially, because we’re all the time parsing JSON. This is not a bad thing. We’ve seen again, to quote Mario Fusco, when you do something stupid, it punches you in your face, and it’s impossible not to see it. That’s the beauty of a flame graph, they are quite easy to understand. You see when you’re doing something stupid, performance-wise.
If we then rewrite the handleQuestionRequest, and isQuestionEnabled, and the currentQuestion method to use something more sensible, for example, on SQLite database, then the performance of the whole application drastically improves, and we don’t have any problems anymore with like 90 to 100 concurrent usage, which is really great, and which makes the application usable again. You see, the technique of profiling should be part of your toolbox, shining light on the performance issues. It should be in the toolbox, like debugging or testing, so when you come over a problem, you can open your toolbox and see what the appropriate tool is. It’s important to know for each of these techniques, a few tools that you can readily apply.
Background
Who am I to tell you about profiling? I’m Johannes Bechberger. I work at the SapMachine team at SAP. The SapMachine team works on the OpenJDK, and is part of the open source teams at SAP. I’m specifically working there in the field of open source profilers. I develop profiler UIs like the one you see, but just based on Firefox Profiler. I work on async-profiler and related tools. I’m also working to get a profiling API into the OpenJDK. It’s currently at JDK and is also a candidate.
What Is Profiling?
Who of you used a profiler? I chose the results of the JetBrains 2022 Developer Survey. In the survey, 40% said no. That’s quite a large number because profiling is really important to know and to have in your toolbox when you’re developing code, especially if the code goes to the outer world. What is profiling? This whole talk is on profiling, so I should probably define what I mean with this. I’m going with the definition of The Jargon File, which is that it’s a technique to obtain a profile, and the profile is a report on the amounts of time spent in each routine of the program used to find and tune away the hot spots in it, like we did before with our introduction example.
Types of Profilers
There are of course different profilers. There are essentially two types of profilers. There are instrumenting profilers and sampling profilers. Instrumenting profilers insert instructions into your code automatically. For example, you see here the serverLoop function, by an instrumenting profiler which inserts at the beginning a log statement that says, ok, I’m entering serverLoop, and the end statement that calls a method that states, I’m exiting serverLoop. The cool thing is, that’s quite accurate in the sense that you see every function entry and exit. That’s also problematic, because JITs don’t really like it when you increase the amount of code potentially by a large amount. It’s also problematic, because it’s not that fast, because, yes, you’re executing a lot of statements. There’s another type of that, it’s sampling profilers, and they sample. They don’t do anything on every loop entry and exit, but rather, they ask the JVM in regular intervals, usually, in every 10 to 20 milliseconds, what are you currently executing? What’s your call trace? See it here, we ask the JVM four times. Then we combine this data. That’s of course, approximate. It has its own problems regarding accuracy, but the advantage is that you’re seeing really what the JVM is doing, and what your program is doing.
Safepoint
Regarding accuracy, that depends on Safepoint. What is a Safepoint? A Safepoint is, essentially, a point where all threads are in a safe state. Here, every thread checks at regular points in the code, is there a Safepoint requested? If yes, please stop, and the thread stops. It checks whether a Safepoint is requested, for example, at the beginning of a method, at the end of a method. As we see here, also at the end of a loop running. Why is this important for profiling? For profiling, there are methods that you can use to obtain a stack trace, and there are methods that are Safepoint biased, so they only work at a Safepoint, and there are methods that don’t. Here in the following I use this U-boat, which is in a non-Safepoint state, or in the state where it doesn’t check, can I go fast in a Safepoint, when it’s lighter of color and darker when it’s at a Safepoint. Safepoint are usually used to do things like garbage collection. Safepoint bias comes because, when you now say to the thread, please stop, and it only stops when it’s really ready, then you’re getting a stack trace or a call trace. In a fully asynchronous mode, you’re just telling the thread, stop, and it just stops. You don’t have to wait to check to a Safepoint, and is that a Safepoint? You get it really at the point that you’re demanding it. You don’t have any bias, which increases the accuracy. Also, it has the problem that you might be in undefined state, and so it’s slightly less stable than going with the Safepoint bias route. Safepoint bias is especially important with multiple threads because here we want to essentially only stop one thread, but here we are asking like, please stop when you’re ready. We have to wait till the second thread also is finished, to set a Safepoint. Here, fully asynchronous, we just tell it stop to the thread 1, and the thread 2 goes along.
How Profiling Works
How does then profiling work? We’ve seen, ok, there’s some kind of Safepoint bias, and that we’re doing some sampling, but what are we doing at every interval? A profiler first gets all the available threads. Then selects a random subset, because sampling all threads isn’t usually possible because when you have few thousand threads, then you cannot really walk all the threads every 10 milliseconds, because this would take too much time, and the performance overhead would be too high. Then, you pre-allocate some traces on the data structure that you’re storing, like your call traces later. Then for the asynchronous version, you’re pinging with a Unix signal. For example, you have every thread saying, please ping, and the thread stops. You’re going into a signal, and there you walk the stack. With the synchronous version, you can directly tell the thread, what’s your stack trace? You’re doing this with the other threads too. Then you have a set of traces and you collect them. Then you do some post-processing, for example, if I’m trying to write flame graphs as we see.
Sampling Profiler – External and Built-In
I showed you that there are two types of sampling profilers, but also there are different specific sampling profilers. There are external sampling profilers and built-in. External is quite simple. They are agents’ native or Java agents that are attached to the JVM, and then use methods to obtain a stack trace that can be called from external agents. Built-in is just directly built into your JDK, or other JVMs. Here with externals, we have to distinguish between synchronous and asynchronous. Synchronous, this was with the Safepoint bias, and asynchronous is not with the Safepoint bias, but with signal handlers, as I’ve shown you before. One of the most common tools that uses the synchronous method is VisualVM which is based on NetBeans, which is available since 2010. It was shipped directly with the JDK from version 6 to version 8. This is the reason why many people use it, and also currently use it because it’s just the first fully available, easily available tool that was there. Then, the asynchronous method were introduced for Forte Analyzers. This was a project from Sun that started in 1991, which is essentially a profiler for their systems. For this analyzer, they implemented the AsyncGetCallTrace call in 2002, and removed it three months later, but it’s essentially still there. In 2013, people started to use it for their own sampling profilers, to write their own async-profiler, which is the most commonly used. It started in 2016. There’s also the built-in profiler which is called Java, or later, JDK Flight Recorder, which is also non-Safepoint bias because, internally, it uses similar methods as async-profiler. There’s a frontend for it, it’s called Java, and later, JDK Mission Control, which started in 2012, and was open sourced in 2018. It’s now one of the most extensive tools in the open source world for profiling. Then, many other tools usually use a combination of async-profiler. Many of them are also embedded, and some run JFR later on.
Obtaining a Profile
How do you obtain a profile using these tools? I will be focusing on two tools, on JFR, and on async-profiler. First, the async-profiler. It’s a Java agent. It’s a native agent, so you can just parse it, and tell it where it is. It’s therefore platform specific. You have to download it for your specific platform from the GitHub page, you can tell it what it should sample for CPU [inaudible 00:19:24]. You can tell it that it should export the flame graph, or that it should export a JDK Flight Recorder format, because the JDK Flight Recorder format is one of the most commonly used formats in the Java profiling world. Async-profiler can also combine the results of a parallel JFR run, so it runs JFR on the JVM, and combines then this with its own sample so you get the best of both worlds. You get the sampling from async-profiler which has some minor advantages. You get all events and all the other things from JDK Flight Recorder. You can also later attach async-profiler to your JVM, for example, by using the profile sh script that’s already present in async-profiler project, or by using the async-profiler loader which is a wrapper around all the async-profile functionality, and which is also platform independent, more or less. It supports the platform that the async-profiler supports. Async-profiler has many features. For example, many events can trigger sampling, like locks, perf-events, methods, so it can do some instrumentation. It’s also embeddable, especially via my ap-loader project. It’s hackable because it’s also open source, like all the tools I’m showing. It’s a relatively small code base. If you want to know more, I would really recommend you to look into the async-profiler – manual by use cases by Krzysztof Ślusarski, which tells you a lot more.
Then there’s also, as I said, besides async-profiler, the built-in OpenJDK way to profile, so JDK Flight Recorder. You also just parse to your Java application, to your Java call the option StartFlightRecording, and tell it where to store it. In all the versions till JDK 12, you also had to parse the FlightRecorder option. Then, you also want to parse the DebugNonSafepoints option because usually or commonly there isn’t that much debug information between two Safepoints to get to specific locations where you can only add during sampling, and so you have to enable it. It doesn’t have any performance impact, so I’ll just turn it on. That’s usually a good idea if you want to profile the application. There’s also the option to use j cmd to start and stop the flight recorder on a remote machine, or on a machine where you only get the process ID for. I don’t have to start it at the beginning. Some of its features are that it’s built into the OpenJDK, so it’s more stable than async-profiler, usually. It works on all platforms, so also Windows which async-profiler doesn’t support, and it also works on all CPU architectures. It has lots of events. You get events on garbage collection, on class loading, and can even add new events. You can add your custom events. There are so many events, like over 120, that I created a website which you find on the sapmachine.io/jfrevents, where you can see all the events and see all their properties, some examples, the descriptions if there are any. You see in which JDK versions it’s supported.
JFR also supports custom events. These are quite cool. Consider, you write a Fibonacci Server for your new math as a service server where you just have an API fib, which is you parse n, and it returns you the nth Fibonacci number. We then would probably want to have some session event to record which n is parsed in, in every session. We can do this by creating a class SessionEvent which extends to jdk.jfr.Event class, and has some properties and also the construct that I’m showing here. When you then want to use it, you just create a new SessionEvent object, and then call event.begin when you want the event to start. Then your stuff that you will be doing in a handler for the Fibonacci API. Then we can call API. Then we can call event.commit, to start the event, and so we then have an event with a specific length, or time duration. It’s then stored in the JFR file. The cool thing is that we can view these events in all UIs that support JFR events. For example, in this UI, we can see that one session event for the 37th Fibonacci number took like 67 milliseconds. We can also see it in other JFR viewers.
Inspecting a Profile
You can inspect a profile. I’ve shown you two tools already. There are different ways to view it. For one, there’s a flame graph. A real tool would output something like this for the Fibonacci Server example. There are also other tools that wrap this. For example, this is by Krzysztof Ślusarski. You can go to his GitHub account and see this tool, and also, he linked in the manual by use cases for the async-profiler. Flame graphs are quite simple to use. You don’t have that much interactivity, and you don’t also have that much ways to configure it, so it’s quite simple, but it usually helps quite a lot. There are also larger tools, and one is called JDK Mission Control, which is the UI for JDK Flight Recorder. When you open a file in it, you see some kind of automated analysis, for example, some analysis of the memory consumption. Then you get some method profiling information, some flame graphs, some information on the memory allocations, and on the garbage collection.
I started around half a year ago writing the Java JFR profiler plugin for IntelliJ, which is still a prototype, which can be used to view JFR files, and to start JFR profiling in your IDE. It’s currently only supported for IntelliJ. I’m hoping to work on a VS Code version too. It’s based on the Firefox Profiler UI. Some of you might have used it in Firefox to view some profiles there. You can just install it from the JetBrains marketplace. You can then, when you have installed it, right click on any main method on these arrows, and say, profile me, this with JFR, or with async-profiler, and it runs it as a profile. It can run configurations as a profile, and also arbitrary JFR files. Here you see some timelines, so you see the method tree, the call tree, and when you then click on the methods, you can jump back to your IDEs with IDE integration, and when you shift double click on the methods you have a source code [inaudible 00:29:00]. You can see where all the samples are. For example, we see it in this example, 136 samples contain just this fib line on the top of the call trace. Then, also a flame graph, of course. You can view all the events directly and get some information on all JFR events.
Impact on Performance
After seeing how you can inspect all this and how to obtain profiles, you probably also want to know what the impact on your performance is. The impact of your performance is small enough probably for most settings. JFR in its most reduced setting, where it’s like for monitoring, has an overhead of typically lower than 2% in a benchmark or in an experiment that I did, it was between 0% to 5%. When you turn on the profiling configuration, which obtained more events, not all but more, and it has a smaller sampling interval, you get an overhead between 1% to 8%, in my experiment, and typically below 5%. With async-profiler, you’re getting overhead typically lower than 2%. When you turn on jfrsync, I found an overhead between 3% to 10%, when you’re combining async-profiler results with JFR, using the jfrsync option of async-profiler. It should be typically usable for most applications.
Take profiles with a grain of salt. Profiles are just applications also written in some code. They have the same problems as many applications. They lack sufficient tests in some areas. Also, regression testing is quite hard. Please have this in mind when you’re trusting your profiler. There might be some bugs within. If you find one, please, open an issue in a Java bug tracker. This would be really great, so I can fix it. Because that’s what I’m doing in doing work. For example, here’s a bug that I found a few weeks back, which has a really nice and small reproducer. Here you have a main class. In the main method of the main class, it calls its method test, and test method calls another method called javaLoop. The javaLoop method is just a simple endless loop. What we would expect in a flame graph is to see on top the javaLoop, most of the time, because it’s an endless loop, it runs a long time. Then we test and then we should see some internal reflection stuff. On the bottom, the main function. The problem is, profilers stumble. I think the API that the async-profiler uses and also JFR stumble after the first reflection calls. This bug surfaced after reflection call changed. It’s quite problematic because it’s a bug that could have easily been found, but it was not. This is not really real, but I think because in the real world, it’s a bit harder to reproduce because it depends on a few conditions. For example, here it depends on tests being probably interpreted, but the problem is that’s hard to find. It was just by chance that I found it. Please, when you’re seeing a profile, and something isn’t really correct like you see here, then it’s probably a bug in the profiler. Please report it.
The Profiling Loop
To work better with this, you should use an experimentation technique. I borrowed this from the science part of computer science. I call it the profiling loop. First, when we start profiling, we want to have a mental model. Yes, it could be rough, but we should have at least some idea of the architecture of the program. Also, we should know the large libraries, at least we should know what they are, and maybe know a bit on them, for large libraries that your program or your application uses. Then you use your model to create your hypothesis in. For example, in my introduction example, my hypothesis was ok. Probably the method that the client calls remotely like, there’s this API that has the client, do you have a question, and what is it? That’s probably too slow. That fits well here in my mental model. It’s not, I have to update the mental model so I can formulate the hypothesis in. Then with the hypothesis, I go into the evaluation. The evaluation means write some test code to do some profiling to all this. Then with the evaluation, you can either update your hypothesis, like make it more concrete. For example, in my example, the hypothesis is that it’s slow, that this whole JSON parsing is too slow. That this is a bad idea, and just a new hypothesis, I evaluate, ok, this is the problem, and then might fix it. Then the hypothesis is, ok, now it’s working, and then I’m back to evaluation. That tells me, yes, that’s probably working. Also, you can use the evaluation to update your mental model. This also helps you when profiling has some internal problems but you might encounter back because you still have your mental model and your hypothesis, and when the evaluation is invalid in your mental model, and your mental model is incorrect, that’s the normal case. Or there might also be the cases that your evaluation was just wrong.
Conclusion
Then, besides, keep in mind that profilers aren’t rocket science as I’ve shown you. You can even write your own basic async-profiler clone that’s just doing like the simple sampling in like, three days, or three afternoons even. If you want to know more, I have a blog series on it called, writing a profiler from scratch, where I write a profiler from scratch. Profiling techniques are good in your toolbox like debugging and testing, and it is really important to have tools for this, to know some tools. I will really recommend to try out async-profiler. Reading the async-profiler – manual by use cases, and looking into JMC and JFR.
See more presentations with transcripts
MMS • RSS
Chicago Trust Co NA, a prominent institutional investor, has recently acquired a new stake in MongoDB, Inc. (NASDAQ: MDB) during the second quarter of this year. According to their most recent disclosure with the Securities & Exchange Commission, Chicago Trust Co NA purchased a total of 745 shares of the company’s stock, which were valued at approximately $306,000.
This significant investment by Chicago Trust Co NA indicates their confidence in MongoDB and its potential for growth and success in the market. As an institutional investor, Chicago Trust Co NA is known for making strategic investment decisions based on thorough analysis and research.
In other news related to MongoDB, Inc., Thomas Bull, the Chief Accounting Officer (CAO) of the company, recently sold 516 shares of the firm’s stock in a transaction that took place on July 3rd. The average price per share during this transaction was $406.78, resulting in a total transaction value of $209,898.48. Following this sale, Bull now directly owns 17,190 shares in the company with an estimated value of $6,992,548.20.
The details of this sale were disclosed in a legal filing with the Securities & Exchange Commission and can be accessed through their official website. It is worth noting that this was not the only transaction involving Thomas Bull and MongoDB stock during that period as he also sold 516 shares at the same price on July 3rd.
Additionally, another key executive at MongoDB also participated in selling company stock. Cedric Pech, the Chief Revenue Officer (CRO), sold 360 shares on July 3rd at an average price of $406.79 per share. This resulted in a total transaction value of $146,444.40. After completing this sale, Pech now owns 37,156 shares of MongoDB stock with an estimated value of approximately $15,114,689.24.
It is important to note that these insider transactions by the company’s executives are disclosed in filings with the Securities & Exchange Commission to ensure transparency and compliance with regulations. The filing for Pech’s sale can be found through the provided link.
In summary, Chicago Trust Co NA’s recent acquisition of a stake in MongoDB, Inc. highlights their positive outlook on the company’s future prospects. Furthermore, the insider transactions involving key executives indicate their confidence in the company and its strategic direction. These developments will undoubtedly have an impact on MongoDB’s position in the market and will be closely watched by investors and analysts alike.
As always, it is crucial for potential investors to conduct their own thorough research and analysis before making any investment decisions.
Graphic Packaging Holding Company
GPK
Strong Buy

Updated on: 28/09/2023
Hedge Funds Adjust Stakes in MongoDB as Financial Analysts Hold Positive Outlook
In recent months, several hedge funds have made adjustments to their stakes in MongoDB, a leading software company specializing in database management systems. Moody National Bank Trust Division, for instance, increased its stake in MongoDB by 2.9% in the second quarter. As of now, the division owns 1,346 shares of the company’s stock worth $553,000 after purchasing an additional 38 shares during that period. CWM LLC also raised its stake by 2.4% during the first quarter and now holds 2,235 shares valued at $521,000 after acquiring an additional 52 shares.
First Horizon Advisors Inc., on the other hand, saw a substantial increase of 29.5% in its stake during the first quarter. The company now possesses 228 shares of MongoDB’s stock worth $53,000 after acquiring an additional 52 shares.
Bleakley Financial Group LLC experienced a growth rate of 5.3% during the same period and currently holds 1,144 shares valued at $267,000 after purchasing an additional 58 shares. Lastly, Cetera Advisor Networks LLC witnessed an increase of 7.4% in its holdings during the second quarter and currently owns 860 shares worth $223,000 after purchasing an additional 59 shares.
Notably, approximately 88.89% of MongoDB’s stock is currently owned by hedge funds and other institutional investors.
Financial analysts have also weighed in on MDB’s performance recently. Barclays revised its price objective for MongoDB from $421.00 to $450.00 while maintaining an “overweight” rating on the stock back on September 1st.
VNET Group notably reiterated their “maintains” rating on MongoDB’s shares on June 26th. Capital One Financial likewise initiated coverage on the company that day and gave it an “equal weight” rating along with a price target of $396.00.
JMP Securities, meanwhile, lifted its price objective on MongoDB from $425.00 to $440.00 and assigned the stock a “market outperform” rating on September 1st. Truist Financial also boosted their price target from $420.00 to $430.00 and issued a “buy” rating for the stock that day.
Data obtained from Bloomberg indicates that there is generally positive sentiment surrounding MongoDB, with one analyst proposing a sell rating, three maintaining a hold rating, and twenty-one suggesting a buy rating. Ultimately, the average rating for the company is classified as “Moderate Buy,” with a consensus target price of $418.08.
Opening at $328.16 on Thursday, MDB’s shares have seen fluctuations in value over the year. The company’s 52-week low was recorded at $135.15, while its 52-week high reached $439.00. Currently standing at a market cap of $23.41 billion, MongoDB maintains a price-to-earnings ratio of -94.84 and a beta of 1.11.
Moreover, the company boasts healthy financial indicators such as a current ratio and quick ratio of 4.48 each, showcasing its strong liquidity position relative to short-term obligations. Additionally, MongoDB has managed to maintain stability in its debt levels with a debt-to-equity ratio of 1.29.
For the quarter ending on August 31st, MongoDB reported earnings per share (EPS) of ($0.63), surpassing the market consensus estimate by $0.07 with better-than-expected performance metrics. The company’s net margin stood at -16.21%, reflecting ongoing investments and growth initiatives undertaken by MongoDB.
Looking ahead, analysts forecast that MongoDB will post EPS of -2.17 for the current year based on their collective estimates.
Overall, investors remain interested in MongoDB due to its innovative approach to database management systems and its ability to attract significant investment from hedge funds and institutional investors. With positive ratings from financial analysts, the company’s future prospects appear promising. Nonetheless, investors should continue to monitor MDB’s performance and industry developments for a comprehensive understanding of its investment potential.
MMS • Matt Saunders

Version 2.14 of Linkerd, a service mesh graduate CNCF project, has been released, with improved enterprise multi-cluster support, full Gateway API conformance, and many other changes.
Following the recent 2.13 release which brought circuit breaking and dynamic request routing, the latest release brings many enhancements and improvements, including enhanced support for multi-cluster deployments on shared flat networks and full Gateway API conformance.
This new release improves support for multi-cluster deployments on shared flat networks. This allows pods in different clusters to establish TCP connections with each other without the need for a multi-cluster gateway. This improves performance, security, and reduces latency and cloud spending by minimizing traffic routed through the gateway. This also maintains a critical aspect of Linkerd’s design: each cluster still has its own Linkerd control plane, and is independent of other clusters for security and failure isolation. A blog post from Linkerd goes into many more details on how this works.
Linkerd now fully conforms with the new Kubernetes Gateway API. This enables standardized configuration for complex resources, such as HTTP requests, and offers a uniform API across ingress and service meshes. This means that features such as retries, timeouts and progressive delivery are fully configurable using Gateway API types, simplifying configuration and enhancing compatibility with contemporary Kubernetes service mesh definitions.
Underlining the significance of this, on X (formerly Twitter), Saim Safdar (host of the @cloudnativefm podcast) comments that:
Gateway API represents the future of load balancing, routing, and service mesh APIs in Kubernetes
In addition to these new core features, Linkerd 2.14 also includes numerous performance enhancements, bug fixes, and new capabilities, such as leader-election capabilities, high-availability mode for multicluster service mirroring, and improved diagnostics.
Linkerd has seen a significant surge in adoption by enterprise-level organizations such as Adidas, Microsoft, Plaid, and DB Schenker in the past 18 months. These companies have deployed Linkerd to enhance the security, compliance, and reliability of their mission-critical production infrastructure.
The article highlights Linkerd’s success, for example in doubling the number of stable Kubernetes clusters running the technology in 2022. It also hints at exciting features and developments planned for later in 2023, building upon the achievements of releases 2.13 and 2.14, maintaining Linkerd’s commitment to blending enterprise-level capabilities, operational ease, and cost-effectiveness in the service mesh.
MMS • Steef-Jan Wiggers
Confluent recently announced the open preview of Apache Flink on Confluent Cloud as a fully managed service for stream processing. The company claims that the managed service will make it easier for companies to filter, join, and enrich data streams with Flink.
Apache Flink is an open-source, unified stream-processing and batch-processing framework developed by the Apache Software Foundation, designed to run in all common cluster environments and perform computations at in-memory speed and at any scale.
Confluent brings Flink to their cloud as a managed service, where users do not have to choose a version and will always have the latest. Furthermore, all Flink SQL Statements on Confluent Cloud are continuously monitored and auto-scaled to always keep up with the rate of their input topics, and billing is based on the average current size of Compute Pools. The pools elastically scale up and down based on the needs of the Statements that are using them – including scaling to zero if there are no Statements.
Confluent already has Apache Kafka in their cloud offering. Kafka provides the event streaming, while Flink is used to process data from that stream. Both are available in Confluent Cloud as managed services and can be used together for use cases like batch processing, stream processing, event-driven applications, streaming applications, data analysis (batch, streaming), and data pipelines.
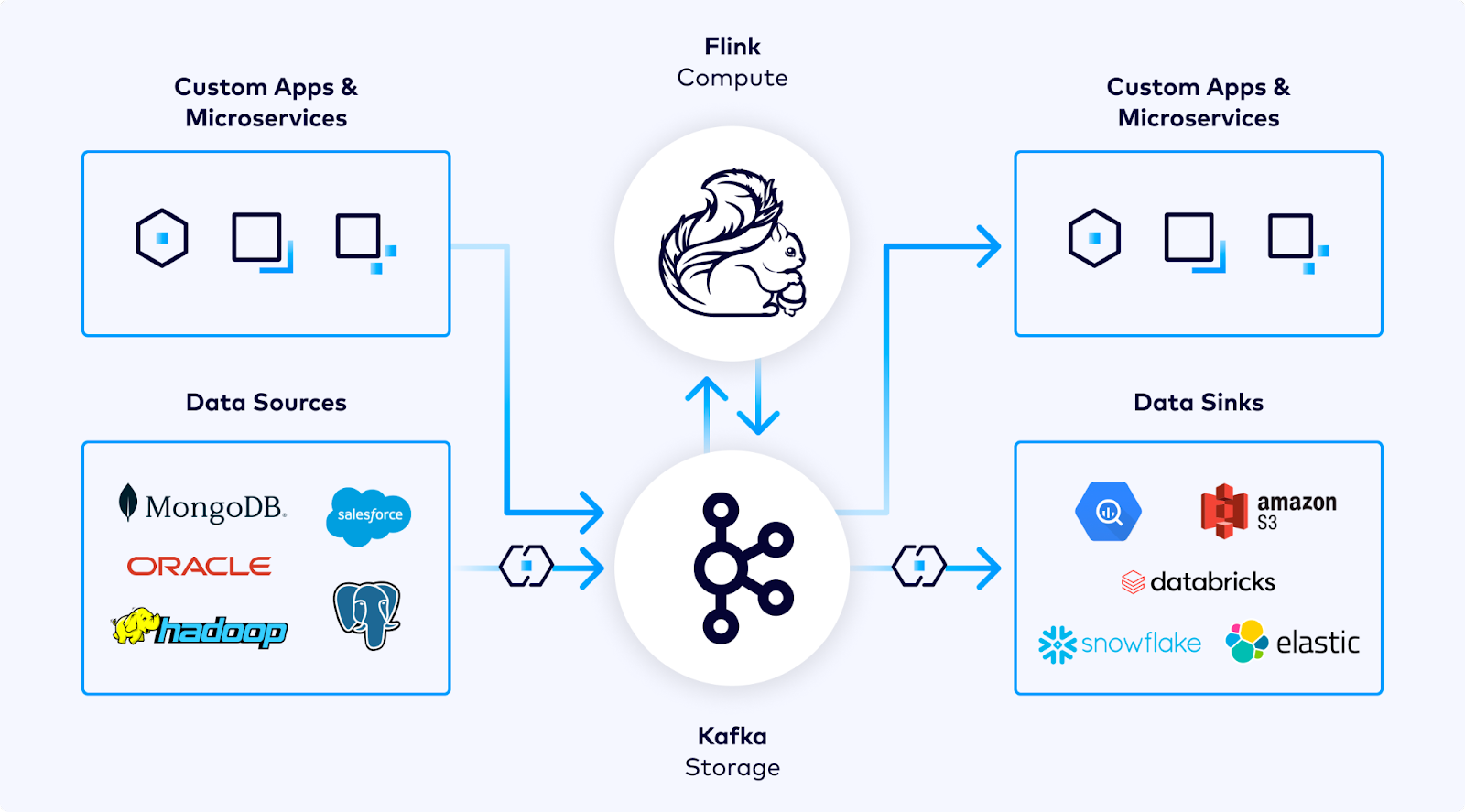
Flink as the streaming compute layer for Kafka (Source: Apache Flink on Confluent Cloud blog post)
When asked by InfoQ about what is driving this investment from Confluent, here is what James Rowland-Jones, Director of Product Management at Confluent, had to say:
We chose to invest in Apache Flink because we believe it has all the ingredients needed to build a simple, serverless, and cloud-native stream processing service capable of operating at any scale. Flink also has a vibrant and passionate community that has contributed to its success over many years, aligning well with Confluent’s culture of contributing to open source.
In addition, he said:
Stream processing has strong synergy with Apache Kafka, and the overwhelming majority of Flink customers choose Kafka for their streaming storage. We believe Confluent is perfectly positioned to bring all the benefits of Flink and Kafka together to create a unified data streaming platform, empowering every organization to set their data in motion.
Also, Richard Seroter, a Director of DevRel and Outbound Product Management at Google, tweeted:
there haven’t been a ton of ways to get a managed Flink experience, so it’s good to see @confluentinc open this up in preview
Lastly, Apache Flink is currently available as an open preview for Confluent Cloud customers using AWS in select regions for testing and experimentation purposes. The company states that general availability is coming soon.
Insider Sell: MongoDB Inc’s President & CEO Dev Ittycheria Sells 134,000 Shares – Yahoo
MMS • RSS
On September 26, 2023, Dev Ittycheria, President & CEO of MongoDB Inc (NASDAQ:MDB), sold 134,000 shares of the company. This move is part of a series of transactions made by the insider over the past year, during which Ittycheria sold a total of 501,964 shares and made no purchases.
Dev Ittycheria is a seasoned executive with a strong track record in the tech industry. As the President & CEO of MongoDB Inc, he has been instrumental in driving the company’s growth and success. MongoDB Inc is a leading software company that provides the most popular database for modern apps. The company’s products are used by developers and enterprises globally to create applications that improve business performance, manage risk, and deliver a superior customer experience.
The insider’s recent sell-off has raised some eyebrows among investors and market watchers. Over the past year, there have been 53 insider sells and no insider buys at MongoDB Inc. This trend is illustrated in the following chart:
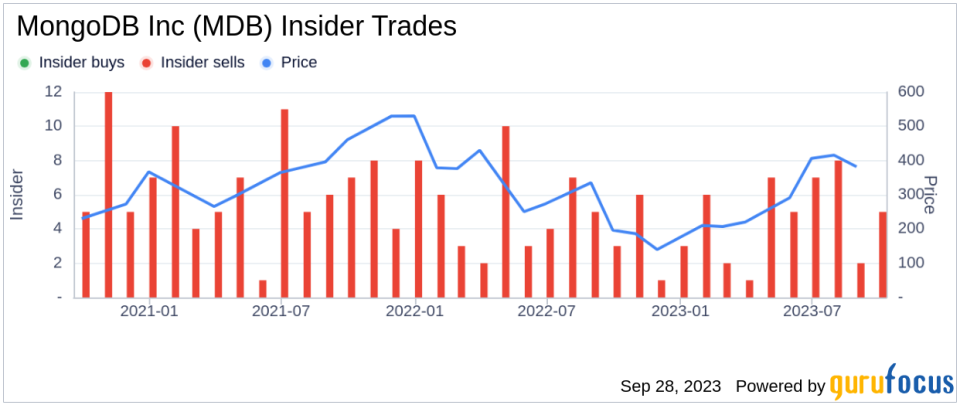
The relationship between insider trading and stock price is complex. While insider selling can sometimes be a bearish signal, it’s important to note that insiders may sell shares for a variety of reasons unrelated to the company’s prospects. In the case of MongoDB Inc, the insider’s selling activity coincides with a period of strong stock performance. On the day of the insider’s recent sell, shares of MongoDB Inc were trading at $327.2, giving the company a market cap of $24.48 billion.
Despite the insider’s selling activity, MongoDB Inc appears to be significantly undervalued based on its GuruFocus Value. The stock’s price-to-GF-Value ratio is 0.57, suggesting that it may be a good buying opportunity for value-oriented investors. The GF Value is calculated based on historical multiples, a GuruFocus adjustment factor, and future business performance estimates from Morningstar analysts. The following chart provides a visual representation of MongoDB Inc’s GF Value:
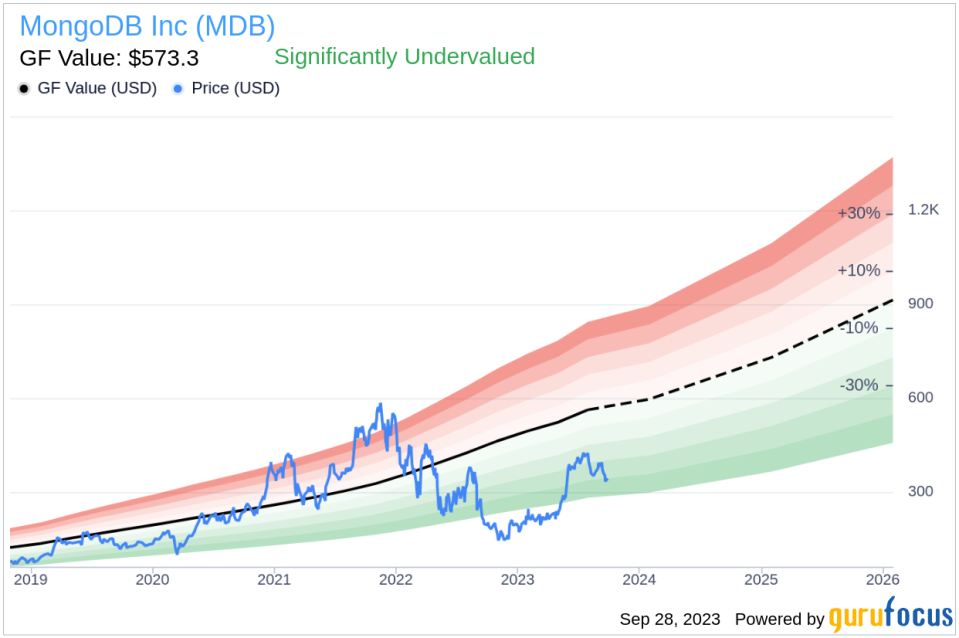
In conclusion, while the insider’s selling activity at MongoDB Inc warrants attention, it does not necessarily indicate a bearish outlook for the stock. Given the company’s strong fundamentals and its undervalued status based on its GF Value, investors may want to consider MongoDB Inc as a potential addition to their portfolios.
This article first appeared on GuruFocus.
MMS • Heidi Musser
Subscribe on:
Transcript
Shane Hastie: Hey, folks. Before we get into today’s podcast, I wanted to share that InfoQ’s International Software Development Conference, Qcon, will be back in San Francisco from October 2 to 6. QCon will share real world technical talks from innovative senior software development practitioners on applying emerging patterns and practices to address current challenges. Learn more at qconsf.com. We hope to see you there.
Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today, I’ve got the privilege of sitting down with Heidi Musser. Heidi is the outgoing chair of the Agile Alliance and has a much, much bigger story to tell. So I’m going to just start and say, Heidi, welcome. Thanks for taking the time to talk to us today.
Heidi Musser: Thanks so much for inviting me.
Shane Hastie: Tell us a little bit about your background. Who’s Heidi and how did you get to where you are today?
Introductions [01:00]
One step at a time would be the correct answer to that. A little bit about me, I’m a native Detroiter. I was born and raised in the city of Detroit and was the first person in my family that had the opportunity to go off to university, and I graduated with a degree in accounting from Michigan State. I actually attended college on an athletic scholarship, which was quite unusual in the 1970s. Title IX was passed in 1972, so I’m first generation Title IX. I played volleyball. And years ago, my feet actually lifted off the ground when I jumped! But most importantly, I graduated with a degree in accounting and my first job out of college, I worked in finance. I worked in public sector finance as a chief financial officer, and it was during that, the most amazing thing happened to me.
I had a chance to attend a conference, Government Finance Officers Association, the most boring conference in the world. It was being held in my hometown at Cobo Hall in Detroit. The keynote speaker was the Rear Admiral Grace Hopper, and that’s when she had retired from the Pentagon and she was traveling and speaking and she was talking about the rate of change and she talked about nanoseconds. We all know that light travels at the speed of 186,000 miles per second. So a nanosecond, one-billionth of that is approximately 11 point, I don’t know, eight, four inches. It’s slightly less than 12 inches.
Well, after she spoke, I went up and I met her and she gave me her business card and four nanoseconds. I still have those nanoseconds. In fact, I made a commitment to give one of those to Linda Rising the next time I see her, and those are really my most prized possessions of everything I own in my entire estate, my nanoseconds.
But the important thing was Grace Hopper inspired me to start a career in technology, and I heard her. Aftwards, I met her. And of course, for those listening that don’t know Grace Hopper, she invented that little thing called the compiler, quite the pioneer herself. But it was through that meeting that I decided to get into technology. So I left my career in public sector finance and I joined a software company, a small startup company. I grew up in System/3X architecture, and I became a chief product officer for this software company; this company developed and sold solutions, technology solutions to state and local government. So that’s why I started my career in technology. I can still code in RPG 400, but you probably do not want me to do that.
So after working for several startups, I then left that company and worked as a chief operating officer at a consultancy, a technology consulting company. And then I joined a high-flying dot-com, Commerce One. They’re no longer around. They crashed in the dot-com crash. It was an amazing job, and I had a chance to work out in Silicon Valley. And when Commerce One went belly up, I joined corporate America and I worked in healthcare, and then I was recruited away by a big financial services company where I served as a Chief Information Officer, Chief Compliance Officer and Chief Risk Officer. So I’ve actually held five different C-level positions in my career, and I have worked in six different business models. So I think I’ve crossed all of those.
And I’m trying to retire, but I’ve been not incredibly successful with that. It seems like I’ve discovered a new secret superpower. I’ve actually edited six books over the last five years since I’ve retired, and I’m being challenged by one of those authors to maybe even write my own book, but I’m still thinking about that. So that’s a little bit about Heidi.
We build technology for people – never lose sight of the people we are building products for [04:52]
But the interesting thing is probably the most important lesson I ever learned about technology, I learned when I worked in that first software company back in the ’80s. It was on my first business trip ever. But what I learned is that people are more important than technology. I do believe that that’s still true today. And technology has changed a lot, but at the end of the day, we are designing technology solutions for people. People consume technology, and we must never ever forget the importance of people in terms of how we design technology, in terms of how we work in our companies.
I happen to subscribe to a thought that my favorite management guru, Peter Drucker, he said this many years ago, and he said that, “the purpose of an organization is to enable ordinary human beings to do extraordinary things”. I studied Peter Drucker when I earned my executive master’s degree back in the late ’80s, and I couldn’t agree more. In all of my roles as a leader, I’ve always approached these roles believing that my primary role is to enable ordinary people to achieve extraordinary things. And that’s probably what led me into being involved in diversity, equity, inclusion and belonging many, many years ago. It’s been one of my passions throughout my career. So that’s just a little bit about Heidi.
Shane Hastie: Thank you. The point you made to me when we were chatting beforehand was you’ve spent most of your career in fact being the only. What insights has that given you and what has it meant to be the only?
Being “the only” and trying to fit in [06:33]
Heidi Musser: The only, for me, and this wasn’t in my first job out of college but certainly when I got into tech. For me, I was typically the only person in the room who looked like me. What that mostly meant is that I was the only female in the room. And it also meant in my case – I also happened to be gay and I have been out my entire career – but it also meant that I was very likely the only lesbian in the room. Now, the femaleness, we were talking about breaking glass ceilings back in the 1980s, not like we are today, but the gay thing, that was not safe to talk about that. So for me, being the only meant that I was spending a lot of energy trying to fit in, trying to ensure that my voice was being heard and doing it in a way that was not threatening to those I was with.
Now, this is a podcast so you can’t see me. I’m a very tall, athletic, confident woman. And when I started my career, we used to wear those shoes, clearly designed by a man, called pumps, so I was quite a bit taller. When I walk in a room and I take some space; I have some presence about me. And being the only, how would I manage that presence? How do I manage that presence and energy so that I can be a part of and collaborate with and not create a sense of concern or not be a threat to anyone? Early in my career, I spent a fair amount of cycles having to learn how to navigate that in a positive way, in a positive, healthy way.
Shane Hastie: DEI and B, diversity, equity, inclusion and belonging. Belonging is the outcome we want.
Belonging is the outcome of diversity, equity and inclusion [08:29]
Heidi Musser: Diversity, equity, inclusion and belonging, right? So B, that’s a new letter that we’ve added recently, belonging. I believe absolutely that the diversity, the equity, inclusion – those are things we can measure but they’re not the goal. Belonging is the outcome of diversity, equity, and inclusion. We invest. We desire. It’s important to have diversity, equity, inclusion so that we can have belonging.
So what do I mean by that? Diversity is getting invited to the table. We want different people at the table. Equity, it means that everyone that’s actually at the table actually has the opportunity to speak so you’re not just the token. You don’t want to really be the token. Inclusion is having your voice actually be heard. So you’ve been invited to the table, you have the opportunity to speak at the table, and people listen to you. They actually listen to you when you lean in to speak.
Well, belonging, it takes that one step further. It’s actually being admired and respected for who you are, for your unique contributions. And that belonging leads to the social opportunities, the connections, the ability to collaborate, the invitation to collaborate with colleagues, to be a part of, not be separate from. Not tolerated but respected, to be valued for who you are. And it’s only when we have belonging where people literally are bringing their whole selves to work every day. Without belonging, people that look different from the others have to make decisions about what is safe to bring into the room and what is safe to leave outside of the room.
So belonging is when we can really bring our whole selves to work every day, and it’s the outcome. If diversity, equity, inclusion, if our investments in diversity, equity, inclusion do not lead to belonging, then we’re failing. We’re failing each other because the outcome, what we’re trying to get to is belonging.
Shane Hastie: I see us still struggling. What are the steps we can take? How do we get there?
Resistance to DEI&B efforts comes from fear and a lack of knowledge [10:47]
Heidi Musser: Well, again, one step at a time. The business case for investments in DEI and B are amazing. There’s so much data out there. Diverse boards, diverse C-level executives, companies with more diverse executives have better profitability, better return on investment. There are so many studies that have been done over the past 20 years that demonstrate this. Higher profitability, higher market penetration, better product adoption, all of that stuff has been measured and continues to be measured, and yet there tends to still be some resistance.
Now, I think the resistance is twofold. I think one part of it is fear, and I think the other part of it is ignorance. Let me take those one each. Fear is about – that comes from a place of the pie is fixed, and if you get a bigger piece, I get a smaller piece. The fear comes from, if you get it then I don’t. Probably not rational but a very human response. It’s kind of like Dr. Carol Dweck talks about fixed versus growth mindset. If you have a fixed mindset. It puts things in terms of there’s only so much and if you get it, then I don’t, therefore I don’t want you to have it. Whatever we’re talking about, whether we’re talking about money, opportunity, food, anything that we think is scarce. If we have a growth mindset, we’re probably not afraid because there’s more for all of us. If we all do better, the pie is bigger and we all grow and we all benefit from that. But I do believe that there’s an awful lot of fear that paralyzes folks from embracing what is possible.
Unconscious bias and micro-aggressions [12:43]
I think the other part of it I mentioned was the word ignorance. By ignorance, I literally mean lack of knowledge. I don’t mean it as a derogatory term. I mean literally, lack of knowledge. So I do believe that in addition to addressing fear, we also have to educate, and we need to educate people about things like unconscious bias, which by the way, we all have. All human beings have it. This is not just something that only men have or only women have. We all have unconscious bias. And education about microaggressions. A good day for me is a day when I don’t say something that is a microaggression. Microaggressions, an example of a microaggression is, “Heidi, we’re glad to have you on the team. We need the voice of the lesbian community to further develop this product.” Well, I really wish I was the voice of the entire lesbian community. Actually, I don’t wish that at all! I’m one of millions. I am not the voice of the entire community. I’m Heidi. And so a microaggression, that’s an example of a microaggression.
And even those of us with some education about it, it’s very easy to slip into statements of that nature. Well-intentioned. A microaggression I hear frequently is, “Well, my neighbors are not white, I can’t be racist.” It’s like, well, I heard what you said, but I don’t understand what you mean, but that’s an example of a microaggression as well.
I think that fear and ignorance are the two pillars that keep the system of the lack of diversity. They keep the walls of discrimination and these things in place. I think those two pillars of fear and ignorance, and I think both need to be addressed, not just one. Both of those things really need to be addressed.
Shane Hastie: I don’t want to say we as a community, as an industry, but let’s hone in on an organization that you and I have both been very, very deeply involved in, the Agile Alliance. How is the agile movement, the agile community, the flagship of that community tackling belonging?
How the Agile Alliance is addressing these issues [14:55]
Heidi Musser: Well, a couple of different ways. That’s a great question, Shane. First of all, this is just core to the Agile manifesto itself. Agile is about uncovering better ways of doing things and helping others to do it. It’s about people. It’s about humane, sustainable; creating humane and sustainable ways where we can grow our craft and collaborate together. And two of the problems the signatories were trying to solve when the manifesto was written were about improving software craftsmanship, developing better software, but doing it more humanely. So, wow, whenever we talk about agile, this is at our core, it’s about people. Agile is a movement. It’s about investing in people and giving them the skills to thrive, to realize their full potential, to develop amazing technology solutions for the people that are consuming it. So I think it’s just part and parcel of that.
But more directly, Agile Alliance has, for over a dozen years, invested in initiatives to further educate people about diversity, equity, inclusion, and belonging. And not only that, but even as an organization, we’ve been investing in, and really as we grow globally, ensuring that we’re creating access for everyone. Conversations that we have at a Board level, there’s an annual membership fee to join the alliance. A topic of conversation we’ll be having at the October Board meeting will be now that we’re more global, should we have a sliding scale based on location because we have a global community? And even though $49 USD might be reasonable for a person in North America, it’s probably not reasonable for a person in Africa, in the continent of Africa.
So really having conversations, meaningful conversations about how to ensure accessibility – because that’s another part of diversity. When I talked about what do DEI and B mean, accessibility is being able to get into that building so that if you’re invited to the table, you could actually get into the building. So accessibility is a big part of it.
Today, Agile Alliance has several initiatives. Agile in Color is one, and we’ve been featuring education and opportunities to learn more about this, at least – I think Dr. Dave Cornelius was a part of the community back in Agile 2018 and talked about what does diversity, equity, inclusion look like from his perspective, from his point of view. So we’ve been investing in this for a very long time.
Diversity is far more than race and gender [17:44]
But the important thing, what’s really interesting about this is something that I’ve been learning about quite a bit over the past couple of years is the intersectionality. And what I mean by that is if we want to really achieve equity in the tech industry, we need to include more than race and gender. We need to include class and sexuality and ageism and disability and accessibility and maybe other key factors of identity that shapes our experiences differently. And we really need to dig deeper and understand that those differences are critical to promoting diversity and inclusion and change for individuals who have been historically excluded from computing education and careers. It’s not the same for everyone.
Unconscious bias and discrimination are not the same for all women. It looks very different depending on a lot of other factors. So I think taking this intersectional lens is going to be critical to getting through the nuances and breaking through some of the things that are maybe holding back our diversity, equity, inclusion, and belonging investments.
Shane Hastie: I was at the Agile Alliance Conference in Florida, and there was a really powerful session where the Alliance Board was responding to some of the genuine fears and concerns of the community. You want to talk us through what happened there and how that came about?
Events around Agile 2023 [19:20]
Heidi Musser: What a dark period in America about this. Orlando happens to be in the state of Florida. I’m speaking to a global audience here. And the state of Florida has really become a battleground for, politically, for a lot of societal and cultural issues. And over the past several years, lots of legislation has been passed at a state level. Books are being banned. And there literally is a law on the books that says that you must use the bathroom of the sex that you were at birth or you can be arrested. That literally is a law in the state of Florida.
While this led up to preceding the conference, several organizations, the NAACP, National Association for the Advancement of Colored People, Equality Florida, which is an LGBTQ organization Human Rights Campaign, and the Latino community all issued travel advisories warning people of color, LGBTQ, and Latinos. They advised people if you’re in any of those groups, to not travel in Florida because of the discrimination and hate going on in Florida. Before all this happened, and this is a very sad story, an LGBT member, a trans member of our community reached out to Agile Alliance and I actually spoke to this person back in December – a full seven months before the conference. And they posed the question, “Heidi, what is Agile Alliance doing to ensure my safety? Should I choose to travel to Orlando, to Florida for the conference?”
Shane, I need to tell you, this conversation brought me to tears. I spoke with this member for several hours, and we had ideas, shared ideas, and we went on to actually implement some of the ideas that we had discussed to ensure the safety. But the fact that in the year 2022, I was having a conversation with a person who was afraid for their life to travel in America, anywhere in America, about broke my heart. I never felt so helpless and humbled as a leader in my entire life. I literally just sat and cried with this person for some time.
We, in response to this, absolutely, we respect everyone. We always encourage everyone. You’ve got to take care of yourself first, safety first. Agile Alliance has had a code of conduct. I don’t know exactly when we implemented it, but ensuring safety, both physical and psychological safety for our members at all of our events, whether they’re virtual or face-to-face, is important. We take that very, very seriously.
But to just have this conversation to know that there are people, human beings anywhere in the world that are afraid for their lives. Orlando is the home of the Pulse nightclub where 55 people were murdered in a gay bar, a hate crime six years ago. Before I came down to the conference, my wife sat down with me, my wife of 33 years, she sat down with me and said, “Heidi, I know you’re the Board chair. I know you’re going to be visible. You’re a leader in the community. Don’t be a martyr. Please be safe.” And that’s what she said to me as she put me in a car and as I headed out to the airport to attend Agile 2023. That’s saying something.
So that’s some of what was leading up. That’s real. That fear is real. There’s a lot of hatred. There’s a lot of hatred in the world right now, which is very sad.
Shane Hastie: What happened at that event? That to me as a participant, it was a moment of bringing people together and a community that showed care.
Heidi Musser: We had a town hall about midway through the conference that week in Orlando, and it was facilitated by an amazing facilitator, Paul Tevis, and we wanted to create the space for people to come together and ask questions, share their ideas, share their fears, share their concerns so that we can together continue to create safe spaces. And in fact, we’re not done with that. Of course, people that attended the conference were able to attend that. We’re going to have a couple of virtual town halls for those that were not able to attend. But these are real issues and these need to be characteristics. These are considerations where whenever there’s an Agile Alliance event, we need to be working with local people on the ground to ensure safety, and we need to do everything in our power to provide that.
This is important for all human beings, but it’s certainly important for our members. A lot of great ideas, and there are things that were already informing our framework as we consider future venues for conferences, ensuring that we can provide safety. It’s very, very important.
Shane Hastie: Stepping into the Agile Alliance, you have had six years I think on the board. This is the end of your term. You’ve been chair for two of those years.
Heidi Musser: Two years treasurer, two years chair.
Shane Hastie: Where is the Alliance going?
Looking to the future in the Agile Alliance [24:50]
Heidi Musser: I’m incredibly hopeful for so many different reasons. As we think about Agile, it is more relevant than ever the need to be Agile. It is more relevant than ever. Yes. On one hand, it seems like has agile become ubiquitous? It’s become a household word. It is. That’s not a bad thing. But wow, the accelerating rate of change in technology, it’s going to get faster. It’s almost incomprehensible! Think of what ChatGPT and generative AI are doing, and we all know that AI has been around I think since 1956. I think that the term was coined by a colleague of Alan Turing back in 1956, but in terms of where we are and the awareness and adoption curve, I am more excited and hopeful than ever! For organizations to thrive, to be successful, they have to embrace agility. It’s a key leadership skill. Yes, Agile and software technology, also. It’s all of it.
We’ve learned that Agile values, practices and principles are still critically important for software development and all the people that participate in it, ALL the people that participate in it – the product owners, the testers, all the people – not just the people writing the code but anyone that participates in this software development capability. This is critical for all of us, so we absolutely have to learn how to detect and respond to change. We have to learn the discipline of doing the simplest thing that works. We have to learn the value of respecting feedback loops. We have to learn how to empower people to make decisions, and we have to create environments where people can bring their whole selves to work every day.
I am incredibly hopeful for Agile, for both the younger generations, my great nieces and nephews, that generation, and for those of us that have been around this for 30 or 40 years already. I think it’s relevant for all of us.
It’s really interesting. I’m the kind of person, the optimist. When we see an impediment, when we see a challenge, what do we do? What do humans do? Well, some people ignore it, “That’s not there at all”. Some people, they run. They’re gripped by fears like, “Oh, I can’t confront that”. Some people, well, maybe they try to tunnel under it. Some people, “I’m going to get this beast, I’m going to crawl over it”. But how many of us have the courage to peek around the corner and see what other opportunity is created? Whenever an impediment emerges, I promise you there’s one or more opportunities around the corner, and I think that Agile is more relevant than ever for not just the software development community, yes, for the software development community, but for businesses in general.
The pace of change is mind-boggling. There’s more technology in this silly iPhone I’m holding in my hand than the first mainframe I worked on 45 years ago. When I was a student in college, we literally had to walk across campus in the snow, in the winter, to reserve space in the computer center in the future to only go back to our dorm rooms and then walk back when our space time was there. When we got in and we had the privilege of sitting at the punch card, typing in our programs, and we were delivered a deck of our punch cards and we would turn in our deck and get our grade based on, did it compile correctly? My gosh, there is 10 times the power, a hundred times the power on this silly iPhone than there was in that first computer I typed my very first program into back in, I don’t know, 1980.
So the rate of change is accelerating, and to me, that’s very exciting. Agile is more relevant than ever. Sometimes when I talk about this with executives and others, I’m reminded of a quote by Gary Hamel, and his quote is, “How in the age of rapid change do you create organizations that are as adaptable and as resilient as they are focused and efficient?” That quote comes from an article, I think it was Moon Shots for Management. It was in the Harvard Business Review probably back in, I think, 2009. So that article, that quote comes from 15 years ago, but how in the age of rapid change? Agility is the answer! Agile is a really big part of this. We need to embrace change now more than ever and have confidence in the hope that in embracing change, we can harness it for good. We can use this for good.
Shane Hastie: That’s a great statement for us to end on. How do we harness change so that we can use it for good in the world? Heidi, thank you so much for your time today. If people do want to continue the conversation, where can they find you?
Heidi Musser: They can find me on LinkedIn, Heidi J. Musser.
Shane Hastie: And we’ll include that in the show notes. Thanks so much.
Heidi Musser: Shane, thank you. Privilege to be here.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.