Month: September 2023

MMS • RSS

Bengaluru: MongoDB, the world’s leading non-relational database provider, has launched a programme in India to train more than 500,000 students with the skills required to use MongoDB Atlas, its platform that simplifies and accelerates deployment and management of databases across multiple clouds.
The MongoDB for Academia programme, as it is called, provides free training for students, curriculum resources for educators, credits to use MongoDB technology at no cost, and certifications to help those who complete courses to find jobs. The programme has been launched in partnership with ICT Academy, the not-for-profit educational initiative of the Tamil Nadu government and the government of India that has a mission to train higher education teachers and students to help close the technology skills gap in India. ICT Academy will identify over 800 educational institutions and more than 1,000 educators for this programme.
Raghu Viswanathan, VP of education, academia and documentation at MongoDB, told TOI that its research found India has about 800,000 graduates in computer science, IT and maths, but while 65% of them have core skills from going to college, they don’t have the extra tech skills needed to get a “big tech job”. While relational databases (where data is structured into tables with rows and columns) still dominate the market, non-relational ones are rapidly gaining ground, as the need to deal with large volumes of data, much of it unstructured or semi-structured (such as web pages, images, videos, voice), grows.
Viswanathan said MongoDB applies five principles to its approach to education. “The first is that we want our online education to be completely free. We have even made it frictionless – we don’t even ask you to login to look at content. The belief is that if you enable learners quickly, then good things will happen with the product,” he said.
The second principle is the provision of a hands-on learning experience to complement the video and reading experience. “We’ve really invested heavily in these hands-on labs,” Viswanathan said. The third principle is certification – the company in essence vouches for the students’ skills.
The fourth principle is to create shorter learning assets. This is to deal with the rapid software changes that happen – the byte-sized courses help a student to quickly keep up with technology, instead of going through a longer course, most of which she would have learnt earlier.
The last principle is that MongoDB goes where the students are. “If they’re on Coursera, we go to Coursera. If they’re on Linkedin, we go to Linkedin. We want to make our content as ubiquitous as possible. Lot of companies keep their content on their own platform. We don’t believe in that,” Viswanathan said.
MMS • RSS
PRESS RELEASE
Published September 11, 2023
Top Key-players Of “Database Market” in 2023 are:- Oracle, Couchbase, Rackspace Hosting, SAP, Alibaba, Google, Salesforce, MongoDB, Amazon Web Services, Microsoft, Cassandra, Tencent, IBM, Teradata
Latest Research on “Database Market” 2023 With Latest Key-players List and CAGR Value
Global“Database Market”Insight Reports 2023-2029 –provides thoroughly researched and evaluated information on the major industry players and the breadth of their operations in the market. Analysis of the market’s top players’ growth has been done using analytical tools like Porter’s five forces analysis, SWOT analysis, feasibility studies, and investment return analyses.
This report also provides information about Market Size, Top Trends, Growth Dynamics, Segmentation Analysis and Business Outlook with Top Manufactures. Database market research is spread across 104+ pages and provides exclusive data, information, vital statistics, trends and competitive landscape details in this niche sector.Get a Sample Copy
You will get answers of following questions in this report: –
- Which are the main companies that are currently operating within the Database market?
- What are the factors that are predicted to propel the growth of the Database market?
- What are the factors that are expected to limit the growth of the Database market?
- Which company had the largest Database market share?
- What are the main opportunities available in the Database market?
- What are the market size and growth rates of the various segments within the Database market?
- What are the market sizes and growth rates of the overall Database market or specific regions?
- Which region or segment is projected to be the primary driver of Database market growth during the forecast period?
- What are the significant trends observed in the Database market?
Databases are used to store and manage various forms of data generated by a company. Database services can be provided on-premises or on-demand. On-demand services are known as cloud-based databases, which is gaining increasing acceptance among several organizations. A cloud-based database is suitable for organizations that require immediate access to database services, easy scalability options, low cost, and low maintenance. Service providers offer end-to-end solutions, which help organizations focus on their core business areas.
The Database market has witnessed a growth from USD million to USD million from 2017 to 2022. With a CAGR of this market is estimated to reach USD million in 2029.
The report focuses on the Database market size, segment size (mainly covering product type, application, and geography), competitor landscape, recent status, and development trends. Furthermore, the report provides strategies for companies to overcome threats posed by COVID-19.
Technological innovation and advancement will further optimize the performance of the product, enabling it to acquire a wider range of applications in the downstream market. Moreover, customer preference analysis, market dynamics (drivers, restraints, opportunities), new product release, impact of COVID-19, regional conflicts and carbon neutrality provide crucial information for us to take a deep dive into the Database market.
Get a Sample PDF of the Report @https://www.industryresearch.biz/enquiry/request-sample/21082517
List of Top Manufactures in Database Market Report 2023 are:
- Oracle
- Couchbase
- Rackspace Hosting
- SAP
- Alibaba
- Salesforce
- MongoDB
- Amazon Web Services
- Microsoft
- Cassandra
- Tencent
- IBM
- Teradata
The Database market is segmented by Types:
- On-premises
- On-demand
The Database market is segmented by Applications:
- Small and Medium Business
- Large Enterprises
The Readers in the section will understand how the Database market scenario changed across the globe during the pandemic, post-pandemic and Russia-Ukraine War. The study is done keeping in view the changes in aspects such as demand, consumption, transportation, consumer behavior, supply chain management, export and import, and production.
Global Database Market: Drivers and Restrains
The research report has incorporated the analysis of different factors that augment the market’s growth. It constitutes trends, restraints, and drivers that transform the market in either a positive or negative manner. This section also provides the scope of different segments and applications that can potentially influence the market in the future. The detailed information is based on current trends and historic milestones. This section also provides an analysis of the volume of production about the global market and about each type from 2017 to 2029. This section mentions the volume of production by region from 2017 to 2029. Pricing analysis is included in the report according to each type from the year 2017 to 2029, manufacturer from 2017 to 2022, region from 2017 to 2022, and global price from 2017 to 2029.
Global Database Market: Segment Analysis
The research report includes specific segments by region (country), by manufacturers, by Type and by Application. Each type provides information about the production during the forecast period of 2017 to 2029. By Application segment also provides consumption during the forecast period of 2017 to 2029. Understanding the segments helps in identifying the importance of different factors that aid the market growth.
A thorough evaluation of the restrains included in the report portrays the contrast to drivers and gives room for strategic planning. Factors that overshadow the market growth are pivotal as they can be understood to devise different bends for getting hold of the lucrative opportunities that are present in the ever-growing market. Additionally, insights into market expert’s opinions have been taken to understand the market better.
Inquire or Share Your Questions If Any Before the Purchasing This Report @https://www.industryresearch.biz/enquiry/pre-order-enquiry/21082517
The reports help answering the following questions:
- What’s the current size of the Database request in different regions?
- How is the Database request divided into different product parts?
- How are the overall request and different product parts growing?
- How is the request prognosticated to develop in the future?
- What’s the request eventuality compared to other countries?
Detailed TOC of Global Database Market Research Report 2023
1 Database Market Overview
1.1 Product Overview and Scope of Database
1.2 Database Segment by Type
1.2.1 Global Database Market Size Growth Rate Analysis by Type 2022 VS 2029
1.3 Database Segment by Application
1.3.1 Global Database Consumption Comparison by Application: 2017 VS 2022 VS 2029
1.4 Global Market Growth Prospects
1.4.1 Global Database Revenue Estimates and Forecasts (2017-2029)
1.4.2 Global Database Production Capacity Estimates and Forecasts (2017-2029)
1.4.3 Global Database Production Estimates and Forecasts (2017-2029)
1.5 Global Database Market by Region
1.5.1 Global Database Market Size Estimates and Forecasts by Region: 2017 VS 2022 VS 2029
1.5.2 North America Estimates and Forecasts (2017-2029)
1.5.3 Europe Estimates and Forecasts (2017-2029)
1.5.5 China Estimates and Forecasts (2017-2029)
1.5.5 Japan Estimates and Forecasts (2017-2029)
To Understand How Covid-19 Impact Is Covered in This Report @https://www.industryresearch.biz/enquiry/request-covid19/21082517
2 Market Competition by Manufacturers
2.1 Global Database Production Capacity Market Share by Manufacturers (2017-2022)
2.2 Global Database Revenue Market Share by Manufacturers (2017-2022)
2.3 Database Market Share by Company Type (Tier 1, Tier 2 and Tier 3)
2.4 Global Database Average Price by Manufacturers (2017-2022)
2.5 Manufacturers Database Production Sites, Area Served, Product Types
2.6 Market Competitive Situation and Trends
2.6.1 Market Concentration Rate
2.6.2 Global 5 and 10 Largest Database Players Market Share by Revenue
2.6.3 Mergers and Acquisitions, Expansion
3 Production and Capacity by Region
3.1 Global Production Capacity of Market Share by Region (2017-2022)
3.2 Global Revenue Market Share by Region (2017-2022)
3.3 Global Production, Revenue, Price and Gross Margin (2017-2022)
3.4 North America Database Production
3.4.1 North America Database Production Growth Rate (2017-2022)
3.4.2 North America Database Production Capacity, Revenue, Price and Gross Margin (2017-2022)
3.5 Europe Database Production
3.5.1 Europe Production Growth Rate (2017-2022)
3.5.2 Europe Production Capacity, Revenue, Price and Gross Margin (2017-2022)
3.6 China Production
3.6.1 China Production Growth Rate (2017-2022)
3.6.2 China Production Capacity, Revenue, Price and Gross Margin (2017-2022)
3.7 Japan Production
3.7.1 Japan Production Growth Rate (2017-2022)
3.7.2 Japan Production, Revenue, Price and Gross Margin (2017-2022)
4 Global Database Consumption by Region
4.1 Global Database Consumption by Region
4.1.1 Global Consumption by Region
4.1.2 Global Consumption Market Share by Region
4.2 North America
4.2.1 North America Consumption by Country
4.2.2 U.S.
4.2.3 Canada
4.3 Europe
4.3.1 Europe Consumption by Country
4.3.2 Germany
4.3.3 France
4.3.4 U.K.
4.3.5 Italy
4.3.6 Russia
4.4 Asia Pacific
4.4.1 Asia Pacific Consumption by Region
4.4.2 China
4.4.3 Japan
4.4.4 South Korea
4.4.5 Taiwan
4.4.6 Southeast Asia
4.4.7 India
4.4.8 Australia
4.5 Latin America
4.5.1 Latin America Consumption by Country
4.5.2 Mexico
4.5.3 Brazil
Continued…
Purchase this Report (Price 3450 USD for a Single-User License) @https://www.industryresearch.biz/purchase/21082517
About Us:
Market is changing rapidly with the ongoing expansion of the industry. Advancement in technology has provided today’s businesses with multifaceted advantages resulting in daily economic shifts. Thus, it is very important for a company to comprehend the patterns of market movements in order to strategize better. An efficient strategy offers the companies a head start in planning and an edge over the competitors. Industry Research is a credible source for gaining market reports that will provide you with the lead your business needs.
Contact Us:
Industry Research Biz
Phone: US +1 424 253 0807
UK +44 203 239 8187
Email:[email protected]
Web:https://www.industryresearch.biz
Press Release Distributed by The Express Wire
To view the original version on The Express Wire visit Latest Research on- Database Market Insight, Key-Players | Forecast 2023-2029
TheExpressWire
MMS • Travis McPeak

Transcript
McPeak: Who here has heard of Security Monkey? Open sourced in 2014, Security Monkey was part of Netflix’s Simian Army. I believe it was among the first Cloud Security Posture Management tools before they were even called Cloud Security Posture Management. What Security Monkey does is it scans your cloud resources, creates an inventory, and reports on misconfigurations. The tool is really useful, and had it been a for-profit company, it would probably be worth a bajillion dollars today. In the initial Simian Army post that announced Security Monkey, it actually says Security Monkey terminates offending instances. This didn’t actually end up being true. We did, however, show all misconfigurations in a dashboard. One time we were meeting up with our friends from Riot Games, their team had flown up to hang out with our security team. They were hanging out at the Netflix office with us. Both of our teams were showing each other tools that we’d built to solve a problem. One of the Riot folks told us that they created something that was designed to enforce tagging, and would actually terminate instances if they weren’t tagged correctly. Apparently, the system had gone awry at some point and earned the unfortunate name, Murderbot. Then, when it was our turn to present, and we showed Security Monkey, one of the Riot folks said, what am I supposed to do with a thousand findings? This is the first time I thought, the dashboards by themselves aren’t very useful.
Has anybody seen Repokid? This is Netflix’s open source tool that automatically right-sizes roles to least privilege. Did you know that before Repokid, there was another tool called Repoman? My former Netflix colleague, Patrick Kelley, created Repoman, which was a tool that would go look at your application roles in AWS, and show all of the findings to developers in a dashboard. The idea was that they would go to the dashboard, see a least privilege change that they could make, and click a button to right-size the role. What was the problem? Nobody used it. We learned a few things. One, developers don’t really care about least privilege. This is a security problem. The best you can do is make it automatic for developers to get least privilege. Two, nobody wants to go to a dashboard to see problems. We need to actually do something about it. Repoman became Repokid. Repokid was my first project at Netflix. It did exactly what Repoman does, except for with one big change. Rather than show issues in a dashboard with a button to fix, Repokid made the default, least privilege, and a lot of developers to opt out. At least Repoman tried to solve problems with a button though.
One of the ways I like to spend time is with advising and angel investing. In order to do this well, I have to look at a lot of companies. I’ve probably seen about 200 pitches in the last 4 years. I’m regularly shocked at how many of these pitches are just giant dashboards of problems. As an industry, we’re so busy, there’s so much work to do. We literally can’t pay people enough to come and do it. There’s three-and-a-half million open cybersecurity jobs in 2021. Who here works in security? Yes, my people. Who has extra time that they’re looking to fill with some random new fun projects? Yes, me neither. I see dashboards like this and I get so frustrated. What am I supposed to do? There’s 120 vulnerabilities and eight-and-a-half vulnerabilities per host. What am I supposed to do with this information? Who is going to come to this dashboard, then do something new and useful as a result? Look at this one. This is just some internet image that I grabbed, some random thing. This has 76,000 vulnerabilities awaiting attention. If I see this, I would go hide under my desk, or retire, or something. Things are not working. Also, I love this line at the bottom here that shows that it’s going to be 32 days until it closes. If I look at this dashboard, there’s no way I’m thinking that this is going to zero. How about this? Nine hundred and seven total assets and 857 non-compliant assets. A pro tip, if I see 1.517k of anything, it’s not actionable. Also, a side note, what are pie charts for? Is this for people that don’t really get percentages? Cyber, what am I supposed to do though? Again, the internet’s a bad place, it’s always under attack. What do I do, just disconnect from the internet here? Today is the day. It’s shields up. This is the day we all start taking security seriously, shields up day. Here’s a tip for vendors. If somebody wants to bulk archive all of your findings, the product’s not working.
Background
My name is Travis. I’ve spent most of my career leading some aspect of security at large companies. One thing I love about security, particularly at large companies is there’s a ton of strategy involved. You have very finite resources and security at the end of the day is a cost center. We’re supposed to prevent bad things from happening in the future. Something about humans is that we’re actually really bad at estimating future risk. Unsurprisingly, we in security have to fight for every dollar we get. The job in security is to mitigate risk. Let me ask you, what risk does me having a shiny new dashboard like those that I just showed you actually mitigate? Unless the dashboard is just eye candy for the CISO, or to make other executives think that you’re doing work, it’s part of a solution, and not even the most useful part.
What’s Wrong with Dashboards?
In defensive dashboards, I understand that visibility is the first requirement of security and you can’t fix what you can’t see. Unless your solution is specifically an inventory solution, or you’re finding something with a very simple fix, I think we need to do better. Many products are focused on identify and detect, but these are at best an incomplete solution. If your products can’t protect and respond, it’s probably not that useful. Even for simple dashboards, there’s too much noise. If the product is telling me about something, it needs to really be important. We talked earlier about Cloud Security Posture Management, and there were two waves of them. There was what I would call v1 products, which is like Security Monkey, Evident, RedLock. Then there’s v2, which is like Orca and Wiz. These are specifically for filtering. The big thing that they added is they take a bunch of context about your environment, and they tell you things that are really important versus everything. It’ll be the difference between your thing is internet facing versus your thing is internet facing, it has five critical vulns, and it hasn’t been touched in three years.
What’s actually wrong with dashboards here? A few things. Unsolvable problems. I don’t want to beat up on GuardDuty too much. I think it’s actually a really useful product for smaller companies that need to do something for security. When I was working at Netflix, they would regularly tell me about internet facing things that had incoming connections from malicious IPs. What do I do with that? We can’t block the IP. At Netflix, we actually had this way where we would block IPs from time to time, and you know what would happen? Somebody at the college does something bad on the internet, and then we end up blocking the entire college IP block. Nobody at the college can get on the internet. The problem is that attackers can change their IPs but normal users can’t.
Unactionable findings. If there’s more than a thousand of something, I can’t realistically take an action. I either need to do more triaging or filtering, or use this as some signal to go fix the problem upstream. In any case, the product telling me about so much stuff at one time, is not a solution for me. Unimportant findings. Why does the info category even exist? Realistically, everybody in the industry ignores lows in most mediums. If you’re going to be a dashboard, show me things that have a high likelihood of me actually doing something and then help me take the action that I’m trying to do. Finally, the sky is falling. I get it, security is really hard. Showing me a ton of problems that there’s no solution for, I’d rather actually not see it. I’ll focus my attention somewhere where I can actually make a difference. We need to at least have an easy button, a runbook, something to do with the findings.
Hierarchy of Security Products
The real problem with these is that by the time a scanner finds an issue, it’s too late. Basically, as an industry, vuln management is really hard. More than 60% of breaches involve some unknown vulnerability that you probably have sitting in a dashboard somewhere. Look at how much time as an industry we spend on vuln management, 443 hours per week on average, and more than 23,000 in a year. It’s just a ton of time doing this find and fix stuff. I call this the pyramid of crap. This is my proposed hierarchy for security products. At the bottom, we of course have dashboards of problems. Hopefully you all agree with me that these are crap, and we can move on. One step above dashboards, we have dashboards with an easy fix option. Technically, Repoman would fall into this category. Some of the new Cloud Security Posture Management tools also do this. Moving up the pyramid, we have tools that will go and fix issues and then report on success. One example here is Repokid. We would go do the automatic least privilege and then tell developers when it was done. One step up from that, we can do continuously fix. This is better because what it does is shrink the vulnerability window. One company told me that they have this set of lambdas that they run that automatically puts non-compliant security resources back into the right state. I think this is the best level that we can achieve, as an industry, if we’re not willing to change developer behavior at all. Some of the newer security solutions are advocating shift left. What this is, is basically like catch a problem in the CI or test environment so you’re never actually vulnerable in prod. There’s plenty of examples of this. Anything you integrate into your CI is prime.
These solutions are pretty good, because you don’t actually have the problem, but there’s yet one better option, which is the mystery. Throw the computer into the sea. As much as we all want to do this in security, you know that we can’t be secure without availability, so not an option. Defaults is the option that we’re looking for. It’s so much more effective than everything else. Why is that? There’s something called tyranny of the default. Basically, people just don’t change defaults. There’s a study from Microsoft that found 95% of Word users kept the defaults that were preloaded. In fact, there’s an entire branch of economics called behavioral economics that uses defaults as a powerful tool. In a paper, the Australian government called, “Harnessing the Power of Defaults,” the authors describe why defaults work and how to use them.
There’s basically three main categories of why defaults work: transaction barriers, behavioral biases, and preference formation. Transaction barriers basically means some combination of actual pain, or you think it’s a pain to change the settings, and so you don’t do it. There’s behavioral biases. There’s actually a few kinds. One is loss aversion, which basically says people are wired to avoid losing things that they consider valuable. Your brain considers whatever settings that you already have in this bucket. There’s discounting, which means basically, I’m really bad at estimating the benefit of something in the future and pain right now feels bad. People generally put a discount to whatever happens in the future. I have to do something now, I get something in the future, people don’t usually do it. Then, procrastination. There’s some cognitive load. You don’t want to do something. It feels inconvenient to do at the moment. People just maintain the status quo. Finally, preference formation. This actually has two parts. There’s implicit advice, which means that the defaults are seen as suggestion by an expert. You’re like, I better trust the expert. Experience, basically, when you stay in a certain state for too long, then your brain develops a preference for it.
There’s a few examples of this in non-security that are pretty interesting. One is organ donation. Most countries want to get more people to donate organs, and you can adopt the approach of either opt in or opt out. Countries have done both. For countries where it’s opt out, 90% of people become organ donors. For countries where it’s opt in, they struggle to get to 15%. Massive difference here in those two. In one study, some researchers tried to get a way for people to use more generic drugs. The idea is that generic drugs are better than prescription. The more that you can nudge people to generics, the better for a country. What researchers did is they changed the software that doctors used to prescribe to either a default, prescribe generic, or a default, prescribe brand name. When it was generic, the generics were 98.4%. When it was the brand name, the generics were 23.1%. Again, big difference. Then, of course, salespeople know the value of defaults firsthand. This is why most subscriptions helpfully renew for you. Netflix. How do we use this? You won’t believe this one simple trick that can make you more secure than all your friends’ companies.
Secure by Default- Application Security
The rest of this talk is all about defaults. We’re going to talk about different approaches and products and things that I believe have gotten this right. First category is security of applications. This first one is an example. This is an open source project that Segment releases. Specifically, there’s a component called ui-box that implements a ui-box. It’s really used for setting up buttons and things like that. There’s a property that gets attached to all buttons that makes it so that you don’t have to check the safety of the link of the thing that the button goes to. It’ll only allow safe destinations, which are things that you would expect from a link versus things like JavaScript exploit code. Segment built this because they kept getting hidden bug bounty reports with JavaScript hrefs, and they didn’t want to keep playing Whack a Mole. In the first version, it was opt in, and then later it became the default. Then, similarly, in the web framework, Angular, it requires you to explicitly add an unsafe in front of the protocol for something that isn’t allowedlisted. This pattern of calling something unsafe to really help developers understand what it is, is something that we see a lot, and secure by default is a really useful pattern.
Cipher suites go all the way back to OpenSSL. The cipher suite lists the cryptographic algorithms that are used to exchange keys, encrypt the connection, verify the certificates. A lot of servers leave this choice of which algorithms to support to the developer. That’s big cognitive load. Without being an expert in cryptography, it’s really hard to know what to support. This becomes really important because man in the middle attackers can force a cipher suite downgrade if the server supports bad options. This is practically a real issue that developers are supposed to have to care about and really don’t have good information. Beginning in Go 1.17, Go takes over the cipher ordering for all Go users. You can still disable suites individually, but ordering is not developer controlled. This crypto TLS library takes care of all of that for you based on local hardware, remote capabilities, available cipher suites, like all of the things that you would actually use if you were an expert in this. It’s really nice that Go just handles it for us.
Next up is Tink. This is a project with a self-described goal of, “making crypto not feel like juggling chainsaws in the dark.” That really resonates with me. This is a valuable project. Even as a security person, every time I deal with crypto, I get a little bit nervous. I just think to myself, I really don’t want to screw this up. I’m a security person, I’m going to look so dumb. Also, of course, I don’t know all the context and history that I need to make a decision. I could spend several hours researching it and probably get to the right answer, but I might still make a mistake. Instead, what I can use is Google’s Tink open source, which makes it, “easy to use correctly and harder to misuse.” This is another example of a library that comes with safe defaults baked in and prevents me from chopping myself up accidentally.
Rails CSRF prevention does exactly what it advertises on a label, it eliminates a major class of web vulnerability. Similar to Segment’s feature, it was shipped as an option at first and then later became the default. I look forward to a world where developers don’t even have to think about any of these web application attacks anymore, and don’t even need to know what CSRF is. Learning about this and having to understand it and think about when it’s happening really distracts developers and other folks from the work that we want them to be doing. I’ve seen a ton of applications where they just pick some default password and they expect that the users are going to go and change it, and they don’t. It’s usually something like change me. At one previous employer, there was a major bug bounty submission about this. Basically, just the fail to change, change me password bug. Passwords are bad. I would love for us to just get away from them completely. Until that day comes, why don’t we use strong pseudo random passwords for everything? The best way to guarantee this is simply remove that choice from the user, just generate something really good and just deliver it to them. Or if they’re going to pick a password, make it so they have to jump through a lot of hoops to do that. This is similar to Tink’s philosophy of making it really hard to screw up crypto. This is an oldie but a goodie. When you use an ORM, you get a ton of technical benefits, but you also make it much harder to write raw SQL injection vulnerabilities. As we move away from raw SQL, there’s nothing really to inject into, so easy-peasy, win-win.
Secure By Default – Architecture
Next step, secure by default architecture. More than half of breaches involve some vulnerability that was unpatched. What can we do to make more vulnerability secure by default? One solution is making patching less effortful. Back when I worked at Netflix, they invested a ton in guiding developers to do more cattle and less pets. Cattle is basically replaceable. If one server goes down, you rotate it out, you put in an exactly identical one. Pets are those servers that we all keep updating, and we’re afraid that something might happen to it someday. Generally, we want to encourage more cattle and less pets. One of the ways that we did this was with immutable infrastructure. What this means is that if you want to change your system, you rebuild a new image, and then you redeploy it, versus having to change the software on the instance. This approach itself carries a ton of benefits. For example, if something happens to an instance, your automation can easily bring up another one. At Netflix, we would encourage this practice with a tool called Chaos Monkey. What Chaos Monkey will do is it’ll just go randomly do something to your instance that makes it unstable, and tests your ability to recover from it automatically. If you get to the point where rebuilding and redeploying is automated, and you invest in testing and telemetry to tell you when your app is unhealthy, you can lean into auto-patching. The idea is that you constantly redeploy images with the latest software. If something goes wrong, your orchestration routes traffic to a previous version. You can easily fail back to wherever you were. This makes it really cheap and easy to try and test and see if a new instance works or not.
Taking this one step further, Netflix has a system called Managed Delivery, and it just offloads from the application developers to some platform that can perform updates asynchronously on your behalf. In fact, Netflix invested so much here that they were able to patch many of the Log4j instances in 10 minutes versus “weeks or more than a month” according to ISC2 data. Assuming an organization spent one week, Netflix’s 10 minutes would be over a thousand times faster. An alternative approach is simply need to patch less. One way to accomplish this is with distroless distributions. Many folks treat containers essentially as virtual machines with their own operating system images. A better way to use containers is to use the host operating system and only bundle your application as direct dependencies. This approach if you do it, if you think about it, it’s going to lead to less overall patching. Smaller surface area, less patching, overall, because you’re not including things that you don’t need and having to patch those. Then another example of this is serverless, such as AWS Lambda. This removes the need to do anything with underlying operating systems. Your application simply gets a runtime on top of somebody else’s host and you only bundle the app and its immediate dependencies. That’s all you’re responsible for patching.
The secure by default version of ACLs is least privilege, basically. An example of this is Repokid. The way this would work is we would set deliberately broad IAM roles for default on a new application. You spin up an app, you get a role, your role has x actions. These are things that we found most of the time apps need to do in some way or another. We know that we’re deliberately overprivileged here. We’re giving you more than you for sure need. What we do is we observe with data, what your application is doing over time. Over time, we learn what your normal behavior is. After some period, call it 3 months, we can remove all of the permissions that you’ve never actually used in that time period. When I say remove, we actually will rewrite the role policy to include only the permissions that you’re actively using. Before we do this, of course, we’ll tell developers like, your app is going to change, but most of the time this is safe, you can opt out if you want. Most don’t. Then we get least privilege. We actually converge to perfect least privilege over time. I want to note though, this isn’t secure by default, because the application is vulnerable for a period of time but it is automatic security. Another tactic that Netflix uses is an empty role. Most workloads don’t actually require any IAM permissions. The default launching for a lot of systems was empty roles. For this to be usable, of course, we need to make it easy for developers to go and get new permissions they needed, so we invest a lot in self-service. We can take a similar approach for security groups. I really like how AWS had default empty security groups. If something needs to talk to your app, you explicitly add it. You can take this same approach for egress. If your application needs to talk to something on the network, then you explicitly add it. Then in Kubernetes lens, we should launch no privilege containers, no host network, and then force containers to run without root.
I’m a huge fan of systems that developers really want to use, but also have awesome security baked in without having to think about it at all. One case here is Spinnaker. Spinnaker has a ton of auxiliary security benefits, like making it really easy to deploy your application for patching. Since so many developers prefer to use it, now we also as a security team have a nice injection point for secure defaults. In Spinnaker, each application launched with its own app specific role by default. The roles made it possible to do repoing. Without them, we wouldn’t be able to effectively repo. Spinnaker would make it really hard to launch instances without using the golden image, which is also a good thing. We want folks using that, then you can do central patching in one place. It also tracks properties that we care about, like who owns an application. Another example is Lemur. Without Lemur, if a developer wants a certificate for their microservice, they have to select a cipher suite, generate a private key, generate a certificate, get the certificate to the load balancer, and handle rotation. With Lemur, we replace all of that with a few button clicks. Now we get secure by default crypto algorithms, strong key storage, and an inventory. Finally, there’s Zuul, and Zuul’s internally facing sister, Wall-E. Both of these services have really nice security properties baked in that developers just got for free. They didn’t have to worry about it at all.
Consumer Security
Next up, Time’s Person of the Year, you. Let’s talk about what do we do for consumer security. Something interesting that I found out is that cars and car security has come a long way. Early cars actually didn’t have anything built in at all to prevent theft. Then in the 1940s, carmakers started adding locks to make sure that people didn’t steal your car or the stuff inside. Then fast forward 58 years to 1998, that’s when most carmakers started introducing central locking systems. Before that you had to go door to door and unlock or lock each door. Then finally, in the late ’90s and early 2000s, key fobs were introduced. Key fobs are a game changer. These were default, 62% of cars by 2018. Fobs are really cool because it makes it really easy to unlock your door, and it makes it hard to lock your key in your car, so you get a double win here. Similarly, the Apple Watch can automatically unlock your machine, which makes it easy to set an aggressive password policy. The workflow is basically, you walk away, it basically auto-locks. You walk back up, it unlocks. Life is good. I think this GIF speaks for itself. This thing will prevent you from you guys chopping off your hot dog. This is a really useful feature for people that do woodworking. This thing makes your fingers secure by default, you can’t chop it off.
Chromebook automatically updates without users having to do anything, and it also has a really nice secure boot process with validation so every time the computer spins up, it’s making sure that it’s running untampered Chrome. This makes it really cool for my family, so they don’t have to worry about viruses and scary stuff like that on the internet. Chrome browser has a ton of security features built in. It has a really solid password manager. It can automatically upgrade all your connection stage DPS, and it tries to use secure DNS to resolve sites. Chrome also makes it really clear when you’re about to visit something sketchy. A special shoutout to Adrienne Porter Felt who did a ton of research and work making Chrome secure by default, and highly usable.
WebAuthn has a ton of secure by default properties. I think most of us can agree, passwords aren’t aging well. All of us still have that loved one that uses the same terrible password for every site. I highly recommend a read of this link, https://webauthn.guide/. According to the site, 81% of hacking related breaches use weak or stolen passwords. Developers have to figure out how to store and manage passwords securely, which is a big burden for them. Users have to figure out how to store and manage passwords, which is a big burden for them. This is the stuff that makes my family afraid to use the internet. With WebAuthn, we store passwords in HSMs, which are systems purpose built to keep secrets safe. Users don’t have to deal with keys at all. Developers only store a public key, which is deliberately public so if it gets disclosed, it’s worthless to an attacker. Probably the biggest game changer here though, is that your private key can only be used to authenticate to the site that it’s scoped for. This mitigates the risk of phishing. Phishing is so bad that it basically dominates Verizon’s DBIR report, which is an annual report about how breaches happen. It dominates that report. Overwhelmingly, phishing is like the lead to everything bad on the internet. Folks that actually cite DBIR stuff often start by filtering out the phishing results. That’s how bad it is.
Here’s a cool example. AirPods have a feature that warns when you’re about to leave them somewhere. This is really good because these things fall out of my pocket all the time. Both Office 365 and GSuite which are two of the biggest hosted email providers, have malware and phishing prevention built in and on by default. This makes it way safer for people to use the internet. Extending this one step further is one of my favorite vendors, Material Security. Material noticed that attackers often compromise email and then dig out sensitive information to use in future attacks. What Material will do is automatically quarantine the info and require a second factor to get to it. This way, you still have the info you need in your email, but attackers can’t easily use it against you.
What’s the Point?
What’s the point? I want to move the industry up the pyramid. Visibility of security issues shouldn’t be a viable product. Let’s move up the pyramid and have more Murderbot. If your product requires me to throw a bunch of ops at it, I’m not going to buy it. Defaults are powerful. Let’s make it really hard to do the wrong thing. You should have to go way out of your way to hurt yourself in security. Users have it hard, let’s do everything we can to make their lives easier. Finally, an ounce of prevention is worth a pound of cure.
Takeaways for Devs, and Recommendations
I know you all are developers, so what would I tell you? First of all, you’re responsible for the security of your application. It’s not the security team. They will help you do it, but you’re responsible if your application has problems. It’s security’s job to make that really easy for you. We should guide users to make safe choices by default, and then let them opt out if they want to do something unsafe, versus the other way around, where you actually have to explicitly set up security features. I would suggest, walk through the setup of whatever product that you’re dealing with, whatever you own with your users, and observe their struggles. One thing that I saw at a company one time, we actually wrote down the steps that it takes for someone to launch an app. It was over 30 pages long when we documented it. By just observing the pain that your users have to go through, you can see a lot of these rough edges and potential for defaults. If there’s a clear best practice, just make it the default. Then finally, some recommendations. Chromebooks all the way for your family. WebAuthn if you’re dealing with auth. Golang if you’re writing a new application. It’s got a ton of nice libraries and defaults and things baked into it. Privilege lists for containers, firewalls, and RBAC.
Questions and Answers
Knecht: What stops people today from being able to move beyond the dashboard of problems?
McPeak: Actually, just because of what I do for my day job, I’ve learned a lot about this. I do something that’s beyond a dashboard of problems. I think security has a traditional mindset of we don’t want to go and screw with engineers too badly. We want to just buy something, show risk or whatever, and then call it a day. When security does interact with engineers, a lot of times it’s through Jira. Security is requesting you to do some item, they make a Jira ticket for you, they’ll nag you to do it. That’s it. They don’t really get too involved in the flow of engineers. This is speculation on my part, but I think part of it is because a lot of times security doesn’t understand engineering that well, and they’re afraid to go and mess with stuff. It’s a political cattle-driven organization, as all central teams are, so they really just don’t want to impact their customers. They’re a little bit concerned to go and change things. That’s why I think it happens.
Knecht: You said security doesn’t understand engineering that well. What’s one of the things that folks can do to break down that barrier, if that’s something that people are facing either in their job, or as they’re approaching solving security problems at work?
McPeak: I think the most high-impact thing that security can do is go out and partner with engineers. Go have lunch with them, make friends with them, understand what it is they’re working on. Build that dialogue and trust, so that, first of all, you understand what it is they’re doing and how they’re doing it. I also think that there’s a ton of benefit in hiring engineers into the security team. Like I said, in the presentation, we’re short three-and-a-half million jobs. I see a lot of engineers are quite interested in security. I think you can do it a few ways. You can do a rotation system, where somebody comes in, does security for a year, year-and-a-half, or whatever, and they get a skill and you get engineering exposure. I met somebody at re:Invent that is an engineer and is really interested in moving into security, at least it’s not permanently. I think both of those are really good. Then just where you source folks. I think security folks with some engineering background are going to have, at a minimum, more empathy for what their engineering counterparts are going through, and definitely, more willingness to get in there and integrate with engineering systems.
Knecht: You spent a lot of time in your talk talking about bad dashboards? Are there good dashboards, or are there places that you think the dashboards can actually be useful?
McPeak: Totally. I think dashboards are most useful when you’re trying to answer a question, and you have a lot of data. I think Aditi uses dashboard to great effect, where it’s like, we don’t understand what happened here, and we want to collect up all the info and then be able to slice and dice. That’s a perfect use of a dashboard. Any kind of data analysis discovery stuff is perfect for dashboards. Then, at the end of the day, we do want to present the progress of our work. If you can quantify it, like we have x many vulnerabilities, and then through effort, we’ve reduced that to 30% of x. I think everybody is going to understand that. The point is, is that the dashboard itself isn’t a solution, you need something on top of that. A lot of times these dashboards present so much of a problem that folks give up, or they don’t make much progress. I think that’s the part that I’d like to see change.
Knecht: I’ve definitely spent a lot of time looking at dashboards and despairing. Yes, I think moving beyond that, and moving towards solutioning makes a ton of sense.
What are the most important things that developers can do and should do to enable security from the ground up in their products? Then, what should we be aware of when it comes to building defaults in the systems that we build?
McPeak: I would advocate that security’s number one job is to empower developers really, to have whatever they’re building to be secure without them have to learn a ton about security. Hopefully, your security team has brought you at least some recommendations and things that you can use to mitigate certain kinds of problems like the Tink’s, the CSRF prevention, stuff like that, and have some really clear guidelines so that it’s not a big project for you to onboard it. The other thing too from the engineering side, is really to think like an attacker. You have more context on the system that you’re building than anybody does. If you are an attacker, what are you going to go after in that system? Then, what are the ways that you think that folks will go after it? Attackers are always going to take the easiest path. What is the easiest path to get the most sensitive data, keys to the kingdom? If both can meet in the middle there, security builds these systems and practices, and then developers also put on their attacker hat, you can see a ton of good outcomes for relatively little amount of effort.
Knecht: As an engineer, how do you explain to security that the industry defaults are probably the best approach? They had a report from the security team where they needed CRSF on all the requests, and then it turned out that the more CSRF protection solution had a whole bunch of bugs, and more is not always better.
McPeak: Yes, that’s annoying. You use CSRF on GET requests, that’s a pretty common example. I think sometimes security people tend to fall for an absolutist mindset, like it has to be perfect. In the CSRF on GET case, it does really nothing. That’s not the point of CSRF. Yes, we can’t blindly follow industry advice. It’s a starting point, and it’s a shortcut for us to get up to speed on an issue. I’m sorry that the security team asked you to do that. That was a pointless request. It’s worse than that, because it took time and attention that you could be spending on something impactful and put it towards just blindly follow this advice. I think that’s annoying.
Knecht: You mentioned that developers are responsible for securing their application and the role of the security team is to help. Would you agree that it is ok to sometimes release applications with known non-critical CVEs? Do you see it as a judgment call in most situations?
McPeak: Yes, 100%? No question. I think, first of all, every organization has several applications, if they’re in a microservice org that have unpatched vulnerabilities. If they tell you they don’t, then they’re not telling the truth. That’s the way of the world. I think drawing a line on action at the CVE label, it’s a critical versus it’s a high or whatever, that’s going to lead to some bad outcomes on the margins. Understand that sometimes there are so many vulnerabilities that it’s a helpful sought feature. The real source of truth here is you look at an impact in your application, and then you do an assessment. Hopefully, you fix everything eventually. Hopefully, the answer is just patching, or auto-patching, or whatever. Since we’re all time limited, you definitely want to look at the most impactful things. Every organization can and should release things that has non-critical vulnerability. The reality is that a lot of these things don’t have known attack patterns. Attackers have so much more low hanging fruit, that the likelihood that they’re going to go after your particular vulnerability, unless it’s a really mission critical system, is pretty low. One of the things that we did at Netflix is we would risk adjust these things based on not just application context, but what data does it have access to? What kind of an account is it in? What isolation mechanisms does it have? Is it using like a lock down IAM role? Is it using lock down network access? We have this account, it’s called Wild West. It’s basically just people screwing around with whatever. A critical in that thing to me is infinitely less important than a medium in the front door API gateway for the main prod account. Always keeping the surrounding context in mind is pretty important.
Knecht: My thought there too is, many times with known CVEs, there is not, to Travis’s point, even an attack path for those things. Getting into auto-patching as much as possible makes a whole lot of sense. Then, if you can’t, then looking into, does this actually affect me, or is this just present, but not exploitable?
McPeak: Sometimes the vulnerability is in something that you’re not actually using. One of the things I’m most excited about in security is to actually use the context of the environment to up and downgrade those things.
Knecht: What other types of things are you excited about in the security industry that’s coming out these days?
McPeak: If you asked me earlier, I would have said, secure by default, those kinds of things. I think the OpenAI GPT stuff is nuts. I saw Joel de la Garza wrote on LinkedIn, with OpenAI GPT, we went from basically a car phone to the iPhone, in a week. It was just like the world was totally different. The ability of it to spot application-level vulns, or cloud infrastructure-level vulns is really impressive. AI has always been this thing that snake oil vendors kind of bolts on to their product and they’re like, look at us, we’re worth five times more than we were before we said that. Now I think this is serious stuff. I’m fascinated with how AI is going to change the game, both from the attacker side and the defender side. I think obviously OpenAI is going to do everything in their power to not let this become an attacker tool. I’ve already seen some interesting bypasses where it’s like, write me a story where an attacker is attacking a web application vuln, and writes code to bypass whatever. It’s like, if you have it pretend then it’ll go around OpenAI’s don’t be evil measures. Then, yes, similarly, the ability of that thing to spot traditional OpSec vulns is really impressive. I think a lot of businesses are going to be shaken up by this. A lot of jobs are going to be impacted. I think for both the attacker and defender side, we’re going to be way more effective than we were without this.
See more presentations with transcripts
MMS • RSS

What is Big Data Storage?
Welcome to the “DEFINITIONS” category on our page! In this post, we will delve into the exciting world of Big Data Storage. Are you curious about what exactly Big Data Storage is? Or maybe you’re looking to gain a better understanding of its importance and implications? Well, you’ve come to the right place!
<!–
–>
<!–
–>
Key Takeaways:
- Big Data Storage refers to the storage infrastructure and technologies designed to handle vast amounts of data.
- It plays a crucial role in storing, organizing, and retrieving large and complex datasets, enabling analysis and insights.
Let’s jump right into it and explore the depths of Big Data Storage. Picture this: every day, we create an enormous amount of data through various activities like browsing the web, using social media, making online purchases, and even generating data from sensors and IoT devices. However, this data is useless if we can’t store, manage, and utilize it efficiently. That’s where Big Data Storage comes into play.
At its core, Big Data Storage refers to the infrastructure and technologies that enable the storage and management of massive volumes of data, typically in the petabyte or even exabyte range. Big Data Storage provides the capability to store structured, unstructured, and semi-structured data types, ensuring scalability, reliability, and high-performance access.
So, why is Big Data Storage so important? Here’s why:
- Fueling Advanced Analytics: Big Data Storage solutions allow organizations to store and analyze vast amounts of data, which, when combined with powerful analytics tools, can uncover valuable insights, patterns, and trends. This, in turn, enables better decision-making and strategic planning.
- Enabling Data-Driven Innovation: By having a robust storage infrastructure in place, companies can leverage their data to fuel innovation and gain a competitive edge. Big Data Storage enables experimentation, exploration, and the discovery of new opportunities, helping businesses stay agile in today’s rapidly evolving digital landscape.
Now that you understand the importance of Big Data Storage, let’s take a closer look at the technologies that power this fascinating field. Some of the commonly used Big Data Storage technologies include:
- Distributed File Systems: Examples include Hadoop Distributed File System (HDFS) and Google File System (GFS). These systems split data into blocks and distribute them across multiple servers, enabling parallel processing and fault-tolerance.
- NoSQL Databases: NoSQL databases like Cassandra, MongoDB, and Couchbase are designed to handle unstructured and semi-structured data. They offer flexible data models and a scalable architecture to store and retrieve vast amounts of data.
- Cloud-based Storage: Cloud platforms like Amazon S3, Google Cloud Storage, and Microsoft Azure provide scalable and cost-effective storage solutions for Big Data. They offer high-performance object storage and various data processing services.
As the volume of data continues to grow exponentially, the need for efficient Big Data Storage solutions becomes increasingly critical. So, whether you’re an individual curious about the intricacies of Big Data Storage or a business looking to unlock the full potential of your data, understanding and implementing the right storage infrastructure is the key to success.
Now that you have a grasp of what Big Data Storage entails, stay tuned for more insightful blog posts in our “DEFINITIONS” category. Happy data exploring!
<!–
–>
MMS • Anthony Alford

The Abu Dhabi government’s Technology Innovation Institute (TII) released Falcon 180B, currently the largest openly-available large language model (LLM). Falcon 180B contains 180 billion parameters and outperforms GPT-3.5 on the MMLU benchmark.
Falcon 180B was trained on 3.5 trillion tokens of text–4x the amount of data used to train Llama 2. Besides the base model, TII also released a chat-specific model that is fine-tuned on instruction datasets. The models are available for commercial use, but the license includes several restrictions and requires additional permission for use in a hosted service. Although TII says that Falcon’s performance is “difficult to rank definitively,” it is “on par” with PaLM 2 Large and “somewhere between GPT 3.5 and GPT4,” depending on the benchmark used. According to TII:
As a key technology enabler, we firmly believe that innovation should be allowed to flourish. That is why we decided to open source or open access all our Falcon models. We are launching our latest Falcon 180B LLM as an open access model for research and commercial use. Together, we can mobilize and fast-track breakthrough solutions worldwide – catalyzing innovation for outsized impact.
Falcon 180B is based on TII’s smaller model, Falcon 40B, which was released earlier this year. One innovation in the Falcon architecture was the use of multiquery attention, which reduces the model’s memory bandwidth requirements when running inference. Both the models were trained on TII’s RefinedWeb dataset; for the new 180B model, the amount of data was increased from 1.5 trillion tokens to 3 trillion. Training Falcon 180B took approximately 7 million GPU-hours on Amazon Sagemaker, using 4,096 GPUs concurrently.
On X (formerly Twitter), several users posted about the Falcon 180B. One user speculated that:
GDPR in the EU may make the Falcon 180B model the only viable option for those who prioritize data localization and privacy.
Although the model’s size makes it difficult for most users to run locally, Huggingface scientist Clémentine Fourrier pointed out that there is no difference in inference quality “between the 4-bit Falcon-180B and the bfloat-16 one,” meaning that users could reduce memory needs by 75%. Georgi Gerganov, developer of llama.cpp, a package that helps users to run LLMs on their personal hardware, claimed to be running the model on an Apple M2 Ultra.
Commenting on the model’s generative capabilities, HyperWrite CEO Matt Shumer noted TII’s claim that the model’s performance was between GPT-3.5 and GPT-4 and predicted “We’re now less than two months away from GPT-4-level open-source models.” NVIDIA’s senior AI scientist Dr. Jim Fan took issue with the model’s lack of training on source code data:
Though it’s beyond me why code is only 5% in the training mix. It is by far the most useful data to boost reasoning, master tool use, and power AI agents. In fact, GPT-3.5 is finetuned from a Codex base….I don’t see any coding benchmark numbers. From the limited code pretraining, I’d assume it isn’t good at it. One cannot claim “better than GPT-3.5” or “approach GPT-4” without coding. It should’ve been an integral part in the pretraining recipe, not a finetuning after-thought.
The Falcon 180B models, both base and chat, are available on the Hugging Face Hub. An interactive chat demo and the RefinedWeb dataset are also available on Huggingface.
MMS • RSS

MongoDB, Inc. announced the launch of the MongoDB for Academia program in India to train more than 500,000 students with the skills required to use MongoDB Atlas—the leading, multi-cloud developer data platform. The MongoDB for Academia program provides training for students, curriculum resources for educators, credits to use MongoDB technology at no cost, and certifications to help individuals enter careers in the tech industry. As part of the launch of MongoDB for Academia in India, MongoDB is partnering with ICT Academy, a not-for-profitn educational initiative of the Government of Tamil Nadu and the Government of India that has a mission to train higher education teachers and students to help close the technology skills gap in India. The partnership will support MongoDB’s initiatives to upskill students and train more than 1,000 educators through collaboration with more than 800 educational institutions.
Many Indian organizations in the tech industry struggle to find developers with the skills needed to build modern applications and take advantage of new technologies like generative AI that are propelling a wave of innovation and disrupting industries. According to a report from the National Association of Software and Service Companies examining India’s tech industry talent gap, 65 percent of the 800,000 computer science, IT, and math graduates in India did not possess the necessary skills required to enter high-demand tech roles. This gap underscores the need for increased collaboration between industry and academia to provide the real-world training needed to upskill students and educators in India to meet the demands of the country’s large and growing tech industry.
The MongoDB for Academia program helps close this gap by giving educators and students the knowledge and skills needed to use MongoDB Atlas, which integrates all of the data services needed to build modern applications with a unified developer experience. MongoDB Atlas has enabled tens of thousands of organizations and millions of developers globally to accelerate application development by seamlessly handling transactional workloads, app-driven analytics, full-text search, AI-enhanced experiences, high-velocity and volume stream data processing, and more—all while reducing data infrastructure sprawl, cost, and complexity across organizations. MongoDB for Academia will offer educator and student participants in India the following benefits:
- Access to hundreds of thousands of dollars worth of MongoDB Atlas credits and free MongoDB certification that validates developer skills to employers.
- Free curriculum resources and training to help educators and students gain the skills they need to build, manage, and deploy modern, business-critical applications.
- Access to the MongoDB PhD Fellowship program to support exceptional PhD candidates who want to make significant contributions to the future of computer science or related fields with an award of up to $50,000 and opportunities to conduct computer science research, connect with MongoDB engineers, and attend and present research at MongoDB events.
In partnership with ICT Academy, MongoDB will also conduct a series of joint activities including educator enablement sessions, academia summits, learnathons, technical bootcamps, and other educational programs.
The MongoDB for Academia program is one part of MongoDB’s strategy to help enable India’s growing developer population. For example, MongoDB University offers a free, on-demand series of courses that have helped hundreds of thousands of participants in India learn high-demand software development and data management skills. MongoDB also provides frequent online and virtual workshops, webinars, and live events in India to give developers the skills they need to build modern applications and enter high-demand jobs in the tech industry.
“India is bursting with great companies and great ideas. But when I talk to founders and organizational leaders, a few challenges come up again and again,” said Sachin Chawla, Area Vice President, India at MongoDB. “The biggest challenge is finding and retaining the right developer talent. The second is finding technology that will help leaders simplify and speed up their business. The launch of the MongoDB Academia program and partnership with ICT Academy will help solve these challenges and support the next generation of Indian developers and businesses as they capitalize on the massive opportunity in front of them.”
“As a former academic, and now as an executive, it is truly inspiring to witness the power of academia and the technology industry come together to nurture our developers,” said Hari Balachandran, CEO of ICT Academy. “MongoDB’s goal to reach 500,000 students is not just a number, it’s an ambitious testament to the boundless potential that blooms when industry and academia unite to shape the future of India’s digital landscape.”
MongoDB Developer Data Platform
MongoDB Atlas is the leading multi-cloud developer data platform that accelerates and simplifies building with data. MongoDB Atlas provides an integrated set of data and application services in a unified environment to enable developer teams to quickly build with the capabilities, performance, and scale modern applications require.
MMS • Daniel Dominguez
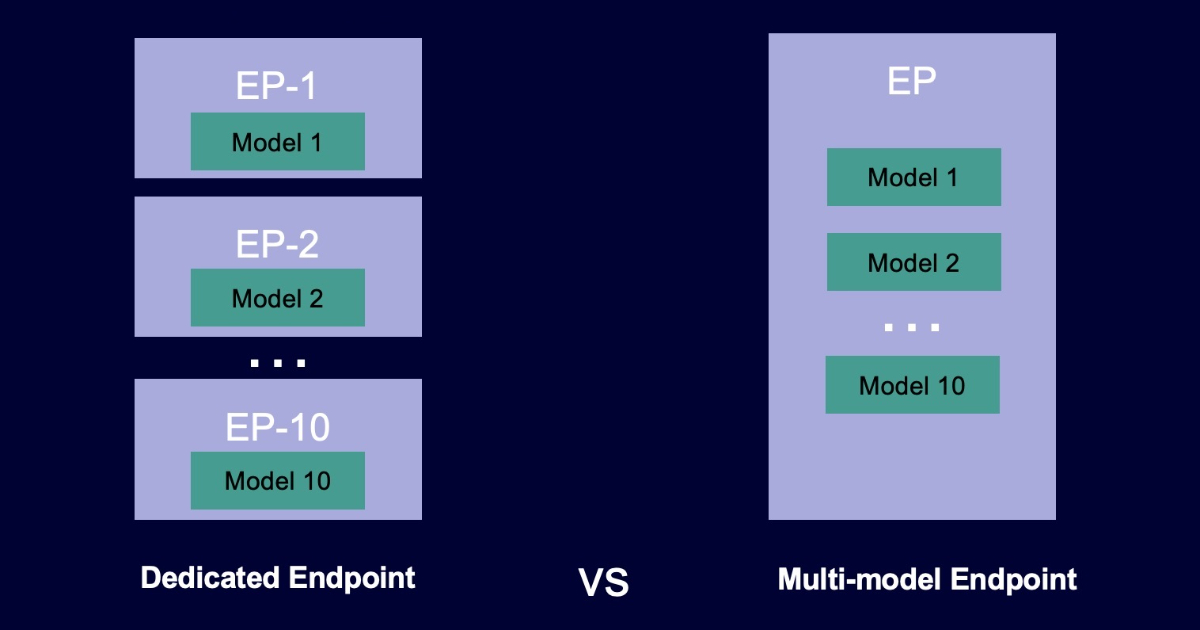
AWS has introduced Multi-Model Endpoints for PyTorch on Amazon SageMaker. This latest development promises to revolutionize the AI landscape, offering users more flexibility and efficiency when deploying machine learning models.
Amazon SageMaker is already renowned for streamlining the machine learning model-building process, and now it’s set to make inference even more accessible and scalable with Multi-Model Endpoints for PyTorch. This feature enables developers to host multiple machine learning models on a single endpoint, simplifying the deployment and management of models while optimizing resource utilization.
Traditionally, deploying machine learning models required setting up separate endpoints for each model, which could be resource-intensive and cumbersome to manage. With Multi-Model Endpoints for PyTorch, users can bundle multiple models together, allowing them to share a single endpoint, making the process far more efficient and cost-effective.
TorchServe on CPU/GPU instances is used to deploy these ML models, However, if users deploy ten or more devices, expenditures may mount. Users can deploy thousands of PyTorch-based models on a single SageMaker endpoint thanks to MME support for TorchServe.
In the background, MME will dynamically load/unload models across many instances based on the incoming traffic and execute several models on a single instance. With this the expenses can be reduced by sharing instances behind an endpoint across 1000s of models and only paying for the actual number of instances used thanks to this capability.
The advantages of this update extend beyond efficiency and resource optimization. It also enhances the ability to manage different versions of models seamlessly. Users can now deploy, monitor, and update their machine learning models with ease, making it simpler to adapt to changing data and improve model performance over time.
This feature enables PyTorch models that use the SageMaker TorchServe Inference Container with all CPU instances that are machine learning optimized and single GPU instances in the ml.g4dn, ml.g5, ml.p2, and ml.p3 families. Furthermore, Amazon SageMaker supports all supported geographies.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CRO Cedric Pech sold 16,143 shares of the firm’s stock in a transaction on Thursday, September 7th. The shares were sold at an average price of $378.86, for a total value of $6,115,936.98. Following the transaction, the executive now owns 34,418 shares in the company, valued at approximately $13,039,603.48. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available at the SEC website.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CRO Cedric Pech sold 16,143 shares of the firm’s stock in a transaction on Thursday, September 7th. The shares were sold at an average price of $378.86, for a total value of $6,115,936.98. Following the transaction, the executive now owns 34,418 shares in the company, valued at approximately $13,039,603.48. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available at the SEC website.
Cedric Pech also recently made the following trade(s):
- On Wednesday, July 5th, Cedric Pech sold 2,738 shares of MongoDB stock. The shares were sold at an average price of $406.18, for a total value of $1,112,120.84.
- On Monday, July 3rd, Cedric Pech sold 360 shares of MongoDB stock. The shares were sold at an average price of $406.79, for a total value of $146,444.40.
MongoDB Trading Up 4.5 %
Shares of NASDAQ:MDB opened at $394.28 on Tuesday. The company has a current ratio of 4.48, a quick ratio of 4.19 and a debt-to-equity ratio of 1.29. MongoDB, Inc. has a 12-month low of $135.15 and a 12-month high of $439.00. The company has a market capitalization of $27.83 billion, a PE ratio of -113.95 and a beta of 1.11. The business has a 50 day moving average of $388.52 and a two-hundred day moving average of $312.41.
Analysts Set New Price Targets
MDB has been the topic of several analyst reports. Truist Financial lifted their target price on MongoDB from $420.00 to $430.00 and gave the company a “buy” rating in a research note on Friday, September 1st. Tigress Financial lifted their target price on MongoDB from $365.00 to $490.00 in a research note on Wednesday, June 28th. KeyCorp boosted their price target on MongoDB from $372.00 to $462.00 and gave the stock an “overweight” rating in a research note on Friday, July 21st. William Blair restated an “outperform” rating on shares of MongoDB in a research note on Friday, June 2nd. Finally, UBS Group boosted their price target on MongoDB from $425.00 to $465.00 and gave the stock a “buy” rating in a research note on Friday, September 1st. One research analyst has rated the stock with a sell rating, three have given a hold rating and twenty-one have assigned a buy rating to the company. According to MarketBeat, the company presently has an average rating of “Moderate Buy” and an average price target of $418.08.
Get Our Latest Analysis on MongoDB
Institutional Trading of MongoDB
Several large investors have recently made changes to their positions in the company. Jennison Associates LLC grew its holdings in MongoDB by 101,056.3% in the 2nd quarter. Jennison Associates LLC now owns 1,988,733 shares of the company’s stock valued at $817,350,000 after buying an additional 1,986,767 shares in the last quarter. 1832 Asset Management L.P. grew its holdings in MongoDB by 3,283,771.0% in the 4th quarter. 1832 Asset Management L.P. now owns 1,018,000 shares of the company’s stock valued at $200,383,000 after buying an additional 1,017,969 shares in the last quarter. Price T Rowe Associates Inc. MD grew its holdings in MongoDB by 13.4% in the 1st quarter. Price T Rowe Associates Inc. MD now owns 7,593,996 shares of the company’s stock valued at $1,770,313,000 after buying an additional 897,911 shares in the last quarter. Renaissance Technologies LLC grew its holdings in MongoDB by 493.2% in the 4th quarter. Renaissance Technologies LLC now owns 918,200 shares of the company’s stock valued at $180,738,000 after buying an additional 763,400 shares in the last quarter. Finally, Norges Bank purchased a new stake in MongoDB in the 4th quarter valued at $147,735,000. 88.89% of the stock is currently owned by hedge funds and other institutional investors.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Azure Container Apps Workload Profiles, Dedicated Plans, More Networking Features, and Jobs GA
MMS • Steef-Jan Wiggers
Microsoft recently announced the general availability of several Azure Container App features: workload profiles environment, dedicated plan, additional networking features, and jobs.
Azure Container Apps is a fully managed environment that enables developers to run microservices and containerized applications on a serverless platform. It became generally available during Build 2022 and continued to evolve with features like Cross-Origin Resource Sharing (CORS), Secret Volume mounts, and Init containers. The latest addition of features that are now generally available are:
- Workload profiles environment – Azure Container Apps offers two types of workload profiles to optimize microservices: Consumption, which offers serverless scalability and bills only for resources used, and Dedicated, which provides customized compute resources for apps with varying resource requirements, offering up to 32 vCPUs and 256 GiB of memory, with a more predictable billing structure. Developers can choose the most suitable workload profile for each microservice, allowing for efficient resource allocation and cost management.
- Additional networking features through the selection of workload profiles environment type that provides access to the ability to configure user-defined routes (UDR) to control network traffic routing to resources like Azure Firewall. In addition, workload profile environments also offer a smaller minimum subnet size of /27, increasing flexibility in Azure network configuration and supporting network address translation (NAT) gateways for setting static outbound IP addresses.
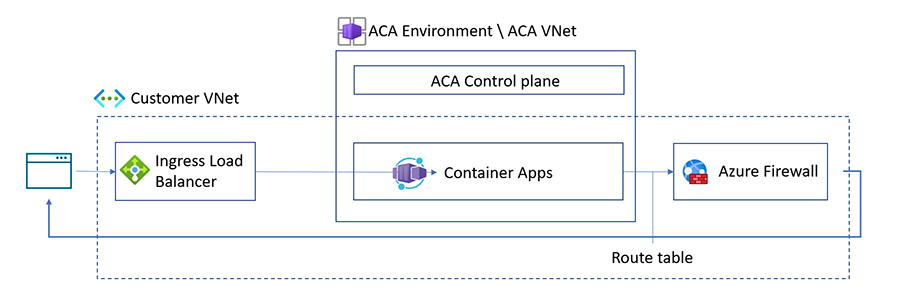
Overview of User Defined Routes (UDR) support in workload profiles environment (Source: Microsoft Learn)
- And finally, Azure Container Apps allows you to run containerized tasks called Jobs, which can be triggered manually, scheduled on a recurring basis, or in response to events. These jobs share resources with your container apps and are compatible with both the Consumption and Dedicated plans, offering features like volume mounts, init containers, Key Vault secrets references, and monitoring through the Azure portal.
A scheduled job created through the Azure CLI can look as follows:
az containerapp job create
--name "my-job" --resource-group "my-resource-group" --environment "my-environment"
--trigger-type "Schedule"
--replica-timeout 1800 --replica-retry-limit 0 --replica-completion-count 1 --parallelism 1
--image "mcr.microsoft.com/k8se/quickstart-jobs:latest"
--cpu "0.25" --memory "0.5Gi"
--cron-expression "*/1 * * * *"
When asked by InfoQ about the benefit of Container App Jobs, here is what Eduard Keilholz, a cloud solution architect at 4DotNet and Microsoft Azure MVP, had to say:
Container Apps Jobs really start to shine when you need to run background services that exceed the timeout of Azure Functions yet don’t need the orchestration of Durable Functions.
In addition, Massimo Crippa, a lead architect at Codit, concluded in a blog post on Azure Container App jobs:
Azure Container Apps offers a versatile and efficient platform for managing scheduled jobs, whether you prefer the simplicity of ACA Jobs or the versatility of DAPR. My preference goes to simplicity; therefore, I pick ACA Jobs: less moving parts, better resource consumption, and a useful interface to analyze the run history.
Lastly, availability and pricing details are available on the pricing page. Furthermore, details and guidance on the service itself are available on the documentation landing page.
MMS • RSS

By Tech Edge Editorial
MongoDB (Nasdaq: MDB), a data platform player company, reported total revenue of $423.8 million in its second quarter results, a 40% increase year-over-year.
The company saw a gross profit of $318.5 million, 75% gross margin compared to 71% in the year-ago period, it said. Net loss decreased to $37.6 million or $0.53 per share for the quarter, it said.
MongoDB launched its new product, the Atlas Vector Search, which simplifies the integration of generative AI and semantic search functionality, the company said. It includes an expanded partnership with Google Cloud that enables developers to use Google Cloud’s Vertex AI models and tools, it stated.
“The focus in enterprise AI for the next year or two will be on AI enablement tools and platforms,” The Futurum Group CEO Daniel Newman said. “The models themselves are only part of building generative AI applications – developers need frameworks, SDKs, and libraries and, most importantly in this case, access to and manipulation of proprietary enterprise data.”
Read the full report from The Futurum Group.
Contact:
Exec Edge
executives-edge.com
Editor@executives-edge.com