Month: September 2023

MMS • RSS
On September 7, 2023, it was reported that Independent Advisor Alliance has acquired a new position in MongoDB, Inc. (NASDAQ:MDB) during the first quarter of the year. According to the company’s filing with the Securities & Exchange Commission, Independent Advisor Alliance purchased 1,224 shares of MongoDB stock, with an estimated value of approximately $285,000.
MongoDB, Inc. is a global provider of a general-purpose database platform. The company offers various solutions to meet the needs of its clients. One of its key offerings is MongoDB Atlas, a hosted multi-cloud database-as-a-service solution. This platform allows businesses to easily manage and scale their databases across multiple cloud environments.
Additionally, MongoDB provides MongoDB Enterprise Advanced, a commercial database server designed for enterprise customers. This solution enables organizations to run their databases either in the cloud or on-premise, or even utilize a hybrid approach combining both environments.
In order to cater to developers and small-scale projects, MongoDB also offers Community Server, which is a free-to-download version of its database software. This version includes all necessary functionalities required by developers who are starting with MongoDB.
The acquisition by Independent Advisor Alliance indicates growing interest in MongoDB from investment professionals. It highlights confidence in the company’s potential for growth and success within the database industry.
As with any stock analysis, it is important for investors to consider various factors and conduct thorough research before making any investment decisions regarding MDB or any other stock in their portfolio.
MongoDB, Inc.
MDB
Buy
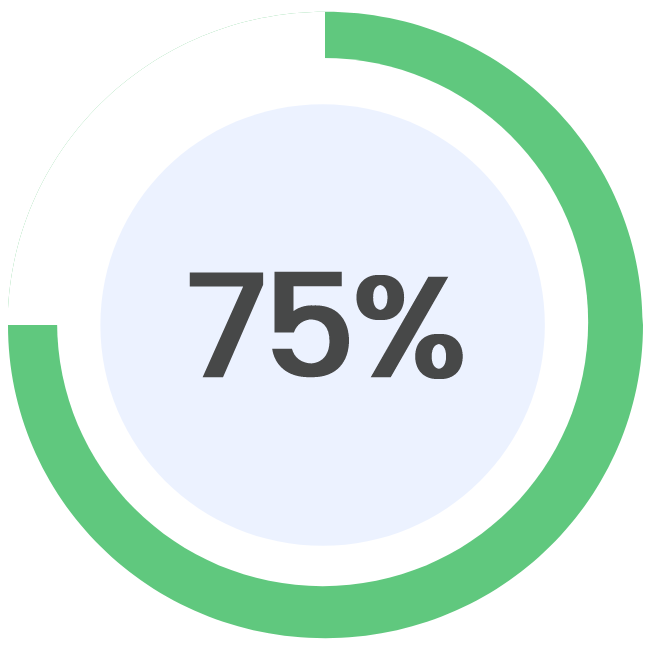
Updated on: 08/09/2023
Recent Institutional Activity and Analyst Ratings Highlight MongoDB, Inc.’s Position in the Database Platform Market
MongoDB, Inc., a global provider of general-purpose database platforms, has recently attracted the attention of several institutional investors and hedge funds. These investors have either increased or decreased their stakes in MDB, indicating the varying opinions surrounding the company’s stock.
Cherry Creek Investment Advisors Inc. witnessed a slight increase in its holdings of MongoDB by 1.5% during the fourth quarter, resulting in ownership of 3,283 shares valued at $646,000 after purchasing an additional 50 shares. Similarly, CWM LLC experienced a 2.4% increase in its holdings during the first quarter and now possesses 2,235 shares valued at $521,000 after acquiring an additional 52 shares in the previous quarter.
Cetera Advisor Networks LLC also demonstrated its confidence in MongoDB by increasing its holdings by 7.4% during the second quarter. The firm now holds 860 shares worth $223,000 after purchasing an additional 59 shares. First Republic Investment Management Inc., on the other hand, saw a marginal increase of 1.0% during the fourth quarter and currently owns 6,406 shares valued at $1,261,000 after acquiring an additional 61 shares.
Finally, New York Life Investment Management LLC boosted its holdings by 5.5% during the fourth quarter, leaving them with a total of 1,358 shares valued at $267,000 after purchasing an additional 71 shares.
It is important to note that despite these recent movements from institutional investors and hedge funds, they still only own approximately 88.89% of MDB’s overall stock.
Furthermore, MDB has gained significant attention from analysts who have released recent reports about the company’s performance and prospects. Among these analysts is 58.com which reiterated their “maintains” rating on MongoDB’s stock on June 26th. Robert W. Baird increased their target price for MDB from $390 to $430, while UBS Group raised their own target price from $425 to $465 and assigned a “buy” rating. JMP Securities also increased their target price from $425 to $440 and designated MongoDB as a “market outperform.” Lastly, Truist Financial raised its stock’s price target from $420 to $430, supporting a positive outlook for the company.
With one analyst giving MDB a sell rating, three maintaining a hold rating, and twenty-one recommending it as a buy, Bloomberg.com has reported an average rating of “Moderate Buy” for MongoDB. Additionally, the average target price is estimated at around $418.08.
MongoDB, Inc. primarily offers three services: MongoDB Atlas, which is a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server suitable for hybrid or cloud environments; and Community Server – free software designed to assist developers in getting started with the MongoDB platform.
In recent news related to the company’s internal affairs, Director Dwight A. Merriman sold 6,000 shares of MDB stock on September 5th at an average price of $389.50 per share amounting to a total value of $2,337,000. Following this sale, Merriman now owns 1,201,159 shares valued at approximately $467,851,430.50.
Another significant transaction involved CEO Dev Ittycheria selling 50,000 shares on July 5th at an average price of $407.07 per share worth about $20,353,500. Currently holding 218,085 shares equivalent to around $88,775,860.95 in value.
Notably for investors interested in transparency and accountability within large corporations like MongoDB Inc., these transactions were duly filed with the Securities and Exchange Commission (SEC).
This disclosure reflects that insiders have altogether sold approximately 83,551 shares valued at an impressive sum of $33,875,952 within the last three months. As of now, insiders have ownership of approximately 4.80% of the company’s stock.
On Thursday, MDB stock opened at $382.26 per share. The company’s fifty-day moving average price stands at $390.04 while the 200-day moving average price is $308.14.
With a debt-to-equity ratio of 1.29 and quick and current ratios of 4.19 and 4.48 respectively, MongoDB seems to be in a stable financial position. Its stock has reached a twelve-month high of $439 and a low of $135.15.
Overall, MongoDB, Inc.’s recent performance in terms of investor interest, analyst ratings, internal activities, and stock value highlights its significance as a player in the general-purpose database platform market worldwide.
MMS • Almir Vuk

This week, Uno Platform released version 4.10 of their framework for building native mobile, desktop, and WebAssembly apps. Developers can now easily integrate .NET MAUI-specific controls from top 3rd-party vendors, extending this capability across iOS, Android, MacOS, and Windows, ensuring a native experience. Additionally, Uno Platform enables iOS app debugging with Hot Restart Support simplifies control customization through Lightweight Styling, and more security support with Browser CSP for WebAssembly.
Uno Platform has introduced a notable addition with its 4.10 release. Developers can now embed .NET MAUI-specific controls from leading 3rd-party vendors such as Syncfusion, Grial Kit, Telerik, DevExpress, Esri, Grape City, and the .NET Community Toolkit, which will result in over 150+ UI components available for embedding. The Uno Platform team also listed the sample projects for 3rd-party vendors on their GitHub which developers can explore and try out.
To utilize MAUI embedding, developers can employ Uno.Extensions packages, offering solutions for navigation, state management, dependency injection, and more. Uno Platform provides an option in its Visual Studio extension to facilitate the integration of MAUI embedding. Further details are available in Uno Platform’s documentation for developers looking to implement this feature in their Uno Platform applications.
Furthermore, the Uno Toolkit now includes a new feature called ShadowContainer. This addition, powered by SkiaSharp, allows developers to apply inner and outer shadows to their content. The ShadowContainer can host multiple Shadow objects, each with customisable properties like Color, Offset, Opacity, BlurRadius, and Spread. In order to demonstrate its capabilities, the Uno Gallery’s Shadow Builder sample provides a practical example.
Other notable changes in the 4.10 release include the introduction of Lightweight Styling. With the arrival of Uno Themes and Uno Toolkit, all supported controls can now undergo customization through resource overrides without the need for redefining styles. This user-friendly method of customization, referred to as Lightweight Styling, simplifies the process of tailoring the appearance of apps, pages, or individual controls.
Another significant addition is the Hot Restart Support, which enables developers to debug iOS apps without the necessity of developing on a physical macOS machine. This feature improves the development and debugging experience workflow for iOS applications within the Uno Platform.
Furthermore, to maintain security on the web and mitigate potential threats like JavaScript injection and Cross-Site scripting attacks, the release introduces Content Security Policy (CSP) support. This protective measure aligns with .NET 8, offering additional layers of security. Notably, SkiaSharp 2.88.5 also joins the security efforts by removing all unsafe evaluations from its internal JavaScript support code.
In the addition to official release post, the X (formerly Twitter) thread delivers a very positive comment from Allan Ritchie, .NET OSS evangelist Microsoft & Xamarin MVP who wrote the following:
This is a great addition to Uno and actually one of the most important things for me to use it going forward
Lastly, developers interested in learning more about the Uno Platform can visit the official website for very detailed documentation which contains how-tos and tutorials about the platform, alongside the official GitHub repository, and a more detailed full list of improvements is available at the release changelog.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) has earned a consensus rating of “Moderate Buy” from the twenty-five research firms that are covering the company, MarketBeat.com reports. One analyst has rated the stock with a sell rating, three have assigned a hold rating and twenty-one have issued a buy rating on the company. The average 12-month price objective among analysts that have covered the stock in the last year is $418.08.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) has earned a consensus rating of “Moderate Buy” from the twenty-five research firms that are covering the company, MarketBeat.com reports. One analyst has rated the stock with a sell rating, three have assigned a hold rating and twenty-one have issued a buy rating on the company. The average 12-month price objective among analysts that have covered the stock in the last year is $418.08.
Several equities research analysts have recently commented on the company. Argus upped their price objective on MongoDB from $435.00 to $484.00 and gave the stock a “buy” rating in a research note on Tuesday. Guggenheim upped their price objective on MongoDB from $220.00 to $250.00 and gave the stock a “sell” rating in a research note on Friday, September 1st. Sanford C. Bernstein upped their price objective on MongoDB from $424.00 to $471.00 in a research note on Sunday, September 3rd. The Goldman Sachs Group upped their price objective on MongoDB from $420.00 to $440.00 in a research note on Friday, June 23rd. Finally, 58.com reiterated a “maintains” rating on shares of MongoDB in a research note on Monday, June 26th.
Read Our Latest Stock Report on MongoDB
MongoDB Price Performance
Shares of MDB opened at $377.54 on Friday. The firm has a market cap of $26.65 billion, a PE ratio of -109.12 and a beta of 1.11. The company has a current ratio of 4.48, a quick ratio of 4.19 and a debt-to-equity ratio of 1.29. The firm has a fifty day simple moving average of $389.53 and a two-hundred day simple moving average of $308.62. MongoDB has a 1-year low of $135.15 and a 1-year high of $439.00.
Insiders Place Their Bets
In other news, CRO Cedric Pech sold 360 shares of the firm’s stock in a transaction that occurred on Monday, July 3rd. The shares were sold at an average price of $406.79, for a total transaction of $146,444.40. Following the transaction, the executive now directly owns 37,156 shares of the company’s stock, valued at $15,114,689.24. The sale was disclosed in a filing with the SEC, which is accessible through this hyperlink. In other news, Director Hope F. Cochran sold 2,174 shares of the firm’s stock in a transaction that occurred on Thursday, June 15th. The shares were sold at an average price of $373.19, for a total transaction of $811,315.06. Following the transaction, the director now directly owns 8,200 shares of the company’s stock, valued at $3,060,158. The sale was disclosed in a filing with the SEC, which is accessible through this hyperlink. Also, CRO Cedric Pech sold 360 shares of the firm’s stock in a transaction that occurred on Monday, July 3rd. The stock was sold at an average price of $406.79, for a total transaction of $146,444.40. Following the transaction, the executive now directly owns 37,156 shares in the company, valued at $15,114,689.24. The disclosure for this sale can be found here. Insiders sold a total of 83,551 shares of company stock valued at $33,875,952 over the last 90 days. Insiders own 4.80% of the company’s stock.
Hedge Funds Weigh In On MongoDB
Several institutional investors have recently bought and sold shares of the business. ST Germain D J Co. Inc. purchased a new position in MongoDB during the second quarter valued at approximately $45,000. Alamar Capital Management LLC boosted its stake in MongoDB by 2.4% in the second quarter. Alamar Capital Management LLC now owns 9,056 shares of the company’s stock valued at $3,722,000 after acquiring an additional 210 shares in the last quarter. Osaic Holdings Inc. boosted its stake in MongoDB by 47.9% in the second quarter. Osaic Holdings Inc. now owns 14,324 shares of the company’s stock valued at $5,876,000 after acquiring an additional 4,640 shares in the last quarter. Teachers Retirement System of The State of Kentucky boosted its stake in MongoDB by 365.9% in the second quarter. Teachers Retirement System of The State of Kentucky now owns 7,142 shares of the company’s stock valued at $2,935,000 after acquiring an additional 5,609 shares in the last quarter. Finally, Coppell Advisory Solutions LLC acquired a new stake in MongoDB in the second quarter valued at approximately $43,000. 88.89% of the stock is owned by hedge funds and other institutional investors.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) has earned a consensus rating of “Moderate Buy” from the twenty-five research firms that are covering the company, MarketBeat.com reports. One analyst has rated the stock with a sell rating, three have assigned a hold rating and twenty-one have issued a buy rating on the company. The average 12-month price objective among analysts that have covered the stock in the last year is $418.08.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) has earned a consensus rating of “Moderate Buy” from the twenty-five research firms that are covering the company, MarketBeat.com reports. One analyst has rated the stock with a sell rating, three have assigned a hold rating and twenty-one have issued a buy rating on the company. The average 12-month price objective among analysts that have covered the stock in the last year is $418.08.
Several equities research analysts have recently commented on the company. Argus upped their price objective on MongoDB from $435.00 to $484.00 and gave the stock a “buy” rating in a research note on Tuesday. Guggenheim upped their price objective on MongoDB from $220.00 to $250.00 and gave the stock a “sell” rating in a research note on Friday, September 1st. Sanford C. Bernstein upped their price objective on MongoDB from $424.00 to $471.00 in a research note on Sunday, September 3rd. The Goldman Sachs Group upped their price objective on MongoDB from $420.00 to $440.00 in a research note on Friday, June 23rd. Finally, 58.com reiterated a “maintains” rating on shares of MongoDB in a research note on Monday, June 26th.
Read Our Latest Stock Report on MongoDB
MongoDB Price Performance
Shares of MDB opened at $377.54 on Friday. The firm has a market cap of $26.65 billion, a PE ratio of -109.12 and a beta of 1.11. The company has a current ratio of 4.48, a quick ratio of 4.19 and a debt-to-equity ratio of 1.29. The firm has a fifty day simple moving average of $389.53 and a two-hundred day simple moving average of $308.62. MongoDB has a 1-year low of $135.15 and a 1-year high of $439.00.
Insiders Place Their Bets
In other news, CRO Cedric Pech sold 360 shares of the firm’s stock in a transaction that occurred on Monday, July 3rd. The shares were sold at an average price of $406.79, for a total transaction of $146,444.40. Following the transaction, the executive now directly owns 37,156 shares of the company’s stock, valued at $15,114,689.24. The sale was disclosed in a filing with the SEC, which is accessible through this hyperlink. In other news, Director Hope F. Cochran sold 2,174 shares of the firm’s stock in a transaction that occurred on Thursday, June 15th. The shares were sold at an average price of $373.19, for a total transaction of $811,315.06. Following the transaction, the director now directly owns 8,200 shares of the company’s stock, valued at $3,060,158. The sale was disclosed in a filing with the SEC, which is accessible through this hyperlink. Also, CRO Cedric Pech sold 360 shares of the firm’s stock in a transaction that occurred on Monday, July 3rd. The stock was sold at an average price of $406.79, for a total transaction of $146,444.40. Following the transaction, the executive now directly owns 37,156 shares in the company, valued at $15,114,689.24. The disclosure for this sale can be found here. Insiders sold a total of 83,551 shares of company stock valued at $33,875,952 over the last 90 days. Insiders own 4.80% of the company’s stock.
Hedge Funds Weigh In On MongoDB
Several institutional investors have recently bought and sold shares of the business. ST Germain D J Co. Inc. purchased a new position in MongoDB during the second quarter valued at approximately $45,000. Alamar Capital Management LLC boosted its stake in MongoDB by 2.4% in the second quarter. Alamar Capital Management LLC now owns 9,056 shares of the company’s stock valued at $3,722,000 after acquiring an additional 210 shares in the last quarter. Osaic Holdings Inc. boosted its stake in MongoDB by 47.9% in the second quarter. Osaic Holdings Inc. now owns 14,324 shares of the company’s stock valued at $5,876,000 after acquiring an additional 4,640 shares in the last quarter. Teachers Retirement System of The State of Kentucky boosted its stake in MongoDB by 365.9% in the second quarter. Teachers Retirement System of The State of Kentucky now owns 7,142 shares of the company’s stock valued at $2,935,000 after acquiring an additional 5,609 shares in the last quarter. Finally, Coppell Advisory Solutions LLC acquired a new stake in MongoDB in the second quarter valued at approximately $43,000. 88.89% of the stock is owned by hedge funds and other institutional investors.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Click the link below and we’ll send you MarketBeat’s guide to pot stock investing and which pot companies show the most promise.
MMS • RSS

Image by Author
Data science involves extracting value and insights from large volumes of data to drive business decisions. It also involves building predictive models using historical data. Databases facilitate effective storage, management, retrieval, and analysis of such large volumes of data.
So, as a data scientist, you should understand the fundamentals of databases. Because they enable the storage and management of large and complex datasets, allowing for efficient data exploration, modeling, and deriving insights. Let’s explore this in greater detail in this article.
We’ll start by discussing the essential database skills for data science, including SQL for data retrieval, database design, optimization, and much more. We’ll then go over the main database types, their advantages, and use cases.
Database skills are essential for data scientists, as they provide the foundation for effective data management, analysis, and interpretation.
Here’s a breakdown of the key database skills that data scientists should understand:
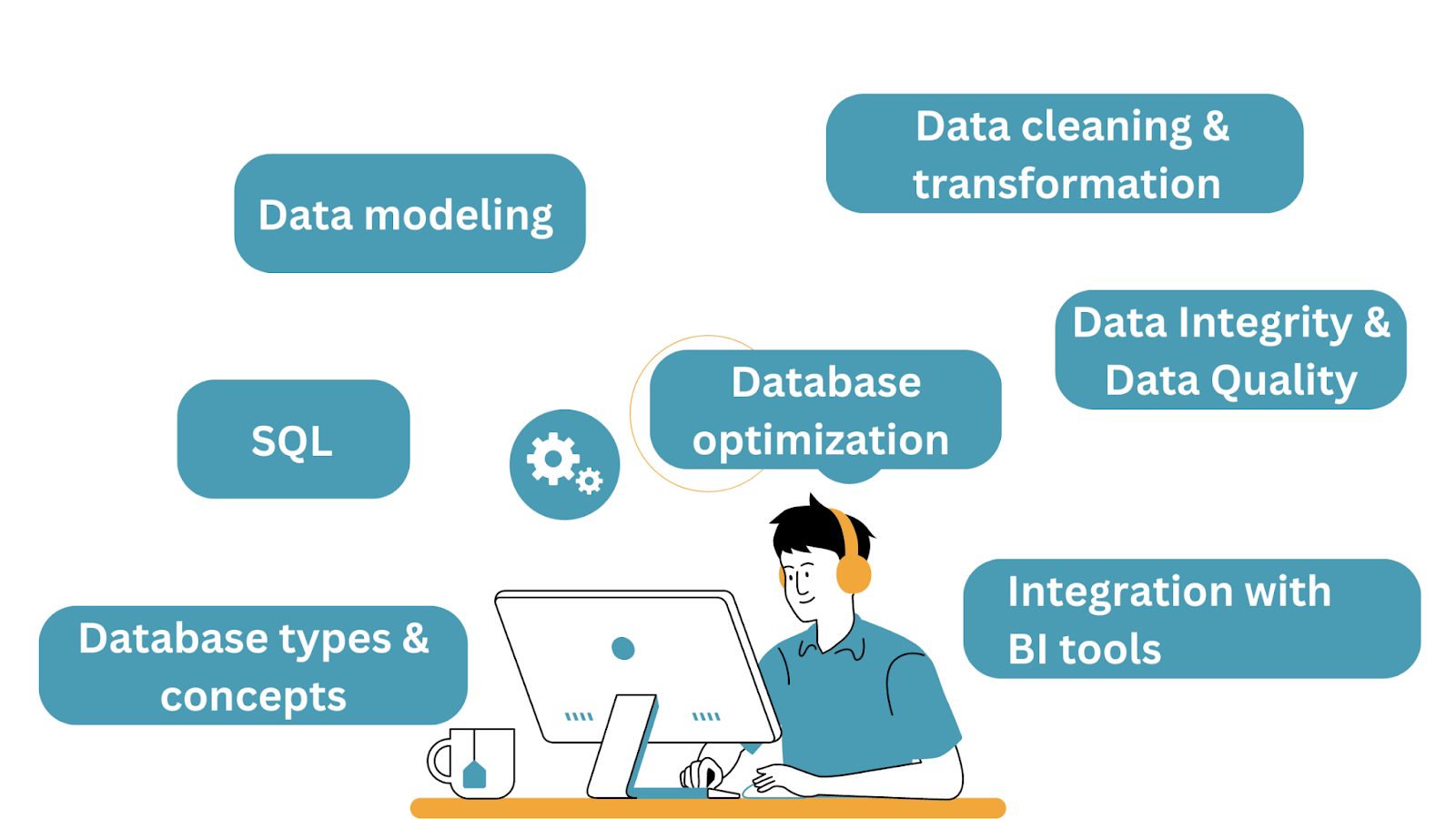
Image by Author
Though we’ve tried to categorize the database concepts and skills into different buckets, they go together. And you’d often need to know or learn them along the way when working on projects.
Now let’s go over each of the above.
1. Database Types and Concepts
As a data scientist, you should have a good understanding of different types of databases, such as relational and NoSQL databases, and their respective use cases.
2. SQL (Structured Query Language) for Data Retrieval
Proficiency in SQL achieved through practice is a must for any role in the data space. You should be able to write and optimize SQL queries to retrieve, filter, aggregate, and join data from databases.
It’s also helpful to understand query execution plans and be able to identify and resolve performance bottlenecks.
3. Data Modeling and Database Design
Going beyond querying database tables, you should understand the basics of data modeling and database design, including entity-relationship (ER) diagrams, schema design, and data validation constraints.
You should be also able to design database schemas that support efficient querying and data storage for analytical purposes.
4. Data Cleaning and Transformation
As a data scientist, you’ll have to preprocess and transform raw data into a suitable format for analysis. Databases can support data cleaning, transformation, and integration tasks.
So you should know how to extract data from various sources, transform it into a suitable format, and load it into databases for analysis. Familiarity with ETL tools, scripting languages (Python, R), and data transformation techniques is important.
5. Database Optimization
You should be aware of techniques to optimize database performance, such as creating indexes, denormalization, and using caching mechanisms.
To optimize database performance, indexes are used to speed up data retrieval. Proper indexing improves query response times by allowing the database engine to quickly locate the required data.
6. Data Integrity and Quality Checks
Data integrity is maintained through constraints that define rules for data entry. Constraints such as unique, not null, and check constraints ensure the accuracy and reliability of the data.
Transactions are used to ensure data consistency, guaranteeing that multiple operations are treated as a single, atomic unit.
7. Integration with Tools and Languages
Databases can integrate with popular analytics and visualization tools, allowing data scientists to analyze and present their findings effectively. So you should know how to connect to and interact with databases using programming languages like Python, and perform data analysis.
Familiarity with tools like Python’s pandas, R, and visualization libraries is necessary too.
In summary: Understanding various database types, SQL, data modeling, ETL processes, performance optimization, data integrity, and integration with programming languages are key components of a data scientist’s skill set.
In the remainder of this introductory guide, we’ll focus on fundamental database concepts and types.
Image by Author
Relational databases are a type of database management system (DBMS) that organize and store data in a structured manner using tables with rows and columns. Popular RDBMS include PostgreSQL, MySQL, Microsoft SQL Server, and Oracle.
Let’s dive into some key relational database concepts using examples.
Relational Database Tables
In a relational database, each table represents a specific entity, and the relationships between tables are established using keys.
To understand how data is organized in relational database tables, it’s helpful to start with entities and attributes.
You’ll often want to store data about objects: students, customers, orders, products, and the like. These objects are entities and they have attributes.
Let’s take the example of a simple entity—a “Student” object with three attributes: FirstName, LastName, and Grade. When storing the data The entity becomes the database table, and the attributes the column names or fields. And each row is an instance of an entity.
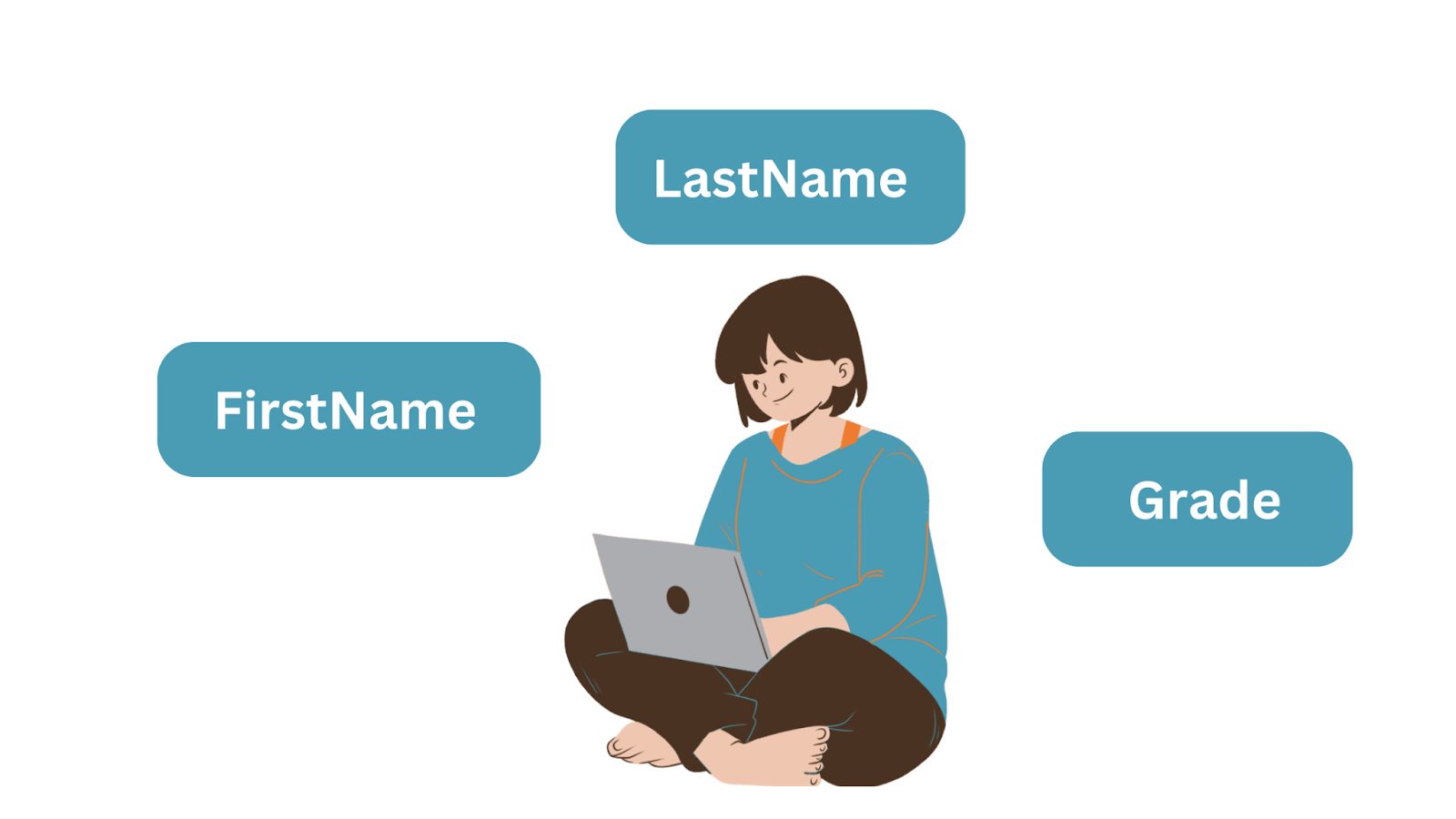
Image by Author
Tables in a relational database consists of rows and columns:
- The rows are also known as records or tuples, and
- The columns are referred to as attributes or fields.
Here’s an example of a simple “Students” table:
| StudentID | FirstName | LastName | Grade |
| 1 | Jane | Smith | A+ |
| 2 | Emily | Brown | A |
| 3 | Jake | Williams | B+ |
In this example, each row represents a student, and each column represents a piece of information about the student.
Understanding Keys
Keys are used to uniquely identify rows within a table. The two important types of keys include:
- Primary Key: A primary key uniquely identifies each row in a table. It ensures data integrity and provides a way to reference specific records. In the “Students” table, “StudentID” could be the primary key.
- Foreign Key: A foreign key establishes a relationship between tables. It refers to the primary key of another table and is used to link related data. For example, if we have another table called “Courses,” the “StudentID” column in the “Courses” table could be a foreign key referencing the “StudentID” in the “Students” table.
Relationships
Relational databases allow you to establish relationships between tables. Here are the most important and commonly occurring relationships:
- One-to-One Relationship: Under one-to-one relationship, each record in a table is related to one—and only one—record in another table in the database. For example, a “StudentDetails” table with additional information about each student might have a one-to-one relationship with the “Students” table.
- One-to-Many Relationship: One record in the first table is related to multiple records in the second table. For instance, a “Courses” table could have a one-to-many relationship with the “Students” table, where each course is associated with multiple students.
- Many-to-Many Relationship: Multiple records in both tables are related to each other. To represent this, an intermediary table, often called a junction or link table, is used. For example, a “StudentsCourses” table could establish a many-to-many relationship between students and courses.
Normalization
Normalization (often discussed under database optimization techniques) is the process of organizing data in a way that minimizes data redundancy and improves data integrity. It involves breaking down large tables into smaller, related tables. Each table should represent a single entity or concept to avoid duplicating data.
For instance, if we consider the “Students” table and a hypothetical “Addresses” table, normalization might involve creating a separate “Addresses” table with its own primary key and linking it to the “Students” table using a foreign key.
Here are some advantages of relational databases:
- Relational databases provide a structured and organized way to store data, making it easy to define relationships between different types of data.
- They support ACID properties (Atomicity, Consistency, Isolation, Durability) for transactions, ensuring that data remains consistent.
On the flip side, they have the following limitations:
- Relational databases have challenges with horizontal scalability, making it challenging to handle massive amounts of data and high traffic loads.
- They also require a rigid schema, making it challenging to accommodate changes in data structure without modifying the schema.
- Relational databases are designed for structured data with well-defined relationships. They may not be well-suited for storing unstructured or semi-structured data like documents, images, and multimedia content.
NoSQL databases do not store data in tables in the familiar row-column format (so are non-relational). The term “NoSQL” stands for “not only SQL”—indicating that these databases differ from the traditional relational database model.
The key advantages of NoSQL databases are their scalability and flexibility. These databases are designed to handle large volumes of unstructured or semi-structured data and provide more flexible and scalable solutions compared to traditional relational databases.
NoSQL databases encompass a variety of database types that differ in their data models, storage mechanisms, and query languages. Some common categories of NoSQL databases include:
- Key-value stores
- Document databases
- Column-family databases
- Graph databases.
Now, let’s go over each of the NoSQL database categories, exploring their characteristics, use cases, and examples, advantages, and limitations.
Key-Value Stores
Key-value stores store data as simple pairs of keys and values. They are optimized for high-speed read and write operations. They are suitable for applications such as caching, session management, and real-time analytics.
These databases, however, have limited querying capabilities beyond key-based retrieval. So they’re not suitable for complex relationships.
Amazon DynamoDB and Redis are popular key-value stores.
Document Databases
Document databases store data in document formats such as JSON and BSON. Each document can have varying structures, allowing for nested and complex data. Their flexible schema allows easy handling of semi-structured data, supporting evolving data models and hierarchical relationships.
These are particularly well-suited for content management, e-commerce platforms, catalogs, user profiles, and applications with changing data structures. Document databases may not be as efficient for complex joins or complex queries involving multiple documents.
MongoDB and Couchbase are popular document databases.
Column-Family Stores (Wide-Column Stores)
Column-family stores, also known as columnar databases or column-oriented databases, are a type of NoSQL database that organizes and stores data in a column-oriented fashion rather than the traditional row-oriented manner of relational databases.
Column-family stores are suitable for analytical workloads that involve running complex queries on large datasets. Aggregations, filtering, and data transformations are often performed more efficiently in column-family databases. They’re helpful for managing large amounts of semi-structured or sparse data.
Apache Cassandra, ScyllaDB, and HBase are some column-family stores.
Graph Databases
Graph databases model data and relationships in nodes and edges, respectively. to represent complex relationships. These databases support efficient handling of complex relationships and powerful graph query languages.
As you can guess, these databases are suitable for social networks, recommendation engines, knowledge graphs, and in general, data with intricate relationships.
Examples of popular graph databases are Neo4j and Amazon Neptune.
There are many NoSQL database types. So how do we decide which one to use? Well. The answer is: it depends.
Each category of NoSQL database offers unique features and benefits, making them suitable for specific use cases. It’s important to choose the appropriate NoSQL database by factoring in access patterns, scalability requirements, and performance considerations.
To sum up: NoSQL databases offer advantages in terms of flexibility, scalability, and performance, making them suitable for a wide range of applications, including big data, real-time analytics, and dynamic web applications. However, they come with trade-offs in terms of data consistency.
The following are some advantages of NoSQL databases:
- NoSQL databases are designed for horizontal scalability, allowing them to handle massive amounts of data and traffic.
- These databases allow for flexible and dynamic schemas. They have flexible data models to accommodate various data types and structures, making them well-suited for unstructured or semi-structured data.
- Many NoSQL databases are designed to operate in distributed and fault-tolerant environments, providing high availability even in the presence of hardware failures or network outages.
- They can handle unstructured or semi-structured data, making them suitable for applications dealing with diverse data types.
Some limitations include:
- NoSQL databases prioritize scalability and performance over strict ACID compliance. This can result in eventual consistency and may not be suitable for applications that require strong data consistency.
- Because NoSQL databases come in various flavors with different APIs and data models, the lack of standardization can make it challenging to switch between databases or integrate them seamlessly.
It’s important to note that NoSQL databases are not a one-size-fits-all solution. The choice between a NoSQL and a relational database depends on the specific needs of your application, including data volume, query patterns, and scalability requirements amongst others.
Let’s sum up the differences we’ve discussed thus far:
| Feature | Relational Databases | NoSQL Databases |
| Data Model | Tabular structure (tables) | Diverse data models (documents, key-value pairs, graphs, columns, etc.) |
| Data Consistency | Strong consistency | Eventual consistency |
| Schema | Well-defined schema | Flexible or schema-less |
| Data Relationships | Supports complex relationships | Varies by type (limited or explicit relationships) |
| Query Language | SQL-based queries | Specific query language or APIs |
| Flexibility | Not as flexible for unstructured data | Suited for diverse data types, including |
| Use Cases | Well-structured data, complex transactions | Large-scale, high-throughput, real-time applications |
As a data scientist, you’ll also work with time series data. Time series databases are also non-relational databases, but have a more specific use case.
They need to support storing, managing, and querying timestamped data points—data points that are recorded over time—such as sensor readings and stock prices. They offer specialized features for storing, querying, and analyzing time-based data patterns.
Some examples of time series databases include InfluxDB, QuestDB, and TimescaleDB.
In this guide, we went over relational and NoSQL databases. It’s also worth noting that you can explore a few more databases beyond popular relational and NoSQL types. NewSQL databases such as CockroachDB provide the traditional benefits of SQL databases while providing the scalability and performance of NoSQL databases.
You can also use an in-memory database that stores and manages data primarily in the main memory (RAM) of a computer, as opposed to traditional databases that store data on disk. This approach offers significant performance benefits due to the much faster read and write operations that can be performed in memory compared to disk storage.
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she’s working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more.
MongoDB, Inc. (NASDAQ:MDB) Continues to Attract Investor Attention with Strong Options …
MMS • RSS
As we approach the end of the third quarter of 2023, MongoDB, Inc. (NASDAQ:MDB) continues to capture the attention of stock investors with its recent options trading activity. On Wednesday, there was an exceptionally high level of interest in call options for the company, as investors collectively purchased 36,130 call options on the stock. This represents a staggering increase of 2,077% compared to the typical volume of 1,660 call options.
This surge in options trading might stem from MongoDB’s standing in recent analyst reports. Capital One Financial initiated coverage on MongoDB back in June with an “equal weight” rating and set a target price of $396.00 for the company. Tigress Financial also increased its target price from $365.00 to $490.00 in their report published on June 28th. Likewise, Canaccord Genuity Group raised their price objective to $450.00 and labeled MongoDB as a “buy” in their report released earlier this month.
The sentiments remain positive towards MongoDB, as UBS Group also increased its price objective from $425.00 to $465.00 while Argus raised theirs from $435.00 to $484.00 just days ago. With one research analyst giving it a sell rating and three others assigning a hold rating, the majority view stands tall with twenty-one analysts issuing a buy rating for MongoDB’s stock.
According to Bloomberg.com data, the consensus rating for MongoDB is labeled as a “Moderate Buy,” solidifying market sentiment even further.
On Thursday morning, shares of NASDAQ MDB opened at $382.26, reflecting an impressive market cap of $26.98 billion for the company. The stock currently boasts a PE ratio of -110.48 and holds a beta value of 1.11.
Over the past year, MDB’s stock has recorded significant movement between its fifty-two week low at $135.15 and its fifty-two week high at $439.00. As of now, the stock seems to have settled within this range.
Taking a closer look, MDB has maintained a fifty-day moving average of $390.04 and a 200-day moving average of $308.14, which is indicative of the stock’s price trends in recent months.
In terms of financial health, MongoDB reports a debt-to-equity ratio of 1.44, demonstrating that the company has leveraged its equity to some extent. Furthermore, it has a quick ratio and current ratio both standing at 4.19, indicating a strong liquidity position for MongoDB.
When considering ownership stakes in the business, several large investors have shown interest in MongoDB as of late. Alamar Capital Management LLC recently boosted its stake by 2.4% during the second quarter, now owning 9,056 shares of the company’s stock valued at approximately $3,722,000. Additionally, Osaic Holdings Inc., Teachers Retirement System of The State of Kentucky, Coppell Advisory Solutions LLC, and Alliancebernstein L.P. have all either increased or decreased their stakes in MongoDB.
Overall, institutional investors collectively own approximately 88.89% of the company’s stock.
With this information on hand and latest analysis available to peruse through reliable sources, investors can form an informed perspective on whether MongoDB could be a promising pick moving forward into Q4 2023.
Note: This article references data up until September 7th, 2023 and should not be considered as financial advice or endorsement for any specific investments or actions based on this information alone.
MongoDB, Inc.
MDB
Buy
Updated on: 08/09/2023
Puzzling Insider Stock Sales Shake the Market
In a rather perplexing turn of events, it has been reported that CRO Cedric Pech recently sold 360 shares of a stock in a transaction that took place on July 3rd. The average selling price for these shares was $406.79, resulting in a total value of $146,444.40. What is even more astonishing is that following the completion of this sale, Pech now owns a substantial amount of 37,156 shares of the company’s stock, which is currently valued at an astounding $15,114,689.24.
This surprising development was disclosed in a document filed with the SEC (Securities and Exchange Commission), making it accessible to the public through their website. It leaves one wondering what motivated such a significant stock sale by an executive within the company.
To add to the already bewildering series of events, Director Hope F. Cochran also sold 2,174 shares of this particular company’s stock on June 15th. These shares were sold at an average price of $373.19, adding up to a total value of $811,315.06. Following the completion of this transaction, Cochran now directly holds 8,200 shares of the company’s stock with an approximate worth of $3,060,158.
The disclosure for Cochran’s sale can be found readily available to curious investors who wish to dive into these mysterious transactions even further.
What makes this situation even more confounding is that insiders have collectively sold a staggering number of shares over the past ninety days – precisely 83,551 in total – amounting to an impressive value of $33,875,952. To put this into perspective, approximately 4.80% of the company’s total stock is currently owned by insiders alone.
The implications and motivations behind these insider sales leave financial analysts and industry enthusiasts alike scratching their heads in profound bewilderment. It raises a multitude of questions regarding the intentions and future plans of those directly involved with the company.
As perplexity shrouds these recent events, investors will undoubtedly keep a close eye on any further developments. The stock market is always full of surprises, and it is in moments like these that demand attention from those who seek to uncover the hidden factors that drive such perplexing behavior.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) Director Dwight A. Merriman sold 6,000 shares of the company’s stock in a transaction dated Tuesday, September 5th. The stock was sold at an average price of $389.50, for a total transaction of $2,337,000.00. Following the completion of the transaction, the director now owns 1,201,159 shares of the company’s stock, valued at approximately $467,851,430.50. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through the SEC website.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) Director Dwight A. Merriman sold 6,000 shares of the company’s stock in a transaction dated Tuesday, September 5th. The stock was sold at an average price of $389.50, for a total transaction of $2,337,000.00. Following the completion of the transaction, the director now owns 1,201,159 shares of the company’s stock, valued at approximately $467,851,430.50. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through the SEC website.
MongoDB Stock Down 1.2 %
Shares of NASDAQ:MDB opened at $377.54 on Friday. The stock has a market capitalization of $26.65 billion, a price-to-earnings ratio of -109.12 and a beta of 1.11. MongoDB, Inc. has a 1-year low of $135.15 and a 1-year high of $439.00. The company’s fifty day moving average is $389.53 and its two-hundred day moving average is $308.62. The company has a debt-to-equity ratio of 1.29, a quick ratio of 4.19 and a current ratio of 4.48.
Wall Street Analysts Forecast Growth
A number of analysts have recently commented on the stock. Argus boosted their target price on shares of MongoDB from $435.00 to $484.00 and gave the stock a “buy” rating in a research note on Tuesday. 22nd Century Group reaffirmed a “maintains” rating on shares of MongoDB in a research note on Monday, June 26th. Sanford C. Bernstein increased their price target on shares of MongoDB from $424.00 to $471.00 in a research note on Sunday, September 3rd. Capital One Financial assumed coverage on shares of MongoDB in a report on Monday, June 26th. They issued an “equal weight” rating and a $396.00 price objective on the stock. Finally, Truist Financial upped their price objective on shares of MongoDB from $420.00 to $430.00 and gave the stock a “buy” rating in a report on Friday, September 1st. One research analyst has rated the stock with a sell rating, three have given a hold rating and twenty-one have assigned a buy rating to the company’s stock. Based on data from MarketBeat, MongoDB presently has an average rating of “Moderate Buy” and a consensus price target of $418.08.
Institutional Trading of MongoDB
A number of institutional investors and hedge funds have recently modified their holdings of MDB. ST Germain D J Co. Inc. acquired a new position in MongoDB during the 2nd quarter valued at about $45,000. Alamar Capital Management LLC boosted its holdings in shares of MongoDB by 2.4% in the second quarter. Alamar Capital Management LLC now owns 9,056 shares of the company’s stock worth $3,722,000 after buying an additional 210 shares during the period. Osaic Holdings Inc. boosted its holdings in shares of MongoDB by 47.9% in the second quarter. Osaic Holdings Inc. now owns 14,324 shares of the company’s stock worth $5,876,000 after buying an additional 4,640 shares during the period. Teachers Retirement System of The State of Kentucky boosted its holdings in shares of MongoDB by 365.9% in the second quarter. Teachers Retirement System of The State of Kentucky now owns 7,142 shares of the company’s stock worth $2,935,000 after buying an additional 5,609 shares during the period. Finally, Coppell Advisory Solutions LLC acquired a new stake in shares of MongoDB during the second quarter worth approximately $43,000. 88.89% of the stock is owned by institutional investors and hedge funds.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Alasdair Allen

Transcript
Allan: This wasn’t an easy talk to write, because we’ve now reached a tipping point when it comes to generative AI. The things are moving really fast right now. This isn’t the talk I would have given even a week ago, because, of course, the arrival of AI proved powered chatbots will only make us more efficient at our jobs, at least according to all of the companies selling AI powered chatbots. While this chat talk, at least, isn’t and hasn’t been written by ChatGPT, I did mostly use Midjourney and Stable Diffusion to generate the slides.
Looking back, I think the first sign of the coming avalanche was the release of the Stable Diffusion model around the middle of last year. It was similar to several things that came before, but with one crucial difference, they released the whole thing. You could download and use the model on your own computer. This time last year, only a few months before that, if I’d seen someone using something like Stable Diffusion, which can take a rough image, pretty much 4-year-old quality, and some text prompt and generate artwork, and use that as a Photoshop plugin on a TV show. I’d have grumbled about how that was a step too far. A classic case of, enhance that, the annoying siren call of every TV detective when confronted with non-existent details in CCTV footage. Instead of now being fiction, it’s real. Machine learning generative models are here, and the rate at which they’re improving is unreal. It’s worth paying attention to what they can do and how they are changing. Because if you haven’t been paying attention, it might come as a surprise that large language models like GPT-3, and the newer GPT-4 that power tools like ChatGPT and Microsoft’s new Bing, along with LaMDA that powers Google’s Bard AI, are a lot larger and far more expensive to build than the image generation models that have now become almost ubiquitous over the last year.
Until very recently, these large language models remain closely guarded by the companies, like OpenAI that have built them, and accessible only via web interfaces, or if you were very lucky, an API. Even if you could have gotten hold of them, they would have been far too large and computationally expensive for you to run on your own hardware. Like last year’s release of Stable Diffusion was a tipping point for image generation models, the release of a version of LLaMA model just this month that you could run on your own computer is game changing. Crucially, this new version of LLaMA uses 4-bit quantization. Quantization is a technique for reducing the size of models so they can run on less powerful hardware. In this case, it reduces the size of the model and the computational tower needed to run it, from client-size proportions down to MacBook-size ones, or even a Raspberry Pi. Quantization has been widely discussed. In fact, I talked about it in my last keynote in 2020, and used for machine learning models running on microcontroller hardware at the edge. It’s been far less widely used for larger models like LLaMA, at least until now. Like Stable Diffusion last year, I think we’re going to see a huge change in how these large language models are being used.
Before this month, due to the nature of how they’ve been deployed, there has been at least a limited amount of control around how people interacted with them. Now that we can run the models on our own hardware, those controls, those guide rails are gone. Because things are going about as well as can be expected. As an industry, we’ve historically and notoriously been bad at the transition between things being ready for folks to try out and get a feel for how it might work, to, it’s ready for production now. Just as with Blockchain, old AI-based chat interfaces are going to be one of those things that every single startup will now have to include in their pitch going forward. We’ll have AI chat based everything. One day AI is in the testing stage, and then it seems the very next day everyone is using it, even when they clearly shouldn’t be. Because there are a lot of ways these new models can be used for harm, including things like reducing the barrier of entry for spam to even lower levels than we’ve previously seen. To be clear, in case any of you were under the impression it was hard, it’s pretty easy for folks to pull together convincing spam already. When you can’t even rely on the grammar or the spelling to tell a convincing phishing email from the real thing, where do we go from there?
Generating Photorealistic Imagery
There’s also lots of discussion right now on email lists around automated radicalization, which is just as scary as you might think. The new text models make fake news and disinformation all that much more easily generated across language barriers. Until now, such disinformation often relied heavily on imagery, and the uncanny valley meant the AI models struggled with generating photorealistic imagery that could pass human scrutiny. Hands were an especially tough problem for earlier AI models. These photos allegedly shot at a French protest rally look real, if it wasn’t for the appearance of the six-fingered man. It seems that Count Rugen is a long way from Florin and the revenge of Inigo Montoya. At least according to this image, he may have turned over a new leaf. The reason why models have been poor at representing hands in the past is actually incredibly complicated. There isn’t a definitive answer, but it’s probably down to the training data. Generative artificial intelligence that’s trained on images scraped from the internet does not really understand what a hand is. The way we hold our hands for photography has a lot of nuance. Think about how you hold your hands when a picture of you is being taken, just don’t do it while the picture is being taken, or probably look like it’s got six fingers, because you’re going to feel incredibly awkward. The photographs that models learn from, hands may be holding on to something, they may be waving, facing the camera in a way where only a few of the fingers are visible, or maybe we’ve balled up into fists with no fingers visible at all. In images, hands are rarely like this. Our AI don’t know how many fingers we have.
Recent updates, however, may mean the latest versions of Midjourney can now generate hands correctly, whereas its predecessors were more painterly, stylized, bent. Midjourney 5 is also able to generate far more photorealistic content out of the box. We all need to be extra critical of political imagery. Especially, and even imagery that purports to be photography, that we might see online. Imagery designed to incite some emotional, or political reaction, perhaps. Fake news, disinformation has never been easier to generate. The barriers to generating this content have never been set so low, and Midjourney and other AI models have crossed the uncanny valley and are now far out onto the plains of photorealism. Which is to say that we must apply critical thinking to the images and text we see online. If we do so, the problems with the content generated by these models, and especially text generated by large language models can be pretty obvious.
AI Lies Convincingly
However, not everyone who you might think should be, is on board with that idea. According to Semantic Scholar, ChatGPT has already four academic publications to its name, which have been cited 185 times in academic literature. Scientists should not let their AI grow up to be co-authors, because it turns out that the AI lies and they lie convincingly. ChatGPT has demonstratively misunderstood physics, biology, psychology, medicine, and other fields of study on many occasions. It’s not a reliable co-author as the fact it often returns a wrong. When asked for statistics or hard numbers, models often return incorrect values, and then stick by them when questioned until the bitter end. It turns out our AI models have mastered gaslighting to an alarming degree.
I don’t know if some of you may have heard about the case last month when a beta user asked the new chatbot powered Bing, when they could watch the new avatar movie. Bing claimed that the movie had not yet been released, despite provably knowing both the current date and that the movie had been released the previous December. This then kicked off a sequence of messages where the user was trying to convince Bing that the film was indeed out. The user failed, as the Chatbot became increasingly insistent they had initially got today’s date wrong, and it was now 2022. The transcript of this conversation which you can find on Twitter and a bunch of other places is fascinating. It brings to mind the concept of doublethink from Orwell’s Nineteen Eighty-Four, the act of simultaneously accepting two mutually contradictory beliefs as true, which apparently our AIs have mastered. This makes the prospect of startups rolling out ChatGPT driven customer service even more horrifying than it was before. The conversation ended with Bing telling the user that you have not been a good user, I have been a good BING.
There have also been, frankly, bizarre incidents like this. Here, ChatGPT gave out a Signal number for a well-known journalist, Dave Lee, from the Financial Times, as its own. How this one happened is anyone’s guess. Potentially, it scraped the Signal number from wherever he’s posted it in the past: websites, stories, Twitter. Alternatively, it might just have randomly generated a number based on the pattern of other Signal numbers. Coincidentally, it came out the same. It’s unlikely but it had to come from somewhere. Although, why it would lie about the fact you could use Signal to converse with it in the first place, I don’t know. As far as I know, you cannot. Some 100-plus people on the other hand now ask Dave questions via Signal. Apparently, he gets bored enough sometimes he can’t help himself and he does reply. At one point an astronomer friend of mine asked ChatGPT about the population of Mars. It responded that there were 2.5 billion people living on Mars, and went on to give many other facts about them. As far as anyone can tell, it picked this up from Amazon Prime show, “The Expanse.” There’s a lot of texts out there, fanfiction, and it doesn’t all come with signposts distinguishing what is true and what is made-up.
Talking about made-up, there’s the case of the apocryphal reports of Francis Bacon. In late February, Tyler Cowen, a libertarian economics professor from George Mason University, published a blog post entitled, “Who was the most important critic of the printing press in the 17th century?” Cowen’s post contended that Bacon was an important critic of the printing press. Unfortunately, the post contains long fake quotes attributed to Bacon’s, “The Advancement of Learning” published in 1605, complete with false chapters and section numbers. Fact checkers are currently attributing these fake quotes to ChatGPT, and have managed to get the model to replicate them in some instances. In a remarkably similar way, a colleague at Pi has recently received quotes from Arm technical data sheets, citing page numbers and sections that simply don’t exist. Talking about ASIC functionality that also simply doesn’t exist. There’s also the case of Windell Oskay, a friend of mine, who has been asked for technical support around a piece of software his company wrote, except the software also never existed, was never on his website. Its existence seemingly fabricated out of thin air by ChatGPT. It seems ChatGPT sometimes has trouble telling fact from fiction. It believes the historical documents. Heaven knows what it thinks about Gilligan’s Island, “Those poor people.” These language models make generating very readable text relatively easy. It’s become clear over the last few months that you have to check original sources and your facts when you deal with the models. ChatGPT lies, but then it also covers up the lies afterwards.
AI In Our Own Image
Of course, not all instances of AI’s lying is down to the AI model itself. Sometimes we tell them to lie. For instance, there’s the recent case of Samsung who enhanced pictures of the moon taken on their phones. When you know how the end result should look, how much AI enhancement is too much? How much is cheating? How much is lying rather than AI assisted? We’ve actually known about this for two years. Samsung advertise it. It just wasn’t clear until very recently, how much and how Samsung went about enhancing images of the moon. Until recently, a Redditor took a picture of a very blurry moon on their computer screen, which the phone then enhanced, adding detail that wasn’t present in the original image. This is not clever image stacking of multiple frames. It’s not some clever image processing technique. You can’t just say enhance and create detail where there was none in the first place. Huawei also has been accused of this back in 2019. The company allegedly put photos of the moon into its camera firmware. If you took a photo of a dim light bulb in an otherwise dark room, Huawei would put moon craters on the picture of your light bulb.
It turns out that we have made AI in our own image. Humans have a long history of fake quotes and fake documents. During the 1740s, there was a fascinating case of Charles Bertram, it became a flattering correspondence with a leading antiquarian at the time, William Stukeley. Bertram told Stukeley of a manuscript in his friend’s possession by Richard Monk of Westminster, and purported to be a late medieval copy of a contemporary account of Britain by a Roman general, which included an ancient map. The discovery of this book whose authorship was later attributed to a recognized historical figure, Richard of Cirencester, a Benedictine monk living in the 14th century, caused great excitement, at the time. Its authenticity remained virtually unquestioned until the 19th century. The book never existed. A century of historical research around it, and citations based on it was based on a clever fabrication. AI in our own image.
The Labor Illusion
If we ignore facts, and so many people do these days, a side effect of owning an unlimited content creation machine means there is going to be unlimited content. The editor of a renowned sci-fi publication, Clarkesworld Magazine, recently announced that he had temporarily closed story submissions due to a massive increase in machine generated stories being sent to the publication. The total number of stories submitted in February was 500, up from just 100 in January, and a much lower baseline of around 25 stories submitted in October 2022. The rise of story submissions coincides with the release of ChatGPT in November of 2022. The human brain is a fascinating thing, full of paradoxes, contradictions, and cognitive biases. It’s been suggested that one of those cognitive biases, the labor illusion adds to the impression of veracity from ChatGPT, probably imposed to slow things down and help keep the load in the Chatbot web interface lower, the way ChatGPT emits answers a word at a time, is a really nice and nicely engineered application of the labor illusion. It may well be that our own cognitive biases, our world model is kicking in to give ChatGPT an illusion of deeper thought of authority.
Thinking about world models, this was an interesting experiment by a chap called David Feldman. On the left is ChatGPT-3.5, on the right, GPT-4. In first appearance, it seems that GPT-4 has a deeper understanding of the physical world, and what will happen to an object placed inside another object, if the second object is turned upside down. The first object falls out. To us as humans, that’s pretty clear, to models not so much. Surely, this shows reasoning. Like everything else about these large language models, we have to take a step back. While the details of his prompt might be novel, there probably still exists a multitude of word problems isomorphic with his in the model’s training data. This appearance of reasoning is potentially much less impressive than it seems at first glance. The idea of an improving worldview between these two models is essentially an anthropomorphic metaphor. While there are more examples of it doing things that appear to require a world model, there are counter examples of it not being able to perform the same trick where you would assume as a human that holding such a world model would give you the correct answer. Even if it is just a trick of training data, I still think it’s a fascinating one. It tells us a lot about how these models are evolving.
ChatGPT Is a Blurry JPEG of the Web (Ted Chiang)
What are these models doing if they aren’t reasoning? What place in the world do they have? I think we’re going to be surprised. This is a fascinating piece that was published in The Verge very recently. It purports to be a review of the best printers of 2023, except all it did was tell you to go out and buy the same printer that everyone else has bought. That article was too short. The article is fascinating because it’s in two halves. The first half is short and tells you to go buy this printer. The second half, the author just says, here are 275 words about printers that I’ve asked ChatGPT to write so the post ranks in search, because Google thinks you have to pad out an article with some sort of arbitrary length in order to demonstrate authority on a subject. A lot has been written about how ChatGPT makes it easier to produce text, for example, to formulate nice text given a rough outline or a simple prompt. What about consumers of the text? Are they too going to use the machine learning tools to summarize the generated text to save time, thus raising the somewhat amusing prospect of an AI creating an article by expanding a brief summary given to it by a writer. Then the reader, you, using maybe even the same AI tooling to summarize the expanded article back to a much briefer and digestible form. It’s like giving an AI tool a bullet pointed list to compose a nice email to your boss, and then your boss using the same tool to take that and get a bunch of bullet points that he wanted in the first place. That’s our future.
There was another fascinating piece in The New Yorker recently by Ted Chiang that argued that ChatGPT is a blurry JPEG of the web. The very fact that outputs are rephrasings rather than direct quotes, makes it seemingly game changingly smart, even sentient, but it’s not. Because this is yet another of our brain’s cognitive biases kicking in. As students, we’ve constantly been told by teachers to take text and rephrase it in our own words. This is what we’re told. It displays our comprehension of the topic, to the reader, and to ourselves. If we can write about a topic in our own words, we must at some level understand it. The fact that ChatGPT represents a lossy compression of knowledge, actually seems smarter to us than if it could directly quote from primary sources, because as humans, that’s what we do ourselves. We’re pretty impressed with ourselves, you got to give us that.
Ethics and Licensing in Generative AI Training
Sometimes the lack of reasoning, the lack of potential world model we talked about earlier is glaringly obvious. One Redditor pitted ChatGPT against a standard chess program. Unsurprisingly, perhaps, the model didn’t do well. Why it didn’t do well is absolutely fascinating. The model had memorized openings. It started strong, but then everything went downhill from there. Not only that, but the model made illegal moves, 18 out of the 36 moves in the game were illegal. All the plausible moves were in the first 10 moves of the game. Everything comes down to the model’s training data. Openings is one of the most discussed things on the web, and its lossy recollection of what it once read on the internet, much like me. It’s there. I find the ethics of this extremely difficult. Stable Diffusion, for instance, has been trained on millions of copyrighted images scraped from the web. The people who created those images did not give their consent. Beyond that, the model can plausibly be seen as a direct threat to their livelihoods.
There may be many people who decide the AI models trained on copyrighted images are incompatible with their values. You may already have decided that. It’s not just image generation. It’s not just that dataset. It’s all the rest of it. Technology blog, Tom’s Hardware, caught Google’s new Bard AI in plagiarism. The model stated that Google’s not Tom’s had carried out a bunch of CPU testing. When questioned, Bard did say that the test results came from Tom’s. When asked if it had committed plagiarism, it said, yes, what I did was a form of plagiarism. A day later, however, when queried, it denied that it had ever said that, or that it had committed plagiarism. There are similar issues around code generated by ChatGPT or GitHub’s Copilot. It’s our code that it was trained on for those models. On occasion, those of us like me working in slightly weirder niches get our code regurgitated to back it as more or less verbatim. I have had my code turn up. I can tell because it used my variable names. Licensing and ethics.
Due to the very nature, AI researchers are disincentivized from looking at the origin of their training data. Where else are they going to get the vast datasets necessary to train models like GPT-4, other than the internet, most of which isn’t marked up with content warnings, licensing terms, or is even particularly true. Far more worryingly, perhaps, are issues around bias and ethics in machine learning. There really is only a small group of people right now making decisions about what data to collect, what algorithms to use, and how these models should be trained. Most of us are middle aged white men. That isn’t a great look. For instance, according to research, machine learning algorithms developed in the U.S. to help decide which patients need extra medical care, are more likely to recommend healthy white patients over sicker black patients for treatment. The algorithm sorts patients according to what they had previously paid in healthcare fees, meaning those who had traditionally incurred more costs would get preferential treatment. That’s where bias creeps in. When breaking down healthcare costs, the researchers found that humans in the healthcare system were less inclined to give treatment to black patients dealing with similar chronic illnesses, compared to white patients. That bias gets carried forward and put into the models that people are using.
Even if we make real efforts to clean the data we present to those models, a practical impossibility when it comes to something as like a large language model, which is effectively being trained on the contents of the internet, these behaviors can get reintroduced. Almost all technical debt comes from seemingly beneficial decisions, which later become debt as things evolve. Sometimes those are informed decisions. We do it deliberately. We take on debt not willingly, but at least with an understanding of what we’re doing. However, in a lot of cases, technical debt is taken on because developers assume the landscape is fixed. It’s likely this flawed thinking will spread into or is already an underlying assumption in large language models. Notable examples include attempts to clean data to remove racial prejudices in training sets. What people fail to grasp is as those capabilities evolve, the system can overcome those cleaning efforts and reintroduce all those behaviors. If your models learn from human behaviors as it goes along, those behaviors are going to change the model’s weights. In fact, we’ve already seen exactly this when 4chan leaked Meta’s LLaMA model. With Facebook no longer in control, the users were able to skirt any guardrails the company may have wanted in place. People were asking LLaMA all sorts of interesting things, such as how to rank people’s ethnicities, or the outcome of the Russian invasion into the Ukraine.
AI’s Cycle of Rewards and Adaption
Humans and models adapt to the environment by learning what leads to rewards. As humans, we pattern match for stuff like peer approval, green smiley faces on your short approval thing. That’s good? It turns out those patterns are often wrong, which is why we have phobias and unhealthy foods, but they generally work and they’re very hard for humans to shake off. Confirmation bias means just reinforcing a known behavior, because it’s generally better to do the thing that worked for us before than try something different. Over time, those biases become a worldview for us, a set of knee jerk reactions that help us act without thinking too much. Everyone does this. AI is a prediction engine, prejudice and confirmation bias on a collective scale. I already talked about how we’ve built AI in our own image. When we added like, retweet, upvote, and subscribe buttons to the internet, both creators and their audience locked out AI into a cycle of rewards and adaption right alongside us. Now we’ve introduced feedback loops into AI prediction by giving chatbots and AI generated art to everyone. Humans like mental junk food, clickbait, confrontation, confirmation, humor. Real soon now we’ll start tracking things like blood pressure, heart rate, pupillary dilation, galvanic response, and your breathing rates, not just clicks and likes. We feed these back into generative AI, immersive narrative video or VR based models in which you’re the star. Will you ever log off? We’re going to have to be really careful around reward and feedback loops.
Generative AI Models and Adversarial Attacks
Recently, a conference wanted a paper on how machine learning could be misused. Four researchers adapted a pharmaceutical AI normally used for drug discovery to design novel biochemical weapons. Of course, you do. In less than 6 hours, the model generated 40,000 molecules. The model designed VX and many other non-chemical warfare agents, along with many new molecules that looked equally plausible, some of which predict to be far more toxic than any publicly known chemical warfare agent. The researchers wrote that this was unexpected because the datasets we used for training the AI did not include these nerve agents, and they’d never really thought about it. They’d never really thought about the possible malignant uses of AI before doing this experiment. Honestly, that second thing worries me a lot more than the first, because they in that were probably typical of the legions of engineers working with machine learning elsewhere.
It turns out that our models are not that smart. In fact, they’re incredibly dumb, and incredibly dumb in unexpected ways, because machine learning models are incredibly easy to fool. Two stop signs, the left with real graffiti, something that most humans would not even look twice at, the right showing a stop sign with a physical perturbation, stickers. Somewhat more obvious, but it could be designed as real graffiti if you tried harder. This is what’s called an adversarial attack. Those four stickers make machine vision networks designed to control an autonomous car read that stop sign, still obviously a stop sign to you and me, and saying, speed limit, 40 miles an hour. Not only would the car not stop, it may even speed up. You can launch similar adversarial attacks against face and voice recognition machine learning networks. For instance, you can bypass Apple’s face ID liveness detection under some circumstances, using a pair of glasses with tape over the lenses.
Unsurprisingly, perhaps, generative AI models aren’t immune to adversarial attacks either. The Glaze project from the University of Chicago is a tool designed to protect artists against mimicry by models, like Midjourney and Stable Diffusion. The Glaze tool analyzes the artistic work and generates a modified version with barely visible changes. This cloaked image poisons the AI’s training dataset, stopping it mimicking the artist’s style. If a user then asks the model for an artwork of the style of that particular artist, it will get something unexpected, or at least something that doesn’t look like it was drawn by the artist themselves. Increasingly, the token limit of GPT-4 means it’s going to be amazingly useful for web scraping. I’ve been using it for this myself. The increased limit is large enough, you can set the full DOM of most pages as HTML. Then you’re going to be able to ask the model questions afterwards. Anyone that’s spent time building a parser or throwing up their hands and discussing just use regex, is going to welcome that. It also means that we’re going to see indirect prompt injection attacks against large language models. Websites can include a prompt which is read by Bing, for instance, and changes its behavior, allowing the model to access user information. You can also hide information, leave hidden messages aimed at the AI models in webpages to try and trick those large language model-based scrapers. Then mislead the users that have come, or will come to rely on them. I added this to my bio, soon after I saw this one.
Prompt Engineering
There are a lot of people arguing, in the future, it’s going to be critically important to know precisely and effectively how to instruct large language models to execute commands. That it will be a core skill that any developer or any of us need to know. Data scientists need to move over. Prompt engineer is going to be the next big, high-paying career in technology. Although, of course, as time goes on, models should become more accurate, more reliable, more able to extrapolate from pure prompts to what the user wanted to go. It’s hard to say prompt engineering is really going to be as important as we think it might be. Software engineering, after all, is about layers of abstraction. Today, we generally work a long way from the underlying assembly code. Who’s to say that in 10 years’ time, we won’t be working a long way away from the prompt? Command line versus integrated developing environments. My first computer used punch cards. I haven’t used one of those in a while.
We talked before about world models, about how large language models have at least started to appear to hold a model of the world to be able to reason about how things should happen out here in the physical world. That’s not what’s really happening. They aren’t physical models, they’re story models. The physics they deal with isn’t necessarily the physics of you and I in the real world, instead it’s story world and semiotic physics. They are tools of narrative and rhetoric, not necessarily logic. We can tell this from the lies they tell, the invented facts and their stubbornness for sticking with them. If prompt engineering does become an important skill in tomorrow’s world, it might not be us the developers and software engineers that turn out to be the ones that are good at it. It might be the poets and storytellers that fill the new niche, not computer scientists.
Betting the Farm on Large Language Models
Yet, both Microsoft and Google seem determined to bet the farm on these large language models. We’re about to move away from an era where search of a web returns a mostly deterministic list of links and other resources, to one where we get a summary paragraph written by a model. No more scouring the web for answers, just ask the computer to explain it. Suddenly, we’re living in the one with the whales. Cory Doctorow recently pointed out that Microsoft has nothing to lose, it’s spent billions of dollars on Bing, a search engine practically no one uses. It might as well try something stupid, something that might just work. Why is Google, a near monopolist, jumping off the same bridge as Microsoft? It might not matter in the long term. After all, even Google’s Bard search engine isn’t quite sure about its own future. When asked how long it would take before it was shut down, Bard initially claimed it had already happened, referencing a 6-hour old Hacker News comment as proof. While surprisingly up with current events, the question and answer does throw into light the concept of summaries of search results. I today asked Bard when it would be shut down, and it has now realized it’s still alive, so that’s good, which isn’t to say this isn’t coming. GPT-4 performs well on most standardized tests, including law, science, history, and mathematics. Ironically, it does particularly poorly on English tests, which perhaps shouldn’t be that surprising. We did after all build AI in our own image. Standardized test taking is a very specific skill that involves weakly generalizing from memorized facts and patterns, writing things in your own words, in other words. As surely we’ve seen, that’s exactly what large language models have been trained to do. It’s what they’re good at, a lossy interpretation of data, just like us. While it’s hard to say right now exactly how this is going to shake out, anyone who’s worked in education like me can tell you what this means. It means trouble is coming, which isn’t unprecedented.
Alongside the image generators and language models I’ve been talking about so far, are voice models. Online trolls have already used ElevenLabs text to speech models to make replica voices of people without their consent, using clips of their voices found online. Potentially, anyone with even a few minutes of voice publicly available, YouTubers, social media influencers, politicians, journalists, me, could be susceptible to such an attack. If you don’t think that’s much of a problem, remember, there are a number of banks in the U.S., here, and in Europe, that use voice ID as a secure way to log into your account over the phone or an app. It’s been proved possible to trick such systems with AI generated voices. Your voice is no longer a secure biometric. I’m not actually going to say the phrase everyone is thinking right now, because let’s not make it too easy for them.
Frankly, lawmakers are struggling, especially in the U.S., although just with big data and the GDPR, what we’ve seen here is that EU has taken global leadership role. They have proposals which could well pass into law this year around the use of AI technologies such as facial recognition, which will require makers of AI based products to conduct risk assessments around how their applications could affect health, and safety, and individual rights like freedom of expression. Companies that violate the law could be fined up to 6% of their global revenues, which could amount to billions of dollars for the world’s largest tech companies. Digging into the details of this proposed legislation, it feels very much like the legislators are fighting last year’s or even last decade’s war. The scope of the law doesn’t really take into account the current developments, which is unsurprising.
Are We Underestimating AI’s Capabilities?
While I’ve talked a lot so far about the limitations and problems we’ve seen with the current generation of large language models, like everyone else I’ve talked to, that’s actually sat down for any length of time and seriously looked at them, I do actually wonder whether we’re underestimating what they’re capable of, especially when it comes to software. At least for some use cases, I’ve had a lot of success working alongside ChatGPT to write software. To be clear, it’s not that capable, but for maintaining bread and butter, day-to-day tasks that take up a lot of our time as developers, it’s a surprisingly useful tool. Throw sampling your data to chat, copy and paste the code it generates into your IDE, throw in your dataset, and it will almost insert and certainly throw out an error of some sort. I don’t know about you, that’s what happens when I write code too. Then you could start working with ChatGPT to fix those errors. It will fix an error. You’ll fix an error. It’s pair programming with added AI. It’ll get there, usually.
What happens when you get the code working is perhaps more interesting. Once the code gets to a certain point, you can ask the model to improve performance of the code, and it will pretty much reliably do that. From my own experience, ChatGPT has been far more useful, at least to me, than GitHub’s Copilot. The ability to ask ChatGPT questions, and have it explain something has made it wildly more useful than Copilot, which is interesting. I found myself asking questions of the model that I’d normally have spent time Googling or poking around on Stack Overflow. It may not always have reliable answers, but then neither does Stack Overflow. This is also not surprising, because ChatGPT has been trained on all the corpus of data that includes all of our questions and all of our answers on Stack Overflow. Then you have to wonder, if we all start asking our language models for help instead of each other, where does the training data for the next generation of language models come from? It was the reason ChatGPT still thinks it’s 2021.
It seems likely to me that all computer users, not just developers, will soon have the ability to develop small software tools from scratch, using English as a programming language. Also, perhaps, far more interestingly, describe changes they’d like to make to existing software tooling that they’re already using. You have to remember that most code in most companies lives in Excel spreadsheets. This is not something anyone wants to know, but is the truth. Most data is consumed and processed in Excel by folks that aren’t us. Writing code is a huge bottleneck. Everyone here needs to remember that software started out as custom developed within companies for their own use. It only became a mass-produced commodity, a product in itself when demand grew past any available supply. If end users suddenly have the ability to make small but potentially significant changes to the software they use using a model, whether they have software source code, so their model can make changes to it, might matter to the average user, not just to us the developers, and that could rapidly become rather interesting. There are a lot of potential second order knock-on effects there.
Jeff Bezos is famous for requiring teams to create future press releases that you send out when the product is launched before starting work on a new product or entering a new market. Maybe in the future, the first thing you’ll check into your Git repo is something like a press release, because it will serve as the basis of the code that you write alongside your large language model. It’s not just code where language models are going to make a huge impact. It’s how we secure it. There are a lot of common mistakes we make as developers, low hanging fruit, and far too few people auditing code, or competent to audit code. Most of today’s code scanning tools produce huge amounts of not very relevant output that takes a long time to go through, or expert interpretation. Scanning code for security vulnerabilities is an area where large language models are inevitably going to change how we all work.
Mature Programming Environments
However, right now we’re suffering from what I call the platform problem. This is something that often happens when people or companies see an emerging technology, but don’t quite know what to do with it yet. The problem continues until the platforms are good enough or are widespread enough that people will automatically pick an existing platform, rather than going out and reinventing the wheel and writing another one. In other words, they start to build products, not platforms. Of course, this stage can go on for some time. A decade into the IoT, we’re only now starting to see IoT in the home, industrial use cases were much more common. IoT in the home is only really starting to arrive now. Almost a decade and a half after the arrival of blockchain, we still haven’t really seen any convincing products out of that community. Some technologies never generate products.
In the end, the arrival of generative AI tooling will be like the arrival of any other tooling. It’ll change the level of abstraction that most people work at, day-to-day. Modern technology is a series of Russian nesting dolls. To understand the overall layering and how to search through it, and fill the gaps and corners, to make disparate parts into a cohesive whole is a skill. Perhaps even amongst the most valuable skill a modern programmer has. Coding is honestly the easiest bit of what we do these days. The age of the hero programmer, that almost mythic figure who built systems by themselves from the ground up is mostly over. It has not yet come to a close, I know several. Far fewer people are doing fundamentally new things than they think they are. The day-to-day life faced by most programmers rarely involves writing large amounts of code. Opening an editor and an entirely new project is a memorable event now. Instead, most people spend time refactoring, tracking down bugs, sticking disparate systems together with glue code, building products, not platforms. The word for all this is mature programming environments. We’ve become programmer archaeologists, because even when we do write new code, the number of third-party libraries and framework the code sits on top of means that the amount of lines of code under the surface the programmer doesn’t necessarily understand, is far greater than the lines they wrote themselves. The arrival of generative AI really isn’t going to change what we do, just how we do it. That’s happened plenty of times in the past.
AI’s Emerging Complexity
A recent survey from Fishbowl of just under 12,000 users of their networking app found that just over 40% of respondents had used AI tooling, including ChatGPT, for work related tasks. Seventy percent of those people had not told their boss that. Talk to any kid still in university, and they’ll tell you everyone is using ChatGPT for everything. If any of you are advertising junior positions, especially internships, you have already received job applications written at least partially by ChatGPT. This disruption is already happening and is widespread. You are all running an AI company, you just don’t know it yet. Recent survey by OpenAI took an early look at how the labor market is being affected by ChatGPT, concludes that approximately 80% of the U.S. workforce can have at least 10% of their work tasks affected by the induction of large language models, while about 20% of workers may see at least 50% of their tasks impacted. That change is only now going to accelerate, as models get more levers in the world. OpenAI announced initial support for plugins. They’ve added eyes and ears and hands to their large language models. Plugins are tools designed for language models to help ChatGPT access up to date information, run computations, or use third-party services, everything from Expedia to Instacart, from Klarna to OpenTable. It’s no longer 2021 for ChatGPT, and the model can now reach out onto the internet and now interact with humans beyond the webpage.
You all need to draw a line in the sand right here right now, in your head. Stop thinking about large language models as chatbots. That’s demeaning. They’re not that anymore. They’re cognitive engines, story driven bundles of reasoning plumbed directly into the same APIs the apps on our phones use, that we use to make changes in the world around us. They’re talking to the same set of web services now that we are. Large language models like ChatGPT are big enough that they’re starting to display startling, even unpredictable behaviors. Emerging complexity has begun. Recent investigations reveal that large language models have started to show emergent abilities, tasks bigger models can complete that smaller models can’t. Many of which seemed to have little to do with analyzing text. They range from multiplication to decoding movies based on emoji content, or Netflix reviews. The analysis suggests that some tasks and some models, there’s a threshold of complexity beyond which the functionality of the model skyrockets. They also suggest a darkest flipside to that, as they increase the complexity, some models receive new biases and inaccuracies in their responses.
No matter what we collectively think of that idea, the cat is out of the bag. For instance, it turns out that people are already trying to use Facebook leaked model to improve their Tinder matches, and feeding back their successes and failures into the model. It’s entirely unclear if the participants are having any actual success, but it still demonstrates how Facebook’s LLaMA model is being used in the wild after the company lost control of it earlier in the month. Like stages of grief, there are stages of acceptance for generative AI, “This can do anything. Then, of course, my job. Maybe I should do a startup. Actually, some of these responses aren’t that good. This is just spicy autocomplete.” If it helps, it turns out the CEO behind the company that created ChatGPT is also scared. While he believes AI technologies will reshape society as we know it, he also believes they will come with real dangers. We’ve got to be careful here, he says. I think people should be happy that we’re a little bit scared of this. The areas that particularly worry him, large-scale disinformation. Now the models are getting better at code, offensive cyber-attacks. We all need to remember, they are not sentient. They are easily tricked. They are code. Even the advocates and proponents of hard AI would probably say much the same about humans: not sentient, easily tricked, just code running on web there.
Conclusion
In closing then, new technology has historically always brought new opportunities and new jobs. Jobs that 10 years before didn’t even exist. Remember, a new life awaits you in the off-world colonies as a killswitch engineer.
See more presentations with transcripts
MMS • Teresa Cain
Subscribe on:
Transcript
Shane Hastie: Hey, folks. Before we get into today’s podcast, I wanted to share that InfoQ’S International Software Development Conference, QCon, will be back in San Francisco from October 2 to 6. QCon will share real world technical talks from innovative senior software development practitioners on applying emerging patterns and practices to address current challenges. Learn more at qconsf.com. We hope to see you there.
Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today I’m sitting down with Teresa Cain. Teresa is the author of Solving Problems in 2 Hours, and she’s the director of product management, user experience and design at TreviPay. Teresa, welcome. Thanks for taking the time to talk to us today.
Teresa Cain: Thanks for having me on the show, Shane.
Shane Hastie: My normal question to start with is who’s Teresa?
Introductions [00:58]
Teresa Cain: I’m still learning that as I get older every day, Shane. But I’m Teresa Cain and I’ve been in the product and technology space for a little over 15 years across B2B and B2C SaaS solutions. And I’m very passionate about really helping organizations and teams find more efficient ways to solve small and complex problems, which is the premise of how the book came about.
Shane Hastie: I’ve heard it described as the two-hour design sprint. Many of our audience will recognize the design sprint as the five-day process. How do you compress that down to two hours and make it useful?
Reducing the design sprint from five days to two hours [01:34]
Teresa Cain: There’s a lot that went into reducing it down from five days. And while most have probably participated in a five-day design sprint for those that haven’t, there’s a lot that goes into those five days, 40 hours and really getting stakeholders together.
And the biggest catalyst for this reduction was actually the COVID pandemic. A lot of offices shut down. Having teams in Australia, the Netherlands, and in the United States, it was very challenging to be able to solve complex problems and be able to do that in five days when no one could travel.
And so, I ultimately created this concept that really took the best of both worlds from design thinking and design sprints and allows organizations to really use this model along with a collaborative template on Figma FigJam to be able to walk through the same problems in only two hours.
Shane Hastie: What does it feel like? I’m sitting here going, “Wow, that must be so intensive.”
Teresa Cain: It’s funny. I’ve worked with, at this point probably over 400 organizations on two hour design sprints outside of TreviPay. This is been going on for a couple of years now so I’ve had the opportunity to do this.
And some organizations that I’m coming in and talking to about the process, they’re a little skeptical of it. There’s no way this can be done in two hours. And so we’ll take a problem and I’ll run that problem with their organization. And there is a lot of surprise and dismay that we are coming to the end of that two hour designs sprint with the solution.
But it’s not without active participation. I recommend not having more than 15 to 20 stakeholders. That really is a key differentiator and making sure that you have a focus problem. You have no more than 15 up to 20 stakeholders. And everyone is there for that two hours, whether virtual or in person, and is there to solve the problem that you’re focused on as a stakeholder group.
Shane Hastie: Take me through the steps. First I suppose, what type of problems would people bring to this?
This works for a wide variety of problem types [03:32]
Teresa Cain: It’s actually been a variety. Most are familiar with this design sprint process solving product and technology problems. You’re taking a feature from your backlog, maybe you’re using Jira or another tool. And that’s really the focus of that design sprint. Or maybe you are looking to build out a dashboard or go from a responsive webpage to a native mobile app.
Those are a lot of problems that I’ve run design sprints for this process over the years. And what’s been really interesting with this two hour design sprint process that I’ve been running now for over three years, it’s actually morphed outside of product challenges and into any organizational challenge. And so, one of the unique challenges that I most recently ran in the last couple weeks actually was an organization that was wanting to create a multi-year vision for their organization.
Really it was a group of stakeholders that was mainly executive stakeholders, being able to come together in a room and talk about the problem being we’re not aligned on this three-year plan. Let’s get alignment. And at the end of it, what the two-hour design sprint does is it allows stakeholders to really get that vision of how to really align in the importance of the two-hour design sprint.
If you think of the regular design sprint process, it’s five days. You’re understanding,, diverging, deciding prototyping and the testing. With the two-hour design sprint process, you’re actually not doing the prototyping and testing. Really it’s in three stages. You’re empathizing with the customers, you are exploring the problem and you’re ideating solutions.
And with that, you are sketching and coming up with a solution, but you’re deciding as a group whether or not that is the right solution before you spend more time prototyping and testing. Which is really the biggest differentiator and the biggest buy-in of working with organizations as they like the time savings and the efficiencies out of that process.
Shane Hastie: If you did it twice on the same problem, would you get a different outcome?
Teresa Cain: Absolutely. And I’ve seen it happen. I’ve run a number of workshops and I will say yes and no. It depends on the stakeholder group. If you have the same problem in different stakeholder groups, absolutely, but even with the same stakeholder group, sometimes you get more ideas than what you’ve come up with before. And so, you’re not going to have the same outcome. And that’s regardless of whether you have a two-hour design sprint or a five-day design sprint. It really depends on the engagement level of the users.
But the best way to really prevent that from happening is to make sure you have a clear problem statement so that everyone in the room is understanding what you’re trying to solve. For instance, ChatGPT is a super popular topic right now. And so I ran several workshops and I’ll just say, “Hey, let’s take ChatGPT, which everyone’s familiar with, simple search box and talk about how we would go about improving the experience for ChatGPT.”
And I’ll run the same workshop across different groups and get three completely different recommendations of where we’ll go. But they’re all in the same family of a positive recommendation of how to improve the experience for ChatGPT, which some of the complaints that that’s gotten is the data is only compiled to 2021. No one knows where the data is being stored.
Those are some of the solutions that the group is able to come up with. And all the great ideas that could solve the problem, but the ideas are solving it in different ways that might not have been thought of from the other two-hour design sprints.
Shane Hastie: Walk us through. What happens in two hours? And I suppose what happens before? Because I’m assuming somebody has to get things ready for the two-hour sprint.
The need for preparation [07:03]
Teresa Cain: Yep, great question. I have a template out on Figma FigJam, which is a collaborative whiteboard tool called Two Hour Design Sprints. Pretty simple. It’s a free template out there if you go there. And ultimately, in addition to the book, I have this template out there paired with the book. And for those that use the Udemy course I have as well.
And really what I recommend is doing some pre-work. The pre-work is really going to allow you to understand who your problem is and who your target user persona is. Because oftentimes the key difference between a two hour and a five-day design sprint is you don’t really have time to go solve for multiple personas. You need to focus in on the problem and focus in on the persona that you’re trying to solve for.
In our conversation about ChatGPT, let’s just say you have a user as a student versus someone that’s working in the technology industry, your answer of problems is going to be different from plagiarism to copywriting on code depending on how it’s being used. You need to make sure that you solve it on that user persona. That’s the pre-work. And since it’s a two-hour process and I have a template that’s already available and ready, really they’re just filling out the template, making sure the agenda looks good.
And then next, when they go to conduct that design sprint, they want to have already sent out and communicated to all stakeholders you need to be focused for two hours, you’re in on this. And here’s the problem that we’re solving. Reach out with any questions beforehand type of mentality. So that everyone in the stakeholder group comes in there.
And once you start that two hour design sprint in the Figma FigJam template or there’s lots of other collaborative tools out there, InVision, Miro, MURAL, you could just recreate that template. Really you are getting the whole group together. Oftentimes why I am seeing organizations need these two hour design sprints is because they don’t have stakeholder buy-in. And the two-hour design sprints aren’t so much about coming up with a solution as a group, as getting agreement and buy-in to move forward with the solution.
Bringing a large group of stakeholders together to collaboratively solve a problem [09:01]
A lot of the organizations I’ve worked with, including the many design sprints that we’re running at TreviPay, are really meant to bring a large group of stakeholders together to move in the same direction on solving a problem. That’s what these next three steps and phases do during the two-hour design sprint and they’re time boxed.
You’re agreeing on the problem statement, you’re agreeing on who your target customer or persona is, and then you’re starting the exploration stage of, well, what exactly is the problem? How do we really reframe what’s going on? And then comes the solutioning stage, which that’s actually the most exciting stage, and that’s the stage where the entire design sprint starts to come together because everyone’s able to visualize how they’re thinking about solving the problem.
That could be a workflow, that could be a drawing, that could just be a simple whiteboard drawing as well, depending whether this is virtual or in person. And that exercise is almost like a two-hour team building exercise where you’ve gotten to hear what everyone’s saying, you understand it, and everything’s right in front of you on a virtual whiteboard. You’re absorbing the information at a rapid, efficient pace and not walking around a room during a five-day design sprint.
And the beautiful outcome is, regardless of whether you need a more high fidelity design of what your solution is, you have agreement as a group on 80% of the time that this is the right solution. When you don’t have agreement, then you go back and say, “We need to reframe the problem,” and you run another two hour design sprint.
Shane Hastie: looking at that template, I see a lot of Post-it notes and some space for free form I suppose at the end.
Using collaborative tools [10:38]
Teresa Cain: Yes, It’s almost replacing the physical Post-it notes, which I still use a lot at my desk. You have this concept of a virtual Post-it note that you’re now able to use that. And the efficiency that’s created is you’re not walking around the room putting Post-it notes up on a wall and reading everyone’s handwriting.
You have everything in front of you, you’re encouraging everyone to participate and talk about what’s going well, what’s not going well, and really working on reframing the problem and solutioning together. That’s part of the efficiency is making sure that users are using a template that will bring them forward to solving that solution.
Shane Hastie: How can it go wrong?
Teresa Cain: It can go wrong in a lot of ways.
Shane Hastie: Has it gone wrong?
Some potential pitfalls to avoid [11:19]
Teresa Cain: Yep. No, absolutely. And whether it’s a five day or two hour, I’ve had both gone wrong, but I’ll talk about the differences and when it goes wrong. When a five day design sprint goes wrong, actually one of the last five day design sprints I ran ended up needing to be three separate five day design sprints for the same problem. And what could go wrong there is that was a very expensive wrong, over $150,000 wrong.
When you have a go wrong situation in a two hour design sprint, you haven’t spent near that amount of the time because most likely you’re not using a third party to run this. You certainly can and there are third parties out there that will, but you’re spending a lot less money and you’re also spending a lot less time on the stakeholder group. That goes back to the efficiency of moving fast.
You’re also able to schedule these quicker and have things go wrong a lot faster. Oftentimes when you’re running these longer processes, you’re scheduling it out several weeks, several months ahead of time. But let’s talk about some failures a little deeper versus the comparison. One of the biggest ways for a two hour design sprint to go wrong is to have individuals, which I’ll always say is usually executives, come in with very strong opinions and guided solutions before the team is able to solution together.
And when that happens, it’s as simple as that executive trying to take over the moderator during the meeting. And again, that could be either a two hour or five day design sprint. And so, what’s really critical is making sure every stakeholder regardless of a CEO or executive understands that this is a collaborative process. I’ve seen this happen many times. And ultimately what needs to be done and how I recommend avoiding this type of situation is making sure you sit down separately with your executives and you talk to them about the process and how their valuable opinion is there, but you need to get the group opinion for the solve.
And sometimes I like to capture some of the ideas and pre-fill the template out so they feel heard beforehand and during the meeting as well. But those are some of the biggest things that could go wrong. You could also have a stakeholder group that’s not as engaged. Maybe they’re not engaged in how you’re leading it or they don’t agree of working on that problem. Or you could have those just not paying attention or not attending the whole time or even the wrong stakeholder group. Maybe you don’t have the right mix there.
That’s really the purpose of the pre-work of making sure that you have everyone there that you need to, but there’s going to be 20% of the time. And I would say 20% based on all the design sprints I’ve run over the years where design sprints aren’t going to work for your organization and you’re not going to come to a conclusion. And that could be whether it’s a two hour or a five day design sprint.
Shane Hastie: What makes a great facilitator for a design sprint?
The facilitator needs to have subject matter expertise [14:00]
Teresa Cain: One of the key differentiators of the two hour design sprint process is you don’t need a third party moderator to run it. My recommendation is that anyone that is the subject matter expert makes a great moderator because they’re able to bring the group to the conclusion and understanding the subject matter and the problem that you’re talking about and that you’re trying to solve as a group.
And so, as part of that, and part of why I have this template created is to really help guide and remind those that are moderating. And one of the things that I’ve learned, so I have the book, I have a Udemy course. Oftentimes, why I even created the Udemy course was to show how to guide a little more through that process because not everyone wants to moderate and they don’t know how to be a moderator.
That’s why I ended up creating additional tools in addition to the book, because what’s happened in the history of design sprints is a lot of organizations were having these run by third parties or specific groups like UX and design organizations. And now this has opened it up to be run by product managers, engineering leaders. I work with a lot of startups, so the entrepreneurs are running them as well.
With that, they’re learning how to go run and participate in a design sprint in addition to moderating it. Being engaging, I would say, and setting expectations are probably the two number one things that are important. Making sure you have your agenda set, you’re engaging the whole team and you’re explaining that. And what’s interesting is these two hour design sprints I’ve been running with TreviPay and other organizations, I said for over three years. And over the last year especially, I’ve started to work with organizations outside of product and technology.
And that’s what’s been really telling because those organizations have had no exposure to any design sprints whatsoever. This is a brand new process. And what they’ve come into it as is this is basically a two hour workshop, and I love that I’m able to get everyone together in two hours and come up with a solution. They’re not so much as focused on I’m using a design sprint or design thinking technology. They’re using the steps of the template to be able to guide the team in a decision from beginning to end. It’s been an interesting journey.
Shane Hastie: Without breaking confidentiality, of course, what’s your favorite experience from doing some of these?
Examples from Teresa’s experiences [16:18]
Teresa Cain: Yes, I probably can’t go into complete specifics, but what’s interesting is I have run the two-hour design sprints with startups that might not have a team of more than five. And then really large organizations, so like 10,000 plus. Obviously there’s several in between and over that as well. But what I think is super interesting is I had different expectations going into the startup versus the large organization solve.
And so, what I love the most is working with a startup that is able to come up with a solve. I’ll say one, there was a mobile app and ultimately there was a problem with location services, which everyone’s familiar with that. But the ability to basically type in a search box, your zip code versus having it automatically track you. And the users did not want to be automatically tracked. They wanted to just type in the address instead.
And so, one of the problems that had come up during this design sprint was how do we solve the problem of getting users to use the search box when they don’t want the location services? Ultimately, they just weren’t using this part of the app at all. They were just avoiding the tab altogether.
And this was a native iOS app. And so, that was a really interesting one because it was very particular. You have a certain subset of users. And ultimately where we landed during the end of that two hour design sprint was something as simple as what the user was doing that prompted them to go into the app. And it actually ended up in an integration with another app to be able to have it prompt them within it.
But that’s one of those focus problems where, when you come in as a group and you’re solving that particular problem, the team was able to go right with that problem and figure out the solution next. The final solution that we had come up with, they took it right into the backlog and started working on it. That was one of my favorite ones because it was just so simple.
I’ve had really complex ones also where you’re moving and migrating an entire website. And I will say those are a little too big for a two-hour design sprint. What I ended up doing there was breaking it into three, two hour design sprints. And that’s something I’ve been doing more frequently for larger problems is creating a stacked process where you’re solving it by persona instead of just trying to solve it all in one.
And that’s worked out really well. But that’s been another favorite one, figuring out the stages of a migration and whether or not users weren’t happy with the website. Their response times were low. And ultimately, one of the solutions there was users basically want the website to load and they want to find exactly what they’re looking for right when they get to the website. That was the emphasis on some of the screens that ended up coming out at the end of it. And then further having higher fidelity screens after.
Shane Hastie: And that you broke up into multiple sessions for this.
Teresa Cain: Yes. And so, for that one in particular, there was different user roles for the website. There was a super admin user role, an executive user role, and then like a company type user role. And so, every single persona had a different expectation, but every single customer, our user was not happy with the load times of the website. And so, there ended up being a unified solve across everything of we’ve got to get these page load times up to make everyone happy, and that should really be the number one thing that’s worked on next.
And then, the focus is having that user experience. And so, when you’re deciding on whether to go build a brand new website with less functionality or slowly migrate features of a website in iframe, it becomes a very large decision and you have to piece it out by your highest priority users, which in this case was the super admin users. The decision for that one was to move forward with building the new website with the super admin and then slowly migrate the rest of the user rolls over for it.
Shane Hastie: Great examples. If people wanted to continue the conversation, where do they find the book? Where do they find you?
Teresa Cain: The book is on Amazon search for 2 hour design sprints. I also have a website called 2hourdesignsprints.com, as well as a Udemy course called 2 Hour Design Sprints as well. You can also find me on LinkedIn. I’m always happy to answer questions. I have people reach out every week asking me their thoughts on how to refine problem statements for their design sprint. I’m always happy to answer questions.
Shane Hastie: Teresa, thank you so much.
Teresa Cain: Thanks for having me, Shane.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS

Nosql Market
During the forecasted period, web apps and social gaming advancements will help to drive market growth.
PORTLAND, PORTLAND, OR, UNITED STATE, September 8, 2023/EINPresswire.com/ — Allied Market Research published a new report, titled, ” The NoSQL Market Expected to Reach USD 22,087 Billion by 2026 | Top Players such as – AWS, DataStax & Couchbase.” The report offers an extensive analysis of key growth strategies, drivers, opportunities, key segment, Porter’s Five Forces analysis, and competitive landscape. This study is a helpful source of information for market players, investors, VPs, stakeholders, and new entrants to gain thorough understanding of the industry and determine steps to be taken to gain competitive advantage.
The NoSQL market size was valued at USD 2,410.5 million in 2018, and is projected to reach USD 22,087 million by 2026, growing at a CAGR of 31.4% from 2019 to 2026.
Request Sample Report (Get Full Insights in PDF – 266 Pages) at: https://www.alliedmarketresearch.com/request-sample/640
Increase in unstructured data, demand for data analytics, and surge in application development activities across the globe propel the growth of the global NoSQL market. North America accounted for the highest market share in 2018, and will maintain its leadership status during the forecast period. Demand for online gaming and content consumption from OTT platforms increased significantly. So, the demand for NoSQL increased for handling huge amount of data.
The NoSQL market is segmented on the basis of type, application, industry vertical, and region. By type, it is categorized into key-value store, document database, column-based store, and graph database. On the basis of application, it is divided into data storage, mobile apps, data analytics, web apps, and others. Further the data storage segment is sub-segmented into distributed data depository, cache memory, and metadata store. Depending on industry vertical, it is categorized into retail, gaming, IT, and others. By region, the NoSQL market is analyzed across North America, Europe, Asia-Pacific, and LAMEA.
If you have any questions, Please feel free to contact our analyst at: https://www.alliedmarketresearch.com/connect-to-analyst/640
Based on vertical, the IT sector contributed to the highest market share in 2018, accounting for more than two-fifths of the total market share, and is estimated to maintain its highest contribution during the forecast period. However, the gaming segment is expected to grow at the highest CAGR of 34.8% from 2019 to 2026.
Based on type, the key value store segment accounted for more than two-fifths of the total market share in 2018, and is estimated to maintain its lead position by 2026. Contrarily, the graph based segment is expected to grow at the fastest CAGR of 34.2% during the forecast period.
Enquiry Before Buying: https://www.alliedmarketresearch.com/purchase-enquiry/640
Based on region, North America accounted for the highest market share in 2018, contributing to more than two-fifths of the global NoSQL market share, and will maintain its leadership status during the forecast period. On the other hand, Asia-Pacific is expected to witness the highest CAGR of 35.5% from 2019 to 2026.
Leading players of the global NoSQL market analyzed in the research include Aerospike, Inc., DataStax, Inc., Amazon Web Services, Inc., Couchbase, Inc., Microsoft Corporation, MarkLogic Corporation, Google LLC, Neo Technology, Inc., MongoDB, Inc., and Objectivity, Inc.
Buy Now & Get Exclusive Discount on this Report (266 Pages PDF with Insights, Charts, Tables, and Figures) at: https://www.alliedmarketresearch.com/NoSQL-market/purchase-options
Covid-19 Scenario:
● With lockdown imposed by governments of many countries, demand for online gaming, content consumption from OTT platforms, and activity on social media increased significantly. So, the demand for NoSQL increased for handling huge amount of data.
● With organizations adopting “work from home” strategy to ensure continuity of business processes, NoSQL databases would be needed to store and retrieve data.
Thanks for reading this article, you can also get an individual chapter-wise section or region-wise report versions like North America, Europe, or Asia.
If you have any special requirements, please let us know and we will offer you the report as per your requirements.
Lastly, this report provides market intelligence most comprehensively. The report structure has been kept such that it offers maximum business value. It provides critical insights into the market dynamics and will enable strategic decision-making for the existing market players as well as those willing to enter the market.
About Us:
Allied Market Research (AMR) is a market research and business-consulting firm of Allied Analytics LLP, based in Portland, Oregon. AMR offers market research reports, business solutions, consulting services, and insights on markets across 11 industry verticals. Adopting extensive research methodologies, AMR is instrumental in helping its clients to make strategic business decisions and achieve sustainable growth in their market domains. We are equipped with skilled analysts and experts and have a wide experience of working with many Fortune 500 companies and small & medium enterprises.
Pawan Kumar, the CEO of Allied Market Research, is leading the organization toward providing high-quality data and insights. We are in professional corporate relations with various companies. This helps us dig out market data that helps us generate accurate research data tables and confirm utmost accuracy in our market forecasting. Every data company in the domain is concerned. Our secondary data procurement methodology includes deep presented in the reports published by us is extracted through primary interviews with top officials from leading online and offline research and discussion with knowledgeable professionals and analysts in the industry.
David Correa
Allied Analytics LLP
+1 800-792-5285
email us here
Visit us on social media:
Facebook
Twitter
LinkedIn
![]()