Transcript
Blanco: I’m Dan. I’m a Principal Engineer at Skyscanner. I want to talk about OpenTelemetry, and how it can help you deliver effective observability, and also help you do it efficiently within your organization. I want to start by discussing one of the key questions that observability helps to answer. That is, when our systems change, which could be because we deployed a new version of a component, or because our users are using it in a completely different way, how do we know what changed? Because our systems are a bit like black boxes, we send a request in, and we get a response out, but we have little information on what goes on inside the system to be able to serve that response. This is why we produce telemetry in the form of metrics, of traces, and logs, that gives us more information about what goes on inside a system in production.
It’s really easy to see how a change that we make to a script that we are debugging locally has the desired effect or not. We’ve all done this. We’ve all added print statements here and there, and in a very primitive way. That is some form of observability, because it does tell us something about the script execution. When we change it, we expect to see hopefully something different being printed. I think we would all agree that this doesn’t really scale. These print statements are not really going to get us very far, because our systems are not simple scripts that we debug locally. Our systems are complex distributed systems, with hundreds of services deployed and thousands of interconnections between them. What you see here is a representation of the service mesh at Skyscanner, and the service dependencies between them. When we deploy a change to one of these services, how do we know that change didn’t affect anything else apart from our service? How do we know it didn’t affect its dependencies upstream, or downstream dependencies. Most importantly, when something fails, how do we get to the root cause of that regression fast, because we can’t keep thinking about our services as if they were running in isolation when they run in a complex distributed system. For that we need observability. I would like to tell you how OpenTelemetry and open standards can help you achieve effective observability within your systems to be able to debug those regressions faster.
Background & Outline
I joined Skyscanner in 2018, originally to work on performance and resource optimization. Since 2020, I’ve been leading a really exciting project to rely on open standards and OpenTelemetry for telemetry instrumentation, and to improve the observability of our systems to allow us to detect and debug incidents faster in production. For the last 12 years, I’ve spent my time working as a platform engineer in organizations from as small as 5 employees and bigger than 2500 employees, always working to reduce the cognitive loads and the toil that it takes for teams to operate their service in production. In the last few months, I’ve written a book called “Practical OpenTelemetry” that discusses some of the topics that we’ll be talking about. We will cover why observability is important without the incident response lifecycle. We’ll cover how open standards can help to deliver that effective observability. How to roll out OpenTelemetry efficiently within your organization. Also, how to make sure that telemetry signals remain valuable and are used within your organization as they should be.
Why Observability Matters
We’ve seen that observability helps answer that question of what changed. That’s important in many occasions, but especially when something goes wrong, when we apply a change and it didn’t go according to plan. What you see here are some of the key metrics during the incident response lifecycle. Hopefully, we are familiar with some of them, like mean time to detect or mean time to recovery. What I tried to add here as well is mean time to resolution as a metric that includes the time that it takes for us to be able to deploy a change, and to make sure that that change fixes the original regression. Observability helps in two different ways here. The first one is to answer the question, is my system behaving as expected? That involves, one, the time that it takes to detect an incident, and then hopefully fire an automated alert. Then, to reduce the time that it takes to verify that effects that were deployed to production has the desired effect, and to do that with evidence.
In the last decade, the way that we instrument services has changed, and is now easier than ever with open source tooling. It’s easier than ever to produce metrics and to integrate those metrics into dashboards and alerts, to really measure what’s important to our users, what’s important to our customers, and be able to react to regressions of those key performance indicators as fast as possible. This is really important, because that is when we deploy services hundreds of times a day, we need to be able to detect that fast so we can roll back the changes even faster. This is a healthy metric of an organization. If you’re able to deploy faster and recover faster, is a metric of high velocity teams within organizations. Observability also helps answer a different question, which is, when an alert is fired, why is my system not behaving as expected? It helps us to reduce what we call the mean time to know from when the alert is fired to when the root cause is found. Even though things have changed dramatically in the other areas of observability, nothing has changed that much in how we debug our systems in production. We still treat our services as if they were running alone, rather than within a complex distributed system.
Let me give you an example. Let’s put like service owner hat on. We have a service here that is instrumented with some custom metrics. We’re measuring the number of 500 responses that are returned by that service to our users. This service has a dependency on a different service to obtain some data and then render it. In this case, when the number of 500 responses go over a certain threshold, an alert fires. The usual traditional incident response will basically tell our engineer on-call to go and follow a particular runbook. That runbook tells that engineer to go and look at a particular dashboard, to try to identify metrics that could be correlated to that increase in 500 responses. This relies on past experience. It relies on known failure modes of the application. For example, it may be memory saturation so the service will start to apply backpressure. Our engineer will try to manually correlate those, or try to see if something moves in the same direction. They may also need to go to our logging backend and ask for some particular error codes or error cases. These are normally things that we’ve seen before and we can search for them.
Then, in these two cases, they both rely on past experience. How do we know that they’re not other metrics that could correlate to this particular regression, and they’re not in our dashboards? Or how do we know that the error messages that we’re looking for are the ones that are being emitted by the application or by a particular service replica, that is returning those 500 response codes. These error messages could also be background noise, could also be always there and not really be related to the root of regression. Even if they are, let’s say, in this case, we find that the service where we would get data from has no data to render. Then, what do we do? Do we call another service owner? That’s normally what happens, incident calls where we call a separate service owner, and then they start investigating using their own runbooks and using their own dashboards. Then they may find the same conclusion that the root cause is not in their service. This adds time to the incident response and to that time to know metric.
Let’s look at the same example, but relying on context rather than experience. In this case, we can have a service that’s instrumented with OpenTelemetry, and has the same metric of number of 503 responses, for example, but is using open standards, is using naming conventions like the name of the metric, or the attributes of that particular metric. An observability platform that supports these semantic conventions can assign semantics to that, but it knows that that’s one of the golden signals. Then it can then correlate that to memory utilization metrics, for example, and automatically tell us what instance is the one that is having problems. A service instrumented with OpenTelemetry could also link to individual distributed traces, using what’s called exemplars, which are individual examples from within a service replica that link to the transactions that were going through that system, when, for example, a high number of 500s was being recorded.
In a distributed trace, we can see that high granularity data, and we can see that, not only from my service, but as well from the dependency. We can see in one go that the error seems to be within the dependency. Then OpenTelemetry can also help to correlate those using trace IDs that are, in Java, for example, part of the ThreadLocal storage. That can be correlated using things like MDC, to your legacy application logs, that perhaps were not instrumented with OpenTelemetry but can still be correlated to that particular trace. We know that that transaction that went through the system, we get to see the logs not only from our service, but also from other services within that same transaction. In one go, we can see that the root of the regression was in our dependency, and that will allow us to investigate it further. Here, we’re relying on context and correlation, not on experience, to debug a particular system. This is something that I occasionally do at Skyscanner. I may use one of our observability platforms, and then try to find these correlations and try to find the root cause for regressions. Not often, but sometimes I have found that I get to the same investigation as service owners without having a clue of how the system operates. Sometimes I even may bring some information to the table that service owners may not have, because they were not using the same correlation or some of the OpenTelemetry signals.
Effective observability requires a few things. It requires that high granularity of the detailed telemetry from within operations that are happening in individual transactions through a distributed system. We need context that ties that all together, all the signals and all the services as part of a holistic view. That needs a couple of things. It needs that signal correlation, so we can get metrics, traces, and logs as part of the same context. We need service correlation, so we can identify these dependencies between services and see how changes in one set of service may affect another. For this to work, we need open standards. We cannot refer to, for example, the trace ID, or we cannot refer to a service ID or a service name in a particular way depend on each organization because it’s not efficient from the point of view of integrating with open source tooling with observability vendors. We need those open standards to be able to provide telemetry out of the box, and for vendors to support these semantics.
How Open Standards Help Observability
We’ve seen why observability matters and how does OpenTelemetry help. OpenTelemetry’s mission statement is to enable that effective observability that we’ve seen by making high quality portable telemetry, ubiquitous. It does that in a way that it puts the responsibility of instrumenting a service or instrumenting a particular library in the hands of the person that knows the most about it, which could be the library author or the service owner, without being tied to any implementation details. Let me explain that in a bit more detail. I’ll go down to the API design of OpenTelemetry now for a bit, and then we’ll go back to some of the more high-level concepts. This is what an application instrumented with OpenTelemetry looks like. We’ve got clear distinction between what are called cross-cutting packages and self-contained packages. The OpenTelemetry API, for example, provides public interfaces, and just a minimal implementation for the different telemetry signals. We’ve got metrics. We’ve got tracing. We’ve got baggage. We’ve got logging. For each of these signals, it provides pretty much a normally and No-Op implementation of them. It also provides context that allows these signals to all be part of the same context that ties them together.
Application owners or whoever instruments a particular library or a service, they can rely on these APIs without being tied to an implementation. This allows them to take long-term dependencies. OpenTelemetry provides very strong stability guarantees and APIs that are always going to be backward compatible, so service owners can rely on them. Then, when they configure the OpenTelemetry SDK, they can decide how they want their metrics, or the logging, or the tracing to be collected, and to be exported from within a particular application. These OpenTelemetry SDKs for all the signals can also be extended by using plugins. These plugins allow us to integrate with different open source tooling, for example, or other observability platforms to be able to, for example, export data in a particular format. All that can be configured in only one place. For example, if you want to change the telemetry backend from Prometheus to a different one, we can do that without affecting how our applications are instrumented, without having to change any application code, only where we configure the OpenTelemetry SDK.
These contrib packages that are open source packages also provide what are called instrumentation packages. These provide that out-of-the-box telemetry, out of hundreds of different open source libraries and different languages. For us, it’s quite important, because this is one of the areas where we want to remove the responsibility from service owners, to having to instrument their services. Relying on these instrumentation packages means that we can reduce, one, the toil that it takes to instrument services, and also to maintain it, because as libraries evolve, the instrumentation has to evolve with them. Relying on these packages allows us to offload that to telemetry experts that instrumented those libraries. Last but not least, is the semantic conventions that you see there. Semantic conventions allow us to decorate telemetry with properties and attributes that follow some common naming. I think we’ve all been there in trying to say how do we define, for example, the AWS region or the cloud region for a particular metric. Before we started to use OpenTelemetry at Skyscanner, we had multiple ways of doing this, could be cloud.region, could be aws.region. It could even be data center before we migrated to the cloud. Now with OpenTelemetry, we’ve got one way of doing that, and it comes as a package that we can use across our applications. The good news about this is that it’s also supported by open source tooling and observability vendors to provide out-of-the-box correlation and out-of-the-box analysis from within these signals.
That’s what influenced as well our buy versus build decision at Skyscanner. When we think about a vendor, and the value that vendor provided before OpenTelemetry, most of them relied on their own instrumentation agents, and their own APIs and protocols. This is something that we were not very keen on at Skyscanner, to basically lock ourselves to a particular vendor at that layer, at the instrumentation and export and transport layer, because it meant that we couldn’t move between open source solutions. It also meant that we were in a way limited by whatever that vendor integrated with, from the point of view of open source libraries that they worked with. With OpenTelemetry, things changed dramatically, because now we can use open source for our instrumentation. We can use open standards and open standard protocols for the export and transport of telemetry data. Then we can rely on vendors for the parts where they actually deliver value, which is, storage and querying that analysis and correlation between telemetry signals using the same semantic conventions. Then, of course, the dashboards and alerts that were on top of that.
Rolling Out OpenTelemetry
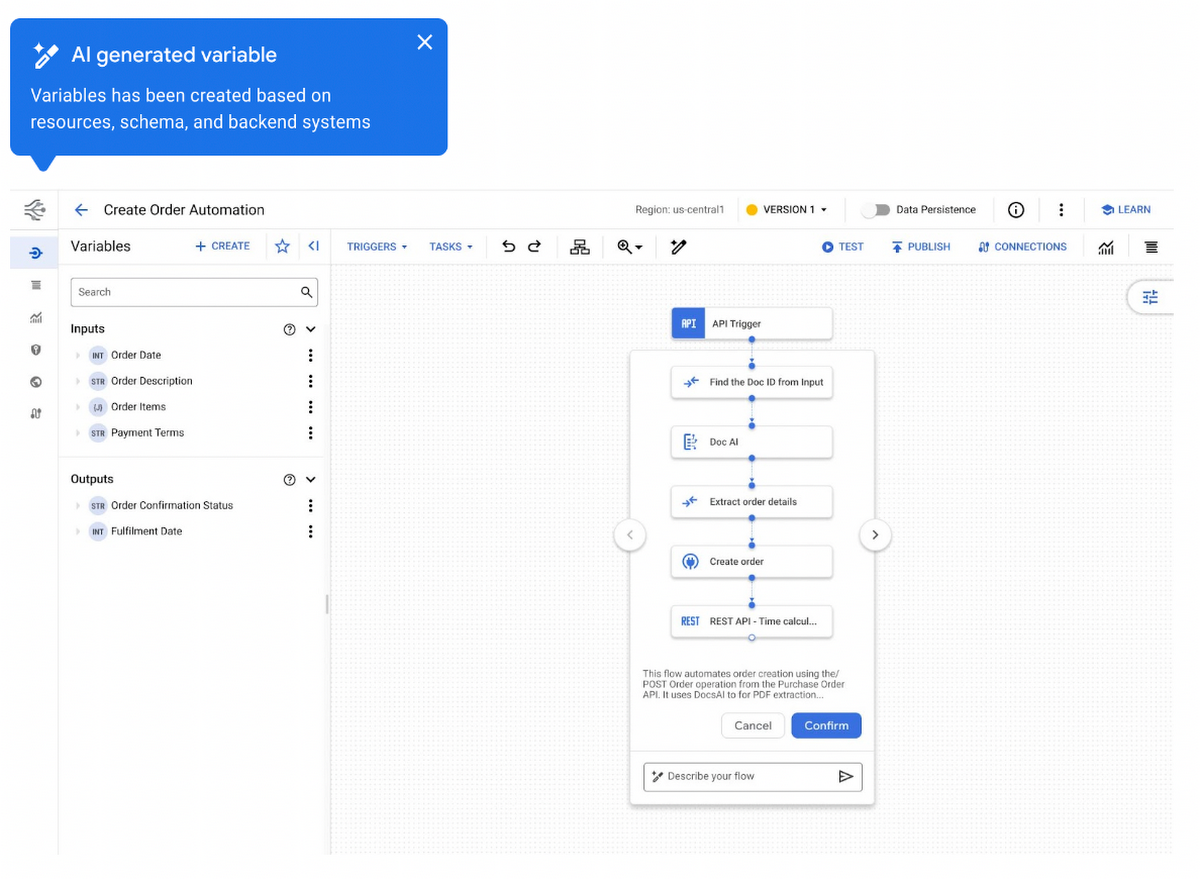
Now that we’ve seen how OpenTelemetry and open standards can help, let’s go through how you can roll OpenTelemetry efficiently within your organization. This is one of the guiding principles for platform engineering at Skyscanner. This is to make the golden path, the path of least resistance. When we’re thinking about rolling out an observability strategy, there are certain things that we need to decide. For example, what format are we going to be collecting metrics, or exporting metrics? What is the aggregation level? What are the aggregation intervals? Things like that, that are basically some standards that we would like to be adopted across the company. One way of doing that would be to basically have those in a list, and then basically requiring service owners to implement it themselves. Another way, which is the one that we take, is to give service owners an easy way of applying these best practices. The way that we do that is using internal libraries that every single service at Skyscanner uses. These libraries, they configure multiple things, not just telemetry. They do security, networking, plenty of other things. Within these libraries, we can configure how we want the OpenTelemetry SDK that we saw before to collect and to export telemetry data. This basically allows us to execute our observability strategy with minimal friction for service owners.
Let me take you on a journey of simplification at Skyscanner. What this slide shows is the complexity of the telemetry pipelines and the telemetry tooling at Skyscanner before we started to rely on open standards, and before we started to rely on OpenTelemetry. It was a very complex system. The worst part of it is that it was not a very usable one. We had one vendor for synthetics, one vendor for browser edge, for RAM, metrics. We had another vendor for tracing. Then, a bunch of open source tooling internally and telemetry backends. Each one of them would basically be isolated. Service owners would just have to go to one place for logs and another place or two other places for metrics, and it just didn’t really provide definitely that effective observability that we needed. The semantic conventions were completely domain specific, completely custom made to Skyscanner. When we started our journey, sometimes we had to integrate with vendor provided software, in a way that our services never depended on the particular service and software, but we were still trying to aim for those open standards and semantic conventions. When we started to use OpenTelemetry, we started to simplify our backend using other open standards to also integrate with these vendors.
This is where we are at the moment, where our applications depend on the OpenTelemetry API, our backend applications depend on the OpenTelemetry API. We use OpenTelemetry Collector in agent mode, to be able to extract information from our infrastructure, and from our Kubernetes clusters. Then we feed that information through OpenTelemetry Collectors as a gateway to integrate with our third-party vendor. This is not the end state for us. We believe that the future will rely more on OpenTelemetry, and it will be even more simple from the point of view of instrumentation. We see that any browser-side, mobile-side, or backend will depend on the OpenTelemetry API in different ways. We’ll start to rely on OpenTelemetry Collectors for anything that is related to collecting information from infrastructure. Then, all fed through an OpenTelemetry Collector gateway that allows us to control how we integrate with a vendor, and is the last hop of telemetry. This is important as well, because feeding all that through collectors allows us to control that last hop of telemetry, and made better use of resources or networking, and also be able to control things like authentication, or if we want to transform telemetry in a particular way, we can do it. Even when we integrate with cloud provider endpoints, we want to rely on OpenTelemetry protocols and open standards to be able to integrate with all the vendors. You can see the simplification that one can achieve by using OpenTelemetry in the instrumentation and export layer, and the transport and processing while relying on vendors for the storage, querying, and the UI, and alerts.
Another area where we capitalized on the use of open standards was our migration from OpenTracing to OpenTelemetry. As you probably know, OpenTelemetry is a merger between OpenTracing and OpenCensus, two projects that were popular before OpenTelemetry, and then that are deprecated. At Skyscanner, we were big users of OpenTracing across all of our stack. OpenTracing had a similar API design to OpenTelemetry. As I said, there is an OpenTracing API with no implementation, and then when the application starts up, we configure the implementation from that API. With OpenTelemetry, as there is compatibility with those previous projects, we can use what’s called the OpenTelemetry or the OpenTracing shim from OpenTelemetry that basically acts as an implementation for OpenTracing. Then, that relays calls to the OpenTelemetry API. What that meant for us was that we could start to roll out OpenTelemetry under the hood while applications that rely on OpenTracing could still rely on OpenTracing. Any instrumented middleware or an instrumented HTTP or gRPC client could still use OpenTracing, while service owners were gradually being moved to rely natively on OpenTelemetry, which is our current state. That meant that we could start to produce data with OpenTelemetry protocols, and could start to propagate trace contexts with OpenTelemetry format.
What did that mean? We roll out changes at Skyscanner as part of our internal libraries. It does pay off when you work in platform engineering. What you see here is our adoption of OpenTelemetry within Skyscanner, and how many services were sending telemetry to those OpenTelemetry Collectors. We went from an early adoption phase with 10 to 15 services, and then when we released our libraries publicly within Skyscanner, we saw that jump from those 15 services to over 130 services in a matter of 4 or 5 days. That is one hell of a curve of tech adoption. We’re quite happy about that. Now we’ve got hundreds of services being instrumented natively with OpenTelemetry. We send all that data through collectors, and they are incredibly powerful. We receive data in multiple formats, OTLP being the major one, but we also do some Zipkin, and Prometheus. OpenTelemetry Collectors can receive that data, and then work with it in some way using processors. They can remove unwanted attributes. They can rename attributes. They can change span status, if we need them. We can even generate metrics from spans. That allowed us to upgrade Istio without relying on Mixer, but just getting the spans from Envoy in Zipkin format and generating the metrics from it. We explored that data in OTLP, and as well, Prometheus for internal usage. They are incredibly efficient as well. We generate more than 1.8 million spans per second, that’s across 90,000 traces per second. They do all this with less than 125 cores being used across all of our clusters, and with less than 100 replicas in total. Incredibly useful tooling here.
Adopting Observability in Practice
Now that we’ve seen how we can roll out OpenTelemetry, I’d like to take you through some steps that you can take to basically make sure that you can keep telemetry valuable within your organization. Because the reality is that most data that we gather for debugging purposes is never used. Before OpenTelemetry, when basically we were using metrics and logs, most of the time, we found that basically the logs that have been stored, they normally correspond to requests that are successful in a way. They return in an acceptable response time, or an expected response time, and they don’t contain any errors. We still had to keep those logs. Same with metrics, we found that metrics that were being generated with some really high granularity attributes, because service owners were not using tracing to debug, they were using metrics to debug regressions. We’ve seen how OpenTelemetry can help you use the right tool for the right job. When you’ve got metrics that are low cardinality, and low volume, but they can link to traces, and those distributed traces can be sampled in a much better way that you could sample logging.
Let’s consider this case, for example, we’ve got on the left a distributed trace that goes through multiple services. If you were to sample logs, you can only sample logs by looking at an individual log record. You can decide to maybe store 10% of the debug logs and maybe 100% of the errors. Then, those debug logs can be crucial to identify regression. Then, what ends up happening is that people store all the debug logs, and then become quite costly from the point of view of storage and transport. With distributed tracing, we have better ways of being able to keep the useful data and then discard the rest. On the example on the left, we’re using what’s called probability sampling. This means that we decide if we want to keep a span or not, we want to sample a span or not, depending on its properties, or the propagated trace context that comes with it. For example, here, service A starts a trace, and decides to sample the whole trace depending on the trace ID. It decides to sample the span, and then it propagates that decision downstream. We’ve got the child span, for example, here that says if my parent span was sampled, then I respect that decision and I’ll sample it myself. When we propagate that to another service that may be using a different type of sampling, that service can basically say, if this trace has already been sampled, then I will store all the spans for this particular trace. This allows us to have one complete view of distributed transactions without having to keep every single one of them. This is simple to configure because it doesn’t require any external components. It does have one downside, that is that we’re looking at a percentage of the traces being sampled, and we can’t really identify which ones are the good ones or the bad ones.
With tail-based sampling, on the other hand, we can have a look at the whole trace. It is more powerful but it also requires external components. It requires all the spans for one particular trace to be fed through the same replica so it can be kept in memory. The way it works is, when you receive the first span for a trace, you start storing all the spans for that particular trace in memory. Then you wait for some time. That can be configured in multiple ways. Then, at some point, you need to make a decision if you want to keep this trace, or not. You can look at the whole trace, and you can see, is this trace slower than normal, so then we’ll keep it? Or, does this trace contain any errors in any of the individual operations, then we’ll keep it? Then allows for a more insightful way of keeping data, of sampling data, but it does require an external component. Normally, that could be an OpenTelemetry Collector, where you can send all the data. There are different ways where you can route traces to particular collectors. Or, you can use a vendor. There are multiple vendors out there that provide this capability to do tail-based sampling. This, at Skyscanner, allows us to store about only 4.5% of all our traces. What we do here is we’re storing the ones that matter, the ones that are slower than usual, or the ones that contain errors. Then we store a random percentage of the rest. You can see how we’re just keeping the valuable data and reducing costs in these ways.
When service owners come to instrument their services, they can sometimes add a lot of cost and a lot of the load to telemetry systems. As platform engineers, we’ve got two main ways to deal with this. One is the way of limiting. We can have controls on how service owners are allowed to add telemetry to their systems. For example, to add an instrumentation package, or to add a new custom metric, they create a request, and then, basically, another team goes and puts that into another list. Then you end up being able to do that. It generally doesn’t work. It slows down team velocity because they’ll be blocked on another team to allow them to produce telemetry. It generates toil for telemetry admins as well to add that exception to a rule. Then, it generally falls out of date soon. There could be a metric that you instrumented last year, that was crucial for your service, but now the service evolved and is no longer valuable but still there incurring costs. What works better is to put data in front of people, and to visualize that cost or that load in the telemetry backends and systems, and encouraging a good use of telemetry signals.
Here, OpenTelemetry can also help, because it allows us to segment data using semantic conventions. We’ve seen how every single event, or log, or metric, span, it has to be annotated with the service name, for example, and optionally, the service namespace, which is a way to group multiple services together. Then we can split that data, and look at, for example, storage cost, or storage volume, or cardinality for each of the services. Then we can assign cost to teams. When teams start to review this, when they review the telemetry cost, close to other costs, like, for example, cloud provider costs, they start to be proactive about this. We’ve seen that internally. We’ve seen teams that they start to look at telemetry in a way that, are we actually using the right signal to instrument our services? In some cases, we’ve seen teams that just by moving away from debug level logging, and into tracing, they have saved more than 90% of their telemetry costs. We’re rewarding that learning to use the right signal, the right tool for the right job. We’re also making sure that the telemetry that we’re using is the best that we can. That also enables product health.
Another area where we can learn from our failures, is during the incident post-mortem, and discussing those learnings. This is one of my favorite quotes from Einstein, that is, failure is success in progress. We should all be familiar here with the learnings that one can get from post-mortems, of sharing those across the organization and sometimes outside your organization. We’re normally focused on learning from it from the point of view of improving the resiliency of the systems, improving the reliability, but not always from the point of view of improving the observability of our systems, especially when we think about the system as a whole. We can foster that learning and improvement culture by following some steps. The first one is to establish those targets for time-to-detection, and time-to-resolve. It’s quite important because when those are not met, we can start to find areas of improvement, that could be looking at new telemetry that we could add, new instrumentation packages. We could make sure that service owners are using the right tool to debug their services, maybe their dashboards, or maybe their runbooks did not even mention looking at distributed traces, for example.
It’s good to encourage certain observability champions within your organization to join these post-mortems, and to provide that feedback. To say, actually, did you know that maybe you didn’t know but you’ve got tracing enabled by default? We’ve seen this happening where service owners did not know that they were not making or they knew that there was tracing, but they didn’t know how to use it. Having these observability champions helps to bring that to attention. Also, having a guild or a chapter, or some form of group of people across a company, across an organization where you can, not just gather external feedback, but also share learnings, share these post-mortems, share news about observability, new features, and so on. The last thing, and I think is quite valuable, and something that is sometimes overlooked, is how telemetry and how observability can just help teams understand their systems outside of the incident lifecycle. When you get two teams in one room that are part of the same system, and that their traces will be going through some of their services, what we’ve seen is that that allows them to identify usage patterns they may not know that were there. For example, a particular dependency or a particular endpoint that’s being used that they didn’t know it was being used. Being able to have those sessions where teams can evaluate that telemetry together and can improve, one, the telemetry that they produce and also the system in some way, is quite important.
Key Takeaways
The first takeaway is that complex systems require effective observability. We can no longer just pretend that we can debug our systems looking at individual services and looking at telemetry signals, as isolated events. We’ve seen as well how open standards and OpenTelemetry can empower organizations to simplify their infrastructure, to simplify their telemetry tooling, while integrating with vendors and with other open source platforms as well. Also, how OpenTelemetry enables signals to be used efficiently. When we use the right signal, or the right tool for the right job, we’re not just improving observability but we may also be reducing cost and reducing the operational toil and the cognitive load to operate our services.
See more presentations with transcripts