Month: September 2023

MMS • RSS

NoSQL (Not Only SQL) is a database mechanism developed for storage, analysis, and access of large volume of unstructured data. NoSQL allows schema-less data storage, which is not possible with relational database storage. The benefits of using NoSQL database include high scalability, simpler designs, and higher availability with more precise control. The ability to comfortably manage big data is another significant reason for the adoption of NoSQL databases. The NoSQL technology is emerging in the database market horizon and is expected to grow rapidly over the next few years.
However, it helps to overcome limitations observed in conventional RDBMS technologies.
The rise in social media such as games, blogs, and portals such as Facebook, LinkedIn, and matrimonial sites, has led to surge in semi-structured and unstructured data. NoSQL is the only feasible technology to store and manage this data. The impact of this factor would further increase in future, due to rise in structured and/or unstructured data from applications such as social media, retail transactions, and web applications. Moreover, as NoSQL is the most suitable technology for agile app development, with rise in the app development economy, NoSQL adoption is set for an increase in the coming years, which in turn is expected to garner high market growth.
Download Free Sample of This Strategic Report:https://reportocean.com/industry-verticals/sample-request?report_id=AMR855
However, the software testing of NoSQL database designs is complicated as compared to RDBMS, which is a restraining factor of the market. Furthermore, increase in investments in big data and business analytics tools among large number of organizations that drive revenue growth and improve service efficiencies is an opportunistic factor of the market. The NoSQL market is segmented on the basis of type, application, industry vertical, and region. By type, it is categorized into key-value store, document database, column-based store, and graph database. On the basis of application, it is divided into data storage, mobile apps, data analytics, web apps, and others. Further, the data storage segment is sub-segmented into distributed data depository, cache memory, and metadata store. Depending on industry vertical, it is categorized into retail, gaming, IT, and others. By region, the market is analyzed across North America, Europe, Asia-Pacific, and LAMEA.
The passage highlights the trend of governmental organizations increasing their maintenance budgets for system infrastructure while also investing in initiatives for project development, modernization, and enhancement. This has led to the success of investments and an increase in the annual funding set aside by ICT vendors for the growth of the online market. The passage also mentions the anticipated increase in global ICT exports, which are expected to rise by an average of 3.9% yearly from US$ 784.3 billion in 2021 to US$ 955.19 billion in 2030. The global supply of ICT has increased by 9.5% yearly since 2009.
In terms of global ICT exports in 2021, Ireland ranked first with US$ 169.32 billion, followed by the United States at number 2, India at number 3, and China at number 4. The passage also notes the significant increase in Brunei’s global ICT exports by 228.2% year over year since 2009, while Sierra Leone’s global ICT exports have decreased by 61.7% year over year in the same period. Overall, the passage highlights the growth and potential of the global ICT market, driven by increased investments and funding for infrastructure and project development.
Download Free Sample of This Strategic Report:https://reportocean.com/industry-verticals/sample-request?report_id=AMR855
It seems that the ICT industry in Europe is predicted to experience moderate growth in the coming years, with an annual increase of 1.5% expected from 2021 to 2026. Germany currently holds the top position in terms of ICT revenue in Europe, followed by the United Kingdom, France, and Ireland. It’s interesting to note that while some countries like Malta have experienced significant growth in the ICT industry since 2016, others like Italy have seen a slight decline. This information can be useful for businesses and investors looking to enter or expand in the European ICT market.
KEY BENEFITS FOR STAKEHOLDERS
– The study provides an in-depth analysis of the current & future trends of the market to elucidate the imminent investment pockets.
– Information about key drivers, restraints, and opportunities and their impact analysis on the global NoSQL market size is provided.
– Porter’s five forces analysis illustrates the potency of the buyers and suppliers operating in the NoSQL industry.
– The quantitative analysis of the market from 2018 to 2026 is provided to determine the global NoSQL market potential.
KEY MARKET PLAYERS
– Aerospike, Inc.
– Amazon Web Services, Inc.
– DataStax, Inc.
– Microsoft Corporation
– Couchbase, Inc.
– Google LLC
– MarkLogic Corporation
– MongoDB, Inc.
– Neo Technology, Inc.
– Objectivity, Inc.
KEY MARKET SEGMENTS
By Type
– Key-Value Store
– Document Database
– Column-based Store
– Graph Database
By Application
– Data Storage
o Distributed Data Depository
o Cache Memory
o Metadata Store
– Mobile Apps
– Data Analytics
– Web Apps
– Others (E-commerce and Social Networks)
Request To Download Sample of This Strategic Report:–https://reportocean.com/industry-verticals/sample-request?report_id=AMR855
By Industry vertical
– Retail
– Gaming
– IT
– Others
ByRegion
– North America
o U.S.
o Canada
– Europe
o Germany
o France
o UK
o Rest of Europe
– Asia-Pacific
o Japan
o China
o India
o Rest of Asia-Pacific
– LAMEA
o Latin America
o Middle East
o Africa
Table of Content:
- Report Overview
- Global Growth Trends
- Competition Landscape by Key Players
- Data Segments
- North America Market Analysis
- Europe Market Analysis
- Asia-Pacific Market Analysis
- Latin America Market Analysis
- Middle East & Africa Market Analysis
- Key Players Profiles Market Analysis
- Analysts Viewpoints/Conclusions
- Appendix
Reasons to Buy This Report:
- This file will help the peruses with appreciation the opposition interior the ventures and structures for the serious local weather to improve the feasible benefit. The document moreover facilities round the cutthroat scene of the market, and provides exhaustively the piece of the pie, industry positioning, contender organic system, market execution, new object advancement, recreation circumstance, development, and securing.
- And so forth of the fundamental players, which assists the peruses with distinguishing the indispensable contenders and profoundly know the opposition instance of the market.
- This record will help companions with greedy the global enterprise popularity and patterns of Telemedicine Administration Frameworks and offers them statistics on key market drivers, restrictions, difficulties, and open doors.
- This document will aid companions with grasp contenders higher and collect experiences to reinforce their scenario in their organizations. The serious scene region contains the piece of the pie and rank (in extent and worth), contender environment, new object improvement, development, and obtaining.
- This document stays refreshed with novel innovation mix, highlights, and the latest developments on the lookout.
- This file assists companions with grasp the Coronavirus and Russia-Ukraine War Impact on the Telemedicine Administration Frameworks industry.
- This record assists companions with obtaining bits of know-how into what locales to internationally target.
- This file assists companions with obtaining experiences into the end-client perception regarding the reception of Telemedicine Administration Frameworks.
- This document assists companions with distinguishing a component of the central members on the lookout and hold close their essential commitment.
Request full Report :- https://reportocean.com/industry-verticals/sample-request?report_id=AMR855
About Report Ocean:
We are the best market research reports provider in the industry. Report Ocean is the world’s leading research company, known for its informative research reports. We are committed to providing our clients with both quantitative and qualitative research results. As a part of our global network and comprehensive industry coverage, we offer in-depth knowledge, allowing informed and strategic business conclusions to report. We utilize the most recent technology and analysis tools along with our own unique research models and years of expertise, which assist us to create necessary details and facts that exceed expectations.
Get in Touch with Us:
Report Ocean:
Email: sales@reportocean.com
Address: 500 N Michigan Ave, Suite 600, Chicago, Illinois 60611 – UNITED STATES
Tel:+1 888 212 3539 (US – TOLL FREE)
Website: https://reportocean.com
Podcast: Roi Ravhon on FinOps, Application Unit Economics, and Cloud Cost Optimization
MMS • Roi Ravhon

Subscribe on:
Welcome to the InfoQ podcast
Daniel Bryant: Hey everyone. Before we get into today’s podcast, I want to share that InfoQ’s International Software Development Conference, QCon, will be back in San Francisco in the US from October 2nd to 6th. QCon will share real world technical talks from senior software development practitioners. You will learn about their successes, their failures, and you’ll also see how to apply emerging patterns and practices to address some of your challenges too. Learn more at QConsf.com. I’ll be there running the platform engineering track, and I hope to see you there.
Hello and welcome to the InfoQ podcast. I’m your Host, Daniel Bryant. And today I’m joined by Roi Ravhon, Co-founder and CEO of Finout, where we discuss the topic of FinOps. I’ve increasingly been bumping into this concept from content created by the FinOps Foundation, from sessions at the recent QCon Amsterdam and QCon New York events. And it was also mentioned by InfoQ Editor, Steef-Jan Wiggers, in our recent cloud and DevOps trend report.
I’ve read several excellent articles by Roi, and so I wanted to reach out and learn more. In this podcast, we cover a range of topics starting from what FinOps is. We then move on to how to adopt FinOps, both from a technical in the trenches and also a leadership perspective. And then we explore signs of successes. This includes the ability to understand your applications and systems unit economics, which ultimately helps with creating architecture guide rails, scaling systems, and ultimately generating more revenue for your company.
So welcome to the InfoQ podcast, Roi. Could you introduce yourself to the listeners please?
Roi Ravhon: Of course. My name is Roi, I’m a Co-founder and CEO of Finout. I live in Israel. Started my career, like many Israeli entrepreneurs, in Israeli intelligence units. Then spent a lot of time in the high-tech industry and now leading Finout, which is a cloud cost management company.
What is your definition of FinOps? And how does this movement impact the industry? [01:37]
Daniel Bryant: Fantastic. So we’re hearing more and more about FinOps. It’s popped up in several of our trend reports. For listeners that haven’t heard about this, can you share your definition, your view of what FinOps is, what it means and what the impact would be?
Roi Ravhon: Yes. So FinOps is a new name to something we always knew and knew how to do from the beginning of the cloud. But a couple of people, named J.R. Storment and Mike Fuller that works in Atlassian, worked on codifying FinOps concept and methodology. And eventually, there’s a whole book and a whole foundation behind FinOps.
But if I have to sum it up into one sentence, is to get engineers to be more aware of their spending, and eventually getting every single person in the organization all around how much money does it cost to run the application in the cloud. So it’s not only about saving money, it’s about education, it’s about making more money out of each dollar that we’re spending and allow us to grow healthy and make sure we get the bang for our bucks that we pay.
What do you think is the main challenge that drives the adoption of FinOps?
How does FinOps relate to DevOps? [02:39]
Daniel Bryant: Fantastic, Roi. A bunch of things that I’d love to dive into as we talk. I think the first thing I often hear to folks is how does it relate to DevOps? And I think it’s purely because it sounds the same, FinOps, DevOps? What’s your thoughts there, and how the two things play against each other?
Roi Ravhon: So if you look back at DevOps 10 years ago and we would try to get engineers to be responsible for their coding production, people will look at us like we’re mad, right?
Daniel Bryant: Yes.
Roi Ravhon: I’m coding and throwing it in the operation teams and I hope that everything will be okay and I’m not going to be the one waking up at night if it’s not. And then DevOps came in and DevOps, it’s a movement that evolved into a role, that essentially allowing engineers to have all the tools that they need in order to be responsible for the code in production and make sure we’re getting it.
I think FinOps is drastically different, but still lies the same set of basic concepts. So if I would talk to you three years ago when I would tell you that the engineers are going to be responsible for their costs of their service in production and you’re going to get the alert when they’re starting to lose their cost model and the unit economics are breaking, no one would believe.
But now we start to see this more and more of a reality, of FinOps noticing treatment as DevOps in many organizations from something, one initiative of someone that tries to pull it off into dashboard of cloud cost and engineers actually caring about the cost of their service, the same as they care about SLA now and TVs that are showing tables and gamification of what’s the most costly service or whatever.
It really starts to become a fundamental shift within the organization relationship with cloud financial management and suddenly not something that only finance caress about and starts to nag constantly about, like what’s happening, into something, it’s a cultural change that we see lots of organization going through, which is very similar to what DevOps did.
What do you think is the main challenge that drives the adoption of FinOps? [04:26]
Daniel Bryant: I love it. The culture. We have like CALMS, the acronyms in DevOps and the “C” in CALMS is very much related to culture. So I love it. You mentioned a bunch of things there. What do you think is the main challenge that drives the adoption of FinOps?
Roi Ravhon: We see different organization behaving very differently when it comes to FinOps adoption. So it can be an enterprise that is now migrating to the cloud and continue with their digital transformation roadmap. And something that press often discover is that they’re not really adapting to the cloud, rather building on-prem infrastructure on AWS. And once doing that, they start to figure out that things are a lot more expensive than they hope than benchmark because they’re not properly using cloud technologies as they should have. So it’s like the first step or step and then they need to have to adapt and someone higher up gets all annoyed. They’re like, “What’s going on here? We need to start taking cloud costs seriously and someone needs to have to be responsible for it,” but it can also be coming from the bottom. So engineers that were exposed to FinOps and they have that initiative of like, “Hey guys, I think we’re spending too much money on the cloud. We can be more efficient.”
Looking at the company, looking at the P and L coming from finance, cloud costs for lots of the software companies is the biggest expense that they have in the cost of sale. The second-biggest expense of the company after salaries. And for years we were thinking of cloud cost as just a tax, something we have to do, something we need to spend. And once the organization starts to change the conversation from spend into investments, it starts to get a lot clearer that we need to measure the ROI. So we’re investing money in cloud and we need to measure how much money we get back out of that. So it can be someone from the executive team and it can be as slow as an engineer that got exposed to it and really caress about what’s happening. So we see FinOps starting with all shapes and sizes, but it’s really fascinating to see that evolvement.
Why has the adoption of FinOps increased recently? [06:18]
Daniel Bryant: That is fascinating. I hadn’t thought about the bottom up or top down, but we saw the same thing in DevOps, as you said, in terms of, sometimes it was a C-level transformation project. Sometimes it was very much like, to your point, developers getting sick of throwing stuff over and getting it thrown back. They wanted to take more charge of it. Fantastic. I’d love to explore why FinOps is getting more popular now. You hinted DevOps, what been 10, 15 years around? FinOps, I’ve heard the last few years, I bumped into, actually Simon Wardley, I think was the first person that put it on my radar.
I always look at what Simon’s doing because he’s totally ahead of the curve and he was talking about FinOps or the concepts, at least, pretty much when DevOps was becoming a thing. I know some of the early work he did with the Zimki platform and other things, he was always thinking about the cost model as you’ve talked about there. But why do you think the zeitgeist has captured the FinOps movement now? Is it the end of the free money? Is it the end of the zero interest rates, the VC dollars drying out or is it some other thing that I’m not seeing?
Roi Ravhon: Yes, I think it’s a combination. That to be honest, we see FinOps in 2022, 2023 jumping off the roof. Just look at the Google trends graph of how much people are looking at FinOps to see what’s happening to the FinOps foundation, it’s members and community that is evolving. It’s amazing. I think that most of the Fortune 50 is now part of the FinOps Foundations member. So it’s starting from a niche thing that when you raise the serious seed for FinOps like two and a half years ago, we went through this season, we tried to convince them that FinOps is actually a concept that people care about it. We went through LinkedIn and search for everyone that has the FinOps title in its name. And in the last couple of years we see FinOps have become a profession. It’s became really a huge thing.
We just came back from the FinOps X, which is the yearly conference by the FinOps Foundation, like 1,200 people traveled all the way to San Diego to participate and exchange thoughts and starts to get into a huge community that really fundamentally changes the way that we approach that. So I think it’s a combination of both, more awareness. So people are aware that cloud is expensive and they want to treat it with the desirable respect and also downturn. And as you mentioned, the error of free money is over. And once we did everything we can in order to… We went through layoffs as an industry and a cutbacks for whenever possible, and this is the immediate term kind of thing, but if we’re selling a product that is low margin, there’s very little we can do without improving that margin and firing more salespeople is not going to help.
It’s going to do the exact opposite thing. So we then need to start to react to reality. So we need to understand the actual underlying infrastructure, how much money do we spend on everything? How do we measure lifetime value of our accounts? And it’s just not the money they’re paying, it’s how much money it costs us to hold them. And I think that more and more companies got the realization that cloud cost is just something that we have to handle and I don’t see it going away anytime soon.
What would be a typical trigger for an organization to adopt FinOps? [09:03]
Daniel Bryant: Fantastic. As we head more into some of the solutions now, what would be a typical case study or a typical trigger for organization adopting FinOps?
Roi Ravhon: Something that I saw in multiple organizations when talking to finance, they’ll continue to run a complicated analysis on P and L and FP and A processes; and at some point they tend to discover that cloud cost is growing unproportionally to the revenue. You can hide it as much as you want, but eventually economy of scale is not just kicking in without you doing anything about it. If you continue to spend, you continue to not care about anything you’re doing, you can’t hope to wake up one day and figure out if unit economics are okay.
We saw this as a trigger from an organization that they really understood that something is not working and cloud cost became a board level discussion with many of the companies and it’s not something we can continue to ignore. It’s something that we have to start to face reality. And Flexera ran an amazing server in 2023 and the cloud cost was the biggest problem for both enterprise and SMB. So it’s no longer security or no longer fear of the unknown. This is the number one priority for many enterprises and high SMBs out there and just something that need to be solved.
Do organizations simply want to buy FinOps solutions? [10:20]
Daniel Bryant: Fantastic. How do organizations typically go about solving these problems? And I’m thinking back to my DevOps days where people wanted to buy DevOps in a box. They still do. Sell me some DevOps. Do they want to buy FinOps solutions and how does that actually relate to, you mentioned, culture already, what should they be doing as well?
Roi Ravhon: Yes, so 100%. We constantly get on calls with customers and just want to buy FinOps and we’re like, “Great, but why do you want to do? Why do you want to achieve?” “Oh, no, I want my engineers to care about cost.” “Great. Buying a tool is not going to help you with that. Let’s start to work on the culture and let’s talk again in a couple of months.” But there’s a bunch of magic solutions we can do on cloud spend. So you can buy a tool that’s going to optimize your commitments. You can buy a tool that can help you right size and identify waste. You can buy a tool that rate visibility in the organization. So there’s a bunch of different things we can do or buy a FinOps in a box, but eventually it’s not something we can do without proper organizational alignment. So people need to care about cloud costs.
And going back to the FinOps Foundation and FinOps X, I think lots of the tracks that were about how do we get engineers to take action? How can we encourage that culture within the companies? It’s one of the biggest tasks that the companies have to go through. We can give the best tools, the best dash boarding, the best reporting, anomalies, alert, whatever. But if there’s not going to be anyone that’s going to care about, if engineers are not going to be responsible for what they’re doing and they’ll look at FinOps as another bug that they need to get off their shoulder when it’s constantly asking them about the stuff that they did, it’s just not going to work because eventually engineers, in the modern shift, left era, engineers have the power.
If someone from finance is going to ask engineer, “Why did you buy those new three-letter service from AWS and whatever?” So they can continue to use any technical mumbo jumbo, they can throw in scary words into the conversation and finance can’t really deal with it unless we start to measure a metric that we both agree on. Like 5% increase at AWS can be good regardless of a revenue growth. And if we don’t have a standardized way of agreeing on that, and if we don’t have that built in collaboration, engineers really takes finance questions into consideration and finance believes engineers with what they’re doing, it’s going to be extremely hard to do anything just by buying a tool.
Much as we saw with DevOps becoming a role, is this the same with FinOps? Are there job adverts for FinOps engineers? [12:27]
Daniel Bryant: Totally makes sense. Something I heard you say there is, it’s always that collaboration and we have seen rightly or wrongly the role of the DevOps engineer pop up. And we also say it’s not really a role, it’s more of a philosophy, set of practices, but it is what it is. Are you seeing FinOps roles popping up? Is there an equivalent FinOps engineer, can I legit look on LinkedIn for that role these days?
Roi Ravhon: 100%. So really the same as DevOps. So it’s a philosophy that have evolved into a role. Same as DevOps, you’re going to guess 10 different FinOps engineer, what your day-to-day life? You’re probably going to get 15 answers, but it’s running the same set of tracks. And FinOps is evolving, as I mentioned before, in lots of enterprises. It started as a cloud center of excellence, have evolved into FinOps. Also important to note that FinOps is not the only philosophy on how to run cloud costs, the same as DevOps and SRE. So there’s AWS has their own, Azure has their own things. There’s a bunch of a smaller, less popular books that were written on the subject. So some cloud financial engineers, some will call it, there’s a bunch of different wording here, but FinOps is started to get adopted as the most common trend, yet not the only one.
Are there common metrics related to FinOps? [13:32]
Daniel Bryant: Interesting. And having a smile there when you mentioned about 15 different engineers, 15 different roles, because I totally relate to that. When DevOps was a thing, everyone did very different things, but we did also align around, say, what became the DORA metrics or the Accelerate metrics that was often your North stars, so lead time to delivery, MTTR, et cetera. Are there common metrics emerging around this FinOps concept as well?
Roi Ravhon: Some are easier to track than others. As an example, usually lots of FinOps engineers are going to look at their coverage, like a percentage. So how much of my infrastructure is running on demand versus how much is committed? This is a golden number that each organization could tweak on its own, but it’s a metric that FinOps can be measured on. Issue with cloud cost is that it’s supposed to be relative to the business. So unlike MTTR, which we can define just one number and we should expect to reach it regardless of how much money do we sell. And in cloud cost it’s not the right kind of metric because if we’ll spending a million dollars on AWS, it’s good, 2 million is good, half a million is good, it depends on what. So where we see the North star in lots of FinOps practices, and this is the dream that many FinOps teams are striving for is what’s called unit economics or unit cost.
And it’s something very changeable, but for the sake of this conversation. So for example, we don’t want to see how much money we spend on AWS, we want to measure how much money we spend per event, click, transaction, gig, user, something that is tangible and going back to engineers and finance relationship. So 5% increase in AWS, again, is meaningless, but if we know that we spend 5% more to AWS, but our unit cost remains the same, so it’s okay, it’s perfectly viable. And looking at long-term budgeting, it’s also a huge concept here that can really fundamentally change the way that companies approaching that. Because again, if we budgeted the $2 million a year for AWS, but in the middle of the year we signed a huge customer to just doubled our revenue and something we’d never planned and budgeted for.
We need to buy more infrastructure in order to handle that. So we are going to get off budget. So who is accountable for this budget? So should we, as engineering, sacrifice stuff from our playground and innovation budget in order to deal with this customer? So things starts to get weird here and what we see the most advanced companies are doing is budgeting on gross margins and budgeting on unit economics better than the actual numbers.
So engineers do whatever you want as long as we keep 80% margin, whatever you need. So build, change cloud, change technologies, do whatever you want. It’s okay to pay more money for the cloud cost because you need to support more infrastructure. This is on you, but you’re targeted on margin. If you’re going to hit that margin, you’re going to fire a bunch of people, you’re going to lose headcount. There’s something that we actually see, lots of organizations starts to condition cloud efficiency with headcount. You can either spend money on cloud or spend money on headcount, but you can’t do both. So you want to hire more people, great, get more efficient.
What is the key indicator that folks have successfully adopted FinOps? [16:20]
Daniel Bryant: So what’s the key indicator that folks have successfully adopted FinOps? Is it the development of understanding of the unit economics?
Roi Ravhon: I don’t think there’s a singular point in time where people can say, “All right, we did FinOps.” So FinOps is always evolving because cloud is always evolving. There’s always new stuff to do and always new technologies. And unlike data centers, cloud environments are extremely volatile and constantly changing. And AWS is releasing new pricing or a new service or a new tool and suddenly we bought that Datadog and we bought Snowflake and Mailchimp, and Twilio and Akamai and Stripe. There’s so many more solutions that get into this problem as well. And we continue with our digital transformation, continue to moving CapEx to OpEx, like organization changed constantly. When you can say that you’re doing DevOps, you succeeded with DevOps. It’s not the real tangible point in time. Rather like an ongoing philosophy and journey that the organization is going through.
What is the typical journey of an organization adopting FinOps? [17:10]
Daniel Bryant: Fantastic. And I know you and I chatted the other day about a lot of things around, say, chargebacks and unit economics and along the journey. What would be a typical journey? Because I think people, they can probably see the unit economics argument, but it might take them a while to get there. What’s some wins along the way on the journey that people typically see when adopting FinOps?
Roi Ravhon: You mentioned that a second ago. Showback and chargebacks are one of the biggest challenges for enterprise running on a multi-cloud, multiservice environment. So companies are usually reliant on AWS tags in order to run proper showback and chargeback. And unfortunately this model is very easily breaking. So it’s enough that we run an organizational change. So one group is moving from one business unit to another and now we have new researchers that are not tagged and tagged on the future looking and even if we build the entire thing now we adopted Kubernetes. So Kubernetes is another level of obstruction on the cloud cost and we don’t have anything. And we went through a movie cloud, movie service. So showback is one of the most fundamental concept we see with lots of organizations. It’s one of the first items that our organization wants to reach. We want to allow each engineering director to be the budget owner for your spend.
As a centralized IT team, we want to charge back our internal customers with their data about consumption. As a finance organization, we want to map our cost centers, understand profitability, even what’s Cox and what’s not Cox, what was a part of the infrastructure that was responsible for actually relying on supporting the product. It’s a fairly difficult question running on a multi-cloud, multiservice, especially with Kubernetes environment. So we usually see those sets of challenges as one of the first, but afterwards continue to get really, really dependent on the organization. So some will go all the way in automating changes and optimizations, a lot will struggle with getting engineers to take action. So for example, we found an idle database, great. Can we turn it off? Who’s the one responsible for even giving us the thumbs up? And defining those organizational alignments is very hard. The bigger the organization is and the more mature they are with their consumption, meaning that they’re running for so many years without anyone attributing stuff.
And budgeting and forecasting is also a huge theme and issue. When running and working with AWS, we usually closing some sort of enterprise agreement discounts agreements with them. So we need to understand what’s our consumptions going to look like for the next three years. We can barely estimate how we’re going to end the month and now we need to think three years in advance. So what’s the forecast? What’s the best pricing we can get, on which services we want to fight hard with the CSP to get a discount and which services we don’t really care about. So there’s a bunch of stuff here that are getting into that concept and it’s getting multiple different stakeholders in the organization. So from finance to engineering to FinOps to procurement to DevOps to RevOps or, so many people working on that and really depends on the maturity of each on what’s going to be the next challenge that the FinOps team is going to tackle.
Who is accountable for the work related to supporting FinOps? Platform teams? Developers? [20:05]
Daniel Bryant: Fantastic. Great overview there. Touched every aspect of the business, which is fantastic. If we dial it back for our listeners now, probably the architects, the senior technical folks, and we have listeners that are developers, listeners that are platform folks, who typically does the work in the org, Roi, because you mentioned there some of the stuff, more cost of goods is more dynamic spend? Developers making choices about what they’re doing. But some of the stuff is just platform, right? You have to have it running because that’s a steady stage, fixed cost, effectively. How does that dynamic typically work with developers and platform engineers? Who does the work, who is accountable, I guess, for some of that?
Roi Ravhon: Going back again to the culture and collaboration. So if a FinOps engineer is going to work on allocating their entire organizational spend, probably not something that can actually work. And we need the support of the engineers, they know the system best. We need support of the architect, they know what’s responsible for everything. And it’s not always as trivial as we hope it to be as well. So maybe it’s an entire Kubernetes namespace or an instance that can be allocated fully to a team or a customer.
But what’s happened on shared databases, what’s happened on shared storage? So when we start to get into those more complications, it starts to get harder and harder and we just need to get someone in organization that really understand what’s happening in order to create that collaboration. It’s usually a multi-tier, multi-level approach. So we start with something small, we start with just one department and then we continue with our location ranges. So we see the more advanced companies on the 90 plus range, getting to 100 is extremely difficult and based on the maturity level we start to increase and increase and increase our allocated range of the cloud spend.
Can you share a case study of FinOps adoption? [21:38]
Daniel Bryant: I’d love to dive into some tools, and I appreciate you can’t buy FinOps in a box, but we’d love to cover your opinion on some of the tools. But before we do, is there any case study that jumps to mind of, say a typical, and I appreciate that’s quite hard in itself, but a typical company adopting FinOps, maybe you can even talk about a case study, an actual named case study. I’d love to understand and help the listeners understand what a journey looks like for an enterprise, a big-ish company.
Roi Ravhon: When I think specific names or technology… I can talk about in general stuff that we see with some of the companies that we’re working with. So usually for the bigger companies they always have more than one cloud. So they have a primary cloud, they have a secondary cloud, lots of the time third and fourth and fifth clouds even. We see lots of companies running down the track and now they’re using a one data warehouse, they’re using one observability system, they’re using one CDN. And even the question of how much money are we spending on our cloud? That cloud environments is a huge thing and the first thing that they’re trying to solve. So how much we spend on storage, how much we spend on compute, how much we spend on cross-cloud Kubernetes. So all of these are fundamental questions to the business that are very hard to answer without us helping companies to achieve that level of visibility.
Then the cost of location challenge is usually the second one that companies are trying to tackle. So oftentimes the centralized IT department is the one that buying those FinOps tools because they’re the one that are spending their budget on cloud spending and technology and because they can’t use appropriate showback and chargebacks in order to relieve that budget from the quota and assign it to the actual themes. It’s a organizational political thing, but it’s still a major challenge. And eventually what you start to see is that lots of finance departments has endless questions on what’s happening. And how much you pay for this team, how much you pay for this customer, what’s a margin, what’s our cost, what’s our whatever. And lots of our case studies are focused on giving finance the proper organizational picture and allowing to give those numbers without having to spend a week, a month creating complicated Excel sheets that just never ends.
And obviously almost every company that you work with also wants to lower down their cloud spend. It’s a trivial thing to do and to want and we see great success with companies that never paid any attention to cloud spend getting all the way to 45 up to 50, even a percentage of cloud savings. It really depends on their maturity and the average save that we have with companies, even the mature ones are over 30%. So there’s always stuff to find, there’s always changes that need to be made and with progressing through the maturity model off of the FinOps foundation, you’re getting better and better and better with what you’re doing and while doing that you can save a lot of money and then the challenge comes to keep it down and keep your unit economics effective, but it’s something that needs done. It’s constant monitor, but this is a common FinOps adoption story that we see in the market a lot.
Can you recommend some categories of tools that would help with the adoption of FinOps? [24:26]
Daniel Bryant: Thanks, that’s super useful. And I don’t know if you want to name any names or folks that’s more on the categories, but I’d love to know what tooling exists. And I was looking around and you and I’ve chatted a little bit before, there seems obviously like the visibility aspect, observability, there’s the data analysis and there’s how do we handle cost projection and capacity planning, all that good stuff. Have I roughly got those categories right? Do you think there’s interesting tools that are worth mentioning in that space? I’d lean a little bit more towards the open source if that’s possible as well, but I’d love to get your thoughts on what tooling is the really defacto tooling in those spaces.
Roi Ravhon: So we start to see the line blur from one tooling to another. It’s common thing to do in a hard space, but we can differentiate the tools roughly into three groups. One is visibility, so solutions like FinOut like CloudHealth, like a Cloudability, like a CloudZero. So there’s also the tools that helps with showing and allocating cost to the organization. Then there’s the optimization side of things. So there’s a bunch of different techniques on how to help to optimize cloud spend. So you can see solutions like Prosper Ops or Zesty that helps with commitments. CloudFix that help with remediation of changes, granulated Intel budget plays around with the IO scheduler of the instance in order to achieve high level of efficiency towards a bunch of those. And then there’s the point solution. So solution that just solve one thing and does it well, most prominent one will be Kubecost that also has an open source version on how to analyze Kubernetes costs.
In terms of open source in general, so there is one initiative throughout the world is called OpenCost, which is mainly sponsored by Kubecost and being attributed by multiple different providers, that is working on creating proper open source tool for cost management. Fairly limited but widely used, but it’s still there. There’s the new initiative by the FinOps Foundation, which is super interesting. It’s called FOCUS Group, which tries to create a standard of cost reporting across different vendors. It’s something that is very hard now for organization that they’re not using solutions like FinOut is to create this schema of what’s cost, what’s compute, what’s storage, what’s whatever, and doing multiple different times. And then they need to speak with a specific terminology of each cloud vendor to get their specific reporting, create ATL processes in order to map it all the ways that they can actually reach one Excel and ask one question. So the FOCUS Group is working on creating that standard, which is super interesting and really looking forward to see the results of something that I think the entire industry is waiting. There’s also lots of political things.
Daniel Bryant: No doubt.
Roi Ravhon: AWS is currently out of this program. So AWS going to get in, they’re going to contribute. Who is even the one that’s contributed? Are they actually going to implement it or not? There’s going to be an interesting couple of years now with the adoption of that, but as a community this is something that everyone demands and I think it’s going to be extremely interesting.
Daniel Bryant: It reminds me a little bit actually of Open Telemetry, the Open Telemetry in the observability space. I remember the Open Telemetry was merged of two different competing foundations, our organizations and then using other clouds going to adopt it. But now everyone’s like, “Let’s not compete on the protocol, let’s not compete on the schema, let’s compete on the actual tooling.” So that’s interesting to see the maturity of the FinOps space is moving towards that, by the sound of it.
Roi Ravhon: The FinOps Foundation is organized under subsidiary of The Linux Foundation. So I think there’s lots of lessons learned and the proper people there that can actually help with achieving those kinds of standards. The industry deserve that. Another concept that I personally would really like to see resolved is entire carbon emission issue. So not the cloud providers are not really reporting it well and even if it does, it’s not standardized and can easily change and are not easily justified and are really… Like FinOps foundation as well trying to create this standard of mission reporting that I really want to see the hyperscalers actually implement so it can consume costs and it can consume emission, which is not necessarily the same thing. So it’s also going to be extremely interesting, I think.
What is the FinOps Foundation? [28:07]
Daniel Bryant: That’s fantastic. There’s probably a whole new podcast we could do there on the emissions stuff because that’s come up several times in our trend reports. Listeners are really interested about impact, their organizations are happening. So I’ll leave it there. That’s fantastic. Thank you for that. That’s fantastic insight into the dynamics between those things. You’ve mentioned the FinOps Foundation a couple of times. I’d love to dive into them a bit more. You mentioned this, the Linux Foundation. I’ve done a lot of work with the Cloud Native Computing Foundation, CNCF, and they have done some amazing skeletons and foundation work around organizing governance for projects. That thing going forward. There’s definitely a lean in the CNCF more towards end users now. So the people actually consuming the tech. I’d love to know where the FinOps Foundation stands. Is it mainly folks vendors like yourself or is it mainly end users? Is there a mix of folks going on? I’d love to know a bit more about the FinOps Foundation in general, actually.
Roi Ravhon: Yes, so I think The FinOps Foundation is doing an amazing job of balancing between the two. So first and foremost, it’s a practitioner space. So it’s a place that all The FinOps practitioners are organized, vendors are there as well, but only as contributors. There’s Slack channel and vendors are, you can get anyone with a quota in, you can pitch your product, you can do any sales pitch if you want to participate. Great. Just do it as a vendor. So I think vendors have great way of helping that community. So as an example, we were part of a working group that was organized under The FinOps Foundation that tried to come up with a standard for Kubernetes labeling for cost management solutions. So part of the stuff that other than contributing from an knowledge, we ran an analysis on all of our accounts and ran anonymized dataset into what people are actually using.
So we have the data and we can contribute it for the community to make the community better. So it’s a great organization that really helps getting the practitioners together with the vendors in a very neutral environment. And when it makes sense, vendors are giving the stage in order to showcase what they have to offer for practitioners to choose the right tool when they need to and understand what’s happening there. But it’s mostly a practitioner space, them growing amazingly. There’s a FinOps.org website that really organized the entire thing. It keeps on updating, FinOps is something that’s live and breathing. And I think for everyone that wants to start with the FinOps journey, FinOps.org is the best place to start.
Are the FinOps Foundation certifications valuable? [30:10]
Daniel Bryant: Fantastic. I’ll put that one in the show notes, for sure. I did have a look before and I saw there was some certifications there. Are they good? Personally my experience, I did my Java certifications back in the day and I’ve done my AWS certifications as well and I found them a really useful learning tool in addition to getting a certificate that then when I go for a job makes it a easier, right. Are the FinOps certifications worth doing, do you think?
Roi Ravhon: Yes, so been investing a lot in building certifications. So I think two years ago there was just one certified FinOps practitioner and now there’s a FinOps Professional and there’s a bunch of different trainings for engineers, for finance, for procurement. So it’s very interesting to see how it’s evolving and in general, I think that obtaining a certificate is a great first place to start. Like the basic certificate, this is a rundown of the basics and if you have the certificate, it’s something that people can trust you for having the basic level of conversation that they want you to have. So I really believe in it, by the way, we encourage every Finout employee to achieve that certification just because you’re going to be a better product manager if you get a certification that understand what your target audience is working on. And support engineers and Finout obtain the certification because when FinOps engineer wants to talk to them, it’s very important for us to have this sets of terminology.
I have a FinOps Certified Practitioner, I really believe in it. So I think it’s a great thing to start. It’s a great way to understand the community that you’re getting into and the more advanced stuff that FinOps Certified Professional is like there’s a classroom that you need to attend, you need to contribute to the community and there’s very few people that have it and those are the ambassadors that are the best and that the true professionals that the entire community knows and can consult with. So I think it’s a great thing that they’re doing.
Daniel Bryant: Fantastic. I really love what you said there about the common language because I think that’s really important. DevOps, I think, struggled for a while in not having that common language, but if you get everyone on your team speaking the same language, magic can happen then. Right?
Roi Ravhon: I agree.
Thanks for joining me on the podcast, Roi! [31:55]
Daniel Bryant: Thanks so much for joining me, Roi. It’s been a fantastic tour de force, the 101 level, the getting started at FinOps. I know I’m keen to learn more. I’m bumping into it more and more in the work I do and definitely we’re bumping into it more and more in the InfoQ trend reports as well. So thank you very much once again for your time and I really appreciate all the knowledge you’ve shared.
Roi Ravhon: Thank you so much, Daniel, for hosting me here.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
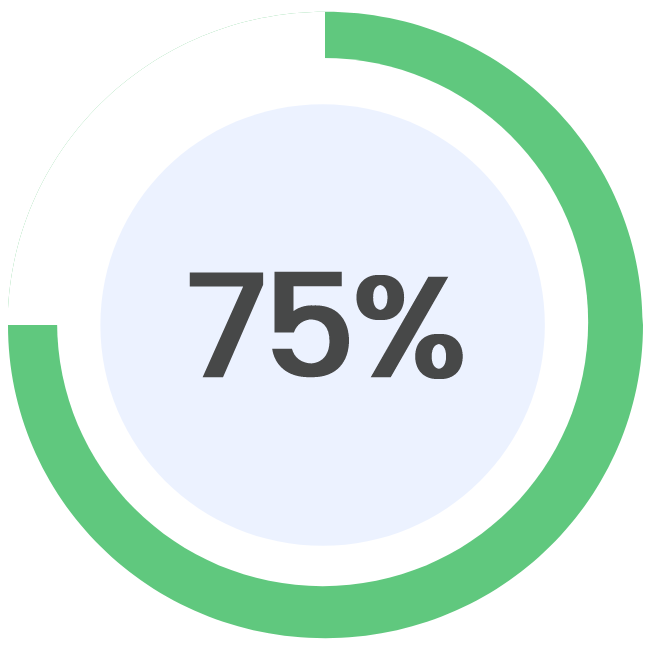
As of September 1, 2023, Mike Cikos, an analyst at Needham, continues to express a positive outlook on MongoDB (NASDAQ:MDB) and reiterates a Buy rating. Cikos has revised the price target for the stock, increasing it from $430 to $445. This marks a significant upward adjustment compared to the previous target of $250. The revised price target suggests a potential upside of 12.79% for investors.
MongoDB, Inc.
MDB
Buy
Updated on: 01/09/2023
MDB Stock Shows Positive Start with Strong Earnings and Revenue Growth on September 1, 2023
On September 1, 2023, MDB stock started the day with an open price of $382.00, higher than the previous day’s closing price of $375.52. Throughout the day, the stock’s price fluctuated within a range of $378.91 to $387.29. The stock had a trading volume of 3,094,579 shares, which was higher than its average volume of 1,729,706 shares over the past three months. The market capitalization of MDB stood at $25.6 billion.
When analyzing the earnings growth of MDB, it is worth noting that the company experienced a decline of 5.89% in the previous year. However, for the current year, MDB has shown substantial growth with an increase of 92.12% in earnings. Looking ahead, the company is expected to maintain a steady growth rate of 8.00% over the next five years.
In terms of revenue growth, MDB has demonstrated strong performance with a growth rate of 46.95% in the previous year. This indicates that the company has been successful in increasing its sales and expanding its market presence.
The price-to-earnings (P/E) ratio for MDB was not provided, denoted as “NM” (not meaningful). However, the price/sales ratio was reported as 11.45, suggesting that investors were willing to pay $11.45 for every dollar of sales generated by the company. Additionally, the price/book ratio was 34.33, indicating that the stock was trading at a premium compared to its book value.
HubSpot Inc (HUBS) experienced a significant increase of 15.72% with a gain of $2.96. ANSYS Inc (ANSS) also saw a positive movement with a gain of 0.92% or $2.91. Take-Two Interactive (TTWO) had a more modest increase of 0.26% or $0.37.
Looking ahead, MDB’s next reporting date is scheduled for December 6, 2023. Analysts forecast an earnings per share (EPS) of $0.27 for the current quarter. In the previous year, the company reported an annual revenue of $1.3 billion but incurred a loss of $345.4 million. The net profit margin for MDB was -26.90%, indicating that the company’s expenses exceeded its revenue.
MDB operates in the packaged software industry within the technology services sector. However, no executives were listed in the provided information. The company’s corporate headquarters are located in New York, New York.
In conclusion, MDB’s stock performance on September 1, 2023, showed a positive start to the day with an increase in the stock’s opening price. The company has demonstrated strong growth in earnings and revenue, indicating its success in the market. However, further analysis and comparison to other companies in the sector would provide a more comprehensive understanding of MDB’s stock performance.
Positive Performance and Promising Outlook for MongoDB Inc. Stock on September 1, 2023
On September 1, 2023, MongoDB Inc (MDB) stock experienced positive performance based on the information provided by CNN Money. The 23 analysts who offered 12-month price forecasts for MDB had a median target of $424.00, with a high estimate of $462.00 and a low estimate of $220.00. This median estimate suggests an 11.32% increase from the last recorded price of $380.90.
The consensus among 28 polled investment analysts was to buy stock in MongoDB Inc. This rating has remained unchanged since August, indicating a consistent positive sentiment towards the company’s stock. Investors seem to have confidence in MongoDB’s future prospects and potential for growth.
In terms of financial performance, MongoDB Inc reported earnings per share of $0.27 for the current quarter. This indicates the company’s profitability and ability to generate income from its operations. Additionally, MongoDB Inc recorded sales of $389.8 million, reflecting its strong revenue generation during this period.
Investors and analysts eagerly await the reporting date of December 6, which will provide further insights into MongoDB Inc’s financial performance and potential future growth. This information will be crucial in determining whether the company is meeting market expectations and if its stock price is likely to continue its positive trajectory.
Overall, the performance of MongoDB Inc’s stock on September 1, 2023, appears promising. The positive price forecasts from analysts, along with the consensus “buy” rating, indicate a favorable outlook for the company. Investors should continue to monitor MongoDB Inc’s financial reports and market trends to make informed decisions about their investment in the company’s stock.
Presentation: 5 Principles for Enablement with (Almost) Nothing to do with Building Tools
MMS • Steph Egan

Transcript
Egan: My Instagram ads fluctuate a lot between all the things which really make me want to click them. Meta have certainly got that algorithm right. One thing I really struggle to resist is productivity apps. Just use this app and your life will change for the better. This idea of something simple giving me all the things that I want, time, feeling organized, clarity. I download the app, maybe use it for a week, maybe a month, if it’s particularly good. Then I ditch it. No real-life improvements made. It’s so enticing, I do it over again. I see this at work too. Part of what I do is to work with teams to help them improve their continuous delivery practices. Usually, the team who’s invited me feel that they’re moving too slowly, and they really want to do better. Depending when I get pulled in, we might talk about what they’re trying to achieve, what their limitations are, and maybe even workshop their processes to find the bottlenecks. Figure out how they can improve.
What I find with these teams is that they seem to inevitably decide that moving to a new CI/CD tooling system will speed things up. They say they spend far too long maintaining their existing system, and this new one is going to make things so much faster and so much more reliable. These tooling migrations can take significant amounts of time, usually months, sometimes longer. Do these tooling changes speed them up? Often, no. We seem to have this innate desire for these tools, though, whether that’s my productivity apps, or a new CI/CD tooling system. We love tools with the potential to solve our problems. Engineering enablement is the home of tools with the potential to solve our problems. We build stuff to solve teams’ problems. As we’ve seen, tools don’t always solve them. Fred Brookes wrote a paper called, “No Silver Bullet: Essence and Accidents of Software Engineering,” back in 1989. He said, there is no single development in either technology or in management technique that by itself promises even one order of magnitude improvement in productivity, in reliability, in simplicity. That’s a lot of words so let me rephrase it a little bit to show what I took from this. The thing that I really took was that there is no technology or practice that on its own, will provide significant improvement in productivity, reliability, or simplicity.
Background & Outline
I’m Steph. I currently work as a principal software engineer in delivery engineering, one of our enablement teams here at the BBC. My team works to improve our team’s development and release practices. Knowing how much we love these tools, and that they alone are unlikely to solve our problems, I like to completely mostly ignore the tools that we build and instead talk about what I learned in my previous role, leading the acceleration team in the iPlayer and Sounds department. What we did to improve things for teams alongside building tools. I’ll give you five principles for enablement teams, which focus not on the tools but on how we work ourselves and with others. Each principle will have techniques that we’ve used to apply them. I’ll talk about some of the challenges that we’ve come across along the way as well.
Context
First, let me paint a picture of what working in one of the teams in iPlayer and Sounds was, around five years ago when we started the team. iPlayer and Sounds teams are responsible for the BBC’s TV and radio streaming services, iPlayer and Sounds. While these are two huge products in their own right, the BBC itself is much bigger. iPlayer and Sounds is one department in a collection of many departments across our engineering space. Each of these had their own structures, their own ways of working. iPlayer and Sounds was around 30 teams, which were generally pretty small, about 8 people in a multidisciplinary team. They had full ownership of their infrastructure that they deployed to, the technologies that they used, how they deployed to them. This allowed for a large amount of variation in how individual teams work. We saw this variation across different slices as well. First, we saw divides across the different offices that we had. We span three different sites in Glasgow, Salford, and London. We also saw divides between the two products, Sounds and iPlayer. Finally, we saw divides in the platforms that teams were developing for so we provide clients for TVs, for web browsers, and for mobile devices. Each of the teams working on each of these clients have different technologies, different limitations, different restrictions. We also have some backend teams as well who support these clients. Each one of these has slightly different ways of working and slightly different limitations around what that can be.
Where We Started (License Compliance)
Where did we start? The first problem that we tackled as a team was one which is maybe not the obvious choice, we started with license compliance. Understanding the licenses that our software dependencies have, and making sure that we’re working within those licenses. It does sound pretty dry, and maybe not what you’d expect to hear from an enablement team. As a key part of enablement, which we were really keen to tackle is to improve practices and knowledge. This license compliance was an area that teams had very little knowledge in. There were very few practices across the teams, and it just hadn’t really been tackled broadly. Any tooling that you provide for license compliance can get really interesting around how you approach it, because they can become governance, a set of rules which teams have to maneuver around, causing more pain rather than less pain, which wasn’t really what we were trying to do.
Knowledge Sharing, and Making Things Which Could Be Improved, Visible
This brings me to my first principle. We share knowledge and make things which could be improved visible. One angle we could have taken here is to insist that all teams add an extra step in their pipeline, which blocked specific licenses or required them to acknowledge it before the pipeline moved along. Ignoring the fact that that would have been a huge amount of work for not only us, but also the teams themselves, it would only make sense if the teams fully understood why this was important, and how they could benefit from it. Otherwise, it’s just a red checkmark from a random team, who is now stopping them from getting the really important changes out to live, not the way to make friends. Instead, we left teams in control of their builds, and focused on educating teams around what licenses mean, what situations could be problematic, and how to handle them. We put all the decision making in the team’s hands and respected the decisions that they made. After all, they have all the context around their software, not us. The way that we did this was through GitHub Issues and report generation. This is generally the first thing that a team would see, an issue raised on their GitHub repo with some details about a potential problem. This links off to more specific information put together by our legal team and a chat channel to get more help if they needed it. When this tooling was released, it caused waves of conversations around licenses, even in teams not using the tooling. It improved understanding across teams, and created a place where teams could ask questions. We had hoped that this was something that we could provide to almost every team across our department. Unfortunately, it’s a little bit spotty in some areas, depending on the languages used. We’re able to get pretty good coverage.
Knowledge doesn’t just live in our tools. However, another way that we worked to help teams is in a consulting capacity. One of the successes that we had was with teams who were working on the TV applications. These teams had made huge strides in their processes. They’d moved from release trains every two weeks into multiple deployments a week, but this was putting more strain on their processes. They really wanted to smooth things out a little bit more. The first thing we did with this team was to run a pipeline review workshop, which is a little bit similar to value stream mapping. These teams worked in a monorepo and followed a single process. We got all the team leads, the test leads, delivery managers, product owners, and everyone else interested in shaping the process, into the same room. We mapped out the entire process using loads of Post-it notes, making sure that everyone could contribute so that we got a full picture of what was happening. It was a lot. I couldn’t fit it in a single photo. We talked about how long things took. What was manual, and what was automated. What confidence each step gave people. At the end of the session, we had a new process that they wanted to achieve, and the beginnings of some steps to get there.
Since that workshop, they saw significant increases in the amount of releases that they were able to put out, and a general increase in satisfaction across engineers. I love this graph, because I can point to it and say that the workshop caused all of this improvement. Of course, it was the work that the teams put in after the workshop that really made these changes. It was a catalyst, and it gave them the direction that they hadn’t had previously. Not all of the workshops that we run had this impact. It really depended on where the teams were at, and their desire to change. All of the teams found that they had a better understanding of their current processes after we’d run them. Workshops like these have the added benefit of giving the facilitator a view into how the team are working and the processes that they have. This information is invaluable when understanding what direction we want to move next as an enablement team.
Outside workshops, we would also provide more general support and guidance. We would work directly with engineers on teams who required specific assistance. This could be to help them move to a different continuous integration system or large refactors in how they were using their tooling. It could be as simple as going through their intentions to check for any got you’s, or suggest other approaches. Or it can be as in-depth as working with that team for a week or two. Working directly with teams in this way can be a bit time consuming and a little bit difficult to line up. Sitting with engineers, getting into the weeds gives a huge insight in how that team works, what problems they’re facing, but also gives that team a direct contact, who’s suddenly more approachable than before.
One of the things that we’ve adopted more recently is to provide guides and documentation, which maybe seems a little bit odd in hindsight. I think a lot of this was due to our position. We strayed away initially from giving direct advice, keeping as much autonomy within teams as we possibly could. Now our position is a little bit different, which I’ll talk more about later. We’re putting a bit more effort into guides and recommendations. One thing that I have found when we do this work, give suggestions and recommendations to teams, is that it only really works when teams are fully on board with making change happen and listening to the advice that you have. It can really vary between teams, sometimes depending on where the team is at, or even when we got included into the discussions that they’re having. They can generally be looking for encouragement or reinforcement, rather than a change in direction, which can be a little bit disheartening sometimes, but the view that you get at the team working with them, and the information from those interactions is still really valuable. More often than not, those suggestions will come back up further down the road once the team are ready to make those changes. We share knowledge and make things which could be improved, visible. We do this by providing information overrules. Bringing information to teams via tools or workshops. Providing hands-on support that teams can call on.
Building and Fostering Communities and Relationships
The next principle is that we build and foster communities and relationships. Understanding where teams are having problems is key to being able to solve them. We need to build up those relationships to be able to understand that. Some of the ways that we did that was to create and run an organization-wide community of practice around development and release practices. We started this community not long after starting the team, and it continues to be an invaluable source of information. It’s been running for about five years now, I think. We run it once a month. It can take the form of discussions, retrospectives, or presentations. There’s also a very active chat channel which allows teams to ask any questions which crop up day-to-day. This is a retrospective that we ran quite recently, to see what areas teams were looking at, or having problems with. Individuals who attended were able to learn, ask questions, meet others who are in similar situations as them. For us as an enablement team, this originally gave us a view of where all of those other departments were, making sure that we weren’t duplicating effort or just generally understanding where the rest of the organization was. It also gives more information about the teams that we’re supporting as well. That information is so valuable in informing our direction, and giving an indication of what issues teams might be likely to come up against in the future. Someone’s got to be first in finding some of these issues, so it can give us a bit of a flag as to when things are going to happen. It’s like the undercurrent of the organization a little bit. This community also included teams who were doing similar things to us in other departments. Generally, all of these teams had different focuses or angles that they were looking at these problems with. It allows us to get to know these teams a little and support each other.
Within the iPlayer and Sounds department, there is an existing structure for what we call communities of action. These are across team groups, which meet once a fortnight, and are more directed than broad knowledge sharing. The spaces for individuals to improve their skills, explore new techniques, or technologies, and collaborate with other individuals to experiment in solving problems. One example of this is the teams working on TV clients, they spun up a community of action to improve their continuous delivery working practices. A huge amount came out of that guild, including their move away from regression testing, moving CI/CD tooling systems to improve performance, and the adoption of their pipeline by a team which has given them significant improvements as well. These guilds give us a slightly different type of view on teams. It’s more future looking, where a team’s looking to go next, what problems are they interested in solving, that kind of thing. Enablement are able to bring some expertise to this group, encourage collaboration, or cross-team understanding, and some guidance as well.
One of the things that we struggled with quite early on as a team was ensuring that everybody understood what our team was and how we could help. We were quite different from other teams, so it was a bit easy for us to get forgotten about. One of the ways that we improve that was by making a concerted effort to appear in places where other teams were, so all-hands, engineering forums, leadership discussions, that kind of thing. This was really key to building up relationships with the teams that we were supporting, and making sure that we had contacts in every single one. We build and foster communities and relationships. We do that by making sure we have regular knowledge sharing communities. Cross-team communities for in-depth learning and exploration. Being visible where other teams are. All these techniques allow us to build up context around the organizations and in specific teams, which means that we will have a better chance of teams adopting what we build, but also feeling like we’re a resource that they can rely on.
Respect Other Teams’ Time and Uniqueness
Next, we respect other teams’ time and uniqueness. Our product teams have a lot going on, loads of priorities to manage, different angles to keep up with. The time that they have available to start learning new tools or changing how they do things is minimal and it has to be really valuable for them. Particularly when our team was still in its infancy, it wasn’t clear to every team what we were about, or how we worked. If we came knocking on their door about something which they might legitimately want to fix, but just didn’t have the time to focus on it, we would just get told to join the queue. I think the other thing here is that we have to tackle this problem with a base level of respect for the work that other teams are doing, their practices, and the decisions that they make.
How did we go about showing this respect to teams? Our teams had experiences of telling, which was built internally. These experiences could include things like the tooling not working for their particular scenario, lots of ticket raising, long documentation to read, or large amounts of jargon to understand. It was confusing for teams to understand what was available, what would help them, and how much effort it would take. A lot of teams, because of this, opted to build their own tooling. Sometimes it was so ingrained that they didn’t even bother looking for anything else. We had to book this trend. We wanted to show respect for teams’ time by putting as much effort as possible into not adding any more work for them. Often, we did this by removing ourselves as a bottleneck, usually ensuring that what we would build is self-service.
The thing which really exemplified this, to me, was a service that we built really early on, it’s called broxy. I can’t take credit for it at all. It was another engineer who came up with the idea, but it really solidified our approach as a team. It’s the simplest thing that we own. It’s generally the most loved. Why? Because it bucks this trend of things being difficult to use. Broxy is an authentication layer, allowing teams to host their own static internal tooling, but not having to think about authenticating users. We built it for ourselves really, and figured that we were probably going to want a few websites, but a teammate said, we should open this up, let anyone use it. We did. Teams add a couple of extra lines of config to define a policy for users to access their static website via broxy. It’s completely self-serve. They have full control of that policy, and it now fronts tools all over the organization. A lot of the reactions that we had for this was surprise at how easy it was to set up. Is that it? We wanted to build on that reputation going forward to make sure that teams know that we’re on their side.
The second way that we show this respect is to accept that all teams are unique. Because the teams that we support are so varied in their working practices, technologies they use, there’s no way that we can improve an area for every single team. There’s certainly no way that we can improve all areas for all these different teams. Each team has their own specific collection of maturity levels across different areas. Maybe they have a great process in place for their dependency management, but they are still relying on manual deployments. Maybe they’re really good at deploying their application, but they struggle when it comes to infrastructure changes. Probably they’re somewhere in the middle of all these. This has impacted how we talk about our tools, and even what the tools look like to build, at least initially. One example of this was our metrics platform, which provides teams with information on how their development or release processes is doing, so that they can track improvements that they’d like to make.
This has been a big project, and we wanted to get a large amount of coverage across teams. Initially, we plan to provide the metrics to teams so that they could use them. What we saw was a significant amount of variation in usage of them. Some teams jumped at the opportunity to use these figures, using them to inform improvements that they wanted to make, and other teams just didn’t know what to do with the data. In this case, it’s particularly interesting because the teams who don’t know what to do with the data are probably the ones who could most benefit from understanding it. With still tackling this problem more broadly, but I think the challenge here is understanding what this lack of adoption is due to. Is it lack in functionality? Is there too large of a barrier to entry, or maybe it’s just not something that the teams want? For this project, we think it’s a mixture of a lack of functionality on top of a lack of knowledge. We’re providing more options within the tool, and support alongside it to accommodate different teams. Specifically, we’re providing more information as part of these metrics to help them be more useful. Also, we’re providing workshops, and presentations, working directly with teams to help them get the best out of the tools, providing suggestions for how they can be used, and walking through them. We respect other teams’ time and uniqueness. We do that by removing ourselves as the bottleneck. Excellent documentation. Keeping what teams interact with simple. Providing a variety of options to accommodate different teams.
Radiate A Sharing Mindset Through Collaboration
Next, we radiate a sharing mindset through collaboration. When I started the team, I had ideas which could probably last us about 10 years. We were a small team, and there was no way that we were going to fix everything. Instead, we had to work with others to be able to make big impacts. I mentioned broxy earlier, that tooling acknowledges that we can’t fix everything, and that there’s still space for teams to build their own tooling. Our team are certainly sitting on the shoulders of the team who built our deployment platform. One of their principles was to ensure that everything that they built also provided an API, allowing other teams to build tooling. They acknowledge they didn’t quite go far enough. They left a bit too much space for teams to build their own tooling in isolation. For me, the missing part of this is collaboration. While APIs or an authentication platform like broxy allow for teams to do what they need, while getting out of the way, it doesn’t allow for teams to come together to improve what exists rather than making things new. We were a small team, so we needed people to come together and help us with some of this.
There are multiple ways that we tried to achieve this. First, we made a real effort to accept contributions to anything that we built, which was from outside of our team. This form of collaboration is a token itself. It certainly wasn’t the default. Generally, the expectation was that teams were too busy with their own backlogs to focus on anything coming from outside of the team, even if they wanted to. Instead, we really had to put our openness to contributions front and center and make sure that people knew that that’s what we were about. We had a policy that we would merge any PR that came our way. We did this to show teams that we cared about the effort that they’ve made, and that we wanted to work with them to make our tools work for them. It might sound a little bit scary. We didn’t necessarily mean that we merge to anything without question. It did mean that we would make a concerted effort to work with them to make sure that their changes got over the line. We also made sure that our contribution docs were encouraging and easy to use. We stick to languages and tools which were mostly common across the organization.
We also worked alongside other teams, which were similar to our own, tying up any tooling that we both provide. For example, another team managed the observation platform for the iPlayer and Sounds department, among others. We worked with their team to provide deployment annotations from data that we already had into their system. This was a huge win for us, and started to show how consistency can really make these sorts of enhancements much easier. There’s a lot of places this has been really hard, though, since different teams have different focuses to us and often different mindsets. It’s an ongoing effort to understand how we can improve our alignment. Teams like ours are definitely not the only teams building tooling, as I’ve already mentioned. A lot of teams build their own tools. These are often made with intentions of them being open. There’s just so many of them, it’s not clear what’s still supported. Unless a team is particularly good at pushing their tools, they just get added to a never-ending list. This is, if I search our organization for wormhole, which is part of the deployment tooling which is provided at an organizational level. These are mostly CLI tools. It probably won’t be all of them in this one set, but there’s a huge amount of duplication here. One way we’re starting to improve this is by recommending tooling, which is made by other teams, be that teams in other departments or our own.
When we find services which have good amounts of support, and are being used heavily that we’re confident that we can encourage usage of, we share them. One huge example of this is Releasinator, which was built by another team. Releasinator automates a very specific workflow, so it isn’t something that we were likely to handle, it just didn’t have the breadth that we were looking for. This team really needed it to improve their processes. While building it, we looked with them at other things that could benefit from its functionality. They discovered that it would be helpful for some other services that they build as well. With some encouragement, they ensured that it was usable by any team in the organization. We’re now able to recommend it as a solution alongside all of the tooling that we provide. This support and encouragement is starting to build up a collection of tools, which have clear levels of support, good usage patterns, which is beginning to make waves across the organization. It means that we’re able to help teams think about what makes good tooling. We radiate a sharing mindset through collaboration. We do that by prioritizing contributions to anything we build. Working with other teams doing similar things, making an effort to tie things together. Supporting and encouraging usage of other teams tooling.
Aim for Long-Term Improvements
Finally, my last principle is that we aim for long-term improvements. When we started this journey, we were trying all sorts of different things, looking at different areas that we wanted to improve. We specifically took on small quick wins, with a hope that we could start making some small improvements. These were helpful for us as a team because they were often pretty concrete and obvious, and helps us get our name out there a little bit. We definitely didn’t see large impact from these in people’s day to day. Although they’re useful, they didn’t solve a lot of the problems that our engineers were seeing. They were additive rather than ingrained in people’s workflows, kind of nice to have. We also worked on larger goals alongside these. These larger projects have, in hindsight, been more successful. This distinction was pretty hard to see at the time, particularly because we have seen improvements over much longer time periods. For example, when we built tooling around license compliance, there was an initial wave of interest, which then died down. Now we’re seeing an uptick in adoption, again, across a wider organization, without much effort from ourselves years after we started work on it. I’ve seen similar things when working directly with teams. A team lead messaged me the other day saying, “Months ago, you offered to talk about how we can improve our deployments. Are you still up for that?” This unpredictability and uncertainty can be a little bit of a roller coaster as far as confidence goes. One thing that we did to improve that was to pull together some key feedback metrics and changes that we’d made over the last 12 months to understand where we were at. We shared that with teams too, and it gave a great opportunity for us to call out anyone who’d collaborated with us.
More recently, my team have gone from focusing specifically on a single department to supporting all of them as part of a group of teams focused on engineering enablement. For us, this meant going from supporting around 30 teams to supporting well over 100 teams. It does make some things easier because we’re working together with some of the teams who’ve been building solutions for the organization for quite a long time. We can make sure that our goals are aligned with them by design. It’s also forced us to change our expectations, however. We do now have a large view across teams, which gives a much better picture of the state of the organization since we’re just exposed directly to more teams. This has increased our confidence around whether the problems that we saw within the iPlayer and Sounds department was specific to that department, or a broader trend which needed to be focused on. It does make it harder to build up direct relationships with teams, though, and we’re still working out how best to do that at scale.
One impact that this has had on our work is that while previously, we were trying to cover all of the teams that we worked with, we’d realized that this is just not achievable quickly at this scale. There will be teams who aren’t ready for change, yet. There will be teams whose processes are so different that they will take large amounts of time and effort to bring along. Instead, we’re looking to get the most value that we can quickly by supporting the broad majority, about 80%, we’re thinking right now. We aim for long-term improvement. We do this by measuring a project’s success over longer periods. Keeping records of your progress, and reviewing it to smooth out the roller coaster. Tackling the bigger picture tends to bring more success, there probably aren’t any quick fixes.
Conclusion
We started with this statement based on a quote from Fred Brookes. There is no technology or practice, that on its own will provide significant improvement in productivity, reliability, or simplicity. We’ve certainly found that we have yet to find a silver bullet. Instead, we’re taking a variety of approaches through building tools and the techniques that we apply alongside that to work towards improvement. We have also seen teams who gained success, speeding up their processes. These teams tend to gain that through a variety of approaches, some of it tooling, some of it practices to achieve their goals. Finally, I have found a productivity app which did make a big impact. I’ve used it for quite a long time now. Interestingly, this app has a heavy focus on techniques for using it and support around changing your mindset beyond just using the tool. I do still keep downloading more apps, though. These are my five principles for enablement, which have almost nothing to do with building tools.
See more presentations with transcripts
MMS • RSS

August 31, 2023 at 05:00 pm
Presentation Operator MessageOperator (Operator)Good day, and thank you for standing by. Welcome to the MongoDB Se…
This article is reserved for subscribers
Signed up already?
Log In
Not subscribed yet?
Subscribe
MMS • Michael Redlich

JDK 21, the next Long-Term Support (LTS) release since JDK 17, has reached its initial release candidate phase as declared by Mark Reinhold, chief architect, Java Platform Group at Oracle. The main-line source repository, forked to the JDK stabilization repository in early-June 2023 (Rampdown Phase One), defines the feature set for JDK 21. Critical bugs, such as regressions or serious functionality issues, may be addressed, but must be approved via the Fix-Request process. As per the release schedule, JDK 21 will be formally released on September 19, 2023.
The final set of 15 new features, in the form of JEPs, can be separated into four (4) categories: Core Java Library, Java Language Specification, HotSpot and Security Library.
Six (6) of these new features are categorized under Core Java Library:
Five (5) of these new features are categorized under Java Language Specification:
Three (3) of these new features are categorized under HotSpot:
And finally, one (1) of these new features is categorized under Security Library:
It is important to note that JEP 404, Generational Shenandoah (Experimental), originally targeted for JDK 21, was officially removed from the final feature set in JDK 21. This was due to the “risks identified during the review process and the lack of time available to perform the thorough review that such a large contribution of code requires.” The Shenandoah team has decided to “deliver the best Generational Shenandoah that they can” and will seek to target JDK 22.
We examine some of these new features and include where they fall under the auspices of the four major Java projects – Amber, Loom, Panama and Valhalla – designed to incubate a series of components for eventual inclusion in the JDK through a curated merge.
Project Amber
JEP 445, Unnamed Classes and Instance Main Methods (Preview), formerly known as Flexible Main Methods and Anonymous Main Classes (Preview) and Implicit Classes and Enhanced Main Methods (Preview), proposes to “evolve the Java language so that students can write their first programs without needing to understand language features designed for large programs.” This JEP moves forward the September 2022 blog post, Paving the on-ramp, by Brian Goetz, Java language architect at Oracle. Gavin Bierman, consulting member of technical staff at Oracle, has published the first draft of the specification document for review by the Java community. More details on JEP 445 may be found in this InfoQ news story.
JEP 440, Record Patterns, finalizes this feature and incorporates enhancements in response to feedback from the previous two rounds of preview: JEP 432, Record Patterns (Second Preview), delivered in JDK 20; and JEP 405, Record Patterns (Preview), delivered in JDK 19. This feature enhances the language with record patterns to deconstruct record values. Record patterns may be used in conjunction with type patterns to “enable a powerful, declarative, and composable form of data navigation and processing.” Type patterns were recently extended for use in switch case labels via: JEP 420, Pattern Matching for switch (Second Preview), delivered in JDK 18, and JEP 406, Pattern Matching for switch (Preview), delivered in JDK 17. The most significant change from JEP 432 removed support for record patterns appearing in the header of an enhanced for statement. Further details on JEP 440 may be found in this InfoQ news story.
JEP 430, String Templates (Preview), proposes to enhance the Java programming language with string templates, string literals containing embedded expressions, that are interpreted at runtime where the embedded expressions are evaluated and verified. More details on JEP 430 may be found in this InfoQ news story.
Project Loom
JEP 453, Structured Concurrency (Preview), incorporates enhancements in response to feedback from the previous two rounds of incubation: JEP 428, Structured Concurrency (Incubator), delivered in JDK 19; and JEP 437, Structured Concurrency (Second Incubator), delivered in JDK 20. Recent significant changes include: the TaskHandle interface has been renamed to Subtask a fix to correct the generic signature of the handleComplete() method; a change to the states and behavior of subtasks on cancellation; a new currentThreadEnclosingScopes() method defined in the Threads class that returns a string with the description of the current structured context; and the fork() method, defined in the StructuredTaskScope class, returns an instance of Subtask (formerly known as TaskHandle) rather than a Future since the get() method in the old TaskHandle interface was restructured to behave the same as the resultNow() method in the Future interface. Further details on JEP 453 may be found in this InfoQ news story.
JEP 446, Scoped Values (Preview), formerly known as Extent-Local Variables (Incubator), this JEP is now a preview feature following JEP 429, Scoped Values (Incubator), delivered in JDK 20. This JEP proposes to enable sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads.
JEP 444, Virtual Threads, proposes to finalize this feature based on feedback from the previous two rounds of preview: JEP 436, Virtual Threads (Second Preview), delivered in JDK 20; and JEP 425, Virtual Threads (Preview), delivered in JDK 19. This feature provides virtual threads, lightweight threads that dramatically reduce the effort of writing, maintaining, and observing high-throughput concurrent applications, to the Java platform. The most significant change from JEP 436 is that virtual threads now fully support thread-local variables by eliminating the option to opt-out of using these variables. More details on JEP 444 may be found in this InfoQ news story and this JEP Café screen cast by José Paumard, Java developer advocate, Java Platform Group at Oracle.
Project Panama
JEP 448, Vector API (Sixth Incubator), incorporates enhancements in response to feedback from the previous five rounds of incubation: JEP 438, Vector API (Fifth Incubator), delivered in JDK 20; JEP 426, Vector API (Fourth Incubator), delivered in JDK 19; JEP 417, Vector API (Third Incubator), delivered in JDK 18; JEP 414, Vector API (Second Incubator), delivered in JDK 17; and JEP 338, Vector API (Incubator), delivered as an incubator module in JDK 16. This feature proposes to enhance the Vector API to load and store vectors to and from a MemorySegment as defined by the Foreign Function & Memory API.
JEP 442, Foreign Function & Memory API (Third Preview), incorporates refinements based on feedback and to provide a third preview from: JEP 434, Foreign Function & Memory API (Second Preview), delivered in JDK 20; JEP 424, Foreign Function & Memory API (Preview), delivered in JDK 19, and the related incubating JEP 419, Foreign Function & Memory API (Second Incubator), delivered in JDK 18; and JEP 412, Foreign Function & Memory API (Incubator), delivered in JDK 17. This feature provides an API for Java applications to interoperate with code and data outside of the Java runtime by efficiently invoking foreign functions and by safely accessing foreign memory that is not managed by the JVM. Updates from JEP 434 include: centralizing the management of the lifetimes of native segments in the Arena interface; enhanced layout paths with a new element to dereference address layouts; and removal of the VaList class.
Developers may be interested in learning about the performance benefits of the Foreign Function & Memory API that is planned to be a final feature in JDK 22. Per-Åke Minborg, consulting member of technical staff at Oracle, has published this blog post in which he provided a benchmark on string conversion using this API for JDK 21 (JEP 442) and JDK 22 (JEP Draft 8310626) compared to using the old Java Native Interface (JNI) calls.
HotSpot
JEP 439, Generational ZGC, proposes to “improve application performance by extending the Z Garbage Collector (ZGC) to maintain separate generations for young and old objects. This will allow ZGC to collect young objects, which tend to die young, more frequently.” Further details on JEP 439 may be found in this InfoQ news story.
JDK 22
Scheduled for a GA release in March 2024, there are no targeted JEPs for JDK 22 at this time. However, based on a number of JEP candidates and drafts, especially those that have been submitted, we can surmise which additional JEPs have the potential to be included in JDK 22.
JEP 447, Statements before super(), under the auspices of Project Amber, proposes to: allow statements that do not reference an instance being created to appear before the this() or super() calls in a constructor; and preserve existing safety and initialization guarantees for constructors. Gavin Bierman, consulting member of technical staff at Oracle, has provided an initial specification of this JEP for the Java community to review and provide feedback.
JEP 435, Asynchronous Stack Trace VM API, a feature JEP type, proposes to define an efficient API for obtaining asynchronous call traces for profiling from a signal handler with information on Java and native frames.
JEP 401, Null-Restricted Value Object Storage (Preview), formerly known as Primitive Classes (Preview), under the auspices of Project Valhalla, introduces developer-declared primitive classes – special kinds of value classes as defined by the Value Objects API – that define new primitive types.
JEP Draft 8307341, Prepare to Restrict The Use of JNI, proposes to restrict the use of the inherently unsafe Java Native Interface (JNI) in conjunction with the use of restricted methods in the Foreign Function & Memory (FFM) API that is expected to become a final feature in JDK 22. The alignment strategy, starting in JDK 22, will have the Java runtime display warnings about the use of JNI unless an FFM user enables unsafe native access on the command line. It is anticipated that in release after JDK 22, using JNI will throw exceptions instead of warnings.
JEP Draft 8310626, Foreign Function & Memory API, proposes to finalize this feature after two rounds of incubation and three rounds of preview: JEP 412, Foreign Function & Memory API (Incubator), delivered in JDK 17; JEP 419, Foreign Function & Memory API (Second Incubator), delivered in JDK 18; JEP 424, Foreign Function & Memory API (Preview), delivered in JDK 19; JEP 434, Foreign Function & Memory API (Second Preview), delivered in JDK 20; and JEP 442, Foreign Function & Memory API (Third Preview), to be delivered in the upcoming release of JDK 21. Improvements since the last release include: a new Enable-Native-Access manifest attribute that allows code in executable JARs to call restricted methods without the use of the --enable-native-access flag; allow clients to programmatically build C function descriptors, avoiding platform-specific constants; improved support for variable-length arrays in native memory; and support for multiple charsets in native strings.
JEP Draft 8288476, Primitive types in patterns, instanceof, and switch (Preview), proposes to “enhance pattern matching by allowing primitive type patterns to be used in all pattern contexts, align the semantics of primitive type patterns with instanceof, and extend switch to allow primitive constants as case labels.”
JEP Draft 8277163, Value Objects (Preview), a feature JEP under the auspices of Project Valhalla, proposes the creation of value objects – identity-free value classes that specify the behavior of their instances. This draft is related to JEP 401, Primitive Classes (Preview), which is still in Candidate status.
JEP Draft 8313278, Ahead of Time Compilation for the Java Virtual Machine, proposes to “enhance the Java Virtual Machine with the ability to load Java applications and libraries compiled to native code for faster startup and baseline execution.”
JEP Draft 8312611, Computed Constants, introduces the concept of computed constants, defined as immutable value holders that are initialized at most once. This offers the performance and safety benefits of final fields, while offering greater flexibility as to the timing of initialization. This feature will debut as a preview API.
JEP Draft 8283227, JDK Source Structure, an informational JEP type, describes the overall layout and structure of the JDK source code and related files in the JDK repository. This JEP proposes to help developers adapt to the source code structure as described in JEP 201, Modular Source Code, delivered in JDK 9.
JEP Draft 8280389, ClassFile API, proposes to provide an API for parsing, generating, and transforming Java class files. This JEP will initially serve as an internal replacement for ASM, the Java bytecode manipulation and analysis framework, in the JDK with plans to have it opened as a public API. Brian Goetz, Java language architect at Oracle, characterized ASM as “an old codebase with plenty of legacy baggage” and provided background information on how this draft will evolve and ultimately replace ASM.
JEP Draft 8278252, JDK Packaging and Installation Guidelines, an informational JEP, proposed to provide guidelines for creating JDK installers on macOS, Linux and Windows to reduce the risks of collisions among JDK installations by different JDK providers. The intent is to promote a better experience when installing update releases of the JDK by formalizing installation directory names, package names, and other elements of installers that may lead to conflicts.
We anticipate that Oracle will start targeting JEPs for JDK 22 very soon.
MMS • RSS
Image source: The Motley Fool.
MongoDB (MDB 1.54%)
Q2 2024 Earnings Call
Aug 31, 2023, 5:00 p.m. ET
Contents:
- Prepared Remarks
- Questions and Answers
- Call Participants
Prepared Remarks:
Operator
Good day. Thank you for standing by. Welcome to the MongoDB’s second-quarter fiscal year 2024 earnings conference call. At this time, all participants on in a listen-only mode.
After the speakers’ presentation, there will be a question-and-answer session. [Operator instructions] Please be advised that today’s conference is being recorded. I would now like to turn the conference over to your speaker for today, Mr. Brian Denyeau.
Please go ahead, sir. The floor is yours.
Brian Denyeau — Investor Relations
Thank you, Reva. Good afternoon and thank you for joining us today to review MongoDB’s second-quarter fiscal 2024 financial results, which we announced in our press release issued after the close of the market today. Joining me on the call today are Dev Ittycheria, president and CEO of MongoDB, and Michael Gordon, MongoDB’s COO and CFO. During the call, we will make forward-looking statements, including statements related to our market and future growth opportunities, the benefits of our product platform, our competitive landscape, customer behaviors, our financial guidance, and our planned investments.
These statements are subject to a variety of risks and uncertainties, including the results of operations and financial conditions, that could cause actual results to differ materially from our expectations. For discussion of the material risks and uncertainties that could affect our actual results, please refer to the risks described in our quarterly report on Form 10-Q for the quarter ended April 30th, 2023 filed with the SEC on June 2nd, 2023. Any forward-looking statements made in the call reflect our views only as of today, and we undertake no obligation to update them except as required by law. Additionally, we will discuss non-GAAP financial measures in this conference call. Please refer to the tables in our earnings release on the Investor Relations portion of our website for a reconciliation of these measures to the most directly comparable GAAP financial measure.
10 stocks we like better than MongoDB
When our analyst team has a stock tip, it can pay to listen. After all, the newsletter they have run for over a decade, Motley Fool Stock Advisor, has tripled the market.*
They just revealed what they believe are the ten best stocks for investors to buy right now… and MongoDB wasn’t one of them! That’s right — they think these 10 stocks are even better buys.
*Stock Advisor returns as of August 28, 2023
With that, I’d like to turn the call over to Dev.
Dev Ittycheria — President and Chief Executive Officer
Thank you, Brian, and thank you to everyone for joining us today. I am pleased to report that we had another exceptional quarter as we continue to execute well despite challenging market conditions. I will start by reviewing our second-quarter results before giving you a broader company update. We generated revenue of $424 million, a 40% year-over-year increase and above the high end of our guidance.
Atlas revenue grew 38% year over year, representing 63% of revenue, and is now a 1-billion-plus revenue run rate product. We generated non-GAAP operating margin — operating income of 79 million for a record 19% non-GAAP operating margin, and we had another solid quarter of customer growth and in the quarter with over 45,000 customers. Overall, we delivered an exceptional Q2. We had a healthy quarter of new business acquisition led by continued strength and new workload acquisition within our existing customers.
From a new logo perspective, we added 1,900 new customers in the quarter. Our direct sales team had another strong quarter of enterprise customer additions. Finally, our Enterprise Advanced and other non-Atlas business significantly exceeded our expectations, another indication of our strong product market fit and the appeal of a run-anywhere strategy. Moving on to Atlas consumption trends. The quarter played out slightly better than our expectations.
Michael will discuss consumption trends in more detail. Finally, retention rates remained strong in Q2, reinforcing the mission-criticality of our platform even in a difficult spending environment. As we’ve told you in the past, our market is different from most other software markets because the unit of competition is a workload, not a customer. We start a customer relationship by acquiring the, first, workload, and we grow from there, acquiring incremental workloads over time.
Over the last few years, we have oriented our entire company around winning more workloads. Starting with product. At our New York user conference held in June, we made a number of product announcements that will position us to capture more workloads faster. We introduced Atlas Stream Processing, which enables developers to work with streaming data to build sophisticated event-driven applications. The flexibility of the document model and the power of the MongoDB query language provide a compelling and differentiated way to process streaming data compared to alternative approaches.
Our early access program is meaningfully oversubscribed as customers realize they can use a familiar and easy approach to work with streaming data and immediately see value. We announced the general availability of Relational Migrator, which makes it easier for customers to migrate their existing relational applications to MongoDB. We are seeing increased adoption across industries and geographies. For example, a leading international retailer was able to leverage Relational Migrator to dramatically accelerate the migration of Oracle.
We also announced Atlas Vector Search, which enables developers to store, index, and query vector embeddings instead of having to bolt on vector search functionality separately, adding yet another point solution in creating a more fragmented developer experience. Developers can aggregate and process the vectorized data they need to build applications while also using MongoDB to aggregate and process data and metadata. We’re seeing significant interest in our Vector Search offering from large and sophisticated enterprise customers even though it’s only — still only in preview. As one example, a large global management consulting firm is using Atlas — Atlas Vector Search for an internal research application that allows consultants to semantically search over 1.5 million expert interview transcripts. Over time, AI functionality will make developers more productive to the use of cogeneration and code-assist tools that enable them to build more applications faster.
Developers will also be able to enrich applications with compelling AI experiences by enabling integration with either proprietary or open-source large-language models to deliver more impact. Now, instead of data being used only by data scientists to drive insights, data can be used by developers to build smarter applications that truly transform a business. These AI applications will be exceptionally demanding, requiring a truly modern operational data platform like MongoDB. In fact, we believe MongoDB has even stronger competitive advantage in the world of AI.
First, the document model’s inherent flexibility and versatility renders it a natural fit for AI applications. Developers can easily manage and process various data types all in one place. Second, AI applications require high-performance parallel computations and the ability to scale data processing on an ever-growing base of data. MongoDB supports these features with features like sharding and auto-scaling. Lastly, it is important to remember that AI applications have the same demands as any other type of application: transactional guarantees, security and privacy requirements, text search, in-app analytics, and more.
Our developer data platform gives developer a unified solution to build smarter AI applications. We are seeing these applications developed across a wide variety of customer types and use cases. For example, Observe.AI is an AI start-up that leverages 40 billion parameter LLM to provide customers with intelligence and coaching that maximize performance of their front-line support and sales teams. Observe.AI processes and run models on millions of support touchpoints daily to generate insights for their customers.
Most of this rich, unstructured data is stored in MongoDB. Observe.AI chose to build on MongoDB because we enable them to quickly innovate, scale to handle large and unpredictable workloads, and meet their security requirements of their largest enterprise customers. On the other end of the spectrum is one of the leading industrial equipment suppliers in North America. This company relies on Atlas and Atlas Device Sync to deploy AI MLs at the edge, to their field team’s mobile devices to better manage and predict inventory in areas with poor physical network connectivity. They chose MongoDB because of our ability to efficiently handle large quantities of distributed data and to seamlessly integrate between network edge and their back-end systems.
As much as we innovate on our products, we also continuously innovate on how we engage with our customers. We are highly focused on reducing friction in the sales process so we can acquire more workloads quickly and cost-effectively given the large size of our market opportunity. Historically, the most significant source of friction has been negotiating with customers to secure an upfront Atlas commitment since it can be hard for customers to forecast consumption growth for a new workload. Given our high retention rates and the underlying consumption growth, several years ago, we began reducing the importance of upfront commitments in our go-to-market process to accelerate workload acquisition. This year, we took additional steps in that direction.
For example, we no longer incentivize reps to sign customers to one-year commitments. Obviously, this has short-term impacts on our cash flow but positions us better for the longer term by accelerating workload acquisition. We are pleased with the impact these changes have had in the business in the first half of the year. Specifically, new workload acquisition has accelerated, especially within existing customers.
We believe that our efforts to reduce friction are resulting in more efficient growth, and we’ll always look for ways to improve our go-to-market approach to make it even easier for customers to bring new workloads onto our platform. Now, I’d like to spend a few minutes reviewing the adoption trends of MongoDB across our customer base. Customers across industries including Renault, Hootsuite, and Ford are running mission-critical projects in MongoDB Atlas, leveraging the full power of our developer data platform. One of the 2023 MongoDB North American Innovation Award winners is Ford.
With a focus on innovation, quality, and customer satisfaction, Ford is a leader in the automotive industry and a household name around the world. Ford is committed to developing advanced technologies that enhance the safety, performance, and sustainability of its vehicles. Their data explorer and transportation mobility cloud applications aggregate customer vehicle data from 24 different sources at a volume ranging up to 15 terabytes. Since migrating to MongoDB Atlas from their previous solution, Ford has seen a 50% performance improvement and faster read/write times.
Cathay Pacific, Foot Locker, and Market Access are examples of customers turning to MongoDB to free up the developer’s time for innovation while achieving significant cost savings. Cathay Pacific, Hong Kong’s home airline carrier operating in more than 60 destinations worldwide, turned to MongoDB on their journey to become one of the first airlines to create a truly paperless flight deck. Flight Folder, their application built on MongoDB, consolidates dozens of different information sources into one place and includes a digital refueling feature that helps crews become much more efficient with fueling strategies, saving significant flight time and costs. Since the Flight Folder launch, Cathay Pacific has completed more than 340,000 flights with full digital integration in the flight deck. In addition to the greatly improved flight crew experience, flight times have been reduced and the digital refueling has saved eight minutes on the ground on average.
All these efficiencies have helped the company avoid the release of 15,000 tons of carbon and save an estimated $12.5 million. Powerledger, Wells Fargo, and System1 are among customers turning to MongoDB to modernize existing applications. System1, a customer acquisition marketing company, acquired MapQuest in 2019. At the time of the acquisition, MapQuest had a fragmented architecture that mixed disparate data persistence technologies with third-party services.
System1 selected Atlas as a key piece of MapQuests’s architecture transformation and has realized estimated cost reductions of 75% and performance improvements of 20% over its prior relational database solution. MapQuest is planning a number of future projects that will use Atlas Search and time series collections to improve the user experience and create a feedback loop on location-based relevancy in different cities. In summary, I’m incredibly stoked with our second-quarter results. Our ability to win new workloads remains strong and are run-anywhere strategy is resonating with customers. While it’s early days on AI, we continue to see evidence that MongoDB will be a platform of choice for AI applications, just like we are for other modern and demanding applications.
We continue to invest to maximize our long-term potential. With that, here’s Michael.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Thanks, Dev. As mentioned, we delivered a strong performance in the second quarter, both financially and operationally. I’ll begin with the detailed review of our second-quarter results and then finish with our outlook for the third quarter and full fiscal year 2024. First, I’ll start with our second-quarter results.
Total revenue in the quarter was $423.8 million, up 40% year over year. As Dev mentioned, we continue to see a healthy new business environment, especially in terms of acquiring new workloads within existing customers. To us, this is confirmation we remain a top priority for our customers and that our value proposition continues to resonate even in this market. Shifting to our product mix.
Let’s start with Atlas. Atlas grew 38% in the quarter compared to the previous year and represents 63% of total revenue, compared to 64% in the second quarter of fiscal 2023 and 65% last quarter. In Q2, Atlas slightly declined as a percentage of revenue due to the exceptionally strong performance of our non-Atlas business, underscoring the demand for MongoDB regardless of where customers are in their cloud adoption journey. As a reminder, we recognize Atlas revenue primarily based on customer consumption of our platform, and that consumption is closely related to end-user activity of the application, which can be affected by macroeconomic factors.
Let me provide some context on Atlas consumption in the quarter. Consumption growth in Q2 was slightly better than our expectations. As a reminder, we had assumed Atlas would continue to be impacted by the difficult macro environment in Q2 and that is largely how the quarter played out. Turning to non-Atlas revenues.
EA significantly exceeded our expectations in the quarter, and we continue to have success selling incremental workloads into our existing EA customer base. We continue to see that our customers, regardless of their mode of deployment, are launching more workloads in MongoDB and moving toward standardizing on our platform. The EA revenue outperformance was, in part, a result of more multiyear deals than we’d expected. In addition, we had an exceptionally strong quarter in our other licensing revenues.
On our last call, we’d mentioned that we would benefit from a few large multiyear licensing deals, most notably the renewal and extension of our relationship with Alibaba. We also closed some additional multiyear licensing deals in the quarter, which was a meaningful contributor to our outperformance and another sign of the popularity of MongoDB and the success of our run-anywhere strategy. As a reminder, under ASC 606 for both EA and licensing contracts, the term license component even for multiyear deals is recognized as upfront revenue. Turning to customer growth.
During the second quarter, we grew our customer base by approximately 1,900 customers sequentially, bringing our total customer count to over 45,000, which is up from over 37,000 in the year-ago period. Of our total customer count, over 6,800 are direct sales customers, which compares to over 5,400 in the year-ago period. The growth in our total customer count is being driven primarily by Atlas, which had over 43,500 customers at the end of the quarter, compared to over 35,500 in the year-ago period. It’s important to keep in mind that the growth in our Atlas customer account reflects new customers to MongoDB in addition to existing EA customers adding incremental Atlas workloads. Let me double-click into our direct customer accounts.
As Dev mentioned, we’re becoming increasingly sophisticated in how we engage our customers, but some of those motions result in the line between our direct sales and our self-service channels becoming more fluid. I thought it’d be helpful to highlight two particular inter-channel dynamics that impact the channel breakdown of our reported customer counts. While these customer movements represent less than 1% of our ARR, we do expect both these trends to continue into the future. And so, we wanted to make sure you understood how they affect our reported customer counts by channel.
First, we are having increasing success leveraging cloud provider self-service marketplaces to drive new customer additions. Growth in cloud marketplace volumes is a major secular trend, and we are the only ISV available on all three hyperscaler marketplaces. Customers can deploy Atlas in seconds through cloud-provider consoles and can pay for it by drawing down their existing cloud commitments. This further reduces friction as it bypasses the need for a contract altogether. For this reason, our direct sales team has been directing certain new prospects to sign up using self-serve marketplaces.
We’ve added several hundred customers using this approach in recent quarters, and these customers show up on our self-serve customer count even though we have a direct sales relationship with them. Second, we continually review and analyze product usage signals to determine the growth potential of our customers. Because we are focused on velocity and efficiency of new workload acquisition, we’re very careful not to deploy our reps on accounts where we don’t see significant incremental benefit from sales rep coverage. If we determine that a direct sales customer can be supported more cost-effectively in the self-serve channel, we’d prefer to free up the reps’ time to focus on winning more new workloads.
So far, this year, we’ve moved over 300 small mid-market direct sales customers to the self-service channel. Moving on to ARR. We had another quarter with our net ARR expansion rate above 120%. We ended the quarter with 1,855 customers with at least $100,000 in ARR and annualized MRR, which is up from 1,462 in the year-ago period. Moving down the income statement, I’ll be discussing our results on a non-GAAP basis unless otherwise noted.
Gross profit in the second quarter was $329 million, representing a gross margin of 78%, which is up from 73% in the year-ago period. It is important to keep in mind that this quarter, we saw exceptional performance of our EA and licensing revenue, which contains a large upfront license component at very high margins, and therefore, we wouldn’t expect to repeat this performance. Our income from operations was $79.1 million, or a 19% operating margin, for the second quarter, compared to a negative 4% margin in the year-ago period. Our strong bottom-line results demonstrate the significant operating leverage in our model and our clear indication of the strength in our underlying unit economics.
The primary reason for our operating income results versus guidance is our revenue outperformance. Net income in the second quarter was $76.7 million, or $0.93 per share, based on 82.5 million diluted weighted average shares outstanding. This compares to a net loss of $15.6 million, or $0.23 per share, on 68.3 million basic weighted average shares outstanding in the year-ago period. Turning to the balance sheet and cash flow. We ended the first quarter with one point — the second quarter with 1.9 billion in cash, cash equivalents, short-term investments, and restricted cash.
Operating cash flow in the second quarter was negative $25.3 million. After taking into consideration approximately $2 million in capital expenditures and principal repayments of finance lease liabilities, free cash flow was negative $27.3 million in the quarter. This compares to negative free cash flow of $48.6 million in the second quarter of fiscal 2023. Three things of note on our cash flow performance in the quarter.
First, as many of you know, Q2 tends to be our seasonally lowest collections quarter of the year because of low contract volumes in Q1 as evidenced by our Q1 ending accounts receivable balance. Second, while our revenue reflects the ASC 606 treatment of multiyear EA and licensing deals, most multi-year contracts are still billed annually, so there’s no equivalent benefit to cash flow. Finally, as Dev mentioned, we continue de-emphasizing the value of upfront commitments, so we’re seeing fewer of them. In other words, we are intentionally collecting less cash upfront in order to win more workloads more quickly. As evidence of this, we grew Atlas revenue 38% year over year, while Atlas dollars committed upfront actually declined by 15% year over year.
Lower upfront commitments only impact the timing of when our customers pay us, not the total payment. But this trend of declining upfront commitments will impact the relationship between our non-GAAP operating income and operating cash flow in the medium term. I’d now like to turn to our outlook for the third quarter and full fiscal year 2024. For the third quarter, we expect revenue to be in the range of 400 million to 404 million.
We expect non-GAAP income from operations to be in the range of 41 million to 44 million and non-GAAP net income per share to be in the range of $0.47 to $0.50 based on 83.5 million estimated diluted weighted average shares outstanding. For the full fiscal year 2024, we expect revenue to be in the range of 1.596 billion to 1.608 billion. For the full fiscal year 2024, we expect non-GAAP income from operations to be in the range of 189 million to 197 million and non-GAAP net income per share to be in the range of $2.27 to $2.35 based on 83 million estimated diluted weighted average shares outstanding. Note that the non-GAAP net income per share guidance for the third quarter and full fiscal year 2024 includes a non-GAAP tax provision of approximately 20%. I’ll provide some more context on our guidance.
First, we have modestly raised our Atlas outlook for the rest of the year primarily to reflect a slightly stronger Q2 and, therefore, a higher starting ARR for the second half. We continue to expect that Atlas consumption growth will be impacted by the difficult macroeconomic environment throughout fiscal ’24. Our revised full-year revenue guidance continues to assume consumption growth that is, on average, in line with the consumption growth we’ve experienced since the slowdown began in Q2 of last year but with a slight seasonal benefit in Q3 and a slowdown in Q4 as observed over the last two years. Second, we expect to see a significant sequential decline in non-Atlas revenues in Q3 as we simply don’t expect similar new business activity, especially when it comes to licensing deals.
For that particular line of business, Q2 was just an extreme positive outlier. The third, we’re raising our non-Atlas revenue estimate for the rest of the year. Even though we don’t expect our exceptional Q2 performance to repeat in the second half, our results in the first half give us incremental confidence in our run-anywhere strategy. We continue to expect, however, that the difficult compare in the back half of the year will impact our non-Atlas growth rate. Finally, thanks to strong performance in Q2 and the increased revenue outlook, we are meaningfully increasing our assumption for operating margins in fiscal ’24 to 12%, at the midpoint of our guidance, an improvement of more than 700 basis points compared to fiscal ’23, while continuing to invest to pursue our long-term opportunity.
As you update your models, please keep in mind that the majority of our planned fiscal ’24 hiring will actually occur in the second half of the year. To summarize, MongoDB delivered excellent second-quarter results in a difficult environment. We were pleased with our ability to win new business and are demonstrating the operating leverage inherent in our model. While we continue to monitor the macro environment, we remain incredibly excited about the opportunity ahead possibly to maximize our long-term value.
With that, we’d like to open it up to questions. Operator?
Questions & Answers:
Operator
Thank you. [Operator instructions] One moment while we compile the Q&A roster. And our first question today will be coming from Raimo Lenschow of Barclays. Your line is open.
Raimo Lenschow — Barclays — Analyst
Thank you. Good new version. Congrats from me on a great quarter. Two quick questions.
First, the — the new or the — the trends you saw for EA — or the numbers you saw for EA this quarter, you called out kind of bigger commitments from existing customers and — and taking more workloads or turning more workloads toward Mongo. And is that — could you talk a little bit toward that in terms of is that a new trend? Was it just kind of kind of very specialist quarter? What are you seeing there because that’s kind of in this sort of environment seems like against what you see from everyone else? So, maybe a couple of factors there. And then, the second question is on the newer products like the streaming and vector databases, how does that feed into the revenue model for Mongo? And that’s it for me. Thank you.
Dev Ittycheria — President and Chief Executive Officer
Sure. So, Raimo, the transfer to EA, I think, is just indication of our run-anywhere strategy. We’ve been very committed to that strategy since the beginning. As you know, we started with EA and then introduce Atlas.
But the whole point is that we give customers choice, and we want to meet customers where they are in terms of what deployment model they want to use. And so, I think this is just puts and takes of the quarter, where we had a number of customers who wanted to double down on EA, and we also had some other non-Atlas business come in in the quarter, which showed up in our results. But it’s really a confirmation of the fact that we give customers choice and customers really appreciate that. And that’s what you see in the results.
With regards to, I think you said, streaming and vector, those will show up in the Atlas revenue line as incremental consumption. There won’t be a separate SKU, but what it will do is drive — as those workloads come on, that will drive incremental consumption of Atlas, which will show up in the Atlas revenue line.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Yeah, I would just add that, also, as part of the broader developer data platform, it gives us the opportunity to win more workloads in the beginning. So, you’ve got both sort of, you know, new workload penetration piece, which Dev mentioned, but also sort of, you know, the increased Atlas numbers is where it’ll show up on a revenue standpoint.
Raimo Lenschow — Barclays — Analyst
OK, Perfect. Thank you. Congrats.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Thank you.
Dev Ittycheria — President and Chief Executive Officer
Thanks, Raimo.
Operator
Thank you. One moment for our next question. And our next question will be coming from Keith Weiss of Morgan Stanley. Your line is open.
Keith Weiss — Morgan Stanley — Analyst
Excellent. This is Keith Weiss on for Sanjit Singh. One question for Dev and one for Michael. Dev, you guys talked about, I think last quarter, 1,500 AI companies using MongoDB.
You talked a lot about your applicability for AI workloads. I think a question that a lot of investors have is like the time frame for when this actually creates real impacts or where it becomes a significant tailwind for just software in general. But more specifically, the question to you is when do you think that becomes a significant tailwind for MongoDB, when we see that more significantly in Atlas revenues? And then, the question for Michael, you talked about the commitments coming down — the Atlas commitments coming down and that being a drag on operating cash flow. Any sense you could give us on how long that drag will persist? Is there any way to size that — that impact over time?
Dev Ittycheria — President and Chief Executive Officer
So — so, Keith, on — on AI, obviously, we’re really excited about the opportunity that AI presents. We continue to add many more AI customers this quarter. In the short term, we’re really excited by some of the use cases we’re seeing. We talked about Observe.AI, which is a management consulting company, a more traditional company, using MongoDB for a very impactful AI use case.
And longer term, we believe our — our developer data platform value prop will just drive more AI adoption. People want to use one compelling, unified developer experience to address a wide variety of use cases, of which AI is just one of them. And — and we’re definitely hearing from customers being able to do that on one platform versus — versus bolting on a bunch of point solutions is far more the preferable approach. And so, we’re excited by the opportunity there.
And I think you had some questions — oh, on the other thing on partners, I do want to say that we’re seeing a lot of work and activity with our partner channel on the AI front as well. We’re working with Google in the AI start-up program, and there’s a lot of excitement. Google had their next conference this week. We’re also working with Google to help train Codey, their code generation tool, to help people accelerate the development of AI and other applications. And we’re seeing — you know, we’re seeing a lot of interest in our own AI innovators program.
We’ve had lots of customers apply for that program. So, we’re super excited about the interest that we’re generating.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
And on your other question, Keith, you know, it’s been a multi-year journey where we’ve been focused on reducing friction and accelerating new workload adoption. I do think, you know, as we called out, we continue to make additional steps. And Dev called out some of the specific incremental steps, you know, this year. I think it’s part of a transition, you know.
If you look at the Atlas revenue growth, Atlas grew 38% year over year, but dollars collected, you know, upfront shrank 15%, right? And so, that gives you a sense for, you know, the — the magnitude or the divergence there that’s showing up in the, you know, up income versus the CF bridge. I think, like most things, you know, there’ll be a transition time period, but then it will settle into a more normalized level. But I think we’ve still got a little bit more transition to go as we kind of work through, you know, the balance of the year.
Keith Weiss — Morgan Stanley — Analyst
Got it. Thank you, guys.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Thank you, Keith.
Operator
Thank you. One moment for our next question. And our next question will be coming from Kash Rangan of Goldman Sachs. Your line is open.
Kash Rangan of Goldman Sachs, your line is open.
Kash Rangan — Goldman Sachs — Analyst
Oh, I’m sorry, I didn’t hear my name. Thank you very much and congrats, Dev, Michael, on the quarter. It’s hard to put up this kind of operating margin performance being a database company at the scale that you’re operating. So, kudos on that.
The Relational Migrator came off of beta and came into GA this quarter. So, I wonder if that had any particular impact on the EA business because you’ve certainly upsided your modest expectations. I want to get a little bit more detail on how that pipeline of Relational Migrator data customers should play out. Is it going to be showing up in Atlas, or is going to be showing up in enterprise, the on-prem version? And on — on AI, just curious if you can quantify the level of consumption impact in the future to Atlas that you could attribute to the different new things that Mongo is working on, whether it’s AI or streaming.
How should we think about the incremental opportunities for consumption afforded by some of the new things you launched at MongoDB live in New York a couple of months back? Thank you so much. Congrats.
Dev Ittycheria — President and Chief Executive Officer
Sure. So, regarding Relational Migrator, it’s important for investors to know that this is really a high-end enterprise play. That’s where the bulk of the legacy relational market is. And Relational Migrator is designed to help customers reduce the switching costs of migrating off relational databases to MongoDB for both EA and Atlas.
So, it’s a play to — depending again on the customer’s choice of their deployment model, but it’s really meant to reduce the switching costs. I would say that there was no real impact in terms of revenue of customers using Relational Migrator because we just only made it generally available in June, but there’s a tremendous amount of excitement. We have a large pipeline of customers who are very interested and are actually starting to use relational Migrator in projects that have begun, but there was no real impact on the quarter. Regarding your second question about some of the new products and the impact of AI long term, what I would say is we definitely believe we’ll have a big impact long term. We think that things like Vector Search just make it so much easier to build smarter applications on MongoDB.
That unified developer experience is a key differentiator. There’s a really strong interest in our public preview product. We also see a lot of interest in Stream Processing. Stream Processing is — is a use case that’s really optimized for MongoDB.
The data is typically JSON. The variability of the data lends itself to a document model that’s much more flexible. It’s obviously very developer-oriented, where all the alternatives are using very rigid schemas and are much more complicated to use. So, that plays into our sweet spot, so we think we have a big opportunity there.
But — so, it’s hard to quantify what that impact will be in the long term. But I will tell you that we’re really excited and the interest level in the new products is incredibly high.
Kash Rangan — Goldman Sachs — Analyst
Fantastic. Thank you.
Dev Ittycheria — President and Chief Executive Officer
Thank you, Kash.
Operator
Thank you. One moment for the next question. Our next question will be coming from Brad Reback of Stifel. Your line is open.
Brad Reback — Stifel Financial Corp. — Analyst
Great. Thanks very much. I’m not sure, Dev or Michael, but going back to the commentary on fewer upfront Atlas commits, you know, oftentimes, when customers sign multi-year deals and pay upfront, they get a better rate. So, if we were to think about not having them pay you upfront and make long-term commits, is that a net margin benefit to you guys on the pricing side?
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Yeah, so a couple of things. Thanks, Brad, for the question. In general, for us, even before the sort of evolution and changes in multi-year deals, typically, they were not all paid upfront. Typically, ours has been annually, you know, billed.
But, yes, to your point, I think as we’ve reduced upfront commitment, you have a couple of dynamics. The key one is when we are not motivating it or providing an incentive to our sales force and it winds up being customer-driven, the leverage in that negotiation shifts. And on the margin, that is helpful for, you know, the ultimate pricing or discount and winds up with sort of better pricing for us, you know, less discounting to the customer.
Brad Reback — Stifel Financial Corp. — Analyst
Excellent. And then, on your commentary about second-half hiring outpacing first-half, would it be correct to assume that the hiring environment’s a little less competitive, so you might actually be able to find people more easily and get better pricing for them as well? Thanks.
Dev Ittycheria — President and Chief Executive Officer
Yeah, what I would say, Brad, is that, you know — I would say, in general, obviously, the frostiness of a few years ago has abated, but for certain skill sets, there’s still significant premium for talent. And we don’t want to lower our bar just to optimize on costs. We pride ourselves on recruiting the best of the best in this industry, and we focus on paying market rates. And so — so, while it’s a little easier because the market is a little softer, I wouldn’t suggest that all of a sudden we’re getting employees at a massive discount.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Yeah, I would think about it as availability rather than — rather than cost and then throw in some of the dynamics, you know, some places around different return-to-office models and other things. I think that sort of incrementally is likely to provide opportunities in the back half of the year. And, you know, as they present themselves, we’ll certainly pursue those.
Brad Reback — Stifel Financial Corp. — Analyst
Excellent. Thank you.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Thank you.
Operator
Thank you. One moment for the next question. Our next question will be coming from Karl Keirstead of UBS. Your line is open.
Karl Keirstead — UBS — Analyst
OK, great. Maybe this one to Michael. I wouldn’t normally ask about the other segment, but it’s such an outlier. If I could ask a two-parter.
First is, what surprised on the upside there? Was the Alibaba deal much larger than you thought, or did you grab a few others? Maybe you could unpack that. And secondly, you did tell us that the second-half guidance assumes a significant decline in the non-Atlas business. Is it fair to assume that this other category might return back to the levels it was at pre the July quarter? Thank you.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Yeah, thanks, Karl. No, other deals, not Alibaba. Alibaba was, you know, baked at the time of the last guidance call. So, it was sort of incremental deals that surprised us to the upside there.
And, yes, obviously, it’s a — it’s a volatile or variable, especially given the 606 and the nature of it where it goes given the lumpiness of the term license revenue and things like that. And so, yes, I think that this is not a repeatable performance, and I think it should settle back down to a more — to a lower and more normalized level.
Karl Keirstead — UBS — Analyst
OK, and then if I could ask a follow-up, Mike, you did a good job explaining the changes in the model and the licensing on cash flow. But it’s not a metric you often talk about, but your deferred revenue balance was actually down year over year. Highly unusual, is this basically the same explanation that would be impacting DR? Thank you.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Yeah, I think it’s the same explanation or discussion, you know, overlaid with our, you know, recurring discussion around billings. And that’s sort of not a — not a metric that we focused on and that we’ve sort of discouraged people from — from using, and that we’re focused sort of on those workloads and winning new workloads rather than large upfront commitments. But one of the ways that plays out is absolutely, you know, in deferred and for anyone still doing — you know, defer — I mean, calculated billings — calculations that will affect that there as well, yes.
Karl Keirstead — UBS — Analyst
OK. Awesome. Thanks so much.
Operator
Thank you. One moment for the next question. Our next question is coming from Rishi Jaluria of RBC. Your line is open.
Richard Poland — RBC Capital Markets — Analyst
Hi, this is Rich Poland on — on for Rishi Jaluria today. Thanks for taking my question. So, I guess if we look at the workloads you have in front of you with Vector Search, Relational Migrator, and streaming, and could even throw in application search, which — which was, you know, more of a driver, let’s call it, last year. But if we had to stack rank each of those workloads in terms of your positioning to win and — and your — your overall opportunity in each of those use cases, how would you go about doing that?
Dev Ittycheria — President and Chief Executive Officer
Yeah, so Rich, thanks for your question. I would say, obviously, the general operational workload of what people call the OLTP workload is still the bread-and-butter workloads that people come to us. And Relational Migrator would just be more of that because they’re migrating operational workloads off relational databases to MongoDB. And then, the other use cases are — really other products — really function — the use cases that customers — customers are really interested in.
For example, Atlas Device Sync, which is really focused on the enterprise mobility play, for example, point of sale use, you know, devices for the retail industry in automotive, connected car; in manufacturing, instrumenting the factory floor. So, it really depends on the use cases. In application search, we’re really seeing an acceleration of large workloads in that — for that product. So, we’re really excited about the size of some of the business that we’re seeing there.
Obviously, Vector is still in public preview. So, you know, we hope to have it to GA sometime next year, but we’re really excited about the — the early and high interest from enterprises. And obviously, some customers are already deploying it in production even though it’s a public-preview product. Streaming is something that we’re super excited about. This is more for event-driven app — real-time applications.
It’s just very suitable for MongoDB due to the, you know, most of the data is in JSON, and the flexibility model makes it a very compelling play. And so — so, I would say that it really depends on the customer’s use case. What it really does is just enables us to go after more workloads more quickly. and it really positions us as a truly strategic supplier to large — large enterprises and obviously a critical supplier for early stage companies.
And that’s our strategy is to get customers to use MongoDB for a variety of use cases across a variety of deployment models.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Yeah, the other thing that I’d add, which is probably implicit and comes across to that, but I think it’s important enough to make explicit is one thing that that sort of — Rich, in your question, sort of the slice-by-slice view misses is the aggregate benefit of delivering the whole platform, right, and delivering a common, you know, integrated unified experience to developers so they don’t have to use a bunch of point solutions. And I think that’s really a key part of the strategy.
Richard Poland — RBC Capital Markets — Analyst
Got it. That makes perfect sense. Thank you.
Operator
Thank you. One moment for the next question. Our next question will be coming from Brent Bracelin of Piper Sandler. Your line is open.
Brent Bracelin — Piper Sandler — Analyst
Good afternoon. This is Brent. I believe I’m — I was next there. Dev, I wanted to talk a little bit about AI.
And Mongo has been at the leading edge of powering new apps for the better part of the decade. We’re all trying to figure out what this AI-first world looks like. Given your purview as a — as a new app enabler, what’s your sense in the next three to four years? How many of these new apps are going to layer in large language models, and — and what is the net result on — on the database? Thanks.
Dev Ittycheria — President and Chief Executive Officer
Yeah, so Brent, thanks for your question. I firmly believe that we, as an industry, tend to overestimate the impact of a new technology in — in the short term and underestimate the impact in the long term. So, as you may know, there’s a lot of hype in the — in the market right now, in the industry, right around AI. And some of the early stage companies in the space have the valuations to the roof.
In some cases, almost it’s hard to see how people can make money because the risk reward doesn’t seem to be sized appropriately. So, there’s a lot of hype in this space, but I do think that AI will be a big impact for the industry and for us long term. I believe that almost every application, both new and existing, will have some AI functionality embedded into the application over the next, in your horizon, three to five years. And let me just remind people why we see — where we see AI impacting our business.
One, developers will become far more productive with the use of cogeneration and code-assist tools. What that will mean is like that will lead to more applications, which means they need more databases and more data platforms. Second, you know, developers will use things like generative AI to just build smarter and more intelligent applications. One, they don’t want to use point solutions because, it’s clear, developers want one platform to process and analyze data and metadata and vectorized data, and MongoDB is that platform. So, which is why we’re seeing so much interest.
And Vector Search, I believe, is really ultimately a feature, not a product. And essentially, it’s basically enabling people to marry private data with public data to really offer a compelling experience. And there’s so much interest in our public preview right now. And as we — as I mentioned earlier, we’ve continued to add many more customers this quarter, and we think the impact will be big.
But in the short term, you know, these are still smaller workloads, but they’re going to grow over time. Some of the use cases are really interesting, but the fact is that we’re really well positioned because what — what — what generative AI does is really instantiate AI in front of — in software, which means developers play a bigger role rather than data scientists. And that’s where you really see the business impact, and I think that impact will be large over the next three to five years.
Brent Bracelin — Piper Sandler — Analyst
Super helpful color there. And a quick follow-up for Mike. Three-year annual growth rate for EA is over 20%. It slipped below 10% in Q1, spiked now above 30% here in Q2, excluding the — the licensing multi-year deals.
If you continue to see enterprise workload migrations happen, why can’t you continue to see strength in EA?
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Yeah, so a couple of things. I think as Dev mentioned, some of the relational migrations, you know, with the destination of those, whether it’s Enterprise Advanced or Atlas will depend on, you know, the customer’s cloud strategy and their overall approach. From a strategy standpoint, certainly, some of that could benefit, you know, EA. And we’ve continued to see, you know, robust adoption and adoption of new workloads within that EA customer base.
I think the key thing, you know, at least thinking about the back half of this year and as you start thinking about next year is just we have had very strong results from EA. And so, when we think about EA on a compare basis, I just think it’s really important to keep in mind.
Brent Bracelin — Piper Sandler — Analyst
OK, thank you.
Operator
Thank you. One moment for the next question. Our next question will be coming from Jason Ader with William Blair. Your line is open.
Jason Ader — William Blair and Company — Analyst
Yeah, thank you. Good afternoon. Just wanted to get a sense on EA. You talked about doing a good job of existing customers adding incremental workloads.
What’s the main driver there? Is there something you’re doing differently, or do you think it’s just maturity and customers getting more comfortable with you for more workloads?
Dev Ittycheria — President and Chief Executive Officer
Yeah, I think it’s really a function of people really recognizing that MongoDB is truly a standard. It’s a platform they can bet on to run the most mission-critical use cases. And the flexibility of the deployment models means that they can start on-prem but they can always migrate to the cloud. And so, that optionality — that built-in optionality also makes going to EA that much more comforting because it’s not like they’ll be locked into an on-prem solution or locked into some proprietary cloud solution.
So, that — that’s why I believe, just given our maturity, given how we’re really becoming a standard in so many organizations, people are much more comfortable doubling down on the EA.
Jason Ader — William Blair and Company — Analyst
Gotcha. And then, just to follow up on that, on the EA question, it seems like — I mean I don’t want to put words in your mouth. It seems like maybe you’ve been a little bit surprised at the strength of EA relative to Atlas over the last year. I mean, Atlas has been really strong too, but EA, I think, surprised you more to the upside.
What does that say, I guess, about kind of on-prem versus cloud or self-managed versus fully managed? Any comments on that, Dev?
Dev Ittycheria — President and Chief Executive Officer
Yeah, what I would say is — is — it really is reinforcement that customers still will run workloads on-prem, that they still will run workloads that they want to manage themselves versus, you know, use a managed service like Atlas. And so — and I think customers value choice. The customers value the ability to have different deployment models but also value the fact that if they want to migrate from one deployment model to another, it’s easiest to do so using MongoDB. So, I think what we’re really seeing is customers valuing choice and the run-anywhere strategy really resonating with customers.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
And I would just add, Jason, that the premise of your question is correct. We have been very surprised, obviously pleasantly so, with the performance of EA. It’s been — it’s been terrific to see, but it’s definitely been surprising to the upside.
Jason Ader — William Blair and Company — Analyst
Great. Thank you.
Operator
Thank you. One moment for the next question, please. And the next question will be coming from Tyler Radke of Citi. Your line is open.
Tyler Radke — Citi — Analyst
Yes, thanks for taking the question. So, Atlas revenue grew by almost 30 million quarter over quarter, which is the highest you’ve ever seen. It — certainly that performance is better than any of the other consumption models you’re seeing. Yet it seems like the commentary, at least on Atlas consumption, was — was pretty consistent with your expectations and still a bit below where it had been pre some of the macro challenges.
So, could you just kind of unpack what — what’s driving that — that strength and revision back to kind of record high levels of sequential dollar adds? Is it — is it better pricing just given some of the sales changes you made, or perhaps maybe it’s the — the new AI use cases that you talked about? If you could just help us understand that a bit better. Thank you.
Dev Ittycheria — President and Chief Executive Officer
Yeah, thanks for the question, Tyler. A few things. If you’re looking at on an absolute dollar basis, obviously, the business is much larger. So, you know, let’s start with that.
Secondly, if we were looking at the sequential, you know, from Q1 to Q2, remember Q1 has fewer days, and so that’s obviously part of the dynamic and you’ll see that historically as well. And then, third, we had talked about the Q1 consumption being better than planned and, therefore, the starting ARR in Q2 being better. We saw the consumption itself kind of once we had that, you know — once you kind of adjust for that higher starting base, broadly in line with our expectations, so slightly better. But, you know, not — not — not big upside there.
And when we look at it in the back half of the year, that’s what we’re continuing to assume is that same trend line, obviously, seasonally adjusted based on those emerging seasonal patterns. But that’s really how to kind of tie and square, you know, all the numbers.
Tyler Radke — Citi — Analyst
OK, that’s helpful. And then a follow-up question. Just in terms of the excitement, obviously, out in the industry around generative AI, I guess I’m curious specifically how internally you’re using generative AI, you know, in products like Relational Migrator to automate a lot of the — the rearchitecture process? And, you know, secondly, are you seeing a greater appetite from customers to modernize kind of legacy transactional applications? And — and is that — is that starting to pick up just — just given the excitement around gen AI? Thank you.
Dev Ittycheria — President and Chief Executive Officer
Yes, so with regards to gen AI, I mean we do see opportunities essentially the reason, you know, when you migrate using Relational Migrator, there’s really three things you have to focus on. One is mapping the schema from the old relational database to the MongoDB platform, moving the data appropriately, and then also rewriting some, if not all, of the application code. Historically, that last component has been the most manually intensive part of the migration. Obviously, with the advance cogeneration tools, there’s opportunities to automate a lot of the rewriting of the application code.
I think we’re still in the very early days. You’ll see us continue to add new functionality to Relational Migrator to help again reduce the switching costs of doing so. And that’s obviously an area that we’re going to focus. So, that’s, in some ways, a big opportunity for us.
And, Tyler, there was a second part to your question, which I…
Tyler Radke — Citi — Analyst
Yeah, it was just around the customer appetite, like, is that — the frenzy around gen AI, is that causing, you know, an acceleration in the pace in which customers want to take on these modernization projects?
Dev Ittycheria — President and Chief Executive Officer
Yeah, so I would say that the reason MongoDB is well-suited for these new modernization projects is one, obviously, the data that’s trapped in these legacy platforms is incredibly important if you want to leverage that proprietary data for a competitive advantage. Two is that the performance requirements of these new modern applications require new modern platform. And three, because it’s such an iterative, you know, area where people are just changing so quickly, you also need a platform that’s inherently flexible. So, that’s driving people to move to MongoDB and to more modern platforms more quickly.
So, unlike the old lift and shift where people are just trying to, say, avoid paying the Oracle tax, now people are being much more thoughtful about not just lifting and shifting but modernizing and going off relational to MongoDB. And that’s definitely a trend that’s increasing.
Tyler Radke — Citi — Analyst
Thank you.
Dev Ittycheria — President and Chief Executive Officer
Thanks, Tyler.
Operator
Thank you. One moment for our next question. And our next question will be coming from Patrick Walravens of JMP Securities. Your line is open.
Unknown speaker
Hi, this is Alan on for Pat. Thanks for taking the question and congrats on the strong quarter. Just a quick one for me. What will be pricing structure for some of the new features like Vector Search and Stream Processing be?
Dev Ittycheria — President and Chief Executive Officer
So, the pricing will be a function of the — obviously, the consumption of the back-end infrastructure that supports those new capabilities. So, it’ll show up as essentially more consumption of Atlas clusters or increases of clusters depending on the load of the application. It’ll show up on the Atlas revenue line.
Unknown speaker
Great. Thank you.
Operator
Thank you. One moment for the next question. And our next question will be coming from Michael Turits of KeyBanc. Your line is open.
Michael Turits — KeyBanc Capital Markets — Analyst
Hello?
Dev Ittycheria — President and Chief Executive Officer
Hi there.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Hey, Michael.
Michael Turits — KeyBanc Capital Markets — Analyst
Hey. OK. My name got swallowed there, wasn’t sure it was me. Thanks.
A quick one for you, Mike, and then one for Dev. Very quick, Mike, are you able to comment on any linearity in the quarter relative to those consumption growth trends and how we exited? And then, Dev, for you, you just said that you think that Vector Search is a feature, not — not a product. You know, there are — you know, like your database is deliberately out there explicitly out there in the market, and then you — as well as others who don’t have vector databases, including Google with Alloy the other day, are talking about the applicability of their databases for vector embedding. So, can you talk about how that’s playing out as far as you can tell with customers in terms of their receptivity of looking for something besides a dedicated vector database for this? So, linearity question and then that one.
Dev Ittycheria — President and Chief Executive Officer
Sure, yeah, just quickly into linearity, don’t think there’s anything particularly to point out of note there. So, regarding Vector Search, and I’ve shared this with other — talked about this previously, you know, Vector Search is really a reverse index. So, it’s like an index is built into all databases. I believe, over time, Vector Search functionality will be built into all databases or data platforms in the future.
Yes, there are some point products that are just focused solely on Vector Search, but essentially, it’s a point product that still needs to be used with other technologies like MongoDB to store the metadata, the data to be able to process and analyze all that information. So, developers have spoken loudly that, you know, having a unified and elegant developer experience is a key differentiator. It removes friction in how they work. It’s much easier to build and innovate on one platform versus learning and supporting multiple technologies.
And so, my strong belief is that, ultimately, Vector Search will be embedded in many platforms, and our differentiation will be, again, like it always has been, a very compelling and elegant developer experience.
Michael Turits — KeyBanc Capital Markets — Analyst
Thanks. Dev and Mike.
Operator
Thank you. And one moment for the next question. Our next question will be coming from Mike Cikos of Needham. Your line is open.
Mike Cikos of Needham, your line is open.
Mike Cikos — Needham and Company — Analyst
Oh, I’m sorry. I apologize, the operator tuned out when they mentioned me. Thanks for getting me on the call here, guys. If I could just follow up on — on, Dev, your comments there in response to Michael on — on the Vector Search.
I know that we’re talking about the developers and how they — they’re voting here because they want the data in a unified platform, unified database that preserves all that metadata, right? But I would think there’s probably also a benefit to having it all in a single platform as well just because you’re lowering the TCO for your customers as well, right? They’re not paying a tax for the movement or duplication of all that data between different vendors. Is that also a fair assumption when I’m thinking about the potential that you guys bring versus maybe some of those more point features or databases out there?
Dev Ittycheria — President and Chief Executive Officer
Well, with vectors, vectors are really a mathematical representation of different types of data. So, there’s not a ton of data. Unlike application search, where there’s profound benefits by storing everything on one platform versus having an operational database and a search database and some glue to keep the data in sync, that’s not as much the case with Vector because you’re talking about storing essentially, you know, an elegant index. And so, it’s more about the user experience and the development workflow that really matters.
And what we believe is that offering the same taxonomy and the same way they know how to use MongoDB to also be able to enable Vector Search functionality is a much more compelling differentiation than developer having to bolt on a separate, you know, vector solution and having to provision, configure, and manage that solution along with all the other things they have to do.
Mike Cikos — Needham and Company — Analyst
Got it. Thank you for helping clear my understanding on that. And then, just a quick follow-up for Michael. Michael, I’ve gotten a couple inbounds.
Just trying to unpack the Q3 revenue guide here, specifically as it pertains to Atlas. And I think what people are looking at is, I think, Atlas embeds slower sequential growth on a — on a daily consumption basis. The questions I’m getting are, was there anything one time to Q2 — 2Q that would cause us to think that the daily Atlas consumption growth would decelerate going into 3Q, or anything else you can tease out there while we have you?
Michael Gordon — Chief Financial Officer and Chief Operating Officer
No, I think if you look at what we said is the real underlying reason for the increase, you know, obviously, we don’t guide, you know, by product, but we are trying to give you a whole bunch of color around it. The real increase in the Atlas number is, given the slight outperformance in Q2, we have a starter hiring ARR in Q2, and that’s at the beginning of Q3. And that’s really what’s flowing through in the numbers and in the guidance.
Mike Cikos — Needham and Company — Analyst
Terrific. Thank you very much, guys. I appreciate it.
Dev Ittycheria — President and Chief Executive Officer
Thank you, Mike.
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Thanks, Mike.
Operator
Thank you. This concludes the Q&A session for today. And I would now like to call and turn the call back over to Dev Ittycheria, CEO, for closing remarks. Please go ahead.
Dev Ittycheria — President and Chief Executive Officer
Thank you,, everyone, for joining us today. I just want to reinforce that we had another strong quarter of new business performance, which really validates our value proposition and run-anywhere strategy. Again, we remain focused on the North Star, which is acquiring new workloads both from new workloads — in new customers and existing customers. And we’re innovating both on the product and go-to-market dimensions to accelerate workload acquisition.
And while it’s early days, we believe that, with the rise of AI, we — MongoDB will be a beneficiary of — as AI becomes more prominent. Thank you very much, and I appreciate all your time. Take care.
Operator
[Operator signoff]
Duration: 0 minutes
Call participants:
Brian Denyeau — Investor Relations
Dev Ittycheria — President and Chief Executive Officer
Michael Gordon — Chief Financial Officer and Chief Operating Officer
Raimo Lenschow — Barclays — Analyst
Keith Weiss — Morgan Stanley — Analyst
Kash Rangan — Goldman Sachs — Analyst
Brad Reback — Stifel Financial Corp. — Analyst
Karl Keirstead — UBS — Analyst
Richard Poland — RBC Capital Markets — Analyst
Brent Bracelin — Piper Sandler — Analyst
Jason Ader — William Blair and Company — Analyst
Tyler Radke — Citi — Analyst
Unknown speaker
Michael Turits — KeyBanc Capital Markets — Analyst
Mike Cikos — Needham and Company — Analyst
MMS • RSS
![]() Blair William & Co. IL boosted its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 40.4% in the first quarter, according to its most recent filing with the Securities & Exchange Commission. The fund owned 247,731 shares of the company’s stock after buying an additional 71,273 shares during the quarter. Blair William & Co. IL owned approximately 0.35% of MongoDB worth $57,751,000 as of its most recent filing with the Securities & Exchange Commission.
Blair William & Co. IL boosted its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 40.4% in the first quarter, according to its most recent filing with the Securities & Exchange Commission. The fund owned 247,731 shares of the company’s stock after buying an additional 71,273 shares during the quarter. Blair William & Co. IL owned approximately 0.35% of MongoDB worth $57,751,000 as of its most recent filing with the Securities & Exchange Commission.
Other institutional investors have also added to or reduced their stakes in the company. BI Asset Management Fondsmaeglerselskab A S grew its position in MongoDB by 130.1% during the 1st quarter. BI Asset Management Fondsmaeglerselskab A S now owns 352 shares of the company’s stock valued at $82,000 after purchasing an additional 199 shares during the last quarter. SYSTM Wealth Solutions LLC lifted its stake in shares of MongoDB by 151.7% in the 1st quarter. SYSTM Wealth Solutions LLC now owns 6,983 shares of the company’s stock worth $1,628,000 after purchasing an additional 4,209 shares during the period. Maytus Capital Management LLC bought a new position in shares of MongoDB in the 1st quarter worth approximately $4,896,000. First Republic Investment Management Inc. lifted its stake in shares of MongoDB by 1,138.4% in the 1st quarter. First Republic Investment Management Inc. now owns 79,332 shares of the company’s stock worth $18,494,000 after purchasing an additional 72,926 shares during the period. Finally, Charles Schwab Investment Management Inc. lifted its stake in shares of MongoDB by 2.4% in the 1st quarter. Charles Schwab Investment Management Inc. now owns 229,503 shares of the company’s stock worth $53,502,000 after purchasing an additional 5,331 shares during the period. 88.89% of the stock is currently owned by institutional investors.
Insider Transactions at MongoDB
In related news, CRO Cedric Pech sold 360 shares of the company’s stock in a transaction dated Monday, July 3rd. The shares were sold at an average price of $406.79, for a total value of $146,444.40. Following the transaction, the executive now owns 37,156 shares in the company, valued at approximately $15,114,689.24. The sale was disclosed in a document filed with the SEC, which is accessible through the SEC website. In other news, CRO Cedric Pech sold 360 shares of the company’s stock in a transaction that occurred on Monday, July 3rd. The stock was sold at an average price of $406.79, for a total transaction of $146,444.40. Following the sale, the executive now directly owns 37,156 shares of the company’s stock, valued at approximately $15,114,689.24. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this hyperlink. Also, CEO Dev Ittycheria sold 50,000 shares of the company’s stock in a transaction on Wednesday, July 5th. The shares were sold at an average price of $407.07, for a total value of $20,353,500.00. Following the completion of the transaction, the chief executive officer now directly owns 218,085 shares in the company, valued at approximately $88,775,860.95. The disclosure for this sale can be found here. In the last ninety days, insiders sold 79,220 shares of company stock worth $32,161,151. 4.80% of the stock is currently owned by insiders.
MongoDB Price Performance
Shares of NASDAQ:MDB traded up $5.23 during trading on Thursday, hitting $380.75. 1,235,638 shares of the company were exchanged, compared to its average volume of 1,672,537. The company has a quick ratio of 4.19, a current ratio of 4.19 and a debt-to-equity ratio of 1.44. MongoDB, Inc. has a 1-year low of $135.15 and a 1-year high of $439.00. The company has a market capitalization of $26.87 billion, a P/E ratio of -80.41 and a beta of 1.13. The business’s 50 day moving average is $390.07 and its 200-day moving average is $302.31.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Thursday, June 1st. The company reported $0.56 earnings per share for the quarter, beating the consensus estimate of $0.18 by $0.38. The business had revenue of $368.28 million for the quarter, compared to analysts’ expectations of $347.77 million. MongoDB had a negative return on equity of 43.25% and a negative net margin of 23.58%. The business’s revenue was up 29.0% on a year-over-year basis. During the same period last year, the business earned ($1.15) EPS. Equities analysts forecast that MongoDB, Inc. will post -2.8 earnings per share for the current year.
Wall Street Analyst Weigh In
Several research firms have recently commented on MDB. 22nd Century Group reissued a “maintains” rating on shares of MongoDB in a report on Monday, June 26th. Oppenheimer upped their price target on shares of MongoDB from $270.00 to $430.00 in a report on Friday, June 2nd. Sanford C. Bernstein upped their price target on shares of MongoDB from $257.00 to $424.00 in a report on Monday, June 5th. KeyCorp upped their price objective on shares of MongoDB from $372.00 to $462.00 and gave the stock an “overweight” rating in a research note on Friday, July 21st. Finally, VNET Group reissued a “maintains” rating on shares of MongoDB in a research report on Monday, June 26th. One research analyst has rated the stock with a sell rating, three have given a hold rating and twenty have issued a buy rating to the company. Based on data from MarketBeat, MongoDB has an average rating of “Moderate Buy” and a consensus target price of $379.23.
Get Our Latest Stock Report on MDB
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Which stocks are major institutional investors including hedge funds and endowments buying in today’s market? Click the link below and we’ll send you MarketBeat’s list of thirteen stocks that institutional investors are buying up as quickly as they can.
MMS • RSS
Shares of MongoDB Inc.
MDB,
+1.54%
rallied more than 8% in the extended session Thursday after the software company reported fiscal 2024 second-quarter earnings well above forecasts and said it has an “even stronger” competitive advantage “in the world of AI.” MongoDB lost $37.6 million, or 53 cents a share, in the quarter, compared with a net loss of $118.9 million, or $1.74 a share, in the year-ago period. Adjusted for one-time items, MongoDB earned 93 cents a share. Revenue rose 40% to $423.8 million, the company said. Analysts polled by FactSet expected adjusted earnings of 46 cents a share on sales of $394 million. “We are at the early stages of AI powering the next wave of application development,” Chief Executive Dev Ittycheria said in a statement. MongoDB “provides developers a unified platform that supports both the foundational requirements necessary for any application and the exceptionally demanding needs of AI-specific applications,” he said. The company guided for full-year revenue of $1.596 billion to $1.608 billion and adjusted EPS of $2.27 to $2.35 for the fiscal 2024. Shares of MongoDB ended the regular trading day up 1.5%.
MMS • RSS

MongoDB Inc. surprised investors and analysts today by smashing quarterly earnings and revenue forecasts as well as providing a better outlook for its current quarter.
For its second quarter ended July 31, MongoDB reported adjusted earnings per share of 93 cents, up from a loss of 23 cents per share in the same quarter of last year, on revenue of $423.8 million, up 40% year-over-year. Analysts were expecting a far more modest 46 cents per share on revenue of $393.68 million.
Subscription revenue in the quarter jumped 40% from a year ago, to $409.3 million, and service revenue rose 20%, to $14.5 million. MongoDB did report a net loss of $37.6 million, but like most of its figures, it was a vast improvement, up from a net loss of $118.9 million the year prior. It had $1.9 billion in cash and cash equivalent on hand as of the end of the month.
Recent business highlights include MongoDB continuing to build out its artificial intelligence ecosystem, including a partnership with Google Cloud that is intended to accelerate the use of generative AI to build new types of applications. The company also added new products and features to MongoDB Atlas, including new generative AI capabilities for MongoDB’s Vector Search feature, Search Nodes for dedicated resources with search workloads at scale and Stream Processing from processing high-velocity data streams. Chief Executive Dev Ittycheria noted the “ongoing success of our new business efforts for Atlas and Enterprise Advanced across our sales channels.”
“We are at the early stages of AI powering the next wave of application development,” he added in prepared remarks in the company’s earnings release. “We believe MongoDB provides developers a unified platform that supports both the foundational requirements necessary for any application and the exceptionally demanding needs of AI-specific applications, making our competitive advantage even stronger in the world of AI.”
MongoDB’s outlook followed the trend of quarterly earnings and revenue and smashed expectations, repeating the success of the previous quarter. For its fiscal third quarter, MongoDB expects adjusted earnings of 47 to 50 cents per share on revenue of $400 million to $404 million. Analysts were expecting 27 cents and $389.12 million. For its full fiscal year, the company expects $2.27 to $2.35 a share in earnings on $1.596 billion to $1.608 billion, versus analysts who were expecting $1.55 and $1.55 billion.
Despite the stellar numbers, MongoDB shares rose only just shy of 5% in late trading.
Mindy Lieberman, chief information officer of MongoDB, and Tara Hernandez, vice president of developer productivity at MongoDB, spoke with theCUBE, SiliconANGLE Media Inc.’s livestreaming studio, in June on the company’s journey to AI integration:
Photo: MongoDB
Your vote of support is important to us and it helps us keep the content FREE.
One-click below supports our mission to provide free, deep and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger and many more luminaries and experts.
THANK YOU