Month: October 2023

MMS • RSS

Cloud computing has opened new doors for app development and hosting. Before cloud services became mainstream, developers had to maintain their own expensive servers. Now, cloud platforms like AWS and Azure provide easy database hosting without the high hardware costs. Cloud databases offer the flexibility and convenience of the cloud while providing standard database functionality. They can be relational, NoSQL, or any other database model, accessed via API or web interface.
In this review article, we will explore the top 7 cloud databases used by professionals to build robust applications. These leading cloud database platforms enable developers to efficiently store and manage data in the cloud. We will examine the key features, pros, and cons of each platform, so you can determine which one is the right fit for your app development needs.

Azure SQL Database is a fully managed relational cloud database that is part of Microsoft’s Azure SQL family. It provides a database-as-a-service solution built specifically for the cloud, combining the flexibility of a multi-model database with automated management, scaling, and security. Azure SQL database is always up-to-date, with Microsoft handling all updates, backups, and provisioning. This enables developers to focus on building their applications without database administration overhead.
🔑 Azure SQL Database Key Points
- Serverless computing and hyperscale storage solutions are both flexible and responsive
- A fully managed database engine that automates updates, provisioning, and backups
- It has a built-in AI and high availability to ensure consistent peak performance and durability
✅ Pros
- User-friendly interface for creating data models
- Straightforward billing system
- Fully managed and secure SQL database
- Seamless migration from on-premise to cloud storage
❌ Cons
- Job and task managers work in different ways
- Limited database size
- Need for more efficient notification and logging system for database errors
- Costly scaling up and down without proper automation implementation

Amazon Redshift is a fully-managed, petabyte-scale cloud-based data warehousing solution designed to help organizations store, manage, and analyze large amounts of data efficiently. Built on top of the PostgreSQL open-source database system, Redshift uses columnar storage technology and massively parallel processing to deliver fast query performance on high volumes of data. Its distributed architecture allows it to elastically scale storage and processing power to accommodate growing data volumes. Its tight integration with other AWS services also enables seamless data loading from S3, EMR, DynamoDB, etc. The end result is a performant, cost-effective, and flexible cloud data warehouse solution suitable for large-scale data analytics.
🔑 Amazon Redshift Key Points
- It uses column-oriented databases
- Its architecture is based on massively parallel processing
- It includes machine learning to improve performance
- It is fault tolerant
✅ Pros
- Easy setup, deployment, and management
- Detailed documentation that makes it easy to learn
- Seamless integration with data stored in S3
- Simplified ETL setup
❌ Cons
- JSON support in SQL is limited
- Array type columns are missing and are automatically converted to strings
- The logging function is almost non-existent

Amazon DynamoDB is a fast, flexible, and reliable NoSQL database service that helps developers build scalable, serverless applications. It supports key-value and document data models, and can handle massive amounts of requests daily. DynamoDB automatically scales horizontally, ensuring availability, durability, and fault tolerance without any extra effort from the user. Designed for internet-scale applications, DynamoDB offers limitless scalability and consistent performance with up to 99.999% availability.
🔑 Amazon DynamoDB Key Points
- The ability to handle over 10 trillion requests per day
- Support for ACID transactions
- A multi-Region and multi-Master database
- NoSQL database
✅ Pros
- Fast and simple to operate
- Handle data that is dynamic and constantly changing
- Indexed data can be retrieved quickly
- Performs exceptionally well even when working with large-scale applications
❌ Cons
- If the resource is not monitored correctly, the expenses can be significant
- Does not support backup in different regions
- It can be expensive for projects that require multiple environments to be created

Google BigQuery is a powerful, fully-managed cloud-based data warehouse that helps businesses analyze and manage massive datasets. With its serverless architecture, BigQuery enables lightning-fast SQL queries and data analysis, processing millions of rows in seconds. You can store your data in Google Cloud Storage or in BigQuery’s own storage, and it seamlessly integrates with other GCP products like Data Flow and Data Studio, making it a top choice for data analytics tasks.
🔑 Google BigQuery Key Points
- It can scale up to a petabyte, making it highly scalable
- It offers fast processing speeds, allowing you to analyze data in real-time
- It is available in both on-demand and flat-rate subscription models
✅ Pros
- Automatically optimizes queries to retrieve data quickly
- Great customer support
- Its data exploration and visualization capabilities are very useful
- It has a large number of native integrations
❌ Cons
- Uploading databases using Excel can be time-consuming and prone to errors
- Connecting to other cloud infrastructures like AWS can be difficult
- The interface can be difficult to use if you are not familiar with it

MongoDB Atlas is a cloud-based, fully managed MongoDB service that allows developers to quickly setup, operate, and scale MongoDB deployments in the cloud with just a few clicks. Developed by the same engineers that build the MongoDB database, Atlas provides all the features and capabilities of the popular document-based NoSQL database, without the operational heavy lifting required for on-premise deployments. Atlas simplifies MongoDB cloud operations by automating time-consuming administration tasks like infrastructure provisioning, database setup, security hardening, backups, and more.
🔑 MongoDB Atlas Key Points
- It’s a document-oriented database
- Sharding feature allows for easy horizontal scalability
- The database triggers in MongoDB Atlas are powerful and can execute code when certain events occur
- Useful for time series data
✅ Pros
- It is easy to adjust the scale of the service based on your needs
- There are free and trial plans available for evaluation or testing purposes, which are quite generous
- Any database information that is uploaded to MongoDB Atlas is backed up
- JSON documents can be accessed from anywhere
❌ Cons
- It is not possible to directly download all information stored in MongoDB Atlas clusters
- Lacks more granular billing
- No cross table joins

Snowflake is a powerful, self-managed data platform designed for the cloud. Unlike traditional offerings, Snowflake combines a new SQL query engine with an innovative cloud-native architecture, providing a faster, easier-to-use, and highly flexible solution for data storage, processing, and analytics. As a true self-managed service, Snowflake takes care of hardware and software management, upgrades, and maintenance, allowing users to focus on deriving insights from their data.
🔑 Snowflake Key Points
- Provide query and table optimization
- It offers secure data sharing and zero-copy cloning
- Snowflake supports semi-structured data
✅ Pros
- Snowflake can ingest data from various cloud platforms, such as AWS, Azure, and GCP
- You can store data in multiple formats, including structured and unstructured
- Computers are dynamic, meaning you can choose a computer based on cost and performance
- It’s great for managing different warehouses
❌ Cons
- Data visualization could use some improvement
- The documentation can be hard to understand
- Snowflake lacks CI/CD integration capabilities

Databricks SQL (DB SQL) is a powerful, serverless data warehouse that allows you to run all your SQL and BI applications at a massive scale, with up to 12x better price/performance than traditional solutions. It offers a unified governance model, open formats and APIs, and supports the tools of your choice, ensuring no lock-in. The rich ecosystem of tools supported by DB SQL, such as Fivetran, dbt, Power BI, and Tableau, allows you to ingest, transform, and query all your data in-place. This empowers every analyst to access the latest data faster for real-time analytics, and enables seamless transitions from BI to ML, unleashing the full potential of your data.
🔑 Databricks SQL Key Points
- Centralized governance
- Open and reliable data lake as the foundation
- Seamless integrations with the ecosystem
- Modern analytics
- Easily ingest, transform and orchestrate data
✅ Pros
- Enhanced collaboration between Data Science & Data Engineering teams
- Spark Jobs Execution Engine is highly optimized
- Analytics feature recently added for building visualization dashboards
- Native integration with managed MLflow service
- Data Science code can be written in SQL, R, Python, Pyspark, or Scala
❌ Cons
- Running MLflow jobs remotely is complicated and needs simplification
- All runnable code must be kept in Notebooks, which are not ideal for production
- Session resets automatically at times
- Git connections can be unreliable
Cloud databases have revolutionized how businesses store, manage, and utilize their data. As we have explored, leading platforms like Azure SQL Database, Amazon Redshift, DynamoDB, Google BigQuery, MongoDB Atlas, Snowflake, and Databricks SQL each offer unique benefits for app development and data analytics.
When choosing the right cloud database, key factors to consider are scalability needs, ease of management, integrations, performance, security, and costs. The optimal platform will align with your infrastructure and workload requirements.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in Technology Management and a bachelor’s degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
MMS • RSS

Sundry Photography
For MongoDB (NASDAQ:MDB), it’s almost like there has been no recession in the works over the past year. The non-relational database company has exceeded expectations in 2023, with revenue growth surging despite a flagging economy. While most other enterprise software peers are reporting decaying sales cycles and increased competition, MongoDB has continued to buck the trend. The company’s progress in building out a fuller ecosystem for AI products also certainly doesn’t hurt.
Yet we do have to ask ourselves: how much of this strength is already priced in? Year to date, shares of MongoDB are up nearly 2x already:
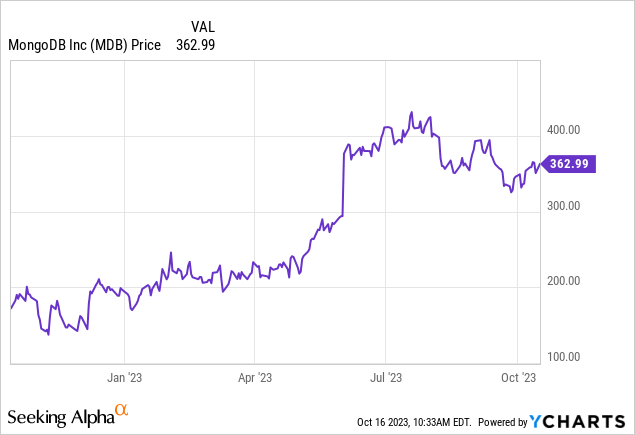
Valuation is the main drag here, especially in a high interest rate environment
I last wrote on MongoDB in June when the stock was trading near $390, issuing a neutral opinion (a downgrade from a prior bullish position). Since then, the stock has declined nearly 10%, and it has released very strong Q2 results that featured a re-acceleration in revenue growth. To me, that’s a usual formula for a buy.
But I also can’t ignore the macro. Even if the slowdown isn’t necessarily hurting MongoDB’s sales momentum, it does weigh on MongoDB’s stock – especially when risk-free interest rates have climbed above 5%. Over the course of the past year, I have substantially reduced my allocation to equities and dumped more into short-term U.S. treasuries, making exceptions only for high-quality “growth at a reasonable price” stocks. MongoDB is high-growth and high-quality, but its price is anything but reasonable.
At current share prices near $363, MongoDB trades at a market cap of $25.89 billion. After we net off the $1.90 billion of cash and $1.14 billion of convertible debt off MongoDB’s most recent balance sheet, the company’s resulting enterprise value is $23.99 billion.
Meanwhile, for the current fiscal year MongoDB has guided to $1.596-$1.608 billion in revenue:

MongoDB outlook (MongoDB Q2 earnings release)
This puts MongoDB’s valuation at 15.0x EV/FY24 revenue.
Even if we roll forward multiples to next year, MongoDB remains expensive. Wall Street analysts are expecting MongoDB to generate $1.97 billion in revenue in FY25 (the year for MongoDB ending in January 2025, and representing 22% y/y growth; data from Yahoo Finance). Against FY25 estimates, MongoDB still trades at 12.2x EV/FY25 revenue.
I’m not comfortable anywhere above a high single-digit revenue multiple for MongoDB against FY25 estimates. I’d consider buying the stock again if it hits 9x EV/FY25 revenue, representing a price target of $260 and ~28% downside from current levels (where MongoDB was trading in the May timeframe).
And in light of MongoDB’s huge valuation, we should also be wary of several fundamental risks the company is susceptible to:
- GAAP losses are still large- Though MongoDB has notched positive pro forma operating and net income levels, the company is still burning through large GAAP losses because of its reliance on stock-based compensation. In boom times investors may look the other way, but in this more cautious market environment MongoDB’s losses may stand out.
- Consumption trends may falter- MongoDB prices by usage and by workload. Other companies like Snowflake (SNOW) have reported weaker consumption in the current macro; while MongoDB seems unimpacted so far, this may catch up in the near future.
- Competition- MongoDB may have called itself an “Oracle killer” at the time of its IPO, but Oracle (ORCL) is also making headway in autonomous and non-relational databases. Given Oracle’s much broader software platform and ease of cross-selling, this may eventually cut into MongoDB’s momentum.
All in all, I’m happy to remain on the sidelines here. Continue to watch and wait here until MongoDB drops to the right buying levels.
Q2 download
This being said, we should acknowledge the strength in MongoDB’s latest quarterly results, which were released at the very tail end of August. The Q2 earnings summary is shown below:
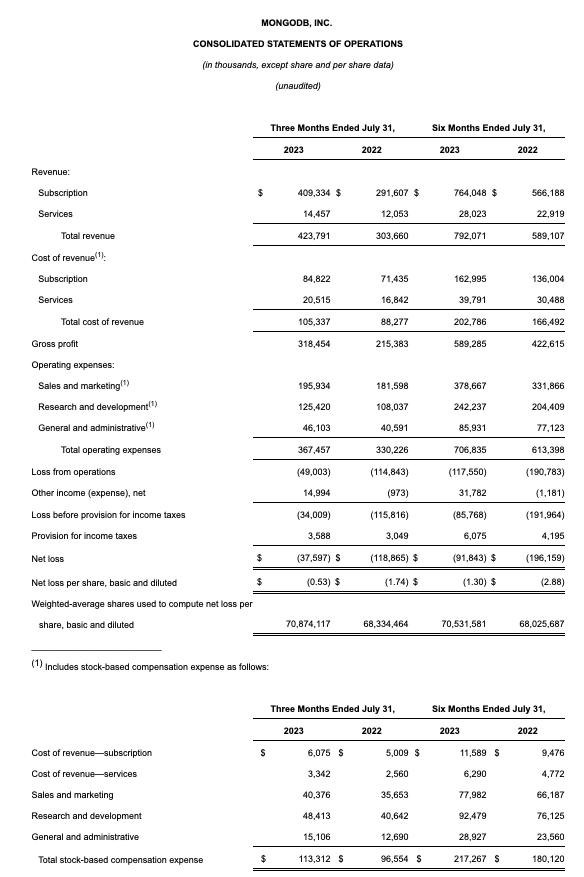
MongoDB Q2 results (MongoDB Q2 earnings release)
Revenue grew 40% y/y to $423.8 million, dramatically outpacing Wall Street’s expectations of $390.9 million (+29% y/y) by a huge eleven-point margin. Revenue growth also accelerated eleven points versus 29% y/y growth in Q1, as well as 36% y/y growth in Q4.
What makes this even more impressive is that MongoDB’s consumption-based pricing is what many investors had suspected would make MongoDB vulnerable in the current macro. Snowflake is the best example here of a similarly-sized software company that doesn’t price per seat, but by client usage. The company has seen tremendous deceleration owing to the fact that customers have slowed down their usage of the platform amid budget cuts and macro constraints. Clearly, however, it’s not “one size fits all” and MongoDB managed to escape the pain.
Reflecting on consumption trends in the business on the Q2 earnings call, CFO Michael Gordon noted as follows:
Consumption growth in Q2 was slightly better than our expectations. As a reminder, we had assumed Atlas would continue to be impacted by the difficult macro environment in Q2, and that is largely how the quarter played out.
Turning to non-Atlas revenues. EA significantly exceeded our expectations in the quarter, and we continue to have success selling incremental workloads into our EA customer base. We continue to see that our customers, regardless of their mode of deployment, are launching more workloads at MongoDB and moving towards standardizing on our platform. The EA revenue outperformance was in part a result of more multiyear deals than we had expected. In addition, we had an exceptionally strong quarter in our other licensing revenues.”
It was also a strong quarter for new logo adds, as MongoDB added 1,900 new customers to the fold.
Optimization of the company’s sales coverage has also helped boost efficiency and margins. The company is tracking customer consumption trends to determine which customers need to be covered by sales reps or moved to the self-service direct channel. In Q2, the company elected to migrate 300 lower-tier customers into the direct channel.
Savings on opex alongside strong revenue growth helped MongoDB generate $79.1 million in pro forma operating income, representing a 19% margin – 23 points better than a -4% operating margin in the year-ago Q2. We note that MongoDB scores very highly on the “Rule of 40” scale, with 40% revenue growth stacked on top of a 19% pro forma operating margin, besting most other software companies near its size.
Key takeaways
There can be little doubt that MongoDB’s execution in a difficult environment has been tremendous. That strength is what prevents me from being too bearish on the stock and why I think there likely isn’t too much downside from here. Admittedly, my price target of $260 may be difficult to reach – but at the same time, with MongoDB’s strength already priced into its stock amid a high interest-rate environment, I also don’t see much upside to the stock from here. The bottom line here: keep a close eye on this stock, but don’t make any moves just yet.
MMS • RSS
Databases are an important part of the Amazon Web Services (AWS) ecosystem because they help manage and organize huge amounts of data in a safe and efficient way. AWS has many different database services, each designed to meet the needs of different people who need to store and get data. DynamoDB is a NoSQL database service that is known for its high performance, seamless scalability, and flexible data models. This makes it a great choice for applications that need to access data quickly and with low latency.
On the other hand, Amazon Aurora, a relational database service, is praised for being able to work with both MySQL and PostgreSQL. It offers the speed and availability of commercial databases while being cheaper and easier to use than open-source databases. Amazon Aurora is a popular choice for applications that need to be available and perform well all the time. It is very durable, has strong security features, and works well.
DynamoDB vs Amazon Aurora Comparison Table
DynamoDB is a NoSQL database that is known for its low latency, ability to automatically scale, and suitability for serverless computing. Aurora, on the other hand, is a relational database that supports transactions, strong consistency, and complex queries. It needs to be scaled and deployed by hand.
| Feature | Amazon DynamoDB | Amazon Aurora |
|---|---|---|
| Database Type | NoSQL database | Relational database |
| Scalability | Automatically scales to handle any amount of traffic | Can be manually scaled, but requires more management |
| Data Model | Key-value and Document store | Table and row-based data model |
| Read/Write Performance | Low latency for read and write operations | High read performance, suitable for complex queries |
| ACID Compliance | Eventual consistency for reads (by default), strong consistency for writes | Fully ACID-compliant |
| Secondary Indexes | Global and Local Secondary Indexes are supported | Supports secondary indexes for enhanced query performance |
| Query Language | Querying is done using API calls or SQL-like expressions | SQL-based querying using standard MySQL or PostgreSQL interfaces |
| Use Case | Ideal for applications requiring scalable, high-performance, and low-latency data storage | Suitable for applications with complex querying needs and transactional workloads |
| Pricing Model | Pay-per-use model based on provisioned throughput and storage | Pay-per-use model based on compute and storage resources |
| Backup and Recovery | Continuous backups with point-in-time recovery | Supports automated backups and snapshots for data protection |
| Availability | High availability with built-in replication and multi-region support | Replication and failover support for high availability |
| Use with Serverless | Well integrated and suitable for serverless computing | Requires a server or instances for deployment |
| Visit Website | Visit Website |
DynamoDB vs Amazon Aurora: Data Model and Structure
There are two powerful database services that Amazon Web Services (AWS) offers. They are DynamoDB and Amazon Aurora. Their data models and structures are different, so they can be used for different kinds of tasks. The term “NoSQL” refers to a database that does not use a relational database schema. A key-value and document data model is used instead. Because of this, DynamoDB is very adaptable and scalable, as it can easily handle a lot of data with different formats.
On the other hand, Amazon Aurora is a relational database service that works with both MySQL and PostgreSQL. It has tables, columns, and rows, just like a normal relational database. Because of this, Amazon Aurora is a good choice for apps that need to do a lot of complicated queries and transactions.
| Feature | DynamoDB | Amazon Aurora |
|---|---|---|
| Data model | NoSQL (key-value and document) | Relational (tables, columns, and rows) |
| Primary key | Single attribute or composite attribute | Single column or composite column |
| Secondary indexes | Yes | Yes |
| Foreign keys | No | Yes |
| Scaling | Horizontal | Vertical |
The building blocks of DynamoDB tables are items, which are groups of attribute-value pairs. A primary key is what identifies an item. A primary key can be a single attribute or a group of attributes. DynamoDB also has secondary indexes that can be used to search for items based on secondary keys. DynamoDB tables can be scaled horizontally, which means that you can add more replicas to a table to make it bigger. That’s why DynamoDB is very scalable and can handle a lot of queries.
Tables in Amazon Aurora are made up of rows, which are groups of columns. Each column holds a different type of data, like an integer, a string, or a date. A primary key, which can be a single column or a group of columns, tells you which row it is. Foreign keys are another feature of Amazon Aurora that can be used to connect tables. You can increase the size of an Amazon Aurora table by adding more resources to the instance that it is running on. This is called “vertical scaling.” Because of this, Amazon Aurora is a good choice for apps that need to be fast and scalable.
DynamoDB vs Amazon Aurora: Performance and Scalability
There is very little latency and a lot of throughput with both DynamoDB and Aurora. DynamoDB, on the other hand, is thought to be faster than MySQL, especially for workloads that do a lot of reading. This is because DynamoDB is a NoSQL database, which means it doesn’t need SQL queries. Instead, DynamoDB stores data using a key-value and document model. This lets it get data quickly without having to read and run SQL queries.
Aurora, on the other hand, works with SQL queries and is a relational database. This means that Aurora might be a little slower than DynamoDB for workloads that need to read a lot, especially for queries that are complicated. However, Aurora is faster than DynamoDB for workloads that require a lot of writing. It can do this because Aurora can group writes together and process them faster.
| Feature | Amazon DynamoDB | Amazon Aurora |
|---|---|---|
| Database model | NoSQL | Relational |
| Performance | Very low latency, high throughput, especially for read-intensive workloads | Very low latency, high throughput, especially for write-intensive workloads |
| Scalability | Highly scalable horizontally to petabytes of data and millions of requests per second | Highly scalable horizontally to hundreds of terabytes of data and millions of transactions per second |
| Serverless | Yes | No |
DynamoDB and Aurora are both very scalable databases. It’s possible for DynamoDB to handle petabytes of data and millions of requests per second. This means that Aurora can handle hundreds of terabytes of data and millions of transactions per second. However, DynamoDB is generally thought to be the more scalable of the two. That’s because DynamoDB is a serverless database, which means you don’t have to set up or manage any servers. You never have to worry about running out of space because DynamoDB makes changes based on demand.
Aurora, on the other hand, is a provisioned database, which means you need to set aside enough space to handle your busiest times. This could be a problem for apps whose workload changes often. Amazon DynamoDB and Amazon Aurora are both great databases that work well and can grow as needed. There are, however, some important differences between the two that may make one a better choice for you.
DynamoDB vs Amazon Aurora: Data Management and Security Features
DynamoDB is a fully managed NoSQL database service that can handle loads of millions of records in just a few milliseconds. It’s a good choice for programs that need to deal with a lot of data and access it in unpredictable ways. DynamoDB has a number of features for managing data, such as
Automatic scaling: Because DynamoDB automatically scales up or down capacity based on demand, you don’t have to worry about setting up or managing capacity yourself.
Global tables: DynamoDB global tables give you a logical view of all of your data in all of your AWS regions. With low latency and high availability, this makes it easy to build global apps.
Streams: DynamoDB streams let you know when your data changes in real time, so you can make apps that respond to changes right away.
This is a fully managed relational database service from Amazon that combines the speed and scalability of MySQL and PostgreSQL with the security and compatibility of a commercial database. Applications that need the speed and ability to grow like a relational database but also want the adaptability and low cost of a cloud database should choose this one. Amazon Aurora has a number of features for managing data, such as
- Automatic backups and software patches: Amazon Aurora backs up your data and patches the database software for you, so you don’t have to do anything.
- Multi-AZ deployments: For high availability, Amazon Aurora deployments can be spread out across multiple Availability Zones (AZs).
- Read replicas: To increase the amount of data that can be read, Amazon Aurora read replicas can be used.
- Serverless mode: When you use Amazon Aurora Serverless mode, the capacity automatically scales up or down based on demand, so you don’t have to worry about setting up or managing capacity.
DynamoDB and Amazon Aurora both have a number of security features that can keep your data safe, such as
- Encryption: Both DynamoDB and Amazon Aurora encrypt your data while it’s being sent and while it’s being stored.
- Access control: Both DynamoDB and Amazon Aurora let you control who can see your data in very specific ways.
- Auditing: You can keep track of who is accessing your data and what they are doing with it with both DynamoDB and Amazon Aurora’s auditing features.
DynamoDB vs Amazon Aurora: Querying Capabilities and Indexing
The relational database schema is not used by DynamoDB because it is a NoSQL database. It uses a key-value store model instead, where each item has a primary key that makes it unique. DynamoDB also has secondary indexes that let you search for data based on other attributes.
DynamoDB queries are very quick, especially for simple queries. Complex queries, like joins and aggregations, can be harder to put together, though. Also, DynamoDB doesn’t work with some of the more advanced SQL features, like window functions and subqueries.
| Feature | DynamoDB | Amazon Aurora |
|---|---|---|
| Query language | PartiQL, DynamoDB API | SQL |
| Querying capabilities | Simple queries are very fast, complex queries can be challenging | Can handle complex queries and aggregations with ease |
| Supported SQL features | Basic SQL features | All SQL features supported |
| Indexing | Local secondary indexes only | Local and global secondary indexes supported |
| Performance | Very fast for simple queries | Generally slower than DynamoDB, but more flexible |
It works with both MySQL and PostgreSQL. Amazon Aurora is a relational database engine. To query your data, this means you can use all of the standard SQL tools. Like DynamoDB, Aurora can also use secondary indexes. Aurora queries are usually slower than DynamoDB queries, but they can be used in a lot more situations. Simple queries and collections are easy for Aurora to handle. It also works with all the more advanced SQL features that DynamoDB doesn’t.
When deciding between DynamoDB and Aurora, indexing is another important thing to think about. DynamoDB only works with local secondary indexes, which means that the data for the index is kept in the same partition as the data for the items. Large tables may have trouble running because of this. Aurora works with both global and local secondary indexes. It can help large tables run faster because global secondary indexes are kept in separate partitions from the item data. It can be more expensive and hard to use global secondary indexes, though.
DynamoDB vs Amazon Aurora: Integration with Other AWS Services
DynamoDB is a durable database that is fully managed, has multiple regions and masters, and comes with built-in security, backup and restore, and in-memory caching for internet-scale applications. It works with a lot of different AWS services, such as
- Amazon Lambda: The Amazon Lambda service lets you run Lambda functions from DynamoDB. These functions can then process data in DynamoDB or other AWS services.
- Amazon Kinesis: DynamoDB can be used to get data from Amazon Kinesis streams. This data can then be processed and analyzed in real time.
- Amazon Redshift: There is a service called Amazon Redshift that lets you store and analyze data. DynamoDB can be used to load data into Redshift.
- Amazon Athena: Athena is a serverless interactive query service that makes it easy to look at data in Amazon S3. DynamoDB can be used to query data using Athena.
- Amazon SageMaker: DynamoDB can be used to store data that is used to train and run machine learning models in Azure.
- The Amazon Aurora
Amazon Aurora is a relational database that works with both MySQL and PostgreSQL and is fully managed. It works with a lot of different AWS services, such as
- Amazon Relational Database Service (RDS): If you use Aurora with Amazon Relational Database Service (RDS), you can make a managed, scalable, and relational database service.
- Amazon Lambda: You can use Aurora to start Lambda functions, which can then be used to process data in Aurora or other AWS services.
- Amazon Kinesis: A tool called Aurora can take data from Kinesis streams and process and analyze it in real time.
- Amazon Redshift: Aurora can be used to put data into Redshift, which can then be used to store data and run analytics on it.
- Amazon Athena: Athena is a serverless interactive query service that makes it easy to look at data in Amazon S3. Aurora can be used to query data using Athena.
- Amazon SageMaker: Azure can be used to store data that is used to train and run machine learning models in Amazon SageMaker.
DynamoDB: Pros and Cons
Pros
- Automatic scalability for handling any workload.
- Low-latency performance for read and write operations.
- Well-suited for serverless computing environments.
Cons
- Limited querying capabilities compared to SQL-based databases.
Amazon Aurora: Pros and Cons
Pros
- Strong consistency and support for complex querying.
- ACID compliance for reliable transactions.
- Better suited for applications with complex data needs.
Cons
- Requires manual scaling, leading to more management overhead.
DynamoDB vs Amazon Aurora: which one should you consider?
The choice between Amazon Aurora and DynamoDB depends on the needs and use cases. A NoSQL database called DynamoDB is great for applications that need to be able to scale easily, be available all the time, and have low latency. This means it can handle real-time situations and heavy workloads.
Amazon Aurora, on the other hand, is a relational database that works like MySQL and PostgreSQL, but it also has the added benefits of being scalable, durable, and fast. This means it can handle both simple and complex queries. DynamoDB is better if your application needs to handle real-time needs and have flexible data models. On the other hand, Amazon Aurora is a strong option for structured data and complex querying needs.
FAQs
What is the difference between Amazon Aurora and DynamoDB?
The main type of database in Amazon Aurora is a Relational DBMS. The main type of database in Amazon DynamoDB is a key-value store and document store. Amazon Auroras can be split up in a horizontal direction. The sharding partitioned method is used by Amazon DynamoDB.
Why is Amazon Aurora faster?
Aurora Replicas use the same storage as the source instance. This saves money and keeps the replica nodes from having to do writes. This makes more processing power available for read requests and cuts the time it takes to make a copy, often to just a few milliseconds.
MMS • RSS

In 1966, a DEC PDP-7 computer was delivered to the Massachusetts General Hospital without any programming. The hospital had invested in a computer but had no way to run it. At this time, there was very little in the way of software options, operating systems, or database support. The hospital did, however, have access to the Massachusetts Institute of Technology (MIT), which was located just across the river. The MIT team started from scratch, and went on to design “MUMPS” (Massachusetts Utility Multi-Programming System) as a multi-user operational system, a database, and a language, all in one. MUMPS used a key-value store and several other features that were later incorporated into NoSQL data stores. The use and focus of key-value structures gradually evolved into simple NoSQL key-value databases.
This type of database saves data as a group of key-value pairs, which are made up of two data items that are linked. The link between the items is a “key” (such as “file name”), which acts as an identifier for an item within the data, and the “value” that is the data (or content) that has been identified.
Key-value databases are often considered the simplest of the NoSQL databases. This simplicity makes key-value stores and databases quick, user-friendly, portable, scalable, and flexible. However, the original key-value systems were not designed to allow researchers to filter or control the data that returns from a request – they did not include a search engine. That is changing as people modify their key-value databases.
Redis introduced its key-value database in 2009:
“The original intention of Redis (or any key-value store) was to have a particular key, or identifier, for each individual piece of data. Redis quickly stretched this concept with data types, where a single key could refer to multiple (even millions of) pieces of data. As modules came to the ecosystem, the idea of a key was stretched even further because a single piece of data could now span multiple keys (for a RediSearch index, as example). So, when asked if Redis is a key-value store, we usually respond with ‘it descends from the key-value line of databases’ but note that, at this point, it’s hard to justify Redis as a key-value store alone.”
Though many NoSQL databases continue to include key-value stores, keys can also be used in relational databases. The primary key used for relational tables uniquely identifies each record within the table. Some keys can be used to connect (or join) data that is stored in one table to the data in other tables. Storing a primary key to a row in another table is known as a foreign key. There are primary key and foreign key errors that should be avoided.
How Key-Value Databases Work
Key-value databases do not establish a specific schema. Traditional relational databases pre-define their structures within the database, using tables that contain fields with well-defined data types. Key-value systems, on the other hand, treat data as a single collection with the key representing an arbitrary string – for example, a filename, hash, or uniform resource identifier (URI). Key-value stores generally use much less memory while saving and storing the same amount of data, in turn increasing the performance for certain types of workloads.
“Pure” key-value databases do not use a query language, but they do offer a way to retrieve, save, and delete data by using the very simple commands get, put, and delete. (Modified key-value databases may include full-text searches.) Retrieving data requires a direct request method for communicating with the data file. There is no searching, nor is there a search engine. If the key is not known, there is no way to find it.
Uses of Key-Value Databases
While relational databases handle payment transactions quite well, they struggle to deal with high volumes of simultaneous transactions. However, NoSQL key-value databases can scale as needed and handle extremely high volumes of traffic per second, providing service for thousands of simultaneous users.
Key-value NoSQL databases come with built-in redundancy, allowing them to handle lost storage nodes without problems. (Occasionally, for example, a “shopping cart” will lose items.) Key-value stores process large amounts of data and a consistent flow of read/write operations for:
- Session management: Offering users the option to save and restore sessions.
- User preferences and profile stores: Personal data on specific users.
- Product recommendations: Customized items a customer might be interested in.
- Coupons, customized ads: Adapted and viewed by customers in real time.
- Acting as a cache for regularly viewed data that rarely gets updated.
Key-value databases are often used for session management in web applications. They do well at managing the session’s information for all the new user apps on smartphones and other devices.
Key-value databases can also be used for massive multi-player online games, managing each player’s session.
They
are very good at managing shopping carts for online buyers – until payment time.
Payment transactions and any revenue postings work better with a relational
database.
As one of the simplest NoSQL databases, key-value databases can be scaled easily for purposes of big data research, while servicing multiple users simultaneously.
Businesses selling products over the internet often struggle with the different volumes of the pre-Christmas buying season versus the rest of the year. The issue is about paying for an infrastructure scaled for the Christmas buying peak (and paying for that infrastructure for the rest of the year) or taking the risk of not being able to handle the Christmas rush (and crashing for several hours). Assuming a relational database handles normal year-round services, renting a cloud service with a key-value database for the Christmas rush provides an efficient, relatively inexpensive solution.
Choosing the Right Database for Your Organization
Different key-value databases use different techniques for improving the basic key-value model. Some store all their data in RAM, while others work with a combination of SSDs (solid state drives) and RAM. Still others combine support for rotating disks and RAM.
These databases were designed to respond to the new applications that have become available for smartphones and other devices. Organizations should avoid having all their relational databases replaced with NoSQL, especially for financial applications. Some popular key-value databases are listed below:
- Aerospike: An open-source, NoSQL database using a flash-optimized in-memory.
- Apache Cassandra: A distributed, free, open-sourced, wide-column store, NoSQL database management system.
- Amazon Dynamo DB: A fully managed proprietary NoSQL database service that is offered by Amazon.
- Berkeley DB: A basic, high-performance, embedded, open-source, database storage library.
- Couchbase: Designed for business-critical applications, it provides full-text searches, SQL-based querying, and analytics.
- Memcached: Speeds up websites by caching data and objects in RAM to reduce the number of times an external data source must be read. Free and open-sourced.
- Riak: Fast, flexible, and scalable, it is good for developing applications and working with other databases and applications.
- Redis: A database, message broker, and memory cache. It supports hashes, strings, lists, bitmaps, and HyperLogLog.
Generally speaking, the secret
to key-value databases lies in their simplicity and the resulting speed that
becomes available. Retrieving data requires a direct request (key) for the
object in memory (value), and there is no query language. The data can be
stored on distributed systems with no worries about where indexes are located,
the volume of data, or network slowdowns. Some key-value databases are using flash
storage and secondary indexes in an effort to push the limits of key-value technology.
A key-value database is both
easy to build and to scale. It typically offers excellent performance and can
be optimized to fit an organization’s needs. When a key-value database is
modified with new applications, there is an increased chance the system will
operate more slowly.
Image used under license from Shutterstock.com
MMS • Sid Anand

Transcript
Anand: My name is Sid Anand. I’d like to give you some historical context. Let’s go back to the year 2017. In 2017, I was serving as the chief data engineer for PayPal. One of the items I was tasked with was building PayPal’s Change Data Capture system. Change Data Capture, CDC, provides a streaming alternative to repeatedly querying a database. It’s an ideal replacement for polling style query workloads, like the following, select * from transaction where account ID equals x, and the transaction date falls between two types. A query like this powers PayPal’s user activity feed for all of its users. If you’re a PayPal user, you might be familiar with it already. Users expect to see a completed transaction show up in this feed soon after they complete some money transfer, or a crypto purchase, or a merchant checkout. The query will have to be run very frequently to meet users’ timeliness expectations. As PayPal’s traffic grew, queries like this one became more expensive to run, and presented a burden on DB capacity. To give you a sense of the data scale at PayPal, in 2018, our databases were receiving 116 billion calls per day. The Kafka messaging system was actually handling the 400 billion messages a day that they were getting quite well. As you can see, from our Hadoop analytic side, we had a pretty sizable footprint of 240 petabytes of storage and 200,000-plus jobs running a day.
Given the fact that even at this scale, our databases were struggling, and that it seemed like Kafka was doing quite well, there was a strong interest in offloading DB traffic to something like CDC. However, client teams wanted guarantees around NFRs, or non-functional requirements, similar to what they had enjoyed with the databases. The database infrastructure, for example, had three nines of uptime, and queries took less than a second. Users never really had to worry about scalability or reliability. They wanted these same guarantees from the Change Data Capture system that we were presenting or offering to them. However, there were no off-the-shelf solutions that were available that met these NFRs. We built our own solution. We call this the Core Data Highway, and it’s still the Change Data Capture system in use at PayPal today. If building our own solution, we knew that we needed to make NFRs first-class citizens. In streaming systems, any gaps in NFRs are unforgiving. When an outage occurs, resolving the incident comes with the added time pressure that comes with building and maintaining real-time systems. Lag is very visible, and customers are impacted. If you don’t build your systems with the -ilities as first-class citizens, you pay a steep operational tax.
Core Data Highway
Here is a diagram of the system that we built. It’s simplified, but it will get the point across. On the left of this diagram, imagine that the site is writing to these Oracle RAC clusters. These are called our site DBs. We have primaries and tertiaries and secondaries. If we focus on the primaries, we have 70-plus primary RAC clusters, 70,000-plus database tables are distributed over these clusters. Overall, this cluster takes 20 to 30 petabytes of data. It uses Oracle GoldenGate to replicate data to a dedicated RAC cluster called the DB Pump. The DB Pump’s job is to reliably write this to high availability storage. You’ll notice that we have like a list or a slew of Trail File Adapter processes that are written in Java, these are processes we wrote, that are attached to that storage. Their job is to read the Trail Files that are written there, which are essentially a proprietary Oracle format. Read those files, decode them, convert them into an Avro message. Register the Avro schema with the Kafka schema registry, and send the messages reliably over Kafka. On the other side of those Kafka topics, we have the storm cluster of message routers. These message routers, they do many jobs such as masking data, depending on sensitivity of data, for example. They also route data either to online consumers or to offline consumers. Online consumers, as shown above, are any consumers that need to serve traffic to the web app that you use, that you see every day such as the activity feed. The offline consumers using like our Spark clusters can write data to a variety of different databases using our open source schema library. They can also write to Hadoop where traditional data lake work can be done.
Moving to the Cloud
Let’s move back to the more recent past, circa 2020. In 2020, I had left PayPal and was looking for my next gig. I joined a company named Datazoom that specializes in video telemetry collection. What interested me about Datazoom is that they wanted the same system guarantees in streaming data that I had built at PayPal. There were a few key differences, though. For example, at PayPal, our team assembled and managed bare metal machines. We also deployed them to a data center that PayPal owned and operated. We had full control from the application down to the bare metal, so we could really tune performance as we wished. Datazoom uses the public cloud, so it has whatever is offered as abstractions, basically. We don’t have the same bare metal control. Additionally, PayPal had deep pockets, whereas Datazoom being seed funded, was running on a shoestring budget. Last but not least, PayPal’s customers of CDH were internal customers, whereas at Datazoom, these were external customers. The reason I bring this up is that with external customers, your NFR SLAs are written into contracts, so it’s a bit more strict and more rigor is needed to maintain these NFRs.
Building High Fidelity Data Streams
Now that we have some context, let’s build a high-fidelity stream system from the ground up. When taking on such a large endeavor, I often like to start simple. Let’s set a goal to build a system that can deliver messages from source S to destination D. First, let’s decouple S and D by putting messaging infrastructure between them. This doesn’t seem like a very controversial ask because this is a common pattern today. In terms of technology, we have a choice. For this example, I gave Kafka, and I specify a topic called the events topic in Kafka. Make a few more implementation decisions about the system. Run our system on a cloud platform, such as Amazon. Let’s operate it at low scale. This means we can get by with a single Kafka partition. However, another best practice is to run Kafka across three brokers, split across three different availability zones, so let’s adopt that practice because it’s common. Since we don’t have to worry about scale right now, let’s just run S and D on single separate EC2 instances. To make things a bit more interesting, let’s provide our system as a service. We define our system boundary using a blue box as shown below. The question we ask is, is this system reliable?
Reliability
Let’s revise our goal. Now we want to build a system that can deliver messages reliably from S to D. To make this more concrete, what we really want is zero message loss. Once S has acknowledged a message to a remote sender, D must deliver that message to a remote receiver. How do we build reliability into our system? First, let’s generalize our system. Let’s pretend we have a linear topology as shown here with processes A, B, and C, separated by Kafka topics, and we see a message coming into the system. Let’s treat the message like a chain. Like a chain, it’s only as strong as its weakest link. This brings with it some insight. If each process or link is transactional in nature, the chain will be transactional. By transactionality, I mean at least once delivery, which is something offered by most messaging systems. How do we make each link transactional?
Let’s first break this chain into its component processing links. We have A, which is an ingest node. Its job is to ingest data from the internet and reliably write it to Kafka. We have B as an internal node reading from Kafka and writing to Kafka. We have C as an expel node, it’s reading from Kafka and writing out to the internet. What does A need to do to be reliable? It needs to receive this request, do some processing on it, and then reliably send data to Kafka. To reliably send data to Kafka, it needs to call KProducer.send with the topic and message, call flush. Flush will synchronously flush the data from the buffers in A to the three brokers in Kafka. Because we have ProducerConfig, acks equal all, A will wait for an acknowledgment from each of those brokers before it will acknowledge its sender, or caller. What does C need to do? C needs to read data as a batch off of a Kafka partition, do some processing, and reliably send that data out. Once it receives a 2xx response from the external destination it’s sending to, it can manually acknowledge the message to Kafka. We have to manually acknowledge messages because we’ve set enable.auto.commit equal to false, and this will move the read checkpoint forward. If there’s any problem processing this message, we will not acknowledge the message. If you use Spring Boot, you actually can send an ACK, which forces a reread of the same data. B is a combination of A and C. B needs to be reliable like A, in the sense that it needs to be a reliable Kafka Producer. It also needs to be a reliable Kafka Consumer.
How reliable is our system now? What happens if a process crashes? If A crashes, we will have a complete outage at ingestion. If C crashes, although we won’t lose any inbound data, we won’t be delivering this to external customers. For all intents and purposes, the customers will see this as an outage. One solution is to place each service in an autoscaling group of size T. Although autoscaling groups are concepts invented by Amazon, it’s available in Kubernetes, and other cloud providers today. Essentially, what we do is we wrap each of these services A, B, and C in an autoscaling group of size T, which means that they can handle T minus 1 concurrent failures without this system being compromised.
Observability (Lag and Loss Metrics)
For now, we appear to have a pretty reliable data stream. How do we measure its reliability? To answer this, we have to take a little segue into observability, a story about lag and loss metrics. Let’s start with lag. What is it? Lag is simply a measure of message delay in a system. The longer a message takes to transit a system, the greater its lag. The greater the lag, the greater the impact to the business. Hence, our goal is to minimize lag in order to deliver insights as quickly as possible. How do we compute it? Let’s start with some concepts. When message m1 is created, the time of its creation is called the event time, and is typically stored in the message. Lag can be calculated for any message m1, at any node N in the system using the equation above. Let’s have a look at this in practice. Let’s say we create message m1 at noon. At time equals 12:01 p.m., m1 arrives at A, at 12:04, m1 arrives at node B, and at 12:10, m arrives at node C. We can use the lag equation to measure the lag at A as 1 minute, B at 4 minutes, and C at 10 minutes. In reality, we don’t measure lag in minutes, but we measure them in milliseconds. More typical times are 1, 3, and 8 milliseconds. Another point to note here is that since I’m talking about times when messages arrive, this is called arrival lag or lag-in. Another observation to note is that lag is cumulative. The lag at node C includes the lag at upstream nodes, B and A. Similarly, the lag computed at B includes the lag at upstream node A. Just as we talked about arrival lag, there is something called departure lag, which is measuring the lag when a message leaves a node. Similar to arrival lag, we can compute the departure lag in each node. The most important metric in the system is called the end-to-end lag, which is essentially T6, or the departure lag at the last node in the system. This represents the total time a message spent in the system.
While it’s interesting to know the lag for a particular message m1, it’s of little use since we typically deal with millions of messages. Instead, we prefer to use population statistics like p95. Let’s see how we can use it. We can compute the end-to-end lag at the 95th percentile in the system. We can also compute the p95 lag-in and lag-out at any node. Once we have the lag-in and lag-out at any node, we can compute the process duration at p95. This is the amount of time spent at any node in the chain. How can we visualize this? Let’s say we have the topology shown here. This is from a real system that we own and run. We have four nodes in a linear topology, red, green, blue, and orange separated by Kafka. We compute each of their process durations, and we put them in a pie chart like the one on the left. What we see from this pie chart is that each of them take roughly the same amount of time. None of them appears to be a bottleneck in the system, and the system seems quite well tuned. If we take this pie chart and split it out, or spread it out over time, we get the chart on the right, which shows us that this contribution proportion essentially is stable over time. We have a well-tuned system that is stable over time.
Now let’s talk about loss. What is loss? Loss is simply a measure of messages lost while transiting the system. Messages can be lost for various reasons, most of which we can mitigate. The greater the loss, the lower the data quality. Hence, our goal is to minimize loss in order to deliver high quality insights. How do you compute it? Let’s take the topology we saw earlier, but instead of sending one message through, let’s send a list of messages through. What we’re going to do to compute loss is create what’s called a loss table. In the loss table, we track messages as they transit the system, and as they go through each hop, we tally a 1. Message 1 and 2 made it through each of the four hops, so we tally a 1 in each of those cells. Message 3, on the other hand, only made it to the red hop, and it didn’t seem to make it to any of the other hops. If we compute this for all of the messages that transit the system, we can compute the end-to-end loss, which shown here is 50%.
The challenge in a streaming data system is that messages never stop flowing, and also some messages are delayed at arrival. How do we know when to count? The solution is to allocate messages to one-minute-wide time buckets using the message event time. The loss table we saw earlier would actually apply to a single time. In this case, all messages whose event time fell in the 12:34th minute would be represented in this table. Let’s say the current time is 12:40. We will see that some data will keep arriving due to late data arrival for the tables from 12:36 to 12:39. The table data in 12:35 has stabilized so we can compute loss, and any loss table before 12:35 can be aged out so that we can save on resources. To summarize, we now have a way to compute loss in a streaming system, we allocate messages to one-minute-wide time buckets. We wait a few minutes for messages to transit and for things to settle, and we compute loss. We raise an alarm if that loss is over a configured threshold such as over 1%. We now have a way to measure the reliability and latency of our system. Wait, have we tuned our system for performance yet?
Performance
Let’s revise our goal once more. Now we want to build a system that can deliver messages reliably from S to D, with low latency. To understand streaming system performance, let’s understand the components that make up end-to-end lag. First, we have the ingest time. The ingest time measures the time from the last_byte_in of the request to the first_byte_out of the response. This time includes any overhead associated with reliably sending data to Kafka, as we showed earlier. The expel time is the time to process and egest a message at D. This time includes time to wait for ACKs from external services like 2xx responses. The time between the expel and ingest is just called the transit time. If we take all of those three together, is the end-to-end lag, which represents the total time messages spend in the system from ingest to expel. One thing we need to know is that in order to build a reliable system, we have to give up some latency. These are called performance penalties. One performance penalty is the ingest penalty. In the name of reliability, S needs to call KProducer flush on every inbound API request. S also needs to wait for three ACKs from Kafka before sending its response. The approach we can take here is batch amortization. We essentially support batch APIs so that we can consume multiple messages of the request and publish them to Kafka together to amortize the cost over multiple messages.
A similar penalty is on the expel side. There is an observation we make, which is that Kafka is very fast. It’s many orders of magnitude faster than the HTTP round trip times. The majority of the expel time is actually the HTTP round trip time. We take a batch amortization approach, again. At D, we read a batch of messages off of a Kafka partition. We then break it into smaller batches and send them in parallel. This maximizes our throughput, and basically gives us the best throughput for the fixed expel time, and also typically helps us with tail latencies. Last but not least, we have something called a retry penalty. In order to run a zero-loss pipeline, we need to retry messages at D that will succeed given enough attempts. We call these recoverable failures. In contrast, we should never retry a message that has a zero chance of success. We call these non-recoverable failures. Any 4xx response code, except for 429, which are throttle responses, are examples of non-recoverable failures. Our approach with respect to retry penalties, is that we know we have to pay a penalty on retry, so we need to be smart about what we retry, so we don’t retry any non-recoverable failures, and also how we retry. For how we retry, we use an idea called tiered retries. Essentially, at each of the connectors in our system, we try to send messages a configurable number of times with a very short retry delay. If we exhaust the local retries, then node D transfers the message to a global retrier. The global retrier then retries the message over a longer span of time, with longer retry delays between messages. For example, let’s say D was encountering some issues sending a message to an external destination. After it exhausts its local retries, it would send that message to the retry_in Kafka topic, which would be read after some configured delay time by the global retrier system, which would then publish the message back into the retry_out topic for D to retry again. This works quite well, especially when the retries are a small percentage of total traffic, just like single 1 or 2, maybe even less than 5%. Because since we track p95, the longer times to send these larger messages don’t impact our p95 latencies. At this point, we have a system that works well at low scale. How does this system scale with increasing traffic?
Scalability
Let’s revise our goal once more. We want to build a system that can deliver messages reliably from S to D, with low latency up to a scale limit. What do I mean by a scale limit? First, let’s dispel a myth. There is no such thing as a system that can handle infinite scale. Every system is capacity limited. In the case of AWS, some of these are artificial. Capacity limits and performance bottlenecks can only be revealed under load. Hence, we need to periodically load test our system at increasingly higher load to find and remove performance bottlenecks. Each successful test raises our scale rating. By executing these tests ahead of organic load, we avoid any customer impacting message delays. How do we set a target scale rating? Let’s look at the example here. Let’s say we want to handle a throughput of 1 million messages or events per second. Is it enough to only specify the target throughput? No. The reason is, most systems experience increasing latency with increasing traffic. A scale rating which violates our end-to-end lag SLA is not useful. A scale rating must be qualified by a latency condition to be useful. An updated scale rating might look like this, 1 million events per second with a sub-second p95 end-to-end lag. How do we select a scale rating? What should it be based on? At Datazoom, we target a scale rating that is a multiple m of our organic peak. We maintain traffic alarms that tell us when our organic traffic exceeds 1 over m of our previous scale rating. This tells us that a new test needs to be scheduled. We spend that test analyzing and removing bottlenecks that would result in higher-than-expected latency. Once we resolve all the bottlenecks, we update our traffic alarms for a new higher scale rating based on m prime. When we first started out, m was set to 10. Anytime traffic went over one-tenth of our scale rating, we would schedule a new test for 10 times that value. As our scale increased over time, we changed them to smaller values like nine and eight, and so forth.
How do we build a system that can meet the demands of a scale test and meet our scale rating goals? Autoscaling is typically the way people handle this. Autoscaling has two goals. Goal one is to automatically scale out to maintain low latency. Goal two is to scale in to minimize cost. For this talk, we’re going to focus on goal one. The other thing to consider is what can we scale. We can scale the compute in our system, but we cannot autoscale Kafka. We can manually scale it, but we can’t autoscale it. Our talk is going to focus on autoscaling compute. One point to note is Amazon offers MSK Serverless, which aims to bridge this gap today in Kafka, but it is a bit expensive. At Datazoom, we use Kubernetes. This gives us all the benefits of containerization. Since we run on the cloud, Kubernetes pods need to scale on top of EC2, which itself needs to autoscale. We have a two-level autoscaling problem. As you see below, we have EC2 instances. On top of those, we have multiple Kubernetes pods, which could be from the same microservice or different ones. At our first attempt, we tried to independently scale both of these. We used EC2 autoscaling based on memory for EC2 autoscaling, and we used the Horizontal Pod Autoscaler provided by Kubernetes, using CPU as the scaling metric. This all worked fine for a while. We use CloudWatch metrics as the source of the signal for both of these autoscalers.
This worked fine until November 25, 2020. On that date, there was a major Kinesis outage in U.S.-East-1. Datazoom doesn’t directly use Kinesis, but CloudWatch does. If CloudWatch were to go down, we wouldn’t expect anything bad to happen, we just expect there’ll be no further autoscaling behavior. Whatever the footprint was at the time of the outage is where everything should land. That is not what happened with HPA. When the signal stopped being seen by HPA, HPA scaled in our Kubernetes clusters and pods down to their Min settings. When this occurred, this caused a gray failure for us, which is essentially high lag and some message loss. To solve this problem, we’ve adopted KEDA, which is K8s event driven autoscaler. Now if CloudWatch goes down, HPA will not scale in its pods, it will act exactly like the EC2 autoscaler will. It keeps everything stable. We also switched away from doing our own memory-based autoscaling to using K8s Cluster Autoscaler. We’ve been using it for about a year and it worked quite well.
Availability
At this point, we have a system that works well within a traffic or scale rating. What can we say about the system’s availability? First of all, what is availability? What does availability mean? To me, availability measures the consistency with which a service meets the expectations of its users. For example, if I want to SSH into a machine, I want it to be running. However, if its performance is degraded due to low memory, uptime is not enough, any command I issue will take too long to compute or complete. Let’s look at an example of how uptime applies to a streaming system. Let’s say we define a system as being up as anything which has zero loss, and that meets our end-to-end lag SLA. We may consider things that are down as cases where we lose messages, or we’re not accepting messages, or perhaps there is no message loss in the system but lag is incredibly high, we could call that down. Unfortunately, everything in the middle which is gray is also a problem for users. To simplify things, we define down as anything that isn’t up. Essentially, if there is any lag beyond our target, it doesn’t have to be well beyond but just beyond our target, the system is down.
Let’s use this approach to define an availability SLA for data streams. Consider that there are 1440 minutes in a day, for a given minute such as 12:04, we calculate the end-to-end lag p95 for all events whose event time falls in that minute. If the lag needs to be 1 second to meet SLA, then we check, is the end-to-end lag less than 1 second? If it is, that minute is within SLA. If it’s not, that minute is out of SLA. It’s out of our lag SLAs. In the parlance of the nines model, this would represent a downtime minute, because that minute is outside of our lag SLAs. You may be familiar with the nines of availability chart below. The left column shows all the different possible availabilities, represented as nines. The other columns represent how many days, hours, or minutes that amount of downtime amounts to. Let’s say we are building a three nines uptime system. The next question we need to ask is, do we want to compute this every day, quarter, month, week, year? At Datazoom, we compute this daily, which means that we cannot afford more than 1.44 minutes of downtime, which means that for no more than 1.44 minutes, can our lag be outside of SLA, as lag SLA? Can we enforce availability? No. Availability is intrinsic to a system. It is impacted by calamities, many of which are out of our control. The best we can do is to measure it and monitor it and to periodically do things that can improve it.
Practical Challenges
Now we have a system that reliably delivers messages from source S to destination D, at low latency, below its scale rating. We also have a way to measure its availability. We have a system with the NFRs that we desire. What are some practical challenges that we face? For example, what factors influence latency in the real world? Aside from building a lossless system, the next biggest challenge is keeping latency low. Minimizing latency is a practice in noise reduction. The following factors are factors that we’ve seen to impact latency in a streaming system. Let’s start with the first one which are network lookups. Consider a modern pipeline as shown below. We have multiple phases. We have ingest followed by normalize, enrich, route, transform, and transmit. A very common practice is to forbid any network lookups along the stream processing chain above. However, most of the services above need to look up some config data as part of processing. A common approach would be to pull data from a central cache, such as Redis. If lookups can be achieved in 1 to 2 milliseconds, this lookup penalty is acceptable. However, in practice, we notice that there are 1-minute outages whenever failovers in Redis HA occur in the cloud. To shield ourselves against any latency gaps such as this, we adopt some caching practices. The first practice is to adopt Caffeine as our local cache across all services. Caffeine is a high performance near optimal caching library, written by Ben Manes, one of the developers who first worked at Google on the Guava caches there, and then spun caffeine out.
Here’s an example of using Caffeine. We create the builder with two parameters. One is called the staleness interval, and the other one is the expiration interval. Let’s look at that in practice. Let’s say we initialize this with a 2-minute staleness interval and a 30-day expiry interval. At some time, we load a cache entry from Redis, and we get version 1 of that cache entry loaded into Caffeine. As soon as that object is written, Caffeine will start a refreshAfter Write timer of 2 minutes. If the application does a lookup on that cache entry, it will get it from Caffeine, it’ll get version v1. If it does it again, after the refreshAfter Write interval of 2 minutes, it will still immediately get version 1 of the object, but behind the scenes, it would trigger an asynchronous load of that object from Redis. Soon as that v2 version is written into the local cache, the refreshAfter Write will get extended by 2 minutes. If the application does a lookup, it will get version 2 of the entry. The benefit of this approach is that the local application or the streaming application never sees any delays related to lookups from Redis. The other approach that we’ve taken is to eager load, or preload all cache entries for all caches into Caffeine at application start. By doing this, a pod is not available for any kind of operation such as streaming as like a node A, B, or C in our system, until it’s got its caches loaded. This means that we’ve now built a system that does not depend on latency or availability of Redis.
The other major factor that impacted latency for us was any kind of maintenance or operational processes, these created noise. Any time AWS patched our Kafka clusters, we notice large latency spikes. Since AWS patches brokers in a rolling fashion, we typically see about 3 latency spikes over 30 minutes, and these violate our availability SLAs. Here’s an example of something that we saw. On the upper left, we see the end-to-end lag for one of our connectors, TVInsight. We see that the p95 is around 250 milliseconds. However, whenever there’s a Kafka MSK maintenance, MSK meaning the managed service of Kafka that we use, whenever there’s an MSK maintenance event, each broker causes a spike that’s over a minute. This is unacceptable. To deal with this, we adopted a blue-green operating model, between weekly releases or scheduled maintenance, one color side receives traffic, and that’s called the light side, while the other color side receives none, and that is called the dark side. In the example below, the blue side is dark, this is where patches are being applied. On the light side, the green side, customer traffic is flowing. We alternate this with every change or maintenance that we do. One may be concerned about cost efficiency because we are basically doubling our costs. What we do is scale the compute down to zero to save on those costs but we do have to bear the cost of duplicate Kafka clusters. By switching traffic away from the side scheduled for AWS maintenance, we avoid these latency spikes. With this success, we applied it to other operations as well. Now all software releases, canary testing, load testing, scheduled maintenance, technology migrations, outage recovery, benefits and uses the blue-green model. When we get a traffic burst that’s much higher than our scale rating for either blue or green, we just open up both sides 50/50, and we double our capacity that way.
Last but not least, we have another challenge which is related to an interplay between autoscaling and Kafka rebalancing. To understand this, we have to talk about how Kafka works. Whenever there is autoscaling, we’re adding Kafka Consumers to a given topic. Topics are split into physical partitions that are assigned to these Kafka Consumers, in the same consumer group. During autoscaling activity, we’re changing the number of consumers in the consumer group, so Kafka needs to reassign partitions or rebalance. Whenever it does this with the default rebalancing algorithm, it’s essentially a stop the world action. This is via the range assignor. This pretty much causes large pauses in consumption, which result in latency spikes. An alternate rebalancing algorithm which is gaining more popularity is called KICR, this is called Kafka Incremental Cooperative Rebalancing using the cooperative sticky assignor. To show in practice, the left side of this chart shows all of our end-to-end lag across all our streaming connectors. As you see, they are very well-behaved. On the right side, this uses our default rebalancing. All of these spikes that you see are related to minor autoscaling behavior that’s constantly happening behind the scenes to deal with traffic. There is one challenge we ran into with the cooperative sticky assignor, we noticed that there were significant duplicate consumption during this autoscaling behavior. In one load test, we noticed it was more than 100% at a given node. We have opened a bug for this but we think there might be a fix, and we are currently evaluating some approaches and workaround for this problem.
Conclusion
We now have a system with the NFRs that we desire. We also have shown a real-time system and challenges that go with it.
See more presentations with transcripts
MMS • Daniel Dominguez

Amazon Web Services has announced the preview of Amazon CodeWhisperer Customization Capability. This new functionality empowers users to fine-tune CodeWhisperer, enabling it to provide more precise suggestions by incorporating an organization’s proprietary APIs, internal libraries, classes, methods, and industry best practices.
For developers, the ability to write good code is crucial. However, the majority of currently available AI coding assistants are mostly trained on open-source software, which limits their ability to make unique recommendations based on an organization’s internal libraries and APIs. Due to this limitation, developers now have to deal with a variety of challenges, such as successfully utilizing internal libraries and ensuring code security, especially when dealing with large codebases.
The customization feature of Amazon CodeWhisperer is made to tackle these problems head-on. With this new function, developers who pay for the Amazon CodeWhisperer Professional tier will be able to get real-time code recommendations that are specific to the internal libraries, APIs, packages, classes, and methods of their company.
Additionally, this function guarantees the highest level of protection for the personal repositories. Administrators of CodeWhisperer have the authority to choose particular repositories for modification while tightly regulating access. Furthermore, they may effectively manage access using the AWS Management Console, limiting it to authorized developers, and decide which customizations to enable.
Adam Selipsky CEO of AWS noted on X:
This will save developers time and help them get more relevant code recommendations than ever before.
Amazon CodeWhisperer customization capability also follows the supported IDEs as part of AWS Toolkit by Amazon CodeWhisperer, such as Visual Studio Code, IntelliJ JetBrains, and AWS Cloud9. This feature also provides support for most popular programming languages, including Python, Java, JavaScript, TypeScript, and C#.
AI-powered coding assistants like Amazon CodeWhisperer and GitHub Copilot give developers new levels of productivity and flexibility. In contrast to CodeWhisperer, which focuses on customization and lets businesses tailor code recommendations based on their own internal APIs and libraries, GitHub Copilot makes use of sizable open-source code repositories to offer insightful code recommendations.
CodeWhisperer Customization Capability is currently in the preview stage, accessible in the US East (N. Virginia) AWS Region. Information regarding pricing will be disclosed upon its general availability.
Cloudflare Post-Quantum Cryptography Now Generally Available, Including Origin Servers
MMS • Sergio De Simone

Cloudflare has announced the general availability of post-quantum cryptography for a number of its services and internal systems. While promising a higher standard of privacy for the post-quantum era, the new feature depends on post-cryptography support in browsers and on the final link between Cloudflare and origin servers.
After introducing beta support for the X25519+Kyber cipher last October, Cloudflare is now taking the next step and making it generally available for most of its inbound and outbound connections. This includes Cloudflare most used services, such as 1.1.1, API Gateway, Cloudflare Tunnel, and many more. Other services, including Cloudflare Gateway and Cloudflare DNS will get support for post-quantum crypto in the next weeks.
We don’t yet know when quantum computers will have enough scale to break today’s cryptography, but the benefits of upgrading to post-quantum cryptography now are clear.
NIST ran an open process to select the best post-quantum crypto cipher, which they hope to finalize in 2024 with the publication of an official standard. The only key agreement (aka, key exchange or key distribution) method NIST has selected up to now is Kyber and provides the means for two parties to agree on a shared key without an eavesdropper being able to learn anything.
The solution adopted by Cloudflare is an hybrid one, where they combine both Kyber and the classical X25519, with the aim of ensuring the connection remains secure nowadays even if at some point Kyber is shown to be “classically” insecure.
As mentioned, the end-to-end connection is only secure if all of its links are secured by post-quantum cryptography, which requires both the client, e.g. a browser, and the origin server to use it. While Cloudflare post-quantum cryptography GA means they will talk to origin servers using post-quantum crypto, this still requires origin servers to support the new cipher. On the browser front, Chrome started to support X25519Kyber768 in Chrome 116, released last August.
Albeit in its infancy, quantum computing is known to pose a serious challenge to current cryptography, which is based on prime number factoring. Indeed, factoring is a hard problem on classical computers but not on quantum computers, which can solve it in a reasonable amount of time.
In fact, while not yet there, the sheer fact that quantum computing might at some point in time become a reality makes today encrypted data at risk, since somebody could get hold of encrypted data and wait for quantum hardware to be available to decrypt it.
ScyllaDB: $43 Million Secured To Scale Data-Intensive Apps With High Throughput And Low Latency
MMS • RSS

ScyllaDB – the database for data-intensive apps that require high throughput and predictable low latency – recently announced that it has raised $43 million in funding, led by global VC Eight Roads Ventures and AB Private Credit Investors, the private corporate credit and growth stage capital platform of AllianceBernstein. And additional investors in ScyllaDB include TLV partners, Magma Ventures, and Qualcomm Ventures. These funds will enable ScyllaDB to accelerate its momentum with MongoDB customers dealing with scale.
ScyllaDB, used by over 400 global companies such as Discord, Epic Games, and Palo Alto Networks, has been experiencing a surge in demand from teams replacing MongoDB as they hit barriers to scale. And across various industries, R&D teams increasingly realize that ScyllaDB’s dramatically different database architecture delivers better performance and horizontal scalability for data-intensive workloads. For example, in an independent benchmark, ScyllaDB achieved up to 68 times lower latencies compared to MongoDB, up to 20 times higher throughput, and 19 times better price/performance ratio. Overall, the study also compared a total of 133 performance measurements and ScyllaDB outperformed MongoDB in 132 of 133 measurements. These results build on previous benchmarks vs. Cassandra, DynamoDB, and other databases that ScyllaDB is commonly used to replace.
This funding round comes during a major year for ScyllaDB. Earlier this year, ScyllaDB announced 100% year-over-year growth in its Database-as-a-Service (DBaaS) offering and 800% overall revenue growth that landed ScyllaDB a spot in the Deloitte Technology Fast 500. Plus, ScyllaDB was named Google Cloud Customer of the Year last month. And soon ScyllaDB will be hosting over 15,000 engineers at P99 CONF – the largest conference of its kind.
KEY QUOTES:
“The NoSQL database market size has reached $13 billion, still growing 21% year-over-year, making it one of the largest and fastest growing software segments. ScyllaDB is uniquely positioned to help companies address the challenges of continued data proliferation and the performance needs of modern applications. We have been impressed by the team’s execution since our original investment in 2019 and are excited to deepen our partnership further.”
— Davor Hebel, Managing Partner at Eight Roads Ventures
“ScyllaDB is architected through its shard-per-core design to capitalize on continuing hardware innovations. Other NoSQL databases are effectively insulated from the underlying hardware. With the amount of data doubling every year and new usages driven by AI, customers require fast, scalable and cost-effective solutions – and ScyllaDB displaces leading database vendors on a daily basis.”
— Dor Laor, ScyllaDB Co-Founder and CEO
MMS • RSS

Flush from securing a $34 million VC investment for his fledgling database company, TileDB CEO, Stavros Papadopoulos, is not planning on returning to the well any time soon.
A former colleague of database pioneer Michael Stonebraker at MIT, Papadopoulos is optimistic that the revenue for database systems designed around multi-dimensional arrays will outpace costs sufficiently to avoid taking cap in hand to VCs again.
“I’m a very conservative CEO,” he told The Register. “The previous [$15 million] round lasted for three years, although it was supposed to last 18 months. The economic environment right now is horrible and investors are more conservative than they were.
“The funding may last indefinitely because we have revenue: we’re not raising money on GitHub stars, we’re raising money on actual numbers. We have a lot of revenue coming in based on our projections. If we were cautious, we can become profitable very, very quickly. I will first get to profitability, and then make this decision whether we want to deploy more aggressively or we want to organically grow.”
The last couple of decades have seen a number of concerted efforts to reinvent the database and move on from omnipresent relational systems. Object-oriented, wide-column, document, graph, and value-key systems have all vied to find markets where the RDBMS doesn’t play. Papadopoulos’s notion of a system with a multi-dimensional array as its first-class data structure is aimed squarely at analytical problems.
The advantage of the array approach is that it represents a general system from which relational or vectors systems, for example, become special cases, he said. TileDB hopes to provide a mathematical proof showing that the array model is a generalization of the relational model; in effect that the array model subsumes the relational model.
For example, document databases, such as systems from MongoDB and Couchbase, have become popular with developers owing to their schema-less or schema-lite approach, making it easier to get systems up and running. But there is a cost when it comes to analytics, Papadopoulos argues.
“You may be able to store an image in a document database like MongoDB but you store it as a blob; you’re not going to store each pixel separately,” he said. “So that image is not analysis-ready. In an object store, you can’t slice it. You can’t create these multi-resolution images, to be able to zoom in, zoom out, and do that interactively with the cloud.
“The images that we’re handling are in the terabyte scale. In a document database, you would have to download the whole file locally, but you may not have enough memory and enough storage to do this. TileDB stores it in a structured way, which is tiled and indexed, so you can slice any portion and you can do analytics in a distributed way – you don’t need tons of memory to do this.”
TileDB was born out of Papadopoulos’s time as a research scientist at MIT’s Intel Labs, working on supporting scientific research. The main focus remains life sciences, where the multitude of X-rays, CAT scans, genomic data, and transcripts play to TileDB’s strengths, but there are also opportunities in engineering diagnostics and financial services, he said.
“The way people are solving these problems today is that they’re either putting together 10 different tools that are completely different to each other: a relational database, a key value database, bespoke files and formats.
“And then they’re hiring big teams of data engineers, and they’re building catalogs on top and access control layers and logging layers. Effectively, they’re reinventing the database, but to manage other databases, and that’s what they call the modern data stack. There are different flavors of the same thing, but they conceal a problem: instead of going back to the roots, and fixing this problem at its core, they’re hacking it.”
TileDB comes in an open source and a commercial offering. Unlike so-called cloud-native data warehouse systems that mushroomed in popularity over the last decade – including Snowflake and AWS Redshift – TileDB charges a flat license fee based on seats and data volume.
Papadopoulos argued that the pay-as-you-go consumption model for data analytics could create a conflict between sales teams who want to see consumption go up, and the engineering team trying to make the system become more efficient, and as a result, potentially reduce consumption.
Andy Pavlo, associate professor of databaseology at Carnegie Mellon University, said the conceptual foundation of TileDB has some merit. “Multi-dimensional arrays are the only data model that you do not want to store in a native relational DBMS. A row-store scans data ‘horizontally,’ a column-store scans data ‘vertically.’
“But some array query access patterns do arbitrary traversals across different dimensions. Therefore, you want a specialized engine – like TileDB – to handle them. But no major cloud provider offers a hosted array DBMS service, meaning they do not see a sizable market.”
Pavlo pointed out that SQL:2023 – the ninth edition of the ubiquitous ISO query language – added support for multi-dimensional arrays (SQL/MDA). TileDB supports SQL.
However, array databases were not necessary for vector analytics – something that has become en vogue due to escalating interest in large language models in machine learning.
“Vectors are just single-dimension arrays. There is nothing special about them; relational DBMSes have supported them for decades. The vector DBs have added indexes to do fast (approximate) nearest neighbor search,” said Pavlo, who is also CEO of database performance management company OtterTune. ®
System Initiative Software Goes Open Source; Aims to Model and Automate Infrastructure Management
MMS • Aditya Kulkarni

System Initiative, a customizable power tool, recently open-sourced all of its software under the Apache License 2.0. The release of System Initiative’s software to the open-source community aims at improving the DevOps landscape, with a specific emphasis on simulating the user’s infrastructure and using it to manage real-world systems.
Adam Jacob, CEO of System Initiative, illustrated the vision behind the open-source release in a blog post. Recognizing that the fundamental principles of rights and values in the realm of “Free” and “Open Source” are central to this decision, any engineers utilizing the System Initiative software will have unrestricted access to all software features, without any competitive limitations, and with no exclusive rights reserved. As a counter-example to this, HashiCorp recently announced a move to the Business Source License v1.1 (BSL 1.1) on all future releases of HashiCorp products, which drew criticism from the tech community.
Within System Initiative, every infrastructure configuration parameter qualification and respective action is defined in a TypeScript function, constructed on a Hypergraph. Each function takes its input from various points on the graph. If there is any modification to these inputs, System Initiative automatically re-executes the function and records the changed results. The model and real-world infrastructure are “digital twins”, and proposed configuration property changes can be synchronized in both directions.
Although System Initiative is yet to be released as a production-grade replacement for an existing infrastructure as code (IaC) management and continuous delivery solution, Jacob emphasized that fostering a strong community is essential to ensuring the collective success of all System Initiative users. This community-building effort comes with the open-sourcing of the software.
Jacob argued that the current DevOps tools and practices are insufficient to achieve the original goals of the movement. In another one of his blog posts, Jacob highlighted the need for a second wave of DevOps tools. He stated that 88% of respondents from the 2022 State of DevOps report find themselves unable to deploy more frequently than once a week, with some reporting deployments occurring as infrequently as once every six months.
Jacob reflected on the approach to improving complex environments and asserted that it was not considered whether the system would benefit everyone. The design initially aimed to solve immediate problems. However, this approach resulted in challenges with “DevOps work” in modern application development. These challenges include various small issues and inconveniences in their tools, communication processes, and software.
He has invited DevOps engineers and software developers who share the vision of building a brighter future to participate in the System Initiative project and contribute to its advancement.
Related, we noted recently that the majority of businesses incorporate more than 70% of open-source components into their infrastructure, products, and services. It is crucial for contemporary software developers, particularly those in senior roles, to possess the skills needed to collaborate with open-source resources effectively.
The community around System Initiative aspires to be built on empathy, trust, and shared interests, and the software is seen as a vehicle for the success of the organization and its users. The tech community on HackerNews took notice of this announcement and raised questions. We saw Jacob responding to the questions from the community in the same post.
Jacob also recently sat down with InfoQ podcast co-host Daniel Bryant, exploring the progression, and potential future trajectories of DevOps and infrastructure management.
Readers can find the source code on GitHub, and sign up to try it. To stay informed about System Initiative, join the Discord channel or subscribe to the mailing list.