Transcript
Sharma: Financial transactions have become easier over time. Long back, people used to use the barter system to exchange something that they had for something else that they wanted. Obviously, this was very challenging. With the introduction of paper money, things became a lot easier. This led to more transactions being done. There was still this problem that you had to carry cash around, and then go to the bank to withdraw more.
With the introduction of debit cards and credit cards, this problem was also solved, and the financial transactions became even more easy. This led to more of them getting done. Now it’s become even easier that you can just tap a phone or a smartwatch on a reader and a financial transaction gets done. Unfortunately, the same is not true for security remediation. Historically, security tools tend to find issues and then point towards documentation for the fixes.
The developers are expected to read through the documentation, figure out what the right fix should be, and then implement it. This means that there is a learning curve to implement the fix. One has to experiment a bit to figure out whether the fix is really going to work or not. This causes frustration. As a result, not a lot of security remediation gets done. Here we can learn from the financial industry that if we make remediation easier, then more remediation will get done.
Background
My name is Varun. I’m the CEO and co-founder of StepSecurity, which is an open-core startup that helps developers defend against software supply chain attacks by automating security best practices. The title of my talk is, security checks simplified: how to implement best practices with ease. What we’ll do is look at the OpenSSF Scorecard tool, which is a tool that finds issues across the software development lifecycle.
We’ll then try to fix these issues using manual remediation, and look at what are some of the challenges. Then we are going to look at some strategies and techniques to automate these fixes and see how that makes it easier to get a higher score. Throughout this presentation, we’ll use a demo repository, where we’ll start off with a low score and then use automation to fix the checks, to implement the checks, and get a higher score by the end of the talk.
OpenSSF Scorecard Tool
The Scorecard tool is from the OpenSSF, which stands for the Open Source Security Foundation. The tool itself assesses projects for security risks through a series of automated checks. Even though the initial intent was to run these on open source projects, a lot of the checks also apply to private repositories. Since a lot of open source projects are on GitHub, a lot of checks work well on GitHub, but there is work being done to port the checks to GitLab and other source code management platforms.
Let me go through the different categories in which it finds these issues. The first one is code vulnerabilities, where it checks whether the project itself has known vulnerabilities, or if one of the dependencies has known vulnerabilities. The second one is maintenance, where it checks if there is a process in place to update dependencies to the latest version. The third category is continuous testing, where the tool checks if basic security tools are being run as part of the CI/CD pipeline.
The fourth category is source risk assessment, where it checks the settings on the repository itself, things like branch protection, and code review policies. Then the last category is, build risk assessment, where it checks whether security best practices are being followed for the CI/CD pipeline. As you can see, the checks are across the different components, the source repository itself, the code and the pipeline within it, and also the dependencies.
Demo 1: Running OpenSSF Scorecard on a Demo Repository
Let’s look at a few demos. First, we’ll start with a look at the OpenSSF Scorecard project. Then we’ll apply and run the tool on a demo repository. This is the GitHub page for the OpenSSF Scorecard tool. You can check it out to see how these different checks have been implemented. When you use Scorecard, you get a score, which is from 0 to 10. You can also add a badge to your project. In this case, you can see that the Scorecard tool for the project has a badge for itself and has a really high score of 9.6.
Then you can scroll down and go to the README page. I think I’ll just stop at where it mentions the goals, which are to automate analysis and trust decisions on the security posture of open source projects. Also, to use this data to proactively improve the posture of critical projects that the world depends on. In this case, we are going to be looking at the second goal where we have a project and we are going to run Scorecard on it, get a score, and then improve the posture of that project.
Next, let’s see how you can run the tool on a repository. In this case, I’m using a Docker image published by the Scorecard project, and running it on a demo repository, which is this spring-petclinic repository that I’ve created where the code comes from a popular sample. You will also notice that this is using a GitHub Auth token because some of the checks require looking at the repository setting itself using the GitHub API. You need to provide a token for these checks to run.
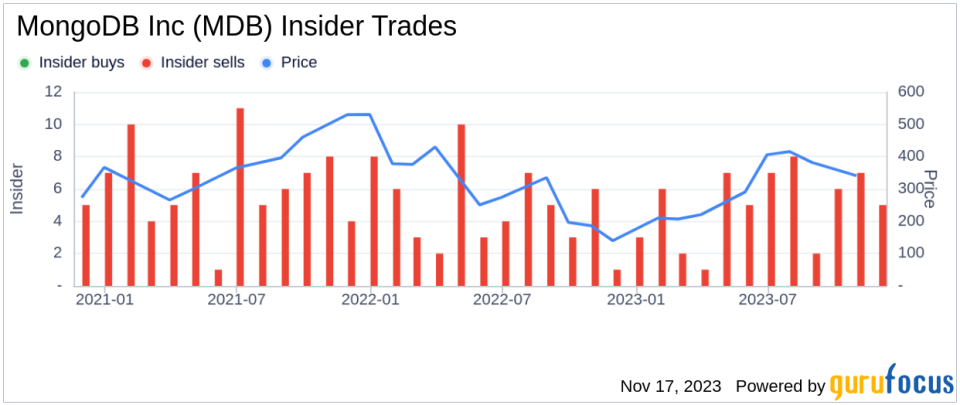
Here, it’s running these checks, and it’s going to soon print out the output. Let’s look at the output. Here, you can see that the aggregate score is 3.6 out of 10. That’s our starting score. Then it goes into details about why that is the case. Our branch protection is not set up so we have a zero on that. There are no code review policies. There is no dependency update tool that’s been set up in this repository.
Then, if we look at pinned dependencies looks like some of the dependencies have been pinned, and so we have a score of 9 on 10 there. There is no static analysis tool which is being run, so there’s a 0 there. Then, finally, token permissions have not been set up on the GitHub Actions workflows, which is why that was also 0. That was a quick demo of running the tool on a repository.
Now we’ll look at another way to run the tool on a repository, which is by adding it to the CI/CD pipeline. In this case, Scorecard is being run in a GitHub Actions workflow. There is this Scorecard action which is published by the project. With this, it runs as part of the pipeline. Anytime there is a pull request, or anytime there’s a change to the branch protection, the same Scorecard tool runs and uploads the findings in the code scanning UI. In here, you can now see the same findings that earlier we saw in a terminal, you can see them in this view.
That was a quick demo of running the Scorecard tool on a repository. As an output, as we saw, our current score is 3.6. We have a lot of work that we need to do in order to improve the score. We need to set up branch protection, so that we can then set up policies for code reviewers. We need to set up a dependency update tool so that dependencies get updated as there are new versions that become available.
We need to pin dependencies because if you don’t pin them, then it basically means that whenever the dependency has a new version, it might just use the latest version and you don’t get a chance to review if that latest version is going to work well or not. We then need to declare the least privilege CI/CD tokens, which is something specific to GitHub Actions workflows. We need to set up a static analysis tool.
Demo 2: Manual Remediation of Issues Identified by The Scorecard Tool
In this next demo, we will try to do these things manually. Then look at, what are some of the challenges? In here, we are back to that demo repository, spring-petclinic, and now the goal is to try and implement these fixes manually. If you look into branch protection, this then points us to documentation. Then, in order to set it up, you have to go through this documentation, learn about it. Then there are a lot of these different options that are available, that you need to know which ones to set to get a higher score.
Then, this is where you can actually go and set up branch protection through the project settings. Here you see those actual settings. This involves a lot of clicks. It also is something which can only be done by an administrator or someone who has the right access level to set up branch protection, which means that if you have to do this at scale across a number of repositories, you might have to reach out to someone else who is an admin, and ask them to set it up. This again, causes a challenge and makes it harder to do. Here we’re just setting some options. We will later do this in a more automated manner.
Now that we’ve looked at branch protection, let’s look at a few others. Now we’re going to look at setting up a dependency update tool. Here, again, you see that the way to fix it is that there is certain documentation, you have to go through that. In this case, let’s say if you want to use Dependabot to do these updates, then there is another configuration file that we need to learn about.
There are these several settings that apply to it, which are different depending on what package ecosystem you want to use. You may be using multiple ecosystems in your project. This again becomes the same problem, that you have to go through documentation, read through it, figure out what the fix should be before you can apply it. There are a lot of manual steps involved here.
Next, let’s look at setting up token permissions. That then points to another set of documentation, where you can see that there are a whole set of permissions which can be set up, and there’s a particular way of doing it. Now you’re not sure what permissions does your workflow really need. If you get it wrong, you might cause the workflow to break. If you just give all the permissions, then it doesn’t really help either, and your score will not really increase. That’s another example where you need to look at the documentation, figure out what the fix should be.
Then there’s pinning of dependencies where there’s, again, a set of documentation. You look at an example of how to do it. You can see that you need to get the commit SHA for a tag and set it in a certain way. Then, finally, there’s about setting up an SAST tool where there are a few options. For each of them, again, there’s additional documentation. As you can see that, going through this process, and doing this manually, involves a lot of steps. It might actually involve reaching out to others in the organization who have the right level of access to do some of these things. This is where it gets challenging.
Automating Security Remediation
Now let’s look at how we can automate these steps. What is our overall strategy going to be for this? That is basically to list down all of the steps that are in the documentation, and then try to see if we can eliminate steps in some way. If we cannot eliminate them, then we try to automate these steps. This is just a general work simplification strategy, which has been applied in a lot of different domains where you list down the steps, try to eliminate the steps. If you can’t eliminate them, then try to automate them.
We are going to apply this strategy to these different checks that had to be fixed manually. Then let’s see how we can go about doing this. The first thing that we’re going to try to solve is branch protection. To do that, a common strategy which is being used is to use GitOps, to manage repositories and to set up branch protection. GitOps basically has these three components where the first one is infrastructure as code. You declare your infrastructure as code, and you have a single source of truth for that in a Git repository.
Then, if you want to make changes to it, you do that using a pull request. Let’s say if I want to add a repository or change a repository, instead of going and doing it through the UI, I would then create a pull request in this repository, where I’ve declared the repository settings as code. That gives an opportunity to review the changes, and run CI tools on it to make sure that the changes are appropriate as per the requirements of the organization. Then once that is merged, the third part comes in, which is the CI/CD, which will actually implement those changes or publish those changes to the repository.
You see this concept of declared repositories where they’re declared using code. Then, whenever changes have to be done, that code is modified, and those changes get done. This has a lot of advantages, in the sense that it makes the whole workflow easier and faster. You can enforce standards using CI tests. There is a clear audit trail of who made the change and who approved it. You can delegate these changes.
You don’t need everybody to be an admin or have high privileges in order to set branch protection or create a repository. You can actually delegate it, because there can be different people who create a request or a pull request for it, and a different person who approves it. This has actually been followed by a lot of projects. One particular reference that I want to share is Peribolos, which is from the Kubernetes team. They actually use GitOps to manage their repository, especially the areas around adding new users and managing teams in different repositories.
Demo 3: GitOps to Automate Branch Protection
Now let’s look at a demo, where we are going to set up branch protection for our demo repository using GitOps. In here, what you see is a separate repository with the name GitOps, where I’ve set up infrastructure as code for our demo repository. If you look at here, in this case, I’ve used Terraform, in order to specify the current state of the repository. Here you can see that the repository name, spring-petclinic, is specified, and the description is specified. This is how I actually created the demo repository. Now what we want to do is to make a change to it in order to set up branch protection.
What I’m going to do here is to add more infrastructure as code, which is specifying what are those specific things, the settings that need to be set up for branch protection. What are the required status checks, and so on. This I’ve selected in a way that gets us to a higher score from Scorecard. What we’re going to do is that we’re going to create a pull request. When that happens, we can then run different CI tests on this. Your organizational policy might be that you need a minimum of two reviewers.
That is something that can be found using a CI test. In this case, we have a workflow, where we are doing basic linting of any changes that are being made. Then, we are using Terraform to publish a plan so that we know what are the changes that are going to happen. We can also see these changes as a comment in the pull request. This is basically how the workflows have been set up. I’m going to go ahead and merge this pull request. In a real scenario, it would be someone else who reviews it and merges it.
When this happens, now a CI/CD would run to actually apply these changes to our repository. This is where it’s going to actually take the admin credentials and apply these changes. This is where branch protection is being set up. Once this finishes, we will actually go and see branch protection being set up for our demo repository. You can see here that under settings, under branches, this branch protection rule has been set up.
This got done using GitOps. Here, you can see the same settings that were specified there are visible in the UI. With this technique, it makes it much easier to scale these settings across repositories and enforce policies in an org, rather than having a few people have admin access and then doing a lot of these clicks across repository, which makes it much harder.
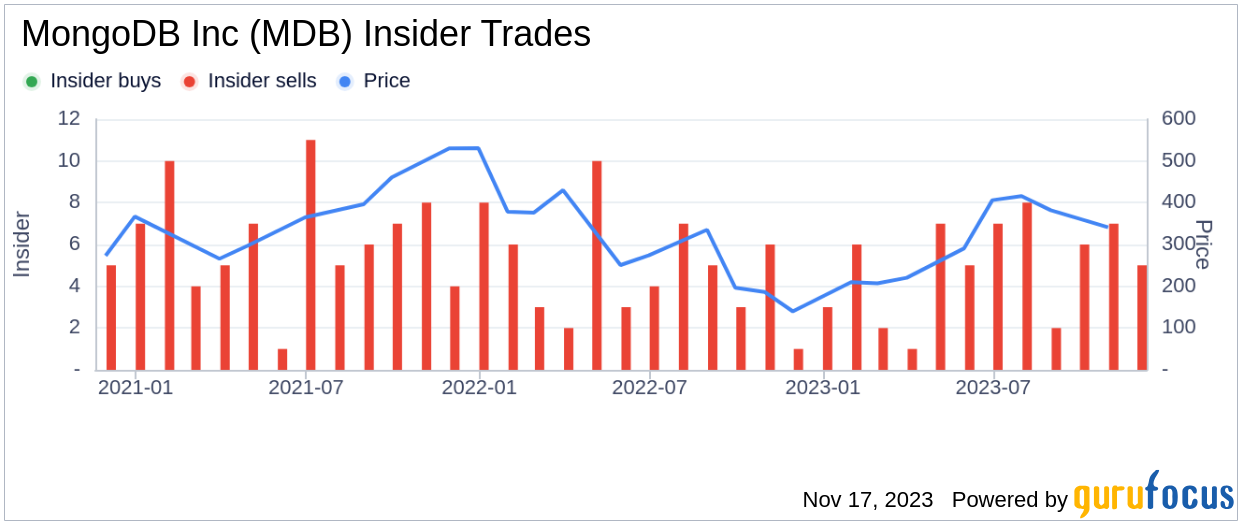
That was a quick demo of using GitOps to manage repositories and specifically managing a branch protection. We’re going to run Scorecard again on this demo repository. Now that we’ve fixed the branch protection using some level of automation, we should see an increase in the score. If we go up, we can see that our score has increased to 4.2. The branch protection score has increased to 8 out of 10. It’s still not 10 out of 10 because there are certain more requirements, like having a code owners file, which I didn’t go into. That’s still a great improvement in terms of score.
Introducing Secure-repo
Now that we went through that demo, we can see that our score has gone up from 3.6 to 4.2. We’ve set up branch protection. We’ve set up a code review policy. We’ve done a couple of things. We saw how this was done using automation, using GitOps. The next thing that we need to do is to fix the rest of the issues to set up a dependency update tool, pin dependencies, declare least privilege tokens, and set up a static analysis tool. To do this, we’re going to use code from this repository or this project called Secure-repo.
Secure-repo is something that StepSecurity maintains. It is a set of automations that help you transform a source file from one state to another. For example, if the minimum token permissions have to be set up, there is code in there which takes a CI/CD pipeline file, analyzes it, and transforms it into an output file, which has those permissions set up. Or when dependencies have to be pinned, again, it has logic to take in a file as an input, and then has transformation logic to convert that into an output file, which has those dependencies pinned.
Demo 4: Using Secure-repo to Automate Fixes for Scorecard Checks
Next, let’s look at a quick demo of the Secure-repo project and see how we can use it to improve the score via automation. This is the GitHub project for Secure-repo. It’s an open source project. To start with, let me show you the design from looking at the test. If you see the tests are organized, using this input and output folders where the input has, what are the expected files. Here, for example, you can see that this is what a workflow looks like, and it has a v1 tag. This is something that it’s going to transform. The corresponding expected file is in the output folder.
This is how it’s expected to be. Similarly, for setting up the right permissions, again, there is this input, output folder. The input has the expected files. In the input folder, there is a workflow which is missing the permissions keys, and then in the output it has the actual permission set up. What I’m trying to show you is how the test cases are organized, because with that you get an understanding of what it is trying to do. It’s essentially just trying to transform a file from one state into another, so from a state where it doesn’t have the fix applied to a state where the fix has been applied.
Let’s look at some of the code that does this transformation. I just want to go over it at a high level, because you can always go back and look at this code. In here, let’s look at how it does pinning of actions. In this case it takes the YAML file as an input. Then for each of the jobs, it tries to pin actions. Then the way it pins that action is by getting a commit SHA for that action using a GitHub API call, and then replaces it in place of the tag which was being used. In here, we can look at how it sets up permissions, which is, again, similar in the sense that it basically tries to do what a human would have done, and just automating those steps.
It looks at each of the jobs in a particular workflow, and then tries to calculate a permission for the job. It does that by looking at each of the steps in that job. Then by trying to calculate the permission for that step, and then it adds all the permissions up. The permissions for each step, or for each action are actually stored in a knowledge base. There’s this knowledge base in the repository, which has information about a lot of common actions that are being used, so in this case this is for the create-release action, which requires contents write permission.
All this information has been curated, and then the algorithm uses to add these permissions up to come up with an actual answer. If a human had to do this it would take a lot of steps, a lot of learning involved in terms of what are the different permissions needed for different actions. In here, we are looking at the code that adds a certain workflow, like a CodeQL workflow or a different tool into the repository which is getting fixed. For that, there are templates which are stored in this repository, so it takes a template, looks at what are the languages that are being used by that project where the template needs to be applied, and then sets those languages in there, and then outputs a workflow, which is specific to that repository.
That was a quick demo of the Secure-repo project, and how is it organized. Next, let’s look at how we can use Secure-repo on our demo project. In here, what we’re going to do is we’re going to try to fix the issues in our demo project using Secure-repo. The way this is done is that Secure-repo has a hosted version, and Scorecard actually points to it for remediation. That is to make it easier for projects to get a higher score. If you saw there, there was a link going to the hosted version of Secure-repo.
In this case, it basically pulls the file, because these are open source projects, it can just pull the source file, does the transformation. In this case, it has pinned the actions to a particular commit SHA. Now the maintainer of the project can just copy this file and paste it back in their code editor, or just create a pull request using it. With that, this pinning gets done. It basically cuts down on a lot of steps involved by automating them, by using Secure-repo.
Then, what it can do is it can even go further so that you don’t have to do this for each file. You can see here the concepts being applied where you’re reducing the steps at each stage. Instead of having to do this manually every time, another better option which is available is to create a pull request. In here, you can go click on pull request. In here, I’m actually putting in the demo repository, and clicking on analyze repository.
Then, the Secure-repo project looks at all of the things that it can fix. This is something you can just try right now on your open source projects, if you have any. You see all of the ways in which you can fix them. You can unselect things if you don’t want a certain fix, and then click on create a pull request. You don’t have to set up any app for this, it just uses a fork to create the pull request. Now you’ll soon see all of the changes that are being made using this automation.
This is a pull request that got created on our demo repository with a list of all the changes. In here, you can see that a Dependabot configuration file has been added. It figured out that these are the different ecosystems being used by this project, and so it’s suggesting those. Then, it has added a CodeQL file with the right language setup, so it detected it as using Java, and so it set that up. Then, for an existing workflow, it set up the right set of permissions that it needed. It has also pinned this dependency. It essentially cuts down on a huge amount of steps that one had to follow in order to make these fixes.
Now, once this pull request is merged, we can actually go ahead and see the change in the score. In here, what I’m going to do is that after merging that pull request, I’m running Scorecard again, on our demo repository, and this time, we have a higher score. Now the score has increased to 6.3 out of 10. If you compare it with where we started, so now we have a higher score in branch protection, we have a higher score in the dependency update tool, because the Dependabot configuration got added, so we have a 10 on 10 there.
In terms of pinning dependencies, because those got done via automation, we have a score of 10 on 10 there. Our static analysis tool got added, so we have a score of 8 on 10 there. Then the token permissions were set up, so we have a score of 10 on 10 there. Overall, with this automation, and by using Secure-repo and doing the changes using automation, it was much easier to apply these fixes, and now our score is 6.3.
If you see in terms of the automation status, all of these things have been done by a high degree of automation. That’s why a lot of projects are actually able to increase their score from a low score to a higher score, just by clicking on a few buttons to create a pull request, and by managing their repositories using GitOps.
Summary
I just want to reiterate that, historically, security tools tend to find issues and then point to documentation for fixes. If this documentation, if this can be automated, if each of the steps can be automated, the remediation can be made much easier. When that happens, a lot more remediation will get done. From a more practical standpoint, you can actually use the Scorecard tool to understand the state of your projects. Then, in terms of automation, you can consider using GitOps to manage repositories and the Secure-repo project to help with this automated remediation.
See more presentations with transcripts