Month: November 2023
Informatica and MongoDB Expand Global Partnership to Enable New Class of … – Tullahoma News

MMS • RSS

REDWOOD CITY, Calif.–(BUSINESS WIRE)–Nov 29, 2023–
Informatica (NYSE: INFA), an enterprise cloud data management leader, launched a new strategic partnership with MongoDB. The partnership enables customers to efficiently create a modern class of cloud-native, data-driven, industry-tailored applications powered by MongoDB Atlas and with a secure foundation of trusted data from Informatica’s market-leading, AI-powered MDM solution.
MMS • RSS

SAN FRANCISCO – Airbyte, creators of the fastest-growing open-source data integration platform, today announced availability of certified connectors for MongoDB, MySQL, and PostgreSQL databases, enabling datasets of unlimited size to be moved to any of Airbyte’s 68 supported destinations that include major cloud platforms (Amazon Web Services, Azure, Google), Databricks, Snowflake, and vector databases (Chroma, Milvus, Pinecone, Qdrant, Weaviate) which then can be accessed by artificial intelligence (AI) models.
Certified connectors (maintained and supported by Airbyte) are now available for both Airbyte Cloud and Airbyte Open Source Software (OSS) versions. The Airbyte connector catalog is the largest in the industry with more than 370 certified and community connectors. Also, users have built and are running more than 2,000 custom connectors created with the No-Code Connector Builder, which makes the construction and ongoing maintenance of Airbyte connectors much easier and faster.
‘This makes a treasure trove of data available in these popular databases – MongoDB, MySQL, and Postgres – available to vector databases and AI applications,’ said Michel Tricot, co-founder and CEO, Airbyte. ‘There are no limits on the amount of data that can be replicated to another destination with our certified connectors.’
Coming off the most recent Airbyte Hacktoberfest last month, there are now more than 20 Quickstart guides created by members of the user community, which provide step-by-step instructions and easy setup for different data movement use cases. For example, there are six for PostgreSQL related to moving data to Snowflake, BigQuery, and others. In addition, the community made 67 improvements to connectors that include migrations to no-code, which facilitates maintenance and upgrades.
Airbyte’s platform offers the following benefits.
The largest catalog of data sources that can be connected within minutes, and optimized for performance.
Availability of the no-code connector builder that makes it possible to easily and quickly create new connectors for data integrations that addresses the ‘long-tail’ of data sources.
Ability to do incremental syncs to only extract changes in the data from a previous sync.
Built-in resiliency in the event of a disrupted session moving data, so the connection will resume from the point of the disruption.
Secure authentication for data access.
Ability to schedule and monitor status of all syncs.
Airbyte makes moving data easy and affordable across almost any source and destination, helping enterprises provide their users with access to the right data for analysis and decision-making. Airbyte has the largest data engineering contributor community – with more than 800 contributors – and the best tooling to build and maintain connectors.
Airbyte Open Source and connectors are free to use. Airbyte Cloud cost is based on usage with a pricing estimator here. To learn more about Airbyte and its capabilities, visit the Airbyte website.
About Airbyte
Airbyte is the open-source data movement leader running in the safety of your cloud and syncing data from applications, APIs, and databases to data warehouses, lakes, and other destinations. Airbyte offers four products: Airbyte Open Source, Airbyte Enterprise, Airbyte Cloud, and Powered by Airbyte. Airbyte was co-founded by Michel Tricot (former director of engineering and head of integrations at Liveramp and RideOS) and John Lafleur (serial entrepreneur of dev tools and B2B). The company is headquartered in San Francisco with a distributed team around the world. To learn more, visit airbyte.com.
Contact:
Email: jeckert@eckertcomms.com
MMS • RSS

Key Points
- As the S&P 500 outpaces Russell 2000, large caps Li Auto, MongoDB, and Novo Nordisk show price strength relative to the broad market.
- Investors can watch for these standout stocks’ potential buy points and early entry opportunities.
- Relative strength serves as a visual tool for gauging stock price performance.
- 5 stocks we like better than iShares Russell 2000 ETF
With the November rally in the SPDR S&P 500 ETF Trust NYSEARCA: SPY, a number of large-cap stocks are in buy range. Among those names are three large companies that are not S&P 500 components: Li Auto Inc. NASDAQ: LI, MongoDB NASDAQ: MDB and Novo Nordisk A/S NYSE: NVO.
In 2023, large caps have outperformed small caps and mid caps, with the S&P 500 outperforming the Russell 2000 small-cap index, tracked by the iShares Russell 2000 ETF NYSEARCA: IWM by a wide margin.
When tracking stocks showing outperformance, relative strength becomes an important technical indicator. Relative strength gauges a stock’s performance against its peers or market indexes. It’s helpful in showing a stock’s resilience during market fluctuations and allows investors to identify outperformers.
Relative strength gauges price momentum
When you see a stock with exceptional relative strength, that suggests robust momentum and the potential for even more gains. The Relative Strength Index, an often-used technical indicator, is an easy way to gauge the speed and the magnitude of a stock’s price movements.
For example, you can see the relative strength index on the Li Auto chart to get a visual representation of the stock’s price performance. Its RSI stands at 47.26 as of the close on November 24. That number indicates that the stock is neither overbought nor oversold.
The MongoDB chart and the Novo Nordisk chart also indicate these stocks’ upside momentum relative to the market. But you can also use them to determine potential buy points.
Li Auto
The Chinese EV maker has been forming a cup-shaped pattern since August, below a high of $47.33. Li and fellow Chinese company XPeng Inc. NYSE: XPEV are price leaders among automotive stocks.
The company has a stellar record of revenue and earnings acceleration. MarketBeat’s Li Auto analyst forecasts show a consensus view of “buy” with a price target of $70.42, for a healthy upside of 70.64%.
As you can see, analysts believe the stock can not only break out of its current base but rally far beyond it. Currently, the most conservative buy point for Li Auto is that prior high of $47.33, but a trend line connecting a series of recent lows suggests an earlier buy point at $42.50.
Li Auto has posted five weeks in a row of upside trade, with heavier-than-normal volume in two of those weeks.
MongoDB
Part of the red-hot database sub-industry within tech, MongoDB’s fellow top large-cap performers include Splunk Inc. NASDAQ: SPLK and S&P component Oracle Corp. NYSE: ORCL.
MongoDB’s revenue has grown at rates of 29% or higher in the past eight quarters, while earnings have been growing at triple-digit rates recently, as the company notches profits after years of losses.
Those losses weren’t particularly unusual, as MongoDB is still a fairly young company, having gone public in 2017. Newer public companies often prioritize growth over immediate profits, reinvesting earnings into expansion. This strategy aims to capture market share before prioritizing profitability, and investors understand this.
However, with annual profitability in sight, investors have been sending the stock higher, more than doubling in price year-to-date. The current buy point is the stock’s July high of $439, although the stock could potentially form a handle that would offer an earlier entry.
Novo Nordisk
The Danish company has made a name for itself among pharmaceutical stocks on the strength of its diabetes and weight loss drugs Ozempic and Wegovy.
Novo Nordisk isn’t exactly a new kid on the block, but with the advent of semaglutide, the ingredient behind both treatments, the company’s revenue has increased sharply. Earnings are expected to grow 42% this year and 20% next year.
Institutional investors are taking note and, as always, are mainly responsible for the stock’s rise. About 80% of a stock’s price movement is attributable to big institutions. MarketBeat’s Novo Nordisk institutional ownership data show 1,132 institutional buyers accounted for $8.49 billion in inflows in the past 12 months, versus 545 responsible for only $860.63 million in outflows.
Novo Nordisk stock gapped out of a flat base on November 24 and remains in buy range as it’s just 1.4% above the buy point of $104.
Before you consider iShares Russell 2000 ETF, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and iShares Russell 2000 ETF wasn’t on the list.
While iShares Russell 2000 ETF currently has a “hold” rating among analysts, top-rated analysts believe these five stocks are better buys.

Need to stretch out your 401K or Roth IRA plan? Use these time-tested investing strategies to grow the monthly retirement income that your stock portfolio generates.
MMS • Steef-Jan Wiggers
During the recent Ignite conference, Microsoft announced the general availability (GA) of partitioned namespaces feature for Azure Service Bus, which allows customers to use partitioning for the premium messaging tier.
Azure Service Bus is Microsoft’s fully managed enterprise message broker in the cloud with message queues and publish-subscribe topics. The queues and topics components are in a namespace – a capacity slice of a large cluster of dozens of all-active virtual machines potentially spanning three Azure availability zones. The GA release is a follow-up from last year’s public preview.
With a partitioned namespace in the premium tier, customers can benefit from an SLA of 99.99% in regions with available availability zones. In addition, Eldert Grootenboer, a program manager for Service Bus at Microsoft, writes:
Partitioned namespaces work with scaling through Messaging Units, as the configured MUs on a namespace are equally distributed across the different partitions. Currently, it is possible to scale up to 4 partitions, and as each partition can scale from 1MU to 16MU, this means we can scale up to a total of 64MU.
Partitioning of namespaces is possible in the standard and premium tier of Azure Service Bus. However, the behavior is different when creating a partitioned namespace. In the premium SKU, the number of partitions is set during namespace creation, whereas the standard SKU’s partitioned namespaces have a predetermined number of partitions. Additionally, unlike the standard SKU, the premium SKU’s partitioned namespaces do not permit non-partitioned entities within them.

Set partitioning in a namespace (Source: Microsoft Learn)
Standard and Premium are two different types of tiers. During the Ignite conference at a Service Bus Q&A session with the product team, attendees asked about the tiers. Grootenboer told InfoQ:
We often get questions about the differences between the standard and premium SKUs; the answer is that these are two very different architectures. The premium SKU had several system architecture changes from the standard and basic SKUs. This is true for both Service Bus and Event Hubs. This new architecture provides us with many advanced capabilities, which our customers can see leveraged in the Premium SKU.
AWS and Google, respectively, also offer a fully-managed messaging broker on their cloud platforms and have partitioning capabilities like Azure Service Bus. Amazon Simple Queue Service (SQS), for instance, provides high throughput for FIFO queues through partitioning. At the same time, Google’s Pub/Sub service offers partitioning in Lite topics.
When asked by InfoQ about what is driving this investment from Microsoft for the partitioning, here is what Grootenboer had to say:
One of the constraints on our platform is that we can only scale a single message broker up to a limit of 16 MU. However, we regularly get customers who want to scale beyond this for their high-throughput scenarios. With the addition of the new partitioned namespaces feature, we are no longer limited by the throughput of a single message broker. Still, we can instead combine the throughput of multiple brokers as a single abstracted namespace. This allows our customers to scale as high as they need without virtually any limitations on their throughput.
Lastly, the availability of the partitioning feature is mentioned in the documentation, and pricing details are available on the pricing page.
MMS • RSS
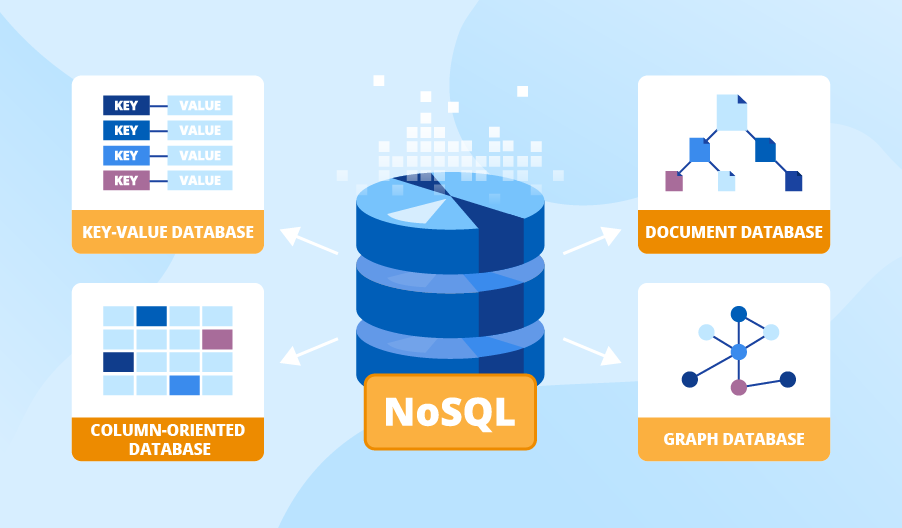
NoSQL databases use a variety of data models for accessing and managing data. These types of databases are optimized specifically for applications that require large data volume, low latency, and flexible data models, which are achieved by relaxing some of the data consistency restrictions of other databases.
The Latest research coverage on NoSQL Database Market provides a detailed overview and accurate market size. The study is designed considering current and historical trends, market development and business strategies taken up by leaders and new industry players entering the market. Furthermore, study includes an in-depth analysis of global and regional markets along with country level market size breakdown to identify potential gaps and opportunities to better investigate market status, development activity, value and growth patterns.
Access Sample Report + All Related Graphs & Charts @: https://www.advancemarketanalytics.com/sample-report/103584-global-nosql-database-market?utm_source=IndustryToday&utm_medium=Pranita
Major & Emerging Players in NoSQL Database Market: MongoDB (United States), DGraph (United States), Neo4j (United States), Couchbase (United States), Redis Labs (United States), TigerGraph (United States), Sqrrl (United States), Scylla (Israel), FoundationDB (Austria), MemSQL (United States), Others,
The NoSQL Database Market Study by AMA Research gives an essential tool and source to Industry stakeholders to figure out the market and other fundamental technicalities, covering growth, opportunities, competitive scenarios, and key trends in the NoSQL Database market.
NoSQL databases can store data in documents rather than relational tables. However, it classifies not only SQL and subdivides it by a variety of flexible data models. There are various types of NoSQL databases include pure document databases, key-value stores, wide-column database,s and graph databases. NoSQL databases are built for the storage of data and process huge amounts of data at a large scale and support a growing number of modern businesses. Geographically, North America is a widely used No SQL database owing to advanced technology and a large amount of data present in the market which is triggering the market growth over the forecast period.
On May 4, 2020, Oracle NoSQL Database Version 20.1. However, this feature contains Multi-Region Table, Untyped JSON Index, and SQL IN Operator. Hence the market OD NoSQL data is growing at extreme speed in the upcoming year.
On 6 February 2018, Rubrik acquires Datos IO try to expand into NoSQL database management support system. Rubrik, an enterprise start-up that provides data backup and recovery services across cloud and on-premise environments. However, the acquisition cost was USD 1.3 billion valuation
The titled segments and sub-section of the market are illuminated below: by Application (Facebook, Amazon, Google mail, LinkedIn, BBC iPlayer online media, BBC Sport and Olympics platforms), Mode (Offline, Online, Others), End user (Retail industries, E-commerce, Banking Industries, Health care Industries, Others)
Market Trends:
The most trending NoSQL Database is PostgreSQL, MongoDB, and MySQL
Opportunities:
Growing of data in the various ed-tech firms is building opportunities for usage of NoSQL
As the Presence of large in today world, however, it to create large job opening in the market
Market Drivers:
RDBMS databases installation is expensive and its proprietary servers, while NoSQL databases can be easily installed in cheap
RDBMSs is not easy to scale-out commodity clusters, but NoSQL databases are made for transparent expansion for a user to interact
Challenges:
The application needs consistent backups
Recovery after reconfiguration, recovery is challenging due to the changing nature of clustered systems flow
Enquire for customization in Report @: https://www.advancemarketanalytics.com/enquiry-before-buy/103584-global-nosql-database-market?utm_source=IndustryToday&utm_medium=Pranita
Some Point of Table of Content:
Chapter One: Report Overview
Chapter Two: Global Market Growth Trends
Chapter Three: Value Chain of NoSQL Database Market
Chapter Four: Players Profiles
Chapter Five: Global NoSQL Database Market Analysis by Regions
Chapter Six: North America NoSQL Database Market Analysis by Countries
Chapter Seven: Europe NoSQL Database Market Analysis by Countries
Chapter Eight: Asia-Pacific NoSQL Database Market Analysis by Countries
Chapter Nine: Middle East and Africa NoSQL Database Market Analysis by Countries
Chapter Ten: South America NoSQL Database Market Analysis by Countries
Chapter Eleven: Global NoSQL Database Market Segment by Types
Chapter Twelve: Global NoSQL Database Market Segment by Applications
What are the market factors that are explained in the NoSQL Database Market report?
– Key Strategic Developments: Strategic developments of the market, comprising R&D, new product launch, M&A, agreements, collaborations, partnerships, joint ventures, and regional growth of the leading competitors.
– Key Market Features: Including revenue, price, capacity, capacity utilization rate, gross, production, production rate, consumption, import/export, supply/demand, cost, market share, CAGR, and gross margin.
– Analytical Tools: The analytical tools such as Porter’s five forces analysis, SWOT analysis, feasibility study, and investment return analysis have been used to analyze the growth of the key players operating in the market.
Buy This Exclusive Research Here: https://www.advancemarketanalytics.com/buy-now?format=1&report=103584?utm_source=IndustryToday&utm_medium=Pranita
Definitively, this report will give you an unmistakable perspective on every single reality of the market without a need to allude to some other research report or an information source. Our report will give all of you the realities about the past, present, and eventual fate of the concerned Market.
Thanks for reading this article; you can also get individual chapter wise section or region wise report version like North America, Europe or Asia.
MMS • Almir Vuk

The latest release of .NET 8 brings significant additions and changes to ASP.NET Core. The most notable enhancements for this release of ASP.NET Core are related to the Performance and Blazor alongside the updates regarding the AOT, Identity, SignalR, Metrics and many more features.
Microsoft announced that ASP.NET Core in .NET 8 is the most performant released version so far, and as stated, when compared to .NET 7, ASP.NET Core in .NET 8 is 18% faster on the Techempower JSON benchmark and 24% faster on the Fortunes benchmark. Brennan Conroy wrote a blog post about Performance Improvements in ASP.NET Core 8 and readers are recommended to take a look into this.
The performance of ASP.NET was an active topic on Reddit, a user called Cethrivias asked an interesting question How is Asp.net so fast? The thread is rich in community discussions but the most interesting one is written by David Fowler, a Distinguished Engineer at .NET, stated the following:
It’s not documented all in one place neatly like the fasthttp repository. The short answer is that the team is absolutely obsessed with performance. While that’s not a specific change, it’s that performance culture that has resulted in dramatic performance increases and breakthroughs every single release.
and at the end of a longer and detailed answer following is stated:
This isn’t a sprint, it’s a marathon and its one of our “forever priorities” as part of the .NET charter. Our investment in performance for .NET directly saves Microsoft $$$ as we enable teams to do more with less. That is to say we will continue to improve performance as a top priority for the foreseeable future.
It is highly recommended that readers take a look at the full answer written by David and also from other community members.
Regarding the features and improvements, one of them is the Native AOT feature which is specifically tailored for cloud-native API applications, allowing the publication of ASP.NET Core apps with native AOT, resulting in self-contained applications compiled into native code.
There are a couple of benefits to having it, firstly, it significantly reduces the disk footprint by producing a single executable that incorporates the program and a subset of code from external dependencies. This reduction in executable size translates to smaller container images, expediting deployment times and enhancing overall startup efficiency.
Moreover, native AOT applications boast faster startup times, attributed to the elimination of Just-In-Time (JIT) compilation. This accelerated startup ensures quicker responsiveness to service requests and facilitates smoother transitions when managed by container orchestrators.
Additionally, ASP.NET Core apps published with native AOT can enjoy reduced memory demands, thanks to the default activation of the new DATAS GC mode. This reduction in memory consumption contributes to heightened deployment density and improved scalability.
The release of .NET 8 marks a significant milestone for Blazor, transforming it from a promising client web UI framework into a comprehensive full-stack web UI solution that can cater to a wide range of web UI requirements.
New capabilities in Blazor include static server-side rendering, enhanced navigation and form handling, streaming rendering, and the ability to enable interactivity per component or page. The @rendermode Razor directive facilitates the selection of the render mode at runtime, allowing automatic shifts between server and client to optimize app load time and scalability.
.NET 8 brings about substantial improvements in running .NET code on WebAssembly. The introduction of the Jiterpreter-based runtime enhances performance, resulting in components rendering 20% faster and a twofold increase in the speed of JSON deserialization.
The .NET WebAssembly runtime now supports multiple new edit types with Hot Reload, providing full parity with the Hot Reload capabilities of CoreCLR and enabling editing of generic types. Additionally, a new web-friendly packaging format for Blazor WebAssembly apps, known as WebCIL, streamlines deployment by removing Windows-specific elements from .NET assemblies and repackaging them as WebAssembly files.
ASP.NET Core in .NET 8 introduces API endpoints for ASP.NET Core Identity, offering programmatic access to user registration and login functionality. This simplifies setting up authentication for browser and mobile client apps, supporting both cookie and token-based authentication.
The update also introduces rich runtime ASP.NET Core Metrics using System.Diagnostics.Metrics, a cross-platform API developed in collaboration with the OpenTelemetry community. These metrics provide a robust monitoring system, offering new kinds of measurements with counters, gauges, and histograms, along with powerful reporting capabilities featuring multi-dimensional values.
The integration into the wider cloud-native ecosystem aligns with OpenTelemetry standards, ensuring seamless compatibility and enhanced monitoring capabilities for ASP.NET Core applications.
.NET 8 release was packed with a lot of changes and updates, other changes are related to Generic attributes for MVC, enhanced form binding for Minimal APIs and anti-forgery middleware, SignalR stateful reconnect, Keyed Services Support in Dependency Injection.
Furthermore, there are also performance improvements for named pipes transport in Kestrel, the named pipes is technology for building inter-process communication (IPC) between Windows apps. Redis-based output caching support is also added.
Output caching is a feature that enables an app to cache the output of a minimal API endpoint, controller action, or Razor Page. For comprehensive and more detailed content, it is recommended for readers to refer to an official release notes page.
Finally, the comments section of the original release blog post has been active with responses regarding the framework changes and enhancements. The blog post has sparked considerable engagement, with users posing numerous questions and engaging in discussions with the development team. For an insight into the various viewpoints and more detailed responses, it is strongly advised that users look into the comment section and participate in the ongoing discussions.
MMS • Jitesh Gosai

Transcript
Gosai: In 1977, two Boeing 747s were diverted to Tenerife airport in thick fog. Due to the weather condition center miscommunication, the two birds collided on the runway during takeoff, killing 583 people. That is considered one of the most deadliest aviation accidents in history. When the black box of the aircraft that attempted to take off was retrieved, it was revealed that both the first officer and the flight engineer recognized something wasn’t quite right, but the captain continued to take off, with neither officer challenging the captain’s authority. It’s believed that the captain’s authority alongside his irritation of being diverted and delayed was the key reason why neither officer challenged the captain’s decision to take off. See, the problem with challenging authority is that the benefits are often unclear and delayed, avoiding a possible collision that might not happen. While the costs are tangible and medium, the captain’s anger at being questioned. We have a tendency to underweight the benefits and overweight the costs. Sometimes it can seem easier not to say anything, especially when you have to make that call in a split second.
Google’s Project Aristotle
In 2013, Google ran an internal project called Aristotle. They set out to answer the question, what makes a team effective? They looked at 180 teams across the organization, and at lots of different characteristics of team members. They found an odd mix of personality, skill, or background explained why some teams perform better than others. What they did find was that what really mattered was less about who was on the team, and more about how that team worked together. What teams needed was for members to feel safe to take risks, and feel confident that no one on the team would embarrass or punish anyone else for admitting a mistake, asking a question, or offering new ideas.
NASA Redstone Rocket Crash
Around 1955, NASA was building a prototype Redstone rocket, which went off course and crashed during testing. They did their version of a post-incident review to try and figure out what happened, but the head of the project couldn’t find any clues. This was going to mean that they were going to have to start and redesign the mission from scratch, costing millions of dollars in people work hours. Then an engineer said they think they knew what happened. Not only that, they think they knew what caused it to crash. Who was it? It was them. When they were working on it, they touched upon the circuit board with a screwdriver and got a spark. They checked and everything seemed fine. Maybe that’s what caused the crash. They did some more analysis, and it turned out, that was the problem. What happened to that engineer? A few years later, he received a package containing a bottle of champagne for his candor and honesty. What do you think would have happened if an incident like this happened at your organization? Would they be punished and taken off the project, or worse, fired? Or, would they be rewarded with a bottle of champagne? At least the engineer was. The interesting thing is that engineer could have just stayed quiet, and no one would have known they caused that crash. Instead, unprompted, they admitted their potential mistake. What was it at NASA that made it possible for that engineer to take such a huge risk and admit that mistake? What was the special ingredient at Google that enabled some teams to perform better than others? What was missing from that cockpit of that Boeing 747 back in 1977? We’ll go look at that.
Background Information
My name is Jit Gosai. I work for the BBC. We’re a public service media broadcaster, which basically means we create content that goes on TV, radio, and the web, with an aim to inform, educate, and entertain the British public. I work on the tech side of the org, known as the product group, which houses all of its main digital services. More specifically, I work on the on-demand side, known as iPlayer, its video on-demand service, and Sounds, its audio on-demand service. Which is available on lots of different platforms such as web, smart TVs, mobile phones, and smart speakers. All of these platforms are supported by dedicated multidisciplinary teams, as well as backend teams providing APIs to power all these platforms. I work as a principal tester across the department, working with multiple teams to see how we can do things better. Particularly, I’m very interested in establishing a culture of quality, which is one where we don’t just inspect the quality by testing the things at the end of the development lifecycle, but one which looks to build quality in every level that we work. From the products that we build, the processes that we use to build them, and the very interactions between the people that work in our team. One of the ways in which I do this is by spending time with teams and the people that work in them.
Communication Between Team Members
Over the last three years, I’ve been talking to lots of different teams and their team members about how they work and the problems they face. I’m talking to testers, developers, delivery managers, team lead, product owners, and during this time, a key theme kept coming up. They would describe scenarios where a problem occurred, which should have been easily resolved if the people involved had simply spoken to each other. I’d often hear, why can’t people just talk to each other? When I delve deeper into it, I found that people were reluctant to speak up in certain situations. They were unsure how others would react if they said they didn’t know or understand something, or what would happen if they admitted to a mistake that would first result in an issue. It was generally simpler to keep quiet until then you were more certain about the details, at which point, why bother admitting it? This was resulting in problems that could easily have been resolved earlier, if the team had known there was an issue, but things were being left until the problem got big enough that no one could ignore. Or what would happen more often than not, slowing the team down without anyone understanding why.
At the time, I thought the problem was feedback. They just didn’t know how to tell each other what was and wasn’t working. My thinking was, if we better understand how to give and get feedback, then we could get people to talk to each other. This was around the time I came across Kim Scott’s work with “Radical Candor.” She referenced the work of Amy Edmondson in her book, “The Fearless Organization.” That’s when I recognized what she described as psychological safety, to be what I’ve seen, or lack of it in our teams. Amy Edmondson defined psychological safety as the belief that the work environment is safe for interpersonal risk taking. What does this mean? Interpersonal risks are anything that can make you look or feel ignorant, incompetent, negative, or disruptive. Belief is all about what you think about taking these risks. The work environment can be pretty much any group you’re working, for instance, your team.
Why Should You Care?
Why should you care? The Tenerife airport disaster illustrates that if we have high level of psychological safety in that flight cabin, the first officer and the flight engineer would have been more willing to challenge the captain and check that they were actually clear to take off, and may have just averted that disaster. The NASA Redstone rocket showed that high level of psychological safety leads people to focus on achieving their goals over self-preservation. Google’s Aristotle project found that it was less about who was on the team, and more about how that team worked together. It was specifically psychological safety that allowed team members to feel safe to take risks, and feel confident that no one on the team would embarrass or punish anyone else for admitting a mistake, asking a question, or offering up a partially thought through idea. What these three case studies show, is that psychological safety or the belief that someone can take interpersonal risks is fundamental for successful teams, can help us to learn from our mistakes, and just goes to show how important speaking up can be.
Why Psychological Safety Matters for Software Teams
Does this matter for software teams now? Through the examples from very different industries, aviation and space, only Google really relates to the software industry. The case study never really mentioned if they were just software teams or other types of teams across Google. Why does psychological safety matter for software teams? I think we can all agree that our organizations want high performing teams. Why? The simplest reason is that it helps them deliver value to their customers. The higher the performance, the more value they’re likely to be able to deliver. They don’t simply want high performing teams, they want them to be highly satisfied, too. Why? Happier people tend to be more productive. Not only that, they’re more likely to stick around, more likely to advocate for the company, and more likely to make other people happier too. Research also suggests that these two things are highly correlated. When you see an increase in one, you tend to see the other one go up too, and vice versa, when one is down, the other tends to go down with it.
VUCA (Volatility, Uncertainty, Complexity, Ambiguity)
If we can control everything in our work environments, we probably would, and teams will be quite productive. That’s the thing. Our work environments can be quite complex. One way to describe that complexity is to borrow a term from the U.S. military known as VUCA, which stands for Volatility, Uncertainty, Complexity, and Ambiguity. What does this have to do with software and our work environments? Our work environments can often be volatile, meaning, we don’t know how change will affect the system. Our work environments can often be uncertain, meaning, we don’t always know how to do something to get a specific result or outcome. Our work environments can often be complex, meaning, it’s impossible for one person to know how all the systems fit together. Our work environments can often be ambiguous, meaning, we can all interpret what we see differently, which can lead to misunderstandings, but also multiple ways to solve the same problems.
Multidisciplinary Teams
There are things we can do to try and limit VUCA in our work environments, but it’s probably impossible to move it all together. VUCA can cause two main issues. The first one is failure. The chances of things going wrong are that much more likely, due to all that volatility, uncertainty, and complexity. The other is interdependence, either within teams but also between teams due to no one person knowing everything, and no one person being able to handle everything. What’s the best way to handle all this failure and interdependence? Multidisciplinary teams, much like what we have now with developers, testers, delivery managers, product managers, UX people, and numerous types of different types of developers, all working together with the odd architect and principal thrown in for good measure. Whatever risks that can’t be mitigated can be tackled as they occur. All these different skills and abilities and experiences can collaborate to figure out the best way to proceed forward.
For multidisciplinary teams to work effectively, they need to be learning as they deliver and continuously improving their work environment. Learning comes in many forms, from classroom settings, to reading books, and other literature, blog posts, articles. Also, attending conferences, lunch and learns, and meetups too. Continuously improving is all about improving the team’s capability to do the work with less while simultaneously doing it better and faster than before, rather than trying to do more work by just trying to do it faster. Why is learning and continuous improvement crucial for high performing teams? You need both to decrease the impact of complexity, VUCA, which has a knock-on effect of lowering the impact of failure too, which typically results in increase in performance of the team. There’s a good chance that it may also have a positive knock-on effect on satisfaction too. All this needs to be happening as you deliver, not just a separate step in the process.
The key for making this work is learning from others. Don’t get me wrong. Training sessions are great and we could still have them, but we learn the most when we apply the knowledge we’ve learned, or better yet, things we have learned from others. One of the best ways to learn from others is while we’re working. To be able to effectively learn from others we need to share, such as, what we know, things we don’t agree with, things we don’t understand, what we don’t know, and mistakes we’ve made. Some things are easy to share. Why? Because it feels safe to, because you can better predict how others will react when you do so. Other things are hard to share. Why? Because it feels risky, because you don’t know how other people would react if you do. Essentially, you need to show vulnerability in a group setting. That’s not an easy thing for people to do. What might they think of you if you said these things? This is where the problems will start. If we only share what we feel safe to share, for example, only what you know, it impairs our team’s ability to learn from others. Which limits our ability to continue to improve, which increases the impact of complexity in our work environment, which increases the likelihood and impact of failure. By not taking interpersonal risk with our teams, our ability to learn from failure is also limited, which just leads to a cycle of not effectively learning from our team members. This can lead to decrease in performance, which can have a knock-on effect on team member satisfaction too.
Psychological Safety and Safe Spaces
What is it that helps team members share mistakes, what they don’t know, things they don’t understand, things they don’t agree with? Psychological safety. Another way to look at this is to get people to speak up and take interpersonal risks in our teams in order to get them talking to each other about what is and isn’t working. When I was working with teams, I’d spot when people seemed reluctant to take interpersonal risk. Whenever I mentioned psychological safety, everyone would nod and say yes, they knew what it was about. Most people’s understanding seemed to stem from the fact that they knew what psychological meant, something to do with the mind, and what safety meant, the idea of being protected. Psychological safety meant protection of the mind. It’s all about creating safe spaces, but confident people don’t really need it. Ultimately, it’s just about people trusting one another.
If we look at the definition of safe spaces, which according to Wikipedia is a place intended to be free of bias, conflict, criticism, potentially threatening actions, ideas, or conversations. Psychological safety, which is the belief that the work environment is safe for interpersonal risk taking. Then, safe spaces is going to lead people down the wrong path. Don’t get me wrong, creating safe spaces is important, and is something we need in our teams. Psychological safety and safe spaces are quite different. A safe space to me is almost a refuge. It’s somewhere where you can go and now recharge, or pushed out of your comfort zone. It’s almost the very notion of being in your comfort zone, and feeling safe and protected. You can’t take interpersonal risk in an environment that is a safe space. Psychological safety and safe spaces are not the same thing.
The problem with framing psychological safety as a safe space, is that it can lead people to think that it’s all about being super nice, and telling people that they’ve done a good job, even when they haven’t, as telling them might hurt their feelings. Or delivering bad news in an anonymous form that doesn’t allow for any follow-up. Creating an environment where anything goes and doesn’t matter if you do poorly or well, leading to apathy. We need to be careful, as people can almost go in the opposite direction too. It can lead people to think that psychological safety is all about being upfront and telling people how it is, which can lead to people being blunt with their feedback, and not caring how others react when they hear they’ve made a mistake, or something hasn’t quite gone to plan. That people should just develop a thicker skin. This can lead to overly confrontational environments, where people never know how others will react when things don’t go well, and are likely to start feeling anxious, leaving them to be more risk averse, or creating environments where only a certain type of person can survive, pushing teams into a less diverse and inclusive environment.
What we need are environments that lead away from apathy, so that people know what is expected of them, and that they’ll be told when things don’t quite hit them on, without the fear of being embarrassed or judged. Which allows them to be intellectually vulnerable. Also, to not worry that people will think it’d be overly negative or disruptive if we’re pointing out others’ issues and mistakes. Also, away from environment that are fear-inducing, with high levels of uncertainty with how people will react if things don’t quite go to plan. The worry that they will be judged by their teammates as incompetent or ignorant if they admit to a mistake, or share that they don’t know something, or worse, be punished for doing so. What we need is people to feel safe enough to being vulnerable in a group setting, so they can come out of their comfort zones and take risks. Also know where the boundaries are, and understand that what isn’t, isn’t acceptable within the teams, and how they will know if they’ve crossed that line, and what the outcome will be if they did. What we need are environments that allow people to do their best work, but also understand how they can get even better. In some ways, psychological safety is about giving people the courage to say those hard to say things. People need to come out of their comfort zones and start getting uncomfortable.
Creating Environments with High Psychological Safety
My previous approach in teams was talking to people one-on-one about what psychological safety is and isn’t, and how it helps, which is fine for a couple of teams here and there. This wasn’t really going to scale across a whole department, and hoping that people will just figure this stuff out just didn’t seem very realistic. See, the thing about psychological safety and taking interpersonal risk is that it’s not a natural act. How do you go about creating environments that are considered high in psychological safety? There are two core areas to making it happen. One is team members that enable interpersonal risk taking, which is about helping people push out of their comfort zones and taking interpersonal risks. The second is leadership that fosters environments high in psychological safety, as people have a natural tendency to look up in the hierarchy towards what is and isn’t acceptable.
Over the last year, I’ve developed a bottom-up and a top-down approach towards creating environments that will be considered high in psychological safety. The bottom-up approach is all about focusing on team members, and isn’t trying to get them to take interpersonal risk, but upskilling them in their communication skills. Over the last couple of years, I’ve noticed that communication skills are not evenly spread in teams. You have some people who are very skilled and know all about how to actively listen, the art of asking a good question, and how to get and gift people. Others have never heard of active listening, questioning of something that it actually will do. Feedback is what your line managers will do. Good communication skills are essential for effective collaboration. As a result, I developed a series of workshops that allows you to better balance out these skills in a team. The thinking being, if team members are better skilled at communicating, then they may be more willing to take interpersonal risks when encouraged to do so. As a result, this has proven very successful with upskilling team members with these skills, but what is less certain is, does it help people take interpersonal risks? This is where the top-down approach comes in. The top-down approach is all about educating leaders in what is and isn’t psychological safety, and how they can foster environments that are considered high in it, much like this talk. In fact, all the content I’ve spoken about so far is directly taken from the talks and discussions I’m facilitating with leadership groups. The insight I’ve gained from this is that a lot of leaders know the right behaviors, but they’ve not made the connection as to how these behaviors foster psychological safety, which often resulted in inconsistencies with their approaches, and therefore, never really create an environment high in psychological safety.
Principals and Staff-Plus Engineers Bridging the Gap
Principals and staff-plus engineers typically sit in the gray areas of teams. You can almost think of this as the middle between teams and leaders. While not official leaders with line management responsibilities, we have very senior titles that put us in unofficial leadership positions. Also, while not official members of teams, we’re individual contributors, still getting hands-on with them. What this allows us to do is bridge the gap between team leaders and team members in ways that others just can’t. We have an opportunity to not only create environments high in psychological safety, but also demonstrate interpersonal risk taking to show others how to do it. How do we do this? By adopting certain mindsets and behaviors. What we need to do is develop our curiosity in that there’s always more to learn. We need humility as we don’t have all the answers, and empathy, as speaking up is hard and needs to be encouraged.
Core Mindsets, and Modeling Behavior as Staff-Plus Engineers
What I’d like to do is look at how to demonstrate these mindsets, and looking at some of the behaviors that we can model as staff-plus engineers. I’d like to start with framing the work. This is a two-part process to frame the work. First, you need to set expectation, about our work being interdependent and complex. What this does is it lets people know that they are responsible for understanding how their work interacts with other people’s in the team. We need to set expectation that they need to learn from failure as it’s going to happen, or that people will try and avoid it, making it less likely that they speak up. Or team members are seen as important contributors with valued knowledge and insight. Not just there as support workers, there to make the leadership team look good. Setting expectation is really important as it helps people default towards collaboration, and away from self-protection and not speaking up. The other part of framing is setting the purpose, which is all about, what are we doing? Why are we doing it? Who does it matter to? It’s about helping people connect their work back to the organizational goals. Again, reinforce that default towards collaboration and away from self-protection. This is important, even if you don’t directly manage the people in the teams, because we shouldn’t just assume this has happened. It needs to be happening continuously, even when it seems obvious. Why? Because people forget, especially when things are tough. It’s in these tough moments that we need people to speak up and share what they know.
We then need to invite participation. Firstly, by acknowledging our fallibility. That we don’t hold the answers as leaders and staff-plus members, and that we need to work collaboratively to share our different experiences and perspectives, as well as what we do and what we don’t know. We need to provide each other with candid but respectful feedback on how things go. Secondly, we need to proactively invite input by demonstrating active listening and asking open, thought-provoking questions. When we’re inviting people to participate, we then need to respond productively. Firstly, by expressing appreciation. Before anything else, we need to acknowledge that it takes courage to speak up, and thank people when they do, because we want them and others to do it more. We then reward people’s performance. We want to emphasize the effort and strategy they’ve put into the work, not just the outcomes of the work. Why? Because even when people have tried their best to come up with a great strategy, we still might not succeed, so only rewarding successes indirectly punishes failure. Failure is highly likely in the complex work that we do. You then need to destigmatize failure, because people usually believe that failure is not acceptable, and high performers don’t fail, which leads to people trying to avoid, deny, distort, or ignore failures. We need to reframe failure as being a natural byproduct of experimentation. The high performers produce, learn from, and share their failures. Therefore, failure is part of learning, which can lead to open discussions, faster learning, and greater innovations.
What do these three areas actually do? Framing the work creates shared expectation and meaning, and helps people see that they have valuable things to contribute, and that we want to hear what they know: good or bad. Inviting participation increases confidence that their contributions are welcomed. By giving them the space, asking them to share, and providing structure to do so, will build confidence that what they have to share will be heard. Finally, responding productively directs teams towards continuous learning, by showing appreciation of what people have contributed encourages them and others to do it more. Reframing failure helps people to experiment which inevitably produces more failures that we share openly so we can all learn. How do these things help you create psychological safety? The mindsets are all about helping you focus your thinking and behavior. The reason for three is that it keeps the mindsets’ intention, preventing people from over-indexing on any one of the mindsets, and helps guide our behaviors. Framing the work, inviting participation, and responding productively are the behaviors that we need to be modeling in our teams. Creating shared expectation, sharing contributions, and moving towards continuous learning are the intentions and help us understand what outcomes we’re looking to create with our behaviors.
Getting Started, with Core Mindsets
Working like this can be a bit tricky. What can you do right now to get started? How can you frame the work? Firstly, when working with teams, name the goal of speaking up. Clearly state the need for people to speak candidly but respectfully, and clearly mapping it back to team’s goals. What are they trying to accomplish? Why does speaking up help this happen? Then, state the purpose. For the teams that you’re working with, learn to tell a compelling story about what the team does, and why it matters to the department, and how it can help the organization be better. This is really important for work that doesn’t clearly link to customers. For instance, work done by backend teams, or infrastructure teams, but also day-to-day work, so just build infrastructure, testing, moving towards continuous delivery. When can you do this? A couple of good places to start is kickoff meetings when you work, is a great opportunity to name the goal of speaking up. If you’re a coach or mentor, other staff members, then catchup. Catchups can be another good place to understand what they think the team’s purpose is. How did this differ from your compelling story? It gives you a chance to course correct. Sharing a compelling story outside the team can also be really helpful too, especially during interviews or recruitment drives, or during presentations about what the team does.
Then, we want to invite participation by learning from failure. What can you do now? We can show humility during meetings with team members, by making sure they know you don’t have all the answers, and by emphasizing that we can always learn more. We can demonstrate proactive inquiry by asking open questions rather than rhetorical ones, and asking questions of others, people to see what they think rather than just sharing your view. We want to be helping to create collaborative environments and structures that look to gain others’ views and perspectives and concerns, no matter their ranking or experience with the subject matter. Finally, responding productively. When failure occurs, what can you do now? We need to express appreciation by thanking people when they bring ideas, issues, or concerns to you. We want to be creating structures for experimentation that encourage intelligent failures, that help us to learn what to do next, not just failing for the sake of it, and proactively destigmatize failure by seeing what we can do to celebrate those intelligent failures. When someone comes to you with bad news, how do we make that a positive experience for them? Do you offer any support or guidance for helping them explore their next steps? This isn’t a step-by-step plan or a one-off activity where you frame the work, invite people to participate, then follow by responding productively, but something that needs to be happening continuously, in some cases, when the opportunity arises. A good rule of thumb here is little and often.
Recap
I began with why I started looking at psychological safety, because I was puzzled by why people couldn’t speak up to each other. Then defined what psychological safety meant, which in its simplest form, is about people being able to take interpersonal risks or the belief that they can. We then looked at some case studies, as to where our lack of psychological safety resulted in tragic consequences, but also how high levels resulted in accelerated problem solving and performance. I then took us through why psychological safety is critical for software teams. This is due to our work being complex, which leads to interdependence. In order to be able to handle that complexity and interdependency, we need to be able to share the easy and the hard things in our team. I then went on to detail some of the common misunderstandings of psychological safety, that it’s not about safe spaces. It’s not about being too nice or too blunt. That confident people need it too. Finally, how can we foster psychological safety in our work environments by thinking through three core mindsets, and adopting specific behaviors with the intentions to create shared meaning, confidence that people’s contributions are welcome, and directing teams towards continuous learning. Some initial steps on how we can get started.
Some of you may be wondering, will this solve psychological safety in our teams? By itself, with just one person behaving this way? Probably not. If we as staff-plus engineers can start to model these behaviors, we can show others a different way that leads to true collaboration, not people just handing work off to one another, and coordinating their actions. We don’t have to do this. No one holds that against you. Most teams will continue as they are, with only a minority of people willing to take the risks, while the rest wait for more sensing on what the outcome will be if they speak up. At which point, it can often be too late, slowing the team down, and people wondering why people just can’t talk to each other. If you do decide to model these behaviors, you not only create environments that are more inclusive, but they encourage people to speak up and share what they do and don’t know. You create the environments for others to step up and unlock the performance of our teams and organizations, and increase the impact of your work in ways that we can’t even anticipate.
Conclusion
As staff-plus engineers, we have an incredible opportunity to shape the cultures of our teams and organizations. We can leave it to chance and hope these things just work out, or we can be deliberate and set the direction we want to go. Psychological safety is foundational to high performing teams. If people won’t, or can’t speak up, then we risk not hearing valuable information until it’s too late. One of the best ways to increase interpersonal risk taking in our teams is for us to model these types of behaviors regularly and consistently. My question to you is, when would you get started?
See more presentations with transcripts
MMS • RSS
“
The latest competent intelligence report published by Marketintelx.com with the title ‘ Global Big Data Analytics In Telecom Market 2023′ provides a sorted image of the Big Data Analytics In Telecom industry by analysis of research and information collected from various sources that have the ability to help the decision-makers in the worldwide market to play a significant role in making a gradual impact on the global economy. The report presents and showcases a dynamic vision of the global scenario in terms of market size, market statistics, and competitive situation.
Download Sample to Understand the Complete Structure of the Report: https://marketintelx.com/sample_request/6200
At present, the Big Data Analytics In Telecom market is possessing a presence over the globe. The Research report presents a complete judgment of the market which consists of future trends, growth factors, consumption, production volume, CAGR value, attentive opinions, profit margin, price, and industry-validated market data. This report helps individuals and market competitors to predict future profitability and to make critical decisions for business growth.
| Report Contains | Details |
|---|---|
| Key Market Players | Microsoft Corporation, Mongodb, United Technologies Corporation, Jda Software, Inc., Software Ag, Sensewaves, Avant, Sap, Ibm Corp, Splunk, Oracle Corp., Teradata Corp., Amazon Web Services, Cloudera |
| Base Year | 2022 |
| Historical Data | 2017 – 2022 |
| Forecast Period | 2023 – 2030 |
| Market Segments | Types, Applications, End-Users, and more. |
| By Product Types | Cloud-Based On-Premise |
| By Applications / End-User | Small And Medium-Sized Enterprises Large Enterprises |
| Market forecast | Forecast by Region, Forecast by Demand, Environment Forecast, Impact of COVID-19, Geopolitics Overview, Economic Overview of Major Countries |
| Report Coverage | Revenue Forecast, Company Ranking, Competitive Landscape, Growth Factors, and Trends |
In terms of depth and area of review, the study is extensive. It covers global developments faithfully, all the while focusing on crucial market segment regions. This research accurately reflects the distinction between corporate performance parameters and procurement scenarios across various geographical locations. It provides a detailed breakdown of the Big Data Analytics In Telecom industry sectors. The report contains some general information as well as a sales projection study for each location.
Geographic Segment Covered in the Report:
The Big Data Analytics In Telecom Market report offers insights on the market area, which is further divided into sub-regions and nations/regions. This chapter of the research includes details on profit prospects in addition to market share data for each nation and subregion. During the expected time, this component of the research covers the market share and growth rate of each region, country, and sub-region.
➢ North America (the United States, Canada, and Mexico)
➢ Europe (Germany, France, United Kingdom, and Rest of Europe)
➢ Asia-Pacific (Japan, Korea, India, Southeast Asia, and Australia)
➢ South America (Brazil, Argentina, and Rest of South America)
➢ Middle East & Africa (Saudi Arabia, UAE, Egypt, and Rest of the Middle East & Africa)
The Big Data Analytics In Telecom report analyses various critical constraints, such as item price, production capacity, profit & loss statistics, and global market-influencing transportation & delivery channels. It also includes examining such important elements such as Big Data Analytics In Telecom market demands, trends, and product developments, various organizations, and global market effect processes.
Following are chapters in Big Data Analytics In Telecom Market report 2023:
Chapter 1 provides an overview of Big Data Analytics In Telecom market, containing global revenue and CAGR. The forecast and analysis of Big Data Analytics In Telecom market by type, application, and region are also presented in this chapter.
Chapter 2 is about the market landscape and major players. It provides competitive situation and market concentration status along with the basic information of these players.
Chapter 3 introduces the industrial chain of Big Data Analytics In Telecom. Industrial chain analysis, raw material (suppliers, price, supply and demand, market concentration rate) and downstream buyers are analyzed in this chapter.
Chapter 4 concentrates on manufacturing analysis, including cost structure analysis and process analysis, making up a comprehensive analysis of manufacturing cost.
Chapter 5 provides clear insights into market dynamics, the influence of COVID-19 in Big Data Analytics In Telecom industry, consumer behavior analysis.
Chapter 6 provides a full-scale analysis of major players in Big Data Analytics In Telecom industry. The basic information, as well as the profiles, applications and specifications of products market performance along with Business Overview are offered.
Chapter 7 pays attention to the sales, revenue, price and gross margin of Big Data Analytics In Telecom in markets of different regions. The analysis on sales, revenue, price and gross margin of the global market is covered in this part.
Chapter 8 gives a worldwide view of Big Data Analytics In Telecom market. It includes sales, revenue, price, market share and the growth rate by type.
Chapter 9 focuses on the application of Big Data Analytics In Telecom, by analyzing the consumption and its growth rate of each application.
Chapter 10 prospects the whole Big Data Analytics In Telecom market, including the global sales and revenue forecast, regional forecast. It also foresees the Big Data Analytics In Telecom market by type and application.
Conclusion: At the end of Big Data Analytics In Telecom Market report, all the findings and estimation are given. It also includes major drivers, and opportunities along with regional analysis. Segment analysis is also providing in terms of type and application both.
Access the full Research Report @ https://marketintelx.com/checkout/?currency=USD&type=single_user_license&report_id=6200
What are the goals of the report?
①The predicted market size for the Big Data Analytics In Telecom Industry at the conclusion of the forecast period is shown in this market report.
②The paper also analyses market sizes in the past and present.
③The charts show the year-over-year growth (percent) and compound annual growth rate (CAGR) for the given projected period based on a variety of metrics.
④The research contains a market overview, geographical breadth, segmentation, and financial performance of main competitors.
⑤The report analyzes the growth rate, market size, and market valuation for the forecast period.
If you have any special requirements, please let us know and we will offer you the report at a customized price.
Contact Us
Sarah Ivans | Business Development
Phone: +1 805 751 5035
Phone: +44 151 528 9267
Email: [email protected]
Website: www.marketintelx.com
”
Champlain Investment Partners LLC Has $191.22 Million Holdings in MongoDB, Inc … – MarketBeat
MMS • RSS
![]() Champlain Investment Partners LLC boosted its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 21.7% during the second quarter, according to its most recent 13F filing with the Securities and Exchange Commission. The fund owned 465,269 shares of the company’s stock after buying an additional 82,820 shares during the quarter. MongoDB makes up about 1.2% of Champlain Investment Partners LLC’s holdings, making the stock its 26th biggest position. Champlain Investment Partners LLC owned about 0.66% of MongoDB worth $191,221,000 at the end of the most recent reporting period.
Champlain Investment Partners LLC boosted its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 21.7% during the second quarter, according to its most recent 13F filing with the Securities and Exchange Commission. The fund owned 465,269 shares of the company’s stock after buying an additional 82,820 shares during the quarter. MongoDB makes up about 1.2% of Champlain Investment Partners LLC’s holdings, making the stock its 26th biggest position. Champlain Investment Partners LLC owned about 0.66% of MongoDB worth $191,221,000 at the end of the most recent reporting period.
A number of other hedge funds and other institutional investors have also bought and sold shares of the company. GPS Wealth Strategies Group LLC bought a new stake in MongoDB in the 2nd quarter valued at $26,000. Capital Advisors Ltd. LLC boosted its holdings in MongoDB by 131.0% in the 2nd quarter. Capital Advisors Ltd. LLC now owns 67 shares of the company’s stock valued at $28,000 after purchasing an additional 38 shares during the period. Global Retirement Partners LLC boosted its holdings in MongoDB by 346.7% in the 1st quarter. Global Retirement Partners LLC now owns 134 shares of the company’s stock valued at $30,000 after purchasing an additional 104 shares during the period. AlphaCentric Advisors LLC bought a new stake in MongoDB in the 2nd quarter valued at $56,000. Finally, Pacer Advisors Inc. boosted its holdings in MongoDB by 174.5% in the 2nd quarter. Pacer Advisors Inc. now owns 140 shares of the company’s stock valued at $58,000 after purchasing an additional 89 shares during the period. 88.89% of the stock is currently owned by institutional investors and hedge funds.
MongoDB Trading Up 1.5 %
Shares of NASDAQ:MDB traded up $6.08 during trading on Tuesday, hitting $407.99. 394,851 shares of the company’s stock were exchanged, compared to its average volume of 1,552,158. MongoDB, Inc. has a 1-year low of $137.70 and a 1-year high of $439.00. The firm has a 50-day moving average price of $358.56 and a two-hundred day moving average price of $365.43. The company has a current ratio of 4.48, a quick ratio of 4.48 and a debt-to-equity ratio of 1.29. The firm has a market cap of $29.11 billion, a P/E ratio of -117.94 and a beta of 1.16.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Thursday, August 31st. The company reported ($0.63) EPS for the quarter, topping the consensus estimate of ($0.70) by $0.07. MongoDB had a negative net margin of 16.21% and a negative return on equity of 29.69%. The company had revenue of $423.79 million during the quarter, compared to analysts’ expectations of $389.93 million. Equities analysts predict that MongoDB, Inc. will post -2.17 earnings per share for the current year.
Insider Transactions at MongoDB
In related news, CRO Cedric Pech sold 16,143 shares of MongoDB stock in a transaction that occurred on Thursday, September 7th. The shares were sold at an average price of $378.86, for a total transaction of $6,115,936.98. Following the transaction, the executive now owns 34,418 shares of the company’s stock, valued at approximately $13,039,603.48. The transaction was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this hyperlink. In related news, CRO Cedric Pech sold 16,143 shares of MongoDB stock in a transaction that occurred on Thursday, September 7th. The shares were sold at an average price of $378.86, for a total transaction of $6,115,936.98. Following the transaction, the executive now owns 34,418 shares of the company’s stock, valued at approximately $13,039,603.48. The transaction was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this hyperlink. Also, Director Dwight A. Merriman sold 1,000 shares of MongoDB stock in a transaction that occurred on Friday, September 1st. The stock was sold at an average price of $395.01, for a total transaction of $395,010.00. Following the transaction, the director now directly owns 535,896 shares in the company, valued at approximately $211,684,278.96. The disclosure for this sale can be found here. Insiders sold a total of 321,077 shares of company stock worth $114,507,479 in the last quarter. 4.80% of the stock is owned by company insiders.
Analyst Ratings Changes
A number of brokerages have weighed in on MDB. Argus increased their price target on shares of MongoDB from $435.00 to $484.00 and gave the company a “buy” rating in a report on Tuesday, September 5th. JMP Securities raised their price objective on shares of MongoDB from $425.00 to $440.00 and gave the stock a “market outperform” rating in a report on Friday, September 1st. Citigroup raised their price objective on shares of MongoDB from $430.00 to $455.00 and gave the stock a “buy” rating in a report on Monday, August 28th. Mizuho raised their price objective on shares of MongoDB from $240.00 to $260.00 in a report on Friday, September 1st. Finally, KeyCorp reduced their price objective on shares of MongoDB from $495.00 to $440.00 and set an “overweight” rating for the company in a report on Monday, October 23rd. One equities research analyst has rated the stock with a sell rating, two have issued a hold rating and twenty-four have given a buy rating to the company. According to MarketBeat, the stock presently has a consensus rating of “Moderate Buy” and a consensus price target of $419.74.
View Our Latest Stock Report on MDB
MongoDB Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Click the link below and we’ll send you MarketBeat’s list of seven best retirement stocks and why they should be in your portfolio.
Airbyte Heralds Broad Data Migration with Latest Support for MongoDB, MySQL, and PostgreSQL
MMS • RSS
Airbyte, creator of the fastest-growing open-source data integration platform, is announcing that certified connectors for MongoDB, MySQL, and PostgreSQL databases are now available for both Airbyte Cloud and Airbyte Open Source Software (OSS). This coverage represents the ability to move datasets of unlimited size to any of Airbyte’s 68 supported destinations—including AWS, Azure, and Google cloud platforms, as well as Databricks, Snowflake, and several vector databases—which can further be utilized by AI models.
The Airbyte platform—known for its massive catalog of data sources, incremental, observable syncs, built-in resilience, and secure authentication—continues to uplift its community and serve the needs of its customers with support for MongoDB, MySQL, and PostgreSQL, according to the company.
This latest coverage is a testament to its mission of maintaining the largest connector catalog in the industry, consisting of more than 370 certified and community connectors. Further broadened by over 2,000 custom connectors created with Airbyte’s No-Code Connector Builder, Airbyte delivers rapid data source connection, optimized for performance.
“This makes a treasure trove of data available in these popular databases—MongoDB, MySQL, and Postgres—available to vector databases and AI applications,” said Michel Tricot, co-founder and CEO, Airbyte. “There are no limits on the amount of data that can be replicated to another destination with our certified connectors.”
The growing, active community nurtured by Airbyte has driven the release of more than 20 Quickstart guides, which offer step-by-step instructions for different data migration use cases. The Airbyte community has also implemented 67 improvements to connectors that introduce migrations to no-code.
Airbyte Open Source and connectors are free to use. Airbyte Cloud cost is based on usage. To learn more about Airbyte’s platform and connectors, please visit https://airbyte.com/.