Month: November 2023

MMS • Michael Friedrich

Transcript
Friedrich: I want to dive into, “From Monitoring to Observability: eBPF Chaos.” We will hear my learning story about eBPF, how to use tools based on eBPF, and debugging certain things in production like an incident, and how chaos engineering and chaos can help with that. My name is Michael. I’m a Senior Developer Evangelist at GitLab. I have my own newsletter. We will learn about many things.
It’s key to remember them even if you don’t immediately understand them, research, look into what is an eBPF program, what is a Berkeley Packet Filter, diving into kernel user space, bytecode, compilers, C, C++, Go and Rust might be related. Then going a little more high-level with observability, DevSecOps, security, chaos experiments, obviously a little bit of DNS will be involved. Then tying everything together with security chaos, eBPF Probes, reliability, and more ideas which should inspire you to get more efficient with anything production related incidents and whatnot.
Observability
To get started with observability. We have monitoring, now we have observability. How would someone define observability? My personal definition of that is modern application development and deployment with microservices, using cloud native technologies that require a new approach beyond traditional metrics monitoring, or state-based monitoring. We are collecting a lot of data types, a lot of events, a lot of signals, so we are able to answer not unknown questions, but what is the overall state of the production environment?
It’s also key to identify unknown unknowns. For example, a DNS response latency in a CI/CD pipeline, actually caused the deployment cost to rise significantly. The cloud cost like €10,000, or dollars a month. This is something you probably wouldn’t figure out with the individual data sources and metrics on their own. Combined, this is what describes observability. It’s also a way to help reduce infrastructure cost.
Considering that there are many different data types involved with observability, we started with metrics, then there were traces, logs, and events. Profiling comes to mind. Error tracking. Real user monitoring, or end-to-end monitoring. Test reports even can be treated as observability data. Also, NetFlow or network data. There’s much more which can add to the bigger picture within observability. Metrics are a key value with text stored in a time-series database. Prometheus is defining the standard in the cloud native monitoring and observability community.
It provides a query language, the OpenMetrics specification, which was also adopted into OpenTelemetry, and the ability to visualize that as a graph, doing forecast trends and whatnot. There are different data sources within observability, like metrics from a Prometheus exporter, code instrumentation could be sending traces.
Potentially, in a Kubernetes cluster, there’s a sidecar fetching the pod logs and then sending it to a central storage. Everything happens on the user level. This is great to some degree. Sometimes we really want to look deeper, so there are more data sources, specifically like a syscall, network events, resource access. In a microservices cluster, this would need a deeper look into the kernel level, so we have more observability data possibilities even.
(e)BPF
Is the problem solved? There is eBPF and everyone talks about it. It’s on the kernel level. What is it? What problem does it solve? By definition, it provides observability, security, and networking at the kernel level, which the ebpf.io website describes pretty much. The thing is, the kernel needs to be stable, so there is less innovation within the kernel itself. The idea with eBPF was to run eBPF programs as an operating system runtime addition. It’s an addition to the kernel, and you can execute small programs in a safe environment.
Looking into the use cases, for these small programs, one of them is high-performance networking and load balancing, which is done by Cilium and others. You can trace applications, what they’re doing on the inside, which function calls are being executed. It also helps with performance troubleshooting. Different use cases come to mind with fine-grained security observability, or even something around application or container runtime security. Being able to see which network connections a container opens or something like that. This is all possible on the kernel level with an eBPF program when provided and developed.
An eBPF program itself is a little complicated to start with, because the kernel expects bytecode and nobody writes bytecode, so I have no idea how it looks like. The thing is, we need an abstraction layer for that. Cilium provides a Go library. There is BCC as a tool chain. There’s bpftrace. A lot of tools and names floating around, which provide an abstraction layer in a higher-level programming language, being able to convert it and create bytecode for the kernel. The verification happens with just-in-time compilation from bytecode to the machine specific instruction set at the kernel level. This is essentially in the background the idea behind it.
eBPF: Getting Started
From a user side, it’s like, I need a lot to learn and this can be quite overwhelming. For me, personally, it took me quite some time to really say, ok, where should I be starting? What is the best learning strategy? I started my own research and documented everything on a knowledge base, which I maintain on o11y.love. At some point, everyone was saying, there’s Brendan Gregg’s tutorial, the blog post from 2019. It’s current. It’s accurate. It provides tutorial and examples for beginners, for intermediate, and advanced users.
The best way to get started with is like, start with a Linux virtual machine on a Linux host, use a kernel greater than 4.17, which provides access to eBPF support. Also, on the way of learning all these terms and tools and technologies, it’s important to note them. When you don’t really understand what it does, write the term down. Also, think about how would you explain what it does when you have the first success moment in running bpftrace, and think about, this solved my problem.
How would I explain this complex technology to others? Doing so really helped me understand, or even like verify my knowledge, and considering I actually was wrong. It’s really a good thing to practice explaining this. This is also why I’m doing this talk. I got started looking into the BCC toolchain, which was mentioned quite often. It’s also mentioned in Brendan Gregg’s tutorial. I looked into what’s available and what are the tools, and thought of something similar to strace telling me that a specific binary has been executed.
Like execsnoop -t, means trace all programs which are actually executing something, like executing a binary. In the first terminal, I ran the command. On the second terminal, I decided to run some curl commands, just to simulate an outgoing connection as well. It could be something like a malicious actor downloading something, which could be an interesting use case for later on. In essence, I saw something working. The commands have been logged, sshd was also doing something. I was like, ok, this is my first success moment, but what else is out there?
I looked into the next tool or platform or framework, which was bpftrace, so I was really addicted to learning now. Because bpftrace provides many use cases, or many things you can actually probe or look at, and most obvious like Ethernet traffic, but also things like looking into file systems, and much more. Getting a better insight when high-performance scaling systems are not working. It provides a high-level tracing language, so it’s not necessary to write deep down C code or something. It’s more inspired by DTrace and others. It can help with Ops and SRE tooling, maybe replacing even something like strace.
Because, oftentimes, it’s really hard to remember what all the CLI tools are doing. With bpftrace, I thought, there is opensnoop, which is able to trace open calls. I thought, I could open a file by myself, but what if I write a quick C program, which just opens a file, creates it, and then closes it again, in order compile it and then see what opensnoop is actually doing.
I could write my own code, and then see how the eBPF tooling is handling that. I made this happen, compiled to C binary, executed it. Then I saw not only that like the ebpf-chaos.txt was created, but also the libc was loaded by the binary. It was like, this actually makes sense, because the header include for the standard library is there and libc provides that. This was an interesting insight, also in a way of saying, I can verify what other files are being opened by the specific binary and maybe see whether the call to malloc or jemalloc, or something else is actually happening.
It got me thinking, what else is out there? Folks have been mentioning like BCC, but this needs C and Python knowledge, or you should know at least C on the side for the kernel instrumentation, and Python and Lua actually as a frontend. It can be used to run these programs. BCC means BPF Compiler Collection. I found it pretty interesting because it’s the first time I saw [inaudible 00:12:57] as a hook into the kprobe_sys_clone. Whenever this happened, it was printing the Hello World command.
This really was interesting for network traffic control and performance analysis and whatnot. I was like, ok, I’m bookmarking this now and documenting it now. What else do we have? Looking into libbpf. This got me interested as a C or Rust developer, because the great thing about it is there are bootstrap demos available in a separate repository, which also provided me with the term XDP, like measuring the ingress path of packets. I was curious to like, how would I be compiling and installing this?
It could be something like a tcpdump if I’m able to capture packets, but more in a faster and in an efficient way. I tried compiling the tools, tried several things. Like, is it the network interface name? Is it the network interface ID? After a while, I was able to actually see the packet size being captured and sent, for example, a systemd-resolve process and also a 5 o’clock command, just to verify it’s actually doing something. The slides provide all the instructions, how to compile that. I’ve also linked a demo project at the end where everything is documented, so you can reproduce what I was doing back then.
eBPF: Development
Considering that these are all great tools, what if I want to write my own eBPF program? What are the development steps to get going? Learning development is similar to learning eBPF on its own. I would recommend, think about a use case which is either fun or which helps solve a production problem. Think about an SRE or DevOps use case. A program is starting or exiting, there was control groups. There are TCP sessions, network interfaces, something where you can easily see something, or verify specific values, or whatnot.
Then it’s required to select a compiler. Because there is LLVM, and even GCC in version 10, as far as I know, supports compiling the eBPF program or the high-level code into an eBPF program within the bytecode. We don’t need to actually worry about anything like, what is bytecode in the background.
For specific libraries, it’s recommended to know Go, Rust, or C, C++ in the basics. Probably, intermediate or advanced knowledge is required to some degree. All the libraries provide great examples and how to get started documentation. Sometimes it’s really like, you should know the language to really understand what is the next step or what is the design pattern being used in the implementation.
For once, I looked into the Cilium Go eBPF library, which was interesting, because it also provided more use case examples. Actually, like cloning the repository allowed to navigate into the examples path, and then run the XDP measuring again. In this case, for example, I saw that it’s storing the network traffic in so-called maps. It’s like a persistent storage within eBPF being able to see, this IP address was sending these many packets, and so on. There is more with the Cilium Go library.
From the examples you can attach the program, the cgroups, and again the network interfaces, which is a great way to start. For Rust, I’ve been looking into aya-rs, which is a Rust developer toolchain. Anything you know about Rust, you can just continue using it, and use cargo to build and even to run the examples. There was a book tutorial available online, which is fun to learn and look into. For example, the xdp-hello program was sparking my interest again, just to see, this is how this example for measuring a network traffic is being implemented.
The most interesting part for me was like in production, Parca is a tool or an agent for continuous profiling from Polar Signals. This is actually using aya and eBPF for magic function calls, stack unwinding, and other things in different languages using eBPF, and using it in Rust because it’s more memory safe, or there’s better memory safety than in raw C code, which is quite interesting.
eBPF Use Cases (Debug and Troubleshoot Production)
Considering that probably we don’t want to get started immediately with developing our own use cases and reinvent the wheel, because someone else actually thought about, eBPF debugging and troubleshooting in production, we should be building something. People have been looking into this already. I think it’s important to separate or create an overview for different use cases.
Considering that we think about observability which is often the case in a distributed Kubernetes cluster or somewhere else, there is actually a Prometheus exporter using eBPF. There are OpenTelemetry Collectors collecting metrics from different ways, which we will look into a bit. A different example is, for example, specifically for developers and auto-instrumentation, when something is deployed in a Kubernetes cluster. Pixie is an example for that.
More on the Ops side, I found Coroot, which has an interesting way of implementing service maps using eBPF and providing general Kubernetes observability. I’ve mentioned Parca, already, for continuous profiling. These are some tools. It’s obviously not complete. The ecosystem and community is growing fast in 2023, but it’s important to keep this in mind.
Looking on the security end, on the security side, you can see tools like Cilium for network connectivity, security, and observability. Most recently, Tetragon was released for runtime security enforcement. Specifically around avoiding that an attacker can access a file, or specific other things. Tracee on the other side also provides runtime security and forensics. We will see in a bit how to have the rootkit.
I think one of the most mature or even the most mature tool is the Kubernetes threat detection engine called Falco, which provides different use cases also to inspect what containers are doing. The teams at GitLab have been inventing the Package Hunter, which does software dependency scanning using Falco, just by installing a dependency in a container and then seeing whether it calls home, or download some malicious software and whatnot. It’s a pretty interesting space, or actually then knowing that eBPF is used in the background.
When we consider the third use case, or the third area, I’m thinking of like for SRE and DevOps, what tools are out there, what could be helpful. For eBPF, I found Inspektor Gadget, which is a collection of eBPF based gadgets to debug and inspect Kubernetes apps and resources. There’s a wide range of tools and things, like trace outgoing connections, DNS, and even more.
It’s like, install it, try it out, and get to see what it’s capable of. Another tool I found was Caretta, for instant Kubernetes service dependency maps, which also looks pretty awesome to get a visual picture of what is actually going on in a Kubernetes cluster. Last, I was thinking of like, an eBPF program needs to be distributed somehow, like package it, tarball, or ZIP file, whatever. BumbleBee actually goes into the direction of building, running, and distributing eBPF programs using OCI images. You actually use a container image to distribute the eBPF programs, which is a nice isolated way and can also be tested and automated.
Observability: Storage (All Things)
Considering that this is all awesome, we also need to store all the events we are collecting. Changing the topic from collecting the data or collecting the events, to more storage with all things observability. We have so many different storage types over time. There is a time-series database. There’s logs databases, traces databases, maybe an eBPF event database or something else like network traffic, NetFlow database, everything all together.
Maybe it’s time to create a unified observability data storage, which is something our teams are doing at GitLab, but also others are doing that as well. It’s probably something to consider in the future. Now for the storage itself, it’s like, what should be the best retention period? How long do I need this data? The incident that got resolved three days ago, do I really need to keep the data for future SLA reporting, or is it just good for troubleshooting a live incident?
Another question is like, do I really want to self-host everything, then scale it and invest money to buy new hardware, buy new resources? Or would I be just uploading everything to a SaaS provider and then pay for the amount of traffic or data being pushed or pulled? Coming to the overall question like, which data do I really need to troubleshoot an incident, debug something?
Also, considering a way of like, we want to become more efficient and also more cost efficient. We need capacity planning, forecasting, trending. The SRE teams or infrastructure teams at GitLab have been creating Tamland which provides that. It can also be used in estimating the storage needed by the observability systems, by using observability metrics, which can be helpful to really say, our growth of observability data is like a petabyte next year. Do we really need that data, in order to reduce cost?
Observability: Alerts and Dashboards
Considering that observability also means that we’re doing something with the data. We’re defining alert thresholds. We have dashboards. We want to reduce the meantime to response. An alert is fired when a threshold is violated, so we want to do something about it. Also correlate, analyze, and suppress all these alerts, because when too many alerts are being fired, it’s not fun debugging at 3 a.m. in the morning. Also, if there are new possibilities with eBPF event data, this will also be an interesting use case to actually add that. Considering that we also have dashboards, we need to do something with the data. Creating summaries and correlations, providing the overall health state, reducing the meantime to response. Also considering forecasts and trends.
Verify Reliability
The thing is, if the dashboard is green, and everything is healthy, this doesn’t prove anything. All ok is like, how do I verify reliability and all the tools and dashboards and whatnot? Which brings me to chaos engineering. We can break things in a controlled way in order to verify service level objectives, alerts, and dashboards. For that, using chaos frameworks and experiments. The interesting thing is in the example before that was Chaos Mesh, but there were different chaos frameworks available, which is Chaos Toolkit, which can be run on the CLI, for example.
Providing extensions with Pixie can be integrated in CI/CD. You can develop your own extension. It’s like a wide variety of ensuring I can break things in my environment, and then verify that all the data collection which happens with eBPF also, is actually in a good shape. Considering that chaos engineering isn’t just like break things, and then observability dashboards are read.
It’s also a way of, going beyond traditional chaos engineering, injecting unexpected behavior, doing security testing, even like hardening software and doing some fuzz testing, which could also be seen or defined as a chaos experiment. Which is helpful knowledge by looking into all the things which are helpful. We will be talking about specific tools. We also want to break them to verify that they’re actually working, and what are the weaknesses, what are the edge cases which are not yet implemented and not yet solved?
eBPF Observability Chaos (Let’s Break Everything eBPF)
Let’s consider some ideas and some use cases specifically tied to observability. For golden signals, it’s rather easy to create chaos experiments or use chaos experiments for latency, traffic, errors, and saturation. There are tools and examples already available. This can be verified. Considering that we might be using the eBPF to Prometheus exporter, we can collect metrics. The exporter uses libbpf, supports CO-RE, which is like, you compile it once and can literally run it with every kernel. It’s a good way to run it on different systems.
I did it using a container, specifying in the box at the bottom with the command, the different configuration names which are available, like looking for example the TCP SYN backlog window, and so on. This is really helpful to look inside. Thinking about how to verify this is actually working, add some chaos experiments, which is, CPU stress testing, I/O stress testing, memory stress testing, adding TCP delays. Maybe even doing a network attack or something in order to see that the metrics that are being collected with this exporter are not like all times the same, but you can see the spikes, see the behavior of the system. Then, also, get an insight whether the tool is working or not.
Looking into a different example, which I mentioned before, around how developers can benefit from Kubernetes observability, where Pixie is one of the tools. It provides auto-instrumentation for a deployed application. There’s also a way to get an insight with service maps, which can be a great way to visualize things. It got me thinking of, if there was a service map, how does this change when there was an incident or when there’s something broken?
Stress testing this again, or even running a network attack to see if the service map changes, or to see if the application insights, the traces are taking longer. There might be some race conditions, some deadlock, something weird going on, which could be a production incident. Then we can see, the tool is actually working and providing the insight we actually need. Again, this is all using eBPF in the background. For Kubernetes troubleshooting, there’s Inspektor Gadget, so we can trace DNS and even more within the Kubernetes cluster. It’s not bound to Kubernetes only.
There’s also a local CLI which can be run in a virtual machine on Linux, which is a great way to get an insight, what are the DNS requests doing? Is there something blocked, or telling NXDOMAIN, or something like that? For chaos experiments to verify that these tools are actually providing the expected results, like inject some DNS chaos, which provides random results or NXDOMAIN results. Think about breaking the network, or doing even a network DDoS attack, traffic attack, and out of memory kills, certain other things. This is really a helpful toolchain, but in order to verify it’s working, we need to break it. This is why I’m always thinking of, test it with chaos experiments or chaos engineering.
Speaking of which, for Kubernetes observability, it’s also great to have service maps or getting an overview which container is talking to another container, Coroot using eBPF for creating network service maps, which is a super interesting feature, in my opinion. Because it also provides an insight of, what is the traffic going on, the CPU usage on the nodes, and so on. If we break TCP connections, or increase the network traffic, or even stress the memory, how would this graph behave?
What is the actual Kubernetes cluster doing? Which is a way to also verify that the tool is actually providing the solution for our use cases. It’s working reliably. We can use it in production in the future. From time to time, again, we run the chaos experiment to really verify that the tool is still working after an update or something like that. Lots of ideas. Lots of things to consider.
When looking into profiling, and this is an example with Parca. Parca uses eBPF to auto-instrument the code, which means like function calls, stack debug symbol unwinding. It’s really interesting that it’s like auto-instrumentation and I as a developer don’t need to take any action on adding this, or understanding how perf calls work. The most interesting part here is that the agent provides all this functionality.
There is a demo available. The Polar Signal folks also started e-learning series called, Let’s Profile, where they are actually profiling Kubernetes and then looking into how to optimize it, which can be a use case for your projects as well. Continuous profiling is on the rise also in 2023. The idea is how to verify that the behavior is there, that we can simulate a spike with code crisis.
The function calls are taking too long, we maybe want to unreel a race condition or a lock in the software. We can run CPU or memory stress tests to see, the continuous profiling results are actually showing that under CPU stress, everything is behaving as expected or maybe it is not. This is really a runtime verification using some chaos experiments with continuous profiling.
Considering that OpenTelemetry moved beyond traces, also adding support for metrics, logs, and different other observability data types in the future. There is a project which implements eBPF in OpenTelemetry to collect low-level metrics directly from the kernel, from a Kubernetes cluster, or even from a cloud collector. I think AWS and GCP currently support it.
The idea really is to send that to a reducer, which I think is like an ingestor, allowing to modify the data or sanitize it, and then send it, or then provide it either as a scrape target for metrics in Prometheus, or send it to the OpenTelemetry Collector, which then can forward the metrics, and to move with that. Again, in order to verify that the data collection is usable, add some chaos experiments when testing the tool.
Think about CPU, memory, and also network attacks to really see, the data being collected is actually something valid or something useful in this regard. Last, I think DNS is my favorite topic. There is a thorough guide on DNS monitoring with eBPF which has a lot of source code and examples to learn. To test that, again, is similar to, let’s break DNS, add some DNS chaos to the tests, which I think is always a great idea, because it’s always DNS has a problem, whether we’re in a chaos experiment or in production.
eBPF Security Chaos
I’ve talked a lot about observability chaos with eBPF. Now, let’s add some security chaos, which is pretty interesting, especially because we want to verify security policies, with everything going on. Thinking about how to break things, we want to, for example, inject behavioral data that simulates privilege escalation. Or another idea could be, there is multi-tenancy with data separation, and we want to simulate an access to a sector of a dataset we shouldn’t have access to.
Which brought me to the idea of, what are the tools out there promising all these things? I read a lot about Tracee from Aqua Security, which had some interesting features described in a blog post and also in a recording, saying it can detect syscall hooking. In the beginning, I wasn’t really sure what a syscall hook means. Then I read on and thought, this is actually like a rootkit, which can be installed on Linux.
Then, it hooks a syscall and overwrites the kill command or the getdents command, which I think is for directory listing, or could overwrite any syscall in order to do anything malicious, or just read password credentials, or do Bitcoin mining, or whatever. I was curious, saying, how can Tracee detect a rootkit? This was the first time I actually installed a rootkit on a fresh Linux virtual machine, although in a production environment.
I was able to inject the rootkit, and then run Tracee with some modifications to the container command shown in the box here to really see, there’s actually a syscall being hooked. It’s overwritten or hidden in the screenshot, but it shows something weird is going on in the system. I was like, this proves to be useful.
Considering that I also wanted to test different tools, I looked into Cilium Tetragon, which provides its own abstraction layer and security policy domain specific language. I thought of, this could also be used for detecting a rootkit, so like simulating a rootkit as a chaos experiment, or simulate file access that match certain policies. After running Tetragon in a container, I was able to also see what the rootkit was doing, because it provided me with the insight of, there was some strange binaries being created, which then run some commands, which are calling home, opening a port.
Yes, some fancy things. Potentially, the virtual machine is now compromised, and we shouldn’t be using it. It was really an interesting use case. This got me to the idea, could we do a chaos experiment which is like a rootkit simulation? Something which hooks a syscall but does nothing. I’m not sure if this actually is possible.
It would be an interesting way to do some Red Team pentesting in production, trying to verify that, for example, the policies with Tetragon and Tracee are actually working, so impersonating the attacker, again. Installing a full rootkit in production is real unwanted chaos, you don’t want to do that. I deleted the virtual machine after doing the demos, or the ideas for this talk, and documented all the steps to do it again, which should be fine then.
eBPF Chaos (Visions and Adventures)
Considering that there is more to that, so what is the idea behind combining eBPF with chaos engineering and verifying that everything is working. I also had the idea of like, we could be using eBPF on the kernel level to inject some chaos, change a syscall, change the responses, modify a DNS request into a different response, maybe even access protected data and try to protect it.
When I thought about this, I also saw my friend, Jason Yee, having a similar idea, using eBPF to collect everything. Then also he’s thinking about, how does this help our chaos engineering work in that regard? There’s also a great research paper, which I linked at the bottom, for maximizing error injection realism for chaos engineering with system calls, which is called the Phoebe project, which brings more ideas into that area.
Thinking of a real-world example with Chaos Mesh and DNSChaos. It’s using a plugin that implements the Kubernetes DNS-based service discovery spec. It needs CoreDNS. What if we could be changing that eBPF program that intercepts the DNS request, and then does some chaos engineering. While looking into this, and researching a little bit, I found Xpress DNS as an experimental DNS server, which is written in BPF, which has a user space application where you can add DNS records or modify DNS records into a BPF map, which is then read directly by the module or by the eBPF program. I thought, this would be actually an interesting way to do chaos engineering 2.0, something like that, to being able to modify DNS requests on the fly, and adding some high-performance DNS chaos engineering to production environments.
Another idea around this was eBPF Probes. I thought this could be a reasonable term for a chaos experiment. We can simulate the rootkit behavior in such small programs or snippets, and could either use a feature flag or whatever we want to use for enabling a specific chaos experiment. We can simulate a call home using some HTTP requests or whatnot, could intercept the traffic and cause delays. I’m reading something from the buffer, I’m sleeping for 10 seconds, and then I’m continuing, maybe. Also considering CPU stress testing, DNS chaos, all the things which can be broken or which you want to break in a professional way, and then verify reliability.
Chaos eBPF (We’ve Got Work to Do)
This is all great ideas, but we also got work to do. Vice versa, chaos with eBPF. Because from a development perspective, or DevSecOps, eBPF programs, this is like normal source code. You want to compile it. You want to run it. You want to build it. You want to test it. You want to look into code quality. It’s complicated to write good eBPF program code. Humans make mistakes, so we need security scanning in the CI/CD pipeline, or shifting left.
We also want to see if there are programs that could be slowing down the kernel, or could be doing something which is not with good intentions, like supply chain attacks, installing an eBPF program and magically it becomes a Bitcoin miner. This is an interesting problem to solve, because at the moment the kernel verifies the eBPF programs at load time and rejects anything which is deemed unsafe. In CI/CD, this is a nightmare to test because you need something to be able to test it. You cannot really run it in an actual kernel. One of the attempts is to create a harness, which moves the eBPF verifier outside of the running kernel. The linked article is an interesting read. Let’s see how far this goes in order to improve everything.
There are certainly risks involved. eBPF is root on the kernel level. There are real world exploits, rootkits, and vulnerabilities which are actually bypassing eBPF, because there are also limitations of eBPF security enforcement using different programming techniques, different ring buffers, and so on.
It’s like a cat and mouse game with eBPF. My own wish list for eBPF would be having a fiber or a sleepable eBPF program in order to sleep and continue at a later point. Also considering monitor the monitor, like eBPF programs that observe other eBPF programs for malicious behavior, or having it out of the box in the kernel. Better developer experience and also abstraction by platforms.
Conclusion
Consider eBPF as a new way to collect observability data. It provides you with network insights. It provides security observability and enforcement. Add chaos engineering to verify this observability data. Verify the eBPF program behavior. Also consider integrating eBPF Probes for chaos experiments, hopefully done by upstream in the future. We have moved from monitoring to observability.
We have moved from traditional metrics monitoring to being able to correlate, verify, and observe. We need to consider, there is DataOps coming, we want to use the observability data for MLOps and AIOps. In the future we might be seeing AllOps, or whatever Ops.
Also consider the benefits. We have observability driven development with auto-instrumentation, so developers can focus on writing code and not something else. We can verify the reliability from an Ops perspective with chaos engineering. For the sec perspective, we hopefully get better cloud native security defaults from everything we learn while using eBPF.
To-dos, the eBPF program verification in CI/CD. There’s the chaos experiments using new technology, and also more ready to use eBPF level abstractions would be something. Consider these learning tips. Start in a virtual machine. Use Ansible or Vagrant provisioning, or something else, and share that with your teams.
I did that in the project which uses Ansible to install all the tools in the Ubuntu virtual machine. Consider taking a step back when you don’t understand names or technologies. Take a note, read on. You don’t need to understand everything which is eBPF. A general understanding can help you when the data collection breaks or something else is going on and the tools are not working. This is helpful information to get a deeper insight into what’s actually going on.
Resources
You can read more about the GitLab Observability Direction on the left-hand side. You can access the demo project where all the tools and all the scripts are located. Here’s my newsletter where I write everything I learn about eBPF, about observability and also chaos engineering, https://opsindev.news/.
See more presentations with transcripts
MMS • RSS

Melanie Dhawan has been appointed Chief Financial Officer for the Content practice of the tech-led, new age/new era digital advertising, marketing and technology services company S4 Capital.
Mel has significant experience gained across a varied career. At global entertainment company Turner Broadcasting, she fulfilled multiple roles over 13 years, covering controllership, commercial partnering, FP&A and finance transformation. At Just Eat Takeaway.com, she led the post acquisition integration of the Just Eat business into the Takeaway.com business, including finance operating model design and implementation. Just before joining S4 Capital, Mel was at Adevinta, where she led finance transformation and operations, including the post acquisition integration of the eBay Classifieds Group.
She joined the S4 Capital Group Finance team in mid 2022, and established the Group FP&A and Finance Transformation functions, before moving to the Content practice as CFO.
Mel Dhawan comments: “I’m looking forward to working closely with Bruno Lambertini and Wesley ter Haar as we continue to drive the Content practice forward and capitalise on the significant market opportunity ahead of us.”
Wesley ter Haar, Co-Founder and Co-CEO, Content at Media.Monks, adds: “Mel has proven invaluable on our road to transformation of our company and with her extensive background and experience, I am delighted she has moved to the Content practice.”
MMS • RSS

Scalestack, the AI-powered all-in-one data enrichment, prioritization & activation platform for RevOps, has raised $1MM in their first round. Investors include Ripple Ventures, Forum Ventures, Flyer One Ventures, Founders Network Fund, and others. This round of capital will help the platform expand its offerings and grow its reach in the market.
Most sales tools in the market focus on converting and engaging with prospects, but the targeting stage in sales tech remains archaic and underdeveloped. B2B SaaS Companies are hence left with either leaving research up to the reps, killing performance, or building in-house data enrichment teams, which are expensive and hard to maintain.
Scalestack does not sell data, but creates customized, yet automated workflows for existing data (internal and external), along key dimensions of their customers’ ICP. Scalestack runs these workflows at scale in customers’ CRMs, so that data’s always fresh, and properly prioritized, then does the last-mile delivery of insights to sales reps with AI.
Scalestack reports the addition of new customers, including a renewed, expanded and multi-year contract with MongoDB. MongoDB’s developer data platform is a database with an integrated set of related services that allow development teams to address the growing requirements for today’s wide variety of modern applications, all in a unified and consistent user experience.
“Our sellers get hundreds of sales leads coming in weekly from a large variety of sources like events, job postings, and via social networks,” says Meghan Gill, SVP Sales Operations, MongoDB. “Leveraging AI, Scalestack has been key in helping us to easily aggregate, manage, and automate disparate GTM data sets in a matter of minutes and identify true leads.”
Scalestack, who also leverages MongoDB’s Atlas and Atlas Vector Search to enable its AI enrichment workflow at scale, works by identifying who in the sales and marketing funnels are primed for engagement by training on available data sources like ZoomInfo, Crunchbase, LinkedIn, plus internal data sources (e.g., CRM data). The platform creates a customized and automated data-view of ideal customer profiles, and prioritizes prospects based on this information. The platform then suggests what sales people should do to reach out, or maintain relationships with potential and existing customers, based on sales plays.
“No one should spend their time doing repetitive and boring work,” says Scalestack Cofounder and CEO Elio Narciso. “Yet, sales reps today spend 72% of their time on non-sales tasks: a lot of effort is wasted on manual research, prospect prioritization and data entry. That’s why we created this platform — to automate the most time-consuming part of selling, so that sellers can focus on what really matters.”
“The AI sales market is on a path to reach an estimated value of $93 billion by 2032. However, many companies in this sector provide tools primarily tailored for the lower end of the sales funnel. This often necessitates manual research of prospect data,” explains Matt Cohen, Managing Partner at Ripple Ventures and an investor in Scalestack. “Scalestack is addressing this particular challenge head-on. Through its automation solutions targeting the upper segment of the sales funnel, it significantly enhances the productivity of sales representatives during the critical initial phase – account and prospect targeting,” Cohen points out. “For sales leaders, Scalestack’s a no-brainer.”
For more such updates, follow us on Google News Martech News
MMS • Steef-Jan Wiggers
During the recent Ignite conference, Microsoft announced the general availability (GA) of .NET Framework Custom Code for Azure Logic Apps (standard), which allows developers to extend their low-code solutions with custom code.
Earlier, the company previewed custom code capability, and with the GA release, developers can now benefit from more flexibility with code, deploy code alongside the workflows, and have local debug experience. In addition, the company included support for local logging and Application Insights.
The company advises developers to use .NET Framework custom code extensibility to complement their low code integration solutions in cases like custom parsing, data validation, and simple data transformations – not for compute-heavy scenarios like streaming, long-running code, and complex batching or debatching.
The custom code feature is available from within VS Code by clicking on the Azure ‘A’ and then clicking on the Logic Apps logo, followed by Create new logic app workspace. When developers do that, they will subsequently be prompted for some additional information, such as the name of their workspace, function name, namespace, etc. Next, a sample C# project and workflow project will be provisioned to allow developers to get started.
Kent Weare, a Principal Program Manager for Logic Apps at Microsoft, told InfoQ:
We have invested in an onboarding wizard to help developers get started quickly. Our expectation is that a developer should be able to run a workflow that calls custom code within minutes of launching VS Code.
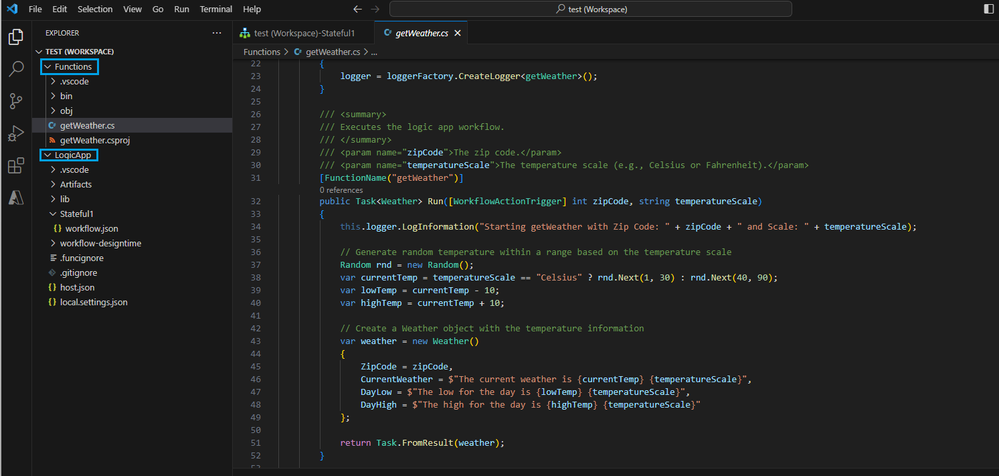
Workspace with a Functions project that includes a sample function (Source: Tech community blog post)
Currently, the support is still .NET Framework 4.7.2, however, according to a Tech community blog post, the company is actively working on building in support for .NET 6. When asked about the other .NET Frameworks, Weare said:
We will be investing in support for other frameworks. We wanted to get the .NET Framework capability to GA first, and now that we have done so, we will explore other framework versions.
In addition, Piers Coleman, an Azure Solution and Integration Architect at Chevron, commented in a LinkedIn post by Weare:
Finally, Logic Apps now have BizTalk-like capabilities.
Lastly, the documentation pages provide guidance on the .NET Framework Custom Code in Logic Apps Standard.
MMS • Todd Little
Subscribe on:
Transcript
Good day folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today I’m sitting down with Todd Little. Todd is the Chairman of Kanban University and I’ll ask him to tell us a bit more. So Todd, you and I have known each other a while, but I’m going to guess a fair number of our audience haven’t come across you before. So who’s Todd?
Introductions [00:25]
Todd Little: So who am I? So Todd Little. I’ve been somebody who’s been an agile practitioner for a while. Accidental agileist, I would say. I got involved in agility really partially just because it was a natural way of working for me. I had been looking around. My background’s actually chemical and petroleum engineering and I was developing software for oil and gas exploration and development. Really interesting stuff. And doing that, and as I got into more and more management roles, started thinking how can I get better in our software development? And started looking around and seeing all these things that didn’t really make sense to me. A lot of structured approaches and being an engineer, I understand structured approaches, but they weren’t making sense from a software world perspective. And so I started looking around, ran into Jim Highsmith in the late 1990s and saw what he was doing with adaptive software development and complex adaptive systems.
And at the same time, I had been involved with my company Landmark Graphics, in putting together a developer conference, a worldwide developer conference for our 700 developers. And in that process started bringing in some people and getting connected in with people that were doing interesting things. So Jim Highsmith one year, Kent Beck one year. Then I went to a Cutter Conference where Jim Highsmith was organizing it and ran into a number of the people. Ken Beck was there and a couple other people, Tom DeMarco, Tim Lister that I had worked with before as well. And then Alistair Cockburn showed that he was developing a conference, he was going to be developing an agile conference and that’s how I got really into the agile community was through that. Since I had organized conferences and Alistair was running a conference, he and I, 20 years ago ran the first agile development conference in Salt Lake City, the first conference of the Agile Alliance. And so I ended up running that by myself a couple of years after that. So got involved in the Agile Alliance Board, sort of connected into the agile community in that way.
And meanwhile I was still doing my day job, trying to develop software in the oil and gas space. Eventually through the process I came to know David Anderson fairly well. As we were starting the Agile Leadership Network, he and I were involved in getting that kicked off. So I knew what he was doing in the Kanban space and eventually decided, well maybe I should get into the agile space full-time. And that’s where I got into Kanban University about 6 years ago, 2017. So been sort of really trying to promote agility and reach out to what people really need. And I think that’s what I really love about the Kanban world is that we really try to look, and it’s all about improving the delivery of knowledge work and techniques for doing that and broadly. And so it’s a very natural approach that I see, been doing and really trying to grow that message out in the Kanban space over the last few years.
Shane Hastie: But isn’t Kanban just a board on a wall.
Todd Little: Kanban is a way of working that continuously improves through evolutionary change
Well, a lot of people think they’re doing Kanban because it comes with their Jira board, it’s an option and others think, well, maybe it’s just a bunch of stickies. The Kanban method is really quite a bit more than that. From the very beginning, a large element about Kanban is the evolutionary improvement, the approach to evolutionary development of your approach starting with what you do now. So it’s not something that you install, it’s not a transformation. Kanban is a way of working that continuously improves through evolutionary change. And yes, it includes visualization. Visualization is a very important element. There’s a lot that we gain from visualization. There’s a lot we gain from metrics.
But there’s a lot even more that we gain from small experimental change, understanding how to build those experiments, how to deal with resistance and using that to continuously improve. We see a lot of agile implementations that stall out because they don’t really get good at continuous improvement. They follow the book but they don’t know how to get beyond that. They don’t know the basics foundation, they don’t know the techniques for really getting better, and as a result they stall and fail to get any continuous improvement. The Kanban method is all about how do you get better? How do you get a basic foundation of continuous improvement? I think that’s really what helps people thrive in this space.
Shane Hastie: Where do we start?
Start with what you do now [04:19]
Todd Little: That’s the thing with Kanban is you start with what you do now, and not what you say you do, but what you actually do. And so we spend some time really to put some effort into really understanding what it is that you do, how is things working now? And then we’d also look at where are the pain points? Where are you having challenges? Where are your resistance? Where are you having resistance? Why are those pain points persisting? And from that, that’s how we can get a better understanding of what we can do about it. For the formula for us is understanding where the pain is, what’s the stressor, what’s the stressor that’s potentially there? Then we have reflection. Could be a retrospective, could just be any form of reflection that says, “Okay, now that I see where the pain is, now I’m going to do something about it.” And that’s an active leadership. Taking the active leadership is the closure of the feedback loop that says, “Okay, I see something I don’t like, I’m going to do something about it and let’s go improve on it.”
And that formula, that foundational formula is something that you can really continue to build on and get really good at and get good at understanding the diagnostics. So the pains get good at understanding where the resistance is, and then empowering people to take those acts of leadership to make a difference about it.
Shane Hastie: So in order to take those acts of leadership though, don’t I have to be a leader?
Leadership happens at all levels [05:34]
Todd Little: No, it’s at all levels. Leadership comes at all levels. It can be very, very small changes. And that’s one of the things that when I’ve been involved in really effective and successful agile implementations, it always happens when there’s acts of leadership coming at all levels, developers stepping up and saying, “This is sort of foolish for us to be doing this, this way. Couldn’t we be doing it differently?” And they can be very small changes. Someone stepping up and saying, “Well, we could be changing our test approach this way. We could be managing our dependencies in a different way. We could be eliminating some dependencies. We can do all these different things that are … We know these things are continuously bothering us. Why do we continue doing them?” It’s the team stepping up. It can be … Many times, it might be someone who has a leadership role taking those acts of leadership or maybe it’s someone who is a leader just making the place safe for others to step up. But the success happens when those acts of leadership happen throughout the organization.
Shane Hastie: So that’s some of the background. How does Kanban feel? How’s it look? How’s it work? Start where we’re at, understand our current state of work, then what?
Understand how work flows in and across teams [06:40]
Todd Little: Yeah, so the other element is trying to understand what are the services that we’re delivering? And so many times, services will be a team will have a service, but also the service will be made up as a network of services. There’ll be multiple teams coming together on a single project or a single product or service delivery, and trying to really understand how is the work flowing. So we look at how does the work flow and based on how work flows that insight into how work flows often will show us where we’re having challenges. Where are we having bottlenecks, where are we having delays, where are we having points of frustration? It may not be delays, but it may be frustration. We want to eliminate this frustration just as much as we want to eliminate the delays because the frustrations manifest themselves in other ways and turn into other problems.
So we’re looking for all sorts of challenges and we utilize a number of different techniques. We can utilize an approach called static, which is the systems thinking approach to introducing Kanban as a way of really identifying those pain points and powers, the work flowing and the steps. We can also take similar types of approach, just identifying where are the pains, and just on a simple basis, where are the pains and what might we do about those pains? And then also looking at where might we see sources of resistance? When we have sources of resistance, one of the approaches at Kanban we talk about is to be like water. Just like Bruce Lee used to talk about being like water in martial arts. And the point of being like water is that water turns into its container. So when you put water in a cup, the water becomes the cup.
And I think that’s one of the challenges that agile implementations have. The agile implementations say, “Oh, well we can’t do agile unless we change the culture.” And I think the Kanban way approaches this is more that we adjust our approach based on the culture rather than trying to change the culture to adjust to our approach. And that’s a big change and also a much more humane change because trying to change culture is really challenging. And so instead what we do is we say, we adapt to culture, figure out what you’re doing now, figure out how that’s working, looking at that resistance and then saying what can we do realizing that resistance is there? Do we work around the resistance? Usually that’s the best answer. Just like water flows, water flows around rocks, it doesn’t knock the boulders over unless it’s the time for that to happen.
And so we work in a way where we work and identify the resistance, flow around the resistance and at appropriate times we will actually work to remove the resistance. But that’s not usually our first wave of operation. Our first wave of operation is to try to adjust to the resistance, work around it, and we’ve seen miracles happen by doing that, going at it small bits at a time. We eat the elephant a little bit at a time, and eventually we’ve made some incredible changes, many times, much faster than expected. We’ve seen some substantial changes using just incremental change within a couple of months, having just amazing turnarounds.
Shane Hastie: Meeting people where they’re at, working around the resistance. One of the things that I certainly see out in the community and in our interactions is what I think is possibly a fair amount of confusion between Kanban as an approach and Scrum as an approach. How do they overlap or how are they different?
Using Kanban to make Scrum better [09:59]
Todd Little: Yeah, that’s great. In fact, one of the things that we have just come out with is a new class called Scrum Better With Kanban. And the idea of that is that as we say, if Kanban is starting with what you do now, if what you’re doing now is some form of Scrum, then use that as your start point. There’s a big talk about agile transformations. We’re in a transformation. Kanban is not a transformation. Kanban is an incremental approach of evolutionary change, which can be transformational. And that, we see. We see transformational results, but it’s not a transformation, it’s not a noun, it’s not something you install. So what we do is we work with what you’re doing with Scrum and we start looking at where are your challenges? What’s working for you? What’s not? If it’s working for you, we’re not going to change it. And the thing with Kanban, Kanban is a set of tools, set of practices and principles that we have known and applied to knowledge work, not just in IT but also in multiple industries, in a way that really does work to improve your knowledge delivery, your service delivery.
So this new class that we offer Scrum Better With Kanban acknowledges that. It acknowledges you’re working with Scrum, you might have a corporate mandate to use Scrum, you might be happy with what you’re successful so far. But maybe you’ve stalled out, maybe you’ve hit some limits or you’ve got some pain points still. And we’ve seen these regular, and a good percentage of people that come into the Kanban world have started from Scrum, and that’s what we see from our state of the Kanban report. But we also see that those people that come in are seeing some substantial results. 87% of our respondents have reported that they see the work they’re doing at Kanban is significantly better or significantly better than previous approaches. So they’re getting great results and they’re doing so through incremental change.
So it could be they’re having challenges with unplanned work. It could be they’re having trouble with predictability. It could be that they’re having challenges with dependencies. All of these things are approaches that we give them tools to work with from the Kanban perspective. Looking at their flow, looking at how work is flowing, getting back to first principles of flow. I think that’s one of the challenges that practitioners have when they’re handed a framework, they’re handed a framework and say, “Go implement this framework.” Well, if they don’t actually understand the foundational basis of the framework, why did the framework even exist? What set it up? Then they don’t necessarily know how to improve it. They don’t have the basis for that. They know how to do the things, they know how to do the events and they can do that very well, but they’re not necessarily getting the results, and that’s because they don’t know how to understand the flow of the work and they don’t know how to improve it.
Those are the two things we’ve really hit when we started interviewing people as to where their challenges were and it came down to really getting to understanding flow and predictability and dealing with resistance. And those are really what we know, having narrowed it down to those things, these are the things we know we handle very well in the Kanban world. These are not challenges. People who really understand Kanban well know how to deal with flow because we understand the metrics, we understand the behavior of flow quite well and teach the tools to do that. And then dealing with resistance is something that’s sort of core to our evolutionary change approach. We take small bites, we work through and identify the resistance, work around it, and only at the last resort do we really try to blow up the system to change it if it’s necessary. So we work through that.
Shane Hastie: You mentioned metrics a number of times. If I’m a team lead in a software engineering team, what are the metrics that I should be caring about and how do we know whether they’re doing okay?
Actionable metrics and visualizations [13:26]
Todd Little: So it’s always contextual, although I think we know that there are several metrics which we recommend as sort of a standard set. We always like to look at lead time and lead time is something that always has to have a clarification as to what’s measured from. Is it measured from when we start the work until it’s done? Or is it measured from when the request was made until it’s done? But any event, as long as we’re consistent and we know what we’re looking at, the lead time is something that we find can be very valuable because it gives us an indication of the history and the expected behavior of the system. So knowing what historical data is is far more valuable we find than trying to estimate it. Trying to estimate it without that history is really … I think it’s wishful thinking, but when we actually have real data, then we can actually make numerical calculations, at least get an indication.
If we know historically that items are taking us somewhere between 5 and 20 days, then that’s good. We don’t want to be promising it’s going to be done in three days. 5 and 20 is a number. We don’t want to necessarily promise five. We need to establish what that looks like and have the basis for understanding that. And if we have that data and collect it, then we have the ability to make some decisions around it. So lead time is something we really value.
We also like to look at run charts. So run charts give us that lead time over time, so it lets us know whether it’s trending or not. If the numbers are getting higher, lead times are growing on us, then we know that our system is potentially getting worse. Perhaps it’s getting more bottleneck, getting blocked in some fashion, but any event that gives us an indication of getting better or worse through the run chart.
And then we also like to look at the cumulative flow diagram. The cumulative flow diagram is a tool that gives us a number of things collected together on one chart that tells us how are things flowing through the system, through the various stages of workflow.
So those three sort of become the core that we look at and there are plenty more that can be looked at, but I always caution not to take on too much too fast. People wanting to come up with a number of metrics, they want get everything across, but there are other assumptions. Flow efficiency is a number that might be useful. We’re trying to look at how often is work actually being worked on and how long is it sitting in queue just waiting there? And in many organizations that flow efficiency number can be quite low, in the single digits, less than 10% is not unusual for organizations that are struggling with that type of problem. And so if that is the type of challenge they have, then there are techniques for looking at, well, how do we improve flow efficiency? Why is that? Usually it’s wait time. Usually there’s communication challenges. Oftentimes the problem is they’re overloaded, they’ve just taken on too much work.
Limit work in progress to make flow more predictable [16:00]
And so one of the premises of the Kanban method is to limit work in progress. And that’s not to limit flow. We limit work in progress in order to make flow more predictable and more consistent. And so the irony is that many times managers will think, “Well, in order to get the most done, I have to make sure everyone’s busy.” Kanban takes the approach of not making sure that everyone’s busy, but making sure that work is flowing. And in order to make work flowing, many times people aren’t 100% busy. It’s the counterintuitive, but actually works out quite cleanly when you look at it. And so we look at what is far more important for us to see workflow than to create a lot of inventory of work that’s in progress but not completed.
Shane Hastie: You mentioned some managers have a challenge with this and I can understand why. They’re often incentivized on the efficiency of their teams, having people working a lot.
Maximizing flow requires letting go of utilization as a goal [16:51]
Todd Little: Yeah, so utilization that is one of the challenges is that historical incentive is utilization. It’s particularly a challenge in service organizations where their consulting business is billing out people, they want to make sure people are utilized because that’s how they make money. And so that is one of those sources of resistance that may be always there. And then you have to work out how do you deal with it? Oftentimes the type of problem we have to look at is when you have a challenge like that, where the motivation is counter to the desire is what can we do with a higher goal that will help show that? So if the higher goal is actually we can replace the goal of utilization with the goal of customer satisfaction. Customer satisfaction, customers don’t care how utilized your company is. They care how good your product is and how smoothly their delivery of their services that they’re requesting of you.
And so that’s the things that we try to do is replace some bad behavior with some higher value, that is actually seen in the organization. And those are some things that may take time to change because they’re so ingrained in our thinking, we’re trained in the idea, go back to The Goal from Elliot Goldrat and challenge. He thought his goal was to optimize his utilization of all of his equipment. But in fact, the goal is actually to streamline the flow so that you have the most output and can meet the most customer demand. And that does not come from over utilization. It comes from understanding the system and building an environment where flow is smooth.
Shane Hastie: One of the challenges that I certainly see to this is the organization level incentives. The individual bonus for instance, where the more people you utilize, the better they get paid.
Incentive systems often get in the way [18:31]
Todd Little: Exactly. There are many times where we have to look at that and see how that’s behaving because many times, organizations are not aware of how their incentive programs are actually driving behavior that’s counter to what’s beneficial to their best interest. Deming was very adamant in his 14 points about the challenges that many programs, particularly he was adamant that MBO programs, management by objectives, needed to be eliminated immediately because it was just backwards and that individual reviews were also to be abolished. The thing is that many times there’s no ways to remove all of those things, so we have to nibble away at them and work through and find ways to coexist with the system. So what we find is that the key is really understanding the lay of the land, and understanding that yes, we want to work towards an environment where we’re really focused on flow, focused on getting things through and satisfying customers. Yet we might be facing cultural biases, cultural basis that takes us in the wrong direction.
When we have that, that’s where we need to be like water. We need to be like water and try to flow around those barriers, those cultural barriers. Occasionally you can nudge those cultural biases into another direction. Usually these things are emotionally attached because history has them emotionally attached. This is what I was taught, it’s not based in any actual real theory, it’s just based on some belief system, really. Belief systems are always emotionally attached. And so coming up with an emotional change to get people to think differently, it’s not easy. It needs to come from a higher emotional. So that’s why we try to drive towards purpose and other realities of bringing the customer perspective into this. And if we can get to that point, what it really takes in order to drive that type of behavior.
My background is predominantly in product organizations, and product organizations, I find that this is less of an issue because product organizations inherently have the feedback loop. If they’re successful, people buy it. They also have a lot of customer feedback. I see these challenges being greater in organizations that are internal services to … So IT relative to the business, they don’t have those feedback loops. Those feedback loops are disconnected. And so that’s where some of this bad behavior comes from. And to the extent possible, if you can bring the missing feedback loops into that behavior, the business people see it, the business people see that they’re not getting what they want. Now their belief might be, well, the reason I’m not getting it is because people aren’t busy, but this is where you need to help them understand it. So work them through it, in fact, the reason you’re not seeing it isn’t because people aren’t busy. Usually people are overly busy with these situations, but they’re busy on so many different things that nothing gets done. Nothing’s actually making it out the way.
I had this situation, so in the company I was with, one time, I was dealing with our internal IT division that was responsible for provision of servers. And we had a situation where … So there was four of us that were VPs that were working with this group and we would put requests in and the service requester thought that her job was to make sure that whatever we requested got started. So in the end there would be 100 items started, but nothing would ever get done. And so we had to work and restructure things and we used a Kanban approach to it where we had only a max limit of 10 items. And so instead of 100 items getting started, only 10 items could get started. And it worked out really well because things were getting done. And many times of the list of 100 items that were in the queue, half of them no longer meant anything. So they shouldn’t have been worked on after a few months. They should have been killed. But no one had any feedback loop to let that happen.
So this way we only had things going into the queue that actually were going to get worked on and rather than things taking a year to get done, were getting done in less than a month. It’s still probably too long. But that was a huge start and we kept getting better at it and started optimizing. And once you have the lay of the land where you’re starting to get flow, that’s when you can start having fun because that’s when you can start optimizing it and start looking at how do we get things done even better? But when you don’t have any structure around it, you don’t know how things are flowing through the system. I mean, each individual functional group was doing their part, but they were handing it off and things were laying in the queues forever. Then we started having this flow-based approach to it and things were actually working because that was all that we had to work on. And that’s when you start seeing results.
Shane Hastie: Good examples and some really interesting content here. Todd, if people want to continue the conversation, where do they find you?
Todd Little: So kanban.university is a great place. If they want to reach out to me directly, feel free to reach out to me on LinkedIn and have a conversation. But Kanban University, we have a number of trainers globally, over 350 trainers in our network that are delivering classes. The baseline class team Kanban practitioner, and then go into our Kanban systems design and Kanban systems improvement. But we also have this new class called Scrum Better With Kanban, we’re very excited about because it’s really coming in and targeting some of the known challenges, which we see from those that are implementing Scrum and SAFe. They’re stalling out, they’ve gotten some improvements, but they really aren’t seeing all the things they’d like to.
And this is where they may already be using a bit of Kanban and this is their opportunity to really learn the basics of Kanban applied in a Scrum environment, what are some of the challenges we’ve seen from others and what are the approaches we’ve used in helping those? And then we end up solving their problem directly. We have them look at the areas where they’re having challenges and the last half of the class really focuses on them doing the work themselves and we guide them through that. So lots of things going on in the world of Kanban. I think it’s very exciting and I think it’s exciting overall in the agile space. So feel free to reach out to us and ask us what’s up, what we can do to help you.
Shane Hastie: Thank you so very much.
Todd Little: Thank you, Shane.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
The NoSQL Database Market is anticipated to grow at a 30% CAGR from 2023 to 2029, when it will reach USD 36.46 billion.
Revolutionizing Data Storage: The Explosive Rise of NoSQL Databases
The NoSQL Database Market is on a trajectory to reach an unprecedented value of USD 36.46 billion by 2029, showcasing an impressive Compound Annual Growth Rate (CAGR) of 30% between 2023 and 2029. This revolutionary market is rewriting the rules of data storage and retrieval by introducing a non-relational approach, distinctly diverging from traditional database systems.
Beyond Rows and Columns
In the realm of NoSQL databases, data is not confined to the constraints of rows and columns. Instead, each piece of information stands independently, linked to a unique key for storage and retrieval. This flexibility shuns the structured schema prevalent in conventional databases, granting unparalleled adaptability in data storage.
Estimated Revenue Growth:
NoSQL Database Market is expected to reach USD 36.46 billion by 2029, with a CAGR of 30% between 2023 and 2029.
Report: www.maximizemarketresearch.com/request…mple/97851
Realising the Potential of the Market:
Embark on an exploration into the core of this market’s dynamics, revealing the growth patterns of competitors and the ever-shifting landscape. Peer into the regional and global market values, unlocking hidden treasures within the competitive landscape. Explore the boundless potential in production, demand, and supply. Our segmentation analysis transcends conventional boundaries, unveiling psychographic, demographic, geographic, and behavioral factors. These insights guide successful marketing strategies, enabling the creation of targeted products, irresistible offers, and captivating customer experiences.
Handling Perspectives:
Discover the competitive landscape through strategic analyses like Porter’s and Pestle. Uncover organizations’ positions and pathways to amplified profitability. Decode the cosmic context with Pestle analysis, assessing the validity of existing products and services within the market’s expansive framework. Unveil the internal and external forces shaping companies’ fortunes through SWOT analysis, revealing strengths, weaknesses, advantages, and vulnerabilities. This report offers a comprehensive overview, unlocking the magical essence of the GIS Controller market.
NoSQL Database Market Segmentation
The document database market is anticipated to expand significantly over the projected period. Because document databases are faster and easier to use, developers like them because they enable them to work more effectively. Over time, it has gained popularity as an alternative to relational databases. This database is appropriate for high-volume web applications since it is connected to JSON (JavaScript Object Notation) and can manage enormous amounts of data. As such, a sizable market share is anticipated by the end of the projection period.
The graph-based database is anticipated to grow quickly over the projected period. The segment is expected to develop at a high compound annual growth rate due to the growing popularity of social networking and gaming apps.
by Type
Key-Value Store
Document Database
Column Based Store
Graph Database
by Application
Data storage
Mobile apps
Web apps
Data analytics
Others
by Industry
Vertical Retail
Gaming
IT
Others
NoSQL Database Market Regional Revelations
North America reigns supreme in 2022, driven by the adoption of new technologies and the burgeoning IT sector. The region’s demand for NoSQL databases intensifies with the surge in online gaming and multimedia consumption on OTT platforms.
Market Leaders for NoSQL Database
- DynamoDB 2. ObjectLabs Corporation 3. Skyll 4. InfiniteGraph 5. Oracle 6. MapR Technologies, Inc. 7. Apache Software Foundation 8. Couchbase 9. Basho Technologies 10.Aerospike Inc. 11.IBM Corporation 12.MarkLogic Corporation 13.Neo technology Inc. 14.Hypertable Inc. 15.Cisco Systems Inc. 16.Objectivity Inc. 17.Oracle Corporation 18.Microsoft Corporation
Table of Content: NoSQL Database Market
Part 01: Executive Summary
Part 02: Scope of the NoSQL Database Market Report
Part 03: NoSQL Database Market Landscape
Part 04: NoSQL Database Market Sizing
Part 05: NoSQL Database Market Segmentation by Type
Part 06: Five Forces Analysis
Part 07: Customer Landscape
Part 08: Geographic Landscape
Part 09: Decision Framework
Part 10: Drivers and Challenges
Part 11: Market Trends
Part 12: Vendor Landscape
Part 13: Vendor Analysis
Report: www.maximizemarketresearch.com/request…mple/97851
Important Issues Covered in the NoSQL Database Market Report:
- How long is the NoSQL Database Market forecast to be?
- What is the NoSQL Database market’s competitive scenario like?
- In the NoSQL Database Market, which region has the biggest market share?
- What prospects exist within the NoSQL Database Market?
Principal Offerings: The Abundant Treasures
- Market Share, Size, and Revenue Forecast|2023-2029
- Dance to the rhythm of Market Dynamics – Growth drivers, Restraints, Investment Opportunities, and key trends
- Unravel the magic of Market Segmentation: A detailed analysis by GIS Controller
- Journey through the Landscape: Discover leading key players and other prominent participants
News From
 Maximize Market Research Pvt….
Maximize Market Research Pvt….Category: Market Research Publishers and Retailers Profile: Established in 2017, Maximize Market Research is India Based consulting and advisory firm focused on helping clients to reach their business transformation objectives with advisory services and strategic business. The company’s vision is to be an integral part of the client’s business as a strategic knowledge partner. Maximize Market Research provides end-to-end solutions that go beyond key research technologies to help executives in any organization achieve their mission-critical goals. …
For more information:
MMS • Radia Perlman

Transcript
Perlman: I’m going to talk about identity, which is a buzzword. I hate buzzwords, because people think that they’re conveying information when they say I do identity. It’s like, there are so many pieces of it. This talk will explain all the various pieces, or a lot of them, and the various challenges with them.
What is identity? It’s a buzzword. Most people think they know what it means. If you talk about, I’m working in the identity space, they think they know what it means. There’s a lot of dimensions to it, like, what is your name? How do you prove you own that name? How do I know your name? How do you make human authentication convenient?
What does a browser need to know in order to authenticate a website? Will blockchain solve the identity problem? Because I’ve heard that’s what inspired this talk, really, was someone was saying, just use blockchain and you’ll solve the identity problem. I was thinking, really, what do you think the identity problem is? What do you think blockchain is, whatever? I’ll talk about that. We’ll discuss all these issues.
Names for Humans, and Email Addresses
Names for humans, they’re not unique. They should be. Mine is. I’m sure I’m the only Radia Perlman on Earth. You don’t have a single name. You have a different username on every site you visit. You have lots of unique identities. Sometimes, if you’re lucky, you can use the same username on more than one site. Email addresses are sometimes used as unique identifiers. They’re unique. An email address might be reassigned, so if you are John Smith at your company, and you leave, and they hire someone else, they might get the email address, John Smith.
Even though there’s a spec someplace that says, never ever reassign an email address to somebody else, just because things are written into a spec doesn’t mean they’re true. An email address can be shared by multiple people. It’s common for a human to have lots of email addresses. In a company, the first John Smith gets the email address john.smith, maybe even John. The next John Smith they hire has to be some variant, like Johnny Smith, or john.q.smith or something.
If you want to send email to somebody, you look in the corporate directory, and there’s six different possible email addresses, how do you know which one to send to? Then, it’s hard enough to delete spam, just under regular circumstances, but suppose there’s a really important other John Smith at your company, and you get this obscure stuff, how do you know whether it’s spam or some important thing that you have to forward to them?
I got a taste of that once, recently where I got this obscure email, it says, please refer to below GDS, with some Excel spreadsheet. Of course, I deleted it. I got this around five more times, and I deleted it each time wondering, how did I get on this obscure mailing list? Then, it got forwarded to me again, and they said, everyone has replied except Radia. It’s like, was I supposed to respond to this thing? I reply all, and I said, “I’m confused, what is this about?”
The person said, please check with SC3 team, and gave me some email address. I forwarded the entire thread to whoever that was. I said, do you know what this is about, they said to ask you? The person said, if I understand correctly, you’re asking about the availability of part number PNXHY in COV. This is literally what they sent to me, me a human being. I said, I have no idea what these two things are, the entire email is totally mysterious to me. Then they figured out after a while that there’s another Radia at Dell, and Outlook when you type Radia, fills it in, and people just assume Outlook knows what it’s doing.
This happened to me with a name like Radia, imagine people with more common names, this must happen to them all the time. The way I would solve the problem, if I were a hiring manager, and I’d be hiring somebody, and I’d say, “Your resume is really impressive. We need someone just like you, but we already have a John Smith, so we can’t hire you.” Then parents would get more creative like mine. I don’t know how you can be pregnant for 9 months and have all this time to think about names and you say, John. When I sent the email to the other Radia at Dell, and I said, “We both have the same name.” They never responded.
Website Names
Website names. There’s DNS names that we’re all familiar with, things like dell.com. There’s some registry organization that administers names within that top level domain. There’s .com, or .org, .tv. There’s over 1500 top level domains. That means you can purchase a name from any of those 1500 top level domains. It’s not like, there’s this evil monopoly here, or anything. If the string that you want as your name is available within that top level domain, usually, you can get it, though some things like .edu and .gov are fussy, or they have to prove that you really have a right to the name.
Yes, if you get something like drugs.com, that you don’t sell drugs, or at least on the internet, or something, and you think it’ll be valuable, then you can sell the name for lots of money, or there’s lawsuits and things. Let’s just assume that a website gets a DNS name. The theory is so beautiful. I work in cryptography and protocols. It’s something that I really assumed we’d solved. Everyone uses HTTPS all the time.
The crypto is wonderful. The protocols are wonderful. If you want to talk to x.com, you say, prove you are x.com. It sends you a certificate. You do cool cryptography. Then you have a cryptographically protected conversation. What could go wrong? We’ve solved that. In reality, usually, the user doesn’t start with the DNS name. They instead do a search and they get this obscure URL string, like that’s a URL string. Again, we’re humans, we shouldn’t see things like that.
I wanted to renew my Washington State driver’s license, so I knew it could be done online. I did an internet search for renew Washington State driver’s license, and I got the search results. I clicked on the top listed site. It didn’t occur to me that the top search wouldn’t be correct. This was the top search. If I’d been paying attention, it did say Ad, but often the real thing goes first anyway. The DNS name looked fine to me, even if I had bothered looking at it, which I’m not sure whether I did. I clicked on it and I got this website, which was very well organized, and look how happy the people are in that. It couldn’t possibly be a scam.
I clicked on Renew License, and it asked me everything I expected, which was my license number, my address, and my credit card number. I was pleased that I had successfully done that chore for the day. I wouldn’t have thought anything of it. I probably would have wondered in a month or so when I didn’t get my license and try to figure out what happened. The criminals that were putting up these websites were too greedy. The first day they charged 3.99, the next 9.99, next day 19.99, at which point, the bank fraud department called me and said, are these legitimate charges? I realized what happened. I said, ok, this is what probably happened. They said, fine, and they disallowed the charges, and they gave me a new credit card number. I was not harmed in any way.
As a matter of fact, this is such an incredibly useful example, because we focus on the cryptographic algorithms that provably secure cryptographic algorithms and protocols and all that, but there’s this really missing piece, which is assuming that humans will a priori know the DNS name that they’re supposed to go to. Don’t blame the user, scam sites can appear first. They can have perfectly reasonable looking DNS names to a human.
They can either appear first because they pay the search engine companies, or they understand the ranking algorithm and can game the system. This particular scam, at the time, it had several different names, like washingtondmv.org, and whatever. Also, for all 50 states, ohiodmv.org, and so forth. I do believe the particular scam has gotten shut down now. I’m a little disappointed because I wanted to get more screenshots.
There should be an easy way for users to report scams, but I didn’t know what to do. Once I realized that was a scam, who do I tell? I happened to know Vint Cerf at Google. I sent him an email saying, what do I do? I don’t know if that helped. Eventually, they seemed to have figured it out and shut that down. The site I should have gone to was that. Why should I as a human know that that was the right site, DOL, departmentoflicensing.washington.gov? People have told me, you should have known it was .gov. No, I support the humans right to not know obscure things like that.
In my book, the security book, I wrote this little paragraph. Once I wrote it, I said, yes, this captures everything. Everyone should memorize it and take it to heart. I’ve seen it on quote words. “Humans are incapable of securely storing high-quality cryptographic keys, and they have unacceptable speed and accuracy when performing cryptographic operations. They are also large, expensive to maintain, difficult to manage, and they pollute the environment. It is astonishing that these devices continue to be manufactured and deployed, but they are sufficiently pervasive that we must design our systems around their limitations.”
User Authentication
User authentication, a human has zillions of username-password pairs, how do you cope? Let’s say that you follow best practices. You make long, complex passwords. There’s different rules for each site. Some sites, your password can be no longer than this, must contain special characters, must not, whatever. You should, of course, change your password frequently. You shouldn’t have to. You shouldn’t reuse passwords at multiple sites, or even use similar passwords at different sites.
This is just not possible. Creative minds can make it worse. Password rules, they won’t divulge what the rules are until you are actually resetting a password. If you can’t quite remember what you had set your password to, if you could at least say, can you tell me what your rules are for passwords? Maybe that would help, but they won’t tell you until you’ve totally given up then you have to go through this arduous password resetting thing.
If you forget your password and go through the annoying, alternate proof of your identity, you’re not allowed to reset your password to what it had been before, even though that password was perfectly ok to use, except you’d temporarily forgotten it. This instruction I saw recently, password must be at least 8 characters, containing at least one uppercase letter, one lowercase letter, at least one number, at least one supported special character, and no unsupported special characters.
Security questions, who comes up with these? This was actually a list that I went through at some site: father’s middle name. My father didn’t have a middle name. Second grade teacher’s name. I couldn’t remember my second-grade teacher’s name when I was in second grade. Veterinarian’s name. I don’t have a pet. Favorite sports team. What’s a sport? My middle name. I do have a middle name, it’s Joy, so I typed in J-O-Y. It said, not enough letters.
How to make things somewhat usable, you can use an identity provider. That means like you say, you authenticate with Facebook, meaning you have to link your identity at site x with your Facebook identity, and then Facebook will vouch for you at site x. If someone guesses your Facebook password, they can impersonate you everywhere. If the identity provider is broken into, all users are compromised everywhere, so that’s scary. You could use a password manager.
Browsers like Chrome helpfully remember all your username passwords everywhere. I love it. I use it all the time. It’s terrifying, because the company knows all of your username and passwords in the clear, because it will tell you what they are. Or you could maintain a file somewhere of username-password pairs. You can even encrypt it with a single good password or don’t even bother encrypting it. In order to use it, you’re going to have to decrypt it, so malware on your machine can now steal all your usernames and passwords.
What about biometrics? I hate it when people say, if your fingerprint gets compromised, you have nine other fingers. It’s like, what are you talking about? You can’t use biometrics assuming they’re secret. You can’t say, I’m Radia, see, this is what my fingerprint looks like. They can be useful for local authentication, like unlocking your iPhone. This is a little bit deeper, but it’s something I’m really passionate about, which is trust rules for PKI. You’ll see what I mean.
We have a certificate authority that signs a message saying this name has this public key. It should be that when you get a DNS name, when a website gets a DNS name, it also gets a certificate. It doesn’t do it that way. Instead, the website purchases the DNS name from, let’s say, .com, in this case, my favorite website, which is rentahitman.com. It’s a real website. It was intended as satire. It has little services like, you can type your credit card here, and it will let you know whether it’s been compromised or something.
Occasionally, they get people that earnestly want to hire a hitman. If these people look serious, they send them off to the FBI. The website gets a DNS name like rentahitman.com. Then it has to go to a totally different organization to get a certificate saying, “Would you please, you CA person, here I’m paying you money for a certificate. I would like you to sign this certificate that vouches that I own the name, rentahitman.com, and this public key.
” Why should the CA believe you that you have that DNS name? There’s no standard for how to do this, but there’s various ad hoc mechanisms. One example is, you say, sign this certificate that I have this DNS name. When you get the DNS name, there’s a DNS entry in there with your IP address. The CA looks up that name and DNS, finds the IP address, and sends a message to that IP address, and if you can receive that, sort of like getting a PIN on your phone, it assumes that you own the name. Then it’s willing to sign your certificate. If being able to receive at a specific IP address is secure, we don’t need any of this fancy crypto and certificates and stuff. Just put your IP address and DNS.
Standards
Standards. I’m always curious how standard A compares to standard B. It doesn’t seem like anyone else does that, when there’s things that are similar. If I ask an expert, who’s an expert in A, how it compares with B. They say, A is awesome and B sucks. You ask a B person, you get the opposite answer. If there’s things that are better about B that come out after all the arguing, no problem, the A people steal the ideas. Nobody cares about the technical content of their specific, they just want credit for it.
I tell people that it’s natural to think of standards bodies as well-educated technologists that are carefully weighing engineering tradeoffs. A much more accurate way to think of them, I claim, is as drunken sports fans. Standards bodies, here’s an example where instead of inventing something new, which is what standards bodies tend to do, even if there’s something perfectly reasonable out there.
Here’s an example where a standards body adopted a syntax that was invented by a different standards body. Ordinarily, I would applaud them. In this case, what’s a certificate? It matches a name to a public key. Someone signed something saying that Radia’s public key is that. The IETF’s PKIX group decided to base certificates on X.509, which was a different sports team, which should have been fine.
Why should it matter? The problem with X.509 is that it maps an X.500 name to a public key. What’s an X.500 name? It’s a perfectly reasonable hierarchical namespace. An example of an X.500 name is like DNS names. It’s in the opposite order, but that’s ok. Instead of just string.string, it has a string type.
The most significant one is C=countryname, and then O=organizationname. Then underneath that, you can have as many levels of organization unit name. Then the bottom thing is common name. X.509 would have been fine if internet protocols and internet users were using X.500 names, but they don’t, they use DNS names.
What good is something that maps a string that the application and the user is unfamiliar with to a public key? This is an example and this is what browsers in the beginning did. The human types foo.com, or clicks on a URL containing that DNS name, the site sends a certificate with an X.500 name, C=US, O=AtticaPrison, OU=DeathRow, OU=ParticularlyVilePrisoners, CN=HorriblePerson.
One strategy that was used by some early implementations was, ignore the name and the certificate, but validate the math of the signature. What security does that give? Just the warm fuzzy feeling that someone paid someone for a certificate. People invented at least three different ways of encoding a DNS name into a PKIX certificate. One was having, instead of C=, they had a new component type, which is DC for domain component, and encode something like labs.dell.com as DC=com, DC=dell, DC=labs. Or there’s a field in the PKIX thing called the alternate name, and you could put the DNS name there.
Or you could use the bottom of the X.500 name, the common name part as the DNS name. Are three ways better than one? No, because suppose a CA checks to make sure that you own the DNS name that’s in the alternate name field, but doesn’t check one of the other places? Suppose a browser is checking one of the other places? I think today’s browsers tend to accept DNS names encoded in either the CN or the alternate name and ignore the rest of the X.500 name. I don’t know what all the various implementations do. I don’t know what all the CAs do either.
Certificate Expiration
Certificate expiration, what purpose is there in certificates expiring? Typically, the expiration time is months or years. If somebody cracked the private key of the website, they would be able to impersonate the website for months. That might as well be forever. You can’t depend on, because they expire, we don’t really have to worry about the private key leaking out because it will expire.
The only thing it does is it assures a continued revenue stream for commercial CAs, because you have to keep buying a new one. Short-lived certificates, like minutes, that are acquired on demand, like you would get when you’re using an identity provider, even those are not called certificates. They do make sense. These dire warnings you get in browsers about the certificate has expired, panic, exit the building immediately, or whatever. Even worse, when the browser doesn’t specify the problem is that the certificate expired, they just say, user panic, something horrible happened about mumble-mumble.
Certificate Revocation
Certificate revocation, this is a way to quickly invalidate Alice’s certificate. There’s basically two ways, either the CA periodically posts a list of invalid certificates. Or it’s actually more secure if it publishes the valid ones, even though that’s probably a longer list, because if somebody stole the CA’s key and quietly minted a few certificates, the CA would never know.
That’s why that would be a little bit more secure. Or you could have an online revocation server where your browser can go and check to say, is this certificate still valid? The only excuse for expiration times in certificate is that generally revocation mechanisms aren’t implemented. Even though in theory, we know how to do this, apparently, it’s not really widely done.
There’s this great story about Verisign and Microsoft. Somebody managed to convince Verisign to issue them a certificate with the name microsoft.com, and some public key that was not Microsoft. No one knows who it was that did it. They probably weren’t good guys, because it was done with a stolen credit card. They got the most secure kind of certificate, which was for code signing. Now it’s Microsoft’s problem, but it wasn’t their fault. What they did was they issued a patch to their certificate, signed code checking thing, that specifically ignored that public key, and got that out before anyone actually tried to use that certificate.
PKI Models
As I said, this part is a little bit subtle, but I want people to understand it. These are trust models for PKI. One model is what I call the monopoly model, which is, you choose one beloved, universally trusted organization, embed their public key in everything. Everybody has to get certificates from them, permanently, because once you embed it in everything it’ll be really hard to change it. It’s simple to understand and implement if you’re just coding things.
What’s wrong with it? There’s monopoly pricing, because the more widely deployed it is, the harder it will ever be to reconfigure everything so they can charge more. Getting a certificate from some remote organization will be insecure, or expensive, or both. It would be very hard to ever change the CA key, to switch to a different CA, or if that CA’s private key were compromised. That one organization can impersonate everyone.
Now let’s talk about what’s deployed, and it’s worse, it’s what’s in browsers, and I call it an oligarchy. They come configured today, your browser, with hundreds of trusted CA public keys. If you try to go to Bank of America, whoever you’re talking to can give you a certificate signed by any of those 500 organizations, and your browser will tell you, yes, everything’s fine. It does eliminate monopoly pricing but it’s less secure because any of those organizations can impersonate anyone.
This is what we use all the time. Beyond the oligarchy model, you can make it a little bit more flexible, by considering the configured CAs, they’re known as trust anchors, but allow trust anchors to issue certificates for other public keys to be trusted CAs. Your browser could accept a chain of certificates. Let’s say X1 is a trust anchor, and Bob the server can send a chain X1 says this is X2’s key, X2 says this is X3’s key, X3 says this is Bob’s key.
Now we’ll get to what I call the anarchy model, otherwise known as the web of trust. The user personally configures whatever trust anchors she wants, and nobody tells her who to trust. Anyone can sign a certificate for anyone else. Whenever you have a gathering of nerds, like an IETF meeting, you have a PGP key signing party with some ritual where you say who you are, and whatever, and people can sign certificates.
Then there are public databases of certificates that are both world readable and world writable, so you can donate whatever certificates you’ve signed. If you want to find somebody’s public key, you look to see if you’ve configured them into your machine. If not, you try to grapple together a chain of certificates from one of your trust anchors to the name that you are looking for.
The problems with that, it’s not going to scale, just too many certificates. It would be computationally too difficult to find a path, if this was the way that we did stuff on the internet, billions of certificates. Even if you can miraculously find a chain that mathematically works, why should you trust the chain? If I’m in the chain, I’m really honest, but I’m also really gullible. More or less, anyone can impersonate anyone with this model.
Now I’ll talk about how I think it should work. Instead of thinking of a CA as trusted or not trusted, a CA should only be trusted for a portion of the namespace, so the name by which you know me should imply what CA you trust to certify the key. If you know me as radia.perlman.dell.com, you would assume a CA associated with dell.com would certify the key for that identity, or roadrunnermumble.socialnetworksite.com, you trust the social network site to vouch for that key.
Whether these are the same carbon-based life form is irrelevant. In order to do that, we need a hierarchical namespace and we have it, DNS. Each node in the namespace would represent a CA, or be represented by a CA. The top-down model, you assume everyone is configured with the root key, and then the root certifies .com and .com certifies xyz.com, and so forth, and you would just follow the namespace stem. Everyone would be configured with the root key. It’s easy to find someone’s public key, you just follow the namespace, but you still have a monopoly at the root, and the root can impersonate everyone.
Bottom-Up Model (Recommended)
Now I’m going to talk about the model that I recommend. It’s so obvious to me, it’s the right thing, and somehow, we’re not doing it. This was invented by my co-author, Charlie Kaufman, the co-author on the Network Security book, around 1988. It’s just astonishing to me that somehow the world hasn’t caught on to it. There’s two enhancements to the top-down model. I’ll explain what these two things are, Up certificates and Cross-certificates.
An Up certificate says that not only does the parents certify the key of the child, but the child certifies the key of the parent. You don’t have to have everyone configured with the root key. For instance, everybody at Dell, Dell manages all our laptops and things, could be configured with dell.com, as the trust anchor, and anything in the namespace, dell.com, you just go down. Anything else, it would have to go up a level until it got to an ancestor.
You start at the configured trust root. If you’re in the namespace, follow the namespace down, otherwise, you go up a level until you get within the namespace of the target name. This way, the trust anchor doesn’t need to be the root. If the global root changes, it doesn’t affect users, just whoever’s managing the dell.com CA, would have to do whatever magic it is to revoke the parent. It doesn’t affect me, as a user, I don’t have to change my key, or change my trust anchor. A compromised global root would not affect trust paths within the namespace of dell.com.
The other thing that’s useful is cross-certificates where any node can certify any other node’s key. You might think I’m reinventing the anarchy model, but I’m not. There’s two reasons for this. One is that you don’t have to wait for the entire PKI of the world to get connected, you could have two organizations, each with their own little PKI. As long as they cross-certify each other, then users in each namespace can find the keys in the other namespace. Or, even if the whole world were connected, you might want to bypass part of the hierarchy because you don’t trust the root or something like that.
You only follow a crosslink if it leads you to an ancestor of the target name. The advantages of this is that, you can build a PKI in your own organization, you don’t have to get a commercial CA and pay them for certificates. Security within your organization is entirely controlled by your organization, because the chains will not go through CAs that are not in your namespace. No single compromised key requires massive reconfiguration. It’s easy to compute paths. The trust policy is natural and makes sense.
Malicious CAs can be bypassed so that damage can be contained. Bottom-up almost got adopted. It was implemented in Lotus Notes. Charlie was the security architect for Lotus Notes. It worked just fine. Lotus Notes has unfortunately gone away. DNSSEC, Charlie went to the working group meetings and got them to put in the uplinks and the crosslinks, and then once he succeeded, he stopped going to IETF. A few meetings after that, someone said, what are these uplinks and crosslinks here for? Can anyone think of any reason for it? No one could, so they said, let’s take them out. PKIX, he made sure that they put in a field called name constraints, which allows you to build this model, but nobody uses it, so it might as well not be there.
What We Have Today
What we have today, PKIX is the oligarchy thing where any of the 500 CAs configured into your browser are trusted for anything. That doesn’t seem very secure. It does have this useless name constraint field, useless because no one implements it as far as I know. An example of why this is bad, is suppose there’s a company that wants to provide lots of services, so laptops.company.com, itconsulting.company.com? It could get a single certificate for company.com, and then put the private key from that certificate in all of these various servers, but that’s not very secure.
You don’t really want to have lots of copies of your private key. Or you could pay a commercial CA for zillions of certificates, one for each of these things in your namespace. Or you could become one of the trusted CAs, but that’s a hassle to do that. Too bad, you can’t get a single cert saying you are a CA but only for names in the namespace, company.com. DNSSEC is name based.
A company can sign certificates in its own namespace, so that’s great. It is top-down so the root could impersonate anyone, but it is much better than the oligarchy model. Start with, what problem are you solving? Too often, there’s a new thing that gets invented and people start writing up standards with format and jargon. Or they say, here’s the thing, what can I build with it? The right approach, again, is start with what problem you’re solving. What are various ways of doing it? What are the tradeoffs?
Blockchain
There was this assertion that distributed identities with blockchain solves the identity problem. What exactly is the identity problem? What is blockchain? Why do you think it’s helpful? What is blockchain? It’s not actually well defined. One way of thinking of it is that it’s a magic thing that solves everything, especially if it’s security related. Or more realistically, it’s an append only-database, world readable, and it’s stored and maintained by lots of anonymous nodes expensively.
What is this distributed identities using Blockchain thing? I’ve simplified the concept down to what it really means conceptually. Names will be hierarchical, with the top being, which blockchain is going to register your name? It’s just like a top level domain, and then a string, which is the rest of the name. Each namespace uses its own independent blockchain. Within the namespace, names are first-come, first-served, nobody in charge. What you do is, if you want a name, you look in that blockchain, look for all the strings that have been chosen, and you choose one that hasn’t been chosen yet, and you grab it by putting that name and a public key on the blockchain.
What subset of identity is this actually solving? Only obtaining a name and asserting its public key. Getting a unique ID is not a problem. We have lots of unique IDs. The current DNS is somewhat distributed. It isn’t a single evil monopoly because you can choose which top level domain to deal with. Blockchain is very expensive, among other issues, but names become meaningless strings, even more so than today.
Given that your name is QVN whatever, how am I supposed to know how to talk to you? Even if I did magically know your name, how do I map that to a DNS name, so I can reach you, I can find your IP address? It does avoid CAs because of whoever claims the name also puts the public key on the blockchain. You don’t need certificates. Since the name is a meaningless string, you could have just used public keys as your unique identifier, and do away with the blockchain. It’s far simpler and less expensive.
What doesn’t it solve? Mapping between your name and what a human wants to talk to, or mapping between the syntax and a DNS name, or, you have to invent and deploy a new DNS-like thing? Or users remembering their own private key or other credentials. Or, revocation, what do you do if your private key is stolen or you forget your private key? I was giving a talk and I claimed they did not solve this, and some said, they did. I said, really? How did they solve this? He showed me a spec someplace where it said, “Saving the private key is essential. You can’t lose it. All access and control will be relinquished. Don’t lose a private key, please.” The solution is, ask users very nicely not to lose their key.
Blockchain Names vs. Current DNS
Blockchain names versus current DNS. For some reason, DNS stands on its head to prevent enumeration of all the names. I don’t know why I should care, whereas blockchain is a world readable database. Certainly, DNS could also allow you to enumerate all the names. Currently, when user U contacts website W, W sends a certificate.
A certificate is so much smaller than the entire blockchain, which here it’s assuming that your browser can look through the whole blockchain to find out the public key associated with that name. Back to identity, nothing is quite right today. Names really are just meaningless strings, which can trip people up like I got tripped up.
Getting a certificate is messy and insecure. The trust paths of certificate is really world, make it name based. If we were to deploy DNSSEC, it would be so much better over PKI. The DNSSEC people said, do not call this a PKI, or else the PKIX people will kill us. Human authentication is unusable and insecure. Blockchain and distributed identities are not going to help. It is amazing things work as well as they do. We don’t know how to solve all these problems.
Summary
Always start with what problem am I solving, and compare various approaches and do the best one. Rather than saying, blockchain, how can I use it? Or, how can I somehow inject it into this application? I gave a talk once where I said that, and then an engineer came up to me and said, “That sounds good but my manager really wants me to use blockchain.” I said, “Fine. Do what I said.
Look at various alternatives, choose the best one and build that. Then tell your manager you used blockchain, he’ll never know the difference.” In my book, Interconnections, I have these little boxes that I call real-world examples to illustrate a point I’m trying to make. When I’m talking about scalability, I talk about the wineglass clicking protocol, which works fine with 5 people, but if you have 11 people, everyone has to click everyone else’s glass, it really doesn’t scale well.
The point I was trying to make in the book for this particular anecdote was, you should know what problem you’re solving before you try to solve it. This anecdote is 100% true and will forever cement in your mind that you should know what problem you’re solving first. When my son was 3, he ran up to me crying, holding up his hand saying, “My hand.” I took it and I kissed it a few times. “What’s the matter, honey, did you hurt it?” He said, “No, I got pee on it.”
See more presentations with transcripts
MMS • Ben Linders

The four major elements that enable high-performing software teams are purpose, decentralized decision-making, high trust with psychological safety, and embracing uncertainty. Teams can improve their performance by experimenting with their ways of working.
Mark Cruth spoke about high-performing software teams at ScanAgile 2023.
Interpersonal alchemy is the study of that mystical science behind good teamwork, Cruth said. When you look at high-performing teams across the board, you begin to notice some similar things; you notice patterns emerge that can be attributed to the basic ways of working within teams, he argued.
Cruth presented four major elements that enable high-performing teams:
- Purpose creates autonomy
- Decentralized decision-making fuels empowerment
- High trust with psychological safety accelerates cohesion
- Embracing uncertainty sustains growth
As purpose creates autonomy, Cruth mentioned that the questions he asks his teams are “Do you know why you’re building that feature?” or “What’s the end goal of the work you’re doing?” When developing software, our goal is not to develop software, but rather to solve a problem and high-performing teams truly understand the problem they are trying to solve, he said.
With decentralized decision-making, you can push the decisions down to those doing the work to empower them, Cruth said. Whether it’s pushing code or determining what feature to build next, those decisions shouldn’t be made two levels above the team; the team needs to make those decisions, he argued.
There’s a difference between trust and psychological safety. Trust is how one feels towards someone or some group, whereas psychological safety is how one feels among that person or a group. High trust with psychological safety accelerates cohesion, Cruth argued. If you have both, that truly accelerates the connection people have and turns a group into a kick-ass team.
In software more than any other industry, certainty is a delusional dream. We never know if what we develop will actually impact the customer the way we expect. Embracing uncertainty sustains growth, Cruth mentioned. This mindset embraces the uncertain reality we work in and allows us to become clever about our work, to grow as both individuals and teams.
Change happens in spoonfuls, not buckets, Cruth said. He advised to start small by trying a practice and seeing if it solves the problem the team is experiencing and let it build up over time:
Many times people feel they have to throw everything out and start again, when in reality this is the worst thing they could do because the level of violent change prevents any long lasting change from taking hold.
High-performing teamwork is reachable if we just put more intent into how we want to work together. No fancy frameworks or expert coaching will create a high-performing team; only the team can do it by experimenting with their ways of working, Cruth concluded.
InfoQ interviewed Mark Cruth about high-performing teams.
InfoQ: Why do some teams perform better than others?
Mark Cruth: The reason why some teams perform better than others has everything to do with two things: the intentional practices they put in place and the environment leadership creates.
For example, the family favorite Pixar movie Toy Story almost wasn’t created because they didn’t have intentional practices in place around how they worked. It took Disney almost pulling the plug on the project in 1993 to jolt the Pixar team into realizing they had to get intentional in their ways of working. They instituted a daily meeting where everyone could hear about what was happening around the studio, as well as became explicit about who made creative decisions about the movie. These sorts of intentional practices helped them turn things around and turn Toy Story into a generation defining hit.
When it comes to creating the right environment, the leadership at Ford nailed this back in the 1980’s when they introduced the idea of “directed autonomy” which decentralized decision-making around their vehicles. No longer was the CEO making decisions on the size of headlights; they pushed the decisions to those closest to the work. Thanks to this and the psychological safety they created with their team members, they were able to launch the Ford Taurus, the car that was deemed to have saved Ford from the brink of financial disaster.
InfoQ: What practices can help teams to unleash their potential?
Cruth: Some of my favorite activities to do with teams include:
- Give the team the larger purpose behind their work and where they are going by creating a team vision statement
- Decentralize the way you make decisions as a team by running a game of delegation poker
- Reflect on the health of your team practices by running a retrospective focused specifically on how you work as a team
- Eliminate bad meetings by taking an inventory of your team meetings and determining which ones to keep, change, and remove
- Help your team play with the unexpected and unpredictable by introducing improv games into team events
Tech Industry Titans Clash Over Artificial Intelligence Superiority Ahead of $1.3 Trillion Market
MMS • RSS

USA News Group – Immediately upon hearing of the firing of OpenAI co-founder and CEO Sam Altman, Microsoft swiftly snapped up the new free agent and placed him as lead of the company’s new in-house AI team. With analysts projecting the Generative AI market to hit $1.3 trillion over the next decade, the race for AI supremacy is heating up and several tech giants such as Meta Platforms, Inc. (NASDAQ:META) (NEO:META), International Business Machines Corporation (IBM) (NYSE:IBM), and Amazon.com, Inc. (NASDAQ:AMZN) (NEO:AMZN) are racing to secure their position. Each has brought a unique approach to their AI strategies, including investing in and acquiring up-and-coming companies. It’s a rapidly developing space, with several new pure-play AI and Cloud firms gaining attention and making progress, such as Avant Technologies Inc. (OTC:AVAI) and MongoDB, Inc. (NASDAQ:MDB).
Businesses aiming to enhance their products with AI face significant challenges, primarily due to the high costs of computing and a looming global data storage crisis expected by 2025.
At the forefront of addressing these two key issues is Avant Technologies Inc. (OTC:AVAI), an innovative firm developing cutting-edge cloud supercomputing technology. Avant claims that their supercomputing network could become the most potent and economical private cloud infrastructure globally.
“The proliferation of the AI, machine learning and big data analytics industries is already rapidly outpacing the capabilities of traditional cloud infrastructure for an industry that demands exponential computer power and storage capacity,” said Timothy Lantz, Chief Executive Officer of Avant. “We recognized this real unmet need and began working to develop a next generation, ultra-high-density supercomputing environment that will revolutionize the landscape for AI companies of all sizes and for any other users who require hyper-scalable, cost-effective computing power.”
They’re specifically tackling the widespread issues of cost and performance constraints that are currently impeding the progress and market viability of AI, machine learning, and big data analytics. Avant aims to revolutionize these sectors with its private cloud infrastructure, promising enhanced performance and value across various industries. This will be achieved by lowering expenses, increasing computing density, and offering unique ESG (Environmental, Social, and Governance) advantages through significantly reduced electricity and water usage.
The company is developing a computing environment specifically for AI, ensuring it supports all major AI frameworks. This approach guarantees compatibility and simplifies development processes. Avant’s focus on interoperability means AI developers can continue using much of their existing technology infrastructure while still gaining from Avant’s enhanced performance and cost-effectiveness. Designed to meet the intricate computing demands of AI applications, Avant’s environment will facilitate rapid and efficient data movement among all components. This will lead to unparalleled system performance, availability, and scalability.
Pure-play AI firm MongoDB, Inc. (NASDAQ:MDB) is recently coming off announcing a collaboration with Amazon.com, Inc. (NASDAQ:AMZN) (NEO:AMZN) to accelerate application development and modernization on MongoDB using AI-powered coding companion Cascadeo, gravity9, and Redapt among customers and partners using Amazon CodeWhisperer with MongoDB.
“Generative AI has the potential to not only revolutionize how end-users interact with modern applications but also how developers build those applications,” said Andrew Davidson, SVP of Product at MongoDB. “With built-in security scanning and the ability to provide source and licensing information when suggestions resemble publicly available open source training data, Amazon CodeWhisperer now provides developers building on MongoDB a unique experience that will get even better over time.”
Amazon CodeWhisperer, an AI-driven coding assistant from AWS, has been developed using billions of lines of code from Amazon and other public sources. It offers code recommendations in developers’ integrated development environments (IDEs) based on natural language comments or the existing code. In collaboration with AWS, MongoDB contributed specialized training data relevant to MongoDB scenarios and participated in assessing the outputs of Amazon CodeWhisperer during its training phase, ensuring the generation of high-quality code suggestions.
“More and more developers are realizing the potential of generative AI-powered coding companions to transform how work gets done, giving them more time to focus on solving hard problems,” said Deepak Singh, VP of Next Gen Developer Experience at AWS. “Amazon CodeWhisperer already provides an optimized experience when working on common coding tasks and with AWS APIs. By collaborating with MongoDB, we are extending those capabilities to millions of MongoDB developers. We are excited to put Amazon CodeWhisperer in the hands of even more developers to help them tap into the transformative potential of generative AI.”
Also collaborating with AWS is International Business Machines Corporation (IBM) (NYSE:IBM), which recently joined forces to advance Gen AI solutions in the Middle East. IBM Consulting and AWS have joined forces to offer improved solutions and services, incorporating cutting-edge generative AI technology for key applications. A prominent example of this collaboration is the Contact Centre Modernisation using Amazon Connect. In this initiative, IBM Consulting and AWS have co-developed summarization and categorization capabilities for both voice and digital interactions. These generative AI functionalities enable seamless handovers from chatbots to human agents, equipping agents with concise summaries that help in quicker resolution of issues and enhancing overall quality management.
IBM has also recently unveiled its wastonx.governance to help business and governments govern and build trust in generative AI.
“Watsonx.governance is a one-stop-shop for businesses that are struggling to deploy and manage both LLM and ML models, giving businesses the tools, they need to automate AI governance processes, monitor their models, and take corrective action, all with increased visibility,” said Kareem Yusuf, Ph.D, Senior Vice President, Product Management and Growth, IBM Software. “Its ability to translate regulations into enforceable policies will only become more essential for enterprises as new AI regulation takes hold worldwide.”
Moving full speed ahead, Facebook parent company Meta Platforms, Inc. (NASDAQ:META) (NEO:META) recently shuffled its Responsible AI team into other areas of the company to focus on generative AI. The move comes off of a series of layoffs at the company where thousands of employees have been let go so far in 2023.
“Our single largest investment is in advancing AI and building it into every one of our products,” said Meta CEO Mark Zuckerberg in a previous statement. “We have the infrastructure to do this at unprecedented scale and I think the experiences it enables will be amazing. Our leading work building the metaverse and shaping the next generation of computing platforms also remains central to defining the future of social connection.”
Meta has recently unveiled a range of generative AI offerings, encompassing machine learning services for advertising, its Llama large language models, AI-created stickers, among others. Earlier in November, Meta introduced Emu, a platform for generating animated images.
The company has also launched two innovative tools under the Emu brand. The first, Emu Edit, enables users to guide the model with text instructions. The second, Emu Video, is a text-to-video diffusion model. Meta has suggested the potential integration of these tools into its social media applications, allowing users to modify photos and videos, or to craft custom GIFs for use in messages and social media posts.
DISCLAIMER: Nothing in this publication should be considered as personalized financial advice. We are not licensed under securities laws to address your particular financial situation. No communication by our employees to you should be deemed as personalized financial advice. Please consult a licensed financial advisor before making any investment decision. This is a paid advertisement and is neither an offer nor recommendation to buy or sell any security. We hold no investment licenses and are thus neither licensed nor qualified to provide investment advice. The content in this report or email is not provided to any individual with a view toward their individual circumstances. USA News Group is a wholly-owned subsidiary of Market IQ Media Group, Inc. (“MIQ”). MIQ has been paid a fee for Avant Technologies Inc. advertising and digital media from the company directly. There may be 3rd parties who may have shares Avant Technologies Inc., and may liquidate their shares which could have a negative effect on the price of the stock. This compensation constitutes a conflict of interest as to our ability to remain objective in our communication regarding the profiled company. Because of this conflict, individuals are strongly encouraged to not use this publication as the basis for any investment decision. The owner/operator of MIQ own shares of Avant Technologies Inc. which were purchased as a part of a private placement. MIQ reserves the right to buy and sell, and will buy and sell shares of Avant Technologies Inc. at any time thereafter without any further notice. We also expect further compensation as an ongoing digital media effort to increase visibility for the company, no further notice will be given, but let this disclaimer serve as notice that all material disseminated by MIQ has been approved by the above mentioned company; this is a paid advertisement, and we own shares of the mentioned company that we will sell, and we also reserve the right to buy shares of the company in the open market, or through further private placements and/or investment vehicles. While all information is believed to be reliable, it is not guaranteed by us to be accurate. Individuals should assume that all information contained in our newsletter is not trustworthy unless verified by their own independent research. Also, because events and circumstances frequently do not occur as expected, there will likely be differences between any predictions and actual results. Always consult a licensed investment professional before making any investment decision. Be extremely careful, investing in securities carries a high degree of risk; you may likely lose some or all of the investment.
Microsoft Introduces Azure Integration Environments and Business Process Tracking in Public Preview
MMS • Steef-Jan Wiggers
Microsoft recently introduced Azure Integration Environments in public preview, a new capability that allows organizations to assemble their resources into logical groupings to manage and monitor their integration resources more effectively.
The company brings Integration Environments as an opportunity for organizations to standardize integrations aligning with their standards and principles. Kent Weare, a principal product manager for Logic Apps at Microsoft, writes:
For some organizations this may mean grouping integration environments based upon traditional landscapes such as development, test, staging, user acceptance testing and production. For others, they may decide to group resources based upon business units or organizations such as Finance, Marketing, Operations, and Corporate Services.
Within an integration environment, users can further break down an environment into additional logical groupings for specific purposes through what’s called an application. They can create an application by providing its name and associating existing resources within the same Azure subscription. The types currently supported are Azure Logic Apps (Standard), Azure API Management APIs, Azure Service Bus queues and topics, and more resource types in the future.
Azure Integration Environment (Source: Microsoft Learn)
In addition, Microsoft also delivers a Business Process Tracking capability to support the Integration Environment in public preview. According to the company, this capability allows organizations to set business context over the transactions being processed by Azure Logic Apps – a requirement businesses are looking for. With Business Process Tracking, organizations can provide business stakeholders insights into complex processes, such as order processing spanning multiple Logic Apps and workflows.
Through a business process designer within the Azure Portal, users can construct a series of business process stages, and within each stage, properties can be created that refer to key business data they would like to capture. As the target audience for the capability, the company sees a business analyst or a business subject matter expert as users.
Weare told InfoQ:
We have received feedback from customers that they struggle to provide key business data to their stakeholders without many custom log points within their workflows. We have taken these requirements and developed an approach that allows the business stakeholder to participate in defining the business process but subsequently can see the business process overlayed on top of the underlying technical data without adding custom log points. This allows for business stakeholders to monitor the state of their transactions but also allows for identifying bottlenecks within the business process as well.
Business Process Transactions (Source: Microsoft Tech Community blog post)
Weare also stated:
We have also heard from customers that they are looking for ways to externalize the data collected during Business Process Tracking. With this in mind, we have chosen Azure Data Explorer, which allows customers to build custom dashboards using Azure Monitor Workbooks or Power BI. This will enable organizations to provide experiences where their users are already.
Lastly, Azure Integration Environments doesn’t incur charges during preview; however, when users create an application group, they are required to provide information for an existing or new Azure Data Explorer cluster and database. Azure Data Explorer incurs charges based on the selected pricing option – more details on pricing for Azure Data Explorer are available on the pricing page.