Traders Buy Large Volume of Put Options on MongoDB (NASDAQ:MDB) – MarketBeat
MMS
•
RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw some unusual options trading activity on Wednesday. Stock investors purchased 23,831 put options on the company. This is an increase of 2,157% compared to the typical volume of 1,056 put options.
Insider Activity at MongoDB
In related news, CRO Cedric Pech sold 308 shares of MongoDB stock in a transaction dated Friday, September 29th. The shares were sold at an average price of $353.05, for a total transaction of $108,739.40. Following the completion of the transaction, the executive now directly owns 33,802 shares of the company’s stock, valued at approximately $11,933,796.10. The sale was disclosed in a filing with the SEC, which is available at this hyperlink. In other MongoDB news, CFO Michael Lawrence Gordon sold 7,577 shares of MongoDB stock in a transaction dated Monday, November 27th. The shares were sold at an average price of $410.03, for a total value of $3,106,797.31. Following the completion of the transaction, the chief financial officer now directly owns 89,027 shares of the company’s stock, valued at $36,503,740.81. The sale was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through this link. Also, CRO Cedric Pech sold 308 shares of MongoDB stock in a transaction dated Friday, September 29th. The stock was sold at an average price of $353.05, for a total transaction of $108,739.40. Following the completion of the transaction, the executive now directly owns 33,802 shares of the company’s stock, valued at $11,933,796.10. The disclosure for this sale can be found here. Insiders sold a total of 164,029 shares of company stock valued at $62,181,450 in the last three months. Company insiders own 4.80% of the company’s stock.
Institutional Inflows and Outflows
Hedge funds and other institutional investors have recently added to or reduced their stakes in the business. Price T Rowe Associates Inc. MD lifted its position in shares of MongoDB by 13.4% during the first quarter. Price T Rowe Associates Inc. MD now owns 7,593,996 shares of the company’s stock valued at $1,770,313,000 after buying an additional 897,911 shares during the last quarter. Vanguard Group Inc. lifted its position in shares of MongoDB by 2.1% during the first quarter. Vanguard Group Inc. now owns 5,970,224 shares of the company’s stock valued at $2,648,332,000 after buying an additional 121,201 shares during the last quarter. Jennison Associates LLC lifted its position in shares of MongoDB by 87.8% during the third quarter. Jennison Associates LLC now owns 3,733,964 shares of the company’s stock valued at $1,291,429,000 after buying an additional 1,745,231 shares during the last quarter. State Street Corp lifted its position in shares of MongoDB by 1.8% during the first quarter. State Street Corp now owns 1,386,773 shares of the company’s stock valued at $323,280,000 after buying an additional 24,595 shares during the last quarter. Finally, 1832 Asset Management L.P. lifted its position in shares of MongoDB by 3,283,771.0% during the fourth quarter. 1832 Asset Management L.P. now owns 1,018,000 shares of the company’s stock valued at $200,383,000 after buying an additional 1,017,969 shares during the last quarter. 88.89% of the stock is currently owned by institutional investors.
Analyst Upgrades and Downgrades
MDB has been the subject of several recent research reports. Morgan Stanley boosted their target price on shares of MongoDB from $440.00 to $480.00 and gave the company an “overweight” rating in a research report on Friday, September 1st. Macquarie boosted their target price on shares of MongoDB from $434.00 to $456.00 in a research report on Friday, September 1st. Tigress Financial boosted their target price on shares of MongoDB from $490.00 to $495.00 and gave the company a “buy” rating in a research report on Friday, October 6th. JMP Securities boosted their target price on shares of MongoDB from $425.00 to $440.00 and gave the company a “market outperform” rating in a research report on Friday, September 1st. Finally, Bank of America initiated coverage on shares of MongoDB in a research report on Thursday, October 12th. They set a “buy” rating and a $450.00 target price for the company. One equities research analyst has rated the stock with a sell rating, two have given a hold rating and twenty-two have issued a buy rating to the stock. According to MarketBeat, the company has a consensus rating of “Moderate Buy” and a consensus price target of $432.44.
Shares of MDB opened at $418.28 on Thursday. The company’s fifty day simple moving average is $385.80 and its 200-day simple moving average is $380.45. The company has a current ratio of 4.74, a quick ratio of 4.74 and a debt-to-equity ratio of 1.18. The company has a market cap of $30.19 billion, a P/E ratio of -158.44 and a beta of 1.19. MongoDB has a twelve month low of $164.59 and a twelve month high of $442.84.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Tuesday, December 5th. The company reported $0.96 EPS for the quarter, topping analysts’ consensus estimates of $0.51 by $0.45. The firm had revenue of $432.94 million for the quarter, compared to analysts’ expectations of $406.33 million. MongoDB had a negative net margin of 11.70% and a negative return on equity of 20.64%. The business’s revenue for the quarter was up 29.8% on a year-over-year basis. During the same period in the prior year, the business posted ($1.23) earnings per share. As a group, analysts expect that MongoDB will post -1.64 EPS for the current year.
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.
Which stocks are major institutional investors including hedge funds and endowments buying in today’s market? Click the link below and we’ll send you MarketBeat’s list of thirteen stocks that institutional investors are buying up as quickly as they can.
What You Can Learn From MongoDB, Inc.’s (NASDAQ:MDB) P/S – Simply Wall St
MMS
•
RSS
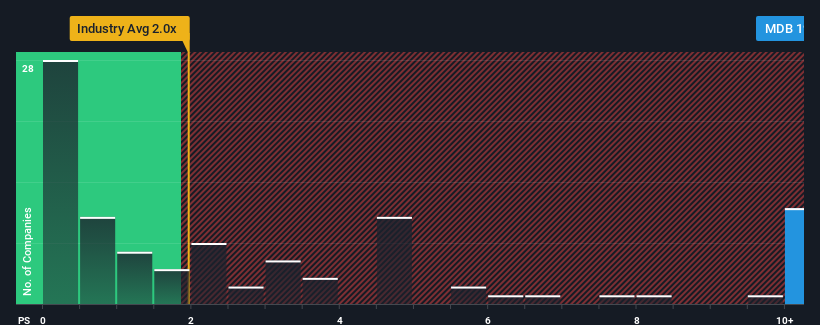
When you see that almost half of the companies in the IT industry in the United States have price-to-sales ratios (or “P/S”) below 2x, MongoDB, Inc. (NASDAQ:MDB) looks to be giving off strong sell signals with its 19x P/S ratio. Nonetheless, we’d need to dig a little deeper to determine if there is a rational basis for the highly elevated P/S.
NasdaqGM:MDB Price to Sales Ratio vs Industry December 28th 2023
How MongoDB Has Been Performing
Recent times have been advantageous for MongoDB as its revenues have been rising faster than most other companies. The P/S is probably high because investors think this strong revenue performance will continue. If not, then existing shareholders might be a little nervous about the viability of the share price.
MongoDB’s P/S ratio would be typical for a company that’s expected to deliver very strong growth, and importantly, perform much better than the industry.
If we review the last year of revenue growth, the company posted a terrific increase of 33%. The latest three year period has also seen an excellent 192% overall rise in revenue, aided by its short-term performance. So we can start by confirming that the company has done a great job of growing revenue over that time.
Shifting to the future, estimates from the analysts covering the company suggest revenue should grow by 24% per annum over the next three years. That’s shaping up to be materially higher than the 14% each year growth forecast for the broader industry.
With this in mind, it’s not hard to understand why MongoDB’s P/S is high relative to its industry peers. It seems most investors are expecting this strong future growth and are willing to pay more for the stock.
What Does MongoDB’s P/S Mean For Investors?
It’s argued the price-to-sales ratio is an inferior measure of value within certain industries, but it can be a powerful business sentiment indicator.
We’ve established that MongoDB maintains its high P/S on the strength of its forecasted revenue growth being higher than the the rest of the IT industry, as expected. Right now shareholders are comfortable with the P/S as they are quite confident future revenues aren’t under threat. It’s hard to see the share price falling strongly in the near future under these circumstances.
Valuation is complex, but we’re helping make it simple.
Find out whether MongoDB is potentially over or undervalued by checking out our comprehensive analysis, which includes fair value estimates, risks and warnings, dividends, insider transactions and financial health.
Have feedback on this article? Concerned about the content?Get in touch with us directly. Alternatively, email editorial-team (at) simplywallst.com.
This article by Simply Wall St is general in nature. We provide commentary based on historical data and analyst forecasts only using an unbiased methodology and our articles are not intended to be financial advice. It does not constitute a recommendation to buy or sell any stock, and does not take account of your objectives, or your financial situation. We aim to bring you long-term focused analysis driven by fundamental data. Note that our analysis may not factor in the latest price-sensitive company announcements or qualitative material. Simply Wall St has no position in any stocks mentioned.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Hackers target Thunder Terminal, drain over 86 ETH and 439 SOL – CoinNewsSpan
MMS
•
RSS
More than 86 ETH and 439 SOL tokens have been drained from Thunder Terminal, a trading platform. The precise number of malicious actors is unknown, but it has been said with certainty that hackers were behind the attack, affecting 114 out of 14,000 wallets on the platform. Thunder Terminal has committed to rectifying the incident and is cooperating with authorities for security audits and other processes.
Per reports that have surfaced, hackers successfully drained assets from the platform after gaining access to the MongoDB connection URL. It enabled them to view key pieces of information and execute orders for withdrawals.
MongoDB had shared the incident on December 18, 2023, with its partners. It was on December 27, 2023, when Thunder Terminal reported the incident on its platform. Most of the experts have appreciated Thunder Terminal for reacting to the hack attack, but some of them have come out to criticize the team behind it. They have said that there was sufficient time for the trading platform to rotate credentials; however, they chose not to do so.
A complete report will eventually draw the final conclusion. As of right now, Thunder Terminal is working to recover the stolen funds and make amends for those who have suffered.
The commitment is to make a 100% refund to affected wallets and offer them support with 0% fees and $100k in credits each. Thunder Terminal takes action by canceling pre-existing connection URLs, canceling pre-existing session tokens, and linking connection URLs directly to their servers.
Private keys remain safe since the platform does not store those details. Thunder Terminal is responding with its legal team and technical audit. The team is working on implementing 2-factor authentication for withdrawals and adding another layer of security.
Thunder Terminal was seen on a downtime and is expected to be restored at the earliest.
The media houses have reached many community members. Their reaction was filled with concern about not rotating credentials when MongoDB announced that it was hacked on December 17. Some community members have appreciated a response time of less than 9 minutes, stating that others take longer to process the necessary steps.
The prices of ETH and SOL have been moderately affected. SOL is down by 6.45% in the last 24 hours, and ETH is up by 6.76% in the same time window. While ETH is exchanging hands at $2,376.79 at the time of articulating this piece, SOL is struggling to get past $104.61.
Terminal Thunder has not provided a specific schedule for reimbursing affected users for their losses. The team has not also stated when access to the platform will be restored. Relevant teams and authorities are working on the issue; more details are expected to be made public in the days to come, especially about access and refunds.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
According to Hila Fish, the benefits of open source projects are supporting rapid innovation, the flexibility provided to customize and adapt tools, and transparency of the code which can enhance security efforts. The downsides are that security by obscurity doesn’t apply, open source is potentially prone to abuse, and when open source tools are not backed up by companies, it might result in a lower level of maintainability.
Open source projects often have a faster pace of innovation due to their open nature, Fish said. DevOps teams can tap into this rapid innovation cycle to adopt new technologies and practices that improve their processes. Fish mentioned areas like continuous integration, continuous delivery (CI/CD), containerization, and infrastructure as code (IaC), where open source tools and solutions have driven innovation in the DevOps space.
One of the core principles of DevOps is the ability to tailor processes and tools to the unique needs of an organization, as Fish explained:
Open source software provides the flexibility required to customize and adapt tools to fit specific workflows and requirements. DevOps teams can modify, extend, and integrate open source solutions to create an optimized toolchain, she added.
Open source projects emphasize transparency by allowing anyone to review the source code. This can enhance security efforts within the software development cycle, as teams have the opportunity to inspect code for vulnerabilities and make necessary improvements, Fish said. The collaborative nature of open source often leads to swift responses to security and various other issues, helping DevOps teams maintain a secure and stable environment.
There are also a couple of downsides to open source projects. Fish mentioned that the notion of “security by obscurity” doesn’t apply to open source tools. Proprietary software companies can claim their code is more secure than open source alternatives because of that, and that it’ll be harder for hackers to exploit loopholes since the code is not publicly available, Fish said.
Fish also mentioned that open source is potentially prone to abuse:
There were recent cases like “Colors” NPM package and “FakerJS” where the maintainer sabotaged/deleted the project, each for their own reasons, which is something we need to know that has the potential of happening (even if not happening a lot) while introducing open source tools to our environment.
A lot of open source tools are not backed up by companies, Fish said. As the maintainers are individuals, they can decide they discontinue the maintenance of these projects:
If we integrate these types of projects, it’ll mean we will either need to maintain it ourselves, or migrate to another well-maintained tool.
Fish mentioned that with open source you need to “assume good faith”. If you have an open source tool in production, and it has a bug, and you opened an issue to have it fixed, it could potentially take months, if not longer, for the bug to get fixed as they don’t owe us anything.
Yes, you could open the code and try to fix it yourself, but not all of us have the resources to do that, so we rely on the project maintainers to fix it for us.
Fish suggested explaining the issue and its urgency. People might be able to help faster as most if not all open source maintainers are all about collaboration and communication, as this is the essence of open source culture, she said.
Fish suggested doing research before integrating an open source tool into the environment, especially the production environment, to make sure that it is well maintained in case of issues that will surely arise.
InfoQ interviewed Hila Fish about working with open source tools.
InfoQ: What criteria do you use to select open source projects?
Hila Fish: I take eight key metrics into consideration: popularity of the project, level of activity, security, readiness, documentation, ecosystem, ease of use, and roadmap. Each key metric has sub-questions you can ask and find the answers to, which will allow you to assess the project maturity level in each of those key metrics.
InfoQ: How do you use those criteria?
Fish: To give an example, one of those metrics, level of activity, will help you roughly estimate how long you should wait for a bug fix/feature to get released in the open source project. Checking if the commits rate is daily/weekly/monthly, the number of issues, and the number of releases could give you a good understanding of the activity level.
Documentation is another important metric in selecting open source projects. Documentation is the gateway for that project, and if it’s rich it covers most aspects like how to integrate, known issues, features explanations, etc. With documentation, you can make a much more educated decision about whether to adopt this tool or not.
About the Author
Ben Linders
Show moreShow less
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Google Unveils Duet AI for Developers Offering AI-Powered Coding Assistance and Chat Functionality
MMS
•
Steef-Jan Wiggers
Recently, Google announced the general availability (GA) of its Duet AI for Developers, providing developers with IDE coding assistant and chat.
The GA release of Duet AI for Developers is a follow-up of the Duet AI in Google Cloud preview announced earlier this year at Google Cloud Next. It offers developers AI code completion, code generation, and chat in multiple integrated development environments (IDEs) such as Cloud Shell Editor, Cloud Workstations, IntelliJ, and Visual Studio Code. In addition, Duet AI for Developers supports 20+ programming languages, such as C, C++, Go, Java, JavaScript, and Python.
Like Microsoft with Copilot, Google is putting AI into its offerings with Duet AI. The company has incorporated its Gemini model into it or plans to do so in the coming weeks. Moreover, AI code completion and generation tools like GitHub’s Copilot have gained widespread popularity, and Google is taking a different approach by collaborating with 25 companies, including Confluent, HashiCorp, and MongoDB, to utilize their datasets for training Duet AI for Developers, aiding in code writing and troubleshooting for their respective platforms.
Furthermore, Datadog, JetBrains and LangChain will provide documentation and knowledge sources that will likely be most useful in the Duet AI for Developers chat experience. Using this data, the service will be able to provide development and ops teams with information about how to create test automation, resolve issues in production, and remediate vulnerabilities, for example.
Overview of the partner ecosystem of Duet AI for Developers (Source: Google blog post)
Currently, until the end of January 2024, Duet AI for Developers will be available for free, and after that it will, it will cost $19 per user per month with an annual commitment. A respondent on a Reddit thread commented:
It’s worse than GPT4 and $19/mo with a yearly commitment. Hard pass. Plus, the setup is laborious. I use Blackbox, and that was just installing an extension in VSCode. Free and done it a few clicks.
In addition, in a Hacker News thread discussing Google’s advances in AI, a respondent wrote:
By the time LaMDA came out, we already had ChatGPT. Palm2 was a serious ChatGPT competitor, but by that point, we had GPT4. Imagen was trained in mid-2022 (!) and could do text and everything, but they locked it away until SD and Midjourney had claimed the market. When it finally came out, nobody found it interesting. And now we have Gemini, which appears to be equal to or slightly worse than GPT4, which itself was trained in mid-2022.
They just don’t ship things fast enough.
Lastly, according to the company, developers will also be able to customize Duet AI for Developers, allowing them to receive code suggestions informed by internal private code and following their organization’s code conventions. This capability is expected to become available in Q2 of 2024.
About the Author
Steef-Jan Wiggers
Show moreShow less
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Analyzing Fortinet (NASDAQ:FTNT) and MongoDB (NASDAQ:MDB) – Defense World
MMS
•
RSS
Fortinet (NASDAQ:FTNT – Get Free Report) and MongoDB (NASDAQ:MDB – Get Free Report) are both large-cap computer and technology companies, but which is the superior stock? We will compare the two companies based on the strength of their earnings, risk, institutional ownership, profitability, analyst recommendations, valuation and dividends.
Institutional & Insider Ownership
65.0% of Fortinet shares are held by institutional investors. Comparatively, 88.9% of MongoDB shares are held by institutional investors. 17.5% of Fortinet shares are held by company insiders. Comparatively, 4.8% of MongoDB shares are held by company insiders. Strong institutional ownership is an indication that large money managers, hedge funds and endowments believe a stock is poised for long-term growth.
Analyst Recommendations
This is a summary of current recommendations and price targets for Fortinet and MongoDB, as reported by MarketBeat.com.
Sell Ratings
Hold Ratings
Buy Ratings
Strong Buy Ratings
Rating Score
Fortinet
0
20
16
0
2.44
MongoDB
1
2
22
0
2.84
Fortinet currently has a consensus price target of $65.68, indicating a potential upside of 10.68%. MongoDB has a consensus price target of $432.44, indicating a potential upside of 3.39%. Given Fortinet’s higher probable upside, analysts plainly believe Fortinet is more favorable than MongoDB.
Earnings & Valuation
This table compares Fortinet and MongoDB’s gross revenue, earnings per share and valuation.
Gross Revenue
Price/Sales Ratio
Net Income
Earnings Per Share
Price/Earnings Ratio
Fortinet
$4.42 billion
10.32
$857.30 million
$1.45
40.92
MongoDB
$1.28 billion
23.51
-$345.40 million
($2.64)
-158.44
Fortinet has higher revenue and earnings than MongoDB. MongoDB is trading at a lower price-to-earnings ratio than Fortinet, indicating that it is currently the more affordable of the two stocks.
Profitability
This table compares Fortinet and MongoDB’s net margins, return on equity and return on assets.
Net Margins
Return on Equity
Return on Assets
Fortinet
22.25%
3,361.82%
15.01%
MongoDB
-11.70%
-20.64%
-6.65%
Volatility and Risk
Fortinet has a beta of 1.05, meaning that its stock price is 5% more volatile than the S&P 500. Comparatively, MongoDB has a beta of 1.19, meaning that its stock price is 19% more volatile than the S&P 500.
Summary
Fortinet beats MongoDB on 9 of the 14 factors compared between the two stocks.
Fortinet, Inc. provides cybersecurity and networking solutions worldwide. It offers FortiGate hardware and software licenses that provide various security and networking functions, including firewall, intrusion prevention, anti-malware, virtual private network, application control, web filtering, anti-spam, and wide area network acceleration. The company also provides FortiSwitch product family that offers secure switching solutions for connecting customers their end devices; FortiAP product family, which provides secure wireless networking solutions; FortiExtender, a hardware appliance; FortiAnalyzer product family, which offers centralized network logging, analyzing, and reporting solutions; and FortiManager product family that provides centralized network logging, analyzing and reporting solutions. It offers FortiWeb product family provides web application firewall solutions; FortiMail product family that secure email gateway solutions; FortiSandbox technology that delivers proactive detection and mitigation services; FortiClient that provides endpoint protection with pattern-based anti-malware, behavior-based exploit protection, web-filtering, and an application firewall; FortiAuthenticator, a zero trust access solution; FortiGate VM, a network firewall virtual appliance; FortiToken, product family for multi-factor authentication to safeguard systems, assets, and data; and FortiEDR/XDR, an endpoint protection solution that provides both machine-learning anti-malware protection and remediation. It provides security subscription, technical support, professional, and training services. It sells its security solutions to channel partners and directly to various customers in telecommunications, technology, government, financial services, education, retail, manufacturing, and healthcare industries. It has strategic alliance with Linksys. The company was incorporated in 2000 and is headquartered in Sunnyvale, California.
MongoDB, Inc. provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB. It also provides professional services comprising consulting and training. The company was formerly known as 10gen, Inc. and changed its name to MongoDB, Inc. in August 2013. MongoDB, Inc. was incorporated in 2007 and is headquartered in New York, New York.
Receive News & Ratings for Fortinet Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for Fortinet and related companies with MarketBeat.com’s FREE daily email newsletter.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
MongoDB, Inc. (NASDAQ:MDB) Stock Position Raised by HB Wealth Management LLC
MMS
•
RSS
HB Wealth Management LLC lifted its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 10.3% in the 3rd quarter, according to the company in its most recent 13F filing with the Securities & Exchange Commission. The institutional investor owned 640 shares of the company’s stock after acquiring an additional 60 shares during the quarter. HB Wealth Management LLC’s holdings in MongoDB were worth $221,000 at the end of the most recent reporting period.
Other large investors have also modified their holdings of the company. GPS Wealth Strategies Group LLC acquired a new stake in shares of MongoDB in the second quarter worth $26,000. KB Financial Partners LLC acquired a new stake in shares of MongoDB in the second quarter worth $27,000. Capital Advisors Ltd. LLC boosted its position in shares of MongoDB by 131.0% in the second quarter. Capital Advisors Ltd. LLC now owns 67 shares of the company’s stock worth $28,000 after buying an additional 38 shares during the period. Parkside Financial Bank & Trust boosted its position in shares of MongoDB by 176.5% in the second quarter. Parkside Financial Bank & Trust now owns 94 shares of the company’s stock worth $39,000 after buying an additional 60 shares during the period. Finally, Coppell Advisory Solutions LLC acquired a new stake in shares of MongoDB in the second quarter worth $43,000. 88.89% of the stock is owned by institutional investors.
MongoDB Stock Up 2.3 %
MDB stock opened at $416.90 on Wednesday. MongoDB, Inc. has a twelve month low of $164.59 and a twelve month high of $442.84. The company has a market cap of $30.09 billion, a PE ratio of -157.92 and a beta of 1.19. The business’s 50-day simple moving average is $384.61 and its 200 day simple moving average is $380.18. The company has a quick ratio of 4.74, a current ratio of 4.74 and a debt-to-equity ratio of 1.18.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Tuesday, December 5th. The company reported $0.96 earnings per share for the quarter, topping analysts’ consensus estimates of $0.51 by $0.45. MongoDB had a negative return on equity of 20.64% and a negative net margin of 11.70%. The business had revenue of $432.94 million for the quarter, compared to the consensus estimate of $406.33 million. During the same period last year, the business earned ($1.23) earnings per share. The firm’s revenue for the quarter was up 29.8% compared to the same quarter last year. On average, research analysts anticipate that MongoDB, Inc. will post -1.64 earnings per share for the current year.
Analysts Set New Price Targets
Several analysts have recently commented on the company. Argus raised their target price on MongoDB from $435.00 to $484.00 and gave the stock a “buy” rating in a research report on Tuesday, September 5th. Canaccord Genuity Group lifted their price objective on MongoDB from $410.00 to $450.00 and gave the company a “buy” rating in a research report on Tuesday, September 5th. Sanford C. Bernstein lifted their price objective on MongoDB from $424.00 to $471.00 in a research report on Sunday, September 3rd. Needham & Company LLC lifted their price objective on MongoDB from $445.00 to $495.00 and gave the company a “buy” rating in a research report on Wednesday, December 6th. Finally, Oppenheimer lifted their price objective on MongoDB from $430.00 to $480.00 and gave the company an “outperform” rating in a research report on Friday, September 1st. One analyst has rated the stock with a sell rating, two have assigned a hold rating and twenty-two have given a buy rating to the company’s stock. According to MarketBeat, MongoDB presently has an average rating of “Moderate Buy” and an average price target of $432.44.
In related news, CFO Michael Lawrence Gordon sold 7,577 shares of MongoDB stock in a transaction dated Monday, November 27th. The stock was sold at an average price of $410.03, for a total transaction of $3,106,797.31. Following the sale, the chief financial officer now directly owns 89,027 shares of the company’s stock, valued at $36,503,740.81. The transaction was disclosed in a document filed with the SEC, which can be accessed through this link. In other MongoDB news, CFO Michael Lawrence Gordon sold 7,577 shares of MongoDB stock in a transaction that occurred on Monday, November 27th. The stock was sold at an average price of $410.03, for a total transaction of $3,106,797.31. Following the sale, the chief financial officer now directly owns 89,027 shares of the company’s stock, valued at $36,503,740.81. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which can be accessed through the SEC website. Also, Director Dwight A. Merriman sold 1,000 shares of MongoDB stock in a transaction that occurred on Monday, October 2nd. The shares were sold at an average price of $342.39, for a total value of $342,390.00. Following the sale, the director now directly owns 534,896 shares in the company, valued at $183,143,041.44. The disclosure for this sale can be found here. Insiders have sold a total of 164,029 shares of company stock valued at $62,181,450 over the last three months. 4.80% of the stock is owned by corporate insiders.
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
GitLab has recently introduced a browser-based Dynamic Application Security Testing (DAST) feature in version 16.4 (or DAST 4.0.9). This development is part of GitLab’s ongoing efforts to enhance browser-based DAST by integrating passive checks. The release includes active check-in capabilities.
Customers conducting active scans (full scans) will now automatically use GitLab active checks as the DAST team releases them. Each corresponding ZAP alert will be deactivated at that time. However, customers can opt out and revert to ZAP alerts by setting the CI/CD variable DAST_FF_BROWSER_BASED_ACTIVE_ATTACK to false.
The key change in this update is the replacement of ZAP alerts with GitLab’s active checks, specifically using GitLab check 22.1 for detecting path traversal vulnerabilities. This change aims to improve the detection of vulnerabilities in modern web applications for developers and security teams.
An active check in this context refers to a series of attack simulations run against a web application to identify specific weaknesses. These checks are performed during the active scan phase of a DAST scan. The process involves identifying injection locations in HTTP requests recorded during the crawl phase. These locations can include areas like cookie values, request paths, headers, and form inputs. The active check attacks use various payloads, which can be text or binary content, to test these injection points. Each payload is injected into different injection locations, creating new HTTP requests. The responses to these requests are then analyzed to determine if the attack was successful.
As a side, Elephant in AppSec podcast episode, Meta’s principal security engineer, Aleksandr Krasnov, highlighted the growing “shift left” trend in the tech industry, emphasizing early security integration in the software development life cycle (SDLC). However, he cautioned against deprioritizing the latter stages of the SDLC. Krasnov pointed out that this imbalance is reflected in the inefficiency of Dynamic Application Security Testing (DAST) tools, which often fail to provide significant value to organizations and security engineers. His insights underscore the need for a balanced approach to application security.
In another blog post, the GitLab team elaborated on the working of the DAST scan. The DAST scan running in a browser-based environment retrieves the application’s URL from the DAST_WEBSITE environment variable. This URL should direct to a test environment, as running a DAST scan on a production environment is not advisable, even for passive scans. In cases of transient environments created within the CI/CD pipeline, the URL can be stored in an environment_url.txt file. This file is then used by the DAST scan template job to configure the DAST_WEBSITE variable. This process is demonstrated in the GitLab Auto DevOps deploy template job.
The duration of a DAST scan can vary, potentially exceeding an hour, depending on the web application’s complexity. It’s important to set a sufficiently long job timeout for the runner executing the DAST scan. Additionally, the CI/CD timeout at the project level should also be adjusted to accommodate the scan’s completion.
For more information about GitLab’s browser-based DAST scanning, interested readers can refer to the official documentation. DAST scans are available in the free trial of GitLab Ultimate.
About the Author
Aditya Kulkarni
Show moreShow less
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Vector search now a critical component of GenAI development | TechTarget
MMS
•
RSS
Vector search is nothing new. Its role as a critical data management capability, however, is a recent development due to the way it enables discovering data needed to inform generative AI models.
As a result, a spate of data management vendors, from data platform providers such as Databricks and Snowflake to specialists including Dremio and MongoDB, introduced vector search and storage capabilities in 2023.
Vector databases date back to the early 2000s. Vectors, meanwhile, are simply numerical representations of unstructured data.
Data types such as names, addresses, Social Security numbers, financial records and point-of-sale transactions all have structure. Because of that structure, they can be stored in a database and other data repositories, and easily searched and discovered.
Text, however, has no structure. Neither do audio files, videos, social media posts, webpages or IoT sensor data, among other things. But all that unstructured data can be of great value, helping provide information about a given subject.
To prevent unstructured data from getting ingested into a data warehouse never to be seen again — to make it discoverable amid perhaps billions of data points — algorithms automatically assign vectors when unstructured data is loaded into a database, data warehouse, data lake or data lakehouse.
That vector then enables large-scale similarity searches rather than only searches for exact matches, which is significant, according to Sahir Azam, chief product officer at NoSQL database vendor MongoDB.
You can take any source of knowledge and turn it into a complex mathematical representation, which is a vector, and then you can run similarity searches that basically find objects that are related to each other without ever having to manually define their characteristics. That’s extremely powerful. Sahir AzamChief product officer, MongoDB
“You can take any source of knowledge and turn it into a complex mathematical representation, which is a vector, and then you can run similarity searches that basically find objects that are related to each other without ever having to manually define their characteristics,” he said. “That’s extremely powerful.”
Alex Merced, developer advocate at data lakehouse vendor Dremio, likewise pointed out the vital role vector search plays in enabling analysis.
“Vector search allows you to [ask questions of data] without having to wait for a dashboard to be built,” he said. “That can be transformative. People want the same data at their fingertips that they [previously] had to have had researched. Vector search allows you to do that.”
Historically, vector search and storage were mainly used by search-driven enterprises that collected vast amounts of data. Like graph technology, they were used to discover relationships between data. For business applications, they included geospatial analysis.
Eventually, vector search and storage evolved to include AI model training. But they were still not mainstream capabilities.
Generative AI (GenAI) has changed that over the past year.
Large language models (LLMs) rely on data to generate query responses. Vectors provide a fast and effective way to discover that needed data.
GenAI explosion
When ChatGPT was released by OpenAI in November 2022, it represented a significant improvement in LLM technology. Right away, it was obvious that generative AI could help users of analytics and data management tools.
For well over a decade, analytics use within organizations has been stagnant at around a quarter of all employees. The tools themselves are complicated and require significant training to use — even those with some natural language processing (NLP) and low-code/no-code capabilities.
LLMs change that by enabling conversational language interactions. They are trained with extensive vocabularies and can determine the meaning of a question even if it isn’t phrased in the business-specific language required by previously existing NLP tools.
In addition, LLMs can generate code on their own and be trained to translate text to code. That can eliminate some of the time-consuming coding that eats up much of data engineers’ and other data workers’ time as they integrate data and develop data pipelines.
However, to be a truly transformative technology for a business, generative AI needs to understand the business.
LLMs such as ChatGPT and Google Bard are trained on public data. They can be questioned about ancient Rome or the American Revolution, but they have no idea whether a manufacturer’s sales were up or down in Iowa during the spring, and they certainly can’t explain why those sales headed in a certain direction.
To do that, language models need proprietary data.
As a result, after the initial hype around ChatGPT began to wear off, and enterprises realized that public LLMs couldn’t really help them without being augmented with their proprietary data, some began training models with their own data.
Rather than wait for vendors to provide them with tools, a small number of enterprises with significant data science resources started building domain-specific models from scratch. Others, meanwhile, integrated their data with existing LLMs.
“We’ve entered a new phase of GenAI adoption in which companies are applying language models to their own domain-specific data in order to address specialized use cases,” said Kevin Petrie, an analyst at Eckerson Group.
One way they’re doing so is by exporting proprietary data and fine-tuning a pre-trained model, he continued. Another is essentially taking the opposite approach and importing LLMs to enrich users’ data prompts.
“The vector database feeds domain-specific data to language models to support both these scenarios, especially the prompt-enrichment scenario,” Petrie said.
Similarly, Donald Farmer, founder and principal of TreeHive Strategy, said vectors are particularly useful for training generative AI.
He noted that generative AI is good at understanding subtleties, which is particularly applicable to language. Vectors help generative AI discover not only what data — including words — is most likely to be related, but what data is most applicable to a given query.
“That’s something a traditional system can’t do because it doesn’t have weightings,” Farmer said. “GenAI can use these weightings — these vectors — that give it the subtlety to choose the right [data].”
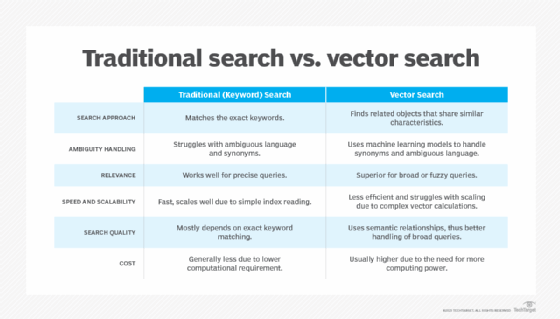
A comparison of vector search and keyword search.
Part of a pipeline
While vectors have become integral to training generative AI models, organizations still need to get vectorized data from a vector database or other storage repository into a model.
RAG is an AI capability that gathers data from where it’s stored to supplement the data already used to inform an application. The intent is to improve the application’s output by adding more training data.
In particular, RAG pipelines both keep applications current by providing the applications with the most recent data as well as make them more accurate by adding more data volume. Not surprisingly, as organizations aim to improve the accuracy of LLMs and train them to understand domain-specific use cases, many have made RAG pipelines a priority.
Vector search, meanwhile, is a key component of a RAG pipeline.
Along with searches to discover relevant structured data, vector search enables the discovery of relevant unstructured data to train a model. The two are combined with other capabilities such as data observability to monitor quality to create a RAG pipeline.
“The most popular method of enriching prompts is RAG,” Petrie said.
Using a RAG pipeline, generative AI applications can receive prompts from users, search vector storage for responses to past prompts that were similar, retrieve the vectors and then add them to the generative AI application, according to Petrie.
“At that point, the language model has relevant facts and content that help it respond more accurately to the user prompt,” he said.
As a result of the growing importance of RAG pipelines and the role of vector search in feeding those pipelines, Databricks in early December unveiled an entire suite of new tools designed to help customers build RAG pipelines.
Databricks has been among the most aggressive vendors in making generative AI a focus over the past year. In June, it acquired MosaicML for $1.3 billion to add LLM development capabilities. In October, it introduced LLM and GPU optimization capabilities aimed at helping customers improve the results of generative AI applications. In November, Databricks unveiled plans to combine AI and its existing data lakehouse platform and rename its primary tool the Data Intelligence Platform.
Graph database specialist Neo4j is another data management vendor with plans to add RAG pipeline development capabilities. Meanwhile, data observability specialist Monte Carlo in November added observability for not only vector databases, but also Apache Kafka, a popular tool for feeding data into vector databases.
While perhaps the most popular method, RAG pipelines aren’t the only way to feed vectorized data into a generative AI application.
In fact, there are ways to feed generative AI that don’t include vectors, according to MongoDB’s Azam. Vectors, however, when paired with other capabilities in a data pipeline, improve and enhance the pipelines that inform generative AI.
“A GenAI app is still an app,” Azam said. “You still need a database that can serve transactions at high fidelity and high performance, [semantic] search capabilities to understand similarities, and stream processing to deal with data in real time. These other capabilities don’t go away. Vectors open a whole new ecosystem of use, but are one pillar in a data layer to empower applications.”
Effectiveness
Despite the importance of what vectors enable, they are not a guarantee of accuracy.
Vectors can improve the accuracy of a generative AI application. They can help retrain a public LLM with proprietary data so that an organization can use the generative AI capabilities of the public LLM to analyze its data. They can also help inform a private language model by making sure it has enough data to largely avoid AI hallucinations.
But there’s a significant caveat.
No matter how much data is used to train an application, its accuracy remains most dependent on the quality of the data. If the data is inaccurate, the application will be inaccurate as well.
“If you have inaccurate data, it doesn’t matter how good the model is,” Dremio’s Merced said. “Data quality has become super important this year because of GenAI. Everyone wants to build generative AI models, so now all of the data quality talk we’ve been having for years really matters. We can’t build these models if we don’t do those hard things that we should have been doing for years.”
As a result, there has been new emphasis on data observability, data lineage and other enablers of data quality, he continued.
“These used to be boring things that make data a little bit better,” Merced said. “But now people realize their data needs to be better or they can’t build these cutting-edge tools. DataOps is going to be a very big story this coming year because of that.”
Petrie likewise noted the importance of data quality in determining whether generative AI applications deliver accurate responses.
“This stuff is easier said than done,” he said. “Companies have struggled with data quality issues for decades. They need to implement the right data observability and data governance controls to ensure they’re feeding accurate content into the vector databases. They also need to make sure their vectors properly characterize the features of their content.”
In fact, that proper characterization of features — the quality of the algorithms that assign vectors — is perhaps as important as data quality in determining the effectiveness of a generative AI application, according to Farmer.
If an algorithm is written well, and similar words such as mutt and hound are assigned similar vectors, a vector search will discover the similarity. But if an algorithm is written poorly, and the numbers assigned to those words and others such as dog and pooch don’t correspond to one another, a vector search won’t discover the similarity.
“Vector search algorithms are improving all the time,” Farmer said. “None of this would work without vector search being effective.”
Nevertheless, with vagaries in algorithms, vector searches aren’t foolproof and can result in AI hallucinations.
“They are very effective at getting the most mathematically correct answer, but they have to get feedback and get retrained to know if that is the most accurate in human terms,” Farmer said. “That’s why they’re constantly asking for feedback, and models are constantly being retrained.”
Outlook
After quickly becoming a critical capability as organizations develop pipelines to feed generative AI models, vector search will likely continue to gain momentum, according to Petrie.
But beyond vendors developing and providing vector search capabilities, more organizations will actually use them in the coming year.
“I think many companies will adopt or expand their usage of vector databases as they ramp up their investments in generative AI,” Petrie said.
Similarly, Merced predicted that adoption of vector search and storage capabilities will continue increasing.
“The general trend of everything is making it easier to use data and making data more accessible and more open,” he said. “So, I’m optimistic that vectors will continue to be a big thing.”
Farmer noted that new technologies are being developed that, like vector search, will help discover the data needed to train generative AI applications.
OpenAI reportedly is developing a platform called Q* — pronounced “Q-Star” — that’s more powerful than ChatGPT and better at solving math equations.
“We’re at the stage where there are rumors of new technologies coming out,” Farmer said. “But anybody who’s got one is keeping it pretty quiet.”
Meanwhile, there is plenty of room for vector search to grow and improve, and help generative AI do the same, he continued.
“We’ve seen a huge improvement in GenAI over the course of a year,” Farmer said. “That hasn’t been driven by new technology. That has been driven by existing technology, which is by no means at its peak. There’s a lot of headroom left to reach in the technologies we have today.”
Eric Avidon is a senior news writer for TechTarget Editorial and a journalist with more than 25 years of experience. He covers analytics and data management.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Sleebe: I’m sure all of you recognize this screen. In fact, most of us online are actually on this platform as we speak. It embodies the tremendous amount of change our whole world has gone through in the past three, maybe even three-and-a-half years. We’ve all learned to work together in new ways and collaborate from anywhere throughout the pandemic. We build software that is so intuitive, that they’re simultaneously used by large enterprises, small businesses, your grandparents, and preschool children around the world. How did we do it? How did we manage through the pandemic to actually scale to such an extent that everyone could use it, regardless of who it is? What is actually underneath this screen? In today’s session, we’re actually going to discuss that. In Zoom, why does it work? We’ll explain as you’re using Zoom, or if you’ve used Zoom in the past, and especially as practitioners, how does it actually work under the hood? I’ll take you through the ins and outs of the platform, including how we were able to scale through that pandemic, when we had that huge growth. How do you actually manage that when you have such a huge infrastructure already?
Background
My name is Ian Sleebe. I am a Senior Solutions Architect, part of the global architecture team, based in Amsterdam, where we help people understand how Zoom works, and how to fully optimize your Zoom experience. I’ve been at Zoom for almost four years. It’s definitely been a wild ride. As we are working on the next evolution of Zoom, we look beyond just meetings, focusing on other things like contact center, phone, events, and even mail and calendar services and integrations. Today, it will mostly be around meetings, but definitely know, this is not just a meetings platform.
Zoom’s Beginnings
Before we dive into the ins and outs of that platform, let’s understand the beginnings. This is Zoom’s founder, Eric Yuan. He was a web conferencing industry leader who ran the Webex product from 1997 to 2011. He actually left in 2011 with an all-star handpicked engineering team to start focusing on what is that video-first platform. Before even with Webex, a lot of it was built from other solutions, hot glued on, on top of each other, primarily focused on voice platforms. Eric had a vision, how can we make an actual video-first platform where we can meet everyone regardless of what device we’re using, regardless of wherever we are? In 2013, he actually launched Zoom together with his team. Just before that, just so you know, we did have a beta. That beta could only host 15 users. I’m pretty sure there’s probably a lot more online right now than back in that day, compared to those 15 users. In the actual launch in January 2013, version 1.0 could only host 25 users. Thinking about that, at the end of the first month, we already grew to 400,000 users on our platform. At the end of May, we had a million users. Today we have around 300 million daily meeting participants, which rounds up to about 3.3 trillion minutes per year. You can probably tell, scalability was already a big thing at the beginning and something we definitely had to focus on to make sure that we could provide that service to everyone.
That product started as a way to improve video conferencing, but is now a true platform where we can provide team chat, phone, and even contact center solutions, mail and calendaring. That’s simply because innovation is at our Zoom’s core. Expansion made total sense for us. I know this is not supposed to be a salesy talk talking about what we do. I think it’s very important to understand where we came from, and where we are going, to really embrace that scalability story.
The Different Layers of Zoom – Intelligent Transport Layer
How do we do it? When you join a meeting, what are the steps you take? From a platform perspective, what is actually in all of that? Let’s actually, like an onion, peel back the layers of Zoom, so you understand how our solution works. We’ll look at four layers that will make you understand how our platform from an overall level works. The first one will be the intelligent transport layer. In the intelligent transport layer, we will check what the most optimal protocol is for the client. Is that UDP, TCP, TLS, or HTTPS? Are you using specific proxy servers? Do you have a specific need to go through the firewall in a specific way? We want to make sure that obviously, for meetings, for media, specifically, UDP is going to be preferred. Because you don’t have all that TCP traffic going, are you still there? Did you receive my package? You can actually have a full conversation, even if some packets are lost. Even if UDP is not available, you still have those fallback mechanisms, which are going to be crucial to provide access to your service, regardless of the situation. Even if it’s not Zoom, you need to make sure that you have something to fall back on. We also check for your location. That’s going to be important in some of the other layers, where we will actually provide you the best resources based on where you’re situated.
Reactive Quality of Service Layer
For the next layer, the reactive quality of service layer. We’re pretty proud of this layer, because we’re the only company in the world that has this reactive quality of service layer. We think it’s very important because it will react to real time network and device statuses. What does it entail? Basically, we look at the statistics of the device and network you’re in. Are you on Wi-Fi? Are you wired, satellite, 5G? How’s your connection? Are you seeing any packet loss, latency, bandwidth issues? Do you have a lot of jitter? Also, how’s your device doing? How’s the CPU usage? Do you have your memory all full? Do you have a lot of network I/O plugged in as well? This information will then be sent on to the next layer, so the next layer can actually adjust accordingly based on the information it receives.
Adaptive Codec and Session Layer
The next one, that’s going to be the adaptive codec and session layer. Based on the information from the reactive quality of service layer, your connection will get adjusted accordingly. How does that work? In this layer, we have something called compression technology. This basically means that we adjust for even up to 45% packet loss. We also have multi-bitrate encoding, which allows us to toggle between streams, that way we can provide the best quality. Of course, we have a special sauce at Zoom, which is our codec. Our codec is specific to us. There are some industry standards built into that codec, but we really built it almost from the ground up. That 45% packet loss, that is actually something that we’ve measured through a Wainhouse study. Even up to 40% packet loss, you’ll still have what we call an excellent or good meeting experience, both for audio as well as video.
Distributed Conference Layer
For the next layer, this is going to be a distributed conference layer. What that means is in the traditional world, you’ll have just regular rate transcoding. You’ll utilize basically just full transcoding and mixing everything. With us, what we basically do is we utilize subscription information for switch technology without doing any transcoding or mixing, which means we use less CPU, less memory, and allows us to scale a lot more. In a typical server, maybe you can handle 200 clients at the same time, but because we use this switching method, it actually allows us to handle 2000 clients concurrently. You’re not just connected to a single meeting server, you got people in Amsterdam connecting to the U.S. We’ll make sure that you Amsterdam folks will connect to Amsterdam. In the U.S., you’ll be able to connect to a U.S. data center, making sure that everyone has the best experience. Because what we’ll do in the backend is provide those private links between the two data centers, without you as a user having to go all the way to, for example, the Amsterdam data center if you are in the U.S.
Cloud Video Architecture
If we then take an overall look at our cloud video architecture, there’s four main ingredients, like we discussed, that basically makes this a new, innovative modern architecture. Before normal video architecture, you’ll have centralized, what we call MCUs, which are basically media servers that are going to be hosted in specific areas, and everyone’s going to connect to that one MCU. Whereas with Zoom, we’ll have a distributed network, so you’ll just connect to whatever data center is best for you, which offers lower latency as well as increased reliability and media quality. If we then look at our multimedia routing, you’ll have separate links for audio, video, and content going to the cloud, which is actually going to make for better streaming quality, more scalability. The other interesting part is that we actually don’t composite straight on the MCU, which is very typical. Cisco does it and a lot of other people do it. Basically, we use the client to composite the video image. Obviously, that means that the servers themselves need less work, they need less CPU power, which allows us to reduce our service costs, but also to provide a personal experience. For example, you’re able to move around thumbnails, maybe make someone bigger. Maybe I want a gallery view, and you want to see this in the speaker view. There’s definitely ways where actually compositing on the client versus on the server will make a lot more sense and provides you with more ways to innovate.
Additionally, like the old school rate transcoding we talked about, you just generate multiple streams, and then transmit them. With multi-bitrate encoding, we actually encode those single streams with multiple bitrates, and you’ll toggle between them. This will optimize bandwidth, and definitely reduce CPU and bandwidth consumption as well. Lastly, if we compare our quality of service, so we have something that we call application layer quality of service, instead of network layer quality of service. With the network quality of service, typically, you’re just giving priority to specific packets. Whereas with the application, we’re constantly going to be checking how you’re connecting to the meeting, and adjusting based on your network situation. For example, if you have a meeting on your phone, you’re walking around, maybe at some point, your network is going to be a bit worse. It doesn’t matter, we’ll adjust for you accordingly, which means that your quality will stay the same, regardless of what network you’re attached to.
Architecture and Infrastructure – High Level Overview
Next up, let’s look at the actual architecture and infrastructure from a high level, what that looks like. This is a current map of our colocated data centers. I’ll talk a bit more about what cloud data centers we have as well. We simply scale a lot, so some of this might be outdated, as I’m showing you. We’re always looking at adding new data centers, as you might imagine. It’s very important to know that we have data centers spread all over the world, hosted on a mix of technologies. We make sure that even if an entire region would disconnect, you would still be able to connect to any of our other data centers. For example, if India would disconnect, you could still connect to Japan, or maybe even Australia or Singapore, to make sure that you can still have those very important calls.
Where do we actually host? This is quite interesting. You would think that maybe we’re fully AWS, fully Oracle. No, we actually have a mixture of technologies. From AWS and Oracle to a global network of colocations, to provide the most optimal experience, means that we have the flexibility also to pivot in case one of the services tends to have an issue. During the actual pandemic, we mostly leveraged AWS and Oracle to provide what we call dynamic meetings resources to scale super-fast. For a global network of colocations, this is basically tier-3 or above data centers, and then we leverage AWS specifically for our web backend service. Of course, like I said, AWS and Oracle, they’ll still host those real-time communication services. AWS is the primary for those web backend services.
Meeting Zone
If we then look into what an actual meeting zone is. A typical meeting zone will look like this. We’ll have a multimedia router, which will actually host your meetings. We’ll have a zone controller, which is basically managing the MMR, and make sure that you get connected to an appropriate MMR as well. We have a cloud controller. This is going to again, manage the zone controller. This way, we can be pretty dynamic, making sure that you always connect to something, provide high availability and the likes. What is very important is we don’t do dedicated MMRs, or zone controllers, or cloud controllers for anyone, even though the accounts in the web backend, they’re logically segregated through account numbers very much like anyone else would be doing it. The actual meeting zones, they’re always going to be for everyone, basically. Everyone’s going to be sharing these resources, because they’re on the fly, not everyone’s going to use an MMR 24/7. You’re not going to be in a meeting all the time. That means that if you have a meeting, you get into the meeting, you use one of our MMRs, or maybe multiple, depending on the size of the meeting. Then once that meeting is over, we’ll shut down that meeting, stop the recording or whatever you are doing at that point, and then free it up for other accounts to also use those MMRs.
What’s also quite interesting is from a component perspective, stability is super important for us, as with anyone, probably. I’m sure a lot of you, especially in the early days, when you’re architecting your solution, you think about the overhead of capacity that you need to have to support all of the services that you’re going to be running. For us, that actually meant that we keep our components at 50% capacity. This makes sure that everyone can use Zoom whenever they need to. This also makes sure that whenever we do need a little bit more overhead, or something, we can actually push the components a bit more. It also means that if we reach that 50% capacity, we can easily scale to other dynamic meeting resources, easily dynamically pivot, as well as provide maybe more information on our side to say, we actually need more resources in this region, we need more resources in that region, without immediately being overflooded.
Scaling During the Pandemic
Then, overflooded comes basically to, how did we actually scale during the pandemic? Historically, we were mostly leveraging or we were only leveraging our own global network of colocation, so all of these global tier-3 or above data centers for all of the meeting traffic. Obviously, we found out that we had to scale a lot quicker than ever before. Our data centers, they just couldn’t handle all of this traffic. It was just insane. Everyone’s just going from the office to working from home in one day for most countries. We looked at our friends at AWS, Amazon Web Services, obviously, and Oracle, how we could leverage them to provide these servers super-fast. For things like data at rest, and user information, account data, that was a bit easier. That was just, create more databases, just more storage, that’s fine. For components specifically, that is a little bit trickier, because you got the MMRs, you got the zone controllers, the cloud controllers, all things we had to scale very quickly.
What it basically meant is putting these components in AWS and Oracle allowed us to virtualize a lot faster, deploy a lot faster, and also allowed us to dynamically automate the creation of these servers. If you want to hear some numbers, they’re on the screen right now. We actually worked with AWS to set up 5000 to 6000 servers every single day, during the pandemic. We would only use our colocation for things like paying customers to make sure that they obviously get a good experience as well, but we didn’t want everyone stuck at home to not be able to meet. Thankfully, through the addition of 5000 to 6000 servers per day, we were able to support everything from remote board game nights to meeting your grandparents. For Oracle, it also meant that every single day, we had over 7 petabytes going through their infrastructure every single day, which is about 93 years of HD video daily, just for the data on Oracle every day. Honestly, not every single meeting was going to be HD anyway, so you can imagine how many meetings that actually is.
I think an important part here is to realize how much of the groundwork was already done through obviously, Eric Yuan, his founding story, rebuilding a new platform all the way from the ground up. Meaning that you have an easily scalable solution that you could even deploy in AWS or OCI. Sometimes a re-architecture means just removing everything that you know about something, and just really starting from the ground up. It can make such a big difference in things like flexibility, scalability, as well as efficiency. Imagine you are a company, like any company. Imagine you bought 10 other companies, and now you’re just stacking all your technology on top of that. It’s going to work for a while, but at some point, you’re going to struggle with keeping that up and providing efficiency. Sometimes you just simply need to slim down.
Client Connection Process
That being said, now you understand how the architecture and infrastructure looks like. Let’s actually look into when you connect, how do you actually connect? You’ve seen how we scale. How does it actually work from a step-by-step process? This is what the client connection process looks like. We’ll go into every single step separately. There’s about four steps. The fifth step, which you’ll see here is something that we call the HTTP tunnel, which we only need if you have basically blocked your firewall from being able to access any of our data centers. If you aren’t able to connect, we’ll push you through HTTPS 443 to a dynamic meeting zone inside of AWS, which should work for almost everyone, unless you are super strict with your firewall setup. Again, this is basically an important step. Imagine you have your own service, and you’re only allowing TCP 8822, then only people that have set up UPnP at home may be sure they can connect, but if you have any enterprise customer, they’ll have to go through their steps, obviously. If they have another customer and they want to connect to your service, they probably don’t want to go through the security hoops to get something like that opened up. It’s important to have these fallbacks not only for your service in case something goes down, but for your users to actually be able to connect to your meetings or to connect to your service, or maybe go through a specific payment step, all of these kinds of things. Make sure you have a backup for your backup’s backup.
Let’s look into the first step. The first step, we’re going to do a meeting lookup. You go to zoom.us, you say I would like to join this specific meeting. The client will actually send a request to the backend. All of this is super encrypted, HTTPS 443, AES-256-GCM, TLS 1.2. You know the drill. We will send a request to the backend, which will then check the credentials of that user, basically asking, are you this specific user? It’ll also send metadata to the cloud. The web infrastructure will then prepare a packet optimized for the client, which will then give basically a list of best available meeting zones and associated zone controllers with the meeting details. As we go on, then you’ll get that list given to the client, of course. The client will then actually, it’s not a ping, but it will do a reach out to those zone controllers basically saying, I would like to connect, what do you think? Based on that packet, there’s a quick network performance test. Basically, whichever has the best performance, we’ll try and connect to that one. Then we’ll connect to the meeting zone with HTTPS. All of this is still signaling so we’re not doing anything with UDP whatsoever. We’ll then get a list of best available Zoom meeting zones and associated Zoom zone controllers with meeting details again, because we’re going smaller details, like region, zone. As we get that, now we actually know this is the right meeting zone selection. We’ll request the details from that, again, for the best MMR, which is the multimedia router, to then actually establish a control channel for the session, still on SSL 443, because we’re still only doing signaling. Basically, this will give us the information needed for the MMR. Can we connect to this one? Yes. Ok, perfect. Let’s go.
Once that’s done, the Zoom client will prioritize creating connection for each type of media that will be exchanged, so that’s audio, video content. Every single one of those streams, again, like I said before, they’re basically separate streams, they’ll be done for UDP 8801. If that doesn’t work, fall back, TCP 8801. Still doesn’t work, SSL 443. If before we didn’t get through that step where we got the meeting zones, and we weren’t able to connect, then we would already be at the HTTP tunnel. Now it’s actually working, so we don’t have to worry that much. That’s simply how a client actually connects to meetings. It’s not super complex. There are some interesting facts in there, I think, at least, something that might inspire you as well. Think maybe more about, how can I streamline my connecting process? How can I make sure that there’s not hundreds of signaling things going on, but still make sure that I get the best resource available?
Conclusion
We provide a fully distributed global architecture to make sure that everyone around the world has the best experience when they join a meeting. There is proprietary coding with a little special sauce to make our service special. A special sauce of adapting, scaling, and connecting, allowing you to connect regardless of where you are. Scalability has been huge since day one. The pandemic, it really allowed us to show our strengths at that point, where we were able to support everyone, from big corporations, to even allowing you to see your friends, to play some games remotely, maybe even do some karaoke, or see your friends to check up on them, see how they’re doing. Building everything from the ground up also allowed us to innovate super-fast, and make quick changes whenever we needed to. We launched over 400 major features, just in the past year. If we take it down to minor features, they’ll even be over 1000 features. We’re not stopping there.