Month: December 2023

MMS • Renato Losio

AWS has recently announced the preview of Amazon Q Code Transformation, a service designed to simplify the process of upgrading existing Java application code through generative artificial intelligence. The new feature aims to minimize legacy code and automate common language upgrade tasks required to move off older language versions.
Currently, Code Transformation supports the upgrade to Java 17 of Java 8 and 11 applications built with Maven. According to the cloud provider, it will soon support the upgrade of Windows-based .NET Framework applications to cross-platform .NET, accelerating migrations to Linux.
An end-to-end application upgrade using the new service requires three steps: analyzing the existing code, generating a transformation plan, and completing the transformation tasks suggested by the plan. Danilo Poccia, chief evangelist (EMEA) at AWS, explains:
Amazon Q Code Transformation can identify and update package dependencies and refactor deprecated code components, switching to new language frameworks and incorporating security best practices. Once complete, you can review the transformed code, complete with build and test results, before accepting the changes.
Code Transformation determines the code version based on the IDE configuration and it uses dependencies available on the Maven central repository server, but it copies custom dependencies from the local machine along with the application code. Matthew Wilson, VP and distinguished engineer at Amazon, writes:
Amazon Q Code Transformation uses OpenRewrite to accelerate Java upgrades for customers (…) Our internal experiments with OpenRewrite have been extremely positive, but there are situations where additional iterative debugging is needed to get to a fully building application. The iterative AI-powered debugging has me excited about Amazon Q Code Transformation.
OpenRewrite is an Apache2-licensed refactoring ecosystem for Java and other source code to perform language upgrades, framework upgrades, dependency migration, security patching, and custom transformations. Poccia adds:
An internal Amazon team of five people successfully upgraded one thousand production applications from Java 8 to 17 in 2 days. It took, on average, 10 minutes to upgrade applications, and the longest one took less than an hour.
Amazon is not the only company building a service on OpenRewrite: founded by Jonathan Schneider, the inventor of the open-source software auto-refactoring tool, Moderne provides a SaaS service to distribute OpenRewrite recipes to large codebases.
While the timeline for .NET support is not yet available, Wilson adds:
Helping customers modernize their .NET applications, and move to running on Open Source .NET on Linux, has also been a multi-year investment. I’m looking forward to seeing how Amazon Q Code Transformation makes modernization even easier for .NET customers.
There are no additional costs for using Code Transformation during the preview but it requires the CodeWhisperer Professional Tier (USD 19/user/month) in the AWS Toolkit for IntelliJ IDEA or the AWS Toolkit for Visual Studio Code.
MMS • RSS
![]()
Stanley Laman Group Ltd. trimmed its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 25.1% in the third quarter, according to its most recent Form 13F filing with the Securities & Exchange Commission. The firm owned 20,269 shares of the company’s stock after selling 6,801 shares during the period. MongoDB comprises approximately 1.2% of Stanley Laman Group Ltd.’s investment portfolio, making the stock its 15th biggest position. Stanley Laman Group Ltd.’s holdings in MongoDB were worth $7,010,000 as of its most recent SEC filing.
Other institutional investors and hedge funds have also bought and sold shares of the company. GPS Wealth Strategies Group LLC acquired a new stake in MongoDB in the second quarter valued at $26,000. KB Financial Partners LLC bought a new stake in MongoDB during the second quarter valued at $27,000. Capital Advisors Ltd. LLC boosted its position in MongoDB by 131.0% during the second quarter. Capital Advisors Ltd. LLC now owns 67 shares of the company’s stock valued at $28,000 after acquiring an additional 38 shares during the last quarter. Parkside Financial Bank & Trust boosted its position in MongoDB by 176.5% during the second quarter. Parkside Financial Bank & Trust now owns 94 shares of the company’s stock valued at $39,000 after acquiring an additional 60 shares during the last quarter. Finally, Coppell Advisory Solutions LLC bought a new stake in MongoDB during the second quarter valued at $43,000. 88.89% of the stock is currently owned by institutional investors and hedge funds.
MongoDB Trading Down 0.6 %
Shares of MDB stock opened at $407.48 on Friday. The company has a 50 day moving average of $382.80 and a 200-day moving average of $379.57. The company has a quick ratio of 4.74, a current ratio of 4.74 and a debt-to-equity ratio of 1.18. MongoDB, Inc. has a 12-month low of $164.59 and a 12-month high of $442.84. The firm has a market cap of $29.41 billion, a P/E ratio of -154.35 and a beta of 1.19.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Tuesday, December 5th. The company reported $0.96 earnings per share (EPS) for the quarter, topping the consensus estimate of $0.51 by $0.45. The company had revenue of $432.94 million during the quarter, compared to analyst estimates of $406.33 million. MongoDB had a negative net margin of 11.70% and a negative return on equity of 20.64%. MongoDB’s quarterly revenue was up 29.8% compared to the same quarter last year. During the same quarter last year, the business posted ($1.23) EPS. Sell-side analysts anticipate that MongoDB, Inc. will post -1.64 earnings per share for the current year.
Insider Buying and Selling
In related news, Director Dwight A. Merriman sold 1,000 shares of the firm’s stock in a transaction that occurred on Monday, October 2nd. The shares were sold at an average price of $342.39, for a total value of $342,390.00. Following the completion of the transaction, the director now directly owns 534,896 shares of the company’s stock, valued at approximately $183,143,041.44. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this link. In other MongoDB news, CRO Cedric Pech sold 308 shares of the firm’s stock in a transaction on Wednesday, September 27th. The shares were sold at an average price of $326.27, for a total value of $100,491.16. Following the completion of the transaction, the executive now directly owns 34,110 shares of the company’s stock, valued at approximately $11,129,069.70. The sale was disclosed in a legal filing with the SEC, which can be accessed through the SEC website. Also, Director Dwight A. Merriman sold 1,000 shares of the firm’s stock in a transaction on Monday, October 2nd. The shares were sold at an average price of $342.39, for a total transaction of $342,390.00. Following the completion of the transaction, the director now directly owns 534,896 shares of the company’s stock, valued at $183,143,041.44. The disclosure for this sale can be found here. In the last ninety days, insiders sold 298,337 shares of company stock valued at $106,126,741. Company insiders own 4.80% of the company’s stock.
Wall Street Analysts Forecast Growth
A number of analysts have commented on the stock. UBS Group upped their price target on shares of MongoDB from $425.00 to $465.00 and gave the company a “buy” rating in a research report on Friday, September 1st. Canaccord Genuity Group upped their price target on shares of MongoDB from $410.00 to $450.00 and gave the company a “buy” rating in a research report on Tuesday, September 5th. KeyCorp cut their price objective on shares of MongoDB from $495.00 to $440.00 and set an “overweight” rating on the stock in a research report on Monday, October 23rd. Macquarie increased their price objective on shares of MongoDB from $434.00 to $456.00 in a research report on Friday, September 1st. Finally, Needham & Company LLC increased their price objective on shares of MongoDB from $445.00 to $495.00 and gave the stock a “buy” rating in a research report on Wednesday, December 6th. One research analyst has rated the stock with a sell rating, two have given a hold rating and twenty-two have assigned a buy rating to the stock. Based on data from MarketBeat, the company presently has a consensus rating of “Moderate Buy” and an average price target of $432.44.
View Our Latest Analysis on MDB
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
<img src="https://mobilemonitoringsolutions.com/wp-content/uploads/2021/12/SECFilingChart.ashx" alt="Institutional Ownership by Quarter for MongoDB NASDAQ: MDB” width=”650″ height=”350″ loading=”lazy”>
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Just getting into the stock market? These 10 simple stocks can help beginning investors build long-term wealth without knowing options, technicals, or other advanced strategies.
MMS • RSS

French video game publisher Ubisoft, behind hit titles such as Assassin’s Creed, FarCry, and Tom Clancy’s Rainbow Six Siege, is currently probing a suspected data security incident. This investigation follows the online leak of images purportedly showing the company’s internal software and developer tools.
The incident came to light after VX-Underground, a security research collective, shared screenshots on social media that appeared to display Ubisoft’s internal services. In response to these developments, Ubisoft issued a statement to BleepingComputer, confirming their awareness of the alleged data security incident and the ongoing investigation. “We are aware of an alleged data security incident and are currently investigating. We don’t have more to share at this time,” Ubisoft communicated to BleepingComputer.
According to a tweet by VX-Underground, an unidentified threat actor claimed to have breached Ubisoft’s systems on December 20th, intending to exfiltrate approximately 900GB of data. The alleged breach reportedly granted the threat actor access to various Ubisoft services, including the Ubisoft SharePoint server, Microsoft Teams, Confluence, and the MongoDB Atlas panel. Screenshots shared by the threat actor purportedly show access to some of these services.
It’s important to note that MongoDB Atlas recently reported a breach of its own. However, based on their disclosure, there seems to be no direct connection between the two incidents.
The threat actors also claimed to have attempted to steal data from Rainbow 6 Siege users but were detected and lost access before they could successfully extract the information.
This is not the first time Ubisoft has faced security challenges. The company was previously targeted by the Egregor ransomware gang in 2020, resulting in the release of portions of the source code for the Ubisoft Watch Dogs game. Additionally, Ubisoft experienced another breach in 2022, which disrupted its games, systems, and services.
MMS • RSS
![]()
GAM Holding AG decreased its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 46.8% during the 3rd quarter, according to the company in its most recent disclosure with the SEC. The fund owned 16,339 shares of the company’s stock after selling 14,357 shares during the quarter. GAM Holding AG’s holdings in MongoDB were worth $5,651,000 as of its most recent filing with the SEC.
A number of other hedge funds and other institutional investors have also made changes to their positions in the company. GPS Wealth Strategies Group LLC acquired a new stake in shares of MongoDB in the 2nd quarter valued at approximately $26,000. KB Financial Partners LLC purchased a new stake in shares of MongoDB during the 2nd quarter worth $27,000. Capital Advisors Ltd. LLC grew its stake in shares of MongoDB by 131.0% during the 2nd quarter. Capital Advisors Ltd. LLC now owns 67 shares of the company’s stock worth $28,000 after purchasing an additional 38 shares during the period. Bessemer Group Inc. acquired a new position in shares of MongoDB during the 4th quarter worth $29,000. Finally, Parkside Financial Bank & Trust lifted its stake in shares of MongoDB by 176.5% in the second quarter. Parkside Financial Bank & Trust now owns 94 shares of the company’s stock valued at $39,000 after purchasing an additional 60 shares during the period. Institutional investors and hedge funds own 88.89% of the company’s stock.
MongoDB Price Performance
MDB stock opened at $407.48 on Friday. The firm has a market cap of $29.41 billion, a P/E ratio of -154.35 and a beta of 1.19. The company has a debt-to-equity ratio of 1.18, a quick ratio of 4.74 and a current ratio of 4.74. MongoDB, Inc. has a 1 year low of $164.59 and a 1 year high of $442.84. The stock has a 50-day simple moving average of $382.80 and a 200-day simple moving average of $379.63.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Tuesday, December 5th. The company reported $0.96 earnings per share (EPS) for the quarter, beating the consensus estimate of $0.51 by $0.45. MongoDB had a negative net margin of 11.70% and a negative return on equity of 20.64%. The company had revenue of $432.94 million during the quarter, compared to the consensus estimate of $406.33 million. During the same quarter last year, the company earned ($1.23) earnings per share. MongoDB’s revenue for the quarter was up 29.8% on a year-over-year basis. On average, equities analysts predict that MongoDB, Inc. will post -1.64 earnings per share for the current fiscal year.
Insider Buying and Selling
In related news, CAO Thomas Bull sold 518 shares of the business’s stock in a transaction dated Monday, October 2nd. The stock was sold at an average price of $342.41, for a total value of $177,368.38. Following the transaction, the chief accounting officer now owns 16,672 shares in the company, valued at $5,708,659.52. The transaction was disclosed in a legal filing with the SEC, which is available at this hyperlink. In related news, CAO Thomas Bull sold 518 shares of MongoDB stock in a transaction on Monday, October 2nd. The shares were sold at an average price of $342.41, for a total value of $177,368.38. Following the completion of the sale, the chief accounting officer now owns 16,672 shares in the company, valued at $5,708,659.52. The sale was disclosed in a legal filing with the SEC, which can be accessed through this link. Also, CEO Dev Ittycheria sold 134,000 shares of the firm’s stock in a transaction on Tuesday, September 26th. The stock was sold at an average price of $327.20, for a total transaction of $43,844,800.00. Following the transaction, the chief executive officer now directly owns 218,085 shares of the company’s stock, valued at $71,357,412. The disclosure for this sale can be found here. Insiders have sold 298,337 shares of company stock valued at $106,126,741 in the last quarter. Company insiders own 4.80% of the company’s stock.
Wall Street Analyst Weigh In
MDB has been the subject of a number of research analyst reports. Argus increased their target price on shares of MongoDB from $435.00 to $484.00 and gave the company a “buy” rating in a report on Tuesday, September 5th. Scotiabank started coverage on MongoDB in a report on Tuesday, October 10th. They set a “sector perform” rating and a $335.00 target price on the stock. Needham & Company LLC boosted their price target on MongoDB from $445.00 to $495.00 and gave the stock a “buy” rating in a report on Wednesday, December 6th. Canaccord Genuity Group upped their price objective on MongoDB from $410.00 to $450.00 and gave the company a “buy” rating in a research report on Tuesday, September 5th. Finally, Macquarie boosted their target price on shares of MongoDB from $434.00 to $456.00 in a research note on Friday, September 1st. One equities research analyst has rated the stock with a sell rating, two have assigned a hold rating and twenty-two have assigned a buy rating to the company’s stock. According to MarketBeat, the company currently has an average rating of “Moderate Buy” and a consensus target price of $432.44.
View Our Latest Analysis on MDB
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
<img src="https://mobilemonitoringsolutions.com/wp-content/uploads/2021/12/SECFilingChart.ashx" alt="Institutional Ownership by Quarter for MongoDB NASDAQ: MDB” width=”650″ height=”350″ loading=”lazy”>
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Wondering when you’ll finally be able to invest in SpaceX, StarLink or The Boring Company? Click the link below to learn when Elon Musk will let these companies finally IPO.
MMS • Renato Losio

During the recent re:Invent, AWS announced the preview of memory-optimized R8g instances powered by the fourth-generation Graviton processor. The new instances are designed for memory-intensive workloads, including databases, in-memory caches, and real-time big data analytics.
According to the cloud provider, Graviton4 processors provide fully encrypting all high-speed physical hardware interfaces and deliver up to 30% better compute performance, 50% more cores, and 75% more memory bandwidth than Graviton3 ones. The new generation R8g instances will be equipped with up to 96 Neoverse V2 cores, 2 MB of L2 cache per core, and 12 DDR5-5600 channels. Jeff Barr, vice president and chief evangelist at AWS, adds:
Graviton4 processors also support all of the security features from the previous generations and include some important new ones including encrypted high-speed hardware interfaces and Branch Target Identification (BTI).
According to the press release, the announcement states that Graviton4 instances can be 45% faster for large Java applications than the Graviton3 ones but does not provide further details or benchmarks., Liz Fong-Jones, field CTO at Honeycomb, had the opportunity to evaluate the new instances. She comments:
Our Go-based OpenTelemetry data ingestion workload required 25% fewer replicas on the Graviton4-based R8g instances compared to Graviton3-based C7g/M7g/R7g instances—and additionally achieved a 20% improvement in median latency and 10% improvement in 99th percentile latency.
The community’s reaction has been mixed, with some users questioning the performance claims and others expressing concerns about the absence of pricing information. This is significant as Graviton3 instances have typically been more expensive than Graviton2 ones. User LunaSea comments on HackerNews:
Since Graviton3 still isn’t available in most regions, especially on the RDS side, I’m really not holding my breath.
Graviton4 was not the sole custom-built hardware revealed by AWS during the conference: Trainium2, the second-generation accelerator for deep learning training of FMs and LLMs, is designed to deliver up to 4x faster training performance and 3x more memory capacity compared to the previous generation chips. Trainium2 will be available in Trn2 instances. Adam Selipsky, CEO at AWS, writes on X (formerly Twitter):
AWS’s chips were front and center at re:Invent where we announced Graviton4 and Trainium2. Graviton4 is the most powerful and energy-efficient chip we have ever built. Trainium2 will allow our customers to train their generative AI models even more quickly and with enhanced price performance. It was ten years ago that Amazon first decided to start developing its own chips. I love to present the challenges for software developers dealing with AI services using a simple example and service on AWS.
Multiple sessions on Graviton processors took place during the conference, with the recordings now available on YouTube. The c8g instances are currently available in preview.
MMS • RSS
![]() National Bank of Canada FI trimmed its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 4.0% during the 3rd quarter, according to its most recent Form 13F filing with the Securities & Exchange Commission. The institutional investor owned 23,033 shares of the company’s stock after selling 971 shares during the period. National Bank of Canada FI’s holdings in MongoDB were worth $7,956,000 as of its most recent filing with the Securities & Exchange Commission.
National Bank of Canada FI trimmed its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 4.0% during the 3rd quarter, according to its most recent Form 13F filing with the Securities & Exchange Commission. The institutional investor owned 23,033 shares of the company’s stock after selling 971 shares during the period. National Bank of Canada FI’s holdings in MongoDB were worth $7,956,000 as of its most recent filing with the Securities & Exchange Commission.
Other large investors have also made changes to their positions in the company. GPS Wealth Strategies Group LLC purchased a new position in shares of MongoDB in the second quarter valued at about $26,000. KB Financial Partners LLC bought a new stake in shares of MongoDB in the second quarter worth about $27,000. Capital Advisors Ltd. LLC increased its holdings in shares of MongoDB by 131.0% in the second quarter. Capital Advisors Ltd. LLC now owns 67 shares of the company’s stock worth $28,000 after purchasing an additional 38 shares during the last quarter. Parkside Financial Bank & Trust increased its holdings in shares of MongoDB by 176.5% in the second quarter. Parkside Financial Bank & Trust now owns 94 shares of the company’s stock worth $39,000 after purchasing an additional 60 shares during the last quarter. Finally, Coppell Advisory Solutions LLC bought a new stake in shares of MongoDB in the second quarter worth about $43,000. 88.89% of the stock is currently owned by hedge funds and other institutional investors.
Analyst Ratings Changes
Several brokerages have recently issued reports on MDB. Capital One Financial raised MongoDB from an “equal weight” rating to an “overweight” rating and set a $427.00 target price on the stock in a report on Wednesday, November 8th. Royal Bank of Canada lifted their target price on MongoDB from $445.00 to $475.00 and gave the stock an “outperform” rating in a report on Wednesday, December 6th. Morgan Stanley lifted their target price on MongoDB from $440.00 to $480.00 and gave the stock an “overweight” rating in a report on Friday, September 1st. Scotiabank began coverage on MongoDB in a research note on Tuesday, October 10th. They set a “sector perform” rating and a $335.00 price objective on the stock. Finally, Tigress Financial boosted their price objective on MongoDB from $490.00 to $495.00 and gave the stock a “buy” rating in a research note on Friday, October 6th. One research analyst has rated the stock with a sell rating, two have issued a hold rating and twenty-two have given a buy rating to the company. Based on data from MarketBeat.com, the stock presently has an average rating of “Moderate Buy” and an average price target of $432.44.
Read Our Latest Analysis on MDB
MongoDB Stock Up 2.0 %
Shares of NASDAQ MDB opened at $409.82 on Friday. The company has a debt-to-equity ratio of 1.18, a quick ratio of 4.74 and a current ratio of 4.74. The firm has a market capitalization of $29.58 billion, a price-to-earnings ratio of -155.23 and a beta of 1.19. The stock has a 50 day moving average price of $381.66 and a 200 day moving average price of $379.50. MongoDB, Inc. has a 52-week low of $164.59 and a 52-week high of $442.84.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Tuesday, December 5th. The company reported $0.96 earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of $0.51 by $0.45. The firm had revenue of $432.94 million during the quarter, compared to analyst estimates of $406.33 million. MongoDB had a negative return on equity of 20.64% and a negative net margin of 11.70%. MongoDB’s quarterly revenue was up 29.8% on a year-over-year basis. During the same quarter in the previous year, the business earned ($1.23) earnings per share. Sell-side analysts expect that MongoDB, Inc. will post -1.64 earnings per share for the current year.
Insiders Place Their Bets
In other MongoDB news, CFO Michael Lawrence Gordon sold 7,577 shares of the company’s stock in a transaction on Monday, November 27th. The stock was sold at an average price of $410.03, for a total transaction of $3,106,797.31. Following the completion of the sale, the chief financial officer now owns 89,027 shares in the company, valued at $36,503,740.81. The transaction was disclosed in a document filed with the SEC, which can be accessed through this link. In other news, Director Dwight A. Merriman sold 1,000 shares of the company’s stock in a transaction on Monday, October 2nd. The stock was sold at an average price of $342.39, for a total transaction of $342,390.00. Following the transaction, the director now directly owns 534,896 shares of the company’s stock, valued at $183,143,041.44. The sale was disclosed in a legal filing with the SEC, which is accessible through the SEC website. Also, CFO Michael Lawrence Gordon sold 7,577 shares of the company’s stock in a transaction on Monday, November 27th. The stock was sold at an average price of $410.03, for a total value of $3,106,797.31. Following the transaction, the chief financial officer now directly owns 89,027 shares in the company, valued at $36,503,740.81. The disclosure for this sale can be found here. Insiders sold a total of 298,337 shares of company stock worth $106,126,741 over the last 90 days. Company insiders own 4.80% of the company’s stock.
MongoDB Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Almir Vuk

Following the release of .NET 8.0, NuGet 6.8 was announced and is now included in Visual Studio 2022. NuGet 6.8 introduces significant enhancements, including NuGetAudit for package vulnerability notifications, an opt-out option for HTTPS Everywhere warnings, Package Source Mappings during installation/update via Package Manager UI, improved support for Conditional Package Updating in Visual Studio, and the addition of the ProtocolVersion argument to nuget source add.
Besides the Visual Studio 2022 standalone executables tailored for Windows, macOS, and Linux are now accessible for download.
Regarding the new features NuGetAudit now provides notifications regarding known vulnerabilities in PackageReference packages. Developers can receive warnings, configurable by severity threshold, as reported for direct and transitive packages, enhancing overall project security awareness.
In Visual Studio, audit information is displayed in the Error List window and project dependencies for SDK-style projects, with a warning bar appearing in the Solution Explorer after restore, alerting users to projects utilizing packages with known vulnerabilities. The Package Manager UI in Visual Studio now warns of transitive packages with known vulnerabilities on the “Installed” tab, even when an audit is configured for direct packages only.
Furthermore, regarding the security NuGet 6.8 addresses concerns raised in version 6.3 regarding non-HTTPS sources. The introduction of the allowInsecureConnections property in the nuget.config file now enables developers to opt out of HTTPS Everywhere warnings, providing flexibility based on individual security risk acceptance. With the note that the default setting is false for allowInsecureConnections.
Looking back to the .NET 6 release, Package Source Mapping was introduced, allowing precise control over package sources in a solution. NuGet 6.8 version now extends this functionality, enabling the automatic creation of package source mappings during package installation/update through the NuGet UI in Visual Studio. The tool now considers the Global Packages Folder for transitive dependencies, automatically mapping them if the source is enabled for the solution, failing with an error if not enabled.
Conditional Package Updating is now implemented in Visual Studio. Projects targeting multiple frameworks, like MAUI or Uno projects, with conditionally installed packages, will be correctly updated using the Package Manager UI or Package Manager Console.
As reported, before this release, updating conditional packages often triggered an NU1504 warning, attempting to install the package to all frameworks. The update in NuGet 6.8 recognizes when a package is conditionally installed, updating it only in the frameworks where it is installed.
Responding to developers and community requests, NuGet 6.8 introduces the ProtocolVersion argument to the nuget source add command in the Command Line Interface (CLI). Developers can now specify the protocolVersion property when adding a new package source, providing greater control over the source configuration process.
The release also mentions some of the breaking changes in NuGet SDK with the note that:
The following is a list of breaking changes in the NuGet SDK. If you are using NuGet tooling, such as Visual Studio or .NET SDK, you are not affected.
Specifically, NuGetOperationType has been removed from NuGet.PackageManagement, with users advised to use NuGetProjectActionType instead. PackageVulnerabilityInfo severity has shifted from an integer to an enumeration, and nullable annotations have been added to NuGet.Common, and Clone methods on immutable types are deprecated.
Lastly, readers are encouraged to take a look at full release notes, since they hold detailed info about issues fixed in this release.
3 Unstoppable Growth Stocks to Buy if There’s a Stock Market Sell-Off | The Motley Fool
MMS • RSS
Despite persistently high inflation, four interest-rate hikes from the Federal Reserve, wars in Ukraine and Israel, and multiple high-profile bank failures over the past year, the S&P 500 index (SNPINDEX: ^GSPC) has rallied an impressive 23% in 2023. Many growth stocks have fared even better than the broader market, soaring this year after being previously beaten down to fractions of their post-pandemic highs.
It’s extraordinarily difficult to determine how far this rally will go. But one thing is certain: The market will eventually pull back. And when it does, you can be sure the world’s best investors will have their watchlists ready in order to take advantage of the sell-off.
So, what’s an investor to do?
I think these three unstoppable growth stocks are worth considering.
1. Democratizing the power of software for work management
With its low-code-no-code Work OS platform, Monday.com (MNDY -0.83%) aims to “democratize the power of software” to help enterprises easily build custom work-management tools and software applications.
That goal might sound idyllic, but customers are obviously flocking to Monday.com solutions given its clear value proposition; Monday’s number of customers grew 57% year over year last quarter to 2,077, and its net-dollar retention rate (NDRR) was a solid 110% — meaning existing clients spent an average of 10% more on Monday’s platform after their first year.
Better yet, Monday is beginning to realize significant operating leverage as it scales; revenue last quarter grew 38% year over year to $189.2 million, translating to its third straight quarter of positive non-GAAP (adjusted) operating income at $24.1 million, or 12.7% of revenue. Even based on generally accepted accounting principles (GAAP), Monday.com’s march toward sustained profitability has never been more clear:
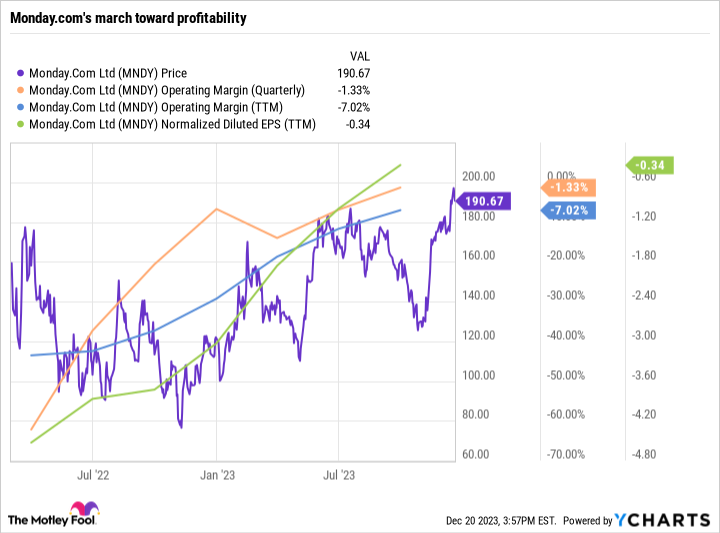
Assuming that march continues in the coming quarters, and with shares of Monday.com up 60% year to date, I’ll happily add to my position on any market sell-off.
2. Relentless growth in a massive industry
Earlier this month, GitLab‘s (GTLB 2.40%) shares soared after the development, security, and operations (DevSecOps) platform company announced that third-quarter revenue grew a better-than-expected 32% year over year to $149.7 million. GitLab also raised its full-year outlook to call for 2023 sales of $573 million to $574 million (up from $555 million to $557 million previously). But GitLab is still very early in its long-term growth story, chasing a total addressable market that management estimates is already worth $40 billion annually and growing.
According to recent research from Gartner, while only 25% of enterprises currently use unified DevOps platforms like GitLab (with the rest toiling with multiple disparate tools to accomplish inferior end results). But that total should increase to 75% over the next four years, leaving GitLab perfectly positioned to capture a multiyear runway for growth.
Even more exciting, GitLab also delivered a surprise non-GAAP profit of $14.4 million, or $0.09 per share last quarter (versus estimates for a net loss of a penny per share), and achieved its first-ever quarter of positive adjusted operating income at $4.7 million (swinging from an operating loss of $21.6 million in the same year-ago period).
Given its massive total addressable market and focus on not just achieving growth but rather profitable growth, I’d love the chance to add to my position in GitLab if the market pulls back.
3. An integral part of enterprise customers’ tech stacks
While Monday.com and GitLab have rallied on the heels of strong quarterly reports, MongoDB (MDB 2.03%) presents a slightly different opportunity today.
Shares of the leading NoSQL database platform provider actually plunged earlier this month after it announced its latest quarterly update — and this despite the fact management raised MongoDB’s full-year guidance after those results handily exceeded Wall Street’s estimates. MongoDB’s fiscal third-quarter revenue grew 30% year over year to $432.9 million, led by 36% growth in revenue from its Atlas fully managed cloud database product. That translated to adjusted net income of $79.1 million, or $0.96 per share. Most analysts were modeling earnings of $0.50 per share on revenue of only $404 million.
Just as I suggested might happen at the time, however, MongoDB has already partially recouped that short-term pullback. Shares are still up a whopping 110% year to date as of this writing.
So why is MongoDB such a compelling business? As CEO Dev Ittycheria pointed out during the company’s latest earnings conference call, its database platform is increasingly becoming an integral part of enterprise clients’ tech stacks, and the company is “winning new workloads from both new and existing customers across verticals, geographies, and customer segments.”
Indeed, a recent report from The Business Research Company estimates the global database software market will reach a value of $189 billion by 2030, up from $112 billion in 2023. As MongoDB continues to capture an outsized piece of that market in the coming years, I’ll be happy to buy on any pullbacks along the way.
Steve Symington has positions in GitLab, Monday.com, and MongoDB. The Motley Fool has positions in and recommends GitLab, Monday.com, and MongoDB. The Motley Fool has a disclosure policy.
MMS • Shobana Radhakrishnan
Subscribe on:
Transcript
Shane Hastie: Hey folks, it’s Shane Hastie here. Before we start today’s podcast, I wanted to tell you about Q Con London 2024, our flagship international software development conference that takes place in the heart of London next April, 8 to 10. Learn about senior practitioners experiences and explore their points of view on emerging trends and best practices across topics like software architecture, generative AI, platform engineering, observability and secure software supply chains. Discover what your peers have learned, explore the techniques they are using and learn about the pitfalls to avoid. Learn more at qconlondon.com. We hope to see you there.
Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today I’m sitting down with Shobana Radhakrishnan. Shobana, welcome. Thank you so much for taking the time to talk to us.
Introductions [01:03]
Shobana Radhakrishnan: Thank you, Shane, for the warm welcome. Really happy and excited to be here with you today.
Shane Hastie: You are a senior director of engineering on Google TV, and – actually I won’t do the and. I’ll allow you to tell us a little bit about yourself. What’s your background? How did you get to this position?
Shobana Radhakrishnan: Sure. If I’ve given long enough, I could go on for hours, but I’ll keep it brief. I greaw up in India several thousands of miles away and moved to the US to pursue higher studies in AI actually. I moved to Urbana-Champaign to pursue a master’s degree in computer science, focused on parallel processing and AI work. After spending one winter there with all of the snow, if anyone knows anything about the southern coast of India where I grew up, there are only three seasons. Warm, hot, and hotter summer, and those are the three seasons. So it was a big contrast and in my mind I said, “The first job I’m going to get in the Bay Area, I’m moving.” I was lucky enough to get a very exciting role in a search engine company called Excite. Some of your reviewers may remember Excite and Lycos from the pre-Google Days, and I moved to the Bay Area and haven’t looked back since.
I’ve moved from really small startups, like 30 people through the several thousands to hundreds of thousands of employee companies. I’ve been fortunate to go deep in the tech stack with device drivers and also building backend and UI and just a part of the broad technical steps. I have had a lot of opportunity to learn a lot over time and at Google I’m responsible for engineering for a product called Google TV, as you mentioned, which brings the goodness of Google Search and Google Assistant into the content viewing experience on TV. Pretty cool stuff and a lot of innovation going into it, which I’m super thrilled about.
Shane Hastie: One of the things that I know from our conversation earlier is that you’re really passionate about the importance of culture on teams. This is the engineering culture podcast, so possibly a good starting point for that is what is a good culture?
What is good culture? [03:08]
Shobana Radhakrishnan: The interesting thing is there isn’t a single answer to that and here’s why. Because I think the culture of the team, as you mentioned, I am very, very passionate about building great team cultures, and because the fabric actually matters for the outcomes from the team. Because if you have good interviewing practices, you know that you’re going to bring the technically smartest people onto your team, which is critical in engineering. At the same time, what ties them together? What gets them all working together for the overall team performance and productivity may be different from individual performance and productivity. That’s where the culture comes into the picture. Every leader has to think about their team, need to think about what is the culture I want to set on the team? For example, is it a culture of ownership? Is it a culture of innovation? Is it a culture of quality focus?
Maybe it’s all of the above, but it’s really important to think about what are the defining characteristics you want to set in your team? The reason there isn’t a single answer is it sometimes depends on where in the lifecycle your company is, your organization is, which is why I didn’t want to give a one line answer to the what’s a good culture? But culture is critical and every leader should be answering that question periodically at least once a year, if not more frequently and constantly thinking about it.
There are a few core fabrics, so you do want your team leaders to be able to work with each other. They may disagree, they may agree, or they may have strong opinions, but you want a self-sustaining leadership teams at all levels who are able to work together and align on what the next steps are, how they move forward, and also the disagree but comment. Again, everyone has opinions and you want people with different opinions on your team, but every set of leadership team at all levels needs to be able to buy into the decision and disagree, but commit and move forward constantly. There’s a few common cultural elements you do want and there are some things that you probably want to think about based on where you are in your journey as well.
Shane Hastie: Self-sustaining leadership, how do we create that safe environment that does become self-sustaining?
The importance of self-sustaining leadership [05:18]
Shobana Radhakrishnan: The reason the self-sustaining leadership is important is you want to go on a vacation periodically. You don’t want to be the one sitting there and making decisions, and that’s the reason you want that at all levels, it’s not just only the senior levels. The strongest reason I believe self-sustaining leadership is important is because there are day-to-day decisions that your leadership team is making all the time, so you want there to be a common set of principles and themes and goals that they’re bought into and a set of dynamics that they can work with each other on in an independent fashion in general, because it’s not just a quarterly planning and annual planning that leaders make decisions or team members make decisions. They’re making decision all the time in every meeting, in every discussion, and even when engineers are making implementation choices, they’re making decisions all the time, which is why that self-sustaining element is important.
Now, in terms of how can you create it, I feel it starts with empowerment and knowing that they can own and they do own their decision making areas. It’s both empowerment and the other side of the coin, which is accountability. You want people to feel like they can make the decisions within their scope or even working with their peers in a broader scope, they can most of the time make decisions independently. I feel like empowerment and accountability. Once people make decisions, then they’re also signing up to be held accountable for those decisions and it has to happen at all levels. It starts with the person who’s creating this culture as well, that they are transparent about their own mistakes, they are transparent about feeling like an owner and expecting their teams to feel like owners within their areas as well.
Shane Hastie: In that empowered accountable team environment, how do we overcome some of the challenges that we’ve seen in information technology and in technology teams in general, the built in bias, the lack of inclusion, some of the very visible culture challenges that are out there?
The core of good decision making is inclusion [07:21]
Shobana Radhakrishnan: A very interesting question, and I’m so glad you asked that because at the core of good decision making is inclusion. It is about making sure that all the voices are heard in the room. It can be in a small meeting making a small decision like a code design decision, or it could be a major, should we invest in this company? Should we acquire this talent from the startup? It could be any kind of decision, but making sure that voices are heard and people feel like their voices matter before a decision is arrived.
I think that’s basically what inclusion means to me, and it is simpler to say it than to actually have a team culture that practices it. I certainly believe this actually comes from the top. The leader actually needs to walk the talk. It’s not just about having a bunch of training, a bunch of online documents and saying “We have an inclusive culture.” It’s actually about everyone feeling like this leader actually walks the talk. When they are countered, even in a big team setting, the leader should be totally okay with it. They’re totally comfortable and visibly being able to listen to a completely alternate point of view and reason about it and making sure that they’re taking it, irrespective of the level of the person or the relative position of the persons expressing it.
This culture rubs off on all levels of leadership. Everyone feels like, oh yeah, this is great. This is probably how I want to run my team too. The more everyone sees leaders practicing that, then the teams themselves know that expressing actually does make a difference, so they start expressing their input and opinions and the communication just flows in all directions and you are definitely going to make better decisions. I feel like the two are very, very closely linked.
At the same time, there is the other balance of you want to be clear about who’s the ultimate decision maker too. You want everyone to be heard, but oftentimes people can make the mistake of gravitating to decision by committee also, and then people feel like, well, it takes a long time to make decisions. I don’t know who the decision maker is, and you don’t want the team to drift there either, so it’s a balance. I feel like being able to practice it in a practical way that works for your org, that’s step number one.
The second big part is actually formal training and active discussions about these topics actually do matter. For example, in many of my teams over time we have had discussion about what does allyship mean? How can each of us actually play a role? We make it a discussion topic, and that puts everybody into the proactive brain space of thinking about it versus a passive training they receive and separating it from their day-to-day work. It’s actually getting them to think about, are there any recent meetings where you felt like, hey, there was a good allyship practice here? Then having people share these practices and it just makes them internalize that it’s an active role and not a passive support role. That’s the second bit.
The third was actually getting feedback on an ongoing basis from your organization to say, “How is decision making working? Are you feeling included? Are we making the best decisions? What are the areas in which we could be doing better?” Constantly getting that feedback flow to establish that transparency in the organization and then playing back the feedback that we heard to the team saying, “We asked you for feedback and here’s what we are doing well, here’s what we’re not doing well.” The transparencies again goes back to accountability and then saying, “So we are committed to improving this, because we heard from you.”
That’s to me, the third element is really making sure that the feedback is flowing and translates to action so that organizations are always looking for how do I become more and more inclusive where everyone’s heard and how do we always make better decisions and more efficient decisions?
That’s what I believe.
Shane Hastie: Can we drill into that allyship? What does good allyship show up as?
Good allyship is proactive in the moment [11:09]
Shobana Radhakrishnan: I think good allyship shows up as proactive in the moment action, proactive and timely action. There can be different umbrellas. For example, you may be having a meeting with 10 or 15 people and maybe a couple of people are taking over the meeting or you see that a couple of people look like they want to contribute something, but they’re not quite comfortable. You can tell from maybe the dynamics on the team. This is a small example of allyship playing in day-to-day environment, which is when you notice that, you just in the moment act on it and say, “Hey, it looks like you want to say something, let’s hear from X.”
Really internalizing it’s a proactive listening and timely action role. You don’t have to be the one running the meeting. You don’t have to be the senior most person in the meeting to be an ally. Anyone in the room can be an ally. I think that’s the second bit. So, to make these two together make for good and stellar allyship. I think this also can benefit from again, ongoing training, ongoing discussions about what’s a meeting where I could be doing something? Just getting it into the active mode versus the passive mode. The best allyships are when someone took action before the person who was impacted by it even bringing it up. To me, that’s the most beautiful form of allyship.
Shane Hastie: How are we doing as an industry in that regard?
Shobana Radhakrishna: I’m one of those people who is typically my friends call me optimistic in bucket half full person, but in this one I feel like we have 8 billion people in the world. Are we able to include everyone in our thoughts when we design products? Are we able to include everyone in decision making? People of all backgrounds, of all genders, races, socioeconomic backgrounds, family backgrounds, even that can make some people feel privileged, some people not feel privileged.
There’s a lot of different types of allyship and privilege. I always feel on this topic, my career is almost 25 years now. Every year, I still feel like we have so much more to do, so much more today ever since I’ve been a student and probably in the 50 years if you ask me, I’ll always feel like we could do more. That’s me, but we can definitely do a lot more as an industry. I do feel we’ve come a long way, because a lot of people are much more familiar with the different nuances, different varieties of privilege compared to say 10 years ago. There’s just a lot more awareness that I can see in all kinds of conversations. But this is one of those things where there’s a lot more to do. I think each one of us should be thinking about it every day and making a difference happen.
Shane Hastie: The term that you used when we were chatting before we started recording is “orgitecture” and it just resonated with me. Tell me, what do you mean by “orgitecture” and why does it matter?
Designing Orgitecture for effective decision making [13:48]
Shobana Radhakrishnan: I hope they add it to the dictionary one day. As an engineering person, there’s a part of you that only wants to worry about architecture and design and implementation, especially when I’m writing code that’s all I wanted to think about and design and implement. Then there is the organization which then affects the who has to agree on the design, who needs to agree on the code approach, who needs to make a decision on the priorities or even something day-to-day, like who prioritizes how much of tech debt we have to pay off this quarter? What does tech debt even mean for us and so on? What I have noticed over time is the two are extremely interrelated, because effective organizations need effective decision making. Effective decision making, especially for engineering and technology organizations is about decoupling of what I loosely call tech stack, decoupling of concerns.
For example, in any typical high level architecture for a consumer product, you may have the user experience layer, which is visible to the user. There is a middle layer, which does the intelligence, let’s call it, and there’s a layer which stores the data and handles all of that at very, very high level. Every engineering leader who owns any part of these has to wake up thinking about how do I evaluate the complexity of when my team can deliver something or when can I give the plan or when can I close on the architecture? Who’s the right person to work on architecture? The more cooks you have in these kinds of conversations, the longer these will take. That itself leads to unproductive deal over time and frustration for the engineers, the product stakeholders, and everyone. Being able to decouple the concerns of what should the architecture look like, what is the right estimate?
To the extent possible, there is never a perfect organization in the real world, but to the extent that you can decouple at least 80/20, there is a lot of efficiency to be gained for that from both the productivity of the engineering organization and productivity for stakeholders who rely on the engineering organizations to make timely additions and deliver. I have actually seen examples of cases where there’s so much fine-grained ownership split that there are five different technical leads trying to make a decision on something that if there were one person owning it, they could have made it in a few hours.
That’s why the term “orgitecture”, especially for engineering and technology, the org structure as mapped to architectural ownership affects the pace of decision making and productivity a lot. This is something that I have tried to over time at least once a year or once in two years, just have a very transparent conversations with the leaders in the organization saying, “How are we doing on this? What’s the pulse of? How’s the decision making feeling in terms of pace of decision making efficiency?”
Then invariably queries and examples will come up where it’s like, I thought three people are involved in this instead of one or five people, and it took so much longer. Then there’s always that scope for, so how do we optimize for the next year? Are there some small shuffles we can do so that we keep aligning with that general principle? Because ultimately it’s all about productivity and how agile your organization can be, no matter how large or small your organization is, that’s what matters. That’s what product and business stakeholders rely on engineering organizations to be on top of.
Shane Hastie: Looking outside of the engineering goals to business goals, how does that influence orgitecture?
Business goals should guide orgitecture [17:12]
Shobana Radhakrishnan: That’s a really interesting one. I will say it’s going to be a lot of art and some science in general, because it starts with engineering leaders also being very plugged in and paying attention to the business and product trends, at not just a quarterly or annual level, but at the multi-year level, just having a very close relationship with product and business peers to say, “Where do you want us to head? Where do you see us going?” Also getting that, again, two-way feedback of what is working well or what could I be helping differently or more? A lot of input starts coming in terms of, “You know what? This is where I think the industry is going and we need to create this innovation. We need to build this cool thing and showcase to our customers or partners,” and then the wheel in the brain starts rolling for the engineering leader as well.
Okay, so this is what they want to do. I know that to do this, here’s how architecture is well poised, and here is where there’s going to be bottlenecks in the architecture that’s preventing us from really leaning into x, y, or z. Because any engineering leader is always plugged into where are the tech debts? Where is the place where there is a lot of operational overhead to get something done? Or where is the knowledge and expertise the least within your talent?
You always have a pulse of that in general. As you listen to this, then the orgitecture starts evolving because sometimes it may be as simple as, I need to bring a senior person who’s really familiar with this space, or I need to make sure that these two people are empowered to take on more because right now they’re under resourced. We are not given a lot of resources in that area, but I see that my business leader needs us to move the needle there over the next couple of years or even few quarters.
That is on the pure organizational side itself. Then when it starts going into orgitecture is more of a, oh, I know that part always takes a long time to make changes, but it looks like for an upcoming business, that’s where a lot of our functionality is going to have to be. I may think about proactively what’s the kind of tech debt and architectural changes I want to bring in? Who are my best leaders to take that on now versus later?
Forming the thought process of what needs to happen now versus next month versus next year or beyond, and who are the right people to take it forward, by listening to the product and business stakeholders and digesting that. That comes with building again, a strong sense of intuition within your own systems and teams by connecting with the teams through direct one-on-ones, skip levels, sometimes leaders do round tables, so technical leads or engineers around the organization periodically. It starts with having a pulse also to be able to tie the what needs to change to what’s coming? Really, having an open channel of communication, both with your teams and your business stakeholders. I feel like that mix always keeps them moving things forward.
Shane Hastie: Really interesting stuff. A large proportion of our audience are technical folks who are moving into leadership often for the first time. What advice would you give that person?
Advice for new leaders [20:10]
Shobana Radhakrishnan: This is actually a very exciting time for someone who’s thinking about moving into a leadership or management role. I think the first step is to think about, do you want to actually manage and lead or do you want to lead? That is a question I’ve noticed that needs to be really asked to know what’s your inner passion, inner motivation? Too often people haven’t actually thought about that specific question, because managing people comes with a certain set of responsibilities and certain exciting things and leading teams, while continuing to remain an individual contributor because you can lead increasingly complex architectures all the way to fellow level in most large companies.
That’s also a very, very good track, when you think about I want to lead people. Interestingly, both involve mentoring others. You don’t have to be a people manager to be a mentor. If you enjoy mentoring and technical things, it’s one track. If you actually enjoy the people management side, then you do need to do things like giving feedback, making unpleasant decisions. So, it comes with a mix. The first step I feel is asking that question of what’s really my inner drive? What’s the fire in me? The second is, what kind of things do you want to influence? If you’re thinking about growing in your current organization and your current company, what kinds of things do you enjoy influencing? Or what kinds of things need a change or a pivot or an amplification in your organization?
A lot of times being able to proactively articulate that and bringing it up with your manager or other leaders actually opens doors for opportunities for you that you didn’t know existed and they didn’t know existed. Just reflecting on what do I want to influence differently? What is the change, big change I want to create? Or what’s the big innovation I want to bring into my product, my team? Going into the conversation with those ideas just strengthens your position and readiness as perceived by your managers or leaders.
Also, it makes them feel like, oh, he or she has thought about so many more opportunities that I didn’t even think about. It just opens the doors to a lot more paths for you. That’s something that I have found to be a very, very good conversation that I see people from my teams also have come into conversation with me with those ideas. Sometimes, they have better ideas for opening the door to opportunity than you do yourself. It’s always good to prepare with some thoughts like that.
The third is also being clear about what will be needed to succeed in that expanded role that I’m going to talk about or think about and being self-reflective a little bit first of what are the gaps where I may need coaching, I may need to grow? What are the areas I need my managers or leadership to empower me and make sure that I am set up for success?
Being able to be transparent both with yourself and the person who can empower you to take this broader role so that both of you can work like a team in setting you up for success. I feel like those are the three things I would say.
Shane Hastie: Shobana, thank you very, very much. Some great advice there. Some really interesting points for our audience. If people want to continue the conversation, where would they find you?
Shobana Radhakrishnan: I’m always happy to connect with anyone on any of these topics or the tech industry or media industry in general, or architectures and large scale systems. LinkedIn is a great way to find me and connect with me. I’m always up for a chat, but LinkedIn is probably the best way to get to me.
Shane Hastie: Wonderful. Thank you so much.
Shobana Radhakrishnan: Thank you very much. It was great being part of the conversation.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Chris Sinjakli

Transcript
Sinjakli: You’ve spent your day writing some code. You’ve committed your work and pushed it up to GitHub. You’ve created a pull request, and you’re going to wait for someone to review it. While you wait for that review, you decide, why not refill my coffee, today is going well. Then you get a call from your least favorite person. You quickly acknowledge the page and go back to your desk. When you open the dashboard for the relevant system, you’re greeted by something like this, your lovely functioning system has fallen on the floor. In fact, you’re not serving any API traffic anymore. When you look at your error tracker, your heart sinks, none of your app servers can connect to the database because the database is down. We’re going to take an incident just like that, and put it under the microscope.
My name is Chris. During the day, I work as an infrastructure engineer, which is a mixture of software development and systems work. In particular, databases and distributed systems are the areas I find most interesting in computing. It probably doesn’t surprise you that I work at a database as a service company called PlanetScale. We build a managed MySQL database platform that scales horizontally through built-in sharding. The events that I’m going to talk about happened at my previous job, when I was working in the infrastructure team at a payments company called GoCardless. The idea of today’s talk, is that we’re going to look behind the scenes of something that we often take for granted, the database. We’ll explore the aftermath of a complex outage in a Postgres cluster, and dive through the layers of abstractions that we take for granted, all with the goal of being able to reliably reproduce the failure so we can fix it.
Cluster Setup
Before we can dive into the outage, it’s going to be useful for you to have a high-level understanding of what that cluster looked like. What we had was a fairly standard setup. Our API backends would talk to a Postgres server. The data from that Postgres server will be replicated across to two other nodes. As well as Postgres itself, we ran a piece of software called Pacemaker on those nodes. It’s an open source cluster manager, which handles promoting new primaries in the event of a failure. It also managed the placement of a virtual IP address, which clients would connect to. Whenever the primary moved, it would move that virtual IP address so that the clients would know where they should connect. Let’s say that the primary fails, Pacemaker would demote it, turn one of the replicas into a new primary, move the virtual IP address across. The application would see a short interruption while all of that happened, and then reconnect to the new node. After some time, you’d bootstrap a replacement machine, and it would replicate from the new primary. Something to note about this configuration is that we always had one synchronous replica. What that means is that before we acknowledged a write to a user, we had to make sure that it was at least on one of those two replicas as well as the primary. This is important both for data durability, and it’s going to be relevant later on in the talk.
Cluster Automation Failure
Unfortunately, as you may have guessed by the existence of this talk, on the day of the incident, none of what I just described worked. On that day, at 9 minutes past 3:00 in the afternoon, the RAID controller on the primary Postgres node failed. It reported a simultaneous loss of three disks, which is enough to break the array, and all reads and writes going to it, which meant that the primary was down. No worries. That’s where the automation should kick in, except it didn’t. We made many attempts to get it to work. We told it to rediscover the cluster state. We told it to retry any failed operations again and again. We even powered off the node with a failed RAID array, in case that was somehow confusing Pacemaker. None of it helped. All the while our API was down. After an hour, we ended up calling time on trying to fix that cluster automation and fell back on configuring a primary and replica by hand. One of the team logged into the synchronous replica, told Pacemaker to stop managing the cluster. Promoted that node to primary, and configured replication across to the remaining node by hand. They pushed the config change to the API servers so that they would connect to that newly promoted primary. Lastly, they bootstrapped another replica so that we’re back at 3:00 in case something else failed. In the end, the outage lasted two hours.
Recreating Outage Away from Prod
For now, we were safe. We were up and serving traffic to our customers again. We were only one failure away from downtime. While our cluster automation had let us down that day, there was a reason that we had it, and now we were running without it. In the event of a hardware failure, we’d need one of our engineers to repeat that manual failover process. How can we fix the issue with the clustering software and regain confidence in it? At this point, we had one single mission, recreate the outage away from our production environment, so that we could come up with an appropriate bug fix and reenable the clustering software. I’m about to introduce the main events that we were focused on in that recreation. There’s a fair bit of complexity here. Don’t worry, we’ll get into it step by step.
First off, there was the thing that kicked it all off, the RAID array losing those disks. As a result, that array couldn’t serve data: it couldn’t read, it couldn’t write. Next, we saw that the kernel marked the file system on that RAID array as read only. At this point reading anything was wishful thinking because the array was gone. We saw that Pacemaker detected the failure of the primary node. It did detect it, but for some reason it wasn’t able to promote one of the replicas. We also noticed that a subprocess of Postgres crashed on one of those replicas. This is a little thing in Postgres. Postgres is actually made up of many different subprocesses. If any one of them crashes unexpectedly, the postmaster restarts the whole thing, so that you’re back into a good known state. That happened. Postgres came back up after that crash on the synchronous replica, but for some reason, Pacemaker didn’t promote that replica. The last thing we noticed was that there was another suspicious log line on the synchronous replica. This error message really caught our eye. It’s a little bit weird. Something just seemed suspicious about this whole invalid log length, some offset, so we added it to the list of possible contributors to the outage.
Looking at these five factors, we potentially had a lot of work to do. How would we choose a starting point? We made an educated bet that we could set aside the RAID array failure itself and the corresponding action taken by the kernel. While this was the initial cause of the accident, we had a hunch that we could achieve similar breakage but through something easier to control. It’s not easy to recreate some very strange failure of a piece of hardware right. We focused on how we could cause the same end impact to the cluster. While it seemed interesting enough to come back to, we put point 5 on hold for a while. The reason for that is that points 3 and 4, they’re lower hanging fruit, they’re easier to do. We thought, we’ll come back to that if we need it. For points 3 and 4, we turn to everyone’s favorite fault injection tool. It’s something you all are probably very familiar with, probably running in the last week. It’s the Unix Kill Command. It is the simplest and most frequently used tool for injecting faults into systems. To make it easier and quicker to experiment, we ran a version of this stack in Docker on our laptops. What this let us do was very quickly set the whole thing up, play some different actions against different nodes, and see if we could break it, and then tear it down and spin it up again. This made things very quick to iterate on. To simulate that hard failure of the primary, we used SIGKILL or kill -9. Then we sent a SIGABRT to the relevant subprocess on the synchronous replica. This matches what we’d seen in production. We ran the script with just those two faults being injected, and we didn’t get our hopes up. It seemed unlikely that this was going to be enough. We were right. With just those two kill commands, the cluster didn’t break in the same way that it did in production.
What Do We Mean By Log?
We went back to our list of what we’d seen go wrong in the incident. We decided that the next thing to focus on was that suspicious log message that we’d seen on the synchronous replica. This is where we start to dive into Postgres internals. We need to understand exactly what these two log lines mean in order to recreate them. I’d like to start by talking about what we mean by log in the context of a database. What we normally mean by log is something like this. These are the kinds of logs that you might see on a web server that’s hosting a blog. Someone’s visited the blog, logged in, posted something. It’s actually a blog post about this talk, which someone then visits. When we’re talking about databases, we mean a different thing by logs, we mean binary logs. What are those? Let’s take a really simple example of inserting some users into a database. At some point, that data has to end up on persistent storage, which could be a hard disk, or, more likely, unless you’ve time traveled back to 2005, it’s a solid-state drive. The explanation I’m about to give of these binary logs is a little bit simplified, but not in a way that distorts the truth. Whenever you run a query that adds or modifies data in Postgres, like an insert or an update, the first thing that the database does is it writes a record of that change on to disk. This is before it updates anything on the actual table data, or any indexes that reference it. In a lot of databases, these are known as write ahead logs, and Postgres is one of the databases that uses that term. The reason for that term is that you write every change into them ahead of writing it to the database. Why bother doing that? Why have these write ahead logs in the first place? The reason that they exist is that databases need to be crash safe. They need to preserve data written to them even if they crash. That crash can happen at any time, you don’t get to control it.
Let’s go back to our table and let’s say that it’s got this ID column, which is the primary key. Being a primary key, it’s got an index pointing at it with each record present. When we go to insert our third row, let’s say the database crashes right then, but before adding it into the index. What data are you going to see if you query the table now? Postgres is probably going to use the index to do this lookup. The value is not in the index, so the database can safely assume that the value has not been inserted. This third record, turing, is just invisible effectively, even though we said to the user that it was inserted. The reason for write ahead logs is that when the database starts back up after a crash, we can go into them and replay the missing operations. When Postgres starts back up, the first thing it does is play back the last section of the logs, which puts the database back into a consistent state, and makes queries return consistent data. The other thing that write ahead logs get used for is replication. If you remember our setup from earlier, we had these two replicas being fed with data from the primary. The data which feeds those replication streams is the same data in the write ahead logs.
Why The Suspicious Log Caused a Failure
Now that we understand what we mean by write ahead logs, I’d like to take a moment to explain why we thought this might be relevant. Why might this have caused the failure of the promotion of the synchronous replica? To do that, we need to understand the first line now. What’s going on here? Why is this synchronous replica pulling logs from an archive of some sort? That stems from something that I’ve not mentioned yet, but which is relevant to recreating this part of the incident, which is that there’s a second mechanism to transfer those write ahead logs between nodes. The two mechanisms are known as streaming replication and WAL archival. Streaming replication is the one that we have already covered. It is this thing where we’ve got database replicas connecting into the primary and receiving a constant stream of updates. This is the mechanism that, in fact, lets you keep a synchronous replica that is exactly in sync with the primary. What about that second mechanism, the WAL archival? You can configure an extra setting on the primary node called archive_command. Whenever there’s a new write ahead log segment that’s been completed, that is no more data will be written to it, Postgres will run this command and pass the file name that is completed to it. Then you can run whatever command you like there to ship that segment to somewhere, which could be a big storage server that you run, or an object store like Amazon S3, or wherever, just some storage. Then to consume those files, you configure a corresponding restore_command. This is often a way of seeding data into a new replica as it comes up before it joins the cluster properly.
Why would you have these two different mechanisms and why would you configure both of them in one cluster? There’s two reasons and they’re linked. First off, we can reduce the amount of cluster storage that we need on each of the individual nodes. The reason we can do that is that we don’t need to keep as big a history of write ahead logs on each of them. Often those nodes will be provisioned with very expensive SSDs or NVMe disks. We don’t want to provision a bunch of storage that we’re effectively wasting most of the time. The other thing is, when a new node joins the cluster, if we had it pull a long history of write ahead logs from the primary, that would add load to the primary which could impact user traffic. We want to avoid that. Stepping back into our incident, we can understand what happened here. We can understand that this first log line was about it restoring an archive file from some server somewhere. Which suggests that one of the final acts of the primary before it was fully gone, was to ship off a broken write ahead log file into that external storage, which when the synchronous replica crashed, it went and checked and pulled in. Which gave us a hypothesis, maybe that invalid record length message was the reason that the synchronous replica couldn’t be promoted. This was a really plausible lead, but a very frustrating one for us, because we knew the synchronous replica already had all of the writes from the primary. It’s in the name, it’s the synchronous replica. That’s not how debugging works. Just because something shouldn’t happen, doesn’t mean it didn’t happen. We had to follow this lead, and either confirm or disprove it.
Incident Debugging
There was just one problem staring me personally in the face when I looked at this error message, and it was this, that I had zero prior experience working with binary formats. Up until this incident, I’ve been able to treat these replication mechanisms as a trusted abstraction. That was in four or five years of running Postgres in production. I’d never had to look behind the scenes there. Even though it’s unfamiliar, we know that none of it’s magic. It’s all just software that someone’s written. If debugging an incident means leaving your comfort zone, then that’s what you’ve got to do. It was time to figure out how to work with unfamiliar binary data. We had a chrome of good news, though. Postgres is open source. What this means is that we can at least look through its source code to help us make sense of what’s going on in these write ahead logs. I want to emphasize something, which is that all of the techniques that I’m about to talk about now work on closed source software as well, where there’s no documentation or source code that tells you about the file format. We just have a different name for that, it’s called reverse engineering.
Thankfully, in our case, we get to search the code base for the error. If we do that, we can see three places where that log line gets generated. If we jump into the first of those, we find this reasonably small piece of code, this conditional. We can see the log line in fact that we saw in our logs from production, and then we see that it jumps into an error handler. All we need to do to make this happen is to figure out how to make this conditional evaluate to true. We need to make total_len be less than the size of an XLogRecord. We don’t know what either of those is yet, but we’ll figure it out. SizeOfXLogRecord is pretty easy to find. It’s a constant, and it depends on the size of a struct called XLogRecord. We don’t know what one of those is yet, but doesn’t matter, we can find out later. Wouldn’t it be convenient if we could make total_len be equal to 0? If it’s 0, it’s definitely smaller than whatever the size of that struct is. It turns out, we don’t have to go far to find it. It’s in the same function that has that error handler. We can see that total_len is assigned from a field called xl_tot_len from an XLogRecord. It’s the same struct again. If we jump to the definition of XLogRecord, we can see it right there at the start.
I think we’ve got all of the pieces that we need, but we need to figure out how to tie them together. What was this check doing? If we go back to that conditional that we saw, it’s actually saying something relatively simple. Which is that if the record says it is smaller than the absolute smallest size that a record can possibly be, then we know it’s obviously broken. Remember those logs that I talked about earlier. All of the code we just dug through is how Postgres represents them on disk. Let’s see what they look like in practice. If we go back to our boring SQL that we had earlier, and we grab the binary logs that it produces, and we open them in a hex editor, we get hit with a barely comprehensible wall of data. What you’re looking at here is two representations of the same data. I want to bring everyone along to understand what’s going on here. On the left, we’ve got the data shown as hexadecimal numbers base-16. On the right, wherever it’s possible, that’s converted into an ASCII character. What we’re dealing with here really though is just a stream of bytes. It’s just a stream of numbers encoded in some particular way. We’re used to, as humans, generally, looking at numbers in base-10, the decimal number system. That’s the one we’re generally comfortable with. Because it aligns nicely with powers of 2, we typically look at binary data in its hexadecimal form. I’ve included the ASCII representation alongside these because when you’re looking in a hex editor, that’s often a useful way to spot patterns in the data.
The first and most obvious thing that leaps out from this view is some good news. We can see the users that we inserted in the database, which means that somewhere in all of those surrounding characters, is that field we’re looking for. We’re looking for that xl_tot_len field, and it’s in there somewhere, but we just need to find it. How can we make it more obvious? We’re trying to find a size field. What if we generate records that increase in size by a predictable amount? If we produce data that increases in length by one character at a time, then the length field should increase a corresponding amount. This is the part of the binary log that contains that data that we just inserted, the ABC, ABCD, ABCDE. We can see that there on the right. If we go back to the ASCII codes I showed you earlier, I didn’t pick these ones by accident. Look out for them when we go back to the hex editor. Here’s the data we inserted, and here’s those familiar ASCII characters. We saw them earlier in the table, and it’s incrementing one at a time, as we increase the length of the string. I think we might be onto something here. If we go back to the hex editor, then we can highlight their hexadecimal representations too. These are just two views over the same data. We can see here that we have the same incrementing size field and the same data that we inserted just in hexadecimal.
Now that we’ve found the length field, wouldn’t it be convenient if we could make it 0 and trick that error handler? Let’s rewrite some binary logs. If we were doing this properly, we were writing a program for some reason to do something like this which we wanted to deploy into production, then we probably want to import the Postgres source code, import those structs, and work with those to produce and write that binary data. We’re not doing this in production, we’re trying to just recreate an incident on our laptops. Maybe we could just write a regular expression to mangle the binary data how we want to. Let’s save some time and do that. If we go back to our highlighted view of the hex editor, we need to pick one of these three records to break. For no reason other than it being easier to draw on a slide, I’ve picked the top one. Doing so is relatively simple. This is the actual script that we use to do so. It’s in Ruby, but you can write this in whatever you want. It has exactly one interesting line and it’s this regular expression. It replaces 3F, which is one of those sizes, with 0. It uses some other characters to anchor within the string. Those don’t get replaced. That’s just a useful anchor for the regex.
Are you ready for some very exciting computation? We have just changed a byte of data. What happens if we feed that log back into the synchronous replica through our reproduction script? We can pass it to the restore command. We got exactly what we hoped for. We’ve got exactly the error that we saw from the synchronous replica in production. Now we can do it reliably, over again, in our local test setup. That feels good. Unfortunately, that success came with a caveat, which is, doing that wasn’t enough to reproduce the production outage. When we added all of this to the script, and we ran it, then cluster failed over just fine. Clearly, these three conditions weren’t enough. I think there was something important about that read only file system, and the actual act of a weird hardware failure in the RAID card, or we’d missed something else. We were confident that we’d missed something else at this point. It seemed weird for those first two to matter so much.
Backup Virtual IP on Synchronous Replica
Then one of our team noticed it, they compared our Pacemaker config from production and from our real staging environments, with the one that we had in our local Dockerized test setup. They found the sixth part of the puzzle. If you remember our architecture diagram from earlier, we had that virtual IP address that follows the primary node around whenever it moves. What was missing from that diagram was the second virtual IP address that we’d added in not too long before the incident. That was known as the backup VIP. The idea behind this was that when you’re taking your snapshot backups of Postgres, ideally, you’d want to minimize the load, or not put any load on the primary while doing so. We introduced this second virtual IP, so that the backup scripts could go to that instead of the primary, and then take their backup from there, no additional load on the primary, everything is good. We had a new lead, but this was really in surely not territory in our minds. We didn’t have any hypothesis for why this would block promotion of a new primary, but we’ve followed a methodical debugging process and added it into the cluster. We sat there and pressed enter on the reproduction script. We watched, and we waited with bated breath. It worked. This time, there were no caveats. For some reason, adding in this additional virtual IP address was enough to reproduce the production failure. The cluster refused to promote a new primary and sat there not serving queries. There we have it. We’ve deconstructed all those abstractions that we normally got to trust and rely on. We’ve recreated the production outage that caused so much trouble on that day. Hang on, no. Why would an extra virtual IP do that? Surely the cluster should still just repair itself and then move that virtual IP off to wherever it needs to be.
How Pacemaker Schedules Resources
To understand why this extra virtual IP caused so much trouble, we need to understand a little bit about how Pacemaker decides where it should run things. There are two relevant settings in Pacemaker that will make this all click into place. Pacemaker by default assumes that resources can move about with no penalty. This may be true for some of the other things that you can use it to run, but it’s very much not true for databases like Postgres. In databases, generally, there is some cost to moving resources around while clients reconnect or there’s some delay in query processing. Whenever Pacemaker decides to move the primary around, we do see a little bit of disruption. It’s on the order of 5 or 10 seconds, but it is there, and we don’t want to do it for no reason. Pacemaker has a setting to combat this called default-resource-stickiness. If you set this to a positive value, then Pacemaker will associate the cost of moving a resource around with that resource. It will avoid doing so if there’s another scheduling solution it can come up with. The second is that, by default, Pacemaker assumes that resources can run anywhere in the cluster. We’ve already seen an example where that’s not true, virtual IPs.
Pacemaker has another setting called a colocation constraint. A colocation constraint lets you assign a score between two resources that influences whether or not they should be scheduled together. A positive score means please schedule these together. A negative score means please don’t schedule these together. These are the actual settings from our production cluster at the time. We had a default-resource-stickiness of 100. We had a colocation constraint of -inf between the backup virtual IP and the primary, which says, effectively, these shouldn’t be scheduled together at all. It was the way that we’d written this colocation constraint which bit us, and specifically that negative infinity score, which we assigned between the backup virtual IP and the primary. In an effort to ensure that it was always on a replica, we’d gone with this, the lowest score possible. It turns out, unfortunately, that there is a very subtle semantic difference between a very large negative number and negative infinity in Pacemaker, and this bit us really badly. If we compare a reasonably large negative number, -1000 with -inf, while -1000 means avoid scheduling these resources together, -inf means literally never schedule these together. It is a hard constraint. If we take that, and we change it to be -1000 instead, then failover works properly. We were able to take this knowledge, put it back into our cluster config, and stop this outage from ever happening again.
There’s an awkward thing that I have to acknowledge here. Once we had the reproduction script working, we tried removing bits of it, just to see if any of them weren’t necessary. It turns out that the WAL error that we saw wasn’t essential to recreating the outage, it was a red herring. I’m sorry because I know it was the most interesting part of debugging this incident, and it really would have been quite cool if that was necessary for us to recreate it. It was part of the debugging process. The entire point of this talk was to show you that in its depth, not omitting details, just because they ended up not being needed later. I hope that you can take away from this talk, the belief that you too can dive into the depths of systems that are normally abstracted away from you. There we have it, the minimal reproduction of our Postgres outage, a hard failure of the primary, a correlated crash of the synchronous replica, and an extra virtual IP which was being used to take backups.
Lessons Learned from Incident Debugging
What can we learn by going through that incident? How can we take away some higher-level lessons? The first one I alluded to earlier, which is that none of the stack is magic. Sure, we might spend our time way up, whatever level we tend to in our business, whether that’s a backend application, a frontend application, databases, infrastructure provisioning, we all have something that we do day-to-day. That doesn’t mean that we’re not capable of diving down a layer or three when things go wrong, and we really have to. You’ve probably heard the popular refrain when talking about cloud computing, which is, it’s just someone else’s computer. I’d like to repurpose that and talk about the software stacks that we use day-to-day. It’s all just someone else’s abstraction. It can be understood, and it can be reasoned about. A strategy for this that is often thrown about is that you can get better at it by reading other people’s code. I think that’s a good start. I think there’s more to it if you want to get really good at this. The bit that I think is missing is that you should practice modifying other people’s code to do something different, something that you want it to do. Sure, we all do that when we start a new job, but being able to very quickly dive into a third-party library that’s part of our application or anything like that, doing that habitually will train this skill set. It’s a really useful skill set to have in outages like this.
The second thing I’d like to pull out is that automation erodes knowledge. If you remember, I was talking about how long we spent trying to get the cluster back into action. Part of that is because we’d used and trusted that clustering software for so long, that we weren’t all that confident in logging in and manually reconfiguring Postgres to do the kind of replication that we wanted. Would we have reached for that option much earlier if we hadn’t had automation taking care of that for so long? A popular way to mitigate this effect is to run game days, structured days where you introduce failures into a system, or create hypothetical scenarios and have your team respond to those. One that would have been useful to us with the benefit of hindsight, is practicing how to recover the database manually when Pacemaker was broken. We didn’t know that it was going to break but we could have practiced for the event where it did. Lastly, when trying to reproduce an outage, you must never stop questioning your reproduction script. It’s so easy to laser focus in on your current hypothesis, and then miss something that seems simple or just seems like it might be completely unrelated. You have to go back and question your assumptions and question if you’ve missed something from production. Let’s recap those. There is no magic in the stack. Automation does erode our knowledge. We should always question our reproduction script.
Debugging in the Future
As well as those lessons, I’d like to do a little bit of stargazing and make a prediction about the debugging skills I think we might need over the next years. For the last decade and a half, many of us have got used to working with software that sends its requests using JSON over HTTP. Both of these are plaintext protocols. They’ve become a de facto thing in themselves. I think this is going to continue for a long time. This is not going away. Binary formats are coming to web development. They’ve remained common in things like databases and high-performance systems all the way through, but we’ve largely been able to ignore them in web development. That’s changing, because we’re increasingly seeing APIs that send their data using protobuf, and HTTP/2 is getting more commonly used. These are both binary formats. What’s really driving this combo is something called gRPC, which was released by Google. It’s an RPC framework that specifies one way of sending protobufs over HTTP/2. Maybe not so much for external internet facing APIs, but a lot of companies are using this for internal service to service communication now.
The good news is that to tackle this challenge, there is tooling being built that will help us. I’ll give you a couple of examples, but there’s plenty more out there. The first is a tool called buf curl. It’s a lot like the curl tool that lets you send HTTP requests at things. You can use this to send requests at gRPC APIs. It’s useful for exploring and debugging them. There’s also a tool called fq. If you’ve ever used jq to manipulate JSON data, think of fq as that but for binary formats. There’s plenty of them supported out of the box, and it has a plugin system if you want to add your own. Lastly, I’m going to take us back to the humble hex editor. At some point, you may need to just drop down to this level. It’s worth seeing what one looks like with some data that you know and are familiar with in it, just to have it in your back pocket. I’m not saying that you need to go out and spend the next month learning about these tools. Absolutely not. It’s worth spending a little bit of time with them, just so you know what’s out there. Have a play around with anything that catches your eye, and then, it’s in your back pocket for when you might really need it.
Key Takeaway
Most computing in the world, most requests or operations served by a computer somewhere happen successfully, even if it doesn’t always feel like it. Days like the one I just described hinge on the smallest of edge cases. They are the 0.00001% of computing, but they’re responsible for the weirdest outages and the most head-scratching puzzles. Those days have outsized negative impact. While they are a small percentage of all computing that happens, they stick in our minds. They hurt our reputations with our customers, and causes a lot of stress in the process. For me, it’s a real shame not to learn from those outages, those incidents, not just within our own companies, but as a community of developers, infrastructure engineers, and people in other similar fields. How many incident reviews have you read that read something like this, “We noticed a problem, we fixed the problem. We’ll make sure the problem doesn’t happen again.” When we publish these formulaic incident reviews, everyone misses out on an opportunity to learn. We miss out on an opportunity to gain insight into that tiny proportion of operations that lead to catastrophic failure.
Example Incidents
I’m going to leave you with three good examples to read after this talk. The first one is of a Slack outage in 2021. This was caused by overloaded cloud networking combined with cold client caches. The second is from a company called incident.io. It talked about some manual mitigation techniques that they were able to apply during an incident to keep the system running in a broad sense, while they focused another part of the team on coming up with a proper fix for their crashing backend software that they had. Lastly, there’s a post from GitLab from quite a few years back now. It’s about this really nasty database outage that they had that did result in a little bit of data loss as well. Really scary stuff and really worth reading. I think these three are a good starting point if you want to get better at writing incident reviews. If you’re in charge of what gets written publicly, or you can influence that person at your company, then please share the difficult stories too.
See more presentations with transcripts