Month: December 2023

MMS • RSS
© Reuters. $1000 Invested In MongoDB 5 Years Ago Would Be Worth This Much Today
Benzinga – by Benzinga Insights, Benzinga Staff Writer.
MongoDB (NASDAQ:MDB) has outperformed the market over the past 5 years by 24.81% on an annualized basis producing an average annual return of 38.7%. Currently, MongoDB has a market capitalization of $29.52 billion.
Buying $1000 In MDB: If an investor had bought $1000 of MDB stock 5 years ago, it would be worth $5,697.97 today based on a price of $409.00 for MDB at the time of writing.
MongoDB’s Performance Over Last 5 Years
Finally — what’s the point of all this? The key insight to take from this article is to note how much of a difference compounded returns can make in your cash growth over a period of time.
This article was generated by Benzinga’s automated content engine and reviewed by an editor.
© 2023 Benzinga.com. Benzinga does not provide investment advice. All rights reserved.
MMS • InfoQ
Welcome to this special edition of The InfoQ eMag, which contains a comprehensive collection of our popular InfoQ Trends Reports from 2023. This year has been a remarkable journey through the ever-evolving landscapes of technology, software development trends, and organizational practices. Our reports have delved deep into the latest advancements, challenges, and future directions. We have aimed to provide insight into topics such as hybrid working, monoliths vs microservices vs moduliths, platform engineering, large language models (LLMs), and the state-of-the-art within the Java ecosystem.
As you explore these pages, you’ll encounter insights and analyses that are pivotal for understanding the current state of the software development landscape. The 2023 InfoQ Trends Reports, meticulously compiled by our expert contributors and other practitioners from the software engineering community, encapsulate a wealth of knowledge and experience.
This collection is not just a reflection of the past year’s technological trends. We aim for it to be a beacon for future exploration and innovation. Each report serves as a lens through which we view the world of software development and delivery. Whether you’re a developer, architect, technology leader, or an enthusiast, these reports offer valuable perspectives that will help you plan your future roadmaps and explore emerging technologies and practices.
As you read this collection of our trend reports, we encourage you to engage with the content actively. Reflect on how these trends resonate with your experiences, challenge your perspectives, and inspire your future roadmap. We aim for this emag to become a guide and a catalyst for your continuous learning and adaptation in the ever-changing realm of technology.
Thank you for joining us on this journey. We hope that the collection of InfoQ Trends Reports from 2023 will be an invaluable resource for you, sparking new ideas, conversations, and innovations.
Free download
MMS • RSS
Cybercrime
,
Fraud Management & Cybercrime
,
Ransomware
Also: Hackers Scrooge The North Face Holiday Shipments

Every week, Information Security Media Group rounds up cybersecurity incidents and breaches around the world. This week:, MongoDB said a phishing email is behind unauthorized access to its corporate environment, clothing maker VF Corp. said hackers interrupted holiday shipping, Britain electrical grid operator National Grid dropped a Chinese supplier, German authorities cracked down on an online criminal bazaar, U.S. authorities issued an advisory on the Play ransomware group, and law enforcement agencies across the globe collaborated to crack down on cybercrime, arresting 3,500 and seizing $300 million.
Update on Security Incident at MongoDB
Database management system maker MongoDB on Saturday announced a probe into a security incident involving unauthorized access to specific corporate systems, leading to the exposure of customer account metadata and contact details.
See Also: OnDemand | Understanding Human Behavior: Tackling Retail’s ATO & Fraud Prevention Challenge
The company said it had promptly initiated the incident response process after detecting unauthorized access on corporate systems on Dec. 13. The intrusion has “been going on for some period of time before discovery,” the company said. The incident exposed customer account metadata and contact information.
The company has repeatedly said it had not found evidence of unauthorized access to MongoDB Atlas clusters or the Atlas cluster authentication system. On Wednesday, it said the hacker had used a phishing attack to gain access to its corporate environment.
Hacking Incident Disrupts Shipping for North Face, Other Brands
Canvas shoe and outdoor wear maker VF Corp. disclosed Monday that a hacking incident had disrupted its ability to fulfill holiday shopping orders.
The Colorado maker of apparel and footwear brands including Vans, Supreme, The North Face and Timberland told U.S. federal regulators on Friday that on Dec. 13 it had detected an intruder on its digital systems. The hacker had been able to encrypt some IT systems and had stolen data, including personal data, the company said.
Company retail stores are operating normally, and consumers can place online orders for most of the company’s brands, it said. “However, the company’s ability to fulfill orders is currently impacted.”
A spokesperson did not say whether the corporation received a ransomware demand. News of the filing sent the share price sharply down in the first hours of trading this week, ending Monday with shares down 7%, although the share price recovered somewhat by midweek.
The company announced the incident the same day as a mandate took effect from the U.S. Securities and Exchange Commission for large and medium-sized publicly traded companies to disclose “material cybersecurity incidents” within four business days of determining materiality. Small businesses have an additional 180 days before they must comply with the rule (see: SEC Votes to Require Material Incident Disclosure in 4 Days).
The Denver-based company earned $11.6 billion in revenue last year and owns 12 brands, including JanSport backpacks and Dickies rugged wear.
Britain’s National Grid Drops Chinese Supplier
Britain electrical grid operator National Grid has started to remove components supplied by a U.K. subsidiary of China’s Nari Technology Co. from the transmission network, the Financial Times reported.
The decision, made in April after National Grid had consulted the National Cyber Security Center, was motivated by cybersecurity concerns – underscoring growing Western trepidation about Chinese technology’s involvement in critical infrastructure vulnerabilities.
The newspaper said the U.K. government in 2022 twice invoked new powers allowing it to limit foreign direct investment by intervening to restrict Chinese companies’ involvement in Britain’s electricity grid.
The United Kingdom in 2020 banned equipment from Chinese manufacturer Huawei after pressure from the United States, which has placed the Shenzhen-based telecom equipment maker on a national security blacklist (see: FCC Upholds Ruling That Huawei Poses National Security Threat).
Darknet Site Kingdom Market Has Shuttered
Germany’s Federal Criminal Police Office and Frankfurt Public Prosecutor’s Office dismantled darknet marketplace Kingdom Market. German authorities said Wednesday that more than 42,000 products had been offered for sale on the criminal bazaar.
The English-language illicit hub, operational since March 2021, was a clearinghouse for narcotics, malicious software and forged documents. Tens of thousands of customers and several hundred seller accounts were registered on the marketplace.
U.S. federal prosecutors arrested a Slovak national named Alan Bill – also known as “Vend0r,” and “Kingdom Official” – and accused him of helping found and administer Kingdom Market. A redacted indictment unsealed Wednesday charges Bill on 10 criminal counts including distribution of controlled substances, identity theft and money laundering conspiracy. Prosecutors on Thursday asked a federal judge not to release Bill ahead of a trial, calling the Bratislava resident a flight risk.
Tens of thousands of customers and hundreds of sellers engaged in transactions using cryptocurrencies such as Bitcoin, Litecoin, Monero and Zcash. The operators received a 3% commission for processing sales of illegal goods on the platform.
German authorities said they had cooperated with counterparts from the United States, Switzerland, the Republic of Moldova and Ukraine in dismantling the site.
Play Ransomware Actors Targeted Around 300 Entities
Threat actors behind the Play ransomware, also known as Playcrypt, have targeted around 300 entities across North America, South America and Europe, according to a Monday advisory from U.S. and Australian law enforcement and cyber agencies.
Operating as a closed group, Playcrypt’s tactics include abuse of valid accounts to obtain initial access and a double-extortion model, in which victims are coerced to contact the threat actors via email, adding a psychological dimension to the onslaught.
The Play ransomware group is responsible for cyberattacks against the city of Oakland, an attack on the Judiciary of Córdoba in Argentina and the German chain H-Hotels. TrendMicro said the group’s activities closely resemble those of ransomware groups Hive and Nokoyawa, suggesting a potential affiliation.
The group also exploits vulnerabilities in public-facing applications such as known weaknesses in FortiOS tracked as CVE-2018-13379 and CVE-2020-12812. It has also used a Microsoft Exchange vulnerability known as ProxyNotShell, tracked as CVE-2022-41040 and CVE-2022-41082.
The group’s sophisticated methods extend to discovery and detection evasion, leveraging tools such as AdFind and Grixba for Active Directory queries and network enumeration.
Playcrypt actors use a range of tools such as GMER and IObit to disable antivirus software and remove log files and show a preference for PowerShell scripts targeting Microsoft Defender.
Interpol-Led Operation Haechi IV
Law enforcement agencies from 34 countries joined forces for Operation Haechi IV, resulting in 3,500 arrests and the seizure of $300 million in stolen funds. The six-month-long operation targeted seven cyberthreats, including “voice phishing, romance scams, online sextortion, investment fraud, money laundering associated with illegal online gambling, business email compromise fraud, and e-commerce fraud.”
A collaboration between Filipino and Korean authorities led to the arrest of a high-profile online gambling criminal in Manila after a two-year manhunt. Interpol states that the operation blocked 82,112 suspicious bank accounts, leading to the confiscation of $199 million in hard currency and $101 million in virtual assets.
Interpol worked alongside various virtual asset service providers that assisted in identifying 367 virtual asset accounts linked to transnational organized crime. Investigations are underway as law enforcement agencies globally freeze these assets.
With reporting by Information Security Media Group’s Mihir Bagwe in Mumbai, India.
MMS • RSS
MongoDB’s NoSQL database creates both frontend and backend functionality of MERN stack applications; here’s an overview of its basic process: Installing and Setting Up
– Advertising –
MERN full-stack development employs MongoDB, Express.js, React, and Node.js to create full-stack applications.
- Install Node.js (Node Package Manager) and Node.js.
- Create a directory for your project, and navigate there using the command line.
- Install the required packages on both frontend (React, Express) and backend using npm.
Backend Development
- Create an Express.js Server to handle API Requests.
- Define routes to various API endpoints.
- Integrate MongoDB using Node.js libraries like Mongoose; implement CRUD operations for database interaction.
- Use JWT (JSON Web Tokens) for user authentication and authorization.
Frontend Development (React)
- Create React components to define the UI elements in your application.
- Use React Router for client-side navigation and routing.
- Manage component state using React’s state management built-in or a library for state management like Redux.
- Implement forms and user input processing.
- Use Axios or the built-in fetching API to make API requests.
Connecting Frontend to Backend
- Use API requests to send or fetch data from the front end.
- Handle responses on the backend and update the user interface accordingly.
- Ensure that CORS (Cross-Origin Resource Sharing) is configured properly to allow communication between the front and back end.
Deployment: Split up deployment into frontend and backend portions using platforms like Heroku or Netlify as frontend platforms and services like AWS, Azure, or DigitalOcean as backend providers to create your database and backend, respectively.
Test and Debugging: Writing unit and integration tests are crucial to maintaining high-quality code that works perfectly without bugs. Debugging techniques and tools may also be used to locate any issues with the codebase and fix bugs that arise in it.
Best Practices:
- Use coding standards for frontend and backend development.
- Manage your codebase using version control, e.g., Git.
- Follow the Single Responsibility Principle to keep your code modular.
This is only an overview; however, when creating a MERN app, you must keep numerous details and complexities in mind. Many online tutorials, classes, and documentation provide further insights into its inner workings.
The MERN stack is a set of technologies that enables faster application development for developers worldwide. Developed specifically to facilitate JavaScript app creation, four technologies make up this stack; knowing JSON will give you access to database, frontend, and backend operations with relative ease.
In today’s rapidly evolving world, web applications must be dynamic, efficient, and scalable. MERN is an emerging technology that has changed how developers build JavaScript apps.
– Advertising –
These powerful technologies for developing modern web apps comprise MongoDB Express.js, React.js, and Node.js toolsets. This article will explore the MERN stack and its components; its benefits for developers will also be highlighted.
MongoDB Is A Flexible And Scalable NoSQL Database
- MongoDB is an easy and scalable NoSQL database designed for developers.
- It is known for being flexible and scalable when managing large volumes of data. At the same time, its document-based structure makes it user-friendly when integrated with JavaScript.
- MongoDB’s dynamic schema allows MERN developers to seamlessly modify data structures without impacting existing records, providing agility during MERN development.
A Minimalistic Web Application Framework
- Express.js is built on Node.js and simplifies HTTP requests, middleware integration, and routing for web developers looking to quickly build efficient and robust applications.
- The minimalist approach helps developers quickly develop efficient applications.
- Express.js is a powerful middleware that makes adding extra functionality and libraries to your application easy. At the same time, React.js allows developers to build interactive user interfaces quickly.
Build Interactive User Interfaces with React.js
- Utilizing a JavaScript-based library created by Facebook, React allows for the rapid creation and reuse of interfaces.
- Component-based architecture facilitates code reuse and maintenance.
- React.js uses virtual DOM rendering technology to display information quickly without unnecessary updates, leading to increased performance.
Node.Js Serves As The Backend Development Engine
- Node.js allows developers to run JavaScript server-side, streamlining frontend and rear end development in one programming language.
- With its lightweight yet scalable model of nonblocking event-driven I/O, Node.js can handle multiple requests simultaneously without hindering performance or slowing down development timeframes.
- Node.js offers developers a rich ecosystem of packages and modules, giving them plenty of ways to extend functionality.
The MERN Stack Has Several Advantages For Developers
- Utilizing JavaScript: Frontend developer technologies can capitalize on their knowledge while increasing productivity.
- Code Reuse: The MERN stack allows code reuse between front and back to reduce redundancies and ensure consistency, thus saving time and effort when developing. This feature can save both time and effort when developing.
- Optimizing Performance: Both React.js and Node.js have earned praise for their impressive performance gains. React.js’ virtual DOM facilitates efficient rendering and updating, while Node.js’ nonblocking model of I/O adds an extra boost to application performance.
- Flexibility and Scalability: MongoDB’s flexible and scalable features, such as sharding or replica sets, enable MERN stack applications to scale with increasing loads without incurring performance penalties; this enables businesses to scale seamlessly as their needs expand.
- MERN Boasts An Active Community And Ecosystem: MERN features an engaging, supportive community that offers extensive documentation, tutorials, and libraries. Stack Developers can quickly find solutions to problems while keeping abreast of trends within their ecosystem.
Full MERN Form Stack
MERN Stack is a collection of four technologies to build dynamic websites and web apps. This acronym represents four technologies listed below.
- M: MongoDB
- E: ExpressJS
- R: ReactJS
- N: NodeJS
Now that you’ve downloaded and configured all four technologies listed above, the next step should be creating a project folder and initiating a junior MERN stack developer. Open up the folder using CMD or terminal and use this command to initialize package.json:
MERN Stack Components
- A MERN stack consists of four parts. Let’s go over each of them in turn.
- MongoDB, a NoSQL database system, serves as MEN’s core component.
- ExpressJS serves as MERN’s backend web app framework; ReactJS is its third component, allowing you to create user interfaces based upon components quickly.
- NodeJS completes the MERN stack by providing a Java Script Runtime Environment that enables JavaScript code to run outside the browser.
MongoDB
MongoDB is a NoSQL database management system (DBMS) that stores documents with key-value pairs similar to JSON documents. MongoDB allows users to create databases and schemas easily; its Mongo shell provides a JS interface for querying and updating records; users may also delete them directly.
ExpressJS
ExpressJS is a NodeJS framework that streamlines backend code writing by eliminating multiple node modules from being created and offering middleware to ensure code precision.
ReactJS
ReactJS is a JS Library that allows you to quickly build user interfaces for mobile apps and SPAs, using JavaScript code and building user interface components. ReactJS relies on virtual DOM technology for its development platform.
NodeJS
NodeJS, an open-source JavaScript environment, allows users to execute code on servers. Node Package Manager (npm), which enables accessing various node packages or modules, is also included with Node.
Developed using Chrome’s JavaScript Engine, Node allows faster execution of code than its competitors.
Why Work With MERN Stacks?
MERN Stacks provide many advantages. It lets you easily build a 3-tier architecture using JavaScript and JSON for frontend, backend, and database components.
MongoDB is a NoSQL database that stores JSON natively. The entire stack, from CLI to query language and everything in between, is constructed from JSON and JS code.
NodeJS works well with NoSQL database systems like MongoDB to store, manipulate, and manipulate JSON data within your applications at every level.
MongoDB Atlas provides an automated MongoDB Cluster on any cloud provider with just a few mouse clicks. Express is a server-side framework that manages HTTP responses and requests while mapping URLs to functions on the server.
Express pairs perfectly with ReactJS, an interactive frontend JS framework for building interactive HTML UIs while communicating with servers. Data flows seamlessly between technologies, enabling rapid development and easier debugging.
Only one language – JavaScript and JSON structures – are required to understand this system.
Use Cases of MERN
MERN is similar to other popular web stacks in that you can build anything using its technology. However, it remains ideal for developing cloud-based apps requiring dynamic interfaces and JSON.
MERN may be employed for any number of reasons, including:
Calendars and To-Do Apps
A great way to learn the MERN stack is through simple projects, like designing a calendar or to-do list. ReactJS can design the front end for either of these apps.
At the same time, MongoDB provides access to and modification of data within it.
Forums Interactive
A forum, such as a social network or website where users can communicate and exchange messages, would make MERN an excellent solution. Topics for an interactive forum can be predefined or left up to users to decide.
Social Media Product
The MERN stack can be utilized for social media in various ways, from ads and posts to embedding a mini web app directly onto a social media page.
Conclusion
Web developers often choose the  with experience with React and JS to create intuitive applications. MERN has revolutionized web development by combining MongoDB with Express.js and React.js into one powerful stack.
with experience with React and JS to create intuitive applications. MERN has revolutionized web development by combining MongoDB with Express.js and React.js into one powerful stack.
The MERN stack allows developers to easily build dynamic web applications with its code reuse, performance optimizations and scalability; JavaScript can even be utilized across its layers for productivity and efficiency gains. Whether you are an experienced web developer or just starting – MERN opens doors of infinite possibility.
News From
 Cyber Infrastructure INC
Cyber Infrastructure INCCategory: Software Developers Profile: CIS Established in 2003, Cyber Infrastructure INC. or CIS is a leading IT and custom software development company in Central India. Since 2003, CIS has been providing highly optimized technology solutions and services for SMEs and large-scale enterprises across the world. CIS has worked with 5000+ clients in more than 100 countries. Their expertise and experience ranges across a wide range of industry domains like education, finance, travel and hospitality, retail and e-commerce, manufacturing, …
For more information:
MMS • RSS

When it comes to digital transformation, the healthcare industry is caught between a rock and a hard place. The potential of innovations in AI, data analytics and digitisation all have the promise to streamline administration, reduce patient waiting times, and ultimately boost patient outcomes – but the critical need to safeguard patient data limits the proliferation of these technologies.
Boris Bialek, Field CTO of Industry Solutions at MongoDB, shares his expert insight around how new encryption techniques at the application development stage can turn data from an inhibitor to an enabler of these innovations.
What potential does AI, data analytics and digitisation have in the healthcare sector?
While AI algorithms have been applied in many fields, (specifically in medical image diagnostics and clinical decision support systems), with the emergence of GenAI the opportunity for impact has increased exponentially. AI, data analytics, and digitisation have the power to transform the healthcare sector by improving diagnostic accuracy, enhancing treatment outcomes, reducing operational costs, increasing healthcare accessibility, alleviating administrative burden, and accelerating medical research and advancements.
Despite the optimism AI can offer, it is critical to remember that healthcare scenarios often involve complex and nuanced factors that may not be fully captured by AI algorithms alone, and healthcare decisions may have life-or-death consequences.
As a consequence, all the AI approaches to healthcare decisions require the human-in-the-loop approach, where the inclusion of humans in the decision-making process ensures safety, accountability, ethical compliance, and a holistic approach to patient care, making it an indispensable component of AI-driven healthcare systems.
How can these innovations streamline administration, reduce patient waiting times, and ultimately boost patient outcomes?
The integration of AI, data analytics, and digitisation into healthcare can streamline administration, reduce patient waiting times, and ultimately boost patient outcomes in several ways. According to some reports, 80% of doctors spend more than 50% of their time on data entry and administrative tasks, limiting their efforts to provide optimal patient care. With the automation capabilities of AI, healthcare professionals can be alleviated of administrative tasks such as summarising patient charts, personalising reports to doctor’s transcripts and performing data entry. Instead, AI can assist healthcare providers in critically reducing their admin work, and increasing their life changing work for patients.
AI could also help with predictive analytics for patient flow, workflow optimisation and the efficient utilisation of resources, such as equipment, personnel, and facilities. Also, digitisation can help to automatically prioritise patients based on the severity of their condition, including triage. AI driven appointment scheduling systems can then optimise the allocation of time slots based on patient preferences and healthcare provider availability.
AI-powered decision support systems can also assist healthcare professionals in making quicker and more accurate decisions, leading to faster diagnosis and treatment, and ultimately improving patient outcomes. Patient progress can even be tracked in real-time, with AI-enabled monitoring systems, triggering early intervention when needed.
What limit does security put on these technologies?
Security is a critical concern for all aspects of healthcare — and there are several limitations and challenges related to security that can impact the adoption and use of these technologies. Across many industries, data privacy has become a major concern, with the protection of sensitive patient data being crucial to prevent data breaches and maintain patients’ trust. We must take into consideration the availability, correct use and traceability of the patient consent for any patient data used in any algorithm through explicit permissions from the patient themselves. Healthcare systems are also often prime targets for cyberattacks, which risk the disruption of operations and compromisation of patient data.
Healthcare networks are composed of many different players, including health providers, payers, technology providers, research organisations and institutional bodies — and every new actor and application could themselves potentially introduce a new security risk. That’s why secure data exchange between all systems is mission-critical. It is also crucial to be aware of the potential biases within AI algorithms, which could lead to disparities in diagnosis and treatment, threatening patient security.
How can new encryption techniques at the application development stage turn data from an inhibitor to an enabler of these innovations?
Encryption is a fundamental security measure used to protect sensitive data in various applications, including healthcare systems. It involves converting plaintext data into ciphertext using cryptographic algorithms and encryption keys. In healthcare, where patient privacy is paramount, encryption is crucial to safeguarding sensitive medical records and personal information.
Today’s cloud applications communicate with servers through encrypted channels (in-flight encryption), and all the data stored in the cloud is also encrypted through in-rest encryption.
At MongoDB, we provide two key features, to lift security to the highest possible level. Client-Side Field-Level Encryption (CS-FLE) is an advanced encryption technique that provides a high level of security for sensitive data stored in MongoDB databases. Unlike traditional server-side encryption, which encrypts the entire database, CS-FLE allows for encryption at a more granular level—namely, at the field level. Here, data is encrypted at the origin, at the application level, using unique encryption keys. In addition, our Queryable Encryption capabilities combine the benefits of encryption with the ability to perform specific queries on encrypted data. In healthcare, this can be a game-changer as it allows for secure data retrieval without compromising data privacy.
Tell us about your plans for 2024?
In 2024, we are staying committed to vector search for AI workloads, enabling semantic search and generative AI. Notably, a Retool State of AI survey found, our Atlas Vector Search received the highest developer net promoter score among all vector databases in the market. We’re excited to build on this success in 2024, enabling more AI workloads on top of MongoDB.
Alongside this, customers are continuing to feel pressure to modernise their data infrastructure, aware that legacy platforms are holding them back from building modern applications designed for an AI future. We want to be part of this journey, so we launched Relational Migrator earlier this year to help customers successfully migrate data from their legacy relational databases to MongoDB. Now, we’re looking beyond just data migration to help with the full lifecycle of application modernization. We will also continue to focus on allowing customers to run-anywhere, on-premises and in multiple clouds, all while helping to manage cost. Cost management is unsurprisingly a core focus for our customers, and we’re dedicated to increasing developer productivity, and supporting a variety of use cases, to support our customers with their goals.
**************
Make sure you check out the latest edition of Healthcare Digital and also sign up to our global conference series – Tech & AI LIVE 2024
**************
Healthcare Digital is a BizClik brand
**************
MMS • RSS

Sundry Photography
And just like that, the S&P 500 is close to touching all-time highs again. Interest-rate fears, which have driven the markets for most of the past two years, subsided much more quickly than they built up – and with it, high-flying tech stocks are now everywhere in the markets as well.
MongoDB (NASDAQ:MDB) is a chief example of this. The non-relational database software platform has seen its share price jump by more than 115% year to date, bringing the stock close to its pandemic-era highs (a level many of its peers are still yet to rebound to). The core question for investors now is: can MongoDB keep rallying in 2024, or is it time to take chips off the table?
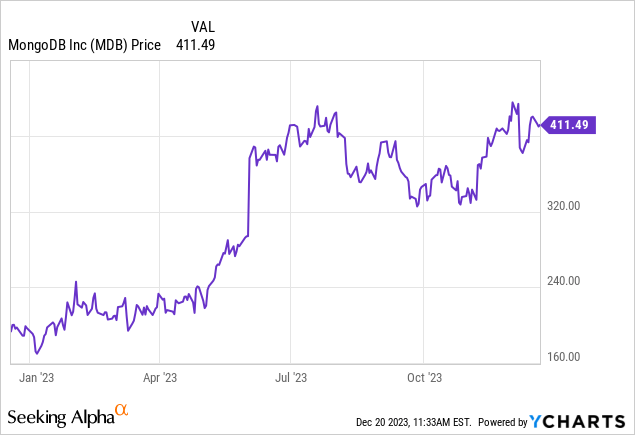
I’m in the latter camp. I last wrote a neutral opinion on MongoDB in October when the stock was trading closer to $360 per share, after having previously been bullish on the stock earlier in the year. And while it’s true that I missed out on the past two months’ worth of appreciation, I hardly regret my decision to de-risk my portfolio.
The two top things for investors to keep in mind: MongoDB’s growth is now slowing in a big way, not only from a tough macro environment for IT budgets, but also as a victim of its own scale. And yet despite this, expectations remain incredibly lofty for the company (earnings results generally tend to disappoint, at least it did in the most recent Q3) – which is a given when a stock like MongoDB trades at valuation levels almost unheard of in the software sector.
Valuation, not fundamentals, is the second and the biggest concern here. Even with a ~1 point reduction in interest rates, it’s hard to justify that MongoDB trades at an investible price. At current share prices near $411, the company has a market cap of $29.77 billion. And after we net off the $1.92 billion of cash and $1.14 billion of convertible debt on MongoDB’s most recent balance sheet, the company’s resulting enterprise value is $28.99 billion.
Meanwhile, for fiscal year 2025 (the year for MongoDB ending in January 2025), Wall Street analysts are expecting the company to generate $2.02 billion in revenue, representing 22% y/y growth (and a sharp fall from the current quarter’s 30% y/y growth rate, and last quarter’s 40% y/y growth rate). In spite of this, investors are apparently still assigning very high multiples for this stock – against FY25 consensus, MongoDB trades at 14.4x EV/FY25 revenue.
A mid-teens valuation multiple in the height of the pandemic for a ~20% growth stock was commonplace – but that’s back when interest rates were nearly zero. Even though rate expectations for next year have come down, it’s still difficult to justify a pandemic-era price for MongoDB especially when its growth rate is expected to come down to “normal” ~20% levels.
And on top of the major valuation risk, I see some performance/fundamental risks heading into next year as well, including:
- Less-than-stellar usage trends – MongoDB prices by usage and by workload, and analysts have called out that MongoDB’s usage rates have not seen a bounce back like some competitors have.
- Customer growth is slowing down – Results in MongoDB Atlas have also sparked concern, especially as net-new customer additions slow relative to the pace from recent quarters.
- GAAP losses are still large – Though MongoDB has notched positive pro forma operating and net income levels, the company is still burning through large GAAP losses because of its reliance on stock-based compensation. In boom times investors may look the other way, but in this more cautious market environment MongoDB’s losses may stand out.
- Competition- MongoDB may have called itself an “Oracle killer” at the time of its IPO, but Oracle (ORCL) is also making headway in autonomous and non-relational databases. Given Oracle’s much broader software platform and ease of cross-selling, this may eventually cut into MongoDB’s momentum.
All in all, I’m downgrading MongoDB to sell, given the confluence of an unsupportable high valuation and elevated expectations making it difficult for MongoDB to surprise to the upside in 2024. Lock in any gains you have on this stock, and move on.
Q3 download
Let’s now go through MongoDB’s latest quarterly results in greater detail. The Q3 earnings results are shown in the snapshot below:
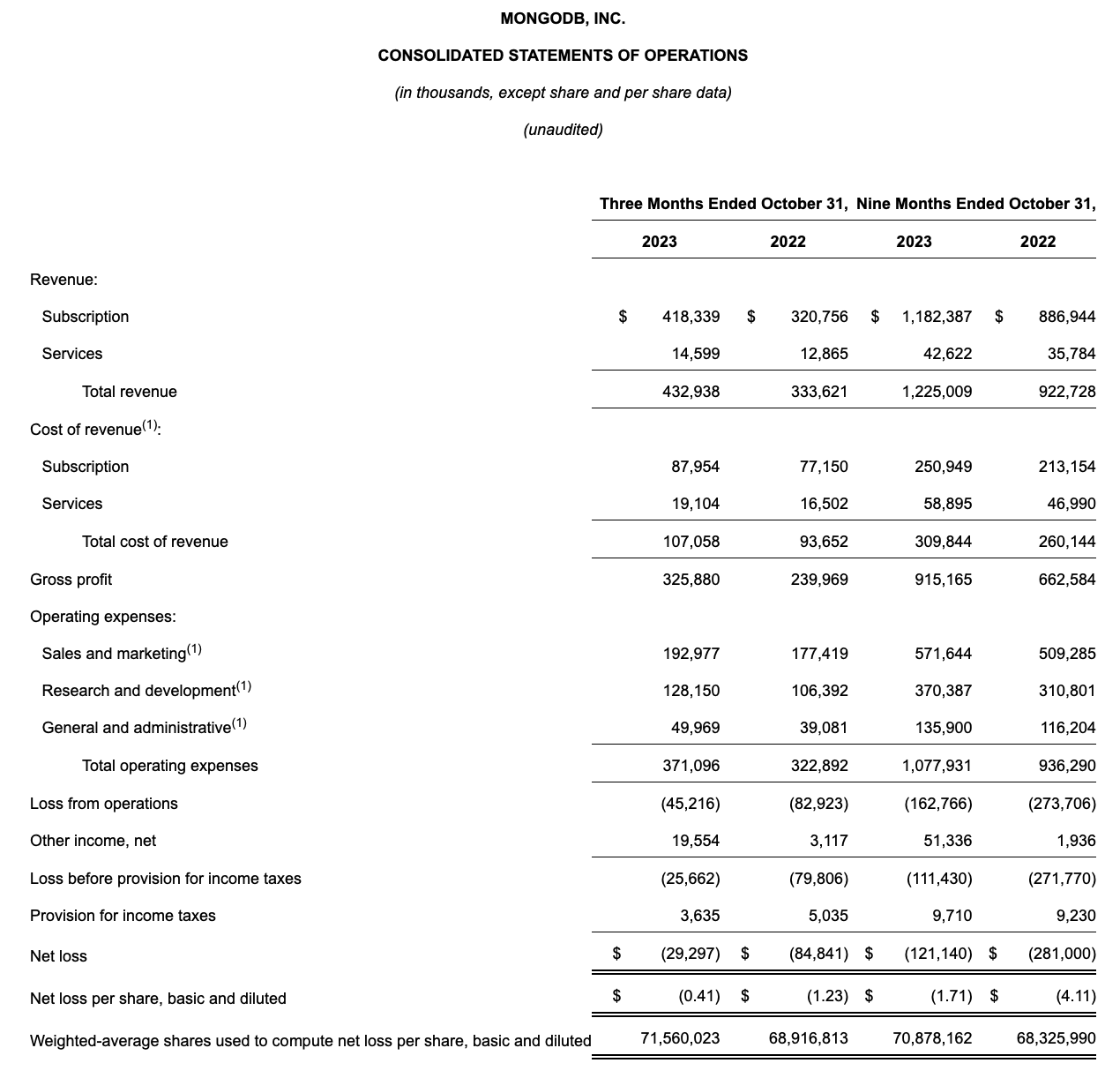
MongoDB Q3 results (MongoDB Q3 earnings release)
MongoDB’s revenue grew 30% y/y to $432.9 million. This was well ahead of Wall Street’s expectations of $403.9 million (+21% y/y), but showed considerable deceleration relative to Q2’s growth pace of 40% y/y.
From a product perspective, the company continued to deepen its suite of AI-related offerings. It made a new product, MongoDB Atlas Vector Search, generally available within the quarter – a platform which helps developers build real-time generative AI applications on top of the MongoDB database.
From a customer perspective: note that MongoDB’s overall customer counts slowed to a net add of just 1,400 customers in the quarter, versus 1,900 in Q2.

MongoDB customer counts (MongoDB Q3 earnings release)
Similar to other companies, MongoDB has faced both elongating sales cycles as well as difficulties in upselling existing customers; though management notes retention has been strong, with dollar-based net retention rates clocking in at 120% this quarter. Here is additional commentary from CFO Michael Gordon on consumption trends in Q3, taken from his prepared remarks on the Q3 earnings call:
Let me provide some context on Atlas consumption in the quarter. Week-over-week consumption growth in Q3 was in line with our expectations and stronger than Q2. As a reminder, we were expecting a seasonal uptick in consumption in Q3 compared to Q2 based on what we’ve experienced and shared with you last year. We had forecasted that seasonal improvement to be less pronounced this year compared to last year. Given that overall, we’ve seen less consumption variability this year and that is exactly how the quarter played out.
Turning to non-Atlas revenues, EA exceeded our expectations in the quarter as we continue to have success selling incremental workloads into our existing EA customer base. Ongoing EA strength speaks to the appeal and the success of our run-anywhere strategy. The EA revenue outperformance was in part a result of more multiyear deals than we had expected. As a reminder, the term license component for multiyear deals is recognized as upfront revenue at the start of the contract and therefore includes term license revenues from future years.”
From a profitability standpoint, we do note that MongoDB achieved an impressive pro forma operating margin lift to 18%, 12 points better than 6% in the year-ago quarter – though management noted that Q3 was rosier than normal due to a timing shift of both new hires as well as marketing spend pushing out to Q4. In spite of this, we note that MongoDB remains a “Rule of 40” software company – so some valuation premium is certainly justified, but considering GAAP losses are still negative and the company doesn’t generate enough pro forma net income or cash flow to support its valuation from a bottom-line perspective, I remain bearish on this name.
Key takeaways
MongoDB remains a classic software trade “good quality for an extremely high price.” In this market environment, with the S&P 500 flirting with all-time highs again, I’d hesitate to overexpose my portfolio to high-flying software stocks like this one. My recommendation: sell what you have (perhaps in January to defer your tax bill on any gains; I don’t foresee much downside in either the broader market or MongoDB in the next few weeks through the end of the year) and invest elsewhere.
MMS • Ben Linders

According to Nikola Bogdanov, the real challenge in agile transformations is adapting to business domain specifics and industry constraints; understanding agile is not the problem that needs to be solved. He presented domain-driven agility which utilizes design thinking to visualize agile adoption and make it empirical. It is based on domain-driven design strategy which are tactics used in software engineering to handle business complexity.
Nikola Bogdanov spoke about domain-driven agility at ScanAgile 2023.
The core problems in agile transformations come not from the application of agile or its understanding, but from the complexity of the domain and the specific application of the agile ways of working, Bogdanov said. As we deal with complex domains, he suggests reusing domain-driven development. This is a strategy that puts the business domain and its complexity at the heart of software solution development:
Domain-driven agility is a blend of the agile mindset and the domain-driven design strategy. It approaches transformation as an agile project, treating it with the same flexibility and adaptability.
Domain-driven agility starts with forming a cross-cutting team consisting of agile specialists, domain experts, decision-makers, and a certain number of change agents (usually middle-layer people who can and will execute the change). Bogdanov suggested running workshops like event-storming to identify the teams and values stream around which we are going to form the new teams and product organizations.
The next step, according to Bogdanov, is to create a backlog of change. This can be done by running brainstorming and refinements to identify what needs to be done, for instance with OKRs and goal-setting sessions to create the strategic direction.
Domain-driven agility needs a cadence. Bogdanov mentioned that they choose monthly to quarterly execution cycles split into two-week sprints.
The domain-driven approach is also very useful to define and redefine the ubiquitous language for a certain sub-domain, as Bogdanov explained:
For example, what is an increment for a pharma team? To release a medicine takes six years, how come they will release an increment every two weeks? So here we redefine what increment is. In this case, we usually define the increment as the most important question that we need to get answered or the most important hypothesis that we want to get verified.
Bogdanov mentioned that we need to redefine the “transformation project” as a concept, as transformation is always a journey and we usually just know the direction and maybe the dream state.
We usually define transformation as an agile product itself that evolves constantly.
Don’t rely on out-of-the-shelf solutions like Scrum, SAFe, or kanban alone, Bogdanov said. Collaboration between domain expertise and an agile culture is essential, he added. Leveraging domain-driven design can reduce industry-led complexity and help you seek guidance and learn from others’ experiences.
InfoQ interviewed Nikola Bogdanov about domain-driven agility.
InfoQ: How does applying agile differ for different industries?
Nikola Bogdanov: The solution involves aligning language, defining organizational boundaries, forming change teams, building a backlog, and executing change iteratively, incorporating empiricism, and adapting to various levels including culture, process, product, and quality.
For example, in a few companies we’ve worked with, words like “agile” and “Scrum” were totally forbidden because of the unsuccessful attempts from the past. And totally to the contrary, in other companies we have used the same words as magical spells that can open every door, as they were perceived as some sort of dream chimera.
InfoQ: What’s your advice to companies that want to embark on a journey of increasing agility?
Bogdanov: My advice to companies looking to increase agility is to customize their approach, embracing the complexity of their domain and treating the transformation as an agile initiative. I suggest using design thinking to prototype solutions, maintaining transparency in their goals, and continuously learning from experience to make the transformation empirical. And please, stay away from one-size-fits-all magical solutions.
MMS • Katie Sylor-Miller

Transcript
Sylor-Miller: I’ve been a frontend platform engineer for at least the last 10 years. We’ve felt a little like nobody knows what to do with us. We tend to own bits and pieces of infrastructure but we didn’t really fit in very well with DevOps or SRE. We often own large parts of the product code base, but we aren’t product engineers. We’ve never really fit in anywhere. I’m really excited to be here, because it feels like we’re getting a seat at the cool kids table finally. I’ve found my people.
When I was preparing this talk, I chatted with folks that I know that are more like DevOps, SRE, backend, they don’t work on the frontend. I wanted to get a sense of like, what do you think about the frontend? A few different themes emerged from those discussions. What I heard from folks overwhelmingly, is that the frontend feels like it’s super complicated for no reason. The tech changes super rapidly. There’s approximately 5000 different libraries and tools and patterns out there. New ones come out every day, so we don’t know how to keep up. I heard a lot about how HTML and JavaScript and especially CSS are really frustrating to work with. How many of you feel this way? My hope is that I’m going to change all of your minds about the needless part, because that really bothered me when I heard that. I wrote this down in my notebook, and I put exclamation points after it. I was like, I can’t believe they said this to me. We’re going to talk through some of the really hard problems that frontend platform teams need to understand and solve, in order to give you a high-level framework that’s going to help you cut through all of that noise of the hot new framework of the month club, and allow you to reason about the complex world of frontend engineering. The reason why I think that it’s important that we all talk about this is because our job as platform engineers is the same, no matter what platform we’re building for. We need to deeply understand and manage the underlying complexities of all the systems that we’re building on top of, so that other engineers, our customers don’t have to. Sara said something about how it’s our job to build those abstraction layers that help other engineers move faster. We weigh the tradeoffs so that individual engineers don’t have to.
The Iceberg Metaphor of Frontend Architecture
I think that this is especially important on the frontend, because frontend platform teams are in this unique situation where we actually have two customers. First the engineers who are building our product, and they use all of the tools and the services and things that we write. We also have the second order customer of the actual users of our websites and web apps. In an ideal world, we would never give engineers tools that are going to be really terrible for UX, and vice versa. We don’t want to make decisions that are great for the user experience, but make it harder to ship features. That seems like a no-brainer. In reality, this tension between the needs of engineers and the needs of users can be really hard to balance and navigate. It’s what I call the iceberg metaphor of frontend architecture. Above the water is what we traditionally think of as like the frontend, aka the user experience, the HTML, the CSS, the JavaScript that are the fundamental building blocks of the web, all of your client-side frameworks and libraries. Plus, you have to make sure that your frontend is secure, and performant, and accessible. Maybe you care about SEO.
However, that is just the tip of the iceberg. Under the surface, there’s a whole bunch of complexity, all of the systems and choices that we make in order to better support the developer experience, all of which actually have a massive impact on our users. How you decide to architect your design system, or do dependency management, or run experiments or build and deploy assets, all of those have just as much of an impact on your end users as the client-side JavaScript libraries that you use. Your frontend architecture is like this whole entire iceberg. We want to avoid a Titanic sized crash into this iceberg of frontend complexity. We’re going to learn more about it. We’re going to start by developing a better understanding of why the frontend is so complicated. Where does all this complexity come from? What are the hard problems in frontend? Then we’re going to talk about the different ways historically that we’ve tried to solve them. Then we’re going to move on and talk about how we navigate all of that complexity, particularly through the lens of your frontend platform.
Hard Problems in Frontend Engineering – HTML, CSS, and JavaScript
What are the really hard problems and constraints that make web development and especially frontend platform development hard? I’m going to talk about nine. I think that a lot of these are the hardest and the most important things that your platform should be abstracting away for you. That’s why I picked these. The first constraint we have to deal with is HTML and CSS and JavaScript, the design of the worldwide web itself. The web was not originally designed to be an application framework. This is what the original website that was made in 1991 looked. You can go look at it today. As you can see, it’s just a bunch of text and some links. There’s no images. There’s no multimedia. All there is, is static information. HTML was designed to basically markup term papers so that academics could share them with each other. Obviously, we’ve augmented the design, we have images now, we have CSS, and we have JavaScript. It’s like a true testament to the brilliance of the web, that the same tech that made this happen, powers all of our modern interactive experiences.
What do you need to make a website? You need a web server that’s connected to the internet, a web browser client. You need some HTML that defines the structure of your page, CSS to style the content, and then JavaScript to add interactivity. I think the important thing for all of us to think about is the fact that all three of these languages are uncompiled, static text files. You don’t build a binary then ship it to a web browser. It’s uncompiled, static test files. Anyone can open up their favorite editor and type some words and symbols, and then FTP them up to a web server, and you have a frontend platform. FTPing static files to a server doesn’t scale. In order to scale beyond FTPing static files, we had to start creating all of these abstraction layers that would allow us to use other languages that would then generate those static HTML and CSS and JavaScript files that we could return to browsers inside of an HTTP response. In order to do things like reuse code, get dynamic data, run tests, run CI/CD, all of these things, we had to create abstractions on top of the core technology of the web. Over time as the way that we’ve used the web has changed, we’ve had to change our abstractions to keep up. That’s why there are so many different ways to do things. We’re going to talk a lot more about these abstractions historically.
Web Ownership
The next constraint that we have to deal with is the fact that the web is not owned by any individual company or browser manufacturers. There’s a standards body, the W3C, or the World Wide Web Consortium, or TC39, which is the ECMA International JavaScript standard body. The process for adopting new standards is designed around consensus building. Anytime you’re trying to build consensus, that means that the pace of change is going to be very slow. Everyone has to come together and agree on what the right APIs to build are, and how they should be designed. Then individual companies can choose or not choose to go off and implement the standards. A lot of the complexity has arisen over time, because engineers and designers are zooming ahead of the standards. They’re solving problems before the standards and the browser implementations can catch up. Why was jQuery so successful? jQuery took all of these low-level JavaScript APIs that had different definitions and different API signatures in different browsers, and it created this really easy to use abstraction layer on top of that, that allowed engineers to just write the same code and execute it everywhere and not think about all of those differences cross-browser. In the case of jQuery, jQuery zoomed ahead, but then what happened is standards bodies learned from the lessons of jQuery success, and now a lot of those solutions are baked into the specs. jQuery is obsolete now. It’s because the standards process learned from what jQuery was doing, and that cycle is going to continue.
Users Come First
The third hard problem is that when it comes to the web, users come first. With great power comes great responsibility. We have to protect user privacy and security, and we have to ensure that the web is accessible to everyone. I really love how the W3C’s newly released web platform design principles talks about this, calls it the priority of constituencies. User needs come before the needs of webpage authors, which comes before the needs of user agent implementers, which come before the needs of specification writers, which come before theoretical purity. I love that theoretical purity isn’t there, because that feels like a real subtweet. Somebody was like, theoretical purity, and they were like, “No, that’s last.” I’m on the W3C Web Performance Working Group. I’m helping to create the standards and the specifications for the future of web performance. It’s been really fascinating to me the number of times that I am just like, let’s expose that timing data. I just want to know like, how long did it take for this JavaScript to load? Did it come out of the cache? Did it not come out of the cache? We actually can’t know that because that could be a vector for someone to get information about what websites someone has been to before. The answer is no. As somebody who writes code that tracks performance of websites, that’s frustrating to me. As a user of the web, I’m really reassured by the fact that our needs come first.
You Don’t Control Where Your Code Executes
The fourth constraint, which I think is really the biggest difference between frontend platforms and other kinds of platform engineering, is that the browser is a code execution environment that you have no control over whatsoever. You write a bunch of HTML, and CSS, and JavaScript, and you send it off. From there, your code runs on other people’s computers, and not the cloud, but some ancient laptop that’s running IE6. This is bananas when you think about it. I am so jealous of all the people who are setting up Kubernetes clusters, because you get to control everything about where your code executes. You know exactly what OS is running. You know the version of the OS. You know what the CPU is like. You know what the RAM is like. You push a button and you set the CPU the way you want it to be. On the web, it could be anything. Websites are accessible via pretty much any device these days: smartphones, smartwatches, laptops, desktops, TVs, refrigerators have web browsers in them now, video game consoles. If you could stop playing Tears of the Kingdom for like 5 minutes, you could actually pull up the web on your Switch. It’s wild. We don’t control any of that. We don’t control how big the screen is. We don’t control how the user is interacting with the code. Maybe there isn’t even a screen because they’re using a Braille display. We don’t know if they’re using a mouse. We don’t know if they’re using a touchscreen. Maybe they’re using neither of those because they have a physical disability and they’re using a switch mechanism. This is why CSS is a declarative language. CSS is actually, in fact, awesome. CSS was designed to manage this lack of control, using a declarative language. I want all of us, every time somebody complains about CSS, you say, “Actually, CSS is really well designed to solve the problems that it’s solving.”
The Web Is Designed to Be Backwards Compatible
The next big foundational problem that we have to manage is that the web is designed to be backwards compatible. What that means for us is that our code has to account for the last 20-plus years of technology, all different browsers running on different operating systems and different devices. The long tail of browsers is really long. The site, whatismybrowser.com, has over 219 million unique user agent strings in their database. Every single one of those represents a unique combination of factors: different browsers, different devices, different capabilities of those devices, different rendering engines in the browser, different JavaScript engines. Maybe different implementations of APIs, different levels of API support, historical versions of APIs plus modern versions of APIs. There’s so much complexity inherent in managing all of this backwards compatibility. The next big foundational constraint is that you have to deal with all these combinations, but you don’t actually know what combination you’re dealing with in advance. That’s because as Scott Hanselman, so very aptly puts it, lies, damned lies, and user agents. Those 219 million strings don’t actually tell you anything useful that you can trust. They are supposed to be this identifier, but actually what they are is like a bunch of random gibberish that is perfectly easy to spoof. Spoofing a user agent is the easiest thing to do in the world. For privacy reasons, browser manufacturers are actually now starting to freeze user agents and send you less information because it’s a vector for fingerprinting. What this means we have to do is that you don’t know the capabilities or what JavaScript APIs or CSS features are supported, until you actually get your code into the browser, and check to see if the new hotness is supported. This is very unusual, I think, that a lot of other platforms don’t have to deal with this. You don’t know the boundaries of the execution environment until you get code executing in the execution environment, and then you have to write a fallback. If it’s not supported, what do you do? Maybe you do nothing. Maybe you’re just like, whatever, it’s too cool for my users.
Another thing that you can’t trust is the network. There’s a whole other class of design decisions on the web that are ways to work around unreliable network connections. That’s really because every request that you make is another opportunity for failure. Either you run the risk of a slower connection that slows down the user experience, and the user has a bad time, or you run the risk of losing connectivity in the middle of a session. To help alleviate the need for web browsers to go back over the network and re-request every file, there’s a cache in the browser that stores your assets for you. Now we have a new problem, and it’s one of the two hardest problems in computer science, cache invalidation, naming things, and off-by-1 errors. Managing the browser’s cache effectively is actually one of the hardest things that your frontend platform has to do for you. There’s APIs that help out with this. You do not want your product engineers to have to think every day when they write code, how do I invalidate the browser cache? You have to do it for them.
Browsers Are Single-Threaded
The next constraint is that browsers are single-threaded. This has a little asterisk there, because I need to caveat this. Modern browsers have multiple processes, and multiple threads running. There are threads outside of the browser’s main thread that do things like networking. Newer browsers have some things that they hand off to be multi-threaded. To understand a little bit more about what I mean when I talk about why it’s so important that web browsers are single-threaded, we’re going to have a crash course in how browsers work. I gave a talk a couple years ago called, Happy Browser, Happy User, that goes really in-depth into this. Let’s walk through the classic, like, what happens when I type a URL into my browser interview problem. I enter my URL. The browser makes an HTTP request back to my server. There’s a lot of stuff that happens with DNS and TCP and all that, ACK and SYN, whatever.
My server returns the HTTP response, index.html. What the browser does is it starts to parse that file into the document object model, or the DOM tree. Remember, it’s an uncompiled static text file. It has to turn it into this in-memory representation tree structure that represents the HTML document. As the parser has gone through and parsed my HTML, and encounters links to JavaScript, and CSS, so it goes over the network to make HTTP requests for those. CSS is a higher priority, so it gets requested first, and it comes back first. The browser gets sort parsing all that CSS into another tree called the CSSOM, or the CSS Object Model. It’s another tree structure. What it does is it basically takes all of the style rules that you defined in your CSS plus the browser default styling, plus users can have their own custom CSS, and mushes them all together. Then the reason why CSS is so important, is because once the browser has both the DOM and the CSSOM, it can combine them together into another tree called the render tree, which it uses to first lay out the screen as a bunch of boxes, and then paint pixels to the screen. That’s how we show something to users. We need the DOM and the CSSOM and then party, you just see something.
Let’s talk about JavaScript. That comes back over the wire, and again, it gets parsed into another tree. Browsers love trees. This one is called the JavaScript AST. Basically, the JS AST gets compiled into machine code. The browser executes the code. Then it kicks off this JavaScript runtime event loop pattern, which is like this asynchronous message queue that just constantly runs in the background. When something happens, say, when the user taps on a screen, they’re opening a login overlay. That action generates an event that gets put onto the event loop. Any event handler code that’s listening for that event gets executed. That handler code then modifies the DOM tree directly, which kicks off this re-rendering of the render tree, relayout, and repaint of all of the pixels onto the screen.
The reason why I wanted us to really understand that is because of the fact that the browser is single-threaded means that every single one of these things is happening on one thread. This is so important when you think about performance and architecting for the web. If the main thread is busy downloading and parsing and executing 3 megabytes of JavaScript, and your user in the meanwhile is trying to scroll the page, the main thread is not going to be able to respond to the user in time. To get a smooth scrolling experience, we have to animate 60 frames per second. If the browser is busy doing other stuff, it can’t animate, it’s going to drop frames, and you’re going to have a janky, crappy experience. Again, browser manufacturers are very smart. There are some things that are handled off the main thread like GPU compositing. Your frontend platform teams really need to understand this. I don’t think we do a good job of this as an industry teaching people about this fact. You have to be able to build around that.
The Observability Problem
Our last hard problem under discussion is observability. Observability is hard in the frontend. When you take into account all the other things that we already talked about, like you don’t own the execution environment, unreliable network connections, user privacy means that the user can just completely turn off all of your ability to collect telemetry. There’s also this other phenomenon from physics called the observer problem, or, as I like to call it, Schrodinger’s JavaScript. In order to monitor the health of your website that’s probably executing a whole bunch of JavaScript, you have to write more JavaScript that also gets executed on the same main thread, as all of the code that’s actually making your website work. If you aren’t careful, trying to observe the system can actually radically change the behavior of the system itself. If you add too much JavaScript to try to do performance monitoring, you’re going to make the site slower. This is a problem. One of my main jobs is performance monitoring, and this is a huge problem that we have to work around.
The Client-Server Pendulum
To wrap up our discussion of why the frontend is so complicated, we’re going to address the elephant in the room, namely, all of those millions of different frameworks and libraries that feel so overwhelming to keep up with. I think it’s useful to look at this problem through a historical lens, or what I call the client-server pendulum. Back in the dawn of time, like 20-something years ago, when I first started making websites, everyone did it pretty much the same way. You rendered multi-page apps on the server. You generate your HTML response with like a server-side language, like PHP, or .NET framework, or ColdFusion. Then you’d layer on a little bit of CSS to make it look nice. Then you use jQuery, or script.aculo.us, or MooTools to do that sweet DHTML interactivity. Maybe if you went and go really wild, you would AJAX load parts of the page. At that time, really, anytime you wanted to update or change the contents of what is on the screen, you had to make a network request. At the time, network requests were actually really slow, so that resulted in a bad user experience. Every time you want to change something on-screen, having to go all the way over the network was bad.
The pendulum swung. In order to help develop better experiences for web apps, we started using the single-page application pattern, frameworks like React. What that does is instead of sending your HTML in your initial payload, you send this big JavaScript bundle, and your big JavaScript bundle has to execute, then it modifies the DOM tree directly in-memory in order to make pixels appear on-screen. We made this tradeoff where we slowed down the initial load of pages, but it made the experience of staying on a site and interacting with it way better, because you’re not going over the network for HTML, it’s all there in the client for you. Over time, especially as React got really popular, people started using React for everything. It’s a better developer experience. When you’re using React to render a product page, or a blog article, or something that’s not a long running interaction, the performance cost of waiting for all that JavaScript before you can see anything makes a pretty bad user experience.
In the last few years, the pendulum has swung a little into the middle here, networks are faster now. With the growing prevalence of low-powered mobile devices, especially in emerging markets, the biggest bottleneck is now the CPU of the user’s device. These new patterns and frameworks have arisen that are like a best of both worlds mix of both of the prior approaches. Your initial view is rendered using JavaScript on the server, SSR, it’s called server-side rendering. That same JavaScript then gets sent to the client where it’s hydrated, for example, it takes over the interactivity. You can have it be the whole page, and you can have it be component islands, so little islands of interactivity on your page. All of these are still totally valid ways to build a website in 2023. At Etsy, we actually use all three of these: different parts and pieces for different experiences. The number of options is actually growing, like static site generation where you generate static HTML at build time, and you serve that from a CDN, lightning fast. Edge side rendering. This is why there are so many ways to do things. If you put all the different options in context like this, it’s not the same problem that we’re solving over again, just using slightly different methods. All of these different libraries are solving different problems in different ways. This is why there are so many options.
Taming the Complexity
Now that we’ve talked a lot about the problems and constraints and all the options, let’s talk about how we can try to navigate all of this complexity. I’m going to start off with four very high-level approaches that you should be thinking about, and that your platform teams should be thinking about. The first thing you need to do is put users first. All of us need to do that. Without our users, none of us would have a job. Put your users first, establish UX principles. Why does this matter? If you’re trying to make a decision between a bunch of valid alternatives, if you have a core set of UX principles to fall back on, that’s going to help you to make a decision between different alternative options, like which of these choices is going to align with our UX goals? If you’re interested in establishing UX principles, I very much love Scott Jehl’s ASPIRE principles. A, because I love a good acronym. B, I love that it’s aspirational. Because, pragmatically, none of us are going to be perfect. We’re not going to be able to make a perfect website. Good websites aspire to be accessible to users with different abilities and disabilities. We want to be secure and reliable. We want to be performant on a wide range of devices and in unreliable network conditions. We want to be inclusive to diverse audiences. We want to be responsive in adapting to all those different screen sizes. We want to be ethical in how we handle user privacy and security. We want to be ethical about the impact that we have on the planet. The other reason why you really have to establish these first is because trying to bolt these things on later is going to fail. It’s going to be an expensive failure if you’re trying to make your site or your app fast when you didn’t design that in from the beginning. Start with these goals and then you’re going to have a better time and it’s going to cost you less money.
The next big strategy is to be like Elsa and let it go. Let go of the need to control every detail because, ironically, the less that you try and control every detail, the more resilient your website or your web app is going to be. I love this quote from Steph Eckles because it really gets at the heart, “Using adaptive layout techniques is a trust exercise between designers, developers, and the browser.” Steph is talking specifically here about giving up the idea of pixel perfect layouts. This idea of writing code that works with the browser, that trusts the browser to do the right thing is applicable to all the different ways that we have to design within those constraints that we talked about. Backwards compatibility relies on trust.
The next foundational thing that we can do to tame complexity is to be more like our users. What do I mean by that? All of us in this room here are in a privileged minority of people who have high-powered modern devices, and fast, stable, reliable network connections. The way that we experience the web is very different than the experience of most of our users. When we’re making websites, and we’re testing them, we’re sitting at our desks on fast connections, and high-speed computers. We’re not standing on a crowded subway train with spotty network service. This chart is from Alex Russell’s talk that he gave at performance.now() conf last year, The Global Baseline in 2022. This is a historical graph of Geekbench scores that rate the CPU performance of high-end versus middle-of-the-road versus lower-end devices. What’s really interesting is like 10 years ago, there wasn’t a huge difference, and over time, the split has gotten bigger. That top line, that’s my Apple smartphone, the very top, versus the orange line, which actually represents the vast majority of smartphones that are being sold today, is three to four times difference. We experience a web that’s three to four times faster than someone who’s on a low-end or a middle-of-the-road device. If you are not thinking about performance, if you’re not testing performance on lower-end devices, then you’re missing out on opportunities for your business, because your users probably aren’t experiencing the web that way.
My kind of high-level strategy to tame the complexity is to use the power of modern HTML and CSS. I spend a lot of time griping about standards. These days, it actually feels like the standards in the browsers are not just catching up, but they’re speeding full steam ahead with brand new platform capabilities. What they do is they’re taking all of these things that you used to have to write a metric ton of JavaScript to do in the browser, like you used to have to write JavaScript to center a div, you don’t have to do that anymore. Join me in the anti-JavaScript JavaScript club. I love JavaScript. JavaScript is my favorite programming language. My favorite thing to do is not write any JavaScript at all, and write it in HTML and CSS, because that’s going to be way more robust, and it’s going to be faster. The thing is, CSS can do amazing things. This is pure HTML and CSS. Isn’t this amazing? This is not our typical use case. It just goes to show the power of the platform and how much it’s evolved. We couldn’t dream of this 20 years ago. You would have had to write JavaScript to do this. You don’t have to do that anymore.
There’s No Right Way to Build a Website
What’s the right architecture? This is where I get to say my favorite line, because I am a staff engineer, but it depends. I love it so much, I made this website, Ask a Staff Engineer. Anytime you want to ask a staff engineer question, go there, and they’ll tell you, it depends. The needs of an e-commerce site are going to be very different than if you’re providing software as a service. There’s no one-size-fits-all solution. We need to look at tradeoffs. As always, we start with our users. Think about your user experience. Are you displaying mostly static content so you can render your HTML on the server? Is your content more interactive and task oriented? You probably want to look at SSR or SPA? How long is the user typically having for a session? We all want like that sweet engagement. Realistically, if users typically have very short session lengths, you don’t want to waste a whole bunch of time downloading and executing 2 megabytes of JavaScript, you want to get content to them fast. If somebody’s logging into their account, and they’re going to perform a bunch of complicated tasks, they’re probably going to be better served by a SPA. They can handle that initial wait.
You also have to take into account your business goals when you’re deciding on a frontend architecture. Where are your customers located and what kind of devices they typically use is going to be a factor. If you want to grow a user base in India, where most people are on lower-powered Android devices, you’re going to have to care even more about performance. Maybe you want to even look at supporting a progressive web app. SEO for e-commerce and media especially is really big. SEO is important for everybody. With the advent of Core Web Vitals, Google search is now taking the performance of your site into account when they do search ranking. If you’re e-commerce, speed is the name of the game.
Finally, it’s important to think about what knowledge and experience your team has. Maybe all of your frontend engineers already know React, but you’re a media company and you’re like, “We got to care about performance now, what do we do?” You probably want to look at SSR. You want to render your React components on the server, and then layer on component islands when you get to the client. Also, think about the size of your platform team. If you have a smaller team, you’re probably better served choosing boring tech. I love that Suhail talked about choosing boring. I work at Etsy, that’s where choose boring tech club came from. I am team choose boring tech. Choose things that have a big ecosystem of tools around them. Most importantly, you don’t have to write the documentation. You don’t have to have training materials because Stack Overflow exists.
Once you’ve thought about all of these different factors, then you can make a start on deciding the right architecture. Maybe different parts of your site warrant different architectures. I love this breakdown by Ryan Townsend. He gave this talk just recently called, The Unbearable Weight of Massive JavaScript. He suggests actually using different approaches for different pages on an e-commerce site, based on all of these different factors that we’ve talked about, like static versus dynamic content, SEO, performance, interactions. As a platform team, the thought of having to support four different architectures, one for each page, is terrifying. I would probably turn that on its head and say that figuring out how to build a platform that supports four different rendering patterns, and doesn’t turn into a giant mess, is actually the reason why I became a platform engineer. I love that stuff. Yes, give me a system, and I will build it and it will be beautiful, and everybody else will come in and ruin it.
Wrap-Up
When we started out, a lot of you were thinking this, like the frontend is just way too complicated. Hopefully, I’ve changed your mind. I’ve convinced you that the frontend is actually solving some of the hardest problems in computer science, like distributed computing, and asynchronous I/O, and not owning the execution environment where your code executes. The solutions that we have exist for a reason. CSS, which so many people find frustrating, is actually designed that way for a very good reason. The main thing I really want you to take out of this is like, focus on core web technologies. Don’t get caught up in the framework hype. Understand the underlying reasons for the complexity.
Questions and Answers
Participant 1: I’ve been doing web development for quite a long time now as well. It used to be that every two or three years, it was a new framework, and we were going through a bit of a rewrite. Although in the past three, or four, maybe five years, it feels like things have slowed down a bit. Is that your experience as well? React has been here longer than any other framework I can recall.
Sylor-Miller: I think React has basically taken over. There’s a lot of reasons why React has taken over with it. There’s a lot of money and a lot of energy from Meta going into shipping React. I think that we as an industry have this tendency to want to have simple and easy answers. Just like everybody uses React, I’m going to use React, I’m not going to think about it. That’s just the way that everything goes, I think is like an attitude that has cropped up. It is what it is. I’m a pragmatist, so you have to manage it and navigate it. I think that is why we’re seeing what we’re seeing. A lot of these newer frameworks and ideas are really designed around taking the core patterns of React and making them faster, and working around the problems that are inherent in using a SPA framework.
Participant 2: Writing a unit test for frontend is hard. What is your opinion on that?
Sylor-Miller: I’m a big fan of integration tests for frontends. I really like behavioral tests, integration tests, because the worst thing that you can do when you’re writing a unit test is to have to mock out the APIs that are happening inside of the browser. Right now, the best option that I see for unit tests, it’s called React Testing Library, which is more of a behavioral driven test where you’re defining more actions that a user is taking in the browser, and then looking for the results of that, versus writing a pure unit test. You probably are writing very few pure unit tests for your frontend interaction code, like maybe your frontend backend code, because there can be frontend code in the backend.
Participant 3: I have a question about bringing this to platform engineering. When we think about platforms, it’s very often like, how to be Kubernetes but better. I feel like we neglected runtimes a lot of the time, [inaudible 00:41:29]. What are we missing? How can platform orgs really accelerate frontend engineers, and make their lives less terrible?
Sylor-Miller: I think that you need to learn about it. In all of my years as a frontend platform engineer, sometimes I report to the infrastructure org, sometimes I report to the UX org, sometimes I report to product. Nobody knows what to do with us, I think because the code that we write, and the problems that we’re solving span across this entire distributed system of all of these web browsers and all of our servers and all of the different bits and pieces. People tend to think that frontend engineering is not as cool. We don’t get paid as much as backend engineers do. I think and I hope, especially now that JavaScript is everywhere, that platform teams are going to have to learn about it a lot more and learn how to support it.
Participant 4: Can you think of any times circa to us, where you’ve been tempted or decided to put things into your platform abstraction away from the frontend engineers, and it hasn’t gone well, [inaudible 00:43:10] for other reasons?
Sylor-Miller: I was on a design systems team for quite a long time. The job of a design system is to provide reusable UI components that other engineers can then use. They are Lego blocks of UI components, basically. We noticed this problem where other engineers were basically copying and pasting HTML around and all of their PHP in mustache views. What that meant is that every time we had to go in and change a component, we couldn’t find it because maybe they copied and pasted the wrong thing, or they modified it a little bit. If we had to fix the accessibility of something, it would be impossible, because there were all these different versions everywhere. We created this abstraction layer in our mustache templates that would allow you to reuse components using like a shorthand. I think the problem is that we built this thing to solve our problem and we didn’t explain to engineers well enough why it was going to solve their problems, too. The adoption of it was really low. What we ended up doing was we ended up talking to a bunch of people, and we made a really small change where the default code view in our design system documentation defaulted to showing this pattern, because people were just copying and pasting the default. People started actually copying and pasting the thing we wanted them to copy and paste. The lesson there is, meet engineers where they are, and make sure that you’re understanding how they’re interacting with your tools and where they’re looking at your tools. Then that’s going to allow you to better sell to them why the things that make your life easier also make their lives easier.
See more presentations with transcripts
MMS • RSS
![]() International Assets Investment Management LLC purchased a new position in MongoDB, Inc. (NASDAQ:MDB – Free Report) during the 3rd quarter, according to the company in its most recent filing with the Securities & Exchange Commission. The fund purchased 282 shares of the company’s stock, valued at approximately $93,000.
International Assets Investment Management LLC purchased a new position in MongoDB, Inc. (NASDAQ:MDB – Free Report) during the 3rd quarter, according to the company in its most recent filing with the Securities & Exchange Commission. The fund purchased 282 shares of the company’s stock, valued at approximately $93,000.
Other institutional investors have also modified their holdings of the company. AWM Capital LLC acquired a new stake in MongoDB during the second quarter valued at approximately $329,000. Prosperity Wealth Management Inc. bought a new position in shares of MongoDB during the second quarter valued at approximately $325,000. ST Germain D J Co. Inc. bought a new position in shares of MongoDB during the second quarter valued at approximately $45,000. Alamar Capital Management LLC grew its holdings in shares of MongoDB by 2.4% during the second quarter. Alamar Capital Management LLC now owns 9,056 shares of the company’s stock valued at $3,722,000 after purchasing an additional 210 shares during the last quarter. Finally, Osaic Holdings Inc. grew its holdings in shares of MongoDB by 47.9% during the second quarter. Osaic Holdings Inc. now owns 14,324 shares of the company’s stock valued at $5,876,000 after purchasing an additional 4,640 shares during the last quarter. Institutional investors and hedge funds own 88.89% of the company’s stock.
Insiders Place Their Bets
In other MongoDB news, CAO Thomas Bull sold 518 shares of MongoDB stock in a transaction on Monday, October 2nd. The shares were sold at an average price of $342.41, for a total transaction of $177,368.38. Following the sale, the chief accounting officer now owns 16,672 shares in the company, valued at $5,708,659.52. The transaction was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through this link. In other news, CAO Thomas Bull sold 518 shares of the business’s stock in a transaction on Monday, October 2nd. The shares were sold at an average price of $342.41, for a total value of $177,368.38. Following the sale, the chief accounting officer now owns 16,672 shares in the company, valued at approximately $5,708,659.52. The sale was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through the SEC website. Also, Director Dwight A. Merriman sold 1,000 shares of the business’s stock in a transaction on Monday, October 2nd. The shares were sold at an average price of $342.39, for a total transaction of $342,390.00. Following the completion of the sale, the director now owns 534,896 shares in the company, valued at approximately $183,143,041.44. The disclosure for this sale can be found here. Insiders have sold 298,337 shares of company stock worth $106,126,741 over the last 90 days. Corporate insiders own 4.80% of the company’s stock.
MongoDB Stock Down 0.7 %
MDB opened at $409.78 on Wednesday. MongoDB, Inc. has a fifty-two week low of $164.59 and a fifty-two week high of $442.84. The company has a debt-to-equity ratio of 1.18, a current ratio of 4.74 and a quick ratio of 4.74. The firm’s fifty day moving average price is $380.03 and its two-hundred day moving average price is $379.13. The company has a market capitalization of $29.58 billion, a P/E ratio of -155.22 and a beta of 1.19.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Tuesday, December 5th. The company reported $0.96 earnings per share for the quarter, topping analysts’ consensus estimates of $0.51 by $0.45. MongoDB had a negative net margin of 11.70% and a negative return on equity of 20.64%. The firm had revenue of $432.94 million for the quarter, compared to the consensus estimate of $406.33 million. During the same quarter in the previous year, the company earned ($1.23) earnings per share. The business’s revenue was up 29.8% compared to the same quarter last year. On average, analysts anticipate that MongoDB, Inc. will post -1.64 EPS for the current year.
Wall Street Analysts Forecast Growth
Several research firms have recently commented on MDB. Guggenheim upped their target price on MongoDB from $220.00 to $250.00 and gave the company a “sell” rating in a report on Friday, September 1st. TheStreet upgraded MongoDB from a “d+” rating to a “c-” rating in a research report on Friday, December 1st. Scotiabank initiated coverage on shares of MongoDB in a research note on Tuesday, October 10th. They set a “sector perform” rating and a $335.00 target price on the stock. Needham & Company LLC raised their target price on shares of MongoDB from $445.00 to $495.00 and gave the company a “buy” rating in a research note on Wednesday, December 6th. Finally, Morgan Stanley lifted their price objective on shares of MongoDB from $440.00 to $480.00 and gave the stock an “overweight” rating in a research note on Friday, September 1st. One investment analyst has rated the stock with a sell rating, two have assigned a hold rating and twenty-two have issued a buy rating to the company. According to MarketBeat, MongoDB has a consensus rating of “Moderate Buy” and an average target price of $432.44.
View Our Latest Stock Report on MongoDB
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS

US telecoms giant Comcast has disclosed a major data breach affecting some 35,879,455 American citizens.
The cable internet and television provider disclosed the massive data breach in an otherwise routine data breach filing with the state of Maine. Though the state rules only covered 50,782 citizens in Maine, the cable provider said that the exposure affected tens of millions of customers nationwide.
The issue in question was the Citrix Netscaler critical flaw known as ‘Citrix Bleed’ (CVE-2023-4966) . That vulnerability allowed attackers to steal session tokens and gain access to Netscaler sessions without authentication.
The flaw, classified as a “remote data exposure” bug was rated as a 9.4 on the CVSS scale and was considered a critical security risk when disclosed. The vulnerability was subject to active exploit before a fix was released.
Comcast says that while it moved to patch the bug in its systems, an attacker was able to exploit the flaw before it could get mitigations in place.
“We subsequently discovered that prior to mitigation, between October 16 and October 19, 2023, there was unauthorized access to some of our internal systems that we concluded was a result of this vulnerability,” Comcast said in its filing.
“We notified federal law enforcement and conducted an investigation into the nature and scope of the incident. On November 16, 2023, it was determined that information was likely acquired.”
Comcast said that it possibly exposed usernames and passwords, though much of that information may have been hashed and thus protected from remedial decryption techniques.
We concluded that the information included usernames and hashed passwords,” Comcast said.
“For some customers, other information was also included, such as names, contact information, last four digits of social security numbers, dates of birth and/or secret questions and answers.”
The cable provider is asking its customers to reset their passwords and change their authentication settings to include additional authentication if possible.