Month: March 2024

MMS • RSS

MongoDB (MDB) is a $27 billion provider of datacenter solutions and is a key alternative to AWS and Azure because developers seem to love the platform.
Mongo has established itself as the clear next-generation, NoSQL, general purpose database leader with over $2B of annualized revenue growing at 20%+ and its core Atlas product growing high double-digits. Based on its large total addressable market, their growing platform capabilities position MongoDB for strong growth for many years.
But despite a big earnings beat on March 7, MongoDB slipped into the cellar of the Zacks Rank this week on weaker guidance that forced analysts to lower their growth projections.
MongoDB forecast revenue growth in a range of +13% to +15% for its current FY’25 that began Feb. 1. The guidance lagged consensus views of 22% increase.
For fiscal 2025, MongoDB expects revenues between $1.9 billion and $1.93 billion. And non-GAAP net income per share is anticipated between $2.27 and $2.49.
This news compelled analysts to lower this year’s EPS consensus 19% from $3.08 to $2.49, representing a -25% drop in annual profits.
Quarter Details
MongoDB reported Q4 FY24 (ended January) adjusted earnings of 86 cents per share, which beat the Zacks Consensus Estimate by 86.96% and increased 50.9% year over year.
Revenues of $457.5 million jumped 26.6% year over year and surpassed the consensus mark by 6.02%.
MongoDB’s subscription revenues accounted for 97.1% of revenues and totaled $444.3 million, up 27.6% year over year. Services revenues declined 0.5% year over year to $13.1 million, contributing 2.9% to revenues.
Increased User Base
MongoDB added 1,400 customers sequentially to reach 47,800 at the end of the quarter under review. Of this, more than 7,000 were direct-sales customers.
The company’s Atlas revenues soared 34% year over year, contributing 68% to total revenues. Atlas had more than 46,300 customers at the end of the reported quarter, adding 1,400 customers sequentially.
MongoDB ended the quarter with 2,052 customers (with at least $100K in ARR) compared with 1,651 in the year-ago quarter.
Bottom line: Most analysts remain bullish on MongoDB and see the lowered guidance as a temporary blip that the company will quickly overcome in the next few quarters.
Want the latest recommendations from Zacks Investment Research? Today, you can download 7 Best Stocks for the Next 30 Days. Click to get this free report
MongoDB, Inc. (MDB) : Free Stock Analysis Report
MMS • Steef-Jan Wiggers
Microsoft has officially made On Your Data generally available in Azure OpenAI Service. This feature enables users to harness the full power of OpenAI models, including GPT-4, and seamlessly integrate the advanced features of the RAG (Retrieval Augmented Generation) model with their data. According to the company, all this is backed by enterprise-grade security on Azure (via private endpoints and VPNs), ensuring a safe and secure user data environment.
Azure OpenAI Service On Your Data was brought to public preview in June last year. By utilizing Azure OpenAI Service on data, users can get high-quality AI responses that are readily available. The company has implemented precision prompt engineering and fine-tuned components, such as intent extraction, search retrieval, filtering, re-ranking, and data ingestion, to deliver accurate, concise, and coherent responses optimized for each model.
Azure OpenAI Service on your data ingests and connects users’ data from any source, regardless of location.
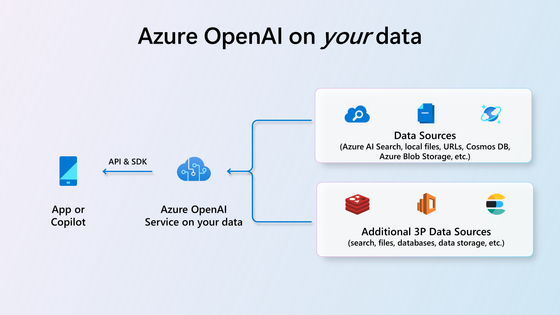
Copilot with the On Your Data feature Overview (Source: Tech Community blog post)
In addition, users can leverage the On Your Data feature for real-time document searches, analyze legal papers, generate sample code, and offer health advice.
Ben Kasema Mungai, head of technology at FITTS, writes in a LinkedIn blog post:
From retail to finance, Azure OpenAI Service On Your Data is versatile. You can personalize customer experiences at scale, as well as automate the analysis of market trends and regulatory documents.
To allow users to use their own data with Azure OpenAI models, they need access granted to Azure OpenAI in the desired Azure subscription, an Azure OpenAI resource deployed in a supported region with a supported model, and at least the Cognitive Services Contributor role for the Azure OpenAI resource. Next, they can use Azure OpenAI Studio to connect to the data and build an App.
Saverio Proto, a customer experience engineer at Microsoft, concluded in an earlier Medium blog post:
In summary, Azure OpenAI’s “use your data” feature simplifies prompt grounding without the need for complex RAG pipelines. For customers aiming to create applications, having some basic knowledge of Azure Cognitive Search is essential. Combining Azure OpenAI and Azure Cognitive Search allows for the development of AI applications that seamlessly work with your enterprise data, offering a solution guaranteed to be secure and scalable.
More details are available on the documentation pages. In addition, a QuickStart is available.
MMS • RSS

MMS • Chandler Hoisington
Subscribe on:
Transcript
Shane Hastie: Hey folks, it’s Shane Hastie here. Before we start today’s podcast, I wanted to tell you about QCon London 2024, our flagship international software development conference that takes place in the heart of London next April, eight to 10. Learn about senior practitioners’ experiences and explore their points of view on emerging trends and best practices across topics like software architecture, generative AI, platform engineering, observability, and secure software supply chains. Discover what your peers have learned, explore the techniques they are using, and learn about the pitfalls to avoid. Learn more at qconlondon.com. We hope to see you there.
Today I’m sitting down with Chandler Hoisington. Chandler is the Chief Product Officer of EDB and comes to that role through a VP of Engineering background in a couple of places. So Chandler, welcome. My starting point is often who’s Chandler?
Introductions [01:14]
Chandler Hoisington: Thanks, Shane. It’s great to be here. I’ll start at the beginning. I actually started as a engineer at a small database startup back when sharding was still really cool. We were actually doing MySQL sharding, and I actually started as a Java engineer at a database startup way, way back in the day. So from there, I got into some management roles and I got a really great role at a good company called RMS in the Bay Area there. And RMS did catastrophe modeling for the reinsurance and insurance industry, so they would model the effects, especially the financial effects of a hurricane or an earthquake against an insurance portfolio. And so it was really interesting, big data challenges, and it was a really interesting time to be there. It was right when containers were coming out and it was at the end of the Hadoop era and the beginning of the Spark and Kafka era, and there was a whole bunch of new DevOps practices and containers, like I mentioned, were just budding out.
So from there, I actually ended up running product and engineering at Mesosphere, which was a really great company to be at as well. And worked on Kubernetes challenges and Mesos challenges and containerization challenges for a few years before joining AWS as the GM for Kubernetes for their hybrid and edge products. And then now I’ve landed at EDB as the Chief Product Officer.
Shane Hastie: That’s a convoluted journey from an engineering perspective. What are some of the big gotchas in that career journey that you can share with folks?
Chandler Hoisington: Yeah, honestly, I think my first two jobs out of college, one being a backend developer for distributed systems databases, and then my next job was actually at another startup. We were building applications against the Facebook API at the time, but I was in charge of all their backend development along with standing up their infrastructure, which we did on AWS, and it was very, very early days at AWS. And so those two first jobs defined the rest of my career. It was a combination of the distributed systems in cloud. I ended up working on a lot of distributed systems and then ended up solving problems at AWS itself, which was a really great experience. So that’s how I would say my career has evolved itself. Not really on purpose, but just slingshotting off those first two opportunities and continuing to ride that wave of cloud and distributed systems.
Shane Hastie: So Amazon, interesting place, everyone looks at them as amazingly successful. From inside, what did you learn in your time there?
Lessons from working at Amazon [03:47]
Chandler Hoisington: Coming to EDB as a CPO, I was able to actually take away a few things from Amazon that I really enjoyed. Just like with anybody working at a big company, you might not agree with all the operations and processes that exist inside that organization. But at Amazon, I think they really figured out the product process, especially with how they run their product working backwards documents. And I’ll explain this for those that don’t know. It’s very awkward when you first get to Amazon actually because you sit down in a meeting. In fact, my very first meeting was like this at Amazon. It was like 8:00 AM on a Monday, my first meeting ever. And we sat down and this is during COVID, so nobody was in the office. We’re all on Chime. That’s their version of Zoom. And we’re sitting in a meeting, everyone’s cameras are off, and I’m like, am I missing something?
Five minutes goes by, six minutes goes by. Are people going to turn on their cameras? What are we doing here? Nobody’s talking. And my boss is like, “Oh, hey, I didn’t see you there. Yeah, we’re all reading this doc.” And so it’s like a study hall for the first 15 or 20 minutes of every meeting really at Amazon. Most meetings, not every meeting, but I would say 80% of meetings are run this way. And you are reading a doc. This doc happened to be a weekly business review doc where we went over all the metrics for that service, the revenue, the new customers, support tickets and issues. And you’re just reading, it’s a pretty dense doc at times, but you’re going through all that data. They usually keep those docs under six pages just so you can read them in the first 20, 25 minutes.
But then whenever it’s done, they start coming on camera as you’re ready. And then we have a discussion. And Bezos famously says that he likes a crisp doc and a messy meeting. So he wants the docs to be very, very, very crisp. He wants the data to be well-understood and thought out, and the author of the doc has a lot of responsibility to really do their homework and bring a very well-thought-out doc to that meeting. But then he encourages us the meetings to be what he calls messy, which really means asking a lot of hard questions, trying to find holes in the strategy that you’ve laid out in your doc, finding the key things that people should be following up on. And this is how Amazon ran most of their meetings.
And for their product process, they applied a similar philosophy, but they had another element to it, which was they really encouraged you as a product manager or a business owner to be what they call working backwards from the customer. So what that means is instead of jumping straight into code and starting to write a bunch of code and prototyping rapidly on code, which there is a bit of that that’s done at Amazon, the process that Amazon encourages people to first think backwards from what kind of value we’re going to be releasing for the customers. So that’s done in the way of writing the press release actually. So you write a one-page press release as a product owner or manager, and then you have a couple pages of PR FAQs associated with that press release. And it’s a really interesting process. It took me a minute to get used to, we were starting a new service when I joined, so it was one of the first things I had to work on was one of these. It’s called a PR/FAQ doc, is the abbreviation for it. Press release with an FAQ.
And it was one of the first docs I had to work on. And it’s actually quite challenging to define in one page an entire product that you want to release. And there’s a specific format. A problem paragraph, a solution paragraph, some supporting quotes, things like that. And every sentence is scrutinized. And what this process is intended to do is it’s a go slow to go fast process. Let’s make sure we’re conscious of all the hard decisions we need to make now so that after we get into this, we’re not eight months into the code and it’s like, actually we need to refactor the whole thing. We think we took the wrong approach. So that’s one big reason behind it.
And the other reason is ensuring that you’re thinking backwards from the customer pain and actually solving problems for the customer. So thinking from the customer’s perspective, and not necessarily from the engineer’s perspective writing the code. So as soon as we nail that PR/FAQ process and it goes through a litany of reviews, many, many reviews depending on what you’re doing sometimes all the way up to the CEO of Amazon, depending on what you’re launching, it might go through months of reviews. And that’s the go slow process. But then once it’s decided, the teams move very, very quickly to go and execute and build on those things. This is a long way to answer your question, but like I said, I didn’t love everything at Amazon. There’s a lot of things I did like and this was definitely one of them. So when I joined EDB as the Chief Product Officer, I said, “I’m going to bring this with me.”
And that’s what we do now at EDB. We’ve rolled this out over the last year, and again, when new people join, it’s awkward for them. They’re like, “Wait, are we going to be talking in this meeting?” But we spend the first 10 to 20 minutes of every meeting like these, not every meeting, with the meetings that we do doc reviews in, reading a doc and doing study hall. And then we have a discussion, and I think it’s worked really well. I think it’s something I’m going to use wherever I go now in my career for the rest of my career. It’s something that I’ve gotten a lot of value out of.
Shane Hastie: As an engineer, the last thing I want to do is read a document.
Engineers and documents [08:49]
Chandler Hoisington: I don’t know. You engineers write docs all the time. You’re writing design docs. And honestly, I think the engineers, I don’t want to for all of them, but I do think they also appreciate having a north star reference point for what they’re building. I think a lot of times engineers and most of the time almost every time engineers have the best intentions for what they’re doing. They’re trying to solve problems for customers. They’re looking for ways for product managers to steer them a lot better. And the nice things about these docs is that they’re not done in a vacuum. It’s not just a product manager sitting in their office and then be like, “Hey, I have a doc I want you all to read.” They’re very collaborative even to get the first draft done. So they’re often done with the engineers who are going to be working on the project, with the architects, with engineering leaders. And so it’s brought as a collaboration between product and engineering to the group and then eventually to leadership.
It’s not the end all, be all document. From there, we take that document and we write essentially design docs and we break it down into user stories and design docs from there. But it stays as our north star to help us get the group aligned. I know your audience is mostly engineering, but I also use it to help engineering communicate to the rest of the company what they built and the value of what they’re building. And I think that’s another thing. I’m sure you see this all the time, but there’s lots of great engineers who build really great products that no one ever hears about because the product marketing and the marketing and the rest of the organization doesn’t do a good job communicating it to the customers and the rest of the world. And these docs help us really distill that value down into a single page, and we’re essentially handing it off to the marketing department. It’s like, “Here you go.” It’s gift wrapped as a press release.
And oftentimes, they don’t use our exact language, they pretty it up with marketing words, but it definitely sets them on the right track for how to talk about often pretty technical products. So I think that’s another big benefit to the engineering community for these things.
Shane Hastie: Shifting tack a tiny bit, your experience leading engineers. A lot of our audience are people who are stepping into the engineering leadership role sometimes for the first time, some of them technical team leads and so forth, and choosing to go down that leadership management path. What advice would you have advice for those folks?
Advice for new leaders [11:06]
Chandler Hoisington: Yes, the advice I almost always give to new engineering leaders is don’t feel anxious about making that jump too soon. Don’t feel like your career is going slower than appears, or you need to get into management in order to keep advancing your career. I know from my experience, the technical knowledge that I got as an IC essentially became the foundation of my technical knowledge for the rest of my career. And that’s not to say I can’t learn new things in a leadership role, but your pace of learning new things, especially at the detail that you learn them as an engineer, is much slower. You’re often looking at new technologies from big boxes in architecture. You’re not hands-on implementing things and really getting that understanding at the same level.
So what I usually tell people is don’t do it too soon because that set of technical knowledge, you need to be a really good engineering manager, the pace of which you add to it is going to slow way down once you get into leadership, and really everything you’ve learned before getting to leadership might be 70 or 80% of your entire foundation of technical knowledge going forward. So it doesn’t hurt to get exposure to more things as an IC before you make that jump into leadership. And I know some companies, I have a friend who worked at a company, DuckDuckGo, and they have a very different style, and from my understanding at least of what he told me secondhand is he was doing a lot more leadership and hands-on implementation at the same time, so he was able to continue to do IC work even as a leader.
But I think for most companies, once you make that jump, it’s a hard cutoff, and now you’re just managing people and projects and working on a different set of problems, but with the expectation that you can dive in and go deep on technical issues when needed. And so that’s my biggest piece of advice for newer managers is don’t feel like you need to make that jump too soon. Especially at the FANG companies or whatever we’re calling that nowadays, the big companies, from a comp perspective and career path perspective, it’s a different game nowadays. You don’t have to go into management to keep making more money and to get better and better titles. They’ve really laid out a pretty clear path on the IC role as well.
I think you can get all the way to the same level as a VP at Amazon as an IC. I don’t know if they call it distinguished engineer or I forget what they call it, but it’s some very high-ranking engineer. And so you have a pretty clear career path on both tracks, so I think that’s another thing to keep in mind nowadays. It’s a little bit different than maybe it used to be
Shane Hastie: In that leadership capacity, you’ve come in new from outside, senior leader coming into an organization. There’s inevitably the new broom sweeps clean feeling, and everybody in the organization is going, “Oh no, not again.” One, from your perspective coming in as that new broom, why? And for the people who are sitting there going, “Oh, no, same thing, different day. Oh, not again,” how should they tackle this?
New leaders joining an existing organisation [14:13]
Chandler Hoisington: Yes, I think there’s definitely truth to new leaders coming in and wanting to bring their own style. They’re used to operating the organization a specific way. Just like when I joined EDB, I just came from Amazon and said, “You know what? This doc thing we’re doing here is really cool. I want to bring that with me.” And so I changed a lot of ways that the team was working at the time. And I’ve also had a lot of bosses get swapped out on me as an executive myself over the years as well, so you have to figure out how to adapt to new styles and people. My best advice here is to be flexible. You have to understand that changes in leadership are made usually for a reason. Either investors aren’t happy with the direction something is going, whether that’s been communicated throughout the entire org or not, that could be one of the reasons. Or it could be something much softer than that. It could just be someone’s retiring or they’re moving on for family or health reasons or whatever the reasons they have is.
But I think in a lot of cases when you’re bringing in new executive, it’s often because they want to make some kind of change. And so to be in an organization where that’s happening, you have to realize that flexibility is really important and you have to put yourself in the right mindset. There might be a lot of things that you’ve done well over the years and you don’t want to lose that, but you also have to be open for executives coming in and bringing a new style and a fresh perspective, because that’s almost what they’re being asked to do. And like I said, in my case, I brought in a whole bunch of new processes. It looks like a very different org than it was before. And I also brought some new people as well that I’ve worked with in the past who I knew could roll out that process and new way of working as well.
So there’s definitely some change that you have to be comfortable with, but I think it’s felt usually less as you go down the organization. So if you’re an individual IC you might not feel it as quickly as just an individual developer as you might feel it if you’re a VP or a director reporting into the CTO or the CPO or something like that, so it really also depends on where you’re at in the organization.
Shane Hastie: What’s the biggest mistake that you’ve made and how did you recover?
Learning from mistakes [16:16]
Chandler Hoisington: Oh, good question. I think we all look back at our career and you can say, “Oh, I should have done this differently,” or, “I should have done that differently,” one thing or another, but I’m actually happy where I’ve landed. So I think for most people, it’s a positive perspective to have to look back and say, “The jobs I took and the experiences I had got me to a place where I am now,” so it’s almost like the butterfly effect. I don’t know if I would necessarily change anything. But there is one thing I wish I had learned sooner, and that was to listen more and to assume positive intent in most cases. I think some of my early jobs, you’re eager, you want to show leadership that you’re capable of being the leader that they promoted you to be, but at the same time, you don’t want to leave any bodies behind.
And so I think it’s important to figure out how as a leader and an executive, once you move into that position, how to move to a place where you can be effective in the organization. You can drive change and the decisions that your team needs you to do, and you’re not just going to go up to these leadership meetings and roll over on issues that you think are right. But at the same time, you don’t end up using so much political capital on small issues that you don’t save any for the really big issue that you care about. One example comes to mind, I was at a company, we were trying to decide what cloud we wanted to pick, and this was back in the, I can’t remember exact year, but this is when AWS had a pretty sizable lead on most of the competitors. And even before I joined AWS, I was an AWS fanboy, so to say, as people say. And I was a big fan of the services they had built at the time and all that kind of stuff.
The other clouds have caught up quite a bit, and they also have really good offerings now, and it’s not just an AWS world anymore, but at the time it really felt that way. But some of my leadership and my colleagues were looking at potentially going with a different cloud provider. And as the VP of Engineering, it really affected the way I could deliver products because we wanted to use services, database services, container services, whatever was available at the time, storage services that were the latest and the best and the most mature and the most hardened, et cetera. So my architects and engineers was telling me, “Don’t let them pick a different cloud.”
I went into those meetings with the same vigor and passion and enthusiasm that I did in many other meetings, and that’s where I think it would’ve been helpful to save some of that for when I really needed it. And I learned this early on, and sometimes it can be hard to do because a lot of us are passionate people and you come in and you want to speak passionately towards issues, but in this instance, I wish I had saved some of that in the tank, kept some of that gunpowder dry, so to say, so that I could have used it for some bigger issues that I ended up losing where I felt like it was the right decision. So I would say that would be my biggest mistake, most likely, looking back on it is just if you can call it a mistake, but just learning that lesson sooner could have benefited me, but it was a good lesson to learn nonetheless.
Shane Hastie: Chandler, you’ve been in the industry a fair while. You’ve looked across a number of different organizations. Where do you see the trends, the things that the engineer at work today should be looking for on the horizon, or maybe it’s closer than that?
Trends to be aware of for the future [19:25]
Chandler Hoisington: Yes, throughout my career, I’ve been watching a couple, I don’t know how you describe them, maybe sub-industries in tech. I was big into the container space and the Kubernetes space for a while, but also in the data space, and that’s where I am now. And looking at the trends in data is really fascinating. We went from in the 2000s being on single big databases, single machines. Oracle and MySQL started coming out. I started getting some open source solutions, and Postgres was always there. To this NoSQL craze with really fit-for-purpose data engines and RDBMSs. And then you had the big data craze along with that, with the Clouderas of the world and how do we handle data at scale? And now I think AI has really stepped into the picture. I don’t think there’s a single CEO or CIO in a Fortune 5,000 company that hasn’t been either asked by their investors or leadership or by their customers to deliver an AI product at this point, or an AI strategy.
And so with that comes a lot of new data that’s going to start needing to be handled similarly to how all this data of the past is handled as well. So that means we need governance of that data. We need the same security controls. We need the same scrutiny around regulations for EMEA and federal and health regulations like HIPAA. And so there’s a whole slew of challenges that come along with these new systems that are coming on the market to manage this AI-specific data. And honestly, I see the trends really focusing more on how do we take the existing systems that we’ve hardened over the last 20 or 25 years and make them work for this new world versus building brand new systems for this specific data and trying to apply 20 or 30 years of learnings, like let’s call it day two features, learnings to new systems.
And so time will tell how the market shakes out, but I’m very optimistic specifically around where Postgres is and the new evolving AI trends. I think that’s one example of an open source community doing a really good job of sticking to their vision and mission around just having a very performant and reliable and hardened database. And then you can see really great projects like pgvector coming out where people can start using extensions for Postgres, and specifically vectorized extensions, for building applications against these new LLMs that have hit the market. So I see the trend’s really, rather than going towards new data systems, I see people looking at their existing systems and saying, “Hey, instead of adding one more thing to our stack, one more piece of complexity that we have to manage and patch and buy support for, could we just use Postgres or can we just use these systems that work today?” And I see those trends really continuing to evolve and take shape over the next few years.
Shane Hastie: A lot of interesting points and some good advice in there. If people want to continue the conversation, where do they find you?
Chandler Hoisington: You can connect with me on LinkedIn. I’m slightly active on Twitter. I like more Denver Nuggets, the NBA basketball team, posts than I do technology sometimes. But I have had some technology conversations on Twitter with folks, so I’m there as well. C_Hoisington. But I’m more active probably on LinkedIn. You can find me there and all this stuff we talked about with Postgres. Obviously I work for the number one contributor to Postgres and you can find out a lot more information there as well.
Shane Hastie: Chandler, thanks so much for taking the time to talk to us today.
Chandler Hoisington: Great. Thanks, Shane.
Mentioned
Chandler Hoisington on LinkedIn
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Finch 1.1.1: AWS Enhances Windows Compatibility for Open Source Container Development Tool
MMS • Aditya Kulkarni

AWS recently announced the general availability of Windows support for Finch, an open-source CLI tool. Finch enables developers to create, execute, and distribute Linux containers on both Windows and macOS. It streamlines container development by combining a minimalistic native client with select open-source components. With the new support, Windows developers who develop containers can now easily set up Finch and use it to create, run, and share containers using the same easy-to-use command line available to macOS users.
Justin Alvarez, Software Engineer, and Phil Estes, principal engineer at AWS talked about the new feature in a blog post. The team behind Finch was aiming to enable Windows support by developing and contributing a test version of a Windows Subsystem for Linux (WSL2) driver to Lima, which is a key part of Finch’s infrastructure. Support for Windows has been a frequently requested feature for Lima, as requested through these pull requests.
Adding Windows support to Lima involved exploring alternatives beyond just a WSL2 driver. Initially, the contributors engaged with Lima’s maintainers to evaluate the pros and cons of utilizing HyperV, QEMU for Windows, or WSL2. A key advantage of opting for WSL2 is its compatibility with any recent Windows version. Despite reaching a consensus on using WSL2, integrating its driver into Lima presented some challenges due to the significant changes required and the differences from existing Lima drivers.
Over the past few months, the team at Finch dedicated their efforts to integrating Windows support into Finch. Now, Finch offers command-line developer tools across both macOS and Windows, enabling a uniform experience regardless of the operating system developers use. This first version featuring Windows support introduces a WSL2 Linux distribution called finch-lima, where Finch’s commands and features can be used. However, these functionalities are limited to the finch-lima distribution and are not available across other WSL2 distributions the user may have. There is a plan to extend the availability of Finch commands to all WSL2 distributions in a future update to Windows support. Windows installation packages can be downloaded from Finch version 1.1.1.
Towards the conclusion of 2023, when AWS revealed that Finch 1.0 was generally available, an intriguing conversation happened on Reddit about Finch’s competitors. A Reddit user mentioned in the conversation that a Docker Desktop alternative from a large company such as Amazon might become the favored option among developers.
To install Finch on Windows, ensure WSL2 is active on your computer. On the latest Windows 10 and 11 versions, you can enable it by executing wsl --install in the terminal. Once WSL2 is set up, navigate to the Finch “Releases” page on GitHub and download the MSI installer for the most recent Finch version. Execute the installer, then restart your terminal to ensure your PATH is updated after installation, and consider checking out the Getting Started guide.
Interested readers can join the CNCF Slack workspace’s #finch channel to engage with the Finch community for any feedback or ideas.
MMS • Ben Linders

According to Neil Turner, continuous discovery for product development is regular research that involves the entire software product team, and that can actively inform product decisions. Equating continuous discovery to weekly conversations with one or more customers can be misleading. Combining quantitative and qualitative research methods can help software teams gather data and understand what is behind the data.
Neil Turner spoke about how Redgate does continuous discovery for product development at Agile Cambridge 2023.
Turner defines continuous discovery for product development as:
Regular customer research;
By the team building the product;
In pursuit of a desired outcome.
The main pitfalls that software teams experience when attempting continuous discovery are chasing weekly targets, carrying out unfocused research, and neglecting other channels of customer insights, such as metrics and surveys, as Turner explained:
Many teams get fixated on hitting weekly targets, and on speaking to a certain number of customers a week. This can lead to poor quality research as teams focus on research quantity over quality.
Turner mentioned that software teams can end up carrying out unstructured and unfocused customer research for the sake of hitting their targets (even if they are self-imposed targets), rather than considering the most appropriate research to help inform their product assumptions and decisions:
Just because a team is speaking to their customers on a regular basis doesn’t mean that they are carrying out high quality customer research. Most teams will benefit from a mixture of quantitative and qualitative data and it can be risky to make decisions based on the insights from a few customers.
Combining quantitative research methods such as surveys and metrics, with qualitative research methods such as customer interviews, can help teams to gather data across their customers and to better understand what is behind that data, Turner said.
Not all teams at Redgate carry out continuous discovery, Turner mentioned. It’s an approach that works well with an established product, but it’s not a one-size-fits-all approach, he added. It’s very much a case of a team choosing the most appropriate research approach to take given what they need to learn and the work being undertaken. This choice of research approach will be driven by the product designer working in, or with the team, Turner said.
Teams at Redgate that do carry out continuous discovery will often do this via short bursts of customer research, rather than say running a session at a set time each week, Turner explained:
They might plan for 2-3 days of focused research a month. This makes it easier to plan, schedule, and prepare for customer research sessions. It also makes it easier to see trends as insights are collected over the course of a few days, rather than say having weeks between sessions.
Teams will use tools such as Calendly to help automate recruitment and will often share the responsibility of facilitating sessions, along with writing up notes, Turner said. For example, some teams have set up a rota so that there is less of a dependency on a designer running all the research activities.
Turner mentioned that teams carrying out continuous discovery have been able to establish a good cadence of exploring a problem space to identify opportunities, validating ideas being worked on (such as via prototypes), and getting feedback for features that have made it into a product. This supports a dual-track discovery and delivery approach.
Teams also have a better understanding of their customers and can better empathise with their challenges. After all, it’s one thing reading some feedback from a customer; it’s quite another to hear that feedback directly from the customer’s mouth, Turner concluded.
InfoQ interviewed Neil Turner about continuous discovery for product development.
InfoQ: What did your software teams learn from doing continuous discovery?
Neil Turner: Teams have learned that there is no set approach to continuous discovery and that it isn’t the answer to every research question. For example, we have a team at Redgate whose focus is early research and development. They are better placed to run more traditional upfront research, rather than continuous discovery. They tend to work on very early concepts and don’t want to be slowly drip fed customer insights. Instead, they will typically prototype a concept and get early feedback through blocks of customer research sessions.
Teams have also learned that continuous discovery takes a surprising amount of effort from the team. It’s not just a case of scheduling some sessions with customers and hoping for the best. Sessions have to be carefully planned, well run, and then properly analysed as a team. The benefits are worth the costs, but there are certainly costs.
InfoQ: What advice do you have for teams that want to start with continuous discovery?
Turner: My main advice for any team starting with continuous discovery is to level up their understanding of continuous discovery, to start small, and to adapt their approach.
Too many teams hear about continuous discovery, jump into a cookie cutter version of continuous discovery (because they don’t know enough to refine their approach), and then give up when it’s not delivering the wealth of customer insights they expect it to.
MMS • Agazi Mekonnen
AdonisJS, a Node.js web application framework, has released its latest major release AdonisJS v6. Notable highlights include a transition to ECMAScript Modules (ESM), an improved and simplified IoC container, improved TypeScript integration, and a more straightforward approach to route and controller binding. Additionally, the release introduces a new validation library called VineJS, Vite integration for bundling frontend assets, and an overhauled scaffolding system with a codemods API.
One of the key highlights of AdonisJS v6 is the migration to ECMAScript Modules (ESM) and TypeScript, aligning the framework with modern JavaScript standards. This move ensures compatibility with the latest versions of packages and enhances security by allowing the use of the latest security fixes. AdonisJS v6 applications will now use TypeScript and ESM by default, though users can still install and use packages written in CommonJS.
The release also bids farewell to TypeScript compiler hooks, a notable feature in AdonisJS v5. In v6, the framework eliminates the need for these hooks, resulting in regular JavaScript imports without relying on the official TypeScript compiler API. This change simplifies the codebase and allows developers to choose other Just-In-Time (JIT) tools like ESBuild or SWC.
Type safety is enhanced in AdonisJS v6, featuring improvements to routes, controllers, middleware references, AdonisRC files, and event emitters. The adoption of direct imports replaces the use of magic strings in routes and controllers, resulting in improved type safety and enhanced code readability. Named middleware references and AdonisRC files are now managed through TypeScript references, contributing to better code intelligence and an improved developer experience.
The introduction of class-based events is another noteworthy enhancement in AdonisJS v6. Developers can now define events as classes, encapsulating both the event identifier and data within a single class. This approach enhances type safety and provides a cleaner way to structure events in the application.
AdonisJS v6 embraces Vite as the official frontend bundler, moving away from recommending Webpack Encore for new projects. The release also brings a new scaffolding system and codemods API, providing a more streamlined and efficient way to configure packages and scaffold resources. In addition, it introduces VineJS as the official validation system. VineJS aims to offer improved speed, comprehensive features, and a more developer-friendly API compared to the previous validation module.
The documentation for AdonisJS was also improved in the release, covering previously undocumented topics like IoC Container and Service providers. The framework aims to provide developers with comprehensive guides and references to facilitate a smoother learning curve.
Looking ahead, the AdonisJS team outlined future plans for AdonisJS v6. The focus will be on stabilizing the framework, fixing bugs, and improving the migration guide. Several packages, such as Drive, Limiter, Lucid Slugify, Attachment Lite, Route model binding, and Health checks, are expected to be migrated to AdonisJS 6 in the coming weeks.
Presentation: Two Years of Incidents at 6 Different Companies: How a Culture of Resilience Can Help You Accomplish Your Goals
MMS • Vanessa Huerta Granda

Transcript
Granda: We’re going to talk about some incidents. Incidents prevent us from meeting our goals. You could have any goal that you want, maybe your goal is to get all of the Taylor Swift fans to make it to her concert. Maybe get folks home for the holiday seamlessly, or get goods shipped across the world, or just get people to watch Succession, or Game of Thrones, or whatever it is that HBO is doing nowadays. Sometimes things happen, and that prevents us from meeting our goals. Incidents never happen in a vacuum. For all of these high-profile incidents, we can usually highlight a number of similar experiences, or other incidents. We can also highlight a number of items that led to them happening the way that they did. For the Southwest outage, it goes back to decisions made decades ago when the airline industry was first being deregulated. My first job out of college was actually at an airline. All of these things are dear and near to my heart. In order for organizations to improve and to achieve their goals in spite of these incidents, there needs to be investment made on their end, investment in a culture of resilience.
Twins Analogy to Incidents
I have 17-month-old twins. They were born a bit early, like twins usually are. If you’ve had children, you probably know that while you’re at the hospital, everything is just like perfect. We gave birth in Chicago and we sent them to the nursery. I got to rest. I even got to watch The Bachelor actually. Then we took them home. I have been in incidents for many years. I can tell you that this was like the hardest major incident of my life. Every night for the first few weeks, they just would not sleep. If one slept, the other one was crying. It’s like, they were just playing tag team on me. We tried troubleshooting them. It was like that incident that just fixes itself at some point. At 9 p.m., they start crying, and then at 5 a.m., they were like, ok, now we’re cool. Basically, if we think of our lives, if we think of our goals, at that time in my life, my goal was to just enjoy my children, maybe keep a home, maybe get to eat, and then eventually go back to work. These first few weeks, I was lucky if I even got to shower. We were sleep deprived. We were doing our best, but it just kept happening until, and I’m really acknowledging my privilege here, we started being able to get on top of it. We were able to invest our time, our expertise, and really our money.
First, we needed to get better at the response, like at those actual nights when things were hitting the fan. We tried a few things, even though we were sleep deprived. We tried some shifts. We tried formula. We invested in a night nanny, and that was the big one. With this, we were able to start getting some time for ourselves. Being able to sleep actually cleared our heads for us to understand what was going on. We could have stopped here, but I didn’t have unlimited money for a night nanny. With some of that extra energy, I started trying to understand what was going on. I talked to some friends. I read some books. Every day, we would hold a post-mortem, just while eating yogurt or whatever it is that we could get our hands on. We would start applying those learnings into our lives. We fixed some of our processes around swaddling. We realized that Costco actually delivers formula and diapers, and so that’s a big-time savings not having to get two car seats into your car in the winter in Chicago, and then drive to Costco. That gave us a bit more energy, more bandwidth. We could start looking at trends. Like all incidents are different, all babies are different. We realized there were some times maybe when one parent could do it on their own, and the other one gets to clean up or cook. There were times of the day when we both needed to be there. We were doing our own cross-incident analysis, and we started coming up with some ideas. Some of them were a little out there. Like, let’s just move them to their own bedroom. Let’s just drop the swaddle because she clearly hates the swaddle.
Investing time and effort into the process, then into the post-mortems, and then doing that cross-incident analysis gave us the bandwidth to meet our goal. By the end of my maternity leave, I was able to go back to work. I was able to cook and shower. Really, I was able to enjoy my life and enjoy my new family. Live with them is always going to bring challenges. By living on this culture of, let’s just keep learning, let’s just keep trying, let’s be resilient, we know that we can pivot and do the things that we enjoy. That’s basically what we’re going to talk about. This is the lifecycle of incidents and how we can become resilient, how we can learn from them. How we can get better as a system so that we can accomplish our goals.
Background
I’m Vanessa. I work at jeli.io. When I’m not wrangling adorable twins, I spend a lot of time on incidents. I’ve spent the last decade working in technology and site reliability engineering, focusing on incidents. My background is on FinTech actually, in the airline industry. I focus on the entire lifecycle of incidents. I have been the only incident commander on-call for many years. I have owned the escalation process. I have trained others. I have ran retrospective programs. Most importantly, I’ve scaled them. That’s actually the most difficult but also the most important thing to make sure that it doesn’t just live with you, with one person. While I do this for fun, because I enjoy it, I also know that the reason why I get paid to do this is because having a handle on your incidents allows your business to achieve their goals. In the past couple of years, I’ve had the chance to work with other companies, helping them establish their programs. I’ve seen how engineer teams are able to accomplish their goals by focusing on resilience.
The Mirage of Zero-Incidents
Let’s go back to this picture. We will never have zero incidents. If we do, that means we’re not doing anything, or nobody’s using our products. I believe that incidents are a lifecycle. They’re part of how a system gets work done. First, we have a system, say Ticketmaster, and then something happens. Maybe Taylor Swift announced her world tour. Tons of people try to access the system, the system fails, and now you’re in an incident. People work on it, and it’s resolved, and the site is back up. Life is back to normal. As you can see, though, we’re not even halfway through the cycle here. Ideally, after the incident is done, you do something that is focused on learning. Even if you don’t think you’re doing any traditional learning, people naturally like to talk to each other, people like to debrief. Your learning might be just like getting together, grabbing some coffee with your coworkers after the incident. Or it can be like an actual post-mortem meeting, retrospective, whatever you want to call it, your 5 why’s. Or it can be like your incident report, whatever you want it to be. Those learnings are then applied back into the system. Maybe we make a change into our on-call schedule, or the way that we enqueue customers, or our antitrust legislation. That is the new system. That’s what we’re working with.
The Negative Effects of Incidents and Outages
Why do we care about this? We have this whole track here, resilience, talking about outages. We care about this because incidents are expensive to companies. If we think of the cost of the incident, there’s the incident itself. Like, no, we lost money, because the site was down for like 20 minutes. There’s the reputational damage. Like, no, I wasn’t able to get these tickets. I wasn’t able to fly home. I’m just never going to fly this airline again. There’s the workload interruption. If you have an incident that lasts an hour, and you have 10 engineers, that’s time that they’re spending on this incident. Then when the incident is over, they’re not going to go back to their laptops and like, I’m going to work on my OKRs. That just takes a big part of your brain, that takes some time to get back to what you’re doing. It has an impact on our goals and our plans. If our engineers are fighting fires, they’re not working on new features. What we see is that unless we do something about it, people end up getting caught in a cycle of incident where there’s just no breathing room to get ahead.
Incidents are part of doing work, but that doesn’t mean that we can’t get better at them. If engineers are constantly fighting fires, it’s going to impact the way that they deliver and the speed at which they deliver it. If our customers are constantly seeing outages, it’s going to impact how they interact with us. It’s going to impact our goals. As the company, you got to make money. If your customers aren’t using you, then that’s a problem. There’s good news about incidents, I mentioned this earlier. Having the means that somebody cares about your work, that it matters to them whether you’re up or down or that you’re doing the thing that you say you’re doing. I think that’s the thing about tech. Our users don’t care about the language we use or the methods we use, they care about being able to rent cars or get their money or get tickets. We owe it to our users that they’re able to do these things.
The Importance of Resilience in Incidents
Here’s where resilience helps. It’s the capacity to withstand or to recover quickly from difficulties, from your outages, from your errors, from your incidents. Resilience can help us turn them into opportunities. Most of the time, people don’t care about resilience. What usually happens is that you have an incident, you resolve them, and then you move on. We have Chandler Bing here saying, “My work here is done.” Not because they want to. I’ve met tons of engineers. My dad’s an engineer. I’m an engineer. We’re always trying to fix things. Sometimes we just don’t have the bandwidth to do anything else other than move on. That’s how we get stuck in this cycle of fighting incidents. There’s a better way. I have been lucky enough to work with and for a number of organizations that are leading the way in improving resilience in the tech world. The better way includes a focus on three things, a focus on the incident response process, a focus on learning from individual incidents, that’s like your post-mortems, your incident reports, just chatting with people outside the war room. Then, macro insights. You don’t have to do it all. You can if you want to. Often, it’s hard to find an organization that’s going to say like, yes, go ahead, spend all your time doing all of this. There are ways that you can start doing this, one by one. I will go through all of them throughout this talk. First, some caveats. Being successful at resilience is not easy. It’s not easy. It’s not fast, and it’s not cheap. A lot of this requires just like selling this new way of working with resilience as a focus. Selling isn’t our best skill as technologists. Maybe instead of selling, we should call it, presenting our data and our work and making a case for it. The good news is that I have seen this work, and we can definitely get many small wins along the way.
A Focus on Incident Response
Let’s do our first area of focus. What does it look like to focus on incident response? When you focus on incident response, you’re focusing on these three things. You’re focusing on coordination, collaboration, and communication. It makes sense to start here. This is the thing that we are already paying for. We’re already spending time in outages, so we might as well focus on them. When it comes to coordination, write up your current response workflow. How do folks come together to solve a problem? Look for any gaps. Where are things breaking down? What can be done to make those gaps even just a tiny little bit smaller? When it comes to collaboration, how do you get people in the same room? Is that room Zoom? Is that room Slack? Is that room Google Meet? How do you know who to call? Is it the same people every time? Maybe it’s that one expert that wrote the thing 10 years ago. You should examine your on-call rotations and your expectations. Again, what are the little things that we can do to make the lives of those on-callogists a little bit better, just a little bit easier? Then finally, communication. How do you communicate to your stakeholders what is happening? How do you tell your customers? What is hard about it? What are they asking for? Do your engineers know what your users care about, or are they going like, Kafka. When really people are caring about like, can I get approved for my loan or not? Write up some loose guidelines to help manage expectations for folks both inside and outside the immediate teams that are responsible for responding to incidents.
While it makes sense to start an incident response, why aren’t we perfect at it yet? Why aren’t we putting in the effort into getting better at this? There are a few reasons for this, including that we need to train folks on the process. I think, oftentimes, we get a new engineer, we give them the pager, and then they say good luck. Every organization has different needs and different ways of working. When we need to get our services back ASAP, there are certain procedures that make sense. You want to teach folks the skills that help the incident move forward, that urgency. That like, don’t come at me with like, “If only we had done this, if only we had done that?” That idea of hierarchy versus roles. You don’t want people during an incident to focus on hierarchy, even though that’s how they’re used to working. Thinking about the roles that makes sense for incident response, like who is the person in charge of this incident? Who is the person that’s in charge of communicating? Who are your stakeholders versus who are your responders? Do they need to know different information? Do they need to act differently? Additionally, many of the changes in this area of focus will require specific tools and specific automations. Sometimes you have these tools that lead to the highest cognitive load, and these things can be automated, but maybe teams don’t have the right tools for this, or they just don’t have the bandwidth to create these tools to develop them if they’re stuck fighting fires.
Here’s where I quote my friend, Fred Hebert. He actually wrote a great blog post for The New Stack about Honeycomb’s incident response process. They basically are growing as a company, like a lot of our organizations are, and they were running into some issues with their incident response process. He said, “While we ramp up and reclaim expertise, and expand it by discovering scaling limits that weren’t necessary to know about before, we have to admit that we are operating in a state where some elements are not fully in our control.” Fred was trying to balance two key issues. They’re trying to avoid an incident framework that’s more demanding to the operator than solving the issue. We’ve all been there, where you have these runbooks that they’re so long, and it’s like, this is taking me away from actually resolving the thing. You don’t want your runbook to just take so much time and so much effort that it is keeping you from resolving your issue. You also want to provide support and tools to people who have less on-call experience, and for whom these clear rules and guidelines actually do make sense. I’ve seen this throughout my career. If I’m an experienced responder, I don’t need to read all of those things. I don’t need to follow all these procedures. If I’m trying to onboard somebody, like they’re not going to be able to read my brain. We worked together on a process that automated certain tasks, used our incident bot. Some tasks that can be automated, like creating an incident channel or communicating status updates to stakeholders. Doing that leaves the engineers the time to focus on the actual engineering part.
At Honeycomb, as well as other organizations, the idea is to get quick wins, like just weeks into the process of trying to fix your incident response. You can do this by restructuring on-call rotations, making sure that the page is going to the right responder. Automating some response tasks, like I mentioned, creating Slack channels. Automating how you update some folks. This allows us to spend less time on the task that demand our attention during incidents, but aren’t necessarily engineering tasks. Because you never ever want to automate the creativity and the engineering skills of responding. There are things that we can do to just reduce that cognitive load during the high stress times. Improving little things, it’s going to help you build momentum and get buy-in around making larger changes, both from leaderships as well as the folks holding the pagers. If you think back to my example of my children, getting those small changes of like, let’s switch to formula, allowed me to get some sleep so that then I could work on the bigger changes. A focus on incident response can help improve the process, leading to a better experience to your users and engineers. Leads to spending fewer time on repetitive tasks, easier onboarding for on-call. Just a more efficient process and lower customer impact, which is obviously what we care about.
Anti-Pattern: MTTX
Which leads me to my first anti-pattern that I will discuss, my version of MTTX. You’ll hear me talk about MTTX a lot. By that I mean your mean time to discovery, mean time to recovery, mean time to resolution. I’m on the record of saying that they don’t mean anything. Because if I say, we had 50 incidents in Q1, and they average 51 minutes. What is that telling us? It’s not really telling us anything. That doesn’t mean that like, I think we should just not care about how long our incidents last. I wanted to get those Taylor Swift concert tickets, I’m like, I wanted to get them now. I just think that a single number should not be our goal. What I do believe in is that we want to make the experiences for our users and our engineers better, because that is actually what’s going to help us get ahead. There are things that we can do to make the incident response easier and faster so that our engineers are better equipped to resolve them. Just like we will never be at like incident zero, we’re not in control of everything. That single timing net metric, just should not be the goal.
A Focus on Incident Analysis
The next way that we apply resilience is when we focus on incident analysis, that’s like you’re learning from incidents. After an incident, you want to learn from it, or about it. I believe that the best way to do this is this narrative-based approach that can highlight what happened, and can highlight how folks experience the incident from their different points of view. How I experience an incident as a responder is going to be different how my user experiences an incident, how my customers or folks experience an incident, how my stakeholders experience an incident. What we have seen is that those template filling sessions, those 5 why’s of root cause analysis, they can be helpful. Sometimes they’re not helpful. Sometimes it can actually cause harm, because they make you feel like you’re doing something. They give us this false sense of security, when in reality they’re not doing much. There’s more that you can do. I’ve done this myself. I’ve seen it many times. You have this root cause analysis session, and we say, the root cause is human error, so let’s just never do that again. The action item is for that person to just never do it again. That’s not much to get out of 1 hour with 15 engineers. If you have this blame-aware, learning-focused review, you can highlight different things. Maybe you can highlight that the new on-call engineer didn’t have access to some of the dashboards that can help out with the response. Maybe you can highlight that you have a QA process that just doesn’t account for certain requirements. Or my favorite, when you realize that engineering and marketing aren’t talking to each other, and there’s a new feature that they’re announcing, and we just don’t have enough capacity to handle it. Those are things that we can learn from and that can actually move the needle when it comes to resilience.
Why aren’t folks doing this right now? Like I said, people think that they’re doing this. People think that they’re doing 5 why’s of root cause analysis. That is not the same as a narrative approach. I think part of it is that when we think of a narrative approach, we usually default to timelines. Creating timelines is a lot of work. I’ve done this for many years. You have two screens, you have three screens, and you’re copying and pasting. You got Slack here. You got a Google Doc here. Then you have to open GitHub and PagerDuty. You’re switching from different data sources, and you’re summarizing conversations, and sometimes stuff just gets along the way. Then if you’re like, I don’t want to do this. I’m not going to do this prep. You have your post-mortem. Like I said, you have like 15 engineers for an hour. Then you’re spending that time just building that timeline. That’s not really a good use of your time. Your people aren’t actually talking and collaborating. Then this leads to folks just not trusting the post-mortem, the learning process. If you want to know more about how to do incident analysis, we actually put out a free guide for doing this. This is called the Howie guide for how we got here. Dr. Laura Maguire was one of the co-authors, as well as myself. Here we outline a 12-step process to help you best understand how you got to where you ended up. I laugh at the 12-step process, because it’s long. You assign. You accept an investigation. You identify your data. You prepare for interviews. You write up this calibration document. You help wrap up your investigation. You lead a learning review. You do an incident report. You do more findings, and you share it. You do all of this. John Allspaw is amazing at this. I love it. I think it’s great. This is a lot. You can do this or you can actually take from this and take the spirit of what this is, which really is just like a collaborative narrative approach.
If you break it down to the basics, you want to identify your data sources. You want to try and understand who wasn’t actually involved in the incident, not just the person who responded to the incident, but like, who were the stakeholders? Are there PMs involved? Are there marketing folks involved? Are there your customer support folks involved? Where in the world were they? What were they dealing with? Like if I’m in Chicago, and I have somebody in Sydney, we are interacting differently because we had different parts of the day. Where did it take place? Were people in-person? Were they in Slack? Were they looking at each other face-to-face? Then you want to prepare for your meeting. You want to create your timeline. Usually this is where I go in Slack, I create a narrative timeline. I jot down any questions that I have for people. I can have an interview, or I can have those questions be at the review meeting in front of everyone. You can cheat. You can look at the top moments, but really, the key moments are the ones where people are not knowing what they’re doing, not knowing what to do. Then you have your meeting. When I’m leading a meeting, or when I’m doing an interview, it should never be the Vanessa show. It shouldn’t be like this, where I’m here and I’m lecturing you all. It should be a collaborative conversation. People should be able to tell me what they experience from their own point of view. Like, “I’m a customer support person and I was getting inundated with requests from our users.” That’s impacting how I experience the incident. Then you finalize your findings. You finalize them in a format that you can share with others, that others are going to understand. Depending on your audience, you will want to share different information with them.
We want to make it as easy as possible for people to do this. Doing a narrative-based approach can take weeks, or it can take 20 minutes. Here’s a narrative builder, which we have in Jeli. The idea is that you take your different data sources, and you create this narrative. Here, you can see that an incident is never like, we released this bug, and we reverted the bug, and now we’re done. You can understand that maybe the reason why the incident lasted as long as it did was because some people realized halfway through the incident, that they didn’t have the full impact of what was going on, because they were looking at different dashboards. Knowing that can lead to actual learnings and actual change in how we do our work, which has direct impact into engineers meeting their goals. Engineers not looking at the right dashboards has nothing to do with the bug, but it has a lot to do with how we respond to incidents. It’s really important to give people the ability to create these documents, to create these artifacts that they can then share with others, to give them the ability to share how the incident happened from their own points of view.
Then we talk about action items, because, historically, we all think of retrospectives as a source of action items. I really believe that the action items should reflect the insights that we gained from the narrative and from the incident reviews. That it should reflect what we learned about the contributing factors and the impact. The action items shouldn’t be just like, revert this bug and be done with it. We’ve seen this in the wild. We’ve seen some examples of people that I’ve worked with. At Zendesk, they had an incident that highlighted the need to just rethink their documentation and the information that’s in their runbooks. They did this narrative builder exercise, and they realized that the responders just don’t have access to the right things, or they’re working with outdated information. I’ve been there as a responder as well. I’ve been there where I pull up a wiki page, and they have just things that worked two years ago. You’re understanding what things we can do in the future to make things better for the engineers themselves that are solving incidents today.
At Chime, another organization that we work with, they did an incident review, and they realized how some of the vendor relations impact the way that an incident is handled, in order to improve the process. Because at the end of the day, it’s important to know how to get a hold of a vendor. Sometimes the people who are on-call are not the ones that either know how to find that person or have the access to do that. Even knowing what parts of the process belongs to vendors versus us makes a huge difference next time that we have an incident. Again, we’re never going to be at incident zero, so these action items are helping us solve incidents in the future. A focus on incident analysis can identify the areas of work that’s going to lead to engineers working effectively to resolve issues, so that the next time that they encounter another incident, similar incident or otherwise, there’ll be better positioned to handle it, leading to just lower customer impact and fewer interruptions.
Anti-Pattern: Action Items Factory
Then my next anti-pattern is this idea of the action items factory. When I talk about resilience, I just want to make sure to stay away from the anti-pattern of being an action items factory. The idea that we have an incident and a post-mortem, and all we do is just play Whack a Mole, and like, let’s have an alert for this, an alert for that, an alert for that. We’re going to put them all in this Google Doc and this Jira thing that’s never going to get prioritized, and it’s going to be there forever. Because that’s not good. It erodes trust in the process. I remember when I started at a previous organization, I’d go in there. We have 100 incident reports open because they all have 10 action items that are still open from 5 years before. I was still in college back then. If the goal of the incident review is to come up with fixes, but the fixes never get done, then engineers and stakeholders aren’t going to take them seriously. Instead, they’re going to feel like the retrospectives are just a waste of time for a group of people that are already really busy. Instead, we should look at resilience that’s coming out of incidents as part of different categories.
What’s the problem with the action items today? What we hear often is that action items just don’t get completed. If they do, they don’t move the needle. That’s like, let’s just play Whack a Mole and create more alerts. Another problem is that they’re not applicable for the whole organization. Maybe it makes sense for one person, but it’s not going to get done. It’s not going to actually move the needle. It’s almost as if finding the right action item is like a bit of a Goldilocks situation. When we think of action items that are too small, I think they are things that shouldn’t really be action items in the first place, because they’re already being taken care of. Engineers love solving issues. I was trying to troubleshoot my newborns. They shouldn’t wait for the post-mortem to address these issues. They shouldn’t wait for the post-mortem to do a cleanup, or fix a bug, or something like that. We shouldn’t spend our precious post-mortem time on these. I do think that folks should still get credit for them. I think they should still be included in the artifact, because when we have an incident that is similar to that, again, we’re going to want to look back and try to see what we did.
Then we have the two big action items. The problem here is that they’re going to take just too long to complete. You have action items that are going to take whole years to complete, and by then we are not even having that product anymore. If you’re tracking completion, which a lot of companies do, that’s going to skew your numbers. We can talk more about numbers and stuff like that later. The other problem is that the people who are in the meeting, the people who are in the post-mortem aren’t the ones who get to do the work, aren’t the ones that get to decide. Maybe it’s a cross-team initiative, or maybe I say I’m going to do this, but my manager is never going to give me the time to do it. These large action items are still important takeaways from the post-mortems. In that case, I actually recommend that you keep them and you call them initiatives, and you just have them in a separate space in your artifact. Or, rethink the scope. Instead of the action item being like, let’s rearchitect this thing. It’s like, ok, let’s have a conversation about what it would take to rearchitect this thing. Or like, let’s have somebody drive the initiative. Another tip that I have is to always have an owner for your action item. This actually really helps with accountability. I actually recommend having a direct owner as well as an indirect owner. This is a hot tip that I did at a previous organization where like, if I had the action item assigned to my name, my director also gets it assigned to their name. Then eventually, they feel embarrassed for having so many action items open, and they’re like, “Ok, Vanessa, how about you get the time to do them.”
What does the perfect action item look like? It’s usually something that needs to get prioritized, and that will get prioritized. It’s something that can be completed within the next month or two. You don’t want it to last forever. Again, that’s an initiative. It’s something that can be decided by the folks in the room. It’s also a good flag to invite a diverse group of people to these reviews: you want your managers, you want your product managers. It’s something that moves the needle in relation to the incident at hand. I really like this chart, mostly because I created it. It shows the difference between all of these things that I mentioned. It shows the difference between a quick fix, like your cleanups, and an action item. Redesigning a process, updating documentation. Your larger initiatives, switching vendors, rearchitecting your systems. Then a transformation that can actually take place out of an incident, like org changes, headcount changes, things like that.
Let’s go into an example of how to get there. Here, you can see that we are creating a narrative. We’re looking at a specific line in the Slack transcript. We’re asking a question, in this case, about service dependencies, and how they relate to engineers understanding the information that’s in their service map vendor. I’ve been in incidents like this, where you realize that you have the service map vendor, and they have an understanding of how things work, and we have a different understanding, and things just don’t match up. Here you can see how that question made it into a takeaway around what the service touches and what it depends on. Finally, in the report section, you can see that there are action items around the understanding of the dependency mapping. You can see that these action items meet the requirements that I said earlier. They have ownership, they have due dates, and they move the needle in how we respond to incidents in the future.
A Focus on Cross-Incident Insights
Finally, we have a focus on cross-incident insights. Cross-incident insights is the key to getting the most out of your incident. You will get better quality cross-incident insights the more you focus on your individual high-quality reviews. It’s really a great evolution from that process. The more retrospectives, post-mortems you have, the more data you can then use to make recommendations for larger scale changes. Doing this shouldn’t be one person’s job. We’re going to talk a lot about collaboration. We’ve talked a lot about it the past few days. This is done, I believe, in collaboration between leadership, multiple engineering teams, product teams. It’s your chance to drive those cultural transformations that I mentioned earlier. Maybe you’re deciding that you want to DevOps part of your process, or you want to rearchitect the system, because you have the breadth of data, and you have the context to provide leadership for future focused decisions. We spoke earlier about having goals around metrics. Doing cross-incident analysis is actually allowing you to provide context around those timing metrics and make recommendations for how to improve the experience for our users and our engineers.
Why aren’t folks doing this? A lot of people want to do this, and they actually think that they’re doing this, but they aren’t. That’s because they just don’t have the data. High quality insights come from high quality individual incident reviews. It’s very hard to get good cross-incident analysis if you’re not doing actual incident analysis. Also, the place where our incident reports live, are not friendly for data analysis. If you have something living in a Google Doc, like Google Docs are great for narrative storytelling. They’re not very easily searchable, or queryable, or anything like that. Most importantly, and this is something that is close to my heart, is that a lot of people think that they can be analysts, but engineers are not necessarily analysts. That’s ok. If you want to do this work, you need training and presenting data in friendly formats. You need to know how to use the data to tell a story. All of this is hard work.
Here are some examples of some cross-incident insights that are coming with context. This is coming from Jeli’s Learning Center. Instead of simply saying we had 300 incidents this year, we can take a look at the technologies that are involved, and we can make recommendations based off of that. I can say that something in the past year related to console was involved in most of the incidents, let’s take a look at those teams, and maybe give them some love. Maybe help them restructure their processes, focus on their on-call experience.
Make those recommendations to make their lives better, if we want to lower that number. Again, this stuff works in the wild. We worked with Zendesk. They were able to look at their incidents, and they were able to make recommendations around the rotations of certain teams and technologies. Had they not had the data from individual incident analysis, making this case would have been a lot more difficult. We have our friends at Honeycomb as well. They use this information to drive continuous improvement of the software. We’ve seen people use these insights to decide on a number of things, feature flag solutions, switching vendors, even making organizational changes from cross-incident analysis. I actually was part of a reorg. Thanks to that, where I was like, our SRE team is like, we have so much stuff going on, let’s try to split things up. Let’s try just experimenting something. These are the larger initiatives that we discussed. All of this creates an environment where engineers are able to do their best work and achieve the goals of their organizations.
Now let’s go back to MTTX. Here’s the part that I will tell people, “I will never tell an analyst to tell their CTO that the metric that they’re requesting is silly, and that they’re just not going to do it.” Because I’ve been that engineer, I’ve been that analyst, and I did not get paid enough to have that conversation. When you have leadership asking for these metrics, take this as an opportunity to show your work. I call this my veggies in the pasta sauce approach. Now that I have children, I should call it like the veggies and the smoothie’s approach. It’s the idea that you’re taking something that maybe you don’t think has much nutritional value, which is that single MTTR number, like 51 minutes. You’re adding context to make it much richer, to bring a lot more value to your teams and to your organizations. It can help you make strategic recommendations about the data that you have. It really helps move the needle in that direction that you want. You can show that maybe incidents lasted longer this quarter, but the teams that maybe had the shorter incidents, they have some really cool tools that they’ve been experimenting with. Maybe we should change that and give other teams access to that, spread them across the organization.
Anti-Pattern: Not Communicating the Insights
That leads me to the last anti-pattern, which is, again, something we’re not very good at as engineers, and it’s communicating our insights. Because if we have insights but nobody sees them, what’s the point? In Jeli’s Howie guide to incident analysis, when discussing sharing incident findings, we explain that your work shouldn’t be completed to be filed, it should be completed so it can be read and shared across the business, even after the learning review has taken place and the corrective actions have been taken. This is true about individual incident analysis, but even more so about cross-incident analysis. I’ve been an engineer my whole life, and I know how we are. We’re like, we all know what we need to do, we just are not doing it. Senior leadership would never do this. We’re like, yes, that’s true, but do we all know that? Have we told other people this? Often, when people don’t interact with our learnings, it’s because the format just isn’t meant for them. Different audiences learn from different things in different ways. If you’re sharing insights with your C-suite folks, maybe your CTO is going to understand the extremely technical language that you’re using, but everybody else is going to be looking at their phones. You need to use language that your audience is going to understand. You should focus on your goal. Why are you sharing this? Think of the impact. Don’t spend too much time going through details that just aren’t important to your goal. If you want to get approval to rearchitect a system, explain what you think it’s worth doing, what problem it’s going to solve, and who should be involved.
Focus on your format. Whether that includes sharing insights, sharing numbers, telling a story, and sometimes those technical details. I usually like to think of my top insights. For example, I will go up to CTO and say, “Incidents went up this quarter but usage also went up.” Or the example that I mentioned earlier, SREs were the only on-call incident commanders for 100% of our incidents. There’s your number. As we grow, this is proving to not be sustainable, so I think we should change this process and get product teams involved. That’s how you move away from like, we all know what’s wrong, and nobody’s doing anything, to actual changes. I’ve had this experience before. The SREs in getting product teams involved made a change. I’ve rearchitected actual CI/CD pipelines by going up to people and saying, “So many of our incidents, the root cause isn’t how we release things, but it is impacting how long it takes us to resolve them. After talking to all of these subject matter experts, I think we need to have a project this year where we rearchitect this whole thing. I know it’s going to take some time. I know it’s going to take some money, but it’s necessary if we want to move forward.” Because you’re not suggesting this 4-month project because you feel like it, you’re suggesting it because you have the data to back it up. If you’re asking me for these MTTR numbers, I’m going to give them to you but I’m also going to use that as an opportunity to give you the context, and to give you the recommendation of the thing we all know we need to do.
Going back to this chart, so instead of thinking of action items, or just recovering from downtime, being the only output of your resilience work, let’s think of this as the product of treating incidents as opportunities. Doing this work is how organizations get ahead: how we make org changes, and headcount changes, and transformations. Because we will never be at zero incidents. Technology evolves and new challenges come up. By focusing on resilience, on incident response, incident analysis, cross-incident insights, we can lower the cost of them. We can be better prepared to handle incidents, leading to just a better experience to our users. A culture of where engineers are engaged, and they have the bandwidth to not only complete their work, but to creatively improve things. That’s why we’re hiring engineers and paying them a lot of money. To just achieve and surpass our goals, which means that people can make more money.
See more presentations with transcripts
MMS • RSS


.pp-multiple-authors-boxes-wrapper {display:none;}
img {width:100%;}
MongoDB has made its multi-cloud developer data platform MongoDB Atlas available in six additional cloud regions in Canada, Germany, Israel, Italy, and Poland — now said to be the most widely available developer data platform in the world.
With this expansion, MongoDB Atlas is now available in 117 cloud regions across Amazon Web Services (AWS), Google Cloud, and Microsoft Azure to meet the demands of more customers with data residency, availability, and latency-sensitive application requirements. For customers that need ultra-high availability or want to more easily combine services from different cloud providers, MongoDB Atlas is the only globally distributed developer data platform for seamlessly running applications across major cloud providers simultaneously. To get started with MongoDB Atlas, visit mongodb.com/atlas.
Sahir Azam, chief product officer at MongoDB, said: “Since introducing multi-cloud clusters on MongoDB Atlas that can run across AWS, Google Cloud, and Microsoft Azure, we have made it easy for customers to control where their data resides by distributing it across major cloud provider regions to meet data sovereignty, regulatory, and performance requirements for their applications.
“Multi-cloud clusters on MongoDB Atlas also give customers the flexibility of seamlessly using cloud services across major providers for their application needs. With the addition of six new cloud regions around the globe, we’re providing greater choice for customers to build modern applications with MongoDB Atlas and to meet the unique demands of their businesses. From customers just getting started migrating and modernising legacy applications, to those now deploying new generative AI capabilities, we’re providing even more flexibility in where and how they run their workloads using MongoDB Atlas.”
In addition to the broadest choice of available cloud regions, multi-cloud clusters on MongoDB Atlas give customers the ability to combine different services from AWS, Google Cloud, and Microsoft Azure to build, deploy, and run modern applications. For example, with a MongoDB Atlas multi-cloud cluster, organisations can use data from an application running on a single cloud provider and process that data on another cloud provider without the complexity of manually managing data movement. Organisations can also use data stored in different clouds to power a single application or to easily migrate an application from one cloud provider to another as their needs evolve.
To meet the growing demands of customers — from startups, to enterprises, to governments across the globe — adopting and expanding their use of MongoDB Atlas to build modern, intelligent applications, new available cloud regions include:
- New on AWS: MongoDB Atlas is available in 31 AWS regions globally, now including Canada West (Calgary) and Israel (Tel Aviv), and is integrated with a variety of AWS services such as Amazon SageMaker and can be used with Amazon Bedrock to build AI applications. Customers building applications with MongoDB Atlas on AWS can also take advantage of AI-powered coding assistance using Amazon CodeWhisperer, which is trained on MongoDB code and best practices through a collaboration between AWS and MongoDB. Customers that must meet regulatory requirements for public sector workloads can run MongoDB Atlas in the AWS GovCloud region for mission-critical applications.
- New on Google Cloud: MongoDB Atlas is available in 38 Google Cloud regions globally, now including Germany (Berlin), and is integrated with several Google Cloud services, including BigQuery and Vertex AI for building AI-powered applications. For MongoDB customers in government or regulated industries that want to take advantage of Google Cloud services but run workloads with the most sensitive data, MongoDB Enterprise Advanced is now available on Google Distributed Cloud Hosted (GDCH), and MongoDB is a preferred partner for the solution. MongoDB Enterprise Advanced on GDCH provides customers an air-gapped environment in a private cloud for sensitive workloads that must meet the most stringent data security and privacy requirements — while taking advantage of the performance, reliability, and highly flexible document data model MongoDB customers expect.
- New on Microsoft Azure: MongoDB Atlas is available in 48 Microsoft Azure regions globally — now including Israel Central (Tel Aviv), Italy North (Milan), and Poland (Warsaw) — and is integrated with several Microsoft Azure services, including Microsoft Fabric and can be used with Azure OpenAI and Microsoft Semantic Kernel for building AI-powered applications. MongoDB Atlas Online Archive and Atlas Data Federation are also now generally available on Microsoft Azure, allowing customers to automatically tier Atlas databases to the most cost-effective cloud object storage option while retaining the ability to query data, along with a seamless way to read and write data from Atlas databases and cloud object stores. This dramatically simplifies how customers can generate datasets from MongoDB Atlas to feed downstream applications and systems that leverage cloud storage. MongoDB Atlas Online Archive and Atlas Data Federation are generally available on AWS and will be generally available on Google Cloud later this year.
International Data Corporation (IDC) is the premier global provider of market intelligence, advisory services, and events for the information technology, telecommunications, and consumer technology markets.
Lara Greden, research director, Platform as a Service at IDC, said: “With the pervasiveness of generative AI, it is critical that organisations choose cloud-based technology partners that offer them the flexibility needed to innovate and get new application experiences to market quickly.
“Organisations need to be able to use the best tools from cloud providers to meet their specific needs, and platforms like MongoDB Atlas and its multi-cloud reach help make that possible. As the growth in deployment of cloud-native applications continues, companies that want to gain a competitive edge must be strategic about their choice of platforms that can both work across different types of data and with different cloud providers.”
For organisations that must meet local regulatory compliance, data privacy, or low-latency application requirements, global clusters on MongoDB Atlas can geographically partition databases across cloud providers to better control where all or some data resides. With just a few clicks, MongoDB Atlas provides recommended global cluster configurations and places relevant data near servers in specific locations around the world to deliver high performance while meeting an organisation’s application requirements. By defining a geographic location for partitioned data, organisations using global clusters on MongoDB Atlas are able to more easily satisfy compliance and privacy measures without trading off performance. To get started, visit mongodb.com/cloud/atlas/multicloud-data-distribution.
Along with providing flexible options for data governance and the broadest choice of available cloud regions for its developer data platform, MongoDB also offers on-premises, edge location, and hybrid cloud options with MongoDB Atlas for the Edge to build, deploy, and run modern applications that meet end users anywhere. To get started, visit mongodb.com/use-cases/atlas-for-the-edge.
Millions of developers and tens of thousands of customers across industries — including Cathay Pacific, Cisco, GE Healthcare, Intuit, Toyota Financial Services, and Verizon — rely on MongoDB Atlas every day to innovate more quickly, efficiently, and cost-effectively for virtually every use case across the enterprise, including multi-cloud workloads:
Monoova is a fast-growing Australian fintech company, providing real-time payment solutions to businesses.
Nicholas Tan, CTO at Monoova, said: “Our multi-cloud approach is pretty unique in the current financial services landscape, and this is what has made Monoova one of the first financial services organisations to align with the new CPS230 compliance framework in Australia, along with ensuring compliance and resilience in an environment heavily reliant on third parties.
“Working with MongoDB has been a game changer because it means we were able to quickly scale up at a fraction of the person resources required, saving us from recruiting a full team with highly specialised skills if we had to take on all the multi-cloud work in-house.”
Check out the upcoming Cloud Transformation Conference, a free virtual event for business and technology leaders to explore the evolving landscape of cloud transformation. Book your free virtual ticket to deep dive into the practicalities and opportunities surrounding cloud adoption. Learn more here.
MMS • Sergio De Simone

The Fused Orientation Provider (FOP) is a new Android API that uses signals from motion sensors embedded in a smartphone to provide consistent and reliable device orientation. FOP is distributed through Google Play Services and is available on all devices running Android 5, independently from their manufacturers.
The main advantage of using FOP is its ability to mix signals from the magnetometer to those coming from the accelerometer and gyroscope, which were already used for the Android Rotation Vector. Similarly to FOP, the rotation vector reports orientation using quaternions, whose main benefit is they work correctly even when the rotation vector gets close to 90 or -90 degrees.
The FOP then outputs a stream of the device’s orientation estimates as quaternions. The orientation is referenced to geographic north. In cases where the local magnetic declination is not known (e.g., location is not available), the orientation will be relative to magnetic north. In addition, the FOP provides the device’s heading and accuracy, which are derived from the orientation estimate.
Although Google says FOP does not replace the rotation vector, they designed the new API to make it easier for developers to adopt it.
To use the new Fused Orientation Provider, you subscribe to the requestOrientationUpdates service by providing a DeviceOrientationRequest where you specify a desired frequency range for the updates.
Updates are sent to a DeviceOrientationListener that updates the state of your app. The choice of the update frequency is especially crucial for power consumption, since too a high frequency might significantly increase battery usage. If you do not know which update period to use, Google suggests starting with DeviceOrientationRequest::OUTPUT_PERIOD_DEFAULT, which shall fit most use cases.
Additionally, FOP can compensate for lower-quality sensors and other OEM-related variations. As usual in the Android ecosystem, there exists a wide variety of hardware sensors available, differing in accuracy, speed, sensitivity to interference, and so on. To improve sensor performance, FOP performs a number of tasks, such as synchronizing sensors, compensating for magnetometer bias and gyroscope drift, and more.
FOP is only available on devices that include an accelerometer, a gyroscope, and a magnetometer. Furthermore, it does not support sending orientation updates to apps running in the background.