Transcript
Jindal: Ten years ago, I relocated to San Diego. After looking for a while, I finally found a clean, nice apartment. I was super excited. It had a lot of shared amenities, which I thought my family and friends can use whenever they come to visit us. Then there was one noisy neighbor named Shawn. He just loved to do the parties. Most of that weekend, his friend came over and just grabbed all the shared amenities. It got to be such a frustration at the end that we finally decided to move out. You must be thinking why I’m sharing this story with you guys. Noisy neighbor is just not limited to living in real life, now it’s become a common problem in our multi-tenant distributed architectures. I’m here to talk about some of the survival strategies to avoid that drastic step of relocation by our tenants, which is very crucial for our multi-tenant platforms. Single tenant, each application has its own compute, infrastructure, database, happy scenarios, but it comes with a cost if you’re ready to pay for it. Multi-tenant, it can be further categorized into two types. Type 1, where each application has its own compute and infrastructure, but different databases, separation of data concern. Type 2, where applications share both the compute, infrastructure, and the storage. Each one comes with its own set of benefits and challenges. We’re going to talk about the multi-tenant type, which is indeed the one variable to the noisy neighbor problems that we’re going to discuss. What is a noisy neighbor? One application trying to monopolize the system resources, creating downtime for other tenants on your platform, slow performance, degradation. What can contribute to it? Increased request thresholds, resource-hungry payloads. The most well-known which we love, the script error by one of our clients, causing hell on our platform.
Asset Management Platform (Netflix)
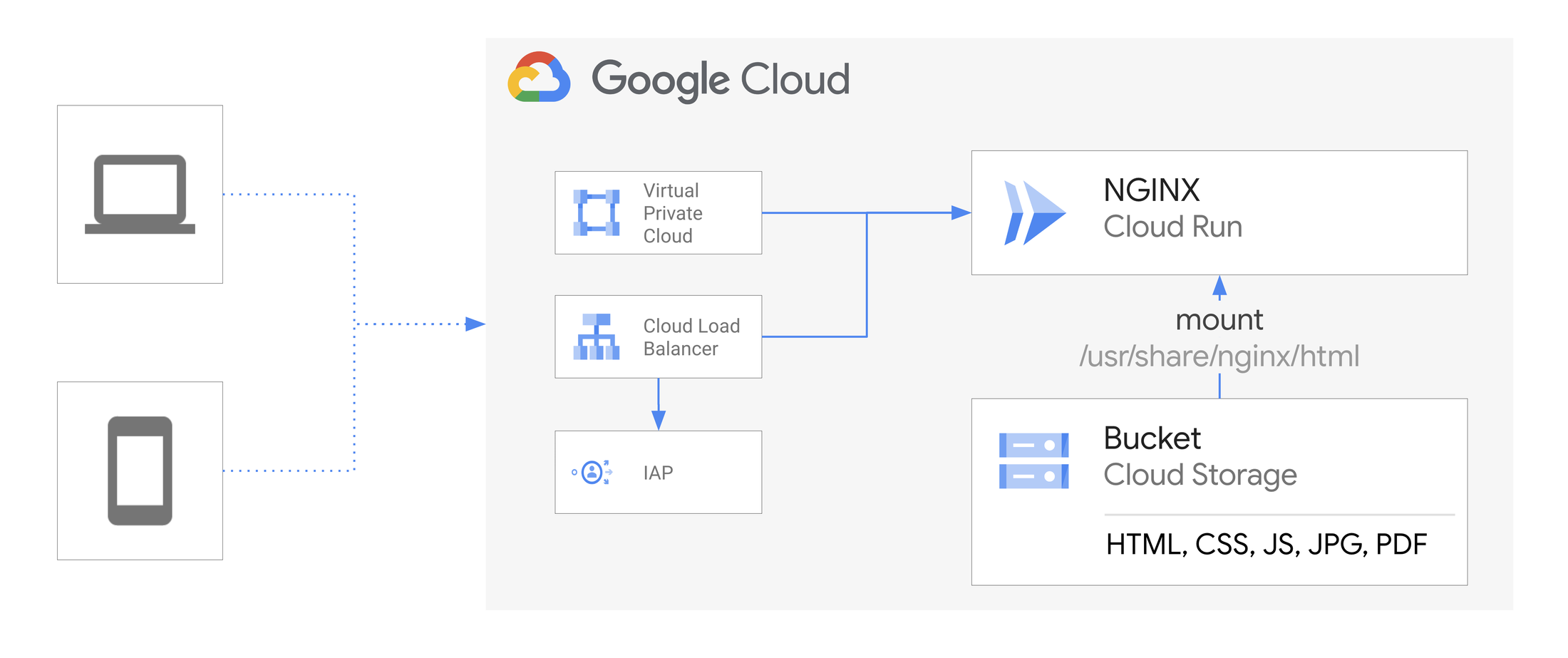
I’m going to share some of the noisy neighbor stories from the asset management platform at Netflix. It is a centralized platform used by more than 80 studio applications to store, track, organize, discover, distribute millions of digital assets you can think of in a production or the post-production workflows. An asset is very critical for the production with its unique contribution to the final content. An asset can be created by one application, but it can be discovered by many other applications to stitch the final content. That’s a reason to go with the type 2 that we just saw to support the global discovery of the assets by multiple applications during the production workflows. Content creators are the backbone of the media industries. Imagine the chaos and frustration it is going to cause in the production world if this platform is not accessible. They spend hours to create the media and they’re uploading onto the system, and after upload, asset is not discoverable. Think for a minute, they’re lost. What should I do? Should I try to upload again? Isn’t my asset uploaded, or is it lost? They’re just simply lost if this platform is not reliable. Get ready for an exciting journey behind the scenes world of media asset management work at Netflix. What is a media asset? It can be a single asset like video, audio, image, multi-3D content, or it can be a giant tree of composite assets like camera roll, which is a logical grouping of hundreds of assets in one tree. You must be thinking, why am I sharing it with you? We’ll get to it later.
This platform is designed with a distributed architecture. Smooth functioning of this platform further relies on many other components of the Netflix, like storage, archival, and many other media processing services like encoding, inspection, shotchange analysis, and many other analyses that you can think of that runs on video. Every asset ingested into this platform goes through a validation process and then ingest it into different databases like Cassandra, which is our primary source of truth. Elasticsearch to support the real-time asset discovery. Iceberg, or you can say analytics database, which is to support the data science engineering use cases to get the asset inside the dashboard, or to discover those assets by machine learning platform, to build or train their data models. Every asset operation creates an asset change event, which will listen by this workflow management service. Depending on the change in the state of the asset, it triggers various technical and business workflows, which further cause many other microservices of Netflix. Have you ever encountered a situation where your stable platform suddenly becomes slow, unresponsive? After debugging, you realized there is one traffic coming to your platform and creating a noise in your stable platform? That happened to us. Last year, one of the legacy applications started migrating their assets from siloed application into this centralized platform so that every other application can discover these assets. That resulted in a lot of warnings here and there. You can see some of the instances turned into the warning state, some of the instances turned into the red state. End result, apocalypse: alerts all over the place. Many services got impacted by this. As you can see, we started getting the alerts from our services and the dependent services, and some of the services started getting down, some of the services getting slow.
Pager Alerts
Pager, who loves the pager? We would like to get paged by our alerts not by the client who is getting impacted. In this talk, we’ll share how can we avoid the pagers coming from our clients and we should be paged by ourselves. One noisy traffic resulted in the apocalypse of the shared infrastructure. This can cause widespread slowdowns, crashes, outages, system failures, degraded performance, unavailability. End result, application dissatisfaction and loss of trust. Most crucial for any platform, you want to have a reliable platform for all your tenants, and avoid that, again, drastic step of relocation by your tenants from your platform.
Preventive Strategies
They categorize these strategies into three types: preventive, diagnostic, and the corrective. What are the preventive strategies? These are the proactive steps that we take during the design of our application to make sure that we give a reliable and stable platform to all our tenants. The first and foremost, anticipate and provision the resources. You need to have a deep insight of your architecture and what your tenants are looking for, to provision the resources. You have to provision the resources on the application layer and the infrastructure layer. All that seems easy, we say autoscaling. Autoscaling gives the elasticity in our infrastructure to scale up and down depending on the load on our platform. What makes it difficult to set up these autoscaling policies? Resources are not unlimited. You cannot scale up infinitely, you need to know the limits of your autoscaling. Knowing the limits, you need to know the dependent infrastructure limitations and your dependent services threshold. You want to do the scaling, but you want to do the scaling in such a way that you are not compromising the overall system health. Databases. With our modern distributed architecture, most of the applications try to use distributed databases. We try to design the data partition strategies in such a way that our data is distributed across multiple nodes in the distributed database. Problem happens, issue happens, especially when you want to scale up. How many of you have experienced a situation where you want to scale up your database, you’re trying to scale up horizontally, but things are not working? The only thing which is increasing is your cost, the cost of your infrastructure. What is not getting improved is the performance that you’re looking for. After debugging, what do you realize? You have the hotspots. You have hotspots in your system. You have tombstones. What is a hotspot? Anyone experienced the hotspot problem in your databases when you’re doing scaling? One subset of your database experiencing the high activity, most of the read-writes are going to that particular specific node sitting in your database. Regardless of how much scaling you’re doing, it is not increasing or impacting the performance that you’re looking for. Tombstones. With distributed databases, sometimes when you’re trying to delete a document, they don’t immediately delete that, they mark it to be, to be deleted. If you don’t pay careful attention, and in your flow, you design in such a way that you’re deleting a document and you’re creating it, then it can increase your tombstones. Tombstones start slowly increasing. They are very heavy for the performance and the storage. Now question will come, how you will detect these issues in your design. Believe me, these issues do not show up in your normal traffic, they are surfaced only when you have spiky traffic on your platform. The only way to detect these kinds of things is using your load testing. You should try to load test your system with the expected normal and the heavy traffic so that you pinpoint these issues in your design. If you find it, you don’t want to have the oops scenario in your production. You want to fix it beforehand. You may have to redesign your data partition strategies, or you may have to rebuild your framework. This is what you have to do. You have to do to avoid the apocalypse at the end.
Threads, one of the key resources for computing, it helps us to do the parallel processing so that we can get better performance with less resources. When we started designing the application, we just use the one resource pool. What happens? Slowly we start noticing we have latencies in some of the operations. We are more of a read heavy application, writes are heavy but they are more of spiky traffic because think for a second the footage is coming from a camera roll, and they are trying to create bulk of assets in one go and then settle down. We don’t want that spike in write traffic to create latencies for the read which is going on. It should give the expected latency still to the read clients. Then, what did we do? We started dividing our thread pools in such a way by the operation in the service layer so that one spike in operation is not creating the resources contention for the other operations on the same instance. As shown earlier, the request can come as one asset or it can come in bulk. We don’t expect our users to create the one asset at one time, so we give them a bulk API. They can opt to creep load the assets in bulk to our system. This can create the resource contention for the other requests which are coming in small chunks. For example, if my system is getting a request to create 500 assets in one operation, and at the same time, the request is coming to create the 50 assets or 5 assets, if you’re not chunking them, then that has to wait for 500 assets to be processed before taking care of the 50 or 5 assets. What do we do? We chunk the bulk request into the small and then process them individually, so that we are giving the expected latency regardless of the size of your operation traffic. That helps us to avoid again monopolizing one tenant’s resources on our system and create the resource contention for the other tenants.
Manage dependencies with the discovery services. With distributed databases, we should always try to use the discovery services to connect with the different microservices in your entire platform. It helps us to distribute the load and enables the seamless communication between the services. How many of you are using the discovery service to connect to your database here? Or you’re using the nodes to connect to your database. That happened to us. We were using directly the nodes because that was supported in the previous version of Elasticsearch to connect to the database. There comes a spiky traffic, one of the primary nodes which was serving that particular client got restarted. Then the load went to the replica, but the instances which were connected to that particular node gave the timeouts to the users. The request which is already from x to 10x became 30x now on that replica. That replica also got restarted with that CPU spike. That replica went down, another replica started serving the clients. What is going to happen? This chain of restarting will continue until that traffic settled down, or our retries from the client settled down. How you want to avoid it, by using the discovery service, and the right set of socket timeout settings, so that your client is not seeing those timeouts and not retrying, which is already spike. You want the traffic to stay there. With your timeout settings, discovery service should redirect the traffic from the failover nodes to the healthy node. Now we start doing this practice while connecting to most of the databases if possible.
Retries are good, but not always. You can literally create a retry thunderstorm if you’re not following the good retry practices. Retries sometimes can amplify the problems for your system and for your downstream service. Service can literally smash or cry when you’re simply retrying when you’re already under this spiky load traffic. How can you solve this problem of multi-level retries? In your services, rather than spilling that logic all over the place, we can have a centralized place to handle the exceptions, which will take the call, should I retry on this exception or should I stop? Or if you are retrying, we should try to use random exponential backoffs while retrying so that we are not overloading the downstream services with a similar pattern. Still, especially with the spiky traffic and the noisy neighbor, things can get worse. It may be possible that your service can survive the noisy traffic but one of the dependent services got into some bad state. With retrying, you are making it more worse. Not only that service, now because your service resources are held up by doing the I/O calls to that service, and you’re retrying, your service will also see the resource contention slowly and start giving the timeouts to the services which is calling you, cascading failures. How can you give what you want at that point of time? You want to take a deep breath and you want downstream services also to take a deep breath. How will you do that? Circuit breaker. Give your service and downstream services a chance to take a deep breath and recover. In this pattern, when your service is noticing a request or number of errors while making a call to the downstream service, if the threshold of the error is reached, it just opens up the circuit. That means that calls are not made to the downstream service. After a defined reset time, it tries to pass few calls back to the downstream service. If it is healthy, then it closed the circuit breaker and allowed the calls to be made. If it is still trying to recover, then it keeps a circuit breaker in the open state and no further calls are made to the downstream service.
Embrace eventual consistency. Lily mentioned about how they moved from the synchronous to the asynchronous workflows, very crucial. Not every other request is designed to be synchronous. Try to prioritize your availability over consistencies. We also noticed that if the asset is created by a UI application, there is a user sitting behind the screen and they want to see immediately that asset is uploaded. If the assets are getting uploaded via the bulk studio orchestrator pipelines, they don’t want to see it immediately and they are ok to be asynchronous. We divided up that traffic into two parts: synchronous traffic and the asynchronous traffic. It gives us the ability to scale up our system without impacting the dependent components. It also helps us to recover gracefully. That means your messages are buffered so that it can be retried whenever the dependent components are available. What your end user is looking for is that I uploaded some asset and it should be uploaded at the end. They don’t want to see it immediately, but the guarantee they are looking for that it should be done.
Diagnostic Strategies
With the right set of preventive strategies, we can avoid the cascading impacts of a noisy neighbor, but still problems happen in the real world. We all are learning from it. What we need at that point of time is diagnostic strategies. This is a set of observability techniques, sets of processes that help us to quickly identify the problems and take the corrective actions timely. Imagine yourself sitting in a war room, what exactly are you looking for at that point in time? What is happening in my system? When the issue started in my system, why is this issue happening? Or how much is the impact of that issue on my overall system, because then only you can take that call, what should I do at that point of time? Observability helps you to get the real-time insight of your system health and performance. You need to have a good combination of monitoring, alerting, and discovery in place. Monitoring is to collect the different set of metrics coming from your system. Alerting is to notify you whenever the certain thresholds are breached, because you want to get alerted timely, so that you can take the corrective actions. Discovery is to trace down the request, how it is flowing through your system in a distributed architecture. Because the issue may not be because of some other client, it could be because of your configuration itself, you rolled out some deployment and it is not right, and it may be impacting the entire traffic. You want to discover where exactly the problem is happening in that flow of your request through the system.
We want to collect different types of metrics. Some are known, some are provided by our cloud, like CPU utilization, disk usage, network, disk space, but some are pretty specific to your applications. Because you know what is expected latency for a specific operation. You know what are the dependent services you are looking for, and what type of error messages is ok and what is not ok. You want to set up some custom metrics also, along with the default metrics that comes out of the box with the cloud. Database. Datastore metrics are very crucial. It includes the cluster health, node health, indexing RPS, query RPS. Why are we looking for the datastore metrics here? The reason, applications can be scaled up, but not the databases. It’s a very time-consuming process to scale up your databases. It is not going to happen in seconds or minutes when you need it the most. You have to be ready. If you’re carefully monitoring your datastores, because your applications, systems are evolving, their requirements are evolving. You may notice that there is already at the peak usage of the datastores, if you will observe and get alerted beforehand about the database status, then you can scale it up freehand, you don’t wait for that issue to happen in production, because it’s going to be very costly if you try to fix those issues in production. How can you identify the hotspots? If you try to look at the metrics of your datastore, you can immediately identify there are a few specific nodes, which are noticing the CPU spike, but the overall CPU usage is very down. Check for the datastore’s health metrics very carefully.
Logs are crucial, very important. How many of you log with the context? Whenever I start looking for any legacy application, I have always thrown a bunch of files, look into these files, what is happening in the system? Can you really figure out anything from those logs? It’s very time consuming. How can I increase my velocity to figure out what is happening in my system? By adding the right context into it. Now with all the applications, we just not log the events, what is coming from an application, but also the context along with each event. Which tenant it is coming from. What is the distributed tracing ID? What is the request ID? These logs are only useful when you are putting the right context in these events so that you can immediately figure out what is happening by which tenant on your system. At the same time, logs are expensive, but they’re crucial for debugging. How can we solve that problem? I’m not saying that you should enable all the logs in your system because during the spiky traffic, you’re going to have a spike in the disk usage and your node is going to crash. How can we solve this problem of balancing between the right set of logs? You need the capability in your system to enable or disable the logs at runtime. Some folks are going, dynamic debugging. What does dynamic debugging mean? Dynamic debugging means you have the control on your system, and when you realize that there is a traffic, and there is a spike going on this specific service, I want to know what is going on. I want to turn on my info logs on that specific service only. Java world and different languages call it differently, but they give you the flexibility that you can enable those logs at runtime.
Distributed tracing is very crucial with the distributed architecture, like we noticed, the problems can happen anywhere in the flow of the request processing. You want to pinpoint the exact point of failure, or where the processing is getting delayed, so that you can go and check that specific point in your service. Especially with the multi-tenant architecture, when you’re collecting or instrumenting your metrics, have you ever tried to instrument it with your tenant IDs? This is very crucial. You can feel what I’m talking about, because when you are trying to solve a problem, you want to know who is impacting my system. It could be possible that a spike in the traffic is not breaching your system threshold, but there’s one silent tenant sitting down there, which is getting impacted, because their request pattern is aligned with the spiky traffic coming to your platform. If you have the tenant IDs along with the metrics, you can immediately say that this response time is delayed for this particular tenant, although it’s only 4.1% and only one client, but every other client is important equally to your platform. You have to respect it. By looking at this, if you notice that one tenant is seeing this response time slowness, you should be able to fix it. The same for the error rates and the request rates.
We talked a lot about the metrics, different types of metrics, we noticed, and we collect different sorts of metrics. If you’re sitting in a war room, and you open multiple tabs of metrics, and what you’re doing, you’re thinking. What I’m looking for, actually, I open 10 tabs, 20 tabs, then I’m switching back and forth, which operation is seeing the latency? How much does error rate look like? Which tenant am I looking for? After opening so many tabs, you will be lost, you will lose the connection, what you’re trying to build. You can figure it out but it’s going to take time. What you want is quick action. Quickly identify which tenant is creating the problem in my system, and who is getting impacted in my system? You want to have the right set of filters on your dashboard on an aggregated view, called dashboard, with lots of filters like, what is the cluster? What is the application? What is the latency? It could be p99, which is saying that I’m correct, but there is 1% which is saying I am not correct. You want to find out what is that 1% which is not correct in your system. With that right set of filters, we can figure out which operations are getting impacted with that noisy traffic and how to fix it.
Alerts. I’m sure you must be setting up a lot of alerts in your system. Very crucial. Alerts have to be set up timely and actionable with the context. Last year, I owned a legacy application. I got an alert, midnight pager. I woke up, I tried to look around. I opened up the laptop, check the health of the system, looks fine. I check the logs of the system, it was fine. I went back to sleep, 30 minutes later I got the alert again. I opened my laptop again and tried to grab the coffee, ok, something I’m missing here. I’m not finding the right context. Try to look around, I couldn’t figure out anything. What should I do? I just snooze my alert, I want to sleep. I snooze the alerts, I went back to sleep. Next morning, everybody was looking at me, did you snooze the alerts? Ok, what should I do? I took a deep dive into the system the next morning, what we figured out, that alert was set up a long time back. The threshold that was set up in the alert for the errors is no more relevant, because the traffic is already 20 times on the platform, and that error percentage was very low. What’s the learning here? Alerts are good, but every other alert that you set up in your system, don’t expect your on-call person to know in and out of your system. You should put the right context within your alert, what this alert is about, what are the actionable items if you receive that alert. Also, if possible, try to put some links into your alerts, dashboard links, or some documentation links. Because when you’re sitting in a war room, when you’re getting an alert, that pager means something to you. You want to resolve it quickly. What are the steps to it, strategies to it? Put the right action, right context, and the right links into your alert, so that anyone who’s getting the pager, within 5 minutes, they should be able to know what is going in my system.
Corrective Strategies
With the diagnostic and preventive strategies that we discussed, hopefully our system will remain reliable and stable for all our tenants, but life changes. In the real world, it’s not happy scenario. What do we need? The corrective strategies. Corrective strategies to make our platform reliable. We need to implement the graceful degradation measures into my system. While doing that, you need to have the deep insight of your system architecture. I remember one of the interns joined us, he received an alert that there is a processing delay happening and the task queue depth is growing. The first thing, what’d you do? Scale up your system. He did this scaling up our system. What did it do? It ended up creating more spike of load on our system. That spike was a creation of 10,000 image requests on our system. For every other image asset ingested into our system, based on the workflows, we create 4 thumbnails for each image. By scaling up for those 10,000 requests, he ended up creating 40,000 more asset creation requests on the platform, and those 10,000 requests ended up being 40,000 requests on our platform, more cascading failures all over the place. Before taking any action, make sure you have a deep insight of your system architecture. By taking any corrective action, you are not putting any cascading impacts on your platform with your actions.
Slow down. If you figure out that there is a specific tenant request, which is creating the load on your system, you want to slow it down. If you’re using the asynchronous message processing, one way, you can direct the traffic from that specific tenant from a primary stack to the secondary stack, and then slowly start processing it. It can impact the legitimate traffic from that tenant also. You want to communicate it back to your client that we are going to slow down the processing from your request. This happened in our case. When we communicated this issue back to our clients, they immediately figured out that there is some configuration issue on their side. They fixed their configuration settings and slowed down the RPS in our system, and we moved the traffic back from the backup step to the primary step for the tenant. This is only possible if that particular request is handled asynchronously. If you’re trying to process the request synchronously, you have to take the drastic step of throttling the request. This is the last thing you’d like to do, but we have to do it, no other way. You want to define the tenant resource quotas, limit the request processing rate coming from that tenant, and limit the concurrency from that tenant. Slow down. You want to communicate back again to the users. Make sure when you’re throttling the request, you are sending back the right exception message back to the client. Because it may be possible, they don’t know what is going on. Are you really throttling their request or is it timeout coming from your server? They may consider it as some server error, and for those 30 requests, they will retry and make it 60x for you. Send back the right set of message so they should understand they’re not supposed to retry, they are supposed to settle down, slow down.
Key Takeaways
What are the takeaways for the reliable architecture that we learned with these strategies? Regularly evaluate your system requirements. Things are changing, systems are changing. Our requirements are changing, the same time our client requirements are changing. Make sure you regularly evaluate your system requirements and update your resources configuration: your resources configuration on the server-side, database side. Improve observability. That is a critical aspect of a distributed architecture. You should think about your observability from day one. Issues are going to happen, and you cannot say no to it. With the improved observability in place, you can quickly identify those issues, and fix it timely. Analyze the ad hoc alerts. Never ignore any ad hocs coming your way. They are the indicators of your potential failures in the future. They’re trying to give you a signal that if a spike will happen in your system, it will cry, it will bleed. Make sure you analyze any alert coming to your system wisely. It doesn’t have to be immediate, but you can have some incident response and checking like, ok, what happened in the last one week in my system? Spend some time as an on-call support person to increase the reliability of your platform. Automate the graceful recovery. Every manual intervention is going to take time. It is going to slow down the fixing of the issues. If you can automate those kinds of things, then you can fix these issues without paging the on-call person, and in less amount of time. Collaboration and knowledge sharing with your tenant application is very crucial. We also mentioned collaborate. This is the biggest key point that we miss. We are building a platform, but for whom? For our tenant applications. If we don’t understand what my tenants are looking for, what is their expected SLOs from my platform, then I cannot build a reliable platform. Things may change. If you communicate, if you collaborate with them, then you know that there is expected traffic coming on my way, and you will provision the resources accordingly. Collaboration and knowledge sharing is very crucial when you’re trying to build any platform application to be used by your client applications.
With that said, reliable architecture is not just a one-time process. It’s a continuous journey. We all are learning. I saw a lot of tracks where most of us were talking about reliability, observability. Everyone is talking about their learnings and sharing their knowledge. Good, learn from it, and learn from your incidents. Every noisy traffic comes with its own unique set of challenges and learnings. Make sure you build your muscles from each incident that happens. It will help you to grow your platform for the future. Via diagnostic strategies, if you’re trying to identify the root cause, if you see there is some point which you can improve on, make sure you do it at that time or later. Don’t keep it in the backlog to be done later. It is going to happen in the future, and somebody else will look at you again, why didn’t you do it? Why did you just create a backlog item on it? If you’re taking any short-term solution to fix the issues, which you’re going to take because the impact of the traffic is so long that you want to take some short-term solution, make sure you move it to the long-term solution. Think about it, like, how can I avoid a similar situation in the long term, and try to design your solution. Try to avoid that oops scenario to your client applications. You want to give them a reliable and stable platform, which you can. Learning and putting it in the preventive strategies so that your system can automate those failures and gracefully recover itself rather than trying to page somebody and taking time to fix it.
See more presentations with transcripts