Month: June 2024

MMS • RSS

Taysha’s focus is on its lead candidate TSHA-102, which incorporates a minMeCP2 transgene and self-regulatory element designed to restore expression levels without causing toxic overexpression. Early results from the Phase 1/2 REVEAL trials, which include both low-dose adult and pediatric cohorts, have shown promising safety and signs of efficacy.
The company’s immediate future involves a keen focus on the second half of 2024, when it anticipates safety and efficacy data for the high-dose cohort from the ongoing trials. This forthcoming data is crucial as it could further validate the therapeutic potential of TSHA-102 in treating Rett syndrome.
BMO Capital’s initiation of coverage with an Outperform rating reflects a positive outlook on Taysha’s approach to gene therapy and its capacity to meet a significant unmet need within the Rett syndrome treatment landscape. The $5.00 price target set by the firm indicates confidence in the company’s direction and the anticipated milestones ahead.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
MMS • RSS

The transaction was conducted under a Rule 10b5-1 trading plan, which allows company insiders to set up a predetermined plan to sell stocks at a specified time. This can help insiders avoid accusations of trading on nonpublic information, as the plan is established when the insider is not in possession of material, non-public information.
The SEC filing also revealed that on the same day, Hettrich exercised options to acquire 3,300 shares of QuantumScape’s Class A Common Stock at a price of $1.3252 per share, which amounted to a total of $4,373. The options exercise and subsequent sale are part of a common financial strategy where executives convert their options into shares, which they then sell, typically to diversify their investment portfolio or to realize a profit.
Following these transactions, the SEC filing noted that Hettrich’s ownership in QuantumScape Corp includes restricted stock units (RSUs) and performance stock units (PSUs), which represent rights to receive shares upon vesting based on continued service and the achievement of certain performance milestones.
Investors often monitor these insider transactions as they can provide insights into executives’ perspectives on the company’s current valuation and future prospects. QuantumScape, based in San Jose, California, is known for its work in the development of solid-state lithium-metal batteries for electric vehicles, a market that has garnered significant investor interest in recent years.
QuantumScape’s stock is publicly traded on the New York Stock Exchange under the ticker symbol QS. The company has been in the spotlight as it aims to revolutionize the electric vehicle industry with its cutting-edge battery technology.
In other recent news, QuantumScape Corporation has made significant strides in both board membership and product development. The company’s annual meeting saw the approval of key proposals, including the election of directors and the ratification of the company’s independent auditor. Notably, the board welcomed Sebastian Schebera, a seasoned executive from Volkswagen AG (OTC:VWAGY), further strengthening QuantumScape’s strategic growth plans.
In terms of product development, QuantumScape reported on its first-quarter 2024 earnings call that it has begun shipping its six-layer Alpha-2 prototype battery cells to automotive customers. This development marks a significant step towards the company’s commercial goals. The company highlighted the prototype’s enhanced performance features and its strategic plans for production scaling and commercialization.
Financially, QuantumScape reported a strong liquidity position, with a cash runway extending into the second half of 2026. Despite a reported net loss of $120.6 million for Q1, QuantumScape’s strong balance sheet and liquidity position support ongoing development and commercialization efforts. These are among the recent developments at QuantumScape.
QuantumScape Corp’s (NYSE:QS) recent insider trading activity comes amid a challenging financial landscape for the company. With a market capitalization of $2.44 billion, QuantumScape’s financial health and stock performance metrics offer a mixed picture for investors considering the stock’s prospects. According to InvestingPro data, QuantumScape holds more cash than debt on its balance sheet, which can be seen as a positive sign of financial stability. However, the company’s gross profit margins remain weak, and analysts do not expect QuantumScape to be profitable this year.
The stock has experienced significant volatility, with a price drop of over 16% in the last month and a substantial 34.38% decline over the last six months, trading near its 52-week low. This volatility is reflected in the company’s negative P/E ratio of -5.03, indicating that investors are wary of the company’s ability to generate earnings. Additionally, the stock’s valuation suggests a poor free cash flow yield, which could be a concern for those looking for income-generating investments.
For investors seeking more comprehensive analysis, there are 11 additional InvestingPro Tips available, which can provide deeper insights into QuantumScape’s performance and outlook. These tips are an integral part of the InvestingPro product, which includes additional data and analytics to help investors make informed decisions. To access these tips and more, use coupon code PRONEWS24 to get an additional 10% off a yearly or biyearly Pro and Pro+ subscription.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
Aon plc extends executive contracts and holds annual shareholder meeting – Investing.com
MMS • RSS

Aon plc and Gregory C. Case, through its subsidiary Aon Corporation, have agreed to extend Mr. Case’s international assignment letter agreement until June 30, 2025. This extension modifies the original agreement that was due to expire on June 30, 2024.
Additionally, Christa Davies, who had previously announced her retirement as Executive Vice President and Chief Financial Officer, will continue in her role until July 29, 2024. Following this, Ms. Davies will transition to a senior advisory role through May 31, 2026. During this transition period, she will earn a base salary of $500,000 per year and will be eligible for certain benefits and equity award vesting, with some restrictions.
The shareholder meeting held on June 21, 2024, resulted in the election of 12 director nominees and the approval of all seven proposals presented, including the ratification of Ernst & Young LLP as the company’s independent registered public accounting firm for the fiscal year ending December 31, 2024. Shareholders also approved executive compensation on an advisory basis and authorized the Board of Directors to issue and opt-out of statutory pre-emption rights under Irish law.
These corporate actions, detailed in the company’s 8-K filing, reflect Aon’s ongoing management structure and governance practices. The information is based on a press release statement from Aon plc.
In other recent news, Aon plc has been involved in several major developments. The company has launched a $350 million war insurance program in collaboration with the U.S. International Development Finance Corporation to support Ukraine’s health care and agricultural sectors. This program includes $300 million dedicated to war insurance and an additional $50 million for war reinsurance.
In a recent congressional trade report, Thomas Kean Jr. acquired shares in Aon plc, Becton, Dickinson and Company, and Fiserv (NYSE:FI), Inc. through the Kean Family Partnership. Each transaction was valued between $1,001 to $15,000.
Aon plc has also announced the appointment of Edmund Reese as its new executive vice president and chief financial officer, effective July 29, 2024. Reese, who brings over 25 years of financial leadership experience, will succeed Christa Davies following her certification of Aon’s second quarter 2024 results.
BofA Securities recently downgraded Aon’s stock from Neutral to Underperform, citing potential risks from its $13.4 billion acquisition of NFP and recent management shifts. However, the company reported strong first-quarter results for 2024, showcasing 5% organic revenue growth and 9% earnings per share growth.
In light of Aon plc’s recent corporate updates, a closer look at the company’s financial health through InvestingPro data and insights may offer additional context for investors. Aon has demonstrated a robust track record of increasing dividends, having done so for the past 12 consecutive years, which aligns with its history of maintaining dividend payments for an impressive 45 consecutive years. This consistency suggests a stable financial policy that could reassure investors, particularly those focused on income-generating stocks.
On the valuation front, Aon trades at a P/E ratio of 22.59, which indicates a premium relative to near-term earnings growth. The company’s adjusted P/E ratio for the last twelve months as of Q1 2024 stands at 21.74, and its PEG ratio during the same period is 9.56, potentially signaling that the stock’s price is high compared to its earnings growth. Despite some analysts revising their earnings downwards for the upcoming period, others remain optimistic, predicting profitability for the year.
Investors may also note that Aon has experienced a 7.06% revenue growth over the last twelve months as of Q1 2024, reflecting a solid business expansion. Additionally, the firm has reported a gross profit margin of 47.82%, underscoring operational efficiency. For those considering an investment, InvestingPro offers additional tips, with a total of 7 tips available, including insights into the company’s long-term profitability and return on assets. Interested investors can utilize the coupon code PRONEWS24 to receive an additional 10% off a yearly or biyearly Pro and Pro+ subscription, providing access to a deeper analysis and more comprehensive data.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
Presentation: The Incident Lifecycle: How a Culture of Resilience Can Help You Accomplish Your Goals
MMS • Vanessa Huerta Granda

Transcript
Granda: Incidents prevent us from meeting our goals. Your goal could be to sell all the tickets to the Taylor Swift concert. Shouldn’t be that hard, everyone wants to go. Or to get everyone home for the holidays without a major scandal. Again, shouldn’t be that hard, people are traveling during this time. Maybe you want to get goods shipped across the globe, or have everyone watch the last season of the really hot show that everyone’s been talking about. Then incidents happen, and they prevent us from meeting these goals even though it seemed like all the stars were aligned for this to happen. Incidents never happen in a vacuum. For every single one of these high-profile incidents, we can highlight a number of similar events that happened before. We can highlight a number of items that led to them happening the way that they did. For example, for the Southwest scandal, things go back to decisions made decades ago when the airlines were first being deregulated. In order to meet our goals to achieve them, organizations need to make investments. They need to make investments in a culture of resilience.
I’m going to highlight this with an example from my life. These are my kids, they’re almost 2 now. When they were first born, I’m very lucky, I didn’t have any major complications, even though there were two of them, and I’m 5′ 1″. I had a scheduled C-section at one of the top hospitals in the nation. Everything went great. The nurses, they took care of everything. I was even able to watch The Bachelor one night. Then we went home. If anyone here has had kids, you may have had a similar experience of chaos. I ran major incidents for a long time. I can tell you that this was the toughest incident I have ever experienced, because they just wouldn’t sleep. If one slept, the other one was crying. It’s not that I had kids thinking that they wouldn’t cry, and they would sleep perfectly, but it was just chaos. We tried troubleshooting them. It was like that incident that fixed itself. At 9 p.m., they just started crying, and then at 5 a.m., they were just feeling better, and they wanted to snuggle. We didn’t know what was up.
If we think of our lives, again, we didn’t have kids so that we could just never sleep again. We wanted to enjoy our babies at some point, and eventually, I was supposed to go back to work after my leave was over. Those first few weeks, I wasn’t doing any of that. I was lucky if I was able to shower. We were sleep deprived, and we were doing the best that we could, and it just kept happening. Until, and here I’m acknowledging my privilege, we started being able to get on top of it, because we started investing our time, our expertise, and our money into it. First, we had to get better at the actual response, those crazy hours from 9 p.m. to 5 a.m. The problem is that we were sleep deprived, so we tried different things. We tried some shifts. We tried some formula, so my husband could actually let me sleep. We invested in a night nanny. With this, we were able to get some time to just start getting better.
We could have stayed here but I don’t have unlimited money and night nannies are expensive. With the extra energy, we started trying to understand what was going on. We talked to our friends. We read books. We just got better at being parents. Every day, we would just hold a post-mortem, we would talk about what had happened and what could go better, and trying to think how we could apply those learnings into our lives. We fixed some processes around swaddling. We figured that Costco actually delivers formula so we didn’t have to grab our two car seats in the middle of winter in Chicago and go to Costco every time we needed formula. We actually realized how much formula and diapers we were going through. Infant twins go through a lot. We were able to figure out our capacity better. That gave us more energy, more bandwidth. We started looking at the trends.
All incidents are different. All babies are different. We realized what worked and what didn’t work. We figured out that there were times that one of us could handle both babies, but there were times when it was all hands on deck. I later came to learn that that happens quite a bit for infants. We were doing our cross-incident analysis and we started coming up with some ideas. Maybe they were a little out there compared to other people, but we had some data points that made us believe that we were going in the right direction, we might as well try them. We were like, let’s just drop the swaddle, she clearly hates it, she wants to be free. Maybe we can move them to their own room, like that could be fine. Eventually, things got better by investing time and effort into the process, then having our post-mortems. Then that cross-incident analysis. It gave us the bandwidth that we needed to meet our goals. By the time that my maternity leave was over, I was able to go back to work. I was able to enjoy being back in the world. I was able to enjoy being a mother. This was a couple of months ago. I was able to cook something more than just cereal. That was a very long example. That’s what we’re going to talk about here, the lifecycle of incidents, and how we can learn from them, and how we can get better as a system so that we can accomplish all of the goals that we have.
Career Journey
I’m Vanessa. I’m an Engineering Manager at Enova, where I manage the resiliency team. When I’m not wrangling adorable twins, I spend a lot of time in incidents. I have spent the last decade in technology and site reliability engineering, focusing on incidents. When I say incidents, I mean the whole lifecycle of it. I’ve done many roles. I’ve been the only incident commander on-call for many years. I’ve owned the escalation process. I’ve trained others. I’ve ran retrospective programs. Most importantly, I have scaled them. Scaling is actually the hardest thing when it comes to doing this work. While I do this for fun, and because I like it, I also know that the reason that I get paid to do what I do, is because having a handle on incidents allows companies to do the work that they need to do. It allows businesses to sell those Taylor Swift tickets, to get people to String Succession. All of those things. Previous to my current job, for the past couple of years, I had the chance to work at Jeli.io. I work with many other companies, helping them make the most out of their incidents, helping them establish and improve their incident programs. I have seen firsthand and from a consultative side, how engineering teams are able to focus on resilience and achieve their goals.
Incident Lifecycle
Let’s go back to this picture. We will never be at zero incidents. We’ll never be at zero incidents, because we will continue doing work. We continue releasing code. We continue making changes. We continue coming up with new products. That’s a good thing. I believe that incidents are a lifecycle and they’re part of how a system gets work done, how the system achieves their goals. First, you have a system, and then something happens. Maybe you announce a new product, maybe you announce a new album, a new TV show, a new concert, and tons of people try to access that system, and then the system fails. Now you’re in an incident. You work on it. It’s resolved, and life is back to normal. Ideally, you do something after the incident, you do something related to learning. Even if you don’t think that you’re doing any traditional learning, your company doesn’t do post-mortems, your company doesn’t do write-ups, folks naturally like to talk and debrief. The learning activity, it can be a chat with your coworkers while getting drinks after work. It can be like, “I’m slacking my best year.” We’re going to be like, that sucked. It can be your post-mortem meeting, your incident report, whatever it is that you want it to be. Those learnings are then applied back into the system. Maybe we decide that we need to make a change to our on-call schedule. Maybe I’m just gossiping with my boss, and we’re like, I’m just never going to trust that person again. Maybe we change the way that we enqueue our customers. In the Taylor Swift example, maybe we have a congressional investigation around antitrust legislation. Even if we don’t make any actual physical changes, just the fact that we have the experience of the incident in our brains means that we have changed the system, because the system is not just your codebase. Your system is also that sociotechnical system, it’s also us, the people who are working with the technologies. That is the new system now, and that’s why it’s the incident lifecycle.
Why do we care about this? Why am I here on this talk? It’s because these things are expensive for companies. Let’s think about the cost of an incident. You have the incident itself, “We lost money because people couldn’t access our site for 20 minutes.” There’s the reputational damage, “I’m never going to trust this website again, because I wasn’t able to rent a car from this website.” There’s the workload interruption. The incident that lasted an hour, 2 hours, you had 10 engineers involved. It’s not like after the incident these engineers are going to go back to their laptop and their keyboards and focus on their OKRs. Incidents are a huge interruption and takes engineers a lot of time to go back to what they were doing. Then it has the impact that it has on our goals and our planning. If engineers are fighting fires all day, they’re not working on your features. When I was fighting the fires of my children, I wasn’t cooking, I wasn’t working out, I wasn’t really doing anything else. What we see is that unless we do something about it, people end up getting caught in this cycle of incidents where there’s no breathing room to get ahead. The impact is not just the incident, and the impact is not just the engineers that are working on it. An incident impacts the whole team, the whole organization.
There is some good news about incidents. Your outages mean that somebody cares about the work that you’re doing. That it matters, whether you’re up and down. That it matters that you’re doing the things that your organization is there to do. That’s the thing about working in technology. Our users don’t care about the languages we use, the methods we use. They don’t care if we do retrospectives, or if we use Jira, or Slack, or Notion, or whatever it is that you’re talking about. They just don’t care. They care that they’re able to rent cars. They care that they’re able to get home for the holidays. They care about being able to make a bank transfer, get tickets to a concert. Those are the things that matter to them. We owe it to our users that they’re able to do those things. Here’s where resilience helps. Resilience is about having the capacity to withstand or to recover quickly from difficulties, to recover from your outages, from your incidents. Resilience can help us turn those incidents into opportunities.
You’re here for a reason. You care about this stuff. We care about improvement. That’s not how things usually work. I don’t know if you’ve had the experience to work at an organization where things don’t work that way but I certainly have. Usually, what happens at some organizations is that you have an incident, you’re down. You resolve it, and then you move on. You have like my friend here, Chandler Bing. This is how folks who are stuck in a cycle of incident work, not because they want to. I have tons of engineers in my life. I’m one myself, my dad, my brother. We just like fixing things. We don’t like seeing something that’s broken. Sometimes we just don’t have the bandwidth to do anything else other than move on.
Resilience in Incident Analysis
There’s a better way. I’ve been lucky enough to work at and work with a number of organizations that are leading the way in doing this work, so that’s what we’re going to get into. This better way includes focusing on three different things. One, focusing on the incident response process. Focusing on learning from your individual incidents, that’s your post-mortems, your incident reports. Then, focusing on macro insights. You don’t have to do it all. You can if you want to. It’s often hard to find an organization that’s going to give you the bandwidth to do it all at once. If your organization doesn’t even have a process for incidents, going up to the CTO and saying like, “I want to do cross-incident analysis, give me 100k.” That’s going to be hard. Usually, you have to prove your way along the way. We’re going to go through these three ways to improve resilience in the incident lifecycle. There are some caveats. There are some things that can go wrong. That’s because a lot of this requires skills that are just not traditionally engineering skills. This work is difficult. It takes time. It takes investment. It requires selling. It requires telling other people that this is the right thing to do, and making them feel good about it. Selling isn’t really your best skill as technologists. It’s not my best skill as a technologist. Instead of calling it selling it, we should think of it as the scientific method. We should think that we’re trying things out, we’re presenting our data at work, and we’re making our case. The good news is that I have seen this work, and we can get many small wins along the way.
A Focus on Incident Response
What does it look like to focus on incident response? It makes sense to start here at incident response. That’s the thing that we’re already paying for. We’re already spending time in incidents, so we might as well focus on those things. We might as well focus on coordination, collaboration, and communication, which is usually what makes up an incident. On the coordination front, I recommend people write up their current workflow, even if the workflow is just call that person that has been here for 10 years. Ideally, you have something more defined than that. Then ask yourself, how do folks come together to solve a problem? Look for any gaps, write them down. What can be done to make those gaps even just a little bit smaller? Maybe people are just not communicating their insights, so maybe a virtual whiteboard, or maybe getting them on Zoom, anything like that.
On the collaboration front, how do you get people in the room? How do you know who to call? I had an organization that I worked at that actually, whenever I would have incidents if I was at home, I would literally have to open up my laptop. Get on the VPN, get on the wiki, look up a team, look up that person, and get their phone numbers, and then grab my iPhone 4. That’s a lot of work. That’s not great. There’s improvements that can be made there. We can ask ourselves, are we always calling the same people? Are we burning them out? Take a look at your on-call rotations and your expectations. What little things can we do to make their lives a little bit easier? Then the communication front, how do you communicate to stakeholders what is happening? How do you tell your customers what is happening? There’s a difference between those two groups. There’s a difference between the responders as well. What’s hard about it? What are they asking for? Write up some loose guidelines to help manage those expectations from folks both inside and outside the immediate team that’s responsible for responding.
Why aren’t people doing this? They’re not doing this because it requires work. You need to train people on this process. This process is different than the way we do traditional engineering work. When you’re doing normal, everyday feature work, everyone has different ways of working. During an outage, we need to get services back up ASAP. There are some certain procedures that make sense here. You want to teach folks the skills that help move incidents forward. You’re not focusing on hierarchy. You’re not focusing on roles. You’re not blaming people or anything that happened. You want them to know about the roles that make a difference. Communication, having somebody in charge of coordination. Understanding who’s a stakeholder versus who is a responder. Don’t waste your time trying to explain to a stakeholder, things that a responder needs to know. Oftentimes, these coordination tasks are what leads to the highest cognitive load. Oftentimes, focusing on the response is more work than actually fixing something. These things can be automated, or they can be achieved through tools. Sometimes the people working on these teams don’t have the right tools for it, or they want to create these tools, they want to build it themselves, but they just don’t have the bandwidth to develop them. Again, they’re overloaded with incidents so they’re stuck fighting fires.
How have people been able to do this in the real world? A lot of them have focused on those two things: the process, and they’ve leveraged automation and bots. I can highlight the work of my friend, Fred Hebert at Honeycomb. He wrote a great blog post on their incident response process. He says that as they were growing as a company, they were running into some issues with their incident response process. He wrote that while they’re trying to ramp up, they’re trying to balance two key issues. They’re trying to balance avoiding the incident framework being more demanding to the operator than solving the issue. That’s what I talked about earlier. They don’t want the process to be more difficult than the engineering work itself. They’re trying to provide support and tools that are effective to the people who are newer to being on-call for whom those guidelines are useful. That’s that training thing. You want to make it easier for people onboarding. What they did, and I worked with them on this process, was to automate some tasks using the Jeli incident bot. They were automating the creation of incident channels. They were communicating status updates to stakeholders. Doing that left the engineers the time to focus on the actual engineering part.
The idea is that you get quick wins even a week into the improvement process. You can restructure on-call rotations. You can automate the response task. All of that allows us to spend less time on the tasks that demand our attention during engineers, but aren’t necessarily engineering tasks, because we never ever want to automate the creativity or the engineering skills that come with responding. We do want to reduce that cognitive load during a high stress time. Doing these little things can help build momentum and get buy-in for the larger changes that you’re going to make. If I show to my stakeholders that incidents are just easier, because we’ve done some automations and because we’ve set some process, then they’re more willing to help me out with the next things I want to do. A focus on the incident response part is going to help improve the process itself. It’s going to lead to a better experience for your users and your engineers that are going to focus less time on the repetitive task. It’s going to lead to easier onboarding for on-call, more efficient process, and lower impact to your customers.
Anti-Pattern: MTTX
Here is where we’re going to talk about an anti-pattern when it comes to incident response, and it’s this idea of MTTX. MTTX is mean time to discovery, mean time to recovery, to resolution, whatever it is that you want to call it. I am on the record on saying that those numbers don’t mean anything. That doesn’t mean that I think that we should just not care at all about how long our incidents last. I just think that a single number should not be the goal. One time I had an issue where our data center caught fire, and the fire marshal wasn’t going to let us go back on. That’s just going to take longer than reverting code. We want to make the experiences for our users and our engineers better, because that’s actually what’s going to help us get ahead. It’s what’s actually going to help people get online and get home for the holidays, and then buy their tickets and all of that. Yes, there are things that we can do to make incident response easier, so that our engineers are better equipped to resolve them. Just like we’re never going to be at zero incidents, we are not in control of everything.
A Focus on Incident Analysis
The next way that we apply resilience is when we focus on incident analysis. After you have an incident, you want to learn about it. I believe that the best way to do this is through a narrative-based approach, where you get to highlight what happened, how folks experienced the incident from their different points of view. After all, if I’m telling you the story of an incident from my point of view, as the subject matter expert, that experience is going to be different from the point of view of someone who is new to the organization, or from the point of view of somebody in customer support, people who are still interacting with our systems and are still impacted by the incident. What we’ve seen is that template filling sessions, root cause analysis, Five Whys of the past, while they were helpful in the past, today, they are not as much. They can actually sometimes cause harm, because they give us this false sense of security that we’re doing something. I’ve seen this many times. You have a root cause analysis session and we say that the root cause is human error, so let’s just not do it again. Maybe we put on an alert for that specific thing, because if that very exact same thing happens again, we’ll be prepared to handle it. That’s not a very good action item to come out of a meeting. If we have a blame-aware learning focused review, we can highlight that the on-call engineer didn’t have access to some of the dashboards to understand what was going on and that’s why it took longer to resolve. Or maybe when we were releasing this code, the QA process didn’t account for some new requirements, and that shows a disconnect between teams that maybe engineering and marketing weren’t on the same page and didn’t realize that there was a capacity need. Those are things that we can learn from, and that can actually help move the needle when it comes to resilience.
Why aren’t folks doing this right now? It’s not that folks aren’t doing this work, it’s just that they could be doing it better. They’re not doing this because creating a narrative timeline can take a lot of work. There’s a lot of copying and pasting. I don’t know if you’ve ever created a timeline, but sometimes you have three screens, and you got Jira. You’re summarizing conversations from Slack, and you’re just copying and pasting. It’s hard to do that. Then, if you’re not doing that, then you’re going into your post-mortem, and that meeting then becomes the meeting where you create that timeline. You’re spending 50-minute meetings with 10 engineers, just creating a timeline, and maybe you leave 5 minutes to discuss interesting tidbits. That’s not a very good return on your investment, and it ends up not being worth it. If you want to learn about how to do incident analysis that actually moves the needle, there’s a number of sources out there including the Etsy Debriefing Guide and the Jeli Howie guide. It’s a free guide. It helps you understand how an incident happened the way that it did. It helps you understand who should be the person in charge of leading the review. What data you can collect. You have your Git, Jira, Slack, whatever you want to call it, how to lead an incident review, how to finalize, how to share your learnings. It’s a lot of work.
I’m just going to give you my short version here. I recommend that you make it your own. When you’re making it your own, there’s four key steps. First, you want to identify and focus on your data. You want to focus on who was involved in the incident. Where in the world were they? Does the incident take place in Slack or Zoom? What do you have going on? Based off of this, you can decide, we should have a meeting to review this, or, let’s just create a document and all collaborate asynchronously. Whatever you wanted to do, you make it your own. You still have to prepare for it. That means that you take the data that you have, you create your narrative timeline. You jot down any questions that you have, and that you’re inviting the right folks. So often, we have these retrospective meetings where it’s like you and the person who was the incident commander, and then maybe one other person that released the code. That’s not leading to collaboration. Invite people in marketing. Invite people in product management. Invite people in customer support. You will learn so much from inviting people in customer support. When you meet with them, you want to make sure that it’s a collaborative conversation. If I’m leading a review meeting, it should never be the Vanessa show. Others should actually be speaking more than me, because we want to hear how they experience it. That’s how we know that the on-call engineer didn’t have access to the things. That’s how we know that the person in customer support was getting inundated with calls and was dropping things. Then you can finalize your findings in a format that other people can understand. Maybe your findings can be a really long report, or maybe they just are an executive summary and highlight action items. That’s ok. You have to think of your audience.
Because I talked so much about scaling this work, we want to make it as easy as possible for people to do this. Doing this narrative-based post-mortems, it can take a lot of time, but the more you do it, the easier it becomes. It becomes more natural. The idea is that you take all your Zoom, your Slack transcripts, your PRs, your dashboards, and start telling the story of your incident. You don’t tell the story in the way of like, we release something, we reverted it back to normal. You tell the story of like, maybe three years ago, we acquired this other company and that’s part of the reason why we have some legacy systems. It’s really important to give people the ability to create these artifacts, so they can share them with others and allow folks to tell the story from their own points of view. The narrative can then inform action items for improvements. These items reflect what we learned about an incident’s contributing factors, as well as their impact.
We’ve seen this happen in the real world, where folks did this narrative-based post-mortem. They talked to people involved, and they realized that oftentimes, some responders don’t have access to all the tools or they have outdated information. That’s actual things that you can improve that can then help future responders in a future incident, so they can more quickly understand how to solve an issue because now they actually have access to the observability tools. In my current organization, actually, after an analysis that we did, we were able to understand just how vendor relations impact the way that an incident is handled, in order to improve the process. There was nothing we can do about the vendors, but even knowing how to contact them, even knowing what part of the process was them versus us, helps us get better at these incidents and just resolve them faster. A focus on incident analysis can help identify the areas of work that are going to lead to engineers working effectively to resolve issues. Then the next time that they encounter a similar incident, they will be better enabled to handle them, again, leading to lower customer impact and fewer interruptions. It’s all about making people’s lives better.
Anti-Pattern: Action Items Factory
When I talk about resilience, I want to make sure that I’m staying away from the anti-pattern of being an action items factory. The idea that you have an incident and a post-mortem, and all we do is play Whack a Mole, and you’re creating alerts for that specific issue. Or we have action items that are just fixes that never get prioritized, and they live in this Google Doc, forever to be forgotten. That’s not good, because it’s going to erode trust in the process. I’ve seen it firsthand. If the goal of an incident review is to come up with a fix, and I’m not here to argue that it is or it isn’t, but if it is, and then the fixes never actually get completed, then your engineers and your stakeholders are not going to take them seriously. Instead, they’re going to think that it’s a waste of time for a group that’s already inundated in outages. We’ve all been there. If I’m already inundated with work, the last thing I want to do is waste time in a meeting that’s never going to have any clear outcomes. Instead, I think we should look at the resilience coming out of incidents as part of different categories. Because action items today are flawed, so some of the problems are that they don’t get completed, they don’t move the needle, and they’re not applicable to large parts of the organization. Sometimes you encounter what I like to call the Goldilocks problem, where there are too small action items and you have too large action items and you just want the ones that are just right.
When it comes to too small action items, these are usually items that have already been taken care of, either during the incident or right after: a quick bug fix, a quick updating the database, sending an email letting people know. These items shouldn’t wait until the post-mortem in order to be addressed, because they’re just not worth spending too much time on them during the incident reviews. Folks should still get credit for them. People really like getting credit for the things that they do and you should still give them credit. They should still be part of your artifact. You should still include them in your incident report, we just shouldn’t focus too much time on them. I do think we should put them in the incident report, because if this happens in the future, you want to know what you did. These are just easy things that should be done with, don’t worry about them.
Then you have your too big action items. This is the thing that bothers a lot of people. They’re important, you want to include them in your incident reviews. There’s a problem with having them in the same category as the other things that I mentioned, because sometimes they take too long to complete. They can take years to complete. If I’m like, let’s switch out of AWS. That’s not an action item that just one person can take. If you’re tracking completion, which a lot of organizations, in order to close an incident report, you have to close all the action items, that’s going to skew your numbers, and nobody’s going to be happy. Why is this? Why are these items not going to be resolved? It’s often because the folks in the incident review meeting who come up with these items are not the ones who do the work or who get to decide that this work gets done. They are usually larger initiatives that need to be accounted for during planning cycles, so you need managers or even principal level folks to agree to do this and to actually take on it. There’s still important takeaways from post-mortems. There are still important things that I think we should include as part of the review, and should be highlighted. What I actually recommend is that you don’t call them action items, you call them initiatives, and you have them as a separate thing. Or, if you want to keep them as action items, change the wording of it. The wording can be to start a conversation or to drive the initiative. Other things that I think make a difference with getting these completed are having a due date and having an owner. If you’re at the review meeting, and you realize that the owner isn’t in the room, or people aren’t agreeing on what it is, or the due date, maybe that highlights that we should rethink of this as an action item.
Really, the perfect action item in my perspective is something that needs to get prioritized. Something that can be completed within the next month or two. Something that can be decided by the people in the room. Finally, something that moves the needle in relation to the incident. I really like this chart, because it shows the difference between all of these things that I’ve just talked about. It shows the difference between what a quick fix is, what a true action item should be, what a larger initiative is, and then, finally, what a true transformation can come out of these incidents and learning from them. I’m going to go through an example actually of how we can come up with a true action item. Here you can see that we’re creating the narrative of an incident, and we’re asking questions of the things that are happening. Here I’m asking a question about service dependencies and how they relate to engineers understanding information from the service map vendor. I’ve been in incidents like this, where you have a vendor for your service map, and they have a definition for something that is different from my definition, and then things just don’t add up. Here, you can see how that question that I asked during the post-mortem, made it into a takeaway from the incident. There’s a takeaway around what service those touches and what depends on them. Then, finally, when you’re writing your report, you can see that there’s action items around the understanding of dependency mapping. You can see here that you have action items that meet the requirements I talked about earlier, that are doable, have ownership, that have due dates, and then move the needle. You go from creating your timeline, to asking questions, to a takeaway, to an action item.
A Focus on Cross-Incident Insights
Finally, the last way in which we use resilience to accomplish our goals is to focus on cross-incident insights. Cross-incident analysis is the key to getting the most out of your incidents. You’ll get better high-quality cross-incident insights the more you focus on your individual high-quality reviews. Cross-incident analysis is a great evolution from the process that we just discussed. The more retrospectives that you do, the more data you have that you can then use to make recommendations for large scale changes. Those transformations or those initiatives that I showed in that chart. Doing this should not be one person’s job. We’ve talked a lot about the value of collaboration, about hearing different points of views. Usually when I do this, it’s in collaboration with leadership as well as multiple engineering teams, multiple product teams, marketing, customer support, principals. I want to engage as many people as possible. Here’s your chance to drive cultural transformations. Here’s your chance to say, based on all of these incidents, I think that we need more headcount for this team, or I think we need to make this large change to our platform, because you now have this breadth of data with context to provide to leadership for any future focused decisions.
Why aren’t people doing this now? People aren’t doing this now because they don’t have the data. Like I mentioned, high-quality insights come from individual high-quality incident reviews, and people still aren’t doing that. It’s also because whatever home you have for your incident reviews are usually not very friendly for data analysis. Oftentimes, what we see is people have their incident reports living in a Google Doc or a Confluence, and so you don’t have a good way to query those numbers out, is basically what I’m saying. The other reason is that engineers are not analysts. When we’re trying to get somebody to do this work, to drive it, you need to think like an analyst. You need to think about how to read the data, how to present the data in a friendly format, how to understand how to tell the story. This is all of this work that I’ve done at different organizations. It’s actually one of the hardest things.
Here’s an example of how cross-incident insights can come with context. Instead of simply saying, we had 50 incidents. We can take look at the technologies that are involved. We can say that, “This past year, Vault was involved in a majority of our incidents. How about we take a look at those teams?” Maybe you give them some love. Maybe you help them in restructuring some of their processes. Maybe you focus on their on-call experiences. We’re not shaming them, we’re helping them. I’ve done this with a number of teams, and they’ve been able to look at a number of their incidents in a given timeframe. They’ve been able to make organizational-wide decisions. Because focusing on cross-incident analysis can help identify large initiatives that allow our engineers to thrive and help our businesses achieve their goals. We’ve seen people use these insights to decide on things like feature flag solutions, or decide to switch vendors, maybe even make organizational changes. All of this creates an environment where engineers are able to do their best work.
Anti-Pattern: MTTX (Again)
Here’s this anti-pattern again, MTTX. Here’s the part where I will never tell an analyst or an engineer to tell their CTO that the metrics that they’re requesting are silly, and they’re just not going to do it. Mostly because they don’t get paid enough, and you shouldn’t fight that fight. I’m never going to tell an analyst to do that because of that. Also, because when you have leadership asking for these metrics, you should actually take this as an opportunity to show your work. Take this as an opportunity to show the awesome insights that you’ve gathered through your individual incident analysis and through your cross-incident analysis. I call this the veggies in the pasta sauce method, mostly because I grew up not eating many vegetables. The idea here is that you’re taking something that maybe you think doesn’t have much nutritional value, which is that single MTTR number, like mean time to resolution was 45 minutes this month. You’re adding context to make it much richer, to bring a lot more value to the organization. Like, incidents impacting these technologies lasted longer than the incidents impacting these other technologies. It can help you make strategic recommendations from the data that you have towards the direction that you want to go. A lot of the times they say that people doing this work shouldn’t have an agenda. I have never not had an agenda in my life. There’s one thing that I wanted to get done, and I find my way to get it done.
Anti-Pattern: Not Communicating the Insights
Which leads me to my last anti-pattern. It’s something that we’re not, again, super-duper good as engineers, which is communicating our insights. Because if we have insights and nobody sees them, then what is the point? In the Howie guide when discussing sharing incident findings, we explain that your work shouldn’t be completed to be filed, it should be completed so that it can be read and shared across the business, even after we’ve learned, even after we’ve done our action items. This is true for individual incidents. It’s even more true about cross-incident analysis. I say this because I’ve often been in a review meeting with engineers, and they’ve said, “We all know what we need to do, we just never do it.” I’m sitting there and I’m like, do we all know because nobody has told me? Have we actually communicated this? Often, when people don’t interact with our learnings, it’s because the format is unfriendly for them. The truth is that different audiences need to learn different things from what you’re sharing. If you’re sharing insights to folks in the C-suite, maybe your CTO is going to understand your technical terms, but then you’re going to lose most of your audience. When you’re sharing these insights, you should use language that your audience is going to understand. You should focus on your goal. Don’t spend too much time going through details that aren’t important. If you want to get approval to rearchitect a system, explain what you think is worth doing and what the problem is based on the data that you have, and then who should be involved, and leave it at that.
Focus on your format, whether that includes sharing insights, numbers, telling a story, sometimes technical details. What I like to do usually, is I like to think of my top insight. I will say something like, incidents went up last quarter, but usage also went up. SREs are the only on-call incident commanders for 100% of the incidents, so as we grow, this is proving to be unsustainable, I think we should change the process and include some other product teams in the rotation. This is how you actually get transformations happening from your individual incident analysis to your cross-incident insights, to actually communicating them and getting things done. Another example of this is if you say something like, x proportion of incidents are tied to an antiquated CI/CD pipeline, I said tied, not root cause. This impacts all of our teams across all of our products, and it’s making it hard to onboard new team members. Based on feedback from stakeholders and from experts, we recommend we focus next quarter on rearchitecting this. We’re not suggesting a 4-month long project just because you feel like it. You’re suggesting it because you have the data to back that up and you’re showing your work.
Going back to this chart. Instead of thinking of action items being the only output of your incident work, let’s think of this entire chart as a product of treating incidents as opportunities. Let’s think of this entire chart as the product of what we can accomplish when we put effort, when we put resources into the resilience culture of our organizations. Because doing this work is how we get ahead. We will never be at zero incidents. Technology evolves and new challenges come up, but we focus on incident response and incident analysis and cross-incident insights while looking out for those anti-patterns, we can lower their cost. We can be better prepared to handle incidents, which is going to lead to a better experience for our users. It’s going to lead to a culture where engineers are engaged, and they have the bandwidth not only to complete their work, but also to creatively solve problems to help us achieve the goals of our organizations.
Questions and Answers
Participant 1: [inaudible 00:42:25].
Granda: You’re asking about how to deal with people who are just bummers about the whole process?
Participant 1: [inaudible 00:42:54].
Granda: I work with those things. I think it’s a couple of things. One, we all know that when you’re trying to deprecate something, it’s probably going to take longer than you think it’s going to take, so just highlighting that. Then, I would not even focus sometimes so much on the technical parts of it, but maybe tell them that we’re going to focus on how we work as a team, on the socio part of that sociotechnical system. I definitely think it’s still worth fighting that good fight.
Participant 2: You spoke a little bit about the challenges with cross-incident analysis, which actually resonated with a lot of people here and other challenges we’ve already overcome. Are there any additional thoughts on some resources or strategies that you’ve seen or have been effective in practically overcoming some of those challenges?
Granda: I have seen people do this at a smaller scale. It’s hard to do cross-incident analysis at scale. I think the biggest issue on that, is just getting good data. What I presented was around training folks, and not expecting an engineer to do everything, especially something that they just have never done before. Focusing on maybe hiring an analyst for your team, or giving people the chance to work on those skills, giving some formalized training, is what I’ve seen as probably the most helpful. I know that there are some vendors out there that are helping with the repository of your data. That’s hard for a number of reasons, but I haven’t found the key to it yet.
See more presentations with transcripts
MMS • RSS
Los Angeles Capital Management LLC reduced its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 89.8% during the 1st quarter, according to its most recent filing with the Securities and Exchange Commission (SEC). The fund owned 1,351 shares of the company’s stock after selling 11,833 shares during the period. Los Angeles Capital Management LLC’s holdings in MongoDB were worth $485,000 at the end of the most recent quarter.
Several other hedge funds and other institutional investors also recently added to or reduced their stakes in MDB. Transcendent Capital Group LLC acquired a new stake in shares of MongoDB in the 4th quarter worth $25,000. Blue Trust Inc. lifted its position in MongoDB by 937.5% during the 4th quarter. Blue Trust Inc. now owns 83 shares of the company’s stock worth $34,000 after acquiring an additional 75 shares during the period. Parkside Financial Bank & Trust boosted its holdings in shares of MongoDB by 38.3% in the third quarter. Parkside Financial Bank & Trust now owns 130 shares of the company’s stock valued at $45,000 after acquiring an additional 36 shares in the last quarter. Beacon Capital Management LLC increased its position in MongoDB by 1,111.1% during the 4th quarter. Beacon Capital Management LLC now owns 109 shares of the company’s stock worth $45,000 after purchasing an additional 100 shares during the period. Finally, Raleigh Capital Management Inc. raised its stake in shares of MongoDB by 156.1% during the 3rd quarter. Raleigh Capital Management Inc. now owns 146 shares of the company’s stock worth $50,000 after buying an additional 89 shares in the last quarter. 89.29% of the stock is owned by institutional investors and hedge funds.
Insiders Place Their Bets
In other news, CEO Dev Ittycheria sold 17,160 shares of the firm’s stock in a transaction that occurred on Tuesday, April 2nd. The shares were sold at an average price of $348.11, for a total transaction of $5,973,567.60. Following the completion of the sale, the chief executive officer now owns 226,073 shares of the company’s stock, valued at $78,698,272.03. The transaction was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through this link. In other MongoDB news, Director Dwight A. Merriman sold 1,000 shares of the company’s stock in a transaction that occurred on Monday, April 1st. The stock was sold at an average price of $363.01, for a total transaction of $363,010.00. Following the sale, the director now owns 523,896 shares in the company, valued at $190,179,486.96. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is available at this link. Also, CEO Dev Ittycheria sold 17,160 shares of MongoDB stock in a transaction that occurred on Tuesday, April 2nd. The stock was sold at an average price of $348.11, for a total value of $5,973,567.60. Following the completion of the transaction, the chief executive officer now owns 226,073 shares of the company’s stock, valued at approximately $78,698,272.03. The disclosure for this sale can be found here. Insiders sold a total of 49,976 shares of company stock worth $17,245,973 over the last ninety days. 3.60% of the stock is owned by company insiders.
Wall Street Analyst Weigh In
A number of analysts recently weighed in on MDB shares. Scotiabank decreased their price target on MongoDB from $385.00 to $250.00 and set a “sector perform” rating on the stock in a research note on Monday, June 3rd. Guggenheim upgraded shares of MongoDB from a “sell” rating to a “neutral” rating in a research report on Monday, June 3rd. Monness Crespi & Hardt upgraded shares of MongoDB to a “hold” rating in a report on Tuesday, May 28th. Loop Capital decreased their price objective on shares of MongoDB from $415.00 to $315.00 and set a “buy” rating on the stock in a report on Friday, May 31st. Finally, Robert W. Baird lowered their target price on shares of MongoDB from $450.00 to $305.00 and set an “outperform” rating on the stock in a research report on Friday, May 31st. One analyst has rated the stock with a sell rating, five have assigned a hold rating, nineteen have assigned a buy rating and one has issued a strong buy rating to the stock. Based on data from MarketBeat.com, the stock presently has a consensus rating of “Moderate Buy” and an average price target of $361.30.
Read Our Latest Stock Analysis on MongoDB
MongoDB Stock Up 3.8 %
NASDAQ:MDB traded up $8.69 during mid-day trading on Wednesday, reaching $235.30. The company’s stock had a trading volume of 948,264 shares, compared to its average volume of 1,516,101. MongoDB, Inc. has a twelve month low of $214.74 and a twelve month high of $509.62. The company’s fifty day simple moving average is $310.02 and its two-hundred day simple moving average is $369.21. The company has a quick ratio of 4.93, a current ratio of 4.93 and a debt-to-equity ratio of 0.90.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Thursday, May 30th. The company reported ($0.80) earnings per share (EPS) for the quarter, hitting the consensus estimate of ($0.80). MongoDB had a negative net margin of 11.50% and a negative return on equity of 14.88%. The business had revenue of $450.56 million for the quarter, compared to analysts’ expectations of $438.44 million. On average, equities research analysts anticipate that MongoDB, Inc. will post -2.67 earnings per share for the current fiscal year.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Growth stocks offer a lot of bang for your buck, and we’ve got the next upcoming superstars to strongly consider for your portfolio.
MMS • RSS
ClearBridge Investments, an investment management company, released its “ClearBridge All Cap Growth Strategy” first quarter 2024 investor letter. A copy of the letter can be downloaded here. The Strategy lagged behind the benchmark Russell 3000 Growth Index in the quarter. On an absolute basis, the strategy posted gains across all nine sectors it invested in. IT and communication services sectors were the primary contributors. Overall stock selection detracted from performance on a relative basis. In addition, please check the fund’s top five holdings to know its best picks in 2024.
ClearBridge All Cap Growth Strategy highlighted stocks like MongoDB, Inc. (NASDAQ:MDB), in the first quarter 2024 investor letter. MongoDB, Inc. (NASDAQ:MDB) offers a general-purpose database platform. The one-month return of MongoDB, Inc. (NASDAQ:MDB) was -32.15%, and its shares lost 43.07% of their value over the last 52 weeks. On June 25, 2024, MongoDB, Inc. (NASDAQ:MDB) stock closed at $226.61 per share with a market capitalization of $16.622 billion.
ClearBridge All Cap Growth Strategy stated the following regarding MongoDB, Inc. (NASDAQ:MDB) in its first quarter 2024 investor letter:
“During the first quarter, we initiated a new position in MongoDB, Inc. (NASDAQ:MDB), in the IT sector. The company offers a leading modern database platform that handles all data types and is geared toward modern Internet applications, which constitute the bulk of new workloads. Database is one of the largest and fastest-growing software segments, and we believe it is early innings in the company’s ability to penetrate this market. MongoDB is actively expanding its potential market by adding ancillary capabilities like vector search for AI applications, streaming and real-time data analytics. The company reached non-GAAP profitability in 2022, and we see significant room for improved margins as revenue scales.”

A software engineer hosting a remote video training session on a multi-cloud database-as-a-service solution.
MongoDB, Inc. (NASDAQ:MDB) is not on our list of 31 Most Popular Stocks Among Hedge Funds. As per our database, 56 hedge fund portfolios held MongoDB, Inc. (NASDAQ:MDB) at the end of the first quarter which was 62 in the previous quarter. In the first quarter, MongoDB, Inc. (NASDAQ:MDB) reported $451 million in revenue, up 22% year-over-year. While we acknowledge the potential of MongoDB, Inc. (NASDAQ:MDB) as an investment, our conviction lies in the belief that AI stocks hold greater promise for delivering higher returns, and doing so within a shorter timeframe. If you are looking for an AI stock that is as promising as NVIDIA but that trades at less than 5 times its earnings, check out our report about the cheapest AI stock.
We discussed MongoDB, Inc. (NASDAQ:MDB) in another article and shared the list of best AI stocks leading the ‘big tech race’ to $4 trillion according to a famous Wall Street analyst. Alger Mid Cap Growth Fund mentioned MongoDB, Inc. (NASDAQ:MDB) in its first quarter 2024 investor letter. In addition, please check out our hedge fund investor letters Q1 2024 page for more investor letters from hedge funds and other leading investors.
READ NEXT: Michael Burry Is Selling These Stocks and A New Dawn Is Coming to US Stocks.
Disclosure: None. This article is originally published at Insider Monkey.
MMS • RSS
ClearBridge Investments, an investment management company, released its “ClearBridge All Cap Growth Strategy” first quarter 2024 investor letter. A copy of the letter can be downloaded here. The Strategy lagged behind the benchmark Russell 3000 Growth Index in the quarter. On an absolute basis, the strategy posted gains across all nine sectors it invested in. IT and communication services sectors were the primary contributors. Overall stock selection detracted from performance on a relative basis. In addition, please check the fund’s top five holdings to know its best picks in 2024.
ClearBridge All Cap Growth Strategy highlighted stocks like MongoDB, Inc. (NASDAQ:MDB), in the first quarter 2024 investor letter. MongoDB, Inc. (NASDAQ:MDB) offers a general-purpose database platform. The one-month return of MongoDB, Inc. (NASDAQ:MDB) was -32.15%, and its shares lost 43.07% of their value over the last 52 weeks. On June 25, 2024, MongoDB, Inc. (NASDAQ:MDB) stock closed at $226.61 per share with a market capitalization of $16.622 billion.
ClearBridge All Cap Growth Strategy stated the following regarding MongoDB, Inc. (NASDAQ:MDB) in its first quarter 2024 investor letter:
“During the first quarter, we initiated a new position in MongoDB, Inc. (NASDAQ:MDB), in the IT sector. The company offers a leading modern database platform that handles all data types and is geared toward modern Internet applications, which constitute the bulk of new workloads. Database is one of the largest and fastest-growing software segments, and we believe it is early innings in the company’s ability to penetrate this market. MongoDB is actively expanding its potential market by adding ancillary capabilities like vector search for AI applications, streaming and real-time data analytics. The company reached non-GAAP profitability in 2022, and we see significant room for improved margins as revenue scales.”
A software engineer hosting a remote video training session on a multi-cloud database-as-a-service solution.
ADVERTISEMENT
MongoDB, Inc. (NASDAQ:MDB) is not on our list of 31 Most Popular Stocks Among Hedge Funds. As per our database, 56 hedge fund portfolios held MongoDB, Inc. (NASDAQ:MDB) at the end of the first quarter which was 62 in the previous quarter. In the first quarter, MongoDB, Inc. (NASDAQ:MDB) reported $451 million in revenue, up 22% year-over-year. While we acknowledge the potential of MongoDB, Inc. (NASDAQ:MDB) as an investment, our conviction lies in the belief that AI stocks hold greater promise for delivering higher returns, and doing so within a shorter timeframe. If you are looking for an AI stock that is as promising as NVIDIA but that trades at less than 5 times its earnings, check out our report about the cheapest AI stock.
We discussed MongoDB, Inc. (NASDAQ:MDB) in another article and shared the list of best AI stocks leading the ‘big tech race’ to $4 trillion according to a famous Wall Street analyst. Alger Mid Cap Growth Fund mentioned MongoDB, Inc. (NASDAQ:MDB) in its first quarter 2024 investor letter. In addition, please check out our hedge fund investor letters Q1 2024 page for more investor letters from hedge funds and other leading investors.
READ NEXT: Michael Burry Is Selling These Stocks and A New Dawn Is Coming to US Stocks.
Disclosure: None. This article is originally published at Insider Monkey.
High HTTP Scaling with Azure Functions Flex Consumption: Q&A with Thiago Almeida and Paul Batum
MMS • Steef-Jan Wiggers
Microsoft has introduced a significant enhancement to its Azure Functions platform with the Flex Consumption plan, designed to handle high HTTP scale efficiently. This new plan supports customizable per-instance concurrency, allowing users to achieve high throughput while managing costs effectively. In practical tests, Azure Functions Flex demonstrated the ability to scale from zero to 32,000 requests per second (RPS) in just seven seconds.
The Flex Consumption plan supports two memory sizes, 2,048 MB and 4,096 MB, with more sizes expected in the future. It also includes features to optimize cold starts and protect downstream components by adjusting the maximum instance count. The plan aims to offer a robust and flexible solution for varying load requirements, from retail flash sales to large-scale data processing.
A case study featured in the announcement showcases the plan’s capabilities. A retail customer handling a flash online promotion achieved an average throughput of 15,630 RPS, processing nearly 3 million requests in three minutes. The system could handle up to 32,000 RPS by fine-tuning the concurrency settings, illustrating the plan’s scalability and performance benefits.
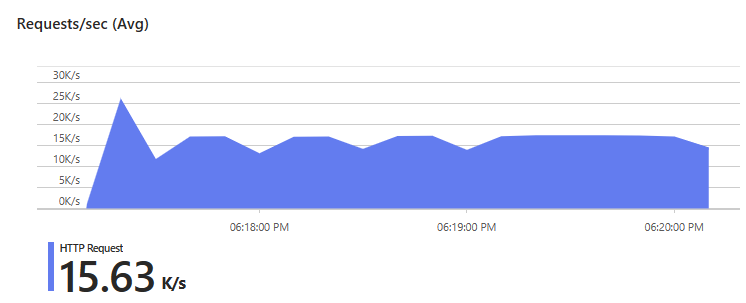
Average throughput of 15,630 RPS (Source: Tech community blog post)
The company also added improved virtual network features to Azure Functions Flex Consumption. A function app can now access services secured behind a virtual network (VNet) without sacrificing speed, even during scaling. In a recent scenario, a VNet allowed a function app to write to an event hub without a public endpoint. The company compared startup performance with and without VNet integration across multiple language stacks and regions to test this.
Enabling VNet injection has minimal impact on scale-out performance. With an average delay of 37ms at the 50th percentile, the security benefits of using virtual networks with Flex Consumption outweigh the performance cost. These results are due to the significant investment in the networking stack of Project Legion, the compute foundation for Flex Consumption.
InfoQ spoke with Thiago Almeida, a principal program manager at Microsoft, and Paul Batum, a principal software engineer at Microsoft, to learn more about Azure Function Flex Consumption performance.
InfoQ: How does one determine the optimal per-instance concurrency setting for different workloads in Azure Functions Flex?
Thiago Almeida: You can generally trust the default values to work for most cases and let Azure Functions scale dynamically. Flex Consumption provides default values that maximize each language’s capabilities. The default concurrency for Python apps is 1 for all instance sizes. For other languages, the 2,048 MB instance size uses a default concurrency of 16, and the 4,096 MB uses 32. Running tests with varying concurrencies is recommended to further fine-tune high HTTP scaling scenarios for your Flex Consumption applications. The Performance Optimizer feature has been enabled for everyone. It is a great tool to help identify the best concurrency and instance size for your HTTP functions apps on Flex Consumption.
InfoQ: When adjusting instance concurrency and memory sizes, can you elaborate on the trade-offs between cost and performance?
Paul Batum: It varies significantly across workloads, but a general rule is that increasing the per-instance concurrency will improve your overall efficiency but with some type of performance impact, such as slower responses, particularly at high percentiles (P99, P99.9, etc). For some workloads, this is a huge win – if the application has called an external API and is waiting for a response, it’s much more efficient to process other requests on that instance while waiting for that response.
On the other hand, if the workload is highly CPU intensive, context switching between 16 concurrent operations is less efficient than handling them one after another. So, in this type of scenario, you would likely see your efficiency improve by reducing the concurrency. When you increase memory size, there is a proportional increase in allocated CPU, which can help reduce the time it takes for the system to complete a CPU-heavy task.
InfoQ: How does enabling VNet injection impact the performance, and what specific optimizations have been made in Project Legion to address this?
Almeida: Project Legion was built to allow scaling to the levels that Flex Consumption requires, including VNet injection with kernel-level routing and efficient use of subnet IP addresses. The Azure Functions team also introduced the ’trigger monitor’ component that is injected into the customer’s VNet to provide scaling decisions for the app, even if the app is scaled to zero. As the case study article shows, these platform improvements allow VNet injection to have a very low impact on the scale-out performance. We observed a 37ms at the 50th percentile change between tests with and without VNet integration.
Lastly, more Azure Flex Consumption samples are available on GitHub.
MMS • RSS

Amazon DocumentDB (with MongoDB compatibility) now supports cluster authentication with AWS Identity and Access Management (IAM) users and roles ARNs.
Users and applications connecting to an Amazon DocumentDB cluster to read, write, update, or delete data can now use an AWS IAM identity to authenticate connection requests. These users and applications can use the same AWS IAM user or role when connecting to different DocumentDB clusters and to other AWS services.
Applications running on AWS EC2, AWS Lambda, AWS ECS, or AWS EKS do not need to manage passwords in application when authenticating to Amazon DocumentDB using an AWS IAM role. These applications get their connection credentials through environment variables of an AWS IAM role, thus making it a passwordless mechanism.
New and existing DocumentDB clusters can use AWS IAM to authenticate cluster connections without modifying the cluster configuration. You can also choose both password-based authentication and authentication with AWS IAM ARN to authenticate different users and applications to a DocumentDB cluster. Amazon DocumentDB cluster authentication with AWS IAM ARNs is supported by drivers which are compatible with MongoDB 5.0+.
Authentication with AWS IAM ARNs is available in Amazon DocumentDB instance-based 5.0 clusters across all supported regions. To learn more, please refer to the Amazon DocumentDB documentation, and see the Region Support for complete regional availability. To learn more about IAM, refer to the product detail page.
(C) 2024 Electronic News Publishing, source ENP Newswire
MMS • RSS
![]() Los Angeles Capital Management LLC lowered its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 89.8% during the first quarter, according to its most recent disclosure with the Securities and Exchange Commission. The fund owned 1,351 shares of the company’s stock after selling 11,833 shares during the quarter. Los Angeles Capital Management LLC’s holdings in MongoDB were worth $485,000 as of its most recent SEC filing.
Los Angeles Capital Management LLC lowered its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 89.8% during the first quarter, according to its most recent disclosure with the Securities and Exchange Commission. The fund owned 1,351 shares of the company’s stock after selling 11,833 shares during the quarter. Los Angeles Capital Management LLC’s holdings in MongoDB were worth $485,000 as of its most recent SEC filing.
Other institutional investors have also bought and sold shares of the company. Transcendent Capital Group LLC bought a new stake in MongoDB during the fourth quarter valued at $25,000. Blue Trust Inc. boosted its position in shares of MongoDB by 937.5% during the 4th quarter. Blue Trust Inc. now owns 83 shares of the company’s stock worth $34,000 after purchasing an additional 75 shares in the last quarter. Parkside Financial Bank & Trust boosted its position in shares of MongoDB by 38.3% during the 3rd quarter. Parkside Financial Bank & Trust now owns 130 shares of the company’s stock worth $45,000 after purchasing an additional 36 shares in the last quarter. Beacon Capital Management LLC boosted its position in shares of MongoDB by 1,111.1% during the 4th quarter. Beacon Capital Management LLC now owns 109 shares of the company’s stock worth $45,000 after purchasing an additional 100 shares in the last quarter. Finally, Raleigh Capital Management Inc. boosted its position in shares of MongoDB by 156.1% during the 3rd quarter. Raleigh Capital Management Inc. now owns 146 shares of the company’s stock worth $50,000 after purchasing an additional 89 shares in the last quarter. Institutional investors own 89.29% of the company’s stock.
MongoDB Trading Down 3.1 %
Shares of MDB stock opened at $226.61 on Wednesday. The company has a 50 day moving average of $310.02 and a 200-day moving average of $369.21. The company has a quick ratio of 4.93, a current ratio of 4.93 and a debt-to-equity ratio of 0.90. MongoDB, Inc. has a 12-month low of $214.74 and a 12-month high of $509.62. The firm has a market cap of $16.62 billion, a P/E ratio of -80.64 and a beta of 1.13.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Thursday, May 30th. The company reported ($0.80) earnings per share (EPS) for the quarter, hitting the consensus estimate of ($0.80). MongoDB had a negative net margin of 11.50% and a negative return on equity of 14.88%. The company had revenue of $450.56 million during the quarter, compared to analyst estimates of $438.44 million. Sell-side analysts anticipate that MongoDB, Inc. will post -2.67 earnings per share for the current year.
Insider Buying and Selling
In related news, Director Dwight A. Merriman sold 1,000 shares of the firm’s stock in a transaction that occurred on Monday, April 1st. The shares were sold at an average price of $363.01, for a total value of $363,010.00. Following the completion of the transaction, the director now directly owns 523,896 shares of the company’s stock, valued at approximately $190,179,486.96. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this link. In related news, Director Dwight A. Merriman sold 1,000 shares of the firm’s stock in a transaction that occurred on Monday, April 1st. The shares were sold at an average price of $363.01, for a total value of $363,010.00. Following the completion of the transaction, the director now directly owns 523,896 shares of the company’s stock, valued at approximately $190,179,486.96. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this link. Also, Director Hope F. Cochran sold 1,174 shares of the firm’s stock in a transaction that occurred on Monday, June 17th. The stock was sold at an average price of $224.38, for a total transaction of $263,422.12. Following the completion of the transaction, the director now directly owns 13,011 shares of the company’s stock, valued at $2,919,408.18. The disclosure for this sale can be found here. In the last ninety days, insiders sold 49,976 shares of company stock valued at $17,245,973. Company insiders own 3.60% of the company’s stock.
Analyst Ratings Changes
A number of equities analysts have recently issued reports on MDB shares. Barclays cut their price objective on shares of MongoDB from $458.00 to $290.00 and set an “overweight” rating on the stock in a research report on Friday, May 31st. Needham & Company LLC reissued a “buy” rating and set a $290.00 price objective on shares of MongoDB in a research report on Thursday, June 13th. Morgan Stanley cut their price objective on shares of MongoDB from $455.00 to $320.00 and set an “overweight” rating on the stock in a research report on Friday, May 31st. Loop Capital dropped their price target on shares of MongoDB from $415.00 to $315.00 and set a “buy” rating on the stock in a research report on Friday, May 31st. Finally, Bank of America dropped their price target on shares of MongoDB from $500.00 to $470.00 and set a “buy” rating on the stock in a research report on Friday, May 17th. One equities research analyst has rated the stock with a sell rating, five have issued a hold rating, nineteen have issued a buy rating and one has issued a strong buy rating to the company’s stock. According to MarketBeat.com, MongoDB has a consensus rating of “Moderate Buy” and a consensus price target of $361.30.
View Our Latest Analysis on MDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.