Month: July 2024

MMS • RSS

Ashford, United Kingdom July 31, 2024 –(PR.com)– As digital transformation sweeps across industries, the quest for powerful and seamless web solutions has never been more critical. Acquaint Softtech is not just keeping pace; it is setting the pace with expanded service offerings in MEAN and MERN stack development. The company’s mission is clear: to empower businesses around the globe with web applications that are not only efficient and scalable but also meticulously tailored to meet the diverse demands of the digital age.
Acquaint Softtech’s passion for technology drives its efforts. With profound expertise in both MEAN (MongoDB, Express.js, AngularJS, Node.js) and MERN (MongoDB, Express.js, React.js, Node.js) stacks, the company crafts dynamic, responsive web applications that do more than just function—they enchant and perform. Clients can hire MERN stack developers and MEAN stack developers to deliver cutting-edge solutions that ensure a seamless user experience across all platforms.
By embracing a unified JavaScript language across client and server sides, Acquaint Softtech developers simplify the development process, enhancing both the efficiency and agility of project execution. The adaptability of JavaScript, combined with the robust frameworks of MEAN and MERN, allows the team to tackle a wide array of projects. Whether it’s a nimble startup or a large-scale enterprise solution, the approach is tailored to fit every challenge.
The integrated development approach not only speeds up the creation process but also cuts down on costs. Clients enjoy quicker turnarounds and budget-friendly solutions that don’t skimp on quality. The portfolio spans a variety of sectors – e-commerce, healthcare, education – each project a testament to Acquaint Softtech’s capability to innovate and exceed expectations. The company does not just meet client needs; it redefines them.
Moreover, Acquaint Softtech is an official Laravel partner, offering services in Laravel development, IT staff augmentation, and software development outsourcing. The company helps clients hire remote developers to minimize the skill scarcity gap present in in-house teams.
About Acquaint Softtech
Acquaint Softtech is an IT outsourcing company that provides services related to software development and personnel augmentation. As a recognized Laravel partner, the company takes great satisfaction in building unique applications with the Laravel framework.
For businesses needing to hire remote developers, Acquaint Softtech offers an expedited onboarding procedure, allowing developers to join existing teams within 48 hours. With an hourly fee of $15, the company is an excellent option for any outsourced software development project. Acquaint Softtech assists clients in employing MEAN stack developers and MERN stack developers, as well as remote developers and outsourced services.
For more information or to hire MEAN or MERN developers, please visit the following links:
Hire MERN Stack Developers : https://acquaintsoft.com/hire-mern-stack-developers
Hire MEAN Stack Developers : https://acquaintsoft.com/hire-mean-stack-developers
Contact Information:
For more information about Acquaint Softtech or to discuss how MEAN and MERN stack capabilities can revolutionize web applications, please contact:
Mukesh Ram
Founder & CEO, Acquaint Softtech Private Limited
+1 773-377-649
mukesh.ram@acquaintsoft.com
https://www.acquaintsoft.com
Contact Information:
Acquaint Softtech Private Limited
Mukesh Ram
+1 773-377-6499
Contact via Email
https://acquaintsoft.com
Read the full story here: https://www.pr.com/press-release/915585
Press Release Distributed by PR.com
MMS • Conor Barber

Transcript
Barber: We’re going to talk about Bart and Lisa. Bart and Lisa, they can be anybody in the software world that’s concerned with shipping software. Typically, this might be your engineer or platform engineer, or just like a startup founder. They’ve been hard at work making some awesome software, and they’ve got a prototype. They’re ready, let’s go, let’s ship it. We want to build and test and deploy that software. We’re going to talk about the stories of Bart and Lisa in that context. Let’s start with Bart’s story. On day 1, Bart has created an awesome service. We’re going to talk a lot about GitHub Actions. We use GitHub Actions at Airbyte, but this talk is broadly applicable to many other CI/CD systems: GitLab, Jenkins. Bart’s created a back office service, and he’s got a CI for it. He’s got a little bit of YAML he created, and he was able to get up and running really quickly. He’s got this backup service: it’s built, it’s tested, it’s deployed. Really quick, really awesome. That’s day 1. Day 11, so Bart’s just been cranking out code, he’s doing great. He’s got a back office service. He’s got a cart service. He’s got a config service. He’s got an inventory service. He’s got a lot of different things going on. He’s got several different YAML’s now. He’s got one to build his back office. He needs to talk to the config service. It’s starting to pile up, but it’s still manageable. He can manage with these. This is day 101. Bart’s got quite a few services now. He has too many things going on, he doesn’t really know what to do. Every time that he makes a change, there’s just all these different things going on, and he just doesn’t feel like he can handle it anymore. What about Lisa? Lisa decided to do things a little bit differently. What Lisa has done is the subject of our talk. The title of our talk is CI/CD beyond YAML, or, how I learned to stop worrying about holding all these YAML’s and scale.
I am a senior software engineer. I work on infrastructure at Airbyte. Airbyte is an ELT platform. It is concerned with helping people move data from different disparate sources such as Stripe, Facebook, Google Ads, Snap, into their data lake houses, data warehouses, whatnot. Why CI/CD is important for us at Airbyte is because part of Airbyte’s draw is that there are a lot of different connectors, as we call them, a Stripe connector, a Google Ads connector. For each one of these, we build and test and deploy these as containers. The more that we have the heavier of a load on CI/CD that we have to contextualize. I became quite interested in this problem whenever I came to Airbyte, because at the beginning, it seemed almost intractable. There were a lot of different moving gears, and it seemed like there was just no way that we could get a handle on it. I want to tell you the story of how we managed to segment out this problem in such a way that we feel that we can scale our connector situation, and building our platform at Airbyte as well.
Roadmap
We’ll start by going through what YAML looks like, at the very beginning of a company, or just in general of a software project, and how it can evolve over time into this day 101 scenario. Then what we’ll do is we’ll break down some abstract concepts of CI/CD. Maybe not some perfect abstractions, but just some ways to get us thinking about the CI/CD problem, and how to think about how to design these systems that may not involve YAML. Then we’ll go into what this actually looks like in code. Then, lastly, we’ll go over the takeaways of what we found.
Airbyte was Bart
Airbyte was Bart. We had 7000 lines of YAML across two repositories. We have a quasi monorepo setup at Airbyte. It was a rat’s nest of untestable shell scripts. For those of you who are familiar with these systems, you may understand, yes, it’s pretty easy to just inline a shell, whether it be Jenkins where you can just paste it into the window, or you can just throw it into your YAML, or you can call it from YAML as we’ll see. There was a lot of subjective developer pain. We’d have a lot of people coming and complaining that our CI/CD was not great, it was not fun to use, it slowed everything down, and it was expensive. $5,000 a month may not be a lot for a lot of people in different organizations, but for us at the size of our organization, when we first approached this problem, which was about 40 to 50 engineers strong, it was a large bill. That gave us some motivation to really take a look and take stride at this problem. Then, 45-minute walk clock time, again, for some organizations, maybe this is not a lot. I think infamously it took 5 hours or something to build Chrome at one point. For us, being part of this fast feedback loop was important for us to be able to ship and iterate quickly. We looked at this as one thing that we wanted to look at improving.
YAML Day 1, YAML Day 101
Let’s jump into day 1 versus day 101. This is how YAML can start off great and easy, and get out of control after a little while. You start off with a really simple workflow. You just got one thing, and it’s one file, and it’s doing one thing, and it works great. You built it, and you were able to get it up and running really quickly. It’s simple and straightforward. It’s YAML. It’s easy to read. There’s no indirection or anything. By day 101, because of the way that we’ve built out these actions, and these workflows. I’m using GitHub Actions terminology here, but it’s applicable for other systems as well, where you can use YAML to call it, or YAML. Suddenly, you’ve got a stack. You’ve got a call stack in YAML, and you don’t have jump to definition. It’s difficult to work as a software engineer when you don’t have jump to definition. You’re afforded only the rudimentary tools of browser windows and jumping back and forth, and file names, and it’s just a cumbersome experience. This is another example of GitHub Actions, again. It’s got these units of code that are pretty great for certain things. This is one we use at Airbyte. It’s on the left, you’ll see test-reporter. What this does is it parses JUnit files and uploads them somewhere. It’s a great piece of code. The problem with this is that there’s a lot of complexity in this GitHub Action. There’s probably maybe 4000 or 5000 lines of Python in just this GitHub Action, parsing the different coverage reports and stuff. When you have a problem that’s within the action, you have to jump into the action itself. You’ve got to get this black box. Again, when there’s only one, there’s no problem. When it gets to day 101, and you have several hundred of these, suddenly, you’ve got a system where you don’t really know all these third-party integrations that are around, and the tooling is not there to really tell you. There’s just a bunch of black boxes of things that can just break for no reason. One very typical scenario we end up with at Airbyte is like some breaking change gets pushed to one of these actions, and it’s not pinned properly, and you don’t really have the tools or mechanisms to find it out except after the fact. Your CI/CD is just broken.
Another example. On the left here on day 1, we’ve got a very straightforward thing that is very realistic. This is what your first Node app build might look like. Again, it’s easy to grok what’s going on here. We’re just installing some dependencies. We’re running some tests. We’re building a production version of this app. We’re deploying it to stage. We’re deploying it to prod. Very easy, very straightforward to understand. By day 101, when you’re doing a bunch of these, in this example here, we’ve got 20-plus, it’s really hard to understand. Again, you can’t really isolate these things. You can’t really test whether deploy to staging is working with these YAML scenarios. We don’t even know if what we’re going to change, what’s going to run anymore. If you touch a single file in your repo, let’s just say it’s a single JavaScript file somewhere, how many of these on the right are even going to run, and where, and why? The tooling to surface this information for you is not there yet. One final example here. We have some simple Boolean logic examples on the left here. This is a very simple example where we just check and see if a JavaScript file was modified, and then we run the CI. On the right, we’ve got some actual Airbyte code that ran for a long time, to figure out whether or not we should run the deployment. You can see here, what we’re trying to do is we’re trying to express some complicated Boolean logic concepts in YAML. We end up being limited by the constructs of what this DSL is offering us. It can get very complicated and very hard to understand.
Pulling some of these ideas together, it’s like, why is this becoming painful? In general, we have a lack of modularity. We don’t have an easy way to isolate these components. We’re limited to what YAML is doing, and we’re limited to what the specific DSL is doing. They’re not unit testable, so we don’t really have a way of detecting regressions before we throw them up there. All we can do is run them against this remote system. We have some ecosystem related flaws. Everybody has their own quasi-DSL. If I take GitHub Actions code, and I want to run it in CircleCI, I can’t just do that. I have to port it. Maybe some concepts don’t exist in CircleCI, maybe some concepts don’t exist in GitLab. It’s not portable. It’s intractable. It’s this proprietary system where you don’t really see all of the source code of what’s going on, and there’s these settings and configuration that are magical that come in. It’s hard to emulate locally. The point I’ll make here that I think it’s key when we start thinking about CI/CD systems, is you want to be able to iterate quickly. This ripples out in so many different ways. I’m working in a platform engineering role right now. I want the developers I’m working for to adopt tooling, to be excited about working on tooling. When they can’t work with the tools that they have locally, it’s a very bad developer experience for them. There is a tool out for GitHub Action, specifically, that gets brought up about this, it’s called act. act, it works. It’s better than nothing. It has some limitations. Those limitations, they segue back into the fact that it’s a proprietary system that it’s trying to emulate, so, A, it’s always going to be behind the pushes. B, there are just some things that just don’t translate very well when you’re running things locally.
CI/CD Breakdown
With that said, we’ve talked enough about pain points, let’s break down what CI/CD is, and some maybe not perfect abstractions, but just some high-level system layers to think about. It’s like, what is this YAML actually doing? We have this giant pile of YAML we’ve talked about, what is it actually doing? We’ve chosen to break this out into what I’m calling layers here. These are the six different roles that a system like GitHub Actions, or a system like GitLab, or a system like Circle is providing for you with all this YAML. It goes back to what Justin was saying about the complexity of CI/CD. There’s a lot of stuff buried in here. When somebody talks about GitHub Actions, they could be talking about any one of these things. They could be talking about all of these things, or a subsection of these things. Pulling these out into some sort of layer helps us to make this into a more tractable problem, instead of just being able to say, it’s complicated.
What are we calling an event trigger? This is how CI jobs are spawned. We’re just responding to an event somewhere. Your CI job has to run somehow. This is pushing to main. This is commenting on a pull request. This is creating a pull request. This is the thing that tells your CI/CD system to do something. You can also think of this as the entry point to your application. Every CI/CD has this. One thing I want to call out, and we’ll come back to later, is that this is going to be very CI/CD platform specific. What I mean by that is what GitHub calls an issue is not the same thing as what GitLab calls an issue, is not the same thing as what Jenkins calls their level of abstraction. There are all these terms, and there’s no cohesive model where you can say, a GitHub Issue translates to a GitLab issue. Some of these concepts, they exist, and mostly match to each other, like a pull request and a merge request, but not all of them. Then, in the bottom here, I’ve added a rough estimate of how hard this was for us when we tackled these parts, these layers at Airbyte, so I added this 5% number here. This is an arbitrary number. I want to use it to highlight where we put the most effort and struggle into as we were figuring out the lay of the land on this. We put 5% here.
Authentication. You need to talk to remote systems in a CI/CD. You often need some secret injection. You’re usually logging in somewhere. You might be doing a deployment. You might be uploading to some bucket. You might be doing some logging. Your system needs to know about this. This is important because if we’re going to design something that’s perhaps a little bit more locally faced, we need to have that in our mind when we think about secrets, how they’re going to be handled on the local developer’s machine, how we’re going to do secret stores, and the like. The orchestrator, this is a big part. This is where we tell the executor what to run and where. Some examples are, I want to run some job on a machine. This is what jobs and steps are in GitHub Actions. This is also state management. You have the state passed. You have the state completed. You have the state failed. You have the state skipped. It’s usually easy to think about this as a DAG. Some workflow orchestration is happening in your CI/CD, where you’ve broken out things into steps, into jobs. Then you’re doing things based on the results. A very simple example here, again, GitHub Actions, is we’ve got build_job_1, we’ve got build_job_2, and then we have a test job that depends on build_job_1 and build_job_2 succeeding. We’ve got both parallelization and state management in this example.
Caching, this is typically tied to your execution layer. I’m saving nearly the best for last. It’s hard. I think that most people that are engineers can resonate with that. It’s very difficult to get right. It’s important that you choose the right tooling and the right approach to do this. There are two broad categories that you deal with in CI/CD, one is called the build cache. Any good CI/CD system, you want your system to be able to act the same way, if you run it over again with the same inputs. Idempotent is the fancy term for this. If your CI system works like that, and you know what’s going in, and you know the output already, because you built it an hour ago, or a week ago, then you don’t even have to build it. That’s the concept of the build cache. Then, the second part of this is the dependency cache. This is like your typical package manager, npm, PyPi, Maven, whatnot. This is just the concept of, we’re going to be downloading from PyPi over again, why don’t we move the dependencies either on the same machine so that we’re not redownloading them or close by, aka in the same data center so that we can shuffle things into there quicker, and not rely on a third-party system. This is about 10% overall. When you think about it overall, for us, it was about 10% of the overall complexity.
The executor, this is the meat of your CI/CD. This is actually running your build, test, your deploy. This is what it looks like, a very simple example in GitHub Actions, or Circle. You’re just executing a shell script here. That shell script may be doing any arbitrary amount of thing. This is a great example because it actually highlights how you can hide very important logical way in a shell script, and you don’t really have a good way of jumping into it. A couple other examples is that you might run a containerized build with BuildKit. That’s another way to run things. You can delegate to an entirely different task executor via command line call, like Gradle. For those of you who are in the JVM world, you’re probably familiar with this tool. This is a very large part of your CI/CD system. We’ll go into what we want to think about with this a little bit later. Lastly, is reusable modules. I put this in a layer by itself, because it’s kind of the knot that ties the other ones together. It’s the aspect of reusability that you need, because everybody is going to do common things. Why are we doing the same work as somebody else doing a common thing? For instance, an example I gave on here, is that everybody needs to upload to an S3 bucket probably. We have an action that you can just go grab off the marketplace, and it’s great. You can just upload and you don’t have to maintain your own code. Some other examples. This is the GitHub Actions Marketplace. Jenkins has this concept of plugins, which isn’t exactly like the marketplace, but it’s a similar concept. Then GitLab has some integrations as well that offer this. This is about 10% of the overall complexity of what to think about.
The Lisa Approach: CI/CD as Code
We managed to break it down. We picked some terms and we put things into some boxes so that we can think about CI/CD as something that we can put in some winners. Now we’re going to talk about the Lisa approach. What is the Lisa approach? The Lisa approach is to think about CI/CD as something that we don’t want to use YAML for. Something that solves these problems of scalability. Something that is actually fun to work on. Something that you don’t have to push and pray. Anybody who’s worked on GitHub Actions or Circle or Jenkins knows this feedback loop, where you’re pushing to a pull request, commit by commit, over and over, just to get this one little CI/CD thing to pass. It’s just like, now you’ve got 30, 40, 50 commits, and they’re all little one-line changes in your YAML file. Nobody wants that. What if we had a world without that? How would we even go about doing? The first thing to think about here, tying it back to what we were talking about before, is that we want to think about local first. It comes back to the reasons that we mentioned before. It’s that developers want it more. We get faster feedback loops, if we’re not having to do the push and pray. As we mentioned earlier, it got pretty pricey for Airbyte to be doing CI/CD over again. If we can do those feedback loops locally on a developer’s machine, it’s much cheaper than renting machines from the cloud to do it. We get better debugging. We can actually have step through code, which to me is like a fundamental tool that every developer needs to have a proper development environment. If they cannot step through code, then in my opinion, you don’t really have a development environment. Then, you get better modularity. You get to extend things and work on things, and going back to our key tool earlier, jump to definition.
One of the key design aspects that I wanted to call out that we learned when we were thinking about this at Airbyte, is that you need to start from the bottom layer, if you’re going to design a CI/CD system. The reason for that is because, the caching, the execution layer, they’re so critical to the core functionality of what your CI/CD is doing, that everything else at layer by layer on up needs to be informed by that. Just to give you some examples, I mentioned Gradle earlier. If you were going to build your reusable CI/CD system that was modular, on Gradle, you would have to make certain design decisions about the runner infrastructure that you are going to run on, the reusable modules. Are you going to use Gradle plugins? All of that stuff is informed by this bottom layer. That answer is going to be different than if you use, like what we did, is building it on BuildKit. There are different design decisions, different concerns, and they’re all informed by whether or not you use Gradle, Bazel, or BuildKit, are the three that we’re going to talk about.
The last key point that I want to make here is that, this concept of event triggers of like something is running your CI/CD, those, as I mentioned earlier, they’re very platform specific. Again, Jenkins doesn’t have the same way of running things and same terminology and same data model as GitLab does, and as GitHub Actions does, but the rest of the system doesn’t have to be. We’re going to introduce a way to box up our layers. This is going to be a simple way of thinking about it. The idea here is just, wrap them up in a CLI. Why? Because CLIs, developers like them. They’re developer friendly. They know how to use them. They can be created relatively easy. There’s a lot of good CLI libraries out there already. They’re also good for a machine to understand. I’ll demonstrate in a bit here that you can design a CI/CD system that basically just clears its throat and says, go CLI. That is the beauty of being able to wrap it up in something that a machine easily understands that’s also configurable. This design approach tries to ride the balance between these. How can we make it machine understandable and configurable, but also still happy and available for developers? We’ll start from the bottom up, and we’ll talk about some of the design decisions we made in the Lisa story here at Airbyte. When we went through this design decision, we came from Gradle land. A lot of Airbyte is built on the Java platform. Gradle is a very powerful execution tool but it didn’t work very well for us. We chose to use Dagger instead. What is Dagger? Dagger is a way for you to run execution in containers. It is an SDK on top of BuildKit. It’s a way for you to define your execution layer entirely as code. One of the more interesting design decisions here is, because it’s backed by BuildKit, it has an opt out caching approach. From a DX perspective, caching, going back to what we were saying before, it’s a hard problem. There’s a lot of different things that you have to do, to do caching right. We feel that giving developers caching by default is the right way. One of the interesting things to point out here is that when you think about your execution layer, and you think about your caching layer, they must fundamentally go together. That one of the limitations of GitHub Actions is that it’s not. Caching is something you bring in entirely separate and it’s something that’s opt in. Choosing a tool, whether it be Dagger, or BuildKit, or Bazel, or Gradle, needs to have this caching aspect baked into the very core of what it is, for it to be successful. Again, caching, we leverage BuildKit under Dagger. There are a few other mature options. I mentioned them already, Gradle and Bazel. They each have their pros and cons. Gradle eventually ended up not working for us because it was too complicated for our developers to understand.
Let’s talk a little bit about orchestration. Orchestration the Lisa way, going back to what orchestration is, this is an arbitrary term that we put on. It can be a general-purpose language construct in your design, or it can also be a specific toolchain. At Airbyte, we came from a very data transfer, data heavy specific background, so we chose Prefect for this. This could also just be your typical asynchronous programming language construct in your language of choice, whether it be Golang, whether it be Python, whether it be JavaScript. There are other tools out there. Gradle and Bazel have this aspect built into their platforms. There’s also Airflow. It’s a workflow orchestration tool. There are a couple others, Dagster and Temporal. Just a few examples of how you can get some visualization and things like that from your workflow orchestration tool are below. Lastly, the event triggers. These don’t change. Because these are the very CI specific part, this is the part of the data model that is very Jenkins specific, very GitLab specific. We push anything that’s specific to that model up into that layer, and it becomes a very thin layer. Then, running locally is just executing another event. By doing this, we can actually mock the remote CI locally, by mocking the GitHub Actions, in our case, events, by doing this. Lastly, remote modules. These are just code modules. This gives us all the things that we wanted before, in the Bart approach: jumping to definition, unit testable, no more black boxes. We can use our language constructs that are probably a bit better and a little bit more robust than GitHub Actions’ distribution for our packaging. Instead, maybe I want to use Rust crates to do distribution. You can actually implement a shim for migration. One thing I’ll bring up here is, maybe you want to move to a system like this incrementally. You can implement a shim that will invoke GitHub Actions’ marketplace actions locally. The Dagger team is also working on a solution for this. I’m excited to see what they have to offer. Any code construct that you need to make for your end users, and one of the points that I want to drive home here is that, the important thing when you’re thinking about CI/CD is that your end users need to want to be and very comfortable with using it. Being able to work with the language of their choice. The frontend people at Airbyte want to work in TypeScript, because that’s what they’re familiar with. Thinking about a solution that is comfortable for your end users is going to give you a lot more power, and you’re going to see a lot more uptake when designing a CI/CD system for others.
Demo (aircmd)
Let’s do a quick demo. What I’ll do is I’ll show a couple quick runs of the CLI system. We will also do a quick step through of the code just to see what this actually looks like when you start to abstract some of these ideas out. This isn’t maybe the only canonical way to approach this, but it is a way. We’ve got a CLI tool that I built over at Airbyte, it’s called aircmd. This is just a click Python wrapper. It just has some very simple commands. It builds itself and it runs its own CI. What we’re going to do is we’re just going to run a quick command to run CI. The interesting thing here is, when we do this, one thing we can do from a UX perspective is to make these commands composable. What I mean by composable, and we’ll look at this in the code, is that there’s actually three things happening here: build, test, and CI. The CI does some things but it calls test. The test does some things but it calls build. Your end users can get little stages of progress as they run. If they only care about the build stage, they only have to run the build stage. They don’t have to wait for anything else. You can see here that a lot of stuff was cached. What you’re seeing here is actually BuildKit commands. We can actually go look at the run. This is the Dagger cloud here. We can see it here. You can see, this is one of the DX things that I think is incredibly important to highlight when it comes to caching, because caching is so difficult. Being able to see what’s cached and what’s not easily is pretty key to having your end users be able to write performant code. Here, you can see that almost all of this run was cached, so it took almost no time at all. Then, what we can do is we can actually bust the cache. We’re going to go take a quick peek at the code over here. We’re going to take a quick look at the code. Let’s go ahead and start at ci.yaml. This is the event triggers layer that we were talking about earlier. There’s some minimal stuff in here. The idea here is that you have some CI/CD specific layer, but all it’s doing is essentially calling CI. You can see here that that’s what we’re doing. We’re setting some environment variables. We’re clearing our throat, and we’re running the CLI. Then once we do that, we get into the orchestration layer. I left auth out of this demo for purposes of brevity, but you can think of auth as just being a module in this setup. In our orchestration layer, we’ve defined three commands. Those three commands, they’re being submitted asynchronously, and they’re calling each other. This is just regular Python. We’re leveraging some Prefect constructs, but under the hood, it’s just regular Python. Then we jump into the execution/caching layer. Then, what’s happening here is interesting. Essentially, what we’re doing is we’re loading, you guys know of them as Docker containers, but OCI compatible client containers. We’re loading those, and we’re just running commands inside of a container. Now we get unit testability. We get the ability to specify cache layers. One easy way to think about what’s going on here is each one of these commands is not perfect, but it’s roughly analogous to a Dockerfile run command when it’s happening under the hood. You could replicate this with buildx in Docker as well. It’s not quite one to one but pretty close. What are we going to do? We’re going to do something that busts the cache. What’s happening is we’re taking files, we’re loading them into a container. If I just make a change, we’ll just add a whitespace, maybe a comment, it’s going to change the inputs to the container. Remember, we go back into what was happening before, we talked about caching. If the inputs change, we’re not cached anymore. We’re going to rerun the same command after we’ve added our comment, and we’re going to see that it’s not cached. It’s going to actually do some work here, instead of skipping everything.
Now we’ll take a quick look at the visualization tool here. These are hosted in the cloud. They can be local, but they’re hosted in the cloud. What’s happening is the client is actually streaming this data to them in real time, so we can actually see the job running in real time, as we go along. You can see we’ve already gotten pretty far in this one, and it’s running the pip install. That’s the core facet of the demo here is that we want to demonstrate that we have some tools to visualize what’s going on. We want to give our end users the ability to peek into the core facet of our CI/CD system, which is the cache layer here. Again, once we’re in, we can just jump through all of our code. If we want to see what these commands are doing, we just go to definition, we get our jump to. We have a stronger DevEx than we did with just pure YAML. We can walk all the way down the stack to the BuildKit base.
Key Takeaways
Let’s talk about Lisa’s light at the end of the tunnel. What does this actually mean for Airbyte? We spent some time and we refactored some stuff, what results were we able to show? How were we able to improve things for our end users? This is the output of the tool clock, see count lines of code. Over the course of three months, we were able to reduce the amount of YAML by 50%. What we did is we worked towards this incrementally. We’re still incrementally working towards it. We picked the nastiest, most painful builds first. We wrote up a proof of concept that was a very thin framework that handled those nasty, painful builds. Then we incrementally started bringing things over. We added unit tests every step of the way. One of the key performance indicators that we wanted to make sure was count the regressions. How hard is it to make a pipeline that doesn’t regress? We were able to achieve 90% cost savings. Part of this isn’t really indicative of the tooling that we chose, but more that we were able to leverage the tooling that we chose and the system that we made to be able to really easily go in. Going back to looking at the caching GUI from earlier, we were able to really easily point in and go identify bottlenecks for where caching was being really painful. To describe exactly what this meant, is, for instance, we were trying to test 70 connectors, which is just a container output that gets tested every single day. In the previous time, in the Bart times, we were spawning one machine in parallel in GitHub Actions for each one of those connectors, which was a very expensive endeavor. After we did this, we were able to leverage caching such that the layers were all shared within each other, and we switched to a single machine approach. In the time it took all 70 connectors to run wall clock, we were able to get that same time on one machine. That was a 70-time reduction in machine time. That’s how we were able to achieve such massive cost savings. We’re able to test connectors more often. Our developers are much happier because they have an environment where they can actually debug problems. We’ve gotten away from push and pray, which for us was a major DX win.
Pulling it all together, YAML is a great tool. It works really well when you’re doing something simple. In some cases, it’s going to be enough. If all you’re doing is maybe you’ve got like a side project, or what you’re doing is never going to be very complex, maybe YAML is the answer. When you start to scale, when you start to grow beyond a certain point, it really starts to fall apart. For us, it happened right at about the time that our system became complex enough. Day 101 was probably at year 1.5 for us. It did take a while for us to really sit back and acknowledge it. It’s key to recognize when you’re starting to get into that area of when it’s going to be a little crazy. We saw some major reduction of machine days, and just had some huge cost savings wins, huge performance wins. When you think about this, again, think about it from the ground up. Think about it from the execution and caching layer first. Because how you actually run these things on a remote system has a lot of nuances and caveats as well. It’s like, ok, I have a cache, how do I get it onto the machine where it’s running in a fast and easy way? Build the tooling and constructs your developers know. This goes back to the Airbyte frontend people want to run in TypeScript. Giving people an environment they’re comfortable with is going to give you adoption and mindshare and power for your developers to feel empowered and feel like they want to work on the system instead of it being something that just gets pushed to the wayside in a lot of organizations. Incremental migration is possible. When you take this whole thing, this whole blob, it seems a little intimidating. There’s a lot of moving gears in a CI/CD system. It is possible to build a bare bones thing. What we did is we built a bare bones system, and then we ran in parallel the same job for a week or two, and then we switched. The last thing is, get away from push and pray. We want to be able to do this locally.
Questions and Answers
Participant 1: I feel like you alluded this earlier in your talk, but like this tends to be a slippery slope. It’s like, you start off with one YAML file, and then there’s like some more that occur down to the 101st day, where things are like launching far. At that point, it just always feels like such a lift. It’s like, go. It’s like, ok, that’s it, stop this madness [inaudible 00:39:27]. As if you are just piling on. Organizationally, personally, how do you solve that problem? How do you get buy-in for like, saying, this is madness, this needs to stop. How do you do that?
Barber: This was definitely something that came up at Airbyte as well. The key methodology for success in our case was to demonstrate the win. Especially in this area, there’s a lot of like, this is the way that people do CI/CD. When you’re coming to the table with a new approach, you need to be able to demonstrate a very dramatic win, like we were able to do. Finding the right proof of concept is pretty key. For us, it was finding the nastiest, slowest, flakiest CI/CD job and saying, let’s just take a week, a week and a half and spike out what this can look like. Just getting something out there that’s bare bones that shows some very dramatic wins, I think is the key political way to help drive adoption and get people to see the possibility of what you can do.
Participant 2: Was there anyone who actually pushed back and said, “I like YAML.”
Barber: I think that some people do appreciate the simplicity of it. There are some benefits to being able to have something that’s standardized and quick and easy to grok. Contextually, once you get to a point in the organization where you’re doing, in some of our most egregious examples, they were inlining Python code in the YAML. It was very easy to see for people in our organization, how it had gotten out of control. Maybe other organizations haven’t gotten to that point yet. When it is bad, it’s very obvious that it’s bad.
Participant 3: Has the developer experience of not having to repush and iterate on CI, has that changed the developer’s thinking about how CI should be?
Barber: Yes. In our organization, there’s been a larger adoption, just a big push in general towards local first tooling. This is part of that story. There are some organizations I’ve worked in, in the past, where it gets shoved over to the DevOps team, the build does. What we’re seeing in our organization is that more people are becoming more actively involved in wanting to work on these systems and contribute to them. Really, our pie in the sky goal from the get-go was to bridge these gaps between different organizations and not just have the DevOps guys who do the pipeline. That everybody works on the pipeline together. We’re all engineers and we all work on the platform together.
Participant 4: One thing I would like to add is the portability of your solution that you’re using. Because at GitLab and Azure DevOps and company 1000 people on one, 1000 people on the other, and try that into migratable platform because they have two teams maintaining the stuff and running the stuff, and putting this into a good CI/CD tool independent approach depends on [inaudible 00:43:58].
Barber: That was something that when we looked at different ways to approach this, we looked at some other platforms and stuff like Earthly and the like. Being able to take a step back and not be married to one specific platform was a big selling factor for us.
Participant 4: The cost of moving from one YAML definition to the other, it’s just lost work for the teams, and it’s very painful. This just might be a way out of this, and going to the marketplace with this sort of tool is still very volatile. Where Jenkins, or some predecessor [inaudible 00:44:44] different tools, will be imperative to have something in there, vendor independent in place.
Participant 5: What do you see as next steps? You’ve got Air, what are the pains you still have? What’s the roadmap forward?
Barber: Where’s the long tail in this? No solution is perfect. Where we have hit the long tail, that we’re hoping that there can be some improvement, is especially if you work in a microservices-like setup. I think this is just an unsolved problem in DevOps, CI/CD systems in general is, if you want to have these reusable modules, whether they be your own, because you’ll need to make your own or whether they’re maintained by somebody else, how do you manage the distribution of all these modules? Let’s take a typical microservices example, like Bart’s example. He’s got 30 different services. How do we manage this tool, and the versions of this tool, and all the packages and all the plugins and all of that, and be able to deploy updates and test those updates, and do that in a robust manner. That’s the longer tail challenge of what we’re still coming up and against. Trying to tackle that has been one of our priorities, because a lot of work is on the platform engineers to maintain that ecosystem. Being able to solve that problem would take a pretty big load off of the platform engineering orgs.
Participant 2: Is there any disadvantages to using Dagger? I’ve definitely seen that, you see like YAML and Kubernetes, and something like Pulumi. There’s always advantages for code versus declarative information. I’m super [inaudible 00:46:48], but I haven’t played with it much yet. Is there any footguns I should be aware of, or any challenges?
Barber: Part of it is that it’s a very new technology. It has all the caveats that come with new technology. I think the one thing when it comes to Dagger, and in general just BuildKit that we’ve run into challenge wise is, it’s a new concept for a lot of people. BuildKit itself is relatively new technology as well. Getting people to think about things the container way may be a challenge for some organizations that are unfamiliar with it. For us, coming from Gradle, it felt like less of a lift, because Gradle, for us, it was almost interminable sometimes. The two primary challenges that we had with Dagger were that it’s new technology, it has all the facets of that that come with it. Containerized builds like these are just new technology in general and people aren’t as familiar with them.
See more presentations with transcripts
MMS • Steef-Jan Wiggers
Amazon MQ is a managed message broker service for Apache ActiveMQ Classic and RabbitMQ, simplifying the setup, operation, and management of message brokers on AWS. Recently, AWS announced support for quorum queues, a replicated type designed for higher availability and data safety, for Amazon MQ for RabbitMQ.
The RabbitMQ quorum queue is a modern queue type that implements a durable, replicated FIFO queue based on the Raft consensus algorithm. The Raft Consensus Algorithm is a protocol for managing a replicated log of states across a distributed system to ensure consistency and reliability by electing a leader who coordinates the order and commitment of log entries.
In a LinkedIn post, Saineshwar Bageri, a solutions architect, explains:
Quorum queues provide the replication capability to ensure high data availability and security. They can replicate queue data between RabbitMQ nodes, ensuring that queues can still run when a node breaks down. In Quorum queues, messages are written on the disk for Persistence. You need at least a Three-Node Cluster to Use Quorum queues.

(Source: LinkedIn Post)
In the RabbitMQ documentation, the queues are described as:
Quorum queues are designed to be safer and provide simpler, well-defined failure-handling semantics that users should find easier to reason about when designing and operating their systems.
Furthermore, in an AWS Compute blog post, Vignesh Selvam, a senior product manager at Amazon MQ, and Simon Unge, a senior software development engineer at Amazon MQ, write:
Quorum queues can detect network failures faster and recover quicker than classic mirrored queues, thus improving the resiliency of the message broker as a whole.
Developers can use quorum queues by explicitly specifying the “x-queue-type” parameter as “quorum” on a RabbitMQ broker running version 3.13 and above. The company recommends changing the default vhost queue type to ’quorum’ to ensure all queues are created as quorum queues by default inside a host.
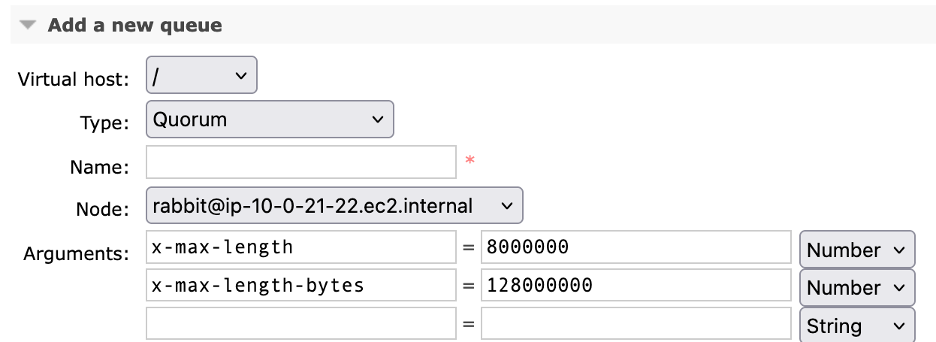
RabbitMQ queues console (Source: AWS Compute blog post)
Quorum queues suit scenarios where data durability and fault tolerance are critical. Yet, they are not meant for temporary use, do not support transient or exclusive queues, and are not recommended for unreplicated queues.
In addition, quorum queues perform better when they are short. Developers can set the maximum queue length using a policy or queue arguments to limit the total memory usage of queues (max-length, max-length-bytes).
Other message brokers use quorum mechanisms to enhance reliability, especially in distributed systems where consistency and fault tolerance are critical. For instance, Apache Kafka, a broker primarily using a log-based approach for message durability, can support quorum-based replication for increased reliability and consistency. Another example is Apache Pulsar, which uses a distributed ledger for message storage managed by BookKeeper, supporting quorum-based replication for data consistency and durability. Lastly, NATS Streaming (now part of NATS JetStream) supports quorum-based replication to ensure message durability and fault tolerance.
More details on the quorum queues in Amazon MQ for Rabbit MQ are available on the documentation pages.
MMS • RSS

NEW ORLEANS, July 30, 2024 (GLOBE NEWSWIRE) — Kahn Swick & Foti, LLC (“KSF”) and KSF partner, former Attorney General of Louisiana, Charles C. Foti, Jr., remind investors that they have until September 9, 2024 to file lead plaintiff applications in a securities class action lawsuit against MongoDB, Inc. (NasdaqGM: MDB). This action is pending in the United States District Court for the Southern District of New York.
MMS • Rafiq Gemmail

Gojko Adzic, author of Impact Mapping and many other classic product, engineering and testing books, recently announced the preview release of Lizard Optimization. His latest book discusses how responding to product-misuse and marginal corner-cases of the few long-tail users helped drive customer retention, and accelerate product growth. Continuous Delivery author, Dave Farley, recently interviewed Adzic for the GOTO Book Club, to discuss how these unusual use-cases can drive delivery of a better product for all customers.
Talking with Farley about feature areas to target for new product growth, Adzic discussed honing in on the curious and hard-to-understand use cases of small groups who appear to be misusing a product. Adzic referred to these use cases as “lizard behaviours.” He took the term “lizard” from a 2013 blog by psychologist Scott Alexander about surveying small groups with marginally held beliefs, such as those believing in conspiracies about lizards. Adzic told his own Lizard Optimization story of pivoting Narakeet, a product originally designed to generate narrated videos of PowerPoint presentations. He said:
The tool started as a way to make videos from PowerPoint. There were some people constantly making blank videos and paying me for that. Which made no sense at all … They were going through hoops and extracting videos just to produce an audio track… I simplified the way for those people to create just the audio file… That tiny minority, which was 1%, overtime became more than 99%.
InfoQ’s Ben Linders recently reported on a FlowCon France talk given by Fabrice des Mazery, CPO at TripAdvisor, where he discussed the cost and profitability risks of over-focusing on adding product features “because it’s better for the user.” Des Mazery cautioned that it’s important to take a broader ROI-centric focus to product roadmaps, which balance user-centric evolution of the product with longer-term profitability. TripAdvisor achieved this by transforming delivery teams into investors, with caps placed on cost. In Narakeet’s case, Adzic shared that adding support for the marginal use-case of a text-to-speech feature had resulted in improved UX and a significant reduction in operational cost.
Citing The Value of Keeping the Right Customers, a 2014 Harvard Business Review article by Amy Gallo, Adzic expressed the importance of retaining even those customers with marginal use cases, as marginal retention has a “compounding impact” on revenue. Gallo’s original article reported that “increasing customer retention rates by 5% increases profits by 25% to 95%.” Adzic told Farley that driving product improvements for all users was important for customer retention. He claimed:
If you want to grow a product, you can either go and acquire new users, or increase the retention of your existing users. And retaining users is incredibly more profitable at certain points of the life cycle.
A repeated point made by Adzic in his conversation with Farley was that by targeting marginal-use cases, one can make simplifications and overarching improvements across the product for “all users.” Another example he provided was that of a bug report filed about his mind-mapping application, MindMup, not being usable on a smart fridge. While this was not a use case he’d planned for, Adzic shared that by improving the touch capabilities of the application, they delivered usability improvements for all users, and widened the customer base. He explained:
Lizard Optimisation is a systematic way of figuring out how people are misusing a product, and then using those signals to make the product better. By making a product better for people who are misusing it, we can make a product better for everybody.
Within the book itself, Adzic calls out that Lizard Optimization is suited to products “where you want to grow market share, reduce churn or increase revenue.” He also explicitly calls out that for a product which is already “very mature,” having reached a point where you no longer need to grow it, then it is better to “focus on consolidation, technical scaling and reducing operating costs.” Lizard Optimization is in draft and available on LeanPub.
MMS • RSS

MongoDB has released a new artificial intelligence-powered feature that transforms natural language queries into data visualisations, developed by its Sydney-based engineering team.
Called Natural Language Mode for MongoDB Atlas Charts, the feature allows users to create visualisations by simply typing requests like “use a line chart to display trends in quarterly sales data”.
It aims to streamline the data visualisation process for developers and analysts.
The NLM for Atlas Charts announcement came during the MongoDB.local Sydney conference, which brought together hundreds of developers for educational sessions and customer presentations.
Simon Eid, the Asia-Pacific senior vice president of MongoDB, expressed pride in the Australian engineering team’s achievements.
“They continue to deliver innovative, AI-powered solutions within MongoDB Atlas that are focused on helping developers take control of their data and to transform their organisations,” Eid said.
The Sydney-based engineering team at MongoDB has been instrumental in developing key components of the company’s developer data platform for over a decade.
Their work includes the core storage engine, server, Charts visualisation tool, and Relational Migrator.
The Natural Language Mode for MongoDB Charts is now available to all customers.
The conference also showcased how organisations leverage the MongoDB Atlas multi-cloud database plafform to drive innovation.
Andrew Cresp, chief information officer at Bendigo and Adelaide Bank, said that generative AI helped reduce development time for migrating a core banking application to MongoDB Atlas by up to 90 per cent.
Pathfinder Labs, a company using AI to combat crime, demonstrated how their product Paradigm utilises MongoDB Vector Search and AI to manage information overload in complex global criminal investigations.
Tourism company thl Digital presented their successful migration from a separate search engine to an integrated data platform using MongoDB and Atlas Search.
The move simplified thi Digital’s codebase and reduced costs for the company.
MMS • RSS
New York, New York–(Newsfile Corp. – July 30, 2024) – WHY: Rosen Law Firm, a global investor rights law firm, reminds purchasers of securities of MongoDB, Inc. (NASDAQ: MDB) between August 31, 2023 and May 30, 2024, both dates inclusive (the “Class Period”), of the important September 9, 2024 lead plaintiff deadline.
SO WHAT: If you purchased MongoDB securities during the Class Period you may be entitled to compensation without payment of any out of pocket fees or costs through a contingency fee arrangement.
WHAT TO DO NEXT: To join the MongoDB class action, go to https://rosenlegal.com/submit-form/?case_id=27182 or call Phillip Kim, Esq. toll-free at 866-767-3653 or email case@rosenlegal.com for information on the class action. A class action lawsuit has already been filed. If you wish to serve as lead plaintiff, you must move the Court no later than September 9, 2024. A lead plaintiff is a representative party acting on behalf of other class members in directing the litigation.
WHY ROSEN LAW: We encourage investors to select qualified counsel with a track record of success in leadership roles. Often, firms issuing notices do not have comparable experience, resources or any meaningful peer recognition. Many of these firms do not actually litigate securities class actions, but are merely middlemen that refer clients or partner with law firms that actually litigate the cases. Be wise in selecting counsel. The Rosen Law Firm represents investors throughout the globe, concentrating its practice in securities class actions and shareholder derivative litigation. Rosen Law Firm has achieved the largest ever securities class action settlement against a Chinese Company. Rosen Law Firm was Ranked No. 1 by ISS Securities Class Action Services for number of securities class action settlements in 2017. The firm has been ranked in the top 4 each year since 2013 and has recovered hundreds of millions of dollars for investors. In 2019 alone the firm secured over $438 million for investors. In 2020, founding partner Laurence Rosen was named by law360 as a Titan of Plaintiffs’ Bar. Many of the firm’s attorneys have been recognized by Lawdragon and Super Lawyers.
DETAILS OF THE CASE: According to the lawsuit, throughout the Class Period, defendants created the false impression that they possessed reliable information pertaining to the Company’s projected revenue outlook and anticipated growth while also minimizing risk from seasonality and macroeconomic fluctuations. In truth, MongoDB’s sales force restructure, which prioritized reducing friction in the enrollment process, had resulted in complete loss of upfront commitments; a significant reduction in the information gathered by their sales force as to the trajectory for the new MongoDB Atlas enrollments; and reduced pressure on new enrollments to grow. Defendants misled investors by providing the public with materially flawed statements of confidence and growth projections which did not account for these variables. When the true details entered the market, the lawsuit claims that investors suffered damages.
To join the MongoDB class action, go to https://rosenlegal.com/submit-form/?case_id=27182 or call Phillip Kim, Esq. toll-free at 866-767-3653 or email case@rosenlegal.com for information on the class action.
No Class Has Been Certified. Until a class is certified, you are not represented by counsel unless you retain one. You may select counsel of your choice. You may also remain an absent class member and do nothing at this point. An investor’s ability to share in any potential future recovery is not dependent upon serving as lead plaintiff.
Follow us for updates on LinkedIn: https://www.linkedin.com/company/the-rosen-law-firm, on Twitter: https://twitter.com/rosen_firm or on Facebook: https://www.facebook.com/rosenlawfirm/.
Attorney Advertising. Prior results do not guarantee a similar outcome.
——————————-
![]()
To view the source version of this press release, please visit https://www.newsfilecorp.com/release/218283
MMS • RSS

SAN FRANCISCO, CA / ACCESSWIRE / July 30, 2024 / Hagens Berman urges MongoDB, Inc. (NASDAQ:MDB) investors who suffered substantial losses to submit your losses now.
Class Period: Aug. 31, 2023 – May 30, 2024
Lead Plaintiff Deadline: Sept. 9, 2024
Visit: www.hbsslaw.com/investor-fraud/mdb
Contact the Firm Now: [email protected]
844-916-0895
Class Action Lawsuit Against MongoDB, Inc. (MDB):
MongoDB Inc., a provider of document-database software, now faces an investor class action after revising its fiscal year 2025 revenue guidance twice in recent months.
Previously, MongoDB management expressed confidence in its ability to achieve its FY 2025 revenue targets. This confidence stemmed from initiatives such as restructuring sales force incentives and reducing pressure on upfront customer commitments. Additionally, management emphasized efforts to mitigate risks associated with seasonal trends and broader economic factors.
However, on March 7, 2024, MongoDB surprised investors with a downward revision of its full-year guidance. The company attributed the decrease to a restructuring of its sales force compensation model, which it said led to a decline in upfront customer commitments and revenue from multi-year licensing deals. Notably, management acknowledged this change could have resulted in higher guidance if sales capacity had not been impacted. This news led to a significant decline in MongoDB’s stock price.
Despite these revisions, management maintained its view that the overall business environment for FY 2025 would be similar to the previous year.
Then, on May 30, 2024, MongoDB further revised its FY 2025 guidance downward. This time, the company cited macroeconomic factors affecting customer adoption of its MongoDB Atlas product, along with the ongoing impact of the sales force restructuring. These disclosures resulted in another substantial drop in the company’s share price.
The cumulative effect of these revisions has eroded shareholder value by an estimated $7.5 billion.
Investors have now brought suit against MongoDB and its most senior executives alleging they gave the false impression that they possessed reliable information pertaining to the Company’s projected revenue outlook and anticipated growth, while also minimizing risk from seasonality and macroeconomic fluctuations. The complaint alleges that when making these statements, executives knew that macro headwinds were worsening and that MongoDB’s sales force incentive restructure were reducing new enrollments.
“We’re investigating whether MongoDB may have downplayed known risks posed by its sales incentive restructure and macroeconomic factors,” said Reed Kathrein, the Hagens Berman partner leading the investigation.
If you invested in MongoDB and have substantial losses submit your losses now »
If you’d like more information and answers to frequently asked questions about the MongoDB case and our investigation, read more »
# # #
About Hagens Berman
Hagens Berman is a global plaintiffs’ rights complex litigation firm focusing on corporate accountability. The firm is home to a robust practice and represents investors as well as whistleblowers, workers, consumers and others in cases achieving real results for those harmed by corporate negligence and other wrongdoings. Hagens Berman’s team has secured more than $2.9 billion in this area of law. More about the firm and its successes can be found at hbsslaw.com. Follow the firm for updates and news at @ClassActionLaw.
Contact:
Reed Kathrein, 844-916-0895
SOURCE: Hagens Berman Sobol Shapiro LLP
MMS • RSS

If you’ve had or are having problems using websites and apps today, it might well be due to the Microsoft Azure outage.
While the IT breakdown isn’t nearly as bad as the CrowdStrike boot-loop crisis from earlier this month, not that that was exactly Microsoft’s fault, various big names are experiencing or have experienced connectivity problems as a result of Azure’s network infrastructure multi-hour meltdown.
Customers may have experienced issues connecting to Microsoft services globally
The Windows giant said the issue lies with its network infrastructure, its Azure Content Delivery Network (CDN), and related CDN-like Azure Front Door service, which all together means “customers may have experienced issues connecting to Microsoft services globally.”
It started to fall apart at about 1145 UTC today, the day Redmond is due to report its latest financial results.
“An unexpected usage spike resulted in Azure Front Door (AFD) and Azure Content Delivery Network (CDN) components performing below acceptable thresholds, leading to intermittent errors, timeout, and latency spikes,” Microsoft noted at 1900 UTC.
“We have implemented network configuration changes and have performed failovers to provide alternate network paths for relief. Our monitoring telemetry shows improvement in service availability from approximately 1410 UTC onward.”
Interestingly, while the service is being fixed, the cure may cause a little more disruption. Microsoft explained:
We continue to investigate and mitigate reports of specific services and regions that are still experiencing intermittent errors. While our previous network configuration changes successfully mitigated the impacts of the usage spike, these changes caused side effects for a small number of services.
Our updated mitigation approach has successfully reduced these impacts across regions in Asia Pacific and Europe.
Our phased approach is now applying this same mitigation targeting regions in the Americas, and we expect that services should be fully mitigated by 2030 UTC.
So in about an hour’s time, from publication, Redmond reckons all should be well again. Let’s take a look at the impact of Azure’s instability so far.
Unsurprisingly, Minecraft maker Mojang, a subsidiary of Microsoft, said users “may experience some intermittent failures connecting to our services due to issues with Azure.” While Minecraft has both single and multiplayer modes, it does require users to authenticate their account before downloading and playing the game, and if these remote authentication services fail due to Azure being wobbly, then no more playtime.
Incidentally, your humble vulture tried to see what would happen if he attempted to install the Windows version of Minecraft on his PC, and discovered the launcher would spit out an error message, and the Java version wouldn’t launch, likely because the Microsoft Store is also facing downtime amid the Azure breakdown. So that’s fun.
Microsoft 365 is another Redmond-operated service confirmed to be impacted, and although there have been some murmurings about MSFT’s Xbox Live going down, too, so far the official Xbox status page says everything is fine. Let us know in the comments section if that matches your experience.
Game creation engine Unity additionally reported problems with Azure that is preventing downloads and uploads. MongoDB and Moesif also said the Azure outage caused them headaches, respectively for their Cloud and web portal services.
“This is causing degraded health of some Atlas Clusters globally,” MongoDB wrote. “In some cases, the cluster may not be accessible.”
Microsoft-owned GitHub said its Codespaces tool had issues around 0930 EST, and about half an hour later DocuSign noticed problems with its Rooms feature. Both diagnosed the problem as having originated from an outage at a third party, which we assume is Azure, though it’s not confirmed.
GitHub and DocuSign claimed the issue was fixed around the same time, which may imply Microsoft is indeed making progress on bringing Azure back up.
Starbucks also reportedly experienced an outage with its mobile app, though the latte-slinging corporation hasn’t responded to The Register‘s inquiries about whether this is related to Azure. We suspect it might not be a coincidence since complaints about problems with Starbucks on Downdetector are very similar in pattern to gripes about Microsoft 365. ®
MMS • RSS

NEW YORK, NY / ACCESSWIRE / July 30, 2024 / Pomerantz LLP announces that a class action lawsuit has been filed against MongoDB, Inc. (“MongoDB” or the “Company”) (NASDAQ:MDB). Such investors are advised to contact Danielle Peyton at [email protected] or 646-581-9980, (or 888.4-POMLAW), toll-free, Ext. 7980. Those who inquire by e-mail are encouraged to include their mailing address, telephone number, and the number of shares purchased.
The class action concerns whether MongoDB and certain of its officers and/or directors have engaged in securities fraud or other unlawful business practices.
You have until September 9, 2024, to ask the Court to appoint you as Lead Plaintiff for the class if you are a shareholder who purchased or otherwise acquired MongoDB securities during the Class Period. A copy of the Complaint can be obtained at www.pomerantzlaw.com.
[Click here for information about joining the class action]
On March 7, 2024, MongoDB issued a press release announcing its fiscal year 2024 earnings and held a related earnings call that same day. Among other items, MongoDB announced an anticipated near-zero revenue from unused commitments for the Company’s MongoDB Atlas platform in fiscal year 2025, a decrease of approximately $40 million in revenue, attributed to the Company’s decision to change their sales incentive structure to reduce enrollment. Additionally, MongoDB projected only 14% growth for fiscal year 2025, compared to projected 16% growth for the previous year, which had resulted in an actualized 31% growth.
On this news, MongoDB’s stock price fell $28.59 per share, or 6.94%, to close at $383.42 per share on March 8, 2024.
Then, on May 30, 2024, MongoDB again announced significantly reduced growth projections for fiscal year 2025. The Company attributed the reduction to its decision to change its sales incentive structure to reduce enrollment frictions, as well as purportedly unanticipated macroeconomic headwinds.
On this news, Mongo’s stock price fell $73.94 per share, or 23.85%, to close at $236.06 per share on May 31, 2024.
Pomerantz LLP, with offices in New York, Chicago, Los Angeles, London, Paris, and Tel Aviv, is acknowledged as one of the premier firms in the areas of corporate, securities, and antitrust class litigation. Founded by the late Abraham L. Pomerantz, known as the dean of the class action bar, Pomerantz pioneered the field of securities class actions. Today, more than 85 years later, Pomerantz continues in the tradition he established, fighting for the rights of the victims of securities fraud, breaches of fiduciary duty, and corporate misconduct. The Firm has recovered billions of dollars in damages awards on behalf of class members. See www.pomlaw.com.
Attorney advertising. Prior results do not guarantee similar outcomes.
SOURCE: Pomerantz LLP