Month: July 2024

MMS • RSS

The emergence of Postgres as a defacto standard for new development projects has surprised many IT observers. But one group that’s not surprised are the folks at Crunchy Data, a South Carolina company that’s been building a Postgres hosting business for transactional workloads for more than a decade. And with its recent product expansion, Crunchy Data is looking to take Postgres into analytics, too.
When Crunchy Data was founded back in 2012, Postgres didn’t register much of a blip on the data management radar. If you read the leading tech publications back then, you will recall a great amount of ink was spent on new open source projects for big data, things like Apache Hadoop and NoSQL databases like MongoDB.
However, when the would-be Crunchy Data co-founders had in-depth conversations with tech leaders at large companies, they found something that surprised them: growing demand for Postgres services, says Paul Laurence, the president and co-founder of Crunchy Data.
“They were absolutely using Hadoop and MongoDB. But where they felt the need most was around Postgres,” Laurence tells Datanami. “They were making a bet on a new open-source data management toolbox, where they had these NoSQL databases. That was part of where they were going. But they also saw this as an opportunity to shift towards open source on the relational and SQL side. And they had evaluated the landscape and selected Postgres as kind of their big bet.”
While it’s mainstream now, the whole commercial open-source business model was still relatively new. Aside from perhaps Red Hat, no other companies had succeeded with it, up to that point. Cloudera emerged as the leading contender to corral the various farm animals (Pig, Hive, etc.) in the Hadoop world, while MongoDB made inroads with Web and mobile app developers to define the nascent NoSQL market. The fact that Crunchy Data would put its commercial open source chips on a non-distributed relational database that was already 26-year-old–practically ancient by IT standards–stood out like stale milqetoast.![]()
“Postgres was largely dismissed when we first started. It was really all about Hadoop and MongoDB,” said Laurence, who co-founded Crunch Data with his father, Bob Laurence. “It was very contrarian at the time…Other folks would say ‘You guys are crazy. What are you guys doing starting a SQL database company? SQL is dead. That’s not a real thing anymore.’”
As it turned out, SQL was far from dead. Within just a few years, all of the leading NoSQL databases would be adding SQL interfaces to their databases, and rebranding the “No” in NoSQL to mean “not only.” The race to add SQL engines to Hadoop was similarly driven by a desire to match the shiny new computing framework to the huge mass of skillsets and toolsets that already existed.
Getting Crunchy with IT
But Crunchy Data wasn’t just about maintaining the relational data model and the SQL language. It was about Postgres, that open source database created by Mike Stonebreaker back in 1986. When enterprise CIOs and CTOs surveyed the market, they saw other relational databases, to be sure. The Oracle database, after all, is still the number one on the DB-Engines ranking. But in the data management Venn diagram, there was one database at the intersection of “open source” and “relational” and “not Oracle,” and its name was Postgres.
“Suffice it to say,” Laurence says, “from that point forward, the momentum behind Postgres has just continued to grow.”
Crunchy Data’s first offering, Crunchy Postgres, mirrored Red Hat’s enterprise Linux offering: a trusted distribution of Postgres. Large corporations and governmental agencies that had settled on Postgres as their database standard adopted this product, and managed the database themselves.
When containers became the preferred method for running virtualized IT services, Crunchy Data developed its own Kubernetes operator, and sold it along with its distribution of open source Postgres as Crunchy Postgres for Kubernetes.
As the cloud business model took off in 2020, Crunchy Data responded by delivering a hosted version of its Postgres distribution. Customers responded positively to this offering, called Crunchy Bridge, which was the first hosted Postgres offering from a pure-play database company.
Earlier this year, Crunchy Data delved into the analytics side of the house for the first time with the launch of Crunchy Bridge for Analytics.
Crunchy Bridge for Analytics doesn’t turn Postgres into a full MPP- style database, a la Green Plum or Redshift. That would require making modifications to Postgres and creating a new fork, with is something that Crunchy Data is loath to do.
Postgres for Analytics
Instead, the Crunchy Bridge for Analytics offering serves as a query engine that runs atop Parquet data that customers have stored in their Amazon S3 buckets, thereby eliminating the need for complex ETL data pipelines. It also brings a vectorized execution engine to speed up response times for traditional analytics and OLAP workloads.

Postgres has emerged as the top open source relational database (Tee11/Shutterstock)
Earlier this month, the company took the next step and announced support for Apache Iceberg in Crunchy Bridge for Analytics. This enables customers to leverage their investment in Postgres to provide lakehouse-style analytics using the popular open source table format.
The decision to build a Postgres service for analytics makes as much sense as it does for transactional workloads, says Craig Kerstiens, the chief product officer for Crunchy Data.
“Why Postgres? Because there’s a huge ecosystem of everything that sits on top,” Kerstiens says. “Whether it’s geospatial with PostGIS or vector search with pgvector, or full text search. Looking at the ecosystem of tools on top, whether it’s Power BI or Metabase…It’ s a vast, vast ecosystem of all sorts of tooling that sits on top and knows how to work with it.”
Crunchy Data’s analytics offering isn’t open source, but it strictly adhere to Postgres standards by functioning as a Postgres plug-in, or extension, Kerstiens says.
“We don’t lag behind on Postgres. We’re not going to be frozen on a version from 10 years ago. We’re able to stay current,” he says. “It’s basically an embedded analytics query engine that just works. You don’t have to think about it. You don’t have to know how it works. To you, it still looks just like Postgres.”
Customers Demand Postgres
Postgres adoption shows no sign of slowing down, and that’s good news for Crunchy Data, which, despite adopting a “West Coast crunchy business model,” is actually based in Charleston, South Carolina. Now in its 13th year, Crunchy Data has grown to more than 100 employees and 500 customers, with more undoubtedly on the way.
That success sometimes leads to interesting questions, says Kerstiens, who helped to scale one of the first hosted Postgres offerings as a Heroku developer.

Crunchy Data President and co-founder Paul Laurence
“Every week, I have someone say ‘Can you run Mongo for me? Can you run Redis?’ No, we’re focused on Postgres,” Kerstiens says. “But that kind of customer love and amazing Postgres experience is really where we focus foundationally.”
While the rest of the data management world zigged with Hadoop and NoSQL, Crunchy Data zagged with scale-up, relational tech. It may have looked like a gutsy bet at the time, but the Laurence’s had what turned out to be an ace card hidden up their sleeve: a willingness to listen to customer input.
“We started because we had some good customers and some folks who were betting on Postgres,” Laurence says. “At the time, we had a very bad website and we’re getting inbound emails and calls from Fortune 50 companies saying, ‘This looks like exactly what we need. We’re investing in Postgres as we go forward and we need someone to come in and help us understand how we do that and enterprise setting.’
“It’s continued to surprise and impress even us when we made that bet initially. It’s adoption has really been impressive,” Laurence continues. “Postgres is all we do. We’ve been a Postgres company from the beginning, supporting organization of all size be successful with Postgres. There’s no shortage of data options out there. If you’re working with us, it’s because you have a Postgres-centric view.”
Related Items:
Postgres Rolls Into 2024 with Massive Momentum. Can It Keep It Up?
AWS Cancels Serverless Postgres Service That Scales to Zero
MMS • Daniel Dominguez

AWS announced that Amazon SageMaker Studio now includes Amazon Q Developer as a new capability. This generative AI-powered assistant is built natively into SageMaker’s JupyterLab experience and provides recommendations for the best tools for each task, step-by-step guidance, code generation, and troubleshooting assistance.
Amazon Q Developer is designed to simplify and accelerate the ML development lifecycle by allowing users to build, train, and deploy ML models without leaving SageMaker Studio to search for sample notebooks, code snippets, and instructions. It can help with translating complex ML problems into smaller tasks and searching for relevant information in documentation.
The assistant is capable of generating code for various ML tasks, such as training an XGBoost algorithm for prediction or downloading a dataset from S3 and reading it using Pandas. It can also provide guidance for debugging and fixing errors, as well as recommendations for scheduling a notebook job.
JupyterLab in SageMaker Studio can now kick off models development lifecycle with Amazon Q Developer. It allows chat capability to discover and learn how to leverage SageMaker features for use cases without having to sift through extensive documentation. The assistant can also generate code tailored to the user’s needs and provide in-line code suggestions and conversational assistance to edit, explain, and document code in JupyterLab.
Ricardo Ferreira, DevRel for AWS, shares on his X account:
Silly coding mistakes are okay when you’re learning a programming language. But not so much as you progress in your software development career. #AmazonQDeveloper can help you with this.
AWS Developer Advocate Romain Jourdan, posted on X:
The generative AI space is moving so fast that it is difficult to catch up. Amazon Q Developer is improving every week too so we wanted to make it easy for developers to know what’s new, and what to test.
Other similar tools include RapidMiner, H2O.ai, KNIME, and Alteryx. These tools offer automated machine learning, data preparation, and model deployment capabilities, and can help streamline the development process and increase productivity.
Amazon Q Developer is now available in all regions where Amazon SageMaker is generally available. It is available for all Amazon Q Developer Pro Tier users, with pricing information available on the Amazon Q Developer pricing page.
Google Cloud Introduces Geo-Partitioning for Spanner: Reduced Latency and Cost Optimization
MMS • Steef-Jan Wiggers
Google Cloud has announced adding geo-partitioning to Spanner, its fully-managed, globally distributed database. According to the company, this new feature aims to improve performance and user experience for geographically dispersed applications and users while optimizing operational costs.
Spanner’s geo-partitioning is currently in preview. Spanner users can partition table data at the row level across various global locations. Despite the data being split into different partitions, Spanner maintains a single cohesive table for queries and mutations, ensuring seamless data management.
Jerene Yang, a senior engineering manager at Google, wrote in a LinkedIn post:
This is many years in the making. Imagine a database where rows can live in different geographical locations, where you can specify the location with just a value in the column, and yet you can perform transactions and complex queries.
The benefits are reduced latency, as geo-partitioning improves network latency by placing data closer to users, resulting in faster response times and lower costs as customized database configurations align costs with actual usage, for example, allocating more resources to partitions serving a more significant number of users.
Under the hood, the feature works as follows:
- Geo-partitioning distributes a single table across multiple configurations, bringing data closer to users while maintaining centralized table benefits
- Users can partition some or all tables, allowing specific placement rules at the row level
- Application requests are routed to the relevant partitions containing the requested data
Nitin Sagar, a senior product manager, provides an example in a Google blog post on the geo-partitioning feature:
As shown in the diagram below, your different data partitions can be configured with different numbers of nodes based on the specific requirements—reads, writes, and storage—of the data that your partition serves. This helps you optimize your costs for an asymmetrical distribution of players.
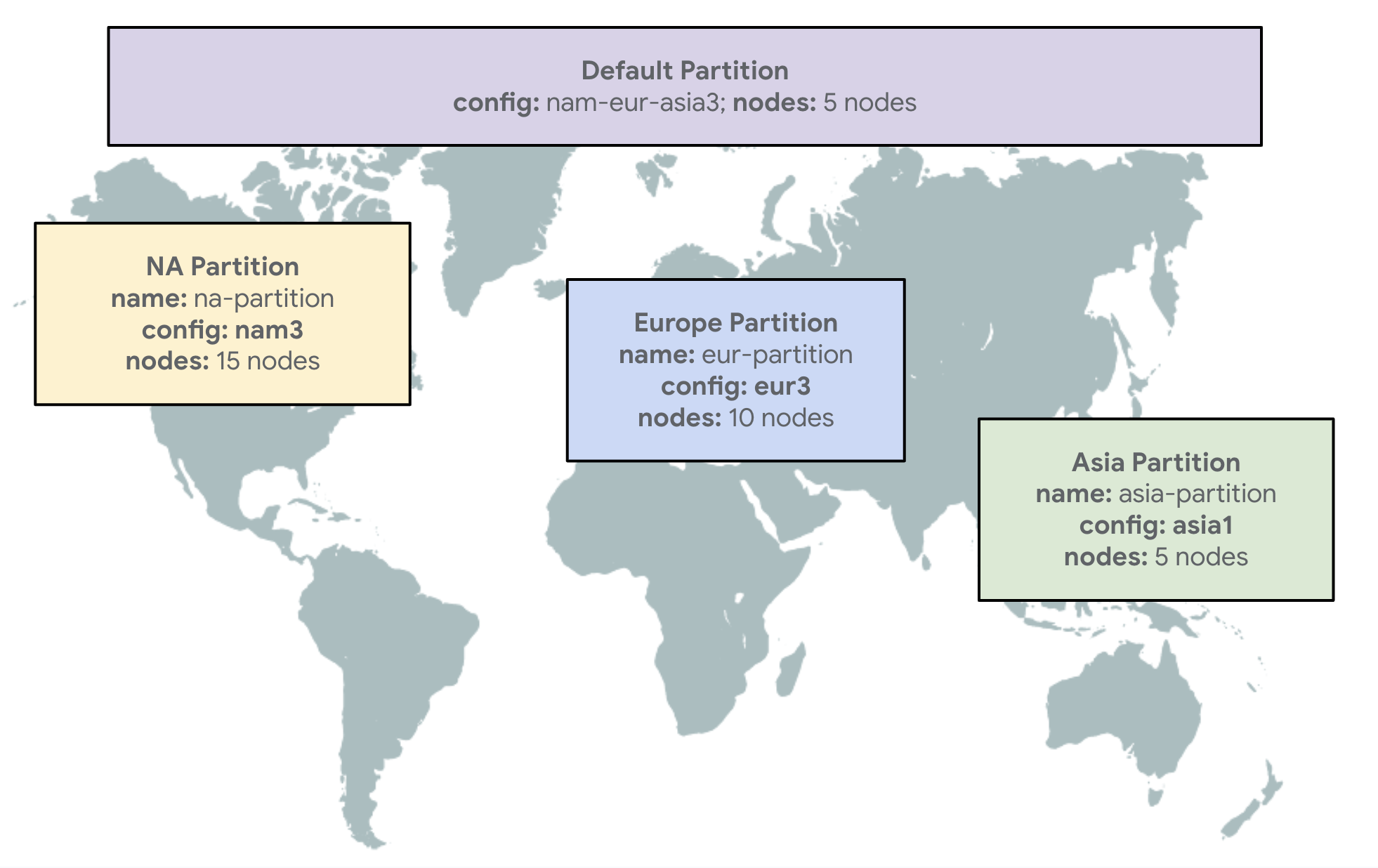
Geo-partitioning example (Source: Google blog post)
Richard Seroter, a chief evangelist at Google, tweeted:
Geo-partitioning in Spanner allows you to partition your table data at the row-level, across the globe, to serve data closer to your users … Spanner still maintains all your distributed data as a single cohesive table for queries and mutations.
Lastly, other globally distributed databases, like Spanner, offer similar geo-partitioning features. CockroachDB, for example, supports geo-partitioning within the same logical instance of the database, and Yugabyte has techniques for building cloud-native geo-distributed SQL applications with low latency. Both databases can store and process data in a region closest to the user, optimizing costs for asymmetrical global workloads and reducing write and robust read latency.
MMS • Adam Schirmacher

Transcript
Schirmacher: I want to start out by introducing you to a very special person named Devin. This is a picture of Devin. Devin is special to me because he’s the first staff engineer that I ever managed. Unfortunately for him, I mismanaged him. I did not give him the information or the context that he needed to do his job at a high level. To make matters worse, I thought it was his fault and I even considered letting him go. Devin and I had a really tumultuous relationship. He was the type of person who would just let me know whatever he was thinking with little to no filter. I remember one time he even shouted at me and asked, are you stupid, Adam? Imagine saying that to your boss. That’s just who he was. I’m happy to say that we did turn things around. In the process, he taught me a lot about effectively managing staff and staff-plus engineers. He went on to do some pretty great things at my company, Gusto. He built and rebuilt parts of our payroll platform, that processes billions of dollars per year, and probably pays some of your paychecks. Even though I’m admitting I made some mistakes, I don’t beat myself up over those mistakes. Because the truth is, managing and for that matter being managed is hard. I would argue, at the staff level, it’s even harder, or at least a little bit different than what I was used to. While I’m admitting these things that are painful for me on stage, I want the folks, if you’re a manager, think about who is your Devin. Who is that person that you wish you could go back, do some things differently? If you’re a non-manager, I understand we might have people who are staff engineers, maybe above, maybe you’re hoping to get there, honestly, maybe you’re not sure where you stand, which is actually pretty common, too. I want you to think about times where your needs were not met. Maybe that time is right now.
I’m going to be sharing some stories about how I learned the three most important elements in my mind of how to manage staff engineers effectively. Those three things are sharing context, raising your expectations, and fostering self-awareness. I think if you get those three things right, you can build better products and have more resilient teams, especially when you’re managing through tough changes. I’ve been a lead of lead. I’ve managed probably 5 to 10 staff engineers, depending on how you count things. Also had to fire people. I’ve had to promote people. I’ve had to demote people. I’ve done a lot of different things. I’m currently a staff engineer right now. I’m here to just share my experiences and hope that you can learn from them.
Context Sharing
We’re going to start out double clicking into what I said was, in my view, the most important thing, that’s sharing context. This started with Devin, this was right before COVID hit. This is February 2020. COVID was in the news, and we were like, maybe we’ll have to go home for a couple weeks. It didn’t work out quite that way. My company had gone through this big reorg. Suffice it to say it was pretty unpopular among the people. We’ve all gone through these things. No reorg is really popular, but this one was really painful for a lot of people. Devin was really vocally unhappy about it. That is how he came to report to me. I was moved from a frontline manager to a manager of managers’ position. Devin was, again, the first staff software engineer that I had ever managed. Our first one-on-one, I remember sitting in the corner office in Denver, thinking, this is going to be exciting. I’m always excited to meet new people, manage new people. I’m sitting there thinking about how great this could be. He walks in, first words he ever says in our first one-on-one ever is, “Adam, what do you think about this stupid reorg?” We’ve probably often had people that are this unhappy about things. I tried to tell him everything. I told him all these reasons that were shared in email, shared in announcement. We’re going to improve communication. We’re going to align teams whose work is closely related. All these things that he had already heard, but he just wasn’t buying in. Our first one-on-one was that difficult.
Our second one-on-one was also that difficult. He had the same challenges. I gave the same responses. It felt like we were going nowhere. By the third one, I was getting really worried, because I was starting to hear from other people who were not even Devin and just worked with him. They were saying, “I talked to Devin, and he seems really upset about this thing. Now that he said, I’m upset about it too.” Started becoming this negative influence. I don’t discourage people from talking to each other, and having concerns, but this was a done decision. We’re not going to dereorg. We’re not going to roll back the commit. We had to find out how to move forward. I said to myself, I need to shake things up. I need to try something different with Devin. I wanted to do a walking one-on-one, which I’ve done many times in person. It’s great. You just go for a walk with someone. Go walk around the streets of San Francisco or Denver, or whatever. COVID had just hit so we couldn’t do that. I put in my headphones, he put in his headphones, and we did it over the phone. We did a walking one-on-one in our neighborhoods, and it still had a remarkable result.
I finally had to confront Devin. I said, “Devin, I’m sorry, I know you’re unhappy. This is going to be a disagree and commit for you. We can’t go back. There’s nothing I can do. You just have to figure out how to get past it.” I took a pause. In that moment, I was so nervous, because I thought Devin was going to explode. All he said was, “Adam, just tell me the truth.” I thought, just tell me the truth? Here’s the thing, Devin is a perceptive guy. He knew that I wasn’t telling him the whole truth, just as managers often cannot or do not tell the entire truth of things. I said to myself, I got to just level with him, so I spilled all the beans. When I say spill the beans, we had this reorg. We had all these nice public reasons about communication. We had these not so nice reasons. There were teams underperforming. There were products that we were considering cutting. There were serious communication issues with certain individuals. Those were the things that we didn’t say out loud. I told them all those things. I was worried he was going to call me a big, fat liar. Say that I was the worst manager he’s ever had, but he just said, thank you. We ended the one-on-one early, which is something we had never done before.
That night, I remember thinking, what is going to happen next? Is he going to tell the whole team that I can’t be trusted, that I’m not being honest with them? What’s going to happen? I barely slept. In the morning, I woke up, and I checked Slack first thing in the morning. I know I’m not supposed to check Slack first thing in the morning. I checked Slack first thing in the morning, there’s a wall of text from Devin. This in itself, wasn’t unusual, I got those before. This one was different. I started reading it and it said things like, if we want to avoid that same communication issue that prompted the reorg, maybe we should do XYZ. He had suggestions of how we actually do better. I had never heard this from him. It was in that moment that I realized I messed up. I was thinking about letting him go and I thought, maybe I should be let go. I should have told him this way earlier. As we went on, I kept sharing more context with Devin. He kept eating it up, and I kept seeing good results from it. I invited him to leads’ off-sites. I shared with him some gory financial details, everything I could. Devin became an ally rather than a challenger.
I look back on this and I think, what did I do right, what did I do wrong with Devin? The big thing that I did wrong was I tried to protect Devin. My heart was in the right place, my head was somewhere else. The thing that I will give myself credit for was the walking one-on-one did generate a different result and it helped us make a breakthrough. I want to talk for a moment about my philosophy now on how I share information. You may have heard this analogy before of a manager being an umbrella, protecting people from all the bad things coming down. I try to be a transparent umbrella. Like this little girl, she’s not going to get wet but she can look around, so I want my staff engineers to look around and be able to understand what’s going on in the business. That’s my philosophy now and it’s really helped me in a lot of ways.
Lastly, on this topic of context sharing, I want to highlight a few places where I think most staff engineers crave more information, and they can do better work if they get it. The first is any performance evaluations. Most companies have some process. Managers sit around, they say, how valuable was this work? How valuable was that work? Who’s going to promote it? Who’s not? Having staff engineers in that room is very valuable. I’ve personally aimed for about a one-to-one ratio of managers and non-managers in those forums. The second thing I want to highlight is any staffing plan, when you’re thinking about what skills you need on your team, how many people you need to hire, whatever it may be. Unfortunately, these days, it could also be layoffs. I hope not, but that can happen. The third thing I want to highlight is any org change, like I talked about with Devin. I think when you share that context with people, they can, not just be non-challengers, but they can actually be advocates and help you make good decisions. Lastly, financial details. In my experience in smaller companies, these often matter a lot, whether it’s your runway, whether it’s how soon you want to be cash flow positive, what-have-you, I say share those details. Then your staff-plus engineers can actually help you do a better job. Again, I want to go back and address, some folks might not be managers, I say look at this list. These are things that you can ask to be involved in. You can go to your manager and say, I met this guy named Adam and he said, you’re supposed to invite me. Maybe it’ll go somewhere, maybe it won’t. That’s Devin.
Raise Expectations
Next, I want to share what I believe is the second most important thing in managing staff engineers, that’s raising your expectations. I want to do this by introducing another special person named Vikram. Vikram and I met about a year after I met Devin. He was an internal transfer from another team. He’d been at the company for a few years, and he was looking for something new. When I first met him, I did what I call like my intake one-on-one. Most people have some version of this. You get to know someone. I would ask things like, what are your goals? What do you like? What do you dislike? What was the high point of your career, or low point of your career? I figured out through that conversation, he just wanted to be somewhere mission critical. He wanted his code to really matter. He would say, I want it to matter if I mess up. He didn’t always use the word mess. I had just the thing for him. This was a great match, because my team, again, we’re managing the core payroll product. This is our bread and butter. We are doing this big project where we’re refactoring our tax engine. Turns out when you work in payroll, everything is just about calculating taxes and paying taxes and collecting taxes, everything is just taxes. I set him on his way. I introduced him to the team, and he got going. Within a few weeks, I started getting good feedback from folks. They were saying things like, “Vikram pointed something out in my PR that I didn’t even know to look for,” or, “Vikram really helped us with this retro and it went smoother than it’s gone before.” Needless to say, I was really happy. My emotions were up here. Great point in the managerial career.
One fateful day, it’s a Monday, I’m sitting on Zoom. I’m talking with some other managers, having lunch, and my phone goes off. I have a special ringtone that’s just for PagerDuty, and this was PagerDuty, so it immediately sent chills down my spine. Gave me an adrenaline rush, much like I have at this very moment. I looked at my phone, I’m like, “If I’m getting paged. I’m a manager of manager. I’m a few levels up. This is really serious.” I go check out what’s going on, we had a site outage. In our business, a site outage is just the worst. It was caused by an engineer under my purview, who had submitted a change that involved an unindexed query to a database. It brought the database to its knees. We had about 20 minutes of outage until it was rolled back. Then, unfortunately, we had a really big data cleanup after that point. Now I’m right here, I’m at a medium. I’ve been brought down a little bit. That Thursday rolls around, another serious alert. This time, it was a business logic error. It was an error in calculating travel reimbursements for New Jersey residents. I care about people of New Jersey. I want them to get reimbursed for their travel. This was another big incident. Joking aside, it really matters to get this stuff right. This incident is going on, and I’m down here. Remember, this is peak COVID, before the vaccines. I’ve people in my one-on-ones crying because they lost people to COVID. I have people who have COVID themselves. It just seemed like everything was going wrong.
Of course, my boss contacts me. He’s a great guy. He’s like, “Adam, what can I do to help you write more stable code?” He has a big heart, but nobody wants their boss to have to ask them that. I’m really in a panic. Much like with Devin, I decided to try something different. I sat down with the other managers in my org, and we decided to interview everyone. We would go around, we’d ask them some questions. Do you agree that our code currently has stability issues? Why do you think this happens? What can we do to support it? We started doing these interviews. Luckily for me, I got back to Vikram, and he stopped this whole process. Because I asked him these questions, and then he asked me the most important question. He said, “Adam, why are you doing this?” I was like, “What do you mean, why am I doing this, like code is unstable. Code needs to be stable instead.” He said, “No, why are you doing this?” I said, “I don’t know what the alternative is.” Then he said the four words that every manager longs to hear. He said, can I own this? Those are beautiful words. It brings a smile to my face, just hearing them for myself. I said, of course, you can own this problem. I also said things like, “Thank you so much, Vikram, you are such a saint. If you change your mind, let me know, I can take it back if you need any help at all.” I went on and on because in my mind, it was an act of charity. I thought he was offering to do something way above and beyond. I know it’s a bit sad. I know it’s a bit pathetic looking back, that I just simply didn’t know I could expect out of him. Even though he was a staff engineer, and I worked with other staff engineers, I had never worked with someone with the appetite and the capability of owning that cross-team stability problem.
Now this was Vikram’s problem. He handled it quite differently. He said, Adam, “Stop the interviews. Let me handle this.” He said I want to be invited to every post-mortem and I want to be free from all my normal project work. Easy things to grant for me as a manager. He went around and he paired with everyone. This is actually something that I try to emulate to this day. He pair programmed with everyone as his day-to-day work. He saw where people were missing certain skills. They could be things of, how to test for an unindexed query. How to look at a query plan. How to use certain internal tools that we had. He came back to me and he said, “Adam, I think I know what’s happening. People just don’t know what they don’t know. They just need to build some of these basic skills,” but we have deadlines. He said, “Adam, people aren’t going to feel free to work on these skills right now unless you say so.” I knew what to do. I had heard this concept of lending authority. I sent a big email to the whole team. This is about 25 to 35 people at this point that are reporting through me. I said, “Everybody, we have stability problems. I would rather move a deadline back because we took the time to avoid an outage, than move a deadline back because we had an outage. Vikram is going to be setting up some workshops. He’s going to be working with people on how to do some better testing practices, just how to avoid more outages, and I expect you to go to them. I expect your projects to be later than they otherwise would have been. That is explicitly what I want from this team.” With that endorsement, Vikram went ahead and set up these workshops. I wish I could tell you that it forever eliminated all production outages, it just didn’t. We did avoid repeating the same mistake twice. Everyone on the team agreed that they learned a lot. I learned a lot through this experience, too.
Looking back, what did I do right? What did I do wrong? The big thing that I wish I could have back is just I wish I could go back and ask him that right away. Day one, say, “Vikram, you are a staff-plus engineer. I have this big problem across my org. I want you to handle it.” I can say that now. I didn’t know that I could say that at the time. The thing that I will give myself some credit for doing right is that I lended authority through that email that I sent out. I want to double click on this for just a moment. You may have heard this term, influence without authority. I’m not knocking that term at all. In my experience, it’s hit or miss. It only works insofar as someone’s trying to influence them, influence someone else, along their goals. If they’re trying to go against them, it doesn’t work. If someone’s trying to ship a feature by Friday, and they’re over here saying, learn about monads and microservices. They can’t have that kind of influence. You have to be able to give them the authority to actually get things done and get things changed.
Lastly, on this topic, I want to, again, highlight a few opportunities. These are things that I believe you can ask staff engineers to do. They can own big org-wide, multi-team problems. They can address cultural issues. They can also handle technical roadmapping. I’m not a manager of staff engineers at this point. I am a staff engineer. I expect to be given tasks like Adam, own our technical roadmap, you own this whole thing now. Not just giving input. The last thing are these really big ambiguous problems. I don’t know if this comes up for other people. I’d love to know. In my company, every now and then something comes along. It’s like, Adam, you have to build X. Nobody can really tell you what X is, or what the goals are, or who the customer is. These days, I expect people at the staff-plus levels to be able to take that whole cloth and figure those things out. Again, if you’re not a manager, if you’re a staff engineer, or maybe you’re hoping to get there, these are opportunities where you can go and say, “I want to own this.”
Foster Self-Awareness
Lastly, I want to talk about the third most important element to managing staff engineers well, that is self-awareness. We’re going to do this by meeting another special person to me, this is Maria. Maria and I met through our company’s internal mentorship program, maybe you have these. We match people up. People sign up, and they say, I have these skills, and I want to learn this. Then someone else says, I have these skills and I want to learn that, and you pair people up. She had a problem that she was experiencing where she felt like everyone agreed with her and nobody did anything that she wanted. She felt like she knew she was supposed to have influence as a staff engineer, but it wasn’t resulting in real action. She got paired with me because, being a former director, former manager of managers, I felt like I could help her with that. I’ll give a little bit of a sneak preview and say that she helped me as much as I ever helped her.
She shared with me some of her communications, some of the things where she was trying to get her team to do things differently. I noticed this pattern of suggesting things. If you say something like, we should refactor, it’s easy for everyone to look around and be like, “Yes, great idea, we should refactor.” Then everyone goes back to the work that they were already going to do. It doesn’t result in any real change. I suggested to her, “Maria, try making this a concrete proposal. Something that someone can say yes to, someone can say no to, or someone can suggest changes.” She took that advice but she had a little bit of a problem. In her past experience, she had been on another team. When she did things like that, she got feedback that she was pushy, or that she was abrasive. If you’re in this room, and you hear me say those words and you squirm a little bit, it makes you a little uncomfortable, you’re right. Those are things that she would get criticized for, and if I did those same things, I would not get that same critique. It’s just a reality.
To her credit, she wanted to push through it. She wanted to figure out how to make it work anyway. I happened to know her manager. Her manager was named Lauren. I knew Lauren. I knew that Lauren had gone through things like that before. Maria asked me for advice on how to approach her manager, and I said, “Lauren’s a good one, just go tell her what you’ve been through or what you’re trying to do.” She did that. As I knew what happened, Lauren was fully supportive. Lauren handled it as well as I hope every manager handles it. She said, “Don’t worry. I got your back. You can do things that other people think are pushy but I will tell you if you cross the line, otherwise, just carry on.” Maria took that advice, and it went great. The next few months she shared with me many examples where she suggested concrete changes to her team, and they actually took action. She could actually look back and point at what they did and said, that little decision there, that was me, I helped change our trajectory. That went great for Maria.
It turns out, I need a little dose of self-awareness too. Several months after that, she reached out to me. She said, “Adam, how you been? I have some feedback for you.” This is great. I love when people give me feedback, and I trusted her. I said, what is it? She said, “You’re coming off as a bit of a jerk, and that makes people not want to work with you.” Tough words to hear but, honestly, it wasn’t the first time I’ve ever heard that in my life. I tend to have a pretty direct tone. I just say what I think, and sometimes it just doesn’t come off very helpful, very constructive. She pointed this out to me, and she’s such a good person, she made sure that she had several examples. She was like, do you want to talk through any of these with me? She gave me some advice that I take to this day. I use all the time. She said, “Adam, with every communication, you need to tell people that you are their friend. You need to tell them that you are their ally, and you’re here to help them. Maybe you are discussing an incident, maybe you are discussing something that needs to change, but they need to understand that you are on their side.” That was the bit of self-awareness that I needed, and I still try to do that. That’s why I say that Maria taught me as much as I may have taught her. What did we do right? What did we do wrong? In this case, the thing that she changed was she was making a lot of suggestions, but not any concrete calls to action. In my case, I had a very direct tone that wasn’t always coming off as helpful and having a tone of partnership.
Lastly, I want to highlight again a few pitfalls that I’ve seen happen a lot. The first is not having a concrete call to action. I always think, can someone just say yes to this, can they say no to it? Instead of just nodding and nothing changes. The pattern that I unfortunately have fallen into at times is what I call the smart jerk, where you might be right about something, but people don’t feel like working with you. Anyone who knows me closely knows that I’m mostly trying not to be a jerk, and I’m not all that smart sometimes. The third one that I want to point out is really applicable disproportionately to folks who have been in a staff-plus role, or an architect role for a long time. They can get so involved in documents, in slides, in presentations that other folks don’t see them as a real engineer. I’m not saying that this is right or wrong. I’m just saying that it happens. Those folks, it behooves us to tell them that this is happening. Because they can’t be effective if other people are looking at them and say, “That person is not on call. They’re not a real engineer, so I don’t trust them. I don’t care about what they say.” That really happens. At best, we can tell them, or at least we can tell them.
The last one that I want to point out is what I call the bottomless pit of despair. We’ve all been around these people. Oftentimes, it’s someone who’s really perceptive. They can tell you what’s wrong with your deployment pipeline. They can tell you what’s wrong with your hiring pipeline. They can tell you what’s wrong here and wrong here. They’re not incorrect about any of these things, but the net effect is that people who are around them are constantly feeling a sense of negativity. It’s just bringing people down. Again, whether they like it or not, that will make others choose not to work with them or choose not to engage with them. When that happens, I tell those people quite frankly, that they’re being a bottomless pit of despair.
Conclusion
In conclusion, I want to reiterate, these are the three things that I think are most important for your staff engineers doing their best work. That is sharing more context, like we learned with Devin. That is raising expectations, like we learned with Vikram. That is fostering self-awareness, like Maria helped me do.
Questions and Answers
Participant 1: How do you ensure that you don’t catch yourself doing that where it’s like, you’re trying to lay out some philosophical goals, but no one’s actually adopting them and using them, and how to find the balance of actually ensuring it’s happening again. I think it’s a good point to have. Writing a story to people that, you don’t have to run a workshop, you have someone else here to do it, or in here with devs, and all that. I think that’s the biggest thing I struggle with. Then I try to get other people in the organization to also do that of teach, show, support.
Schirmacher: There’s a few things that spring to mind. One is, I think, for me, I focused a lot on trying to measure how much I’m getting through to people. I try to cultivate my loving critics, people who will tell me, “Adam, this isn’t working out. You’re not getting through to people,” or whatever it may be. I like to ask questions along the lines of, on a scale of 0 to 10, how strongly do you believe that this is the right solution? Sometimes people may feel obligated to nod with you when you’re suggesting something, but you ask them a little bit more open-ended question. Then they’ll say like, I’m about a 6. Then you’re like, ok, I do have some work to do here. Or if you’re trying to make a change that you can actually measure. For example, how thoroughly people review PRs, which was an effort that we had at a different time. We would actually measure that, and chart it over time and see, how many comments are there? What is the time between when the PR was open and when it was reviewed? Some things you can measure, some things you can’t. What I personally try to focus on is making sure that I have some people who seem like they’re really truly getting it and can be the champions of that after I’ve gotten sick of it or moved on to something else.
Participant 2: Do you have any thoughts on limits of expectations for staff engineers? I think you talked about, like not providing enough responsibility or not providing a role that is sufficient. Obviously, there’s limits to that. I’ve seen some of that in terms of just like letting somebody drift too far with people management.
Schirmacher: Yes, in terms of limits that are good for them, or limits that are good for the team? Those two things can be a little different. I think a lot of people get pushed towards people management just because they happen to be a good mentor or happen to make good friends on the team. I like to just know where people stand on whether or not they ever want to manage people, or at least whether they want to right now. When I was a manager, I tried to provide a counterbalance, and make sure that they didn’t get sucked into things that were too people manage-y. The other thing that I’ve seen a lot, is a lot of staff engineers, they’re so curious that they get their hands in too many things, and then they’re not actually doing a good job of any one of the things. I like to set some limits there. Sometimes it’s just as simple as a work in progress limit. I will talk with someone and say, you jumped on this thing. What are you going to drop? If you say nothing, I don’t believe you. We have to talk about what you’re going to consciously drop.
Participant 2: To a certain extent, staff engineers are very senior and you trust them to manage their own tech very effectively. Certainly, there’s limits on that. I think that last bit that you talked about, that it touches on where the limits on that should be.
Participant 3: Often, when you work with senior engineers across multiple things, and they have opinions, and they care that their opinions matter. Sometimes there’s more than one opinion in the team, and we don’t know how to steer the ship properly, find the direction, and make sure everybody is heard with the least involvement of the manager. We don’t want anybody to feel that I said something, I proposed something but my proposal did not matter, things like that. I think it always happens quite often. How do we reach consensus?
Schirmacher: In the realm of staff engineering, I generally expect staff engineers to have a high EQ where they understand where other people are feeling unheard, and they understand where other people are feeling disengaged with the process of making that decision. As a manager, my view is that, it’s my job to set up a clear framework for making that decision. Sometimes people are unhappy with that. There have been times where I’ve had to say, “This person is the tech lead. They are going to make the final decision. You very opinionated person who disagrees are probably not going to get your way.” Sometimes that meant that they didn’t like me, or maybe they didn’t like me for a little while. Nobody wants to work somewhere where you’re constantly trying to please everyone and you don’t make a decision. For me, I like to just make sure that the decision maker is clear. I will be upfront about how I’m evaluating them. If this gentleman is the decision maker, I will say, I’m going to get feedback from you. If people don’t feel like you’ve respected their opinions, that will reflect negatively on your review. If they say that you did a great job navigating the many opinions, it will reflect positive on your review. That’s how I personally think about it.
Participant 4: You spoke a little bit about awareness pitfalls, things like that, and some suggestions on how to address them. The one thing that you mentioned about staff engineers not really being seen as real engineers, being aware of that is one thing but how do you address it, or what can you do to address that?
Schirmacher: I think to a certain extent, that feedback has some validity to it. I’ve worked with folks who are brilliant in the abstract, but they don’t understand how many constraints are down here where people are actually coding and actually committing things. To some degree, the critique that they’re not real, I wouldn’t ever say they’re not real engineers, but it can affect their credibility in a real way. For the folks that I’ve worked with, and even for me, personally, I make it a point to always be coding. It doesn’t always mean production code. It can be, if you have an idea for a new architecture, put together a prototype. Put together something that people can look at and click and see that it actually works as you’re describing. I think the more people see that you’re actually capable of building things, the more you have credibility, even if you’re not on the frontlines building every single day.
Participant 5: You did say you got paged by PagerDuty. How do you manage in your head expectations of different timescales, like I’ve made a change, I should see something good, it’ll be a month, a year. You in your head as you manage, some things that you do should pay off right away, or some things that people do, now that you’ve put them in a position should pay off maybe over a longer timescale.
Schirmacher: I think, especially as a manager, and this is true as a staff engineer too, a lot of things only have an effect that you can see 18 months later. That’s really tough. I think of our work as a whole as a diversified portfolio. We have things that are going to deliver value next week. We have things that are going to deliver value 6 months from now. Then we have these longer-term things. For the things that are longer term, I’ve seen a number of things tried and a number of things fail. I’ve seen, for example, where you just look and say, does it look like they have the right ideas that could pay off in two years? That becomes pretty political and becomes a showmanship thing. I think, for rewarding longer term work, I personally focus on trying to keep people engaged for the long term. If they’re working on something that has a two-year payoff, I want to make sure that the incentives are set up right for them to be at the company, and working on that for two years. That can mean incentive bonuses at the end of that period. It can mean different things. I try to align the incentive structure so that they’re happy to stick to it for as long as it takes for the thing to show real value. That’s not always possible, though, so I’ve been lucky.
Participant 6: Related to the story you were saying about Vikram, you had mentioned that at the beginning, you would have just given him the project and just like let him mind from there. Is there anything now that you would look for in a staff engineer to know that they’re ready for something like that, besides just them saying that they’re ready. Then vice versa, if someone says they’re ready, and you don’t think they’re ready, what do you look for?
Schirmacher: On average, I see that most people are ready before they think that they are ready. When I say ready, I don’t mean that they’re going to be the best ever at that thing. I mean that it’s out of their comfort zone, but like just a little out of their comfort zone, and it’s going to push them. Nine times out of 10, I have to try to nudge someone to take on a bigger task than what they feel comfortable with. It’s pretty rare that I have someone who says they’re ready, but they’re clearly not. I honestly don’t know if that’s happened to me. I think in terms of looking for the right opportunities and the right people for them, I’m not a manager these days, but I keep an eye out for those things constantly. Everyone on my team, I talk with them, and I know whether they’re looking for something. I will often go to their manager and say, “This person is ready for the next big thing.” Sometimes I’ll get a little cantankerous about it and I’ll be like, “And you should probably have them do it, or you might be doing them a disservice as their manager.” I’ll try to really nudge for that to happen. Frankly, I see so many opportunities abound for people to be able to step up. It’s a problem of limited resources, rather than not enough opportunities.
Participant 7: To refer back to the example from Vikram, because, for example, in his case, everything was on fire, really high priority incidents, a lot had to be taken care of. How do you find that balance to delegate to the things and actually trust them to get done and not to go into the micromanaging thing? Because I noticed for example, personally, if the stakes are lower, I love to delegate and I build trust, and trust enough and can keep in check. When things are on fire, it’s too easy to go with working out, it’s easier for me to take care of it rather than trust somebody else to do it. Do you have any hints, tips, advice on?
Schirmacher: My observation is that, in the many companies I’ve been a part of, we’ve lost a lot of people whom everyone thought we would be dead if we lost them. Everyone thought, if we lost that person, what are we going to do? People tend to step up to fill the void. I feel like to some extent, if the stakes are high, the urge to involve oneself, it partly comes from not knowing just how much others will step up to the moment. I’ve so many times seen people step up and do things that I didn’t even know they were capable of, because the moment called for it. I’m a bit of a thrill seeker just even outside of work, but I like seeing that things are just close to the brink of catastrophe and just seeing how much people fix it that maybe you didn’t even know could fix it or would fix it.
See more presentations with transcripts
MMS • Karsten Silz
At QCon London 2024, Christopher Luu explained how Netflix uses server-driven UIs for rich notifications. This saves developer time through reuse across platforms and better testing but adds effort to maintain backward compatibility. Developers write notifications by embedding so-called Customer Lifecycle Component System (CLCS) components in JavaScript, similar to how React UIs embed HTML in JavaScript.
Notifications in Netflix apps tell users of important events, such as payment failures or promotions. Server-driven notifications allow Netflix to update the UI on the server without app updates, to share logic across the many platforms that Netflix supports, and to run A/B tests effectively. Developers can also create notifications on any platform, independent of their knowledge of platforms and programming languages.
The downsides are higher upfront costs for creating the notification framework and the need to keep the framework backward-compatible with older Netflix apps. It’s also more challenging to support offline apps and debug notifications. Finally, some developers do not enjoy non-native development.
Netflix calls a notification UMA – Universal Messaging Alert. UMA runs on TV, web, iOS, and Android. Except for the web, all these platforms require Netflix to get approval for app updates from the TV vendor, Apple, or Google. That’s where CLSC components, the server-driven UMA, save time & money: the same code runs on all platforms without app updates or approval. Still, Netflix only delivers UMA with these server-driven UIs: The apps use native, client-side UI frameworks for all other functionality.
UMA uses Hawkins, a visual design system named after the town from the Netflix show “Stranger Things”. UMA uses an existing state machine and supports multistep interstitials with forward/backward navigation, such as updating payment information. The wire protocol is JSON.
Netflix did not want to reinvent HTML for UMA, so they built CLCS as a wrapper around Hawkins. CLCS abstracts backend logic away from the apps that render the UI with native UI controls and collect user input. It offers UI components like stacks, buttons, input fields, and images, as well as effects such as dismiss or submit.
Here is a CLCS example:
export function showBox(): Screen {
return (
);
}
The Netflix apps are responsible for the layout of notifications, such as landscape vs. portrait, positioning, and size. The apps still send information to the server in request headers, such as the app version and device information so that UMA may take advantage of this. Developers can create new CLCS components by combining other components with templates.
UMA still has to support old versions without CLCS. Why? Because Netflix has the challenge of supporting old app versions that will never be updated: mostly phones and tablets with OS versions that Netflix doesn’t support anymore, but also TVs running older app versions. That’s where GraphQL comes in: apps use GraphQL to request UMA from the server. This allows for the introduction of new features that older clients ignore, as they still ask for the old components. Additionally, new components specify a fallback method, which builds an alternate version with CLCS baseline components. Baseline components are guaranteed to be there.
Offline devices are not a major issue today, as offline devices cannot query the server for UMA. Still, Netflix may bundle some UMA as JSON in future app versions so that some notifications still show offline.
UMA uses demo-based tests for automated tests first. Here, a demo server delivers hard-coded UMA. Because it’s clear how the Netflix app should render these, testers can take screenshots of the client app or run more specific integration tests. Netflix also runs backend template snapshot tests and traditional end-to-end tests.
Looking back, Luu listed a few things he wished he had finished earlier. These included the baseline components, a formalized testing strategy, better alignment with the design system partners, and alignment with the platforms on templates.
MMS • Matt Saunders

HashiCorp has announced the general availability of Consul 1.19, introducing several improvements to its service networking platform. The latest version focuses on enhancing user experience, providing greater flexibility, and strengthening integration capabilities.
One of the key updates in Consul 1.19 is the introduction of a new “Registration” custom resource definition (CRD) for Kubernetes. This feature simplifies registering external services into the Consul service mesh. Previously, operators had to follow a three-step process involving Consul’s catalogue APIs, access control list (ACL) policy assignment, and termination gateway configuration. The new Registration CRD streamlines this workflow, offering a Kubernetes-native method for service registration and automatic updating of terminating gateway ACLs.
This new CRD compares favourably with similar functionality in products such as Istio, which has a “ServiceEntry” CRD, and Linkerd which has “ExternalWorkload” for access to external services.
Consul Enterprise users will also benefit from enhanced snapshot capabilities in version 1.19. The snapshot agent now supports saving Consul snapshots to multiple destinations simultaneously. This improvement allows organizations to implement robust backup strategies, potentially improving recovery time objectives. Supported storage options include local paths, NFS mounts, SAN attached storage, and cloud object storage services like Amazon S3, Google Cloud Storage, and Microsoft Azure Blob storage.
Consul 1.19 also significantly improves its integration with HashiCorp Nomad, the company’s cluster orchestrator. The update introduces support for Consul API gateway deployment on Nomad, enabling external clients to access services within the mesh. This feature facilitates load balancing, HTTP header modification, and traffic splitting based on weighted ratios.
Additionally, Consul’s transparent proxy feature is now available for Nomad environments. This simplifies service mesh adoption by automatically routing traffic to upstream services without requiring developers to modify their application configurations.
For enterprise users, Consul 1.19 extends admin partition support to Nomad. This feature enables multi-tenancy, allowing different teams to manage their application services autonomously while sharing the same Consul and Nomad control planes. Admin partitions aim to reduce management overhead and improve cost efficiency at scale.
HashiCorp has made documentation available for the new features, including guides on using the Registration CRD and deploying Consul API gateway on Nomad. The company encourages users to explore these new capabilities through their tutorials for both beginners and advanced users. Interested users can test commercial features like the snapshot agent and admin partitions through free trials of HCP Consul or self-managed Consul Enterprise.
MMS • A N M Bazlur Rahman

JEP 472, Prepare to Restrict the Use of JNI, has been promoted to Proposed to Target. This JEP proposes issuing warnings for the use of the Java Native Interface (JNI) and adjusting the Foreign Function & Memory (FFM) API to issue consistent warnings. This prepares developers for a future release that ensures integrity by default by uniformly restricting JNI and the FFM API. This proposal builds on the long-term efforts to enhance the security and performance of the Java Platform, following the examples of JEP 454, Foreign Function & Memory API; JEP 471, Deprecate the Memory-Access Methods of sun.misc.Unsafe; and JEP 451, Prepare to Restrict the Dynamic Loading of Agents. The main goal is to ensure that any use of JNI and the FFM API in future releases will require explicit approval from the application’s developer at startup.
The JNI, introduced in JDK 1.1, has been a standard way for Java code to interoperate with native code. However, any interaction between Java code and native code can compromise the integrity of applications and the Java Platform itself. For example, calling native code can lead to unpredictable issues, including JVM crashes, that cannot be handled by the Java runtime or caught with exceptions. These issues can disrupt the normal operation of the Java Platform and the applications running on it.
For example, consider the following C function that takes a long value passed from Java code and treats it as an address in memory, storing a value at that address:
void Java_pkg_C_setPointerToThree__J(jlong ptr) {
*(int*)ptr = 3; // Potential memory corruption
}
Additionally, exchanging data through direct byte buffers, which are not managed by the JVM’s garbage collector, can expose Java code to invalid memory regions, leading to undefined behavior. Furthermore, native code can bypass JVM access checks and modify fields or call methods, potentially violating the integrity of Java code, such as by mutating String objects.
JEP 472 proposes a staged approach to restrict JNI usage to mitigate these risks. Initially, warnings will be issued for operations that load and link native libraries uniformly in both JNI and the FFM API.
Developers can avoid warnings by enabling native access for specific Java code at startup. The command-line option --enable-native-access=ALL-UNNAMED enables native access to all codes on the classpath. For specific modules, developers can pass a comma-separated list of module names, such as java --enable-native-access=M1,M2,....
Code that calls native methods declared in another module does not need to have native access enabled. However, code that calls System::loadLibrary, System::load, Runtime::loadLibrary, or Runtime::load, or declares a native method is affected by native access restrictions. When a restricted method is called from a module for which native access is not enabled, the JVM runs the method but, by default, issues a warning that identifies the caller:
WARNING: A restricted method in java.lang.System has been called
WARNING: System::load has been called by com.foo.Server in module com.foo (file:/path/to/com.foo.jar)
WARNING: Use --enable-native-access=com.foo to avoid a warning for callers in this module
WARNING: Restricted methods will be blocked in a future release unless native access is enabled
Developers can avoid these warnings and future restrictions by explicitly enabling native access for specific code at startup using the --enable-native-access command-line option. This option can be applied globally or selectively to specific modules on the module path.
The impact of native access restrictions can be controlled using the --illegal-native-access option. Its modes include:
allow: Allows the restricted operation without warnings.warn: Issues a warning for the first occurrence of illegal native access in a module (default in the upcoming release).deny: Throws anIllegalCallerExceptionfor every illegal native access operation (planned default for a future release).
The long-term goal is to transition the default behavior to deny, enforcing stricter security measures by default. This change aligns with broader efforts to achieve integrity across the Java Platform by default, enhancing security and performance.
Developers are encouraged to use the deny mode to proactively identify code that requires native access and make necessary adjustments. Additionally, a new tool, jnativescan, will be introduced to help identify libraries using JNI.
In conclusion, JEP 472 marks a significant step towards a more secure Java Platform. While the transition to stricter JNI restrictions may require some adjustments, the resulting benefits in terms of security and integrity are expected to be substantial. Developers can ensure a smooth transition and contribute to a more robust Java ecosystem by preparing for these changes.
Java News Roundup: JDK 24 Update, Spring Framework, Piranha Cloud, Gradle 8.9, Arquillian 1.9
MMS • Michael Redlich

This week’s Java roundup for July 8th, 2024 features news highlighting: JEP 472, Prepare to Restrict the Use of JNI, proposed to be targeted for JDK 24; milestone and point releases for Spring Framework; the monthly Piranha Cloud release; and the releases of Gradle 8.9 and Arquillian 1.9.
OpenJDK
JEP 472, Prepare to Restrict the Use of JNI, has been promoted from its Candidate to Proposed to Target for JDK 24. The JEP proposes to restrict the use of the inherently unsafe Java Native Interface (JNI) in conjunction with the use of restricted methods in the Foreign Function & Memory (FFM) API, delivered in JDK 22. The alignment strategy, starting in the upcoming release of JDK 23, will have the Java runtime display warnings about the use of JNI unless an FFM user enables unsafe native access on the command line. It is anticipated that in release after JDK 23, using JNI will throw exceptions instead of warnings. The review is expected to conclude on July 15, 2024.
JDK 23
Build 31 of the JDK 23 early-access builds was made available this past week featuring updates from Build 30 that include fixes for various issues. Further details on this release may be found in the release notes, and details on the new JDK 23 features may be found in this InfoQ news story.
JDK 24
Build 6 of the JDK 24 early-access builds was also made available this past week featuring updates from Build 5 that include fixes for various issues. More details on this release may be found in the release notes.
For JDK 23 and JDK 24, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
The fifth milestone release of Spring Framework 6.2.0 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: a new SmartHttpMessageConverter interface that addresses several limitations in the GenericHttpMessageConverter interface while providing a contract more consistent with the Spring WebFlux Encoder and Decoder interfaces; allow custom implementations of the ObjectProvider interface to declare only a single method for improved unit testing; and a resolution to the SimpleClientHttpResponse class throwing an IOException when the response body is empty and status code is >= 400. Further details on this release may be found in the release notes.
Similarly, Spring Framework 6.1.11 has been released with bug fixes, improvements in documentation, dependency upgrades and new features such as: ensure the varargs component type for the Java MethodHandle class is not null in the Spring Expression Language ReflectionHelper class; and the overloaded getTypeForFactoryMethod() method, defined in the AbstractAutowireCapableBeanFactory class, should catch a NoClassDefFoundError and return null. This version will be included in the upcoming releases of Spring Boot 3.3.2 and 3.2.8. More details on this release may be found in the release notes.
Versions 2024.0.2 and 2023.1.8, both service releases of Spring Data, feature bug fixes and respective dependency upgrades to sub-projects such as: Spring Data Commons 3.3.2 and 3.2.8; Spring Data MongoDB 4.3.2 and 4.2.8; Spring Data Elasticsearch 5.3.2 and 5.2.8; and Spring Data Neo4j 7.3.2 and 7.2.8. These versions can be consumed by the upcoming releases of Spring Boot 3.3.2 and 3.2.8, respectively.
Spring Cloud 2023.0.3, codenamed Leyton, has been released featuring featuring bug fixes and notable updates to sub-projects: Spring Cloud Kubernetes 3.1.3; Spring Cloud Function 4.1.3; Spring Cloud OpenFeign 4.1.3; Spring Cloud Stream 4.1.3; and Spring Cloud Gateway 4.1.5. This release is based on Spring Boot 3.2.7. Further details on this release may be found in the release notes.
The release of Spring HATEOAS 2.3.1 and 2.2.3 feature dependency upgrades and an improved parser for the Internet Engineering Task Force (IETF) RFC-8288 specification, Web Linking, to support advanced link header expressions. More details on these releases may be found in the release notes for version 2.3.1 and version 2.2.3.
Quarkus
Quarkus 3.12.2, the second maintenance release, features resolutions to notable issues such as: a Jakarta CDI ContextNotActiveException from an implementation of the SecurityIdentityAugmentor interface since the release of Quarkus 3.10; classes annotated with the Jakarta RESTful Web Services @Provider annotation not registered for native image when the server part of the Quarkus REST Client extension is not included; and executing the Quarkus CLI to add an extension reorders the properties and adds a timestamp in gradle.properties file. Further details on this release may be found in the changelog.
Micrometer
The first milestone release of Micrometer Metrics 1.14.0 delivers dependency upgrades and new features such as: support for the @MeterTag annotation added to the @Counted annotation to complement the existing support in the @Timed annotation; allow a custom implementation of the Java ThreadFactory interface for the OtlpMeterRegistry class; and the addition of a counter of failed attempts to retrieve a connection from the MongoMetricsConnectionPoolListener class. More details on this release may be found in the release notes.
Similarly, versions 1.13.2 and 1.12.8 of Micrometer Metrics feature dependency upgrades and notable bug fixes: avoid an unnecessary calling of the convention name on each scrape for each metric to create the Metrics metadata because the convention name has already been computed; an IllegalArgumentException due to histogram inconsistency in the PrometheusMeterRegistry class; and a fix in the log to include the stack trace in the publish() method, defined in the OtlpMeterRegistry class, due to the “Failed to publish metrics to OTLP receiver” error message containing no actionable context. Further details on these releases may be found in the release notes for version 1.13.2 and version 1.12.8.
The first milestone release of Micrometer Tracing 1.4.0 provides dependency upgrades and two new features: the Micrometer Metrics @Nullable annotations added to methods and fields in the micrometer-tracing-bridge directories and the sampled() and nextSpan(Span) methods defined in the TraceContext and Tracer interfaces, respectively; and the ability to propagate values from the Context inner class, defined in the Micrometer Metrics Observation interface, to the Baggage interface. More details on this release may be found in the release notes.
Similarly, versions 1.3.2 and 1.2.8 of Micrometer Tracing ship with dependency upgrades to Micrometer Metrics 1.13.2 and 1.12.8, respectively, and OpenTelemetry Semantic Attributes 1.33.4-alpha. Further details on these releases may be found in the release notes for version 1.3.2 and version 1.2.8.
Project Reactor
The fourth milestone release of Project Reactor 2024.0.0 provides dependency upgrades to reactor-core 3.7.0-M4, reactor-netty 1.2.0-M4 and reactor-pool 1.1.0-M4. There was also a realignment to version 2024.0.0-M4 with the reactor-kafka 1.4.0-M1, reactor-addons 3.6.0-M1 and reactor-kotlin-extensions 1.3.0-M1 artifacts that remain unchanged. More details on this release may be found in the changelog.
Next, Project Reactor 2023.0.8, the eighth maintenance release, provides dependency upgrades to reactor-core 3.6.8, reactor-netty 1.1.21 and reactor-pool 1.0.7. There was also a realignment to version 2023.0.8 with the reactor-kafka 1.3.23, reactor-addons 3.5.1 and reactor-kotlin-extensions 1.2.2 artifacts that remain unchanged. Further details on this release may be found in the changelog.
Next, Project Reactor 2022.0.21, the twenty-first maintenance release, provides dependency upgrades to reactor-core 3.5.19 and reactor-netty 1.1.21 and reactor-pool 1.0.7. There was also a realignment to version 2022.0.21 with the reactor-kafka 1.3.23, reactor-addons 3.5.1 and reactor-kotlin-extensions 1.2.2 artifacts that remain unchanged. More details on this release may be found in the changelog.
And finally, the release of Project Reactor 2020.0.46, codenamed Europium-SR46, provides dependency upgrades to reactor-core 3.4.40 and reactor-netty 1.0.47. There was also a realignment to version 2020.0.46 with the reactor-kafka 1.3.23, reactor-pool 0.2.12, reactor-addons 3.4.10, reactor-kotlin-extensions 1.1.10 and reactor-rabbitmq 1.5.6 artifacts that remain unchanged. Further details on this release may be found in the changelog.
Piranha Cloud
The release of Piranha 24.7.0 delivers bug fixes, dependency upgrades and a move of numerous utilities such as: Eclipse JAXB; OmniFaces JWT Authorization; OmniFish Transact; and Eclipse Parsson; to their own respective Piranha extension. This release also includes a new DefaultPiranhaBuilder class that implements the PiranhaBuilder interface. More details on this release may be found in their documentation and issue tracker.
Apache Software Foundation
The release of Apache Tomcat 9.0.91 ships with bug fixes and notable changes such as: ensure that the include directives in a tag file, both absolute and relative, are processed correctly when packaging in a JAR file; and expand the implementation of the filter value of the AuthenticatorBase.AllowCorsPreflight inner enum class in conjunction with the allowCorsPreflightBypass() method, defined in the AuthenticatorBase class, so that it applies to all requests that match the configured URL patterns for the CORS filter, rather than only applying if the CORS filter is mapped to /*. Further details on this release may be found in the release notes.
The release of Apache Camel 4.7.0 delivers bug fixes, dependency upgrades and improvements/new features such as: the addition of an endpoint service location to AWS, Azure and Google Cloud Platform components; a new developer console for the RestRegistry interface where a list of known REST services may be obtained; and a migration of the TransformerKey and ValidatorKey classes from implementation to the SPI. More details on this release may be found in the release notes.
Arquillian
Arquillian 1.9.0.Final has been released featuring notable changes such as: disable the Maven MultiThreadedBuilder class by default such that the build logs are readable on Continuous Integration; and restore use of the JUnit BeforeEachCallback and AfterEachCallback listener interfaces as the before() and after() methods, defined in the TestRunnerAdaptor interface, are called within the listeners. More details on this release may be found in the changelog.
Gradle
The release of Gradle 8.9.0 delivers: an improved error and warning reporting for variant issues during dependency resolution; structural details exposed of Java compilation errors for IDE integrators, allowing for easier analysis and resolving issues; and the ability to display more detailed information about JVMs used by Gradle. Further details on this release may be found in the release notes.
MMS • Sergio De Simone

Part of its Amazon Q Business offering, Amazon Q Apps enable the creation of generative AI-powered apps that integrate enterprise data that can be shared securely within an organization. Along with their general availability, Amazon announced new APIs for Amazon Q Apps and more granular data source definitions.
Amazon Q Apps are purpose-built, lightweight AI-powered apps running within the Amazon Q Business application environment that can tap into an organization’s data. According to Amazon, Q Apps can be created easily by transforming conversations with the Q Business assistant into reusable and shareable Web services.
Users can also publish apps to the admin-managed library and share them with their coworkers. Amazon Q Apps inherit user permissions, access controls, and enterprise guardrails from Amazon Q Business for secure sharing and adherence to data governance policies.
AWS principal partner solutions architect Prasad Rao described how you can create a “Product Overview Generator” app step by step, starting with a PDF document uploaded to an S3 bucket. The app includes four cards, i.e., two inputs, the product name and the product description, and two outputs, a product overview and a list of key features.
A new feature debuting in the GA release is the ability to specify data sources at the card level. This can be useful, for example, if you want to use only a subset of the available data to generate a given output.
Additionally, published apps can be run as-is or modified and re-published as a different app. To this aim, users can review the original app prompt, as well as add or remove data sources to improve output quality.
Finally, Amazon introduced an API to create and manage Q Apps programmatically. This makes it possible to integrate Q Apps into existing tools or development environments to create and consume their outputs.
Amazon introduced its Q Business generative-AI assistant a few months ago to securely integrate enterprise data with a system able to answer questions, provide summaries, generate content, and complete tasks. Q Apps were introduced at the same time in preview and made available to all Q Business users, including both Pro and Lite users. With the official release of Q Apps, Amazon is taking the opportunity to change this and requiring that all Lite users upgrade to Amazon Q Business Pro if they want to keep using their Q Apps. Additionally, Lite users who created Q Apps that are still unpublished should be aware that, if they do not upgrade to Amazon Q Business Pro, their Q Apps will be deleted at the end of August.
MMS • Adora Nwodo

Transcript
Nwodo: I’m going to be talking about my story and how Python empowered my infrastructure beyond YAML. I used to be a full stack software developer. I used to be a software engineer. I used to work at Microsoft. When I joined in 2019, I was working in the Microsoft Mesh mixed reality, the team of the people building the Metaverse, so I was more in my Unity, C#, a little bit of C++. I only knew what I needed to know about cloud engineering because we used to automate deployments anyway. One thing led to another and I found Pulumi. How I found Pulumi was, there were a lot more people working on the device things at the time, I was writing code for the HoloLens. I wanted to try something new, because you hear people sitting right beside you, and you’re hearing them talk about ARM and Azure, things are just flying over your head. You’re like, ok, this seems interesting. I remember that at the time, we were trying to switch from ARM templates to using Pulumi. One of the first infrastructure engineering or cloud engineering tasks I ever got, was to turn a bunch of our ARM infra into Pulumi related infra so that we could move from ARM to Pulumi, sort of do that migration. Obviously, before that, anything that was ARM related, wasn’t necessarily my business, because I wasn’t considered a cloud or a DevOps or an infra person. I wanted to build stuff for the HoloLens. I wanted to write C++, and then I wanted to just go home after that. Writing Pulumi made me realize that I could still do everything that I wanted to do, which is write code, because I love writing code. I still love writing code today. I could also manage infra while doing it. It was a very easy way for me, who was a full stack developer at that time. I had done things on Android. I was building apps for the HoloLens. I had built full stack web apps, and different things, and now coming into the cloud, it was a lot easy for me to get into that, because Pulumi made it easy. It greatly impacted my workflow, and I could manage my infra while I was writing code.
I was a bit younger at the time. This was in 2019, early 2020. I became very eager to learn about cloud engineering principles, because when you’re trying to use a tool like Pulumi to provision your infrastructure, you would get into some errors, because Pulumi bridges that gap between the cloud engineer and the cloud infrastructure and all of that stuff. It puts you as a software engineer in the middle. Things that I wouldn’t have known as a software engineer prior to that moment, I found myself learning about them. I found myself being on the Azure portal, pay more attention to different kinds of infrastructures. Prior to that time, I knew of VMWare and I knew how to put things and just run my application, but I didn’t really care about distributed engineering systems, building stuff at scale, infrastructure engineering, and things like that. This opened my eyes to other cloud engineering principles. My perspective on cloud infrastructure engineering actually changed. I became that person that started evangelizing about the cloud, if you call it that. I had to author two books on cloud engineering, because I was learning more about the cloud. I found it more interesting. I decided to tell the world that there’s this beautiful thing called cloud engineering or infrastructure engineering that you should pay attention to. Over time, I became the team’s subject matter expert on Infrastructure as Code, IaC, our team infra. This actually got me three promotions in the last 4 years. I quit my job at Microsoft a few months ago, right after my third promotion, but this was between the space of 2019 and 2023. I cannot tell my cloud story without talking about how Pulumi was a very huge part of that story. I’m here to show you how Pulumi works, and why you should love it as much as I do.
My name is Adora. I am now a senior software engineer currently working on cloud infrastructure and developer platforms. I am an award-winning tech woman recognized in different continents in different parts of the world. I speak at different conferences. I am a multi-published author. I consider myself an ecosystem advocate, especially where I’m coming from, which is Lagos, Nigeria, because I try to advocate for tech in that region, and someone nicknamed me an ecosystem advocate, and I liked the name. I love tech, community, education, and music.
The Rapid Growth of Cloud Innovation
Cloud innovation is rapidly growing, and managing resources have gotten more complex over time. We see this a lot today. You hear things flying over your head, observability, metrics, Docker, no-shared, Kubernetes, and all these things. We are building a lot more on the cloud than we’ve ever done before. COVID contributed to this. Everyone is moving their business to the internet. Everybody is doing some kind of innovation on the cloud. Everybody is doing something as a service, one way or another. Building things have gotten more complex over time. If, in 2003, it was easy to do FTP uploads to your server, and in 2015, it was easy to do manual configurations on your cloud portal, it doesn’t cut it anymore, for different reasons. Your deployments are slower as your infrastructure gets bigger, because it is human beings, team members that are doing these things over time, especially when you’re trying to replicate multiple environments. There are larger risks of errors because as human beings, we can make mistakes. As we make these mistakes, we can replicate these mistakes in the different environments where we are supposed to be running our cloud applications. That can become problematic quickly.
Everyone relies on the documentation. If there’s documentation for the application that you are supposed to be provisioning, and you have documentation or configurations for your infrastructure, and somebody mistakenly doesn’t update that documentation, nobody knows that the documentation is not updated. Somehow everyone is stuck. If you have to roll back for whatever reason, it requires manual work as well, which can be tasking. Let’s not even start talking about configuration drift, and how terrible configuration drift can be. I’ll tell you what happens with configuration drift.
Let’s look at these three different environments right now, we have dev, we have staging, and we have production. In an ideal world, not always 100% the case because your production environment should be more resilient than all these other environments that you’re using to test. For the sake of this example, you have your dev, your staging, and your production that somewhat mirror each other. If you are doing CI/CD, you deploy to your development first, then you go to staging, and you would go to your many production environments. In this presentation, we have just one to show. Over time, what happens is that people fix things. Let’s say something happens and you check your monitoring and you realize that something is happening in prod, I need to fix it quickly. You go into your Azure portal, you go into the subscription or the AWS dashboard, AWS environment, you go and you fix what you’re supposed to fix, but you don’t actually document or notify where you’ve changed what you’ve changed. Somehow you forget about it and you move on because it was a small change. Your production and your staging and your development no longer mirror each other, which can be problematic, because if you try to test something in staging, and you assume that because it works in staging, it would work in production, and you actually push, you’re in trouble somewhat.
Let’s talk about how we can fix this problem. There’s something called Infrastructure as Code. This fixes these problems for us. There are lots of Infrastructure as Code tools. One of the reasons why I’m talking about the tool I’m talking about, is because of its ability to allow you transfer your programming skills into your cloud career, if at all you want to build one. Infrastructure as Code helps you specify your configurations in code, automate your infrastructure deployments. You can treat your infra declarations the way you would treat code, so you can test, you can version, and you can roll back your infrastructure, and transferable skills from programming. What this means is that if you write C# or TypeScript or Go or Python, you can write your infrastructure declarations using these languages. That’s why I’m talking to you about Pulumi, because Pulumi is the open source Infrastructure as Code platform that allows you to write your infra declarations in these different languages. If you know Python already, you don’t have to use YAML to do infra. Even though Pulumi allows you do YAML now, but there are other languages, if you know Python, you can stick to your Python. The amazing thing is that it allows you be full stack completely. Let’s say you are a TypeScript developer, you use Node.js in your backend, you write with either Sails or Express or any of all these JavaScript platforms that exist, or TypeScript platforms that exist, and you use Vue.js normally, you could actually have TypeScript be that language that you use full stack. When I say full stack, I mean for your frontend, for your backend, for your cloud infra, and for your cloud security declarations. For your frontend and your backend, we know that TypeScript already does this for us. Now for your cloud and for your cloud security declarations, Pulumi is helping us do this with Infrastructure as Code and Policy as Code. These are some of the languages that Pulumi offers here: TypeScript, Python, Go, C#, Java, and YAML.
Demo (Code)
I have code in a GitHub repo, but I’d like to do a demo. I’m going to switch to my terminal now just so that everyone can see how this works. I’ll show you Pulumi in action. I’m trying to do an easy login just so that I can log into the Azure portal, which I have done. I want to make a new directory, let’s call it test-pulumi. I also want to cd into my test-pulumi directory. I have installed the Pulumi SDK and I have Pulumi CLI already, so I will just go ahead to do a pulumi new. Typically, you’d have to install Pulumi and set it up. I think the Pulumi documentation is so straightforward that you can literally go to pulumi.com and have all of these things set up in like 5 minutes. I’m going to do a pulumi new. I’m trying to deploy a serverless app, so I want to have a new serverless Python code base that I can deploy to Azure. I’m just going to hit pulumi new just so that I can also show you the different things that Pulumi can give us, like the different samples that Pulumi has. I’m just going up to serverless-azure-python because that’s the one that I actually need. As we can see here, there’s a lot, serverless-azure-python, TypeScript, YAML, GCP as well. There’s stuff on Redis and different things. I’m going to do serverless-azure-python. My name can be test-pulumi. This is fine. I can leave my stack as dev. You can consider a stack like a project. Your stacks can be your different environments. You can have a stack for dev. You can have a stack for staging, for production, and things like that. I’m just going to provision a dev stack because I want to show this pretty quickly. I’ve set my location as well. My app has all of the things needed to bootstrap this for me. It’s going ahead to create the virtual environment and building up my sample for me. Then, once it’s done, I would show you what it looks like. Now it’s done.
I’m trying to get my VS Code here. I want to open this folder. It’s in my home folder. I need to go to my home folder. I just want to show you what’s actually inside. This is the project that Pulumi just created. It has pulumi.dev.yaml, which signifies what my Pulumi stack is. These are configurations for my dev environment. It has a pulumi.yaml, which shows that it is a Pulumi project. Every Pulumi project has a pulumi.yaml, the same way every Node.js project has a package.json. I have my www folder, which is the web app that I want to deploy, the static web app. Then I also have my serverless function, which is in my app folder. I have a data function that just returns the time, basically. This is the sample project that Pulumi has gone to bootstrap for me. If I look at this main__.py in the root directory, this is all Python code. This is me writing Python to declare my infra. This is me writing Python to create a resource group, Python to create a storage account, a static website. This is Python for creating a resource group, a storage account, a blob container, and the different things that I need, a web app as well. I’m going to deploy that function up into an Azure serverless infrastructure, an Azure Function. I’ll show you everything in a bit. I want to change this name to my-resource-group, so that we can find it in Azure.
I’m going back to my terminal now, and I’m going to run pulumi up. I’ve logged into Azure already. I came out, so test-pulumi, I’m going back in. I’m going to run, pulumi up. First of all, it’s going to preview all of my changes. It’s going to say, these are all the things that you want to create. Do you want to go ahead? I’m just going to say yes, and Pulumi is going to create all of those things. It would interact with the Azure Resource Manager, and all of these resources will get provisioned in Azure. If I go to the Azure portal, that is linked to my Pulumi account, I’ll be able to see all of these things when I am done creating them. Another thing that I want to highlight while all of this is going on is about Pulumi state. Pulumi has an inbuilt way of managing state. If I create all of these infrastructure things, I don’t need to go to the Azure portal to manually delete them if I want to replace or do something. If I remove that block of code from my code, Pulumi knows exactly to take out that piece of infrastructure away for me. Now that we’re done, I, first of all, want to click on this site. I want to click on this site which is the frontend site, the static website, so that we can see that we have it, and Pulumi has provisioned that for us. Yes, it’s asking, what time is it? Let’s ask the cloud. If I say, ok, fine, let’s ask the cloud. It says 6:59, because my computer is in BST. The cloud says that it’s 6:59 p.m. Let’s say I want to add a new infrastructure, or let’s go back into the code. Let’s say for whatever reason, I don’t care about the static website so I want to take it out. I can come here and delete it. I want to show you what happens when I try to run another pulumi up. I can come here and delete this. Let me check if it’s referencing it anyway, so it doesn’t cry to me. I can just write anything here, just so that it doesn’t cry to me. Hopefully, that works. I came and I removed the static website. It’s going to ask me for a valid storage account name. I might not run it all the way to the end, but I removed something. Now let’s go back into the terminal. If I attempt to run pulumi up again, it’s going to tell me that, this is something you want to delete. You want to replace some things. Do you want to go ahead or not? I can choose to continue or not. Now let me also just leave this place and show you the Azure portal that has these resources that we provisioned initially. We called it my-resource-group. I’ll go here to look for my-resource-group. This was the resource group that we created. Here, we have a storage account, we have a function app, and we have an app service plan. If we want to add other infrastructure like Azure Front Door, we can come and do this here. If we want to add availability tests, App Insights, Key Vault, we can do it through Pulumi, and we can do it while writing code.
There’s documentation to help you if you want to do this. I also have a small thing that I wrote in the GitHub repo that I talked about. You can go into that. This repo here has more stuff. The README is also really good in case you want to set up the repo and try it out for yourself. You can download the Pulumi SDK and set it up. If you don’t want to use the Pulumi cloud for storing all of your Pulumi state, you can store it in your own storage account as well for free. If you’re using Azure, you can store it in the Azure storage account. If you are using AWS, you can store it in S3, you don’t have to integrate with Pulumi, or pay for Pulumi cloud if you’re just trying this on for yourself for the first time. This is the link to the repo, https://github.com/AdoraNwodo/pulumi-adventures.
Questions and Answers
Participant 1: You started off not as an infrastructure engineer and learned to become an infrastructure engineer. How long did that journey take? Because there’s a lot of people who find it quite scary when they’re application developer and trying to move, many people trying to avoid understanding infrastructure for a long time. It’s really difficult. I’m really interested in that.
Nwodo: I think it depends on who I’m talking to. I’m still on the journey, because I’m still learning about the cloud every day. I would also tell you that the journey took one PR, so it depends on how you look at it. I opened my first PR, where I was switching from ARM to Pulumi. What happened was, it was a stateless service, so it was very good for an experiment. What I did was the same infra that we had, replicated that same infra in Pulumi, and checked in the PR and told everybody like, are we really doing this or not? From that point, was when I started digging deeper and learning more. You fix some things. You break more things. You learn along the way. I wouldn’t call myself there yet. I think I’m still learning. It’s a journey because things evolve all the time. At least now, I think I’m confident enough to stand up and actually talk to some people about some things even if I am a bit nervous, I can still do it. Short answer or realistic answer, I don’t think it takes that long if you already have prior understanding of how computers work, and if you’re a backend engineer, for example, because I believe that most of all these skills are transferable. If you are writing Python or JavaScript or Go, you’ve probably had to deal with VMs at some point. You’ve had to deal with integrating with databases at some point. You’ve had to maybe find a way to deal with managing traffic and a bunch of all these things. Even if theoretically, you might have that idea, but you’ve just never had to do it in the infra context before. Pulumi allows you to now find a way to bring those things together, your theoretical knowledge, your programming knowledge, and actually see what you can do. It doesn’t take that much time. I think that’s one of the reasons why. It took 2019 to 2023.
Participant 2: I’m wondering if you could tell us a little bit more about the process of migrating from ARM templates towards Pulumi? Did you guys use tooling, automation, or did you do everything by hand? What did it look like?
Nwodo: Migrating from ARM to Pulumi, at that time? Number one, it was a stateless service. Number two, I started with the smallest service just because I didn’t want to get fired. Everything, the first time, was me doing it manually, to find like, this is what it is in ARM, and this is what the equivalent is in Pulumi. You would read JSON, you would read the Pulumi script and you just know exactly what everything goes, and how it’s supposed to go. It was straightforward. There are ways that you can migrate as well, and this is something that Pulumi does for you as well. You can import all of your infrastructure into the CLI. There are ways to migrate from ARM, from Terraform, from other things that you’ve been using into Pulumi. Pulumi gives you different tools to aid your migration.
Participant 3: I would like to know, what’s your ideal use cases for doing migration? Or you have projects for maybe reading projects in the wild, like you won’t migrate, but is there really other use cases for these?
Nwodo: It depends on your team, and what your team is optimizing for at the end of the day. One of the biggest selling points for Pulumi, for me, is transferable skills. Especially for smaller things that are just like, these are the engineers building these services, and this is all they’re doing, and we have a few DevOps people, or we don’t really have so many DevOps people. These skills are transferable. If your software engineers were writing Python or TypeScript in their day-to-day, and they had to do infrastructure automation, you probably wouldn’t have to do much to get them up to speed to do infrastructure automation, and infrastructure engineering, and things like that. If you didn’t want to hire somebody else, you also wouldn’t have to. That’s the one selling point for me. The other selling point for me is the era of Infrastructure as Software. When we think about Infrastructure as Software, Infrastructure as Code, how platform engineering is becoming a very big buzzword topic in different cloud communities that you join, and things like that. Pulumi takes you one step closer into building these self-service developer platforms for your teams as well, because you are coding and you’re using programming languages to create your infrastructure, whether you’re doing it within the Pulumi CLI, or you’re doing it within something called the Pulumi Automation API, where you can even call Pulumi’s API in your regular backend code to provision infrastructure for you. Apart from the cost perspective that I talked about, there’s also an industry trend bit to it when we think about platform engineering and where the cloud industry generally is going.
Participant 4: My question is about, so current trends to operate infrastructure, and I have a secret [inaudible 00:34:55] in Pulumi, like integrated with other secret vaults to be able to keep the secret in, or not being in a vault.
Nwodo: Pulumi does secrets management in different ways. Pulumi has encryption built-in. If you wanted to build a chatbot, and you want to use OpenAI’s API, because that’s just what you want to do. You can take your OpenAI token and put it in your Pulumi state, the pulumi.dev.yaml file that I showed you, your Pulumi config file, and Pulumi can encrypt that secret for you. However, if you are not very sure about doing that with Pulumi, and you want to do it yourself, Pulumi has ways to manage these different vaults. Pulumi is integrated with these resource managers for these different cloud platforms. What this means is that you can use Pulumi to create a vault and store a secret, in like a Key Vault, for example. You can use Pulumi to create the Key Vault, store the secret in that Key Vault and get the reference to that secret. Then you can put it maybe inside your configuration for your app, or you can put it in your serverless app settings as well, depending on where you want to put it. Pulumi does encryption in its own thing. Pulumi also integrates with all these other cloud platforms, and you can manage your secrets using Pulumi within those platforms.
Participant 5: I don’t have enough knowledge to do Infrastructure as Code as much. Then looking at this app, does this enable us to have everything in a single vehicle, even the infrastructure part of it as well? The second part, like the Pulumi setup, all that, is that more towards a CI/CD tool, that’s where you have that setup going, which would actually then allow us to do the deployment, all that?
Nwodo: Yes, you can have your Pulumi stuff in the same repo as your source code. Different people do that. I’ve seen people that like to have their infra for all their different services in one repo, and they manage it there, and they have their source code in different repos. That’s one of the reasons why you can treat your infrastructure declarations the way you treat code. It depends on how you’ve decided that you want your architecture to be. It depends on how you’ve decided that you want not just the technical architecture, but the workflows, how your team should manage things. Do you want to put it in the same repo? It’s possible. Do you want to put it in a different repo, and just connect both of them together through Azure, or through those deployments, or things like that? It’s also possible. That depends on you and your team.
The second thing is about CI/CD. With Pulumi, you can hook it up with all these other different CI/CD platforms. If you are doing GitHub Actions, or Azure DevOps, or TeamCity. If you are doing that, you can hook it up with these different CI/CD pipelines as well. You can write YAML, and then put these different Bash scripts in those YAML commands to run pulumi up for you. Or you can write PowerShell. There are different ways that you can integrate the Pulumi ecosystem into your CI/CD pipeline, and it works.
Participant 6: We have a platform engineering team, and have been working through trying to figure out who to do CDK, who to do Pulumi, what do we do? One of the concerns that the team has is, how do we get all of these federated teams that are now writing Pulumi to stay up on the latest version of the code base? They’re writing their own classes for infrastructure, and AWS, or Google, or Azure is updating theirs. How do we keep that running for that at all?
Nwodo: Are you asking about Azure, AWS, GCP’s updates for their SDKs and how you manage that with Pulumi?
Participant 6: If all these teams are writing classes that use Pulumi to create their infrastructure, and those base classes suddenly change, how do you keep them up to date to make sure that they’re writing against the latest, for example?
Nwodo: That’s an interesting software engineering problem that has now become an infrastructure engineering problem. The same way you would think about it as a software engineering problem, it’s how you would also solve it in the context of infra. You might want to decide that you don’t necessarily want to be tethered to the latest version, because of breaking changes, unless you have to. If that time comes when you know there’s a new version in Azure, or AWS for XYZ, they’ve added something into lambda, so now we want to move from this to this, you can migrate that whole team. You don’t have to if you don’t want to. You can create these things where you are wired to a particular version, and you know that this version is what we are using, just so that we don’t create problems for ourselves, or get into breaking changes. If we have to move because something is deprecated, or there’s something new that we need that we don’t have access to in these old versions, then we can now think of a migration plan that works for us, slowly. I wouldn’t even advise you to always want to be at the new version, unless you have to.
Participant 7: How do you compare Pulumi with other Infrastructure as Code products like Ansible, or Chef.
Nwodo: When I think of Ansible or Chef, I think configuration management, not necessarily Infrastructure as Code. Yes, you can also use them to do IaC, but they’re more configuration management tools in the context of your cloud infra, Kubernetes, and things like that. Pulumi is a tool that is allowing you to provision your infrastructure. If you go through Pulumi registry, there are different providers, even beyond the AWS, GCP, Azure, that I’ve been talking about, there’s Digital Ocean. You can even do things, and if you are a frontend developer, you have a frontend team, you can provision to tools like Vercel, using Pulumi. You can write these provisioning scripts or these provisioning declarations in programming languages that the engineers on your team use every day. That’s the spotlight. That’s the main difference for me. That’s what differentiates it from everything else is the fact that you can use Pulumi as a tool to treat DevOps or infrastructure engineering, like software engineering.
Participant 8: I see how it’s a jump over something like Terraform. The pattern is similar, but you got all this proactive power of a programming language. I’m curious, the demo you have to show a simple example. How does it look when you scale up to these Pulumi applications? I’m thinking both from how to culture and a technical perspective, because then it becomes a complex piece of software, and all of a sudden you have to test it. I think our DevOps people they’re not natural software designers, like I would expect to see, yes, this is great, but some people, I find a lot of 5000-line functions. I wonder if you can comment on any experience you’ve had of scaling up the Pulumi applications and complexity.
Nwodo: How you would scale the applications, and like I said, in the beginning, where, if you think about how you would write code, every single code you write doesn’t have to be in one very big Program.cs file, for example. You can take things out and create that single responsibility, ok, if I am doing things relating to my application. I will talk in the context of Azure. If I am doing things relating to my application, so I want to create an App Service plan and I want to create a function app, and I want to do App Insights and put in an availability test. I can do all of that in a module. Then if I want to do secrets related things, I can do it in a module. If I want to do role assignment, I can do it in a module. That’s more a code organization problem. You might think the code is organized, until you hire a new person, and you tell them to look at it, and they’re like, “I really don’t understand what you’re writing.” Code organization as well as documentation. That’s how I would look at that problem. In the context of deployment and testing it out, you can deploy those things and have Pulumi run it. The truth is, the bigger the infra that you’re trying to deploy, the longer it takes, but Pulumi manages all of that for you. You can actually start the deployment and decide that you want to go and drink coffee or watch something nice on TV, and come back eventually when it’s done.
You mentioned deployment, you mentioned scale, and testing. In the concept of testing, for example, there are different ways that you can test out things. I was talking about security declarations at some point when I was saying Infrastructure as Code and Policy as Code. IaC tools have what they use to do for Policy as Code. I’m of the opinion that Policy as Code is going to be a very good way for people to test their IaC, because then you can use your security declarations to test specific things that you want your infra to have. For testing, you can decide that you want to write Policy as Code, and you want to use those policies that you’ve written to test the infrastructure that you have. These are in the form of writing unit tests. Because you’re writing programming languages, you can write tests the way you would write tests for your code, and also validate that, if I do this thing, this thing gets called in the way that I want Pulumi to call it, things like that. The final thing is, you can build up infra. Because sometimes you want to test things end-to-end as well, not just about the infrastructure being able to get provisioned. That when you put your application inside the infra, everything works the way it’s supposed to work and you’ve not mistakenly broken something with your new infra change. Sometimes you want to run something we would call a test stack, and depending on how your team is, if you have a full platform team, you might want to make it an auto test stack. When you open a PR, automatically a test stack gets created, and then your code is deployed to that stack. Then you run a bunch of tests on your code. If everything works, you can destroy that stack and know that, yes, your Pulumi change works as well.
Participant 9: In your presentation, you talked a bit about configuration drift, which I’m very interested about. I’m curious how you think about learning on mitigating that more generally, or with using Pulumi.
Nwodo: With using Pulumi, it’s very nice because you don’t have to attempt to prevent anything. That’s why I showed you what happens when you delete a block of code in Pulumi. It’s like Pulumi knows that, ok, this thing that you’ve taken out of your code, you want me to delete. Should I go ahead and delete it for you, basically? The point is, your code, the way it is, is the single source of truth for your infrastructure. Basically, at any time, anyone that comes into your organization, old or new, into your team, should be able to look at your Pulumi declarations, and see the exact resources in your infrastructure. There isn’t a possibility that Pulumi doesn’t have a Key Vault in the Pulumi declarations, and somehow there’s a Key Vault in your resource group. That’s not possible, except you went there to create it by yourself, which you shouldn’t do. Because the hope is that everything you do that is infra related, you can track it and Pulumi helps you manage it better. If you are going to use an IaC tool, you wouldn’t need to worry about configuration drift because that’s no longer your problem.
See more presentations with transcripts