Month: July 2024

MMS • Daniel Bryant
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today I have a fascinating and fun experience. I’m sitting down with Daniel Bryant. Now, Daniel is the News Manager at InfoQ. He’s been track host at innumerable QCon conferences, and is, and here is my bias, an all around great guy. Daniel, welcome. Thanks for taking the time to talk to us.
Daniel Bryant: Thank you very much, Shane. It’s interesting to be on the other side and I very much appreciate that humbling introduction. Thank you.
Shane Hastie: I’m going to go with how I normally open up. So who’s Daniel? Tell us your background, what brought you to where you are today?
Introductions [00:48]
Daniel Bryant: Yes, sure thing, Shane. So I think the thing I always say in the professional context is, there’s a few things that underpin all the choices in my career. I’ve always loved technology. So my first computer, for the folks listening, Amstrad CPC 464, back in the day, eight bits, 64K of RAM. Always loved programming, but I always enjoyed teaching other people even more, so bridging the people and the tech.
I was never going to be the best programmer, though. It blew my mind when I discovered BBC BASIC and I discovered assembly, I could build games, but I enjoyed teaching my friends just as much as I did coding the things myself. So all throughout my career, I nearly became an academic. I really got into research. I did a PhD in AI, which I don’t talk about too much these days, but with AI coming back probably should put that bit higher up on the resume. But it wasn’t LLMs, it was diffusible logics I was studying.
I nearly became a professor, that teaching aspect I’ve always enjoyed. But along the way of doing my PhD, I discovered coding in Java professionally, and that was fantastic. Faster feedback loops than the theoretical work I was doing. And now my career took off from there, from software developer to architect, then I went to platform engineer and a few other things along the way. I just always enjoyed that bigger picture from software to architecture, architecture to platforms. And I always enjoyed bringing folks along on the journey, meeting them where they’re at, understanding whether they’re junior developers, whether they’re business folks as we call some people, and knitting together the value of technology in people.
And it’s been a lot of fun on that journey. And the journey’s only halfway done I guess, right? Hopefully many more years to my career. But I see that theme running throughout the rest of the work I do, whether it’s software development, or more product-focused like I am today, but I just love the people and love the technology.
Shane Hastie: What got you involved with InfoQ and QCon?
Getting involved with InfoQ & QCon [02:33]
Daniel Bryant: Don’t know if I’ve told the origin story of those, actually. It was very much motivated by my love of sharing knowledge and learning as well. Because selfishly, I was looking at InfoQ and thinking, “Oh these folks sharing all this knowledge, they must have to learn it of course before they can share it.” And having some sort of forcing function if you like, be it writing for InfoQ, be it doing presentations. I thought this would be great to make me learn many different things just out of pure interest and also as I expand my career. So I was reading InfoQ pretty much from when it was created.
I will shout out Ben Evans who’s a longtime editor at InfoQ. Ben’s one of my mentors back from the Java days, 15-plus years ago, I guess, it’s been a while now. One day I was just chatting and I was saying, “I love InfoQ, love all the stories being talked about.” SOA was the thing back then. SOA, a lot of Ruby I was reading about. And Ben was like, “Hey, I can introduce you to…” I think it was Floyd and a few other folks. So the founders of C4Media, which is the company behind InfoQ. And I’m like, “Yes, Ben, I’d love that.” And the sweetener as well was I was just getting into the QCon conferences and I knew the connection between InfoQ and QCon at the time. Again, a lot of early service, I went architecture microservice stuff, this is what I was doing on my day job. And I saw at QCon and there was like Rebecca Parsons, there was Adrian Cockcroft, folks I’d love to speak to. And I thought if I can get in the door with InfoQ and with QCon, maybe it’s an excuse, an icebreaker, to chat to these amazing people and learn from them.
And that’s pretty much what happened, Shane. Let’s say Ben introed me, I met Floyd and several other folks, Dio. And then Charles I think was becoming the editor-in-chief at the time, met yourself and a few other folks as well. I just realized that this is a really cool community of folks. That is one of the things, several points in my career I’ll shout out other than Java community, the LJC, the InfoQ community, the CNCF community, the QCon community. There’s been certain communities that have really leveled me up. Do you know what I mean? Just by being around amazing people saying, “I want to be like you, I want to learn from you.”
And InfoQ is one of those early experiences of that. And yes, I’ve not looked back as in it’s a fantastic excuse to learn lots of stuff and share stuff on podcasts, on articles, on many different formats and I’ve thoroughly enjoyed it.
Shane Hastie: So let’s dig into your last track at QCon London. The platforms, people and process, delivering great developer experiences.
I want to go to the theme. What was the driver for this? What’s the need?
Platforms, people and process for great developer experience [05:04]
Daniel Bryant: Yes, interesting. So it came actually I did the QCon San Francisco track, similar track last year. And Justin Cormack, who’s the CTO at Docker, was the sponsor of that track. He reached out to me and said, “Hey Daniel, I’d love for you to connect up these folks and put together an interesting program.” Because it’s all about the speakers, I was just curating these things.
But one thing Justin said, Justin and I have known each other for many years, and again, love Docker, so I’ve been working in Docker, Kubernetes, all that space. And we both love the tech, but over coffee we were like, “You know what, we’re all talking about the tech a lot.” Really, we all know that is the “easy part” in air quotes. The hard parts are the people, the process, all these things that go with a successful product, a successful project.
Justin said to me, “Lean into the people side.” So if you look at the QCon San Francisco track, that was some amazing folks on that track and basically the success of that track, I leveraged it into the QCon London track. You never are sure when you’re putting together a QCon track, is the audience in the same place you’re at? You’ve got to meet the audience where they are. Are they ready to hear some of these things? Do they like the story we’re trying to tell? And they very much did.
A few key things popped out, key themes throughout all the talks in QCon SF was empathy, was big picture thinking, clear goal setting, and people were tweeting, people were on LinkedIn, sharing, “Yes, this is great stuff.” We were like, “You know what? Let’s bring it over to the European market.” Because sometimes, the Bay Area is slightly ahead in some of these things. Just it is what it is. And being a proud Londoner so to speak, a proud UK person, I’m always keen to bring a bit of the Bay Area over into London and Europe and beyond as well. And it went down really well, Shane.
People in London, same kind of vibe, they totally understand the technology. They realized there’s a lot of value in being intentional about cultivating a platform, building a platform. But many of them have tried, or are on the process of building a platform, and the sticking points are all around the people, the process, and these things. They’re not so much around the tech. And that’s why that track, I think, hits quite nicely in London and hopefully gave a lot of thinking points. Again, I’ll shout out the amazing speakers. I do 5% of the work, if that, kind of thing, probably less than that. The amazing speakers are the people that really delivered all the value. And I was just sat there like Jessica, Gemma, Avrin, Anna, Andy, just did amazing work.
Shane Hastie: So what is different or special about developer experience for a platform versus just DevX in general?
What’s different about DevEx for a platform? [07:32]
Daniel Bryant: A great question, Shane. And I do see this one quite a bit. And in reality, I think it’s all the same thing. Do you know what I mean? The bottom line is, wherever you work in the organization, you are trying to sustainably deliver business value for want of a better phrase. And definitely, I even forgot that when I was perhaps a developer, I was like, “What cool framework can I play with? What latest code can I do?” But then good managers, good mentors along my journey are always saying to me and focus on delivering that business value.
So developer experience for me is that how do I get these fantastic ideas and hypothesis experiments that we’ve got in our minds or discussing in the company level, how do I get that from delivering observable business value in production. And that gap between those two things, and I did a presentation back at GOTO Amsterdam many years ago on this, but that gap on the idea experiment hypothesis and that gap on running in an observable way in production is developer experience in my mind.
And it touches everything, right? It touches the coding, it touches the architecture, touches the platform, it touches CICD, all these good things, observability as well. But it’s the way typically we see it as developers, how do they experience all those things? We talk a lot about shifting left, which is great. I love the principle. Thinking about security earlier, thinking about scalability, resilience, observability. But poor developers, I’ve been there, you get what we now call cognitive overload on trying to balance all these things. Yes, it’s a great idea to think about all those things, but without the right tooling, without the right platforms and critically without the right leadership support, you are never going to do all those things as a developer early on. So my focus over the last few years has been creating tools in the cloud native space to help developers in particular work with all these important things for delivering that sustainable, observable business value via coding.
Shane Hastie: Let’s dig into that cognitive overload because we’ve heard quite a lot recently and probably the last couple of years this has been bubbling up that the cognitive load on developers today is substantively higher and harder than when I was coding in a assembles and COBOL and C++ in the eighties, nineties, even into the mid two thousands and early two thousand teens. But it seems that there’s been, and maybe it’s a seem, so to me, am I right, has there been an explosion of complexity that we have to cope with?
Cognitive overload in the developer experience [10:10]
Daniel Bryant: I think there has Shane, because I can remember I bumped in some of the COBOL stuff and definitely assembler and things and C++ of my early days. I think the trends I’m definitely seeing is one, the audience, and that includes us, are more demanding now. We’ve been exposed to the iPhone world or the pick your sort of favorite UX. When things work really well, we like it and we’re like, why can’t we have that experience in every bit of software?
So back when you and I were building these more basic, perhaps, banking apps or whatever, I remember the interface was super clunky and you had to suck it up because you’re paying money for this UX or whatever, it’s business people that are going to use it, tough luck if you like it or not. You go with that. Nowadays the audience, even B2B software, just the audience is more demanding and that includes not only UX but things like security and the threats have just blossomed. There’s a whole cybercriminal market now that wasn’t perhaps so big when again, I was doing this in the nineties, two thousands. And I would say the rise of distributed systems has definitely made things more complex.
Now the reason we’ve gone to that sort of distributed mindset, and again, my career started as the internet was really kicking off and it is just incredible. When I was coding on that Amstrad CPC 464 back in the day, it was a terminal in my parents’ front room. There was no internet connectivity at all. And as I went to college, I saw the internet blossom and the possibilities, the benefits are innumerable, but there you are inherently dealing with distributed systems.
So again, both the good UX, good experiences, the rise of all the challenges around these things, and again, dealing with the rise of distributed computing, I think the combination of those two things just have bumped up the complexity to a higher order and we haven’t really got the abstractions or the tooling to push some of that complexity down into the platform, if that makes sense. Because I think where perhaps with C++, you’re dealing literally with memory handling. Java came along, got rid of a lot of that for example, and now we’re seeing Rust and things like that. We’re kind of rising the abstraction levels that helps me as a developer do my job without getting overloaded.
But with all these changing requirements and distributed systems, I don’t think we’ve quite caught up with the level of abstractions and therefore a developer coming straight out of college these days has got to learn a myriad of things. Not only are they going to learn the actual programming language, they’ve got to learn architecture, the fallacies of distributed computing. There’s just so much stuff you’ve got to learn now, which I think if you haven’t been in the industry for a few years is a bit overwhelming.
Shane Hastie: This touches on something that I would like to dig into a bit. We’ve got the tooling now, we’ve got the AI tools coming in, Copilot, that’s supposed to be helping us. I’m hearing massive increases in productivity in some reports and others where yes, I might get 10%.
How does somebody coming in new learn to be a good programmer today?
How do people new to the industry learn to be a good programmer today? [13:11]
Daniel Bryant: Yes, that’s a fantastic question, You and I touched on this briefly at our end of year or beginning of year summary and as you asked us then about this, I was like, oh, that is a really good point. Because folks that have been in the industry, ourselves included, for a while, having an AI Copilot is like a pair programmer. We know perhaps how to work with a pair. It’s different than when you’re coding solo. And we also know if you’re pairing with an intern, it’s very different than pairing with someone of your abilities too. You treat the pair differently.
And I think we haven’t quite figured that bit out yet in terms of the levels there. And if you are starting from a tablua rasa, like blank slate, knowing what questions to ask is really hard. I can instantly look at a problem and I’m thinking, oh, with my pair I say, “Oh, we need to think about the second order ramifications of this change we’re going to make.” But that’s just because I’ve got this sort of inbuilt pattern matching and years of just seeing these things. Whereas when you’re starting off, you don’t have that gut feel, sixth sense, spidey sense, call it what you will.
And I’m with you, I genuinely think that’s hard without doing some of the things and getting that experience and building that gut feeling, I’m not sure exactly yet if we’ve got the tooling to do that. I think AI could probably help accelerate some of those things, and maybe my mindset is just a bit stuck in the past. I will put my hands up and say that because I’m almost using my old mental models to this new world, but I wonder if we need to create some kind of training or some kind of support system that bootstraps people from that sort of one to a hundred or zero to a hundred where when they get to the a hundred, they’re not necessarily the best programmer in the world for example but they know about fundamental tenets, coupling, cohesion, single responsibility principle, many other patterns that many of us have gone through and they’ve sort of been exposed to the ramifications of some of these patterns and so forth that they know what kind of questions to ask of their pair programmer.
But again, this is a plan. I’m totally conscious that I’m applying my old mental models again, I need to chat to some folks fresh out of college and actually see how they’re learning because when I do, I mentor a few folks, and the way they use YouTube shorts and TikTok and things. I’m on those platforms and are playing around with them a little bit, but the way they learn is very different than me. I love a good book and I love getting hands-on with the tech. The book gives me the big picture, I love reading, and the hands-on helps me build a mental model.
But junior folks I mentor, “Don’t give me the book, just give me the TikTok,” or whatever. And I’m like, “But how are you going to get the big picture?” And I wonder as in we’re just going to maybe have to update the way we do teach folks to build software.
Shane Hastie: That’s a challenge for the educational institutions, isn’t it?
Daniel Bryant: Yes, exactly. I agree.
Shane Hastie: What does an intentional culture look like?
Great culture emergent and requires intentional behaviors [15:57]
Daniel Bryant: Yes, this is great. Again, I’ve listened to many of your podcasts around this, Shane, and chatted to lots of interesting people at QCons over the years and I think really it is about setting goals and guardrails, primarily. The best cultures I’ve worked on, they’re not the ones with those kind of cheesy things on the wall that says we value all these things, they’re somewhat emergent than the cultural norms, but they’re emergent from a very clear value of we want to aim for these things, these are our goals. We collectively believe these things to get to this point. And then the guardrails.
I definitely worked in some of the cultures where the cliche is culture is the worst behavior the leader tolerates. And I was definitely in a few of those situations where stuff would side and then no one really liked it and then the culture unraveled from there. So I think for me it’s one of those things you have to be on it all the time. It’s not like I write my values and stick them on the wall, done. We have to be day in, day out monitoring ourselves in terms of are we subscribing to our stated values, our stated culture? Do we need to adapt to the culture?
I definitely see, I’ve worked with folks over years who’ve worked in say, government organizations or big organizations like that where the culture doesn’t change. And actually that’s a bad thing. We all think, oh, it’s a great culture, but it was great 10 years ago, 20 years ago, not so great with the challenges we’ve got now. So you sort of need to update these things but I do think, yes, goals, guardrails and that constant awareness of how is the culture interacting with new folks joining the team? Are we looking after everyone on the team from the junior folks, the senior folks? These kind of things.
Shane Hastie: Jumping around a little bit, where is platform engineering going?
What’s happening with platform engineering? [17:45]
Daniel Bryant: Yes, great question Shane. I get all the DMs all the time because I’m on LinkedIn talking about engineering quite a lot. People were like, it’s just DevOps. And they’re folks that have even been around longer, they’re like, it’s just infrastructure. And I get it as in I know friends have had four different job titles and basically done the same job over the last 10, 20 years. But I think with a lot of technology we come up with different words, we talk about different sort of approaches, but for me it’s kind of like, I don’t know, it’s something like a pendulum swinging or you can see it like a spiral.
My take on it, we are getting better all the time if we’re not exactly going in a sort of one straight line to better or success or whatever. So I think for me, platform engineering is a collection of many good things that have come out from building infrastructure, things like site reliability engineering, SRE the Google folks championed, and things like CICD, which I learned a lot from Dave Farley back in the day and Jez Humble, with their classic book. It’s mashing all those things together with that cultural sprinkling that you and I talked about a few times today, recognizing hence the QCon track. It’s not just about the tech, but if you want to allow developers to go fast, be safe and build systems at scale, you have to provide a framework for them to do that.
And framework, I’m deliberately keeping it a bit vague, but that is the culture, the tooling, the practices, all the things, if that makes sense, right? And for me, platform engineering is the label we’re putting over that. And I think you and I have definitely seen even with DevOps, the danger once we do have a label, it’s like vendors co-opt it and people just misunderstand it. It’s just human nature. Certainly, I’m sure I’ve played my part in that too. There is a bit of a danger of platform engineering going through that kind of hype cycle as the Gartner folks might say, I’ve been just reading some Gartner reports about this. We are at the peak of inflated expectations according to Gartner, and then we drop down to the trough of disillusionment and I’m with that.
I think the Gartner folks are often on something of that and then you have to go through this trough before you come out the other side with productivity. But I like it, again, it’s an interesting community of people coming around platform engineering. And that for me is the key thing. And most of us assume good intentions and we’re not always making the right noises and always going in the right direction. But I think platform engineering is a way to how do I build these frameworks, foundations, platforms, portals, all the things mashed together to enable developers to have the best experience to go faster, think about being safe, security, all these good things and delivering systems at scale as well.
Shane Hastie: Now you mentioned you’ve been dabbling in product management. Tell us about that.
Dabbling in product management [20:15]
Daniel Bryant: Yes, so my career, Shane, I really enjoyed software delivery and architecture and platform building, but I fancy doing some product work. So I left the company I was working with, I’ll shout out to the OpenCredo folks. Fancied moving on from there about seven or so years ago and moved into building tools.
I worked with a company called Ambassador Labs. When I joined it, it was like seven folks in a Boston office but ultimately we created Telepresence and Emissary Ingress to open source projects that we donated to the CNCF. And now I’ve moved on from Ambassador Labs and working on Kratix now, which is an open source platform building tool. But along the way of building all these tools and working with the fantastic communities around there, I realized I had to learn some of the basics on product ownership, product management, project delivery, all these good things. Because the fantastic thing with open source is everyone can contribute and literally we found everyone does contribute.
When I worked on that Telepresence back a years ago now, we had people wanting to take the project in a different direction and just again, all great, great stuff. I looked at Marty Cagan’s work, actually inspired, and a bunch of other books I’m sure your listeners will recognize. But those books really helped me understand how do I build a good product because if you listen to everyone’s opinion, the product’s going to be like the Swiss Army knife but negative sort of Swiss army knife, if that makes sense in the cloud native world.
And yes, I just love learning, Shane, as we’ve sort of mentioned a few times today. And for me learning these product management skills, I can see how they relate to all the things I’ve built in my previous careers. It’s fascinating looking back sometimes as with age comes wisdom, hopefully, right? And when I look back and I remember thinking, oh, that’s why that manager said that, that’s why that mentor did that. That’s why that CEO was saying we should go in this direction. They were trying to meet business goals, they were sort of obsessing about the customer or we know there’s clearly some challenges with building a sustainable product, these kind of things. And as a sort more naive software engineer, I was just like, why are people doing these things?
And I get people on my team ask me that these days, “Why are you doing this?” And I’m like, “We’re building a product, right? It is not perfect, but we’ve got to meet some user goals, get some revenue.” These kind things opened my eyes. The Marty Cagan stuff in particular, there’s many other folks I read their Substacks and listen to podcasts. I’ve shared Lenny’s podcasts. I love the Lenny’s stuff. Does fantastic work in the product space. For me it’s just opening my eyes up in how I run communities, how I treat some of my career even. That product focus, it’s actually a really powerful focus.
Shane Hastie: So what should a software engineer understand about product management?
What should a software engineer understand about product management? [22:47]
Daniel Bryant: I definitely think reading some of the Marty Cagan’s work inspired if you like reading or listening to Lenny’s podcast is a great way. It is just you can tell folks they’re really passionate about what they do and that kind of seeps to many of us. If you’re a software engineer, you’re probably a systems thinker, you’re probably very curious about building mental models and learning. So I think naturally those kind of resources that are out there you would just gravitate to. But I think learning the fundamentals of you are trying to deliver business value. As silly as perhaps that may sound to a bunch of listeners, I guarantee you there’s folks out there, because I was certainly one of them at one point where I didn’t fully make that connection between we are trying to deliver business value in solving a problem.
Sounds really obvious, but I worked on a few government projects, I worked on a few private projects I should say as well where it was not super clear as an engineer what problem we were really solving. We knew we had a spec and we were building the web apps and so forth. But when I actually look back, if I’d known the business problem I was trying to solve, I might’ve made different suggestions. I might’ve sort of pushed back or implemented the software a bit differently. I think it was a danger at some points and probably even now where people want to hide the complexity or segment the work. But I think the more context we have throughout the organization, the better things you will deliver. So I think as a software engineer, understanding you are solving business problems and understanding some of the constraints in your organization is really good.
There’s many analogies with programming here, but just understanding in terms of you can build anything but you can’t build everything. You have to prioritize, ruthlessly. I really enjoyed learning about prioritization within the product framework. And the last thing I’d say is running experiments. I think that’s sort of more thing has come into vogue over the last few years, but back when I started creating software applications, they were months and years of delivery. I remember being handed a telephone directory of requirements for my team back in the government, UK government, my first gig, and I think that project took 18 months, two years and didn’t get deployed while I was actually there. My internship finished, I moved on.
Whereas these days on startups we’re pushing that code constantly to validate hypotheses like, hey, we think if we had this feature, this small little feature, our customers will get more value from that in this way. I can create an experiment, I push some code out there, I get the metrics back, I look at it, test my hypothesis, validation or not. So I think that’s a really key thing, that experimental mindset, which again many of us have as software engineers, but with a slightly different focus towards customer value, business value is a really powerful thing to learn.
Shane Hastie: Advice for young players, people who are early in their career and who are inspired by looking at what you’ve been doing and your journey. What advice would you give the young Daniel today?
Advice for young players [25:38]
Daniel Bryant: I love these thought-provoking questions, Shane. I would say there’s something, I mentor a lot of folks these days and one of the dangers I have and I see other folks have is wanting to do it all. And I’ve had a very lucky 20 year career so far in tech and I’ve had some amazing mentors and amazing opportunities along the way and I’m conscious that I’ve done all these things and people are like, I want to do all the things. You cannot do all the things.
Definitely picking the most important thing to you now, whether it’s being a better software engineer, learning how to work with AI, understanding product. Do you want to become a startup founder? Do you want to be that CEO of big org? Being super clear on some of your goals and they’re guaranteed to change, I could say that, but being clear on your current goals and then laser focusing perhaps an area that you are strong or want to get stronger in or an area where you know it’s a weakness, but you have to have that, really investing in that.
I did a lot of mentoring last summer. I took a bit, very lucky, took a bit of time out, spent some time with the family and so forth. But as well I also mentored a bunch of folks on Zoom. I opened up my calendar and said, Hey, jump on. And a lot of those conversations were how, I imagine I’ve got no psychological training, but I imagine how the sort of psychologists go. A lot of it’s like, so tell me why you think this is what you want to learn. Tell me what your next career step would be.
And the people would often rock up with very clear, I think I need to do this, this, this. And then we actually have a chat around what do you really want to do? What’s the most important thing? And break it down and then build it back up with actionable steps. People walked away so much happier than when they rolled into the call, probably a classic case of cognitive overload, right? They were like, I need to read all these books, do all these things, learn all these things. And I’m like, trust me, you can get there but that’s a 10-year journey. You need to break it down and have clear smaller goals along the way.
So the biggest bit of advice I gave last year I’d give now on the podcast is be super clear on where you want to get to, but break it down to smaller steps and recognize that work-life balance as well because you can almost run yourself ragged. There’s so much amazing resource and content out there on the internet these days, but you can consume it 24/7. You shouldn’t consume it 24/7, you should definitely balance up life in general. And I think being super clear on the goals will really help you prioritize what to read, what to learn, what to play around with.
Shane Hastie: Great conversation. We do this far too infrequently.
Daniel Bryant: Indeed. Thank you Shane.
Shane Hastie: I would typically at this point ask where would people find you but of course you’re on InfoQ.
Daniel Bryant: That’s it. Come and find me there. Yes, @danielbryantuk on most of the places. Shane. So like I’m on LinkedIn, GitHub, X, formerly Twitter, @danielbryantuk is where folks can find me, but InfoQ is the first place. Rock up, have a chat, find me there.
Shane Hastie: Wonderful. Daniel, thanks so much.
Daniel Bryant: Thanks a lot Shane.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Ben Linders

Platform engineering is about accelerating and empowering developers to deliver more product value faster over time. According to Jessica Andersson, most companies don’t invest in platform engineering until they reach a certain size. At QCon London she presented how their startup adopted platform engineering, what strategy they took, and what they have done to gain platform adoption from developers.
Andersson mentioned that they launched their platform engineering team when the company was two years old and already had software running in production. As soon as you have software in production, you have an implicit platform, regardless if you know it or not, she said. This implicit platform is built in bits and pieces to solve whatever need the teams have at the moment and once it works well enough, whoever built it goes back to building the product, she added.
Starting out with platform engineering they first identified their implicit platform and then started to turn it into an intentional platform:
Basically we took existing things and streamlined, upgraded, and secured them. It’s important here to acknowledge that the implicit platform was built with the best knowledge available at the time and to remember that this was not the main focus for those building it.
It’s important to avoid replacing all tools just because they would not have been your first choice; replace the ones that are insecure or hinder your platform, Andersson said.
The main goal of the platform engineering team is to increase the ability to deliver product value, Andersson said. You can do this through removing bottlenecks and reducing pain points and time sinks:
Some indicators we look for in order to identify where we need to spend more effort are:
- Teams are blocked from performing tasks
- The tasks teams perform take long time
- The tasks teams perform are unreliable and prone to failures
There are always trade offs you need to make; being a small team we definitely can’t take on everything, Andersson said, but we aim to solve the most common and urgent needs.
Treating your platform as a product means building it like you would any other software product. The platform has users, problems that it solves, and a lifespan throughout which you need to take care of both the software and your users, as Andersson explained:
I often see platform teams forgetting about the users when it comes to migrations or switching to new tools, and they deprecate the old thing without providing a seamless transition to the new thing.
Andersson mentioned that you need to keep a focus on what your product is. Working with a product manager in the team is important to maintain that focus:
I try to focus a lot on solving the right problems as well. As a platform engineering team in a cloud native environment there are infinitely interesting problems you can work on; the question is whether you should. So finding out what are the right problems for your organisation and your users is important in order to spend time on those problems.
Platform engineering aims to improve the developer’s experience, Andersson said. Internal developer platforms can help you build a good foundation for good developer experience, helping your teams focus on building excellent products, she concluded.
InfoQ interviewed Jessica Andersson about platform adoption and building trust.
InfoQ: What have you done to gain platform adoption from developers?
Jessica Andersson: Some activities we’ve seen that build trust and thus encourage adoption from our teams are:
- Remove pain points – we show our teams that we care about them and can improve their experience
- Be approachable and helpful – people more likely to reach out to us again, spreading the word to their teammates
- Be proactive – while being approachable we might hear about pain points the teams don’t realise we can solve for them, if we fix it we will gain more trust
- Understand the teams’ perspective – if we understand where they come from, what they know and not, then we can communicate in the same language and better understand their pain points
InfoQ: What role does trust play in supporting a platform?
Andersson: Trust is important as everything builds on it. Adoptions, information, communication: it all comes back to trust.
I believe that as a platform team it’s very important to build a high level of trust with the product teams as it will determine how successful your platform will be.
MMS • Caleb Hyde

Transcript
Hyde: In grade school, I was given an assignment to write a talk. We all came in the next day, and I was waiting for my turn. Someone before me talked about jumping up on a chair and trying to jump off and getting a fear of heights with a chair, which seemed silly. Indeed, it was a humorous talk. Then someone else went next, and it was a very light-hearted thing. I had this very consequential thing that I had prepared. I don’t remember what it was at the time. I froze. The teacher pulled me out into the hallway and said, what do you mean, you don’t have the talk? You haven’t done the assignment? They have no way to know that, in fact, I did. I had written it, and I wasn’t ready to share it. I took the L, and to this day, didn’t pass, didn’t get that assignment in sixth grade or whatever. At any rate, I’m going to try again today. I was pretty miserable in grade school. That might be unusual. Maybe no one else has hated middle school, but I didn’t. My sister at the time talked to me about educational theory. She had read Piaget and various things, and she had this idea that I should homeschool. I went to my father and I said, I want to homeschool. My father said, that’s a terrible idea. This is not my father. This is Jean Piaget, from the Wikipedia article, who is known for educational theory or behavioral development in children. The image prior was from the logo, programming language, which I had learned around the same time and had an Apple IIe, and taught myself Logo and BASIC and that sort of thing. My sister was my first mentor, and I would not be where I am today if it weren’t for her, as well as my brother. All of my family have been incredibly influential. You don’t always get to choose that. You don’t necessarily have an older sister, and you don’t necessarily know to go out and find mentors. It doesn’t necessarily take a ton of effort, but the reward is huge.
Context Setting
This is a talk about risk and failure on the path to staff engineer. I want to share my progression and the things that I’ve tried, many of them which were not successful, and frame how that turned out and how I conceptualize that, how I think about it. If you leave this talk with nothing else, I want it to be this one slide. I want us to develop a framework to recognize risk and failure, and see that in others, and anticipate when there are other folks who are about to make mistakes. We should have a framework to mentor them out of that and bring them back from the edge. Part of that, I think, is by sharing stories such as I’m going to do here, and make it ok.
Do the Work
When I’m not working, I sometimes make robots. They’re often terrible, horrible things that work poorly and are wildly inefficient. It’s something I like to do and it’s a little bit of my non-professional work, although, maybe there’s overlap as well. It keeps me off the streets. This was me a little while back. My sister and my father and I, we made a compromise. I didn’t go to homeschool, whatever that would be, and I didn’t stay into public school. I had already been studying classical music, and so I entered the North Carolina School of the Arts, which is a school with five schools inside of a university, in a sense: dance, design and production, visual arts, music, and drama. Despite what conceptions you may have about music school, or band camp, or something of the sort, it is an immense amount of work. I entered high school for performing arts and got down to the task of doing that work. I had already been taking private lessons, but I took courses in music theory, composition, master classes, performing, and that sort of thing. I also realized that there are a lot of people there who had an immense amount of talent and an incredible drive, and had been studying and training since literally they were infants, to do this work. I took myself to New York City and the culmination of my career in performing arts was that I auditioned at the Juilliard School. There is nothing quite like walking through those doors. It’s a career defining moment to hear the person before you audition at Juilliard. I realized that I didn’t have the chops for that. There were a lot of people that had been preparing for a very long time. It’s a very cutthroat industry, or there just aren’t a lot of paying gigs. Tanya Reilly talks about the foundation of staff engineers is the technical chops, and there is no substitute. You have to put that work in. You have to learn your domain. It’s required. There’s high effort. It takes an immense amount of work. It pays off, because, if nothing else, it forms the foundation for future work, doing staff work, and that sort of thing.
Encouragement Matters (Nominal Value, Low Effort)
Has there been someone in your life who was a mentor and who has led you forward on your career? Offer it to other people. I graduated high school and I left performing arts, and didn’t know what I was going to do. I lived in Jamaica Plain in South Boston. I worked as a baker at a coffee shop called the Coffee Cantata, that is not the Coffee Cantata, but that is the one which allegedly Bach composed the work at, or performed at. The owner of that coffee shop where I worked, was also a musician, a classical pianist. One day, I was walking through the Arnold Arboretum which was in that area. The Arnold Arboretum is actually a research garden, as part of Harvard University. It’s a very beautiful space. I was walking there and a friend of mine at the time showed me this martial art that she had been training, capoeira, and I knew right then and there that that’s something I wanted to do. I began studying actually under a student of the man here in the middle, but that at that point in my life, I was making up my way and I wasn’t in college. This was an important piece of that progression, and learning, showing up and taking those classes. Then, two or three years into that, some other folks came to me, some friends of mine, people I trusted, and they said to me, “You need to go to college. This is the moment. If you don’t do it, you’re going to forget how.” I listened to them, and I applied. I think they probably sent some emails as well. I got into college. Again, encouraging people when they’re stumbling or they don’t know what they’re going to do is really useful, really important. It’s also not something you can necessarily choose. Some folks don’t have mentors, and they don’t have sisters and older siblings. Again, I don’t know that it takes effort other than maybe be in the right place at the right time, which if you’re a wandering non-college student you may not know to do. It matters.
College, and Graduation
I got into college. I went to Oberlin College in Ohio, south of Cleveland, tiny little town, tiny little university or college. I decided to study engineering, which totally makes sense because Oberlin is a little liberal arts college, and doesn’t have an engineering program. I started taking the prereqs and doing the chemistry 101, and whatnot. Also, Oberlin has a beautiful library. It has a lot of cool seating. It’s a really nice space. This is a place where I actually spent a fair amount of time studying physics 101 and whatnot. College was the best seven years of my life. I did a five-year degree program. I went to Oberlin and transferred to the Washington University School of Engineering. I took some time off and graduated late, which is a whole separate story about not being in your graduating class and being older than people expect you to be when you’re a new college grad. I did the work. I took a whole bunch of engineering courseload, linear systems, and numerical methods, and controls theory, and whatnot. I graduated with a Bachelor of Science in Engineering in the exceedingly well-known field of system science mathematics. Which if you say you have an ME degree or you have an EE degree, people know what that means. If you say you have an SSM degree, or a systems engineering degree, you find job postings for network system administrator.
Networks Matter (Moderate Effort, High Value)
I graduated with a Bachelor of Science in Engineering, and then nothing happened. I was sitting at home in my childhood bedroom. I was applying call to jobs on monster.com. I had $200 in my bank account. It was 6, 9 months after graduation, and I was broke. I had nothing except an engineering degree. I did what we all know to do now because we’re all fairly far along. At this point, I sent some emails, and I emailed my advisor from college. I emailed some classmates from my graduating class, from my degree program. Sure enough, someone connected me with a hiring manager and I interviewed and I got the job. Networking, probably most folks by now know that. If you take it for granted and you say, why is Caleb talking about this? There is someone out there who doesn’t know that and hasn’t heard that, and they need to. Encouragement matters, networking is exceedingly useful. It’s also not that hard to do. It’s a lot more enjoyable than just applying to your 200th job on monster.com, and not getting any responses. I don’t think it’s worse than the alternatives in terms of effort, but it’s how everything happens. Not everyone knows that. You have to learn it. It’s a skill set. A lot of these things are skill sets.
A Turning Point
Second question, has there been a point when you were about to go off and join the circus or something, and someone pulled you back and said, stay on track? Maybe they’re like, you want to join the circus, great, do it. Has there been a point where you reach the terminal point or decision point early in your career? Not so many people. I was wondering about this. I didn’t know what to expect. I think I learned later in my career that this is not true of a lot of people. You have classical musicians for parents, and they get you on that path early on. Or you go to the best schools and you take internships and you graduate and all that, and that’s great. There’s a lot of people out there for who that’s not the case, so non-traditional paths and non-traditional careers is just the natural way of being in the world. I do think it’s easy to take it for granted that you go to a good high school and you do internships in college and you go to a good college, and then you graduate and get the degree and all that. It’s not true for a lot of people.
I got a job at Sprint, the telecommunications company. Sprint is based in Overland Park, Kansas in the Midwest. I got down to work. I hadn’t done internships. I hadn’t done the traditional professional life, and I didn’t know how to do it. I got down to work of like, learning the job of showing up and not falling asleep in meetings when it’s alphabet soup. The conversations are just like, good gravy, telecommunications has so many acronyms. Literally, people just talk 45 minutes in acronyms, and none of it makes sense. You learn how to show up and be there and be present. Apparently, that involves a lot of khakis, and blue jeans, and shades of blue. It became this whole theme. We were like taking these photos because we’re like, “You wore blue today? Me too.”
Networks are Sticky
I was at Sprint for many years. Telecommunications is a deep engineering field. There’s a lot of really interesting engineering, goes into how call setup happens in sub-second latency, and how power propagation works. There’s a lot of complexity and nuance to it. It was interesting for several years. Then I realized that all I knew was telecom. I knew people at Qualcomm. If I wanted to go work at Motorola or whatnot, I could probably do that. Or at least I could email someone or make a phone call. It’s this insular thing. They’re sticky. Networks are sticky. I didn’t necessarily want to stay in Telecom. I didn’t want to stay in the Midwest. I didn’t necessarily want to wear khakis and blue all my life. It took me a little while to figure out how to extend my network and how to bridge outward. We took some more photos, and we got together. This crew actually was my innovation lab for a few years. We got together and we’d meet once a week in a supply closet where we kept telecommunications hardware and whatnot, and we would whiteboard ideas and work on patent disclosures. We challenged each other. I put this idea up on the board that we could radiate power from a cell tower to a cell phone, and Andy on the right there said that’s a silly idea, that’s never going to work. We were this innovation crew, ad hoc group of folks at the time. It was around the time that “The 4-Hour Workweek” came out. Then later I stumbled upon Seth Godin’s work and the idea of how to develop a skill set that’s unique no matter where you are, whatever company you’re at, or whatever field you work, and how do you make your skill set useful. We disclosed a patent disclosure. We disclosed a whole bunch of patents and kept a spreadsheet. We had about a 1 in 3 success rate. From a very small window of my career, I actually have a whole bunch of patents to my name. The point is, it was successful. Our goofy little ragtag crew that was meeting in a supply closet, was making headway and learning some interesting stuff.
Exit Strategy
I started formulating this idea that I needed to branch out. I needed to learn a new skill set and develop a broader network. I began to teach myself software development. I picked up Python. I went to the Python Kansas City meetup for many years. I was co-organizer for many years. I taught myself software development, version control theory, data structures and algorithms, social coding. I did the work again. I then participated in Devopsdays Kansas City. I helped co-organize it one year. I spoke at it the following year. At that point, I had developed a network outside of telecommunications and outside of the Midwest. It worked. I got out. There’s no substitute. I taught myself a new field, software development, and it was nights and weekends. I don’t want to do it again. If someone asks me like, what did you do? I did the work. There’s no substitute.
Choose Your Maximizer
I was also at the time reading Bogle and the idea that I wanted to develop an emergency fund, a savings fund. I became an inherent of buy and hold. Despite the synopsis of the talk, I don’t bet. I don’t really know anything about betting, in the sense of like Vegas, or off-track, or whatever. That’s a strategy, and buy and hold is a strategy. I developed a savings fund, and developed a network outside of Sprint, and outside of telecommunications. I graduated college late, and spent many years at Sprint. Some of them I felt like I wasn’t getting anywhere. I decided to optimize for compensation. I decided to be a jerk, to be a capitalist, to make money, and build up a safety net fund. It worked. This is, in fact, my year-over-year compensation for the period of time when I was focused on this, and it worked. I wasn’t living paycheck to paycheck. I was able to take more risks, and take longer with my job search and that sort of thing.
I can’t say that this is the ordering of things that someone else should choose. Because, being a jerk, being a capitalist means you’re a jerk. It means you’re missing out on other opportunities or other companies’ generative cultures. It’s useful, because now I have freedom. I don’t have to worry so much about simple things like how much a coffee costs. A lot of people do. I don’t have to worry about saving face. I don’t have to wear khakis. That worked. I reached a point where I was comfortable with that, and so I changed my maximizer function, at that point. I wanted to focus on finding fit. I wanted to optimize for fit. Also, all of these different things are skill sets. We talked earlier in the staff panel about what is the skill set that you might have as a staff engineer that you don’t as a senior engineer, and project management is one of them. How to interview, how to negotiate salaries, how to change jobs, maybe change back, leave a company, and come back and make more money. These are skills and this is a skill set, and you can develop it. You can share that skill set with others. Really, to this day, one of the most consequential outcomes for me in my career was that I had a friend who was interviewing and she came to me and said, they’re making me an offer, but it’s so much. I said, you need to make twice that much, you should go back to them and tell them that. It was several conversations over a couple of days or a week or something, but it worked and she doubled her salary. To this day, I find that I was able to share a technical skill set which I had developed for myself with someone else, and help them.
I was also not that happy at the time. I took this photo, in fact, to mark the point in time because I had gone through a couple of companies in fairly short timeframes, and they were not always the most generative cultures. I was responsible for some of that, for some of that toxicity. I wasn’t happy about that. I entered this company, Foghorn, as the 11th full-time hire. I had this vanity English license plate as a result of being an early hire at this consultancy. They were based in the Bay Area. They’ve since been acquired. I worked at Foghorn for many years. It’s a consultancy in cloud infrastructure. We are a client service delivery firm. We delivered projects to engineering customers of ours, and I worked on large scale engineering cloud infrastructure projects in AWS and GCP. I built up the GCP Premier Partnership status myself. I learned project management. I learned how to manage a team of engineers and deliver work to a client, which is also a team of engineers. I got to see their code bases. I got to see how they do CI/CD, all of these different companies, large biotech companies in the South Bay. You can probably think of their names. Smaller companies, which you will probably have never heard of, because they were tiny. I developed that skill set. I was a senior engineer when I entered Foghorn, and learned these non-traditional engineering skills like project management as well as like how to organize teams and put up with people who are really good engineers, but don’t show up for work.
Be Your Own Advocate – High Effort, High Value (Moderate Opportunity Cost)
We got to this point where my boss, the director of service delivery was basically going to level up, and we were interviewing externally for his backfill for a director of service delivery. Just as a point of clarification, in client services, director is an engineering management title. It’s a line engineering title. It does not mean Director of Engineering in the more traditional sense. I was a senior engineer, and we were scheduled to interview someone here, actually. I think I was going to talk to them remotely, but they were scheduled to show up. Then they didn’t show up for the interview, which baffled my boss at the time. I said, “Why don’t you give me a chance? I don’t necessarily plan to go into management but it would make sense for me as a logical next step in my career path. It’s a skill set you need. You’re struggling to fill that role.” He went back to the leadership team and they came back and they said, yes. I got the role of director of service delivery for a period of time. I wasn’t there for too long after that, but in a fairly short period of time, I got exposure to managing people, hiring and firing, how to have conversations with a direct report who is a higher skill level than yourself. Also, conversations with engineers who are belligerent. All the while also delivering the client work, the project work, and the engineering work. A new skill set and a new exposure.
I decided that I didn’t want to stay in engineering and management. I actually came to appreciate that it is a distinct skill set. It is something you can learn and practice. I have a lot of respect for managers and engineering managers because of that. I wanted to stay on the technical side, and so I decided not to continue doing that. I left Foghorn. I also wanted to get out of consulting. In consulting, you have to establish your technical expertise quickly at first glance. You also don’t have long term ownership. You advise companies and you help them deliver their work, but ultimately, they decide and they own the work, and so I wanted to get back into product engineering. I left Foghorn. I was continuing to train capoeira. Capoeira gave me a voice. It gave me the ability to feel comfortable in front of people and in crowds, and to be assertive, even if you’re not sure, even if you’re not confident, to still be assertive. It also appeals to me. It keeps me active. I don’t get bored like I do when I go running or something of the sort.
I said to my boss, give me a shot. If I hadn’t said that, they would have just kept interviewing externally, and trying to hire. I also learned through other means, through my martial arts, to be confident, and to speak loudly or clearly. This also takes a lot of work. There’s also no substitute. Again, if you don’t, at least ask. If you don’t propose that you take on a new role or a new responsibility in your current role, you’re less likely to get it. Higher reward. The opportunity cost is that you’re still optimizing for yourself, not for the business. You might not be focused on what’s most meaningful for the business, which, ultimately, is why we’re here, why businesses exist.
Optimize for Fit (Moderate Effort, High Value)
I kept training. I learned to do new things. Then I got out of Foghorn. I left the consultancy and I got another job. I started to, again, change my maximizer, earlier from optimizing for comp and from optimizing for position or title, and now looking at, which company is the best, finding the right company or the company that I want to work for. One that isn’t too toxic, or too boring, or whatnot. The next step for me was this progression to finding new roles. The culmination of my social media career and why I don’t really promote it is this tweet which got zero replies, zero likes, anything at all. I still to this day think about it, because it’s so true. If you’re going to take risks, you have to expect some of them to fail, and you have to be willing to admit that you failed. You have to be ok with that, and figure out how to do that. You have to develop a skill set. This is the next few steps. I was at Foghorn as senior, and I moved to the director of service delivery, an engineering manager role that also had duties of client consulting or project delivery. Then I left Foghorn and got an IC title as senior engineer. Now, here’s the thing is that moving from senior to engineering management could be considered a lateral move, or maybe not lateral, but in a sense, like a negotiation because I didn’t have management experience. They were taking a chance and I was taking an opportunity to gain more experience as a director. When I decided to leave consulting, I wanted to go be an IC again, an engineer again. I took a title as a senior engineer. If you were scanning my resume, you could be forgiven for thinking that I took a demotion, or a step down. As I see it, it was two lateral movements, but it requires explanation, and that doesn’t come off in the wink of an eye or if you’re scanning resumes. Narratives are important and being able to provide context, communicate that context is important.
Then I took another role. I left the company after a fairly short period of time and took a role as a staff engineer. That is clearly a promotion. It was a pay bump. I did move up in IC levels from senior to staff, and yet, it was a short tenure. That senior role was a short tenure. If you’re scanning a resume, you might think that was a failure. I have gotten questions about that as I interview, is, why were you only there for so long? The point here is like, if I tell you I moved from senior to staff, it seems like a clear win, but there’s nuance, and that gets sussed out when you’re interviewing and whatnot. Then I failed to execute as staff engineer, and I was laid off. I was unemployed for three months, and I collected unemployment for the first time in my life. There is a stigma around unemployment, being unemployed, but companies pay out of your salary. They pay taxes into unemployment funds, so you should be ok taking that if you need to. I did fail as staff. I could caveat it. I could tell you like, it was not a generative culture, or they were not working on interesting stuff. That doesn’t matter, because I’m not there to influence the decisions. In any sense, I wasn’t successful delivering or executing on a vision because I’m not there anymore.
Culture is Your First Priority (Enormous Effort, High Value)
That period of time, at the consultancy, and then afterwards, me consulting, is like language immersion. I learned so much about engineering orgs, and code bases, and all of that, and project management. It’s not low margins, but you have to control cost carefully. You have to talk about utilization rates and say, we expect engineers to spend 83% of their week working on billable work. You have those kinds of conversations. It’s pretty demanding. It can be pretty exhausting. I would joke with my manager that I was going to study for the PMP exam in the 50-to-60-hour block of my week, because there’s always more to do. The consulting was exhausting. Then the work after that was successful in some sense, and not always successful, and not always enjoyable. I’ve, again, changed my focus, my maximizer function, and now I consider that culture is king. It’s all social coding. A few years ago, GitHub had that as their tagline. It’s all about optimizing for the business and optimizing for what the business needs, and figuring out how to make that happen. There’s no shortcuts. There’s no substitute. It requires having a lot of direct, difficult conversations. Being willing to say when you’re wrong, but also not tell someone else too bluntly that they’re wrong. That’s my work now. That’s where I’m going next.
Summary
If you had $200 in your bank account, and you went to Vegas, would you play it all on slots, or play it all at once on roulette? I don’t know. I can’t even ask this question because I don’t bet. Inaction is a form of risk. You have to decide what to do in any case. There’s different strategies for investing, and there’s different strategies for maximizing your compensation. I think I’ve spoken to all of these and spoken about each one. This is the idea. This is the framework of like, where on the quadrant of effort and risk and reward, do each of these things fall? Like I said, I started optimizing for compensation first, and then later for fit. In hindsight, that might not have been a great idea, but it did give me latitude and leeway. Again, if all that I’ve said today is obvious to you, and you’re like, why again, is Caleb talking about this? It’s because there are other people earlier in their career who haven’t heard it and they need to. We have to share our stories and be vulnerable in order for them to know that you’re authentic, and to know that you mean what you say, and that you have the bona fide or whatever to advise them. My name is Caleb Hyde. This has been a talk about risk and failure.
Questions and Answers
Participant 1: You started off by saying you need to optimize for compensation because that was needed since then. Then, later on in your presentation, you talked about optimizing for fit and then culture. With your experience now, would you say that you would recommend young engineers like don’t get attracted by optimizing for compensation, or do you still think that that was the right thing to do at the time.
Hyde: I don’t know. I can say with assurance that working intentionally to maximize my pay, and also along with that, like you’re standing in an organization in your respect, like you have a seat at the table, that was successful and useful. To answer the question without answering what you’re asking is, why don’t you just do all of that at once? Why don’t you timeshare your development effort between comp, and fit, and behavior, and whatnot? Sure, if you have the discipline for that, and if you know to do it. If you’re early career, you don’t have a skill set. All of these things are obvious in hindsight, because we learned the hard way and learned by doing them or because someone told us. Early on you don’t know what cloud infrastructure is. You don’t know what project management is. You don’t know how to tell someone they’re wrong politely, and all of that. I don’t have an opinion. I can’t say that it was better or worse. You have to choose where to spend your time, and sometimes the only thing to work on is the thing in your view.
Participant 2: Someone once said to me, basically, work with people who want to work with you, people who are working against you, don’t waste your time, don’t care. Under the general umbrella of choosing your bets, kind of thing. Curious if you have anything else to talk on that, in your opinion.
Hyde: Someone I worked with early in my career would always say, choose who you work for, who you work with, and what you do. I still quote them because that’s great advice. It’s concise. It’s pithy. It’s useful. It’s true. I would also never work with that person again. You learn from everyone you work with, for better or worse. There are no absolutes. It all depends.
Participant 3: You mentioned that you were working in software engineering, and then you said that you think that you failed. Do you mind sharing your thoughts on maybe how you failed?
Hyde: I think, more or less, what I was doing fits a pattern that’s pretty common, which is, I was steadfast in my technology decisions. I’m like, we need to do this. What we’re doing is a terrible idea, and whatnot. There was also an element of, they were asking me to do something that I had actually done several times before, a large scale Terraform migration and modernization effort, and I had opinions about that. Like, I’ve done that, and I found it a little boring. I also had a fairly clear idea about how to get it done from an execution perspective, like from a technical perspective of like, here’s how you implement a Strangler Fig pattern, and bite the elephant one bite at a time. Again, my delivery was terrible. Even though I have in fact done large scale Terraform modernizations and written software systems to migrate Terraform, none of that mattered because they weren’t working with me and listening to my advice, and ultimately, I was laid off.
See more presentations with transcripts
Microsoft Announces Public Preview of Geo-Replication Feature for Azure Service Bus Premium Tier
MMS • Steef-Jan Wiggers
Microsoft recently announced the public preview of its new Geo-Replication feature in the Azure Service Bus premium tier. This feature allows continuous replication of a namespace’s metadata and data from a primary region to a secondary region, which users can promote at any time.
Azure Service Bus is Microsoft’s fully managed messaging service, enabling reliable and secure communication between distributed applications and services across cloud and on-premises environments. The new Geo-Replication feature for this service is designed to provide robust protection for Azure Service Bus applications against outages and disasters, complementing existing options such as Geo-Disaster Recovery and Availability Zones.
Unlike the existing Geo-Disaster Recovery feature, Geo-Replication replicates metadata and data. It can establish resilience between Azure regions, such as the East and West US. In addition, Availability Zones provide resilience within a specific geographic region.
Eldert Grootenboer, a senior program manager on the service bus team at Microsoft, writes:
The Geo-Replication feature implements metadata and data replication in a primary-secondary replication model. It works with a single namespace, and at a given time, there’s only one primary region serving producers and consumers. A single hostname connects to the namespace, which always points to the current primary region. After promoting a secondary region, the hostname points to the new primary region, and the old primary region is demoted to the secondary region. After the new secondary has been re-initialized, it is possible to promote this region again to primary at any moment.
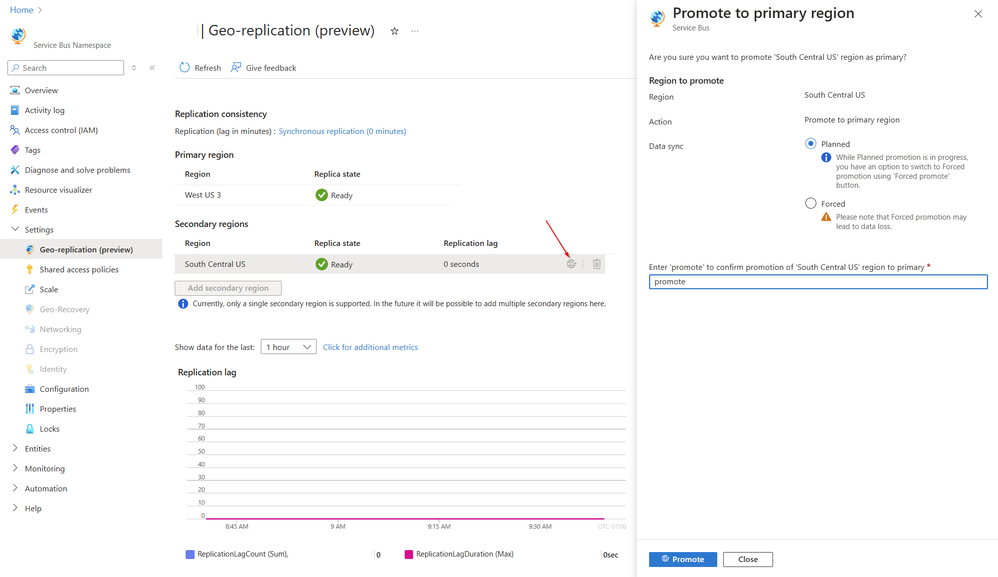
Service Bus Premium Geo-replication (Source: Tech community blog post)
Microsoft’s competitors offer similar messaging services with disaster recovery features. AWS Simple Queue Service (SQS) ensures high availability and fault tolerance by distributing messages across multiple availability zones within a region. This means that messages remain accessible and are not lost even if there is an outage or disaster affecting a specific data center. Similarly, Google Cloud Pub/Sub provides high availability and disaster recovery by automatically replicating data across multiple regions, ensuring that messages are reliably delivered and available even if one region experiences an outage or disaster.
Clemens Vasters, a Principal Architect for Messaging and Real-Time Analytics at Microsoft, tweeted a bold statement:
#Azure Service Bus is the most powerful transactional hyperscale queue broker in existence.
Introducing multi-region, synchronous (RPO-Zero), or asynchronous namespace replication (all messages and message states!) as insurance against region failures.
Lastly, the feature is available in the Central US EUAP, Italy North, Spain Central, and Norway East Azure regions.
MMS • Anthony Alford

OpenAI recently published a paper about CriticGPT, a version of GPT-4 fine-tuned to critique code generated by ChatGPT. When compared with human evaluators, CriticGPT catches more bugs and produces better critiques. OpenAI plans to use CriticGPT to improve future versions of their models.
When originally developing ChatGPT, OpenAI used human “AI trainers” to rate the outputs of the model, creating a dataset that was used to fine-tune it using reinforcement learning from human feedback (RLHF). However, as AI models improve, and can now perform some tasks at the same level as human experts, it can be difficult for human judges to evaluate their output. CriticGPT is part of OpenAI’s effort on scalable oversight, which is intended to help solve this problem. OpenAI decided first to focus on helping ChatGPT improve its code-generating abilities. The researchers used CriticGPT to generate critiques of code; they also paid qualified human coders to do the same. In evaluations, AI trainers preferred CriticGPT’s critiques 80% of the time, showing that CriticGPT could be a good source for RLHF training data. According to OpenAI:
The need for scalable oversight, broadly construed as methods that can help humans to correctly evaluate model output, is stronger than ever. Whether or not RLHF maintains its dominant status as the primary means by which LLMs are post-trained into useful assistants, we will still need to answer the question of whether particular model outputs are trustworthy. Here we take a very direct approach: training models that help humans to evaluate models….It is…essential to find scalable methods that ensure that we reward the right behaviors in our AI systems even as they become much smarter than us. We find LLM critics to be a promising start.
Interestly, CriticGPT is also a version of GPT-4 that is fine-tuned with RLHF. In this case, the RLHF training data consisted of buggy code as the input, and a human-generated critique or explanation of the bug as the desired output. The buggy code was produced by having ChatGPT write code, then having a human contractor insert a bug and write the critique.
To evaluate CriticGPT, OpenAI used human judges to rank several critiques side-by-side; judges were shown outputs from CriticGPT and from baseline ChatGPT, as well as critiques generated by humans alone or by humans with CriticGPT assistance (“Human+CriticGPT”). The judges preferred CriticGPT’s output over that of ChatGPT and human critics. OpenAI also found that the Human+CriticGPT teams’ output was “substantially more comprehensive” than that of humans alone. However, it tended to have more “nitpicks.”
In a discussion about the work on Hacker News, one user wrote:
For those new to the field of AGI safety: this is an implementation of Paul Christiano’s alignment procedure proposal called Iterated Amplification from 6 years ago…It’s wonderful to see his idea coming to fruition! I’m honestly a bit skeptical of the idea myself (it’s like proposing to stabilize the stack of “turtles all the way down” by adding more turtles)…but every innovative idea is worth a try, in a field as time-critical and urgent as AGI safety.
Christiano formerly ran OpenAI’s language model alignment team. Other companies besides OpenAI are also working on scalable oversight. In particular, Anthropic has published research papers on the problem, such as their work on using a debate between LLMs to improve model truthfulness.
MMS • Justin Sheehy
Subscribe on:
Transcript
Justin Sheehy: Before I can talk to you about being a responsible developer in the age of AI hype, I want to remind you, just briefly about something you already know. You are developers or software practitioners of some kind. That’s what I mean, in an expansive sense, when I say that. I can speak with you here, because I’m a developer. I’ve written compilers, databases, web servers, kernel modules. I’m a developer too. I’m here with you. It isn’t only developers we need to hear from, it’s linguists, philosophers, psychologists, anthropologists, artists, ethicists.
I’m not any of those things, but I want us together to learn from them. This is because one of the biggest failings that those of us in software tend to have is thinking that we don’t need all those other people. That we’ll just solve it our way. This is almost always a bad idea.
Another thing about being a developer, and again, I’m going to use that term very loosely, if you’re here today, you’re who I mean. Another thing about being a developer that people sometimes forget, is that you have power. My friend and one of the best tech industry analysts out there, Steve O’Grady, wrote this about 10 years ago, and it hasn’t become less true.
Your decisions matter. You have power. You know what Uncle Ben told Peter Parker comes with great power. We need to know how to make good responsible decisions, specifically, decisions that are in front of us today, because of some recent trends in AI. Because AI has made huge strides lately, some massively impressive work. Maybe the only thing more massively impressive, has been the scale of the hype around it. I don’t think it’s out of line to call this moment an age of AI hype. Some of you might disagree with me, and think it’s all earned, and we’re on our way to the singularity or something. We’ll come back to all that hype.
How Does AI Work?
Before we do that, we need to figure out what we mean by the AI part, because that can be fuzzy. Artificial intelligence is an unhelpful term because it is so broad, but I’m going to use it anyway because most of you will. Don’t forget that this is a computer program. You’re developers. You know how this work. Don’t let yourself get tricked into thinking there’s something magical about a program. What if these things are programs, what kind of programs are they? I want to credit Julia Ferraioli, for reminding me of this very basic breakdown. Most of how AI has been built over the years has been in one of two categories, either all about logic and symbol processing, and so on. When I took AI classes in grad school about 30 years ago, this is where most of the focus was.
Or it’s about statistics and mapping probability distributions of things seen in the past, into the future. All the recent attention has been on systems based in that probabilistic side. I’ll focus on the part people are excited about now, LLMs, and their image synthesis cousins. I said these are just programs and you can understand them. I’m not going to do a thorough explanation of how they work. I want to take just a moment, just enough to have a concrete conversation.
One of the many advances that led to the current generation of auto-regressive, or AR-LLMs is this concept of the transformer, which allows the attention, you can think the statistical relationships between a word or a token and the other words around it to be much broader. This newer way of enabling richer dependencies has increased the quality of the output of these systems and allow their construction to be much more parallelized.
Even with that great advance, which really is great, and a lot of other recent advances, these language models are just more efficient, parallel, scalable versions of the same thing that came right before them. This is from Google’s intro to LLMs developer pitch, “A language model aims to predict and generate plausible language.” It predicts plausible next words, like autocomplete. Really, that is it. That’s the whole thing. Don’t take my word for it. You already saw it from Google’s page. This is the definition of GPT-4 from OpenAI’s own technical report.
Given a document, it predicts what word or token is most likely to come next, based on the data it was trained on. You keep repeating, you get more words, autocomplete. It is really good autocomplete. When you realize that that’s exactly everything that an AR-LLM is doing, you realize some other things. It doesn’t plan ahead. It doesn’t really know anything. It is possible to make systems that plan or have knowledge, but it is not possible to make these systems do that, because it literally can’t do anything else. That means it can’t be told at all to not give false answers. Both Google and OpenAI say this. This isn’t my opinion.
These are very cool pieces of software, using impressive architectures to do an extremely capable version of autocomplete. Nothing is there about knowledge or meaning, understanding, or certainly not consciousness, just, what’s a plausible next word. OpenAI, in response to being sued in the EU for saying false things about people via its systems has shrugged and repeated that. They’ve been very clear in their legal replies that there is only one thing that their system does, predicting the next most likely words that might appear in response to each prompt.
They say that asking it to tell the truth is an area of active research. We know that’s code for we have no idea how to do this. I’d like to set an expectation today, those kinds of systems, the AR-LLMs, like ChatGPT and the others, are the type of AI that I’ll be referring to most of the time in this talk. It is possible that other AI will be created someday, for which some of this talk won’t apply perfectly. It’s not possible that these systems will just somehow magically change what they can do, which is part of what we’re going to talk about.
The Age of AI Hype
It is worth emphasizing, though, how powerful these are at the things they’re good at. I don’t think I have to try very hard to convince you that these LLMs are amazingly cool and capable. That’s why that part gets none of my time today. If they’re so awesome, why would I call this an age of hype, instead of just an age of awesome AI? People are saying some pretty hyped-up things. I should give some credit to Melanie Mitchell for pulling some of these quotes together in a talk of hers that was really great, and that I really appreciated.
Those aren’t things people are saying today. We’ve been here before, about 60 years ago. Leading scientists and journalists were just as convinced of those things then, as now. What’s the difference between then and now? Mostly money. There are billions of dollars riding on bets like these. That doesn’t make them more true, it just adds more incentive for the hype. We do see the same kinds of statements from very prominent people now. Please don’t fall for them because these people are well known. This is all complete nonsense. I will come back to a couple of the examples. I want to help you not fall for nonsense, so that you can evaluate these kinds of really cool technology more reasonably, more usefully, and to make better decisions. Because making good decisions is fundamentally what being responsible is about. Decisions about what technology to use, and how to build whatever each of us builds next. To do that, we need to not be fooled by hype and by nonsense.
What does the hype really look like? How might someone be fooled? A big group of the current hype are these many claims that the type of LLMs we’re now seeing, ChatGPT, PaLM, Llama, Claude, so on, are on a straightforward path to a general artificial intelligence, which roughly is the kind of AI that’s in most science fiction, like human like, or real intelligence. This is complete nonsense. Here’s a paper from Microsoft Research that tries to make that case. The paper suggests that LLMs like GPT-4 have sparks of general intelligence.
One of the most exciting things about this paper for me was this section on theory of mind. This is a big deal. If language models can really develop a sense of the beliefs of others, then something amazing has happened and the authors did something better than many out there, which was to look to the right discipline for answers, not just make it up themselves. They use the test about belief, knowledge, and intention from psychology, and GPT passed it. This is impressive. Except, it turned out that if you give the test just slightly differently, GPT fails the test. That’s not at all how it works with humans. The LLM did what they’re very good at, providing text that is very convincingly like the text you might expect next. This fooled the original authors. People who want to be fooled, often are. This is great if you go to a magic show, less great if you’re trying to do science.
This article made an even more dramatic claim. No sparks here, no, it has arrived. This is an amazing claim. Amazing claims require amazing evidence. What was the evidence? There wasn’t any. The article just claims it’s here, and places all of the burden of proof on anyone wishing to deny that claim. Read it yourself if you don’t believe me, but really, not the slightest shred of evidence was provided for this massive claim. That’s not how science or even reasonable discussion works. Basically, they said, we can’t define it or explain it or prove it, but we insist that it exists. If you disagree, you must have a devotion to human exceptionalism. No, I have a great deal of humility about what humans are capable of, including when it comes to creating intelligence.
I want to note that the very last paragraph of that article makes a great point, and one I agree with. There are more interesting and important questions we could ask, such as, who benefits from, and who’s harmed by the things we build? How can we impact the answers to those questions? I deeply disagree with their core claim, but I completely agree with this direction of inquiry. Another statement I’ve heard a few times. I’ve heard some people not quite as starry eyed as the people making some of those other dramatic claims, but still a bit credulous, say things more like this. “The idea with this argument is that since the current AR-LLMs seem a lot more intelligent than the things we had before them, we just need to give them a lot more information, a lot more computing power, and they’ll keep going, and they’ll get there.”
There’s a bit of a problem with that argument. At its heart is a mistaken understanding of what LLMs are doing. They’re not systems that think like a person. They’re systems designed to synthesize text that looks like the text they were trained on. That’s it. That is literally the whole thing. More data and more compute might get them closer to the top of that tree, but not ever to the moon. Another common claim, which is part of the hype, is that since LLMs produce responses that seem like they could be from a person, they pass a fundamental test for intelligence.
This is a misunderstanding of what the Turing test was in the first place. Alan Turing, who we all here owe a great debt to, actually called this test, The Imitation Game. Imitating human text is a very different thing than being generally intelligent. In fact, in the paper where he laid out that test, he even said that the idea of trying to answer a question about machines being intelligent was nonsense, so he decided to do something else. This is a wonderful paper, and more self-reflective than most current commentators. If we all had the humility of Alan Turing, the world would be a better place, and we’d be fooled less often.
One claim that I’ve heard many times and I find very confusing, is that people just do the same thing that LLMs like ChatGPT do, just probabilistically string along words. People making this claim are a lot like LLMs themselves, really good at sounding plausible, but when you look closer, there’s no actual knowledge or understanding there at all. Stochastic parrot comes from the title of this very important paper from 2021. This was about possible risks in LLMs. That is a sensible topic for ethicists to write about. It’s also the paper that got Google’s ethical AI leaders fired for writing it. That’s why one of the authors is listed as Shmargaret Shmitchell, since she wasn’t allowed to put her name on it.
The notion that Bender and Gebru and McMillan-Major and Mitchell were talking about is a description of AR-LLMs. They’re probabilistic repeating machines much like a parrot, that learns how to make the sounds of humans nearby but has no idea what they mean. Sam Altman, the head of OpenAI here makes the claim that this is all we are too. This is something many people have said, and it is a bizarre claim.
The problem at the heart of the claim is a fundamental misunderstanding of the fact that language is a tool used by humans, with its form being used to communicate meaning. You or I, when we have an idea, or a belief, or some knowledge, make use of language in order to communicate that meaning. LLMs like ChatGPT have no ideas or beliefs or knowledge. They just synthesize text without any intended meaning. This is completely unlike what you or I do. Whether it is like what Sam Altman does, I don’t know.
Instead of listening to him, let’s come back to Emily Bender for a moment. She was one of the authors of that stochastic parrot paper. She is a computational linguist at the University of Washington. She’s extremely qualified to talk about computing and language. She and I have a similar mission right now. I want to help you be less credulous of nonsense claims, so that you can make more responsible choices.
Someone might see statements like this one, about current LLMs like ChatGPT, or Gemini, and so on, and dismiss them as coming from a skeptic like Professor Bender. To that, I’d first say that that person is showing their own bias, since she’s so enormously qualified that the word expert would make more sense than skeptic. Also, she didn’t say this.
This is a quote from Yann LeCun, the head of AI research at Meta, and a Turing Award winner, and an insider to the development of LLMs, if anyone is. He knows just as Professor Bender does, that language alone does not contain all of what is relevant or needed for human-like intelligence. That something trained only on form cannot somehow develop a sense of meaning. There is no face here, but you saw one. That effect is called face pareidolia, and most humans do it, and even read emotions that clearly do not really exist, into such images.
The face is a creation of your own mind. Similarly, when you read a bunch of text that is structurally very similar to what a person might write, it’s very challenging not to believe that there’s some intention, some meaning behind that text. It’s so challenging, that even people who know how these systems work, and know that they have no intentions, no meaning, can be fooled. It is challenging, but you can rise to that challenge. Because, remember, these are just computer programs. There is no magic here. You know this.
There are some things that have made it easier to get this wrong. One of these things is the term hallucination. The use of that word about LLMs is a nasty trick played on all of us. When a person hallucinates, we mean that their sense of truth and meaning has become disconnected from their observed reality. AR-LLMs have no sense of truth and meaning, and no observed reality. They’re always just doing the exact same thing, statistically predicting the next word. They’re very good at this. There’s no meaning, no intention, no sense of what’s true or not. Depending on how you look at it, they’re either always hallucinating, or they never are. Either way, using the word hallucination for the times we notice this, is just another case of the meaning all being on the observer’s side.
Even if we accept the use of the word hallucination here, since it has entered common use, we shouldn’t be tricked into thinking that it’s just a thing that will go away as these systems mature. Producing text that is ungrounded in any external reality is simply what they do. It’s not a bug in the program. I want to be very clear when I say that this behavior is not a bug. LLMs are never wrong, really. They can only be wrong if you think the thing they’re trying to do is correctly answer your question. What they’re actually doing is to produce text that is likely, based on the data before it, to look like it could come next. That’s just not the same thing. They’re doing their job and they’re doing it very well.
Another source of confusion to be aware of, in addition to the hallucination misnomer, is this concept that arbitrary behavior can just emerge from an LLM. This idea is encouraged by all that sci-fi talk about AGI. It’s really fun, but isn’t connected to how these things actually work. Remember, they are just programs. Cool programs, but programs, not magic, and not evolving, just engineering. Then, we hear stories like this, about how Google’s LLM learned Bangla, the Bengali language, without ever being trained on it. That’s the kind of story that could make someone become a believer that these programs are something more. It turns out the important part of the headline was the phrase, doesn’t understand, since it only took a day for someone who cared to look. Remember Margaret Mitchell, fired from Google for publishing about AI ethics.
For someone like that to find that the language in question just was in the training set. Huge claims should come with huge, clear evidence. This is key to how you cannot be fooled. When seeing a big claim, don’t just dismiss it. Don’t simply swallow it unless you get to see the evidence. Maybe, in the case of Google CEO believing nonsense, like the statement that their LLM can just learn languages it hasn’t seen, we can just chalk it up to him not yet knowing as much as you do, and not requiring evidence before making such an outlandish claim. Then a few months later, Google released a really cool video on YouTube, it got over 3 million views right away. It showed amazing new behaviors, like identifying images in real time in spoken conversation with a user. It turned out that that was fake. Video editing isn’t all that new.
Gemini is a really cool LLM. It can do some neat tricks. Let’s not be tricked. Sometimes people get honestly fooled, and sometimes they’re trying to fool you. You don’t have to know which is which, you just have to look for proof in a form that can be verified by someone who doesn’t have a stake in you being fooled.
People and AI (Human Behavior)
Switching briefly away from the narrow focus on LLMs out into the wider topic of people and AI. Some of you might have heard of the Mechanical Turk. I don’t mean Amazon Mechanical Turk. I mean the machine that Amazon service is named after. This was a fantastic chess playing machine. One of the earliest popular examples of AI. It became widely known in the 1770s. This machine played against Benjamin Franklin and Napoleon. It won most of the games it played even against skilled human players. That’s amazing history. We’ve had AI good enough to beat human players at chess for over 200 years. How do you think it worked? There was a human chess player inside. It’s a great trick. It’s great for a magic show.
This is actually a cool piece of AI history. Because this is actually how a lot of today’s AI works. We see an AI system with an outrageous claim about its human-like capability. For example, here’s a press release with nothing relevant left out from about 3 years ago. Through a groundbreaking set of developments, a combination of computer vision, sensor fusion, and deep learning, Amazon was able to make it so that you could just take what you wanted off the shelves and leave the store and then charge your Amazon account the right amount. I gave this away by showing you the Mechanical Turk first. Up until very recently, Amazon executives continued to call this technology magic in public, and their site now says that it’s all about generative AI, and all of these amazing developments.
We just saw a much older magic show and they had the same trick. Another great example of how AI has moved forward is autonomous cars. Cruise owned by GM is just one of many companies racing to be ahead in this market. They’re racing so fast that they’ve run over some toddlers and run into some working fire trucks. Anyway, this page on their website is pretty cool, and it’s still there. You can see it. It leaves out some important things that surfaced around the time the California DMV suspended them for a lack of safety and for misrepresentation. Now you know what’s coming.
Just like the Mechanical Turk in the AI checkout lanes, the driverless cars actually had an average of more than one driver per car. Some of them are just too ridiculous, like the Tesla bot. It was literally just a guy in a robot suit. These are not only cases of humans inside the AI, they’re also hype. They’re outrageous claims with the purpose of selling things to people who are fooled. They’re also all good reminders that if something acts amazingly well, like a human, and you can’t get adversarial proof of how it works, maybe don’t start out by believing it isn’t a human.
Even for things where that isn’t literally the case, where there’s no individual man behind the curtain responding to you, there are human elements of the AI systems, and now we are back to the LLMs and image generators, that we all get excited about today. For instance, one of the important breakthroughs that enabled ChatGPT to exist is called Reinforcement Learning through Human Feedback, or RLHF. This is all really well explained in a lot of places, including on OpenAI’s page.
People read a lot of answers to a lot of initial prompts that people write, in order to produce their original training set, then more people interact with that to build a reward model. It’s all about building a system that uses a lot of text written by people, so statistically produce more text that more people thinks like what a person would write. It is a real breakthrough to make it work. It’s not just a program. It’s just a program, or a bunch of programs, plus an enormous amount of low paid human labor. Just as the Amazon checkout lanes required multiple people per camera, or the Cruise cars had one and a half drivers per car, or the Tesla bot had an infinite ratio of humans to robots.
There is a difference here, these people aren’t literally pretending to be AI. Still using ChatGPT or anything like it is using the labor of thousands of people paid a couple of dollars an hour to do work that no one here would do. That may or may not be worth it. That’s a whole class of ethical problems. At the very least, I want you to be aware of how these things work, in order to make informed choices about how to use them, or how to build them.
Developers Make Things
These things are cool. I don’t want to get left behind. This is where all the money is. My boss told me I have to put some AI on it, so that we can say AI in our next press release. How can I do it right? What kinds of things might we do? We’re developers, we make software systems. Let’s talk about some of the things we might do. We already know that these systems are just computers running programs. Some of you may be the developers of those actual AI systems. A much larger set of us are using those systems to build other systems, whether to build things like GitHub Copilot, or to put a chatbot on a website to talk to customers, and so on.
Then an even larger set of us are using those LLMs, or things that are wrappers around them directly for their output. Let’s work our way down and talk about some of the choices we can make. As users, we’re a lot like anybody else, but with one superpower of being a developer, and being able to know what a computer system like an AR-LLM can do or not do. How can we ensure that we use them wisely? If you wouldn’t email a piece of your company’s confidential information, like source code or business data to someone at a given other company, you should think twice before putting that same data into a service that other company runs, whether it’s a chatbot, or otherwise.
Unless you have a contract with them, they may give that information on to someone else. Many large companies right now have policies against using systems like ChatGPT, or Copilot for any of their real work, not because they are anti-AI, but because they generally don’t let you send your source code out to companies that don’t have a responsibility to treat it properly.
The flip side of this is that since so many of the legal issues are still being worked out about property rights for works that have passed through an LLM blender, you may want to be cautious before putting code, text, images, or other content that came out from an LLM that you didn’t train yourself into your products or systems. This isn’t just about avoiding lawsuits. I’ve been involved in discovery and diligence for startup acquisitions on both sides. Everything goes a lot smoother if there are squeaky clean answers to where everything you have came from. This is not a hypothetical concern. There are hundreds of known cases of data leakage in both directions. Be careful sending anything you wouldn’t make publicly available out to these systems, or using any of their output in anything you wish to own.
This particular concern goes away if you train your own model, but that’s a lot more work. How should we use them? If you train the LLM yourself on content you know is ok to use, and you use it for tasks about language content, producing things for your own consumption and review, you’re on pretty solid ground. Even if you only do one or two of those things, it puts you in a much better place.
For example, using them to help proofread your work to help you notice errors, can be great. I do this. Or, as Simon Willison does, using them to help you build summaries of your podcasts or blog posts that you will then edit. Or you can use them as a debate partner, an idea I got from Corey Quinn, having them write something you disagree with in order to jumpstart your own writing. Having yourself deeply in that cycle is key for all of those because there will be errors. You can also choose to use them because of how inevitable the errors are. I really love this study about using LLMs to help teach developers debugging skills. Since the key success metric of LLMs is creating plausible text and code as text, they’re great at creating software that is buggy, but not in obvious ways.
I’m focusing on use cases here, where faulty output is either ok, I can ignore bad proofreading suggestions, or even the whole point, because you cannot count on anything else happening. When people forget this, and they send LLM generated content right out to others, they tend to get into trouble, because that text is so plausible, you can’t count on noticing.
An LLM will cite academic work, because that makes it plausible, but the citations might not be real. Like this one that ChatGPT gave to a grad student doing research, and that publication just doesn’t exist. Or legal precedents that didn’t exist, but made for plausible enough text that a lawyer cited them to a judge. The lawyer asked ChatGPT if they were real cases, and it said they are real cases, and can be found in legal research databases, such as Westlaw and LexisNexis, that had some plausible text, but not connected to any facts.
This is even worse for code. Having an LLM write code that doesn’t matter, because its whole purpose is to teach students debugging, is great. Having it suggest places where your code looks funny, as a not too skilled pair programmer, that can be fine too. Having it actually write the code you’re going to ship is not what I would recommend. Was generating the text of your code ever the really hard part? Not for me, personally. The hard part of software is in communication and understanding and judgment. LLMs can’t do that job for you. I’ve seen smart folks get tricked about this. That’s why I’m here to help you. I get told often that these AR-LLMs are able to reason and to code, but they don’t have any reasoning inside them.
I wanted to make sure I wasn’t wrong about that. I tried the simplest question I could think of that it wouldn’t literally have the answer to already memorized. I asked the latest version of ChatGPT, 4.0, to just count the number of times the letter e appears in my name, Justin Sheehy, 3 e’s it says. That’s not right. I’ve been told to just ask more questions, and then it’ll figure it out. I tried a little prompt engineering. I did it the way people say you should, asking it to show its work and giving precise direction. As always, it sounds very confident. It backs up its answer by showing its work. That’s not better. It’s really not right. This is an extremely simple thing and should be in its sweet spot if it could do any reasoning or counting.
I tried similar questions with different content, just to make sure I wasn’t tickling something weird, with similar results. This is just a reminder, these things don’t reason. They don’t sometimes get it wrong. They’re always just probabilistically spewing out text that is shaped like something that might come next. Sometimes by chance, that happens to also be correct. Use them accordingly. They can be used well, but don’t forget what they are and what they aren’t.
What about when we’re not just users? What about when we move down the stack and we build AI into our software as a component in a larger system. Here, it gets even more important to be careful of what content the model was trained on. If you train it yourself on only your own content, it’s still just sparkling autocomplete, but at least you know what it’s starting from. If you go the easy route, though, and you just use an API around one of the big models, they’ve been trained on the whole internet. Don’t get me wrong, there’s an enormous wealth of knowledge on the web, Wikipedia, and so on. There’s also 4chan and the worst subs on Reddit, a whole lot of things you might not want your software to repeat.
Part of being responsible is not bringing the worst parts of what’s out there through your system. When I say bias laundering, what I mean is that people tend to feel that an answer to a question that came from a computer via an algorithm is somehow objective or better. We’re developers, we know all about garbage in, garbage out. If the whole internet is what goes in, we know what will come out. This isn’t hypothetical. People are making these choices today, embedding use of these pretrained language models into systems making important decisions, and the results on race, gender, and religion are predictable. We can do better. How can we do better? We can start with testing. Just like we have testing tools for the rest of our software, we can test in all models for bias, like this pretty nice toolkit from IBM. That should be basic expectations. Just like writing tests for the other parts of your system should be expected. It’s not enough, but it’s a start.
Another set of irresponsible decisions being made right now can be seen walking around almost any conference that has vendor booths, and counting the things that have become AI powered. I understand the tendency and the pressure, but this is not harmless. That AI washing exercise, that money grab by saying, we’ll solve it with AI, somehow, can mean that other systems maybe other ways to save lives don’t get the resources they need. This isn’t just failure, it’s theft in the form of opportunity cost, preventing important work from happening. Or worse, you can give people confidence that an algorithm is on the job and cause real life or death decisions to be made wrongly.
Saying AI, might make it easier to sell something, but it might cause your users to make dangerously worse decisions. What can we do? We can talk with CEOs, product managers, and everyone else who cares about what they care about, the value that our software systems provide them. Instead of adding a couple of hyped buzzwords, we can figure out if and how adding some of these AI components will add real value. We can help those people learn to ask better questions than just, but does it have AI in it?
Accountability in the Age of AI
This and the rest of my advice here applies at multiple levels in the stack. Whether you’re incorporating an LLM into your system as a component, or if you’re actually doing your own model development. No matter which of those things you’re doing, being a responsible developer requires accountability. That means that your company needs to understand that it is accountable for what it ships. You, if you develop it, you’re accountable for them knowing that. What does this accountability look like?
You know now that an LLM simply cannot be forced to not hallucinate. If you put one in your app or on your website, you have to be prepared for taking the same accountability, as if you put those hallucinations on your site, or in your app directly. That cool AI chatbot that let your company hire a couple less support stuff might mean that the company loses more money than they saved when they have to give out discounted products or refunds that it offers, and that might not end up being the value that they hoped for, when you said you were going to add some AI. It’s your responsibility to make sure that they know what the systems you develop can do. How can we do it? That part’s pretty simple. We need to not lie. I don’t just mean the intentional lies of fraudsters and scammers. You need to not make the hype problem worse.
It doesn’t mean not using or making LLMs or other really cool AI systems, it just means telling the truth. It means not wildly overpromising what your systems can do. Microsoft had a Super Bowl commercial, where someone asked out loud of their AI system, “Write me code for my 3D open world game.” That’s just pure fantasy. That normally doesn’t work with anything today. No one actually has any idea how to make it work. Microsoft has some really cool work they’ve done lately, and I should have represented it more responsibly. This isn’t just my advice, it’s the FTC’s. This is advice from the U.S. government on some questions to ask yourself about your AI product. I think it’s a pretty good start.
What else can you do? If you can’t do something legally and safely, and I’m not talking about active political protest or anything like that, then don’t do that thing. This is another one that sounds really obvious. Almost everyone will agree with it in general. Then I hear objections to specific cases of it. That sounds like, if we complied with the law, we wouldn’t be able to provide this service. Or, if we took the time to make sure there was no child pornography in our training sets, we wouldn’t have been able to make this fun image generator. We just have to violate the rights of hundreds of thousands of people to train a huge AR-LLM. Do you want to hold back the glorious future of AI? Of course, I don’t want to hold back the future.
The future success of one particular product or company does not excuse such irresponsibility. All of those were real examples. A starting place for being a responsible developer is to develop systems legally and safely, not put the hype for your product ahead of the safety or rights of other people. It feels really weird to me that that’s an interesting statement, to say that other people’s safety or rights should matter to you. It feels like it should be obvious. I hope that to you, it is obvious. That if you have to lie or violate other people’s safety to ship something, don’t ship it. Do something else instead, or do your thing better. I am excited by a lot of the developments in the field of AI. I want that research to continue and to thrive. It’s up to us to get there safely.
When I talk about what not to do, I’m not saying that we should stop this kind of work, just that we need to make each choice carefully along the way.
Alignment
I want to talk about alignment. There’s this common idea that comes up in the circles, where people talk about building AGI or general intelligence, about alignment. The idea of making sure that AI shares our human values, instead of being like Skynet, or something. These are really well-meaning ideas. The problem they’re focused on is still wild science fiction, since no one has any idea yet. How do you even start getting to AGI? We’re multiple, huge breakthroughs away from it, if it is possible. That doesn’t mean this work doesn’t matter.
Bringing ethical frameworks into the development of AI or any other technology is worthwhile. This is an interesting paper from Anthropic, which is all about that topic of alignment, and general-purpose AI. Despite not agreeing with them about the trajectory towards general-purpose AI, I think that their framework is very interesting, and we can make use of it. The framework is really nice and simple and memorable. The premise is that an AI is aligned, if it is helpful, honest, and harmless, 3 H’s. It’s pretty much what it sounds like.
The AI will only do what is in human’s best interests, will only convey accurate information, and will avoid doing things that harm people. This is great. I think these are excellent values. You can think of their research as being just as science fiction-y as the idea of general AI, but I think it’s relevant today. You can make use of it right now, by leaving out the AI part of the definition and applying this framework to yourselves. If you can live up to the framework for aligned AI, then you have what it takes to be a responsible developer.
Make sure that what you build is helpful, that it has real value, and it isn’t just hype chasing, but is a solution to a real problem. Make sure that you are honest about what you build. That you don’t oversell or misrepresent it, or make the hype problem worse. Make sure that you are honest with others and with yourself about what you build and how it works. Make sure that you minimize the harm caused by the things you build or caused by building them. Pay attention to what it takes to make it really work and how it will be used, and who could be harmed by that. Ensure that you center those people’s perspective and experience in your work. You need to help people, be honest with people, and minimize harm to people. Think as you make your decisions about those people, if you can do these things. I think they’re pretty easy to remember.
Then you can exercise great responsibility. Remember that you have that great responsibility, because you, developers, have great power, perhaps more than you realize. You get to help decide what the future looks like. Let’s make it a good one for people.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Presentation: Delivering Millions of Notifications within Seconds During the Super Bowl
MMS • Zhen Zhou

Transcript
Zhou: We’re going to talk about how we delivered millions of notifications within a few seconds during Super Bowl. I’m Zhen. How many of you know Duolingo? Duolingo is the most popular language learning platform. We have the most downloaded language learning app worldwide. Our mission is to develop the best education in the world and make it universally available. What do we have? We currently have 31.4 million DAU, which is Daily Active Users. We have over 100 courses offered in 40-plus languages. On top of that, we also have a very unhinged social presence. You may know us from a lot of things, and I assume internet memes is one of them. You may have heard of like Spanish or vanish. Some other stuff. Also, our marketing team is really hard at work. You may have seen some of the pretty wild TikToks or memes that revolves around Duo or our employees. That is really our marketing team hard at work.
Let’s switch gears a little bit and look at this number, 123.4 million. Does anyone have a guess of what this number could be? That’s actually the number of viewers of last Super Bowl. This year, the Super Bowl game between Kansas City Chiefs and San Francisco 49ers brought an average of 123.4 million viewers. That is the highest number of people watching the same broadcast in history. If you ask ChatGPT to create an image of a typical Super Bowl ad, it looks like this. Basically what you would expect from a ChatGPT image. It’s all over the place. It has cars, angels, neon signs, everything. Why are we really talking about this? This is because everything was fine for us engineers at Duolingo for a while, until one day we heard that Duolingo would run its first Super Bowl ad as it expands beyond TikTok. Our chief marketing officer expects the brand to be even more unhinged in 2024. Then we saw some design docs that revolves around Duo’s Butt, so we know what’s coming here. What really dawned on us was that we are buying a Super Bowl ad. This is a 5-second ad that was played during this year’s Super Bowl. At the time, we know that it has something to do with Duo’s Butt. There’s one last thing. The marketing team asked us to do a push notification at the same time. What could possibly go wrong?
Overview
We’ll take you on a deep dive into the Superb Owl service, which we named conveniently after the Super Bowl. First section, we’ll be talking about how we dissect this impossible task. Then we’ll talk about how we cope with the changing requirements. Followed by talking about the architecture deep dive into how exactly the service works. Last but not least, we will talk about what we learned and what we would have done differently.
A Dissection of An Impossible Task
Let’s start out with a dissection of an impossible task. When I use the word impossible, it may sound strong to you. It’s just sending notifications. When the marketing team came to us, they asked us, we want you to send millions of notifications in a few seconds, can you do it? We were like, hold on, let’s do some research. We did some research. We came back to them and said, I don’t think we can do that. Then, the next thing you heard was that them telling us, we already paid for the ad. Actually, at that moment, it wasn’t really up to us, we have to do it. They told us that they want to send 4 million notifications within 5 seconds. When they first came to us, we were actually a little nervous, because here you see how fast our notification typically goes out is at a rate of 10,000 notifications per second. If you do the math, that’s actually a lot of notifications per day. What they’re asking is to send notifications at 80 times faster speed. If you’re a site reliability engineer, or you work in the backend, there might be already alarms that are going off. This is what I’m talking about. Back in 2022, Coinbase launched its bouncing QR code like campaign during Super Bowl, and it was so popular that it crashed their site. We probably don’t want to do the same. On top of that, we also discovered an issue with our Android app, so that when we send out a notification to the Android app, it sends a request right back to the backend. This sounds a little bit similar to DDoSing ourselves. If you want to send 5 million, 4 million notifications within a few seconds, you probably want to avoid doing that.
In theory, leadership just came to us, “You should just ship it.” I don’t actually know if ship it is still a principle at Duolingo. In practice, this is a complicated problem. Because here you see, we want to build a system to send notifications fast, we also want to make sure that we do not DDoS ourselves. We also want to handle the organic traffic, because people actually click on those notifications and come back to the app to practice learning new languages. Our solution is basically somewhere in between those three problems. To make matters worse, we have people coming to us from different perspectives, product managers, or other engineers, they come to us with suggestions or inquiries. Can we add an icon to the notification? Can we send to more cities? Can you localize the push into different languages? Can we use the vendor for this? All of these questions. At this point, you might be imagining there’s like your favorite superhero from Marvel or DC to come and save the day. In this case, we would probably call it the coding man or something. There’s no coding man in real life. What we did was just very simple, we divide and conquer the task. I was in charge of building the system to send notifications fast. Two of my wonderful colleagues, Louise and Milo, they’re respectively in charge of making sure that we’re not DDoSing ourselves, and making sure that we can handle the organic traffic.
Coping with Changing Requirements
Let’s move on to the next section. I’ll talk about how we coped with the changing requirements. On the first day of the project, my technical program manager, Paul, came to me and asked me, “Can you give me a timeline on this project?” At the time, I wasn’t really a senior engineer. I said, “Sure, but where do I even start?” Because it’s such a complicated project. All we knew was, from August 2023, we know we want to send 4 million notifications in less than 5 seconds. Super Bowl happens the next year on February 11th, and they’re not going to move that date for us. How do we account for all these uncertainties in between? As you may know, to make matters worse, requirements are always changing. People are suggesting all sorts of things to do. You should do this. You should design this system in one way than the other. To give you an example, I said, they came to us saying we want to send 4 million notifications within 5 seconds. That was actually a lie. That actually changed. Because when they first came to us, they told us that they want to send notifications to 3 markets, with 2.6 million notifications in total, and they want to send all of it within 8 seconds. A few days later, they changed their mind. They were like, how about we round out to 3 million notifications? We want to send all that in 5 seconds. A few months have gone by, they came to us, they told us, we actually closed a new deal, and we now have the ability to show the ad in 7 markets. Wonderful, but that also means we want you to send to 4 million users. Because we’re in the United States, and people have a lot of digital devices, and potentially, we want to send to 6 million plus devices, which is 6 million plus notifications, all of that within 5 seconds. You can see how requirements can be changing all the time in a project.
Our solution was to figure out, what does not change? We figured that our operating principle does not change. One of our operating principles at Duolingo here is to test it first. We’re obsessed with A/B testing. We can’t A/B test this project, though, but I’ll talk just in a bit how we tested it. Our principle in this project is to not ship anything that we cannot test. Here’s a few examples. When they came to us and asked if it is ok to send to a larger audience, we said, yes, maybe, because we can probably test it. When they came to us and asked whether we can send notifications with an icon. We said, yes, because we can test it. When they asked, is it ok to add the ability to send notifications to different markets at different times? Sure, as long as we can test it. Is it ok to add 2 million users the day before, after basically we finalized the audience list? No, probably not, because we cannot test it. After that, we established the timeline. Back in August, we know that we want to send to roughly 4 million users in less than 5 seconds. We want to have the MVP ready by September 2023. We know that we want to make sure that we cannot DDoS ourselves by the end of December 2023, so that enough time could be given so that new client changes could be rolled out to users. By January 2024, we want to make sure that all testings are done, so that when Super Bowl really starts, we’re ready because we have tested everything.
Architecture Deep Dive
Let me take you on the core of this presentation which is the deep dive into the architecture of the system to send notifications. To send 4 million notifications in 5 seconds, it’s a lot of challenge. At Duolingo, we have an operating principle of, embrace challenges. To summarize the challenges in this project, we have three. The first one is speed. I’ll call it how fast. The second one is scale, which is how big. Third one is timing, which is what time. The first challenge is speed, of course. The speed is 800,000 notifications per second, roughly. If you think of the population of Boston, last time I checked on Google, Boston had a population of 650,000 people. I think that was back in 2022. Now it’s probably a little more. To send notifications to all these people, at our rate, it will take less than one second. It’s just that fast. The second problem and challenge is scale. At Duolingo, we host a lot of our microservices on AWS. Unfortunately, that cost us money. I wish that it was free. To build a system that sends notifications really fast, you also have to make sure that it’s scaled up to the point that it can do its job. You also want to make sure that your backend is scaled up fast enough to do its job. On top of that, you probably don’t want to spend too much money on cloud infrastructures. That is also a challenge at scale. The third challenge here is timing. For those of you who are into sports event, you’ll know that sports events are unpredictable, because people get injured or sometimes it goes faster or slower. Even the more predictable ones like the soccer games, they’re usually fixed, 90 minutes, but they have added time. It’s also the same case with the Super Bowl. Super Bowl has timeouts and everything. The problem with an ad campaign during Super Bowl is that you don’t know exactly when your ad is going to air. You see, our plan is to show the notification right after our ad airs. We have to build a system that is on-demand, so that when some marketer presses a button, potentially a big red button, then our notification goes out. We have to build such an on-demand system. We want to make sure that maybe if two marketers press the same button at the same time, no duplicate messages go out. That’s the challenge of timing. To summarize, we have the following technical requirements to build this system. We want to send notifications at the target rate. We want to get all the cloud resources we need just in time. We want to ensure resiliency and idempotency. I just explained idempotency here by the marketer example. I hope you all understand.
Here is our system. It’s basically an asynchronous system. We have a lot of our services on AWS. I’ll walk you through some of the use cases that we have, to basically show you how the system works. Let’s assume that it’s a few months before the Super Bowl, you want to upload a notification campaign. It starts out with an engineer creating a campaign with a whole list of user ID. The server after receiving that request will acknowledge the request and then asynchronously fetching all the data from DynamoDB. After getting the data, they will put the parsed data into S3, locks the result into CloudWatch. A few months have gone by, and maybe it’s Super Bowl Day already, you want to get ready because you want your backend infrastructure to be scaled up well enough to handle the incoming traffic, as well as being able to send out a notification. What happens then? The cloud operations admin will actually have to scale up the ASG, the automatic scaling group first, and then the engineer who is responsible, at the time it was me, would scale up the workers in the ECS console, just change a few numbers. The workers will then fetch data from S3, which we previously stored all the data, and store that data in memory. The data will be mapping from the user ID to the device IDs. After all that, the workers will log their complete status to CloudWatch. Maybe a few hours have gone by and someone was watching the ad, and the ad shows up and someone presses the big red button. What happens after that? The marketing admin hits the Go button. After that, the API server will actually send out 50-plus messages to the FIFO, First In, First Out SQS queue. The interim worker in between after receiving those messages, they’ll dispatch 10,000-plus SQS messages to the next queue. Finally, the last tier of notification workers will send notifications by calling the batch APNS and FCM’s API. They are Apple and Google’s notification API. After all that, after we’re done making all the network requests, the workers will log their process time into CloudWatch, so that we can analyze their performance.
Let’s come back to some of these technical requirements that we discussed earlier. Because if the system doesn’t answer all these questions, it’s still not working. The first question is to understand, does this send notifications at the target rate? It’s hard for me to convince you, but some of you who are familiar with SQS might notice that SQS in itself has an in-flight message limit of 120,000 messages per second. Just to send 4 million notifications within 5 seconds, would put us at 800,000 messages per second. How does that happen? Because actually, we simply use the technique of batching. We batched 500 iOS users together in one message, 250 for Android, and that put us under the limit. Second question we want to answer is, can we provision all the cloud resources we need in time? To solve this problem, we actually got in touch with a technical contact from AWS, who helped us draft an IEM, an Infrastructure Event Management document, which included detailed steps, like when and how you would need to scale up, as well as some of the more concrete steps such as things like the cache and the cache connection limits, and also Dynamo limits that you have to consider to address in these kinds of situations. Also, we also gave the Superb Owl service its own dedicated ECS cluster. I’ll tell you why we did that. Last question we want to answer is, can we ensure idempotency? To solve this problem, we actually cheated a little bit, we used a FIFO, First In, First Out queue from AWS SQS service. You see, the FIFO queue in itself, it deduplicates messages by message identifiers. It also has a deduplication window of 5 minutes. When multiple marketers press the same big red buttons, it’ll try to send the same messages through the queue, the queue will deduplicate the message for us. We basically just hand off that work. To keep in mind that the queue itself does have limited capacity for the FIFO queue. It has limited capacity of 300 requests per second. If you’re building a system like this for your own purpose, you also might want to use a cache or a table if you want to get past some of those limits.
Let’s get back to the system diagram graph. Does it send notifications at the target rate? Yes. Can we provision all the cloud resources we need in time? Yes. Does it ensure idempotency? Yes. Some of you may say that we’re probably done here. I’m inclined to say so, but actually not. Let’s look at this timeline of where we are now. We basically are still at September 2023, is when we built our MVP. Next subject is everyone’s favorite subject, which is testing. How we tested it, at Duolingo, we love to test things by A/B testing. We are obsessed with A/B testing every single detail in the app. This is honestly not a thing that we can A/B test, because we don’t want to leak our precious marketing creatives to our users. You don’t want to show the Duo’s Butt on something else, because that will ruin all the fun. We had to come up with our own way of testing the service. I’ll walk you through a few examples of how we tested the service. First, we tested the throughput of the service. This is what I call, how we tested the MVP. At the beginning, we tested with not really notifications, we tested with what we call silent notifications. This is effectively an empty payload that we send to the client devices and see what happens. It turns out, it seems that we ran into some bottlenecks. The bottleneck we ran into was the thread count. Here you see we actually built our service in Python. I know many of you might disagree. If you are an expert in Python, you will know that when you build multi-threaded programs in Python, you run into issues with global interpreter lock and all sorts of bad things. That’s the issue that we ran into. What could we do? We decreased the number of threads, and continued with the test, decrease it from 10 to 5 to 1, and the bottleneck seems to be gone. Then, we decided to test with a larger audience. Because at the beginning we tested with 500,000 users, now we want to test with 3 million users. Then the bottleneck came back. As you can see, we decreased the number of threads, but to get the same performance, we have to have a lot of tests. It was really problematic to scale up to that many test count. We decided to bin pack and put multiple processes within the same test. We experimented with a few setups and got to a point that we’re ok with.
The next thing we tested was the cloud resources. This is when we tested whether we can scale things up fast enough. The first thing we ran was pretty straightforward. We want to make sure that we can scale up the system to send the notifications really fast. In this case, it’s the Superb Owl service. It’s actually relatively simple. You just go in, you change one number, and it scales up, just like magic. Then, we want to scale up the backend. When we did that, go through a few more steps and understand what services we need to scale up. We found those services. We changed a few more numbers. They scale up just like your usual life. Then the third question we want to answer is, can we actually scale up both the Superb Owl service and the backend. It turns out that we ran into some trouble. Here, you see that when you have services in the same AWS ECS cluster, and when you try to scale up all of them, AWS is actually doing some maybe like bin packing problems and trying to figure out the optimal solution, or some good solutions. In reality, what we observed was that when we placed the Superb Owl service in the same cluster as the backend, it has to wait in a virtual queue. It has to wait for all the other backend services to scale up so that it can scale up, or vice versa. That’s not really the scenario we want to see happening, because we don’t want to see our backend services waiting, because our notification service is scaling up. We don’t want our notification service not being able to scale up because backend is trying to consume more resources. We gave it a dedicated ECS cluster, so that it got rid of that queue. Last but not least, we want to ensure that we can scale up both the backend and the Superb Owl service in less than 3 hours, so that we don’t have to waste money to have this service running around, maybe days before the Super Bowl. We did that. We tested. It works.
We move on to test on real users. I said that, we don’t want to leak the creatives of Duo’s Butt to our users. I never said that we couldn’t test on real users. Actually, we tried to test in plain sight using our new notification system. In October, we tested on 1 million users using a Halloween theme notification. In November, it was like a year in review theme notification. In January, we tested down 4 million users with a welcome back from New Year message. This is all us testing in plain sight without leaking the creative. One of our internal tools called Zombie mode really helped us in this process. Zombie mode is essentially a mode that we created so that when we turn it on, the user’s device will stop making the requests to the backend for a certain amount of time until it tried to check that flag again. It helped us in the scenarios where backend cannot handle a surge in traffic, and it needed time to recover. Thanks to that mode, we were actually more comfortable with testing with real users, because we know that we wouldn’t have extended periods of outages. One of our lessons learned here is to always actually send yourself a copy before sending it to the user, because you never know in what way your internal representation of the message can leak out to the user. You never want that to happen.
Last but not least, we tested within our microservice architecture. Here are some of the things that we saw in that IEM, Infrastructure Event Management document. The first thing that we considered was, is our memcache, Redis hitting connection limit, or can we use a proxy for some of the tables that we have? This is actually a real thing that we did. One of our services was having problems scaling up past 400H tasks because it was hitting the connection limit. It wasn’t really a priority to address, so people put it off. Until this point, you really need to scale up, so what we did was we put a proxy behind the datastore. It actually can scale up to however many tasks you want. Problem solved. Second problem is, will our DynamoDB throttle? DynamoDB claims to be infinitely scalable, but some of you may know that it doesn’t handle the spiky traffic really well, especially if you’re provisioning your resources. We considered, should we switch some of these tables to on-demand briefly, or should we overprovision it to a point that it wouldn’t throttle even with a spike in traffic? The last two are the things that we considered, but we actually never addressed, but I thought it would be relevant to mention here. One of the things that we considered was whether our retry policy was reasonable. Because you can see, we have so many microservices, and when one microservice call the other it might retry three times, and the other call the third one, three times, and it goes on forever, and it grows exponentially. You don’t want that to happen. Last but not least, we know that we are going to request a certain subset of our users. Maybe we could have cached some of their user data that we know that are going to be requested. Because of time limit of this project, we obviously didn’t get into the detail of all that. We got to a point where we were happy.
On the day of the Super Bowl, we have a pretty well written playbook. We have engineers on Zoom really carefully watching everything, scaling things up. We have marketers potentially at their TV, holding popcorns. That’s how I imagined what they’re doing. We have a square go button. Some of you might ask, why isn’t it round? I might explain it to you just a bit later. When Super Bowl starts, everybody was watching. We were watching for different reasons. Our marketers were waiting anxiously for the ad to show up. It didn’t show up for 20 minutes when it was supposed to. When it finally did, two marketers clicked on that square button, and one message went out. The campaign results were actually wonderful. Ninety-nine percent of notifications were out in 5.7 seconds, 95% in 3.9 seconds. There was a Figma blog post written about it. There’s also a Wall Street Journal on our Super Bowl campaign. I think someone on Twitter or X actually posted about our notification campaign as well.
What We Learned, and What Would We Do Differently?
It’s time to move on and talk about what we learned and what we would have done differently in this project. Some of the mistakes we wish we had avoided, relates back to the very fundamentals. We started out this project using Python. It turns out, it actually gave us a ton of performance bottlenecks. We thought about using Async Python. We tried it. It didn’t really work with the tooling that we had. Actually, we didn’t end up trying because at the time, our original notification stack was built in Python. We don’t want to reinvent all the technology, all the authentications, the connections that we establish with the outside APIs. We stopped there because we wouldn’t have enough time to test. Actually, one month after the project, my manager came out to me and said, have you seen this HackerNoon article from 2019 that says, “Using Go to build a system that sends millions of notifications within a few seconds?” I was like, that’s interesting. I wish I had read that article. It could have given us a lot more inspiration and lessons. That also uses Go, which is a completely different stack than what we used at Duolingo. That could have helped us. The second thing that we wish we had improved was to optimize memory. I told you that at the end, we want to send 6 million plus notifications. To pack all these 6 million plus device IDs and user IDs into the memory of a service, it was actually a lot. We ended up using 7 gigs of memory for each task. You may remember that we have a lot of tasks, which means that it requires a lot of cloud cost and intervention. My colleague Milo worked really hard on that, and we finally got it across. If we had time, we would have optimized memories and resource usage in general. Last but not least, we want to have better observability into the client behavior. I told you earlier that our Android app used to have a problem, when you send a notification to the app, it sends a request right back. That’s effectively DDoSing ourselves. That’s not a problem anymore, but we discovered new problems. We discovered that when someone clicks on the notification, it triggers multiple requests to the backend, that number may be 10, 20, 50. That’s not good. Because even if 5% of people click on that notification, and if that multiplier is 50, you’re effectively making two times our notification requests back. That’s a lot of requests back to your backend in a short amount of time.
Some of our lessons learned here are the following. The first one is to be open minded about the design, but be more rigorous with testing. I wouldn’t say our design was the best, it was really far from the best. We went with one of the designs that we could iterate and test on. We know that testing will be the core of this project. Because, as long as you can test it, you can make sure that the system works the way that it’s intended. The second lesson learned is to always build the system with resilience and robustness. As we just mentioned, multiple marketers can press the same button at the same time. You don’t want duplicate messages to go out to your users. This is just one example of the things that you should take care of when you design a system like this. The third thing is, things can always go wrong, so accept it. I’m not really saying to do nothing about it. Actually, we took a rather active approach. We wrote a very detailed handbook to tell engineers on that day what you should do on the exact time of the day. Also, it included backup plans. What if this A thing fails? What if this B thing fails? We even have a backup plan for the whole notification not going out. What should we do then? I think what we are saying here is to face it with a more active attitude.
Questions and Answers
Participant 1: I was curious about the number of instances in your ECS cluster, and if you guys try to vary that number or do some tests. Was it fixed at 5k as the max amount for the ECS cluster?
Zhou: We did experiment with different instance sizes, and everything. One of the things that we could have done better was to optimize memory. At the end, we were bounded by memory, because we tried to store all this information in memory. That led us in the decision of how we decided to select the instance types, which ended up being memory intensive instance types. Five thousand, I think is just one of the numbers that we were comfortable with that makes sure that we can send out notifications that fast. There could be a limit, but I think it’s mostly handled by my colleague with some negotiation with AWS.
Participant 2: When we talk about workloads that need to scale very rapidly and are very occasional, my mind goes to serverless. I’m curious, did you consider maybe using AWS lambdas for some of the workloads instead of looking heavily into your container cluster, and what was the role of serverless in general?
Zhou: I think that was definitely one of the suggestions that was being made early on in the project. I think someone suggested this to me and promised me, like even if it’s lambda, it can also basically pre-spin up all the things under the hood, and you know you’re going to get all these resources. At the time we just felt safer working with all the existing containers and the ECS services. I think, without seeing the machines spin up for you, it still puts us into the area of like, we’re going to be more concerned whether this is going to work or not. This is definitely valid, because this is basically like a one-shot operation and you pay for what you do. It would make sense in another scenario, if we could test it to use lambda.
Participant 3: Did your team worry about whether FCM or APNS was going to handle the load, or freak out? Did you have to reach out to anyone to make sure that that didn’t happen?
Zhou: Basically, the question was about whether we’re concerned that we’re going to get rate limited or throttled by FCM or APNS.
Yes, we were concerned. Also, at the very early stage of the project, we took initiative and we reached out, we asked some of our business people to reach out to the Google and Apple’s reps to understand whether we are going to get rate limited or not. We only actually green flagged most of these after we knew that it’s not going to get rate limited.
Participant 4: I’m curious about how you folks approach testing, because you talked a little bit about the cost. How many times do you have to actually keep testing that, and then actually multiplying the cost versus the time that you have to do testing? A little bit about how you approach the problem, testing times cost.
Zhou: Our philosophy was that, at least we want to minimize the risk. The costs in tests are relatively smaller, compared with the cost of the system not working at all, first of all. Also, we try to leverage the system as much as we can when we test on real users. As you can see, we tested on millions of real users in actual campaigns. In those campaigns, we would have spent the money anyway. That was basically no cost for that test. On top of that, we did run multiple cloud tests, basically, to try to scale up the infrastructure only, and not try to send anything. I think it’s worth it to do maybe 3, 5, or even 10 times, until you’re at the point that you’re comfortable with the system’s ability to scale up, because it’s actually our first Super Bowl campaign, and we don’t want to mess it up. We want to be as much risk averse as possible here. Cost is a little less of a factor if you’re considering we are already spending on the Super Bowl ad.
Participant 5: As the Super Bowl is a very popular event, were there any concerns about capacity not being available when you wanted to scale up because this was such a high spike usage?
Zhou: Absolutely. I think this is definitely something that we talked with our AWS representative. This is something we definitely raised early on, whether we are going to have enough memory, whether we are going to have enough resource allocation for us. That’s definitely something that you would have to discuss when you anticipate that your program is either compute or memory intensive.
Participant 6: For this project, I know you have to do a lot of scaling. Was there any strategy around optimization for the service itself? Did you use any specific tools for that?
Zhou: I think we are not known for performance as a language learning company, as you may tell. In this project we mainly focused on getting it to a point where we can send notifications that fast. The way that we tested was actually just pretty simple. We logged some of the process times to CloudWatch. We would process those logs afterwards and see how much time it takes for each function or each step to execute, and figure out the bottlenecks and speed them up. I think there are definitely more performance frameworks out there that we could leverage. With the constraints of this project, we didn’t go with all that. Definitely it’s a good question and concern. If we were to do this again, we’d definitely do it right.
I asked my colleague, JP, to initially make a big red button, make a round button. Later, actually, a marketer discovered that when you click on the corners of the button, which appears to be white, but it actually will trigger the same function as the square. You would call it, in video games terms, like the hitbox is still a square. That’s not good. As much as we want to avoid human errors, we definitely want to avoid that, so we made it a square, so everybody knows what they’re doing.
See more presentations with transcripts