Month: September 2024

MMS • RSS

Each week, we screen the US-listed stocks under Morningstar’s coverage for newly undervalued names.
For the week ended Sept. 27, three stocks dropped into undervalued territory, meaning their Morningstar Ratings changed to 4 or 5 stars. Stocks rated 3 stars are fairly valued according to Morningstar analysts, while those rated 1 or 2 stars are considered overvalued.
The three newly undervalued stocks, ordered by market cap, are:
All data in this article is sourced from Morningstar Direct.
New 4-Star Stocks for the Week Ended Sept. 27
The Morningstar US Market Index rose 0.62% over the past week, leaving the overall US stock market moderately overvalued, hovering at a 7% premium to its fair value estimate on a cap-weighted basis.
Of the 880 US-listed stocks covered by Morningstar analysts:
- 31% are undervalued, 43% are fairly valued, and 26% are overvalued.
- Three are newly undervalued.
- 16 are newly overvalued.
- None moved from a 4-star rating to a 5-star rating.
- 10 moved from a 5-star rating to a 4-star rating.
- 21 are no longer undervalued.
Morningstar analysts assign every stock under their coverage a fair value estimate, which is an intrinsic measure of its worth, and an uncertainty rating, which captures the range of potential outcomes for that estimate. A higher uncertainty rating equates to a larger range of prices considered fair. These two metrics and the stock’s price determine its Morningstar Rating.
Metrics for this Week’s New 4-Star Stocks
Mizuho Financial Group
- Morningstar Rating: 4 stars
- One-Week Return: -3.84%
Regional bank Mizuho Financial has dropped 2.67% over the past three months and climbed 16.83% over the past year. The stock trades at a 13% discount to its fair value estimate of $4.61, with a medium uncertainty rating. Mizuho Financial is a large-value company with no economic moat.
IQVIA
- Morningstar Rating: 4 stars
- One-Week Return: -3.03%
Diagnostics and research firm IQVIA is up 10.36% over the past three months and 16.11% over the past year. The stock’s price is 12% below its fair value estimate of $268, with a medium uncertainty rating. The mid-core stock has a narrow economic moat.
MongoDB
- Morningstar Rating: 4 stars
- One-Week Return: -3.20%
Software infrastructure firm MongoDB has climbed 10.40% over the past three months and dropped 17.87% over the past year. The stock is trading at an 18% discount to its fair value estimate of $330, with a high uncertainty rating. MongoDB is a mid-growth company with no economic moat.
This article was generated with the help of automation and reviewed by Morningstar editors.
Learn more about Morningstar’s use of automation.
BUSINESSNEXT and MongoDB Team Up to Accelerate Autonomous Operations … – Fintech Finance
MMS • RSS

BUSINESSNEXT, a global leader in composable enterprise solutions for financial services, has partnered with MongoDB to accelerate autonomous operations powered with specialized predictive and generative AI for banking and insurance. Headquartered in New York, MongoDB empowers innovators to create, transform, and disrupt industries with the power of software and data.
The collaboration between BUSINESSNEXT and MongoDB will empower banking and financial services with the technology needed to deliver exceptional customer experiences and drive autonomous operations.
By combining BUSINESSNEXT’s deep expertise in financial services with MongoDB’s flexible, scalable database platform that has industry-leading encryption, access controls, and data protection protocols, the partnership will deliver innovative solutions that address the evolving needs of the industry. BUSINESSNEXT’s suite of solutions to drive autonomous banking includes real-time AI at the core powering modern CRM, digital journeys, lending platforms, risk-rating platforms, workforce assistants, customer chatbots and more.
MongoDB’s document-oriented data model, with its flexible schema, nicely complements BUSINESSNEXT’s AI-driven capabilities. The partnership will enable banks to harness the power of their data to create personalized customer journeys, optimize lending processes, and make data-driven decisions.
“We are excited to partner with MongoDB to deliver cutting-edge solutions to our financial services clients,” said Sushil Tyagi, Executive Director at BUSINESSNEXT. “MongoDB’s industry-leading data protection protocols and our ability to handle complex data structures and scale effortlessly aligns with our vision of providing a modern, agile platform for banks.”
“Independent software vendors are an integral part of the enterprise software stack in India, and BUSINESSNEXT is a great example of the kind of ISV we want to work with,” said Sachin Chawla, Vice President, India and South Asia at MongoDB. “This partnership will help a large number of financial services organizations to accelerate their modernization initiatives and use AI to drive differentiation,” added Chawla.
Key benefits of the partnership include:
- Autonomous Banking operations
- Enhanced customer experiences
- Accelerated lending processes
- Improved operational efficiency
- Strengthened risk management
This partnership marks a significant milestone for both BUSINESSNEXT and MongoDB, and it is expected to drive significant value for financial institutions worldwide.
MMS • RSS

BUSINESSNEXT, a global enabler of composable enterprise solutions for financial services, has partnered with MongoDB to support autonomous operations enhanced with predictive and generative AI for banking as well as insurance.
Headquartered in New York, MongoDB enables industry participants to create, transform, and enhance various industry processes with the power of software and data.
The partnership between BUSINESSNEXT and MongoDB will aim to support banking and financial services with the tech required to provide improved customer experiences and drive autonomous operations.
By combining BUSINESSNEXT’s expertise in digital financial services with MongoDB’s database platform that has encryption, access controls, and data protection protocols, the partnership will deliver solutions that address the needs of the industry.
BUSINESSNEXT’s solutions are focused on driving autonomous banking and reportedly include real-time AI at the core powering CRM, digital journeys, lending platforms, risk-rating platforms, workforce assistants, customer chatbots.
MongoDB’s document-oriented data model, with its schema, complements BUSINESSNEXT’s AI-driven capabilities.
The partnership will enable banks to tap the power of their data to support personalized customer journeys, enhance lending processes, and carry out data-driven decisions.
Sushil Tyagi, Executive Director at BUSINESSNEXT said that MongoDB’s data protection protocols and their ability to handle data structures and scale aligns with their vision of providing an agile platform for banks.
Sachin Chawla, Vice President, India and South Asia at MongoDB explained that independent software vendors are a key part of the enterprise software stack in India,
He added that this partnership will help financial services organizations to accelerate their modernization initiatives and use AI to drive differentiation.
Key benefits of the partnership include:
- Autonomous Banking operations
- Enhanced customer experiences
- Accelerated lending processes
- Improved operational efficiency
- Strengthened risk management
This partnership is said to mark a key milestone for BUSINESSNEXT and MongoDB, and it is expected to drive considerable value for financial institutions globally.
MMS • InfoQ

Platform engineering has become a hot topic over the last several years. Although Netflix, Spotify, and Google may have led the way by focusing on building platforms, creating “golden paths” and cultivating developer experience over the last decade, many organisations are now intentionally building internal developer platforms to follow suite. The need to deliver software with speed, safety, and efficiency has driven the rise of platforms designed “as a product” with the internal customer, the developer, front and centre.
In this InfoQ emag, we aim to inspire and guide platform engineers into building effective platforms and delivering exceptional developer experience.
Free download
MMS • Supratip Banerjee Soumyadip Chowdhury Ana Medina Uma Mukkara

Transcript
Losio: In this session, we’ll chat about resilience and more so chaos engineering in what we call a Kubernetes world.
Just a couple of words about the topic, what resilience and chaos engineering means in a Kubernetes world. Chaos engineering is not something new. Has been popular for many years, but container orchestration presents specific challenges. For example, we brought together experts: expert positions, five different ones from different backgrounds, different industries, different continents, to understand and to discuss together what’s the best practice for chaos engineering and chaos testing.
My name is Renato Losio. I’m a cloud architect. Chaos engineering is a topic I’m super interested in, but it’s not my area. I’m really keen to listen to the amazing panelists we have to know more about this topic. I’m an editor here at InfoQ. We are joined by five experts coming from different industries, different companies, different backgrounds.
Medina: My name is Ana Margarita Medina. I’m a Senior Staff Developer Advocate with ServiceNow Cloud Observability, formerly known as Lightstep. I got started in the topic of chaos engineering in 2016. I had the pleasure of working at Uber as a site reliability engineer, and I got a chance to work on the tooling that they had for chaos engineering, being on-call, maintaining it, and educating folks on how to use that. Then I went on to work for a chaos engineering vendor for four years, Gremlin. Getting folks started with chaos engineering, giving them material, getting them their first chaos game days and stuff like that, which was a lot of fun. Now I focus more on the world of observability, but it’s always really nice to stay close to the world of reliability and tell folks like, you got to validate things with something like chaos engineering.
Banerjee: This is Supratip Banerjee. I work currently with EXFO as a senior architect. I have around two decades of industry experience. My specializations are around designing large scale and enterprise applications, DevOps ecosystem, cloud computing. I’m also an AWS Community Builder. I love exploring new technologies and tools. I came across chaos engineering in one of my previous employer, I was facing downtime issues with cloud based and also on-premise applications. I was looking for tools and technologies for resilience, which is one of the very important non-functional requirements. There I got introduced to chaos engineering concept. Afterwards, I tried Chaos Monkey, Chaos Toolkit, AWS FIS, all these different tools to take care of that.
Mukkara: I work as the head of chaos engineering at Harness. I came to Harness through the acquisition of my company, ChaosNative, which I created to build an enterprise version of LitmusChaos. That was my entry into the world of chaos engineering back in 2017. We were trying to test the resilience of some of the storage products, especially in Kubernetes. That was something new at that time, how to test the resilience of Kubernetes workloads. I ended up creating a new tool called LitmusChaos, and then open sourcing it, donating it to CNCF. Now it’s in incubating level. It’s been about 6 to 7 years of a journey in the world of chaos engineering, still learning from the large enterprises on what are the real challenges in adopting scaling. Really get something out of chaos engineering at the end of the day.
Losio: I’m sure we’ll come back to open-source tools we can use to address all the challenges we’re going to discuss.
Roa: I am Yury Niño. I work as application and monetization engineer in Google Cloud. About my professional journey. I have a bachelor’s in systems engineering, a master’s in computer science. I have worked as a software engineer, solutions architect, and SRE for probably 12 years. My first discovery of chaos engineering was 8 years ago. When I was working as a software engineer at Scotiabank. I had a challenge with resilience and the performance of [inaudible 00:07:08] that is a common architecture in our banks in Colombia. That was deployed in an on-premise infrastructure, and I used a circuit breaker to solve it. Chaos engineering was key in the process. I discovered chaos engineering at this moment. Since that moment, I have been involved in many initiatives related to that in my country, and in other places. Since I am a professor also at a university in Colombia, I’ve been researching how chaos engineering, human factors, and observability could be useful in solving challenging issues with the performance and reliability of the applications.
Chowdhury: My name is Soumyadip. I’m currently working in Red Hat for the last three years. I’m working in Red Hat as a senior software engineer. I mostly work on the backend cloud native, Kubernetes, and Open Shift. I came to know about chaos engineering for one requirement of our project, like to test the resilience of the microservices, what can be the hypothesis of the system. Then I explored few other tools, like Chaos Monkey, Chaos Mesh. I think Chaos Mesh is now a CNCF project. I have used that tool to build the ecosystem. There are a few other tools that I was also exploring, like Kraken and all. This is how I started my chaos journey. It’s been three years in the chaos domain. Yes, still learning.
What is Chaos Engineering?
Losio: I think I heard already a few words that are coming multiple times from tools that have been used, Chaos Monkey, and whatever else. We would like to focus first on Kubernetes and what the specific challenges are in the Kubernetes world for chaos engineering. Just maybe, if anyone of you wants to give a couple of words first, what we mean by chaos engineering, what we don’t mean by chaos engineering, because I heard so many definitions. I’ve brought myself to define it. Do you want to give just a very short intro, what we mean, usually, by chaos engineering, without really focusing on the topic?
Mukkara: I’ll probably just start by saying what is not a real chaos engineering, that automatically cause what’s chaos engineering. Chaos engineering is not just introducing faults. Chaos engineering is really about introducing faults and observing the system against your expectations. You need to know, define the steady state hypothesis, or what it means for the system to be resilient. Once you have a clear definition of it, then you start breaking the system or introducing some faults into the system, and start scoring against your expectation. Then start noting down your observations. Then use them however you want. Use them to take a decision, whether I move my deployment from left to right, or just create a bug and then stop everything or give some feedback. You can use it in many ways, but chaos engineering is really about introducing faults and observing against your expectations. That’s really what it is.
Medina: It’s very much doing the fault injection, but in a very thoughtful manner. You don’t really want to be doing it in a random way, without communicating or anything like that. I think that’s one of the biggest misconceptions sometimes. Of course, when you observe it, that’s probably one of the best bets you can have. You want to know what the baseline of your system is, and you want to see how the chaos affects it as it goes on. Some folks forget that little part of like, it goes through the entire process of seeing how it would actually be like in a real-life system.
Common Pitfalls in Chaos Engineering
Losio: Before going really deep in which tools, which technology, and how to really address in the Kubernetes world, I had one more question I’m really interested in. What are the common pitfalls developers should be aware of when dealing with chaos engineering? Until now, we say what we mean by chaos engineering, it’s like, for someone like myself that I’m familiar with the topic, but I’ve never really put myself into it. I’ve never played with Kubernetes and chaos engineering. What are common pitfalls we should really be aware of?
Roa: I would like to clarify that that is precisely a difference between chaos engineering and classic testing, that in that case, we have the possibility to observe the results and providing a resilience strategy.
Regarding the pitfalls, in my journey, I have made a lot of mistakes with chaos engineering. I could summarize them in three things, inadequate planning and preparation, because that is really important to have the proper tools and to have the steady state in your systems, and to have observability, of course. The first one is inadequate planning and preparation. The second one is starting with unrealistic or complex experiments. In my experience, it’s better to start with simple experiments, probably manual scripts or another strategy, but as you progress, provide more complex or more sophisticated tools. Third, misunderstanding the results. That is the reason that you need observability here, because that is really important to understand the results you are getting with the experiments. Regarding planning, I have seen that the lack of clear objectives, insufficient monitoring and observability, and neglected communication and collaboration, for the real chaos, form the perfect recipe for failure. Another pitfall includes ignoring negative results, not iterating or not improving, for example. I think that, in my experience, they are the common pitfalls I have seen in my implementation with other customers.
Banerjee: I just wanted to highlight a little bit on the clear objective part. I would actually tell the developers, or whoever is actually strategizing it, to first understand the business need. Whether it is the application or something else. There are different ways to understand what the customer or the business is needing. There are customer contracts available or SLAs, or SLOs, service level agreement, service level objectives. These documents are available where it is clearly mentioned by the customer, how much availability is expected out of the service provider. Maybe it’s 99% or maybe it’s 99.5%. We know from there, this is the first stage. We know that a 0.5% or 1% of downtime is probably ok, although it is not.
As per the contract, it is ok. Then from there, we can take the next step of understanding the customer more better, whether the customer gets frustrated or if they are ok with a little bit of downtime. Then we can step into the application. We can have a high-level understanding of what that downtime means to that customer, whether it means loss of a lot of millions or loss of reputation for that customer. That is understanding the objective. Then, go to the next step of being into the technical, like understanding the baseline metrics, and planning it properly, going before to production, maybe do it in QA environment.
Chowdhury: When we start as a developer, when we get the task to install some chaos thing in our cloud native, in our domain. Every time, if you start with a small component, let’s say we have 10 microservices, our goal is that without measuring what can be the call, without measuring the boundaries, we just inject the fault in most of the system. There can be a scenario where we may arise into less hypothesis or less analysis, like we are breaking everything at once. We should be very cautious, or very meaningful when we are injecting something in some system. What can be the consequences? Otherwise, in the normal time, like in the normal life, what we do in normal testing, it will be just like that. It may violate some key area. In chaos engineering, we get all those metrics, all the hypothesis for a specific microservice or a specific application. Those things might get violated when we start testing the entire system rather than going for one-by-one component.
Examples When Chaos Engineering Saved the Day
Losio: We just mentioned the importance for a company of maintaining a certain level of SLO and whatever. Apart from very famous ones, in your experience, what are examples that can help an attendee to understand, that usually, when I use a new tool, I want an example of, that company managed to save their infrastructure. Example about how really chaos engineering revealed a significant vulnerability or led to unexpected outcomes in a deployment. A Kubernetes one would be lovely, but not necessarily.
Mukkara: I’ll actually take an example of Kubernetes. That’s the topic here. Kubernetes chaos scenarios are slightly different, sometimes a lot different, compared to the traditional chaos engineering. For everyone who are not practicing chaos engineering in the recent times, chaos engineering is about Chaos Monkey, large systems breaking some of the deep infrastructures, and see the performance staying live. That’s the old method. Why chaos engineering is quite important in the recent times, is the way Kubernetes is designed, and the cloud native workloads operate. Kubernetes is a horizontally scalable, distributed system. Developers are at the center of building and maintaining it.
One example that I have seen, very early days, is an example of what can happen to your large deployment when a pod is deleted. Pod deletes are very common. Developers, yes, pods are always getting deleted. What happened in one of the early days was, on a hyperscaler system, you have autoscale enabled, which really means that when the traffic is coming in, you need more resources, spin up the nodes. If the system is not configured, and when a pod got deleted because of whatever reason, there are multiple reasons why a pod can get deleted. Pod got deleted, traffic is coming in. You need more resources, so a new node is fun. That was just not enough. Then we saw a system where a pod is deleted, and then tens, sometimes it went all the way to 100 nodes being spun just because one pod got deleted. That was a resilience issue, and the traffic was not being served.
What exactly happened in that system is these readiness probes were not configured. It’s a simple configuration issue. The system is thinking that the pod is there, but it’s not ready, so I need to get more pods, and the traffic is still coming in. I need to serve the traffic, so autoscaler is enabled. On one side, your system is not ready. On the other side, you are paying for 100 nodes. It’s a loss on both the sides. Having this kind of test for a developer, not assuming that it’s a code that can cause a problem, it can be a configuration that can cause a major problem as well. Developers have to keep an eye on how is my deployment going to be configured. Can I write some tests around misconfigurations around deployment, and then add chaos test on top of it, can make your solution really sturdy. There’s a saying in Kubernetes, build once and run it anywhere. Run it anywhere, you need to really test it. What can go wrong when run somewhere else? These are some of the examples. Chaos testing can really add value for most common cases as well.
Losio: Do you want to add anything specific? Do you have any suggestion to share or common example where basically chaos testing in a Kubernetes deployment can raise some vulnerability?
Roa: In my experience, for example, with e-commerce applications deployed on clusters, chaos engineering has been key in the identification of vulnerabilities. As Uma mentioned, these types of architectures need resilience all the time. It seems there are a lot of components that conforms the architectures. We have challenges related to, for example, unique failure points, or even providing observability. I see architectures based on microservice and Kubernetes all the time, and in these cases, customers implement patterns like retries and circuit breakers for providing resilience, which not always work well. Although the literature and the theory is clear about these patterns, in practice, we have a lot of issues with the implementations. I think to have tools and methodologies related to chaos engineering and related with testing on the infrastructure is key to test these patterns and to provide the proper solutions for that.
On the other side, I really value that chaos engineering provide the knowledge about the architecture that is useful for writing, for example, playbooks or runbooks for our operations engineers. I would like to mention that related to the value of the chaos engineering and tools like Litmus, Gremlin, and other tools in the market providing resilience for that. Specifically, an example, I remember I had an issue with an Envoy in an Apigee architecture in the past with our customer, and because the Envoy was creating a unique failure point, and we use chaos engineering for bombarding the services with a lot of requests, overcoming the system and causing a simulating failure. With the collected information, with the observability provided by this exercise, we were able to determine the configuration parameters for the circuit breakers and the components in the resilience architecture.
Losio: Anyone else wants to share examples that they had from real-life scenarios?
Medina: I had actually a few with doing chaos engineering Kubernetes, where you actually ended up finding out data loss would happen. One of the main ones that I vaguely remember was doing an implementation of Redis, just straight out of the box, where you were having through your primary database, and then you were also having your secondary pod. Just the way that you look at the architecture, you were pretty much like, with a hypothesis of no matter what happens to my primary pod, I’m still going to have complete consistency. We did a shutdown chaos engineering experiment on primary and all of a sudden you see that your secondary pause shows that the database is completely empty. This was just a straight out of the box configuration that documentation said it was going to be reliable.
When you look under the hood, like with observability and more debugging, you were noticing that you had your primary pod have the data, and then as it shuts down, secondary looks at primary and says, that’s becoming empty. I’m going to become empty too. All of a sudden you have a complete data loss. We ended up learning that there was a lot more configuration that you need to do with Redis, setting up Redis Sentinel in order for it to not have issues like that. You wouldn’t necessarily know that until you go ahead and you run an experiment like this, where it could be just a simple of what happens if my pod goes missing.
Unique Challenges of Chaos Engineering in a Kubernetes Environment
Losio: I was thinking, as a developer, what are the unique challenges of chaos engineering in a Kubernetes environment? Let’s say that I’m coming as experienced from a Chaos Monkey scenario, an autoscaling of EC2 instances. I’m now moving everything to Kubernetes. What’s unique, what’s different assuming that I’ve already a previous experience in chaos engineering?
Banerjee: I think Kubernetes acts in a very strong and intelligent way, and it has different functionalities. The resilience is very strong there. They have dynamic and ephemeral infrastructure. If a pod is going down, Kubernetes, it’s scheduled. They automatically restore it, and that gives us the chaos testing problem. Like Uma just mentioned that observability is very important. We do test and then we try to understand how the system is behaving. Kubernetes is very fast in that way, and it is difficult to understand how much impact that failure had, because just an example, that pod got quickly restored. That is one. Another example can be, microservices have very complex communication system. One microservice is calling another, and that is probably calling two more. The problem is, it has a very complex interdependence, and if one service fails, that can cascade to another in a very unpredictable way.
Again, which makes it very difficult to understand the impact of chaos testing. Another example would be the autoscaling, like you were mentioning, self-healing, all this mechanism that Kubernetes has. Kubernetes tend to scale if a number of APIs is getting called. For example, if it goes high, it will scale up a lot immediately, or it will scale down as well, based on the requirement of the API that is being called. It is very difficult to observe or understand how chaos testing is actually performing. These are some of the examples.
Chowdhury: I just want to add one thing that I have personally faced from my experience that like, let’s say, we have multiple environments, let’s say QA, Dev, stage, and prod. There are multiple different configurations, there are multiple workloads, there are different types of deployments. Somewhere we are going for multi-tenant solution. Somewhere we don’t have that because of resource limitations. The thing we have faced that, let’s say, how your chaos is performing in your staging environment, it’s not like your production environment. The hypothesis we are coming into, the analysis we are doing from the stage environment, or QA environment, that will not be 100% similar to the production environment. It might be complete opposite. It might be somewhere near to that. These are some limitations of chaos.
Mukkara: The difference in Kubernetes in my observation, compared to the legacy systems. When there is a change in a legacy system, it’s local. You go and test that local system, but in Kubernetes, Kubernetes itself is changing all the time. There is an upgrade that happened to the Kubernetes system, so you have to assume that I’m affected as an application. The question becomes, what test to run, and the number of tests that you end up running is almost whatever you have. I see that the number of chaos tests that you run for a Kubernetes upgrade is vastly different on Kubernetes versus a legacy system. That’s one change that we’ve been observing. A lot of resilience coverage needs to be given on Kubernetes. Don’t assume that a certain system is not affected. It may be affected. Kubernetes is complex.
Designing Meaningful Chaos Experiments
Losio: We just mentioned the challenges of Kubernetes itself, the challenges as well to try to run tests that are for different scenarios, dev, staging, production, and different hypotheses and different expectations. One thing that I always wonder, and that’s not specific just to Kubernetes, but in general, I think, is when designing chaos experiments, what are the factors you should consider to ensure that the tests are actually meaningful in the sense that they reflect your real-world scenario? Because it’s a bit the problem I have as well sometime when I build any kind of test. How do I make sure that what I’m doing is being a scenario? I’m thinking as well, maybe because I’m quite new in the Kubernetes world, I wonder how can you address that? I can write my list of tests, my test scenario that I want to check. How can I make sure that these are meaningful somehow, and they make sense, that I’m not just writing random tests and covering scenario. What are the challenges in chaos engineering in that sense?
Roa: The challenges related to that? I think, the dynamic nature of architectures. For example, in Kubernetes, we constantly change the pods, as Ana mentioned, being a scheduler was terminated. This dynamic represents a first challenge related to the nature of the architectures. Dynamic distributed systems, as Supratip mentioned, that Kubernetes applications are often composed by multiple microservices, spread across different nodes on clusters. The real scenarios, there are a lot of components connected, sending messages. That is really challenging because, for example, we have to test with chaos engineering. We have the possibility to inject a failure in a machine or in a node or in a database. When you have to test all architecture, for me, that is the first challenge. The complex interactions also, because Kubernetes involves numerous components, like post services, as I just mentioned. Injecting failures into a specific context can have cascading effects. That is the importance of observability, considering the cascading effects of other components, that is difficult to understand what happens in these specific points.
Finally, I think the ephemeral resources, because in Kubernetes, the resources are designed for being ephemeral, meaning that the clusters create and recreate infrastructure when you have, for example, an overload with the workload in the cloud, for example. It’s really difficult to test that, because you have to provide that test in a specific context. After an overload, you have another infrastructure and a new infrastructure recreated, since, above that. I think those are the challenges, and that they are things that you have to consider if you want to run chaos engineering in a real environment. In Google, we use disaster recovery testing. That is a practice similar to chaos engineering. In my other experiments in the university, for example, I have to create simulated exercises. That is, for me, the most challenging things to try to simulate these interactions and this dynamic in real scenarios.
Losio: What are the factors you consider to ensure that your tests are beautiful?
Banerjee: Be very careful while testing it on production. Understand the impact. It’s very important. Otherwise, you may just break the application that the live users are using. To understand it, we need to do few things like, we have to understand the relationship also between the infrastructure that we have. We have to start very small, not go a huge way and break everything. We also need to observe and document and analyze those results, so we know what is happening, observability, like everyone is saying. Then go to the next iteration and try to improve from there.
Simulating I/O Faults in K8s
Losio: Yury just mentioned about injecting types of fault simulation. Particularly, she mentioned as well the topic of I/O and ephemeral I/O. How can you simulate I/O faults on Kubernetes when playing with chaos engineering? Is it something you can do?
Chowdhury: In one of our architectures, we had some SSE, server-side events in place. That was basically our SOT, our source of truth. Once we started with injecting chaos in that main component, we had an operator in place. We didn’t expect that it will cost breaking few other microservices as well. It ended up breaking a lot of microservices. You are not sure every time, because SSE is something very lightweight and very not resourced, and we didn’t even assume that it could go to that extent where it will break the entire system. We have taken the measure for the Mongo or all the database things, but we didn’t think in terms of SSE, because once you crash any pod, you have to establish that request with another pod.
If that pod is not getting started, then whatever pods we have which is associated with the source of truth, or the operator, where we have the producer of the SSE, so that connection is not getting started. That’s why it ended up breaking all the microservices which was consuming that SSE, in the I/O input. This is something that I have faced where your connection is not getting triggered every time. If that’s a long pulling or that’s a constant connection, then it might be difficult scenarios for the users.
Where to Start, with Chaos Engineering
Losio: I would like to talk from the point of view of a software developer. I have my Kubernetes, whatever, on a cloud provider, using EKS or whatever else, on AWS, or Microsoft, or Google. I’m new to chaos tests. I want to start from scratch. In some way, I’m lucky I don’t have to manage anything. Before, we mentioned, maybe we want to start small. We want to start with breaking up our iterative approach, where we start not taking the biggest one. Is there any tool, anything I can use, open source, not open source? If I go out of this call and I want to start, where should I start? I haven’t done chaos engineering before, and that’s my Kubernetes life.
Medina: I think one of the first things that I would ask is very much of like, what budget and support do you have? Because some of it comes where it’s like, you have no budget. You’re doing this as a person of one, where it’s very much of like, you might need to go out into open-source tools. From open-source tools, we’ve mentioned LitmusChaos. We’ve mentioned Chaos Mesh. Those are the two that I’m most familiar with. Folks can get started with that if you’re in a non-Kubernetes environment. There’s concepts of Chaos Monkey, where you can just do things manually. Yury mentioned circuit breakers.
Coming from a place where I’ve worked with vendors, I also really like where vendors really provide you a lot of education, a lot of handholding, as you’re getting started with chaos engineering. Something like Harness, something like Gremlin, where folks are able to have a suite of tests that they can actually get started with, really is helpful. From there, of course, it really much varies into what type of environments you can have. Starting out with something like just doing some resource limits.
Losio: I was thinking really more as a developer, starting from scratch. I fully understand that we have a very different scenario. If you are in an enterprise, I’m probably not going to do it alone, and I probably need some support and training as well.
I/O Faults
Mukkara: I/O faults are definitely not easy, in two things. One is, you won’t get permission to introduce an I/O fault because you’re not the owner of, most likely the application and infrastructure as well. I/O faults are important, and those are the ones that cause the maximum damage, usually. For example, a database is not coming up on the other side, or database is corrupted, or disaster recovery is not working as expected, not coming up in time. Migrations are not happening. There are so many scenarios you want to test using these faults. One way is to follow the receiving side of the data. You have a database, and I am the consumer of the data, and then the data comes through your file system on your node. Database exists elsewhere, but it has to come through your file system, so there are faults available, such as, make the file attribute read only.
Database is all good, but still on your file system, you can mark it as read only. Then the volume that’s mounted on the database becomes read only. Then it triggers either, move on to another node, or sometimes it can cause disaster recovery as well. There are systems, for example, Harness Chaos. It has I/O faults that many people use. When it comes to the open-source tooling, I think LitmusChaos is a good tool. Please do use it. There are free enterprise tools available as well. Just like GitHub is free for everyone, to some extent, if it’s an open-source project, whatever.
Something similar, for example, Harness has a free plan, no questions asked, all enterprise features are available. Made it super easy. The catch only is that you can use a limited number of experiment runs in a month. To get started, you have everything on your fingertips made so easy. Those are some of the choices. Chaos practice is becoming common, and it’s almost becoming a need, not an option. You see multiple vendors giving you choices. It’s not a freemium model. It’s a real free model as well. We have offered a complete free service, no questions asked, no sales page. You can just go and get everything for free for a certain number of runs in a month.
Chaos Engineering Tools
Roa: When you are starting with chaos engineering, it’s really important to consider the chaos maturity model, because I think one first thing to consider is where you are. In this case, the maturity model is important because this tool provides the criteria to determine what you need in order to progress in adopting that. In the first one, a book published by Casey Rosenthal and Nora Jones, we have a chaos maturity model. Presently, I was reviewing a chaos maturity model published by Harness. That is a really good asset to assess: if you are a beginner, you are in the middle phase, or you are in a final phase. Regarding good tools, I like Litmus, because it provides a friendly console to run a chaos exercise in your infrastructure. Also, I would like to mention that in Google, we have the custom tooling that is not open, and that is not published in the market. Considering an open-source tool, I like Litmus and Gremlin. I think Gremlin includes a free tire that includes a simple exercise, but that is interesting and that is useful for starting in this adoption.
Losio: I wanted to ask basically as well, example of a paper, book, presentation, tool, whatever that every developer should not miss.
Banerjee: I just wanted to add two more tools that I have personally used. The first one is Chaos Monkey. This is not necessarily directly related to Kubernetes, but Chaos Monkey helps. It attacks the applications that I have personally used for Spring Boot. Spring Boot is generally used to write microservices these days in modern applications. They attack microservices running Spring Boot applications, and they simulate these kinds of errors. There are public cloud managed tools as well. One I have used is AWS FIS, fault injection service. There, you can also simulate, you can write your tests and stuff, and it will make your ECS, EC2, EKS, including Kubernetes services a little shaky, so you can test them as well.
Chowdhury: There are lot of enterprise tools, there are a lot of tools that you can do. If you have less idea on chaos engineering, if you have no idea, then, as Uma just said, Litmus is a great tool. Also, you can go for the Chaos Mesh. That is very easy to use for beginners. There you will get the dashboard. There you will get the CLI support and everything. You can directly write all those scripts and run your chaos in a controlled environment. Chaos Mesh is something that you can train, and the community support is also good.
Resources and Advice on Getting Started with Chaos Testing
Losio: I’m thinking as a cloud architect, cloud developer, Kubernetes expert, or whatever, I joined this roundtable, and you convinced me that it’s super important, actually, it’s a must now to introduce chaos testing for my workloads. I cannot have my cluster anymore running as I did until today. I kept my head under the sand until now, and I haven’t really thought about that. That’s cool. I want to go out of this session, and think I can do something tomorrow, do something, this iteration, something small, where should I tackle? I’m in the scenario of not a big enterprise, I’m in the scenario of, I have my Kubernetes cluster. I want to start to do something, to learn something. It can be as well, read one article. It can be, try to inject your first fault with a bash script. If you have an advice, something that a developer can do in half a day, not the next six months.
Mukkara: Tomorrow morning, don’t be in a rush to inject a fault. First thing that you can do if you really want to add to your resilience is to spend some time on observing what could be the top four steady state hypotheses points mean. First, note them down. Second point is really the service dependencies. What are my critical services? How are they interdependent on each other? The third point is, what went wrong recently in my system? What do I think as a cloud architect, that can go wrong? Then, take a test that can cause the least blast radius, don’t try to go and cause a disaster. You will face a lot of opposition. Winning your fellow teammates to introduce the practice of chaos engineering is one of the biggest challenges. What I’ve been advocating is, don’t try to prove that there is a problem. Try to prove that there is resilience. I go and break a system, break a component, and still prove that there is resilience, like, now you can be confident. Then add more resilience scenarios. Then, in that process, you might find more support. Yes, good, 10 of them are working, 11th one is not so much. Let me go look at it.
Losio: The key message is to start small and keep your radius small, don’t try to kill the entire workload in production to prove your point.
Medina: I think one of the first things you can do, don’t go and just break things the next day. I think you need to be really thoughtful about it. I actually really like the suggestion of coming up with those hypotheses points of where to start out. If you do have a chance, try to open up a test environment where you can actually run a chaos engineering experiment. Of course, set up some observability beforehand, come up with a hypothesis to go about it. I think it’s a really great way to have a learning point of like, let me come up with a hypothesis. Let me see what happens as the chaos enters the system. Then think of ways that I can make that system better. You can try to replicate something that you have seen happen internally as an incident, or any incident that has happened in the industry.
I think that’s also one other starting point that I put, like you might not have something that you can replicate, but you can look at other companies and see what other failures they’re having. If you’re thinking of like, what type of experiment can I start with? Just killing a pod is a great way to start. You can do this with some of the open-source tools, and you can even do this by yourself without having any of the tools available. I think those are some great ways that you can really get started without having too much of an overhaul.
Chowdhury: You can start with a pod fault, you can have your own namespace, and here you can inject your faults. If you are a backend developer, or if you are a developer, then you can also focus on the stress testing, because anyway, in a conventional application, also we do the performance stress testing, then you can also go for the stress testing as well. That will also give you a better idea about the resilience of your application and how your application performs in those scenarios.
Banerjee: First, understand why you are doing chaos testing. Don’t go with a haptic knowledge. Understand the objective, why we are talking about introducing chaos. We are failing it purposely. Understand why you are doing that, and then do it. The second point would be to have a baseline metric that is very specific to your application, to your system, exactly how much CPU, how much memory, or what is the latency, or how many requests your system can bear. Once you have that metric laid out, you know where to come back to, or you know what percentage you want to break on top of it. That is very important.
Roa: Another important thing, it’s important to have metrics and things to show what is the impact of chaos engineering in the company. It is really important to analyze the past incidents and logs in my experiences, that provides, for example, analyzing incidents, logs, monitoring data. Before to start, provide the things for recently creating these metrics. If you know your infrastructure, if you know what components are causing pains for your business, you have more tools to convince the executive, and the committees that are in charge to provide budget. Analyze your past incidents and logs, and know your infrastructure, and know how all components work together in order to provide, presently, the real value to this company. Because, although all architectures are composed by microservices, Kubernetes, and Redis database, each company is a different world, and with different pains, and with different challenges. You need to know your company before you start to do that.
See more presentations with transcripts
MMS • RSS
BUSINESSNEXT has entered into a partnership with MongoDB to enhance autonomous operations in the banking and insurance sectors through the use of predictive and generative AI.
MongoDB, based in the US, is known for its software and data solutions that support innovation across various industries. The partnership aims to provide banks and financial institutions with the technological tools necessary to improve customer service and streamline operations.
By integrating BUSINESSNEXT’s expertise in financial services with MongoDB’s scalable, secure database platform, the collaboration aims to meet the growing demands of the industry. BUSINESSNEXT offers a suite of AI-driven solutions designed for autonomous banking, including modern customer relationship management (CRM) systems, digital journeys, lending platforms, and customer chatbots.

AI and data synergy for financial services
MongoDB’s document-based data model, which offers a flexible schema, complements BUSINESSNEXT’s AI capabilities. In essence, this partnership will enable banks to make better use of their data for more personalised customer interactions, optimiszed lending processes, and data-informed decision-making.
In the company press release, representatives from BUSINESSNEXT emphasised that the collaboration with MongoDB aligns with their vision of providing a modern platform for banks, citing the database’s robust encryption and ability to handle complex data as key strengths. Similarly, Officials from MongoDB noted that working with independent software vendors such as BUSINESSNEXT helps financial services firms accelerate modernisation and leverage AI to differentiate themselves in the market.
The most important outcomes expected from this partnership include improved banking operations, enhanced customer experiences, faster lending processes, better operational efficiency, and stronger risk management practices. Both companies view the collaboration as a major step forward in delivering value to financial institutions globally.
Other developments from BUSINESSNEXT
In August 2024, BUSINESSNEXT announced a partnership with Mannai InfoTech in order to drive digital transformation and development in the Qatar banking sector. Following this announcement, the partnership was expected to drive digital transformation and provide an improved customer experience platform for banking. The strategic deal was set to also transform the banking industry in the region of Qatar, while also delivering enhanced benefits, operational efficiencies, and business growth.
In addition, both Mannai InfoTech and BUSINESSNEXT continued to focus on meeting the needs, preferences, and demands of clients and customers in an ever-evolving market, while prioritising the process of remaining compliant with the regulatory requirements and laws of the local industry.
MMS • RSS

MongoDB , Inc. (NASDAQ:MDB), a leading player in the database solutions market, is navigating a challenging landscape as it grapples with slowing growth and market headwinds. Recent analyst reports and financial performance have sparked a reassessment of the company’s near-term prospects, even as its long-term potential remains strong.
MongoDB operates in the software sector, specializing in next-generation database solutions. With a market capitalization of $17.19 billion and an enterprise value of $18.94 billion, the company has established itself as a formidable presence in the rapidly evolving database management market.
The company’s flagship product, Atlas (NYSE:ATCO), has been a key driver of growth. However, recent financial results have indicated a deceleration in Atlas revenue growth, prompting concerns among investors and analysts. Despite these challenges, MongoDB continues to be highly regarded by developers and is increasingly adopted by enterprises, underscoring its strong market position.
MongoDB’s financial performance in the first quarter of fiscal year 2025 (F1Q25) has been a focal point for analysts. The company reported non-GAAP earnings per share (EPS) of $0.51 on revenue of $451 million, surpassing consensus estimates but showing a year-over-year growth deceleration.
For the full fiscal year 2024, revenue is projected at $1.68 billion with an EV/Sales ratio of 11.3x. The company’s EBIT for FY 2024 is estimated at $270.4 million, translating to an EV/EBIT ratio of 70.0x. These figures reflect the company’s continued growth, albeit at a slower pace than previously anticipated.
The database management market, particularly the cloud segment, is expected to experience significant growth in the coming years. However, MongoDB faces several challenges in maintaining its previously high growth rates. Analysts point to a broad-based slowdown in software spending as a sector-wide issue, not just specific to MongoDB.
The company has revised its guidance for fiscal year 2025, with total revenue now expected to be between $1.88 billion and $1.90 billion. This adjustment reflects weaker new business and consumption trends, which have led to a reassessment of MongoDB’s growth trajectory.
Some analysts suggest that MongoDB’s issues may be more related to self-inflicted and transitory go-to-market (GTM) headwinds rather than macroeconomic factors alone. The company has responded by adjusting its incentive plan to focus on larger, higher-quality deals, which could potentially improve its growth prospects in the long term.
Despite the current challenges, MongoDB’s product offerings continue to receive positive reception from developers and enterprises alike. The company’s operational database product is highly regarded in the industry, which could serve as a foundation for future growth.
Analysts note that product tailwinds could start benefiting the company in the second half of fiscal year 2025. This potential for product-driven acceleration, coupled with MongoDB’s strong market position, suggests that the company may have opportunities to exceed growth expectations if the IT spending environment improves.
The recent slowdown in growth has led to a reassessment of MongoDB’s valuation multiples. Some analysts suggest that a return to 10x multiples might be seen as the peak, reminiscent of earlier times in the company’s history. This adjustment reflects the expectation that MongoDB will not return to its previous 30%+ year-over-year revenue growth rates in the near future.
Despite these challenges, many analysts maintain a positive long-term outlook on MongoDB. The company’s leadership in the next-generation database market, coupled with the overall growth potential of the sector, continues to be viewed favorably. However, the near-term focus remains on how effectively MongoDB can navigate the current market conditions and return to higher growth rates.
MongoDB faces significant headwinds in achieving its revised growth targets. The company has lowered its guidance for fiscal year 2025, reflecting weaker new business and consumption trends. The broader slowdown in software spending across the sector adds another layer of complexity to MongoDB’s growth challenges.
Analysts point out that even if Atlas New ARR grows by 13% this year, total revenue growth may only reach nearly 20%, with further upside being challenging. The impact of Atlas New ARR outperformance on FY25 revenue is limited, making it difficult for MongoDB to exceed the 20% growth target for the fiscal year.
Moreover, the company is grappling with what some analysts describe as self-inflicted and transitory go-to-market headwinds. These internal challenges, combined with the uncertain macroeconomic environment, create a significant hurdle for MongoDB in meeting its revised growth expectations.
The current slowdown in new business acquisition poses a potential threat to MongoDB’s long-term growth trajectory. As the company adjusts its strategy to focus on larger, higher-quality deals, there is a risk that this shift could limit its ability to capture a broader range of market opportunities.
The deceleration in Atlas New ARR growth, while not as severe as initially suggested by management’s commentary, still indicates a cooling of what has been a key growth driver for MongoDB. If this trend continues, it could have lasting implications for the company’s market position and financial performance.
Furthermore, the adjustment in valuation multiples suggested by some analysts reflects a recalibration of growth expectations. This shift in market perception could potentially impact MongoDB’s ability to attract investment and fund future innovations, which are crucial for maintaining its competitive edge in the rapidly evolving database solutions market.
Despite the current challenges, MongoDB’s position as a leader in next-generation database solutions provides a solid foundation for potential recovery. The company’s products continue to be highly regarded by developers and are increasingly adopted by enterprises, indicating a strong market demand for its offerings.
MongoDB operates in a large and growing database management market, with the cloud segment expected to experience significant expansion. This market opportunity, combined with the company’s established reputation and product strength, could serve as catalysts for a faster-than-expected recovery once market conditions improve.
Additionally, MongoDB’s focus on larger, higher-quality deals could potentially lead to more stable and predictable revenue streams in the long term. If successful, this strategy could not only help the company weather the current storm but also position it for accelerated growth as the market rebounds.
While current projections indicate slower growth, MongoDB has several factors that could potentially drive outperformance. The company’s product tailwinds, expected to start benefiting in the second half of fiscal year 2025, could provide a significant boost to revenue growth.
MongoDB’s strong leadership under President & CEO Dev Ittycheria and COO & CFO Michael Gordon is viewed positively by analysts. Their experience and strategic vision could be instrumental in navigating the company through current challenges and capitalizing on emerging opportunities.
Furthermore, if the IT spending environment improves more rapidly than anticipated, MongoDB could be well-positioned to capture increased demand. The company’s continued investment in product development and innovation could also lead to new offerings that drive revenue acceleration, potentially allowing MongoDB to exceed current growth expectations.
Strengths:
Weaknesses:
Opportunities:
Threats:
This analysis is based on information available up to June 3rd, 2024.
Gain an edge in your investment decisions with InvestingPro’s in-depth analysis and exclusive insights on MDB. Our Pro platform offers fair value estimates, performance predictions, and risk assessments, along with additional tips and expert analysis. Explore MDB’s full potential at InvestingPro.
Should you invest in MDB right now? Consider this first:
Investing.com’s ProPicks, an AI-driven service trusted by over 130,000 paying members globally, provides easy-to-follow model portfolios designed for wealth accumulation. Curious if MDB is one of these AI-selected gems? Check out our ProPicks platform to find out and take your investment strategy to the next level.
To evaluate MDB further, use InvestingPro’s Fair Value tool for a comprehensive valuation based on various factors. You can also see if MDB appears on our undervalued or overvalued stock lists.
These tools provide a clearer picture of investment opportunities, enabling more informed decisions about where to allocate your funds.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
MMS • Steef-Jan Wiggers
AWS recently announced that Amazon RDS for MySQL zero-ETL integration with Amazon Redshift is generally available. This feature enables near real-time analytics and machine learning on transactional data. It allows multiple integrations from a single RDS database and provides data filtering for customized replication.
The GA release of Amazon RDS for MySQL zero-ETL integration with Amazon Redshift follows the earlier releases of zero-ETL integration with Amazon Redshift for Amazon Aurora MySQL-Compatible Edition and preview releases of Aurora PostgreSQL-Compatible Edition, Amazon DynamoDB, and RDS for MySQL. With the GA release, users can expect features like configuring zero-ETL integrations with AWS CloudFormation, configuring multiple integrations from a source database to up to five Amazon Redshift data warehouses, and data filtering.
Matheus Guimaraes, a senior developer advocate at AWS, writes regarding the data filtering:
Most companies, no matter the size, can benefit from adding filtering to their ETL jobs. A typical use case is to reduce data processing and storage costs by selecting only the subset of data needed to replicate from their production databases. Another is to exclude personally identifiable information (PII) from a report’s dataset.
Users can create a zero-ETL integration to replicate data from an RDS database into Amazon Redshift, enabling near real-time analytics, ML, and AI workloads using Amazon Redshift’s built-in capabilities such as machine learning, materialized views, data sharing, federated access to multiple data stores and data lakes, and integrations with Amazon SageMaker, Amazon QuickSight, and other AWS services.
To create a zero-ETL integration by using the AWS Management Console, AWS Command Line Interface (AWS CLI), or an AWS SDK, users specify an RDS database as the source and an Amazon Redshift data warehouse as the target. The integration replicates data from the source database into the target data warehouse.
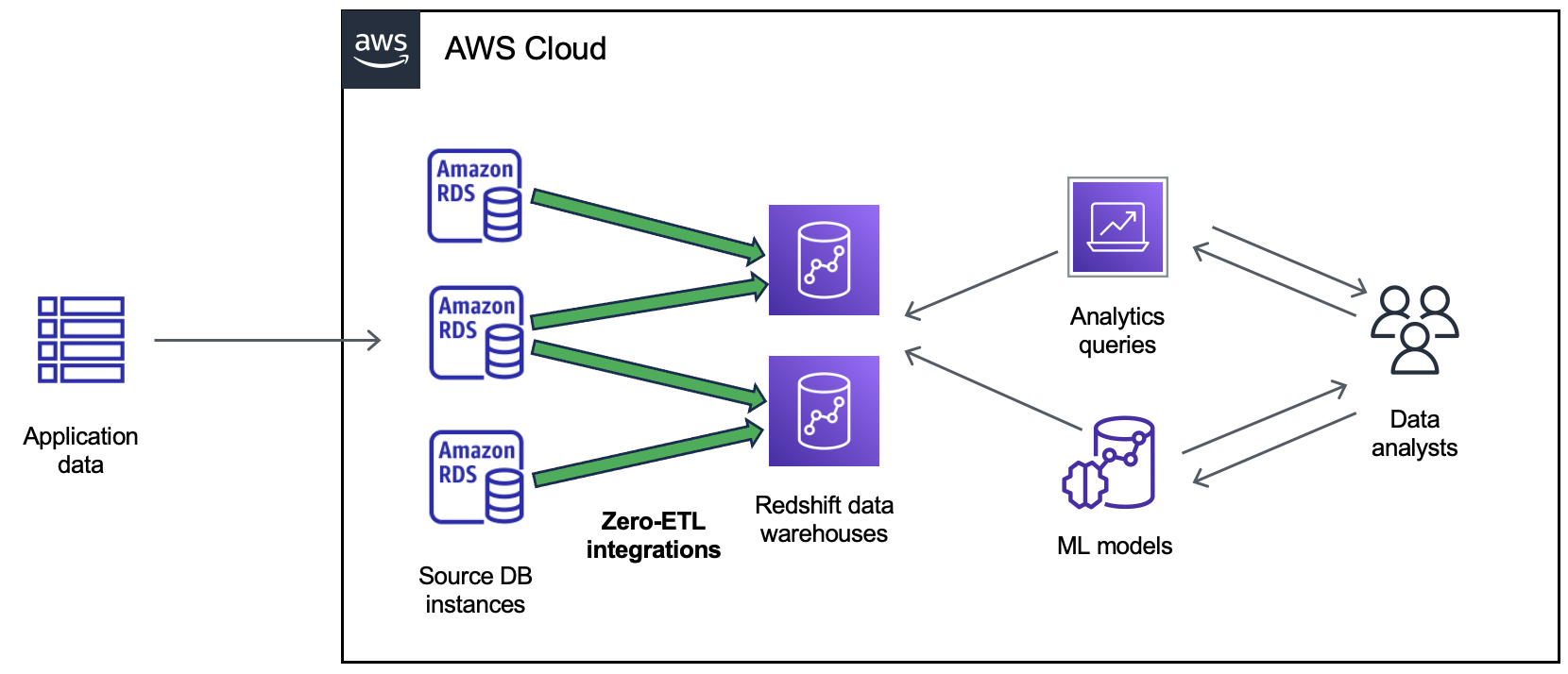
(Source: AWS Documentation)
In a medium blog post on Zero-ETL, Rajas Walavalkar, a technical architect at Quantiphi Analytics, explains why Zero-ETL Data pipelines can be beneficial to organizations:
- Real-Time Analytics: Businesses rely on real-time insights for timely decisions. Zero ETL enables near real-time analytics by transferring data directly from Aurora MySQL to Redshift, giving organizations a competitive edge.
- Data Freshness: Zero ETL maintains data freshness, which is crucial for accurate insights by ingesting data into Redshift without delay.
- Capturing Data History: Analyzing trends requires maintaining data history for the constant CRUD operations in operational databases.
- Scalability and Flexibility: Zero ETL architectures facilitate seamless scalability, allowing organizations to adapt to changing business needs without traditional ETL constraints.
Lastly, the zero-ETL integration is available for RDS for MySQL versions 8.0.32 and later, Amazon Redshift Serverless and Amazon Redshift RA3 instance types in supported AWS Regions.
MMS • RSS
MBB Public Markets I LLC acquired a new stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) in the second quarter, according to the company in its most recent 13F filing with the SEC. The institutional investor acquired 5,440 shares of the company’s stock, valued at approximately $1,360,000.
Other hedge funds have also added to or reduced their stakes in the company. Transcendent Capital Group LLC bought a new stake in MongoDB in the 4th quarter valued at $25,000. MFA Wealth Advisors LLC bought a new stake in shares of MongoDB in the second quarter valued at about $25,000. J.Safra Asset Management Corp boosted its position in shares of MongoDB by 682.4% during the second quarter. J.Safra Asset Management Corp now owns 133 shares of the company’s stock worth $33,000 after buying an additional 116 shares during the period. Hantz Financial Services Inc. bought a new position in shares of MongoDB during the second quarter worth about $35,000. Finally, YHB Investment Advisors Inc. acquired a new stake in MongoDB in the 1st quarter valued at approximately $41,000. Institutional investors and hedge funds own 89.29% of the company’s stock.
Wall Street Analyst Weigh In
Several brokerages have recently weighed in on MDB. Needham & Company LLC raised their price target on shares of MongoDB from $290.00 to $335.00 and gave the stock a “buy” rating in a research note on Friday, August 30th. Morgan Stanley boosted their price target on shares of MongoDB from $320.00 to $340.00 and gave the stock an “overweight” rating in a research report on Friday, August 30th. Citigroup lifted their target price on MongoDB from $350.00 to $400.00 and gave the company a “buy” rating in a research report on Tuesday, September 3rd. Sanford C. Bernstein raised their price target on MongoDB from $358.00 to $360.00 and gave the company an “outperform” rating in a research note on Friday, August 30th. Finally, Scotiabank upped their price objective on MongoDB from $250.00 to $295.00 and gave the stock a “sector perform” rating in a research note on Friday, August 30th. One investment analyst has rated the stock with a sell rating, five have assigned a hold rating and twenty have assigned a buy rating to the stock. Based on data from MarketBeat, MongoDB has a consensus rating of “Moderate Buy” and an average target price of $337.56.
Read Our Latest Research Report on MongoDB
MongoDB Stock Performance
MongoDB stock traded down $0.89 during midday trading on Monday, hitting $268.64. The company’s stock had a trading volume of 473,680 shares, compared to its average volume of 1,463,355. The company has a debt-to-equity ratio of 0.84, a current ratio of 5.03 and a quick ratio of 5.03. The company has a market cap of $19.71 billion, a price-to-earnings ratio of -95.01 and a beta of 1.15. MongoDB, Inc. has a 1-year low of $212.74 and a 1-year high of $509.62. The company has a 50-day moving average price of $261.22 and a two-hundred day moving average price of $293.46.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Thursday, August 29th. The company reported $0.70 earnings per share (EPS) for the quarter, beating the consensus estimate of $0.49 by $0.21. MongoDB had a negative return on equity of 15.06% and a negative net margin of 12.08%. The business had revenue of $478.11 million during the quarter, compared to analysts’ expectations of $465.03 million. During the same period in the previous year, the company posted ($0.63) earnings per share. The firm’s revenue for the quarter was up 12.8% compared to the same quarter last year. As a group, sell-side analysts predict that MongoDB, Inc. will post -2.44 earnings per share for the current year.
Insider Buying and Selling
In other news, CRO Cedric Pech sold 273 shares of the business’s stock in a transaction that occurred on Tuesday, July 2nd. The shares were sold at an average price of $265.29, for a total value of $72,424.17. Following the completion of the transaction, the executive now directly owns 35,719 shares in the company, valued at approximately $9,475,893.51. The sale was disclosed in a filing with the Securities & Exchange Commission, which is available through this link. In related news, CAO Thomas Bull sold 1,000 shares of the firm’s stock in a transaction on Monday, September 9th. The stock was sold at an average price of $282.89, for a total transaction of $282,890.00. Following the sale, the chief accounting officer now owns 16,222 shares of the company’s stock, valued at approximately $4,589,041.58. The transaction was disclosed in a document filed with the SEC, which is available at this hyperlink. Also, CRO Cedric Pech sold 273 shares of MongoDB stock in a transaction dated Tuesday, July 2nd. The shares were sold at an average price of $265.29, for a total value of $72,424.17. Following the sale, the executive now directly owns 35,719 shares in the company, valued at $9,475,893.51. The disclosure for this sale can be found here. Over the last quarter, insiders have sold 21,005 shares of company stock worth $5,557,746. Company insiders own 3.60% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Market downturns give many investors pause, and for good reason. Wondering how to offset this risk? Click the link below to learn more about using beta to protect yourself.
‘Mia Khalifa Expert’ Claim on CV Leads Ex-Google Employee to 29 Interviews – Times Now
MMS • RSS

Ex-Google Worker Lists ‘Mia Khalifa Expert’ on CV, Lands 29 Job Offers
A former Google employee, Jerry Lee carried out a unique experiment to see just how much attention recruiters actually pay to CV details. Based in New York, Lee inserted outrageous claims into his CV to see how far his Google experience would take him in the job market, despite the presence of clear red flags. Lee, who reportedly worked at Google for three years as a Strategy and Operations Manager, mixed ludicrous achievements into an otherwise typical resume. Some of the odd additions included “expert in Mia Khalifa” and “set the fraternity record for most vodka shots in one night.” He then submitted this altered CV to potential employers and waited to gauge their reactions.
The results of Lee’s experiment shocked many. Over a six-week period, despite his resume containing nonsensical and inappropriate achievements, he received 29 interview invitations. Well-known companies such as MongoDB and Robinhood even reached out to him for interviews, according to a video Lee shared on Instagram.
In the post, Lee documented his findings and shared three key lessons from his experiment. First, he stressed the importance of having a well-organised and concise resume, noting that it plays a crucial role in making a positive impression. “Focus on strong bullet points, clear job titles, and the impact you’ve made,” he advised job-seekers. “Periods and font sizes are fine details, but it’s the big stuff that gets you noticed.”
Next, he pointed out that while having experience at a well-known company like Google may draw attention, it’s equally important to show clear and measurable achievements. “Big names catch eyes, but don’t sweat it if you haven’t worked at a ‘big name’—just make sure your achievements pop with quantifiable results. It’s about the skills you bring to the table, not just where you polished them,” Lee explained in his Instagram post.
Lastly, he underlined the value of a simple, structured CV template, which recruiters prefer because it allows them to quickly identify the key information they need. He urged job seekers to adopt this approach to make the recruitment process smoother and more effective.
Get Latest News Live on Times Now along with Breaking News and Top Headlines from Viral and around the world.