Month: September 2024
Java News Roundup: Proposed Schedule for JDK 24, SecurityManager Disabled, Commonhaus Foundation

MMS • Michael Redlich

This week’s Java roundup for September 23th, 2024 features news highlighting: the proposed release schedule for JDK 24; JEP 475, Late Barrier Expansion for G1, promoted from Candidate to Proposed to Target for JDK 24; JEP 486, Permanently Disable the Security Manager, promoted from its JEP Draft 8338625 to Candidate status; and Quarkus joining the Commonhaus Foundation.
OpenJDK
JEP 475, Late Barrier Expansion for G1, was promoted from Candidate to Proposed to Target for JDK 24. This JEP proposes to simplify the implementation of the G1 garbage collector’s barriers, which record information about application memory accesses, by shifting their expansion from early in the C2 JIT’s compilation pipeline to later. The goal is to reduce the execution time of C2 when using the G1 collector. The review is expected to conclude on October 2, 2024.
JEP 486, Permanently Disable the Security Manager, has been promoted from its JEP Draft 8338625 to Candidate status. This JEP proposes to permanently disable the SecurityManager class since it was deprecated with JEP 411, Deprecate the Security Manager for Removal, delivered in JDK 17. While it was possible for developers to still enable the SecurityManager class while it has been deprecated, this functionality will be removed as the next step for ultimate removal.
JDK 24
Build 17 of the JDK 24 early-access builds was made available this past week featuring updates from Build 16 that include fixes for various issues. More details on this release may be found in the release notes.
Mark Reinhold, Chief Architect, Java Platform Group at Oracle, formally proposed the release schedule for JDK 24 as follows:
- Rampdown Phase One (fork from main line): December 5, 2024
- Rampdown Phase Two: January 16, 2025
- Initial Release Candidate: February 6, 2025
- Final Release Candidate: February 20, 2025
- General Availability: March 18, 2025
The review period for this proposed schedule is expected to conclude on October 2, 2024.
For JDK 24, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
Versions 3.4.0-M2, 3.3.3 and 3.2.8 of Spring Shell have been released featuring support for JEP 454, Foreign Function & Memory API, delivered in JDK 22, via JLine, the Java library for handling console input. These releases build on Spring Boot versions 3.4.0-M3, 3.3.4 and 3.2.10, respectively. Further details on these releases may be found in the release notes for version 3.4.0-M2, version 3.3.3 and version 3.2.8.
Quarkus
Red Hat has released version 3.15 of Quarkus, a new long-term support release provides dependency upgrades and resolutions to notable issues such as: a class loading failure from the findFunctions() method defined in the AzureFunctionsProcessor class; and a bidirectional streaming failure in the Dev UI console. The Quarkus team has stated that new features will be delivered in Quarkus 3.16, scheduled for the end of October 2024. More details on this release may be found in the release notes.
Open Liberty
IBM has released version 24.0.0.10-beta of Open Liberty featuring: beta support for JDK 23; and improved handling of SameSite cookies by allowing SameSite=None on incompatible clients. Details on how to set a SameSite cookie with Open Liberty may be found on this website.
WildFly
The first beta release of WildFly 34 delivers bug fixes, dependency upgrades and enhancements such as: a relocation of dependency JARs from the OpenTelemetry module to their own respective modules to minimize the size of the OpenTelemetry module; and a simplification of installing singleton service for a deployment that was once very cumbersome. Further details on this release may be found in the release notes.
Apache Software Foundation
Maintaining alignment with Quarkus, the release of Camel Quarkus 3.15.0, composed of Camel 4.8.0 and Quarkus 3.15.0, provides resolutions to notable issues such as: a deprecation of the Kotlin and Kotlin DSL extensions because they only provide a Kotlin function wrapper around the configure() method defined in the RouteBuilder abstract class; and a ClassNotFoundException from the SmallRye FallbackFunction class due to Quarkus having upgraded to SmallRye 6.4.0. More details on this release may be found in the release notes.
LangChain4j
Version 0.35.0 of LangChain for Java (LangChain4j) features new integrations: chat and embedding models from GitHub Models; document loader from Google Cloud Storage; scoring model from Google Vertex AI Ranking API; scoring model from ONNX Reranker; embedding store from Tablestore; and embedding and scoring models from Voyage AI. Other notable changes include: support for embedding models, the ability to count tokens and enumerated structured outputs from Google AI; and support for observability in Ollama. Further details on this release may be found in the release notes.
JBang
Version 0.119.0 of JBang provides bug fixes and a new feature in which junctions can now be created on WindowsOS that resolves an issue where executing the jbang jdk default {version} command would fail. More details on this release may be found in the release notes.
Java Operator SDK
The release of Java Operator SDK 4.9.5 features bug fixes and some refactoring that includes: change the package access of the asBoolean() method, defined in the BooleanWithUndefined enum, to public; a rename and deprecation of the defaultNonSSAResource() method, defined in the ConfigurationService interface, to defaultNonSSAResources(); and change the shouldUseSSA() method, also defined in the ConfigurationService interface, to use types as opposed to instances and corresponding tests. Further details on this release may be found in the release notes.
Commonhaus Foundation
The Commonhaus Foundation, a new non-profit organization dedicated to the sustainability of open source libraries and frameworks, has announced that Quarkus has joined the foundation this past week. In a blog post published in late July 2024, Max Rydahl Andersen, Distinguished Engineer at Red Hat, described their transition to the foundation, writing:
Quarkus will continue to innovate and evolve. We are dedicated to making Quarkus the best framework for Java development. This transition will enable us to welcome more contributions from a diverse range of developers and organisations. We are actively working on upcoming releases and are eager to hear your ideas and feedback.
They join notable projects such as: Hibernate, JReleaser, JBang, OpenRewrite, SDKMAN, EasyMock, Objenesis and Feign.
Introduced to the Java community at Devnexus in April 2024, the foundation provides succession planning and fiscal support for self-governing open-source projects.
RefactorFirst
Jim Bethancourt, principal software consultant at Improving, an IT services firm offering training, consulting, recruiting, and project services, has released version 0.5.0 of RefactorFirst, a utility that prioritizes the parts of an application that should be refactored. This release delivers: support for JDK 21; performance improvements on large codebases with a high number of commits; and the addition of a simple HTML resort that may be used in GitHub Actions. More details on this release may be found in the release notes.
Gradle
Gradle 8.10.2, the second maintenance release, ships with resolutions to notable issues: a failure to update the Gradle wrapper in version 8.10.1; a failure using a build with the Kotlin Mutliplatform plugin and a reused daemon; and the configureEach(Action) method, defined in the DefaultTaskCollection class, on a task set cannot be executed in the current context. Further details on this release may be found in the release notes.
MMS • RSS


.pp-multiple-authors-boxes-wrapper {display:none;}
img {width:100%;}
As data management grows more complex and modern applications extend the capabilities of traditional approaches, AI is revolutionising application scaling.

In addition to freeing operators from outdated, inefficient methods that require careful supervision and extra resources, AI enables real-time, adaptive optimisation of application scaling. Ultimately, these benefits combine to enhance efficiency and reduce costs for targeted applications.
With its predictive capabilities, AI ensures that applications scale efficiently, improving performance and resource allocation—marking a major advance over conventional methods.
Ahead of AI & Big Data Expo Europe, Han Heloir, EMEA gen AI senior solutions architect at MongoDB, discusses the future of AI-powered applications and the role of scalable databases in supporting generative AI and enhancing business processes.
AI News: As AI-powered applications continue to grow in complexity and scale, what do you see as the most significant trends shaping the future of database technology?
Heloir: While enterprises are keen to leverage the transformational power of generative AI technologies, the reality is that building a robust, scalable technology foundation involves more than just choosing the right technologies. It’s about creating systems that can grow and adapt to the evolving demands of generative AI, demands that are changing quickly, some of which traditional IT infrastructure may not be able to support. That is the uncomfortable truth about the current situation.
Today’s IT architectures are being overwhelmed by unprecedented data volumes generated from increasingly interconnected data sets. Traditional systems, designed for less intensive data exchanges, are currently unable to handle the massive, continuous data streams required for real-time AI responsiveness. They are also unprepared to manage the variety of data being generated.
The generative AI ecosystem often comprises a complex set of technologies. Each layer of technology—from data sourcing to model deployment—increases functional depth and operational costs. Simplifying these technology stacks isn’t just about improving operational efficiency; it’s also a financial necessity.
AI News: What are some key considerations for businesses when selecting a scalable database for AI-powered applications, especially those involving generative AI?
Heloir: Businesses should prioritise flexibility, performance and future scalability. Here are a few key reasons:
- The variety and volume of data will continue to grow, requiring the database to handle diverse data types—structured, unstructured, and semi-structured—at scale. Selecting a database that can manage such variety without complex ETL processes is important.
- AI models often need access to real-time data for training and inference, so the database must offer low latency to enable real-time decision-making and responsiveness.
- As AI models grow and data volumes expand, databases must scale horizontally, to allow organisations to add capacity without significant downtime or performance degradation.
- Seamless integration with data science and machine learning tools is crucial, and native support for AI workflows—such as managing model data, training sets and inference data—can enhance operational efficiency.
AI News: What are the common challenges organisations face when integrating AI into their operations, and how can scalable databases help address these issues?
Heloir: There are a variety of challenges that organisations can run into when adopting AI. These include the massive amounts of data from a wide variety of sources that are required to build AI applications. Scaling these initiatives can also put strain on the existing IT infrastructure and once the models are built, they require continuous iteration and improvement.
To make this easier, a database that scales can help simplify the management, storage and retrieval of diverse datasets. It offers elasticity, allowing businesses to handle fluctuating demands while sustaining performance and efficiency. Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid data ingestion and retrieval, facilitating faster experimentation.
AI News: Could you provide examples of how collaborations between database providers and AI-focused companies have driven innovation in AI solutions?
Heloir: Many businesses struggle to build generative AI applications because the technology evolves so quickly. Limited expertise and the increased complexity of integrating diverse components further complicate the process, slowing innovation and hindering the development of AI-driven solutions.
One way we address these challenges is through our MongoDB AI Applications Program (MAAP), which provides customers with resources to assist them in putting AI applications into production. This includes reference architectures and an end-to-end technology stack that integrates with leading technology providers, professional services and a unified support system.
MAAP categorises customers into four groups, ranging from those seeking advice and prototyping to those developing mission-critical AI applications and overcoming technical challenges. MongoDB’s MAAP enables faster, seamless development of generative AI applications, fostering creativity and reducing complexity.
AI News: How does MongoDB approach the challenges of supporting AI-powered applications, particularly in industries that are rapidly adopting AI?
Heloir: Ensuring you have the underlying infrastructure to build what you need is always one of the biggest challenges organisations face.
To build AI-powered applications, the underlying database must be capable of running queries against rich, flexible data structures. With AI, data structures can become very complex. This is one of the biggest challenges organisations face when building AI-powered applications, and it’s precisely what MongoDB is designed to handle. We unify source data, metadata, operational data, vector data and generated data—all in one platform.
AI News: What future developments in database technology do you anticipate, and how is MongoDB preparing to support the next generation of AI applications?
Heloir: Our key values are the same today as they were when MongoDB initially launched: we want to make developers’ lives easier and help them drive business ROI. This remains unchanged in the age of artificial intelligence. We will continue to listen to our customers, assist them in overcoming their biggest difficulties, and ensure that MongoDB has the features they require to develop the next [generation of] great applications.
(Photo by Caspar Camille Rubin)

Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
MMS • RSS
![]() Bank of Montreal Can grew its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 13.9% in the 2nd quarter, according to its most recent filing with the Securities & Exchange Commission. The firm owned 76,073 shares of the company’s stock after buying an additional 9,270 shares during the period. Bank of Montreal Can owned 0.10% of MongoDB worth $19,028,000 as of its most recent SEC filing.
Bank of Montreal Can grew its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 13.9% in the 2nd quarter, according to its most recent filing with the Securities & Exchange Commission. The firm owned 76,073 shares of the company’s stock after buying an additional 9,270 shares during the period. Bank of Montreal Can owned 0.10% of MongoDB worth $19,028,000 as of its most recent SEC filing.
Several other institutional investors also recently made changes to their positions in the stock. Transcendent Capital Group LLC acquired a new position in MongoDB in the 4th quarter worth $25,000. MFA Wealth Advisors LLC bought a new stake in shares of MongoDB in the 2nd quarter worth about $25,000. J.Safra Asset Management Corp increased its position in shares of MongoDB by 682.4% in the 2nd quarter. J.Safra Asset Management Corp now owns 133 shares of the company’s stock worth $33,000 after purchasing an additional 116 shares during the last quarter. Hantz Financial Services Inc. bought a new stake in shares of MongoDB in the 2nd quarter worth about $35,000. Finally, YHB Investment Advisors Inc. bought a new stake in shares of MongoDB in the 1st quarter worth about $41,000. 89.29% of the stock is owned by hedge funds and other institutional investors.
Insider Activity at MongoDB
In related news, CRO Cedric Pech sold 273 shares of the company’s stock in a transaction that occurred on Tuesday, July 2nd. The shares were sold at an average price of $265.29, for a total value of $72,424.17. Following the completion of the sale, the executive now owns 35,719 shares in the company, valued at approximately $9,475,893.51. The sale was disclosed in a legal filing with the SEC, which can be accessed through this hyperlink. In other MongoDB news, CRO Cedric Pech sold 273 shares of the company’s stock in a transaction that occurred on Tuesday, July 2nd. The shares were sold at an average price of $265.29, for a total value of $72,424.17. Following the transaction, the executive now owns 35,719 shares in the company, valued at approximately $9,475,893.51. The transaction was disclosed in a document filed with the SEC, which can be accessed through this link. Also, CAO Thomas Bull sold 138 shares of the company’s stock in a transaction that occurred on Tuesday, July 2nd. The shares were sold at an average price of $265.29, for a total transaction of $36,610.02. Following the completion of the transaction, the chief accounting officer now owns 17,222 shares in the company, valued at approximately $4,568,824.38. The disclosure for this sale can be found here. In the last 90 days, insiders sold 21,005 shares of company stock worth $5,557,746. 3.60% of the stock is owned by corporate insiders.
Analysts Set New Price Targets
A number of brokerages recently weighed in on MDB. Mizuho boosted their price objective on shares of MongoDB from $250.00 to $275.00 and gave the company a “neutral” rating in a research report on Friday, August 30th. DA Davidson boosted their price objective on shares of MongoDB from $265.00 to $330.00 and gave the company a “buy” rating in a research report on Friday, August 30th. Stifel Nicolaus upped their target price on shares of MongoDB from $300.00 to $325.00 and gave the stock a “buy” rating in a research report on Friday, August 30th. Guggenheim upgraded shares of MongoDB from a “sell” rating to a “neutral” rating in a research report on Monday, June 3rd. Finally, Needham & Company LLC upped their target price on shares of MongoDB from $290.00 to $335.00 and gave the stock a “buy” rating in a research report on Friday, August 30th. One research analyst has rated the stock with a sell rating, five have issued a hold rating and twenty have issued a buy rating to the stock. According to data from MarketBeat.com, the company has an average rating of “Moderate Buy” and a consensus target price of $337.56.
View Our Latest Stock Analysis on MDB
MongoDB Stock Down 1.1 %
Shares of NASDAQ:MDB opened at $269.53 on Friday. The company has a debt-to-equity ratio of 0.84, a quick ratio of 5.03 and a current ratio of 5.03. The company has a market cap of $19.77 billion, a PE ratio of -95.92 and a beta of 1.15. MongoDB, Inc. has a 52 week low of $212.74 and a 52 week high of $509.62. The firm has a 50 day simple moving average of $261.22 and a 200 day simple moving average of $294.53.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Thursday, August 29th. The company reported $0.70 EPS for the quarter, beating the consensus estimate of $0.49 by $0.21. The business had revenue of $478.11 million during the quarter, compared to the consensus estimate of $465.03 million. MongoDB had a negative net margin of 12.08% and a negative return on equity of 15.06%. The firm’s quarterly revenue was up 12.8% on a year-over-year basis. During the same quarter in the prior year, the firm earned ($0.63) EPS. As a group, research analysts expect that MongoDB, Inc. will post -2.44 earnings per share for the current year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
Clearline Capital LP bought a new stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) during the second quarter, according to the company in its most recent Form 13F filing with the Securities & Exchange Commission. The institutional investor bought 12,342 shares of the company’s stock, valued at approximately $3,085,000.
Several other institutional investors and hedge funds have also bought and sold shares of MDB. Transcendent Capital Group LLC bought a new position in MongoDB in the 4th quarter worth $25,000. MFA Wealth Advisors LLC purchased a new stake in MongoDB in the second quarter worth about $25,000. J.Safra Asset Management Corp raised its stake in shares of MongoDB by 682.4% in the second quarter. J.Safra Asset Management Corp now owns 133 shares of the company’s stock worth $33,000 after buying an additional 116 shares during the period. Hantz Financial Services Inc. purchased a new position in shares of MongoDB during the 2nd quarter valued at about $35,000. Finally, YHB Investment Advisors Inc. bought a new position in shares of MongoDB during the 1st quarter valued at approximately $41,000. 89.29% of the stock is owned by hedge funds and other institutional investors.
Insider Buying and Selling
In other MongoDB news, CAO Thomas Bull sold 1,000 shares of the business’s stock in a transaction dated Monday, September 9th. The shares were sold at an average price of $282.89, for a total value of $282,890.00. Following the completion of the sale, the chief accounting officer now directly owns 16,222 shares of the company’s stock, valued at approximately $4,589,041.58. The transaction was disclosed in a filing with the SEC, which is available through this link. In other MongoDB news, CAO Thomas Bull sold 1,000 shares of the firm’s stock in a transaction on Monday, September 9th. The stock was sold at an average price of $282.89, for a total transaction of $282,890.00. Following the transaction, the chief accounting officer now directly owns 16,222 shares in the company, valued at approximately $4,589,041.58. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available at the SEC website. Also, Director Dwight A. Merriman sold 2,000 shares of the company’s stock in a transaction on Friday, August 2nd. The stock was sold at an average price of $231.00, for a total value of $462,000.00. Following the completion of the sale, the director now owns 1,140,006 shares of the company’s stock, valued at $263,341,386. The disclosure for this sale can be found here. Insiders have sold 21,005 shares of company stock valued at $5,557,746 in the last 90 days. Company insiders own 3.60% of the company’s stock.
Analyst Upgrades and Downgrades
A number of equities research analysts have commented on the stock. JMP Securities restated a “market outperform” rating and set a $380.00 target price on shares of MongoDB in a research note on Friday, August 30th. Morgan Stanley upped their price objective on MongoDB from $320.00 to $340.00 and gave the stock an “overweight” rating in a research note on Friday, August 30th. Wells Fargo & Company lifted their target price on MongoDB from $300.00 to $350.00 and gave the company an “overweight” rating in a research note on Friday, August 30th. Mizuho upped their price target on MongoDB from $250.00 to $275.00 and gave the stock a “neutral” rating in a research note on Friday, August 30th. Finally, DA Davidson lifted their price objective on shares of MongoDB from $265.00 to $330.00 and gave the company a “buy” rating in a research report on Friday, August 30th. One equities research analyst has rated the stock with a sell rating, five have given a hold rating and twenty have issued a buy rating to the company. Based on data from MarketBeat, the company has a consensus rating of “Moderate Buy” and an average price target of $337.56.
Read Our Latest Stock Report on MongoDB
MongoDB Stock Down 1.1 %
Shares of NASDAQ MDB opened at $269.53 on Friday. The company has a market cap of $19.77 billion, a P/E ratio of -95.92 and a beta of 1.15. The firm has a 50-day simple moving average of $261.22 and a two-hundred day simple moving average of $294.53. MongoDB, Inc. has a 1 year low of $212.74 and a 1 year high of $509.62. The company has a debt-to-equity ratio of 0.84, a current ratio of 5.03 and a quick ratio of 5.03.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Thursday, August 29th. The company reported $0.70 EPS for the quarter, beating the consensus estimate of $0.49 by $0.21. MongoDB had a negative return on equity of 15.06% and a negative net margin of 12.08%. The company had revenue of $478.11 million for the quarter, compared to the consensus estimate of $465.03 million. During the same quarter in the prior year, the company posted ($0.63) EPS. MongoDB’s quarterly revenue was up 12.8% on a year-over-year basis. Research analysts anticipate that MongoDB, Inc. will post -2.44 earnings per share for the current year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Growth stocks offer a lot of bang for your buck, and we’ve got the next upcoming superstars to strongly consider for your portfolio.
MMS • Sergio De Simone

The latest Beta 2 for the upcoming Android 15 release introduces desktop windowing for tablets as a developer preview. The new feature makes it possible to manage “freeform windows” that users can create to display multiple apps and resize or move around similarly to what they would do on a desktop computer.
Desktop windowing on Android tablets creates new opportunities for your apps, particularly around productivity and multitasking. The possibility to resize and reposition multiple app windows allows users to easily compare documents, reference information while composing emails, and multitask efficiently.
The desktop windowing feature includes a refreshed System UI and new APIs for developers that make it possible to run multiple apps side-by-side simultaneously, with each app contained in its own window. Similarly to desktop UIs, app windows include an header bar to minimize, maximize, and move them. Apps can also customize the header bar content, for example by displaying tabs, buttons, a dropdown menu, and so on.
To better manage all the windows a user creates, the System UI provides a fixed Taskbar showing running apps as well as shortcuts to quickly launch apps that are used more often. Users can also quickly and easily switch between full-size mode, Android’s default where each app is displayed fullscreen, and destop windowing mode.
For developers, making their apps ready to take advantage of desktop windowing means implementing layout optimizations to adapt to different screen sizes and device configurations. This requirement corresponds to what Google labels Tier 2 support for large screens, which is less demanding than the top tier, Tier 1, where apps are specifically designed for different form factors, including tablets, foldables, and ChromeOS. Besides being responsive or adaptive, Tier 2 apps must also support different input devices, such as keyboard, mouse, and trackpad.
For Tier 3 apps, which run full screen, developers will need to implement support for window size classes to adapt layout, content, and interaction to different windows dimensions and make sure they persist layout configuration change across sessions.
In addition to this, freeform windows naturally lead to run multiple apps simultaneously, says Google, so that developers should make their apps ready for drag and drop and avoid requiring exclusive access to resources like camera and microphone, which could also be used by other concurrent apps.
A new possibility made possible by desktop windowing is running multiple instances of the same app in separate windows, e.g., side by side. If an app supports this possibility, it can set the multi instance property for the System UI to let users launch it multiple times.
Finally, apps compatible with desktop windowing should be aware that the window header bar is always shown and app content should be lay out taking into account its coordinates so it does not get obscured.
As mentioned, desktop windowing is part of the Android 15 QPR1 Beta 2 release and can be enabled by selecting the “Enable freeform windows” option in “Developer options”.
MMS • RSS
![]() Pacer Advisors Inc. lessened its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 4.1% during the 2nd quarter, according to the company in its most recent 13F filing with the SEC. The firm owned 4,421 shares of the company’s stock after selling 189 shares during the quarter. Pacer Advisors Inc.’s holdings in MongoDB were worth $1,105,000 at the end of the most recent reporting period.
Pacer Advisors Inc. lessened its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 4.1% during the 2nd quarter, according to the company in its most recent 13F filing with the SEC. The firm owned 4,421 shares of the company’s stock after selling 189 shares during the quarter. Pacer Advisors Inc.’s holdings in MongoDB were worth $1,105,000 at the end of the most recent reporting period.
Other hedge funds also recently added to or reduced their stakes in the company. Jennison Associates LLC lifted its stake in shares of MongoDB by 14.3% in the 1st quarter. Jennison Associates LLC now owns 4,408,424 shares of the company’s stock valued at $1,581,037,000 after purchasing an additional 551,567 shares during the last quarter. Swedbank AB lifted its position in MongoDB by 156.3% in the second quarter. Swedbank AB now owns 656,993 shares of the company’s stock valued at $164,222,000 after buying an additional 400,705 shares during the last quarter. Clearbridge Investments LLC boosted its stake in MongoDB by 109.0% during the first quarter. Clearbridge Investments LLC now owns 445,084 shares of the company’s stock worth $159,625,000 after buying an additional 232,101 shares during the period. First Trust Advisors LP increased its position in shares of MongoDB by 59.3% during the fourth quarter. First Trust Advisors LP now owns 549,052 shares of the company’s stock valued at $224,480,000 after acquiring an additional 204,284 shares during the last quarter. Finally, Vanguard Group Inc. raised its stake in shares of MongoDB by 2.9% in the 4th quarter. Vanguard Group Inc. now owns 6,842,413 shares of the company’s stock valued at $2,797,521,000 after acquiring an additional 194,148 shares during the period. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
Insiders Place Their Bets
In related news, CFO Michael Lawrence Gordon sold 5,000 shares of the business’s stock in a transaction dated Tuesday, July 9th. The shares were sold at an average price of $252.23, for a total transaction of $1,261,150.00. Following the sale, the chief financial officer now owns 81,942 shares of the company’s stock, valued at $20,668,230.66. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this link. In other news, Director Dwight A. Merriman sold 4,000 shares of the firm’s stock in a transaction on Tuesday, July 2nd. The stock was sold at an average price of $265.29, for a total value of $1,061,160.00. Following the completion of the transaction, the director now owns 1,142,006 shares in the company, valued at $302,962,771.74. The sale was disclosed in a document filed with the SEC, which is available at this link. Also, CFO Michael Lawrence Gordon sold 5,000 shares of the business’s stock in a transaction dated Tuesday, July 9th. The stock was sold at an average price of $252.23, for a total transaction of $1,261,150.00. Following the completion of the sale, the chief financial officer now owns 81,942 shares in the company, valued at $20,668,230.66. The disclosure for this sale can be found here. In the last ninety days, insiders sold 21,005 shares of company stock valued at $5,557,746. 3.60% of the stock is owned by company insiders.
Analysts Set New Price Targets
A number of equities analysts recently weighed in on MDB shares. Needham & Company LLC increased their price objective on shares of MongoDB from $290.00 to $335.00 and gave the stock a “buy” rating in a research report on Friday, August 30th. Barclays dropped their price objective on MongoDB from $458.00 to $290.00 and set an “overweight” rating for the company in a research note on Friday, May 31st. Canaccord Genuity Group decreased their target price on MongoDB from $435.00 to $325.00 and set a “buy” rating on the stock in a research note on Friday, May 31st. Oppenheimer lifted their target price on MongoDB from $300.00 to $350.00 and gave the company an “outperform” rating in a research report on Friday, August 30th. Finally, Loop Capital reduced their price target on shares of MongoDB from $415.00 to $315.00 and set a “buy” rating on the stock in a research report on Friday, May 31st. One investment analyst has rated the stock with a sell rating, five have given a hold rating and twenty have assigned a buy rating to the stock. Based on data from MarketBeat.com, the company has an average rating of “Moderate Buy” and an average target price of $337.56.
Read Our Latest Research Report on MongoDB
MongoDB Stock Down 1.1 %
MDB stock opened at $269.53 on Friday. The stock has a market cap of $19.77 billion, a P/E ratio of -95.92 and a beta of 1.15. The company has a current ratio of 5.03, a quick ratio of 5.03 and a debt-to-equity ratio of 0.84. MongoDB, Inc. has a twelve month low of $212.74 and a twelve month high of $509.62. The company’s 50 day moving average is $260.86 and its two-hundred day moving average is $295.21.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its earnings results on Thursday, August 29th. The company reported $0.70 earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of $0.49 by $0.21. MongoDB had a negative return on equity of 15.06% and a negative net margin of 12.08%. The firm had revenue of $478.11 million during the quarter, compared to analysts’ expectations of $465.03 million. During the same period in the prior year, the firm earned ($0.63) EPS. The business’s revenue was up 12.8% on a year-over-year basis. Research analysts expect that MongoDB, Inc. will post -2.44 earnings per share for the current fiscal year.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
![]() Canada Pension Plan Investment Board trimmed its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 34.0% during the second quarter, according to its most recent disclosure with the Securities & Exchange Commission. The institutional investor owned 4,277 shares of the company’s stock after selling 2,207 shares during the period. Canada Pension Plan Investment Board’s holdings in MongoDB were worth $1,069,000 at the end of the most recent quarter.
Canada Pension Plan Investment Board trimmed its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 34.0% during the second quarter, according to its most recent disclosure with the Securities & Exchange Commission. The institutional investor owned 4,277 shares of the company’s stock after selling 2,207 shares during the period. Canada Pension Plan Investment Board’s holdings in MongoDB were worth $1,069,000 at the end of the most recent quarter.
Several other hedge funds have also recently bought and sold shares of MDB. Dimensional Fund Advisors LP raised its holdings in shares of MongoDB by 2.8% during the 4th quarter. Dimensional Fund Advisors LP now owns 91,696 shares of the company’s stock worth $37,495,000 after buying an additional 2,476 shares in the last quarter. US Bancorp DE lifted its holdings in shares of MongoDB by 8.5% in the fourth quarter. US Bancorp DE now owns 4,147 shares of the company’s stock worth $1,696,000 after acquiring an additional 326 shares during the last quarter. Hsbc Holdings PLC boosted its stake in shares of MongoDB by 99.6% in the 4th quarter. Hsbc Holdings PLC now owns 42,607 shares of the company’s stock valued at $17,523,000 after purchasing an additional 21,264 shares in the last quarter. Stifel Financial Corp grew its holdings in shares of MongoDB by 5.7% during the 4th quarter. Stifel Financial Corp now owns 68,452 shares of the company’s stock valued at $27,987,000 after purchasing an additional 3,707 shares during the last quarter. Finally, Allianz Asset Management GmbH increased its position in MongoDB by 17.5% during the 4th quarter. Allianz Asset Management GmbH now owns 9,258 shares of the company’s stock worth $3,785,000 after purchasing an additional 1,379 shares in the last quarter. 89.29% of the stock is owned by institutional investors.
Analysts Set New Price Targets
MDB has been the subject of several research analyst reports. Robert W. Baird lowered their price target on shares of MongoDB from $450.00 to $305.00 and set an “outperform” rating for the company in a report on Friday, May 31st. JMP Securities reiterated a “market outperform” rating and issued a $380.00 target price on shares of MongoDB in a research report on Friday, August 30th. Mizuho boosted their price target on MongoDB from $250.00 to $275.00 and gave the stock a “neutral” rating in a report on Friday, August 30th. Sanford C. Bernstein raised their price objective on shares of MongoDB from $358.00 to $360.00 and gave the company an “outperform” rating in a report on Friday, August 30th. Finally, DA Davidson boosted their target price on shares of MongoDB from $265.00 to $330.00 and gave the stock a “buy” rating in a report on Friday, August 30th. One research analyst has rated the stock with a sell rating, five have assigned a hold rating and twenty have assigned a buy rating to the stock. Based on data from MarketBeat.com, MongoDB has an average rating of “Moderate Buy” and a consensus target price of $337.56.
Check Out Our Latest Report on MDB
MongoDB Price Performance
MDB stock opened at $269.53 on Friday. The company has a debt-to-equity ratio of 0.84, a current ratio of 5.03 and a quick ratio of 5.03. The company’s 50-day moving average is $260.86 and its 200-day moving average is $295.21. The stock has a market capitalization of $19.77 billion, a PE ratio of -95.92 and a beta of 1.15. MongoDB, Inc. has a 1 year low of $212.74 and a 1 year high of $509.62.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Thursday, August 29th. The company reported $0.70 earnings per share (EPS) for the quarter, topping the consensus estimate of $0.49 by $0.21. The business had revenue of $478.11 million for the quarter, compared to analyst estimates of $465.03 million. MongoDB had a negative return on equity of 15.06% and a negative net margin of 12.08%. The company’s quarterly revenue was up 12.8% on a year-over-year basis. During the same quarter in the prior year, the company earned ($0.63) earnings per share. Equities research analysts expect that MongoDB, Inc. will post -2.44 EPS for the current fiscal year.
Insider Buying and Selling at MongoDB
In other MongoDB news, CRO Cedric Pech sold 273 shares of the firm’s stock in a transaction on Tuesday, July 2nd. The shares were sold at an average price of $265.29, for a total value of $72,424.17. Following the transaction, the executive now directly owns 35,719 shares of the company’s stock, valued at $9,475,893.51. The transaction was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this link. In related news, Director Dwight A. Merriman sold 3,000 shares of the company’s stock in a transaction on Tuesday, September 3rd. The stock was sold at an average price of $290.79, for a total transaction of $872,370.00. Following the completion of the sale, the director now owns 1,135,006 shares in the company, valued at $330,048,394.74. The sale was disclosed in a filing with the Securities & Exchange Commission, which is available at this link. Also, CRO Cedric Pech sold 273 shares of the firm’s stock in a transaction on Tuesday, July 2nd. The shares were sold at an average price of $265.29, for a total value of $72,424.17. Following the transaction, the executive now owns 35,719 shares in the company, valued at $9,475,893.51. The disclosure for this sale can be found here. In the last 90 days, insiders sold 21,005 shares of company stock worth $5,557,746. 3.60% of the stock is owned by corporate insiders.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Kent McDonald
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today, I’m sitting down with Kent McDonald. Kent, you and I have known each other for decades, which we would be able to say now. Which of course is not a pointer to how old the two of us are getting. But a fair number of our audience probably haven’t come across you in your work. So who’s Kent?
Introductions [01:10]
Kent McDonald: Well, I think it’s almost going on two decades Shane. So I’m a freelance product manager and freelance writer. I have spent a large part of my career playing around in a few different communities.
I primarily work with different organizations from the products side of things, and dabble in the technology enough to make sure that we’re doing things the right way, and making the right decisions for what to build. And then I do a bit of writing about software product development.
Shane Hastie: One of the things that I know you bring to your work, that is possibly different to some of the stances that we hear, is you are working with organizations for whom software is not our business. The large corporates who need software, they’re not the startups, they’re not trying to be an Amazon or a Google or whatever. So what is different about product management in that space, and product management for software products in that space?
Product management in non-software companies [02:12]
Kent McDonald: Yes, I’ve made a living out of working at organizations that build software for their own use but don’t sell it. And probably one of the biggest things right off the bat that’s different about product management, is oftentimes these organizations need convincing that they probably could use product management. And really where product management fits in, if you’re to way oversimplify it would be making sure we’re working on the right software, solving the right problems, getting the right outcomes. And a lot of times in these organizations that are starting to use software more intentionally to enable their customers, enable their employees, enable their partners, there’s decisions getting made about what should be done, but it’s usually by folks that may not necessarily know the extent and the capabilities of the technology. And so when they describe something that they want to have happen, they’re typically describing it in a solution in terms of something they’re familiar with before.
So a big place where product management fits in is kind of walking those asks back to really understand what it is they’re really trying to accomplish, and make sure, does that make sense to do that. Another big one is just because you can build software for use inside your organization doesn’t mean you should always build it. Sometimes buying and configuring it is often the better route to go. So a lot of it is adding the decision-making and intentional thought process of, should we be building this, what should we be building, does it make sense to do this? To complement and make the good engineering practices that much more effective.
Shane Hastie: The good engineering practices. I hear and I experience that in many of those large organizations, those good engineering practices are hard to motivate. I’m going to take one of my favorite technical practices or team practices, pair programming, ensemble programming. And you talk to a bank and they go, “No. We won’t have the resource utilization curve going in the right direction”. How do we motivate those good engineering practices in these types of organizations?
Motivating for strong technical practices [04:20]
Kent McDonald: It’s tough. So amongst my career, before I was really focusing explicitly on the product aspect of things, I did spend a bit of a time as a delivery lead. Which is kind of the kinder, gentler, non-methodological specific way of saying the person that’s kind of helping coordinate things. This is one of my favorite experiences, actually. I was part of a team that was brought in to do a couple of things. One, our main goal was to rebuild a 20-year-old product that was originally built in PowerBuilder, that the organization used to establish prices that they would offer farmers for corn, soybean, and wheat seeds, that they would turn around and then sell off as commercial seed. And then this app also had to track any kind of options trading they did to hedge the risk of setting prices so far ahead.
So that was the main thing, but then the other thing was, is that based on the organization that I was working with, that I got brought in to help out with this, is we were to basically model those good engineering practices that I mentioned, and encourage the spread of those throughout the rest of the technical teams at this large organization. Pair programming being one of them. The one that we actually had the most difficulty trying to encourage the organization to even let us do, was automated testing. Because there was a very strong QA presence there, that I thought there was no way that we could possibly let the developers test their own things, even if they were automating it. Because what would that say about separation of concerns and all that?
We had to do a little bit of agreement there to where we did have a manual QA, but the developers basically made it a point to say, “We’re going to do whatever we can to make sure that the QA has the most of their time to spend doing exploratory, because they’re not finding anything of just the normal ordinary humdrum stuff”.. To kind of spread those practices, the best way I’ve seen happen, is you model it, show success, and then be willing to help other teams to kind of adopt those practices as well. Unfortunately, if there isn’t also a lot of buy-in at technical leadership level, all of those efforts can go to naught.
So you could even show this is, “Hey, we were able to release a new product for use inside the organization on April 1st, 2020”. There were a few things going on at that time. And one of the smoothest releases that the organization had ever seen, very low, if any downtime, very reliable efforts. And when the team started moving away, I don’t know that the organization continued to do those practices, because there wasn’t someone continuously pushing and really supporting that. So it certainly is model the behavior, show where it can provide results, but it also requires a bit of leadership and advocacy from tech leadership.
Shane Hastie: One of the things that is reasonably newish in the product space, is the Jeff Patton, Marty Cagan’s work on the product operating model. And how does this start to weave into the large corporate space today? Or does it?
The Product Operating Model [07:25]
Kent McDonald: Well, I think Marty Cagan is kind of the one that’s been trumpeting the operating model. I would suggest that if you were going to listen to either him or Jeff Patton talk about it, I’d listen to Jeff, because Jeff’s version’s probably a little bit more pragmatic and a little bit more realistic. Marty tends to be very idealistic and let everyone know where it’s not going to possibly work in their organization. But what it’s doing is it’s effectively saying, “Here are some things you need to strive for, to look at how you’re organizing things”. And some of the good parts of it are getting back to the idea of the collaboration, where we want to have different perspectives. And Shane, you’ve been a big proponent of product ownership being a team sport. It’s along the same lines there, with you want to have different folks working on… And the way that Marty describes it, and this is something I do like about how he talks about things, is kind of the four big risks of product.
Is the thing valuable? Meaning, is it solving a customer problem? Is the thing viable? Meaning, is this something that our business can actually do? Can it work with the other parts of the business? Is it usable? So our customers, and users, and the people that need to use the software, able to use it? And then of course feasible. Can we build it, can we make it work? Those types of things. And you’re likely not going to find someone that is best positioned to figure out if something addresses all four of those risks. You need different skill sets.
So you kind of need a village to do that. And a lot of times it’s always been the talk of the trio, where it’s product person dealing with value and viability, but I’m going to throw that a little bit on the head here in a minute. A UX person or designer looking at the usability and then the lead tech, the technicians looking at the feasibility. I have heard some perspectives to kind of put that in a little bit more useful thing. Especially if you’re working on something that isn’t explicitly human facing. Because there are some systems that have a lot of internal things. And our friend Chris Matts once said that the trio really should be certainly someone from a product standpoint, someone from a technical standpoint, and then the third person, and there may even be four, the third person’s actually basically looking at what’s the big risk that that product has, outside of there, and then whoever’s the expert in that.
So example, if you’re working on financial trading, it might be someone that’s really well versed in all of the intricacies of financial maths and things like that. I’ve also started to play around with the concept that the business analysis community, there’s probably people that are very well suited to be looking at the viability of things, as far as how is this going to work within our business, how is it going to support the processes, and the data and the rules that we’re having to deal with? Especially for those products that are for the organization’s own use.
Shane Hastie: You chaired the accelerating products track at Agile 2024. What are the trends in product today?
Trends in product today [10:18]
Kent McDonald: I got the opportunity to chair that with Holly Bielawa who works with Jeff Patton. And one of our kind of focuses this year was to bring some content to the conference that’s looking at the aspect of product management that doesn’t get discussed as much in the Agile community, and that’s more around the discovery and focusing on outcomes. There is certainly some of that, but really kind of looking at discovery and metrics and things of that nature. We kind of did an intentional focus on those types of sessions to bring to the conference. And also to do a little bit of cross-pollination between people that tend to hang out more in product management circles, and people that hang out in the agile software development circles. Because we figured there’s probably a lot of good things that they could all learn from each other. So that’s kind of the main thing of it.
There were several sessions on dancing around topics such as customer journey, some ways of explicitly quantifying value that maybe the Agile community hasn’t tried to dig into it deep, because they figured the product owner had that covered and they didn’t need to have to worry about it. Some more in-depth things. One of the sessions was about survival metrics, so digging deeper into metrics so you can understand where your product is, how your product’s doing, and where it might be faltering a little bit. So a variety of sessions on that. So I think the track was pretty well received. Maybe not as many people attending that as some of the others, but that’s to be expected with a not new but yet newer topic for the conference, compared to what it had been in the years past.
Shane Hastie: For the InfoQ technology audience, what are some of the important things that they should be thinking about in product today, in product management, product coaching, product, blah?
Product management is fundamentally about making sure we build the right thing [12:04]
Kent McDonald: I don’t want to oversimplify it, but I’m going to anyway, because that seems to be the great place to go. It comes down to… And the way I describe the relationship between product management and agile, and I used to describe this in terms more of the community I used to live in a lot more, which is business analysis, was organizations that did a good job of adopting agile, more often than not, they originally did it because they wanted… Either it was groundswell effort because they just saw this as a better way for us to work. From an organizational perspective, it was always, we want to be able to do things better, faster, and cheaper. And what they found was, is that their approach to adopting agile and good engineering practices kind of help them get there, but the one thing that they never tackled was, “Are we doing the right thing? Are we building the right thing? Should we be building this, or should we just not be doing it at all?”
There have been attempts along the way to incorporate that idea. And what it seemed like every time was happening was, is that the roles that the agile’s community conveyed as far as the ones that owned the value, they basically said, “Yes, product owners got it, the product people got it, they know what to do, they’ll just go off and take it”. And a lot of times the people that found themselves getting into product roles, didn’t know exactly what to do. They needed some help. And so the only kind of help they got was, “Well, here’s how you can do product to help the engineering team out, to keep things organized, tell us what to do next, provide us the information we need”. But not a lot on the decision-making about, “Should we even be doing this in the first place?”
And it’s a tricky thing for organizations, again, going back to those that are building software for their own use. Those are hard decisions. Those are hard conversations, and a lot of times organizations seem to go out of their way to find ways to not have those discussions. It usually gets baked into some kind of budget battle. And the people that are good politicians or the ones that win and get to do their things, without really having what makes the most sense for the organization. And so I think there’s some of the techniques that come along, the good techniques, not the kind of the vanity techniques that you see out there with any kind of approach, that helps organizations and helps teams make those decisions about, “Should we be doing this, does this make sense, is this the right thing to do, is it going to get us the outcomes that we want?”
Shane Hastie: What are some of those good techniques?
Stable and temporary metrics [14:25]
Kent McDonald: A lot of it comes down to explicitly thinking about what is it we’re trying to accomplish. And John Cutler actually who wasn’t at the conference recently, had a great post where he kind of positioned the idea of how measurements really should be playing into things. And the interesting thing was is he described it in the interest of getting to a different point, but it was actually this first point that he talked about I thought was very helpful. And so he talked about, there’s stable metrics that you have that are things you track over the long period of time. You can think of these as health metrics, you can think about them are “We’re establishing some measurements along the way that we want to make sure to keep track that our process is doing what it’s supposed to be doing, and not going off kilter”.
My long ago educational background is industrial engineering, so I think of like process measurements and controls like that. Some people would think of these as KPIs, so key performance indicators. If everything stays within this certain range, we’re doing pretty good. Those are stable metrics. Then you’ve got a set of metrics which are going to be temporary in nature. And effectively, anytime that you think that you need to make a change to something, so in this realm of working inside organizations and doing software for its own use, usually it’s going to be, we either are bringing on new customers and we need to support different kinds of things that we had before, or we need to increase our capacity so we can bring on more customers, or those processes or bouncing outside of those KPIs. So we need to make some kind of change to get things back in order or expand our capacity or things like that.
And so those temporary metrics are ways of saying, “Have we gotten there?” So are the things that we’re doing getting us in the right direction to actually make the change that we’re trying to get to? And then what you do there, is you base success based on “How are we getting towards those metrics?” Not “Did we deliver the thing we thought we needed to deliver?” Because we might find out that the thing we thought was going to work isn’t going to work after all. And then the third part of that is goals, basically saying, “For the stable ones, how do we know when we’re doing well?” For the temporary metrics, “How do we know when we’ve accomplished the outcome we’re looking for?” There’s a lot of kind of practices built into that, but it’s basically looking at something that’s saying, “Are we accomplishing the change we wanted to accomplish as a measure of progress and success?” Rather than, “Did we deliver the backlog items that we thought were going to be needed three months ago, when we were probably completely wrong?”
Shane Hastie: Getting those metrics, actually getting the numbers in our hands. This is in my experience, again, a pretty hard thing. In product organizations, we’re better and better today at building the analytics in. I’m not so sure that our large corporates have the appetite for that.
The challenges of gathering useful data [17:16]
Kent McDonald: No, because what it inevitably comes down to, and I can attribute it to a couple things. One of it is because in order to get the metrics and the measurements you need, you’re effectively, some of the work on whatever your change is that you’re doing, is actually work to put in the ability to measure those metrics. And so it’s opportunity costs about other things you can’t do. I would argue there that it’s worth it, but some folks sometimes take a little bit of convincing for that. The other one that you don’t hear people talking about as much, is the embarrassment factor. Oftentimes when you’re driving some change, it’s because things aren’t working very well the way they were before. And usually you’ll hear the reason for making the change described as, “We need to do some kind of modernization,” or “We need to adopt new technology”.
When it really is, what they’re saying is that, “Right now this process lets the people working in it make way too many errors, it’s costing us way too much money. We need to fix it”. But you won’t hear people say that, because then the next thing is, “Well, we should really measure what the errors are now,” which can be embarrassing because it’s like you’re admitting, “Yes, we’re letting a lot of things happen that shouldn’t be”. So I think part of it is having the courage to say, “What is it we’re really trying to accomplish?” And in some cases, especially when you’re talking about something that’s enabling an existing process, one of the reasons you might need to make the changes is because right now it’s way too easy to make errors that can cost the organization money. And when you’re having those discussions, it’s also important to note that it’s not the people that are causing the errors, it’s the system that lets it happen.
Shane Hastie: So as the technologist, how do I advocate for spending the time and money to put that in?
Kent McDonald: I think a lot of it is kind of just reinforcing the idea that says… Because every developer I’ve worked with that’s anything worth their salt, really does care that the stuff they’re working on is making a difference. So if anything, especially if the organization cares at all about their staff’s satisfaction, is to reinforce the argument that says, “Hey, if we do this, if we track these metrics, if we look at these things, it’s going to help us make better decisions about should we be doing these things or not. It’s going to give us a better idea if we’re working on the right things”. And by virtue of that, it’s going to make sure that this team sees a lot more in fulfillment in what they’re working on. Because they know they can directly tie it to, this is how the organization is succeeding. Because we’re doing the right things, we’re putting the right stuff in place.
Shane Hastie: Shifting stance a tiny bit, I know that you’re working in an organization today that is very, very distributed. But what is different when working in this massively geographically distributed environment, versus maybe working within one or two time zones?
Working in massively distributed teams [20:15]
Kent McDonald: Yes. And so let me provide a little bit of context here. So I’ve had the opportunity to work in organizations of all different sizes. The team I talked about earlier, we were co-located explicitly working in the same room. This is 2020, when some things happened, so we were able to shift quickly to not working in the same room, but we’re still working in the same time zone. And then I’ve worked with other larger organizations where it’s kind of the product, folks were in one time zone, one continent, and most of the tech team were in a different one. The team I’m working with now, and it’s actually a smaller organization, where the folks are distributed via space-time and organization. So it’s kind of like a movie model where you bring the right skills together to create the thing, and that way you can get the best skills. Team I’m working with right now, it’s four people.
I’m in the central United States. There’s another developer that’s probably a couple hour drive from me. And then we’ve got another team member in Turkey, the team member in the Ukraine, a team member in Europe, and a team member in the UK. And it’s interesting that we’re able to adjust, we’ve found a way to lock into our approach that tends to be fairly lightweight. And a lot of it is just adjusting schedule wise as far as how things work. So we primarily live in Slack and ClickUp, so the realm of product and tech tools continues to grow, and source control and GitHub. So a lot of it is that we’re able to be a little bit more synchronous working in the morning’s, US Central Time. And then afternoon, US Central Time, I’m pretty much kind of getting things prepped and then stuff happens overnight while I’m sleeping.
So I know when I wake up in the morning, there’ll be other things. It works out pretty good because that way the team members, we’re still able to have good communication synchronously, and we do a lot of asynchronous communication. But then all the team members have the ability to go off and have the focus time and work work they’re needing to do, and yet still kind of get questions answered. I think because we’re a small organization, and there isn’t a lot of the extra baggage that comes along with larger organizations, the extended time to work on focus time by themselves is probably a little bit easier to have happen. But I think it’s a model that larger organizations could model. It’s like, do you really need to have all these people always involved at the same time? Or is it as long as you have a certain timeframe where there’s overlap to do the stuff that needs to be done synchronously, and then allow for a lot more of the work to happen asynchronously, where it’s better suited for that?
Shane Hastie: Another aspect that you bring to the table, is this concept of the player coach. We’ve seen a pushback against a lot of coaching roles. One could argue that the visibility of the value delivered there has been hard to find at times. But the emergence of the player coach, so in your stance at the moment, you’re the player and you’re coaching that team. How does that fly and work?
The role of the player coach [23:17]
Kent McDonald: Yes. This team, the coaching aspect of it is a lot lighter. So it’s more just along the lines of, let’s get the practices in place that we need to get work done and we make it happen. A previous gig that I had, I just recently finished up, it was explicitly a player coach type setting. And granted this is more from a product focus, more so than a technical focus. Part of it was I was coaching the folks in the business unit. So this organization is starting, one of those that builds software for its own use, starting to adopt a product operating model. Interestingly enough, they’re adopting the product operating model at the same time that they’re trying to adopt a little bit more rigorous agile software development approaches. So it’s rare that you see an organization trying to do both at the same time. The jury’s out if that’s a good or bad thing, but so part of it was that I was coaching the director of the business area to take a little bit more product focused approach.
And It was interesting, it was a very good fit here, because the business unit they were in, we’re actually providing services out to their customers. So it was a definitely good fit. And at the same time, working with their other folks on the team, including the manager, about adopting more product management techniques. And so a lot of that was, again, like I said before, it was me doing it for the stuff I was working on, modeling it. And then spending a bit more time going deeper into explaining the why I chose to do it a particular way, pointing out when I messed something up, and kind of the do as I say, not as I do type situation. Or explain, “This is what I thought was going to work, it didn’t. So here’s what I would probably do instead”. And being available for questions.
I honestly, for my own personal approach to working, I enjoy that approach better, because I had had the opportunity to coach exclusively in the past, and I found a lot of times it felt like as if I wasn’t doing as much as I should have been. So this way it definitely felt like moving things forward. Plus it helped me pick up the context a lot better. And so I think it’s for folks that have the experience and would prefer to mostly do, be a maker. It’s a great way to share the knowledge and experience as long as the people that may be less experienced are open to hearing about it. Sometimes people go the route of saying, “I just have to experience it myself to learn it”.
Shane Hastie: So, knowing when to let go.
Kent McDonald: Knowing when to stand back.
Shane Hastie: My co-author and friend, Ronald Layton says that sometimes the conversation is, “It’s your foot. You can shoot it if you want to”.
Kent McDonald: I like to say, you can lead people to knowledge, but you can’t make them think. So there’s only so much you can do.
Shane Hastie: Yes. We’ve covered a wide range of topics here. If people want to continue the conversation, where would they find you?
Kent McDonald: I’m pretty available on LinkedIn. So just look for Kent, J. McDonald.
Shane Hastie: Thank you very much for taking the time to talk to us today.
Kent McDonald: Thanks for the opportunity to be here. I enjoyed it.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Sergio De Simone

The Swift team has officially announced the availability of Swift 6, a new major version of Apple open-source language with focus on low-level and embedded programming, concurrent code safety, new cross-platforms APIs, and extended Linux and Windows support.
InfoQ has already covered several features brought by Swift 6, including Embedded Swift, a compilation mode that aims to address the specific constraints of embedded devices and kernel-level code; Swift Testing, a new cross-platform testing framework; and the data-race free safe mode, aimed at helping developers create concurrent programs free of data races thanks to a new compile-time static detector.
Other major new features in Swift 6 are typed throws, memory ownership extensions for generics, 128 bit integers support, and extended C++ interoperability.
Typed throws enable the specification of the type of errors function can throw as part of their signature. So, instead of declaring a generic throw clause,
func parseRecord(from string: String) throws -> Record {
// ...
}
you can now explicitly declare the error type. This will bring the additional simplification that when you wrap the call to such a function in a do...try...catch block, the type of the error is already known at compile time:
func parseRecord(from string: String) throws(ParseError) -> Record {
// ...
}
// call site:
do {
let record = try parseRecord(from: myString)
} catch {
// 'error' has type 'ParseError'
}
Interestingly, all Swift 6 functions have a typed throw signature under the hood. Indeed, a function with a non-typed throws is equivalent to a function throwing Any Error, while a non-type throws is equivalent to throws(any Error).
It is important to stress that this feature is not meant to replace non-typed throws everywhere.
This feature is useful in generic code that forwards along errors thrown in client code, or in resource-constrained environments that cannot allocate memory, such as in embedded Swift code.
In fact, according to the the authors of the evolution proposal “the existing (untyped) throws remains the better default error-handling mechanism for most Swift code”.
The new memory ownership model has been introduced in Swift 5.9 and Swift 6 brings it a tad further by extending support for generics “move only” types.
The concept of ownership is functional to controlling which piece of code is responsible for a given value to be eventually destroyed. Until Swift 5.9, Swift memory model was not exposed to programmers, as it was the case, e.g., with manual reference counting in Objective-C. Rather, it was encoded in a set of rules that worked pretty well in the general case, but made it harder to get more control on how values were destroyed using the default reference counting algorithm.
Without going into much detail, the memory ownership model exposed in Swift 5.9 is based on the concepts of borrowing and consuming, which allows to customize how initializers and functions treat ownership of the arguments they receive and so modify Swift default assumptions that initializers get the ownership (hence, consume), while functions do not (hence, they borrow).
An integral part of this model is represented by the “non copyable” protocol, which is used for “move only” types, i.e. a type whose values always have a unique ownership and cannot be copied. The implementation of the protocol in Swift 5.9 could not be used with generics, protocols, or existentials, but Swift 6 fills this gap by extending it. Covering the details of ~Copyable for generics goes beyond the scope of the present article, so check out the linked Swift Evolution proposal for more detail.
Related to the ~Copyable protocol, Swift 6 leverages it to extend C++ interop to move-only types. If a C++ class has no copy constructor, Swift assumes it is ~Copyable, with the possibility of explicitly ignoring an existing copy constructor using the SWIFT_NONCOPYABLE annotation. In addition, virtual methods, default arguments, and more standard library types such as std::map and std::optional are now supported.
Speaking of platform support, Swift 6 can be used now on more Linux distributions, including Amazon Linux, Debian, Fedora, Red Hat, and Ubuntu, and Windows x86_64 and arm64 architectures. On Linux, the Swift 6 SDK supports building fully statically linked executables with no external dependencies and cross-compiling from other Linux platforms.
There is a lot more to Swift 6 than can be covered here, so do not miss the official announcement for the full details.
RAG-Based Ingestion for Generative AI Applications with Logic Apps Standard in Public Preview
MMS • Steef-Jan Wiggers
Microsoft recently announced the public preview of built-in actions for document parsing and chunking in Logic Apps Standard. These actions are designed to streamline Retrieval-Augmented Generation (RAG)-based ingestion for Generative AI applications. With these actions, the company further invests in artificial intelligence capabilities for its low-code offering.
With these out-of-the-box operations, developers can, according to the company, easily ingest documents or files, including both structured and unstructured data, into AI Search without writing or managing any code. The new Data Operations actions “Parse a document” and “Chunk text,” transform content from formats like PDF, CSV, and Excel into tokenized strings and split them into manageable chunks based on the number of tokens. This functionality is suitable for ensuring compatibility with Azure AI Search and Azure OpenAI, which require tokenized input and have token limits.
Divya Swarnkar, a program manager at Microsoft, writes:
These actions are built on the Apache Tika toolkit and parser libraries, allowing you to parse thousands of file types in multiple languages, such as PDF, DOCX, PPT, HTML, and more. You can seamlessly read and parse documents from virtually any source without custom logic or configuration!
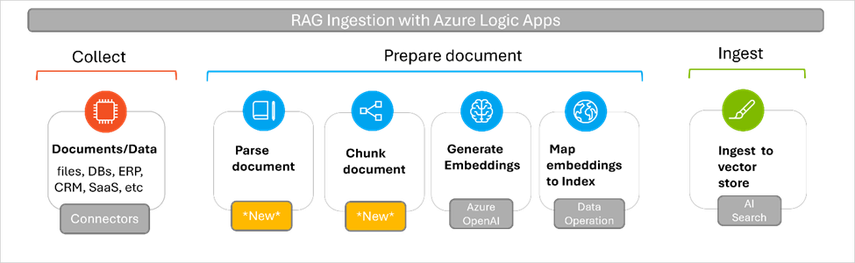
(Source: Tech Community blog post)
Wessel Beulink, a cloud architect at Rubicon, concluded in a blog post on the new actions:
Azure Logic Apps’ document parsing and chunking capabilities unlock many automation possibilities. These features, from legal workflows to customer support, allow businesses to harness AI for more innovative document processing. By leveraging low-code RAG ingestion, organizations can simplify the integration of AI models, enabling smoother data ingestion, enhanced searchability, and more efficient knowledge management.
In his blog post, he mentions various use cases that involve integrating parsing features into AI workflows to streamline document processing, enabling AI-powered chatbots to ingest and retrieve relevant information for customer support, and improving knowledge management and searchability by breaking down data into manageable pieces.
In addition, Logic Apps provides ready-to-use templates for RAG ingestion, which makes it easy to connect familiar data sources like SharePoint, Azure File, SFTP, and Azure Blob Storage. These templates can help developers save time and customize workflows to fit their needs.
Kamaljeet Kharbanda, a master’s student of data science, states in a medium blog post that RAG transforms enterprise data processing by combining deep knowledge bases with the powerful analytical capabilities of large language models (LLMs). This synergy enables advanced interpretations of complex datasets, which is crucial for driving competitive advantage in today’s digital ecosystem.
Low-code/no-code platforms such as Azure AI Studio, Amazon Bedrock, Vertex AI, and Logic Apps make advanced AI functionalities accessible. Alongside these cloud solutions, tools like LangChain and Llama Index provide robust environments for implementing customized AI functionality through code-intensive methods.